
Live Spoofing Detection for Automatic Human Activity Recognition Applications


Abstract
:1. Introduction
- 1.
- A deep learning-based approach that can be used to detect spoof attacks from video frames capturing humans. The algorithm precisely detects the spoofing attacks and is also able to cope with video resizing and streaming artifacts, while it remains lightweight enough to run it on a mobile device alongside the main HAR algorithms.
- 2.
- A strategy to combine detection of the proposed deep learning network, temporally on a captured video or on a live video stream, for detection of video replay spoof attacks systematically while maintaining real-time performance.
- 3.
- A new database comprising real and spoof videos captured from 30 different users in different locations and under different lighting conditions. The database is diverse and precisely captures the required features for training our deep learning network.
- 4.
- An additional evaluation of the performance of the proposed approach in the context of bio-metric recognition applications.
- 5.
- An IOS mobile application that implements the proposed approach in real-time on a mobile device.
2. Related Work
2.1. Depth Analysis
2.2. Texture Analysis
2.3. Image Quality
2.4. Frequency Domain Analysis
2.5. Methods Based on Deep Learning
2.6. Summary of State-of-the-Art Methods
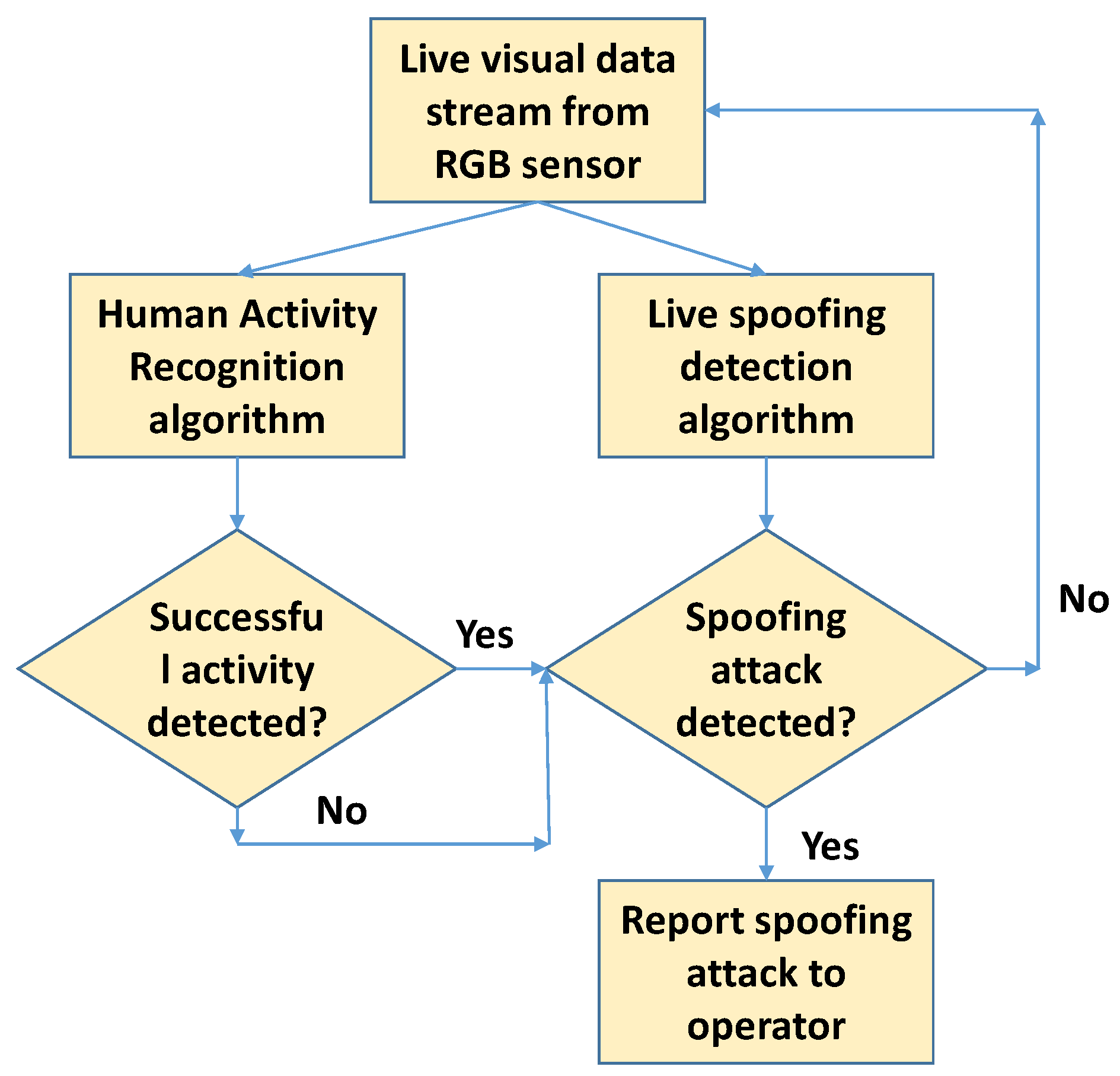
3. Visual Analysis for Video Replay Spoofing Detection
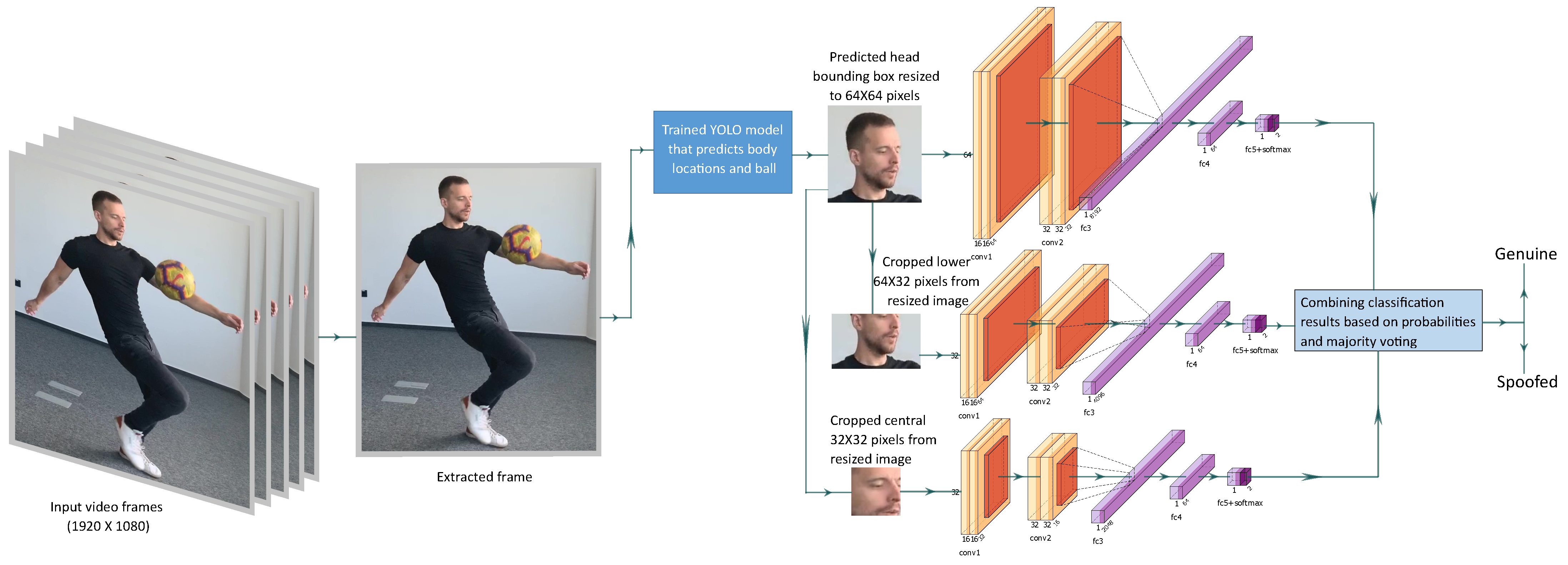
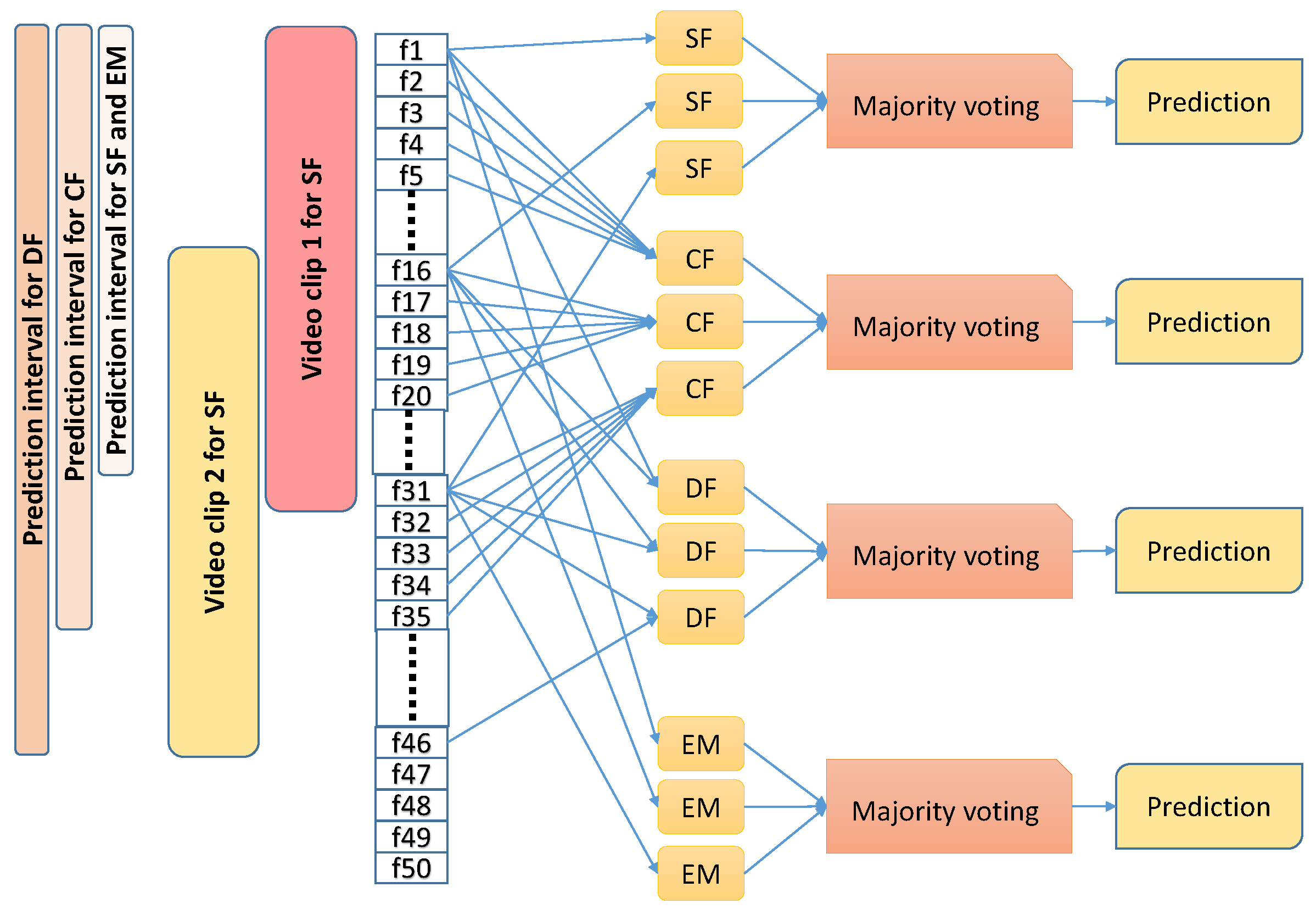
3.1. Context Selection for Spoofing Detection
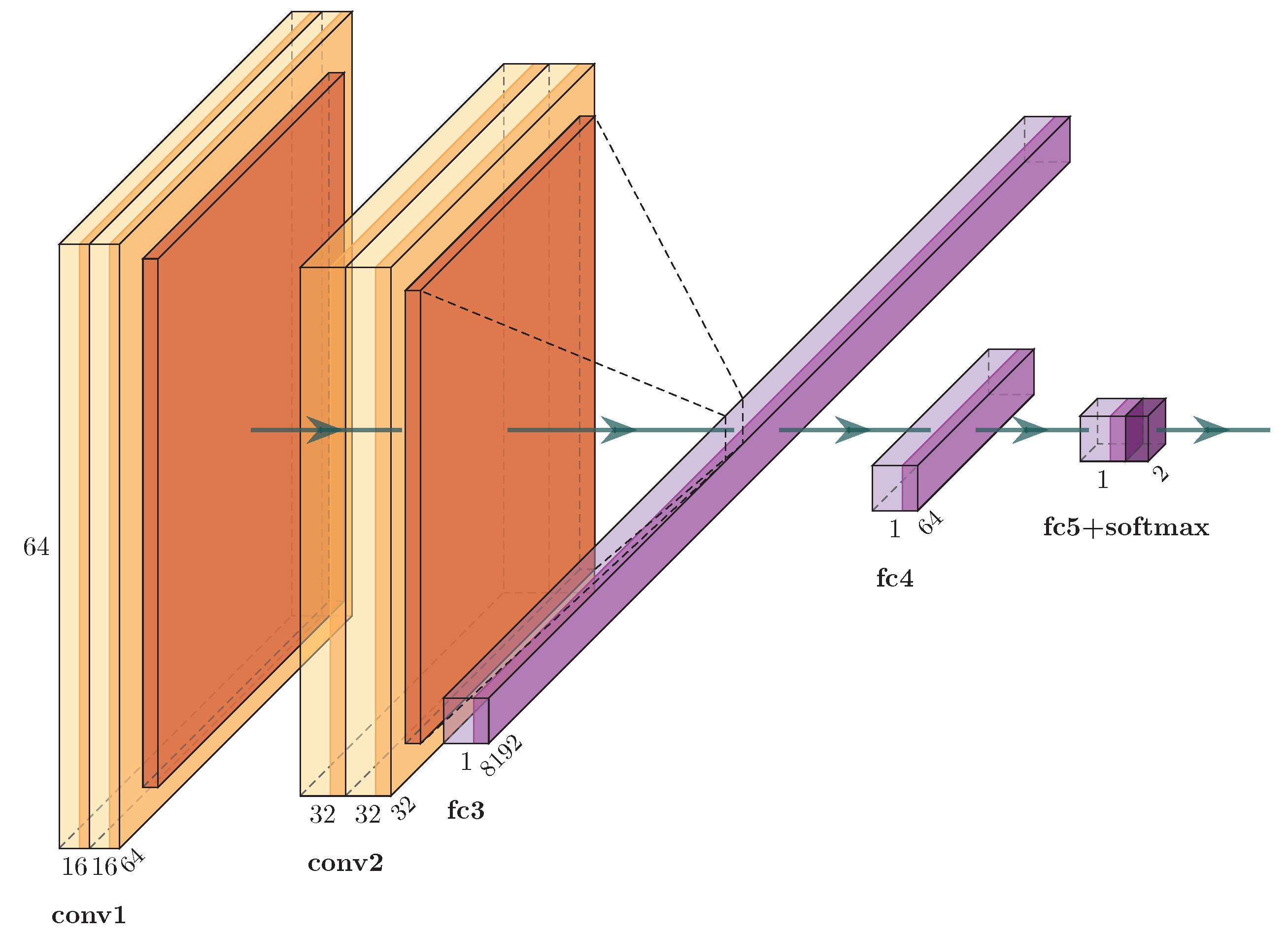
3.2. Models
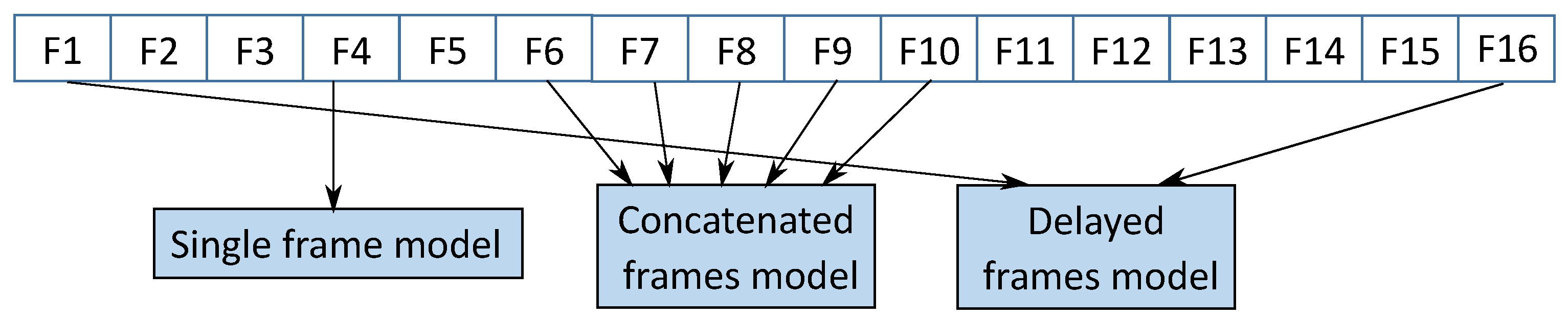
3.2.1. Single Frame Model (SF)
3.2.2. Concatenated Frames Model (CF)
3.2.3. Delayed Frames Model (DF)
3.2.4. Ensemble Multi-Stream Model (EM)
3.3. Learning
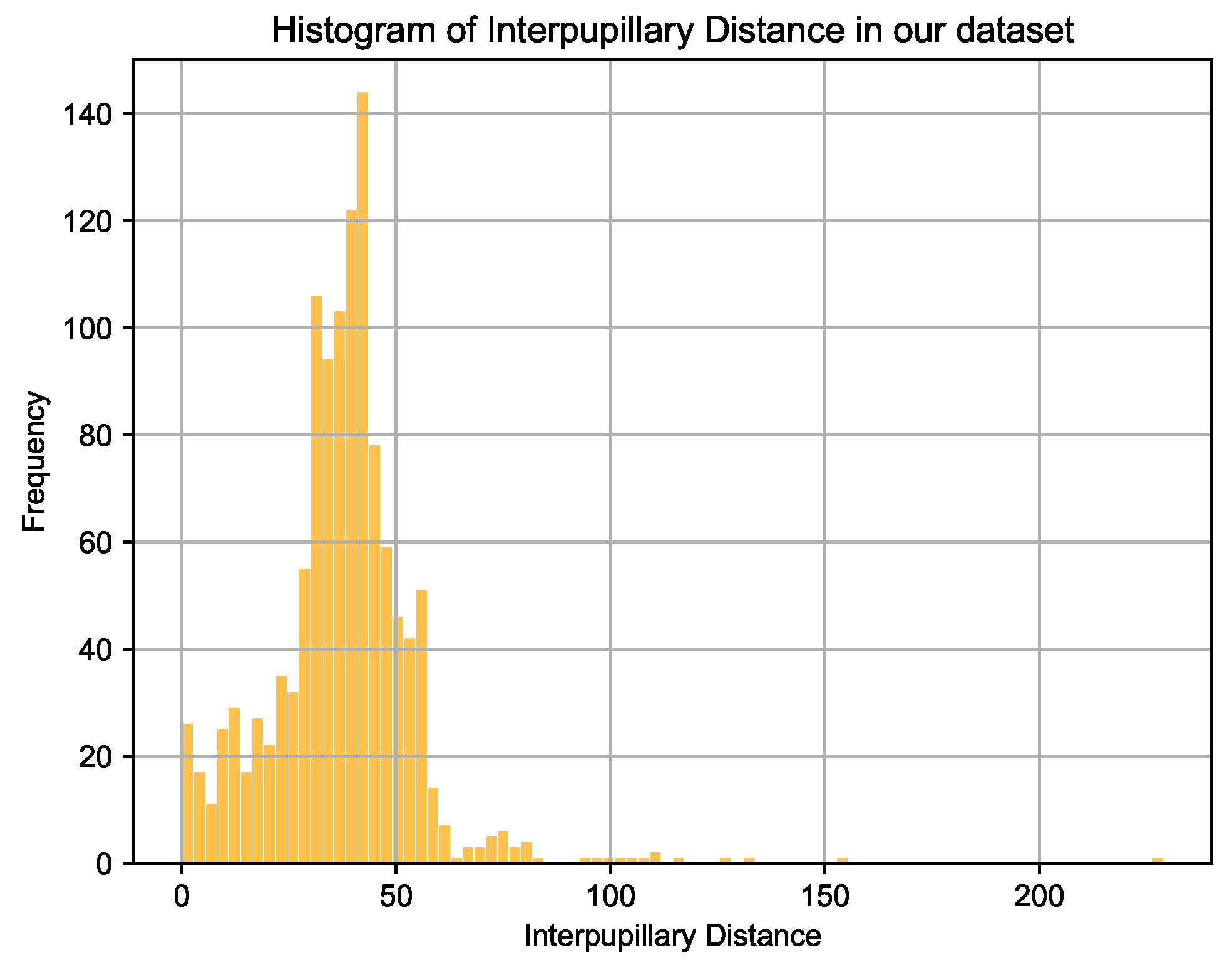
