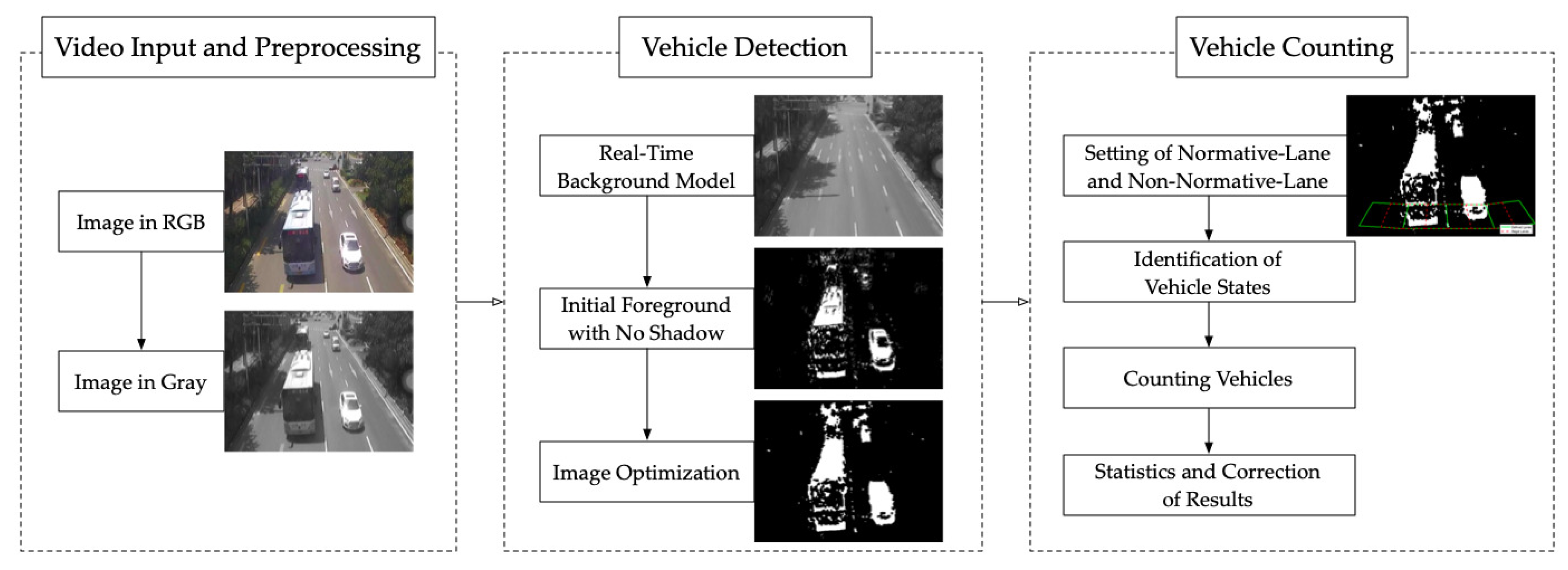
Getting an accurate detection result is an essential process before the counting part. For ideal scenes, this goal is easy to achieve. However, when the detection environment is poor, many algorithms become ineffective. For example, the sudden change of illumination will bring great challenges to the establishment of real-time background, which may affect the extraction of real foreground directly; the shadow moving with vehicle caused by the sunlight could be easily mistaken for the foreground, which greatly increases the chances of unwanted counting; at the same time, incomplete foreground extraction may cause an error of missing the target vehicles.
In this section, a vehicle detection algorithm based on motion was proposed. Our algorithm could be divided into four steps. A real-time background model should be set at first, which can resist sudden illumination changes in cloudy weather or other situations. Second, an algorithm for removing vehicle shadows based on motion was proposed, which can greatly improve the accuracy of foreground extraction. Then, a vehicle filling method based on vehicle edge was studied in this paper, which could be used as a supplementary means for extracting a more complete foreground. At last, denoising methods were brought into our system to obtain an optimized foreground extraction.
