
A Time-Series-Based New Behavior Trace Model for Crowd Workers That Ensures Quality Annotation

 ,
,  , and
, and
Abstract
:1. Introduction
- It proposes novel time-series-based models in the field of crowdsourcing quality control.
- It introduces two new models with various experiments. The first was based on time-series feature generation, showing the important features of crowd workers’ behavior. The other model was based on converting time series into heatmaps and then leveraging from their recurring characteristics to classify the tasks of crowd workers. The latter model establishes a baseline for research in the application of a lightweight deep learning model in the field of crowdsourcing workers’ assessment control.
- The proposed models possess superior performance. We demonstrated that our models outperform time-series state-of-the-art models such as dynamic time warping (DTW) and time-series support vector classifier (TS-SVC), as well as leading research works by Rzeszotarski and Kittur [32] and Goyal et al. [34].
2. Related Work
2.1. Traditional Approaches
2.2. Behavior Tracing Approaches
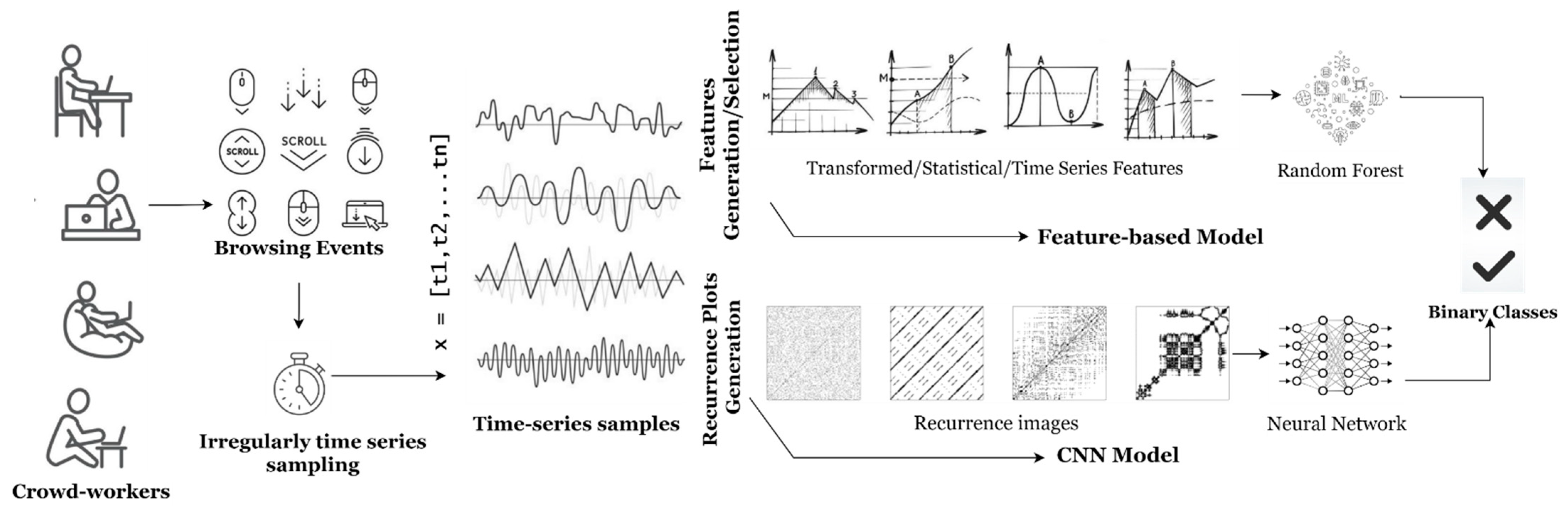
3. Method and Materials
3.1. Dataset
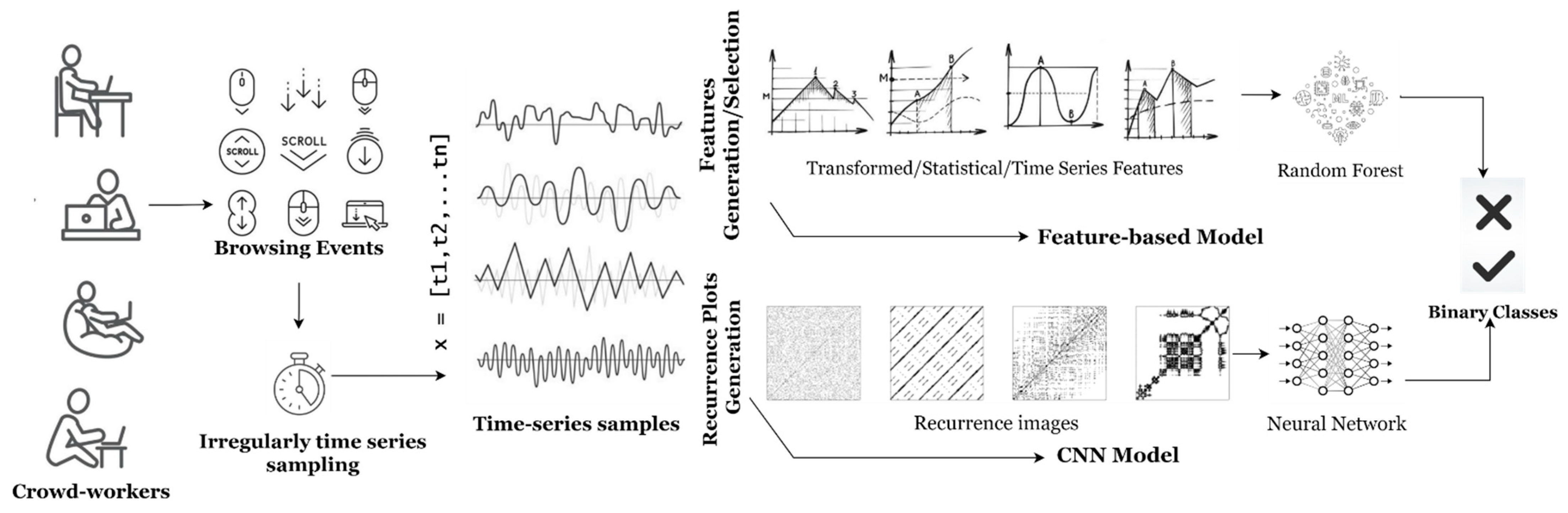
3.2. Proposed Models
3.2.1. Feature-Based Model
Feature Generation
- Statistical:
- Transformed:
- Information theory/entropy:
- Time-series-related/others:
Feature Selection/Reduction
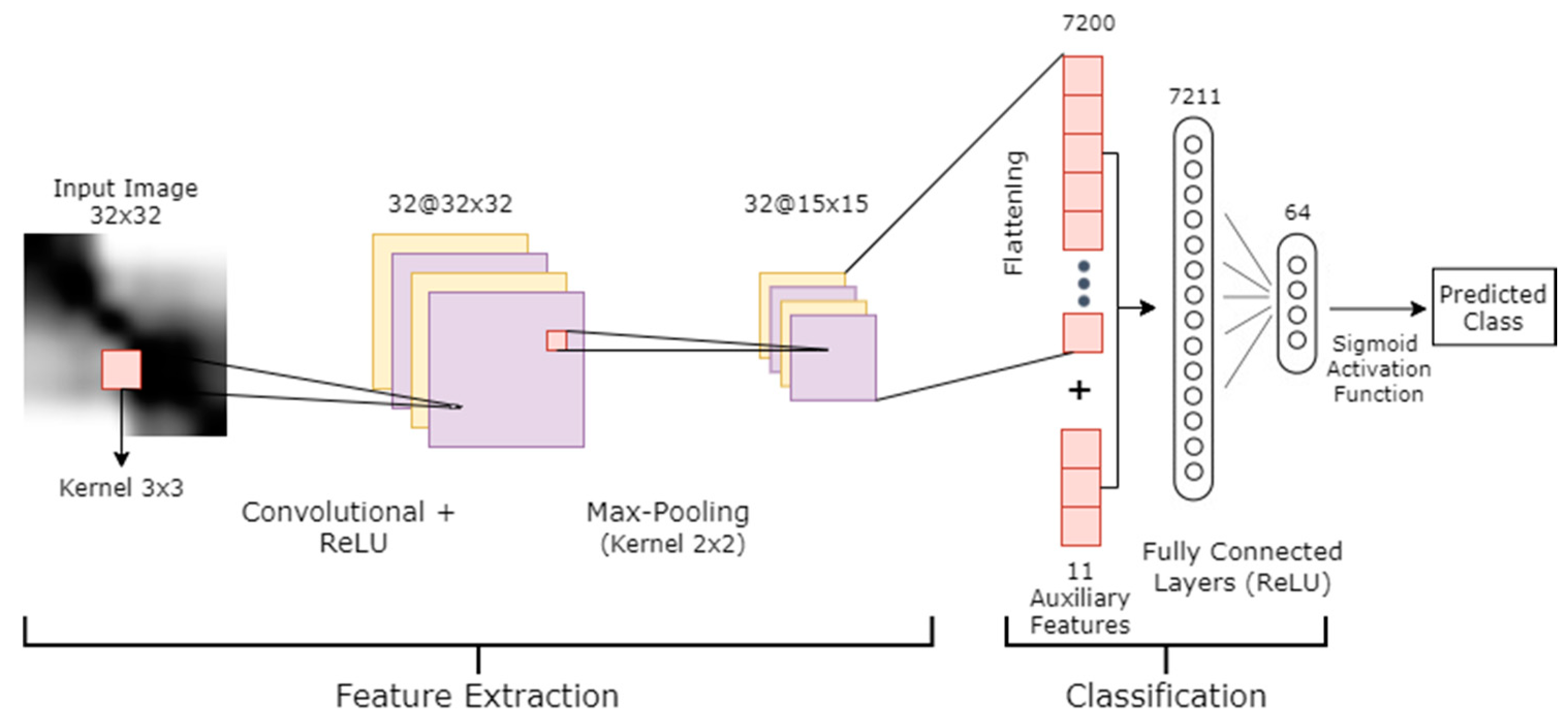
3.2.2. Image-CNN Model
Recurrence Plot
CNN Model
4. Experimental Results and Evaluation
4.1. Experimental Results
4.1.1. Evaluation Metrics
4.1.2. Features-Based Model
- Parameters tuning:
- Feature generation and selection:
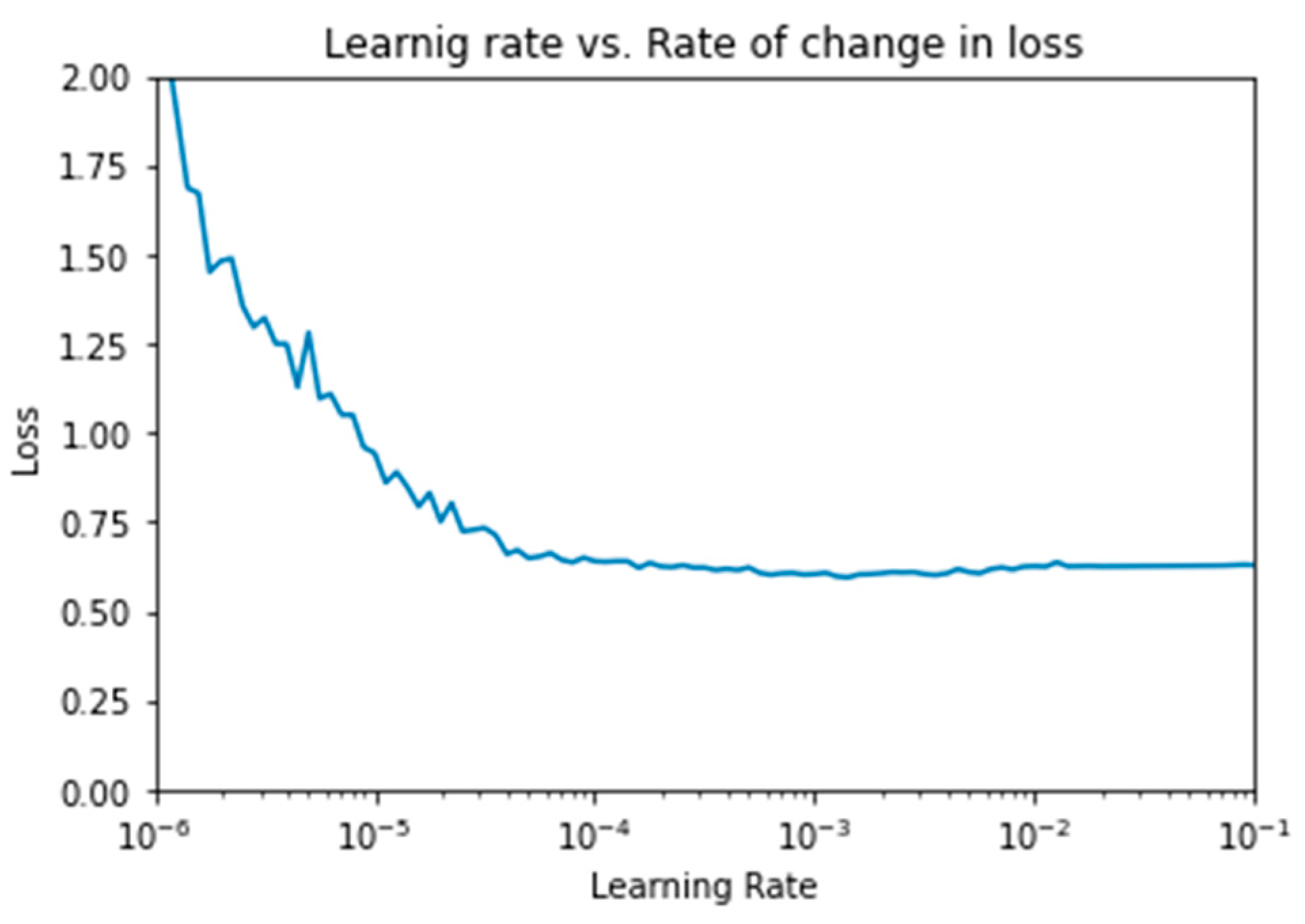
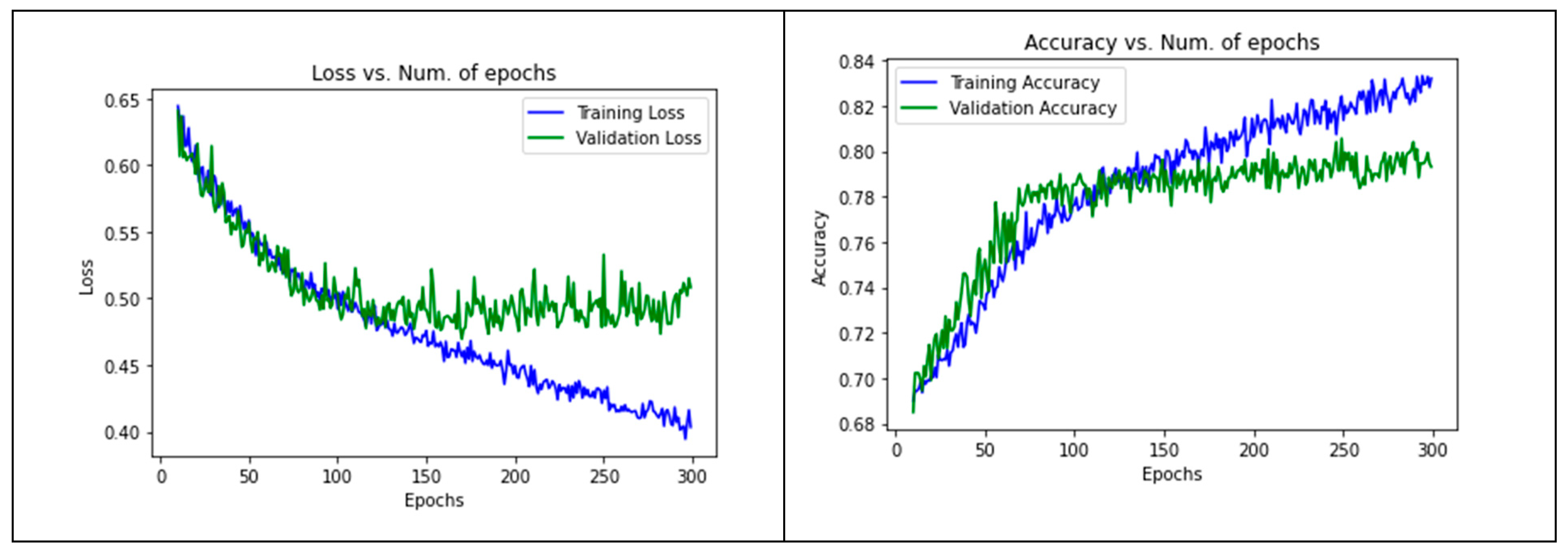
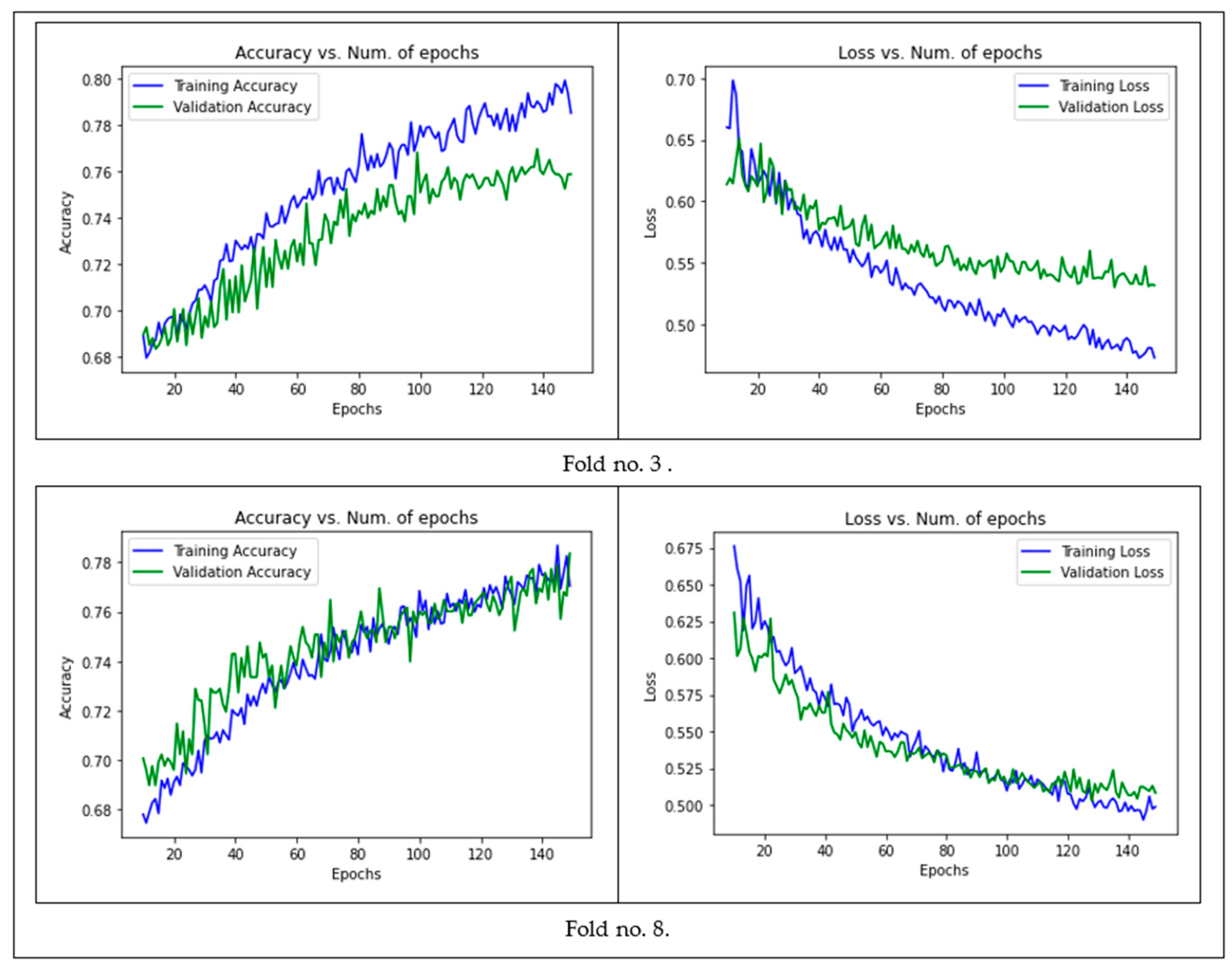
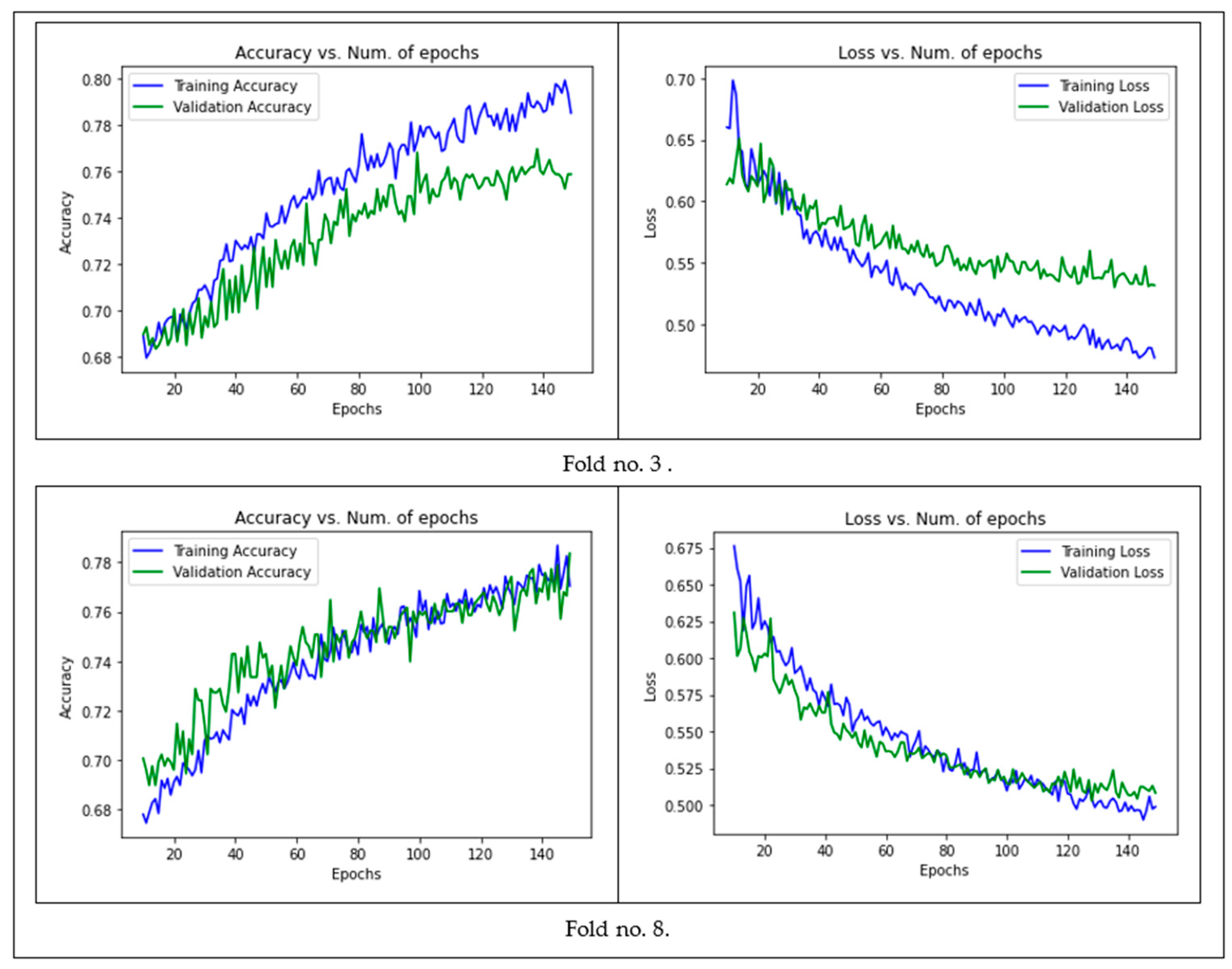
4.1.3. Image-CNN Model
- Parameter tuning:
4.1.4. Baselines
4.1.5. Parameters and Software
5. General Discussion
5.1. Feature-Based Models
5.2. Image-CNN Model
5.3. Baselines
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Feature Description | Action Name | Importance Order | Parameters |
|---|---|---|---|---|
| Continuous Wavelet Transform coefficients | The Continuous Wavelet Transform for the Mexican hat wavelet | MMT * | 1 | 1st Coefficient width 2 |
| 8 | 1st Coefficient width 5 | |||
| 15 | 1st Coefficient width 10 | |||
| 18 | 1st Coefficient width 20 | |||
| 63 | 2nd Coefficient width 5 | |||
| 68 | 2nd Coefficient width 20 | |||
| 71 | 2nd Coefficient width 10 | |||
| 72 | 2nd Coefficient width 2 | |||
| FCT * | 28 | 1st Coefficient width 10 | ||
| 33 | 1st Coefficient width 2 | |||
| 36 | 1st Coefficient width 20 | |||
| 38 | 1st Coefficient width 5 | |||
| CST * | 64 | 1st Coefficient width 2 | ||
| 66 | 1st Coefficient width 10 | |||
| 77 | 1st Coefficient width 5 | |||
| Quantile | The q quantile of the sample (10 quantiles) | MMT | 2 | The 9th quantile |
| 6 | The 1st quantile | |||
| 7 | The 2nd quantile | |||
| 9 | The 3rd quantile | |||
| 10 | The 6th quantile | |||
| 11 | The 7th quantile | |||
| 12 | The 8th quantile | |||
| 14 | The 4th quantile | |||
| 78 | The 5th quantile | |||
| FCT | 22 | The 1st quantile | ||
