Applications of Deep Learning for Dense Scenes Analysis in Agriculture: A Review



Abstract
1. Introduction
1.1. Types of Dense Scenes in Agriculture
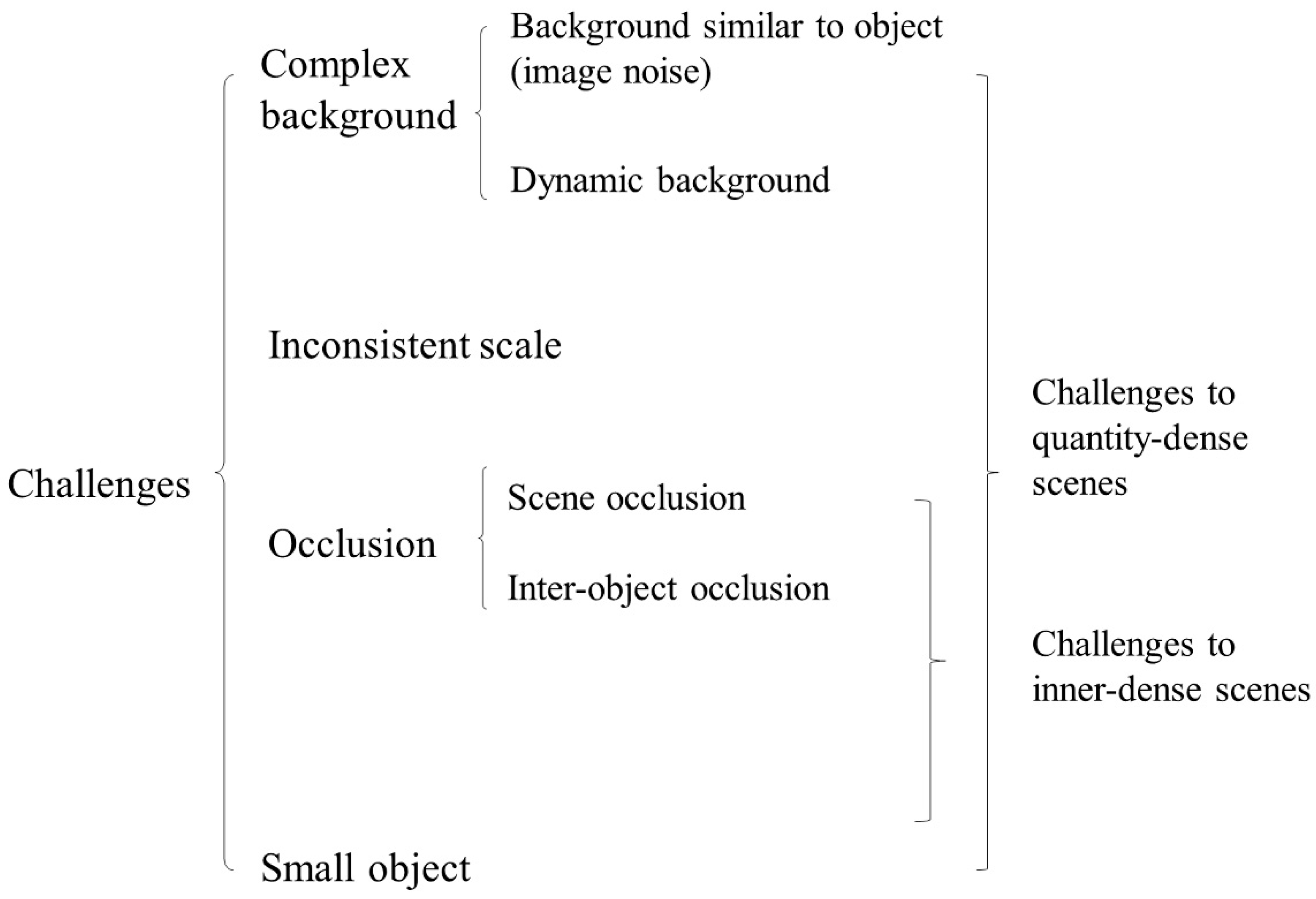
1.2. Challenges in Dense Agricultural Scenes
1.3. Outline
2. Deep Learning Methods
2.1. Convolutional Neural Networks (CNNs)
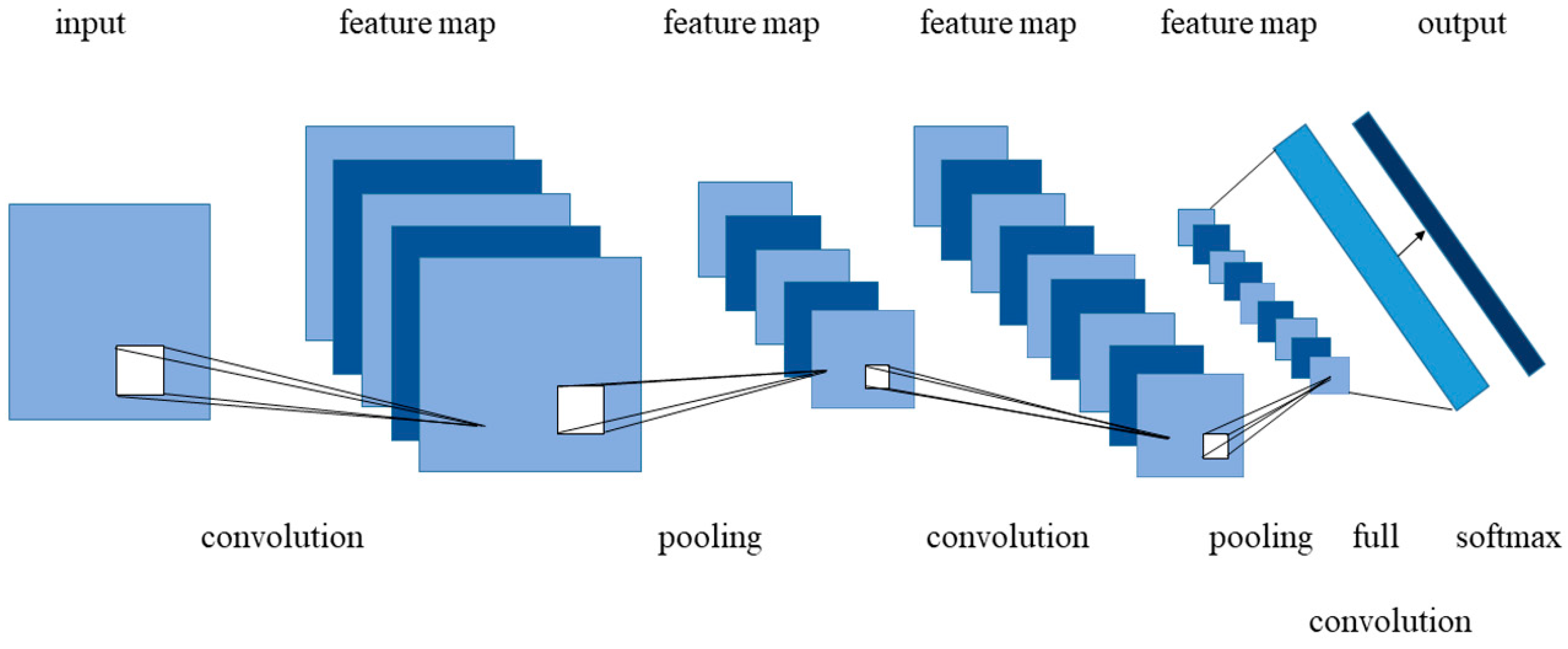
2.1.1. Review of CNNs
2.1.2. CNNs’ Backbone Network
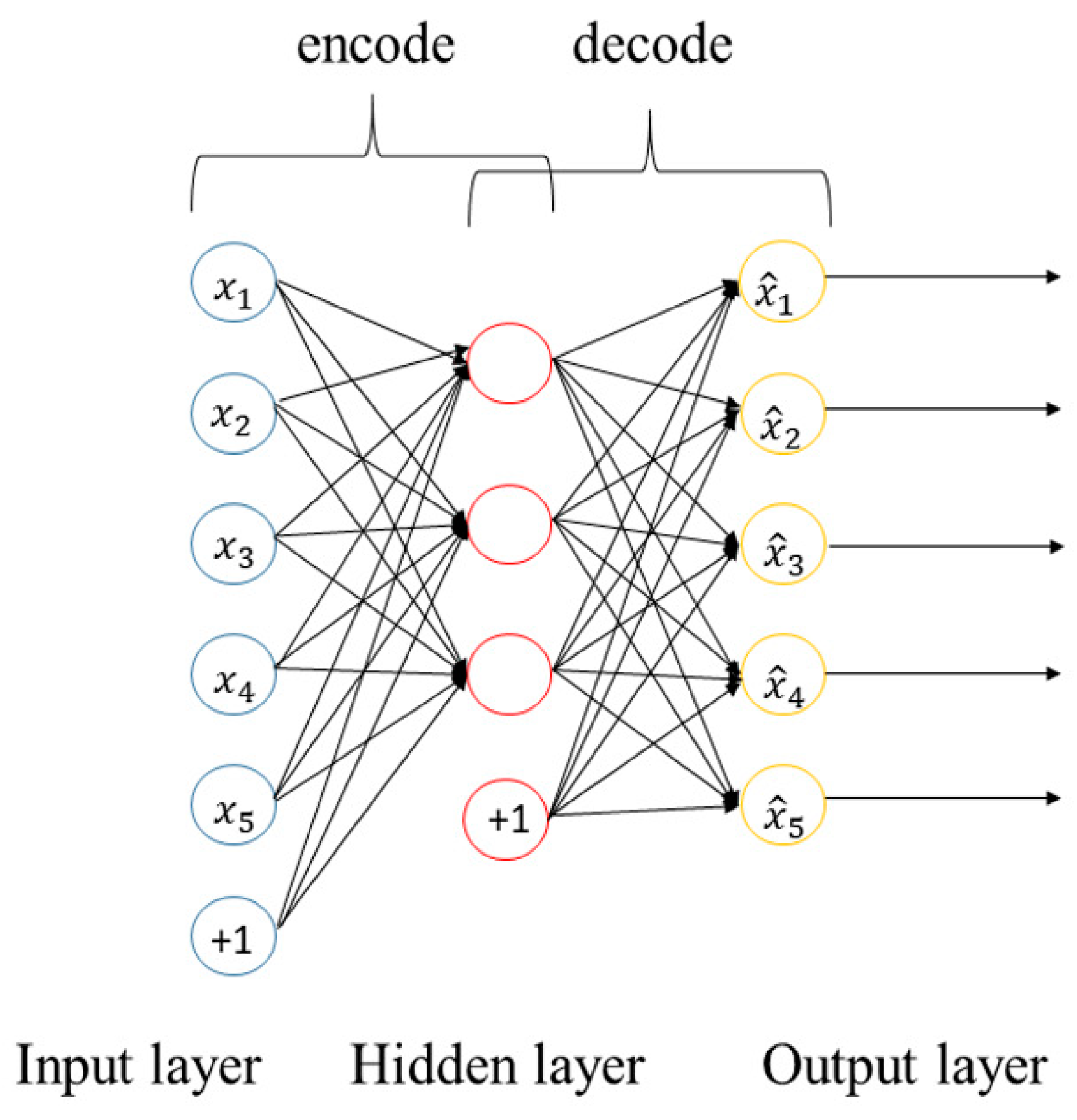
2.2. Autoencoder
Overview
2.3. Conclusion
3. Applications
3.1. Recognition and Classification
3.2. Detection
3.3. Counting and Yield Estimation
4. Discussion
4.1. Analysis of the Surveyed DL Applications
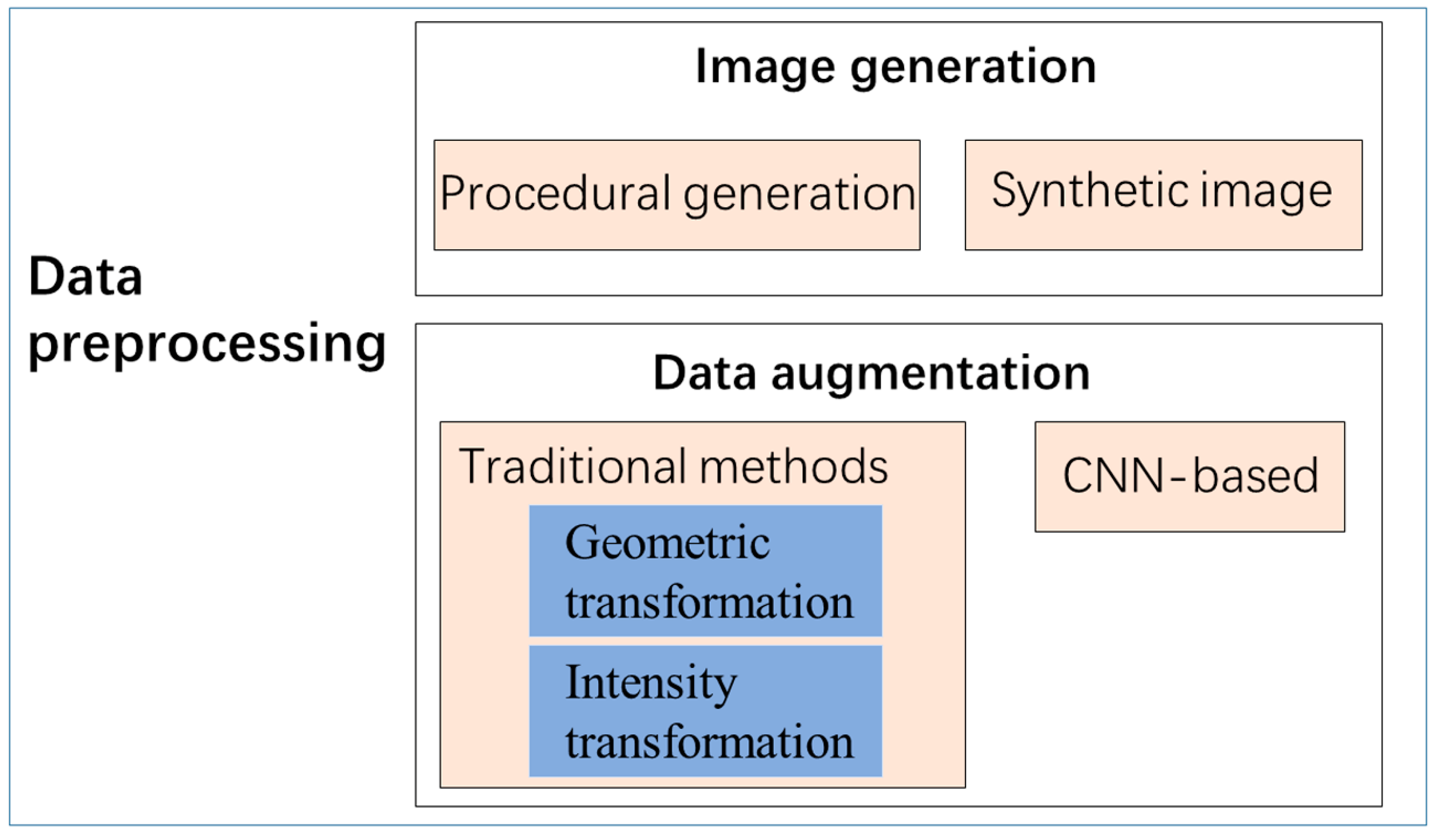
4.2. Limitations to DL Applications
4.3. Future Work
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tyagi, A.C. Towards a Second Green Revolution. Irrig. Drain. 2016, 65, 388–389. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; Mcallester, D.; Ramanan, D.J.I.T.o.P.A.; Intelligence, M. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Vision, L.V.G.J.C.; Understanding, I. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2018, 110, 346–359. [Google Scholar] [CrossRef]
- Viola, P.A.; Jones, M.J. Rapid Object Detection using a Boosted Cascade of Simple Features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Pérez, A.J.; López, F.; Benlloch, J.V.; Computers, S.C.J.; Agriculture, E.i. Colour and shape analysis techniques for weed detection in cereal fields. Comput. Electron. Agric. 2000, 25, 197–212. [Google Scholar] [CrossRef]
- Chen, S.W.; Shivakumar, S.S.; Dcunha, S.; Das, J.; Okon, E.; Qu, C.; Taylor, C.J.; Kumar, V. Counting Apples and Oranges With Deep Learning: A Data-Driven Approach. IEEE Robot. Autom. Lett. 2017, 2, 781–788. [Google Scholar] [CrossRef]
- Gongal, A.; Amatya, S.; Karkee, M.; Zhang, Q.; Lewis, K.J.C.; Agriculture, E.i. Sensors and systems for fruit detection and localization: A review. Comput. Electron. Agric. 2015, 116, 8–19. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y.J.a.p.a. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Bordes, A.; Chopra, S.; Weston, J. Question Answering with Subgraph Embeddings. arXiv 2014, arXiv:1406.3676. [Google Scholar]
- Min, S.; Lee, B.; Yoon, S. Deep learning in bioinformatics. Brief. Bioinform. 2017, 18, 851–869. [Google Scholar] [CrossRef] [PubMed]
- Olmos, R.; Tabik, S.; Herrera, F. Automatic handgun detection alarm in videos using deep learning. Neurocomputing 2017, 275, 66–72. [Google Scholar] [CrossRef]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: A Neural Image Caption Generator. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, CHILE, 11–18 Decemeber 2015. [Google Scholar]
- Rui, Z.; Wang, D.; Yan, R.; Mao, K.; Fei, S.; Wang, J. Machine Health Monitoring Using Local Feature-based Gated Recurrent Unit Networks. IEEE Trans. Ind. Electron. 2017, 65, 1539–1548. [Google Scholar]
- Nweke, H.F.; Teh, Y.W.; Al-garadi, M.A.; Alo, U.R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Song, D.H.; Liu, H.M.; Dong, Q.C.; Bian, Z.C.; Wu, H.X.; Lei, Y. Digital, Rapid, Accurate, and Label-Free Enumeration of Viable Microorganisms Enabled by Custom-Built On-Glass-Slide Culturing Device and Microscopic Scanning. Sensors 2018, 18, 3700. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, S.; Mishra, B.; Kolomeisky, A.B.; Chowdhury, D. First-passage processes on a filamentous track in a dense traffic: Optimizing diffusive search for a target in crowding conditions. J. Stat. Mech. Theory Exp. 2018, 2018, 123209. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.B.; Wang, Z.; Mccarthy, C.J.C.; Agriculture, E.i. Deep learning – Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. A review of the use of convolutional neural networks in agriculture. J. Agric. Sci. 2018, 156, 312–322. [Google Scholar] [CrossRef]
