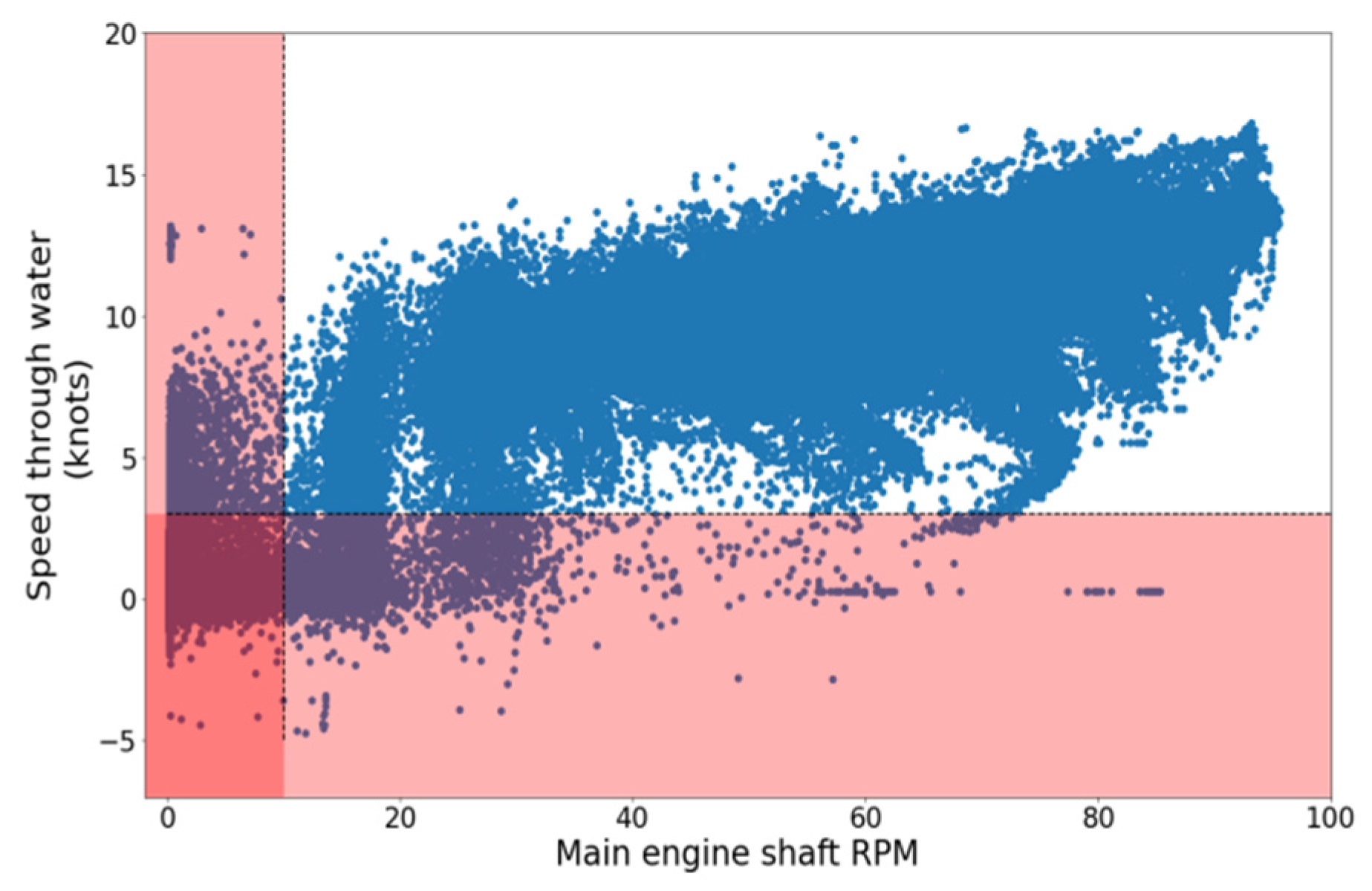
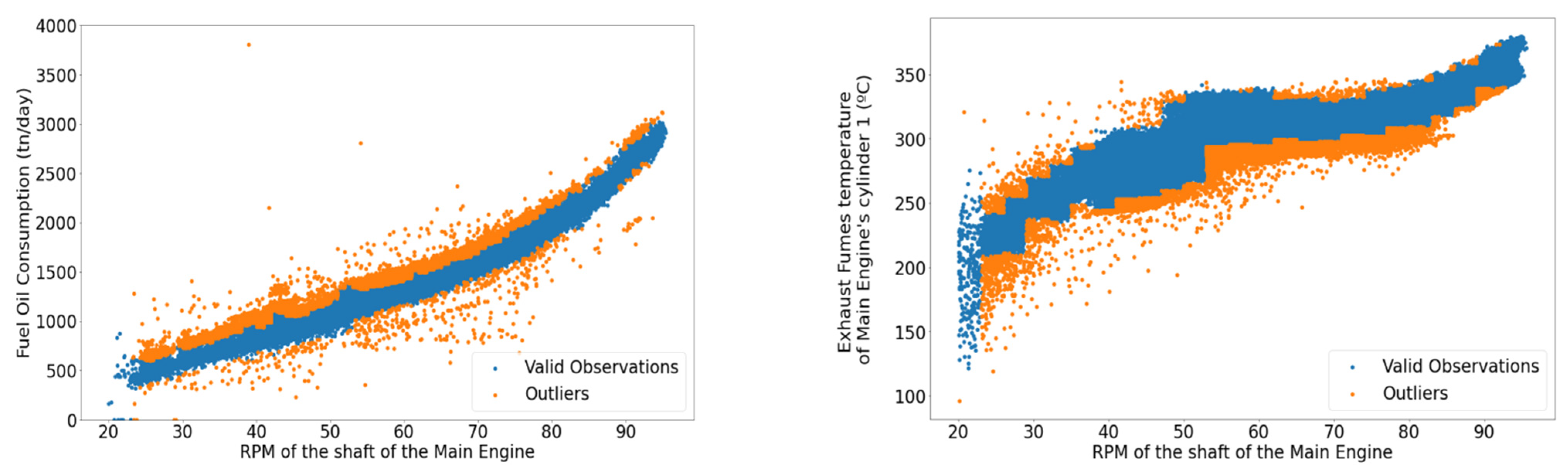
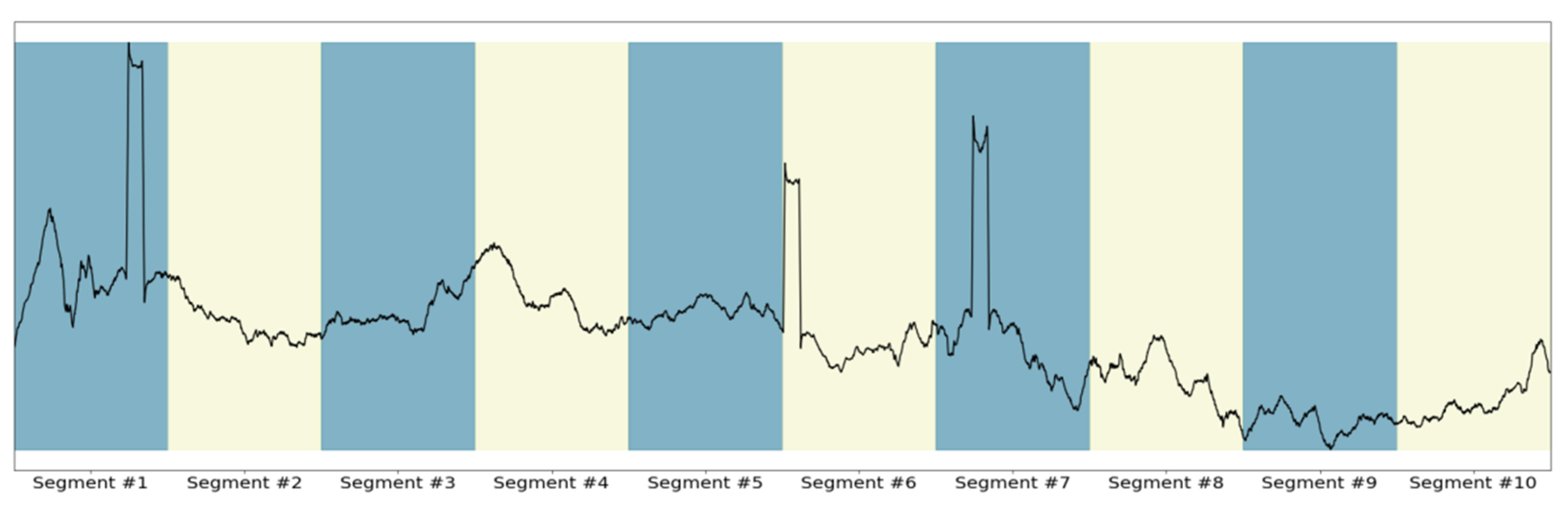
The maritime industry is one of the most crucial pillars of modern economy. To substantiate the level of impact, in 2015, 80% of merchandise trade [
1] and 90% of the European Union’s (EU) external trade were transported by ships, illustrating the importance of the marine sector for both the European and global markets [
2]. An essential requirement of the maritime industry is the reliability and availability of vessels. Safety-oriented and environmental regulations have become more stringent during recent years, demanding increasingly higher regulation for the condition and operation of ships to achieve higher safety standards. As a result, efficient, precise, and timely maintenance is becoming of paramount importance [
3]. One of the most critical problems in the maritime industry is the adoption of the maintenance schedule.
Initially, corrective maintenance policies were adopted, in which maintenance was performed after the occurrence of breakdowns. Inevitably, this approach incurs high costs, downtime, and in some cases, hazardous operations. A more sophisticated approach, and currently the most common, is Preventive Maintenance (PM). In PM, a component is replaced when it is considered to have reached the end of its useful lifetime. The most widely adopted and conservative technique is to estimate the mean time to failure of a component according to experience with components of the same type. Despite a safer approach, it can result in unnecessary costs as well, particularly if a very conservative estimation is used. Moreover, this method does not guarantee a decrease in the number of breakdowns in a fleet, as the replacement of equipment can still be performed too late. Naturally, this method is based on a tradeoff between the number of failures and the lifetime estimation of the components on board. However, a favorable balance between the two is not easy to achieve, mainly due to the different operating conditions between any two vessels. For the maritime domain, a rather new approach is Condition Based Maintenance (CBM), where the actual condition of an asset (vessel) is monitored in real-time to decide the level of required maintenance [