| 23 | The 9th quantile | |||
| 25 | The 8th quantile | |||
| 26 | The 4th quantile | |||
| 27 | The 6th quantile | |||
| 29 | The 7th quantile | |||
| 32 | The 3rd quantile | |||
| 34 | The 2nd quantile | |||
| CST | 48 | The 9th quantile | ||
| 52 | The 8th quantile | |||
| 57 | The 4th quantile | |||
| 59 | The 2nd quantile | |||
| 73 | The 6th quantile | |||
| 74 | The 7th quantile | |||
| 75 | The 1st quantile | |||
| Fast Fourier Transform coefficient | The fourier coefficients of the one-dimensional discrete Fourier Transform | MMT | 16 | Real 1st coefficient |
| 17 | Absolute 1st coefficient | |||
| 76 | Absolute 2nd coefficient | |||
| FCT | 30 | Absolute 1st coefficient | ||
| 35 | Real 1st coefficient | |||
| Sum values | The sum over the sample values | MMT | 19 | |
| FCT | 37 | |||
| Benford correlation | The correlation resulted from the Newcomb-Benford’s Law distribution | MMT | 39 | |
| FCT | 40 | |||
| CST | 56 | |||
| Absolute energy | The absolute energy of the sample which is the sum over the squared values | MMT | 41 | |
| Energy ratio by chunks | The sum of squares of chunk i out of N chunks expressed as a ratio with the sum of squares over the whole series. (10 segments) | MMT | 43 | First segment |
| 42 | Second segment | |||
| Fast Fourier Transform aggregated | The spectral centroid (mean), variance, skew, and kurtosis of the absolute fourier transform spectrum. | MMT | 44 | Centroid |
| 61 | Variance | |||
| Change quantiles | The average, absolute value of consecutive changes of the series x inside the corridor of quantiles q-low and q-high. | MMT | 45 | Mean without absolute difference of (the higher quantile and the lower quantile) |
| 55 | Mean with absolute difference of (the higher quantile and the lower quantile) | |||
| Variation coefficient | The variation coefficient (standard error/mean, give relative value of variation around mean) of x | MMT | 46 | |
| Mean absolute change | The mean over the absolute differences between subsequent sample values | MMT | 47 | |
| Mean change | The mean over the differences between subsequent sample values. | MMT | 49 | |
| Linear trend | The linear least-squares regression for the values of the sample versus the sequence from 0 to length of the sample minus one. | MMT | 50 | Slope |
| 60 | Intercept | |||
| Complexity Estimator | The estimation for a sample complexity (A more complex sample has more peaks, valleys etc.). | MMT | 53 | Without normalization |
| Standard deviation | The standard deviation of the sample x. | MMT | 69 | |
| Absolute sum of changes | The sum over the absolute value of consecutive changes in the series x. | MMT | 62 | |
| Maximum | The largest value of the sample x. | MMT | 3 | |
| FCT | 20 | |||
| CST | 70 | |||
| Minimum | The smallest value of the sample x. | MMT | 4 | |
| FCT | 21 | |||
| CST | 58 | |||
| Mean | The mean of the sample x | MMT | 5 | |
| FCT | 24 | |||
| CST | 54 | |||
| Median | The median of the sample x | MMT | 13 | |
| FCT | 31 | |||
| CST | 65 |
References
- Howe, J. Wired Magazine 2006, The Rise of Crowdsourcing. Available online: https://www.wired.com/2006/06/crowds/ (accessed on 21 July 2021).
