Aerial Laser Scanning Data as a Source of Terrain Modeling in a Fluvial Environment: Biasing Factors of Terrain Height Accuracy




Abstract
1. Introduction
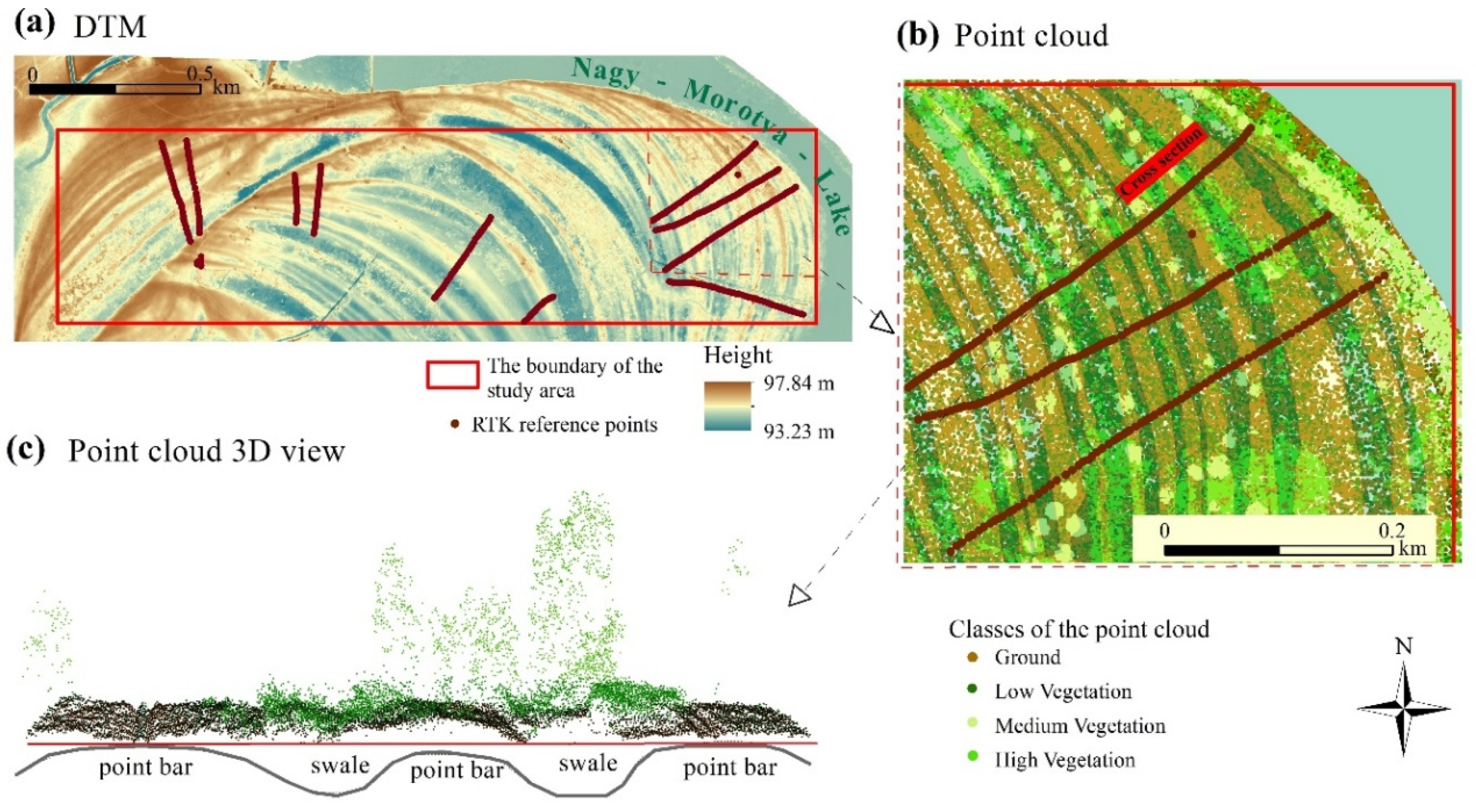
2. Study Area and Topographic Characterization
3. Materials and Methods
3.1. Aerial LiDAR Dataset
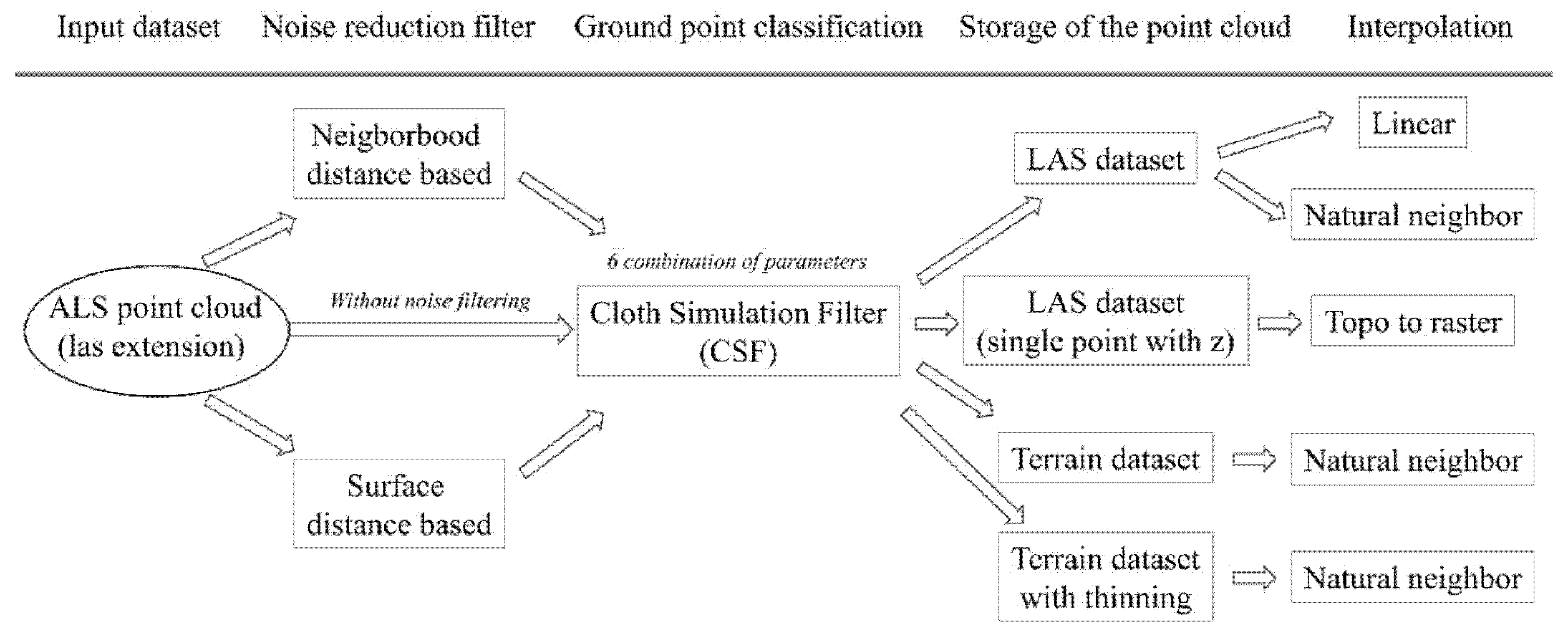
3.2. Data Preparation
3.2.1. Neighborhood Distance-Based Filter
3.2.2. Surface Distance-Based Filter
3.2.3. Ground Point Classification
3.3. DTM Generation
3.4. Validation and Statistics Analyses
- -
- df: degree of freedom
- -
- F: F-statistic
- -
- p: significance
- -
- pmc: Monte Carlo simulation based p-value (significance)
- -
- Q: Q-statistic for 2-way ANOVA (analysis of variance)
- -
- r: Spearman correlation
- -
- W: Wilcoxon test statistic
- -
- z: z-score
4. Results
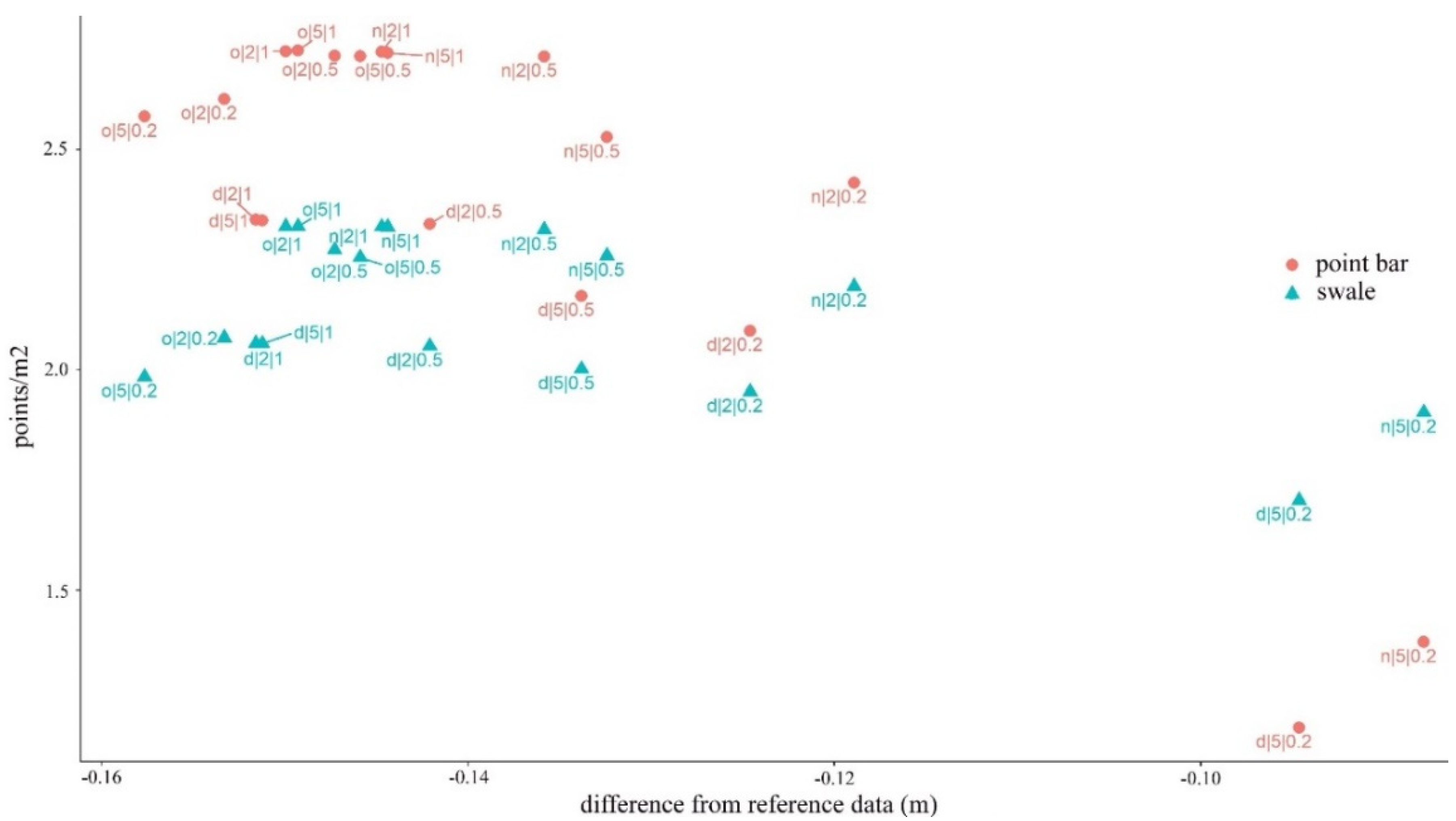
4.1. Number of Points and Accuracy
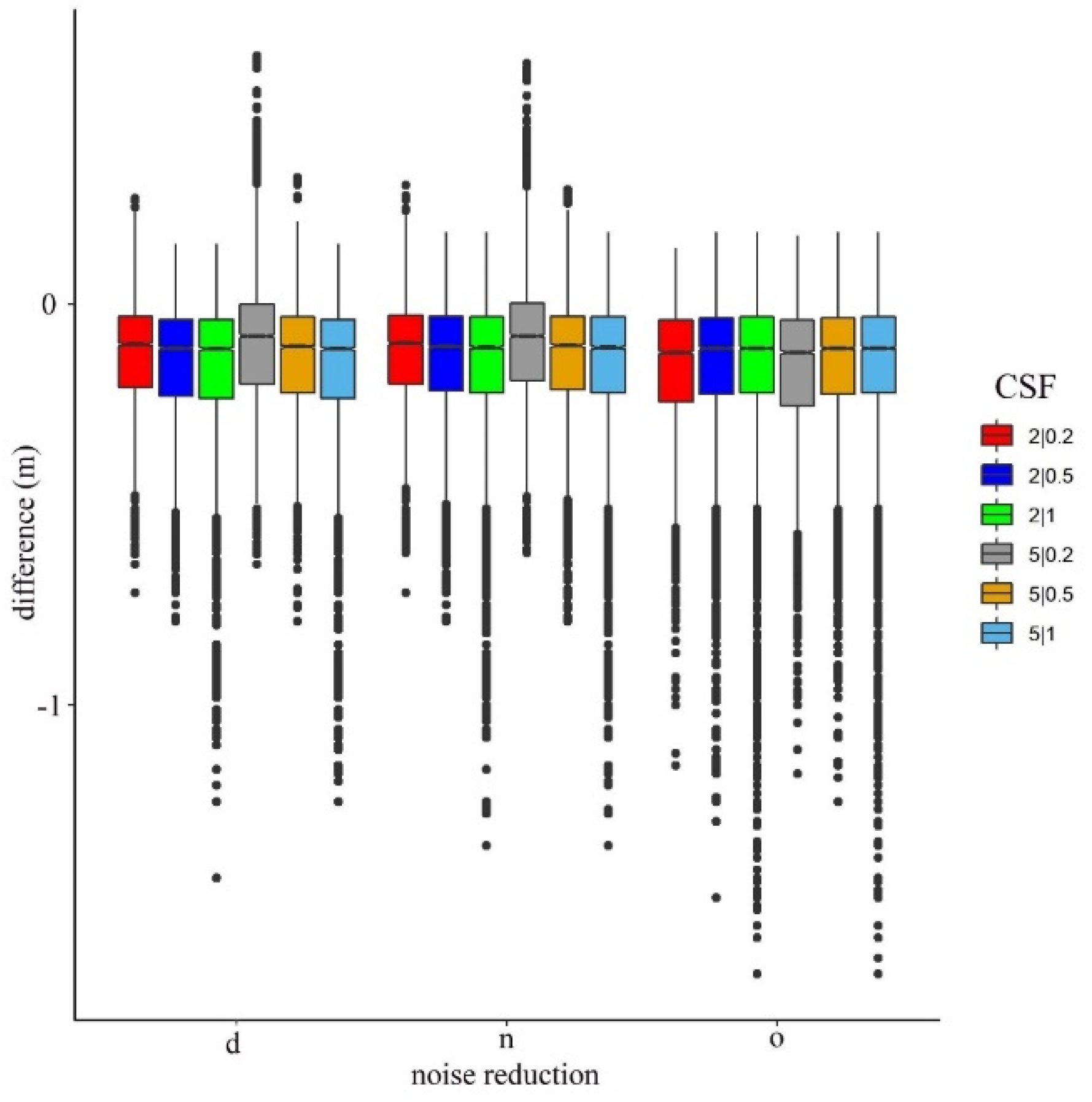
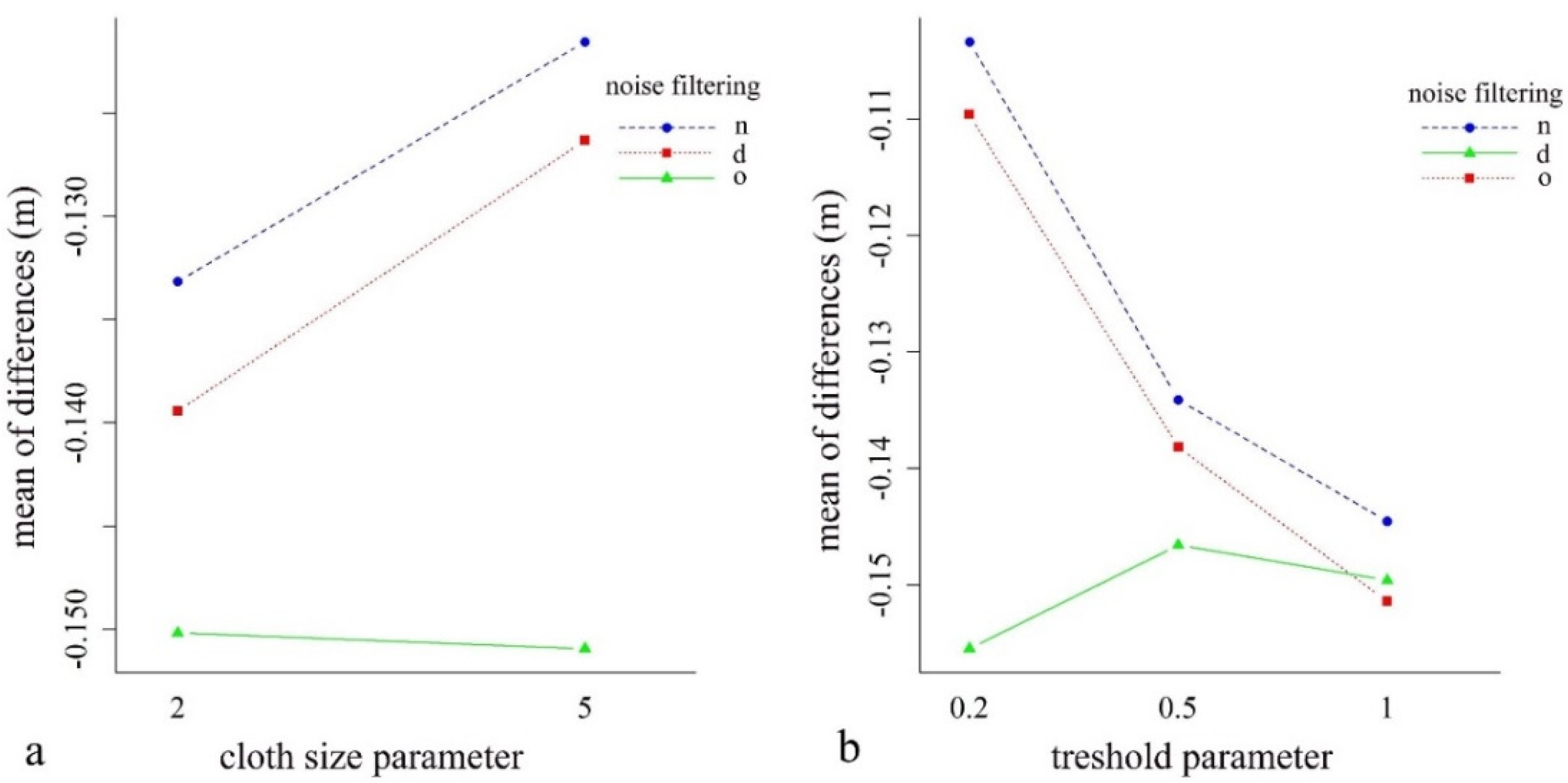
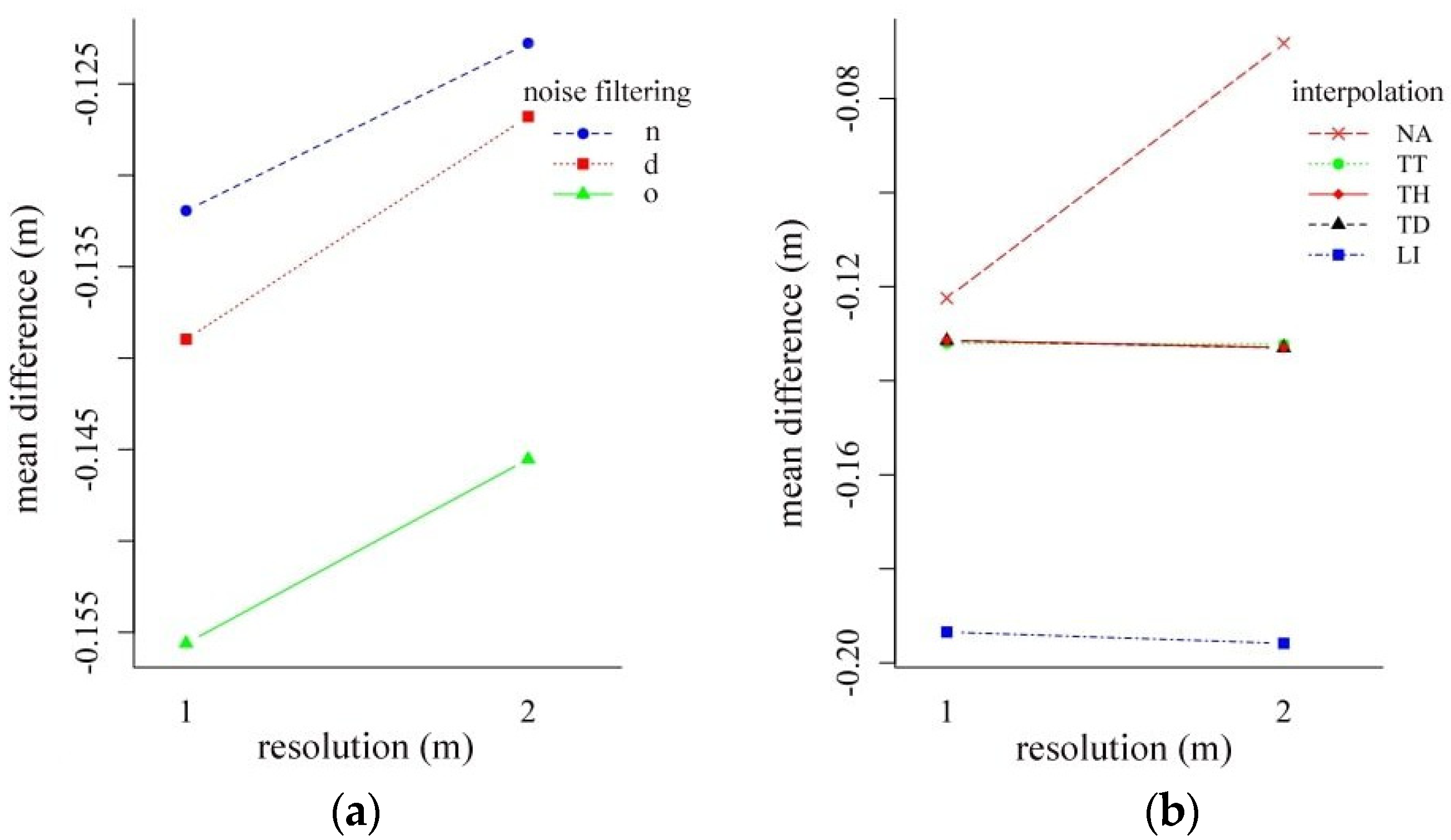
4.2. Effect of Noise Reduction and the CSF Parameters
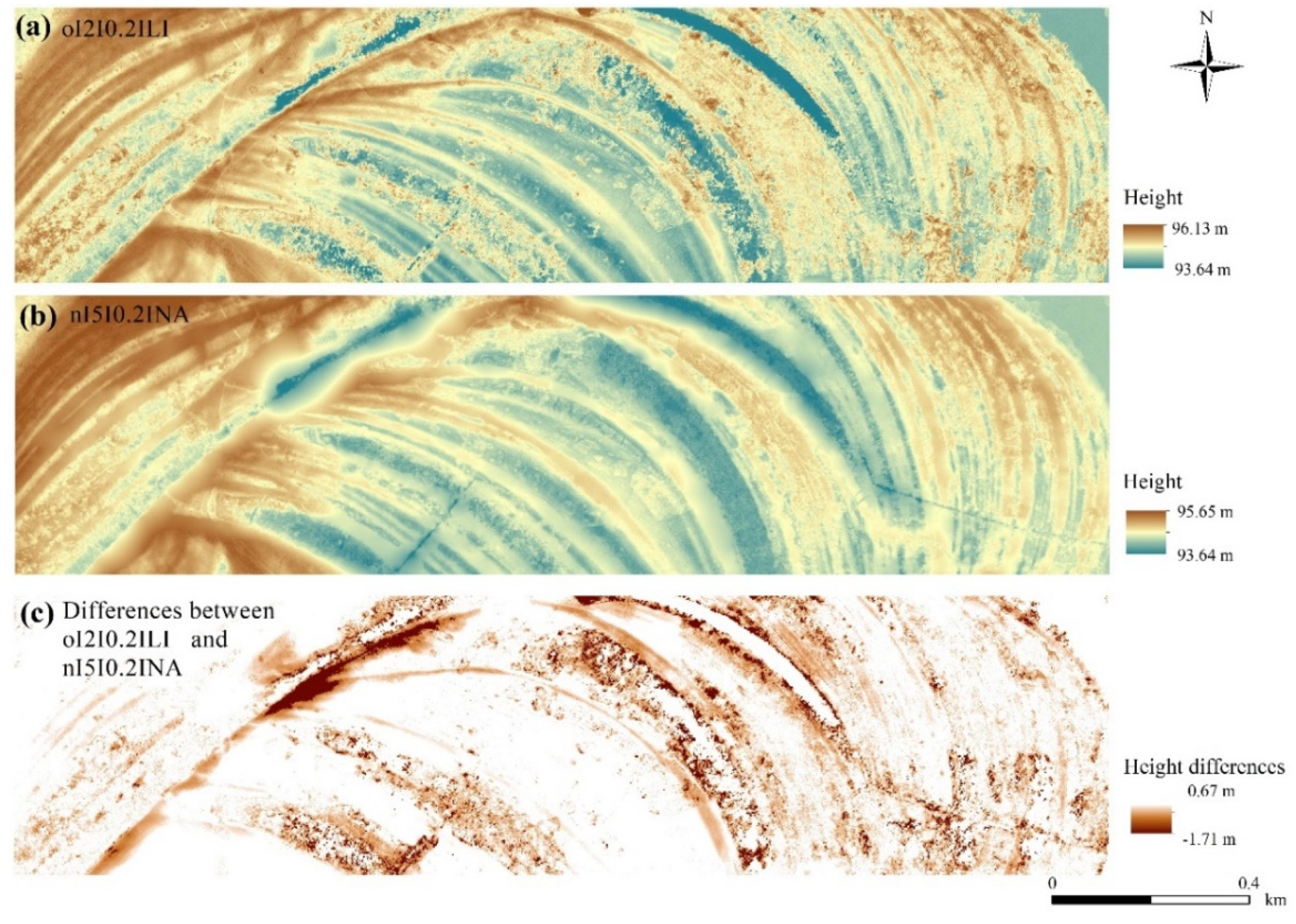
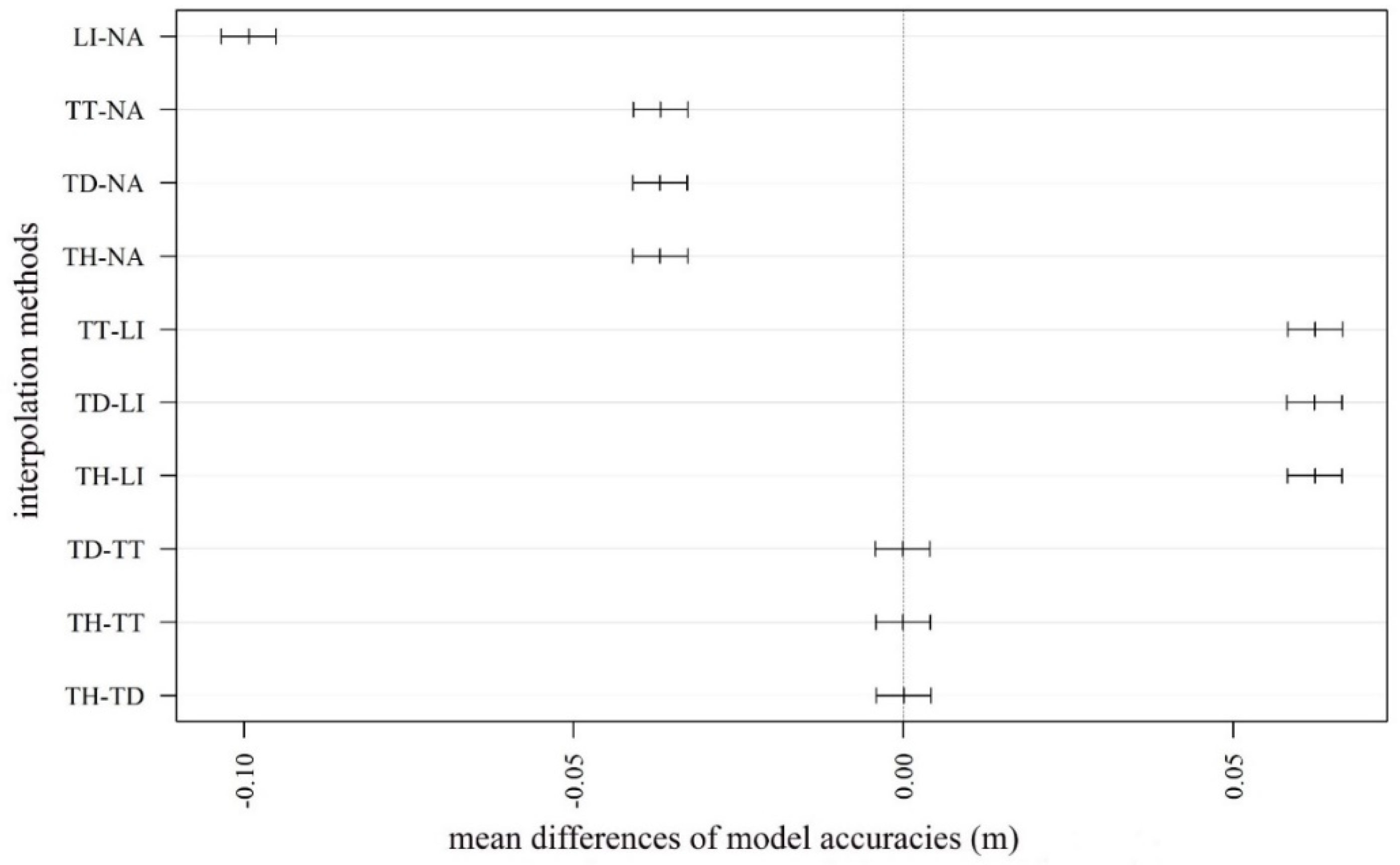
4.3. Consequences of the Interpolation Algorithms
4.4. Effect of the Resolution on the Accuracy
