1. Introduction
Currently, the control system is showing a trend of complexity and large-scale. Along with this phenomenon, there are various types of system failures. The occurrence of the fault will cause the behavior of the control system to deviate from the regular running track inevitably. As a result, the performance of the system will be weakened, unstable, and even severe accidents such as property loss and casualties will occur. Since the 1970s, the emergence and development of fault detection and diagnosis technology have opened up a new way to ensure the safety and reliability of the system. It has appeal to growing scholars at home and abroad [
1,
2,
3].
In practical engineering, the equipment operation data reveals the working state of the system. It is feasible for us to diagnose the status [
4] and judge whether the system faults in time via collecting these data. Nevertheless, a sea of data and the requirements of timely diagnosis improve the complexity and difficulty of real-time fault diagnosis. Due to the introduction of feedback in the closed-loop system, when a fault occurs in one part of the system, it may cause the fault behavior to spread within the control system and make other parts abnormal. A double closed-loop exists in a cascade system, and the behaviors between the major and vice loops are closely related. Consequently, the phenomenon of fault propagation in the double closed-loop system makes fault diagnosis more complex and more difficult [
5]. All parts of the cascade control system may fail in engineering applications, and the probability of sensor failure is the highest.
Fault detection and diagnosis are essential measures to improve system reliability and availability [
6,
7]. Numerous methods have been proposed since the development of fault detection and diagnosis technology, including roughly three categories [
8,
9]. First, the analytical model-based approach, for example, parameter estimation and equivalent space method [
10,
11], which is based on the system operation mechanism. For a large-scale system, it is arduous to establish an accurate mathematical model. Knowledge-based method as the second one, such as fault tree [
12] and Expert System (ES) [
13,
14]. The limitation of the ES lies in relying on the domain knowledge acquisition of experts. Last but not least, the data-driven method [
15,
16]. The way based on data-driven is to collect, analyze and diagnose the data generated during the operation of the equipment without knowing the accurate system model. Data-driven strategies include information processing methods, statistical analysis methods, machine learning methods, et cetera. Since it can diagnose without a precise system model description, and the historical data [
17,
18] can be obtained entirely and sufficiently, both academia and industry attach positive importance to this method [
19,
20]. For instance, Rashidi et al. [
21] proposed a multivariable process fault diagnosis method based on data-driven, used the normalized transfer entropy (NTE) between the measured process variables and residual signal variation to estimate the strength of causality, which reduced the amount of calculation required for analysis. Renga et al. [
22] put forward a transparent, exploratory, and detailed data mining workflow based on data characterization, time window, association rule mining, and association classification. For the PEMFC system, a deep belief network (DBN) was adopted by Zhang et al. [
23] to the fault diagnosis. They used the simulated annealing genetic algorithm fuzzy c-means clustering (SAGAFCM) method to eliminate redundant and invalid data. Hu et al. [
24] gave a data-driven rotating machinery fault diagnosis method based on compressed sensing (CS) and an improved multi-scale network (IMSN), which can effectively identify faults under different working conditions.
In contrast with the open-loop system, the feedback effect of the closed-loop system will cause the fault to propagate within it, make other parts of the data abnormal, and reduce the performance of the system [
25]. For sensors in closed-loop systems, fault detection methods of Kalman filter, parameter estimation, and maximum likelihood estimation were used by Doraiswami et al. [
26]. However, they suffered from complicated calculations, time-consuming, and initialization problems. Shi [
27] took the traction motor of the closed-loop system as the research object and adopted the diagnosis method based on the analytical model. However, the actual non-linear factors were not considered in the modeling process. More realistic system properties are inseparable from more precise mathematical models. Sheriff [
28] adopted the fault detection methods of kernel PCA (KPCA) and kernel PLS (KPLS) to improve the accuracy, but there was still exists the false alarm and missed detection rate of more than 3%. This study proposes a real-time single fault diagnosis of sensors in a cascade system based on data-driven by studying the off-line historical data of the double tank. This method solves the shortcomings of the above techniques and has the following advantages. It calculates the collected data directly with less calculation amount, has a low missed detection rate, and well real-time performance; it does not rely on the system operating mechanism and avoids the problem of error in the modeling process.
The novelty of this research: In principle, the first is to study fault diagnosis methods according to system classification to facilitate the realization of system configuration. Here is the cascade system; Secondly, it combines real-time data, which reflects the dynamic characteristics of the system; Last is to integrate analytical geometric modeling methods. In terms of functionality, first, establishes the static models of sensor fault detection, fault location, fault estimation and fault separation in cascade system; The second is proposes a method of calibrating static models by using on-line data to obtain real-time fault diagnosis models; Then, gives the workflow and anti-interference measures of the real-time diagnosis system. This method can be applied to the single sensor fault diagnosis of the general cascade system. The effectiveness and accuracy of fault diagnosis were verified by experiments.