2.2.1. Real-Time Background Model
(i) Initial Background
A background of a scene only consists of static pixels, and it is the basis for foreground extraction. However, for a highway or an urban road, it is extremely rare that there is no moving object in a frame, and even if this particular frame exists, it is hard to be found. Therefore, to establish a background model, the general method is analyzing the distribution characteristics of pixel value at each pixel position in a series of original frames, and selecting or calculating the static pixel values. Among the existing mature methods, there are three main approaches: the Gaussian mixture model (GMM) [
31], the statistical median model (SMM) [
32], and the multi-frame average model (MAM) [
33].
In terms of extraction accuracy, the GMM is better than the SMM and the MAM, while the SMM is better than the MAM. However, the GMM cost 40–50 times longer than the other two, which makes it unsuitable for online video. In addition, the GMM contains two parameters:
(the learning constant) and
N (the number of video frame should be analyzed in the model), while the other two only contain
N [
34]. Considering the accuracy and the running speed comprehensively, the SMM is the most suitable for online background extraction among these three methods.
Let and represent the height and the width of an image, and each pixel position could be expressed as , where , . The total number of frames is represented by , and the sequence number of each frame could be expressed as k, where . The first step is changing RGB images into gray images. We call it here, which represents the gray value vector of pixels for Frame k.
For SMM, there is only one parameter (
N) that needs to be tuned. We set
here, and these
N frames were selected per second. For a video with a frame update rate of 30 fps, this algorithm only needs to be operated every 30 s, which greatly reduces the computer running time. The initial background extraction at each position could be expressed as:
where
is the frame rate of video,
n represents the sequence number of the initial background, and
is the gray value vector of the
initial background.
(ii) Real-Time Background
A good background must adapt to the gradual or sudden illumination changes [
35], such as the changing time of a day or clouds, etc. However, the initial background has poor resistance to such situations, especially for sudden changes. To illustrate this phenomenon better, we chose the Video M-30-HD [
30] with lots of sudden illumination changes, which was shot on a cloudy day. Two frames were selected for display here, which were badly affected by the cloudy weather. The selected frame numbers (
k) are 4711 and 5724 and the result of foreground extraction using the initial background is shown in
Figure 3c.
It is clear that not only were the actual foreground pixels extracted, but a large part of the background was also mistaken for the foreground. This is because the establishment of initial background must be based on a series of images, which results that the difference between the initial background and the real-time background is always present. Worse, it will not be effective even if the running frequency of the algorithm is greatly increased at the cost of high computational complexity. In this case, the solution is modifying the background of each frame in real time based on the initial or previous background. Toyama [
36] proposed an adaptive filter based on the previous background in 1999:
where
is the gray value vector of the current background (Frame
k), and
is the previous background (Frame
);
is the parameter that decides the rate of adaptation in the range 0–1. However,
is an experienced parameter, which is hard to be tuned appropriately for different cases. Moreover, there will be a cumulative error if the previous background is extracted inaccurately. In this case, we proposed an adaptive algorithm to obtain a real-time background, which only contains one parameter that is easily determined.