4]. While being able to achieve significant maintenance cost reductions, CBM has strict requirements, such as the use of a multisensor monitoring approach for each component onboard, due to the multiple failure modes that are manifested using different monitoring technologies [
5]. As such, successful adoption of CBM is strongly connected with the use of sophisticated models that can diagnose the health status of a component based on data from sensor networks onboard. Following rapid development progress, it has been proved that Artificial Intelligence (AI) and machine learning models have numerous applications in all engineering fields [
6,
7,
8,
9,
10,
11], producing remarkable results. More specifically, one prominent field in which AI-based solutions have been producing reliable and accurate results, surpassing other methodologies, is the failure detection and classification domain [
12,
13,
14,
15]. Following this trend, the maritime industry is evaluating different AI-based solutions for improving the quality of their operations both in terms of performance efficiency and safety assurance [
16]. Considering the wide variety of systems on-board, Machine Learning (ML) approaches that apply to the maritime sector are practically endless. Data-driven techniques and ML-related research in marine engineering are mainly featured on subjects such as energy and performance optimization of the vessel [
17], albeit there are studies in which emphasis has been given on solutions regarding the task of fault detection approaches [
18,
19]. Several studies have demonstrated the successful employment of ML-based approaches in maritime maintenance, to improve the maintenance strategy of marine diesel engines [
20], hull condition assessment [
21], or the combination of the propeller, hull, gas turbine, and gas turbine compressor [
5,
22]. The use of ML for fault detection and isolation on gas turbines (prevalent in naval applications) has been extensively studied [
23]; rolling element bearings are among the most well-studied components in the literature [
24], asynchronous [
25], and synchronous [
26] motors, and batteries [
27], have seen successful applications of ML. ML applications will play a key role in the maritime sector during the coming decades for the estimation and degradation modeling of assets [
28,
29].
