1. Introduction
The Internet is initially designed as a “collection of hosts” which is used to access available resources that are distributed in the network. The traditional TCP/IP Internet architecture supports the host-centric content retrieval mechanism, where the contents are accessed using the IP addresses of network nodes. The Internet has become a global infrastructure and with its tremendous growth in applications, the IP-based network traffic is estimated to be 4712 Exabytes per year at the end of 2022 [
1]. Moreover, modern Internet applications [
2,
3] impose intensive Quality-of-Service (QoS) requirements during content retrieval operations such as minimal content access delay, network traffic, and effective use of available network resources, etc. The quality improvements in the IP-based environment have various techniques implied in recent research as per authors Tiwari et al. [
4,
5]. However, the patch-based TCP/IP architecture starts showing its limitations towards the current Internet applications and their increased new requirements due to its host-centric nature [
6,
7].
In this context, the Content-Centric Networking (CCN) is proposed as a clean slate architecture for the future Internet [
8]. CCN supports a content-name-based data retrieval mechanism instead of searching for the IP address-based host in the network to access the required data. Thus, the data can be retrieved from any network node that has a copy of the requested content in CCN. Furthermore, the CCN offers the in-network caching capability and the requested contents can be served from the origin servers or the cache of nearby intermediate network routers. The underlying content caching improves QoS for the end-users by minimizing content retrieval delay, reducing the load on the network nodes, and traffic during data dissemination [
9,
10].
The in-network content caching policy takes decisions related to the selection of suitable locations for the content placement and selection of older contents for replacement operations when the cache becomes full. These caching policies are generally categorized into on-path and off-path caching schemes [
11]. In on-path schemes [
12], the content is cached in the intermediary routers that forward the content from the content provider towards the requester. In recent, several on-path caching schemes are proposed by various researchers that takes content placement decisions based on the content popularity [
13,
14], node importance [
10,
15], content age [
16], and distance-based parameters [
17,
18], etc. Contrarily, the off-path schemes can place the content in any of the network router that may or may not exist in the content delivery route. Generally, the off-path caching schemes considers a hash-based mechanism during content caching decisions such as [
19,
20,
21]. Due to hash-based content caching decisions, most of the off-path caching schemes suffers from higher network traffic and increased path stretch. Additionally, these schemes do not consider the content popularity or topological information during content placement decisions. In contrast to these schemes, the on-path schemes creates lesser communication overhead and computational complexity during content caching decisions. Therefore, the on-path caching schemes are widely implemented in the CCN. After exhaustive analysis of the existing on-path caching strategies, there are mainly two reasons that motivated us for the proposed content caching scheme.
Network traffic and redundancy: The conventional on-path caching policy of CCN, called ubiquitous caching [
22] allows each intermediary router in the retrieval path to temporarily store the incoming contents. This increases the availability of contents near the end-user devices and reduces content retrieval delay up to certain extent. However, the scheme suffers from higher content redundancy as the same content is placed in all the on-path routers during content forwarding. Due to this, the other content requests need to be served by the server, which causes excessive network traffic due to poor cache diversity. This leads to degraded network performance and QoS for end user devices. Therefore, although caching of contents in the intermediate routers improves network performance, the determination of appropriate network routers and the selection of contents for the caching operations is an open research gap that needs to be addressed.
Content retrieval delay: Most of the existing on-path caching schemes takes autonomous caching decisions. Before forwarding the content to downstream nodes, each on-path router needs to perform certain computations for content caching decisions. This excessive computation for content caching becomes an obstruction in real-time content delivery and also causes excessive consumption of computational resources in the network routers. Therefore, it is essential to reduce the computational delay during caching decisions and the suitable contents need to be placed in appropriate network routers.
With these motivations, the objective of this paper is to propose an efficient content caching scheme that reduces the content retrieval delay and resource consumptions to offer improved network performance in CCN networks. Towards this, the proposed scheme provides two-folded content caching strategy. First, it partitioned the network nodes into the non-overlapping clusters using the topological information of the network. The clustering is performed to reduce content placement/replacement operations and to decrease computational latency in the network routers. During content retrieval, at most one copy of the incoming content is cached in that cluster from where the request is generated. The intermediate routers that do not belong to requester’s cluster in the path, cannot cache the forwarded contents. Hence, the computational latency is significantly reduced for the network routers. Secondly, to take caching decisions, the proposed scheme considers the content popularity and the hop count information to place popular contents near the end-user devices. When an intra-cluster router cache the incoming content, the remaining routers of that cluster just forward the content towards the requester without further caching operations. Thus, the proposed heuristics also control the excessive content redundancy and lead to comprehensive use of the caching capacities of the network. The major contributions of the paper are as follows:
A clustering-based in-network content caching scheme is proposed for the CCN to improve QoS for end-user devices and comprehensive use of cache space. By clustering the network nodes, the proposed scheme constrains excessive caching operations and content redundancy in the network.
The proposed caching scheme considers content popularity and hop-count metrics along with the clusters information for the caching decisions. Using these heuristics, the caching probability increases for the frequently accessed contents near the end-user devices to reduce content access delay.
