3.2. Classification
Recent surveys in the indoor positioning domain have proposed various classifications. For instance, the survey of Yassin et al. [
1], which addressed the entire domain of indoor localization (not limited to vision based solutions), proposed a two-level classification. The first level grouped the solutions based on the positioning algorithms, which were divided into three classes: triangulation, scene analysis, and proximity detection. The second level classified the solutions within the first level classes based on the measurement techniques as follows: the triangulation class had two sub-classes: lateration and angulation; the scene analysis class had only one sub-class: fingerprinting based; and the proximity detection class had two sub-classes: cell-ID and RFID. Another general survey in indoor localization [
10] classified existing research solutions into local infrastructure dependent techniques (ultra-wideband, wireless beacons), local infrastructure independent techniques (ultrasound, assisted global navigation satellite systems, magnetic localization, inertial navigation systems, visual localization, infrared localization), and visual/depth sensors (structured light technology, pulsed light technology, stereo cameras).
Mendoza-Silva et al. [
9] presented a meta-review of indoor positioning systems, resulting from the analysis of 62 indoor localization-related surveys. They reviewed the most commonly used technologies for localization applications and proposed the following classes: light, computer vision, sound, magnetic fields, dead reckoning, ultra-wideband, WiFi, Bluetooth Low Energy, RFID, and Near-Field Communication (NFC). In the computer vision class, they discussed several positioning techniques, such as visual odometry and vision based SLAM, and mentioned different acquisition devices (monocular, stereo, omnidirectional). However, they did not propose any classification for this domain. They also observed the complete lack of recent surveys on computer vision based indoor localization solutions and claimed the necessity of such a work.
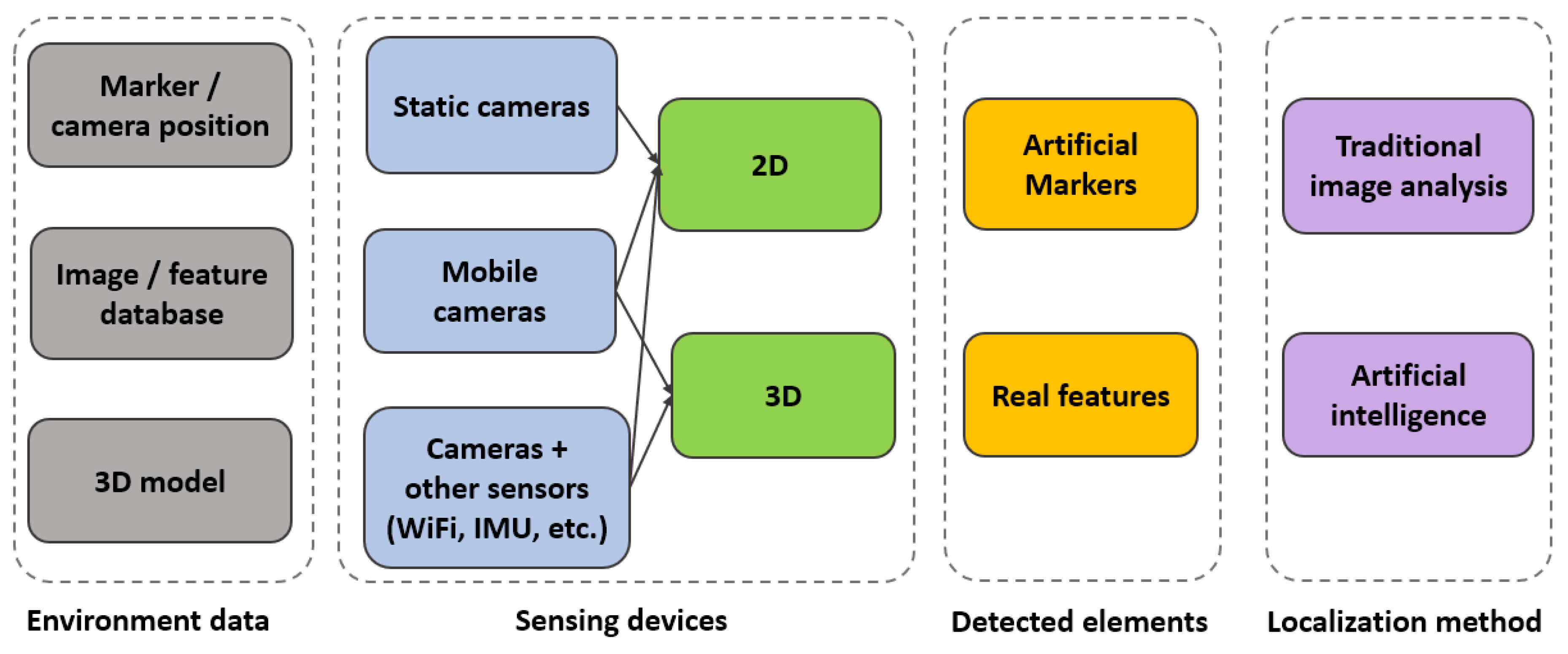
Analyzing the research papers mentioned in the previous section, several discriminating characteristics emerged. Therefore, we propose a new classification of computer vision based indoor localization solutions, as illustrated in
Figure 3.
All indoor positioning methods have a configuration stage, in which the environment is filled with landmarks and sensors, images from the environment are saved into a database, or a 3D representation of the indoor space is created. Therefore, environment data could consist of information about the position of the markers (e.g., QR codes, geometric synthetic identifiers) or the location of the static cameras placed within the scene. Another type of environment data is represented by databases with images or features from images, annotated with position and orientation information. Lastly, environment data could consist of a 3D model of the environment, a point cloud, a 3D mesh, or a 3D map, obtained with various methods such as manual modeling, SLAM, or SfM.