Working toward the same direction, in our previous work we investigated how different Deep-Learning (DL) models could provide enhanced information for the support of decision-making [
30] within the maritime industry, based on deep learning algorithms. It was shown that the method could accurately predict issues that are caused by long-term degradation (e.g., hull performance) but its effectiveness when instantaneous faults occurred was limited. In this study, our primary focus is to transcend our previous work and progress one step further in the preventive maintenance spectrum implementing condition-based monitoring aspiring to detect failure proneness. It is aspired to develop a CBM scheme to monitor the state of the vessel under study and identify suspicious patterns that indicate failure proneness. More specifically, the signals of the temperature of the main engine’s cylinders are monitored, trying to identify patterns in the signals that signify proneness to failure of the monitored part of the machinery. The type of degradation aspired to detect is either caused by trigger events, such as impacts, or by fracture propagation. These types of degradation are demonstrated in the monitored signal by the inflated jittering in the signal.
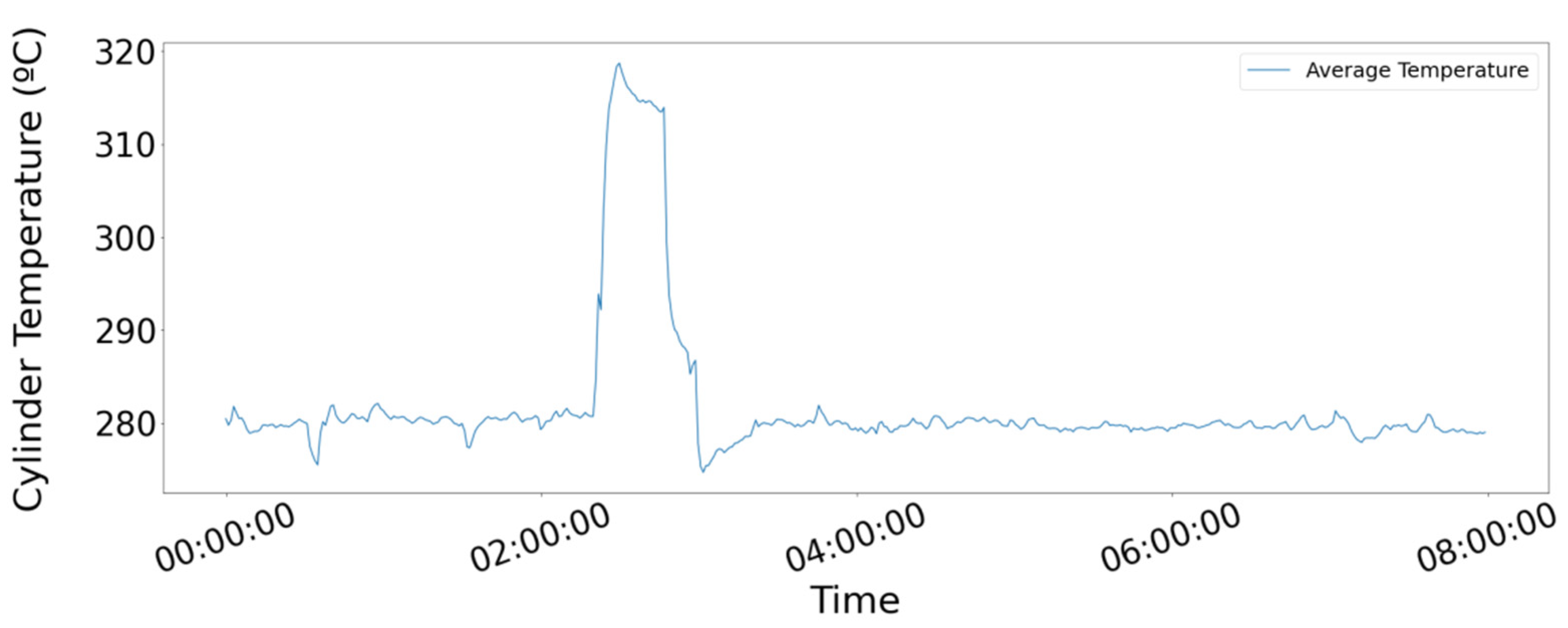
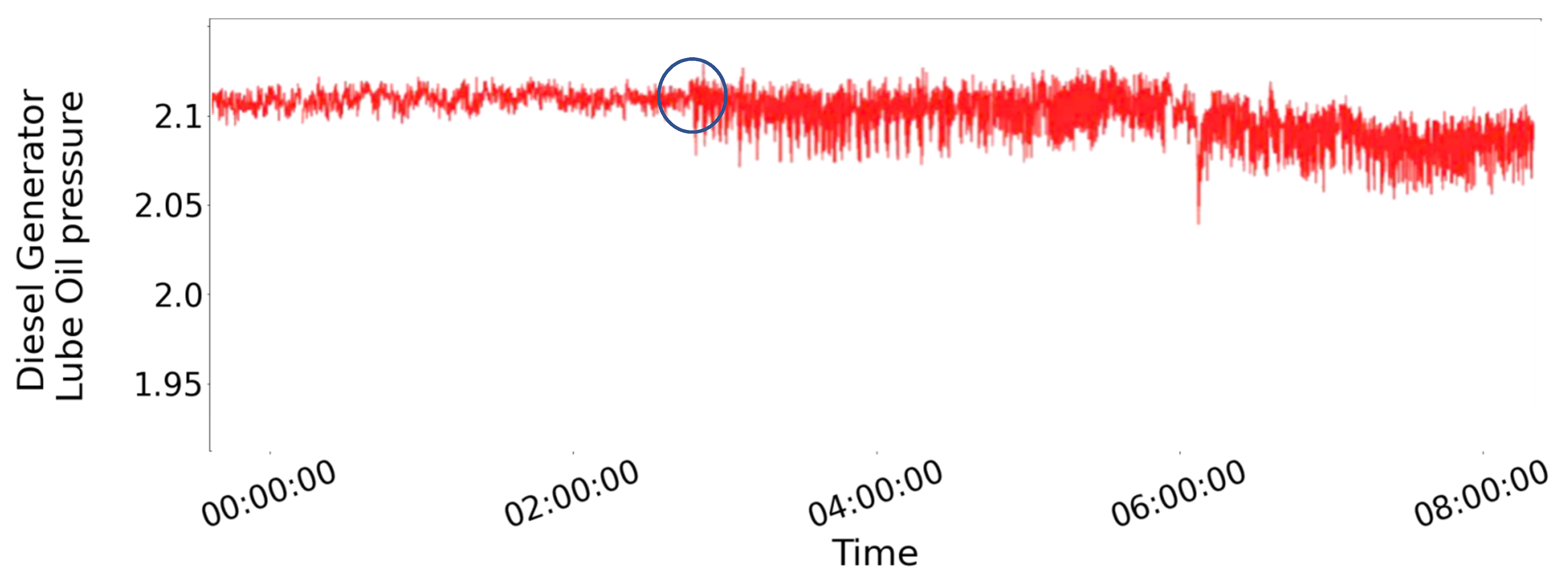
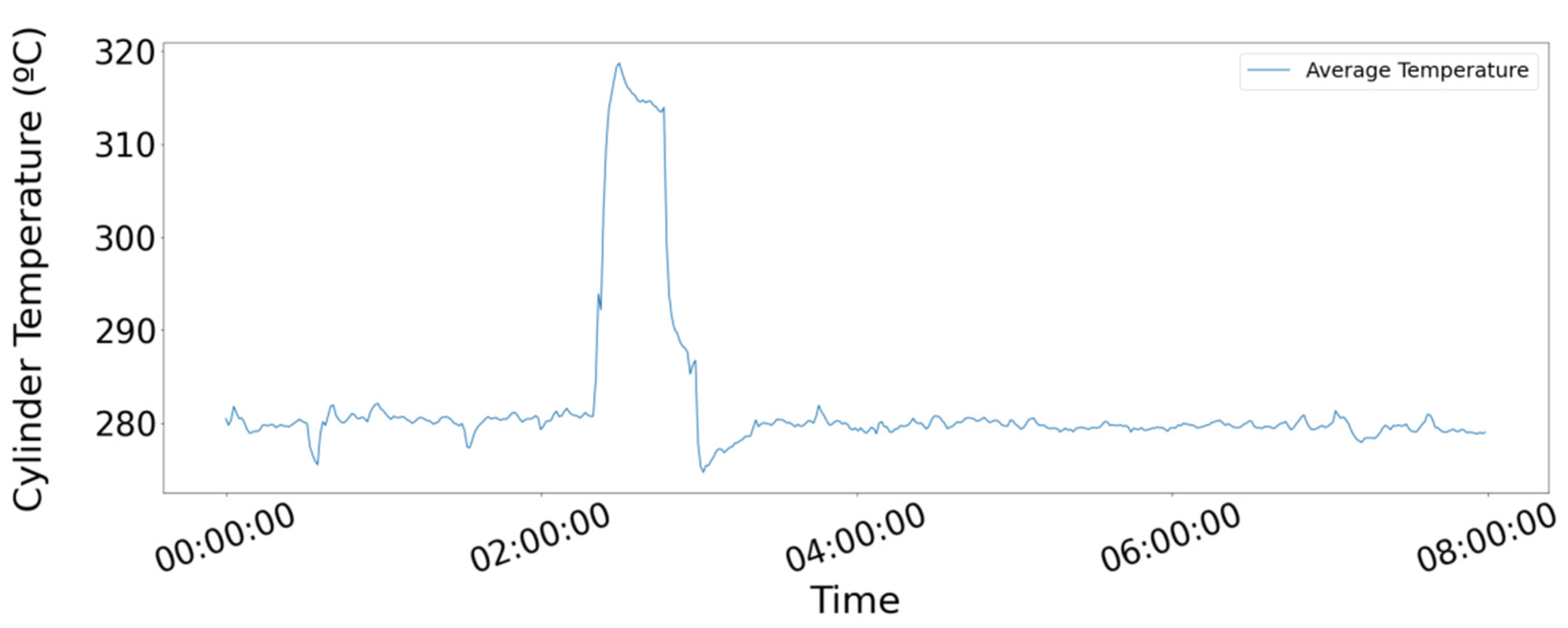
Figure 1 demonstrates the type of deficiency we aspire to detect with our methodology, illustrating the occurrence of a trigger, even to the actual signal collected from the Diesel Generator (D/G) Lube Oil (LO) pressure over approximately 2 days, as the impairment manifests itself through the inflated volatility due to a crack in the crankshaft. The blue circle in the figure shows the commencement of damage. According to the vessel operator, the fault was not visible by the instruments onboard and the root cause was found only after costly unscheduled maintenance.