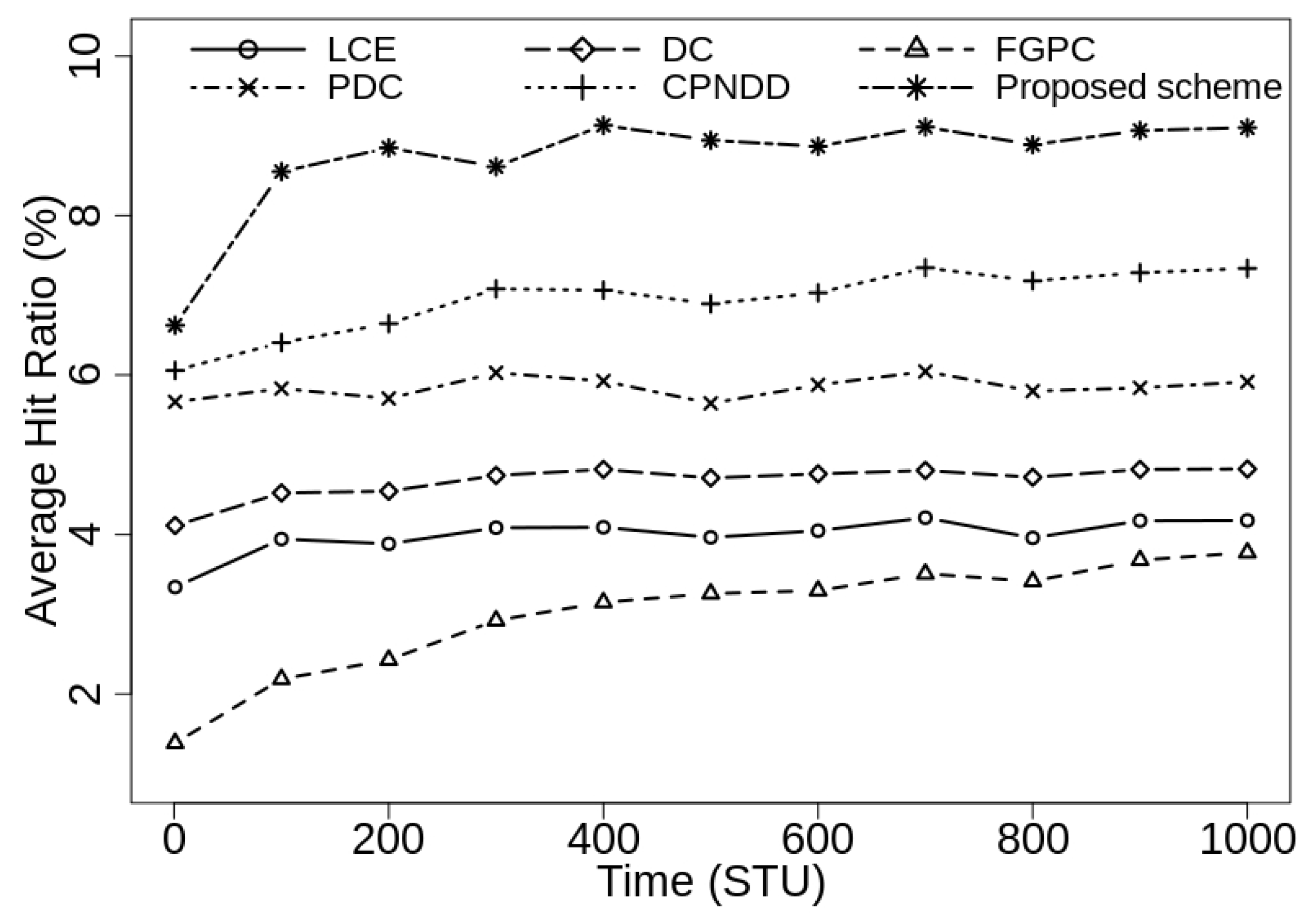
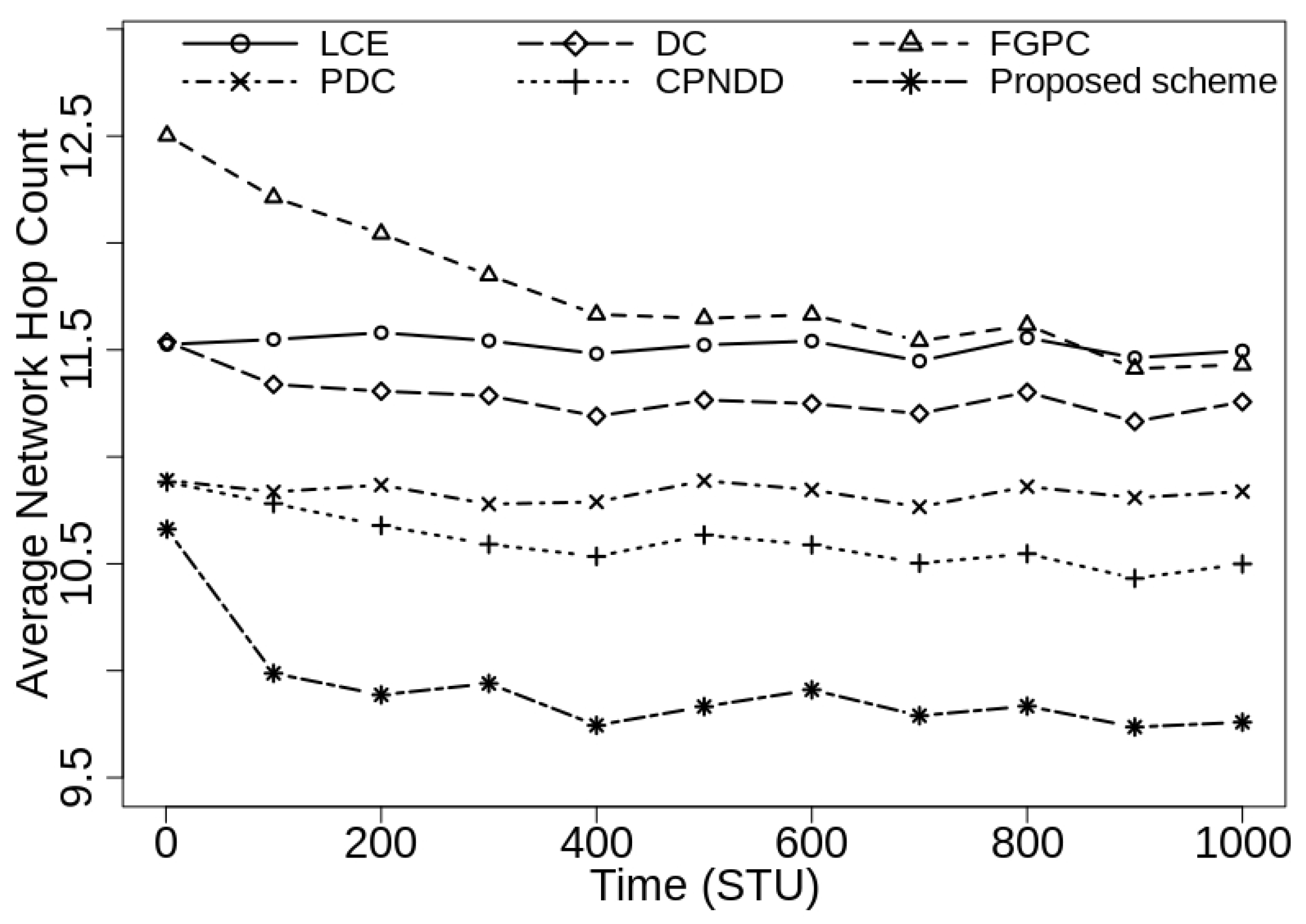
The performance of the proposed caching scheme is examined through extensive simulations on the realistic network topology. Simulations results show the necessity of the proposed clustering-based caching scheme since the conventional scheme does not achieve a considerable hit rate in the network. Moreover, the proposed scheme demonstrates a significant decrease in the content retrieval delay and network traffic from the existing caching strategies.
The organization of the remaining paper is as follows. The next section (
Section 2) provides the overview of CCN.
Section 3 discuss the brief survey of the prior related works. The system model is presented in
Section 4. In
Section 5, the novel clustering and the caching schemes are proposed. The performance of the proposed scheme is evaluated and compared with peer caching schemes in
Section 6. Finally, the paper is concluded in
Section 7.
2. Overview of CCN Architecture
This section briefly describes the CCN architecture and its operations to provide the foundation for further discussions. As CCN is a data-centric network, the content retrieval mechanism relies on two types of messages: Interest message and Content message [
23]. The end-user device generates the Interest message to request for the specific content and the in-network router/provider replies with the corresponding Content message. For the routing and caching operations, each router maintains a Forwarding Information Base (FIB), Content Store (CS) and the Pending Interest Table (PIT) [
24]. The FIB contains the interface information to forward the Interest message towards the content source. The incoming content can be cached in the CS of on-path routers based on the caching policy. When a router receives an Interest message from one or more interfaces, the information of those pending Interest messages and their interfaces is stored in the PIT.