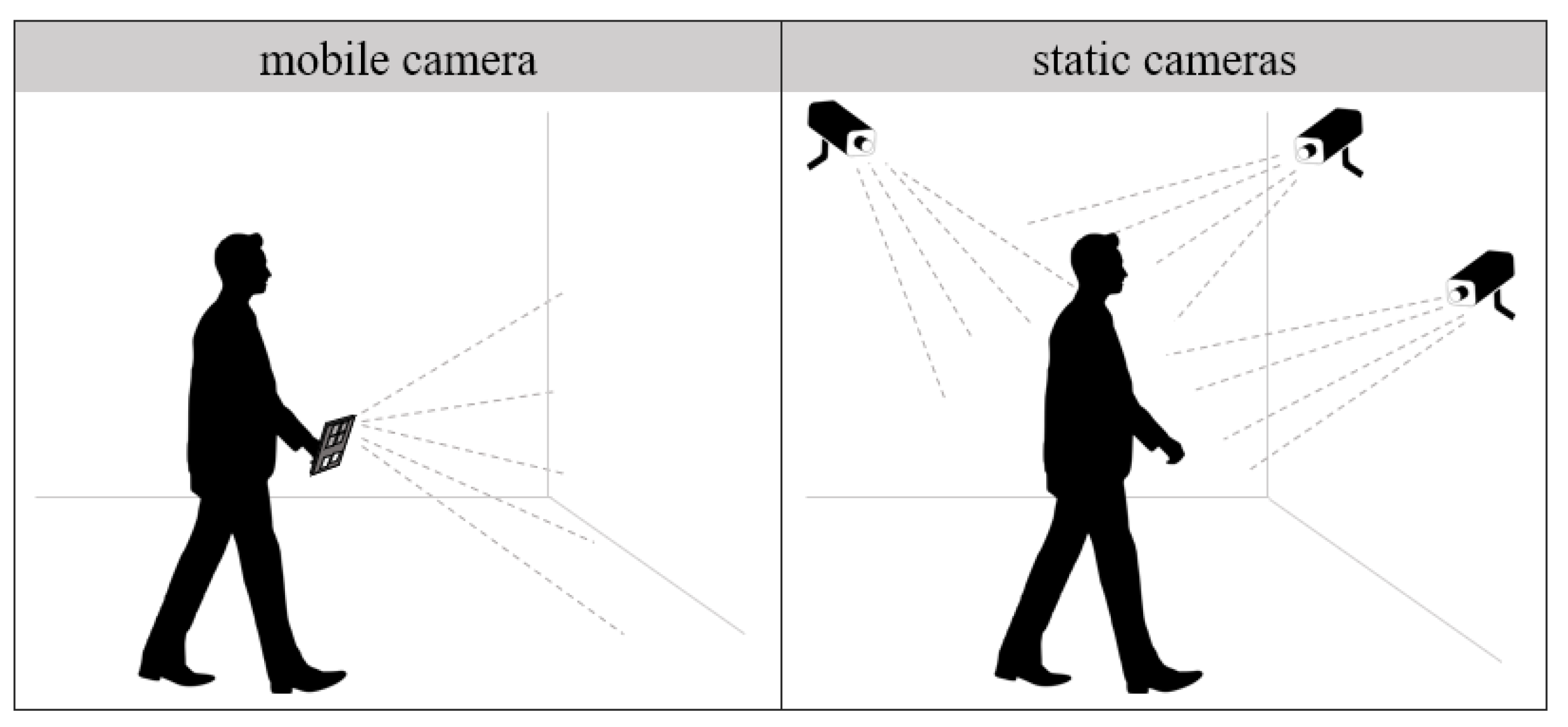
Another element that helps discriminate between methods is the type of employed sensing devices. As previously mentioned in
Section 1 and illustrated in
Figure 1, the main acquisition devices are static and mobile cameras. Furthermore, the input information can be enriched with data from other sensors, such as WiFi access points or IMU devices. Another differentiating aspect of image based localization methods is the type of visual input, which can be either 2D or 3D.
The localization methods can search for artificial markers (e.g., QR codes and other fiducial markers such as AprilTags [
66], ARTags, and CALTags [
8]) or for features from the real environment. The latter category includes any type of element that can be extracted from the real environment (without the need to insert synthesized items into the scene), either features of interest such as Speeded Up Robust Features (SURF) and Scale-Invariant Feature Transform (SIFT) or semantic objects. Therefore, we propose a new level of classification, namely the
detected elements, which refers to the type of features (artificial markers or natural, real elements from the environment) that are tracked or matched within the images.
Indoor positioning solutions employ various localization methods, which range from low-level feature matching to complex scene understanding. We divided the techniques into traditional image analysis and artificial intelligence. The ones belonging to the second category include any type of artificial intelligence, such as Bayesian approaches, Support-Vector Machine (SVM), and neural networks.
We applied the proposed classification to the selected indoor localization solutions.
Table 1 assigns each of the chosen research papers to a class, based on environment data, sensing devices, detected elements, and localization method.
Out of all the classes that could result from combining the differentiating elements from
Figure 3, we chose only 17 of the more popular ones, which were represented by a large number of research papers.
The following sub-sections analyze each category, presenting representative indoor localization solutions and discussing their advantages and drawbacks. For each examined scientific paper, we include in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11,
Table 12,
Table 13,
Table 14,
Table 15,
Table 16,
Table 17 and
Table 18 information about the characteristics of the datasets used for evaluation, the computing time or refresh rate (related to a certain running platform), and the achieved accuracy. If there were papers that did not report information about a certain characteristic, the field corresponding to that characteristic is marked with “-”. Some papers evaluated their solutions only visually, while others applied various metrics, such as average and/or absolute errors for position and orientation, percentage of tested cases when accuracy was within certain intervals, Detection Success Rate (DSR), Root Mean Squared Error (RMSE), Navigation Success Rate (NSR), Relative Pose Error (RPE), and Absolute Trajectory Error (ATE).
3.2.1. Indoor Localization Solutions with 2D Static Cameras, Markers, and Traditional Image Analysis
This class of indoor localization methods uses an infrastructure of 2D static cameras with known locations. The images from these cameras are processed with traditional computer vision algorithms in order to detect synthetic identifiers carried by people or robots.