4.5. Effects of the Noise Reduction and the Ground Point Classification on the Fluvial Forms
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, Z.; Zhu, Q.; Gold, C. Digital Terrain Modeling: Principles and Methodology; CRC Press: New York, NY, USA, 2004; ISBN 9780203486740. [Google Scholar]
- Mason, D.C.; Garcia-Pintado, J.; Cloke, H.L.; Dance, S.L. The potential of flood forecasting using a variable-resolution global digital terrain model and flood extents from synthetic aperture radar images. Front. Earth Sci. 2015, 3, 1–14. [Google Scholar] [CrossRef]
- Tarolli, P.; Arrowsmith, J.R.; Vivoni, E.R. Understanding earth surface processes from remotely sensed digital terrain models. Geomorphology 2009, 113, 1–3. [Google Scholar] [CrossRef]
- Ramos, J.; Marrufo, L.; González, F. Use of Lidar data in floodplain risk management planning: The experiene of Tabasco 2007 flood. Intech 2009, 659–678. [Google Scholar]
- Gesch, D.; Palaseanu-Lovejoy, M.; Danielson, J.; Fletcher, C.; Kottermair, M.; Barbee, M.; Jalandoni, A. Inundation Exposure Assessment for Majuro Atoll, Republic of the Marshall Islands Using A High-Accuracy Digital Elevation Model. Remote Sens. 2020, 12, 154. [Google Scholar] [CrossRef]