3.3.1. Data Preparation and Pre-Processing
3.3.2. Optimization
4. Results and Discussion
4.1. Testing Scheme
4.2. Experiments on Our Dataset
4.2.1. Training
4.2.2. Video-Clip Level Predictions
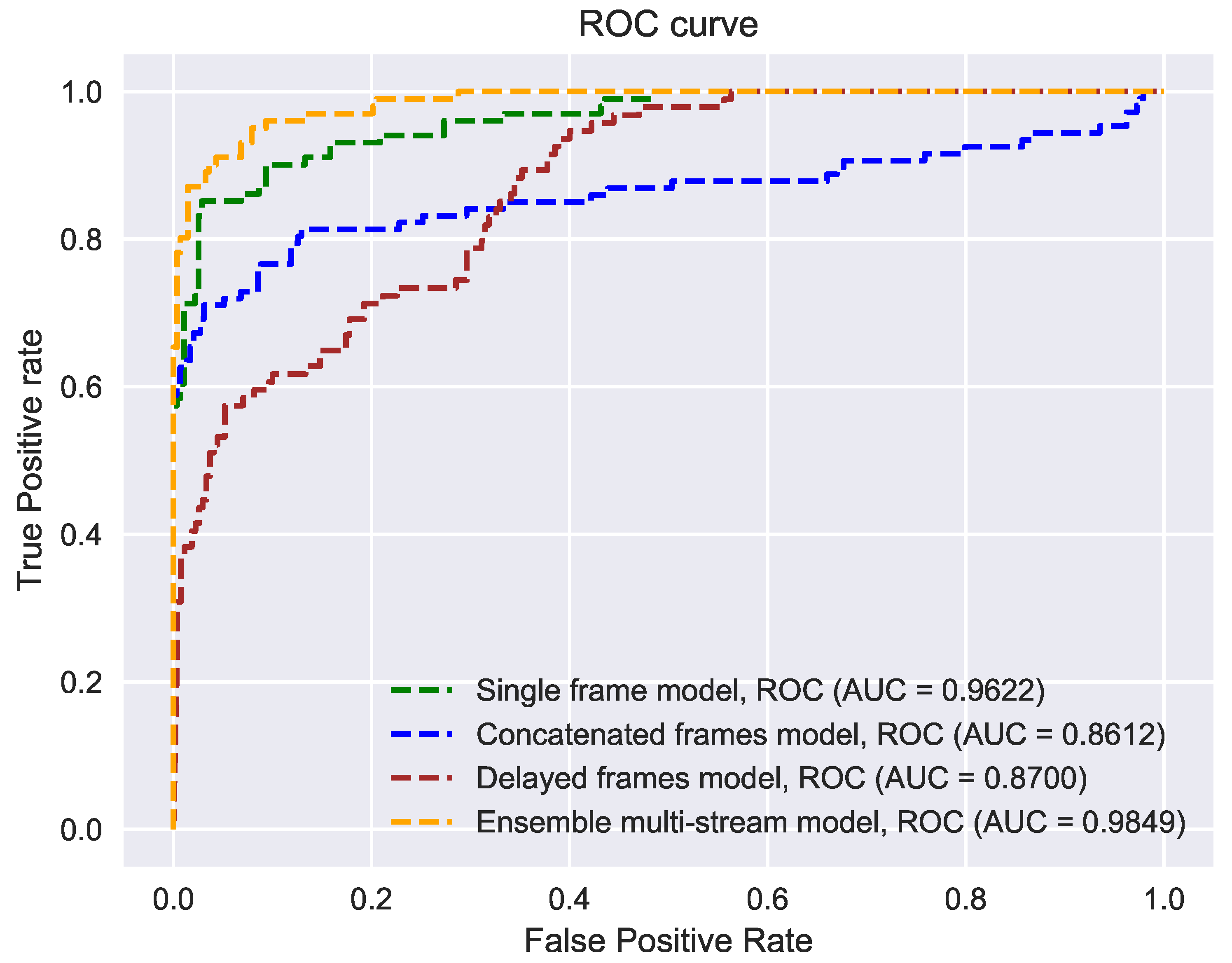
4.2.3. Comparison with Existing Baseline Spoofing Detection Methods
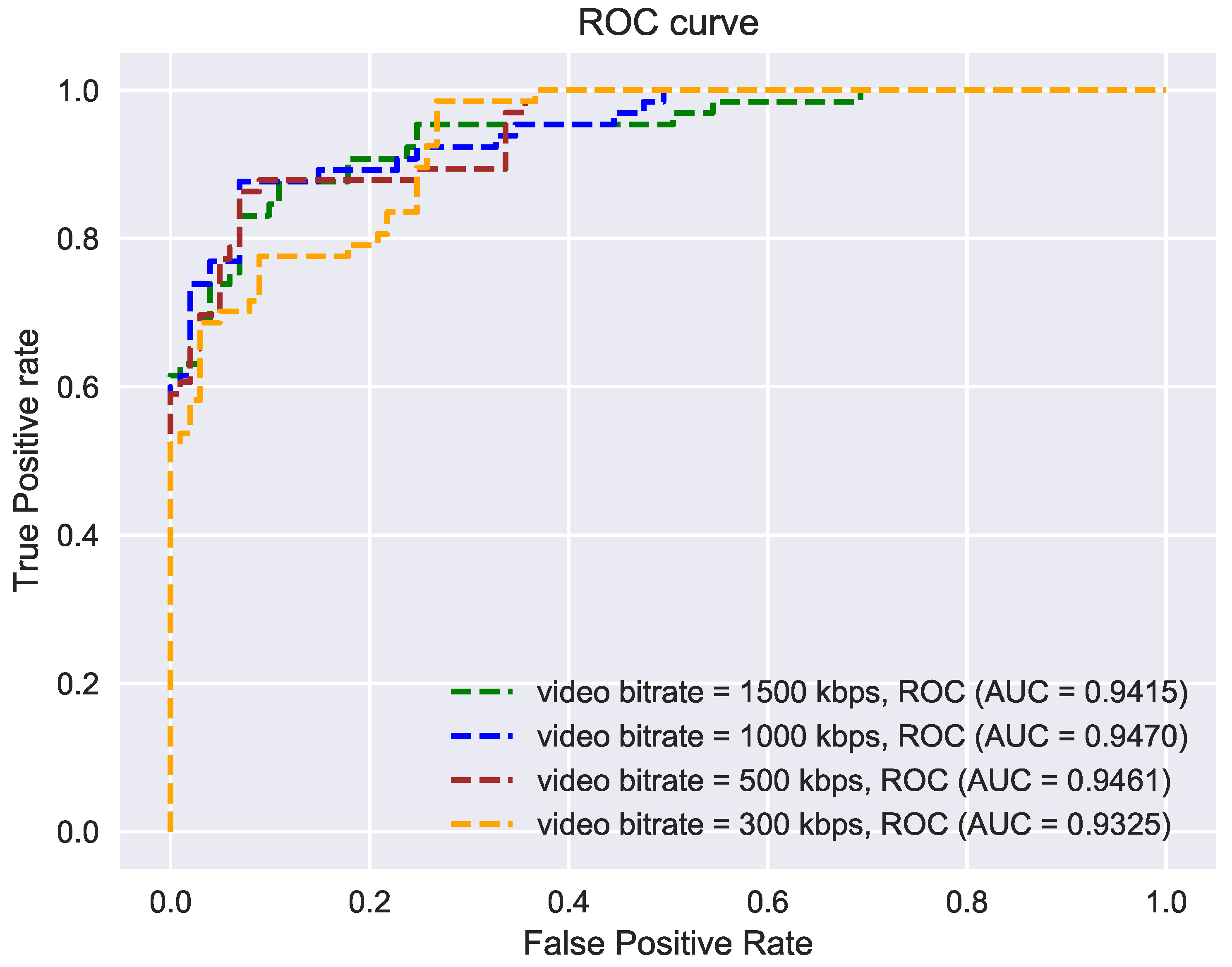
4.2.4. Experiments with Video Compression
4.3. Experiments with Face Recognition Databases
4.4. Mobile Implementation and Performance
4.5. Performance Constraints
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jones, S.E.E. Wearable smart sensor systems integrated on soft contact lenses for wireless ocular diagnostics. Nat. Commun. 2017, 8, 14997. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.E. Genetic studies of accelerometer-based sleep measures in 85,670 individuals yield new insights into human sleep behaviour. bioRxiv 2018. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.E. Wearable biosensors for healthcare monitoring. Nat. Biotechnol. 2019, 37, 389–406. [Google Scholar] [CrossRef]
- Jalal, A.; Uddin, M.Z.; Kim, T. Depth video-based human activity recognition system using translation and scaling invariant features for life logging at smart home. IEEE Trans. Consum. Electron. 2012, 58, 863–871. [Google Scholar] [CrossRef]
- Xing, Y.; Lv, C.; Wang, H.; Cao, D.; Velenis, E.; Wang, F. Driver Activity Recognition for Intelligent Vehicles: A Deep Learning Approach. IEEE Trans. Veh. Technol. 2019, 68, 5379–5390. [Google Scholar] [CrossRef] [Green Version]
- Revathi, A.R.; Kumar, D. A Survey of Activity Recognition And Understanding The Behavior In Video Survelliance. Vis Comput. 2013, 29, 983–1009. [Google Scholar]