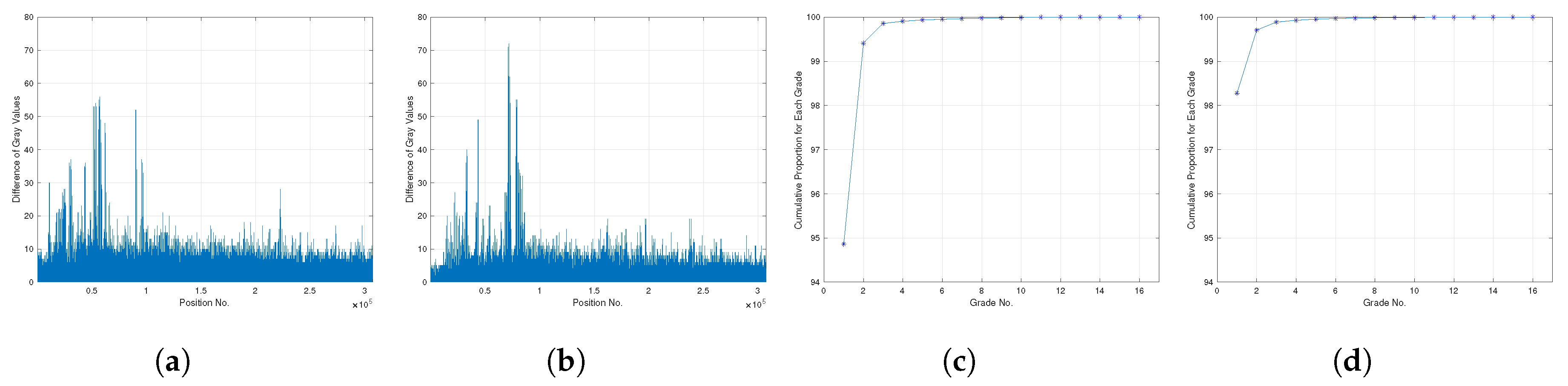
First of all, the difference of gray value between the initial background and the current frame should be studied, which could be expressed as:
where
is the difference vector of gray values between the initial background and current frame, and the
of two frames are shown in
Figure 4a,b. It is easy to see that
could be divided into three classes at each position, that is:
where
is the threshold of the classification that needs to be tuned.
Class 1 means the position for Frame k belongs to the background, Class 3 means belongs to the foreground, while Class 2 also means belongs to the background but the initial background needs to be adjusted with .
In order to determine the value of
, the distribution of
should be studied more clearly. It is easy to find that
fluctuates directly between 0–80, so we divided 100 into 20 grades with an interval of five to calculate the percentage of position numbers, and the cumulative distribution of each grade is shown in
Figure 4c,d. It is obvious that more than 90% of
are distributed in [0,5], more than 99% are distributed in [0,10], and more than 99.5% are distributed in [0,15]. Therefore, for the sake of careful estimation, we could conclude that
should be set in [5,15].
Based on the study above, we proposed an adaptive algorithm to obtain the real-time background, which could be expressed as:
where
is the weight of the current frame and
is the weight of the initial background.
According to Formula (
6), the higher the
, the lower the
. In this case,
and
can make up for the errors of setting
adaptively together. Therefore, the parameter
has no vital effect on the generation of real-time background, which greatly improves the adaptability and accuracy of the algorithm. As mentioned before, we set
in [5,15] here, and the extraction of foreground using our real-time background is shown in
Figure 3e. As can be seen, the real-time backgrounds overcome the adverse effects of sudden illumination changes well.
2.2.2. Initial Foreground with No Shadow
(i) Light and Dark Foreground
Subtracting the current frame from the background directly and converting it into a binary image is the most used method to extract the foreground, however, it will remain the shadow unwanted. As we all know, shadows have three features [
37] different from moving vehicles, which are intensity values, geometrical properties, and light directions. Based on the features, the shadow will be darker than the background, and it has nothing to do with the pixel value of the vehicle that produces it. In this case, the foreground image could be divided into two parts for analysis:
where
is the difference vector of gray value between current frame and background, which only contains the darker pixels, and
only contains the lighter pixels. Moreover, the Otsu’s method [
38] was used here to get
and
.
The Video Mofan Rd [
28] on an urban road was chosen as an example, which was recorded by ourselves on a sunny day and contains lots of vehicle shadows. We selected a frame (
) which contains a large bus and some small vehicles for display. The
and
are shown in
Figure 5b,c. As we can see, the
contains no shadow. Although the vehicles obtained in this way were incomplete, to get ‘clean’ vehicles, we only choose the
as a part of initial foreground and abandon the
for the time being.
(ii) Removing Shadows
Most algorithms for removing shadows are based on color features and run in a color model. The Hue-Saturation-Intensity (HSI) model could be used to detect the shadows, which is based on the fact that the chromaticity information will not be affected by the change of lighting. By selecting a region which is darker than its neighboring regions but has similar chromaticity information, the shadow could be detected. Cucchiara et al. [
39] proposed an algorithm to achieve this goal:
where
is the judgement of shadow;
,
,
are the color vectors of the current frame in the HSI model, while
,
,
are the color vectors of background;
,
,
and
are the four parameters to be determined.