3. Fault Detection and Diagnosis Method
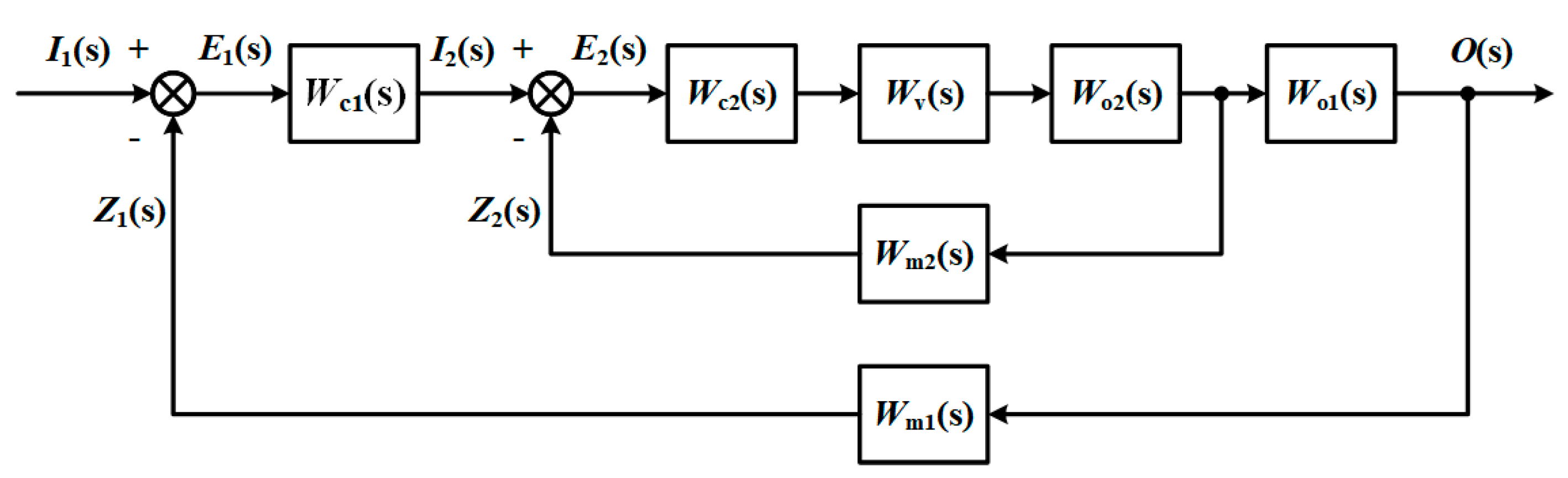
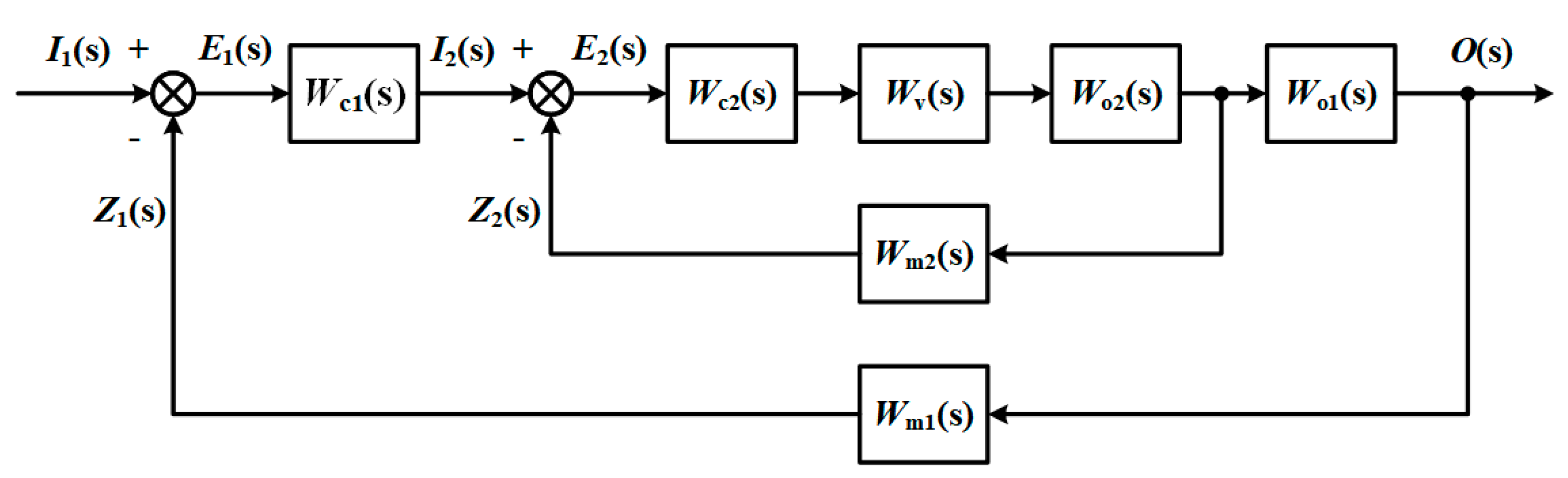
The cascade system is a double-loop system with a major loop and a vice loop. Each circle has a sensor to measure the data of the corresponding object.