- Poesio, M.; Chamberlain, J.; Kruschwitz, U. Crowdsourcing. In Handbook of Linguistic Annotation; Ide, N., Pustejovsky, J., Eds.; Springer: Dordrecht, The Netherlands, 2017; pp. 277–295. ISBN 978-94-024-0879-9. [Google Scholar]
- Von Ahn, L.; Dabbish, L. Labeling images with a computer game. In Proceedings of the 2004 Conference on Human factors in Computing Systems—CHI’04, Vienna, Austria, 24–29 April 2004; ACM Press: Vienna, Austria, 2004; pp. 319–326. [Google Scholar]
- Zong, S.; Baheti, A.; Xu, W.; Ritter, A. Extracting COVID-19 events from Twitter. arXiv 2020, arXiv:2006.02567. [Google Scholar]
- Zhang, D.; Zhang, Y.; Li, Q.; Plummer, T.; Wang, D. CrowdLearn: A crowd-AI hybrid system for deep learning-based damage assessment applications. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; IEEE: New York, NY, USA, 2019; Volume 2019, pp. 1221–1232. [Google Scholar]
- Olivieri, A.; Shabani, S.; Sokhn, M.; Cudré-Mauroux, P. Creating task-generic features for fake news detection. In Proceedings of the 52nd Hawaii International Conference on System Sciences, Grand Wailea, HI, USA, 8–11 January 2019; Volume 6, pp. 5196–5205. [Google Scholar]
- Albarqouni, S.; Baur, C.; Achilles, F.; Belagiannis, V.; Demirci, S.; Navab, N. AggNet: Deep learning from crowds for mitosis detection in breast cancer histology images. IEEE Trans. Med. Imaging 2016, 35, 1313–1321. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Zhang, Y.; Xu, H.; Cao, Y.; Qin, Z.; Zha, H. Visually explainable recommendation. arXiv 2018, arXiv:1801. [Google Scholar]
- Quinn, A.J.; Bederson, B.B. Human Computation: A Survey and Taxonomy of a Growing Field. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 1403–1412. [Google Scholar]
- Kazai, G.; Kamps, J.; Milic-Frayling, N. Worker types and personality traits in crowdsourcing relevance labels. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management—CIKM’11, Glasgow, UK, 24–28 October 2011; pp. 1941–1944. [Google Scholar]
- Hung, N.Q.V.; Thang, D.C.; Weidlich, M.; Aberer, K. Minimizing efforts in validating crowd answers. In Proceedings of the 2015 ACM International Conference on Manage. of Data—SIGMOD’15, Melbourne, VI, Australia, 31 May–4 June 2015; ACM Press: New York, NY, USA, 2015; pp. 999–1014. [Google Scholar]
- Garcia-Molina, H.; Joglekar, M.; Marcus, A.; Parameswaran, A.; Verroios, V. Challenges in data crowdsourcing. IEEE Trans. Knowl. Data Eng. 2016, 28, 901–911. [Google Scholar] [CrossRef]
- Nakatsu, R.T.; Grossman, E.B.; Iacovou, C.L. A taxonomy of crowdsourcing based on task complexity. J. Inf. Sci. 2014, 40, 823–834. [Google Scholar] [CrossRef]
- Vuurens, J.B.P.; De Vries, A.P. Obtaining high-quality relevance judgments using crowdsourcing. IEEE Internet Comput. 2012, 16, 20–27. [Google Scholar] [CrossRef]
- Eickhoff, C.; de Vries, A.P. Increasing cheat robustness of crowdsourcing tasks. Inf. Retr. Boston. 2013, 16, 121–137. [Google Scholar] [CrossRef] [Green Version]
- Gadiraju, U.; Kawase, R.; Dietze, S. Understanding Malicious Behavior in Crowdsourcing Platforms: The Case of Online Surveys. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015. [Google Scholar]
- Mok, R.K.P.; Chang, R.K.C.; Li, W. Detecting Low-Quality Workers in QoE Crowdtesting: A Worker Behavior-Based Approach. IEEE Trans. Multimed. 2017, 19, 530–543. [Google Scholar] [CrossRef]
