1. Introduction
Ambient Assisted Living (AAL) is now a well-established area of research, fuelled by the continuously ageing and longer life expectancy of the population [
1]. The majority of video monitoring applications for AAL make use of RGB images to provide clinically relevant measurements [
2]. While the presence of monitoring CCTV (Closed-Circuit Television) cameras is nowadays accepted in public spaces, such as shops and city centres, due to privacy reasons, people are often reluctant to install them in their own homes for any purpose other than security, for example, even for constant health monitoring [
3,
4,
5]. Silhouettes constitute an alternative form of data for video monitoring in privacy-sensitive environments [
6]. Due to their light weight representation, silhouettes are often the preferred form of data in Internet of Things (IoT) and AAL applications [
7]. In our previous works, we demonstrated that silhouettes can be reliably employed for long-term home monitoring applications to measure important health-related parameters, for example, measurement of calorie expenditure [
8] and the speed of transition from sitting to standing or standing to sitting (StS) [
9], which are proxy measurements for sedentary behaviour, musculoskeletal illnesses, fall history and many other health-related conditions. Previous work in the field also showed that silhouettes can be successfully employed for fall detection [
10] and abnormal gait analysis [
11]. The recent work from Colantonio et al. [
12] highlighted some of the challenges that are still open in AAL from a Computer Vision perspective, including the assessment of reliability of these measurements for clinical purposes, the robustness of the operating conditions in real-life settings and the final user acceptance of the monitoring system, which we will address through this paper.
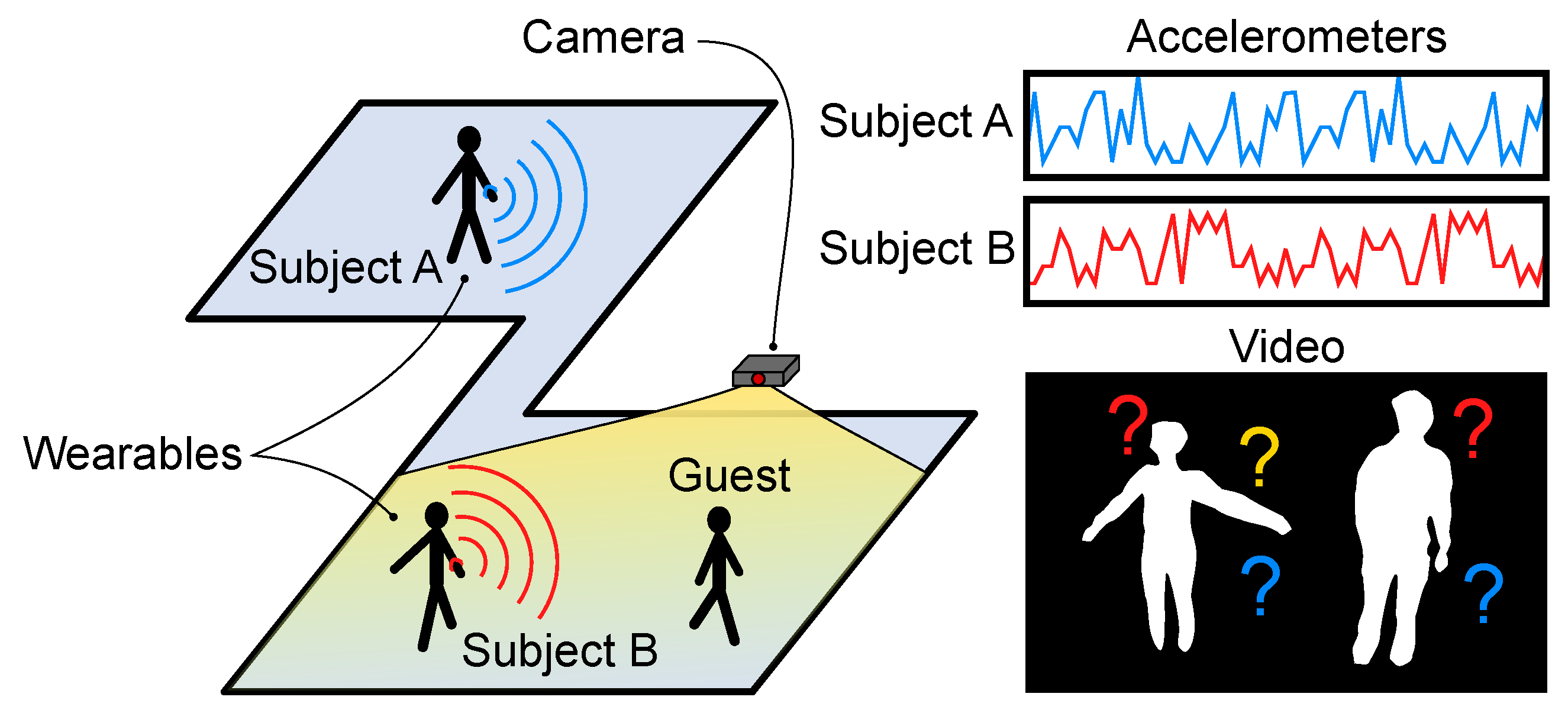
Under the auspices of the SPHERE project [
13] (a Sensor Platform for HEalthcare in a Residential Environment), we recorded data from voluntary participants in 52 real-world homes, including silhouettes, body accelerations and a variety of different environmental sensors’ data. The latter are outside the scope of this present work and not used here. The analysis of these silhouettes allows monitoring the health of the participants while respecting their privacy; however, silhouette-based measurements are limited in that they cannot be assigned to a specific individual in the house. Due to their anonymous and often noisy nature, silhouettes hinder the discrimination of different individuals, preventing a subject-tailored analysis of the data. This problem is of critical importance for scenarios of home monitoring, particularly in long-term observations. For example, in the HEmiSPHERE project [
14], patients undergoing hip and knee replacement spend their rehabilitation period at home while being monitored with the SPHERE sensors. It is essential to be able to automatically discriminate between the silhouettes of the patient to be monitored and the rest of the household or occasional guests such that clinicians can investigate the recovery trends of their patient only, while also respecting the privacy of all those within view.
The solution we propose is to take advantage of wrist-worn accelerometers, for which the measurements can be unequivocally assigned to the person wearing it. Matching the motion from the video silhouettes with the motion from the accelerometers enables us to assign each video measurement to a specific individual. Thanks to this approach, not only can we reliably monitor each participant in the house but we can also enable a sensor fusion approach to improve the quality of the silhouette-based measurements, overcoming the limitations of both wearables and videos. While matching video and acceleration streams has already been attempted in the past, previous works only focused on the use of RGB images and long observation times (i.e., >1 min). Moreover, existing methodologies require all subjects appearing in the video to be carrying an accelerometer, which is not suitable for real world monitoring applications. Patients may have guests, and they cannot be required to wear accelerometers at all times.