- Mukherjee, A.; Misra, S.; Mangrulkar, P.; Rajarajan, M.; Rahulamathavan, Y. SmartARM: A smartphone-based group activity recognition and monitoring scheme for military applications. In Proceedings of the 2017 IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS), Bhubaneswar, India, 17–20 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- SQILLER App. The Digital Football Game. 2019. Available online: https://sqillerapp.com/ (accessed on 19 July 2021).
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Nweke, H.F.; Teh, Y.W.; Al-garadi, M.A.; Alo, U.R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Bresan, R.; Pinto, A.; Rocha, A.; Beluzo, C.; Carvalho, T. FaceSpoof Buster: A Presentation Attack Detector Based on Intrinsic Image Properties and Deep Learning. arXiv 2019, arXiv:1902.02845. [Google Scholar]
- Bharadwaj, S.; Dhamecha, T.I.; Vatsa, M.; Singh, R. Computationally Efficient Face Spoofing Detection with Motion Magnification. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 105–110. [Google Scholar] [CrossRef]
- Pan, G.; Sun, L.; Wu, Z.; Lao, S. Eyeblink-based Anti-Spoofing in Face Recognition from a Generic Webcamera. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Uzun, E.; Chung, S.P.; Essa, I.; Lee, W. rtCaptcha: A Real-Time CAPTCHA Based Liveness Detection System. In Proceedings of the NDSS Symposium, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Zhang, Z.; Yi, D.; Lei, Z.; Li, S.Z. Face liveness detection by learning multispectral reflectance distributions. In Proceedings of the 2011 IEEE International Conference on Automatic Face Gesture Recognition (FG), Santa Barbara, CA, USA, 21–25 March 2011; pp. 436–441. [Google Scholar] [CrossRef]
- Erdogmus, N.; Marcel, S. Spoofing in 2D face recognition with 3D masks and anti-spoofing with Kinect. In Proceedings of the 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September– 2 October 2013; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Bao, W.; Li, H.; Li, N.; Jiang, W. A liveness detection method for face recognition based on optical flow field. In Proceedings of the 2009 International Conference on Image Analysis and Signal Processing, Linhai, China, 11–12 April 2009; pp. 233–236. [Google Scholar] [CrossRef]
