Open-Source Federated Learning Frameworks for IoT: A Comparative Review and Analysis

 , ,
, ,
Abstract
:1. Introduction
- Verification of the current capabilities of the analyzed open-source FL frameworks;
- Comparison of the built model’s accuracy;
- Comparison of the training process performance;
- Assessment of the ease of studying and deploying the FL frameworks;
- Analysis of the FL frameworks’ development and support states.
2. Federated Learning Concepts
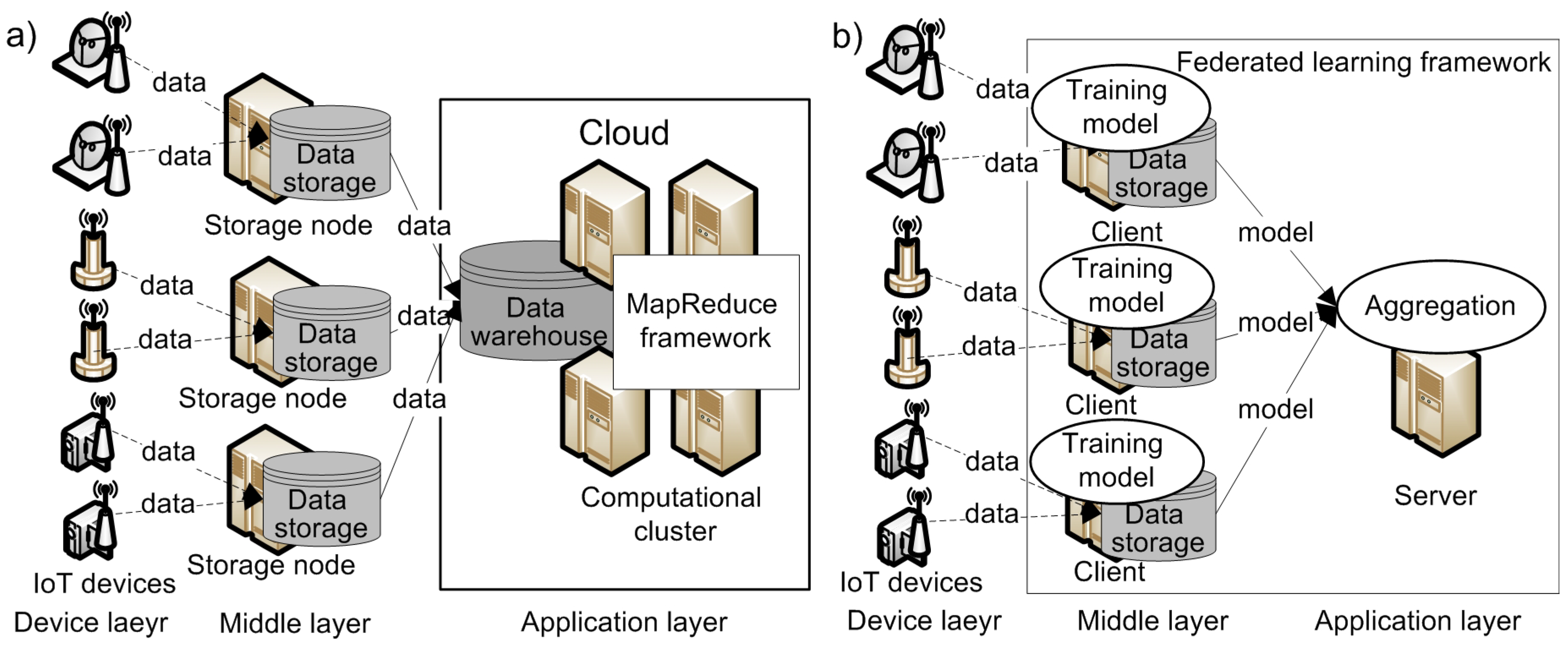
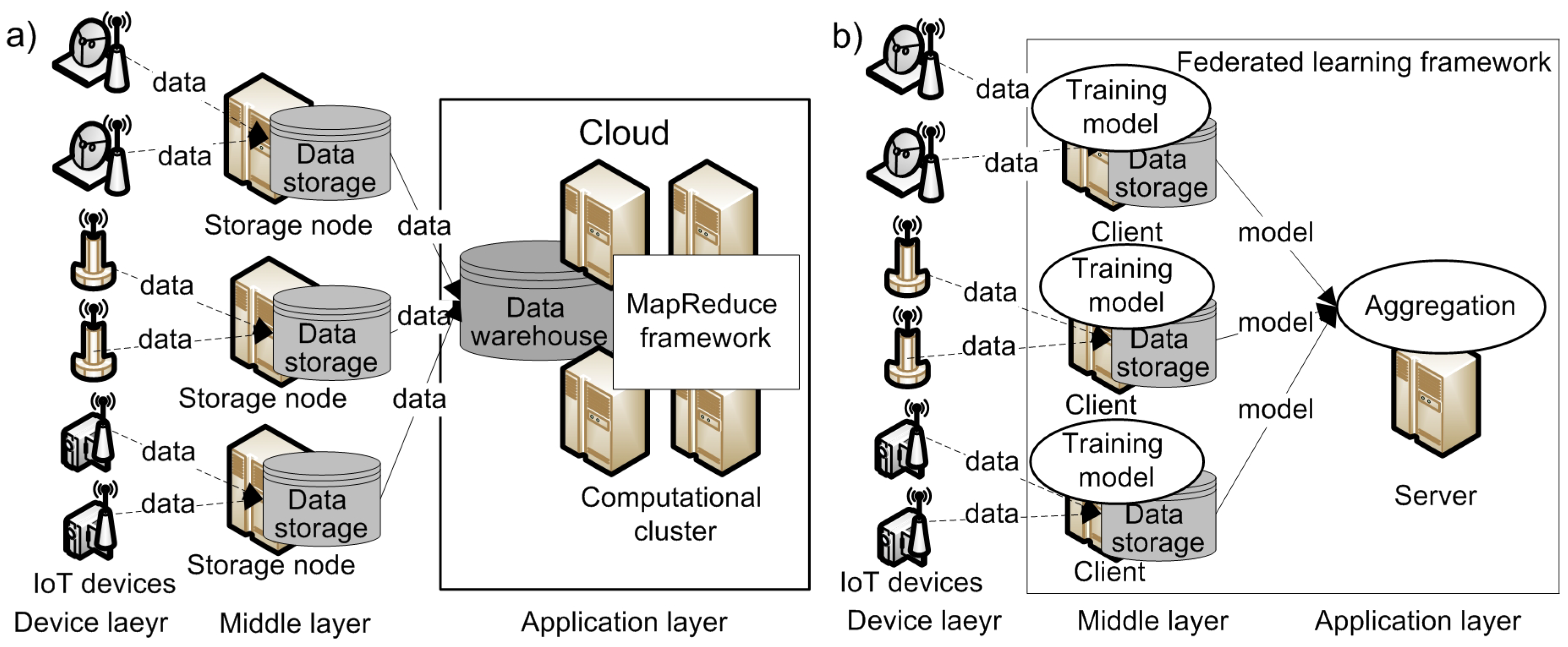
- The device layer, which includes hardware devices that produce and collect data;
- The middle layer, which is responsible for transferring data from the device layer to the application layer for further processing;
- The application layer, which provides services or applications that integrate or analyze the data received from the middle layer.
- Server (e.g., manager);
- Communication–computation framework;
- Clients (e.g., parties, data sources).
- Identifying a problem to be solved;
- Modifying the client’s application (optional);
- Simulating prototyping (optional);
- Training the federated model;
- Evaluating the federated model;
- Deploying FL at the server and clients.
- The risk of unauthorized data access, since data are not transmitted over the network;
- Network traffic because the training results are usually much smaller in volume than the data themselves;
- Time and cost of information transfer by reducing the amount of data transmitted;
- Requirements to the central computational cluster and the central storage, as there is no need to store all data in one place.
- Processing IID data as non-IID data, which can have different data partitions;
- Working with clients with different computing and storage capacity, as well as scale and stability;
- Implementation of different communication schemes: centralized and decentralized;
- Protection of transmitted analysis results from various types of attacks;
