Deep Learning-Based Human Activity Real-Time Recognition for Pedestrian Navigation


Abstract
1. Introduction
- (1)
- This paper summarizes MEMS measurement preprocessing strategies, including de-noising filtering algorithms, FFT, posture transformation, body acceleration extraction from total acceleration, and feature extraction from measurements. Traditional ML classification methods and commonly used deep learning methods are reviewed, and recognition evaluation methods and navigation update algorithms are presented.
- (2)
- Four main experiments were performed, namely pedestrian motion mode recognition, smartphone posture recognition, real-time comprehensive pedestrian activity recognition, and pedestrian navigation experiment. Seven traditional ML classification methods and two deep learning methods were used in the procedure of recognition. Several test results are presented for comparison and analysis in this paper.
- (3)
- We designed deep learning models using LSTM network and CNN network. On the basis of the trained models, we converted the trained model to a lightweight model, which can be run in Android smartphones. This way provides the possibility to recognize pedestrian activity in real-time.
- (4)
- Real-time recognition was performed in a Huawei Mate20 smartphone. Five comprehensive pedestrian postures, frequently used in pedestrian navigation, were designed. Test results show that the right recognition rate was up to , which was useful to enhance the optimization of pedestrian navigation algorithms.
2. Methodology
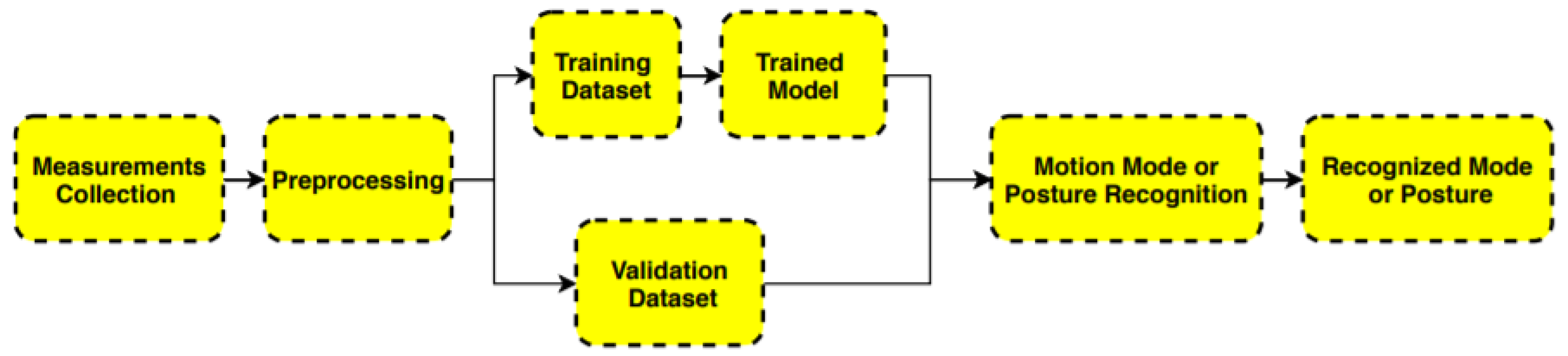
2.1. General Procedure of Recognition
- (1)
- Collect measurements from smartphone MEMS sensors.
- (2)
- Preprocess sensor measurements and divide the data to training and validation dataset.
- (3)
- Train and optimize the model, and conduct precision test.
- (4)
- Perform prediction.
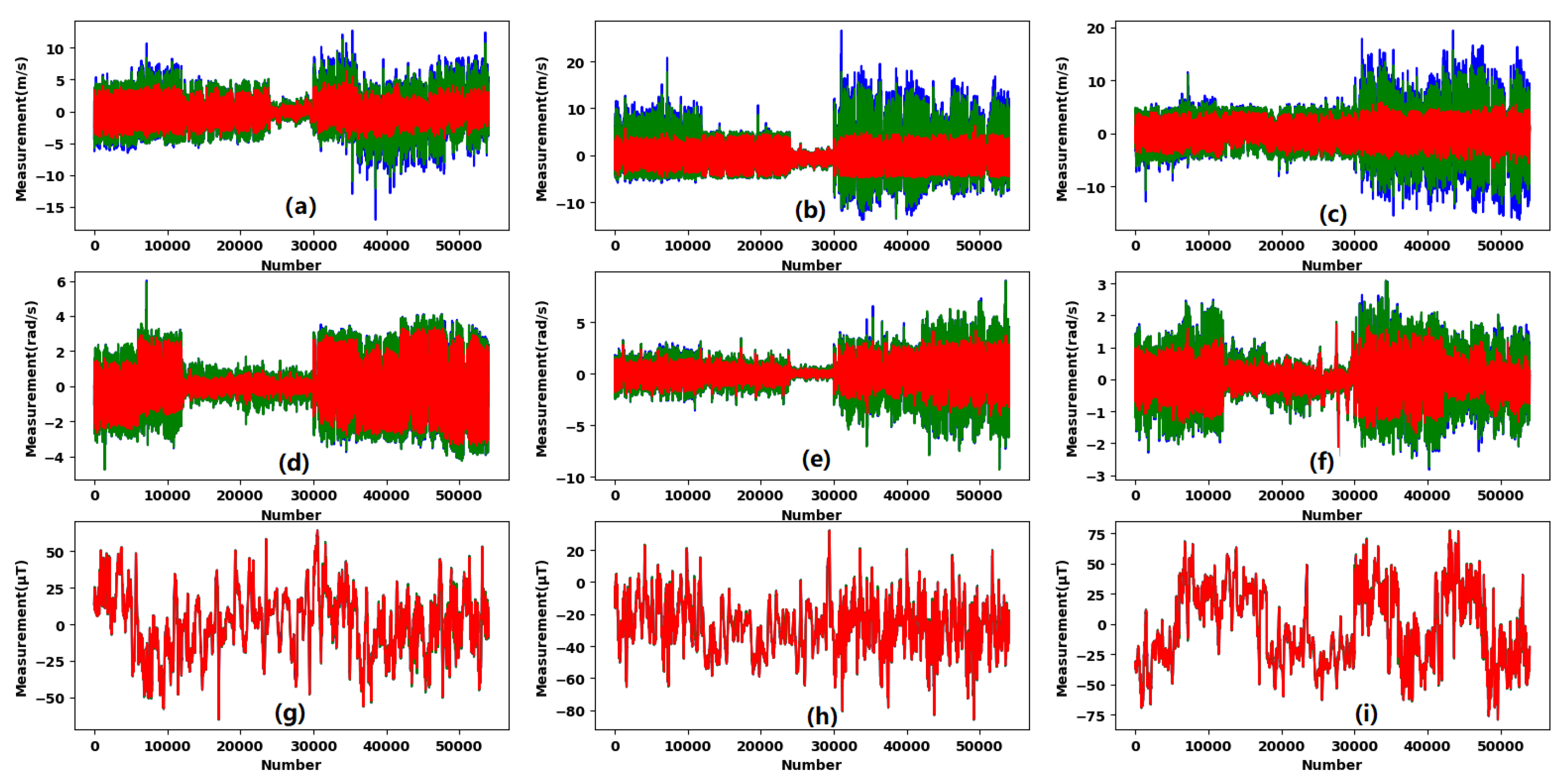
2.2. Preprocessing of Measurements
2.2.1. De-Noising
- (1)
- Digital low-pass filter: Use a conventional low-pass filter with a pre-defined cut-off frequency. A low-pass filter is a circuit that can be designed to modify, reshape, or reject all unwanted high frequencies of an electrical signal and accept or pass only those signals wanted by the circuits designer. In this study, we used Butterworth low-pass filter. The related formula is given as follows:where is the input signal, is the filtered signal in last epoch, and a is the low-pass filter coefficient.