- Deshpande, S.S. Improved Floodplain Delineation Method Using High-Density LiDAR Data. Comput. Civ. Infrastruct. Eng. 2013, 28, 68–79. [Google Scholar] [CrossRef]
- Darmawan, H.; Walter, T.R.; Brotopuspito, K.S.; Subandriyo, S.; Nandaka, M.A. Morphological and structural changes at the Merapi lava dome monitored in 2012–15 using unmanned aerial vehicles (UAVs). J. Volcanol. Geotherm. Res. 2018, 349, 256–267. [Google Scholar] [CrossRef]
- Palaseanu-Lovejoy, M.; Bisson, M.; Spinetti, C.; Buongiorno, M.F.; Alexandrov, O.; Cecere, T. High-resolution and accurate topography reconstruction of Mount Etna from pleiades satellite data. Remote Sens. 2019, 11, 2983. [Google Scholar] [CrossRef]
- Bertalan, L.; Túri, Z.; Szabó, G. UAS photogrammetry and object-based image analysis (GEOBIA): Erosion monitoring at the Kazár badland, Hungary. Landsc. Environ. 2016, 10, 169–178. [Google Scholar] [CrossRef]
- Casula, G.; Mora, P.; Bianchi, M.G. Detection of terrain morphologic features using GPS, TLS, and land surveys: “Tana della Volpe” blind valley case study. J. Surv. Eng. 2010, 136, 132–138. [Google Scholar] [CrossRef]
- Carrara, A.; Bitelli, G.; Carla, R. Comparison of techniques for generating digital terrain models from contour lines. Int. J. Geogr. Inf. Sci. 1997, 11, 451–473. [Google