- Wang, A.; Zhang, W.; Wei, X. A review on weed detection using ground-based machine vision and image processing techniques. Comput. Electron. Agric. 2019, 158, 226–240. [Google Scholar] [CrossRef]
- Boominathan, L.; Kruthiventi, S.S.S.; Babu, R.V. CrowdNet: A Deep Convolutional Network for Dense Crowd Counting. In Proceedings of the 24th ACM Multimedia Conference, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Wang, C.; Hua, Z.; Liang, Y.; Si, L.; Cao, X. Deep People Counting in Extremely Dense Crowds. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015. [Google Scholar]
- Zhu, D.; Chen, B.; Yang, Y. Farmland Scene Classification Based on Convolutional Neural Network. In Proceedings of the International Conference on Cyberworlds, Chongqing, China, 28–30 September 2016. [Google Scholar]
- Garcia, R.; Nicosevici, T.; Cufí, X. On the way to solve lighting problems in underwater imaging. In Proceedings of the OCEANS ’02 MTS/IEEE, Biloxi, MI, USA, 29–31 October 2002. [Google Scholar]
- Labao, A.; Naval, P. Weakly-Labelled Semantic Segmentation of Fish Objects in Underwater Videos using ResNet-FCN. In Proceedings of the 9th Asian Conference on Intelligent Information and Database Systems, Kanazawa, Japan, 3–5 April 2017. [Google Scholar]
- Bresilla, K.; Perulli, G.D.; Boini, A.; Morandi, B.; Corelli Grappadelli, L.; Manfrini, L. Single-Shot Convolution Neural Networks for Real-Time Fruit Detection Within the Tree. Front. Plant Sci. 2019, 10, 611. [Google Scholar] [CrossRef] [PubMed]
- Hasan, M.M.; Chopin, J.P.; Laga, H.; Miklavcic, S.J. Detection and analysis of wheat spikes using Convolutional Neural Networks. Plant Methods 2018, 14, 100. [Google Scholar] [CrossRef] [PubMed]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [PubMed]
- Zhu, N.; Liu, X.; Liu, Z.; Hu, K.; Wang, Y.; Tan, J.; Huang, M.; Zhu, Q.; Ji, X.; Jiang, Y.J.I.J.o.A.; et al. Deep learning for smart agriculture: Concepts, tools, applications, and opportunities. Int. J. Agric. Biol. Eng. 2018, 11, 32–44. [Google Scholar] [CrossRef]
- Chou, Y.-C.; Kuo, C.-J.; Chen, T.-T.; Horng, G.-J.; Pai, M.-Y.; Wu, M.-E.; Lin, Y.-C.; Hung, M.-H.; Su, W.-T.; Chen, Y.-C.J.A.S. Deep-learning-based defective bean inspection with GAN-structured automated labeled data augmentation in coffee industry. Appl. Sci. 2019, 9, 4166. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Jian, S. Identity Mappings in Deep Residual Networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Scene Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Fukushima, K. Neocognitron: A Hierarchical Neural Network Capable of Visual Pattern Recognition. Neural Netw. 1988, 1, 119–130. [Google Scholar] [CrossRef]
- Zeiler, M.D. Hierarchical Convolutional Deep Learning in Computer Vision. Ph.D. Thesis, New York University, New York, NY, USA, 2013; p. 3614917. [Google Scholar]
- Scherer, D.; Mueller, A.; Behnke, S. Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition. In Artificial Neural Networks; Diamantaras, K., Duch, W., Iliadis, L.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6354, pp. 92–101. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Proc. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Hong, H.; Yamins, D.L.K.; Majaj, N.J.; DiCarlo, J.J.J.N.N. Explicit information for category-orthogonal object properties increases along the ventral stream. Nat. Neurosci. 2016, 19, 613–622. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar]