In this paper, we extend our previous work [
15] on the Video-Acceleration Matching problem that sets new state-of-the-art results in privacy-sensitive Home Monitoring applications. We consider real-life monitoring scenarios and we tackle the rather complex case where only the monitored participants wear an accelerometer whilst being visually recorded amongst other persons, as
Figure 1 illustrates. Moreover, our pioneering solution to the Video-Acceleration matching problem can operate on even short (≈3 s) video snippets, so that quick and clinically relevant movements (e.g., Sit-to-Stand [
9]) can be associated to a specific individual in spite of the length of the event. We propose a novel multimodal deep-learning detection framework that maps video silhouettes and accelerations into a latent space where the Euclidean distance can be measured to match video and acceleration streams. Further, we propose a novel loss function that may be used as an alternative to triplet loss for dual stream networks. We present results for video-acceleration matching on the challenging SPHERE-Calorie dataset [
16,
17].
3. Materials and Methods
Before matching video sequences with accelerations, the video stream must be processed to detect different subjects appearing in the frame. In our work, we use the person detector and tracker from OpenNI [
43], which provides bounding boxes and tracking information. Similarly to the works in Active Speaker Detection, we developed our framework to match short video/acceleration clips (≈3 s). The reason behind this choice is that we are interested in identifying subjects while performing short, clinically relevant movements. Shorter clips also helps to minimise possible errors of the trackers, for example, exchanging bounding boxes of different subjects.
3.1. Video-Acceleration Matching
A typical installation of a real-life home in the SPHERE project [
6] provides for a camera in each communal room and corridor, and an accelerometer for each participant. Guests can visit the monitored house at any time but will not carry an accelerometer. All the video and accelerometer sensors are synchronised via their time-stamps.
Let us consider a set of
K silhouette video clips
portraying one person at a time (i.e., the sequence of frames cropped around the bounding boxes) while wearing the wristband. Time-synchronised acceleration samples from the wristband are also recorded and grouped into consecutive sequences
. The accelerations
constitute a positive match for the videos
V by construction. We can define a set of non-matching accelerations
by selecting for each
the acceleration from a different monitored subject (details on different types of negatives will be discussed in
Section 3.3). The objective of the video-acceleration matching is to find two optimal encoding functions
and
, so that the Euclidean distance
d is minimised for
and maximised for
. The functions
f and
g are two CNNs that take as input of the video clip and the raw accelerations respectively, and produce for output feature vectors. During testing, the matching between a generic video stream and a specific accelerometer can be verified by comparing the Euclidean distance of the two encoded streams with a threshold, the optimal value of which can be derived from the Receiver Operating Characteristic (ROC) curve described in
Section 4.1.
3.2. Loss Function
One potential way to address the problem of video-acceleration matching is to reformulate it as a classification problem. Given the videos
V and the accelerations
and
, we can build the pairs
and
for the classes “matching” and “non-matching”. With this setting, standard cross-entropy can be used to train the video and acceleration encoders
and
. However, it has been shown in [
33] that for audio and video matching, the binary classification task constructed in this way is difficult to train and we therefore discarded it.
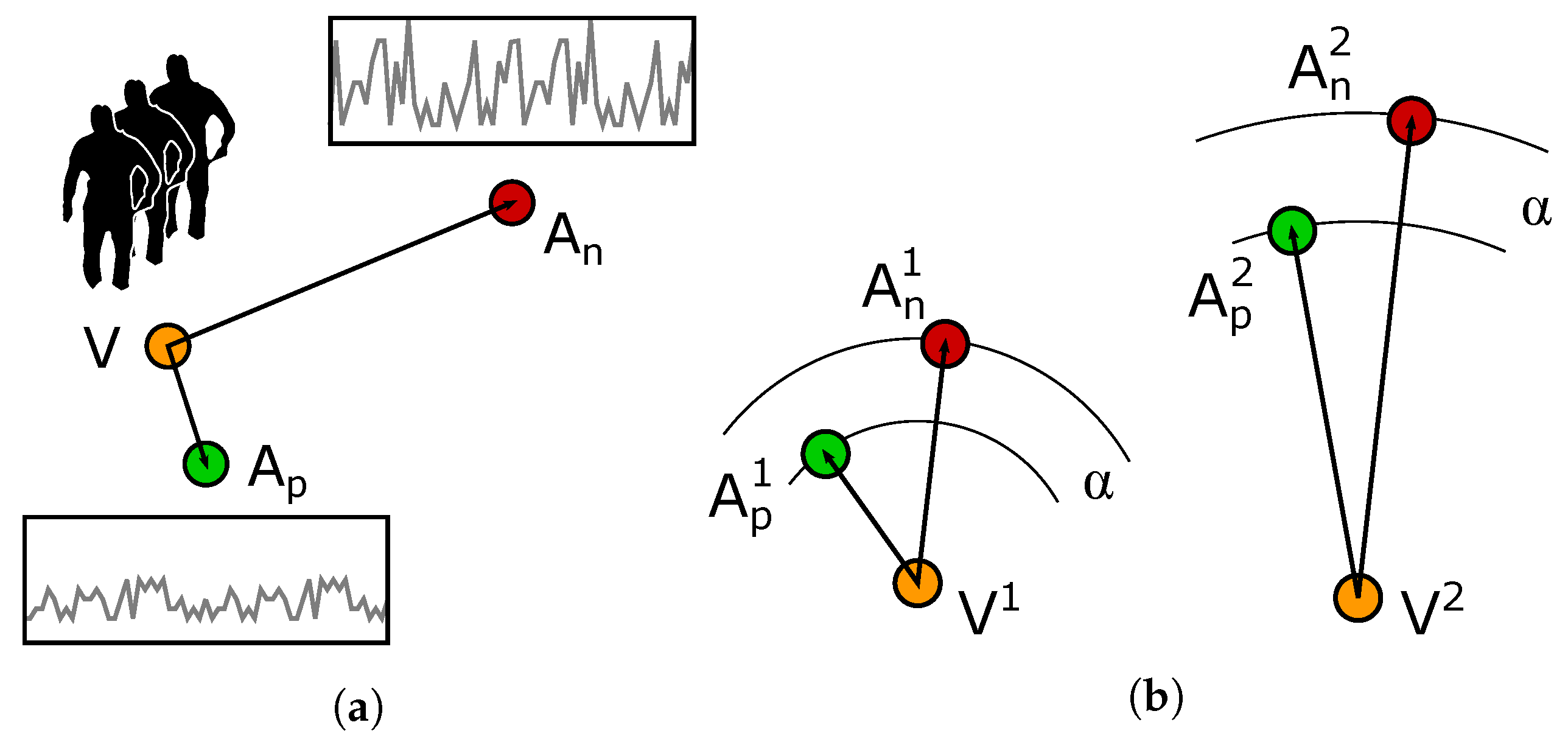
A valid alternative to the cross-entropy for binary classification is the triplet loss, that was first proposed to train Siamese Networks for face recognition [
44]. A triplet is defined as a set of three elements comprising an anchor, a positive match and a negative match. Here, we use the video as anchor, and a matching and non-matching sequence of accelerations for the positive and the negative match respectively,
With this definition of triplet, the loss is defined as:
where
is a constant, empirically set to 0.2. The behaviour of the triplet loss is described in
Figure 2a: by minimising the quantity described in Equation (
2), the pairs of
are pulled together, while
are pushed apart, to a distance greater than
.