- De Marsico, M.; Nappi, M.; Riccio, D.; Dugelay, J.L. Moving face spoofing detection via 3D projective invariants. In Proceedings of the 2012 5th IAPR International Conference on Biometrics (ICB), New Delhi, India, 29 March–1 April 2012; pp. 73–78. [Google Scholar] [CrossRef]
- Chingovska, I.; Anjos, A.; Marcel, S. On the effectiveness of local binary patterns in face anti-spoofing. In Proceedings of the 2012 BIOSIG—Proceedings of the International Conference of Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 6–7 September 2012; pp. 1–7. [Google Scholar]
- Määttä, J.; Hadid, A.; Pietikäinen, M. Face spoofing detection from single images using micro-texture analysis. In Proceedings of the 2011 International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011; pp. 1–7. [Google Scholar] [CrossRef]
- Bai, J.; Ng, T.T.; Gao, X.; Shi, Y.Q. Is physics-based liveness detection truly possible with a single image? In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 3425–3428. [Google Scholar] [CrossRef]
- Tan, X.; Li, Y.; Liu, J.; Jiang, L. Face Liveness Detection from a Single Image with Sparse Low Rank Bilinear Discriminative Model. In Computer Vision—ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 504–517. [Google Scholar]
- Boulkenafet, Z.; Komulainen, J.; Hadid, A. Face Spoofing Detection Using Colour Texture Analysis. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1818–1830. [Google Scholar] [CrossRef]
- Komulainen, J.; Hadid, A.; Pietikäinen, M.; Anjos, A.; Marcel, S. Complementary countermeasures for detecting scenic face spoofing attacks. In Proceedings of the 2013 International Conference on Biometrics (ICB), Madrid, Spain, 4–7 June 2013; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Galbally, J.; Marcel, S.; Fierrez, J. Image Quality Assessment for Fake Biometric Detection: Application to Iris, Fingerprint, and Face Recognition. IEEE Trans. Image Process. 2014, 23, 710–724. [Google Scholar] [CrossRef] [Green Version]
