
Real-Time Learning and Recognition of Assembly Activities Based on Virtual Reality Demonstration


Abstract
:1. Introduction
- We construct a virtual reality demonstration system that uses virtual reality equipment for assembly activities demonstration.
- We built a module for activity recognition and reasoning of human demonstrations.
- The action sequence can be used as knowledge to transfer to different robots in different environments to perform the same task goal.
2. Related Works
2.1. Virtual Assembly
2.2. Activity Recognition
3. Methodology
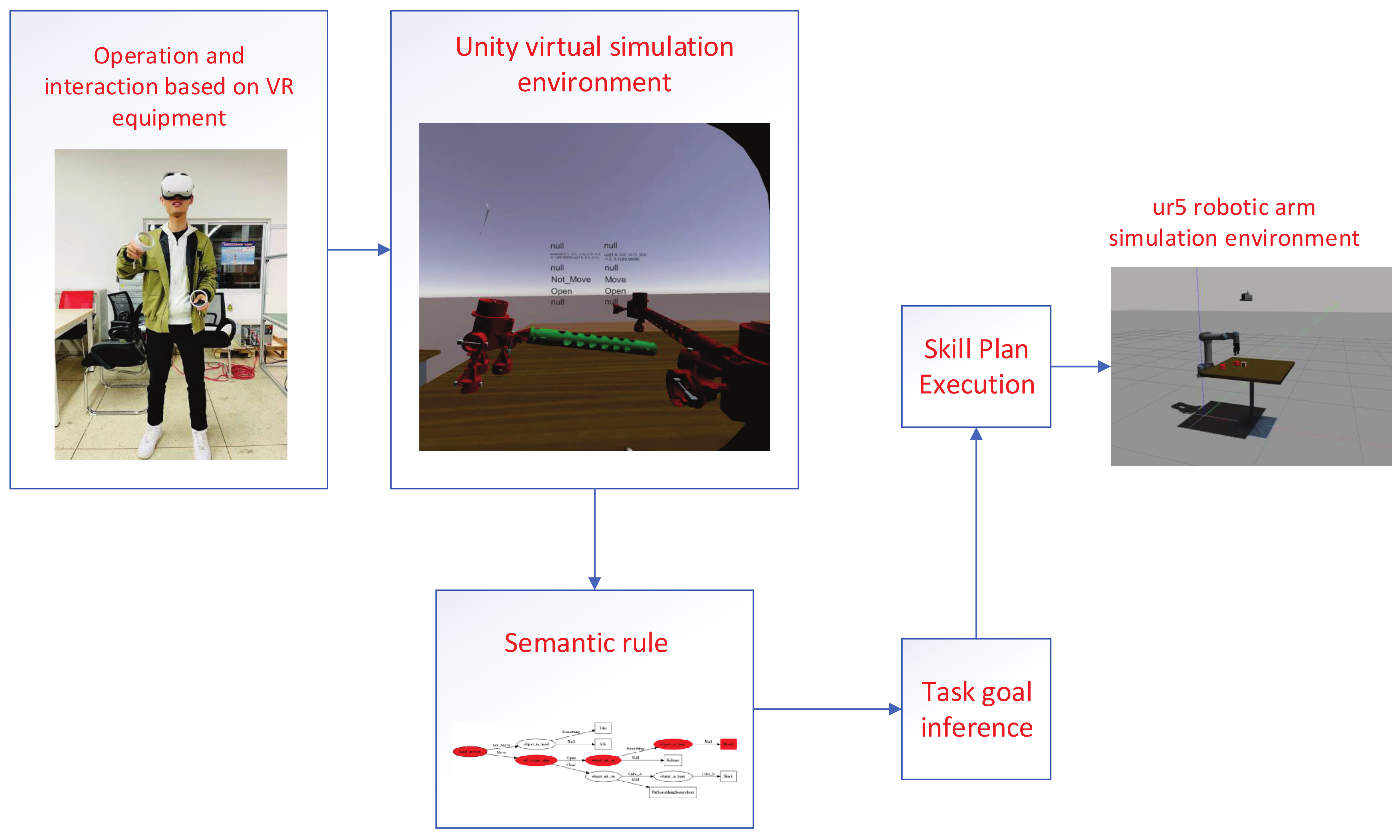
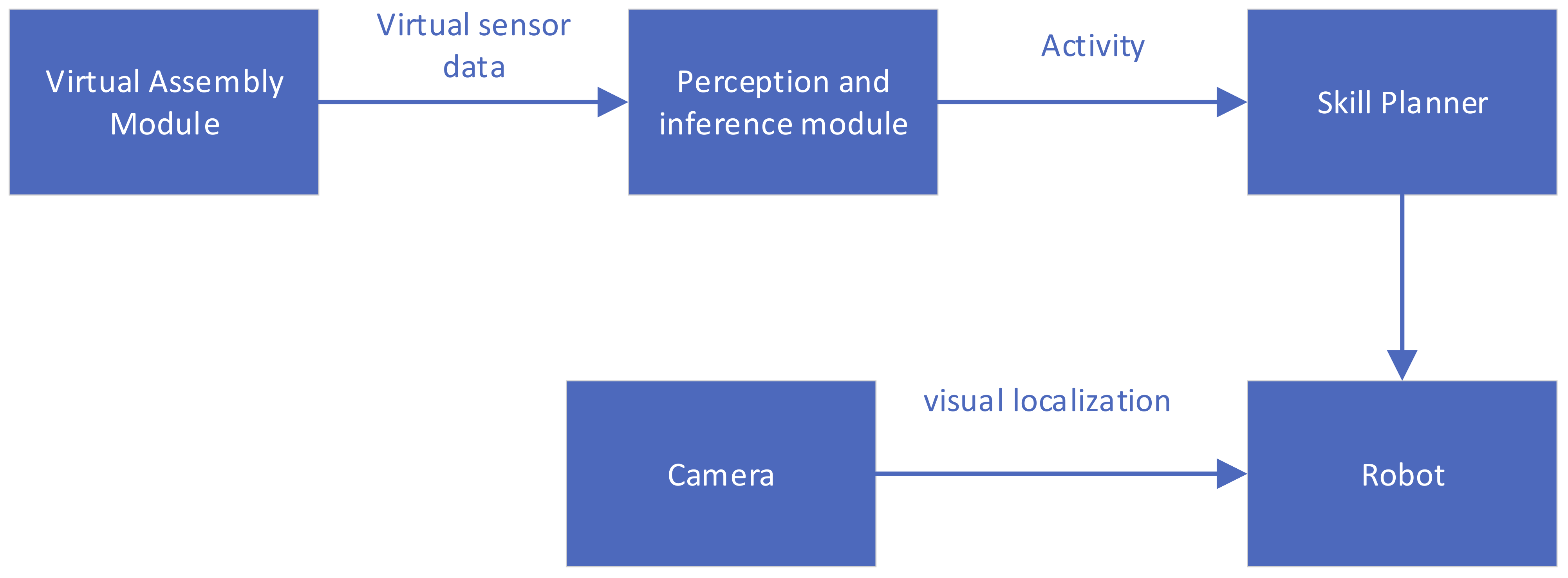
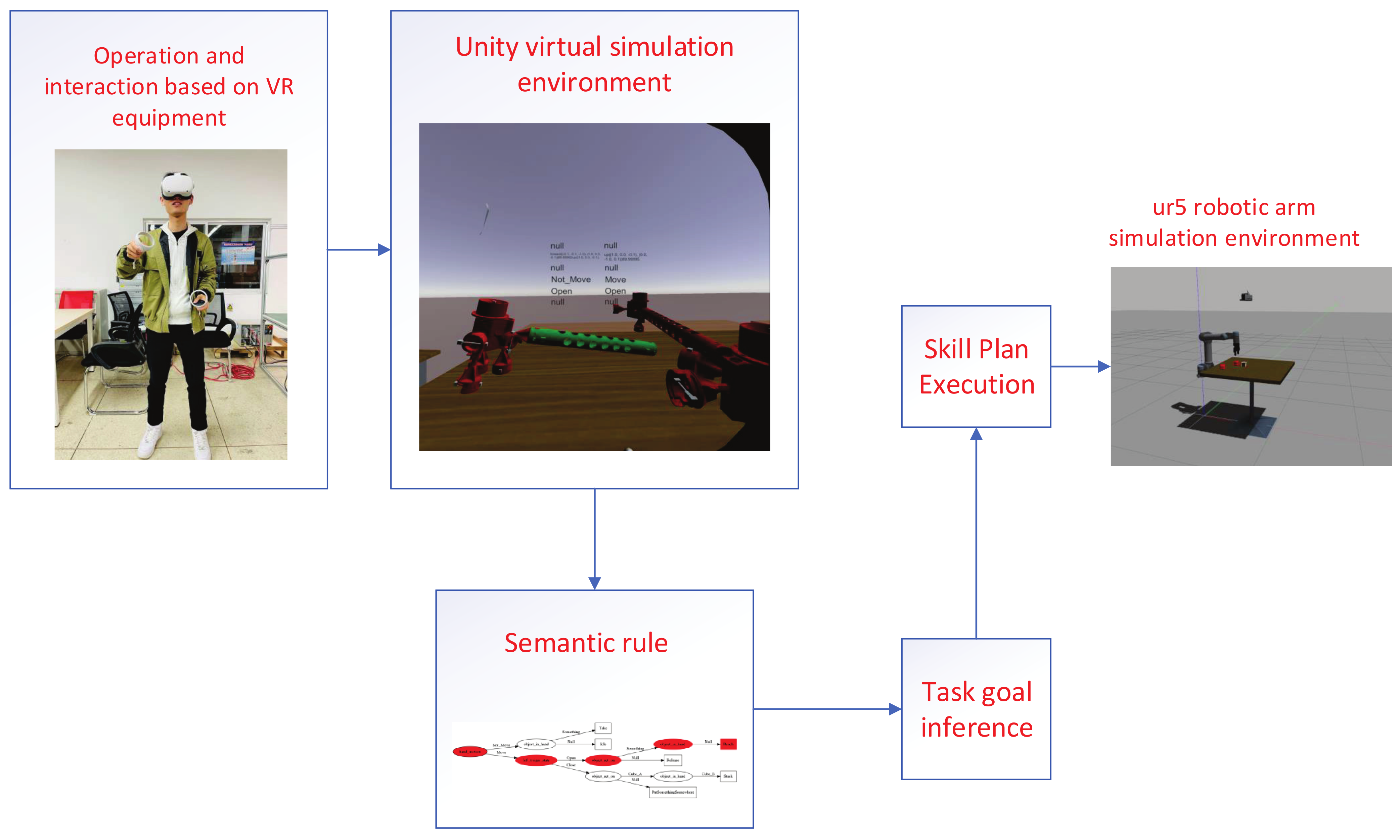
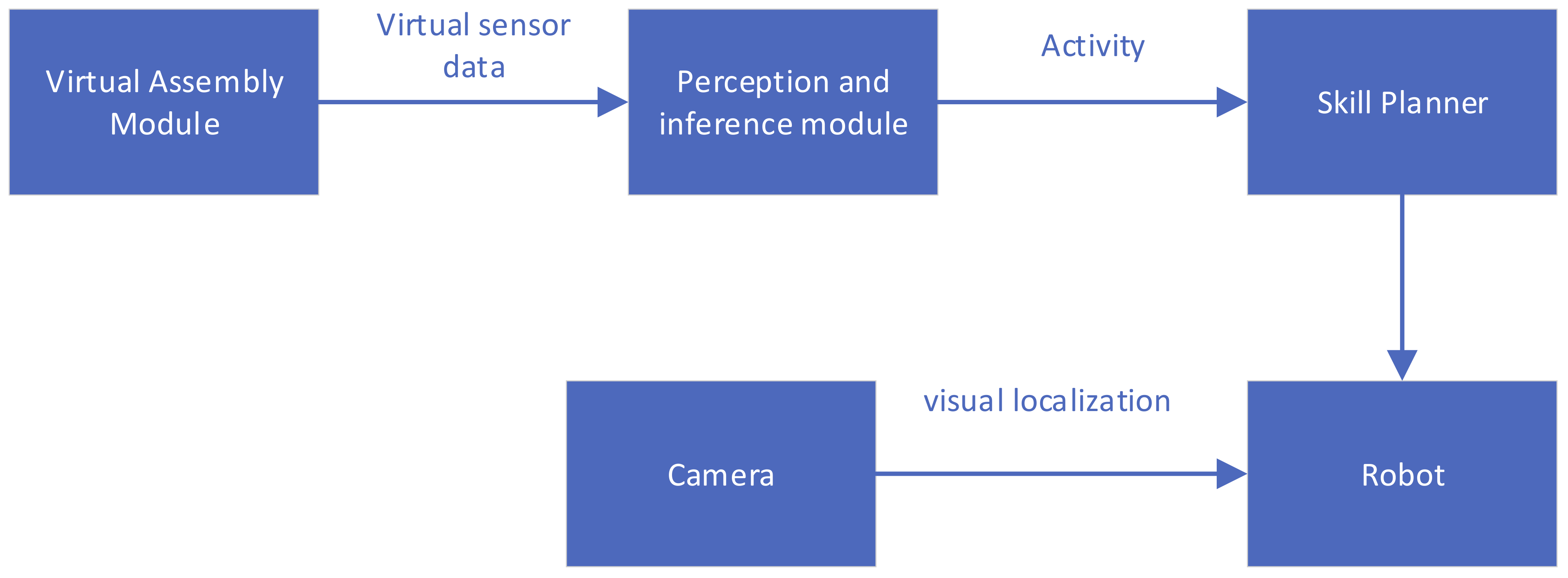
3.1. System Overview
3.2. Virtual Assembly Environment
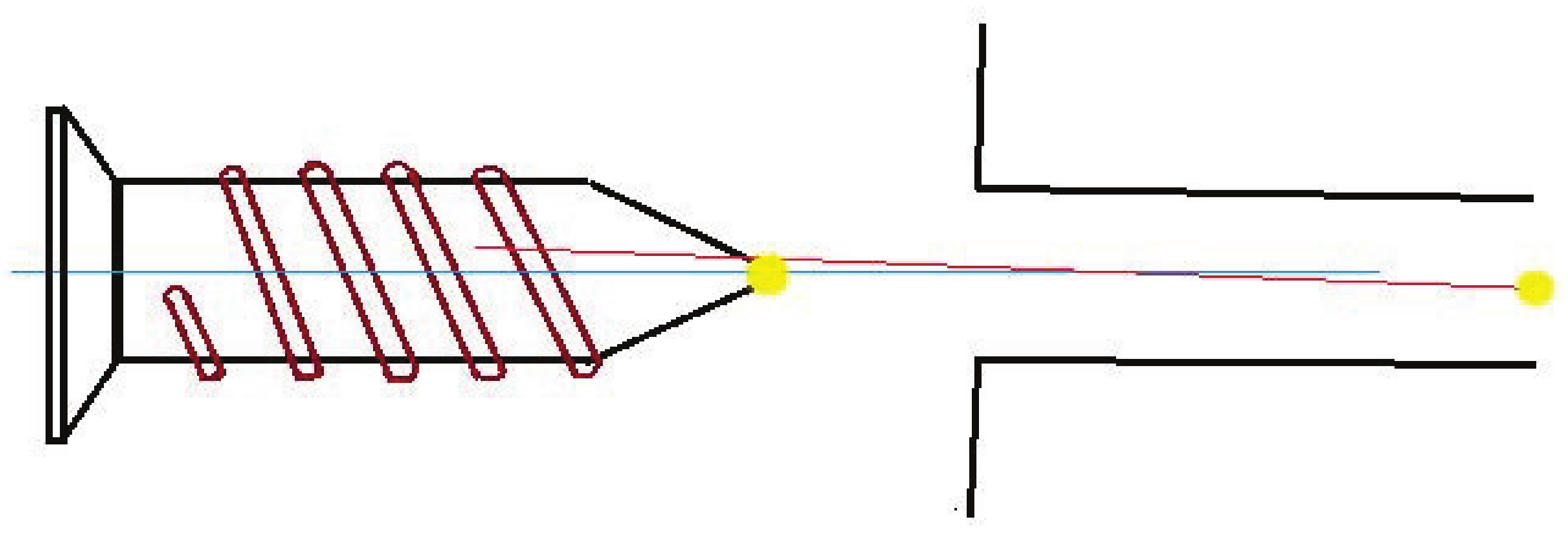
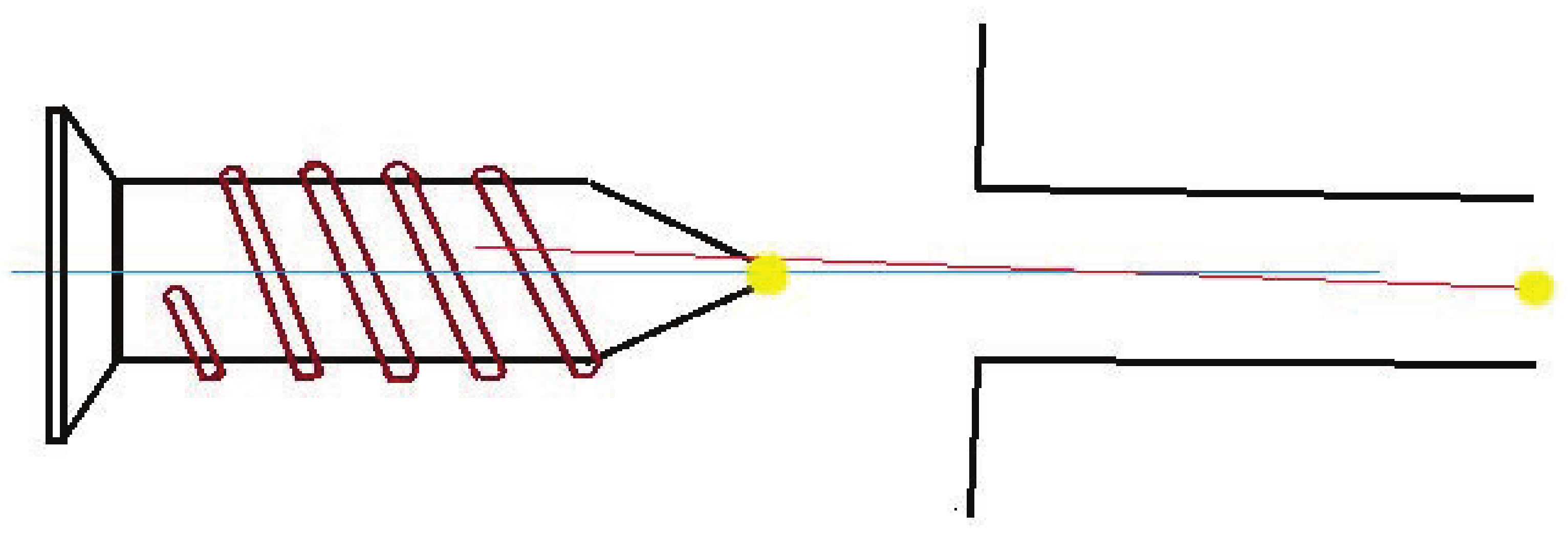
3.3. Define and Extract Virtual Sensor Information
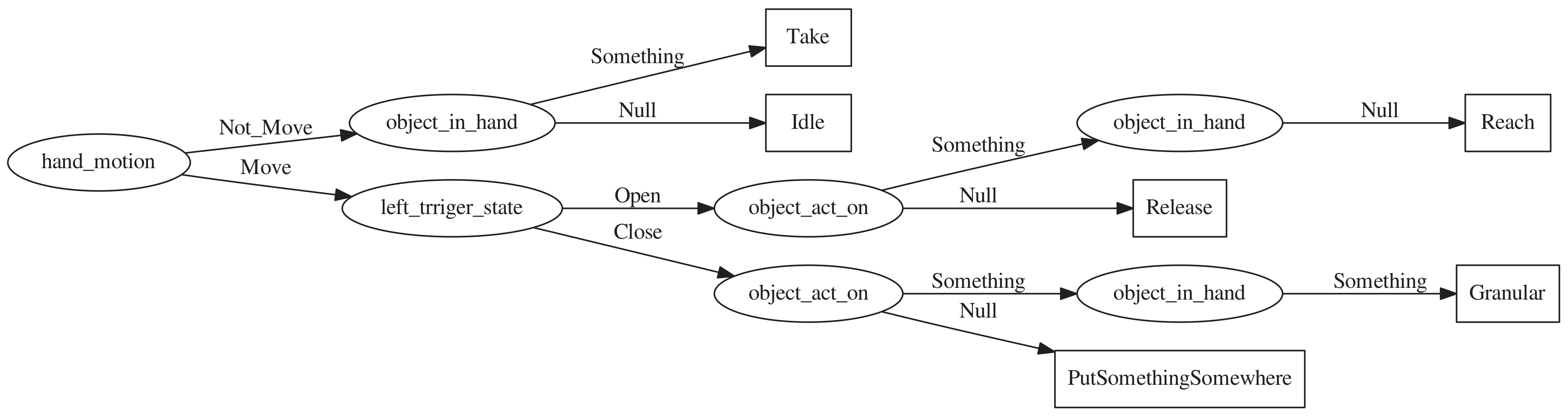
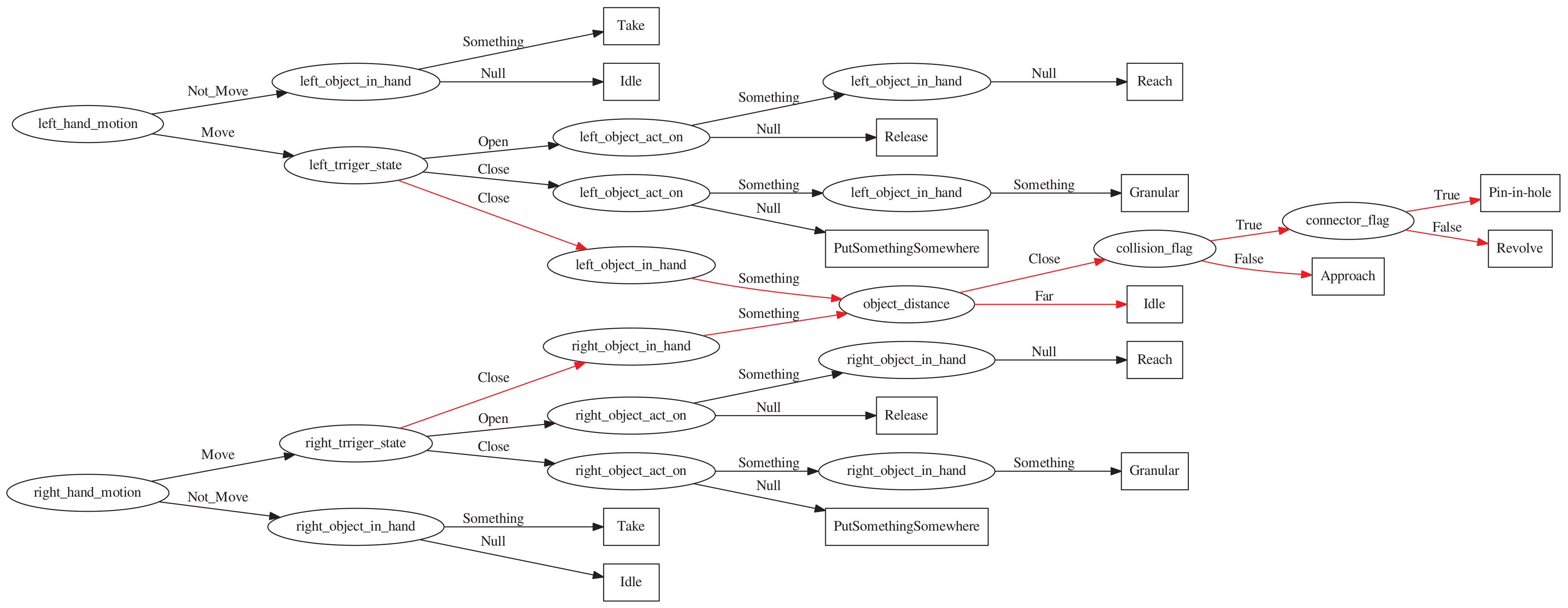
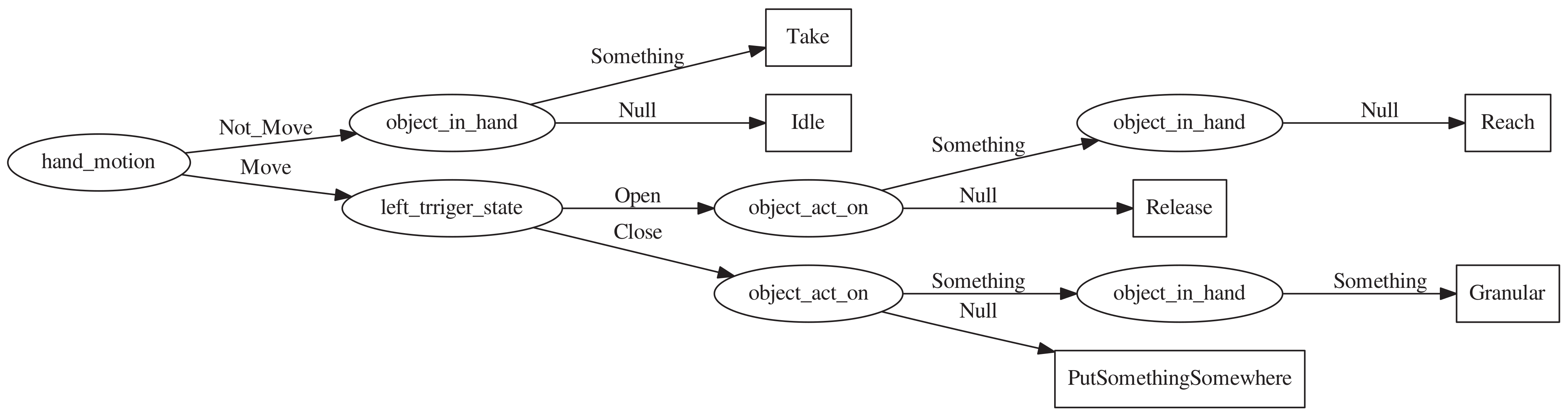
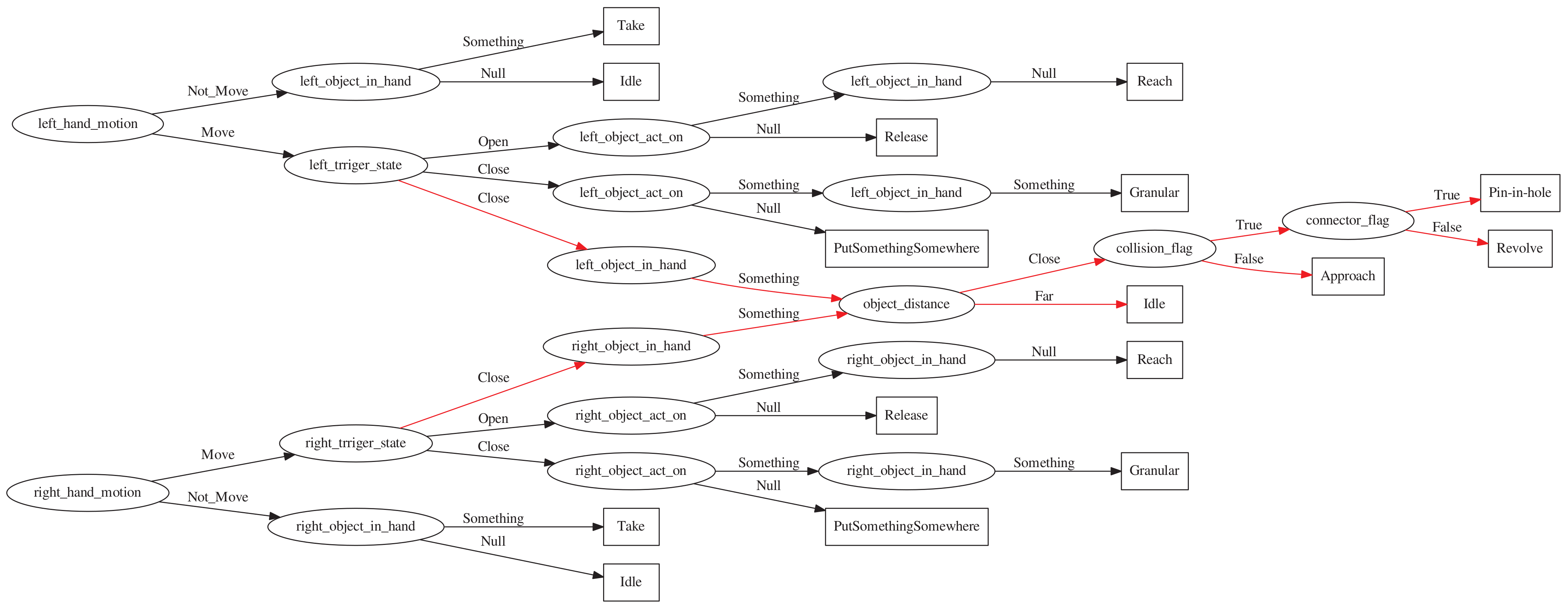
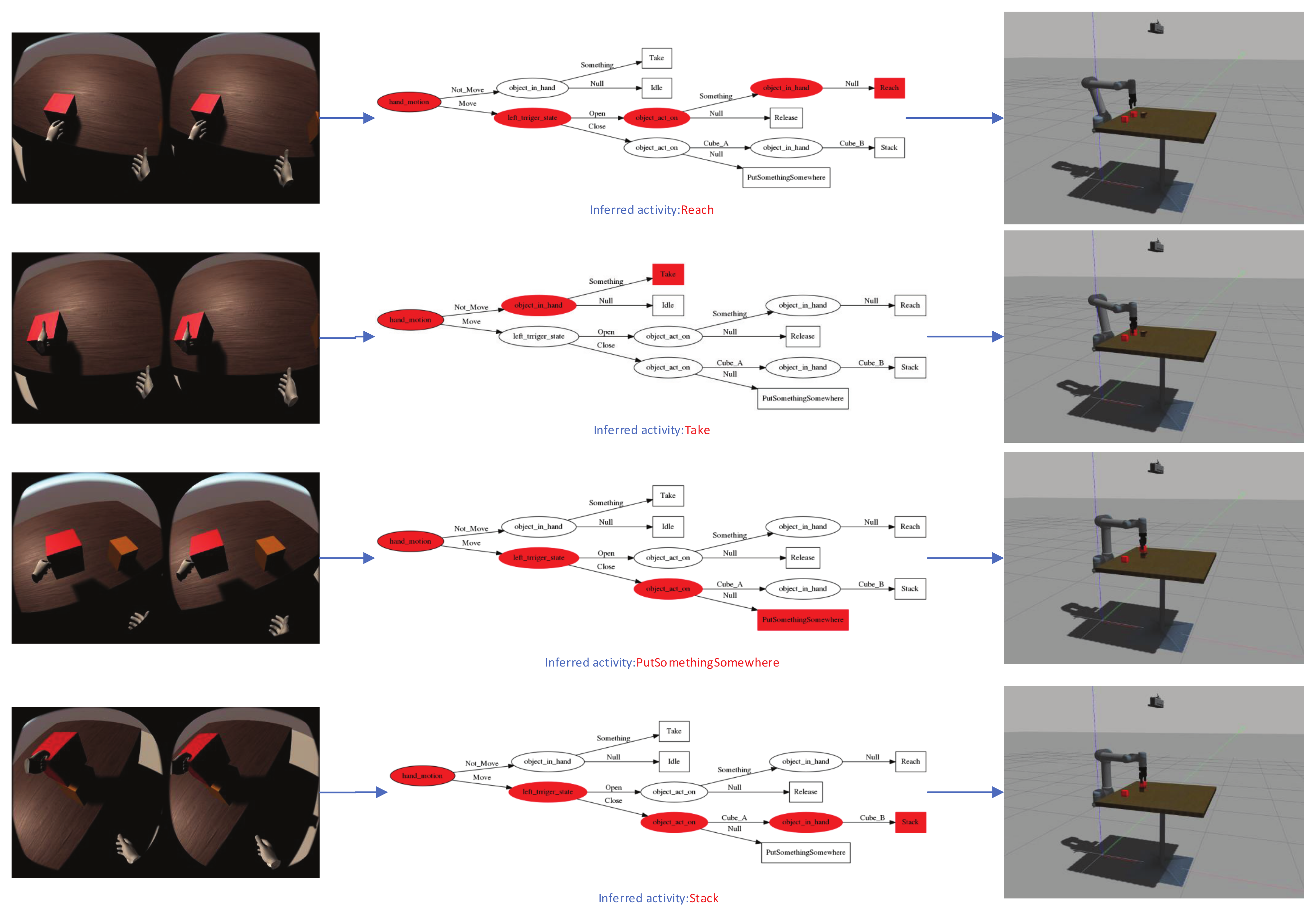
3.4. Infer the Activity Semantics of the Demonstrator
3.5. Decision Tree
3.6. Transfer the Task to the Robot and Execute
4. Results and Discussion
4.1. Semantic Representation of Results