Sensor faults contain many types according to different classification standards. Based on the external characteristics of the defect, the sensor faults are divided into additive fault and multiplicative fault. The symptom of additive failure is that the measured value is different from the actual value by a constant, while the sign of multiplicative failure is a constant multiple.
Sensor fault diagnosis is based on big data reflecting the dynamic characteristics of the system. Analyze the characteristic relationship of data after the system reaches control stability requirement. In the fault detection part, the data is used for fault detection in the form of windows. The following fault location, estimation, and separation diagnosis steps are performed based on the fault signs found by the fault detection.
3.1. Fault Detection Method
3.1.1. Fault Detection Method
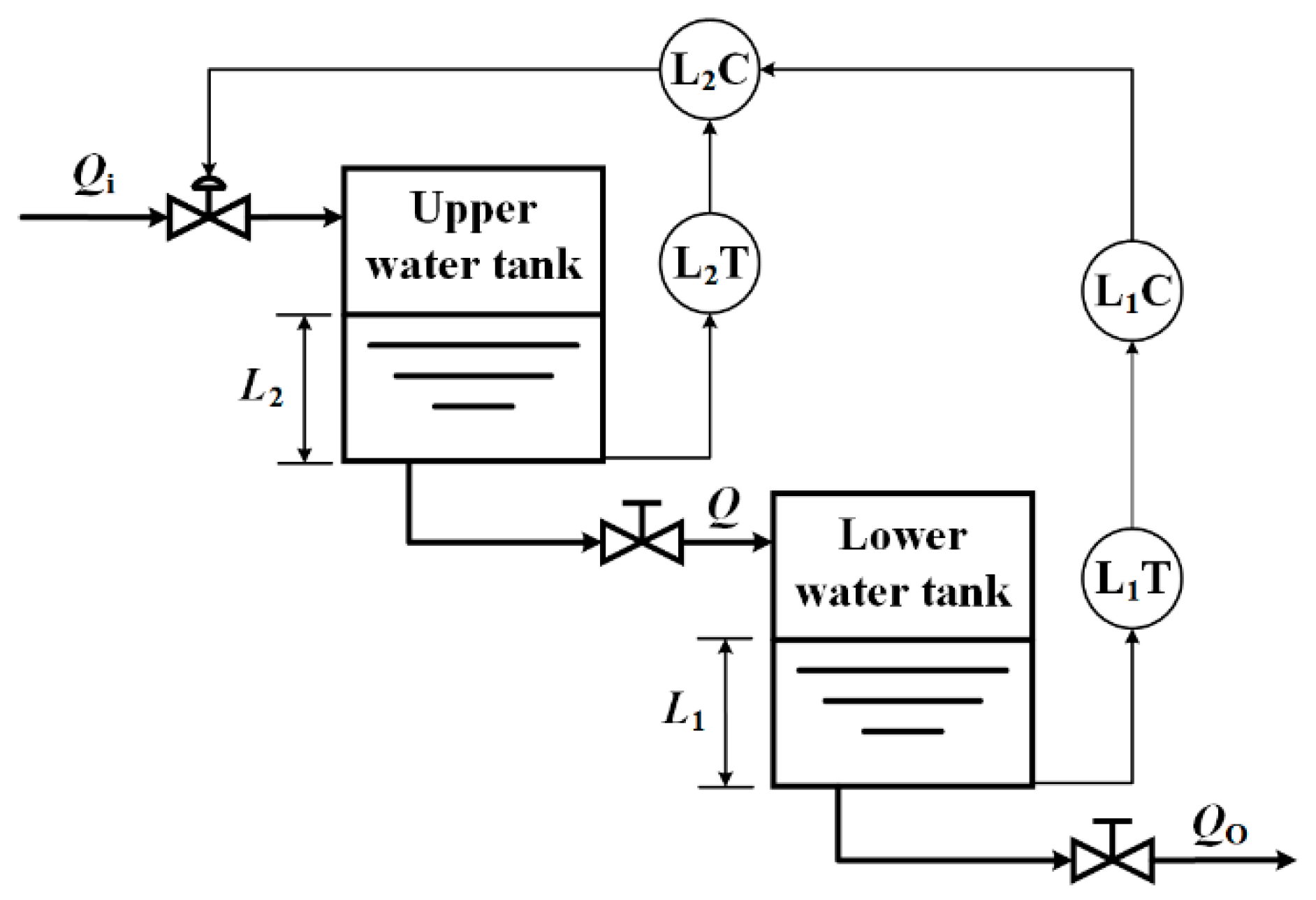
The fault detection algorithm is performed after the system reaches the control stability requirements. When the system is running stably, the liquid level of the water tanks will fluctuate slightly. The liquid level fluctuation refers to the slight difference between the liquid level data of two adjacent sampling points collected by sensors. It has a specific range so that the fault can be detected according to the degree of the liquid level fluctuation. Calculate the liquid level fluctuation value (LLFV) of the experimental data obtained under fault-free conditions:
where
Mfl and
Vfl denote the LLFVs of the lower water tank (LWT) and upper water tank (UWT), respectively,
Mc and
Vc are the measured values of these two water tanks,
t is a sampling time, and
T is the sampling step.
Suppose that one group of experimental time is
ta and liquid level adjustment time is
ts. Calculate the LLFV after it has stabilized for a while
t1, and the LLFV number of two water tanks is
Num:
Carry out multi-group fault-free experiments to reduce the error and improve fault detection accuracy. Obtain the maximum LLFV of two water tanks in each group of experiments:
where
r represents the number of fault-free experimental groups.
Mflmax and
Vflmax stand the maximum values of the liquid level data of the LWT and UWT of each group of experiments calculated by Equation (1), respectively.
Take the LWT as the example to calculate the mean value and sample variance
σM:
Take 3
σ as the trade-off of abnormal data, obtain the fluctuation threshold of the LWT liquid level for primary loop sensor fault detection can as follows:
Similarly, the liquid level fluctuation threshold of the UWT is:
Then the static models of fault detection of the major and vice sensors are, respectively:
where
Mfl (
t) and V
fl (
t) are the LLFVs of the LWT and UWT at a sampling time
t, respectively.