- .Haykin, S.; Kosko, B. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R.J.I.T.o.P.A.; Intelligence, M. Mask R-CNN. In Proceedings of the 2017 IEEE INTERNATIONAL CONFERENCE ON COMPUTER VISION, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Improved inception-residual convolutional neural network for object recognition. Neural Comput. Appl. 2018, 32, 279–293. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Maninis, K.-K.; Pont-Tuset, J.; Arbelaez, P.; Analysis, L.V.G.J.I.T.o.P.; Intelligence, M. Convolutional Oriented Boundaries: From Image Segmentation to High-Level Tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 819–833. [Google Scholar] [CrossRef]
- Xie, S.; Vision, Z.T.J.I.J.o.C. Holistically-Nested Edge Detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1395–1403. [Google Scholar]
- Bengio, Y.J.; Foundations, T.i.M. Learning Deep Architectures for AI. Found. Trends® Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Ranzato, M.A.; Poultney, C.; Chopra, S.; Lecun, Y. Efficient Learning of Sparse Representations with an Energy-Based Model. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 1137–1144. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008. [Google Scholar]
- Bengio, Y.; Courville, A. Deep Learning of Representations; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Rifai, S.; Vincent, P.; Muller, X.; Glorot, X.; Bengio, Y. Contractive Auto-Encoders: Explicit Invariance During Feature Extraction. In Proceedings of the International Conference on Machine Learning, Bellevue, WA, USA, 2 July 2011. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Yi, M. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 589–597. [Google Scholar]
- Cheng, X.; Zhang, Y.; Chen, Y.; Wu, Y.; Yue, Y. Pest identification via deep residual learning in complex background. Comput. Electron. Agric. 2017, 141, 351–356. [Google Scholar] [CrossRef]
- Liu, Y.-P.; Yang, C.-H.; Ling, H.; Mabu, S.; Kuremoto, T. A Visual System of Citrus Picking Robot Using Convolutional Neural Networks. In Proceedings of the 5th International Conference on Systems and Informatics (ICSAI), Nanjing, China, 10–12 November 2018; pp. 344–349. [Google Scholar]
- Bozek, K.; Hebert, L.; Mikheyev, A.S.; Stephens, G.J.; IEEE. Towards dense object tracking in a 2D honeybee hive. In Proceedings of the 2018 IEEE/Cvf Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: New York, NY, USA; pp. 4185–4193. [Google Scholar]
- Fawakherji, M.; Youssef, A.; Bloisi, D.D.; Pretto, A.; Nardi, D. Crop and Weeds Classification for Precision Agriculture using Context-Independent Pixel-Wise Segmentation. In Proceedings of the Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019. [Google Scholar]
- Häni, N.; Roy, P.; Isler, V. A Comparative Study of Fruit Detection and Counting Methods for Yield Mapping in Apple Orchards. J. Field Robot. 2019, 37, 181–340. [Google Scholar] [CrossRef]
- Grimm, J.; Herzog, K.; Rist, F.; Kicherer, A.; Töpfer, R.; Steinhage, V. An adaptable approach to automated visual detection of plant organs with applications in grapevine breeding. Biosyst. Eng. 2019, 183, 170–183. [Google Scholar] [CrossRef]
- Dyrmann, M.; Jørgensen, R.N.; Midtiby, H.S. RoboWeedSupport - Detection of weed locations in leaf occluded cereal crops using a fully convolutional neural network. Adv. Anim. Biosci. 2017, 8, 842–847. [Google Scholar] [CrossRef]
- Christiansen, P.; Nielsen, L.; Steen, K.; Jørgensen, R.; Karstoft, H. DeepAnomaly: Combining Background Subtraction and Deep Learning for Detecting Obstacles and Anomalies in an Agricultural Field. Sensors 2016, 16, 1904. [Google Scholar] [CrossRef]