- Wang, G.; Mohanlal, M.; Wilson, C.; Wang, X.; Metzger, M.; Zheng, H.; Zhao, B.Y. Social Turing Tests: Crowdsourcing Sybil Detection. arXiv 2012, arXiv:1205.3856. [Google Scholar] [CrossRef] [Green Version]
- Rivera, V.A.; Lee, D.T. I Want to, but First I Need to: Understanding Crowdworkers’ Career Goals, Challenges, and Tensions. In Proceedings of the ACM on Human-Computer Interaction, Yokohama, Japan, 8–13 May 2021; Volume 5, pp. 1–22. [Google Scholar]
- Marcus, A.; Parameswaran, A. Crowdsourced Data Management: Industry and Academic Perspectives. Found. Trends® Databases 2015, 6, 1–161. [Google Scholar] [CrossRef]
- Jain, A.; Sarma, A.D.; Parameswaran, A.; Widom, J. Understanding workers, developing effective tasks, and enhancing marketplace dynamics: A Study of a Large Crowdsourcing Marketplace. In Proceedings of the VLDB Endowment, Munich, Germany, 28 August–1 September 2017; Volume 10, pp. 829–840. [Google Scholar]
- Le, J.; Edmonds, A.; Hester, V.; Biewald, L. Ensuring quality in crowdsourced search relevance evaluation: The effects of training question distribution. In Proceedings of the SIGIR 2010 Workshop on Crowdsourcing for Search Evaluation—(CSE 2010), Geneva, Switzerland, 23 July 2010; pp. 17–20. [Google Scholar]
- Oleson, D.; Sorokin, A.; Laughlin, G.; Hester, V.; Le, J.; Biewald, L. Programmatic gold: Trargeted and scalable quality assurance in crowdsourcing. In Proceedings of the Workshops at the Twenty-Fifth AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011; pp. 43–48. [Google Scholar]
- Burmania, A.; Parthasarathy, S.; Busso, C. Increasing the Reliability of Crowdsourcing Evaluations Using Online Quality Assessment. IEEE Trans. Affect. Comput. 2016, 7, 374–388. [Google Scholar] [CrossRef]
- Vuurens, J.; de Vries, A.; Eickhoff, C. How much spam can you take? An analysis of crowdsourcing results to increase accuracy. In Proceedings of the ACM SIGIR Workshop on Crowdsourcing for Information Retrieval (CIR’11), Beijing, China, 28 July 2011; pp. 21–26. [Google Scholar]
- Sheng, V.S.; Zhang, J.; Gu, B.; Wu, X. Majority Voting and Pairing with Multiple Noisy Labeling. IEEE Trans. Knowl. Data Eng. 2019, 31, 1355–1368. [Google Scholar] [CrossRef]
- Nazariani, M.; Barforoush, A.A. Dynamic weighted majority approach for detecting malicious crowd workers. Can. J. Electr. Comput. Eng. 2019, 42, 108–113. [Google Scholar] [CrossRef]
- Tao, F.; Jiang, L.; Li, C. Label similarity-based weighted soft majority voting and pairing for crowdsourcing. Knowl. Inf. Syst. 2020, 62, 2521–2538. [Google Scholar] [CrossRef]
- Kazai, G.; Zitouni, I. Quality Management in Crowdsourcing using Gold Judges Behavior. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, San Francisco, CA, USA, 22–25 February 2016; ACM: New York, NY, USA, 2016; pp. 267–276. [Google Scholar]
- Zhang, Y.; Van der Schaar, M. Reputation-based Incentive Protocols in Crowdsourcing Applications. In Proceedings of the INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 2140–2148. [Google Scholar]