Belonging to this class is the work of Heya et al. [
31], where the screen of the user’s smartphone was detected with a simple color tracking algorithm. Each user was assigned a color, which was displayed on the smartphone, and the system tracked the screen of the device, which was placed on the user’s shoulder. Another example of indoor localization solution using static 2D cameras and traditional image processing was an ambient navigation system proposed by Chaccour and Badr [
32], which detected the users’ location and orientation based on markers located on their heads. The system was evaluated within a home composed of three rooms, kitchen, living room, and bedroom, each containing an IP camera placed on the ceiling. The tests performed with eight people, including dynamically added obstacles, proved the reliability of the system.
The methods in this class require the map of the building and a configuration step that consists of annotating the positions of the static cameras on the map. They can achieve good, centimeter-level, accuracy, as can be seen in
Table 2, which makes them viable solutions for scenarios requiring high accuracy positioning in small spaces. However, maintaining this accuracy level in large indoor spaces comes with high costs in terms of both effort and infrastructure, due the cumbersome configurations and the high number of cameras required.
3.2.2. Indoor Localization Solutions with 2D Static Cameras, Real Features, and Traditional Image Analysis
In this class of indoor localization solutions, the images from the static cameras are processed with traditional computer vision algorithms in order to track objects or people and compute their positions within a certain room. Localization solutions within this class identify people or robots without the need for the tracked entities to carry devices or artificial markers.
Bo et al. [
67] recursively updated the position of multiple people based on the detected foreground and the previous known locations of each person. The foreground was identified by analyzing changes in image structure (edges) based on the computation of the normalized cross-correlation for each pixel. They applied a greedy algorithm to maximize the likelihood of observing the foreground for all people. The efficiency of their algorithm was evaluated on public datasets, using the Multiple Object Tracking Accuracy (MOTA), a metric computed based on object misses, false positives, and mismatches.
Shim and Cho [
69] employed a homography technique to create a 2D map with accurate object position, using several surveillance cameras. Dias and Jorge [
68] tracked people using multiple cameras and a two level processing strategy. Firstly they applied region extraction and matching to track people, and secondly, they fused the trajectories detected from multiple cameras in order to obtain the positions relative to a global coordinate system, using homography transformations between image planes.
Sun et al. [
60] proposed a device-free human localization method using a panoramic camera. They employed pre-processing, human detection with background subtraction (with mean filtering and a Gaussian low pass filtering), and an association between the location of users in the image space and their location on a given map of the indoor environment.
Compared to the previous class of solutions that use artificial markers, the methods in this class have slightly higher localization errors, as can be observed in
Table 3. However, this accuracy level (tens of centimeters) is still good for many types of applications, and these methods have a wider applicability, especially in the monitoring and surveillance domains, due to them not requiring the tracked entities to carry devices or markers.
3.2.3. Indoor Localization Solutions with 2D Static Cameras, Real Features, and Artificial Intelligence
This class of indoor localization methods differs from the class described in
Section 3.2.2 by the type of employed algorithms for determining the entities’ positions. An alternative to traditional image processing algorithms is artificial intelligence, in the form of Bayesian approaches, SVM, or neural networks. For instance, Utasi and Benedek [
70] proposed a Bayesian method for people localization in multi-camera systems. First, pixel-level features were extracted, providing information about the head and leg positions of pedestrians. Next, features from multiple camera views were fused to compute the location and the height of people with a 3D Marked Point Process (MPP) model, which followed a Bayesian approach. They evaluated their method on two public datasets and used the Ground Position Error (GPE) and Projected Position Error (PPE) metrics for accuracy computation. Cosma et al. [
73] described a location estimation solution based on 2D images from static surveillance cameras, which used pose estimation from key body points’ detection to extend the pedestrian skeleton in case of occlusion. It achieved a location estimation accuracy of approximately 45 cm, as can be observed in
Table 4, in complex scenarios with a high level of occlusion, using a power efficient embedded computing device. See-your-room [
74] represents another localization solution that uses cameras placed on the ceiling. It employs Mask R-CNN and OpenPose [
128] to detect people and their pose (standing, sitting) and the perspective transformation to obtain the position of the users on a map. Hoyer et al. [
71] presented a localization framework for robots based on Convolutional Neural Networks (CNN) using static cameras. In a first stage, they used a CNN object detection to estimate the type and the bounding box of a robot. In the second stage, they ran two more neural networks, one for computing the orientation of the robot and another one to provide identification (based on a code placed on the robot). An algorithm was also proposed for generating synthetic training data by placing contour-cropped images of robots on background images. The solution described by Jain et al. [
72] was based on the assumption that, in an office, employees tend to keep their phones lying on the table and that the ceiling layout is unique throughout the building, containing different tiles. They used a combination of artificial intelligence and traditional image processing to detect landmarks such as ceiling tiles, heating or air conditioning vents, lights, sprinklers, audio speakers, or smoke detector sensors. First, they applied the Hough transform to extract tiles, then SURF for feature extraction, and SVM to classify the type of landmark with the ECOCframework [
129].
Table 4 presents the characteristics of the localization methods that use 2D static cameras, real features, and artificial intelligence based algorithms. The computational challenge of using neural networks or other AI based implementations can be met with the use of GPUs, as can be observed for several methods [
71,
73], which achieve interactive or real-time performance. Although a higher complexity of the algorithms would lead to expecting a higher accuracy level compared to the previous class of solutions, relevant accuracy comparisons cannot be made due to the evaluations being performed on different datasets/scenarios.
3.2.4. Indoor Localization Solutions with 2D Mobile Cameras, Markers with Known Positions, and Traditional Image Analysis
This class of indoor localization solutions employs a configuration step, in which artificial landmarks, predominantly QR codes, are placed at known locations inside a building (generally on the ceiling, walls, or floor). These solutions make use of cameras attached to people or robots and apply traditional image processing during the localization stage. Each QR image codifies its position within the coordinate system of the building. Based on the appearance of the QR code in the acquired images during the localization stage, compared to the raw images of the QR codes, the orientation of the camera can also be estimated by computing the projective transform matrices.