In addition to the standard triplet loss, we also experimented using alternative formulations that take advantage of the triplets. One of the problems we experienced with the standard triplet loss is that it does not guarantee that a single threshold can be used to discriminate between matching and not-matching pairs. In fact, the objective of the triplet loss is to separate the
pair from the
pair, no matter what the intra-pair distances are. For example, given two triplets
and
as described in
Figure 2b, optimising for the standard triplet loss ensures that:
and
However, it is entirely possible that the distances are such that . As it will be shown later, this behaviour is very common for some training strategies and renders the model inoperative, since no single threshold can be used to discriminate between matching and non-matching sequences.
The objective of the training must therefore be such that the model can be used with a single universal threshold. The limitation of the standard triplet loss is that it becomes identically zero once the distances in Equation (
2) are greater than
. To overcome this limitation, we propose a new loss function, Reciprocal Triplet Loss (
), which does not involve any distance margin
and continuously optimises the distances between anchor, positive and negative match:
As it will be shown in the experiments, the use of the RTL function helps in improving the performance of our model and enables it to be operable more robustly with a single universal threshold.
3.3. Negative Samples
When the standard triplet loss is used to train a deep learning model, the samples constituting each triplet must be cleverly selected in a way that they can actively contribute to improving the model. In fact, if the distance between the video anchor and the accelerations from Equation (
2) is greater than
, the triplet will have zero loss and it will not contribute to the training. In the original paper on the triplet loss [
44], hard mining of triplets was considered as a crucial step to deal with this problem. In our case, the triplets are constrained by the problem of matching videos with accelerometers, and the anchor-positive pair must be a video clip with the matching acceleration sequence. However, the choice of the non-matching acceleration can vary substantially and it has a strong effect on the outcome of the training process.
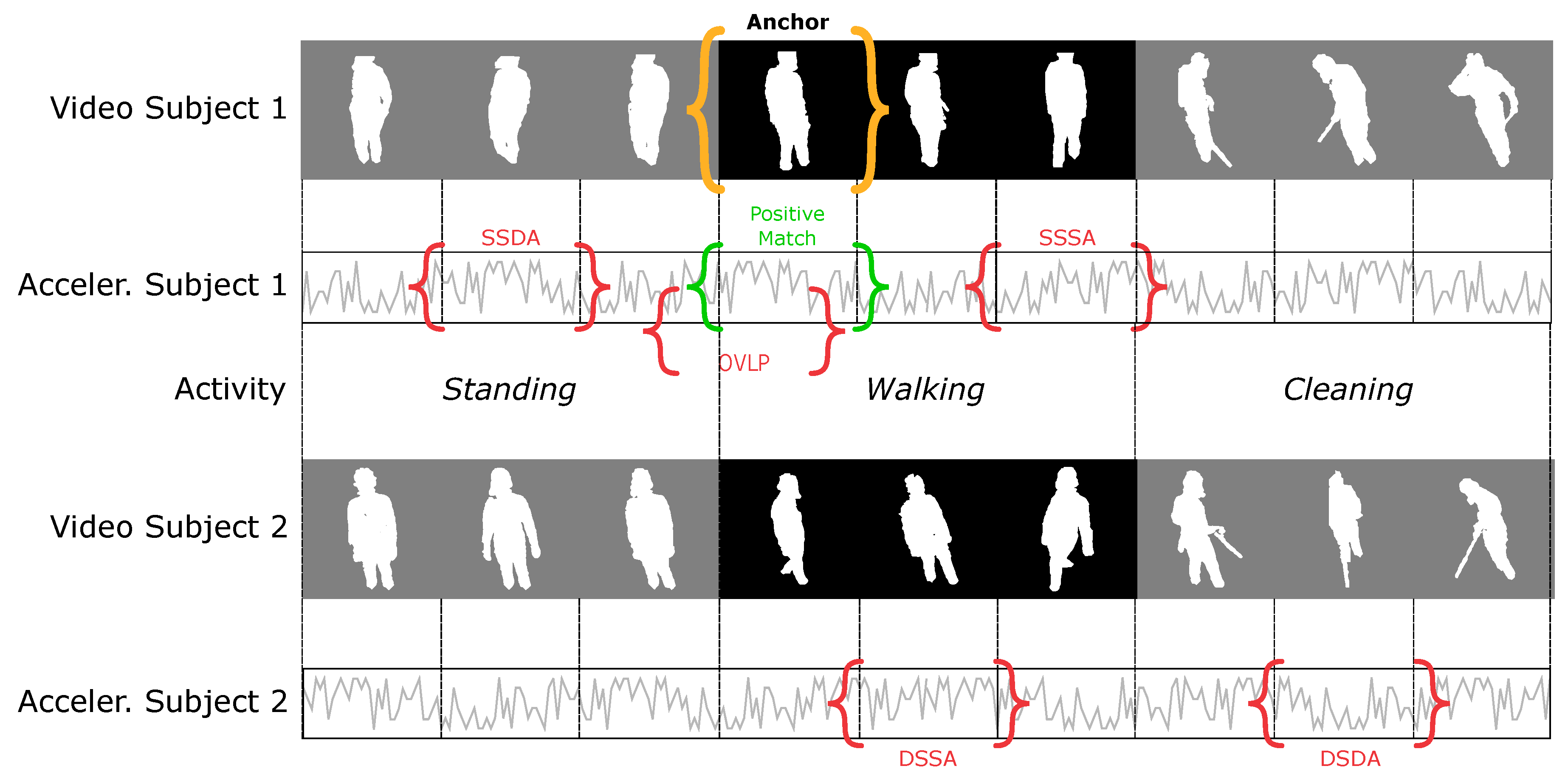
Let us consider an example where a group of
N subjects
is performing a set of activities (
standing,
walking,
cleaning, …). Given an anchor video portraying a subject doing a specific activity, as depicted in
Figure 3, a non-matching acceleration can be selected from a different subject doing a different activity (DSDA) or doing the same activity (DSSA), or it could be from the same subject doing the same activity (SSSA) or a different activity (SSDA). The possible combinations of negative samples are summarised in
Table 1 for clarity.