- Aggregation of the results obtained from data sources to calculate inequality (2).
3. Federated Learning Challenges
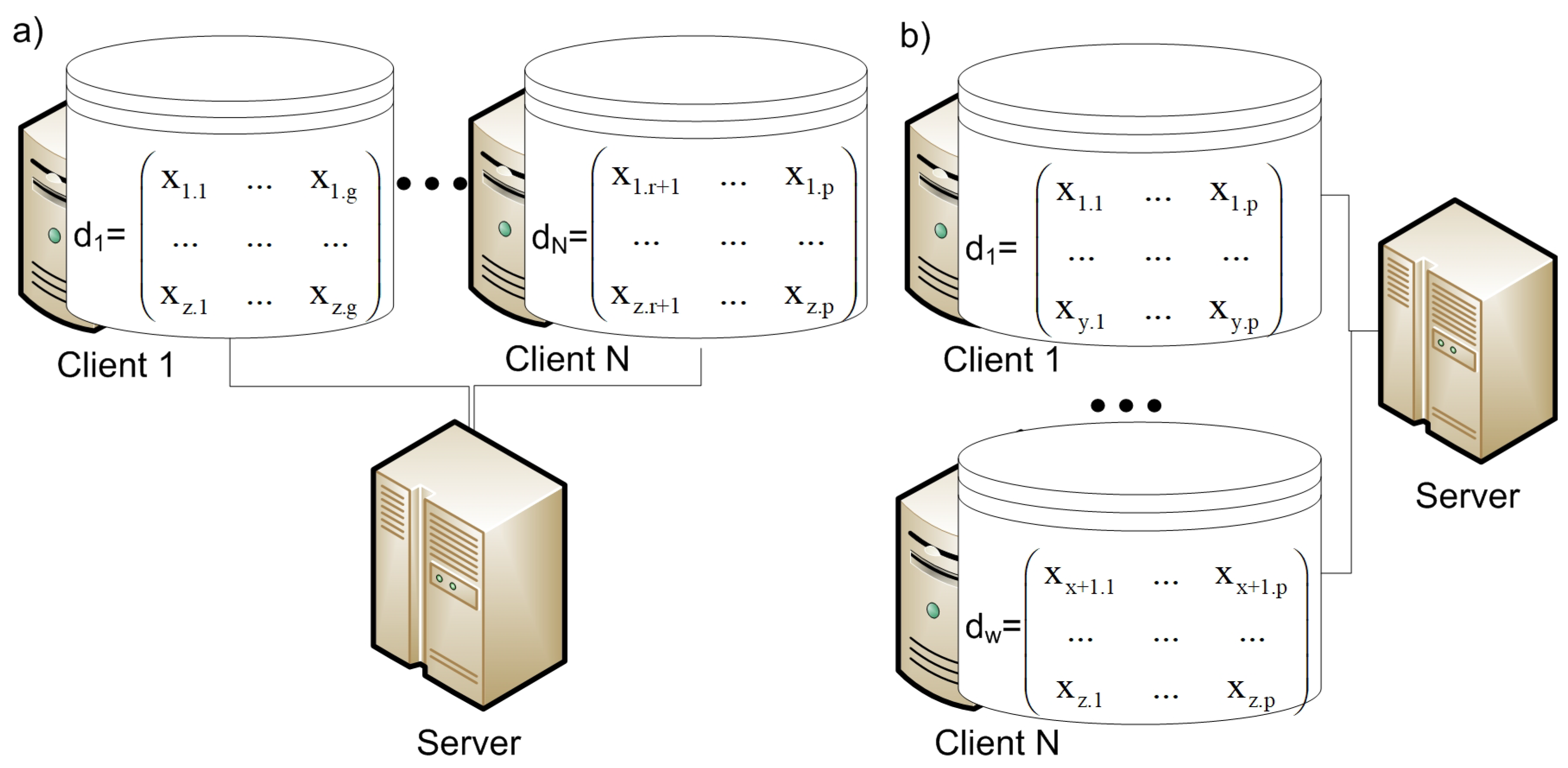
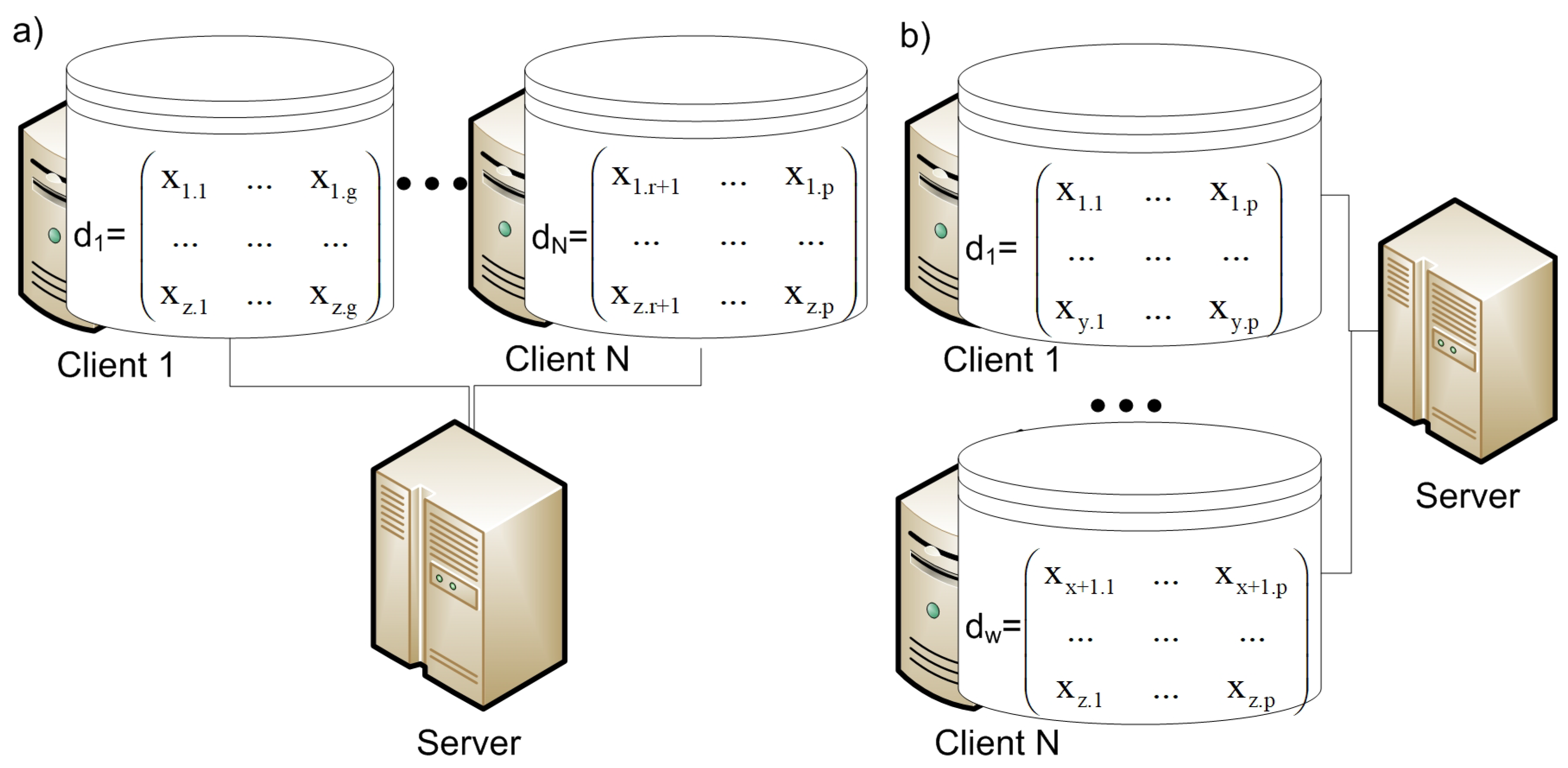
3.1. Data Partitioning
- Vertical partitioning, in which each storage node collects and stores data about different features of all objects;
- Horizontal partition, in which each storage node collects and stores data about all features of different objects.
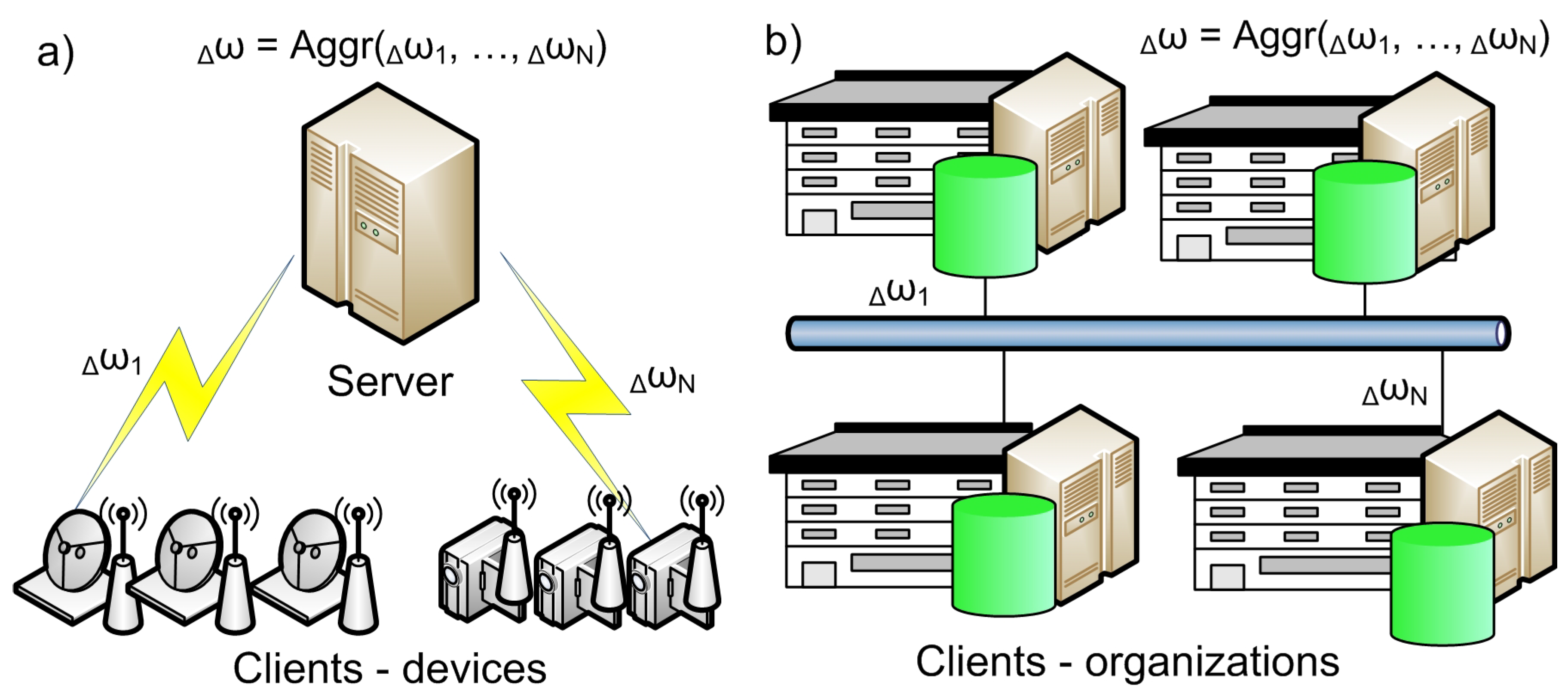
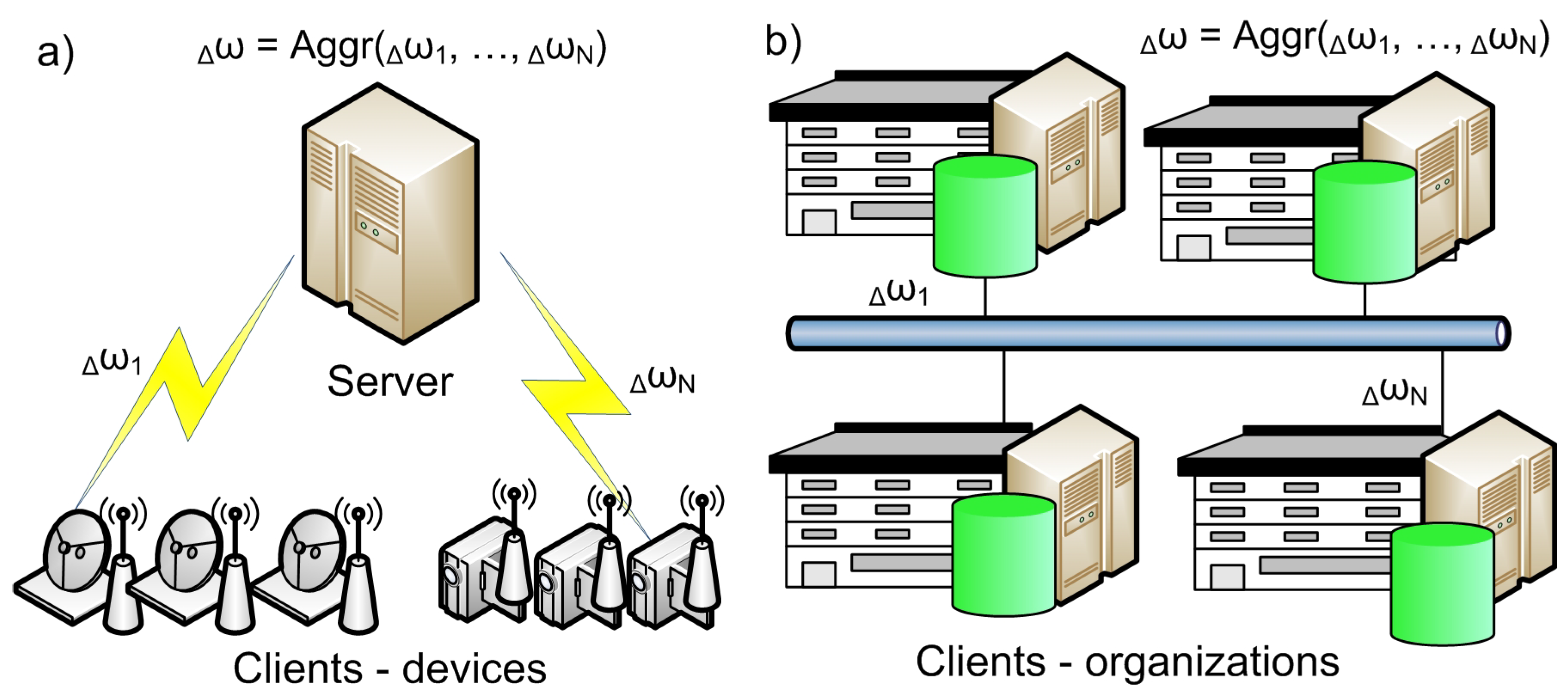
3.2. Clients’ Settings
- Cross-silo systems have low scalable federation. They include organizations or data centers. Their numbers are small and rarely change;
- Cross-device systems have a scalable number of clients. They can be added and disabled at any moment of time. These are usually mobile devices and IoT devices.
3.3. Communication Schemes
3.4. Data Privacy and Security Mechanisms
- Training data set;
- Trained model;
- Client, and
- Server.
- Secure multi-party computation (MPC) is a family of cryptographic protocols that allow a set of users to perform computations that use some private inputs without revealing them to other participants of the protocol [25]. The most widely used implementations of MPC are the ABY3 [26] and SecureML [27] protocols. These protocols implement a server–aided computational model in which data owners send their data in encrypted format to a number of servers, usually two or three, which perform model training or apply a pre-trained model to analyze input data.
- The Secure Aggregation (SecAgg) protocol proposed by K. A. Bonawitz et al. is another class of MPC-based technique used to secure the privacy of neural network training. However, in contrast to the ABY3 and SecureML protocols, the data owners participate in the training process by performing the training process locally and sending encrypted model weights to the aggregator, which implements the aggregation of the network gradients [28].