QR codes allow for fast detection and decoding of stored information. However, in cases where the video camera is moving fast, the detection of these codes can be difficult. This led Lee et al. [
75] and Goronzy et al. [
76] to surround their codes with simple borders such as circles or rectangles, which can be detected faster than QR codes with Hough transform.
Ooi et al. [
79] used QR codes to reposition mobile sensor networks, in the form of four wheeled robots. When QR codes were not in range, the system estimated the position of the robot using dead reckoning.
Lightbody et al. [
78] proposed WhyCode, a new family of circular markers that enable faster detection and pose estimation, of up to two orders of magnitude compared to other popular fiducial marker based solutions. They extended the WhyCon algorithm [
130], which localizes a large number of concentric black and white circles with adaptive thresholding, flood fill, and a circularity test. The position of a marker, along with the pitch and roll, was estimated based on eigenvalues with a method proposed by Yang et al. [
131]. The yaw was computed by detecting the Necklace code contained in the WhyCode marker. Benligiray et al. [
80] presented STag, a fiducial marker system that used geometric features to provide stable position estimation. The markers contained an inner circular border and an outer square border used for detection and homography estimation. They compared their detection capabilities against the ARToolkit, ArUco [
132], and RUNE-Tag [
133] fiducial markers. Khan et al. [
81] proposed a generic approach for indoor navigation and pathfinding using simple markers (ARToolkit) printed on paper and placed on ceilings. The orientation of the smartphone relative to a marker enabled the computation of the user’s direction along a certain path.
As can be observed in
Table 5, the performance of these methods is quite impressive. The centimeter or even sub-centimeter level position accuracy is achieved due to the precise matching mechanism when dealing with synthesized images. The fast detection and decoding of QR codes and fiducial markers enables real-time applications.
Compared to the previously presented static camera based solutions, even though deploying such a system in a large built environment also comes with a considerable effort in the configuration stage, it is significantly less expensive (artificial markers are practically free in comparison to static cameras). However, the tracked entity is required to carry a mobile camera, which in certain scenarios can represent an inconvenience, and mapping a building with artificial images can have a negative impact on the building’s appearance.
Another important aspect when choosing marker based localization solutions is their detection success when facing occlusion. This problem was addressed in the solution proposed by Garrido-Jurado et al. [
132], which combined multiple markers with an occlusion mask computed by color segmentation. Sagitov et al. [
8] compared three fiducial marker systems, ARTag, AprilTag, and CALTag, in the presence of occlusion, claiming that CALTags showed a significantly higher resistance for both systematic and arbitrary occlusions.
3.2.5. Indoor Localization Solutions with 3D Mobile Cameras, Markers with Known Positions, and Traditional Image Analysis
Localization based on fiducial markers can also be performed by analyzing RGB-D images with traditional image processing methods. Li et al. [
82] used RGB-D images in order to detect and recognize QR landmarks with the Zbar [
135] code reader. The distance to the QR code was computed based on the depth image. Dutta [
83] proposed a real-time application for localization using QR codes from RGB-D images, based on the keystone effect in images from range cameras (the apparent distortion of an image caused by projecting it onto an angled surface).
Some solutions achieve centimeter accuracy when computing the distance from the camera to the artificial marker (see
Table 6). These solutions are very practical, since 3D cameras already offer a depth map of the environment, allowing for a faster and less complex computation of the position in a 3D coordinate system. However, as can be observed in
Section 3.2.4, detection and pose computation for markers is very fast for 2D cameras as well, due to the geometric properties of the synthetic images. Therefore, using 3D cameras could represent an unnecessary excess of resources. Furthermore, RGB-D cameras usually have a lower resolution than RGB cameras, both for the color and depth maps. Thus, their use is rarely justified for marker based solutions.
3.2.6. Indoor Localization Solutions with 2D Cameras + Other Sensors, Markers with Known Positions, and Traditional Image Analysis
Synthetic identifiers represent a very powerful tool when estimating the subject’s position and orientation in indoor scenarios. However, the use of other sensors, such as inertial sensors, WiFi, or beacons, could enrich the information, thus increasing the accuracy, or could help reduce the number of necessary synthetic landmarks. Nazemzadeh et al. [
37] proposed a localization solution for unicycle-like wheeled robots, using Zbar and OpenCV to detect QR codes that were placed on the floor. They applied an Extended H-Infinity Filter (EHF) to compute the odometry based on dead reckoning and on a gyroscope platform. Babu and Markose [
36] also invoked dead reckoning with accelerometer and gyroscope information, increasing the accuracy of their QR based localization solution.
Gang and Pyun [
84] configured the indoor space, in an offline phase, by creating a fingerprint map with the RSSI of the beacon signals and the intensity of the geomagnetic field at each reference point. In the localization stage, they combined the information from the beacons and the inertial sensors with the coordinates extracted from QR codes, obtaining an accuracy of approximately 2 m, as can be observed in
Table 7.
The use of other sensors besides cameras can add many benefits to a localization solution, especially if there is no need to acquire supplementary equipment. This is the case for WiFi access points, already installed in a building for other purposes. However, most of the WiFi localization solutions are based on the WiFi fingerprinting procedure, a manual and cumbersome configuration stage in which the signal strengths of the access points are recorded for known locations on the map of the building.
Since smartphones have become very popular and their cameras have reached impressive capabilities, they can be successfully used as acquisition devices in computer vision based localization solutions. Another advantage of using a smartphone is represented by the built-in inertial sensors. Thus, an application that combines input from the camera and the inertial sensors of a smartphone does not require equipment that is not already owned by the users.
3.2.7. Indoor Localization Solutions with Real Image/Feature Databases, 2D Mobile Cameras, and Traditional Image Analysis
Using a database of real images or features from real images of the environment in localization solutions represents an alternative to decorating the indoor space with QR codes or other synthesized images.