On receiving the Interest message from the end-user device, the network router first searches its CS for the requested content. If a cache hit occurs then the Content message is created by the router and forwarded towards the end-user device using the interface through which the Interest message arrived. If a cache miss occurs, then the router investigates its PIT. If a matching entry is found in PIT then the interface information of the incoming Interest message is aggregated in the PIT and the message is disposed from the network. Otherwise, a record is created in the PIT and the Interest message is forwarded towards the source using FIB.
When an intermediate router receives a Content message, it checks its PIT for the matching records. If the entry is found then the router forwards the Content message toward those interfaces that are mentioned in the PIT and cache the Content message in its CS based on the content placement and replacement policies. After content forwarding, the router removes entries for that Content message from the PIT.
3. Literature Review
In-network content caching is an inherent characteristic of CCN architecture that raises several challenges during content placement and replacement operations. To improve the network performance and QoS for the end-user devices, various content caching schemes are proposed by the research community [
25,
26]. The traditional Leave-Copy-Everywhere (LCE) [
27] caching scheme places the content in each intermediate router throughout the delivery path. The scheme cache the contents near the end-user devices and reduces content retrieval delay for future Interest messages. However, this excessive caching causes high energy consumption and cache replacement operations. Moreover, the excessive content redundancy also increases cache miss probability as the cache size is limited in realistic networks. Therefore, a trade-off exists between the caching and no-caching operations. Excessive caching operations can reduce the latency up to a certain extent but causes extreme exploitation of network resources. On the other side, no-caching in the network routers leads to higher delays and network traffic. Hence, it is necessary to focus on frequently requested contents and suitable locations for optimal network performance.