- (2)
- Mean filtering: Use a moving average window replacing each data element with the mean of the group of data elements before and after it.
- (3)
- Median filtering: Use a moving average window but return the median rather than the mean. The median filter provides a nonlinear approach to filter that can be extremely effective in combating impulse noise with ease of implementation. It does not require multiplication or addition but needs only a fairly quick sorting after each sample. It creates some artifacts, particularly clipping. However, these artifacts are tolerable for most applications [35]. The formula is expressed as follows:where is the input signal and is the filtered signal.
2.2.2. Fast Fourier Transform
2.2.3. Transforming Measurements to Horizontal
2.2.4. Body Acceleration Extraction
| Algorithm 1 Body Acceleration Vector Extraction. |
Input: 1. Low-pass filter coefficient 2. Total acceleration measurement vector (,,) 3. Gravity vector (,,) Output: Body acceleration (,,) If Total acceleration measurement vector update = * + (1−) * = * + (1−) * = * + (1−) * = − = − = − |
2.3. Feature Extraction
2.4. Traditional ML Classification Methods
2.4.1. k-Nearest Neighbor
2.4.2. Random Forrest
2.4.3. Support Vector Machine
2.4.4. Decision Tree
2.4.5. Naive Bayes
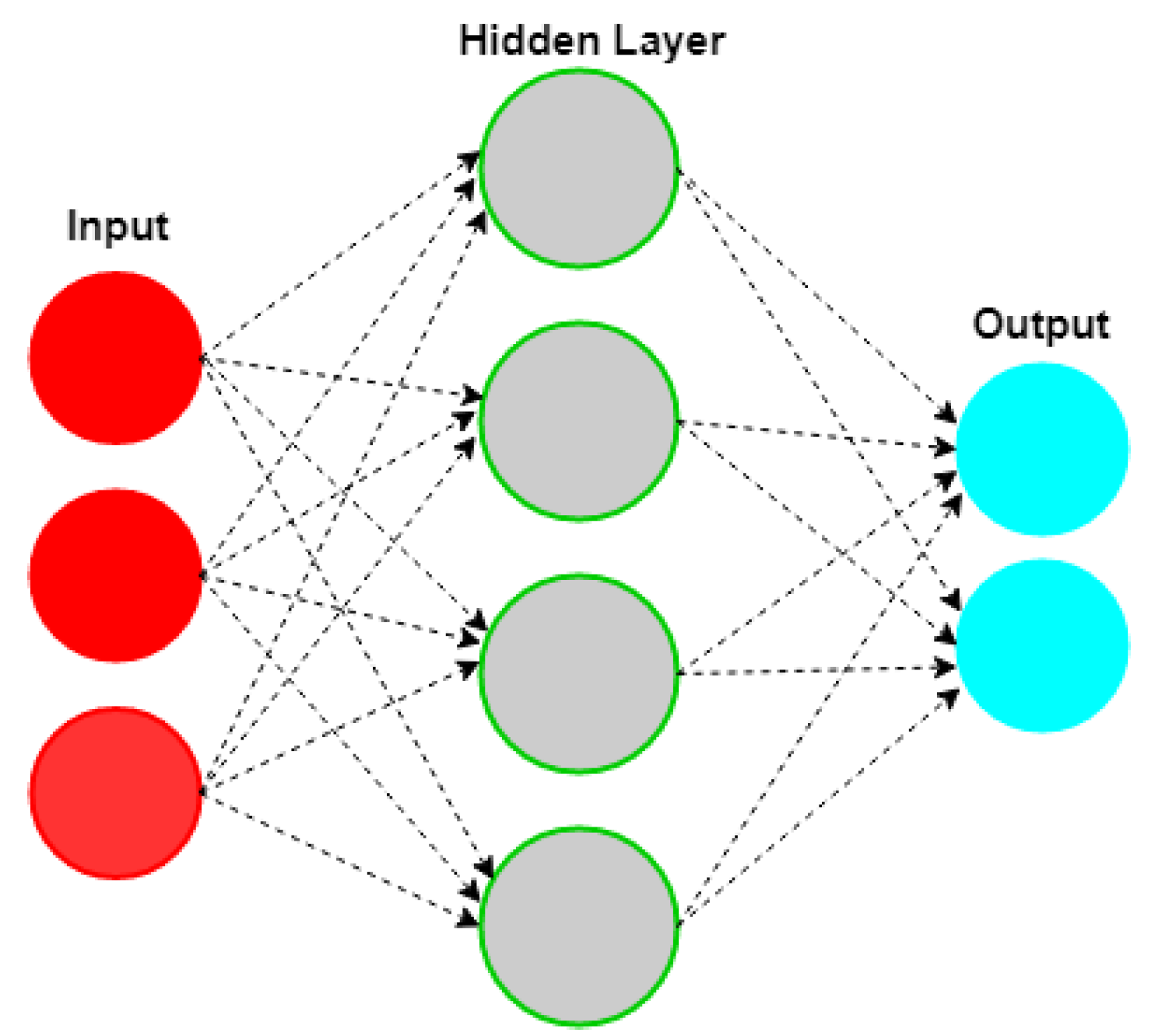
2.4.6. Neural Network
2.4.7. Stochastic Gradient Descent
2.5. Deep Learning Methods of Classification
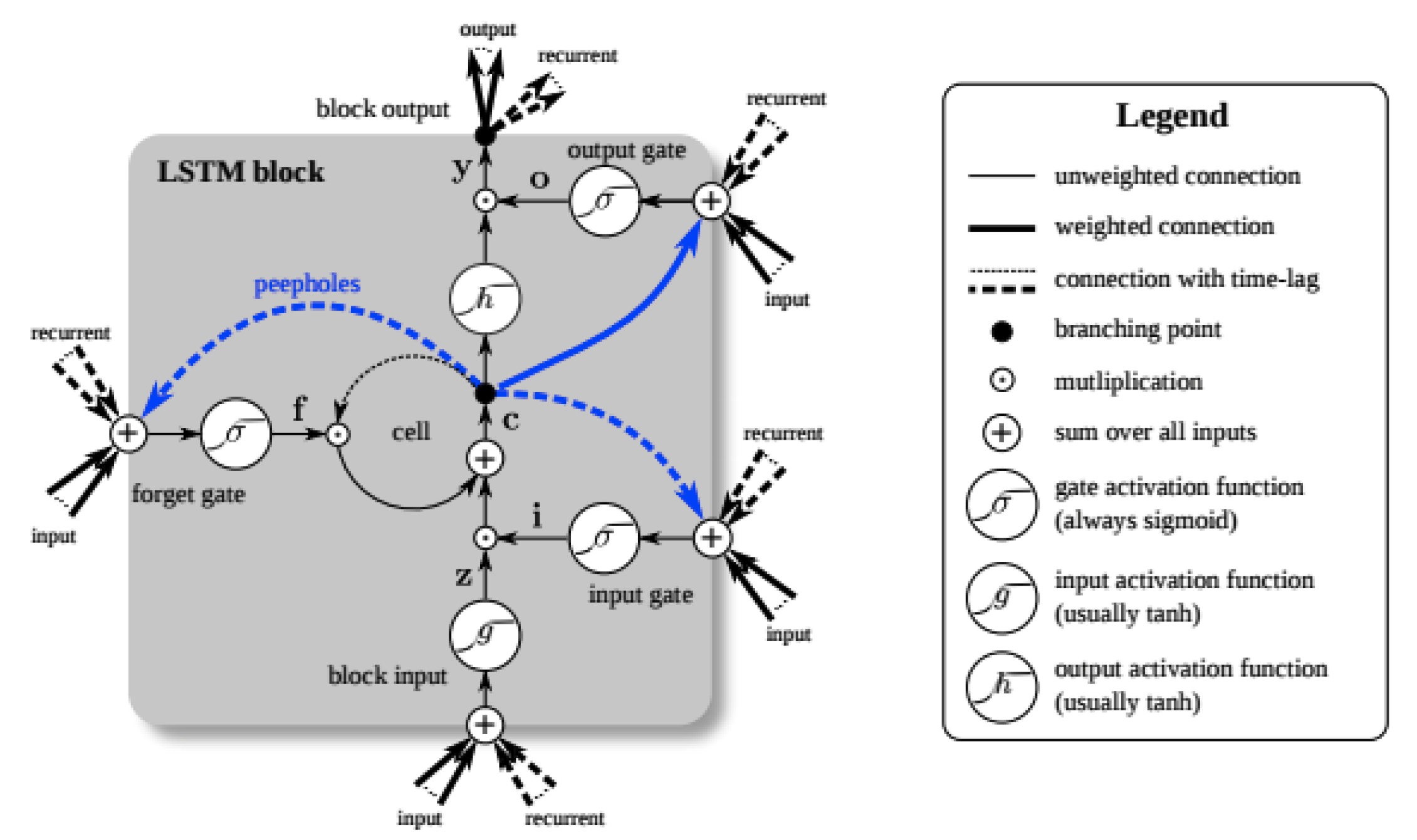
2.5.1. LSTM Network
2.5.2. CNN Network
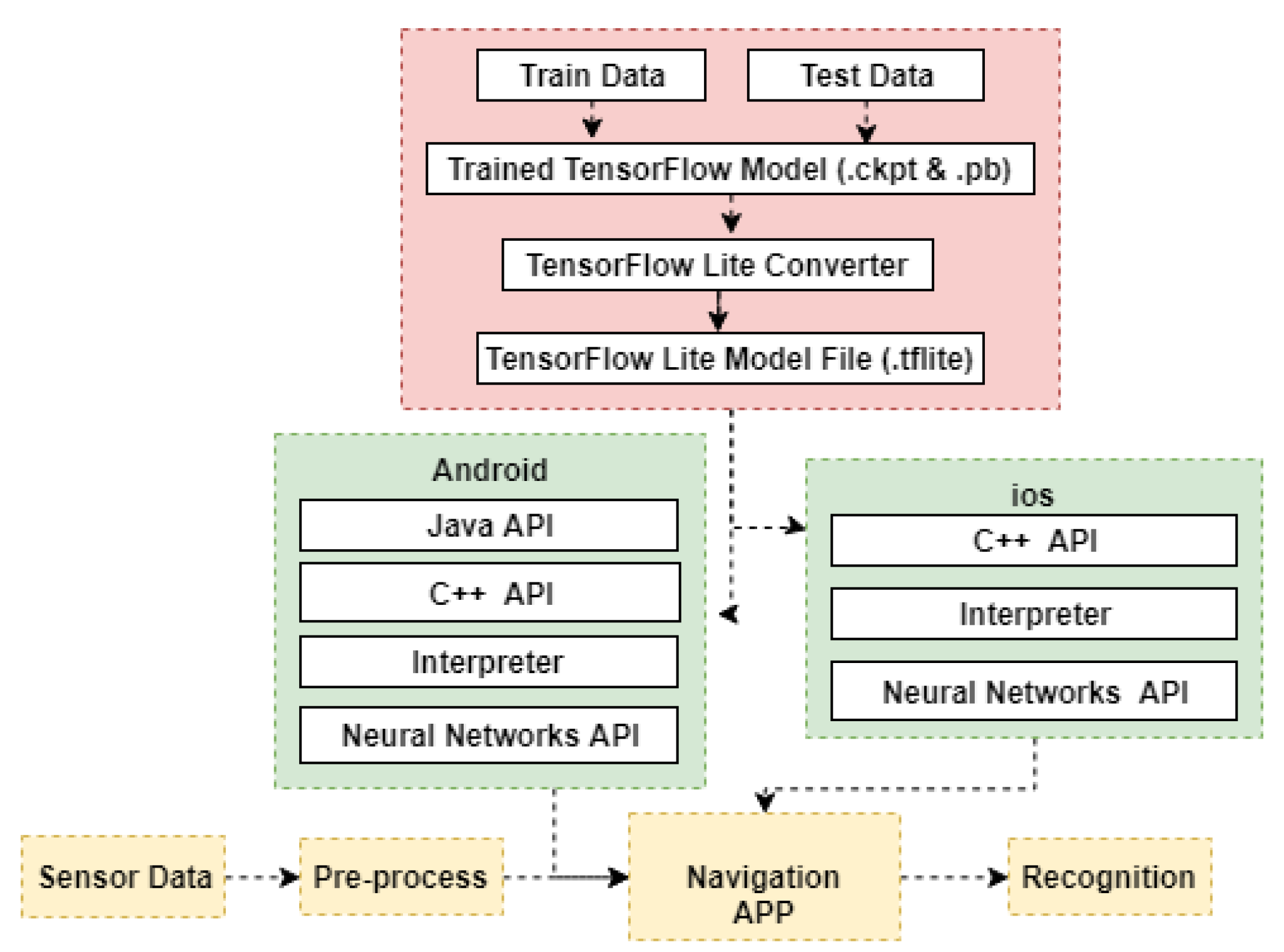
2.6. Real-Time Recognition Using Trained Model
Transformation of Trained Model
2.7. Analysis and Evaluation of Recognition Results
2.8. Navigation Location Update
3. Validation and Experiment
3.1. Pedestrian Motion Mode Recognition
3.1.1. Test Description and Preprocessing
3.1.2. Classification Using Traditional ML Methods
3.1.3. Classification Using Deep Learning
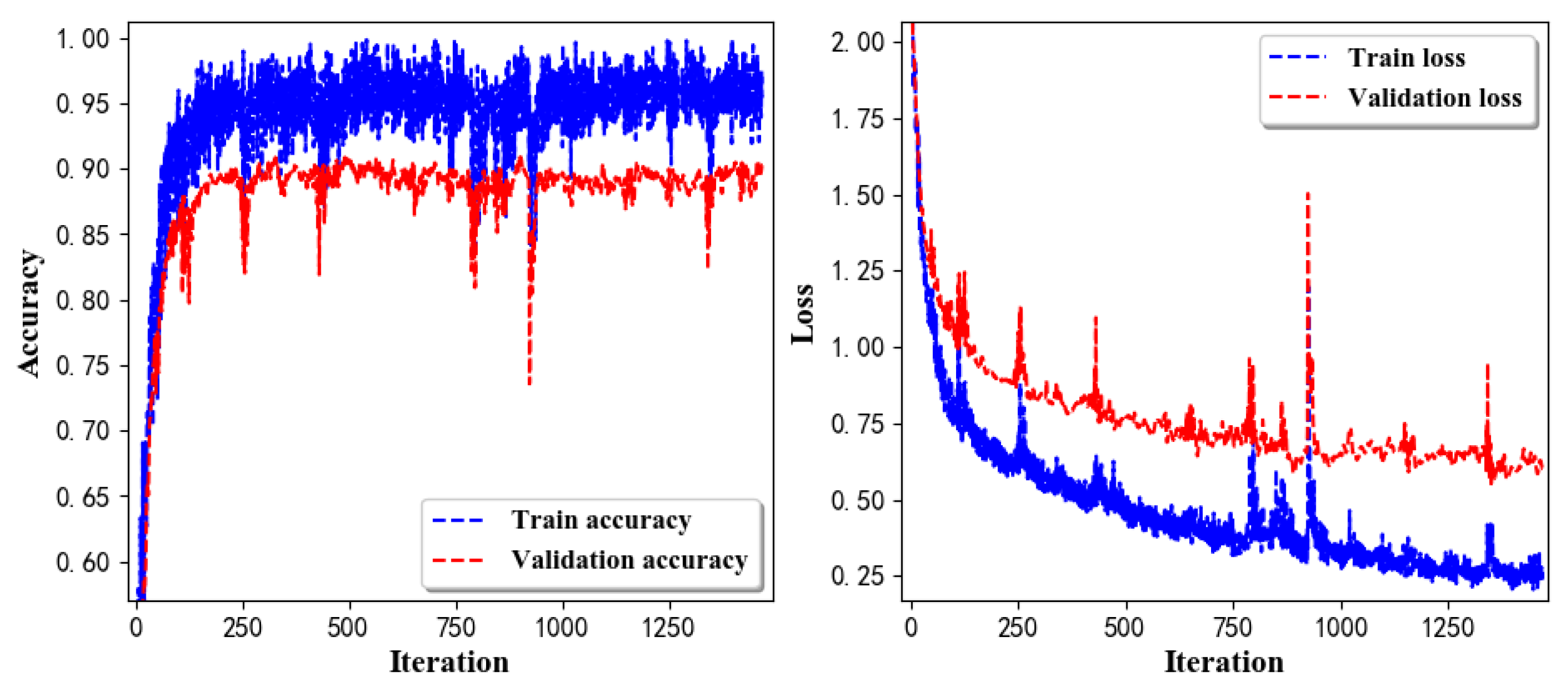
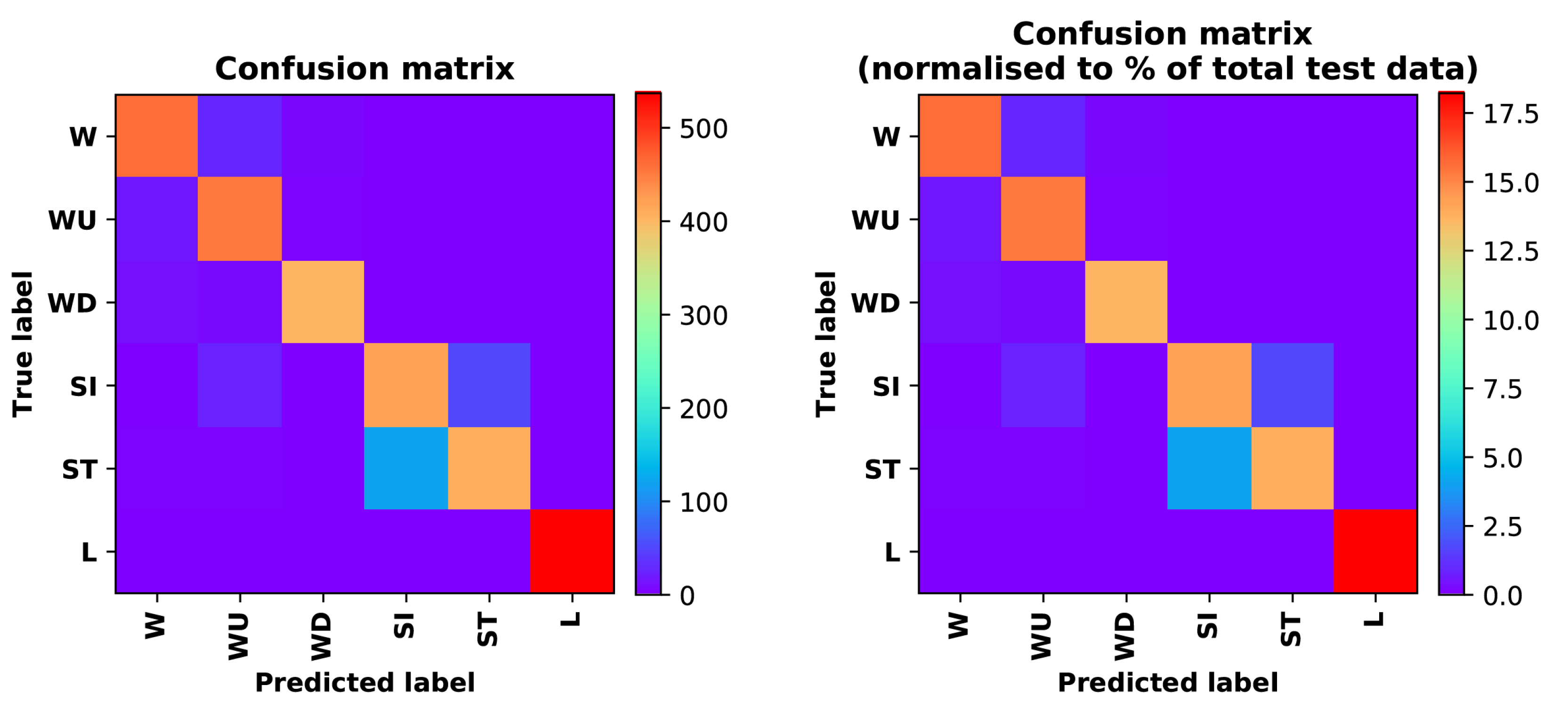
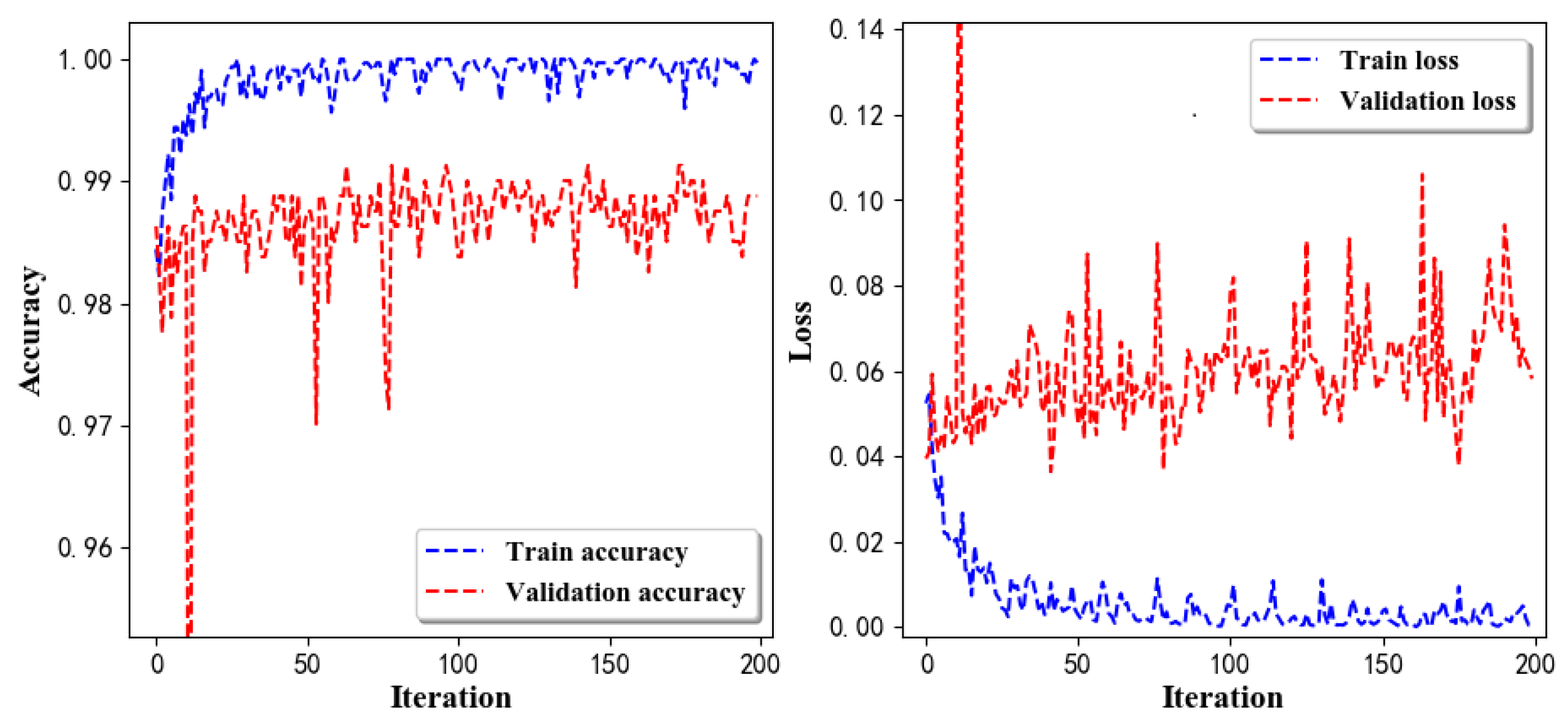