- Hirth, M.; Scheuring, S.; Hossfeld, T.; Schwartz, C.; Tran-Gia, P. Predicting result quality in crowdsourcing using application layer monitoring. In Proceedings of the 2014 IEEE 5th International Conference on Communications and Electronics, IEEE ICCE, Danang, Vietnam, 30 July–1 August 2014; pp. 510–515. [Google Scholar]
- Rzeszotarski, J.M.; Kittur, A. Instrumenting the crowd: Using implicit behavioral measures to predict task performance. In Proceedings of the 24th Annual ACM Symposium on User interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; ACM: Santa Barbara, CA, USA, 2011; pp. 13–22. [Google Scholar]
- Dang, B.; Hutson, M.; Lease, M. MmmTurkey: A Crowdsourcing Framework for Deploying Tasks and Recording Worker Behavior on Amazon Mechanical Turk. In Proceedings of the 4th AAAI Conference on Human Computation and Crowdsourcing (HCOMP), Austin, TX, USA, 30 October–3 November 2016; pp. 1–3. [Google Scholar]
- Goyal, T.; Mcdonnell, T.; Kutlu, M.; Elsayed, T.; Lease, M. Your Behavior Signals Your Reliability: Modeling Crowd Behavioral Traces to Ensure Quality Relevance Annotations. In Proceedings of the Sixth AAAI Conference on Human Computation and Crowdsourcing, Zürich, Switzerland, 5–8 July 2018; pp. 41–49. [Google Scholar]
- Hata, K.; Krishna, R.; Li, F.-F.; Bernstein, M.S. A glimpse far into the future: Understanding long-term crowd worker quality. In Proceedings of the 2017 ACM Conference on Computer Supported Cooperative Work and Social Computing—CSCW’17, Portland, OR, USA, 25 February–1 March 2017; ACM Press: Portland, OR, USA, 2017; pp. 889–901. [Google Scholar]
- Sheng, V.S.; Provost, F.; Ipeirotis, P.G. Get another label? Improving data quality and data mining using multiple, noisy labelers. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD 08, Las Vegas, NV, USA, 24–27 August 2008; ACM Press: Las Vegas, NV, USA, 2008; pp. 614–622. [Google Scholar]
- Scholer, F.; Turpin, A.; Sanderson, M. Quantifying test collection quality based on the consistency of relevance judgements. In Proceedings of the 34th International ACM SIGIR Conference Research and Development in Information Retrieval—SIGIR’11, Beijing, China, 24–28 July 2011; ACM Press: Beijing, China, 2011; pp. 1063–1072. [Google Scholar]
- Difallah, D.E.; Demartini, G.; Cudré-Mauroux, P. Mechanical cheat: Spamming schemes and adversarial techniques on crowdsourcing platforms. In Proceedings of the CrowdSearch Workshop, Lyon, France, 17 April 2012; pp. 26–30. [Google Scholar]
- Yuan, D.; Li, G.; Li, Q.; Zheng, Y. Sybil Defense in Crowdsourcing Platforms. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; ACM: New York, NY, USA, 2017; pp. 1529–1538. [Google Scholar]
- Hettiachchi, D.; Schaekermann, M.; McKinney, T.; Lease, M. The Challenge of Variable Effort Crowdsourcing and How Visible Gold Can Help. arXiv 2021, arXiv:2105.09457. [Google Scholar]
- Lee, W.; Huang, C.H.; Chang, C.W.; Wu, M.K.D.; Chuang, K.T.; Yang, P.A.; Hsieh, C.C. Effective quality assurance for data labels through crowdsourcing and domain expert collaboration. In Proceedings of the Advances in Database Technology—EDBT, Vienna, Austria, 26–29 March 2018; pp. 646–649. [Google Scholar]
- Rzeszotarski, J.; Kittur, A. CrowdScape: Interactively visualizing user behavior and output. In Proceedings of the 25th Annual ACM Symposium on User Interface Software and Technology—UIST’12, Cambridge, MA, USA, 7–10 October 2012; pp. 55–62. [Google Scholar]
