Gait-Based Identification Using Deep Recurrent Neural Networks and Acceleration Patterns



Abstract
1. Introduction
2. State-of-the-Art
3. Proposed Methods
3.1. Data Pre-Processing
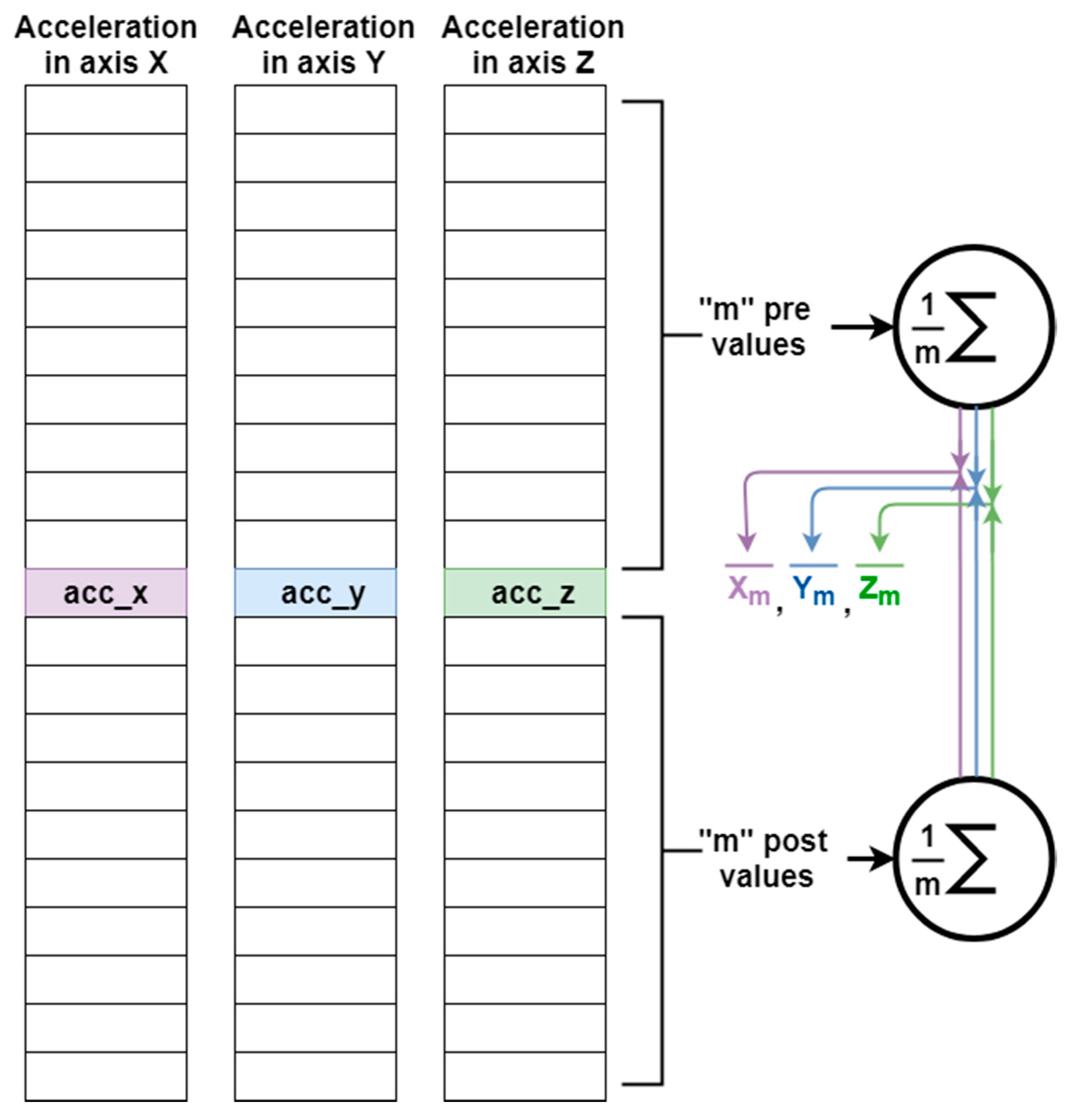
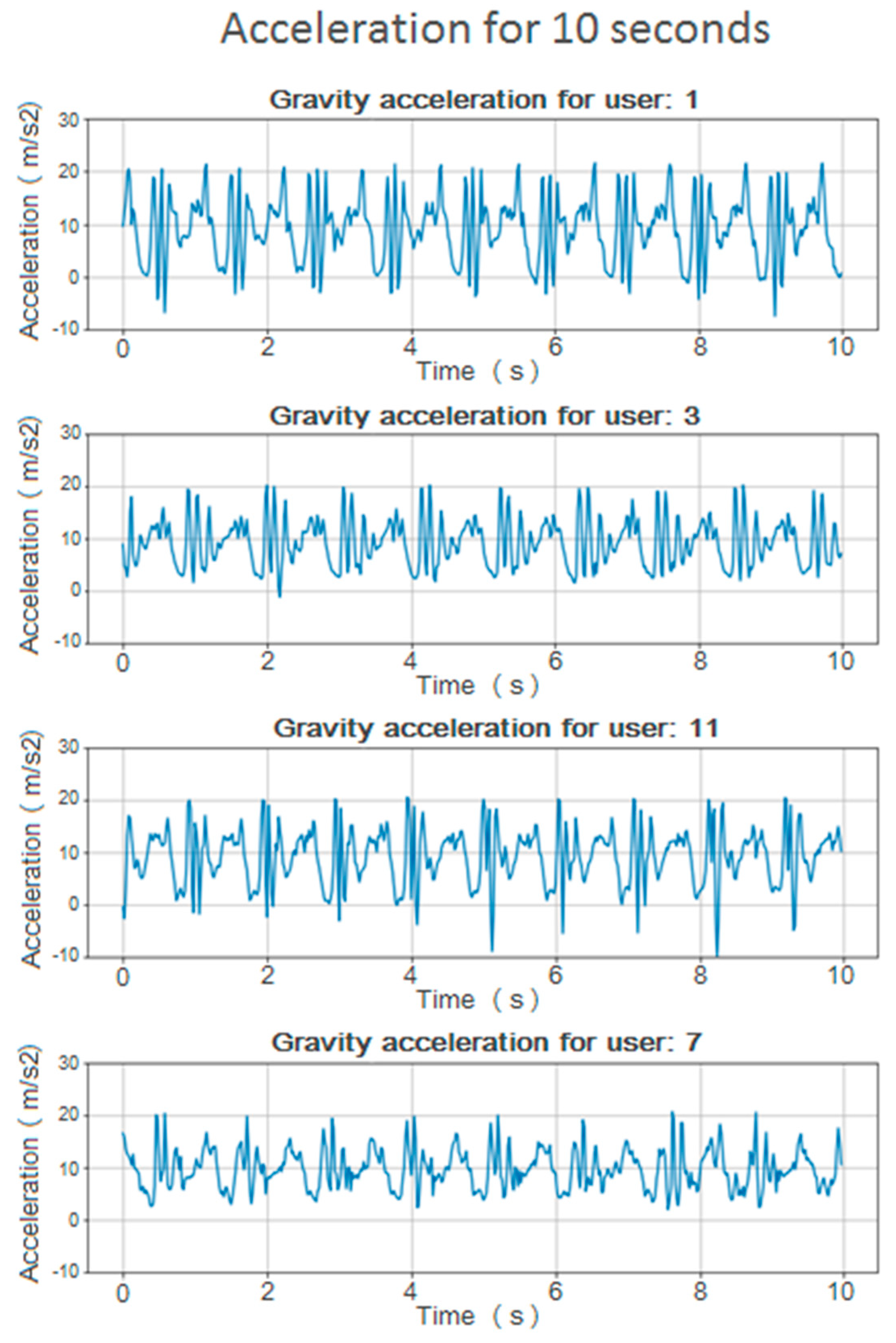
3.1.1. Calculating the Vertical Acceleration Component
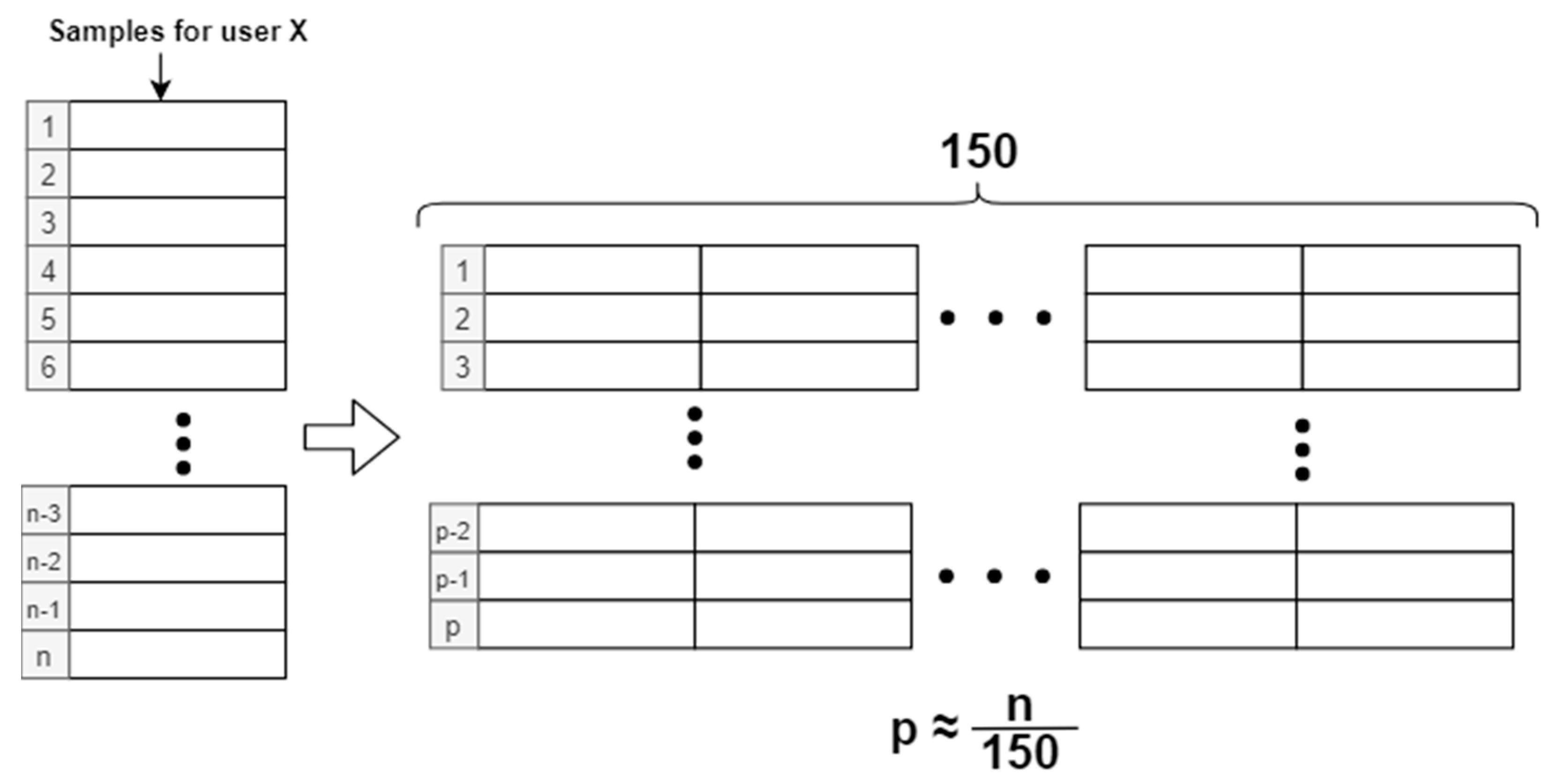