- Training Recognition Model Using LSTM NetworkTable 7 presents the structure of the designed LSTM network model. Notably, three LSTM layers are configured. In the table, ‘None’ denotes the batch size. We set the batch size to 200 and adopted the ‘adam’ optimizer in this test. These parameters in the table were only used for motion model recognition. The network structure in the next section is the same, but the parameters are updated.Figure 7 presents the accuracy and loss information after training the data using the LSTM model: training accuracy exceeds 0.95, the validation precision exceeds 0.9, and the loss is close to 0.6.Figure 8 presents the confusion matrix graph. The true labels were obtained from the test data, and the predictions were the recognition results obtained from above trained model using the test data.
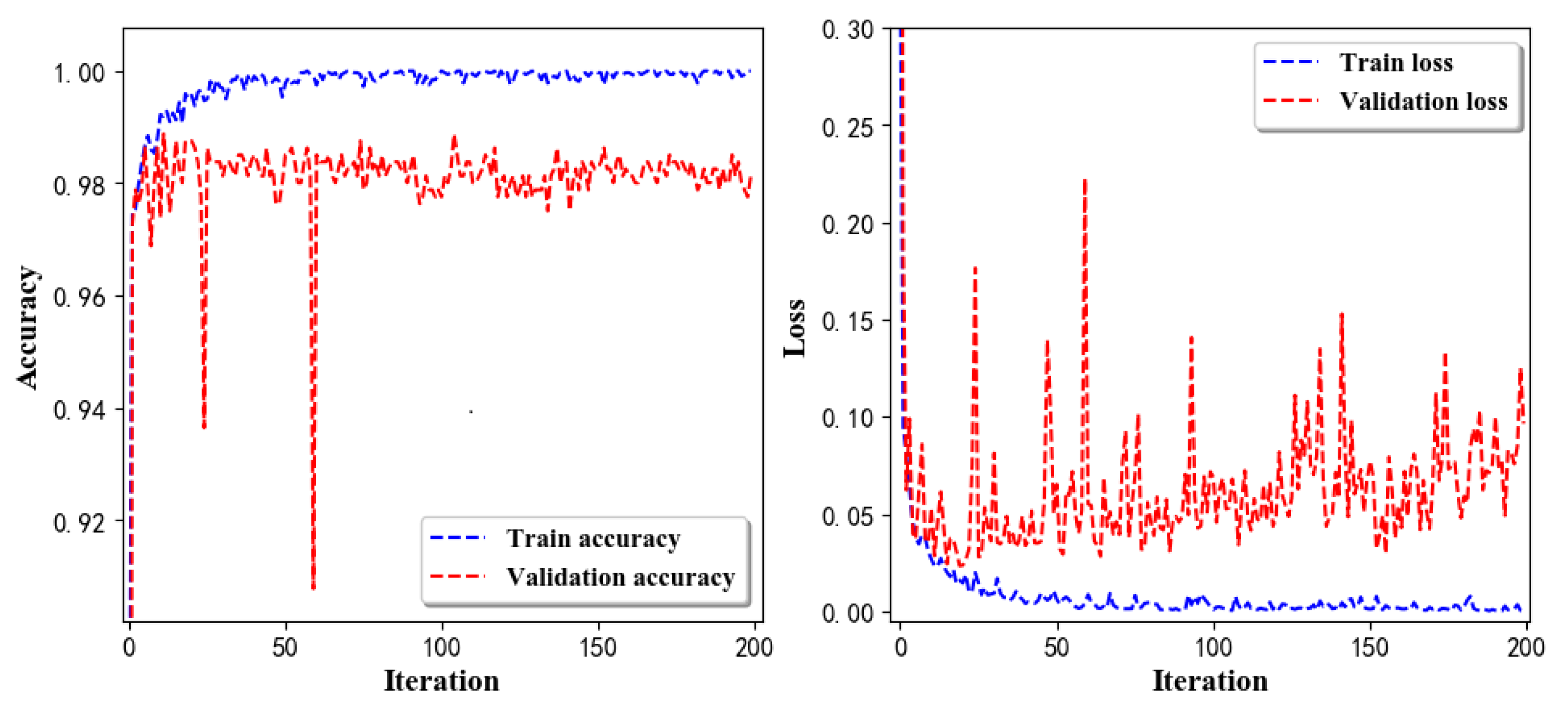
- Training Recognition Model Using CNNOur CNN architecture involves four consecutive blocks, each including a convolutional and RELU activation layer. Each convolutional kernel performs a 2D convolution over the time dimension, for each sensor channel independently. Preliminary experiments show that models with convolutions performed across all sensor channels degrade performances on the opportunity dataset. Similar to MLP (Multi-Layer Perceptron), adding a batch normalization layer right after the input layer yields significant performance improvements.Table 8 presents the structure of the designed CNN model that contains four 2D CNN layers. In the table, ‘None’ denotes the batch size. We set the batch size to 200 and adopted the ‘adam’ optimizer in this test. These parameters list in the table were only used for motion model recognition. The network structure in the next section is the same, but the parameters are updated.Figure 9 presents the training accuracy and loss graphs. The blue curve represents the training accuracy and loss, and the red curve denotes the validation precision and loss. The training and validation accuracies exceed 0.95, and the losses converged below 0.1.Figure 10 presents the confusion matrix graph. The true labels were obtained from the test data, and the predictions were recognized from the trained model using the test data.