- Zhu, D.; Carterette, B. An analysis of assessor behavior in crowdsourced preference judgments. In Proceedings of the SIGIR 2010 Workshop on Crowdsourcing for Search Evaluation, Geneva, Switzerland, 19–23 July 2010; pp. 17–20. [Google Scholar]
- Alqershi, F.; Al-Qurishi, M.; Aksoy, M.S.; Alrubaian, M.; Imran, M. A Robust Consistency Model of Crowd Workers in Text Labeling Tasks. IEEE Access 2020, 8, 168381–168393. [Google Scholar] [CrossRef]
- Williams, A.; Willis, C.G.; Davis, C.C.; Goh, J.; Ellison, A.M.; Law, E. Deja Vu: Characterizing worker quality using task consistency. In Proceedings of the Fifth AAAI Conference on Human Computation and Crowdsourcing, Quebec, QC, Canada, 23–26 October 2017. [Google Scholar]
- Dong, G.; Liu, H. Feature Engineering for Machine Learning and Data Analytics; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Benford, F. The Law of Anomalous Numbers. In Proceedings of the American Philosophical Society; American Philosophical Society: Philadelphia, PA, USA, 1938; Volume 78, pp. 551–572. [Google Scholar]
- Mallat, S. A Wavelet Tour of Signal Processing; Elsevier: Amsterdam, The Netherlands, 2009; ISBN 9780123743701. [Google Scholar]
- Delgado-Bonal, A.; Marshak, A. Approximate Entropy and Sample Entropy: A Comprehensive Tutorial. Entropy 2019, 21, 541. [Google Scholar] [CrossRef] [Green Version]
- Bandt, C.; Pompe, B. Permutation Entropy: A Natural Complexity Measure for Time Series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef] [PubMed]
- Christ, M.; Braun, N.; Neuffer, J.; Kempa-Liehr, A.W. Time Series FeatuRe Extraction on basis of Scalable Hypothesis tests (tsfresh—A Python package). Neurocomputing 2018, 307, 72–77. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Eckmann, J.-P.; Kamphorst, S.O.; Ruelle, D. Recurrence Plots of Dynamical Systems. Europhys. Lett. 1987, 4, 973–977. [Google Scholar] [CrossRef] [Green Version]
- Nair, V.; Hinton, G. Rectified Linear Units Improve Restricted Boltzmann Machines Vinod. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; IEEE: New York, NY, USA, 2017; pp. 464–472. [Google Scholar]
- Hatami, N.; Gavet, Y.; Debayle, J. Classification of time-series images using deep convolutional neural networks. arXiv 2017, arXiv:1710.00886. [Google Scholar]
- Pavlov, Y.L. Random forests. Random For. 2019, 1–122. [Google Scholar] [CrossRef]
- Jeong, Y.S.; Jeong, M.K.; Omitaomu, O.A. Weighted dynamic time warping for time series classification. Pattern Recognit. 2011, 44, 2231–2240. [Google Scholar] [CrossRef]
- Müller, M. Dynamic Time Warping. In Information Retrieval for Music and Motion; Springer: Berlin, Germany, 2007; pp. 69–84. ISBN 9781402067532. [Google Scholar]
- Geler, Z.; Kurbalija, V.; Radovanović, M.; Ivanović, M. Comparison of different weighting schemes for the kNN classifier on time-series data. Knowl. Inf. Syst. 2016, 48, 331–378. [Google Scholar] [CrossRef]
- Cristianini, N.; Schölkopf, B. Support Vector Machines and Kernel Methods The New Generation of Learning Machines. AI Mag. 2002, 23, 31–42. [Google Scholar]