- Unnikrishnan, S.; Eshack, A. Face spoof detection using image distortion analysis and image quality assessment. In Proceedings of the 2016 International Conference on Emerging Technological Trends (ICETT), Kollam, India, 21–22 October 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Garcia, D.C.; de Queiroz, R.L. Face-Spoofing 2D-Detection Based on Moiré-Pattern Analysis. IEEE Trans. Inf. Forensics Secur. 2015, 10, 778–786. [Google Scholar] [CrossRef]
- Arashloo, S.R.; Kittler, J.; Christmas, W. An Anomaly Detection Approach to Face Spoofing Detection: A New Formulation and Evaluation Protocol. IEEE Access 2017, 5, 13868–13882. [Google Scholar] [CrossRef]
- Li, J.; Wang, Y.; Tan, T.; Jain, A.K. Live face detection based on the analysis of Fourier spectra. In Biometric Technology for Human Identification; Jain, A.K., Ratha, N.K., Eds.; International Society for Optics and Photonics, SPIE: Orlando, FL, USA, 2004; Volume 5404, pp. 296–303. [Google Scholar] [CrossRef]
- Kim, G.; Eum, S.; Suhr, J.K.; Kim, D.I.; Park, K.R.; Kim, J. Face liveness detection based on texture and frequency analyses. In Proceedings of the 2012 5th IAPR International Conference on Biometrics (ICB), New Delhi, India, 29 March–1 April 2012; pp. 67–72. [Google Scholar] [CrossRef]
- Pinto, A.; Schwartz, W.R.; Pedrini, H.; Rocha, A.d.R. Using Visual Rhythms for Detecting Video-Based Facial Spoof Attacks. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1025–1038. [Google Scholar] [CrossRef]
- Pinto, A.; Pedrini, H.; Schwartz, W.R.; Rocha, A. Face Spoofing Detection Through Visual Codebooks of Spectral Temporal Cubes. IEEE Trans. Image Process. 2015, 24, 4726–4740. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Liu, Y.; Jourabloo, A.; Liu, X. Learning Deep Models for Face Anti-Spoofing: Binary or Auxiliary Supervision. arXiv 2018, arXiv:1803.11097. [Google Scholar]