3.2. Smartphone Posture Recognition
3.2.1. Test Description and Preprocessing
3.2.2. Classification Using Traditional ML Methods
3.2.3. Classification Using Deep Learning
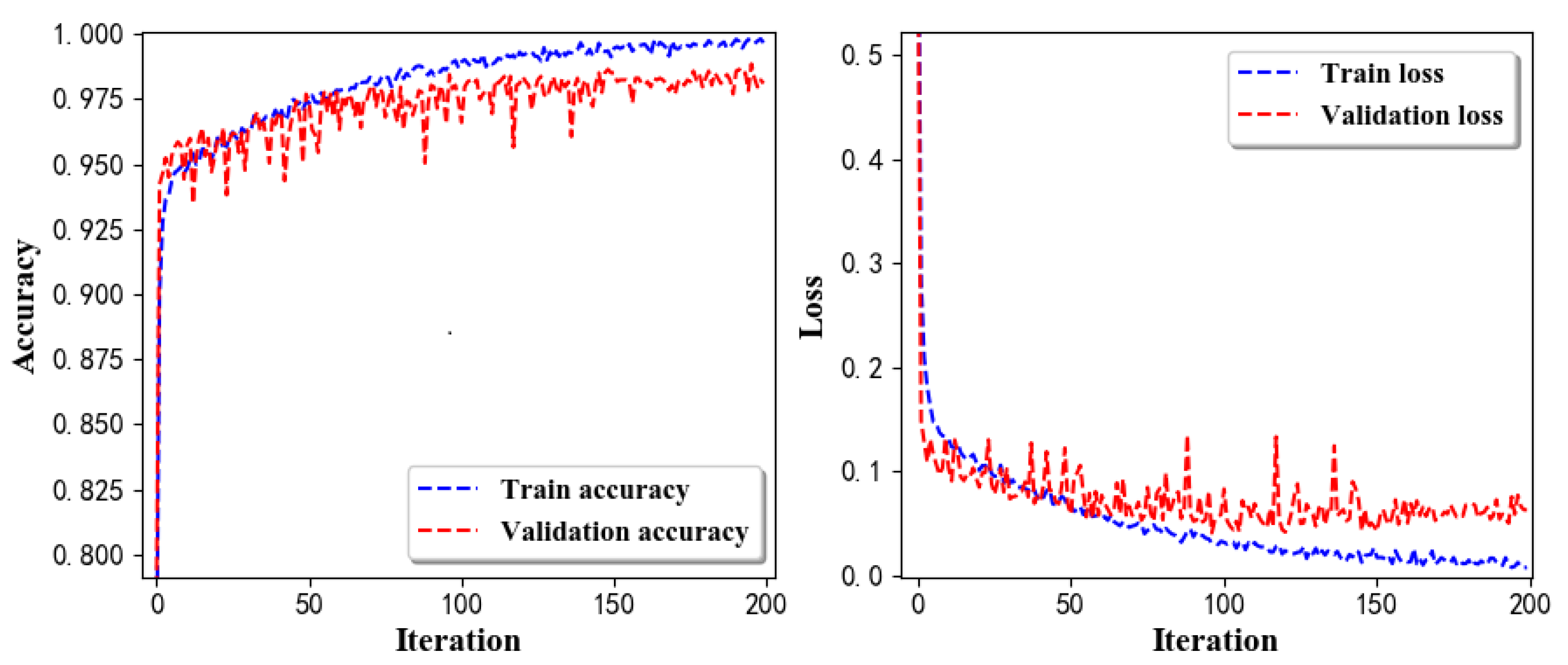
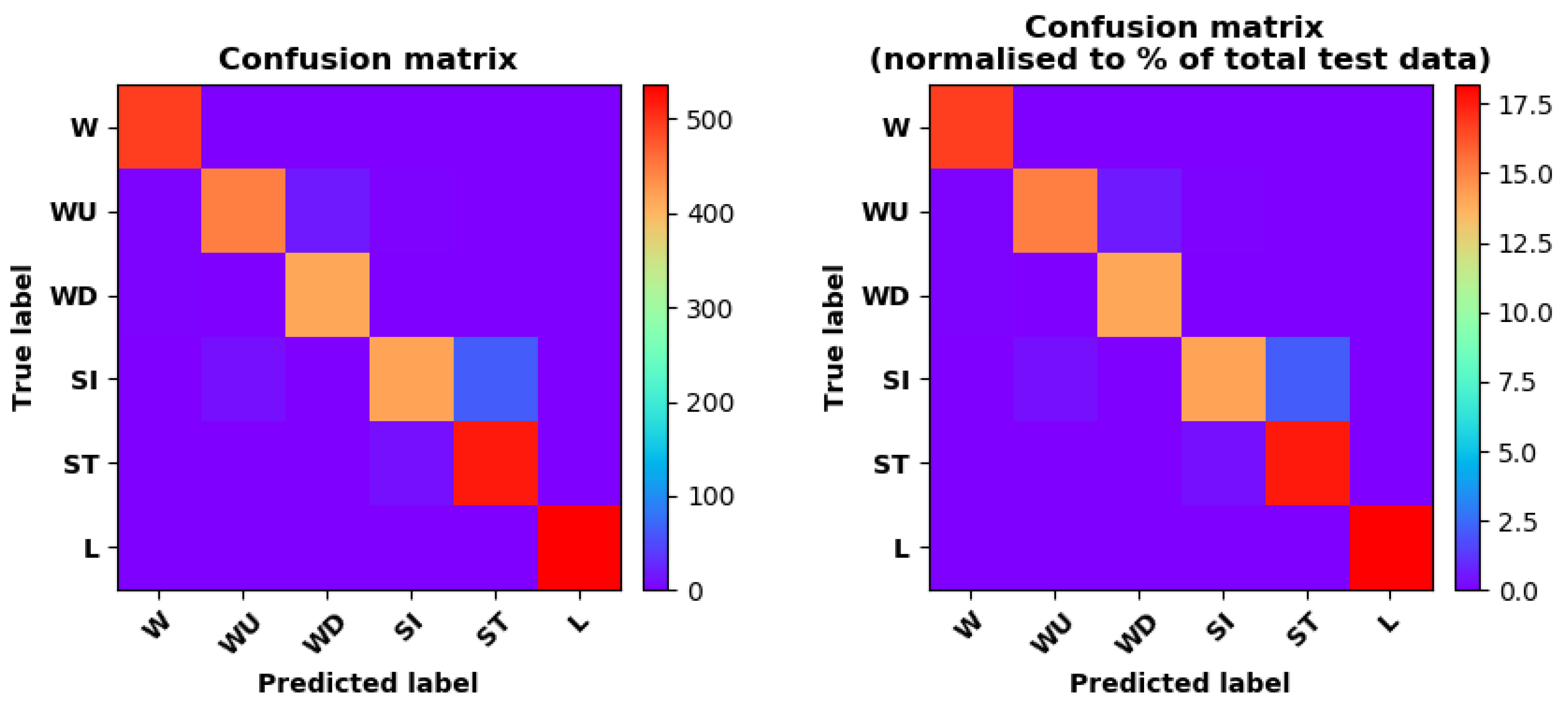
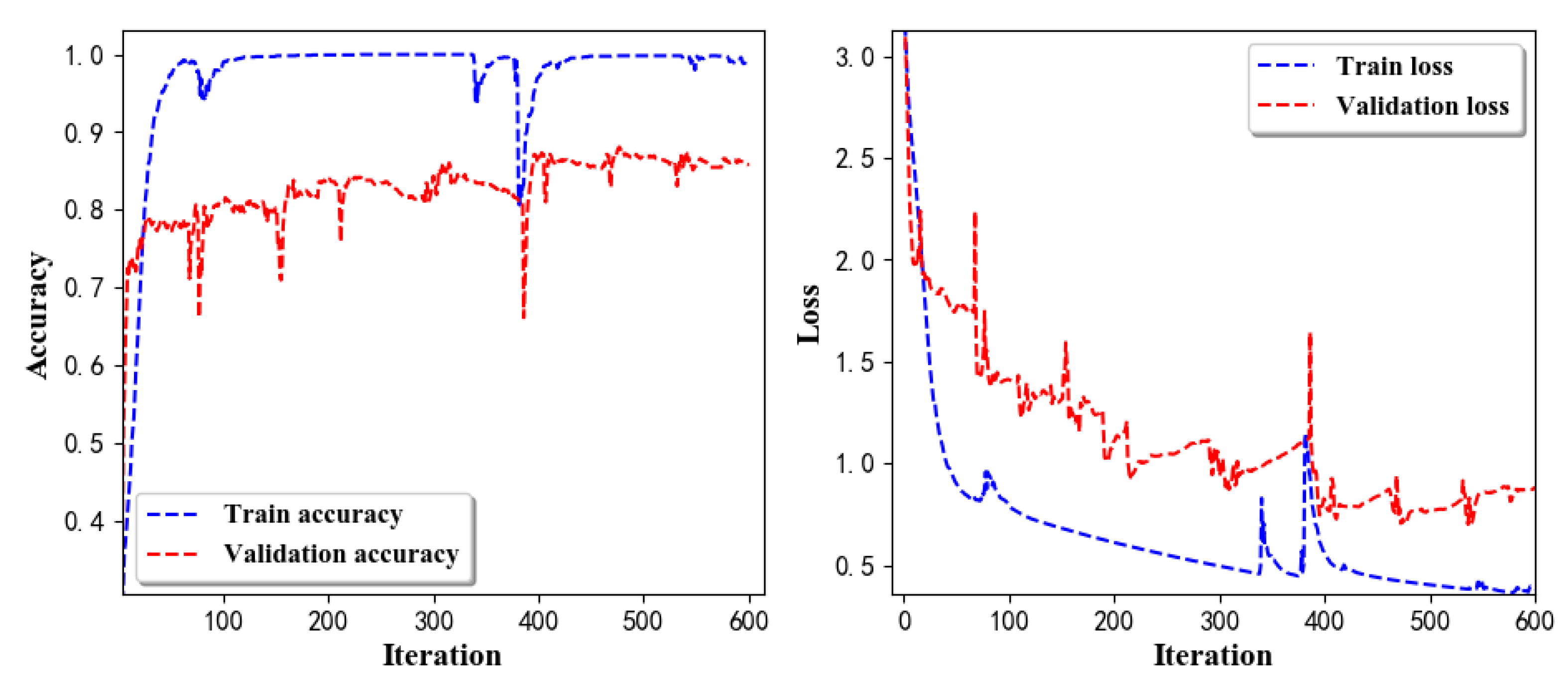
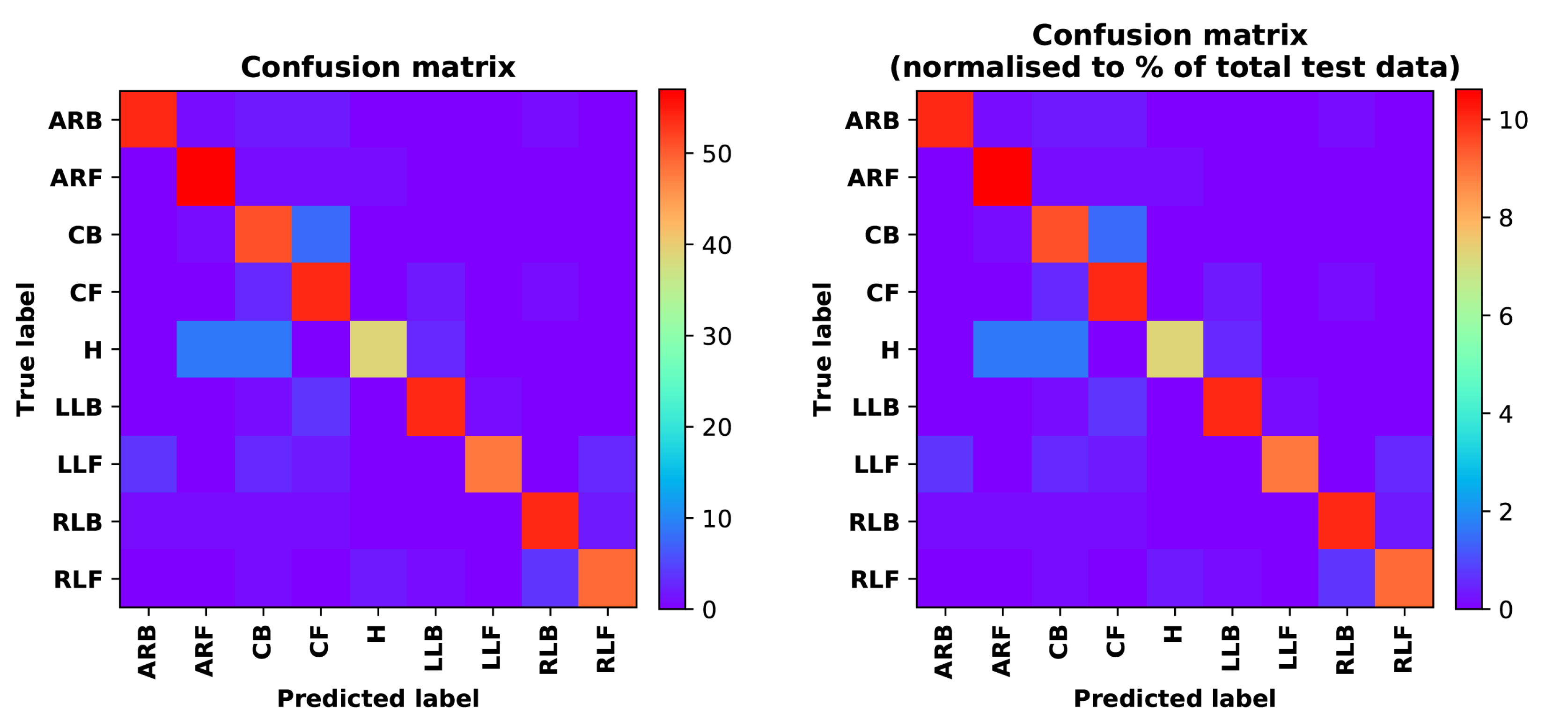
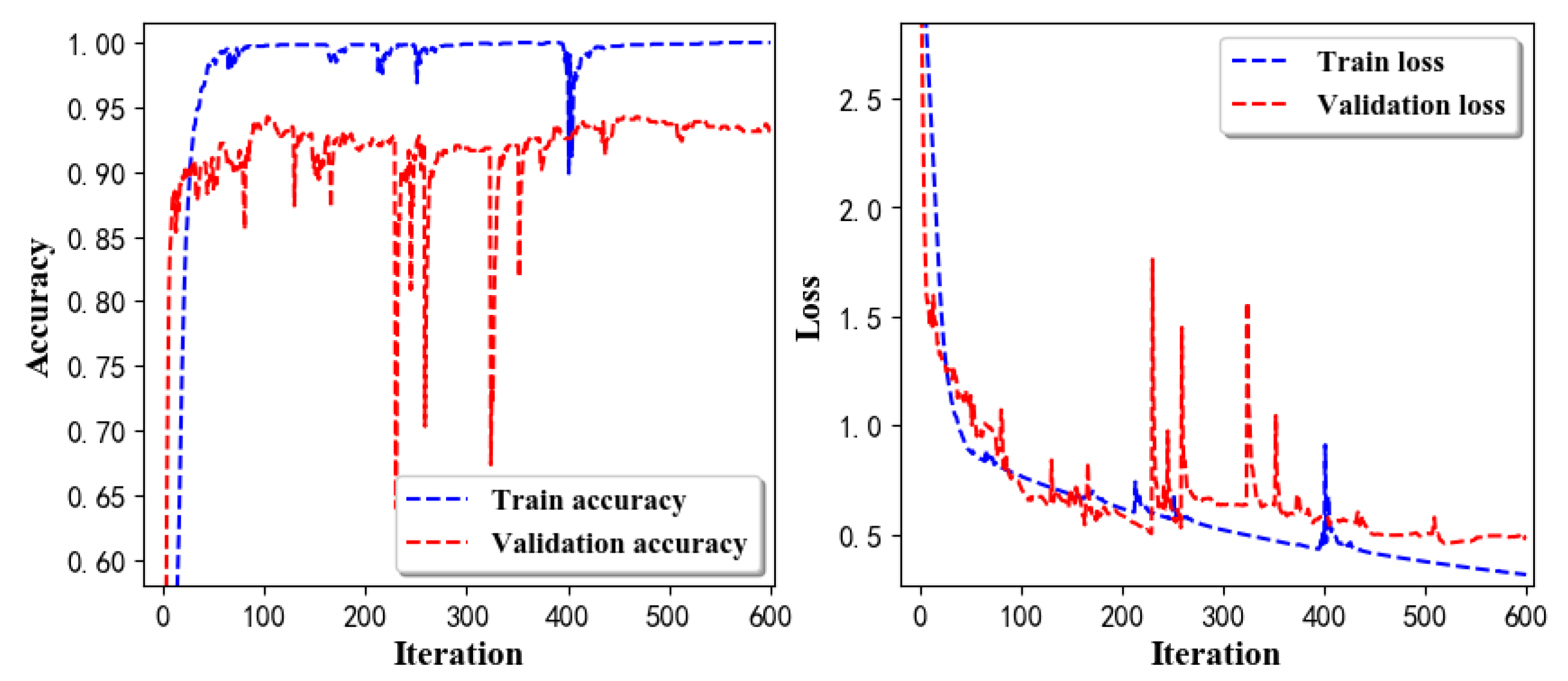
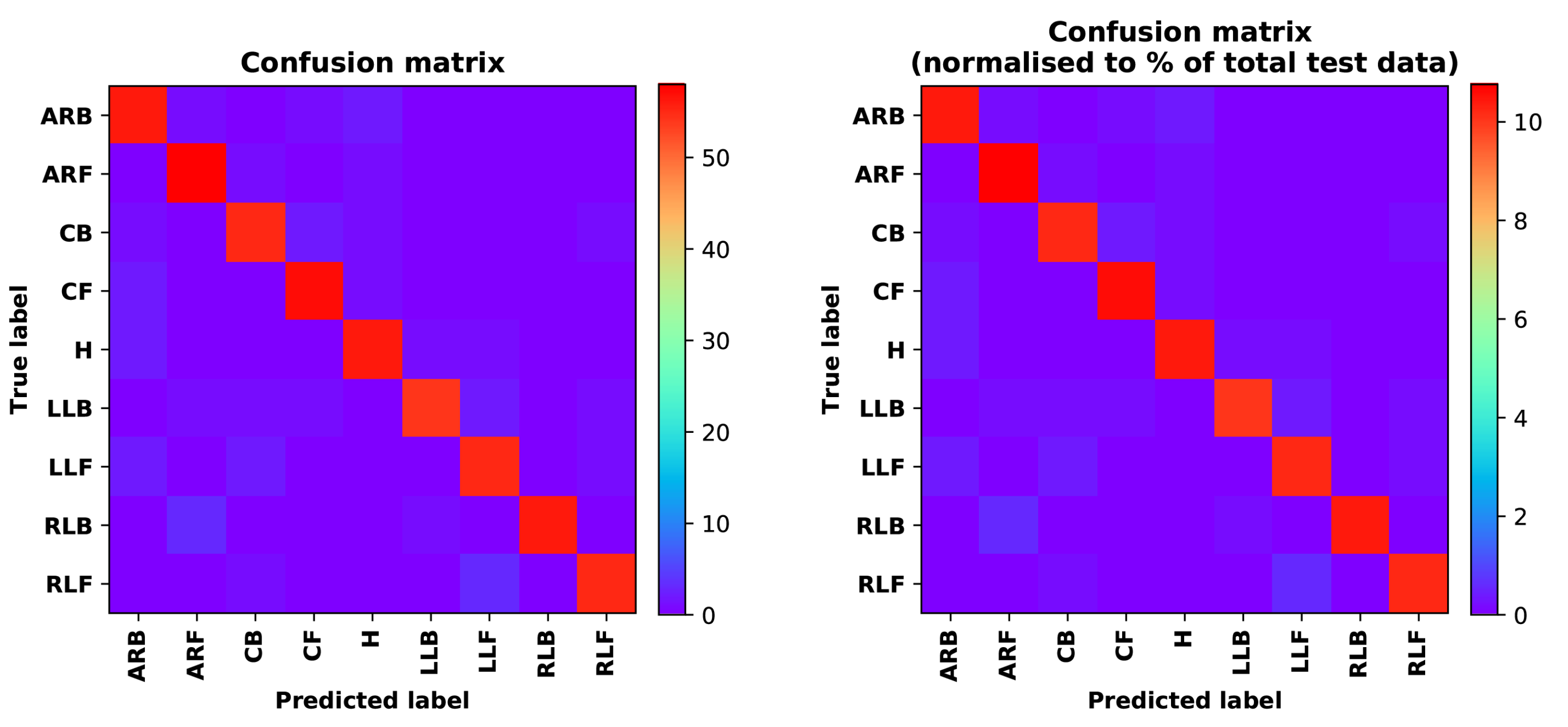
- Training Recognition Model Using LSTM NetworkWe used the designed LSTM model to train the raw data. Figure 13 presents the accuracy and loss information in the process of training and validation.Figure 14 presents two confusion matrix graphs; the right one is the normalized confusion matrix. The confusion matrix shows large prediction errors. Large proportions of ‘CB’ were recognized as ‘CF’. The same situation occurs for ‘H’. Moreover, most predictions were recognized as ‘ARF’ and ‘CB’.Figure 14 presents the confusion matrix graph. The true labels were obtained from the test data, and the predictions were recognized from the trained model using the test data. From the results in Figure 14, we still find some bright spots; they are in the off diagonals, meaning the wrong classification numbers or proportion. In the above graph, for example, several “CB” were recognized as “CF”, and many “H” were classified as “ARF” and “CB”. Thus, we know the training model still