- Cuturi, M.; Vert, J.-P.; Birkenes, O.; Matsui, T. A Kernel for Time Series Based on Global Alignments. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing—ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; IEEE: New York, NY, USA, 2007; Volume 2, pp. II-413–II-416. [Google Scholar]
- Kim, K.J. Financial time series forecasting using support vector machines. Neurocomputing 2003, 55, 307–319. [Google Scholar] [CrossRef]
- Kampouraki, A.; Manis, G.; Nikou, C. Heartbeat time series classification with support vector machines. IEEE Trans. Inf. Technol. Biomed. 2009, 13, 512–518. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Tavenard, R.; Vandewiele, G.; Divo, F.; Androz, G.; Holtz, C.; Payne, M.; Woods, E. Tslearn, A Machine Learning Toolkit for Time Series Data. J. Mach. Learn. Res. 2020, 21, 1–6. [Google Scholar]
- Yentes, J.M.; Hunt, N.; Schmid, K.K.; Kaipust, J.P.; McGrath, D.; Stergiou, N. The appropriate use of approximate entropy and sample entropy with short data sets. Ann. Biomed. Eng. 2013, 41, 349–365. [Google Scholar] [CrossRef]
- Dogo, E.M.; Afolabi, O.J.; Nwulu, N.I.; Twala, B.; Aigbavboa, C.O. A Comparative Analysis of Gradient Descent-Based Optimization Algorithms on Convolutional Neural Networks. In Proceedings of the International Conference on Computational Techniques, Electronics and Mechanical Systems (CTEMS), Belgaum, India, 21–22 December 2018; IEEE: New York, NY, USA, 2018; pp. 92–99. [Google Scholar]
- Dos Santos, A.A.; Marcato Junior, J.; Araújo, M.S.; Di Martini, D.R.; Tetila, E.C.; Siqueira, H.L.; Aoki, C.; Eltner, A.; Matsubara, E.T.; Pistori, H.; et al. Assessment of CNN-Based Methods for Individual Tree Detection on Images Captured by RGB Cameras Attached to UAVs. Sensors 2019, 19, 3595. [Google Scholar] [CrossRef] [Green Version]
- Yu, D.; Ji, S. Grid Based Spherical CNN for Object Detection from Panoramic Images. Sensors 2019, 19, 2622. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, C.; Li, G.; Ding, Y.; Yan, F.; Bai, L. Chimney Detection Based on Faster R-CNN and Spatial Analysis Methods in High Resolution Remote Sensing Images. Sensors 2020, 20, 4353. [Google Scholar] [CrossRef] [PubMed]
- Talbi, E. Optimization of deep neural networks: A survey and unified taxonomy. HAL 2020, Id hal-02570804. [Google Scholar]
- VanderPlas, J.T. Understanding the Lomb–Scargle Periodogram. Astrophys. J. Suppl. Ser. 2018, 236, 16. [Google Scholar] [CrossRef]
- Bahadori, M.T.; Liu, Y. Granger Causality Analysis in Irregular Time Series. In Proceedings of the 2012 SIAM International Conference on Data Mining, Anaheim, CA, USA, 26–28 August 2012; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2012; pp. 660–671. [Google Scholar]
- Salvador, S.; Chan, P. FastDTW: Toward accurate dynamic time warping in linear time and space. Intell. Data Anal. 2007, 11, 561–580. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Mei, H.; Lu, H.; Kuang, H.; Ma, X. A Vehicle Steering Recognition System Based on Low-Cost Smartphone Sensors. Sensors 2017, 17, 633. [Google Scholar] [CrossRef]



| Feature Name | Type | Feature Description |
|---|---|---|
| total_mouse_movements | Action-based | The total number of mouse movements. |
| total_scrolled_pixels _vertical | The total number of scrolled pixels. | |