In a configuration stage, images or features, labeled with location and orientation information, are stored in a database. For instance, Hu et al. [
85] obtained a panoramic video of the scene, which was processed with traditional computer vision algorithms for computing omni-projection curves. Bai et al. [
86] constructed a landmark database by using a laser distance meter to measure the distance between the location of the camera and selected landmarks.
In the localization stage, the images acquired with the mobile camera were compared with the ones from the database using feature matching algorithms such as SIFT, SURF, or ORB. The processing time in this stage is highly affected by the number of images/features in the database, which must be compared against the images from the mobile camera’s video flow. The first line of
Table 8 is a good example, as it shows that running the localization algorithm with a database of 1000 frames was eight times faster than with a database of 8000 frames. To reduce the processing time, Elloumi et al. [
87] limited the similarity search of two images to only a selection of areas within the images, thus reducing the number of features by 40%. These areas were considered to contain the most important characteristics and were selected based on a metric that combined orientation, color, intensity, flickering effects, and motion.
Compared to solutions that use artificial markers, the solutions in this class do not require decorating the indoor space with visual markers, thus not affecting the aesthetics of the indoor space. Although they have a higher localization error (few meters), this error level can still be acceptable for certain applications.
3.2.8. Indoor Localization Solutions with Real Image/Feature Databases, 2D Mobile Cameras, and Artificial Intelligence
Artificial intelligence includes a plethora of localization algorithms for systems that use mobile cameras. For instance, Lu et al. [
89] proposed a multi-view regression model to determine the location and orientation of the user accurately. Xiao et al. [
90] determined the location of a smartphone, based on the detection of static objects within images acquired with the smartphone’s cameras. Faster-RCNN was used for static object detection and identification. Another deep CNN, Convnet, was used in the localization system proposed by Akal et al. [
91]. This network uses compound images from four non-overlapping monocular images placed on a ground robot, achieving centimeter accuracy, but requiring a sizeable dataset of compound images for training. As can be observed in
Table 9, the machine learning based solutions achieved interactive computing times or even real-time performance and a localization accuracy of under one meter to tens of centimeters. These solutions seemed to have better accuracy performance compared to the solutions in the previous class, while benefiting from the same advantages of not requiring deploying visual markers in the indoor space.
3.2.9. Indoor Localization Solutions with Real Image/Feature Databases, 3D Mobile Cameras, and Artificial Intelligence
Another class of indoor localization methods uses RGB-D images acquired with mobile cameras that are processed with the help of CNN. Guo et al. [
92] used a CNN (PoseNet network) for exploiting the vision information and the long short-term memory network for incorporating the temporal information. Zhang et al. [
63] applied visual semantic information for performing indoor localization. A database with object information was constructed using Mask-RCNN, extracting the category and position for each object. Then, using the SURF descriptor, keypoints of the recognized objects were detected. Furthermore, CNN features were obtained using a pre-trained ResNet50 network. The visual localization was performed in two steps: the most similar key frames were obtained using the selected CNN features; the bundle adjustment method [
137] was used to estimate the matrix between the current image and candidate frames. Both methods were tested on public datasets. Localization results were within 0.3 m and 0.51 m (as shown in
Table 10).
3D cameras give access to a depth map of the environment, either through built-in algorithms, as in the case of structured light or time-of-flight devices, or through stereo matching algorithms that have multiple implementations, available to the public. However, these cameras come with various limitations. For instance, the estimation of the depth map with stereo cameras in the case of untextured surfaces (such as white walls) is very inaccurate. Furthermore, structured light and time-of-flight depth cameras cannot estimate the distance to reflective surfaces or in case of sunlit environments. Moreover, although 3D cameras have gained popularity, they are not as common as 2D cameras, and therefore, their applicability is reduced. While localization solutions with 2D mobile cameras can be easily deployed, using generally available smartphones, 3D cameras are more appropriate for specialized applications, in areas like assistive devices or autonomous robots.
3.2.10. Indoor Localization Solutions with Real Image/Feature Databases, 2D Cameras + Other Sensors, and Traditional Image Analysis
If WiFi signals, inertial sensors, beacons, or other sensors can increase the accuracy of marker based localization solutions or can help reduce the number of synthesized images that should be placed on the ceiling/floor/walls of the building (as discussed in
Section 3.2.6), a hybrid approach can be even more useful when dealing with natural features from the environment. Acquiring additional information from various sensors can help reduce the search space in the image matching stages.
Yan et al. [
94] also used WiFi information to increase the accuracy and improve the processing time of a natural feature extraction algorithm, which combined Features from Accelerated Segment Test (FAST) with SURF.
Marouane et al. [
93] used accelerometer data for step counting and gyroscope information for orientation and transformation of images into histograms for more efficient image matching. Rotation invariance was achieved by adding the perspective transformation of two planes. Another solution that used inertial sensors was the one proposed by Huang et al. [
95]. They applied the vanishing points method and indoor geometric reasoning, taking advantage of rules for 3D features, such as the ratio between width and height, the orientation, and the distribution on the 2D floor map. Arvai and Dobos [
96] applied the perspective-n-point algorithm to estimate the user’s position inside the 2D floor-plan of a building, relative to a series of landmarks that were placed in the configuration stage. They used an extended Kalman filter to estimate the position by combining visual and inertial information.
Table 11 presents the characteristics of indoor localization solutions that combine data from 2D cameras and other sensors, estimating the position and orientation of the subject with traditional image processing. Several such solutions achieved centimeter location accuracy, due to this fusion between images and information from inertial sensors, WiFi signals, RFID devices, or beacons. However, this fusion of data from several sensors brings a computational load.
3.2.11. Indoor Localization Solutions with Real Image/Feature Databases, 2D Cameras + Other Sensors, and Artificial Intelligence
The solutions based on the detection of objects or markers from RGB images offer a relative position and orientation estimation, but are unreliable when markers or objects are not visible. Furthermore, detection is influenced by camera exposure time. Thus, images combined with data from other sensors can increase the precision of the localization.