The objective of this work is to train a model that learns the matching between video and acceleration streams. However, if negative samples are only drawn from a different subject doing a different activity (DSDA), the video-acceleration matching problem degenerates into a simple activity or identity classifier. Let us consider, for example, a triplet where the anchor is the video of
while “walking”. The positive match will be the acceleration of
while “walking”, whereas a DSDA negative could be
doing “cleaning”, as depicted in
Figure 3:
Since the non-matching acceleration will always be from a different subject doing a different activity, the neural network will try to learn either the identity of the subjects or the activity being performed through the encoding functions and . Equivalently, training only with DSSA negatives reduces to an activity-agnostic identity classifier, while training with SSDA negatives leads the classifier to only learn activities. A model trained exclusively on DSDA, DSSA or SSDA negatives will not learn anything about the actual correlation between the video and the accelerations, but it will merely compare the action or identity predicted from the video with the one predicted from the accelerations. This type of model is therefore expected to fail when tested on unseen subjects or activities.
To overcome this limitation and truly associate visual and acceleration features in the temporal domain, a non-matching acceleration can be selected from the same subject while performing the same activity (SSSA). We call this type of negative “hard-negative” (in contrast to the “easy-negatives” DSDA, DSSA and SSDA), since a simple activity or subject classifier is unable to solve this problem and it requires the network to encode information about the actual correlation between video and accelerations. Similarly to Korbar et al. [
33], we also consider a further type of negative sample constituted by an acceleration that is out-of-synchronisation with the video but it is still overlapping with it, as presented in
Figure 3. The out-of-synchronisation negative will be very similar in shape to the synchronised positive match; we call this type of negative overlapping (OVLP), and we refer to is as “very hard-negative”. It is important to clarify that amongst all the negative types tested, those from the “Same Subject” or “Overlapping” category are only used for training purposes, since the same subject cannot really appear in multiple locations of the same video clip.
In this work, we tested a variety of training strategies that include different combinations of easy, hard and very-hard negatives, as described in
Table 2. From an inference point of view, the same subject cannot appear in multiple locations at the same time, therefore the validation data only includes negative types of DSDA and DSSA, while the SSSA and SSDA negative types are only used for training.
The data used in this study (described in detail in
Section 3.7) was split into training and testing based on subject identities, so that the subjects used for testing were never seen during training. Regarding the choice negative samples, a 50% balance between DSDA and DSSA was chosen and was kept constant across all the experiments.
3.4. Data Preprocessing
Silhouettes from each subject detected in the scene are cropped around the bounding boxes and resized to a constant value of 100 pixels (keeping the original aspect-ratio). The video sequence of each subject is then truncated into short clips of 100 frames (≈3 s) each. In order to avoid any loss of information from the cropping process, bounding box coordinates are also fed into our video encoder network together with the silhouettes. The logic behind this is that the human body can be seen as a deformable body that can either translate or change its shape, and bounding boxes will better capture large rigid displacements (e.g., walking) while the cropped silhouettes will address smaller changes within the body shape (e.g., wiping a surface).
The accelerometer data comprises a 3-channel vector, i.e., the IMU measurements in
x,
y and
z. Typically, machine learning algorithms for audio analysis make use of some transformation of the audio signal in the frequency domain, for example, using Perceptual Linear Predictive coefficients (PLPs) [
45] or variations of the MFCC [
32,
46,
47]. However, since the accelerometer signal is sampled at a frequency that is several orders of magnitude lower than audio (typically around 50 Hz for IMU [
48] and 32–48 kHz for audio [
49]), we feed the raw amplitude of the accelerometers into the network, leveraged by our previous work [
8] where we observed that the direct convolution of acceleration amplitudes yielded satisfactory results. Due to the variability of the sampling rate of the accelerometers used in our experiments, the only pre-processing we perform on the acceleration stream is sub-sampling of the data to match the video frame rate (while sub-sampling in our experiment was dictated by the minimum sampling rate of the accelerometer devices, our method does not require the video sampling rate to match the accelerometer and it can be applied to mismatching rates by simply adjusting the input size of the network). Conceptually, this leaves data transforms to be a responsibility of the network itself.
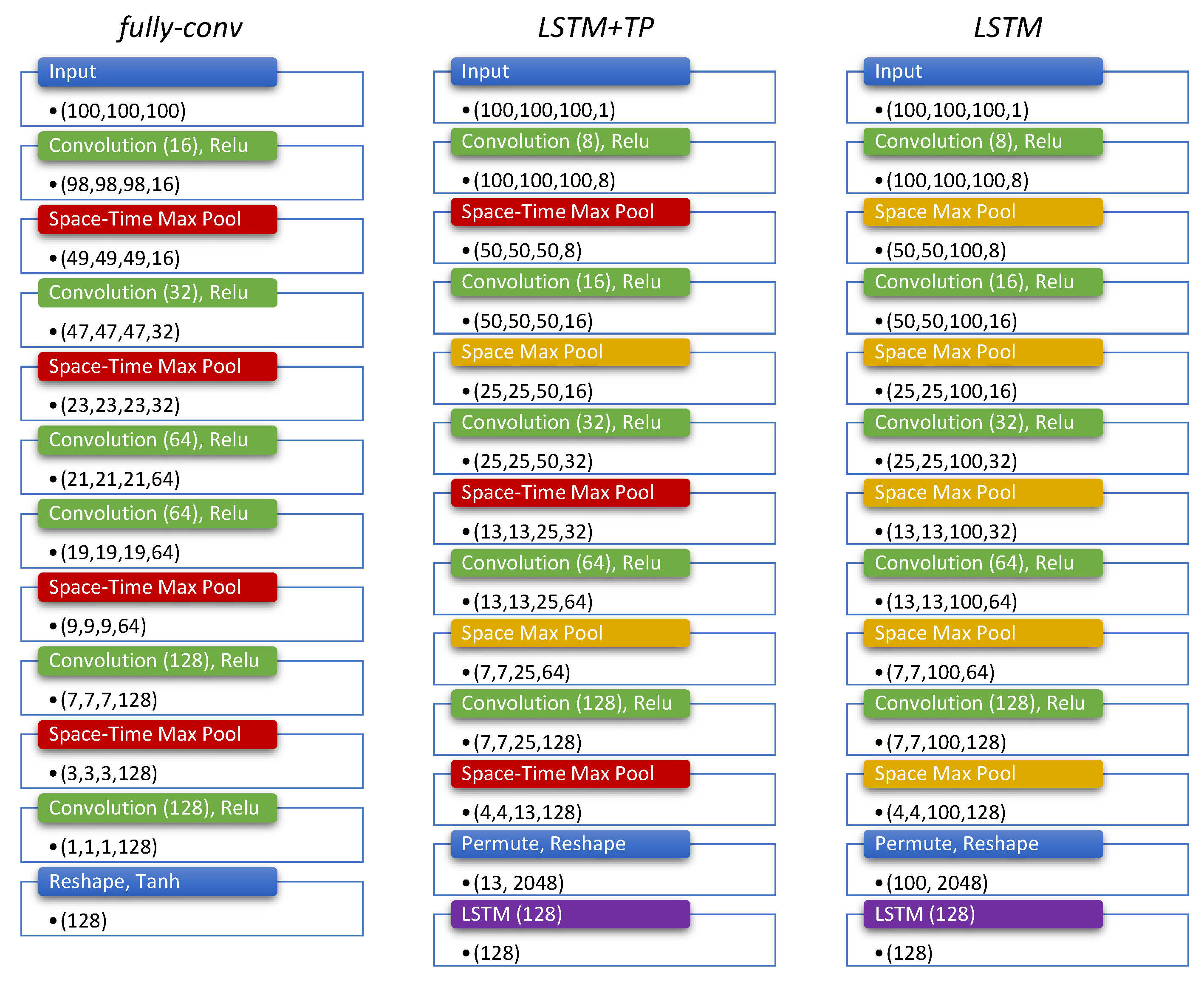
3.5. Network Architecture
The most important element of our algorithm is the function of the two encoders and , represented by different CNNs, that process the video and acceleration streams independently to produce the feature vectors. In particular, the video encoder is the sum of the silhouettes encoder and the bounding box encoder . Our encoders , and then constitute a three-stream architecture that is able to take video and acceleration data as input and produce the distance between the two in the latent space as output.