4.2. Transfer the Target to the Robot and Execute
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ravichandar, H.; Polydoros, A.S.; Chernova, S.; Billard, A. Recent Advances in Robot Learning from Demonstration. Annu. Rev. Control. Robot. Auton. Syst. 2020, 3, 297–330. [Google Scholar] [CrossRef] [Green Version]
- Siciliano, B.; Khatib, O. Learning from Humans; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Ambhore, S. A Comprehensive Study on Robot Learning from Demonstration. In Proceedings of the 2020 2nd International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bangalore, India, 5–7 March 2020. [Google Scholar]
- Finn, C.; Yu, T.; Zhang, T.; Abbeel, P.; Levine, S. One-shot visual imitation learning via meta-learning. In Proceedings of the Conference on Robot Learning, PMLR, Mountain View, CA, USA, 13–15 November 2017; pp. 357–368. [Google Scholar]
- Sheh, R.K.M. “Why Did You Do That?” Explainable Intelligent Robots. In Proceedings of the Workshops at the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–5 February 2017. [Google Scholar]
- Kim, B.; Pineau, J. Socially Adaptive Path Planning in Human Environments Using Inverse Reinforcement Learning. Int. J. Soc. Robot. 2016, 8, 51–66. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2014, 3, 2672–2680. [Google Scholar] [CrossRef]