Rituerto et al. [
97] estimated the user’s location using values acquired from inertial sensors combined with computer vision methods applied on RGB images. The particle filtering method was used for combining all these data. A map with walls, corridors, and rooms and some important signs (such as exit signs and fiducial markers) was also considered.
Neges et al. [
98] combined an IMU step based counter with video images for performing indoor localization. IMU data were used to estimate the position and orientation of the mobile device, and different semantic objects were extracted from the video (e.g., exit signs, fire extinguishers, etc.) for validation of the obtained position. The recognition of different markers was achieved using Metaio SDK [
140], a machine learning based development tool. In Sun et al. [
99], RSS samples, surveillance images, and room map information were used for performing indoor localization. People were detected using background subtraction from images acquired with a camera placed on the ceiling of the room. The foreground pixel that was the nearest to the location of the camera would approximate the person position in the image. Then, this position was mapped to a localization coordinate using a multi-layer neural network (with three layers). The iStart system [
100] combines WiFi fingerprints and RGB images for indoor localization. The system proposed by Zhao et al. [
101] was based on a combination of CNN with a dual-factor enhanced variational Bayes adaptive Kalman filter. Channel State Information (CSI) was extracted from an MIMO-OFDM PHY layer as a fingerprint image to express the spatial and temporal features of the WiFi signal. CSI features were learned with a CNN inspired by the AlexNet network obtaining the mapping relationship between the CSI and the 2D coordinates. Results were processed with the Bayes adaptive Kalman filter in order to achieve noise attenuation. These methods were evaluated on their own datasets with good results (position accuracy of approximately 1 m), as shown in
Table 12.
Even though artificial intelligence and especially deep convolutional networks have become very popular, they still come with certain limitations. First, they require a large amount of training data, usually manually annotated. Second, the training stage is both time consuming and hardware demanding. Even though in the online stage, the already trained network requires less resources, adding the complexity of fusing the visual data with information from other sensors can have a negative impact on the runtime, as can be observed for several selected papers [
97,
100].
3.2.12. Indoor Localization Solutions with Real Image/Feature Databases, 3D Mobile Cameras + Other Sensors, and Traditional Image Analysis
Localization precision can be increased by matching of RGB-D images using traditional feature descriptors combined with information obtained from an IMU sensor. In Gao et al. [
102], key points were extracted from the RGB-D images using an improved SIFT descriptor. Then, the RANSAC algorithm [
141] eliminated mismatched points from the matching pairs. Their corresponding depth coordinates were obtained from the depth images. Using this information, the rotation matrix and translation vector were computed from two consecutive frames. Furthermore, IMU data were used to eliminate the noise, improving the stability and positioning accuracy. Adaptive fading extended Kalman filter fused the position information of Kinect and IMU outputs. Furthermore, this fusion eliminated the noise and improved the stability and accuracy of the system. A similar idea was proposed by Kim et al. [
103]. Their solution generated 3D feature points using the SURF descriptor, which were next rotated using IMU data to have the same rigid body rotation component between two consecutive images. The RANSAC algorithm [
141] was used for computing the rigid body transformation matrix.
Table 13 shows the dataset characteristics and obtained accuracy for the localization methods based on RGB-D images processed with traditional image analysis algorithms and sensor fusion. Since robots can be equipped with many sensors, including 3D cameras and inertial units, the solutions in this class have been successfully applied to the autonomous robots domain.
3.2.13. Indoor Localization Solutions with a 3D Model of the Environment, 2D Mobile Cameras, Real Features, and Traditional Image Analysis
Simultaneous Localization and Mapping is a very popular algorithm in several domains, such as autonomous robots or Augmented Reality. During recent years, various solutions to the problem of localization and mapping have been proposed. For instance, Endo et al. [
29] used LSD-SLAM for map construction, localization, and detection of obstacles in real time. Teixeira et al. [
104] used the pattern recognition SURF method to locate natural markers and reinitialize Davison’s Visual SLAM [
142].
Several SLAM based solution use 3D cameras in the configuration stage, to create a 3D reconstruction of the environment, and then change the acquisition device to a monocular camera in the localization stage. Sinha et al. [
105] applied RGBD-SLAM on images acquired with Microsoft Kinect to reconstruct 3D maps of indoor scenes. In the localization stage, they used monocular images acquired with a smartphone camera and estimated the transformation matrix between frames using RANSAC on the feature correspondences. They applied SIFT or SURF for feature extraction, in order to detect landmarks, which were cataloged as sets of distinguished features regularly observed in the mapping environment, being stationary, distinctive, repeatable, and robust against noise and lighting conditions. Deretey et al. [
106] also applied RGBD-SLAM in an offline, configuration stage, to create 3D point clouds that contained intensity information. 2D features were extracted with a matching algorithm (SIFT, SURF or ORB), and then, a projection matrix of matched features between 2D images and 3D points was computed. A comparison with RGBD-SLAM was offered by Zhao et al. [
109], which used Kinect to collect the 3D environment information in a configuration stage. They also built a 2D map of the indoor scene with Gmapping, an ROS package that used Rao–Blackwellized Particle Filters (RBPF) [
143] to learn grid maps. In the online phase, they applied Monte Carlo localization based on the previously created 2D map.
Ruotsalainen et al. [
107] performed Visual SLAM for tactical situational awareness by applying a Kalman filter to combine a visual gyroscope and a visual odometer. The visual gyroscope estimated the position and orientation of the camera by detecting straight lines in three orthogonal directions. The visual odometer computed the transformation of the camera from the motion of image points matched using SIFT in adjacent images. A similar approach, which took into account the structural regularity of man-made building environments and detected structure lines along dominant directions, was the solution proposed by Zhou et al. [
108]. They also applied an extended Kalman filter to solve the SLAM problem. Ramesh et al. [
110] combined imaging geometry, visual odometry, object detection with aggregate channel features, and distance-depth estimation algorithms into a Visual SLAM based navigation system for the visually impaired.