- Homomorphic encryption (HE) is a form of encryption that allows application of some mathematical operations directly on ciphertexts without decrypting them; the produced output is also encrypted, and after decryption, it corresponds to the result of the mathematical operations performed on the corresponding plain texts [29]. Currently, there are only a few implementations of fully homomorphic encryption, and all of them require significant research to increase speed performance. That is why, in major cases, partially homomorphic encryption protocols based on the RSA or Paillier encryption schemes are used as a compound part of security mechanisms [30].
- Differential privacy (DP) mechanisms preserve the privacy of data by adding noise to input data in order to mask the impact of the particular sample on the output. The privacy loss parameter defines how much noise is added and how much information about a sample could be revealed from the output, and the application of these mechanisms requires finding a balance between privacy loss and accuracy of the federated analysis model [31]. Different versions of differentially private algorithms for data classification [31,32,33] and clustering [34,35] are suggested.
- The trusted execution environment (TEE), e.g. Intel SGZ processors, guarantees the protection of the code and data loaded inside. This computational environment can be used inside the central server to increase its credibility [36].
3.5. Aggregation Algorithms
4. Open-Source Federated Learning Frameworks
- Installation in simulation mode (on one computer) and in federated mode (on several nodes);
- Training of all machine learning models documented in the framework on all data sets using all available deep learning frameworks;
- Training time and system performance;
- Accuracy of trained models on test data using the methods available in the frameworks;
- Ease of use and study;
- Quality and availability of documentation;
- Development intensity;
- The framework support and development community.
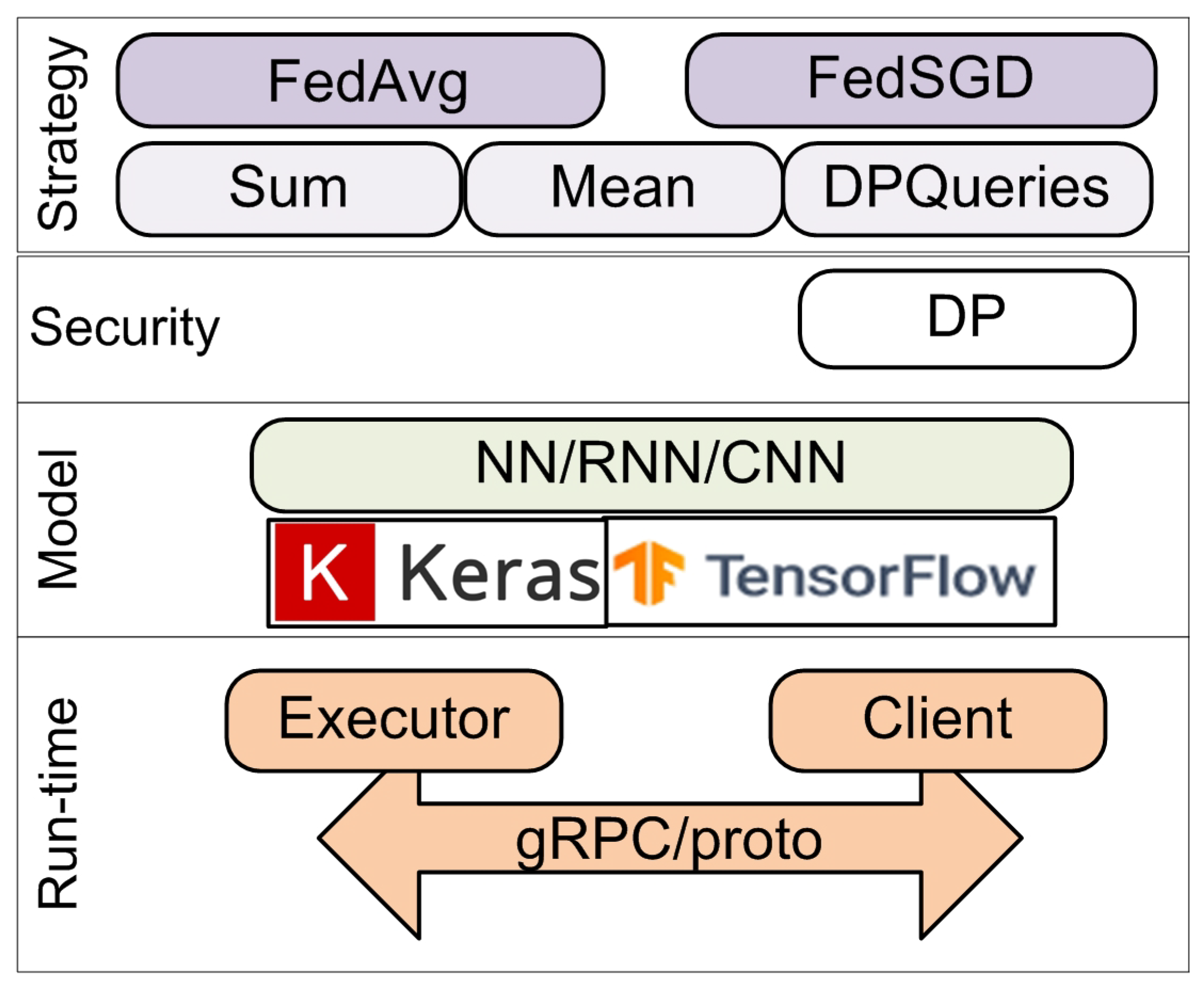
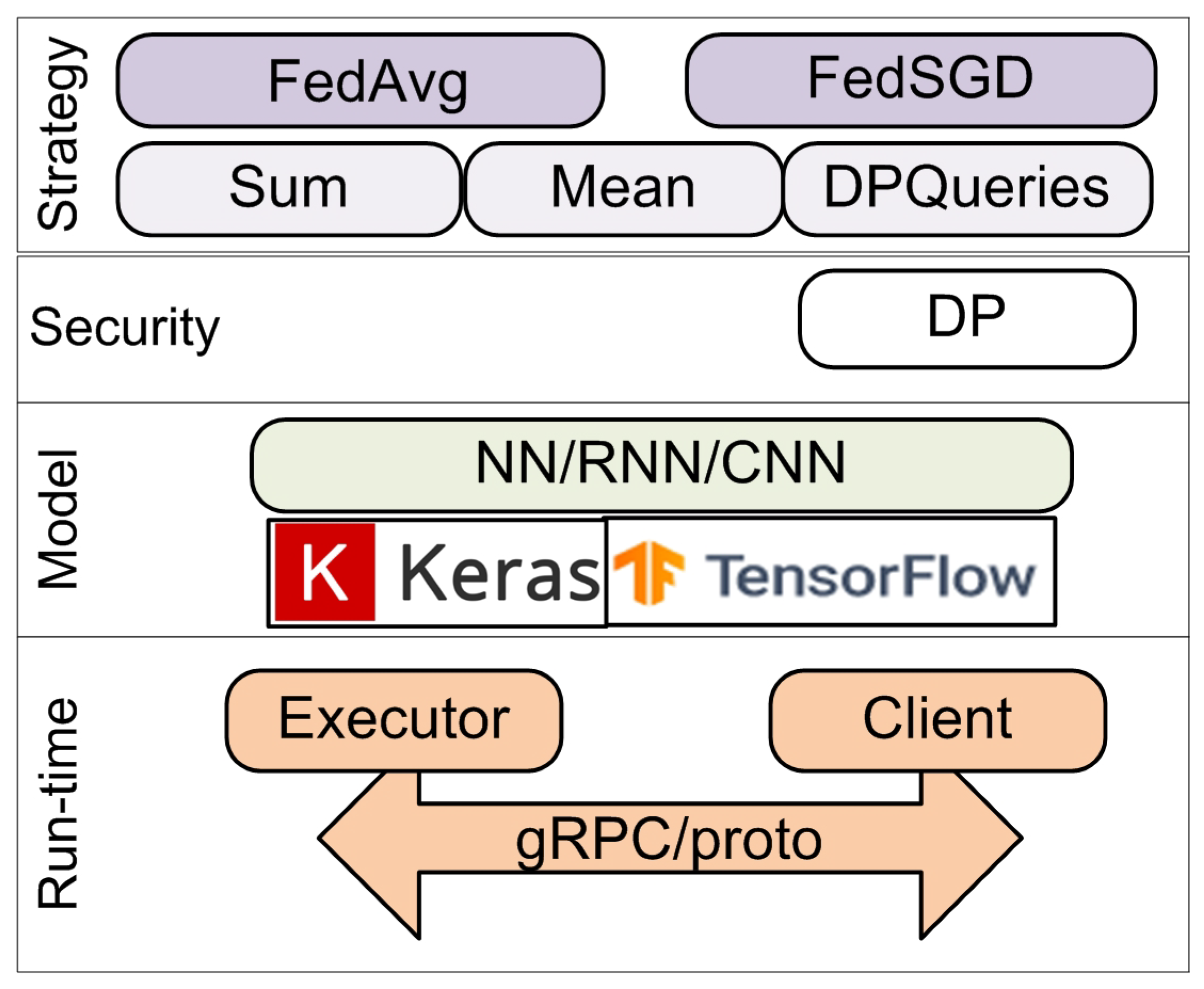
4.1. TensorFlow Federated Framework
- “Sum”, which sums values located at clients and outputs the sum located at the server;
- “Mean” computes a weighted mean of values located at clients and outputs the mean located at the server;
- “Differentially private” aggregates values located at clients in a privacy-preserving manner based on the differential privacy (DP) algorithm and outputs the result located at the server.
- Native backend, which implements its own interaction between executors and clients based on gRPC technology and proto-object exchange;
- Non-native backend, which uses third-party distributed computing tools, such as the Hadoop cluster and MapReduce programming model.
- The federated mode of operation is not implemented;
- Vertical and hybrid data splitting is not supported;
- The decentralized architecture of building the system is not supported;
- Only a differential privacy mechanism is used.