- Yu, J.; Sharpe, S.M.; Schumann, A.W.; Boyd, N.S. Deep learning for image-based weed detection in turfgrass. Eur. J. Agron. 2019, 104, 78–84. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J. Deep Fruit Detection in Orchards. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Dias, P.A.; Tabb, A.; Medeiros, H. Apple flower detection using deep convolutional networks. Comput. Ind. 2018, 99, 17–28. [Google Scholar] [CrossRef]
- Gonzalez, S.; Arellano, C.; Tapia, J.E. Deepblueberry: Quantification of Blueberries in the Wild Using Instance Segmentation. IEEE Access 2019, 7, 105776–105788. [Google Scholar] [CrossRef]
- French, G.; Fisher, M.; Mackiewicz, M.; Needle, C. Convolutional Neural Networks for Counting Fish in Fisheries Surveillance Video. In Proceedings of the Machine Vision of Animals and their Behaviour, Swansea, UK, 10–29 July 2015. [Google Scholar]
- Zhong, Y.; Gao, J.; Lei, Q.; Zhou, Y. A Vision-Based Counting and Recognition System for Flying Insects in Intelligent Agriculture. Sensors 2018, 18, 1489. [Google Scholar] [CrossRef] [PubMed]
- Rahnemoonfar, M.S.C. Deep Count: Fruit Counting Based on Deep Simulated Learning. Sensors 2017, 17, 905. [Google Scholar] [CrossRef]
- Liu, X.; Chen, S.W.; Aditya, S.; Sivakumar, N.; Dcunha, S.; Qu, C.; Taylor, C.J.; Das, J.; Kumar, V. Robust Fruit Counting: Combining Deep Learning, Tracking, and Structure from Motion. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Arteta, C.; Lempitsky, V.; Zisserman, A. Counting in the Wild. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Rahnemoonfar, M.; Sheppard, C. Real-time yield estimation based on deep learning. In Proceedings of the Spie Commercial + Scientific Sensing & Imaging, Anaheim, CA, USA, 9 April 2017. [Google Scholar]
- Yang, Q.; Shi, L.; Han, J.; Zha, Y.; Zhu, P. Deep convolutional neural networks for rice grain yield estimation at the ripening stage using UAV-based remotely sensed images. Field Crop. Res. 2019, 235, 142–153. [Google Scholar] [CrossRef]
- Xie, C.; Zhang, J.; Li, R.; Li, J.; Hong, P.; Xia, J.; Chen, P. Automatic classification for field crop insects via multiple-task sparse representation and multiple-kernel learning. Comput. Electron. Agric. 2015, 119, 123–132. [Google Scholar] [CrossRef]
- Miller, S.A.; Beed, F.D.; Harmon, C.L. Plant Disease Diagnostic Capabilities and Networks. Annu. Rev. Phytopathol. 2009, 47, 15–38. [Google Scholar] [CrossRef]
- Lottes, P.; Hoeferlin, M.; Sander, S.; Müter, M.; Lammers, P.S.; Stachniss, C. An Effective Classification System for Separating Sugar Beets and Weeds for Precision Farming Applications. In Proceedings of the IEEE International Conference on Robotics & Automation, Stockholm, Sweden, 16–21 May 2016. [Google Scholar]
- Tri, N.C.; Van Hoai, T.; Duong, H.N.; Trong, N.T.; Van Vinh, V.; Snasel, V. A Novel Framework Based on Deep Learning and Unmanned Aerial Vehicles to Assess the Quality of Rice Fields. Adv. Intell. Syst. Comput. 2017, 538, 84–93. [Google Scholar]
- Xie, S.; Yang, T.; Wang, X.; Lin, Y. Hyper-class augmented and regularized deep learning for fine-grained image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Booston, MA, USA, 7–12 June 2015; pp. 2645–2654. [Google Scholar]
- Zhang, W.; Hansen, M.F.; Volonakis, T.N.; Smith, M.; Smith, L.; Wilson, J.; Ralston, G.; Broadbent, L.; Wright, G. Broad-Leaf Weed Detection in Pasture. In Proceedings of the 3rd IEEE International Conference on Image, Vision and Computing(ICIVI), Chongqing, China, 27–29 June 2018; pp. 105–107. [Google Scholar]
- Kapach, K.; Barnea, E.; Mairon, R.; Edan, Y.; Ben-Shahar, O. Computer vision for fruit harvesting robots—State of the art and challenges ahead. Int. J. Comput. Vis. Robot. 2012, 3, 4–34. [Google Scholar] [CrossRef]