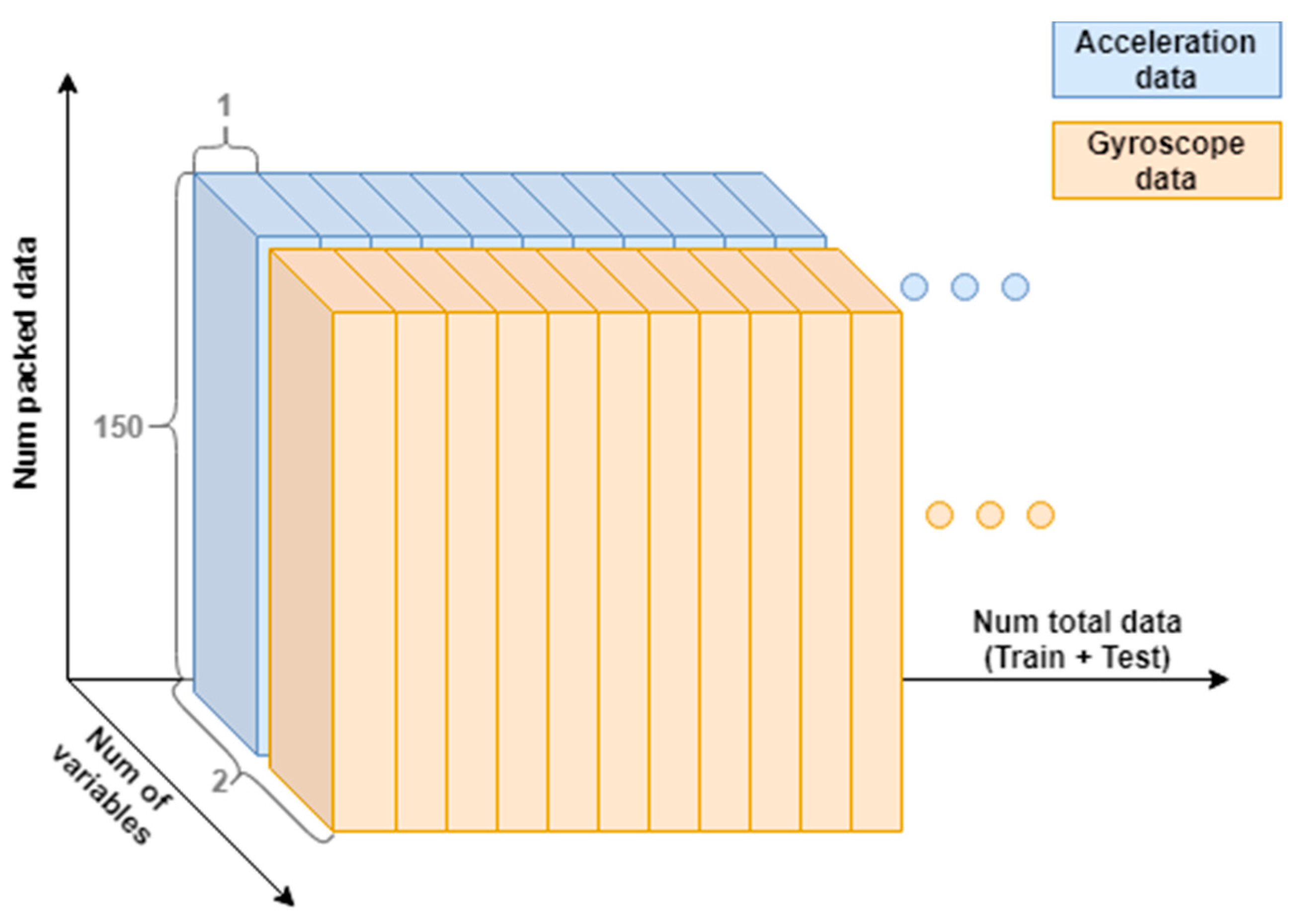
3.1.2. Sample Packaging
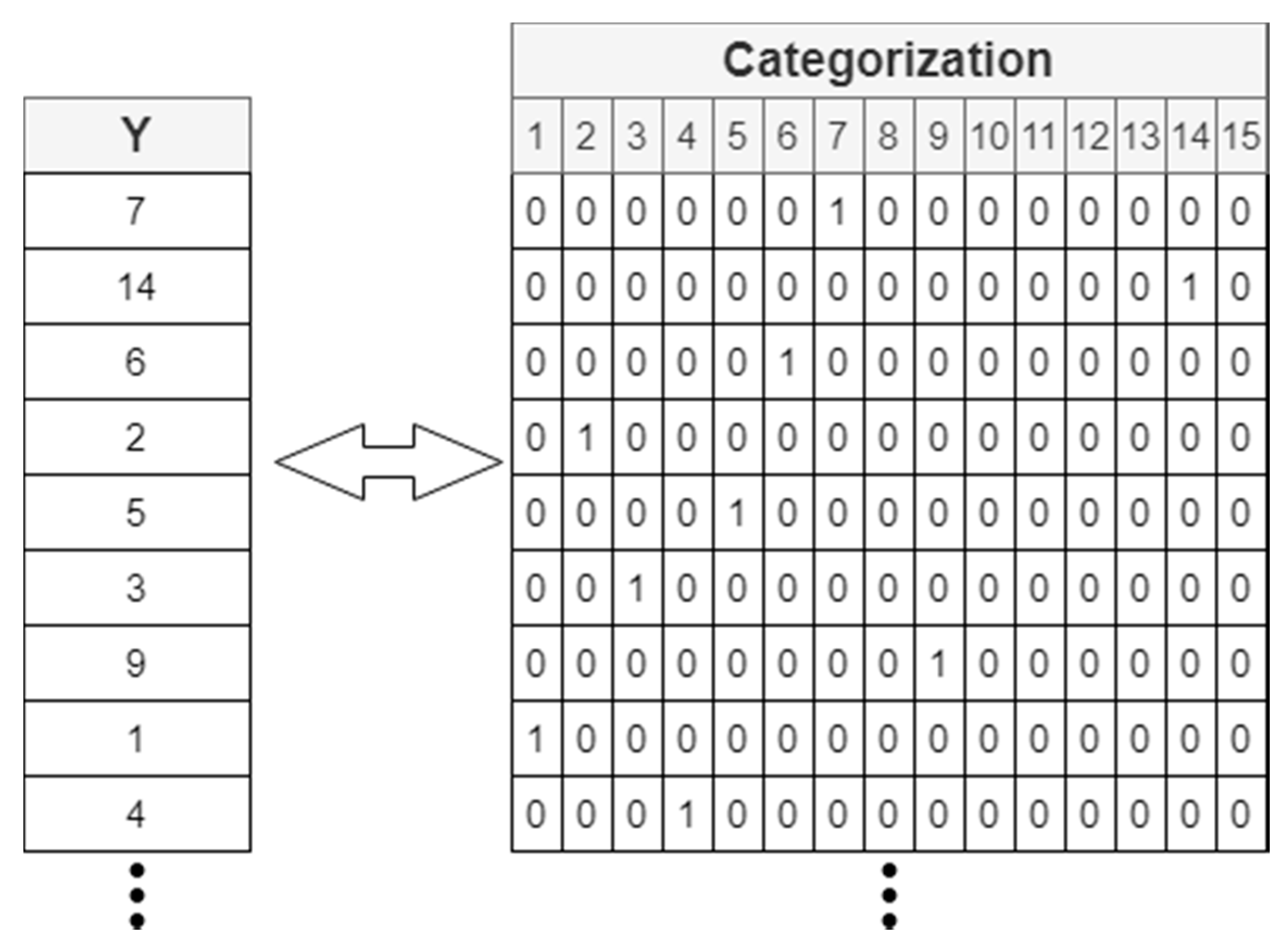
3.1.3. Data Labeling for Training and Testing the Algorithm
3.1.4. Sample Train-Test Division
3.2. Proposed Architecture
3.2.1. Recurrent Neural Networks and LSTM Cells
- The status cell can be interpreted as a continuous flow of information over several instants of time. At each instant of time you have to decide which information is retained, which is modified, and which is allowed to pass.
- Entrance door: Controls when new information can enter the status cell. It also determines how much of that new information will be allowed into the status cell.
- Exit door: Controls when the information from the memory is used for the result and how much information from the status cell will be offered at the output.
- Forget door: Controls when information is forgotten. This way, you can create space for new important data and remove less relevant ones. The function of this door is to determine whether the information will be stored in the status cell, or whether it will be discarded.