For content placement decisions, a random probability-based caching scheme called
is proposed in [
28]. The scheme randomly places the incoming contents in the on-path routers and does not involve significant computational latency during caching decisions. To reduce cache replacements, the Leave-Copy-Down (LCD) scheme is suggested in [
29] that drops the accessed content one-hop downside from the content provider. With this, the frequently accessed contents are gradually placed towards the edges of the network. The
caching strategy [
18] approximates the caching capacity of the path and multiplex the contents between the server and the end-user device (requester). Using the proposed mechanism, the Probcache scheme fairly allocates the network resources among different network flows. However, these caching schemes [
18,
27,
28,
29] do not consider the router’s characteristics and content popularity during caching decisions and hence unable to make efficient use of caching resources.
To increase cache hit probability on those routers that observe high network traffic, various centrality-based caching schemes are also proposed [
30]. A betweenness centrality-based caching approach is suggested in [
31] that eliminates the uncertainty of random-probability-based content placement decisions and shows improved caching gains. An in-depth comparison of several centrality-metrics-based caching mechanisms has been performed in [
15] that involve Degree Centrality (DC-based), Stress Centrality, Betweenness Centrality, etc. The results illustrate that the degree centrality is a simple and effective parameter for efficient cache use. The CPNDD (Content Placement based on Normalized Node Degree and Distance) caching scheme [
17] shows that considering a single parameter for the caching decisions does not achieve significant performance gain. The scheme suggests to jointly consider the degree centrality and hop count parameters for content placement decisions. Using these parameters, the caching probability increases in those routers that have a high degree centrality and are far from the content provider. The results show improved cache hit ratio and reduction in server load from LCE and DC-based caching strategies.
Various researchers have also recommended considering the content popularity for caching decisions in the network. Towards this, in the Most-Popular Content Caching (MPC) scheme [
32], each router computes content access frequencies autonomously. When the content becomes popular enough, the router suggests its adjacent routers to cache the popular content in their storage. Using this approach, the cache redundancy increases for popular contents in the network. The Content Popularity and User Location (CPUL)-based caching scheme [
33] divides the contents into popular and normal contents using a centralized server. The scheme then suggests taking caching decisions based on the type of content and the user location in the network. However, as defined in the scheme, the determination of content popularity on a centralized server causes scalability concerns for large-scale networks. The Dynamic Popularity Window-based Caching Scheme (DPWCS) [
14] proposed to implement a large popularity window in each network router, which is used to determine the popularity of contents. The scheme identifies popular contents based on the request distribution model, caching capacity of the routers, and the number of distinct contents in the networks. One of our prior work proposed in Tiwari et al. [
34] discusses a content Popularity and Distance-based Caching scheme (PDC) for content placement/replacement decisions. The scheme jointly considers the content popularity and hop count-based distance attributes during content caching in the network and shows improved network performance as compared to conventional LCE and DC-based caching strategies.
However, most of the above discussed caching schemes [
14,
15,
17,
27,
28,
29,
34] take autonomous caching decisions where routers do not cooperate for content placement operations. Although autonomous content caching reduces communication overhead in the network, these scheme suffers from higher content redundancy and cache replacement operations. Moreover, many schemes consider at most one parameter for the caching decisions such as node centrality, content popularity, and hop count [
18,
29,
30,
31,
32]. Due to this, these schemes suffers from load imbalance events as the routers that are near the server or have a higher degree centrality would experience more caching operations as compared to other routers in the network.
To alleviate the load im-balancing issues and reduction in excessive caching operations, several cluster-based caching schemes are also proposed in the CCN [
35,
36,
37,
38]. The Hierarchical Cluster-based Caching (HCC) scheme [
35] partitioned the network routers into the core routers and the edge routers. The core routers do not have caching capability and the few selected edge routers can cache the contents. For caching decisions, the scheme jointly considers node degree centrality, hop-count, and delay metrics. In [
36], the authors proposed k-split and k-medoid clustering schemes to partition the network. The scheme performs hash-based caching operations and thus, it does not consider content or router’s characteristics during content placement decisions. The scheme mentioned in [
37] creates a fixed number of partitions in the network based on the hop count information. The scheme performs caching operations using the partition information and the content popularity in the network. A cluster-based scalable scheme is suggested in [
38] that combines the physical routers together and these routers are seen as a single unit to the outside nodes. However, internally, the traffic load has been distributed among the physical routers.
Once the cache of the network routers becomes full, the older content needs to be evicted to cache the incoming content. Generally, this cache replacement operation is performed using the First-In-First-Out (FIFO), Least-recently Used (LRU), Least-Frequently-used (LFU), and optimal cache replacement strategies [
39,
40]. As discussed in [
39,
41], the optimal replacement scheme achieves improved network performance as compared to peer schemes. However, the implementation of the optimal strategy is not feasible as the content requests pattern cannot be predicted in realistic network topologies. Due to this, the LRU and LFU algorithms are widely implemented with the content placement schemes due to their sensitivity towards content access pattern and content popularity, respectively.