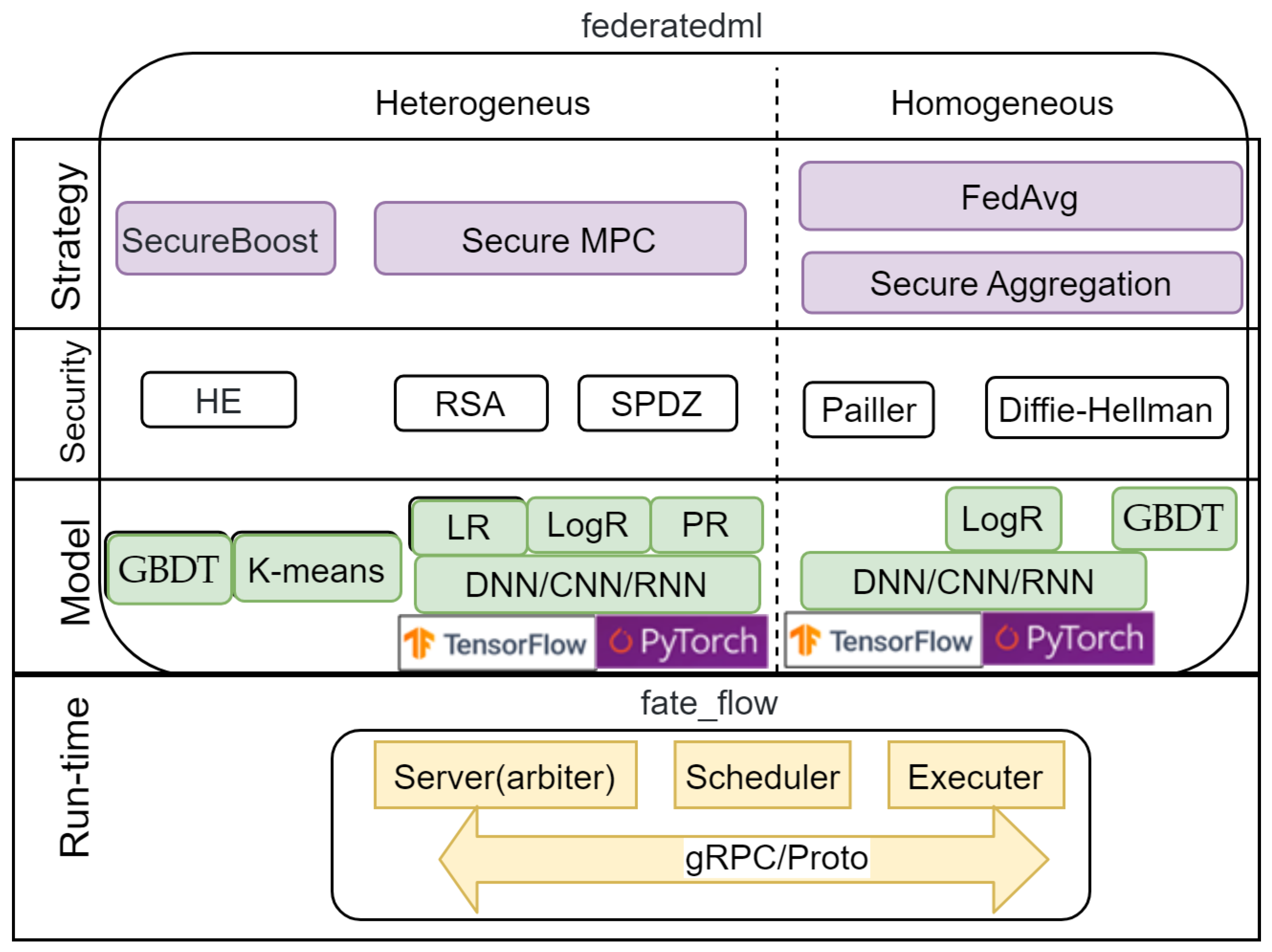
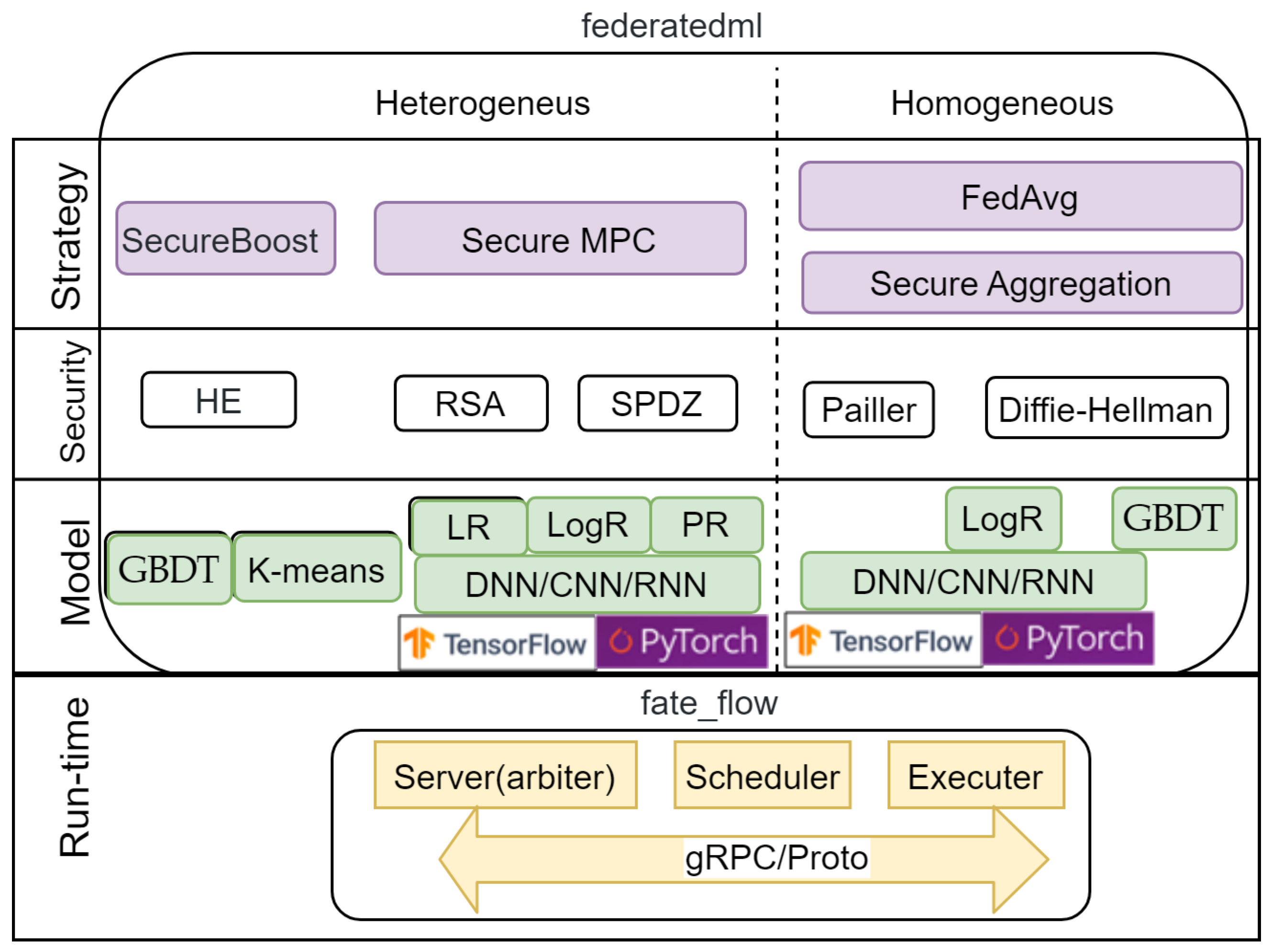
4.2. Federated AI Technology Enabler Framework
- A server (arbiter) providing model aggregation and training management;
- A scheduler responsible for scheduling the FL process;
- An executer that implements the FL algorithm.
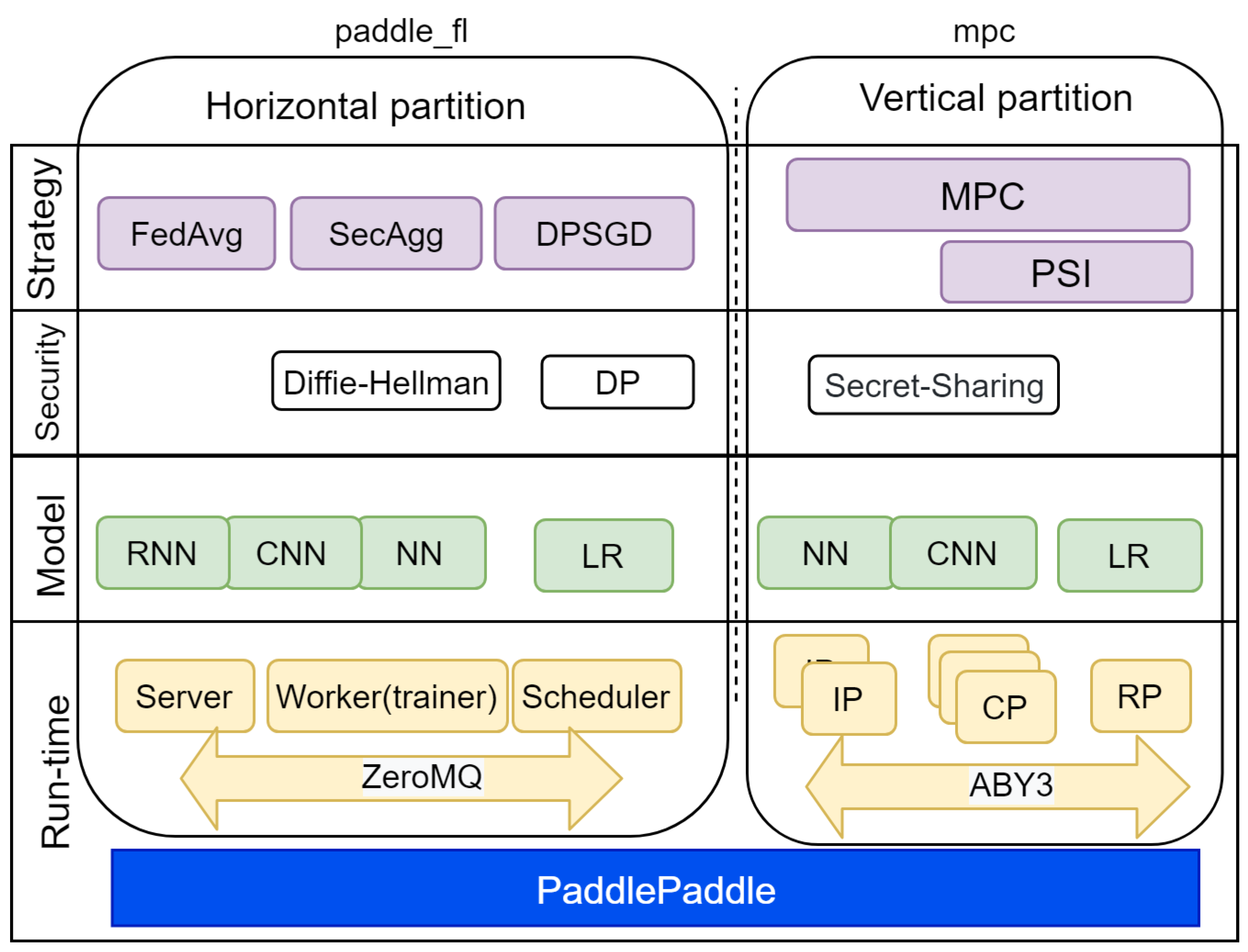
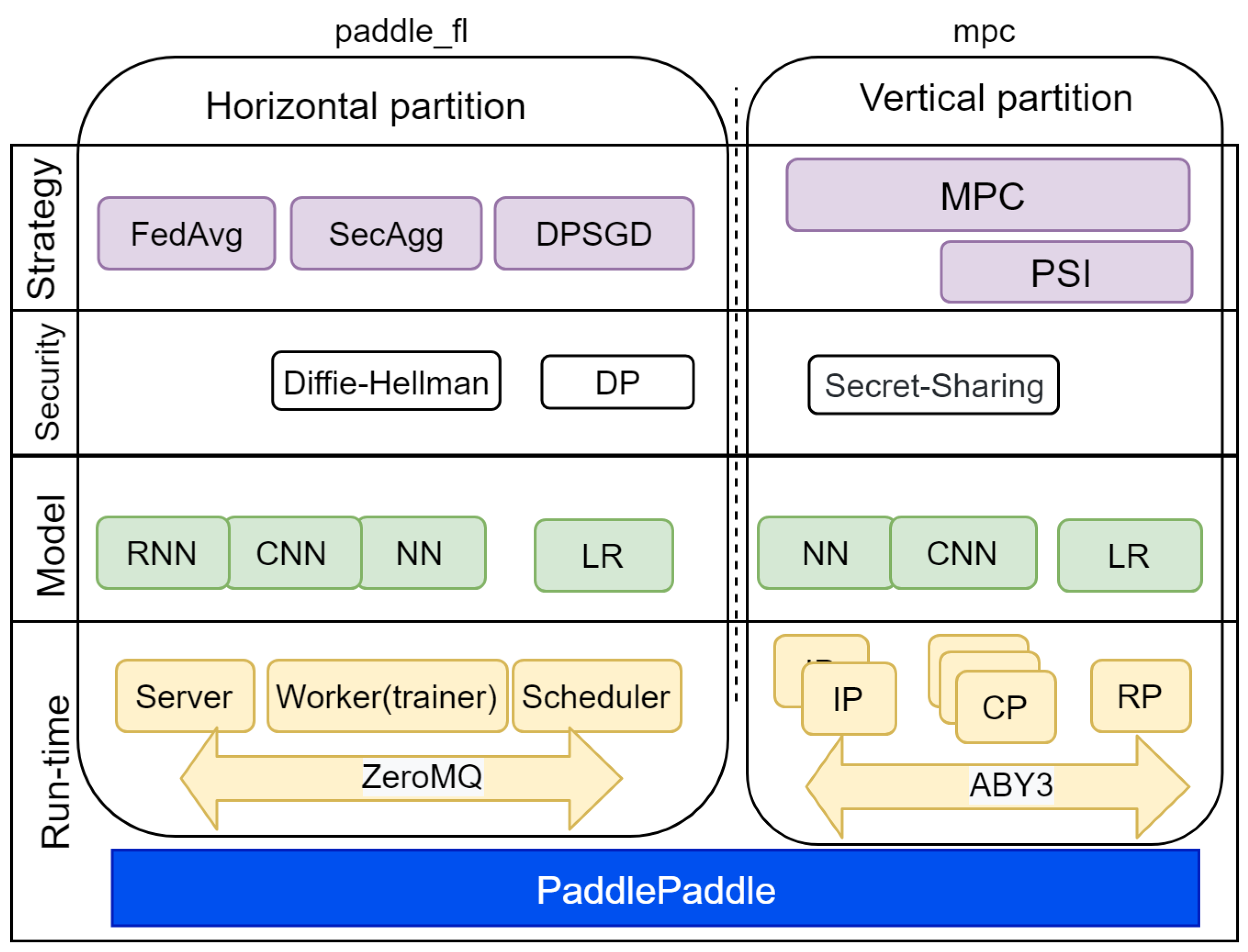
4.3. Paddle Federated Learning Framework
- A server for model aggregation;
- A scheduler for planning the training process;
- A worker (trainer) for data processing and model building.