- Aleotti, J.; Caselli, S. Grasp recognition in virtual reality for robot pregrasp planning by demonstration. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation, Orlando, FL, USA, 15–19 May 2006. [Google Scholar]
- Lv, Q.; Zhang, R.; Sun, X.; Lu, Y.; Bao, J. A Digital Twin-Driven Human-Robot Collaborative Assembly Approach in the Wake of COVID-19. J. Manuf. Syst. 2021, 60, 837–851. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez-Badillo, G.; Medellin-Castillo, H.; Lim, T.; Ritchie, J.; Garbaya, S. The development of a physics and constraint-based haptic virtual assembly system. Assem. Autom. 2014, 34, 41–55. [Google Scholar] [CrossRef] [Green Version]
- Behandish, M.; Ilieş, H.T. Peg-in-hole revisited: A generic force model for haptic assembly. J. Comput. Inf. Sci. Eng. 2015, 15, 041004. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Jayaram, U.; Jayaram, S.; Imtiyaz, S. Methods and algorithms for constraint-based virtual assembly. Virtual Real. 2003, 6, 229–243. [Google Scholar] [CrossRef]
- Murray, N.; Fernando, T. An immersive assembly and maintenance simulation environment. In Proceedings of the Eighth IEEE International Symposium on Distributed Simulation and Real-Time Applications, Budapest, Hungary, 21–23 October 2004; pp. 159–166. [Google Scholar]