The distinguishing features of the reviewed caching strategies are summarized in
Table 1. As defined in
Table 1, in most of the existing on-path caching schemes the routers take caching decisions independently and do not cooperate with each other. This leads to excessive number of caching operations and increases duplicate contents in the network. Due to this, the existing schemes achieves limited gain in the network performance. Additionally, the existing clustering-based caching schemes have not explored the joint effect of content popularity and the distance attributes on caching performance.
Therefore, a novel network clustering scheme is proposed in this paper for efficient use of the caching resources and improved QoS for the end-users. The proposed scheme considers hop-count and link bandwidth information to form tightly coupled clusters. Then, the proposed caching scheme jointly considers the clustering information, content popularity, and the content provider distance for caching decisions. With this, the popular contents are placed near the end-users with fairly multiplexed content redundancy in the path. This makes the proposed scheme suitable for CCN-based applications.
4. System Model and Assumptions
Let
be a network topology having a set of nodes represented as
V = {
,
, …,
,
,
, …,
,
}. Here,
E denotes the set of connections that are used for the Interest/Content message forwarding among nodes in the network.
Figure 1 illustrates an example of the network topology. Here,
represents the
ith end-user device and it generates Interest messages in the network. The
denotes
ith router in the network and these routers perform Interest/Content message forwarding and caching operations. The notation
defines the servers in the network and each server works as an Interest message sink that satisfies all Interest messages. In the system, all the network routers have caching capability (for simplicity, although it is not necessary) and the decisions related to content placement depend on several parameters as described in
Section 5. Our recent studies [
14,
34] establish the effective heuristics for the determination of content popularity that can assist in computing the content access frequencies. However, these previously suggested schemes take autonomous caching decisions and have a further scope of improvement using cooperation among network nodes.
To simplify further discussions, the notations used in the model are defined in
Table 2. It has been assumed that the content packets are of fixed size and the content access pattern follows Zipf distribution model [
15,
42]. The Zipf distribution is widely implemented in large-scale networks to model realistic network traffic patterns as it assigns ranks to the contents based on their popularity. Here, content popularity is defined as the content access frequency from the catalogue [
10]. It has also been assumed that the proposed scheme implements a request-response model [
43] of Content-Centric Networking. In this model, the Content message follows the same route through which the Interest message arrived at the content provider. In general, these assumptions are unbiased under consideration of location independence and name-based routing features of CCN.
As shown in
Figure 1, the network has been partitioned into three clusters namely
and
using the proposed network clustering scheme elaborated in the subsequent section. Cluster
contains routers
,
and
and the end-user devices
to
. In other words,
. Similarly,
and
. Suppose, the end-user device
generates an Interest message for the content name “
” and forward this message towards the server. Lets assume that the Interest message follows a path
and no intermediate router have a copy of the requested content. Then, the server would prepare the corresponding Content message with the required payload and transmit it in the backward direction towards
. In the proposed caching scheme, at most one copy of the incoming content would be cached in the cluster from where its request is generated
. As the Interest message for content “
” is generated from
, the on-path routers
would take content placement decisions based on the content popularity and the hop count parameters (discussed in
Section 5.5). Thus, the remaining intermediate routers in the path
and
simply forward the content “
” towards
without caching operation as
. Therefore, the content redundancy and the number of caching operations are reduced significantly in the network. It has been argued that this would lead to lower content retrieval delay, network traffic, and improved QoS for the end-user devices.
For caching decisions, the content popularity and hop count metrics are determined using the following concepts:
Content popularity determination using Popularity Table: According to the Zipf distribution, there are always few content requests for the unpopular contents in the network. If the caching scheme does not consider content access patterns during placement decisions, then the unpopular contents may be stored for longer durations in the network routers without being accessed again. This leads to poor use of network resources as cache miss probability increases due to caching of unpopular contents. Moreover, it has also been observed that the few routers with high importance receive more number of Interest messages as compared to other routers in the network. To resolve these issues, our previous work [
17] has suggested to integrate a large size Popularity Table with each network router. This table is used to determine the content access frequency. The Popularity Table stores only the name of the requested content in its slots
and hence, this has negligible space overhead on the routers. When, the Popularity Table reaches its maximum size
, then First-In-First-Out (FIFO) replacement mechanism is used to evict oldest content request from the table to store incoming request information. During caching decisions, the router computes the popularity of the incoming content by counting its occurrences in the Popularity Table.
Figure 2 illustrates the working of the Popularity Table. Suppose, the maximum size of the Popularity Table
is 5.
Figure 2a shows the structure of a Popularity Table, implemented in a specific router
, after arrival of Interest messages:
,
, and
in a sequence. As shown in the figure, only the name of the requested contents
are stored in the Popularity Table and therefore, this structure does not causes significant storage overhead in the cache. In
Figure 2a, two slots of the Popularity Table are empty and it has been described as
and
. After arrival of Interest message
and
, the empty slots of the Popularity Table are updated as demonstrated in
Figure 2b and the structure reaches to its maximum capacity
. When a new Interest message
arrives, the router determines that the Popularity Table has no free slot and hence, the FIFO replacement algorithm is used to evict the oldest content name from the Popularity Table to store the information of incoming Interest message. Therefore, the information of oldest Interest message
is replaced with
as shown in
Figure 2c and now,
becomes the oldest content (slot-2) for eviction during future Interest message arrival.