- Bargoti, S.; Underwood, J.P. Image Segmentation for Fruit Detection and Yield Estimation in Apple Orchards. J. Field Robot. 2016, 34, 1039–1060. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Seguí, S.; Pujol, O.; Vitrià, J. Learning to count with deep object features. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition Workshops, Boston, MA, USA, 8–10 June 2015. [Google Scholar]
- Escalante, H.J.; Rodríguez-Sánchez, S.; Jiménez-Lizárraga, M.; Morales-Reyes, A.; De La Calleja, J.; Vazquez, R. Barley yield and fertilization analysis from UAV imagery: A deep learning approach. Int. J. Remote Sens. 2019, 40, 2493–2516. [Google Scholar] [CrossRef]
- Ganin, Y.; Lempitsky, V. $$N^4$$-Fields: Neural Network Nearest Neighbor Fields for Image Transforms. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Stein, M.; Bargoti, S.; Underwood, J. Image Based Mango Fruit Detection, Localisation and Yield Estimation Using Multiple View Geometry. Sensors 2016, 16, 1915. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Nuske, S.; Bergerman, M.; Singh, S. Automated Crop Yield Estimation for Apple Orchards. In Proceedings of the Experimental Robotics, Québec City, QC, Canada, 18–21 June 2012; Springer: Heidelberg, Germany, 2013; pp. 745–758. [Google Scholar]
- Das, J.; Cross, G.; Chao, Q.; Makineni, A.; Tokekar, P.; Mulgaonkar, Y.; Kumar, V. Devices, Systems, and Methods for Automated Monitoring enabling Precision Agriculture. In Proceedings of the IEEE International Conference on Automation Science & Engineering, Gothenburg, Sweden, 24–28 August 2015. [Google Scholar]
- Hung, C.; Underwood, J.; Nieto, J.; Sukkarieh, S. A Feature Learning Based Approach for Automated Fruit Yield Estimation. In Proceedings of the Field and Service Robotics, Naples, Italy, 28 September–3 October 2015; pp. 485–498. [Google Scholar]
- Sinha, S.N.; Steedly, D.; Szeliski, R. A Multi-stage Linear Approach to Structure from Motion. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 1–13. [Google Scholar] [CrossRef]
- Rasti, P.; Ahmad, A.; Samiei, S.; Belin, E.; Rousseau, D. Supervised Image Classification by Scattering Transform with Application to Weed Detection in Culture Crops of High Density. Remote Sens. 2019, 11, 249. [Google Scholar] [CrossRef]
- Ubbens, J.; Cieslak, M.; Prusinkiewicz, P.; Stavness, I. The use of plant models in deep learning: An application to leaf counting in rosette plants. Plant Methods 2018, 14, 6. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Tian, Y.; Yang, G.; Wang, Z.; Li, E.; Liang, Z. Detection of Apple Lesions in Orchards Based on Deep Learning Methods of CycleGAN and YOLOV3-Dense. J. Sens. 2019, 2019, 1–13. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Venkateswara, H.; Chakraborty, S.; Panchanathan, S. Deep-Learning Systems for Domain Adaptation in Computer Vision: Learning Transferable Feature Representations. IEEE Signal Process. Mag. 2017, 34, 117–129. [Google Scholar] [CrossRef]
- Dai, W.; Yang, Q.; Xue, G.R.; Yu, Y. Boosting for transfer learning. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007. [Google Scholar]
- Ramon, J.; Driessens, K.; Croonenborghs, T. Transfer Learning in Reinforcement Learning Problems Through Partial Policy Recycling. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Taylor, M.E.; Stone, P. Cross-domain transfer for reinforcement learning. In Proceedings of the 24th international conference on Machine learning, Corvalis, OR, USA, 20–24 June 2007. [Google Scholar]
- Tang, H.; Lotter, B.; Schrimpf, M.; Paredes, A.; Kreiman, G.J.P.o.t.N.A.o.S. Recurrent computations for visual pattern completion. Pro. Natl. Acad. Sci. USA 2018, 115, 8835–8840. [Google Scholar] [CrossRef]