Scholar] [CrossRef]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital terrain modelling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Chen, Z.; Gao, B.; Devereux, B. State-of-the-art: DTM generation using airborne LIDAR data. Sensors 2017, 17, 150. [Google Scholar] [CrossRef] [PubMed]
- Mallet, C.; Bretar, F. Full-waveform topographic lidar: State-of-the-art. ISPRS Int. J. Geo-Information 2009, 64, 1–16. [Google Scholar] [CrossRef]
- Szabo, Z.; Aletta, S.; Zoltán, T.; Szabo, S. A Review of Climatic and Vegetation Surveys in Urban Environment with Laser Scanning: A Literature-based Analysis. Geogr. Pannonica 2019, 23, 411–421. [Google Scholar] [CrossRef]
- Lloyd, C.; Atkinson, P.M. Deriving ground surface digital elevation models from LiDAR data with geostatistics. Int. J. Geogr. Inf. Sci. 2006, 20, 535–563. [Google Scholar] [CrossRef]
- Thiel, K.; Wehr, A. Performance Capabilities of Laser Scanners—An Overview and Measurement Principle Analysis. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, XXXVI, 14–18. [Google Scholar]
- Dewitt, J.D.; Warner, T.A.; Conley, J.F. Comparison of DEMS derived from USGS DLG, SRTM, a statewide photogrammetry program, ASTER GDEM and LiDAR: Implications for change detection. GIScience Remote Sens. 2015, 52, 179–197. [Google Scholar] [CrossRef]