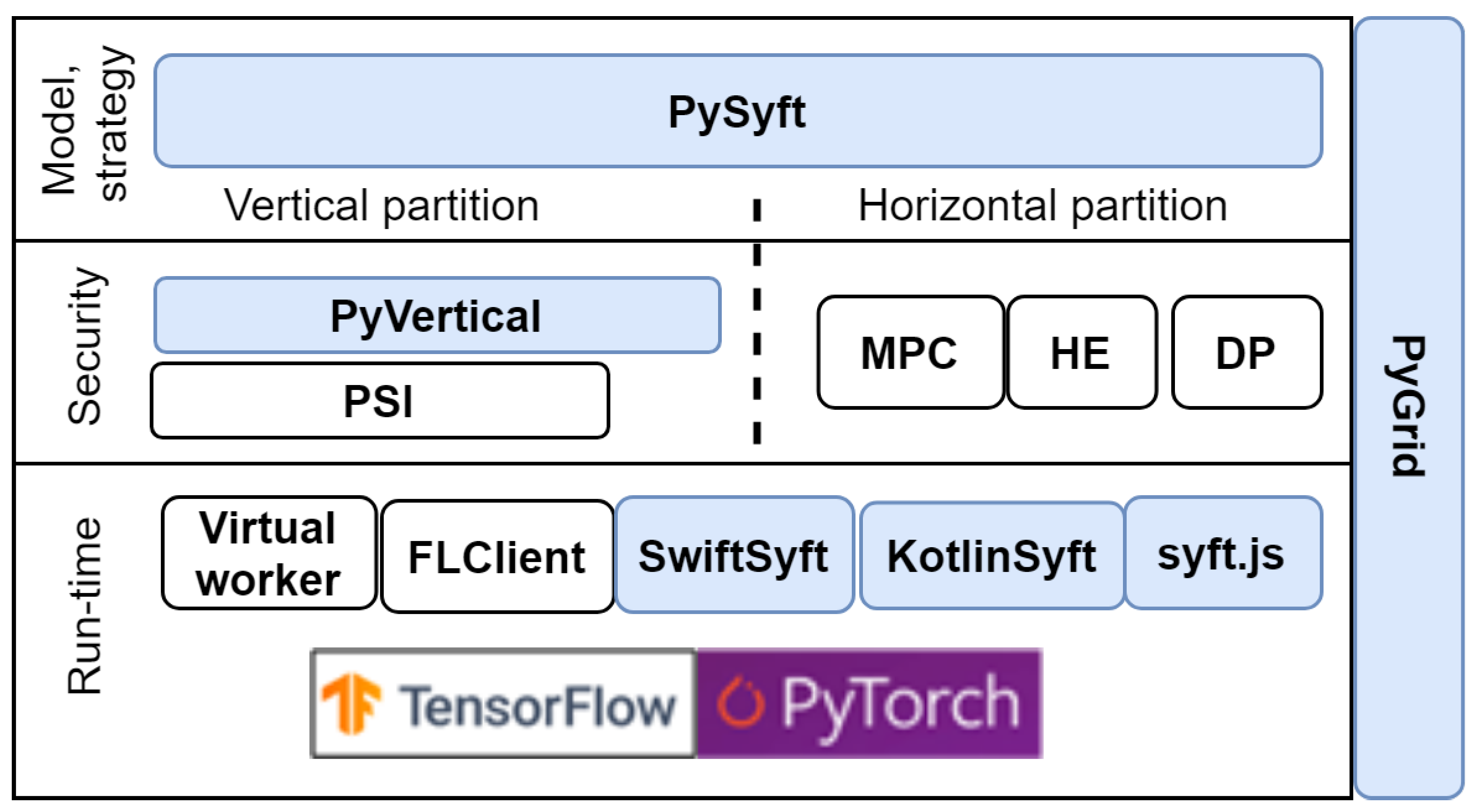
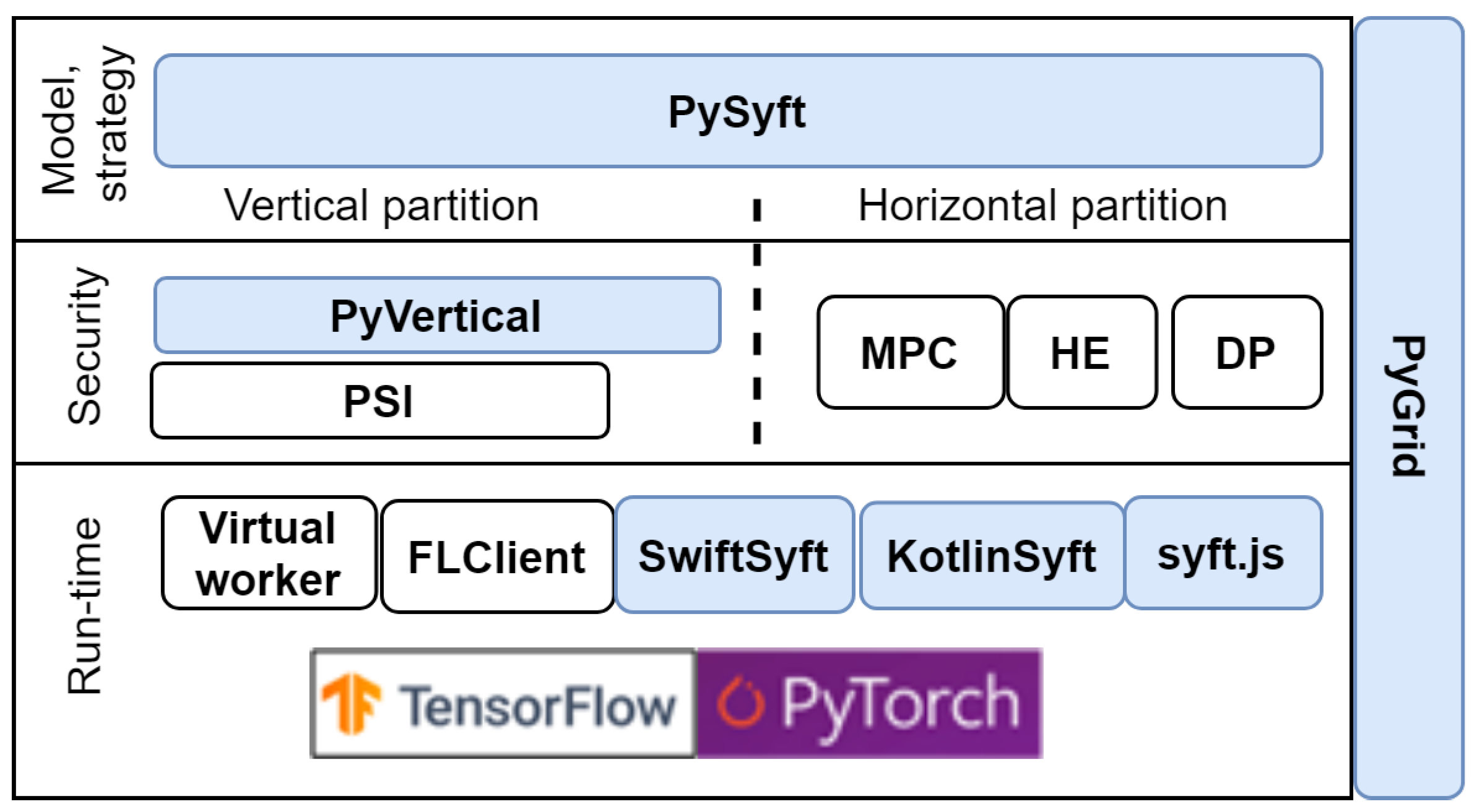
4.4. PySyft Framework
- PyGrid is a peer-to-peer network of data owners and data scientists who can collectively train analysis models using PySyft;
- KotlinSyft is a project to train and inference PySyft models on Android;
- SwiftSyft is a project to train and inference PySyft models on iOS;
- Syft.js provides a web interface for the components listed above.