The proposed fault detection method averaging the maximum value of multiple windows and sets of data has a certain inhibitory effect on normal sampling fluctuations in engineering.
3.1.2. Interference Signal Suppression
Consider the fault detection method in this study is to process the instantaneous value of system running data, so suppressing the interference signal to avoid misjudgment is essential.
For random data burr interference, restrain it during the fault detection process to realize the operation of suppressing interference while detecting. The LLFV in both cases of fault and interference signal will exceed the corresponding threshold. The difference is as follows: in the former, only a single LLFV exceeds the corresponding threshold, namely, its adjacent LLFVs are all below the threshold; in the latter, at least two adjacent LLFVs exceed the corresponding threshold. We can distinguish between a system failure and an interference signal according to the difference between the two. For other disturbances such as system and environment, the fault detection method uses the measure of taking the average value, which itself has a certain function of restraining interference. For disturbance has a linear relationship with the fault, the adjustment period after the defect is used to correct the level data to achieve suppression. The disturbance and the fault are distinguished by the adjustment period.
3.2. Fault Location Method
3.2.1. Fault Location of Major Loop Sensor
The liquid level of LWT is the controlled variable, the loop it is in is the main loop, and its sensor is the major loop sensor. When the sensor in the major loop fails, the measured value of the sensor will change abruptly, and the LLFV in the lower water tank will be greater than the threshold. Through the feedback of the cascade system, the vice loop will tailor according to the measured data for the major loop sensor. In some cases, the liquid level of the UWT over-adjustment may also induce its LLFV to exceed the threshold.
Through the above analysis, we can infer that the judgment conditions of sensor failure in the major loop are as follows:
Meeting either of the above conditions represents the system fault located in the major loop sensor. Where tMF and tVF are the sampling times when the fluctuation value of LWT and UWT exceeds the corresponding threshold, respectively.
3.2.2. Fault Location of Vice Loop Sensor
When the vice loop sensor fails, the measured value of the sensor will change abruptly, and the current fluctuation value of the UWT will exceed the threshold. The fault of the vice sensor is almost no influence on it if the liquid level in the LWT has reached a stable state at this time. Hence, the LLFV in the LWT will not change significantly and will remain below the threshold.