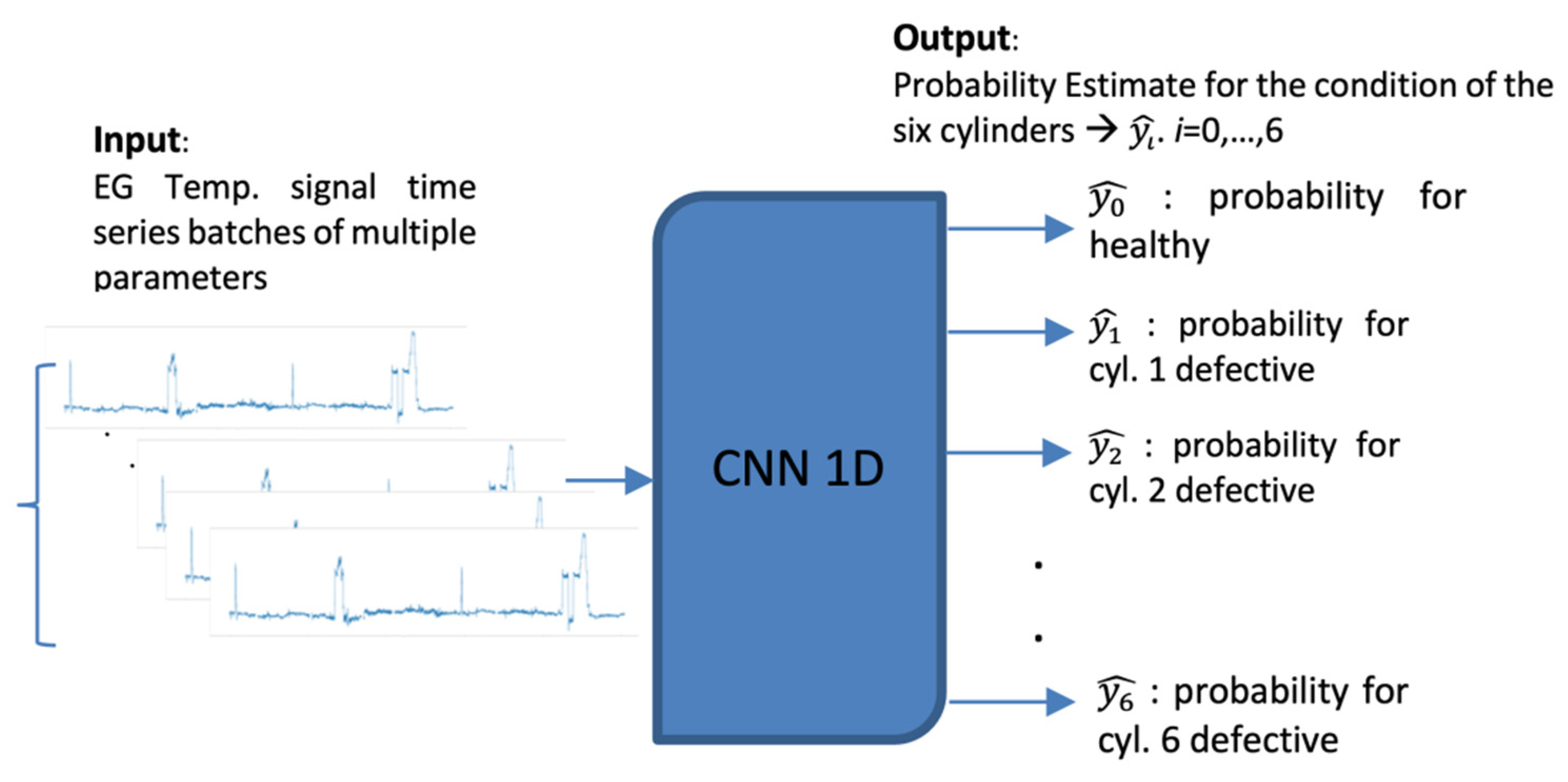
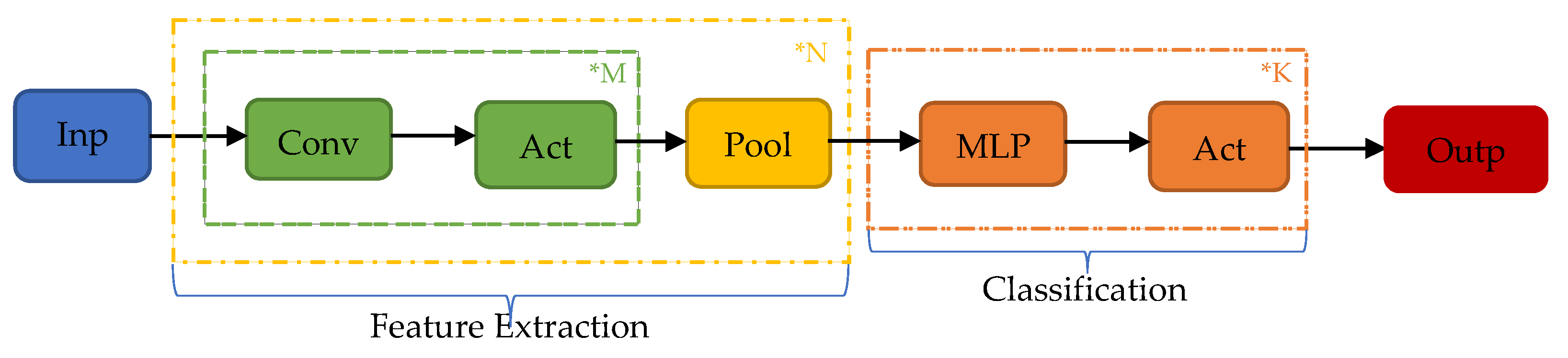
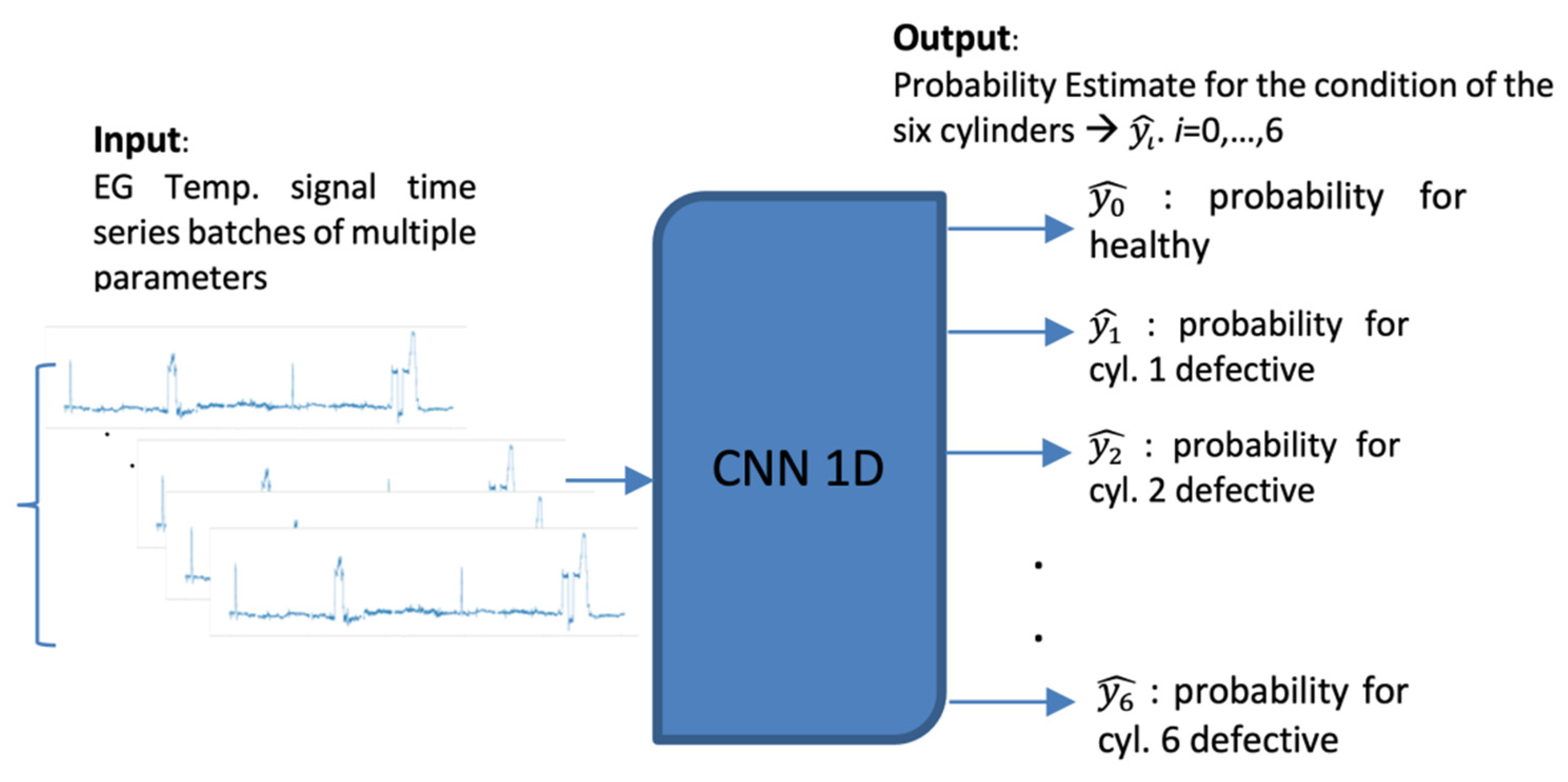
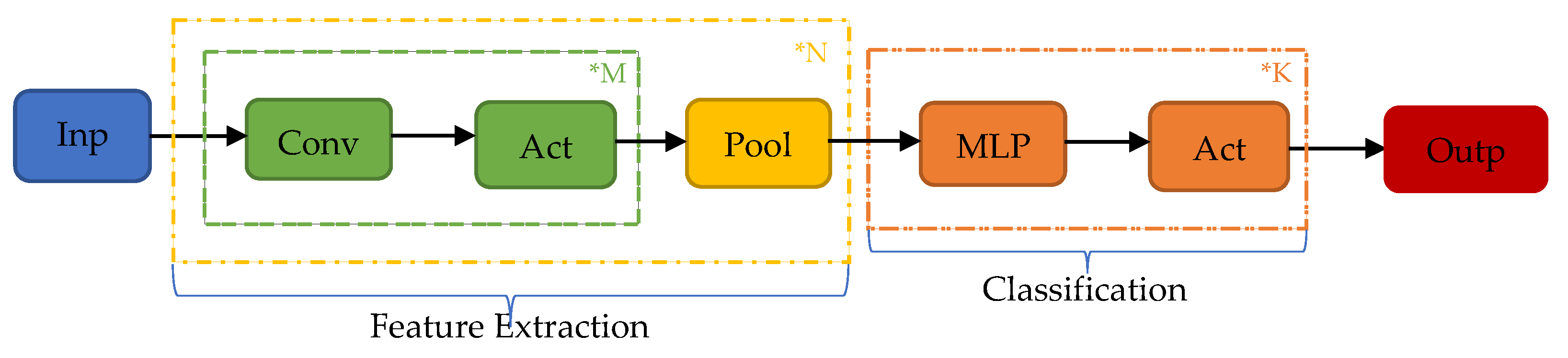
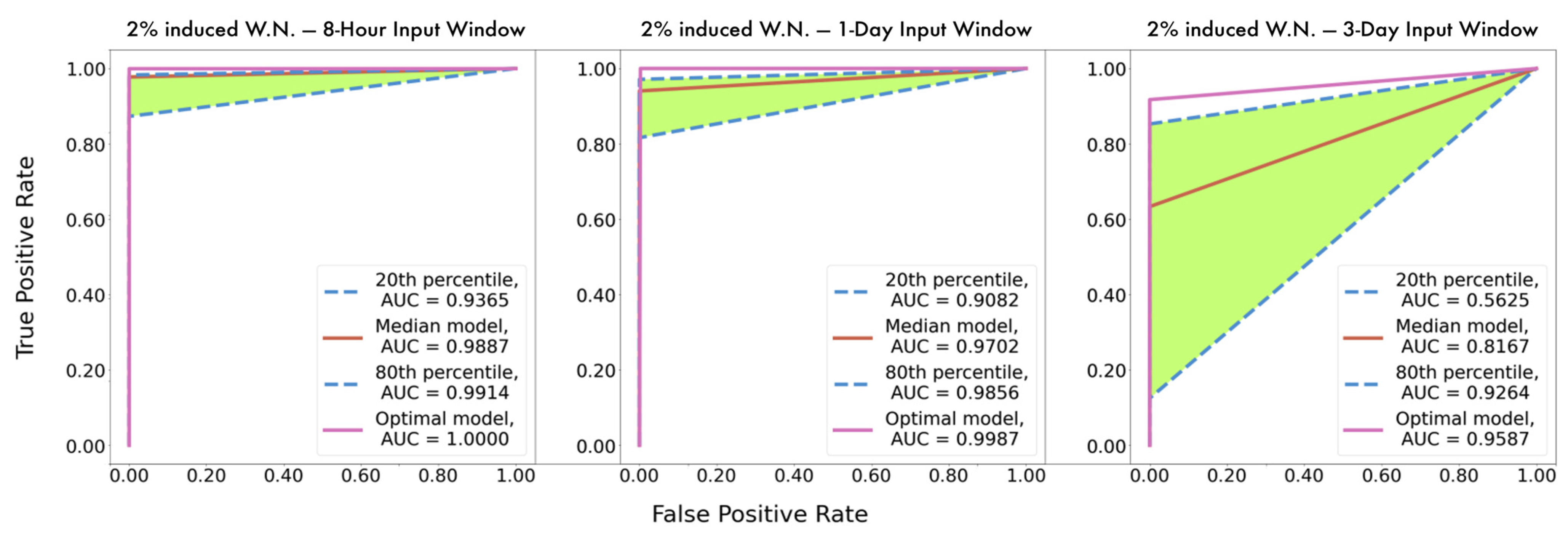
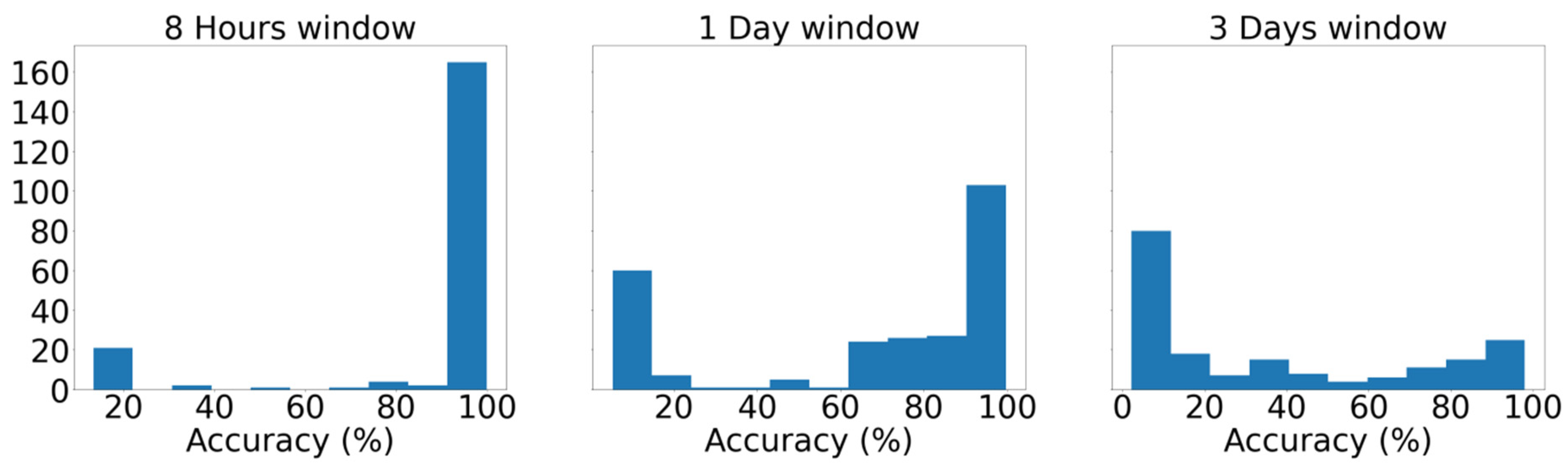
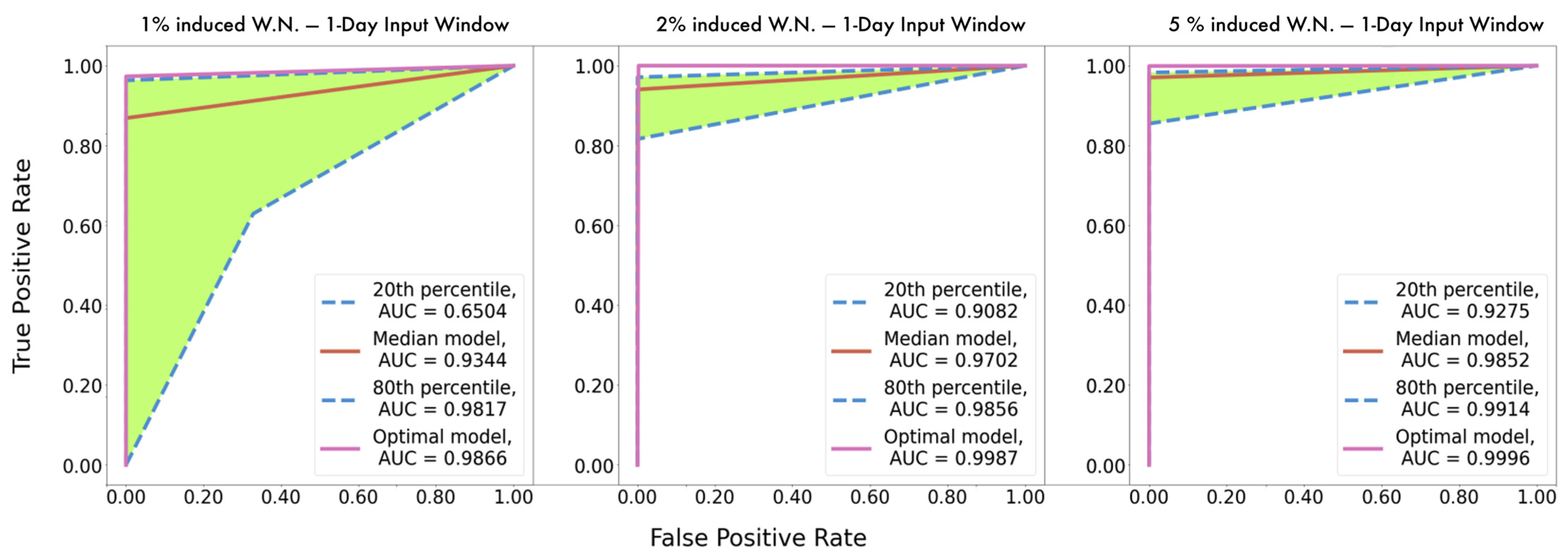
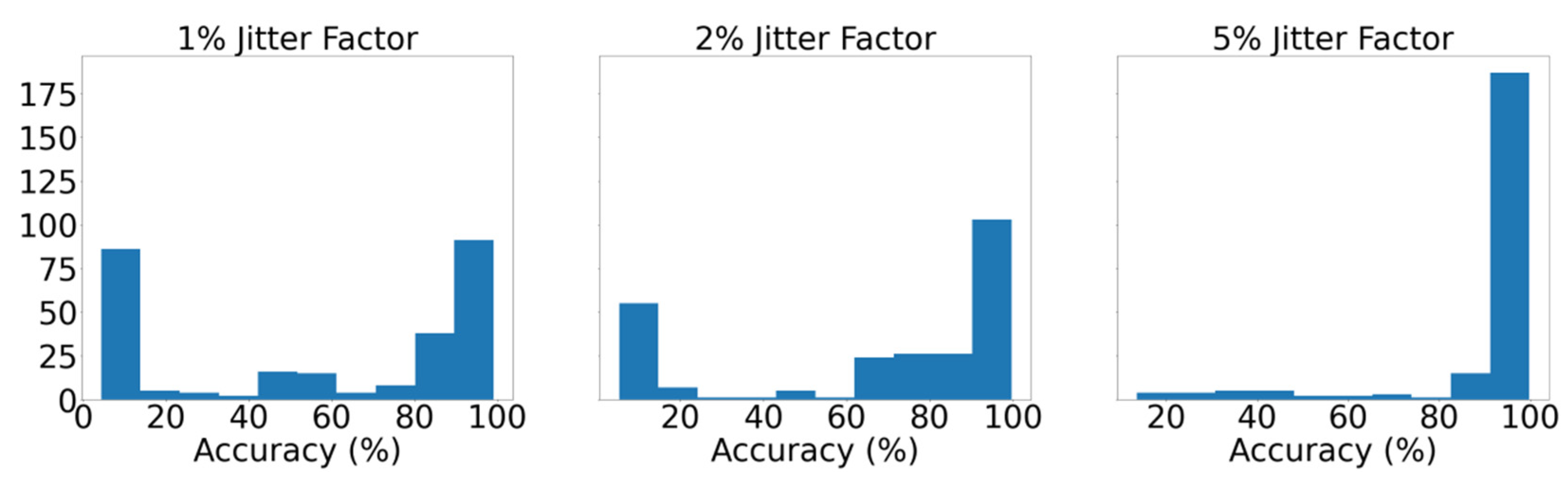
The proposed implementation employs a unidimensional (1D) Convolutional Neural Network (CNN) that monitors of the condition of the main engine, which inspects the signal of the temperature of the main engine’s cylinders (
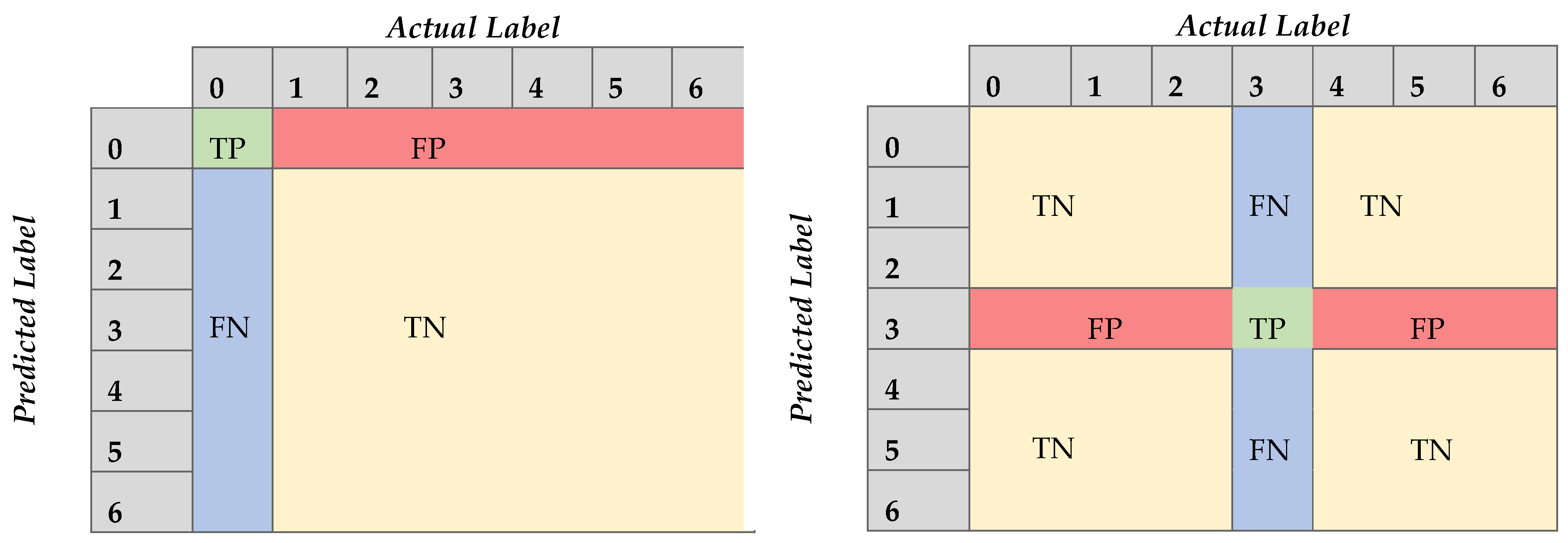
Figure 2). This CBM system facilitates the implementation of a short-term approach, as the time series can be divided into smaller