- Hu, C.; Pan, Z.; Li, P. A 3D point cloud filtering method for leaves based on manifold distance and normal estimation. Remote Sens. 2019, 11, 198. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Marton, Z.; Soos, A.; Beetz, M. Towards 3D object maps for autonomous household robots. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 3191–3198. [Google Scholar]
- Höhle, J.; Höhle, M. Accuracy assessment of digital elevation models by means of robust statistical methods. ISPRS J. Photogramm. Remote Sens. 2009, 64, 398–406. [Google Scholar] [CrossRef]
- Carrilho, A.C.; Galo, M.; Dos Santos, R.C. Statistical outlier detection method for airborne LiDAR data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-ISPRS Arch. 2018, 42, 87–92. [Google Scholar] [CrossRef]
- Axelsson, P. DEM generation from laser scanner data using adaptive TIN models. Int. Arch. Photogramm. Remote Sens. 2000, 33, 110–117. [Google Scholar]
- Vosselman, G. Slope based filtering of laser altimetry data. Int. Arch. Photogramm. Remote Sens. 2000, 33, 678–684. [Google Scholar]
- Evans, J.S.; Hudak, A.T.; Faux, R.; Smith, A.M.S. Discrete return lidar in natural resources: Recommendations for project planning, data processing, and deliverables. Remote Sens. 2009, 1, 776–794. [Google Scholar] [CrossRef]