We implemented 3 different architectures, as illustrated in
Figure 4, and tested their performances under different conditions to find the best configuration.
Fully Convolutional(fully-conv)— The idea behind deploying this architecture is to reduce the input size using a sequence of convolution and max-pooling operations while simultaneously increasing the number of features being produced. For the video branch only, both convolution and max-pooling operations are performed with a 3D kernel to extract spatio-temporal information, while 1D kernels are used for the branches processing bounding boxes and accelerations.
LSTM with temporal pooling(LSTM+TP)— This architecture is similar to the fully convolutional network, but it uses fewer max-pooling layers in time, so that a temporal feature vector is produced by the convolutional stack. This temporal feature vector is fed into a Long Short-Term Memory (LSTM) layer that produces the final embedding.
LSTM without temporal pooling(LSTM)— Inspired by [
45], we developed an architecture that does not involve any temporal pooling at all. The expectation here is that fine temporal information is important to learn the correlations between video and acceleration streams and helps to provide better results with the matching task. As in the previous case, the final temporal feature vector is fed into an LSTM layer to produce the final embedding vector.
All the architectures tested used a kernel size of 3, spatial dropout after each convolutional layer and activation ReLu. Only the fully-conv architecture uses a final activation using tanh after the last convolution, while the remaining networks use the standard LSTM internal activation functions.
3.6. Baseline Method
In order to show the advantages of our method, we implemented some algorithms from the literature to use for baseline comparison. The first work is the state-of-the-art method for matching video and wearable acceleration streams by Cabrera-Quiros et al. [
41], where they estimate acceleration data from the video stream using dense optical flow and then compare it with the actual acceleration stream. The wearable devices adopted in their experiment also included an embedded proximity sensor that they used to cluster neighbouring devices. Since the target of our study is matching video and acceleration streams without any further sensor input, we implemented their algorithm without the hierarchical approach for the Hungarian method.
In addition to Cabrera-Quiros et al., we also implemented a method inspired by Shigeta et al. [
38]. In their work, accelerations are estimated using the centroid of each bounding box detected in the video stream and are compared with a low-pass filtered version of the acceleration stream. While implementing this work, our experiments showed that better results were achieved using a high-pass filtered version of the acceleration. Moreover, Shigeta et al. use normalised cross-correlation to compare the video and accelerometer signal because their target is streams that are temporally not synchronised. Since we are dealing with a case where the video and acceleration streams are always synchronised, we compared the signals using Euclidean distance, as per our work.
3.7. Dataset
Our dataset is a modified version of the SPHERE-Calorie dataset [
16], which includes RGB-D images, bounding boxes, accelerations and calorie expenditure measures obtained from a Calorimeter, from 10 different individuals doing a set of 11 activities in two different sessions. In this work, we discarded the calorie data and converted the RGB-D images into silhouettes. Silhouettes were generated by processing the RGB images with OpenPose [
50] to extract the skeleton joints for each frame of the dataset and then running GrabCut on the depth images using a mask initialised with detected skeletons. Samples for the silhouettes and accelerations in the dataset are shown in
Figure 5. The dataset includes 11 different activities, from which we kept actions that involve movement (i.e., walking, wiping a surface, vacuuming, sweeping, exercising, stretching, cleaning). The dataset includes more than 2.5 million individual silhouettes, which were used to generate ≈50,000 video clips (and matching acceleration sequences). To the best of the Authors’ knowledge, the SPHERE-Calorie dataset is the only large dataset including RGB-D and acceleration data from wearable devices that is suitable for the Video-Acceleration Matching problem using silhouettes (while the Authors are aware of the existence of the MatchNMingle dataset [
51], the combination of high view angle (top view) and low focal lens used to record the RGB data make it very difficult to generate silhouettes).
The data from the SPHERE-Calorie dataset was recorded one subject at a time, which enabled us to automatically pair the correct matches between videos and wearables. To simulate the presence of multiple people in each room, we followed the widely adopted strategy of virtual streams [
34,
41] whereby the video and acceleration streams were split into smaller intervals and treated as if they were occurring at the same time. While this approach might be limiting in that subjects never interact with each other, it allows us to push the number of subjects present in a frame beyond the actual capacity of a room, assessing the limits of our method. The split between training and testing was performed based on the subject identities: subjects 1 to 7 for training the algorithm and subjects 8 to 10 for testing. This split ensured that the network could not exploit any visual appearance cues to identify people and forced it to learn the actual correlation between video and acceleration streams.
