An Improved Method for Road Extraction from High-Resolution Remote-Sensing Images that Enhances Boundary Information


Abstract
1. Introduction
2. Materials and Methods
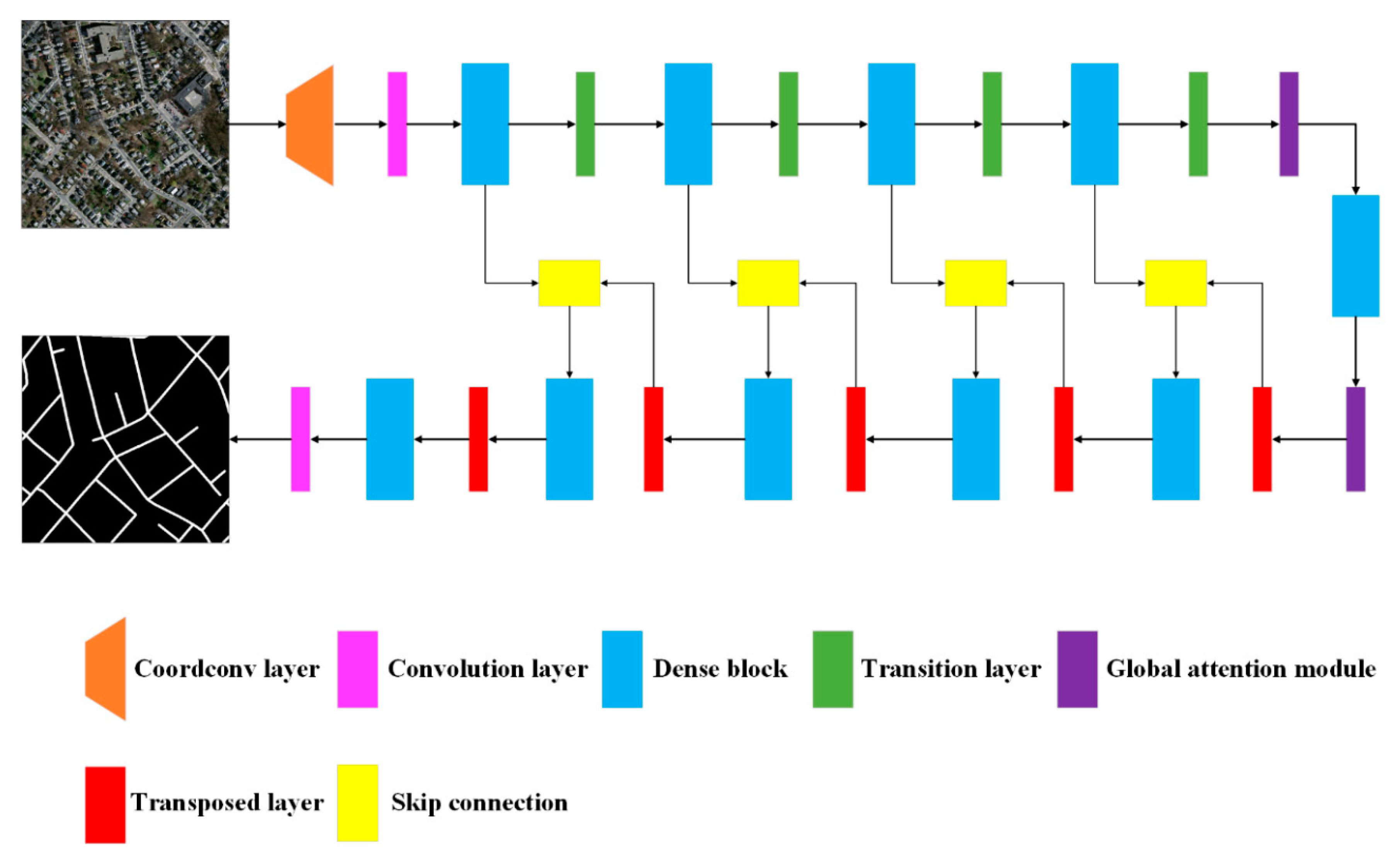
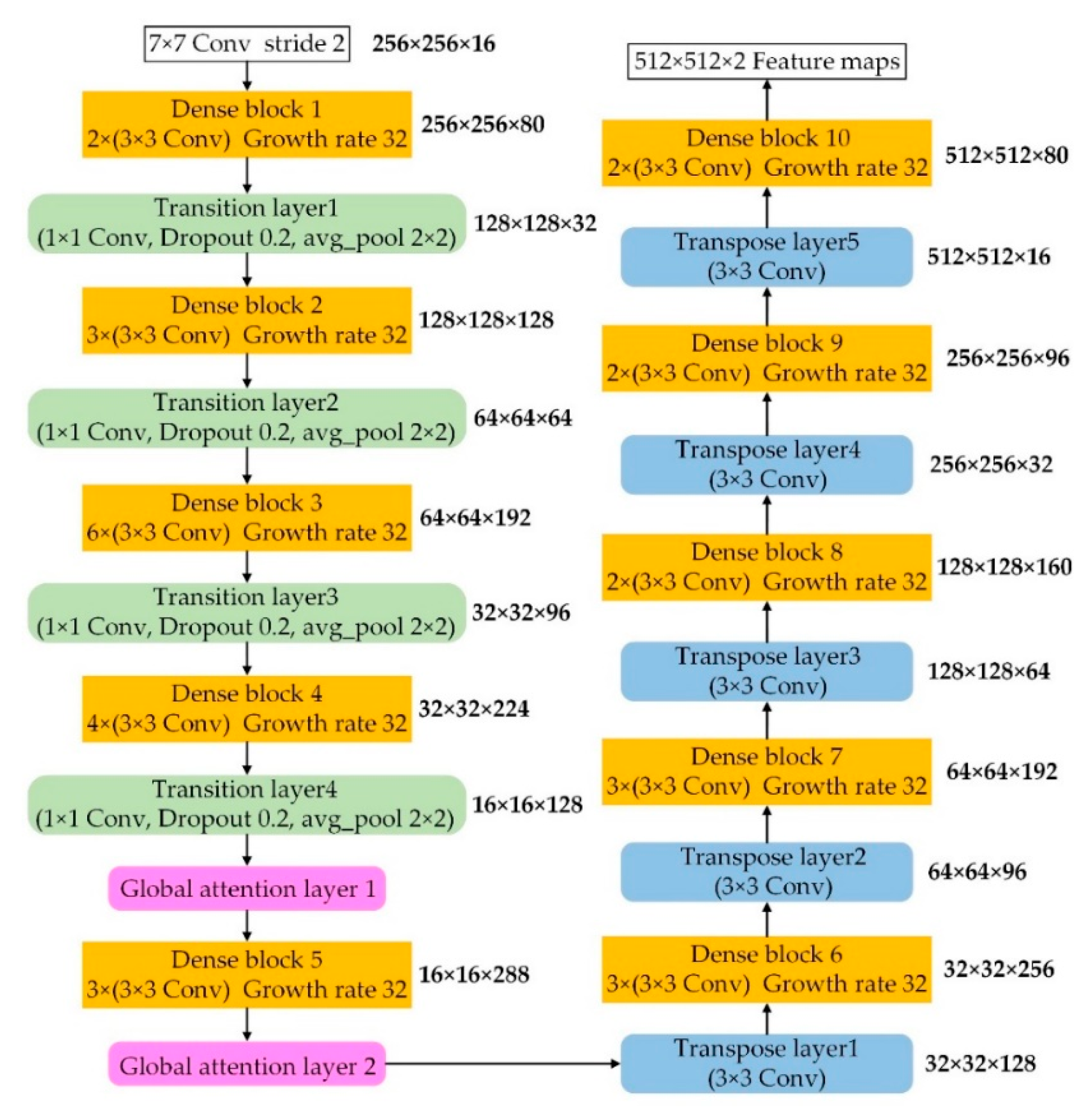
2.1. Proposed Network Architecture
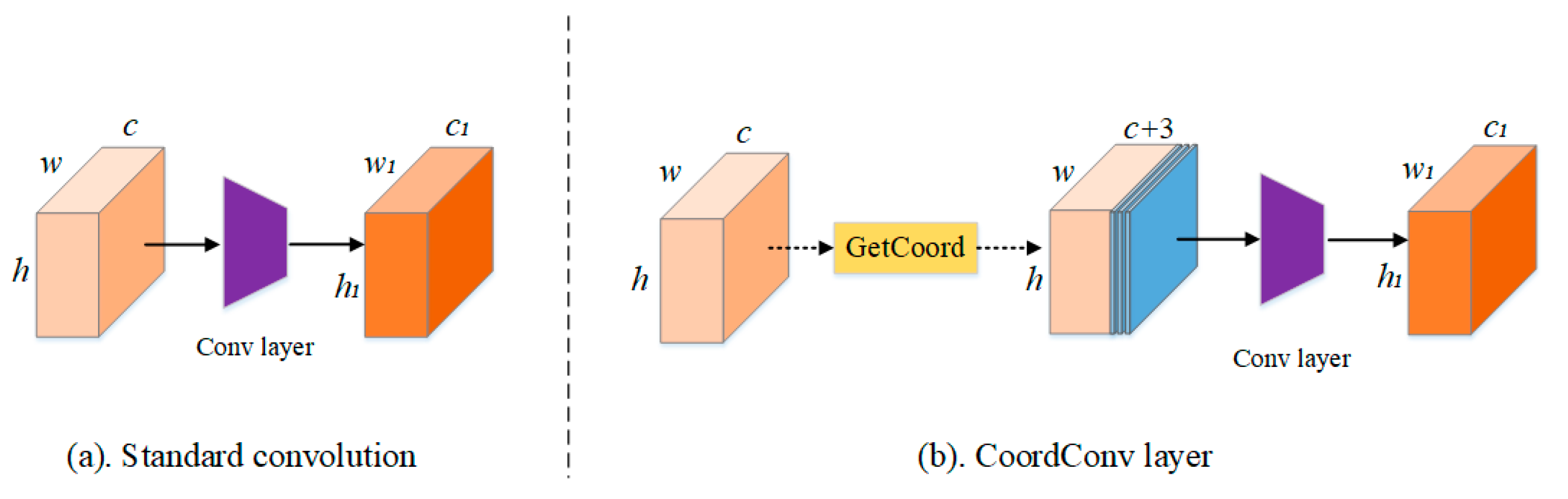
2.2. CoordConv Module
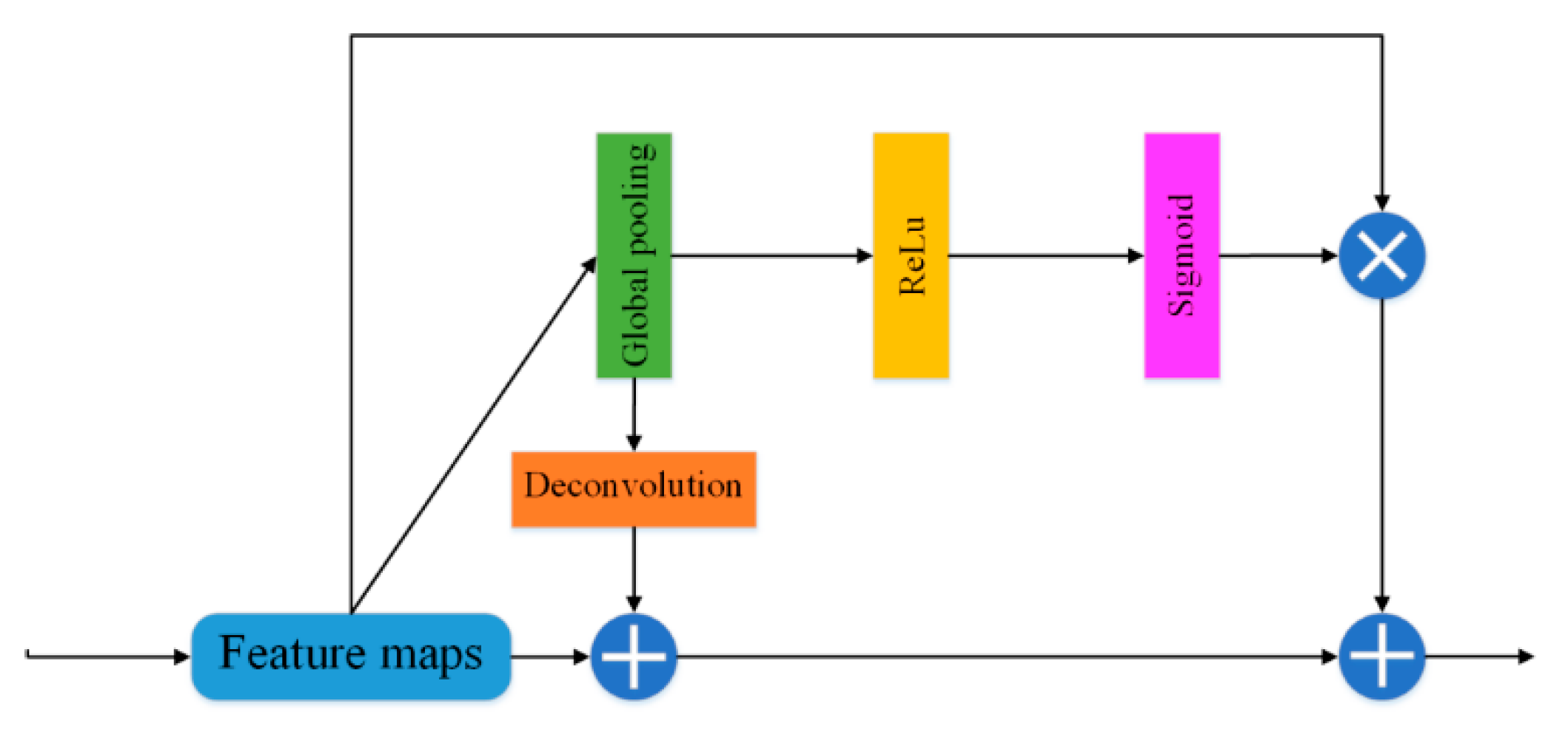
2.3. Global Attention Module
2.4. Implementation
2.5. Data
2.6. Implementation
2.7. Evaluation Metrics
3. Experimental Results
4. Comparison Results and Analysis
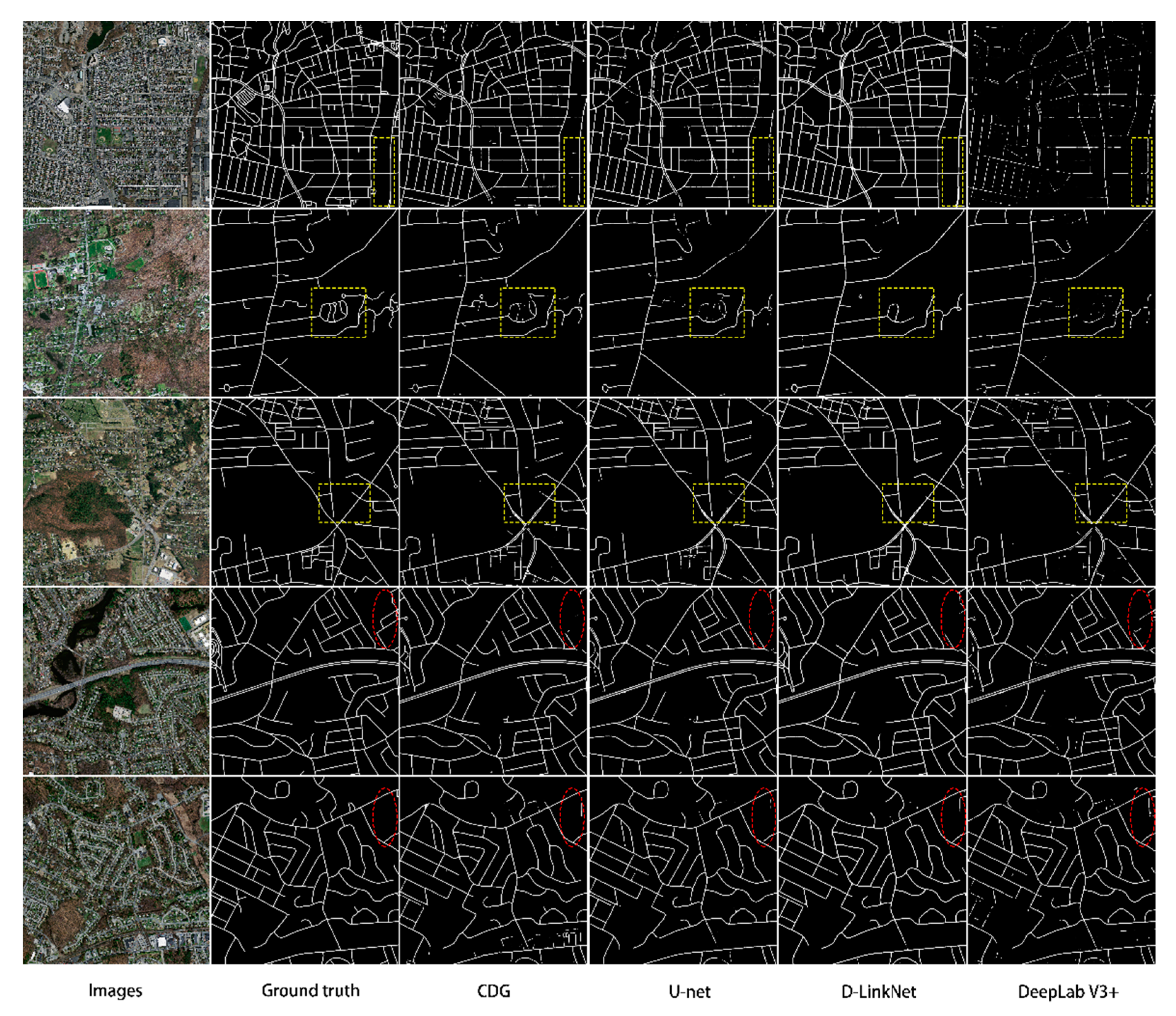
4.1. Comparison with Other Methods
4.2. Analysis of the Effectiveness of the Mechanism of Action
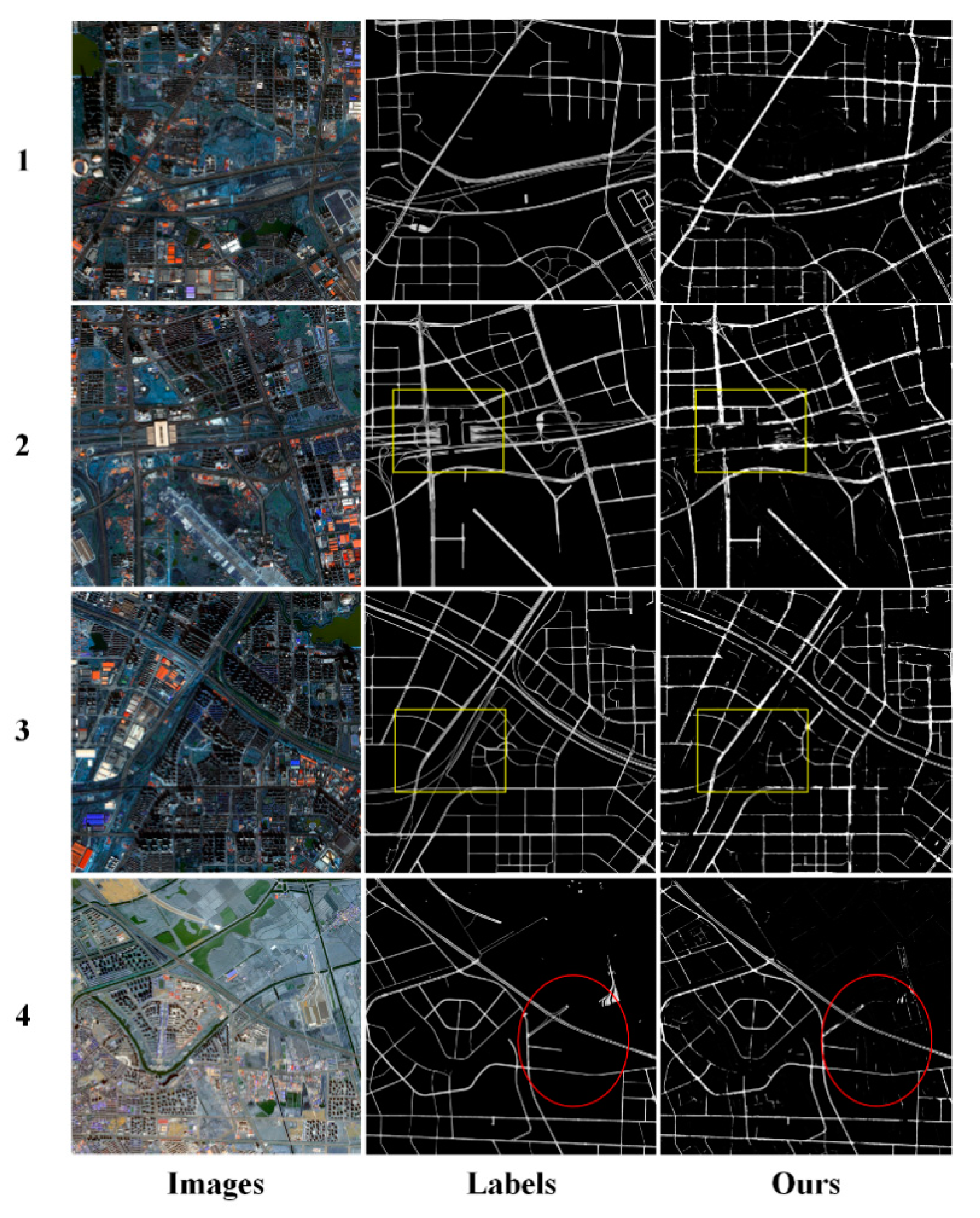
4.3. Generalization Results of the Model
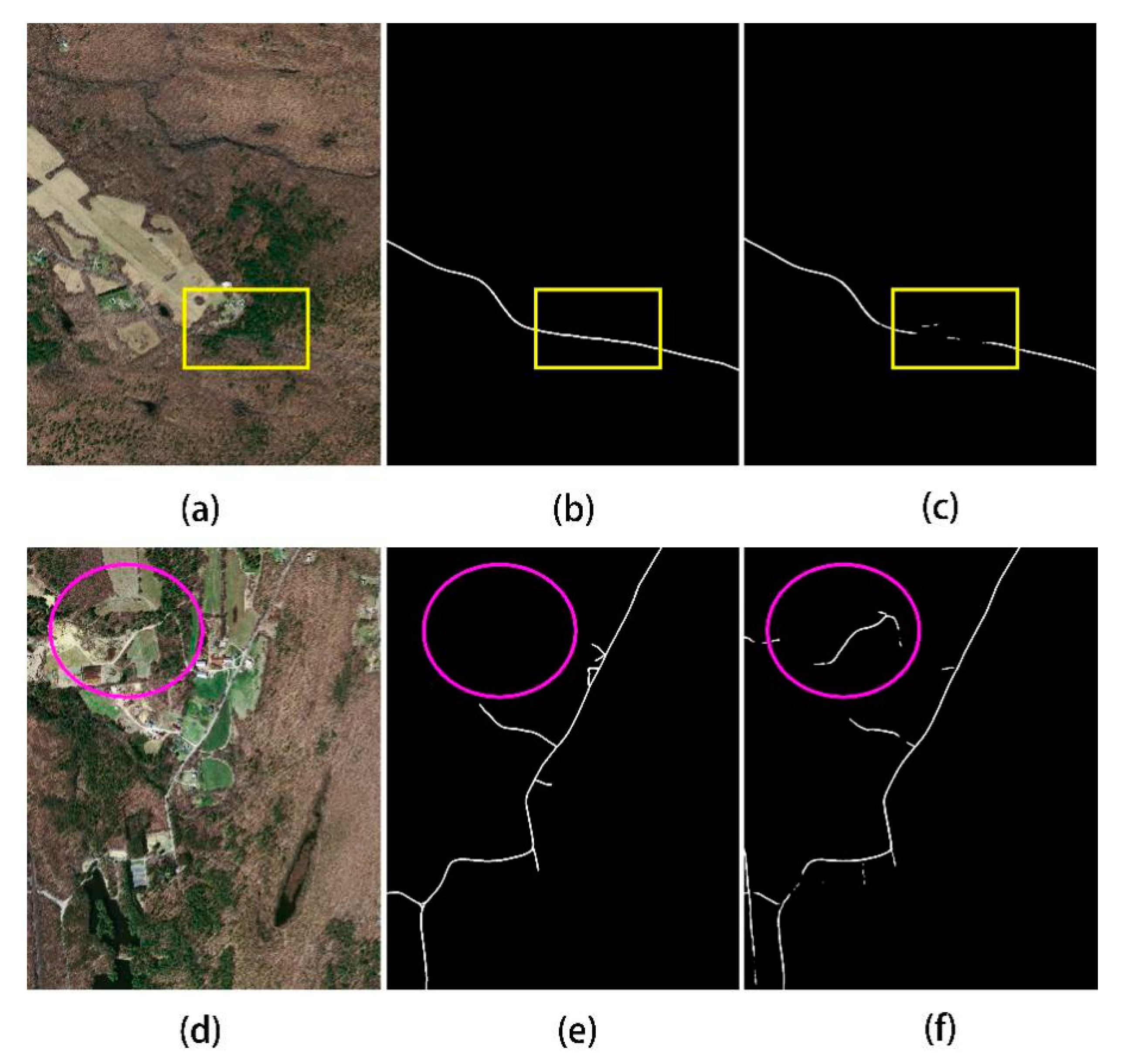
4.4. Problem
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hinz, S.; Baumgartner, A.; Ebner, H. Modeling contextual knowledge for controlling road extraction in urban areas. In Proceedings of the IEEE/ISPRS Joint Workshop on Remote Sensing and Data Fusion over Urban Area, Rome, Italy, 8–9 November 2001; pp. 40–44. [Google Scholar]