There are four parameters to be determined in this algorithm, which greatly increases the instability of the judgement results. Even in a similar scene, the results will vary greatly under different lighting levels (such as different times of one day), which means the parameters need to be adjusted constantly. More importantly, this algorithm will also eliminate parts of the vehicle when the color of the vehicle itself is similar to the shadow color, which leads to the absence of vehicle information. Moreover, an algorithm based on a color model needs longer running time than the gray model.
Since such parameters are difficult to determine, we proposed a shadow removal method without parameters. As mentioned above, the chromaticity of shadow is not affected by the change of illumination for some cases. Based on it, we could suppose that the shadow of a vehicle will remain the same in a very short interval, such as an interval between two frames. Therefore, a pixel position can be judged as shadow if its value remains the same among the current frame and two adjacent frames. In this case, a frame with the shadow removed can be expressed as:
where
is the image with shadow removed. As we can see in
Figure 5d, this algorithm works well in removing shadow, but it may cause some holes in the vehicles.
(iii) Initial Foreground
Combining the result of the previous two steps, the initial foreground can be expressed as:
As shown in
Figure 5e, the shadow has been removed successfully but the vehicles are somewhat incomplete, and more noise was brought. Therefore, some methods for fulfilling the vehicles and denoising are necessary and they will be described in the next sections.
For a scene without shadow, it is not necessary to operate the algorithm for removing shadow. After all, this algorithm may make the vehicle incomplete and bring some noise. As mentioned above, the reason for abandoning
is that the darker foreground contains vehicle shadows. Therefore, the
and
should be both included as initial foreground for scenes with no shadow. In this case, the initial foreground for a scene with no shadow could be expressed as:
A frame (
) from Video M-30-HD [
30] was selected for display, shown in
Figure 6.
2.2.3. Image Optimization
After the foreground extraction based on motion is completed, it is necessary to fill vehicle holes and denoise to obtain a better foreground.
(i) Filling Image with Edge
Let’s review the shadow removal algorithm in
Section 2.2.2. According to Formula (
11), the binary image
is obtained by taking the relative complementary sets of adjacent frames (
and
) in the current frame (
), and this is also the reason why there are more holes in
. In this case, it is necessary to analyze the relationships between the current frame and two adjacent frames again separately from the perspective of the gray value. Let’s analyze the difference in the gray model, which could be expressed as:
where
is the difference gray image between current frame and previous frame, while
is the difference between the current frame and next frame.
Through a further analysis, we found that the difference gray image may contain noise, but the edge of them contains almost nothing more than the actual vehicle profiles. At this point, the edges of
and
play an important role in filling the holes. The edge was extracted with canny method [
40] in this paper, which could be expressed as:
where
is the edge extraction algorithm.
and
is the edge of
and
, while
is the extracted edge of current frame.
For a scene with no shadow, we found that the edge obtained from
was cleaner, while the edge of
may contain more noise. Therefore, the extraction of the edge should based on
only, which could be expressed as:
After the edge has been extracted, the holes in vehicle could be filled with edge. The filling method proposed by Pierre Soille [
41] works well, which could be expressed as:
where
is the filling algorithm, and
is the filled image. It is worth noting that a simple median filtering operation [
42] on the
is very effective in removing redundant noise caused by the edge. The filling and filtering results are shown in
Figure 7c.
(ii) Morphological Closing
As shown in
Figure 7c, the
still contains some big holes and some extra noise. At this point, it becomes necessary to perform a closing operation [
43] on
:
A median filtering operation could be done again and the final foreground is shown in
Figure 7e.
According to
Figure 7, the algorithm works well on a cloudy day. As for a shadow scene, there are almost no vehicle shadows left in
and the algorithm works better for small vehicles. Although there are still some holes in large buses, it does not affect the vehicle counting discussed in
Section 2.3.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}