has some drawbacks and needs improvement. We also used the above designed LSTM model to train the filtered data. Figure 15 presents accuracy and loss information of training and validation data.Figure 16 presents the confusion matrix graph. The true labels were derived from the test data, and predictions were recognized from the trained model using the test data. The confusion matrix graph below shows that correct prediction takes up the highest proportion. Most predictions of the nine postures are correct.
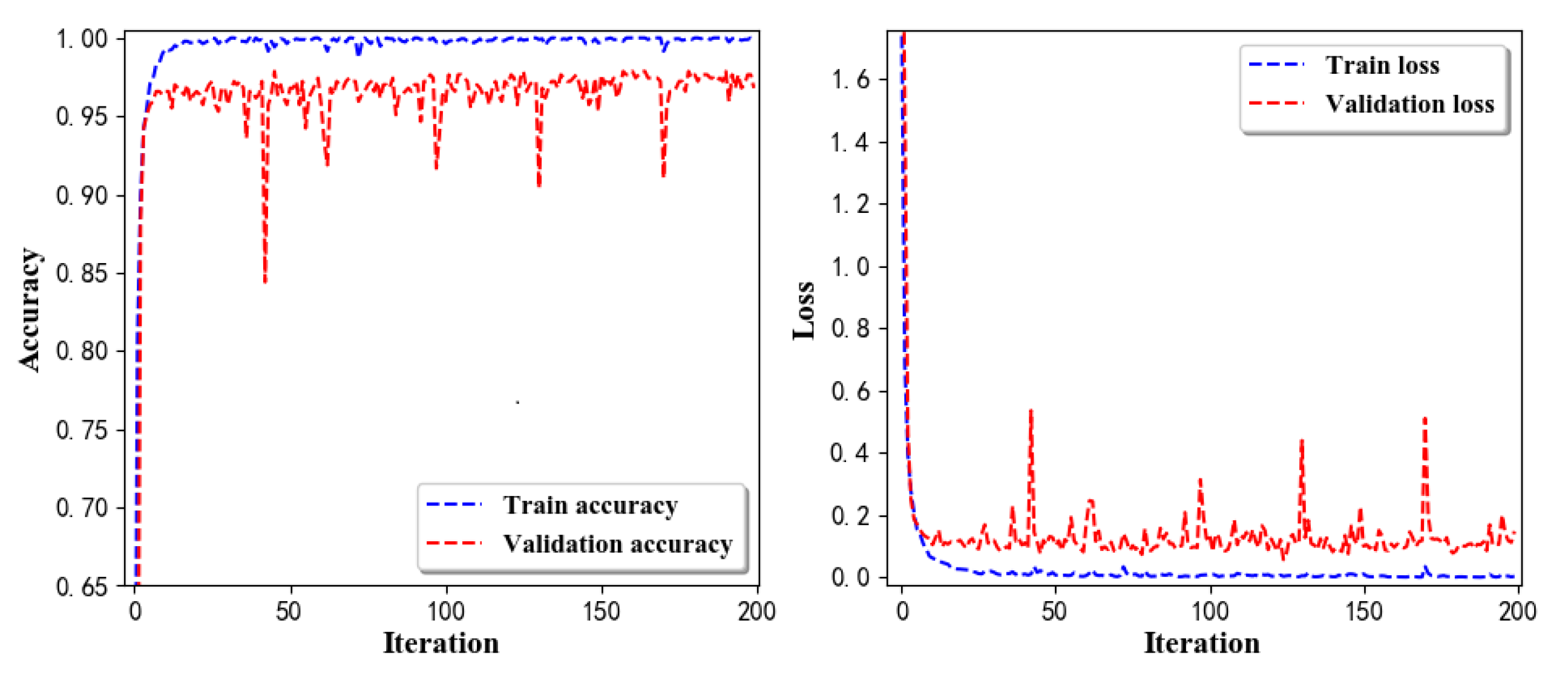
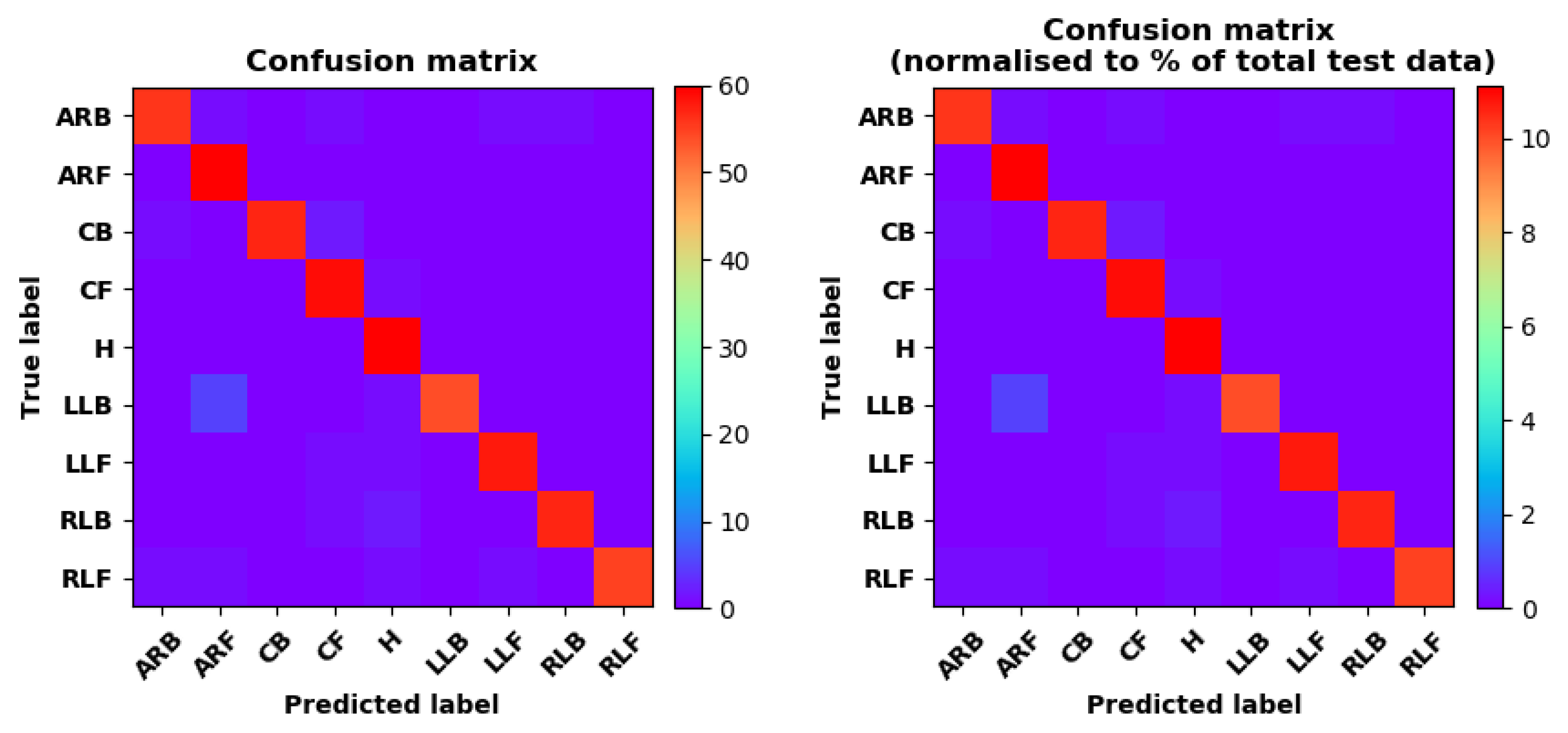
- Training Recognition Model Using CNNApart from the aforementioned LSTM methods, we also trained the preprocessed data using CNN. The CNN structure is same, but the parameters are updated here. Figure 17 presents the accuracy and loss of the training and validation results.Figure 18 shows the confusion matrix of prediction. The model was trained by CNN with the preprocessed measurements. The confusion matrix graph below indicates that the correct prediction takes up the highest proportion. Most predictions of the nine postures are correct. Overall, no large difference from the LSTM network trained results is observed.Figure 18 presents the confusion matrix graph. The true labels were obtained from the test data, and the predictions were recognized from the trained model using the test data.