3.8. Implementation Details
All the networks tested were trained end-to-end using the silhouette video and acceleration streams in input and the triplet of distances over the embedding in output. The code was implemented using Keras and Tensorflow in Python (the code will be available on GitHub at:
https://github.com/ale152/video-accelerometer-matching). Training was performed using the optimiser Adam [
52] with a learning rate of
and a batch size of 16. We monitored the area under the ROC curve (auROC) after each epoch (as later detailed in
Section 4.1) using the validation data and we stopped training when none of the auROC scores improved for more than 50 epochs. In order to improve performances on the validation data, we implemented some data augmentation strategies. Both the streams of video and acceleration data were truncated to short clips of ≈3 s each using 95% overlap. In addition to that, data augmentation for the video silhouettes was implemented by randomly flipping (horizontally), dilating (up to 5 pixels), eroding (up to 5 pixels) and corrupting with salt-and-pepper noise (3%). This strategy, combined with a spatial dropout employed after each convolutional layer, was designed to reduce overfitting of the models on the training data. When OVLP negatives are used, the negative clip is randomly selected to be from −10 to +10 frames out-of-sync with the positive match.
4. Experiments and Results
We present a series of experiments and ablation tests that are targeted at understanding the advantages and performances of our novel method compared to the state-of-the-art. We tested all possible combinations of models (fully-conv, LSTM+TP, LSTM) and training strategies (Easy, Easy/Hard, Hard, Hard/VeryH, VeryH, All) for both the Standard Triplet Loss and our proposed Reciprocal Triplet Loss.
4.1. Area under the ROC Curve
We first evaluate our method on the matching verification task: given a video clip
and an acceleration
, the Euclidean distance between the two embedding
and
is compared with a threshold
to determine the outcome of “matching” or “not matching”. While the true matching pairs
P are unequivocally defined by the correct pairs of video and acceleration, the true non-matching
Q can be any of the possibilities (the reader is reminded that a negative of the “Same Subject” type can never occur in reality, since the same person cannot appear simultaneously in multiple locations; however, we report results for this type of negative because it is useful for our discussion to understand specific behaviours of the models trained) described in
Table 1, resulting in a different score for each negative type. We define the correct true positive matches
, as a function of the threshold
, such that:
and the false positive matches
as:
where
P and
Q are the sets of all positives and all negatives, respectively. By varying the threshold
, we can plot the true positive rate
against the false positive rate
, defined as:
resulting in a ROC curve. The auROC curves tested with each training strategy (
Section 3.3) and the average across negative types (AVG) is presented in
Table 3,
Table 4 and
Table 5.
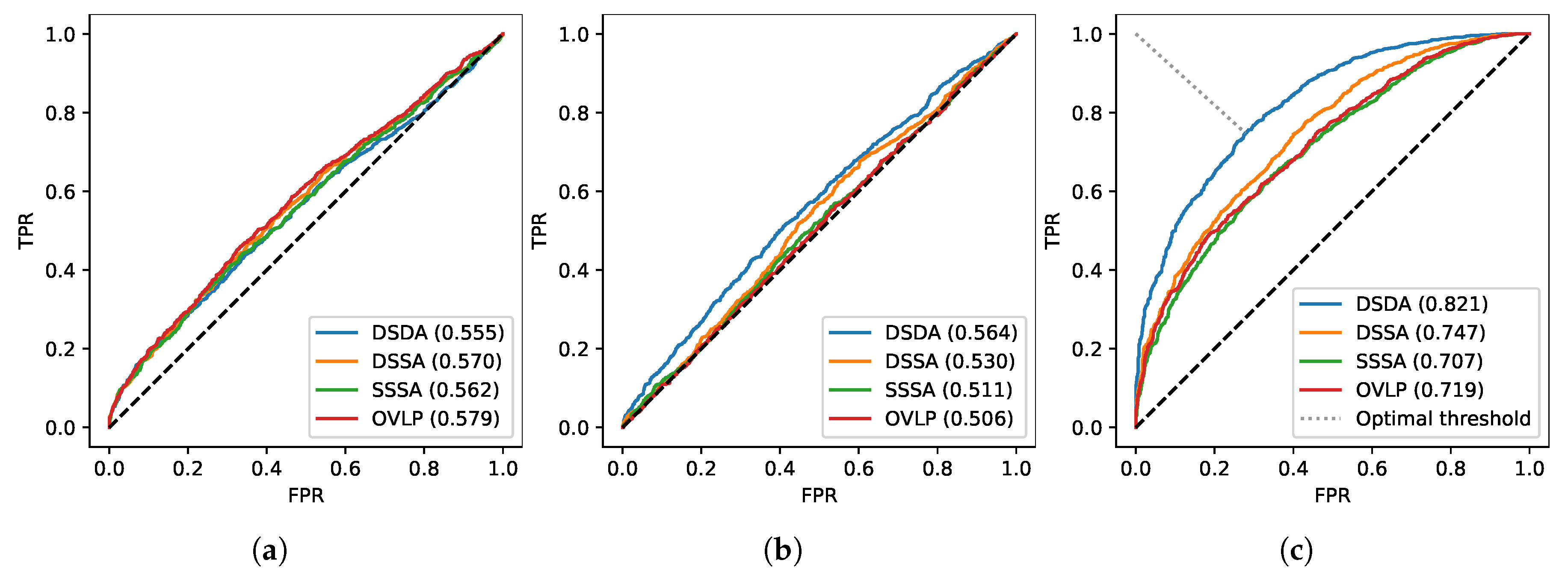
A comparison between the three tested architectures reveals that the best performances are obtained by the
fully-conv model when trained using our novel RTL, with an AVG auROC of 76.3%. The full ROC curves for this particular model are presented in
Figure 6c, together with the ROC curves for the baseline method of Shigeta et al. [
38] in
Figure 6a and Cabrera-Quiros et al. [
42] in
Figure 6b, which only manage to achieve AVG auROCs of 55.6% and 52.1%, respectively. In terms of best AVG auROC, the best model was trained on a combination of Easy and Hard negatives; while adopting harder negatives samples during training may improve the performances for SSSA auROC, the degradation over other scores leads to a lower AVG auROC. As already expected from the discussion in
Section 3.3, the use of Easy negatives exclusively leads to the worst results in the majority of the experiments performed.
If we only consider models trained with the STL, the best one is
LSTM+TP, trained with a combination of Hard and Very-Hard negatives. This model presents an AVG auROC of 61.7%, which is almost 15% lower than the best model trained with our novel RTL, confirming the advantages of our novel loss function. In addition to that, we also experienced a much faster training when using our proposed RTL, that reached maximum performances in fewer iterations when compared to the STL. Comparing the LSTM models in
Table 4 and
Table 5, we notice that the absence of temporal pooling with the LSTM layer does improve performances, as predicted in
Section 3.5. This improvement is likely related to the more granular temporal information that is fed into the LSTM layer, that better captures the correlation between the video and acceleration streams. However, with auROC values of 71.1% for
LSTM and 61.7% for
LSTM+TP, these two models remain inferior to
fully-conv. Moreover, because of the missing temporal pooling,
LSTM requires 50% longer training time with respect to
fully-conv and
LSTM+TP.