- Tching, L.; Dumont, G.; Perret, J. Interactive simulation of CAD models assemblies using virtual constraint guidance. Int. J. Interact. Des. Manuf. (IJIDeM) 2010, 4, 95–102. [Google Scholar] [CrossRef]
- Seth, A.; Vance, J.M.; Oliver, J.H. Combining dynamic modeling with geometric constraint management to support low clearance virtual manual assembly. J. Mech. Des. 2010, 132, 081002. [Google Scholar] [CrossRef]
- Aksoy, E.E.; Abramov, A.; Dörr, J.; Ning, K.; Dellen, B.; Wörgötter, F. Learning the semantics of object–action relations by observation. Int. J. Robot. Res. 2011, 30, 1229–1249. [Google Scholar] [CrossRef] [Green Version]
- Summers-Stay, D.; Teo, C.L.; Yang, Y.; Fermüller, C.; Aloimonos, Y. Using a minimal action grammar for activity understanding in the real world. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 4104–4111. [Google Scholar]
- Cheng, H.T.; Sun, F.T.; Griss, M.; Davis, P.; Li, J.; You, D. Nuactiv: Recognizing unseen new activities using semantic attribute-based learning. In Proceedings of the 11th Annual International Conference on Mobile Systems, Applications, and Services, Taipei, Taiwan, 25–28 June 2013; pp. 361–374. [Google Scholar]
- Antol, S.; Zitnick, C.L.; Parikh, D. Zero-shot learning via visual abstraction. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 401–416. [Google Scholar]