| total_clicks | The total number of mouse clicks. | |
| total_keypresses | The total number of keyboard pressing. | |
| total_pastes | The total number of pastes. | |
| total_focus_changes | The total number of focusing changes. | |
| total_pixels | The total number of pixels movements in x/y directions. | |
| total_task_time | Time-based | The total time of completing the HIT. |
| total_on_foucs_time | The total time that was spent completing the HIT. | |
| recorded_time_disparity | Difference between the total time and the time spent outside the HIT. | |
| avg_dwell_time | Average time between two successive logged events. |
| Importance Threshold (Log10) | Mean/18 −11.156 | Mean/9 −10.463 | Mean/3 −9.365 | Mean −8.266 | Mean 3 −7.1678 | Mean × 9 −6.061 | Mean × 18 −4.970 |
|---|---|---|---|---|---|---|---|
| No. of features | 1629 | 1158 | 984 | 770 | 377 | 78 | 41 |
| Accuracy | 82.9 | 83.3 | 83.1 | 82.1 | 82.8 | 80.6 | 78.2 |
| AUC-ROC | 81.1 | 81.3 | 80.9 | 82.0 | 81.1 | 80.8 | 79.1 |
| Hyper-Parameter | Training Accuracy | Validation Accuracy | Training Loss | Validation Loss |
|---|---|---|---|---|
| Batch size | Learning rate: , Epochs: 150, Input Dimensions 32 × 32, dropout rate for conv. layer and dense layer = 0.5 and 0.25, respectively. | |||
| 25 | 0.8050 | 0.7633 | 0.4446 | 0.6291 |
| 50 | 0.7956 | 0.7712 | 0.4786 | 0.5475 |
| 75 | 0.7827 | 0.7539 | 0.4988 | 0.5517 |
| Dropout rate (for the Conv. layer) | Batch size: 50, Learning rate: , Epochs: 150, Input Dimensions 32 × 32, dropout rate dense layer: 0.25. | |||
| 0.25 | 0.7485 | 0.7649 | 0.5225 | 0.5264 |
| 0.50 | 0.7587 | 0.7367 | 0.5306 | 0.5505 |
| 0.75 | 0.7254 | 0.7179 | 0.5523 | 0.5826 |
| Dropout rate (for the Dense layer) | Dropout rate: Conv. layer: 0.25, Batch size: 50, Learning rate: , Epochs: 150, Input Dimensions 32 × 32 | |||
| 0.25 | 0.8054 | 0.7821 | 0.4551 | 0.5423 |
| 0.50 | 0.7391 | 0.7680 | 0.5495 | 0.5236 |
| 0.75 | 0.6865 | 0.6959 | 0.6121 | 0.6059 |
| Image Input dimensions | Dropout rate: Conv. layer: 0.25, Batch size: 50, Learning rate:, Epochs: 150 | |||
| 32 × 32 | 0.7705 | 0.7837 | 0.4987 | 0.5080 |
| 56 × 56 | 0.8195 | 0.7382 | 0.4271 | 0.5778 |
| 28 × 28 | 0.7991 | 0.7649 | 0.4695 | 0.5408 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Qershi, F.; Al-Qurishi, M.; Aksoy, M.S.; Faisal, M.; Algabri, M. A Time-Series-Based New Behavior Trace Model for Crowd Workers That Ensures Quality Annotation. Sensors 2021, 21, 5007. https://doi.org/10.3390/s21155007
Al-Qershi F, Al-Qurishi M, Aksoy MS, Faisal M, Algabri M. A Time-Series-Based New Behavior Trace Model for Crowd Workers That Ensures Quality Annotation. Sensors. 2021; 21(15):5007. https://doi.org/10.3390/s21155007
Chicago/Turabian StyleAl-Qershi, Fattoh, Muhammad Al-Qurishi, Mehmet Sabih Aksoy, Mohammed Faisal, and Mohammed Algabri. 2021. "A Time-Series-Based New Behavior Trace Model for Crowd Workers That Ensures Quality Annotation" Sensors 21, no. 15: 5007. https://doi.org/10.3390/s21155007
APA StyleAl-Qershi, F., Al-Qurishi, M., Aksoy, M. S., Faisal, M., & Algabri, M. (2021). A Time-Series-Based New Behavior Trace Model for Crowd Workers That Ensures Quality Annotation. Sensors, 21(15), 5007. https://doi.org/10.3390/s21155007