- Sladojevic, S.; Arsenovic, M.; Anderla, A.; Culibrk, D.; Stefanovic, D. Deep Neural Networks Based Recognition of Plant Diseases by Leaf Image Classification. Comput. Intell. Neurosci. 2016, 3289801. [Google Scholar] [CrossRef] [PubMed]
- Fuentes, A.; Yoon, S.; Kim, S.; Park, D. A Robust Deep-Learning-Based Detector for Real-Time Tomato Plant Diseases and Pests Recognition. Sensors 2017, 17, 2022. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wang, W.; Lu, C.; Wang, J.; Sangaiah, A.K. Lightweight deep network for traffic sign classification. Ann. Telecommun. 2019. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, C.; Li, X.; Kim, H.-J.; Wang, J.J.M.B.E. A full convolutional network based on DenseNet for remote sensing scene classification. Math. Biosci. Eng. 2019, 16, 3345–3367. [Google Scholar] [CrossRef] [PubMed]
- Jianming, Z.; Xiaokang, J.; Juan, S.; Jin, W.; Tools, S.A.K.J.M. Applications. Spatial and semantic convolutional features for robust visual object tracking. Multimed. Tools Appl. 2018. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, Y.; Feng, W.; Wang, J.J.I.A. Spatially attentive visual tracking using multi-model adaptive response fusion. IEEE Access 2019, 7, 83873–83887. [Google Scholar] [CrossRef]
- Zhang, J.; Jin, X.; Sun, J.; Wang, J.; Li, K.J.I.A. Dual model learning combined with multiple feature selection for accurate visual tracking. IEEE Access 2019, 7, 43956–43969. [Google Scholar] [CrossRef]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Labao, A.B.; Naval, P.C., Jr. Cascaded deep network systems with linked ensemble components for underwater fish detection in the wild. Ecol. Inform. 2019, 52, 103–121. [Google Scholar] [CrossRef]
- Zhang, W.; Yao, T.; Zhu, S.; Saddik, A.E. Deep Learning–Based Multimedia Analytics. Acm Trans. Multimed. Comput. Commun. Appl. 2019, 15, 1–26. [Google Scholar] [CrossRef]
- Tao, Y.; Zhou, J. Automatic apple recognition based on the fusion of color and 3D feature for robotic fruit picking. Comput. Electron. Agric. 2017, 142, 388–396. [Google Scholar] [CrossRef]
- Barnea, E.; Mairon, R.; Ben-Shahar, O. Colour-agnostic shape-based 3D fruit detection for crop harvesting robots. Biosyst. Eng. 2016, 146, 57–70. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Ma, L.H.; Cheung, Y.M.; Wu, X.; Tang, Y.; Chen, C.L.P. ApLeaf: An efficient android-based plant leaf identification system. Neurocomputing 2015, 151, 1112–1119. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Networks | Number of Layers | Architectures | Highlights in Dense Images | First Used in |
|---|---|---|---|---|
| VGGNet | 11/13/16/19 | Conv + FC | Very small convolutional filter size and the increase of network depth effectively improves network performance | [36] |
| GoogLeNet | 22 | Conv + Inception + DepthConcat + FC | Multiscale convolution and reorganization extract features of different scales | [13] |
| ResNet | 18/34/50/101/152 | Conv + ReLU + Residual block + Shortcut + FC | ResNet architecture is deeper through residual block and easier to optimize | [37] |
| DetectNet | - | - | Predicting the existence of the object and the position of the object relative to the center of the grid square | - |
| DarkNet | 19/53 | Conv + Residual layer | Recognizing background correctly and detecting most occluded and overlapped objects | - |
| FCN | 8/16/32 | Conv | Accepts input images of any size and is more efficient | [38] |
| SegNet | 13 | Conv + up-Conv | Improve the edge depiction and reduce the training times | [39] |
| U-Net | 9 | Conv + up-Conv | Each pixel can be segmented, with higher segmentation accuracy and support a small number of training models | [40] |
| Application | Model | Description of Method | Accuracy (%) | Computing Time | Ref. |