Hop count monitoring: The hop count is a simple and effective metric to increase caching probability towards the edges of the network [
18,
34]. The hop count metric for the Interest/Content message has been computed as the number of hops (routers/server) traversed by the message to reach the content provider/requester, respectively.
5. Proposed Caching Scheme
In this section, the proposed network clustering scheme is discussed in
Section 5.1.
Section 5.2 defines the updated structures of the Interest and Content message for the caching decisions. Then, the proposed Interest and Content message processing mechanisms are introduced in
Section 5.3 and
Section 5.4, respectively.
5.1. Proposed Clustering Scheme
Algorithm 1 shows the proposed clustering mechanism to form the clusters. The intra-cluster nodes collaborate with each other to take caching decisions without any additional communication overhead. In the proposed clustering strategy, initially the top “
” routers are identified according to their degree centrality in the network. The degree-centrality is computed as the total number of inbound and outbound links connected to a router. The optimal number of clusters are obtained by observing the network performance (in terms of cache hit ratio) for different number of clusters. Therefore, the network clustering is dynamic and changes for different network topologies. These “
” routers are designated as the initial centroids
before start clustering of the network nodes. Using degree centrality metrics, the clusters would be tightly coupled as more number of routers become adjacent to the centroids. It is mentioned in
-1 and
-2 of Algorithm 1. It would also be interesting to analyze the other metrics for selection of initial centroids such as betweeness centrality and closeness centrality. However, the earlier works [
15,
44] in this direction have shown that the node degree centrality is a sufficiently good criteria for network clustering. Additionally, the time complexity to determine the degree centrality in a network topology is
, which is much lesser than the time complexity to compute betweeness and closeness centrality measures that have the time complexity of
. Therefore, the degree centrality measure is used to select initial centroids.
| Algorithm 1: Proposed network clustering scheme |
| Input: All the network routers , where . |
Output: Set of “” clusters , where .
Sort the routers according to their decreasing order of degree centrality. Designate top “” routers as initial centroids that have higher degree centrality . Iterate step-3(a), 3(b) and step-4, till there is a change in centroids: - (a)
Determine the distance between the routers and each of the centroid using following equation:
- (b)
Assign each router to the closest centroid , i.e., .
Determine the new centroid in each cluster that has minimum distance from the intra-cluster routers.
|
Then, the scheme determines the distance of each router
from all the centroids
as illustrated in
-3(
a). The distance between a centroid
and the router
is determined using the hop count and bandwidth parameters as defined in Equation (
1). The probability to associate a router into a specific cluster increases with a decrease in the number of hops between its centroid and the router. The value of distance parameter
decreases with an increase in the bandwidth between the centroid and the router. Therefore, using Equation (
1), the router is assigned to a centroid that has minimum hop count from the router and is also connected through the high bandwidth links to form tightly coupled clusters (shown in
step-3(
b)). It improves the efficiency of content forwarding from one node to another node within the clusters using higher bandwidth connections. After each iteration of the cluster formations, the router that has minimum distance (computed using Equation (
1)) from its intra-cluster routers is designated as a new centroid for its cluster. If the centroids are changed as compared to the previous iteration, then
-3 is executed again. Otherwise, if there is no change in centroids, then it indicates that the cluster formation process is completed and the routers are partitioned into “
” clusters. After clustering of the network routers, the end-user devices connected with the edge routers also become part of their respective clusters.
5.2. Structure of Interest and Content Message
The proposed caching scheme considers the cluster information, content popularity, and hop count parameters for caching decisions. Therefore, the structures of Interest and Content messages are updated to store information for these parameters.
Towards this, each Interest message is updated with the novel fields, and as shown below.
| Structure of Interest message: |
| | | … |
Here, the name of the requested content is stored in the field. The field stores the total number of hops traversed by the Interest message . The field contains the unique identification number of the cluster in which the is generated by the end-user device in the network. This unique cluster identification id is identical for all the end-user devices and routers that are grouped together in a cluster and unique for different clusters.
As the content caching operations are performed during the Content (Data) message forwarding towards the end-user devices, the , and fields are appended in for efficient caching decisions. The structure of the content message is illustrated below.
| Structure of Content message: |
| | | | | | … |
The name of the requested content is stored in the field. The field contains the hop count information which is traversed by the Interest message from the end-user device to reach the content provider. The value of and field in the are replicated from the Interest message to and the count of hops traversed by is stored in the field .