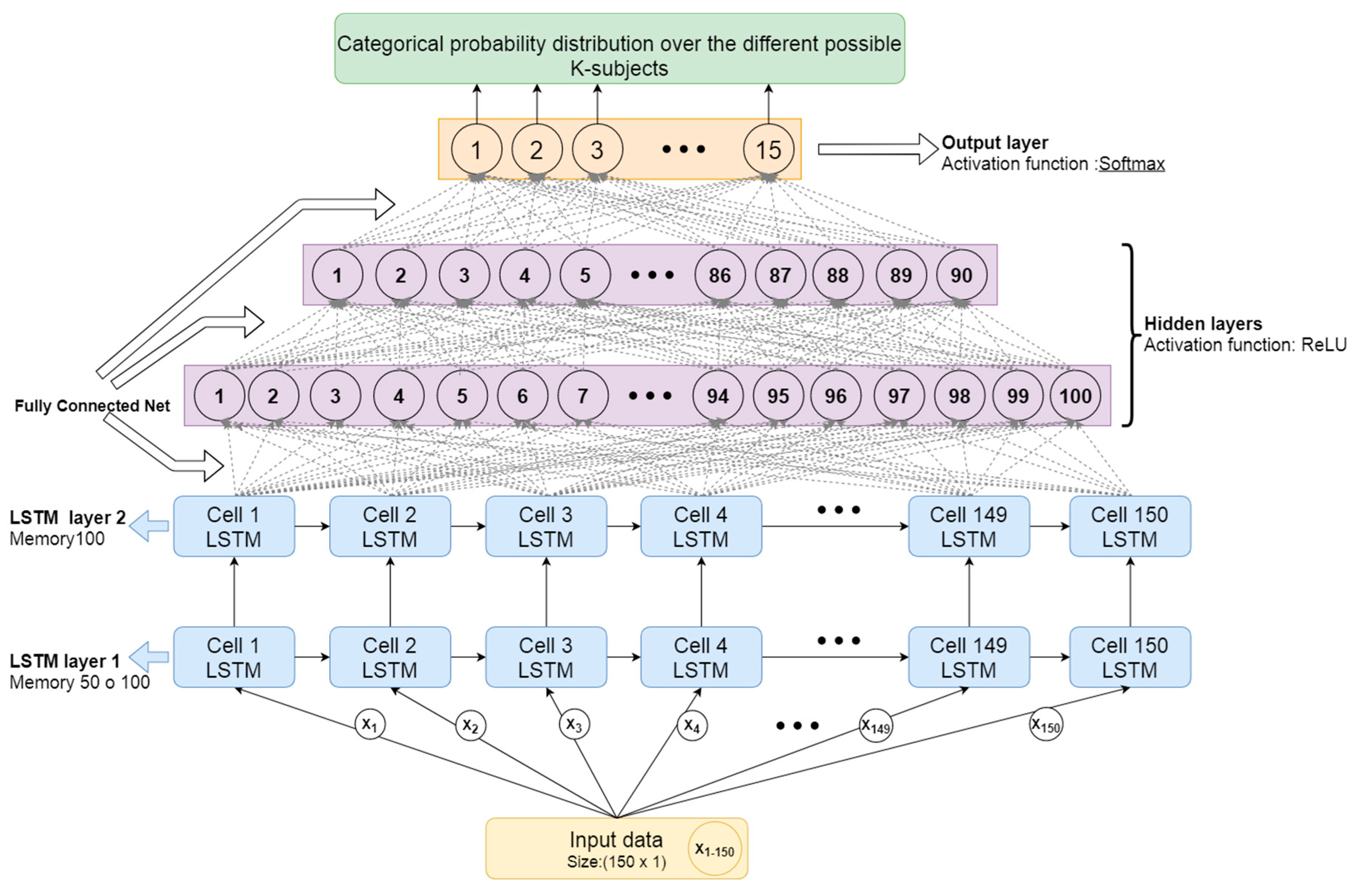
3.2.2. Proposed Architecture for User Identification Based on Gait Data
- The first two layers are RNN based on LSTM cells, formed by as many LSTM cells as there are moments of time (samples) in the packaged input data. Since the samples have been packed in windows of 150 samples (3 s), there will be 150 LSTM cells processing each time window of input samples. The first one has shown optimal results for 50 to 100 memory units (offering more or less similar results), and the second layer LSTM has shown better results for 100 memory units (as captured in Section 4). Memory units represent the internal state of the LSTM cell and are able to learn and forget time-dependent patterns based on the previous state and current inputs. The optimal number of memory units will therefore depend on the complexity of the time dependencies in the patterns to be detected.
- Then two hidden layers will be stacked, fully connected, with 100 and 90 neurons respectively. The activation function of these layers will be ReLU, as it offers a fast convergence that is especially useful in deep neural networks. This activation function usually works very well in the intermediate hidden layers.
- Lastly, there is a layer formed by as many neurons as the number of total users you want to differentiate. Since in this case the database has 15 users, there will be 15 neurons. The activation function for these neurons is softmax. As this is a multi-class classification problem, with this activation function it will be possible to obtain a categorical probability distribution over the different possible K-subjects.
- Loss function (the function used to estimate how far the current parameters are from the optimal ones when training the model and therefore the function to be minimized in such training): Categorical cross entropy. Used for multi-class classification problems.
- Optimizer (the numerical algorithm used to find the optimal value for the parameters in the model that minimize the loss function): Adam. It has the advantages of other optimizers such as RMSprop and SDG (Stochastic Gradient Descent) with momentum. It offers fast convergence and its operation is based on the use of first and second moment gradient estimates, adapting its learning rate to each weight of the neural network.
- Metric (the mechanism used to measure the achieved performance): Categorical accuracy. Accuracy of sample identification in multi-class classification problems.