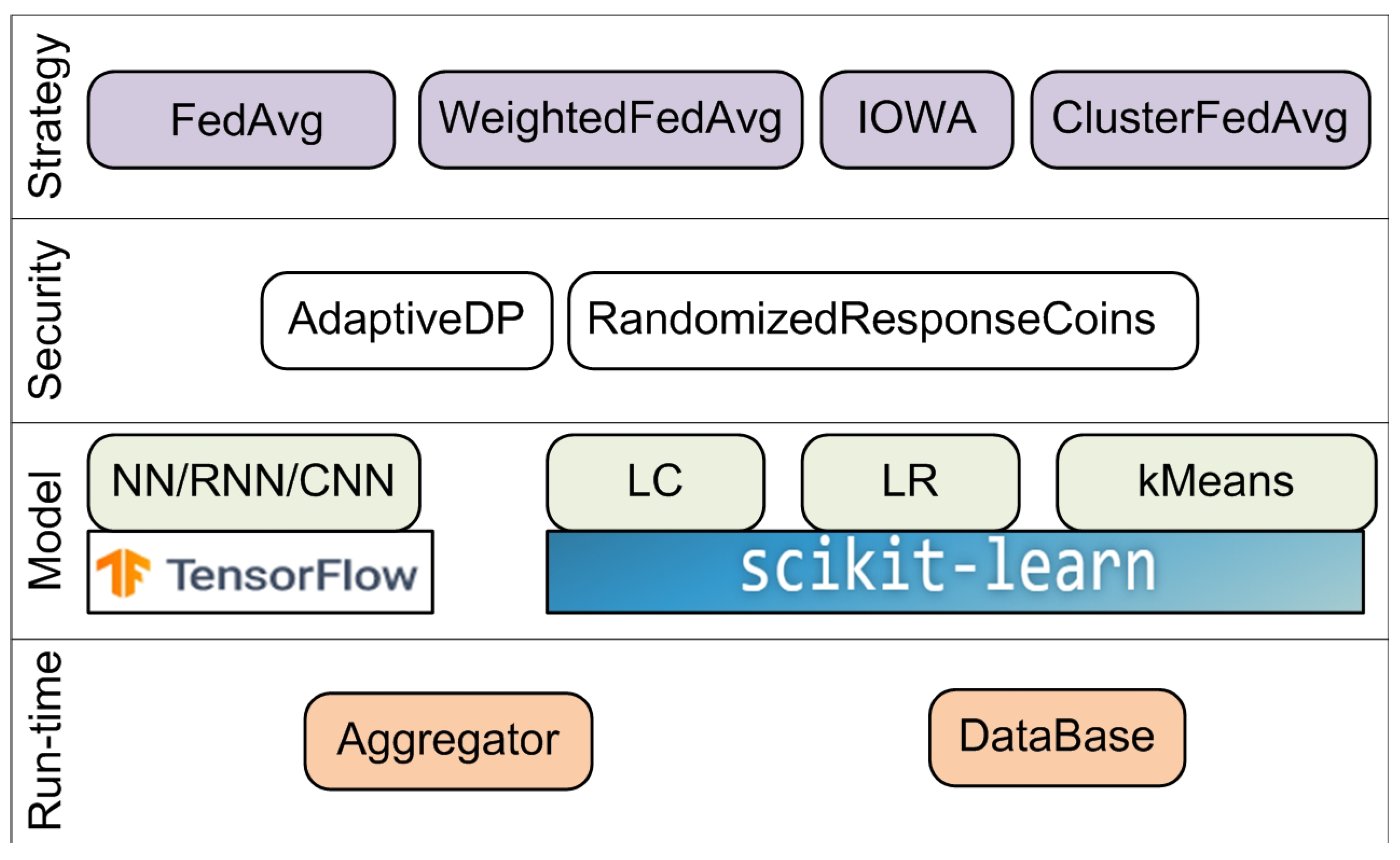
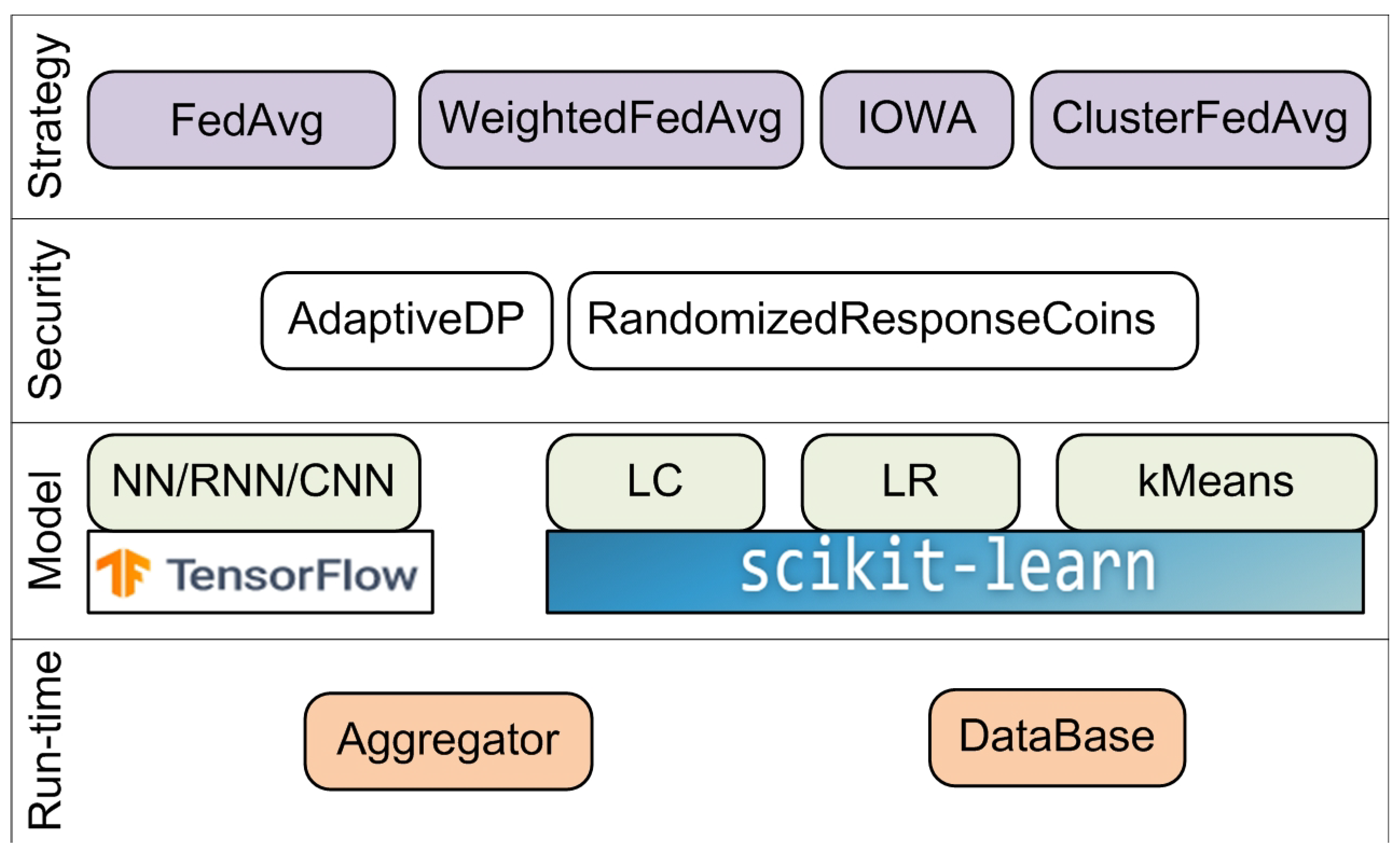
4.5. Federated Learning and Differential Privacy Framework
- A FedAvg aggregator for NN and LR;
- A weighted FedAverage aggregator and IOWA FedAverage aggregator for LR;
- A cluster FedAverage aggregator for centroid cluster models.
4.6. Proprietary Federated Learning Frameworks
5. Evaluation of Open-Source Federated Learning Frameworks
5.1. Experimental Settings
- The first one was used to test the simulation mode on one virtual machine; it had the following characteristics: single-hardware hyper-thread in a 2.0–3.8 GHz core, 6.5 GB RAM (RW speed: 24 Mb/s), swap: 180 GB, HDD: 200 GB (RW speed: 24 Mb/s);
- The second one was used to test the federated mode; it consisted of three instances: one server and two clients. The server and the clients had the following characteristics: single-hardware hyper-thread in a 2.0–3.8 GHz core, 6.5 GB RAM (RW speed: 24 Mb/s), swap: 180 GB, HDD: 30 GB (RW speed: 24 Mb/s).
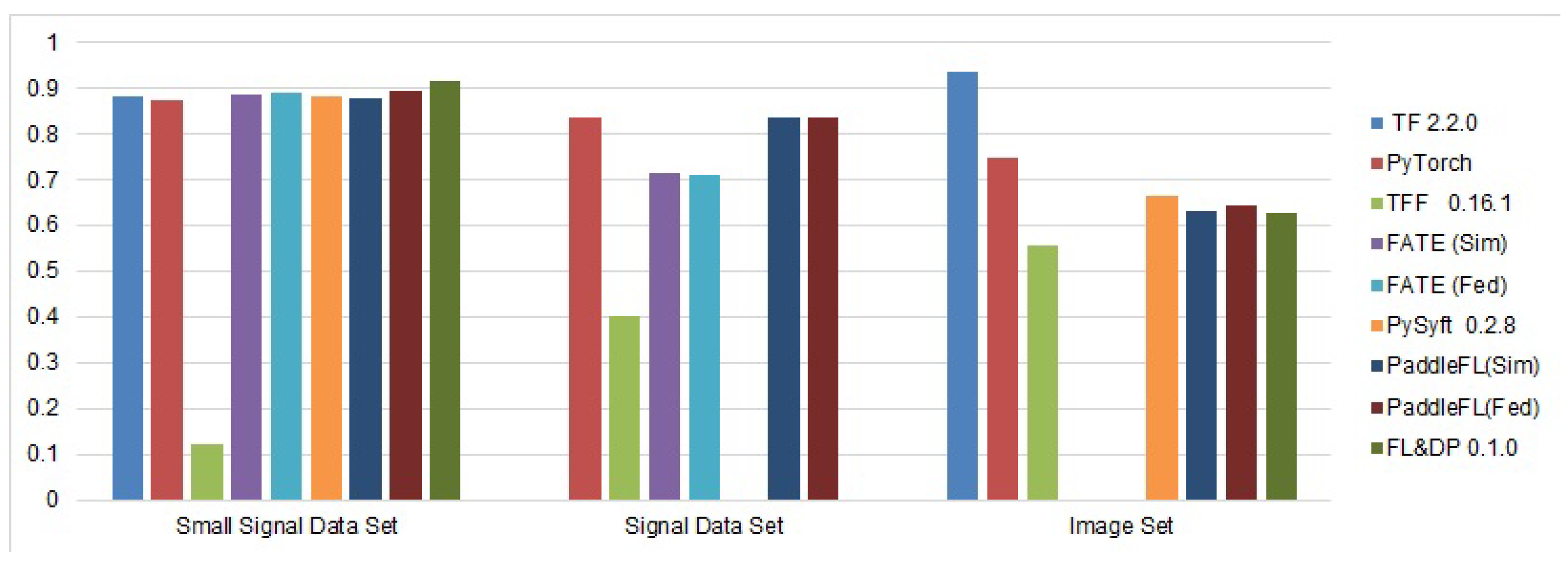
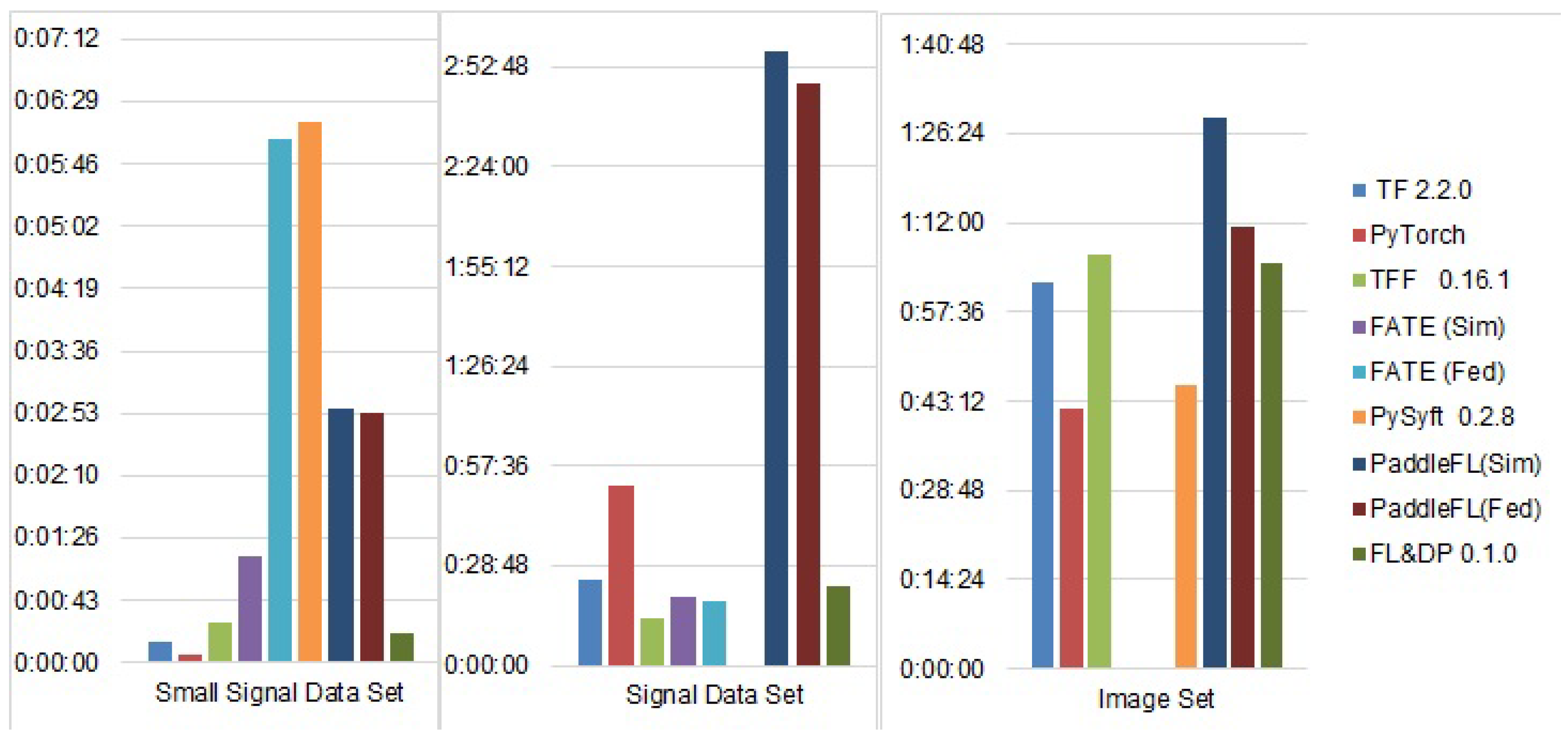
- A small signal data set that contains data that describe a car’s parameters during its movement. These parameters are collected using smartphones and include such features as altitude change, vertical and horizontal accelerations, average speed and its variance, engine load, cooling temperature, revolutions per minute (RPM), etc. The data were collected from two vehicles—a Peugeot 207 1.4 HDi (70 CV) and Opel Corsa 1.3 HDi (95 CV). The goal of the data set is to determine the overall state of the system consisting of the car, driver, and road, and therefore, the target labels are the road surface, driving style, and traffic state [50].