- Atoum, Y.; Liu, Y.; Jourabloo, A.; Liu, X. Face anti-spoofing using patch and depth-based CNNs. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 319–328. [Google Scholar] [CrossRef]
- de Freitas Pereira, T.; Anjos, A.; De Martino, J.M.; Marcel, S. Can face anti-spoofing countermeasures work in a real world scenario? In Proceedings of the 2013 International Conference on Biometrics (ICB), Madrid, Spain, 4–7 June 2013; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Yan, J.; Liu, S.; Lei, Z.; Yi, D.; Li, S.Z. A face antispoofing database with diverse attacks. In Proceedings of the 2012 5th IAPR International Conference on Biometrics (ICB), New Delhi, India, 29 March–1 April 2012; pp. 26–31. [Google Scholar] [CrossRef]
- Tirunagari, S.; Poh, N.; Windridge, D.; Iorliam, A.; Suki, N.; Ho, A.T.S. Detection of Face Spoofing Using Visual Dynamics. IEEE Trans. Inf. Forensics Secur. 2015, 10, 762–777. [Google Scholar] [CrossRef] [Green Version]
- Kim, W.; Suh, S.; Han, J.J. Face liveness detection from a single image via diffusion speed model. IEEE Trans. Image Process. 2015, 24, 2456–2465. [Google Scholar] [CrossRef]
- Menotti, D.; Chiachia, G.; Pinto, A.; Robson Schwartz, W.; Pedrini, H.; Xavier Falcao, A.; Rocha, A. Deep Representations for Iris, Face, and Fingerprint Spoofing Detection. IEEE Trans. Inf. Forensics Secur. 2015, 10, 864–879. [Google Scholar] [CrossRef] [Green Version]
- Boulkenafet, Z.; Komulainen, J.; Hadid, A. face anti-spoofing based on color texture analysis. arXiv 2015, arXiv:1511.06316. [Google Scholar]
- Arashloo, S.R.; Kittler, J.; Christmas, W. Face Spoofing Detection Based on Multiple Descriptor Fusion Using Multiscale Dynamic Binarized Statistical ImageFeatures. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2396–2407. [Google Scholar] [CrossRef] [Green Version]