5.3. Interest Message Forwarding Mechanism
In this section, the Interest message forwarding and processing mechanism are discussed and summarized in Algorithm 2 (Interest message forwarding mechanism). As shown in
-1 of the algorithm, when an end-user device
requires a content (Data)
, then it prepares the corresponding Interest message
with the requested content name as
and initializes the
field as 0. The network is already clustered according to the proposed clustering scheme and each cluster has a unique identification number which is same for all the intra-cluster nodes (end-users and routers). Therefore, the device
write its cluster identification id in the
field of
and forwards it to the adjacent router
(
-2). On receiving the message
, each on-path router
increases the value of
field by 1 (
-3(
a)) and insert the requested content name
in its Popularity Table according to FIFO replacement mechanism as shown in
-3(
b). Then,
searches its cache for the requested content and if the content exists then Algorithm 3 (Content message forwarding and caching mechanism) (discussed in
Section 5.4) is executed. Otherwise, the traditional Interest message forwarding process is executed as illustrated in
-3(
d) to (
f) and elaborated in
Section 2.
| Algorithm 2: Interest message forwarding mechanism |
prepares an Interest message to retrieve the content and initialize . writes its unique cluster identification id in the field of and forward towards its adjacent upstream router . Then, any intermediate router performs following steps after receiving . - (a)
Update the value of field as . - (b)
If > , then insert in , where “” represents the next empty slot in the Popularity Table of . Else, if =, then insert in using replacement mechanism. - (c)
If requested content exists in the then navigate to Algorithm 3: Content message forwarding and caching mechanism. - (d)
Else, if PIT of has a record for , then aggregate in its PIT. - (e)
Else, Search the FIB of to forward to appropriate upstream router. If entry found, then forward accordingly and create an entry in the PIT. - (f)
Else, discard from the network.
|
| Algorithm 3: Content message forwarding and caching mechanism |
If requested content exists in the or reaches the server , then following steps are performed: - (a)
Prepare a Content message with initializing corresponding field and the requested payload. - (b)
Replicate the values of and fields from to the and fields of . - (c)
Initialize, . - (d)
The content provider writes its unique cluster identification id in the field of . - (e)
Initialize the boolean field as TRUE. - (f)
Transmit towards .
When reaches to an intermediate router , then perform following steps for caching decisions and content forwarding towards . Update the value in field as = . If or , then move to -6. Else, - (a)
Compute, in . - (b)
Compute, - (c)
If and then,
forwards towards the using its PIT.
|
5.4. Content Message Forwarding and Caching Mechanism
This section elaborates Content message forwarding and caching mechanism which is summarized in Algorithm 3: (Content message forwarding and caching mechanism). When requested content is found in the cache of router or the Interest message reaches the server , then prepares a Content message with the requested payload as shown in -1 of Algorithm 3. Then, the content provider replicates the values of and fields from to corresponding fields of and reset the value of to 0. Subsequently, the write its unique cluster identification id in the field of and set the value of boolean variable to “TRUE” which indicate that the caching is enabled for the content in the on-path routers -1(d) to 1(e). The content provider then forward the message towards its requester . In the path, the intermediate router perform -2 to 6 for content caching and forwarding operations. As illustrated in -3, the on-path router increases the hop count value of field by 1.
In the proposed caching scheme, at most one copy of the content is cached in those routers which belong to the cluster that has generated the request . The routers that belong to other intermediate clusters perform content forwarding operations without its caching. This approach minimizes computational and caching delay as shown in -4. Moreover, to reduce cache replacements and content redundancy, the content is not cached in the intermediate routers if the content provider and the requester exists in the same cluster as shown in step-4. Otherwise, if the Interest message is generated from the different cluster than the content provider then, following steps are performed. For caching decisions in , the popularity of is determined by counting the occurrences of requests for in the as mentioned in -5(a). Then, the is computed as the product of content popularity and the normalized hop count parameter (-5(b)). The normalized hop count is determined as the ratio of and . According to -5(b), the increases with an increase in the content popularity and the distance traversed by the content message . Therefore, the popular contents are placed near the edges of the network with a higher probability, and the excessive content redundancy is controlled using the proposed clustering-based mechanism. Once the cache of the intermediate router is full, the replacement algorithm is used to substitute the least popular content with the incoming content that has . The content caching operation is performed only when the value of is “TRUE” which indicate that the content is not cached in the cluster . To ensure that at most one router cache the incoming content in the requester’s cluster, the value is reset to “FALSE” after content caching. Finally, each intermediate router forwards the Content message towards the requester , irrespective of the caching decision as defined in -5.
5.5. An Illustration of Proposed Content Message Forwarding and Caching Mechanism
As discussed in
Section 4, suppose the network is partitioned into three different clusters as shown in
Figure 1 and an Interest message for “
” (represented as
now onwards) is generated by
and forwarded in the network through the route:
. It has also been shown in
Section 4 that in the proposed caching scheme, the content caching decisions are taken by
and
based on the content popularity and hop count parameters as the request has been generated from Cluster
. Suppose the size of the Popularity Table is 10 in
and
and the count of Interest messages for
in the Popularity Table are 5
and 6
, respectively. As the requested content is fetched from the server, the value of
would be 5. The value of
would be 4 and 3 at router
and
, respectively. Then, the
would be computed for router
using
-5(
b) of Algorithm 3 as follows:
Suppose, the value of
is 0.4, then according to
-5(
c), the content would not be cached in
because
. Then, the content message
would be forwarded towards
with
. On receiving
,
would compute the
as follows:
In this case, the value of . Therefore, the content would be placed in the cache of and then it would be forwarded to end-user device .
On the other side, if the content is cached in after computation of , then the value of become and the router does not cache the content. Therefore, the proposed caching scheme ensures that at most one copy of the incoming content message is cached in the routers of requesting cluster to increase content diversity in the network.