3.3. Real-time Activity Recognition Test Combining Pedestrian Motion and Smartphone Posture
3.3.1. Test Description and Preprocessing
3.3.2. Real-time Recognition of Comprehensive Pedestrian Activities
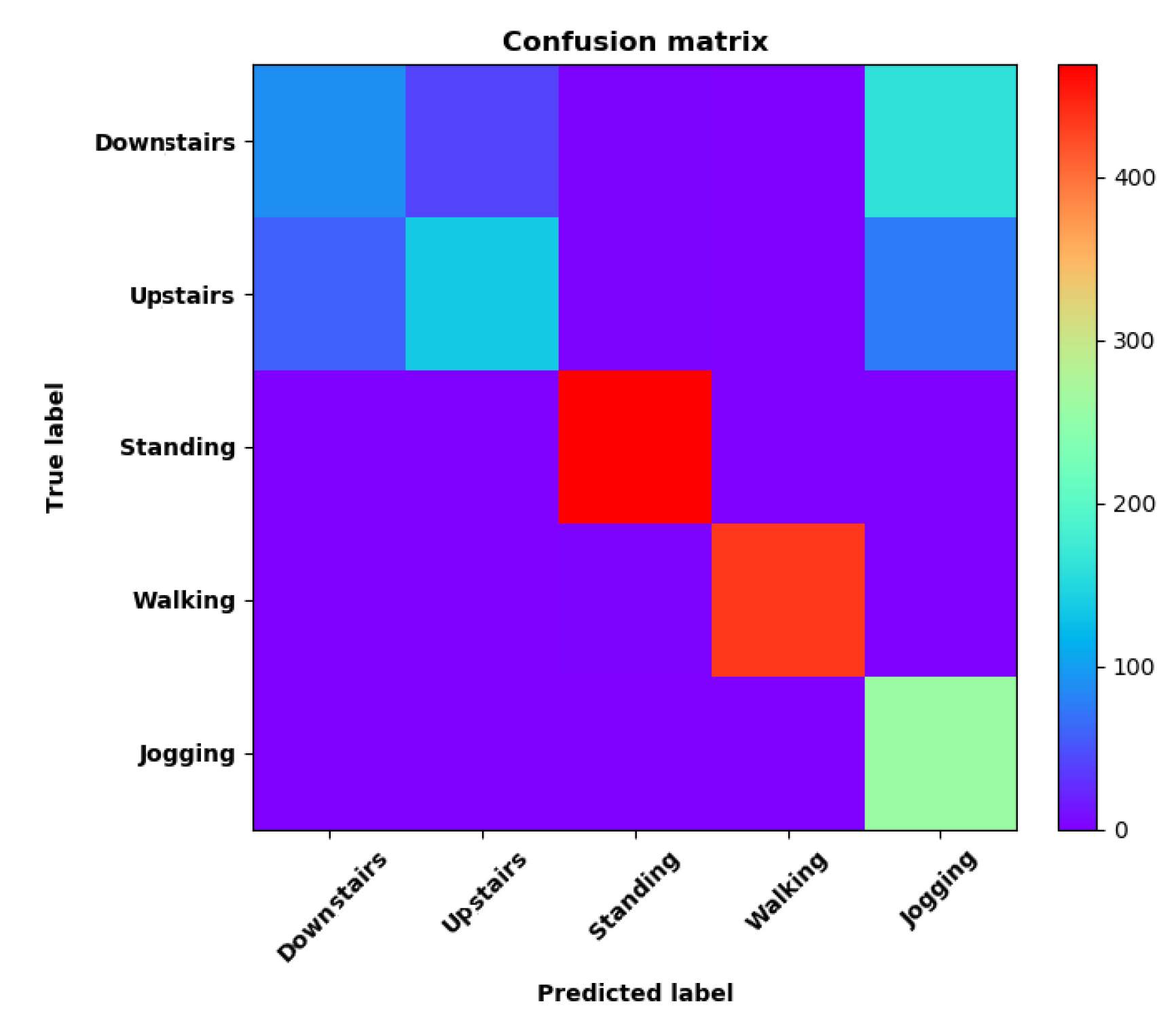
- Training Recognition Model using Gyroscope + Accelerometer + Magnetometer MeasurementsWe trained the data and used the feature vector [, , ,, , , , , , , , ] with 12 features under the window size of 200. Figure 20 presents the accuracy and loss graphs of training procedure.Validation tests were performed in the same test fields, and five separate tests were done. Figure 21 shows the confusion matrix of real-time test.Figure 21 presents the confusion matrix graph. The true labels were derived from the test data; predictions were recognized from the above-trained model using the test data. The confusion matrix indicates that ‘Downstairs’ and ‘Upstairs’ have large prediction errors. Among the 296 instances of ‘Downstairs’, the number of correct predictions was only 89; 42 were recognized as ‘Upstairs’ and 162 were detected as ‘Jogging’. Therefore, the accuracy is only . With regard to ‘Upstairs’, the number of correct predictions is 136; 76 of these instances ertr recognized as ‘Jogging’ and 59 were detected as ‘Downstairs’. Therefore, the accuracy was only . ‘Standing’, ‘Walking’, and ‘Jogging’ had high correct prediction proportions. The total prediction accuracy is .
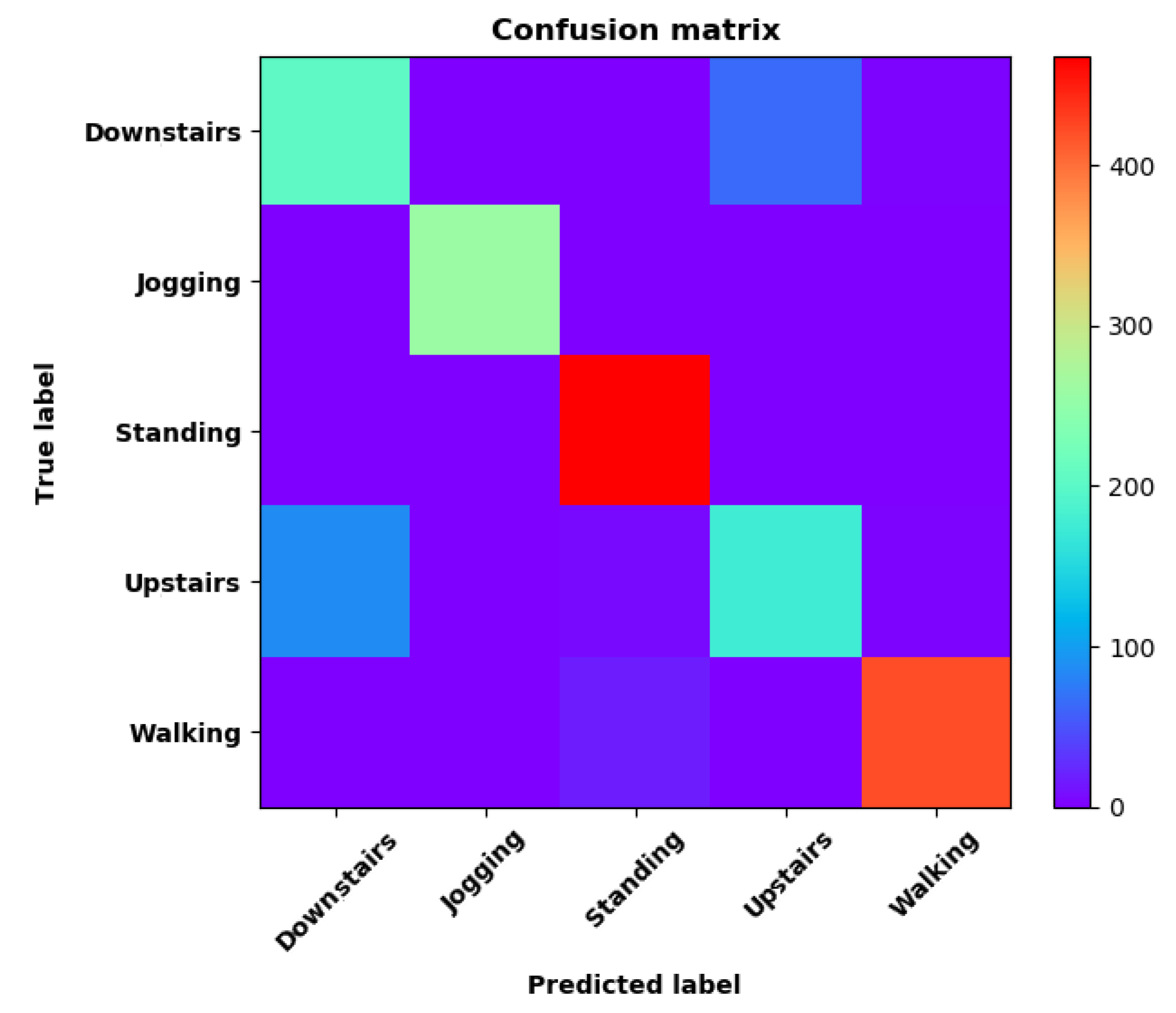
- Training Recognition Model Using Gyroscope + Accelerometer + Magnetometer + Light MeasurementsIn the above section, we found that ‘Downstairs’ and ‘Upstairs’ had high incorrect recognition rate. Thus, we added ‘Light’ as one of the features. The feature vector was [, , ,, , , , , , , , , ] with 13 features under the window size of 200. Figure 22 presents the accuracy and loss graphs of training and validation procedure.Test was performed in the same test fields, and five separate experiments were done. Figure 23 presents the confusion matrix graph.Figure 23 presents the confusion matrix graph; true labels were obtained from the test data and the predictions were recognized from the above trained model using the test data. Among the 270 instances of ‘Downstairs’, the correct prediction rate was ; 65 of these instances were recognized as ‘Upstairs’. Among the 274 instances of ‘Upstairs’, 177 were predicted correctly; 87 of these instances were detected as ‘Downstairs’. Therefore, the correct prediction rate was only .