|---|---|---|---|---|---|
| Recognition | ResNet | Using 50-layer and 101-layer depth residual networks | 50-Layer:94.6/101-Layer:101:98.67 | x | [63] |
| Recognition | YOLOv3/ResNet 152/ResNet50 | Yolov3 and two Mark R-CNNs with ResNet-50 and ResNet-152 | MaskRCNN-152: 86.83 | √ | [64] |
| Recognition | U-Net | Combining U-Net and a recurrent component | - | - | [65] |
| Classification | U-Net + VGG-16 | VGG-U-Net initialized by VGG-16 for segmentation, and VGG-16 for classification | 90 | - | [66] |
| Detection | GMM/U-NET | The detection methods of using GMM and image segmentation, U-NET and object-based detection network are compared | 91.27 | √ | [67] |
| Detection | FCN | An encoder and a decoder part based on the idea FCN | - | - | [68] |
| Detection | DetectNet | Consisting of a FCN based on the GoogLeNet architecture and clustering function | 86.6 | √ | [69] |
| Detection | Caffe reference + VGGNet | DeepAnomaly algorithm that using DL combined with anomaly detection | - | √ | [70] |
| Detection | VGGNet/GoogLeNet/DetectNet | Using VGGNet, GoogLeNet and DetectNet for detecting weeds in bermudagrass | - | - | [71] |
| Detection | ZF network and VGG-16 | Faster R-CNN with ZF network and VGG-16, and different types of transfer learning are used to initialize the network | 95.8 | √ | [72] |
| Detection | YOLO | Modified YOLO with two other blocks. The “splitter” block at the entrance divided the image into four separate images, and the “joiner” block at the end splices the four pieces together | 87 | √ | [31] |
| Detection | VGG-16 | VGG-16 with early and late fusion, and combining multiple modes (RGB and NIR) images | - | √ | [33] |
| Detection | Author-defined CNN | Fine-tuned the Clarifai model combined CNN with color and morphological information | 92.0 | - | [73] |
| Detection | ResNet101/ResNet50/MobilNetV1 | An instance segmentation algorithm based on mask T-CNN. Experiments on ResNet101, ResNet50 and MobilNetV1 | - | √ | [74] |
| Counting | Author-defined CNN | -Fields algorithm is used to foreground segmentation predict edge maps | 90.39 | √ | [75] |
| Counting | FCN | A blob detector based on a FCN | - | √ | [9] |
| Counting | YOLO+SVM | Adding convolutional layer to the pre-trained YOLO model transforms classification model into detection model | 93.71 | √ | [76] |
| Counting | Inception-ResNet | Modified the Inception-ResNet-A layer to capture the characteristics of multiple scales | 91 | √ | [77] |
| Counting | FCN | Using FCN model to segment targets and non-targets | - | √ | [78] |
| Counting | FCN-8 | Enhance and interleave density estimation by foreground background segmentation and explicit local uncertainty estimation | [79] | ||
| Yield Estimation | Inception-ResNet | Modified the Inception-ResNet-A layer to capture the characteristics of multiple scales | 91 | √ | [80] |
| Yield Estimation | AlexNet | Two independent branches CNN structures for processing RGB and multispectral images respectively | - | √ | [81] |
| Yield Estimation | R-CNNs | R-CNNs optimized for implementation method and hyper-parameter | 93.3 | √ | [32] |
| Ref. | Description of Datasets | Type of Image (Is It a Real Image) | Resolution(Pixels) | Objects and Numbers for Training | ||
|---|---|---|---|---|---|---|
| Objects | Training | Validation/Testing | ||||
| [63] | Dataset obtained from [82] | √ | Pest | 800 | 300 | |
| [64] | 300 images captured by binocular color camera in Fruit Garden and Citrus Experimental Base | √ | 1024 × 768 | Fruit | 250 | 50 |
| [65] | A dataset of 8, 640 30 FPS and 12, 960 70 FPS images containing total of 375, 698 annotated bees | √ | 512 × 512 | Bees | 19,434 | 2176 |