- Li, Q.; Chen, L.; Li, M.; Shaw, S.L.; Nüchter, A. A sensor-fusion drivable-region and lane-detection system for autonomous vehicle navigation in challenging road scenarios. IEEE Trans. Veh. Technol. 2014, 63, 540–555. [Google Scholar] [CrossRef]
- Bonnefon, R.; Dherete, P.; Desachy, J. Geographic information system updating using remote sensing images. Patt. Recog. Lett. 2002, 23, 1073–1083. [Google Scholar] [CrossRef]
- Mena, J.B. State of the art on automatic road extraction for GIS update: A novel classification. Patt. Recog. Lett. 2003, 24, 3037–3058. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Sghaier, M.O.; Lepage, R. Road extraction from very high resolution remote sensing optical images based on texture analysis and beamlet transform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1946–1958. [Google Scholar] [CrossRef]
- Miao, Z.; Wang, B.; Shi, W.; Zhang, H. A semi-automatic method for road centerline extraction from vhr images. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1856–1860. [Google Scholar] [CrossRef]
- Shi, W.; Miao, Z.; Debayle, J. An integrated method for urban main-road centerline extraction from optical remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3359–3372. [Google Scholar] [CrossRef]
- Kaliaperumal, V.; Shanmugam, L. Junction-aware water flow approach for urban road network extraction. IET Image Process. 2014, 10, 227–234. [Google Scholar]