Thus, the judgment condition for the failure of the vice loop sensor is as follows:
If the above condition is satisfied, the fault occurs in the vice loop sensor.
3.3. Fault Estimation Method
Fault estimation consists of the estimation for fault occurrence time and intensity.
3.3.1. Fault Time Estimation
Combine the fault detection and fault location algorithm to determine the time of the failure.
When the major loop sensor fails, the LLFV in the LWT at the failure sampling moment can be known by the fault detection algorithm, and then the fault occurrence time is known as tMF by the fault location algorithm Formulas (10) and (11). Similarly, the fault time is tVF described in Formula (12) when the vice loop sensor fails.
3.3.2. Fault Intensity Estimation
The fault intensity is the comparison between the liquid level sampling value at the time of failure and the one before the failure.
When the major loop sensor generates an additive fault, the fault intensity
MFp is the result of the sampling value at the fault time minus the value at the previous time:
When the major loop sensor has a multiplicative fault, the fault intensity
MFm is the result of dividing the sampling value at the fault time by the value at the previous time:
Similarly, when the vice loop sensor has an additive fault, the fault intensity
VFp is:
When the vice loop sensor occurs a multiplicative fault, the fault intensity
VFm is:
The above equations can estimate the additive and multiplicative fault intensities of the major and vice sensors.
3.4. Fault Separation Method
Fault separation is to analyze the properties of the faults detected by the above methods and judge whether the faults belong to additive fault or multiplicative fault.
3.4.1. Fault Separation of Major Loop Sensor
After failure, the measured level of LWT will mutate and then change in the opposite direction to the fault until it returns to a stable state again. In this process, the controller will adjust the liquid level for UWT according to the deviation degree of the liquid level for LWT. There exists a specific relationship between the liquid level changes of two water tanks. Consider the different states on the dynamic relationship due to different types and intensities of failures, regard the changing data as the preliminary characteristic data set. Then the measured data of the lower and upper water tank as independent and dependent variables, respectively, the first non-linear regression analysis of the characteristic data set is carried out by using Equation (17) to obtain a smooth characteristic data set:
Select multiple groups of data with different failure types and intensities for regression analysis according to Equation (17). These curves are equivalent to parabolas with different coefficients and represent the liquid level change trace after different types and intensities faults. Therefore, one of the three elements of the parabola, namely the axis of symmetry, can be used as the fault eigenvalue. According to the symmetry axis formula:
We can acquire the eigenvalue set
SP of additive fault is:
where,
p11,
p12,
p13, … represent the characteristic values of the symmetry axis under different strength additive faults. The eigenvalue set
SM of multiplicative fault is:
where,
m11,
m12,
m13, …represent the characteristic values of the symmetry axis under different strength multiplicative faults. After selecting the fault eigenvalue
S, the second non-linear regression analysis uses the least square principle. The independent and dependent variables are fault intensity and eigenvalue
S, respectively. Thus, we can acquire the fault separation model of the major loop sensor.
The additive fault model is:
The multiplicative fault model is:
Finally, compare the real-time fault eigenvalue
S with the
Sp and
Sm obtained by the above fault separation models:
If e1 < e2, it is judged that the major loop sensor generates an additive fault; otherwise, multiplicative fault.
3.4.2. Fault Separation of Vice Loop Sensor
After the vice loop sensor fails, the direction of liquid level change is completely different from the failure. At this time, the liquid level of the LWT has reached a stable state, so the change has little impact on it. Therefore, the characteristic data set only includes the data of UWT with apparent changes. Pay significant concern on the different initial change rates feature data for the UWT among various faults. Smooth the characteristic data set according to:
Select multiple groups of data with different failure types and intensities for regression analysis according to Equation (24) to obtain a series of primary linear functions with different coefficients. The coefficients of each primary term are regarded as fault eigenvalues and bring the following results:
The eigenvalue set
SLP of additive fault is:
where,
p21,
p22,
p23, … represent the characteristic values of the symmetry axis under different strength additive faults. The eigenvalue set
SLM of multiplicative fault is:
where,
m21,
m22,
m23, … represent the characteristic values of the symmetry axis under different strength multiplicative faults. The additive fault model is:
The multiplicative fault model is:
Finally, compare the real-time coefficient of the first-order term with the
SLp and
SLm obtained by the above fault separation models:
The judgment method is the same concept as that of the major loop sensor. That is, the valid result is the one with a smaller value.