3.4. Pedestrian Navigation Test
3.4.1. Test Description
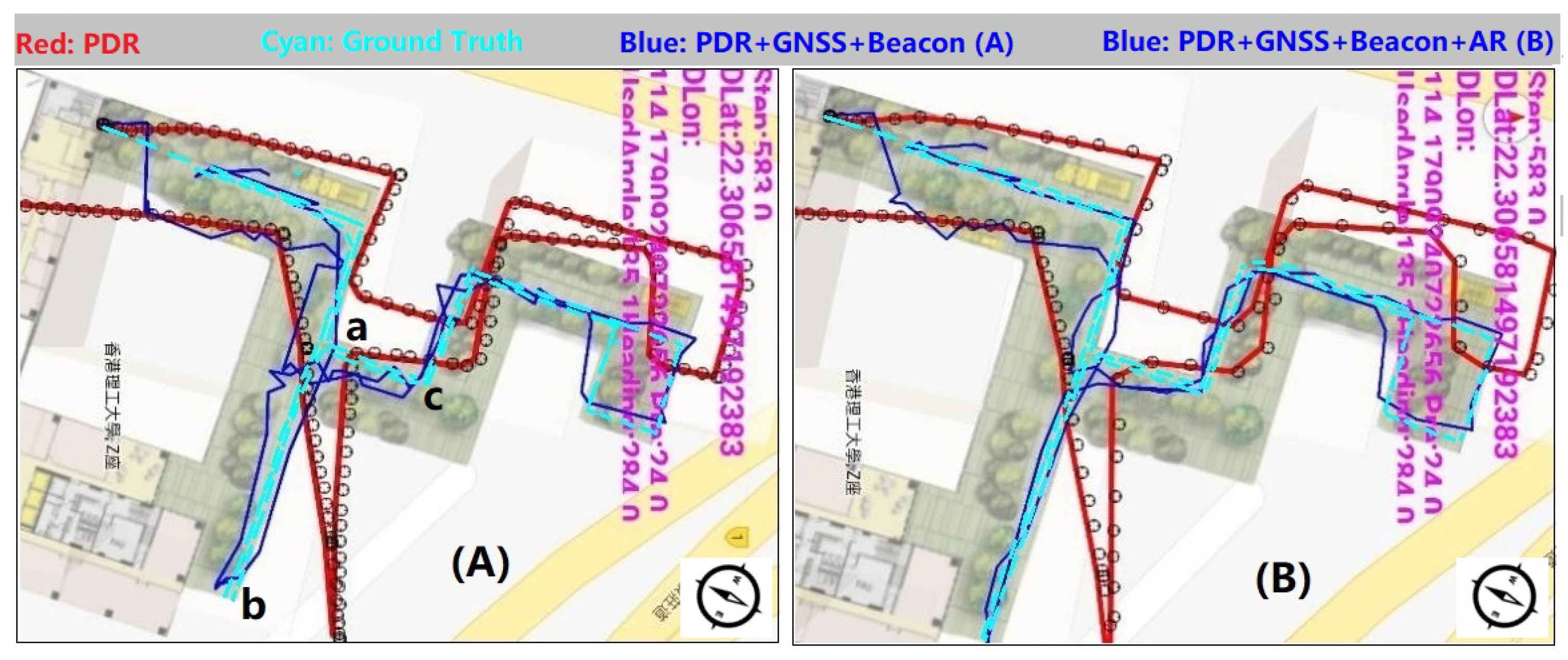
3.4.2. Navigation Test Result
4. Discussion
4.1. Motion Mode Recognition
4.2. Smartphone Posture Recognition
4.3. Real-time Recognition of Comprehensive Pedestrian Activities
4.4. Navigation Test Result Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| PDR | Pedestrian Dead Reckon |
| MEMS | Micro-electromechanical System Sensor |
| RNN | Recurrent Neural Network |
| CNN | Convolutional Neural Network |
| kNN | k-Nearest Neighbor |
| SGD | Stochastic Gradient Descent |
| SVM | Support Vector Machine |
| RF | Random Forest |
| NN | Neural Network |
| ANN | Artificial Neural Network |
| DCNN | Deep Convolutional Neural Network |
| DBN | Deep Belief Network |
| MLP | Multi-Layer Perceptron |
| ML | Machine Learning |
| GNSS | Global Navigation Satellite System |
| DT | Decision Tree |
| LSTM | Long Short-Term Memory |
| IOT | Internet of Things |
References
- Ye, J.; Li, Y.; Luo, H.; Wang, J.; Chen, W.; Zhang, Q. Hybrid Urban Canyon Pedestrian Navigation Scheme Combined PDR, GNSS and Beacon Based on Smartphone. Remote Sens. 2019, 11, 2174. [Google Scholar] [CrossRef]
- Kakiuchi, N.; Kamijo, S. Pedestrian dead reckoning for mobile phones through walking and running mode recognition. In Proceedings of the International IEEE Conference on Intelligent Transportation Systems, The Hague, The Netherlands, 6–9 October 2013. [Google Scholar]
- Micucci, D.; Mobilio, M.; Napoletano, P. UniMiB SHAR: A Dataset for Human Activity Recognition Using Acceleration Data from Smartphones. Appl. Sci. 2017, 7, 1101. [Google Scholar] [CrossRef]
- Khan, A.M.; Tufail, A.; Khattak, A.M.; Laine, T.H. Activity Recognition on Smartphones via Sensor-Fusion and KDA-Based SVMs. Int. J. Distrib. Sens. Netw. 2014, 10, 503291. [Google Scholar] [CrossRef]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity Recognition using Cell Phone Accelerometers. In Proceedings of the Fourth International Workshop on Knowledge Discovery from Sensor Data (at KDD-10), Washington, DC, USA, 25–28 July 2010. [Google Scholar]
- Yang, J.; Cheng, K.; Chen, J.; Zhou, B.; Li, Q. Smartphones based Online Activity Recognition for Indoor Localization using Deep Convolutional Neural Network. In Proceedings of the 2018 Ubiquitous Positioning, Indoor Navigation and Location-Based Services (UPINLBS), Wuhan, China, 22–23 March 2018. [Google Scholar]
- Klein, I.; Solaz, Y.; Ohayon, G. Smartphone Motion Mode Recognition. Proceedings 2017, 2, 145. [Google Scholar] [CrossRef]
- Li, F.; Shirahama, K.; Nisar, M.A.; Köping, L.; Grzegorzek, M. Comparison of Feature Learning Methods for Human Activity Recognition Using Wearable Sensors. Sensors 2018, 18, 679. [Google Scholar] [CrossRef]
- Wang, B.; Liu, X.; Yu, B.; Jia, R.; Gan, X. Pedestrian Dead Reckoning Based on Motion Mode Recognition Using a Smartphone. Sensors 2018, 18, 1811. [Google Scholar] [CrossRef]
- Zhou, B.; Yang, J.; Li, Q. Smartphone-Based Activity Recognition for Indoor Localization Using a Convolutional Neural Network. Sensors 2019, 19, 621. [Google Scholar] [CrossRef]
- Ceron, J.D.; López, D.M. Human Activity Recognition Supported on Indoor Localization: A Systematic Review. Stud. Health Technol. Inform. 2018, 249, 93–101. [Google Scholar]
- Wu, J.; Feng, Y.; Sun, P. Sensor Fusion for Recognition of Activities of Daily Living. Sensors 2018, 18, 4029. [Google Scholar] [CrossRef]
- Zhu, Y.; Luo, H.; Wang, Q.; Zhao, F.; Ning, B.; Ke, Q.; Zhang, C. A Fast Indoor/Outdoor Transition Detection Algorithm Based on Machine Learning. Sensors 2019, 19, 786. [Google Scholar] [CrossRef]
- Niitsoo, A.; Edelhäußer, T.; Eberlein, E.; Hadaschik, N.; Mutschler, C. A Deep Learning Approach to Position Estimation from Channel Impulse Responses. Sensors 2019, 19, 1064. [Google Scholar] [CrossRef] [PubMed]
- Manos, A.; Klein, I.; Hazan, T. Gravity-Based Methods for Heading Computation in Pedestrian Dead Reckoning. Sensors 2019, 19, 1170. [Google Scholar] [CrossRef] [PubMed]
- Plötz, T.; Guan, Y. Deep Learning for Human Activity Recognition in Mobile Computing. Computer 2018, 51, 50–59. [Google Scholar] [CrossRef]
- Chen, R.; Chu, T.; Liu, K.; Liu, J.; Chen, Y. Inferring Human Activity in Mobile Devices by Computing Multiple Contexts. Sensors 2015, 15, 21219–21238. [Google Scholar] [CrossRef] [PubMed]
- Nweke, H.F.; Teh, Y.W.; Al-Garadi, M.A.; Alo, U.R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Fan, L.; Wang, Z.; Wang, H. Human Activity Recognition Model Based on Decision Tree. In Proceedings of the 2013 International Conference on Advanced Cloud and Big Data, Nanjing, China, 13–15 December 2013; pp. 64–68. [Google Scholar]
- Akhavian, R.; Behzadan, A.H. Construction equipment activity recognition for simulation input modeling using mobile sensors and machine learning classifiers. Adv. Eng. Inform. 2015, 29, 867–877. [Google Scholar] [CrossRef]
- Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.; Wu, P.; Zhang, J. Convolutional Neural Networks for human activity recognition using mobile sensors. In Proceedings of the 6th International Conference on Mobile Computing, Applications and Services, Austin, TX, USA, 6–7 November 2014; pp. 197–205. [Google Scholar]
- Bayat, A.; Pomplun, M.; Tran, D.A. A Study on Human Activity Recognition Using Accelerometer Data from Smartphones. Procedia Comput. Sci. 2014, 34, 450–457. [Google Scholar] [CrossRef]
- Altun, K.; Barshan, B. Pedestrian dead reckoning employing simultaneous activity recognition cues. Meas. Sci. Technol. 2012, 23, 025103. [Google Scholar] [CrossRef]
- Guo, J.; Zhou, X.; Sun, Y.; Ping, G.; Zhao, G.; Li, Z. Smartphone-Based Patients’ Activity Recognition by Using a Self-Learning Scheme for Medical Monitoring. J. Med. Syst. 2016, 40, 140. [Google Scholar] [CrossRef]
- Kwon, Y.; Kang, K.; Bae, C. Unsupervised learning for human activity recognition using smartphone sensors. Expert Syst. Appl. 2014, 41, 6067–6074. [Google Scholar] [CrossRef]
- Ignatov, A. Real-time human activity recognition from accelerometer data using Convolutional Neural Networks. Appl. Soft Comput. 2018, 62, 915–922. [Google Scholar] [CrossRef]
- Wang, K.; Wang, X.; Lin, L.; Wang, M.; Zuo, W. 3D Human Activity Recognition with Reconfigurable Convolutional Neural Networks. In Proceedings of the 22nd ACM International Conference on Multimedia, Mountain View, CA, USA, 18–19 June 2014; pp. 97–106. [Google Scholar]
- Hammerla, N.Y.; Halloran, S.; Plötz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition using Wearables. arXiv 2016, arXiv:1604.08880. [Google Scholar]
- Morales, F.J.O.; Roggen, D. Deep convolutional feature transfer across mobile activity recognition domains, sensor modalities and locations. In Proceedings of the 2016 ACM International Symposium on Wearable Computers, Heidelberg, Germany, 12–16 September 2016. [Google Scholar]
- Hassan, M.M.; Huda, S.; Uddin, M.Z.; Almogren, A.; Alrubaian, M. Human Activity Recognition from Body Sensor Data using Deep Learning. J. Med. Syst. 2018, 42, 99. [Google Scholar] [CrossRef] [PubMed]
- Hassan, M.M.; Uddin, M.Z.; Mohamed, A.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Future Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Jiang, W.; Yin, Z. Human Activity Recognition Using Wearable Sensors by Deep Convolutional Neural Networks. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1307–1310. [Google Scholar]
- Alsheikh, M.A.; Seleim, A.A.; Niyato, D.; Doyle, L.; Lin, S.; Tan, H.P. Deep Activity Recognition Models with Triaxial Accelerometers. In Proceedings of the Workshops at the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, Arizona, 12–13 February 2016. [Google Scholar]
- Wang, Q.; Ye, L.; Luo, H.; Men, A.; Zhao, F.; Huang, Y. Pedestrian Stride-Length Estimation Based on LSTM and Denoising Autoencoders. Sensors 2019, 19, 840. [Google Scholar] [CrossRef]
- Elhoushi, M.; Georgy, J.; Noureldin, A.; Korenberg, M.J. A Survey on Approaches of Motion Mode Recognition Using Sensors. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1662–1686. [Google Scholar] [CrossRef]
- Fast Fourier Transform. Available online: https://en.wikipedia.org/wiki/Fast_Fourier_transform (accessed on 10 August 2019).