- Aoki, T.; Nishihara, J.; Nakamura, T.; Nagai, T. Online joint learning of object concepts and language model using multimodal hierarchical Dirichlet process. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 2636–2642. [Google Scholar]
- Cheng, H.T.; Griss, M.; Davis, P.; Li, J.; You, D. Towards zero-shot learning for human activity recognition using semantic attribute sequence model. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; pp. 355–358. [Google Scholar]
- Aggarwal, J.K.; Ryoo, M.S. Human activity analysis: A review. ACM Comput. Surv. (CSUR) 2011, 43, 1–43. [Google Scholar] [CrossRef]
- Ramirez-Amaro, K.; Beetz, M.; Cheng, G. Transferring skills to humanoid robots by extracting semantic representations from observations of human activities. Artif. Intell. 2017, 247, 95–118. [Google Scholar] [CrossRef]
- Dianov, I.; Ramirez-Amaro, K.; Lanillos, P.; Dean-Leon, E.; Bergner, F.; Cheng, G. Extracting general task structures to accelerate the learning of new tasks. In Proceedings of the 2016 IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids), Cancun, Mexico, 15–17 November 2016; pp. 802–807. [Google Scholar]
- Haidu, A.; Beetz, M. Action recognition and interpretation from virtual demonstrations. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 2833–2838. [Google Scholar]