3.5. On-Line Fault Diagnosis Algorithm Flow
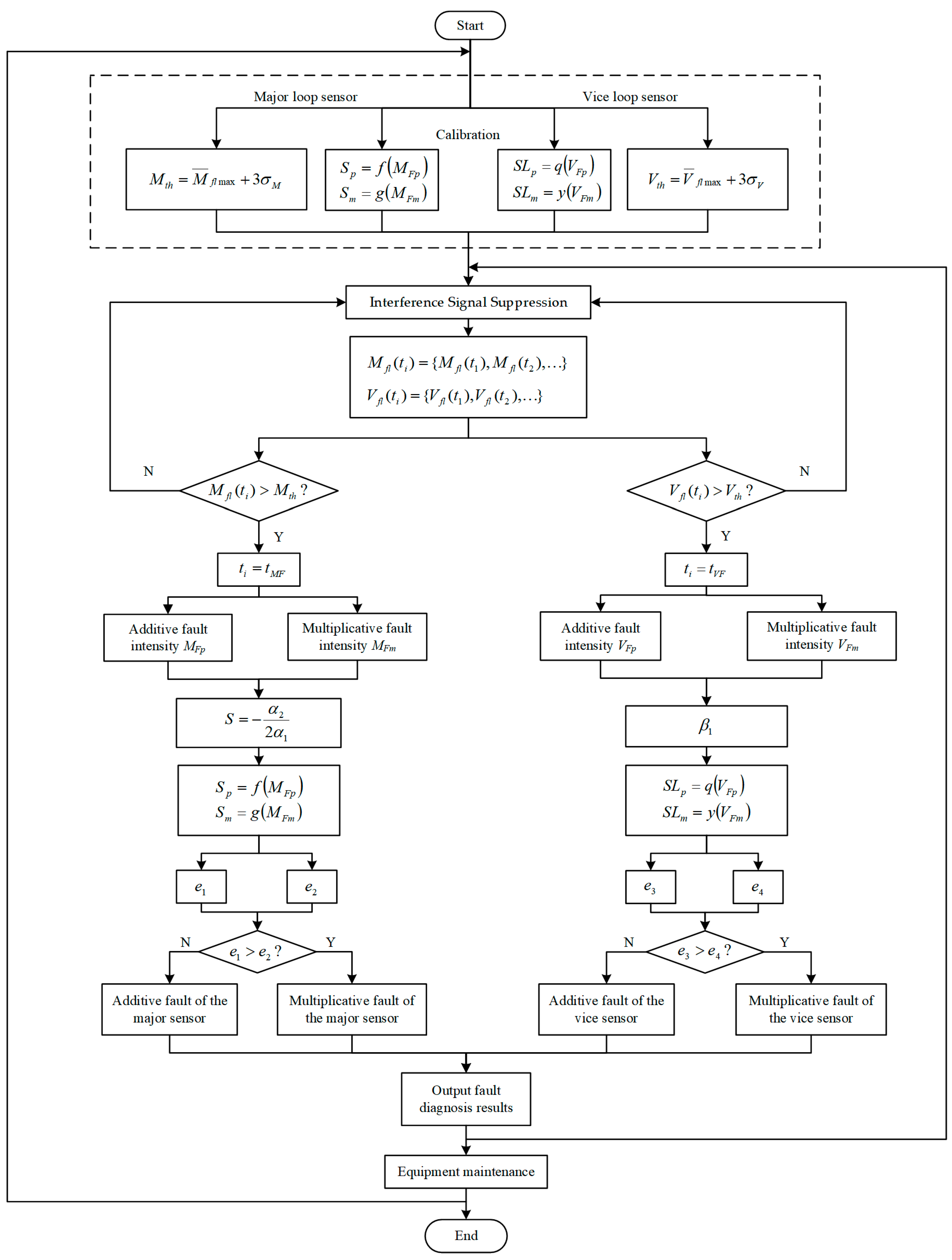
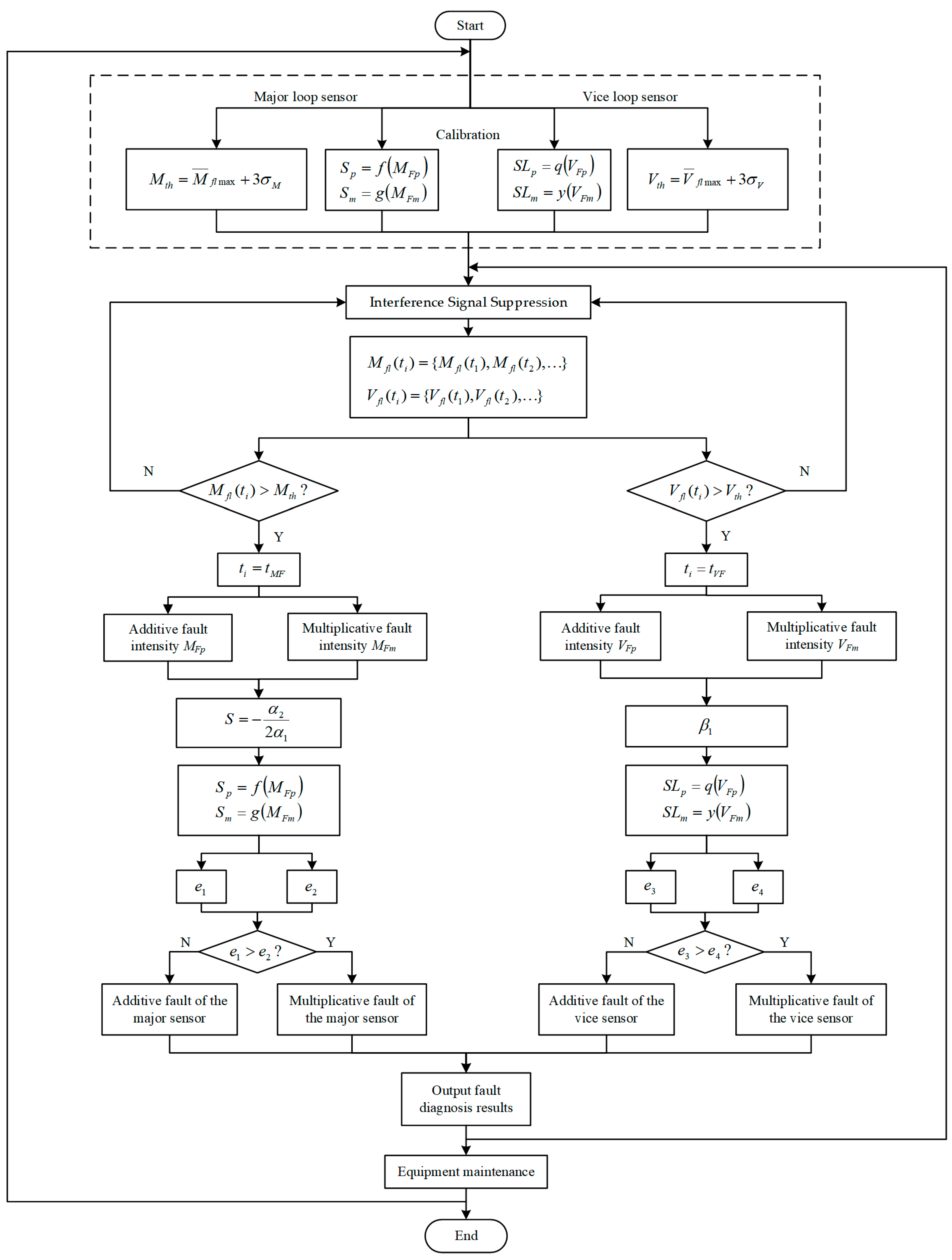
Static models of fault diagnosis are given above. In practical applications, calibrate can convert the static model into a dynamic model. Calibration is based on the static model, and the steps are as follows: (a) combine the eigenvalues of historical data for different faults; (b) obtain various parameters through the non-linear least square principle; (c) acquire the data change law caused by faults suitable for the states of various components of different engineering cascade systems; (d) complete the calibration.