- Zhang, K.; Chen, S.C.; Whitman, D.; Shyu, M.L.; Yan, J.; Zhang, C. A progressive morphological filter for removing nonground measurements from airborne LIDAR data. IEEE Trans. Geosci. Remote Sens. 2003, 41, 872–882. [Google Scholar] [CrossRef]
- Tóvári, D.; Pfeifer, N. Segmentation based robust interpolation—A new approach to laser data filtering. In Proceedings of the ISPRS Workshop Laser Scanning 2005, Enschede, The Netherlands, 12–15 September 2005; pp. 79–84. [Google Scholar]
- Meng, X.; Lin, Y.; Yan, L.; Gao, X.; Yao, Y.; Wang, C. Airborne LiDAR Point Cloud Filtering by a Multilevel Adaptive Filter Based on Morphological Reconstruction and Thin Plate Spline Interpolation. Electronics 2019, 8, 1153. [Google Scholar] [CrossRef]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An easy-to-use airborne LiDAR data filtering method based on cloth simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Python Software Foundation Python: A Dynamic, Open Source Programming Language. 2019. Available online: https://www.python.org/ (accessed on 1 April 2020).
- CloudCompare GPL Software (Version 2.10.2) 2019. Available online: http://www.cloudcompare.org/ (accessed on 1 April 2020).