batches without affecting adversely the performance of the model. In this instance, we attempt to classify the signal obtained from the exhaust gas temperature of the six cylinders of the ship’s main engine, detecting divergence from the healthy state, caused by degradation and wear, assuming that in the context of our study case, the cases examined refer to occasions with only up to one cylinder being degraded. This form of deficiency is typically expressed as increased jitter of the monitored signal. The networks receive as inputs time series batches of the six signals of the exhaust gas temperature of the six cylinders representing the same time interval. The output is the probabilities of the validity for each possible state of the seven distinct states. Let the available label range be 0–6, then the label 0 signifies a well-functioning vessel, or equivalently, the label i expresses that the respective cylinder i is defective (i.e., 1–6). Therefore, it is aimed to not only identify the operational condition of the ship through the classification of time series batches derived from the dataset, but also, in case of deficiency, to explicitly localize the damage. In this regard, the prominence of CNNs in pattern recognition is examined through their capacity to extract and represent features at high levels of abstraction. To the knowledge of the authors, no similar effort has been presented in the maritime industry. The remainder of the paper is structured as follows: In
Section 2, the theoretical background of the model is provided along with a description of the evaluation metrics adopted. In
Section 3, a presentation of the data collection and preprocessing procedures are provided. Both steps are required in almost every data-driven analysis, assuring optimal quality of the data utilized. In
Section 4, a descriptive overview of the function of CNNs is provided followed by the results yielded in the parametric inquiry. Benchmarking with different optimization models is also provided in this section. Concluding remarks and future steps are discussed in
Section 5.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}