A different approach was the one proposed by Dong et al. [
111], which reused a previous traveler’s (leader) trace experience to navigate future users or followers. They used ORB features for the mobile Visual SLAM. To combat environmental changes, they culled non-rigid contexts and kept only the static contents in use.
SLAM based approaches can attain centimeter or even millimeter location accuracy, but at a high computational cost. They also require significant memory resources to store the 3D representation of the scene.
Table 14 presents the characteristics of some solutions that create a 3D reconstruction of the environment in an offline stage, acquire images with a monocular camera in the localization stage, and perform low-level image processing to estimate the position and orientation of the user/robot.
3.2.14. Indoor Localization Solutions with a 3D Model of the Environment, 2D Mobile Cameras, Real Features, and Artificial Intelligence
Artificial intelligence based 2D localization methods can also be applied on 3D representations of the space. Han et al. [
112] removed obstacles detected with the Mask-RCNN network to enhance the performance of the localization. It detected persons as potential obstacles and split these obstacles from the background. Then, ORB-SLAM2 [
148] was used for localization. Xiao et al. [
113] proposed Dynamic-SLAM for solving SLAM in dynamic environments. It was based on ORB-SLAM. First, a CNN was used for static or dynamic object detection. Then, applying a missed detection compensation algorithm based on the speed invariance from adjacent frames, the detection recall rate was improved. Finally, tracking was performed using ORB features extracted from each keyframe image for performing feature based visual SLAM by processing feature points of dynamic objects. The pose estimation was obtained by solving the perspective-n-point problem with the bundle adjustment method.
Table 15 presents the characteristics of some solutions belonging to the current class. The neural networks introduce a high computational load, but can help not only with the localization, but also with the scene understanding problem.
3.2.15. Indoor Localization Solutions with a 3D Model of the Environment, 3D Mobile Cameras, Real Features, and Traditional Image Analysis
Several localization solutions use 3D cameras in the configuration step, as well as in the actual localization stage. For instance, Du et al. [
114] created an interactive mapping system that partitioned the registration of RGB-D frames into local alignment, based on visual odometry, and global alignments, using loop closure information to produce globally consistent camera poses and maps. They combined RANSAC inlier count with visibility conflict in the three point matching algorithm to compute 6D transformations between pairs of frames. Paton and Kosecka [
115] applied feature extraction and mapping on RGB-D data with SIFT, motion estimation and outlier rejection with RANSAC, and estimation refinement to compute the position and orientation of a camera. Correspondences established between SIFT features could initialize a generalized Iterative Closest Point (ICP) algorithm.
Salas-Moreno et al. [
116] proposed a GPGPUparallel 3D object detection algorithm and a pose refinement based on ICP. Their real-time incremental SLAM was designed to work even in large cluttered environments. Prior to SLAM, they created a database of 3D objects with KinectFusion. The scene was represented by a graph, where each node stored the pose of an object with a correspondent entry in the database. Their object level scene description offered a huge representation compression in comparison with the usual reconstruction of the environment into point clouds.
A robust key-frame selection from RGB-D image streams, combined with pose tracking and global optimization based on the depth camera model, vertex-weighted pose estimation, and edge-weighted global optimization, was described by Tang et al. [
118].
Most solutions acquire images with structured light or time-of-flight cameras, but stereo cameras can also provide 3D information. For instance, Albrecht and Heide [
117] acquired images with a stereo camera and applied ORB-SLAM2 for poses of the keyframes, creating a 3D reconstruction of the environment with OpenCV’s Semi-Global Block Matching (SGBM) algorithm. Then, they condensed the point cloud into a blueprint-like map of the reconstructed building, based on ground and wall segmentation.
Martin et al. [
119] applied Monte Carlo based probabilistic self-localization on a map of colored 3D points, organized in an octree. They demonstrated that their algorithm recovered quickly from cases of unknown initial position or kidnappings (the robot was manually displaced from one place of the environment to another).
Table 16 presents the computing capabilities and obtained accuracy for several SLAM based localization solutions that apply low-level image processing on data that contain both color and depth information. It can be observed that some of the researchers evaluated their algorithms only through visual inspection. Even so, inspection of the obtained 3D reconstruction and especially loop closure can demonstrate the performance in the case of SLAM based solutions. This class is reduced to a 3D to 3D matching problem, much less complex than the 3D to 2D matching problem described in
Section 3.2.13 and
Section 3.2.14. However, the requirement to have a 3D camera both in the configuration stage and in the online phase greatly reduces the applicability of this kind of solution.
3.2.16. Indoor Localization Solutions with a 3D Model of the Environment, 3D Mobile Cameras, Real Features, and Artificial Intelligence
Another class of indoor localization solutions is the one that uses 3D cameras in the configuration stage, to create a reconstruction of the scene with SLAM or other algorithms, but also in the localization stage, applying high level computer vision techniques for computing the position and orientation of the user.
Guclu et al. [
121] proposed an SLAM method applied on RGB-D images using a graph based approach. The keyframe autocorrelogram database estimated motion between frames. Keyframes were indexed based on their image autocorrelograms [
150], using a priority search k-means tree. Adaptive thresholding was used to increase the robustness of loop closure detection.
Kuang et al. [
120] improved ORB-SLAM. A combination between quasi-physical sampling algorithm (based on BING features [
151], obtained by SVM training) with depth information was used to pre-process an image for decreasing the computing time of the ORB algorithm. Then, improved KD-trees were used to increase the matching speed of the ORB algorithm. Furthermore, using RGB-D images, a 3D dense point cloud map system was constructed, instead of a sparse map from ORB-SLAM.
As can be observed in
Table 17, the use of 3D cameras can improve the accuracy of known localization methods such as ORB-SLAM or ORB-SLAM2. Still, the dimensionality of the data introduces a high computational cost. Furthermore, the lack of 3D training data could represent a limitation of this class.
3.2.17. Indoor Localization Solutions with a 3D Model of the Environment, 2D Mobile Cameras + Other Sensors, Real Features, and Traditional Image Analysis
A hybrid approach that fuses information from 2D cameras and other sensors can be applied on 3D models of the environment as well.