- Huang, H.Y.; Hsieh, C.Y.; Liu, K.C.; Cheng, H.C.; Hsu, S.J.; Chan, C.T. Multi-Sensor Fusion Approach for Improving Map-Based Indoor Pedestrian Localization. Sensors 2019, 19, 3786. [Google Scholar] [CrossRef]
- Guo, S.; Xiong, H.; Zheng, X.; Zhou, Y. Activity Recognition and Semantic Description for Indoor Mobile Localization. Sensors 2017, 17, 649. [Google Scholar] [CrossRef]
- Deng, Z.; Fu, X.; Wang, H. An IMU-Aided Body-Shadowing Error Compensation Method for Indoor Bluetooth Positioning. Sensors 2018, 18, 304. [Google Scholar] [CrossRef]
- Niu, L.; Song, Y.Q. A Faster R-CNN Approach for Extracting Indoor Navigation Graph from Building Designs. In International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences; Copernicus GmbH: Göttingen, Germany, 2019; pp. 865–872. [Google Scholar]
- Wang, Q.; Ye, L.; Luo, H.; Men, A.; Zhao, F.; Ou, C. Pedestrian Walking Distance Estimation Based on Smartphone Mode Recognition. Remote Sens. 2019, 11, 1140. [Google Scholar] [CrossRef]
- Chetty, G.; White, M.; Akther, F. Smart Phone Based Data Mining for Human Activity Recognition. Procedia Comput. Sci. 2015, 46, 1181–1187. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Elhoushi, M.; Georgy, J.; Noureldin, A.; Korenberg, M.J. Motion Mode Recognition for Indoor Pedestrian Navigation Using Portable Devices. IEEE Trans. Instrum. Meas. 2016, 65, 208–221. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition Using Smartphones. In Proceedings of the 21th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, ESANN 2013, Bruges, Belgium, 24–26 April 2013. [Google Scholar]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Type | Definition |
|---|---|---|
| Statistical | Mean | |
| Median | ||
| Root Mean Square | ||
| 75th percentile | percentile , | |
| Variance | ||
| Standard Deviation | ||
| Skewness | ||
| Binned Distribution | bindstbn | |
| Mean Absolute Deviation | ||
| Frequency Domain | Fourier Transform | |
| Short-Time Fourier Transform | ||
| Discrete Cosine Transform | ||
| Continuous Wavelet Transform | ||
| Discrete Wavelet Transform | ||
| Wigner Distribution | ||
| Frequency Domain Entropy | ||
| Energy, Power, Magnitude | Energy | energy |
| Sub-band Energies | energy | |
| Sub-band Energy Ratios | subband energy | |
| Signal Magnitude Area | ||
| Time Domain | Zero-Crossing Rate |
| Actual Mode | Predicted Mode | |||
|---|---|---|---|---|
| Class 1 | Class 2 | Class 3 | Class 4 | |
| Class 1 | ||||
| Class 2 | ||||
| Class 3 | ||||
| Class 4 | ||||
| Measure | Description | Definition |
|---|---|---|
| True Positive | The number of samples of a class that are correctly classified | |
| True Negative | The number of samples of other classes that are correctly classified | |
| False Positive | The number of samples not belonging to a class that are incorrectly classified as belonging to it | |
| False Negative | The number of samples belonging to a class that are incorrectly classified as belonging to other class | |
| Recall | Proportion of cases of a class that are correctly classified | |
| Accuracy | Proportion of all cases that are correctly classified | |
| Precision | Proportion of cases predicted to belong to a class that are correct | |
| F-Score | The weighted average of precision and sensitivity | |
| Sensitivity | The proportion of samples that are correctly classified | Sens |
| AUC | The area under the curve (AUC) combines sensitivity and specificity, reflecting the overall performance of the classification model | refer to [44] |
| Specificity | The proportion of negative samples that are correctly classified to be negative |
| Motion Mode | Navigation Update |
|---|---|
| Stationary | Fix 3D Position |
| Apply ZUPT | |
| Standing on Moving Walkway | Updated 2D Position |
| Walking | Apply PDR (Pedestrian Dead Reckon) |
| Walking on Moving Walkway | Increase 2D Displacement in Direction of Motion |
| Apply PDR | |
| Elevator | Fix 2D Position |
| Update Altitude | |
| Escalator Standing | Update 2D Position |
| Update Altitude | |
| Stairs | Project Displacement to Horizontal Plane |
| Apply PDR | |
| Update Altitude | |
| Escalator Walking | Increase 2D Displacement |
| Project Displacement to Horizontal Plane | |
| Apply PDR | |
| Update Altitude |
| STANDING | SITTING | LAYING | WALKING | DOWNSTAIRS | UPSTAIRS |
|---|---|---|---|---|---|
| 1722 | 1544 | 1406 | 1777 | 1906 | 1944 |
| 16.72% | 14.99% | 13.65% | 17.25% | 18.51% | 18.88% |
| Model | AUC | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|---|
| SGD | 0.664 | 0.446 | 0.427 | 0.419 | 0.446 |
| Naive Bayes | 0.734 | 0.736 | 0.747 | 0.734 | 0.880 |
| DT | 0.850 | 0.748 | 0.746 | 0.745 | 0.748 |
| kNN | 0.895 | 0.707 | 0.706 | 0.806 | 0.707 |
| RF | 0.966 | 0.818 | 0.818 | 0.819 | 0.818 |
| NN | 0.974 | 0.856 | 0.857 | 0.860 | 0.856 |
| SVM | 0.988 | 0.878 | 0.872 | 0.899 | 0.878 |
| Layer (Type) | Output Shape | Parameter |
|---|---|---|
| LSTM | [(None, 128, 32)] | 5376 |
| LSTM | [(None, 128, 32)] | 8320 |
| LSTM | (None,32) | 8320 |
| Dropout | (None, 32) | 0 |
| Dense | (None, 6) | 198 |
| Layer (Type) | Output Shape | Param |
|---|---|---|
| Input Layer | [(None, 128, 9, 1)] | 0 |
| Conv2D | (None, 126, 7, 16) | 160 |
| Batch Normalisation | (None, 126, 7, 16) | 64 |
| Activation | (None, 126, 7, 16) | 0 |
| Conv2D | (None, 126, 7, 16) | 2320 |
| Batch Normalisation | (None, 126, 7, 16) | 64 |
| Activation | (None, 126, 7, 16) | 0 |
| MaxPooling2 | (None, 63, 3, 16) | 0 |
| Conv2D | (None, 61, 1, 32) | 4640 |
| Batch Normalisation | (None, 61, 1, 32) | 128 |
| Activation | (None, 61, 1, 32) | 0 |
| Conv2D | (None, 61, 1, 32) | 9248 |
| Batch Normalisation | (None, 61, 1, 32) | 128 |
| Activation | (None, 61, 1, 32) | 0 |
| Flatten | (None, 1952) | 0 |
| Dense | (None, 128) | 249,984 |
| Batch Normalisation | (None, 128) | 512 |
| Activation | (None, 128) | 0 |
| Dropout | (None, 128) | 0 |
| Dense | (None, 6) | 774 |
| Model | AUC | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|---|
| SGD | 3.882 | 0.108 | 0.075 | 0.080 | 0.108 |
| kNN | 4.259 | 0.190 | 0.186 | 0.183 | 0.190 |
| SVM | 4.867 | 0.185 | 0.181 | 0.208 | 0.185 |
| Naive Bayes | 4.993 | 0.260 | 0.252 | 0.253 | 0.260 |
| DT | 4.660 | 0.310 | 0.307 | 0.308 | 0.310 |
| RF | 5.708 | 0.375 | 0.372 | 0.376 | 0.375 |
| NN | 6.454 | 0.481 | 0.478 | 0.478 | 0.481 |
| Model | AUC | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|---|
| SGD | 4.263 | 0.195 | 0.141 | 0.149 | 0.195 |
| kNN | 4.565 | 0.251 | 0.225 | 0.236 | 0.251 |
| SVM | 4.920 | 0.222 | 0.226 | 0.273 | 0.222 |
| Naive Bayes | 5.959 | 0.304 | 0.291 | 0.290 | 0.304 |
| DT | 5.118 | 0.309 | 0.299 | 0.294 | 0.309 |
| RF | 5.928 | 0.370 | 0.363 | 0.359 | 0.370 |
| NN | 6.171 | 0.473 | 0.449 | 0.465 | 0.473 |
| Model | AUC | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|---|
| SGD | 4.383 | 0.222 | 0.177 | 0.230 | 0.222 |
| SVM | 5.087 | 0.239 | 0.251 | 0.330 | 0.239 |
| Naive Bayes | 6.691 | 0.422 | 0.408 | 0.410 | 0.422 |
| DT | 6.160 | 0.601 | 0.599 | 0.603 | 0.601 |
| kNN | 6.499 | 0.647 | 0.639 | 0.671 | 0.647 |
| RF | 7.390 | 0.723 | 0.724 | 0.726 | 0.723 |
| NN | 7.046 | 0.722 | 0.714 | 0.747 | 0.722 |
| Model | AUC | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|---|
| SGD | 4.034 | 0.143 | 0.114 | 0.197 | 0.143 |
| SVM | 5.548 | 0.253 | 0.249 | 0.324 | 0.253 |
| Naive Bayes | 6.027 | 0.344 | 0.338 | 0.337 | 0.344 |
| DT | 6.245 | 0.640 | 0.638 | 0.640 | 0.640 |
| RF | 7.233 | 0.703 | 0.701 | 0.703 | 0.703 |
| NN | 7.463 | 0.741 | 0.739 | 0.741 | 0.741 |
| kNN | 7.179 | 0.755 | 0.755 | 0.757 | 0.755 |
| Model | AUC | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|---|
| SGD | 4.182 | 0.176 | 0.156 | 0.154 | 0.176 |
| SVM | 5.240 | 0.193 | 0.180 | 0.251 | 0.193 |
| Naive Bayes | 6.311 | 0.392 | 0.381 | 0.378 | 0.392 |
| DT | 6.672 | 0.729 | 0.729 | 0.730 | 0.729 |
| kNN | 7.227 | 0.770 | 0.770 | 0.773 | 0.770 |
| RF | 7.530 | 0.809 | 0.809 | 0.810 | 0.809 |
| NN | 7.608 | 0.814 | 0.814 | 0.816 | 0.814 |
| Accuracy | Precision | Recall | F1-Score Score | |
|---|---|---|---|---|
| Test Results | 90.74% | 90.97% | 90.74% | 90.71% |
| Accuracy | Precision | Recall | F1-Score Score | |
|---|---|---|---|---|
| Test Results | 91.92% | 92.79% | 91.85% | 91.77% |
| Accuracy | Precision | Recall | F1-Score Score | |
|---|---|---|---|---|
| Test Results | 85.77% | 85.67% | 85.68% | 85.66% |
| Accuracy | Precision | Recall | F1-Score Score | |
|---|---|---|---|---|
| Test Results | 93.69% | 93.90% | 93.69% | 93.71% |
| Accuracy | Precision | Recall | F1-Score Score | |
|---|---|---|---|---|
| Test Results | 95.55% | 96.04% | 95.54% | 95.63% |
| Accuracy | Precision | Recall | F1-Score Score | |
|---|---|---|---|---|
| Test Results | 79.82% | 79.82% | 75.62% | 78.35% |
| Accuracy | Precision | Recall | F1-Score Score | |
|---|---|---|---|---|
| Test Results | 89.39% | 89.39% | 87.15% | 89.27% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, J.; Li, X.; Zhang, X.; Zhang, Q.; Chen, W. Deep Learning-Based Human Activity Real-Time Recognition for Pedestrian Navigation. Sensors 2020, 20, 2574. https://doi.org/10.3390/s20092574
Ye J, Li X, Zhang X, Zhang Q, Chen W. Deep Learning-Based Human Activity Real-Time Recognition for Pedestrian Navigation. Sensors. 2020; 20(9):2574. https://doi.org/10.3390/s20092574
Chicago/Turabian StyleYe, Junhua, Xin Li, Xiangdong Zhang, Qin Zhang, and Wu Chen. 2020. "Deep Learning-Based Human Activity Real-Time Recognition for Pedestrian Navigation" Sensors 20, no. 9: 2574. https://doi.org/10.3390/s20092574
APA StyleYe, J., Li, X., Zhang, X., Zhang, Q., & Chen, W. (2020). Deep Learning-Based Human Activity Real-Time Recognition for Pedestrian Navigation. Sensors, 20(9), 2574. https://doi.org/10.3390/s20092574