- A signal data set that also describes the movement of two vehicles—dumpers of AH and HL series. These dumpers operated at a ground remediation site in Sweden, and the collected attributes include the timestamp, speed, gyroscope, and accelerometer data [51]. The objective of the data set is to define the state of the commercial vehicle—movement, idle, loading, and discharge. The data set is not balanced, as it contains a log of more than five hours from the AH dumper and only a 75-minute log from the HL dumper.
- An image data set that contains X-ray images obtained from 5232 patients of pediatric medical centers and labeled according to two categories: pneumonia and normal [52]. It includes 3883 images with signs of pneumonia and 1349 normal images.
- An input layer with the number of nodes corresponding to the number of data set properties;
- An intermediate fully connected layer with 256 nodes;
- An intermediate fully connected layer with 64 nodes;
- An output layer.
- Number of epochs = 20;
- Batch size = 32;
- Number of rounds = 20;
- Stochastic gradient descent (SGD) optimizer;
- Learning step = 0.01.
- An input convolutional layer for a 150 × 150 image;
- Two intermediate convolutional layers with 64 nodes;
- An intermediate convolutional layer with 128 nodes;
- An intermediate convolutional layer with 256 nodes;
- An intermediate Dense layer with 256 nodes;
- An output Dense layer with one node.
- Number of epochs = 10;
- Batch size = 32;
- Number of rounds = 20;
- SGD optimizer;
- Learning step = 0.001.
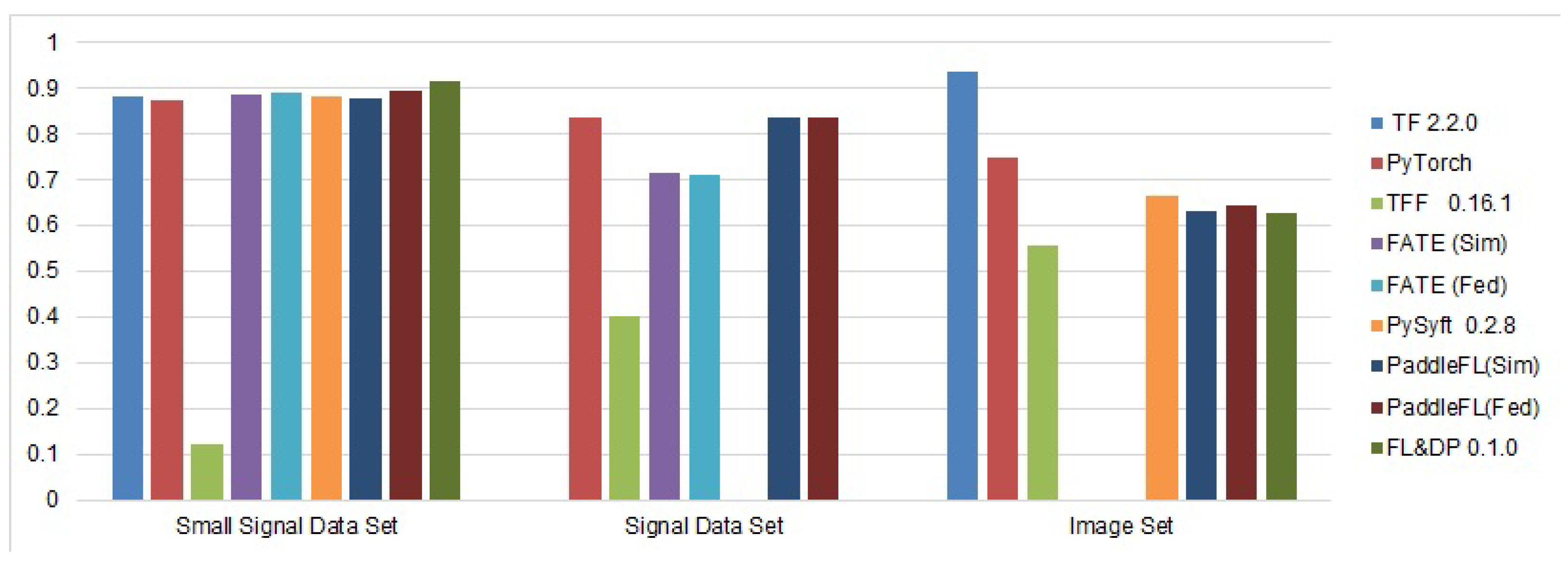
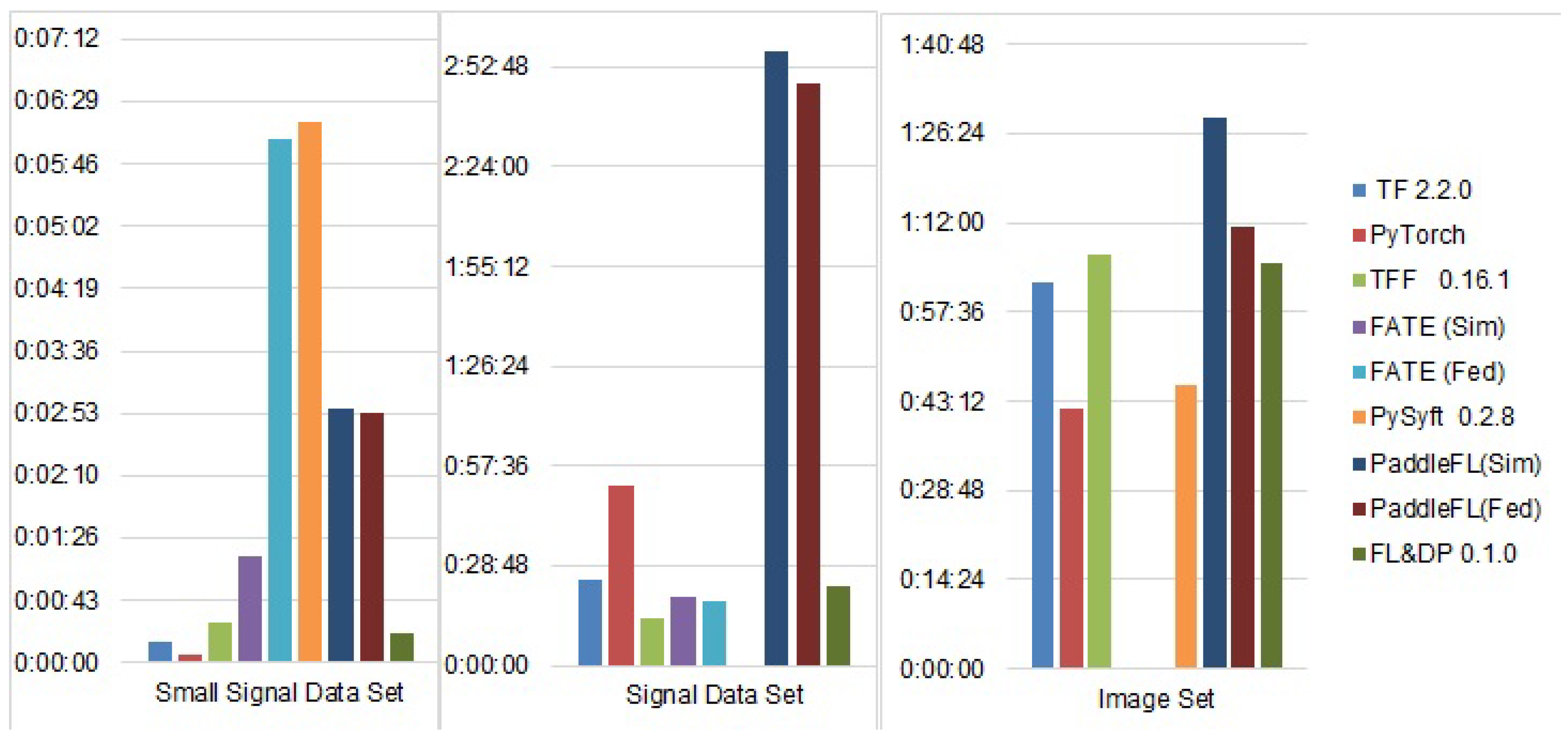
5.2. Experimental Results and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AFL | Agnostic federated learning |
| BTSB | Boosting tree secure boost |
| BYOC | Bring your own components |
| CCPA | California Consumer Privacy Act |
| CNN | Convolutional neural network |
| CP | Computing party |
| DL | Deep learning |
| DNN | Deep neural network |
| DP | Differential privacy |
| DPSGD | Differentially private stochastic gradient descent |
| FATE | Federated AI Technology Enabler |
| FedAvg | Federated averaging |
| FedMA | Federated matched averaging |
| FedProx | Federated proximal |
| FedSGD | Federated stochastic gradient descent |
| FL | Federated learning |
| FL & DP | Federated Learning and Differential Privacy |
| FLS | Federated learning system |
| GBDT | Gradient-boosting decision tree |
| GDPR | General Data Protection Regulation |
| HE | Homomorphic encryption |
| IBM FL | IBM Federated Learning |
| IID | Independent and identically distributed |
| IP | Input party |
| IoT | Internet of Things |
| IOWA | Induced ordered weighted averaging |
| LogR | Logistic regression |
| LR | Linear regression |
| LSTM | Long short-term memory |
| ML | Machine learning |
| MMARS | Medical Model ARchive |
| MPC | Multi-party computation |
| NN | Neural network |
| OWA | Ordered weighted averaging |
| PDPA | Personal data protection |
| PFF | Prefix frequency filtering |
| PFL | Paddle Federated Learning |
| PFNM | Probabilistic federated neural matching |
| PR | Poisson regression |
| PSI | Private set intersection |
| RL | Reinforcement learning |
| RNN | Recurrent neural network |
| RP | Result party |
| RPM | Revolutions per minute |
| SecAgg | Secure aggregation |
| SGD | Stochastic gradient descent |
| SPDZ | SecretShare MPC Protocol |
| TEE | Trusted execution environment |
| TF | TensorFlow |
| TFF | TensorFlow Federated |
References
- Santucci, G. From internet of data to internet of things. In Proceedings of the International Conference on Future Trends of the Internet, Luxembourg, 28 January 2009. [Google Scholar]
- Tsai, C.W.; Lai, C.F.; Vasilakos, A.V. Future Internet of Things: Open Issues and Challenges. Wirel. Netw. 2014, 20, 2201–2217. [Google Scholar] [CrossRef]
- Atzori, L.; Iera, A.; Morabito, G. The internet of things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef] [Green Version]
- Voigt, P.; Von dem Bussche, A. The EU general data protection regulation (GDPR). In A Practical Guide, 1st ed.; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar]
- California Consumer Privacy Act Home Page. Available online: https://oag.ca.gov/privacy/ccpa (accessed on 24 September 2020).
- Personal Data Protection Act 2012. Available online: https://sso.agc.gov.sg/Act/PDPA2012 (accessed on 24 September 2020).