- Mu, H.; Zhang, Y.; Li, H.; Guo, Y.; Zhuang, Y. Road extraction base on Zernike algorithm on SAR image. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1274–1277. [Google Scholar]
- Unsalan, C.; Sirmacek, B. Road network detection using probabilistic and graph theoretical methods. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4441–4453. [Google Scholar] [CrossRef]
- Shi, W.; Zhu, C. The line segment match method for extracting road network from high-resolution satellite images. IEEE Trans. Geosci. Remote Sens. 2002, 40, 511–514. [Google Scholar]
- Das, S.; Mirnalinee, T.T.; Varghese, K. Use of salient features for the design of a multistage framework to extract roads from high-resolution multispectral satellite images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3906–3931. [Google Scholar] [CrossRef]
- Cheng, G.; Zhu, F.; Xiang, S.; Pan, C. Road centerline extraction via semisupervised segmentation and multidirection nonmaximum suppression. IEEE Geosci. Remote Sens. Lett. 2016, 13, 545–549. [Google Scholar] [CrossRef]
- Senthilnath, J.; Rajeshwari, M.; Omkar, S.N. Automatic road extraction using high resolution satellite image based on texture progressive analysis and normalized cut method. J. Indian Soc. Remote Sens. 2009, 37, 351–361. [Google Scholar] [CrossRef]