| [66] | 500 photos in the sunflower field taken by robot | √ | 512 × 384 | sunflower | 1500 | 350/150 |
| [67] | Datasets were acquired by mobile phones in HRC over a period of 2 years. | √ | 500 × 500 | Apples | 5200 | 1300 |
| [68] | Six sets of grape image data provided by Grape Breeding Institute | √ | 5472 × 3648 | ShootsN | 35 | 24/36 |
| ShootsA | 34 | 34/34 | ||||
| InfloresN | 15 | 15/15 | ||||
| PedicelsA | 40 | 40/40 | ||||
| GrapesN | 30 | 30/30 | ||||
| GrapesA | 30 | 30/30 | ||||
| [69] | A dataset consisting of 1,427 images from 10 fields | √ | 1224 × 1024 | Weeds | 1274 | 153 |
| [70] | 104 images on the grass by a stereo camera | √ | 1080 × 1920 | Field | 56 | 48 |
| [71] | Datasets were taken at multiple athletic fields, golf courses, and institutional lawns in FL. | √ | 640 × 360 | Hydrocotyle spp. | 12,000 | 1000 |
| Hedyotis cormybosa | 16,132 | 1000 | ||||
| Hedyotis cormybosa | 13,206 | 1000 | ||||
| Poa annua | 12,030 | 1000 | ||||
| Multiple-species | 36,000 | 1000 | ||||
| [72] | Capture image data by sensors in different orchards | √ | 500 × 500 | Apples | 729 | 112 |
| Almonds | 1154 | 270 | ||||
| Mangoes | 385 | 100 | ||||
| [31] | In total 100 images of apples and 50 of pears were taken. | √ | 1216 × 1216 | - | ||
| [33] | Some data sets are collected by themselves, while the rest are from Google’s image search. | √ | 1296 × 964 and 1920 × 1080, | Sweet pepper | 100 | 22 |
| [73] | Datasets of 147 images from the apple tree were collected by camera | √ | 5184 × 3456 | Apple | 100 | 47 |
| [74] | A dataset of 293 images taken in the field and an annotated dataset of 10,161 blueberries for detection and 228 for segmentation. | √ | images with 3264 × 2448/videos with 1920 × 1080 | Blueberry-V1 | - | - |
| Blueberry-V2 | - | - | ||||
| [75] | A dataset contains 52 videos from six different conveyors with a total of 443 frames. | √ | - | - | ||
| [9] | Orange datasets without lighting during the day and Apples data at night | √ | 1280 × 960 | Oranges | 3600 | 35 |
| Apples | 1100 | 10 | ||||
| [76] | Collection of dataset using capture devices and image | √ | 30 × 30 | - | ||
| [77] | 26400 synthetic images produced by the authors | Synthetic images | - | Synthetic tomato | 24,000 | 2400 |
| [78] | Orange datasets without lighting during the day and Apples data at night | √ | - | - | ||
| [79] | More than half a million images have been generated in more than 40 different locations over three years | √ | - | Penguin | 57,400 | 24,600 |
| [80] | 26,400 synthetic images produced by the authors | Synthetic images | - | Synthetic tomato | 24,000 | 2400 |
| [81] | There were 643 areas of interest in total | √ | 1280 × 960 | Paddy rice | 412 | 102 for validation and 129 for test |
| [32] | 335 pictures of 10 wheat varieties at three different growth stages | √ | 5184 × 3456 | Wheat | 305 | 30 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Liu, Y.; Gong, C.; Chen, Y.; Yu, H. Applications of Deep Learning for Dense Scenes Analysis in Agriculture: A Review. Sensors 2020, 20, 1520. https://doi.org/10.3390/s20051520
Zhang Q, Liu Y, Gong C, Chen Y, Yu H. Applications of Deep Learning for Dense Scenes Analysis in Agriculture: A Review. Sensors. 2020; 20(5):1520. https://doi.org/10.3390/s20051520
Chicago/Turabian StyleZhang, Qian, Yeqi Liu, Chuanyang Gong, Yingyi Chen, and Huihui Yu. 2020. "Applications of Deep Learning for Dense Scenes Analysis in Agriculture: A Review" Sensors 20, no. 5: 1520. https://doi.org/10.3390/s20051520
APA StyleZhang, Q., Liu, Y., Gong, C., Chen, Y., & Yu, H. (2020). Applications of Deep Learning for Dense Scenes Analysis in Agriculture: A Review. Sensors, 20(5), 1520. https://doi.org/10.3390/s20051520