- Ward, J.V.; Tockner, K.; Arscott, D.B.; Claret, C. Riverine landscape diversity. Freshw. Biol. 2002, 47, 517–539. [Google Scholar] [CrossRef]
- Everson, D.A.; Boucher, D.H. Tree species-richness and topographic complexity along the riparian edge of the Potomac River. For. Ecol. Manage. 1998, 109, 305–314. [Google Scholar] [CrossRef]
- William, M.; Lewis, J.; Hamilton, K.S.; Margaret, A.L.; Marco, R.; Saunders, J.F., III. Ecological determinism on the Orinoco Floodplain. Bioscience 2000, 50, 1049–1061. [Google Scholar]
- Szabó, Z.; Buró, B.; Szabó, J.; Tóth, C.A.; Baranyai, E.; Herman, P.; Prokisch, J.; Tomor, T.; Szabó, S. Geomorphology as a driver of heavy metal accumulation patterns in a floodplain. Water 2020, 12, 563. [Google Scholar] [CrossRef]
- Hamilton, S.K.; Kellndorfer, J.; Lehner, B.; Tobler, M. Remote sensing of floodplain geomorphology as a surrogate for biodiversity in a tropical river system (Madre de Dios, Peru). Geomorphology 2007, 89, 23–38. [Google Scholar] [CrossRef]
- Hawker, L.; Bates, P.; Neal, J.; Rougier, J. Perspectives on Digital Elevation Model (DEM) Simulation for Flood Modeling in the Absence of a High-Accuracy Open Access Global DEM. Front. Earth Sci. 2018, 6, 1–9. [Google Scholar] [CrossRef]
- Tarolli, P. High-resolution topography for understanding Earth surface processes: Opportunities and challenges. Geomorphology 2014, 216, 295–312. [Google Scholar] [CrossRef]
- Heritage, G.; Entwistle, N.S.; Bentley, S. Floodplains: The forgotten and abused component of the fluvial system. E3S Web Conf. 2016, 7, 4–9. [Google Scholar] [CrossRef]
- Bentley, S.; England, J.; Heritage, G.; Reid, H.; Mould, D.; Bithell, C. Long-reach biotope mapping: Deriving low flow hydraulic habitat from aerial imagery. River Res. Appl. 2016. [Google Scholar] [CrossRef]
- Van Iersel, W.K.; Straatsma, M.W.; Addink, E.A.; Middelkoop, H. Monitoring phenology of floodplain grassland and herbaceous vegetation with UAV imagery. In Proceedings of the The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Prague, Czech Republic, 12–19 July 2016; Volume XLI-B7, pp. 569–571. [Google Scholar]
- Giglierano, J.D. LiDAR basics for natural resource mapping applications. Geol. Soc. Spec. Publ. 2010, 345, 103–115. [Google Scholar] [CrossRef]
- Milan, D.J.; Heritage, G.L.; Large, A.R.G.; Entwistle, N.S. Mapping hydraulic biotopes using terrestrial laser scan data of water surface properties. Earth Surf. Process. Landforms 2010, 35, 918–931. [Google Scholar] [CrossRef]
- French, J.R. Airborne LiDAR in support of geomorphological and hydraulic modelling. Earth Surf. Process. Landforms 2003, 28, 321–335. [Google Scholar] [CrossRef]
- Hickin, E.J. The development of meanders in natural river-channels. Am. J. Sci. 1974, 274, 414–442. [Google Scholar] [CrossRef]
- Nanson, G.C. Point bar and floodplain formation of the meandering Beatton River, northeastern British Columbia, Canada. Sedimentology 1980, 27, 3–29. [Google Scholar] [CrossRef]
- Allen, J.R. A review of the origin and characteristics of recent alluvial sediments. Sedimentology 1965, 5, 89–191. [Google Scholar] [CrossRef]
- Stereńczak, K.; Ciesielski, M.; Bałazy, R.; Zawiła-Niedźwiecki, T. Comparison of various algorithms for DTM interpolation from LIDAR data in dense mountain forests. Eur. J. Remote Sens. 2016, 49, 599–621. [Google Scholar] [CrossRef]
- Zhu, Y.; Liu, X.; Zhao, J.; Cao, J.; Wang, X.; Li, D. Effect of DEM interpolation neighbourhood on terrain factors. ISPRS Int. J. Geo-Inf. 2019, 8, 30. [Google Scholar] [CrossRef]
- Szabó, Z.; Tóth, C.A.; Tomor, T.; Szabó, S. Airborne LiDAR point cloud in mapping of fluvial forms: A case study of a Hungarian floodplain. GIScience Remote Sens. 2017, 54, 862–880. [Google Scholar] [CrossRef]
- SH/2/6—Swiss-Hungarian Programme Edited by Envirosense Hungary Kft. Updating the Flood Protection Plans for Sections of the River Tisza under the Management of the Environmental and Water Management Directorate of the Tiszántúl Region and the North Hungarian Environment and Water Directorate. Debrecen 2013, 77. Available online: https://core.ac.uk/download/ pdf/43668713.pdf (accessed on 1 April 2020).
- ESRI. Arcgis Desktop: Release 10.5; Environmental Systems Research Institute: Redlands, CA, USA, 2014. [Google Scholar]
- Sibson, R. A brief description of natural neighbour interpolation. In Geostatistics for Natural Environmental Scientists; Webster, R., Oliver, M., Eds.; Wiley: Hoboken, NJ, USA, 2001; ISBN 0-471-96553-7-1981. [Google Scholar]
- Hutchinson, M.F.; Stein, J.A.; Stein, J.L.; Xu, T. Locally adaptive gridding of noisy high resolution topographic data. In Proceedings of the 18th World IMACS Congress and MODSIM09 International Congress on Modelling and Simulation: Interfacing Modelling and Simulation with Mathematical and Computational Sciences, Cairns, Australia, 13–17 July 2009; pp. 2493–2499. [Google Scholar]
- Hutchinson, M.F.; Xu, T.; Stein, J.A. Recent Progress in the ANUDEM Elevation Gridding Procedure. In Proceedings of the Geomorphometry 2011, Redlands, CA, USA, 7–11 September 2011; pp. 19–22. [Google Scholar]
- Field, A. Discovering Statistics Using SPSS; SAGE Publications: London, UK, 2009; ISBN 9781847879066. [Google Scholar]
- Salkind, N. Encyclopedia of Research Design; SAGE Publications: London, UK; ISBN 9781412961288-2010.
- Efron, B.; Tibshirani, R. Monographs on Statistics and Applied Probability 57. An Introduction to the Bootstrap; Chapman & Hall: London, UK, 1993; ISBN 0-412-04231-2. [Google Scholar]
- Field, A. Discovering Statistics Using IBM SPSS Statistics, 4th ed.; SAGE Publications Ltd.: Thousand Oaks, CA, USA, 2013; ISBN 978-9351500827. [Google Scholar]
- R Core Team R. 3.53 Statistical Software. In A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019; Available online: https://www.R-project.org (accessed on 1 April 2020).