A comparison between the STL and RTL functions across all the models and negative strategies tested shows a clear superiority of our novel loss function in terms of auROC. Although 17 of our 18 experiments support the superiority of RTL over STL, we stress that these results are only valid in the context of the Video-Acceleration Matching problem. While the implementation of the RTL to other Computer Vision problems is straightforward, the performance analysis of our novel loss function for general application is out of the scope of this article.
4.2. Temporal Results
Temporal results for our algorithm are presented in
Figure 7 for two example subjects (Subject 9 and Subject 10) from the testing data. We illustrate the situation where both subjects appear in front of the camera but only one of them is wearing a wearable, the other being a guest. The objective is to find which short video clip from each sequence matches the monitored accelerometer. The experiment is even more challenging, since both subjects are simultaneously doing the same sequence of activities. We encoded both the video and acceleration sequences using the
and
deep encoders from the best model we found and we evaluated the Euclidean distances between the two pairs of features:
and
The results show the detailed temporal performances for the best
fully-conv model from
Table 3. A very different behaviour can be seen between activities that involve movement (i.e., walking, exercising) and those that do not (i.e., sitting, reading). In fact, active movements involve a variety of gestures that produce a strong motion signature which can be exploited to match video and accelerations. On the other hand, the output signal of the accelerometers while resting is almost identically nil, no matter which person is wearing it, hindering the ability to match different accelerations to different video streams.
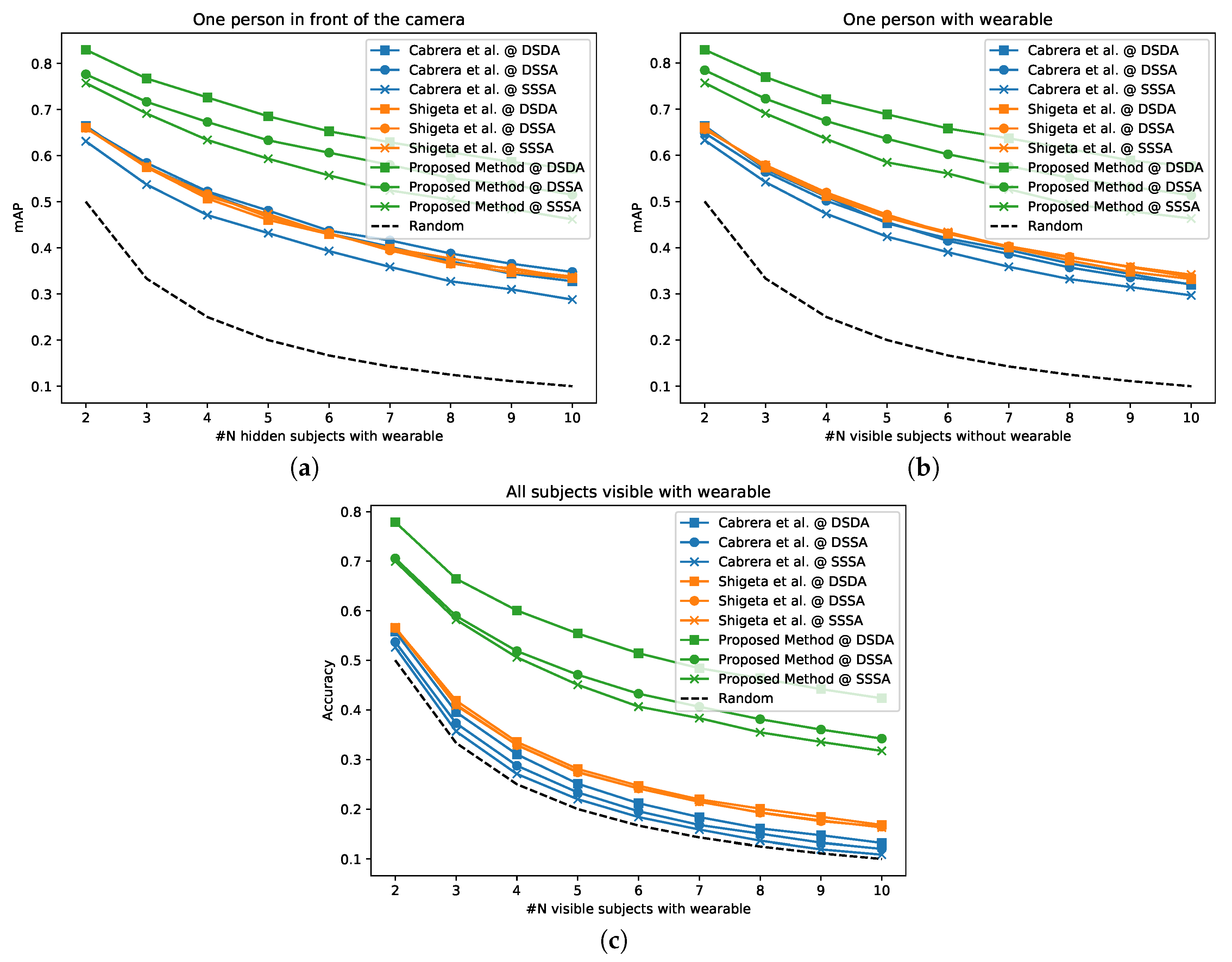
4.3. Performances Varying the Number of People
In this subsection, we set out to study the performance of our matching algorithm when varying the number of subjects, focusing on the effect of multiple guests. We define the number of people appearing in front of the camera
(not necessarily wearing an accelerometer) and the number of people carrying a wearable
(not necessarily appearing in front of the camera). By defining
to denote the number of subjects appearing in front of the camera while carrying the accelerometer, we can compute the number of guests
(people appearing within camera view while not wearing an accelerometer) as
To study all the possible circumstances that can apply to a regular house, we designed three different experiments. In the first, we fix
while we vary
from 2 to 10. This experiment reflects a condition where one single person is wearing the accelerometer in front of the camera, while other monitored participants are in different rooms or simply not in the field of view of the video system. We compute the distance (in the learnt embedded space) between the video of the subject within camera view and all remaining acceleromters. We then sort those distances and obtain the rank of the matching acceleromter
, and thus the mean average precision (mAP) as
In the second experiment, we fix
while we vary
from 2 to 10, which simulates a condition where a total of
people are in front of the camera, but only one subject is being monitored with the accelerometer and the rest are guests. We measure again the mAP, as per Equation (
13), to estimate the performances in retrieving the accelerometer of the monitored participant against the guests.
In the last experiment, we keep and we change their value from 2 to 10. This simulates a condition where all the participants are in front of the camera simultaneously and each is wearing an accelerometer. For each value of we measure the distance matrix between all the videos and the accelerations as for all .