For instance, Wang et al. [
46] used RFID readers for an approximate estimation of the location and calculation of 3D image coordinates with low-level image matching.
Kao and Huy [
41] combined information from WiFi access points with the K-nearest neighbor method, inertial sensors (accelerometer and gyroscope), and a CMOS camera. They chose ORB features in their SLAM implementation to navigate Bluetooth connected wheeled robots in indoor environments.
Yun et al. [
122] saved the WiFi access point information in a configuration stage and assembled the images acquired with an Xtion PRO LIVE depth camera, building a 3D indoor map of the indoor location. In the localization stage, they reduced the per-frame computation by splitting a video frame region into multiple sub-blocks and processing only a sub-block in a rotating sequence at each frame. They applied SIFT based keypoint detection and optical flow for tracking.
Huang et al. [
95] applied an extended Kalman filter to fuse data from LSD-SLAM computed on RGB images, ZigBee localization, and IMU sensors (accelerometer, gyroscope, and magnetometer). Ullah et al. [
125] combined data from a monocular visual SLAM and an IMU with an unscented Kalman filter. Gerstweiler [
45] also fused IMU information with SLAM, using the HyMoTrack framework [
153], a hybrid tracking solution that uses multiple clusters of SLAM maps and image markers, anchored in the 3D model.
Chan et al. [
124] computed a laser based SLAM and a RBPF based visual SLAM. Perspective trajectories obtained from the laser SLAM were mapped into images, and the essential matrix between two sets of trajectories was combined with the monocular camera based SLAM.
Even if the fusion between sensor data and visual information introduces a high computational load, several solutions achieve real-time frame rates on commodity computers, as can be observed in
Table 18.
3.3. Discussion
This section draws conclusions from our analysis of the proposed classes of vision based localization solutions, enabling readers to make better informed choices in terms of indoor positioning technologies to accommodate their specific requirements or particularities. While positioning technologies are numerous and do not limit themselves to image processing, vision based solutions have become popular due to the increasing affordability of cameras and their integration in pervasive devices such as smartphones.
Localization methods that use static cameras can benefit from the camera surveillance infrastructure already available in most modern large office and public buildings. Furthermore, since most robotic platforms have RGB or RGB-D cameras, it makes it easier to port visual positioning solutions on the different platforms, enabling their use in assisted living scenarios. Other applications in the autonomous robots domain can take advantage of 2D/3D cameras already integrated in the robots. Smart glasses with cameras can enable a more seamless user experience for indoor localization applications; however, until they reach a wide market adoption, most applications that localize people (especially in the domains of assistive devices and augmented reality) use smartphones.
Even though 2D cameras have larger applicability due to their ubiquity and the dimensionality of the acquired data, 3D cameras have several advantages. 3D cameras offer a depth map of the environment, either obtained from a disparity map computed with stereo matching algorithms or estimated with time-of-flight and structured light technologies. Stereo cameras require optimal lighting conditions and are affected by lens distortion, similar to 2D cameras. Furthermore, depth cannot be estimated in untextured environments through stereo matching. On the other hand, structured light and time-of-flight cameras work even in unlit environments and can estimate the depth regardless of texture properties. Although these cameras are affected by bright light and reflective surfaces, typical indoor environments contain untextured surfaces (especially uniformly painted walls) and are rarely characterized by bright sunlight. Therefore, we considered that among 3D cameras, structured light, and time-of-flight devices are the most suited for indoor applications.
While cameras have many advantages, they are affected by lighting conditions, occlusion, and position changes of objects from the environment. In order to increase localization accuracy or to decrease the computational load of the computer-vision algorithms, visual data can be combined with data from other sensors. Other popular indoor localization solutions are those based on sensors such as WiFi, beacons, and RFID. WiFi based solutions use the received signal strength and the media access control address of access points to determine the position. WiFi based methods also enjoy the advantage of using existing infrastructure in buildings, as WiFi access points are even more widely available in buildings than camera surveillance systems. While beacon based positioning technologies can reach higher accuracy than WiFi based solutions, they require deploying additional hardware. The RFID technology poses even more limitations in terms of range. Although the positioning algorithms that use sensors such as WiFi, beacons, or RFID have a lower accuracy compared to vision based methods, they also have a lower complexity. Thus, possible localization solutions can benefit from a two-step positioning algorithm: firstly obtaining a quick, approximate location using beacons or WiFi, which tightens the search space of computer vision algorithms; secondly achieving an accurate and also quick location and orientation estimation of the tracked entity.
Vision based indoor localization solutions can detect fiducial markers or features from real images of the environment. The use of artificial markers enables extremely fast detection and position estimation. Due to the geometric properties of the fiducial markers and their accurate localization with 2D cameras, the use of 3D cameras is unjustified. The biggest disadvantage of using markers is the requirement of covering the space with synthetic images, which can have a negative visual impact on the environment. Therefore, the applicability of such solutions is reduced. Features or semantic objects detected from real images of the environment do not visually influence the environment. However, setting up a database of features/images, annotated with position and orientation information, or creating a 3D model of the environment represent cumbersome processes. Furthermore, changes in the environment, such as rearranging furniture or paintings and posters, would require another configuration stage for rebuilding the feature/image database or the 3D model of the scene.
Objects or features from images can be detected using traditional image processing or artificial intelligence methods. Traditional image processing methods perform detection by comparing different features that are extracted from the images, and the recognition success depends on the selected features. On the other hand, the artificial intelligence methods used for object recognition are mainly based on convolutional neural networks, thus not needing to select the features for recognizing objects, as convolutional neural networks learn specific objects directly from images. One disadvantage of these networks is the high number of images required for training the network. Training data can be obtained either by manual acquisition and annotation or from publicly available datasets. Public datasets are very helpful; however, they are only a few available (especially containing 3D data), and they are limited to several semantic classes.

 ,
, 






{kind=link}
{kind=link}
{kind=link}