- Ramirez-Amaro, K.; Inamura, T.; Dean-León, E.; Beetz, M.; Cheng, G. Bootstrapping humanoid robot skills by extracting semantic representations of human-like activities from virtual reality. In Proceedings of the 2014 IEEE-RAS International Conference on Humanoid Robots, Madrid, Spain, 18–20 November 2014; pp. 438–443. [Google Scholar]
- Inamura, T.; Shibata, T.; Sena, H.; Hashimoto, T.; Kawai, N.; Miyashita, T.; Sakurai, Y.; Shimizu, M.; Otake, M.; Hosoda, K.; et al. Simulator platform that enables social interaction simulation—SIGVerse: SocioIntelliGenesis simulator. In Proceedings of the 2010 IEEE/SICE International Symposium on System Integration, Narvik, Norway, 8–12 January 2010; pp. 212–217.
- Bates, T.; Ramirez-Amaro, K.; Inamura, T.; Cheng, G. On-line simultaneous learning and recognition of everyday activities from virtual reality performances. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3510–3515. [Google Scholar]
- Kazhoyan, G.; Hawkin, A.; Koralewski, S.; Haidu, A.; Beetz, M. Learning Motion Parameterizations of Mobile Pick and Place Actions from Observing Humans in Virtual Environments. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NA, USA, 25–29 October 2020; pp. 9736–9743. [Google Scholar]