To each video clip, we then assign an acceleration sequence based on the minimum distance,
and compute the assignment accuracy as
where
is the Kronecker delta.
The results of these experiments are presented in
Figure 8, which shows that our method outperforms the baselines for every case studied, in spite of a degradation of performances when the number of people increases from 2 to 10. Despite Cabrera et al. [
42] being explicitly designed to deal with mingling events and crowded scenes, when their algorithm is applied to the short video clips, their performances drastically drop, with results that are almost on par with random guesses in the hardest scenario (i.e., DSSA, SSSA in
Figure 8c).
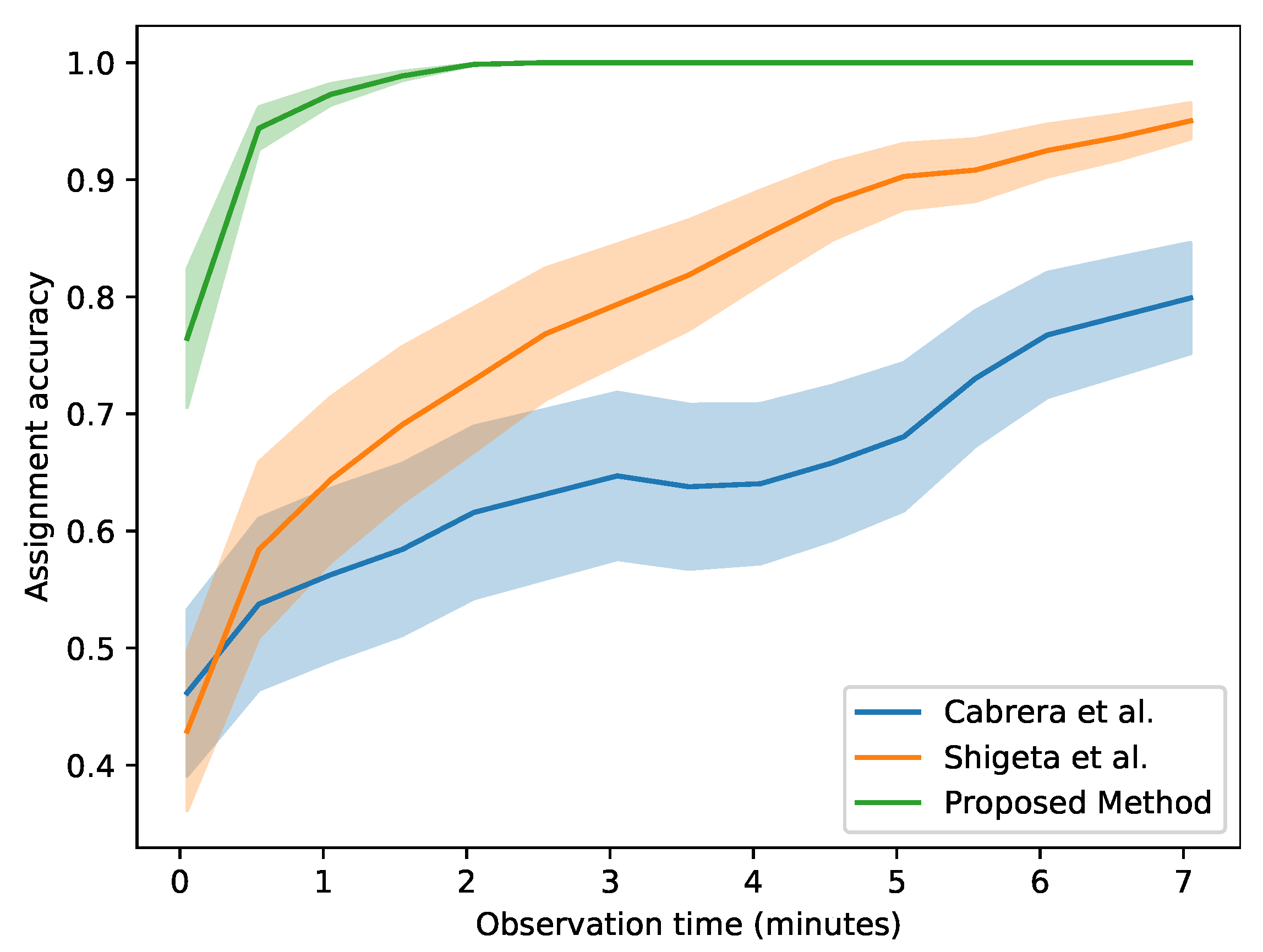
4.4. Variable Clip Length
One of the novelties of our method is its ability to cope with very short clips when matching video and acceleration streams. While we are able to accurately assign each video stream to the correct accelerometer with just ≈3 s of data, the simultaneous lack of motion in both modalities can hinder a correct association. This effect can easily be mitigated by increasing the observation time for each stream. We considered all the three subjects from the validation split (8, 9 and 10) and simulated an experiment where they all appear in front of the camera while wearing the accelerometer. The assignment accuracy was computed again as in the previous section, based on the minimum distance between each of the modalities. We then increased the number of clips observed for each subject and considered the average distance to study the behaviour of the assignment accuracy for a varying time interval.
Figure 9 illustrates the performances of each method for a variable observation time. The plots show that the baseline methods improve drastically with longer observation times, while our proposed algorithm hugely outperforms them by saturating to almost 100% assignment accuracy after only 2 min of observation time.
5. Conclusions
Novel technologies like IoT and AAL are becoming increasingly more popular and can potentially produce a change in the current paradigm of healthcare. An important aspect that needs to be carefully considered while working with these technologies is privacy, and video silhouettes have already shown a great potential in this regard, allowing for digital health monitoring while overcoming the ethical restrictions imposed by the use of traditional cameras. In spite of their compatibility with privacy concerns, silhouettes anonymity is a double-edged sword that both prevents identification of the household and hinders the ability to identify and track the progress of monitored subjects amongst others.
In this paper, we developed a novel deep learning algorithm that allows the identification and tracking of the monitored individuals thanks to the matching of video sequences from silhouettes with the acceleration from a wearable device carried by the subject. Differently to previous works, our algorithm is able to work also in the presence of guests as it requires only the monitored subject to be wearing the accelerometer. Moreover, our algorithm outperforms previous works by enabling the matching of video and acceleration clips of very short durations (≈3 s), making it highly suitable for short and clinically relevant movements like the transition from sitting to standing. We demonstrate the validity of our results in a series of experiments and ablation studies, presenting an average auROC of 76.3% and an assignment accuracy of 77.4%. With our results, we show that a deep-learning algorithm largely outperforms traditional methods based on tailored features when tackling the Video-Acceleration Matching problem.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}