- Wen, D.; Han, H.; Jain, A.K. Face Spoof Detection With Image Distortion Analysis. IEEE Trans. Inf. Forensics Secur. 2015, 10, 746–761. [Google Scholar] [CrossRef]
- Bok, J.Y.; Suh, K.H.; Lee, E.C. Verifying the Effectiveness of New Face Spoofing DB with Capture Angle and Distance. Electronics 2020, 9, 661. [Google Scholar] [CrossRef] [Green Version]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. arXiv 2019, arXiv:1812.08008. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Feichtenhofer, C. X3D: Expanding Architectures for Efficient Video Recognition. arXiv 2020, arXiv:2004.04730. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 1 June 2021).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- ISO. ISO/IEC JTC 1 /SC 37 Biometrics Information Technology—Biometric Presentation Attack Detection—Part 3: Testing and Reporting; International Organization for Standardization: Geneva, Switzerland, 2017. [Google Scholar]
- de Freitas Pereira, T.; Anjos, A.; De Martino, J.M.; Marcel, S. LBP TOP Based Countermeasure against Face Spoofing Attacks. In Computer Vision—ACCV 2012 Workshops; Park, J.I., Kim, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 121–132. [Google Scholar]
- Nguyen, T.P.; Vu, N.S.; Manzanera, A. Statistical binary patterns for rotational invariant texture classification. Neurocomputing 2016, 173, 1565–1577. [Google Scholar] [CrossRef]
- Zhang, Y.; Dubey, R.K.; Hua, G.; Thing, V.L. Face Spoofing Video Detection Using Spatio-Temporal Statistical Binary Pattern. In Proceedings of the TENCON 2018—2018 IEEE Region 10 Conference, Jeju, Korea, 28–31 October 2018; pp. 0309–0314. [Google Scholar] [CrossRef]
- FFmpeg Developers. Ffmpeg Tool (Version be1d324). 2016. Available online: http://ffmpeg.org/ (accessed on 19 July 2021).