- Li, M.; Stein, A.; Bijker, W.; Zhan, Q. Region-based urban road extraction from vhr satellite images using binary partition tree. Int. J. Appl. Earth Obs. Geoinf. 2016, 44, 217–225. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. Road centreline extraction from high-resolution imagery based on multiscale structural features and support vector machines. Int. J. Remote Sens. 2009, 30, 1977–1987. [Google Scholar] [CrossRef]
- Miao, Z.; Shi, W.; Zhang, H.; Wang, X. Road centerline extraction from high-resolution imagery based on shape features and multivariate adaptive regression splines. IEEE Geosci. Remote Sens. Lett. 2013, 10, 583–587. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road structure refined CNN for road extraction in aerial image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Geng, L.; Sun, J.; Xiao, Z.; Zhang, F.; Wu, J. Combining cnn and mrf for road detection. Comput. Electr. Eng. 2017, 70, 895–903. [Google Scholar] [CrossRef]
- Alvarez, J.M.; Gevers, T.; Lecun, Y.; Lopez, A.M. Road scene segmentation from a single image. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Road segmentation of remotely-sensed images using deep convolutional neural networks with landscape metrics and conditional random fields. Remote Sens. 2017, 9, 680. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Wang, Q.; Gao, J.; Yuan, Y. Embedding structured contour and location prior in siamesed fully convolutional networks for road detection. IEEE Trans. Intell. Transp. Syst. 2018, 19, 230–241. [Google Scholar] [CrossRef]
- Buslaev, A.V.; Seferbekov, S.S.; Iglovikov, V.I.; Shvets, A.A. Fully convolutional network for automatic road extraction from satellite imagery. CVPR Workshops 2018. [Google Scholar] [CrossRef]
- Mendes, C.C.; Frémont, V.; Wolf, D.F. Exploiting fully convolutional neural networks for fast road detection. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016. [Google Scholar]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic road detection and centerline extraction via cascaded end-to-end convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 55, 3322–3337. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Cui, W.; Jiang, H. Fully convolutional networks for building and road extraction: Preliminary results. In Proceedings of the 2016 IEEE Geoscience & Remote Sensing Symposium, Beijing, China, 10–15 July 2016. [Google Scholar]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Mnih, V.; Hinton, G.E. Learning to Detect Roads in High-Resolution Aerial Images. In Proceedings of the Computer Vision—ECCV 2010—11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; Proceedings, Part VI. Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv 2015, arXiv:1511.00561. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. arXiv 2018, arXiv:1802.02611. [Google Scholar]
- Rosanne, L.; Joel, L.; Piero, M.; Felipe, P.S.; Eric, F.; Alex, S.; Jason, Y. An intriguing failing of convolutional neural networks and the CoordConv solution. arXiv 2018, arXiv:1807.03247v1. [Google Scholar]
- Yao, X.; Yang, H.; Wu, Y.; Wu, P.; Wang, B.; Zhou, X.; Wang, S. Land use classification of the deep convolutional neural network method reducing the loss of spatial features. Sensors 2019, 19, 2792. [Google Scholar] [CrossRef]
- Gao, H.; Zhuang, L.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. arXiv 2018, arXiv:1608.06993v5. [Google Scholar]
- Jegou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The one hundred layers tiramisu: Fully convolutional DenseNets for semantic segmentation. arXiv 2017, arXiv:1611.09326v3. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- Li, L.; Liang, J.; Weng, M.; Zhu, H. A multiple-feature reuse network to extract buildings from remote sensing imagery. Remote Sens. 2018, 10, 1350. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arxiv 2015, arXiv:1502.03167v3. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. ParseNet: Looking wider to see better. arXiv 2015, arXiv:1506.04579v2. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G.; Wu, E. Squeeze-and-excitation networks. arXiv 2018, arXiv:1709.01507v2. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180v1. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412.6980v9. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Testing Dataset | precision | recall | F1 | IoU |
|---|---|---|---|---|
| All images-average | 81.41% | 71.80% | 76.10% | 61.90% |
| Method | precision | recall | F1 | IoU | test time |
|---|---|---|---|---|---|
| DeepLabV3+ | 79.16% | 60.22% | 67.64% | 51.95% | 245s |
| D-LinkNet | 79.45% | 71.96% | 75.15% | 60.71% | 206s |
| U-net | 84.04% | 68.90% | 75.24% | 60.94% | 167s |
| CDG | 81.41% | 71.80% | 76.10% | 61.90% | 196s |
| Method | precision | recall | F1 | IoU |
|---|---|---|---|---|
| no coordconv | 76.12% | 60.25% | 65.75% | 49.81% |
| no global attention | 76.20% | 75.30% | 75.33% | 60.96% |
| neither | 81.40% | 57.61% | 66.76% | 50.85% |
| CDG | 81.63% | 72.07% | 75.94% | 61.61% |
| Num. | precision | recall | F1 | IoU |