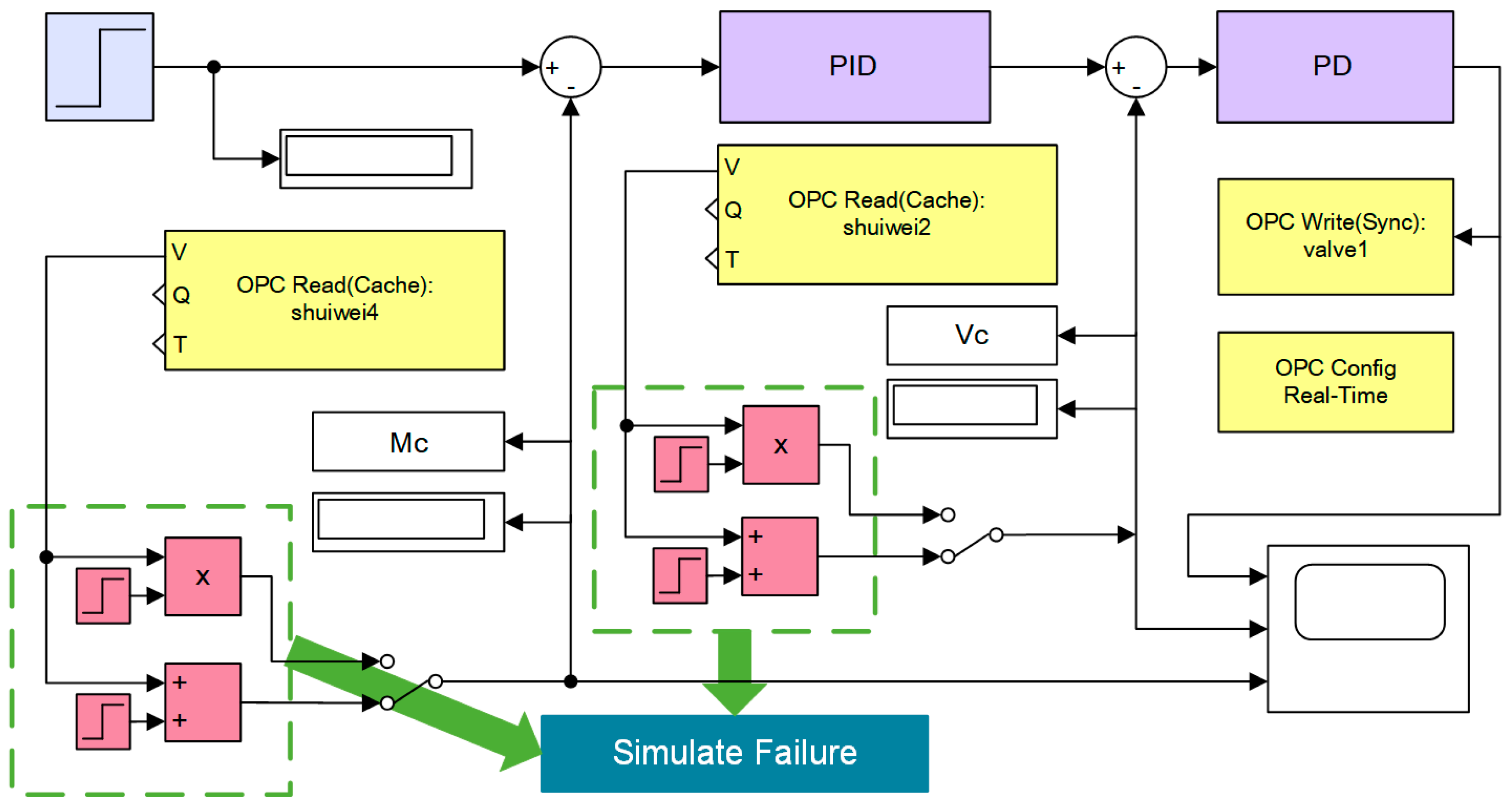
We acquire the on-line fault diagnosis of practical engineering by algorithms and calibration method above. The diagnosis steps in the sequence are fault detection and interference signal elimination, fault location, fault estimation, and separation.
Figure 3 represents the on-line calibration and diagnosis process.
5. Conclusions
In this study, we have taken the major and vice loop sensors of DWTLCCS as the analysis objects. The static models of system fault detection, location, estimation, and separation are established via historical data, which has characteristic information generated by the system operation. On balance, based on the data-driven method. We proposed the measurement to suppress disturbance, giving the calibration method and on-line fault diagnosis process. Experiments verified the effectiveness of the fault diagnosis method. The method is universal for single fault diagnosis of sensors in the cascade control system.
The traditional detection threshold is commonly determined based on the sum of residuals. A clear expectation value is required for this method. Since the vice loop of the cascade system is not the primary control object, and its controller plays the role of serving control and does not need to use integral control, which will generate the steady-state error. In such a case, the liquid level of the secondary has no definite expected value. Suppose calculated threshold value in the form of residual error sum will cause missed or false detection. The detection method we proposed reduces the missed detection rate and the amount of calculation, improving the detection accuracy simultaneously.
The detection threshold is determined according to the method put forward in this paper, and the actual system calibrates the on-line diagnosis model. To some extent, it has a certain inhibitory effect on noise, and higher detection accuracy is obtained. How to further suppress the disturbance effect is the future research focus.
Based on system dynamic characteristics and data mining methods, this study adopts the analytical geometry approach to modeling, fully utilizing data information. A precise mathematical model of the system is needless and analyzes the data generated by the system operation in real-time directly, avoiding the issue of modeling errors that depend on the mathematical model. Diagnosis is carried out in real-time, without an obvious delay problem.
During operation, considering the wear and tear of system components, regular calibration can be carried out to ensure the accuracy of diagnosis. In future work, we plan to investigate further how to enhance diagnosis precision.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}