- Costa-Pazo, A.; Bhattacharjee, S.; Vazquez-Fernandez, E.; Marcel, S. The Replay-Mobile Face Presentation-Attack Database. In Proceedings of the 2016 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 21–23 September 2016; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Swift Developers. Swift Programming Language. Available online: https://developer.apple.com/swift/ (accessed on 19 July 2021).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | State-of-the-Art Performance |
|---|---|
| Face motion analysis | ZJU Eyeblink [13] (Intra-DB, Cross-DB) [13]: (95.7, n/a) |
| Idiap Replay-attack [19] (Intra-DB, Cross-DB) [12]: (1.25, n/a) | |
| CASIA FASD [37] (Intra-DB, Cross-DB) [38]: (21.75, n/a) | |
| Depth analysis | Idiap Replay-attack (Intra-DB, Cross-DB) [39]: (12.5, n/a) |
| Image texture analysis | Idiap Replay-attack (Intra-DB, Cross-DB) [36]: (15.54, 47.1); [40]: (0.8, n/a); [41]:(2.9, 16.7); [42]:(1, n/a) |
| CASIA FASD (Intra-DB, Cross-DB) [41]: (6.2,37.6); [42]: (7.2, 30.2) | |
| Image quality analysis | Idiap Replay-attack (Intra-DB, Cross-DB) [43]: (7.41, 26.9); [25]: (15.2, n/a); |
| CASIA FASD (Intra-DB, Cross-DB) [43]: (12.9, 43.7) | |
| MSU MFSD [43] (Intra-DB, Cross-DB) [43]: (5.82, 22.6) | |
| Frequency domain analysis | Idiap Replay-attack (Intra-DB, Cross-DB) [32]: (2.8, 34.4) |
| CASIA FASD (Intra-DB, Cross-DB) [32]: (14, 38.5) | |
| UVAD [32] (Intra-DB, Cross-DB) [32]: (29.9, 40.1) | |
| Deep learning based methods | PR FASD [44] (Intra-DB, Cross-DB) [44]-ResNet: (n/a, 14.19); [44]-DenseNet: (n/a, 16.97) |
| MSU MFSD (Intra-DB, Cross-DB) [44]-ResNet: (n/a, 20.53); [44]-DenseNet: (n/a, 21.78) | |
| Idiap Replay-attack [19] (Intra-DB, Cross-DB) [44]-ResNet: (n/a, 31.42); [44]-DenseNet: (n/a, 31.52) |
| Method | APCER | BPCER | HTER |
|---|---|---|---|
| SF | 9.9010 | 12.9496 | 11.4253 |
| CF | 36.4486 | 1.7007 | 19.0746 |
| DF | 3.1915 | 45.5556 | 24.3735 |
| EM | 8.9109 | 6.1151 | 7.5130 |
| Method | APCER | BPCER | HTER |
|---|---|---|---|
| LBP | 40.5780 | 48.1586 | 44.3683 |
| LBP-TOP | 27.2727 | 40.3226 | 33.7977 |
| SBP | 3.1915 | 45.5556 | 24.3735 |
| SBP-TOP | 15.4124 | 78.9660 | 47.1892 |
| EM | 8.9109 | 6.1151 | 7.5130 |
| Method | APCER | BPCER | HTER |
|---|---|---|---|
| REPLAY-MOBILE | 5.4678 | 13.7856 | 9.6267 |
| CASIA | 27.0916 | 16.0396 | 21.5656 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huszár, V.D.; Adhikarla, V.K. Live Spoofing Detection for Automatic Human Activity Recognition Applications. Sensors 2021, 21, 7339. https://doi.org/10.3390/s21217339
Huszár VD, Adhikarla VK. Live Spoofing Detection for Automatic Human Activity Recognition Applications. Sensors. 2021; 21(21):7339. https://doi.org/10.3390/s21217339
Chicago/Turabian StyleHuszár, Viktor Dénes, and Vamsi Kiran Adhikarla. 2021. "Live Spoofing Detection for Automatic Human Activity Recognition Applications" Sensors 21, no. 21: 7339. https://doi.org/10.3390/s21217339
APA StyleHuszár, V. D., & Adhikarla, V. K. (2021). Live Spoofing Detection for Automatic Human Activity Recognition Applications. Sensors, 21(21), 7339. https://doi.org/10.3390/s21217339