- Uhde, C.; Berberich, N.; Ramirez-Amaro, K.; Cheng, G. The Robot as Scientist: Using Mental Simulation to Test Causal Hypotheses Extracted from Human Activities in Virtual Reality. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NA, USA, 25–29 October 2020; pp. 8081–8086. [Google Scholar]
- James, S.; Johns, E. 3D Simulation for Robot Arm Control with Deep Q-Learning. arXiv 2016, arXiv:1609.03759. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | Moving | ObjectInHand | ObjectActOn | HandState |
|---|---|---|---|---|
| Value | Move | ObjectName | ObjectName | Open |
| NotMove | Null | Null | Close |
| Activity | Moving | ObjectInHand | ObjectActOn | HandState |
|---|---|---|---|---|
| Idle | NotMove | Null | Null | Open |
| Reach | Move | Null | Something | Open |
| Take | NotMove | Something | Null | Close |
| Release | Move | Null | Null | Open |
| PutSomethingSomewhere | Move | Something | Null | Close |
| Granular | Move | Something | Something | Close |
| Attributes | ObjectDistance | Collide-Flag | Connect-Flag |
|---|---|---|---|
| Collision of two objects | Meet the assembly conditions | ||
| far | True | True | |
| close | False | False |
| Activity | Moving | ObjectDistance | Collide-flag | Connect-flag |
|---|---|---|---|---|
| Idle | NotMove | far | False | False |
| Approach | Move | close | False | False |