- Hothorn, T.; Hornik, K.; Van De Wiel, M.A.; Zeileis, A. A lego system for conditional inference. Am. Stat. 2006, 60, 257–263. [Google Scholar] [CrossRef]
- Dag, O.; Dolgun, A.; Konar, N.M. Onewaytests: An R package for one-way tests in independent groups designs. R J. 2018, 10, 175–199. [Google Scholar] [CrossRef]
- Mair, P.; Wilcox, R. Robust statistical methods in R using the WRS2 package. Behav. Res. Methods 2019. [Google Scholar] [CrossRef]
- Enyedi, P.; Pap, M.; Kovács, Z.; Takács-Szilágyi, L.; Szabó, S. Efficiency of local minima and GLM techniques in sinkhole extraction from a LiDAR-based terrain model. Int. J. Digit. Earth 2018, 8947. [Google Scholar] [CrossRef]
- Alexander, C.; Deák, B.; Kania, A.; Mücke, W.; Heilmeier, H. Classification of vegetation in an open landscape using full-waveform airborne laser scanner data. Int. J. Appl. Earth Obs. Geoinf. 2015, 41, 76–87. [Google Scholar] [CrossRef]
- Sailer, R.; Rutzinger, M.; Rieg, L.; Wichmann, V. Digital elevation models derived from airborne laser scanning point clouds: Appropriate spatial resolutions for multi-temporal characterization and quantification of geomorphological processes. Earth Surf. Process. Landforms 2014, 39, 272–284. [Google Scholar] [CrossRef]
- Parrot, J.F.; Ramírez Núñez, C. LiDAR DTM: Artifacts, and correction for river altitudes. Investig. Geogr. 2016, 90, 28–39. [Google Scholar]
- Pirotti, F.; Tarolli, P. Suitability of LiDAR point density and derived landform curvature maps for channel network extraction. Hydrol. Process. 2010, 24, 1187–1197. [Google Scholar] [CrossRef]
- Yilmaz, M.; Uysal, M. Comparison of data reduction algorithms for LiDAR-derived digital terrain model generalisation. Area 2016, 48, 521–532. [Google Scholar] [CrossRef]
- Jones, A.F.; Brewer, P.A.; Johnstone, E.; Macklin, M.G. High-resolution interpretative geomorphological mapping of river valley environments using airborne LiDAR data. Earth Surf. Process. Landforms 2007, 32, 1574–1592. [Google Scholar] [CrossRef]
- Anderson, E.S.; Thompson, J.A.; Austin, R.E. LIDAR density and linear interpolator effects on elevation estimates. Int. J. Remote Sens. 2005, 26, 3889–3900. [Google Scholar] [CrossRef]
- Bater, C.W.; Coops, N.C. Evaluating error associated with lidar-derived DEM interpolation. Comput. Geosci. 2009, 35, 289–300. [Google Scholar] [CrossRef]
- GRASS GIS. GRASS Development Team Geographic Resources Analysis Support System (GRASS) Software, Version 7.2; Open Source Geospatial Foundation: Beaverton, OR, USA, 2017. [Google Scholar]
- SADA project Team SADA 2009. Spatial Analysis and Decision Assistance, University of Tennessee Research Corporation. Available online: https://www.sadaproject.net/ (accessed on 1 April 2020).
- Golden Software LLC. Surfer Golden Software Surfer® 16 from Golden Software; Golden Software LLC: Golden, CO, USA, 2016. [Google Scholar]
- Gebhardt, A.; Bivand, R.; Sinclair, D. R Topics Documented: Package ‘Interp’. Available online: https://cran.r-project.org/web/packages/interp/interp.pdf (accessed on 1 April 2020).
- Park, S.W.; Linsen, L.; Kreylos, O.; Owens, J.D.; Hamann, B. Discrete sibson interpolation. IEEE Trans. Vis. Comput. Graph. 2006, 12, 243–252. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Designed point density | 4 pts/m2 |
| Average accuracy (horizontal and vertical) | ±0.15 m |
| Overlap | 30–60% |
| Pulse repetition rate | 270 kHz |
| Registration | discrete return |
| Laser wavelength | 1550 nm |
| AGL height | 688 m |
| Extent of the surveyed area | 126 ha |
| Filtering Method | Noise Reduction | CSF Parameters (CS; Thd) | Point Number | Accuracy (mean ± SD; m) |
|---|---|---|---|---|
| Original point cloud | - | - | 10,120,880 | −0.15 ± 0.17 |
| Noise filter | d | - | 8,718,994 | −0.13 ± 0.15 |
| n | - | 10,073,485 | −0.12 ± 0.15 | |
| Ground point filter | d | 2; 1 | 6,943,468 | −0.15 ± 0.17 |
| d | 2; 0.2 | 5,199,607 | −0.12 ± 0.13 | |
| d | 2; 0.5 | 6,375,149 | −0.14 ± 0.14 | |
| d | 5; 1 | 6,875,994 | −0.15 ± 0.17 | |
| d | 5; 0.2 | 3,720,552 | −0.09 ± 0.16 | |
| d | 5; 0.5 | 5,905,299 | −0.13 ± 0.14 | |
| n | 2; 1 | 8,050,253 | −0.14 ± 0.16 | |
| n | 2; 0.2 | 5,958,207 | −0.12 ± 0.13 | |
| n | 2; 0.5 | 7,395,394 | −0.14 ± 0.14 | |
| n | 5; 1 | 7,971,242 | −0.14 ± 0.16 | |
| n | 5; 0.2 | 4,246,638 | −0.09 ± 0.16 | |
| n | 5; 0.5 | 6,842,756 | −0.13 ± 0.14 | |
| o | 2; 1 | 8,293,970 | −0.15 ± 0.18 | |
| o | 2; 0.2 | 6,999,426 | −0.15 ± 0.16 | |
| o | 2; 0.5 | 7,837,259 | −0.15 ± 0.16 | |
| o | 5; 1 | 8,287,750 | −0.15 ± 0.18 | |
| o | 5; 0.2 | 6,729,067 | −0.16 ± 0.16 | |
| o | 5; 0.5 | 7,781,547 | −0.15 ± 0.16 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Szabó, Z.; Tóth, C.A.; Holb, I.; Szabó, S. Aerial Laser Scanning Data as a Source of Terrain Modeling in a Fluvial Environment: Biasing Factors of Terrain Height Accuracy. Sensors 2020, 20, 2063. https://doi.org/10.3390/s20072063
Szabó Z, Tóth CA, Holb I, Szabó S. Aerial Laser Scanning Data as a Source of Terrain Modeling in a Fluvial Environment: Biasing Factors of Terrain Height Accuracy. Sensors. 2020; 20(7):2063. https://doi.org/10.3390/s20072063
Chicago/Turabian StyleSzabó, Zsuzsanna, Csaba Albert Tóth, Imre Holb, and Szilárd Szabó. 2020. "Aerial Laser Scanning Data as a Source of Terrain Modeling in a Fluvial Environment: Biasing Factors of Terrain Height Accuracy" Sensors 20, no. 7: 2063. https://doi.org/10.3390/s20072063
APA StyleSzabó, Z., Tóth, C. A., Holb, I., & Szabó, S. (2020). Aerial Laser Scanning Data as a Source of Terrain Modeling in a Fluvial Environment: Biasing Factors of Terrain Height Accuracy. Sensors, 20(7), 2063. https://doi.org/10.3390/s20072063