|---|---|---|---|---|
| 1 | 62.12% | 77.73% | 69.00% | 52.73% |
| 2 | 70.88% | 75.38% | 72.54% | 56.97% |
| 3 | 71.02% | 76.93% | 73.81% | 58.55% |
| 4 | 69.49% | 81.83% | 75.11% | 60.20% |
| Average Value | 68.38% | 77.72% | 72.62% | 57.11% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Yang, H.; Wu, Q.; Zheng, Z.; Wu, Y.; Li, J. An Improved Method for Road Extraction from High-Resolution Remote-Sensing Images that Enhances Boundary Information. Sensors 2020, 20, 2064. https://doi.org/10.3390/s20072064
Wang S, Yang H, Wu Q, Zheng Z, Wu Y, Li J. An Improved Method for Road Extraction from High-Resolution Remote-Sensing Images that Enhances Boundary Information. Sensors. 2020; 20(7):2064. https://doi.org/10.3390/s20072064
Chicago/Turabian StyleWang, Shuai, Hui Yang, Qiangqiang Wu, Zhiteng Zheng, Yanlan Wu, and Junli Li. 2020. "An Improved Method for Road Extraction from High-Resolution Remote-Sensing Images that Enhances Boundary Information" Sensors 20, no. 7: 2064. https://doi.org/10.3390/s20072064
APA StyleWang, S., Yang, H., Wu, Q., Zheng, Z., Wu, Y., & Li, J. (2020). An Improved Method for Road Extraction from High-Resolution Remote-Sensing Images that Enhances Boundary Information. Sensors, 20(7), 2064. https://doi.org/10.3390/s20072064