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. arXiv 2017, arXiv:1602.05629. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; d’Oliveira, R.G. Advances and open problems in federated learning. arXiv 2019, arXiv:1912.04977. [Google Scholar]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; He, B. A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection. arXiv 2019, arXiv:1907.09693. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership Inference Attacks Against Machine Learning Models. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 3–18. [Google Scholar] [CrossRef] [Green Version]
- Sun, G.; Cong, Y.; Dong, J.; Wang, Q.; Liu, J. Data Poisoning Attacks on Federated Machine Learning. arXiv 2020, arXiv:2004.10020. [Google Scholar]
- TensorFlow Federated: Machine Learning on Decentralized Data. Available online: https://www.tensorflow.org/federated (accessed on 24 September 2020).
- An Industrial Grade Federated Learning Framework. Available online: https://fate.fedai.org/ (accessed on 24 September 2020).
- Baidu PaddlePaddle Releases 21 New Capabilities to Accelerate Industry-Grade Model Development. Available online: http://research.baidu.com/Blog/index-view?id=126 (accessed on 24 September 2020).
- Let‘s Solve Privacy. Available online: https://www.openmined.org/ (accessed on 24 September 2020).
- We Research and Build Artificial Intelligence Technology and Services. Available online: https://sherpa.ai/ (accessed on 24 September 2020).
- Gronlund, C.J. Introduction to Machine Learning on Microsoft Azure. 2016. Available online: https://azure.microsoft.com/en-gb/documentation/articles/machine-learningwhat-is-machine-learning (accessed on 24 September 2020).
- Google Cloud Machine Learning at Scale. Available online: https://cloud.google.com/products/machine-learning/ (accessed on 24 September 2020).
- Barr, J. Amazon Machine Learning-Make Data-Driven Decisions at Scale. Available online: https://aws.amazon.com/blogs/aws/amazon-machine-learning-make-data-driven-decisions-at-scale/ (accessed on 24 September 2020).
- Lally, A.; Prager, J.M.; McCord, M.C.; Boguraev, B.K.; Patwardhan, S.; Fan, J.; Chu-Carroll, J. Question analysis: How Watson reads a clue. IBM J. Res. Dev. 2012, 56, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Kholod, I.; Shorov, A.; Gorlatch, S. Improving Data Mining for Differently Distributed Data in IoT Systems. In Proceedings of the 13th International Symposium on Intelligent Distributed Computing (IDC 2019), Saint-Petersburg, Russia, 7–9 October 2019; pp. 75–85. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 12. [Google Scholar] [CrossRef]
- Bogdanov, D.; Talviste, R.; Willemson, J. Deploying secure multi-party computation for financial data analysis—(short paper). In Financial Cryptography; Volume 7397 of Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; pp. 57–64. [Google Scholar]
- Mohassel, P.; Rindal, P. ABY3: A mixed protocol framework for machine learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 35–52. [Google Scholar]
- Mohassel, P.; Zhang, Y. Secureml: A system for scalable privacy-preserving machine learning. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 25 May 2017; pp. 19–38. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- Zhang, C.; Li, S.; Xia, J.; Wang, W.; Yan, F.; Liu, Y. BatchCrypt: Efficient Homomorphic Encryption for Cross-Silo Federated Learning. 2020. Available online: https://www.usenix.org/conference/atc20/presentation/zhang-chengliang (accessed on 24 September 2020).
- Acar, A.; Aksu, H.; Uluagac, A.S.; Conti, M. A Survey on Homomorphic Encryption Schemes: Theory and Implementation. arXiv 2017, arXiv:1704.03578. [Google Scholar] [CrossRef]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Bernstein, G.; Sheldon, D.R. Differentially private bayesian linear regression. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada, 8–14 December 2019. [Google Scholar]
- Cheng, H.P.; Yu, P.; Hu, H.; Zawad, S.; Yan, F.; Li, S.; Li, H.; Chen, Y. Towards Decentralized Deep Learning with Differential Privacy. In Proceedings of the International Conference on Cloud Computing, Sydney, Australia, 11–13 December 2019; Springer: Cham, Switzerland, 2019; pp. 130–145. [Google Scholar]
- Ren, J.; Xiong, J.; Yao, Z.; Ma, R.; Lin, M. DPLK-means: A novel Differential Privacy K-means Mechanism. In Proceedings of the 2017 IEEE Second International Conference on Data Science in Cyberspace (DSC), Shenzhen, China, 26–29 June 2017; pp. 133–139.
- Balcan, M.F.; Dick, T.; Liang, Y.; Mou, W.; Zhang, H. Differentially private clustering in high-dimensional euclidean spaces. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 322–331. [Google Scholar]
- Sabt, M.; Achemlal, M.; Bouabdallah, A. Trusted execution environment: What it is, and what it is not. In Proceedings of the 2015 IEEE Trustcom/BigDataSE/ISPA, Helsinki, Finland, 20–22 August 2015; Volume 1, pp. 57–64. [Google Scholar]
- Harb, H.; Makhoul, A.; Laiymani, D.; Jaber, A.; Tawil, R. K-means based clustering approach for data aggregation in periodic sensor networks. In Proceedings of the 2014 IEEE 10th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Larnaca, Cyprus, 8–10 October 2014; pp. 434–441. [Google Scholar]
- Yager, R.R. On ordered weighted averaging aggregation operators in multicriteria decisionmaking. IEEE Trans. Syst. Man Cybern. 1988, 18, 183–190. [Google Scholar] [CrossRef]
- Yager, R.R.; Filev, D.P. Induced OWA operators. IEEE Syst. Cybernet Part B 1999, 29, 141–150. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Mohri, M.; Sivek, G.; Suresh, A.T. Agnostic federated learning. arXiv 2019, arXiv:1902.00146. [Google Scholar]
- Yurochkin, M.; Agarwal, M.; Ghosh, S.; Greenewald, K.; Hoang, T.N.; Khazaeni, Y. Bayesian nonparametric federated learning of neural networks. arXiv 2019, arXiv:1905.12022. [Google Scholar]
- Wang, H.; Yurochkin, M.; Sun, Y.; Papailiopoulos, D.; Khazaeni, Y. Federated learning with matched averaging. arXiv 2020, arXiv:2002.06440. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Seth, K. Practical secure aggregation for federated learning on user-held data. arXiv 2016, arXiv:1611.04482. [Google Scholar]
- Chen, H.; Laine, K.; Rindal, P. Fast Private Set Intersection from Homomorphic Encryption. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1243–1255. [Google Scholar] [CrossRef]
- Dwork, C.; Roth, A. The Algorithmic Foundations of Differential Privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Rodríguez-Barroso, N.; Stipcich, G.; Jiménez-López, D.; Ruiz-Millán, J.A.; Martínez-Cámara, E.; González-Seco, G.; Luzón, M.V.; Veganzones, M.A.; Herrera, F. Federated Learning and Differential Privacy: Software tools analysis, the Sherpa.ai FL framework and methodological guidelines for preserving data privacy. arXiv 2020, arXiv:2007.00914. [Google Scholar] [CrossRef]
- Clara Train SDK Documentation. Available online: https://docs.nvidia.com/clara/tlt-mi/clara-train-sdk-v3.1/ (accessed on 24 September 2020).
- Ludwig, H.; Baracaldo, N.; Thomas, G.; Zhou, Y.; Anwar, A.; Rajamoni, S.; Purcell, M. Ibm federated learning: An enterprise framework white paper v0. 1. arXiv 2020, arXiv:2007.10987. [Google Scholar]
- Traffic, Driving Style and Road Surface Condition. Available online: https://www.kaggle.com/gloseto/traffic-driving-style-road-surface-condition (accessed on 24 September 2020).
- Commercial Vehicles Sensor Data Set. Available online: https://www.kaggle.com/smartilizer/commercial-vehicles-sensor-data-set (accessed on 24 September 2020).
- Chest X-ray Images (Pneumonia). Available online: https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia (accessed on 24 September 2020).
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Shin, M.; Hwang, C.; Kim, J.; Park, J.; Bennis, M.; Kim, S.L. XOR Mixup: Privacy-Preserving Data Augmentation for One-Shot Federated Learning. arXiv 2020, arXiv:2006.05148. [Google Scholar]
- Wu, Q.; He, K.; Chen, X. Personalized federated learning for intelligent iot applications: A cloud-edge based framework. IEEE Comput. Graph. Appl. 2020. [Google Scholar] [CrossRef] [PubMed]
- Jeong, E.; Oh, S.; Kim, H.; Park, J.; Bennis, M.; Kim, S.L. Communication-efficient on-device machine learning: Federated distillation and augmentation under non-iid private data. arXiv 2018, arXiv:1811.11479. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distributed Learning | Federated Learning | |
|---|---|---|
| Aims | Scalable parallelized big data processing | Processing distributed data on heterogeneous data sources |
| Datasets | IID (identically and independently distributed) and have roughly the same size | Heterogeneous data sets; their sizes may span several orders of magnitude |
| Nodes | Data centers with powerful computing resources connected by high-performance networks | Often low-power devices, such as smartphones and IoT devices, with limited computing resources connected by less reliable networks, which results in their failures or dropping out of computation |
| Properties of Clients | Cross-Silo | Cross-Device |
|---|---|---|
| Computation and storage capacity | High-performance | Low |
| Scale | Relative small | Large |
| Stability | High | Low |
| Data distribution | Usually non-IID | Usually IID |
| Features | TFF 0.17.0 | FATE 1.4.4/1.5 | PySyft 0.2.8 | PFL 1.1.0 | FL & DP 0.1.0 |
|---|---|---|---|---|---|
| OS | Mac Linux | Mac Linux | Mac Linux Win iOS Android | Mac Linux Win | Linux Win |
| Settings | Cross-silo | Cross-silo | Cross-silo Cross-devices | Cross-silo Cross-devices (in future) | Cross-silo |
| Data Partitioning | Horizontal | Horizontal Vertical | Horizontal Vertical | Horizontal Vertical Transfer | Horizontal |
| Data type | Time series Images | Time series | Images | Time series Images | Time series Images |
| Mode | Simulation | Simulation Federated | Simulation Federated | Simulation Federated | Simulation |
| Clustering model | No | No | No | No | Yes (Kmeans SciKitLearn) |
| ML Model | No | Yes (very slow) | No | Yes | Yes (SciKitLearn) |
| Decision Tree Model | No | Yes (very slow) | No | No | No |
| Protocol | gRPC/proto (in future) | gRPC/proto | Doesn’t use | ZeroMQ | Doesn’t use |
| Data Set | Columns | Rows | Volume |
|---|---|---|---|
| Small signal data set | 13 | 30,000 | 3.5 MB |
| Signal data set | 9 | 1.5 million | 157 MB |
| Image data set | 6000 (Number of images 150 × 150) | 1.15 GB | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kholod, I.; Yanaki, E.; Fomichev, D.; Shalugin, E.; Novikova, E.; Filippov, E.; Nordlund, M. Open-Source Federated Learning Frameworks for IoT: A Comparative Review and Analysis. Sensors 2021, 21, 167. https://doi.org/10.3390/s21010167
Kholod I, Yanaki E, Fomichev D, Shalugin E, Novikova E, Filippov E, Nordlund M. Open-Source Federated Learning Frameworks for IoT: A Comparative Review and Analysis. Sensors. 2021; 21(1):167. https://doi.org/10.3390/s21010167
Chicago/Turabian StyleKholod, Ivan, Evgeny Yanaki, Dmitry Fomichev, Evgeniy Shalugin, Evgenia Novikova, Evgeny Filippov, and Mats Nordlund. 2021. "Open-Source Federated Learning Frameworks for IoT: A Comparative Review and Analysis" Sensors 21, no. 1: 167. https://doi.org/10.3390/s21010167
APA StyleKholod, I., Yanaki, E., Fomichev, D., Shalugin, E., Novikova, E., Filippov, E., & Nordlund, M. (2021). Open-Source Federated Learning Frameworks for IoT: A Comparative Review and Analysis. Sensors, 21(1), 167. https://doi.org/10.3390/s21010167