As the proposed scheme does not consider the router’s importance (such as degree centrality, betweeness centrality etc.) during content placement decisions, the network load is not concentrated on a few network routers. Moreover, the proposed caching scheme does not require cluster heads for Interest/Content message forwarding and caching operations. Thus, the network traffic and computations are distributed among the network routers and the scheme does not suffer from the load balancing and bottleneck issues.
7. Conclusions
This paper starts with presenting various existing content placement schemes for the CCN environment in the literature. Then, a novel network clustering-based content caching scheme is proposed in which the intra-cluster routers cooperate with each other during content placement decisions. The proposed scheme considers the cluster information, content popularity, and hop count parameters to effectively use the available cache resources. In the proposed strategy, the network routers are clustered based on the joint consideration of hop count and the bandwidth parameters. Using the network clustering mechanism, the excessive cache replacement operations and the computational latency reduces significantly without additional communication overhead. Using proposed caching heuristics, the scheme increases the probability to cache the popular contents close to the end-user devices. Finally, the widespread simulations are performed with realistic network configurations and the performance of the proposed caching scheme is examined on cache hit ratio, average network hop count, network delay, and traffic metrics. The results showed that the proposed scheme outperforms the traditional CCN caching scheme along with peer heuristic-based DC-based, FGPC, PDC, and CPNDD caching strategies.
In future works, the performance of the proposed strategy will be analyzed in mobility-based networks and the recent network topologies such as Geant, Tiger2, DTelekom and Internet2 etc. Additionally, more parameters can be integrated with the existing solution for further improvement in network performance.

















{kind=link}
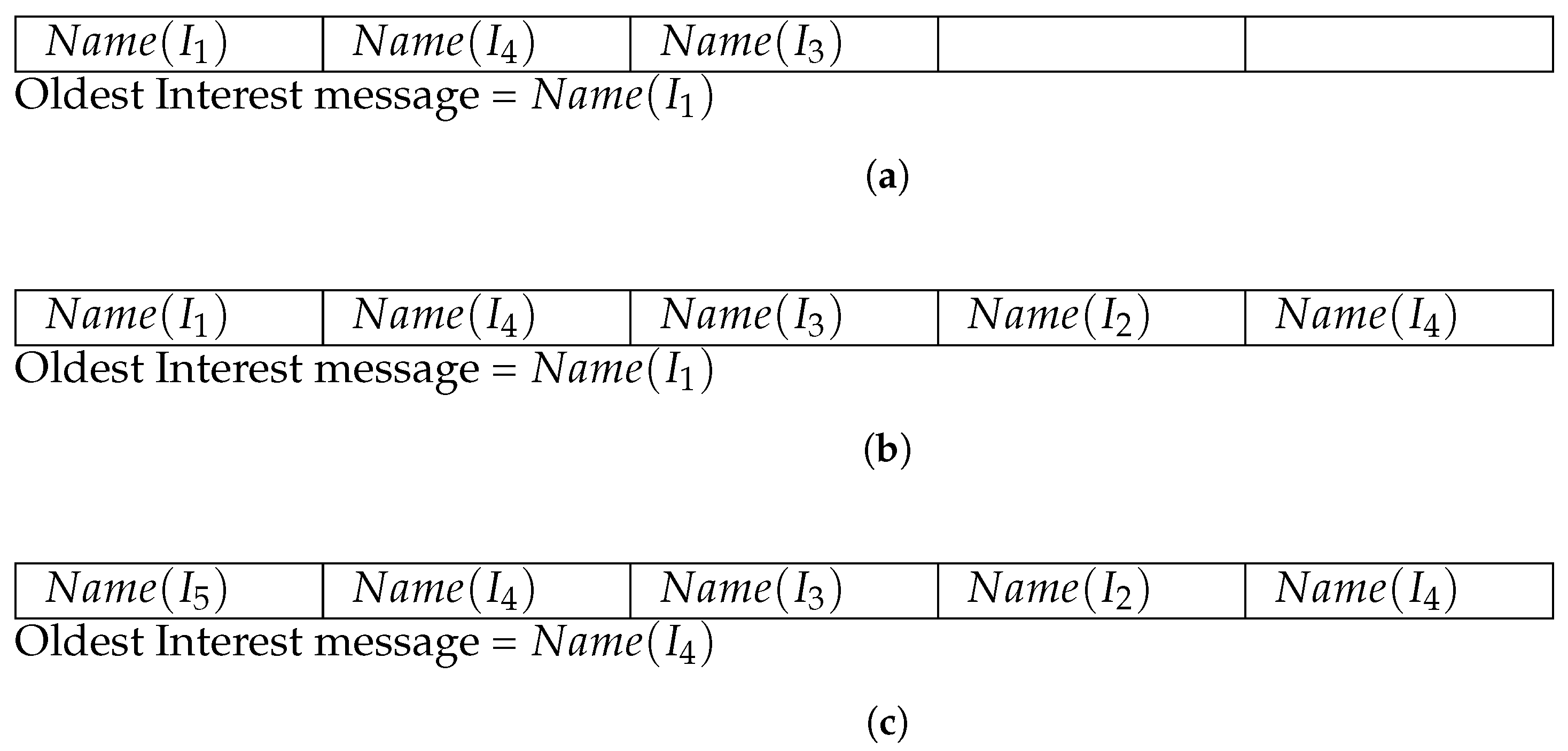{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}