| Revolve | Move | close | True | False |
| Pin-in-Hole | Move | close | True | True |
| Actual Activities | Inference Activities | ||||||
|---|---|---|---|---|---|---|---|
| a | b | c | d | e | f | g | |
| a | 95.5 | 4.1 | 0 | 0.3 | 0 | 0 | 0 |
| b | 20.5 | 94.3 | 2.3 | 3.4 | 0 | 0 | 0 |
| c | 0 | 0 | 98.6 | 1.4 | 0 | 0 | 0 |
| d | 0 | 0 | 8.8 | 91.2 | 0 | 0 | 0 |
| e | 0 | 0 | 0 | 1.2 | 98.7 | 0 | 0 |
| f | 0 | 0 | 0 | 0 | 0 | 96.4 | 3.5 |
| g | 0 | 0 | 0 | 0 | 0 | 3.3 | 96.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, N.; Qi, T.; Zhao, Y. Real-Time Learning and Recognition of Assembly Activities Based on Virtual Reality Demonstration. Sensors 2021, 21, 6201. https://doi.org/10.3390/s21186201
Zhang N, Qi T, Zhao Y. Real-Time Learning and Recognition of Assembly Activities Based on Virtual Reality Demonstration. Sensors. 2021; 21(18):6201. https://doi.org/10.3390/s21186201
Chicago/Turabian StyleZhang, Ning, Tao Qi, and Yongjia Zhao. 2021. "Real-Time Learning and Recognition of Assembly Activities Based on Virtual Reality Demonstration" Sensors 21, no. 18: 6201. https://doi.org/10.3390/s21186201
APA StyleZhang, N., Qi, T., & Zhao, Y. (2021). Real-Time Learning and Recognition of Assembly Activities Based on Virtual Reality Demonstration. Sensors, 21(18), 6201. https://doi.org/10.3390/s21186201