4. Results, Testing, and Experiments
4.1. Results and Precision Test
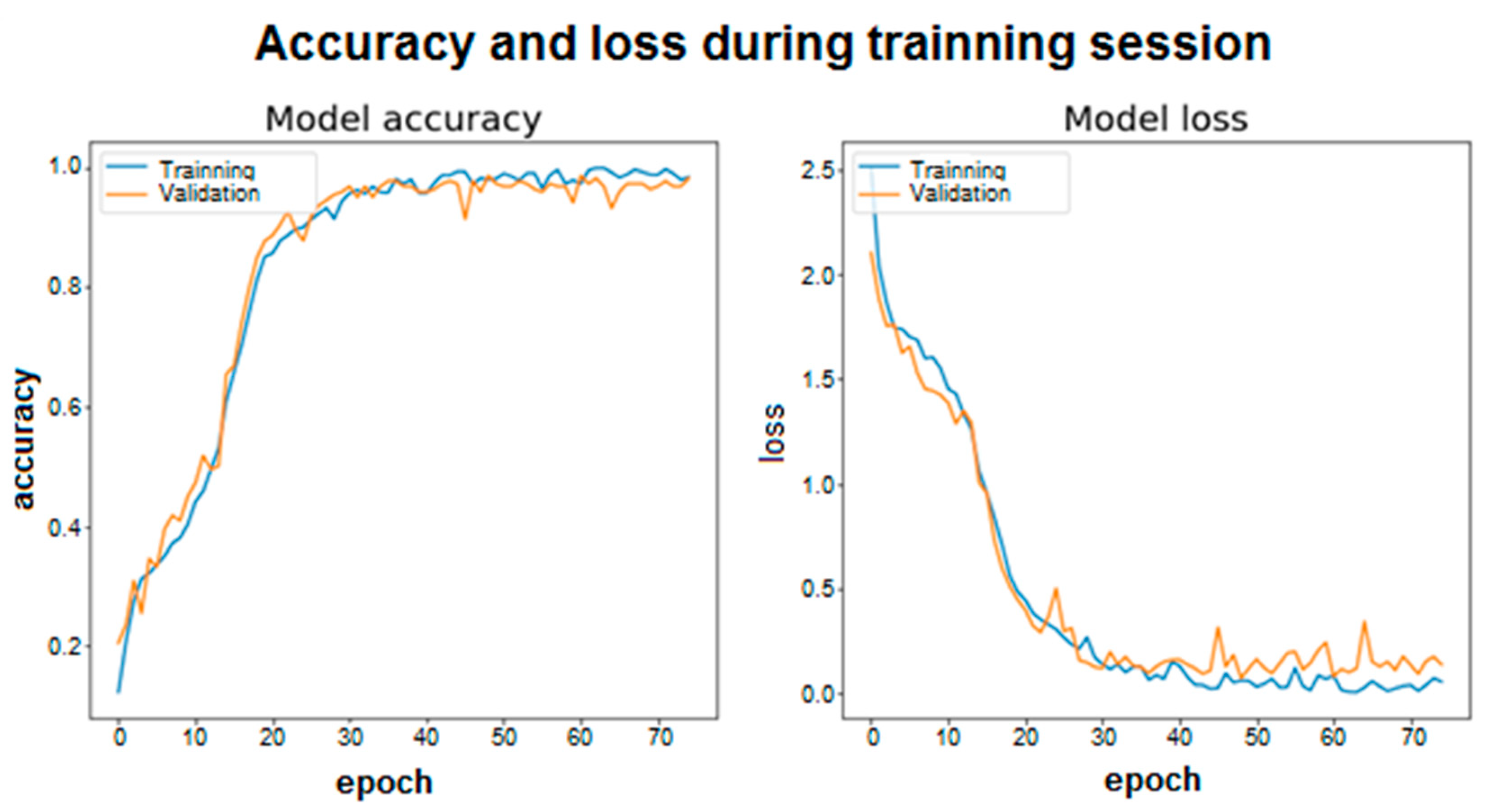
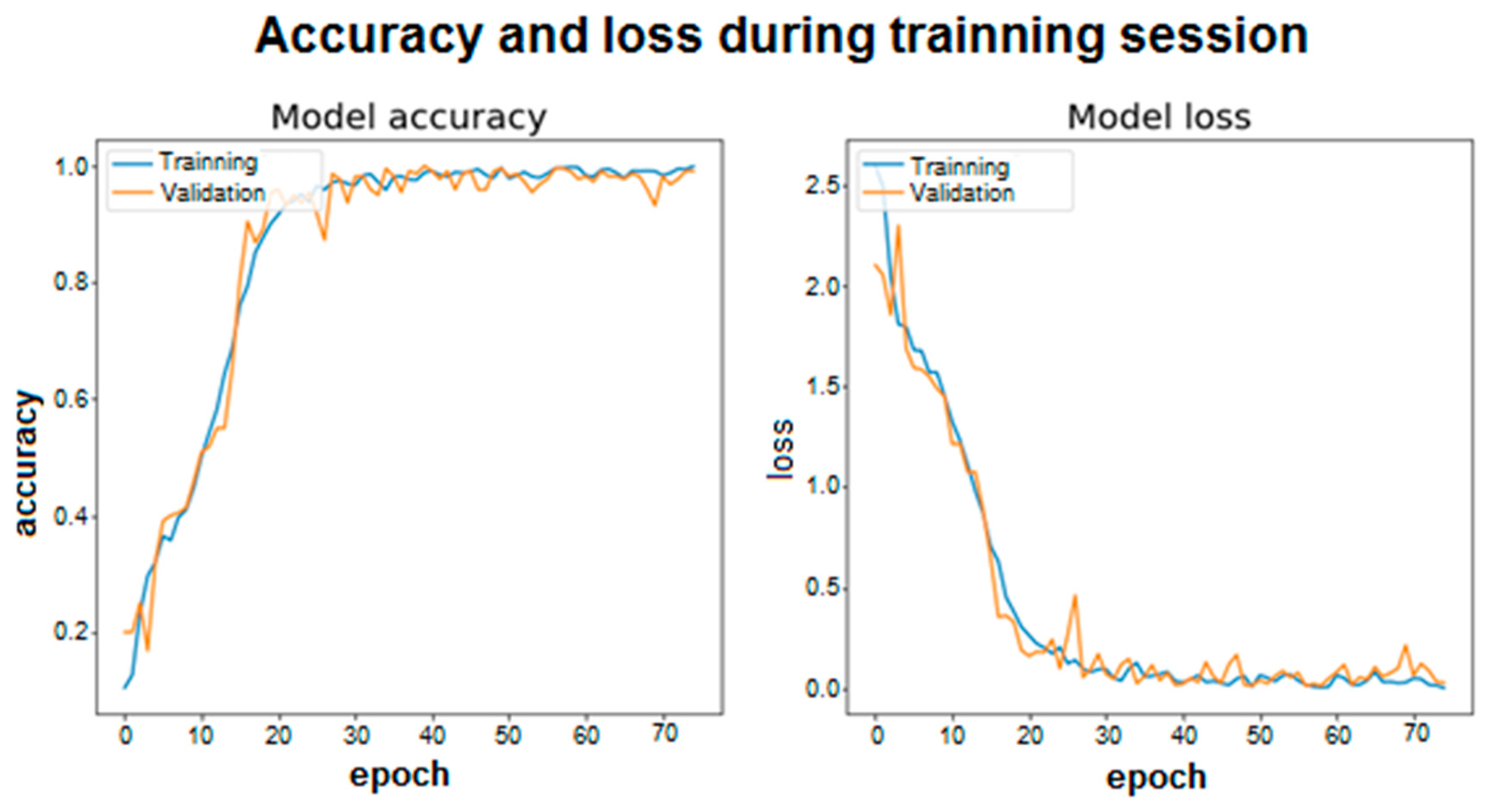
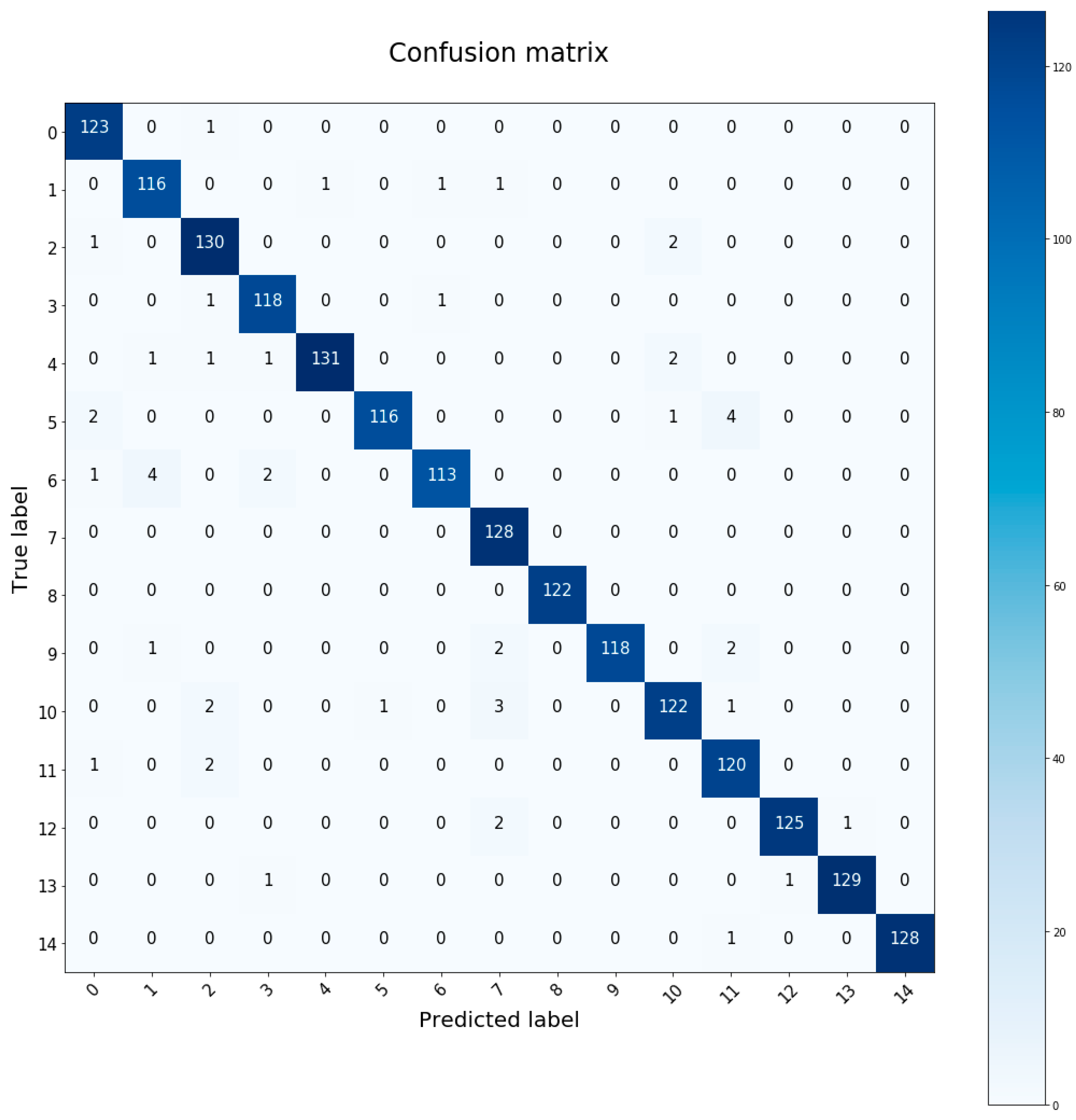
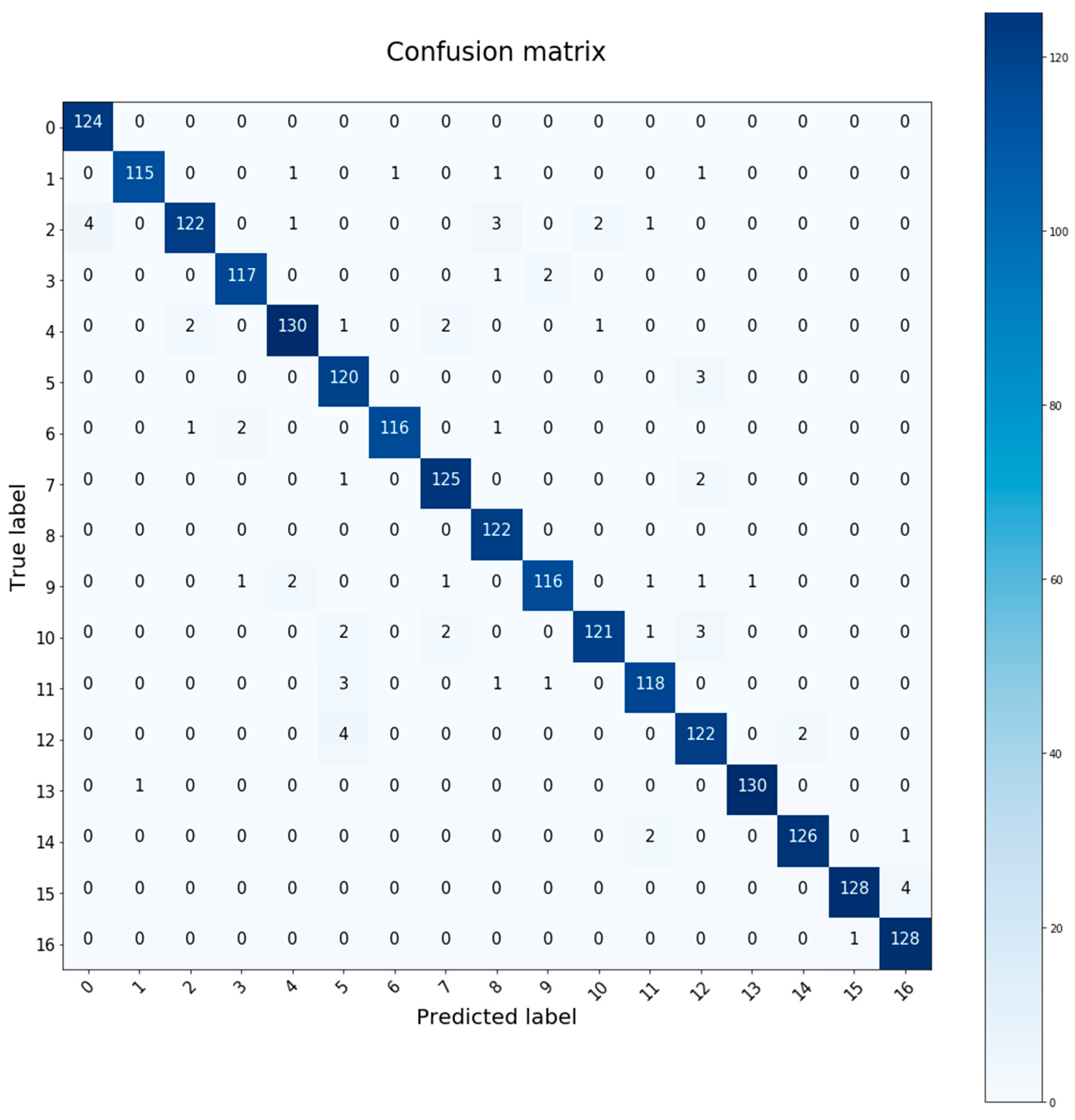
4.2. Training Graphics and Confusion Matrix
4.3. Generalization of Results for the Selected (Best) Neuronal Architecture
4.3.1. Increasing the Database with Additional Data
- Smartphone with accelerometer and gyroscope sensors. In this case, the Xiaomi Redmi Note 4 smartphone is used, which includes these sensors, in particular the LSM6DS3 sensor, which performs both tasks and is available on many other devices. It is a sensor with a high sampling rate (around 200 Hz), so it can be interpolated and adjusted so that samples are taken at 50 Hz as available in the original database. This sensor must be able to capture the axial information in the X-Y-Z axes, so that the pre-processing mentioned before can be done in a similar way to the rest of the data already existing in the database.
- A walking activity was recorded in two subjects (male and female) for 10 min continuously and without interruption.
- Because of the first wave of the COVID-19 pandemic that occurred in March–June 2020, it was impossible to record such activity in an open environment. For this reason, this activity was carried out at home with the help of a treadmill set at 4 km per hour.
- The data provided by the accelerometer and gyroscope were recorded simultaneously and synchronously.
- The CSV files generated for the two users were added with the rest of the database (only with the data of the thigh/pocket sensor walking activity). These will count as two new subjects with identifiers 15 and 16, which are added to the fifteen that previously had identifiers from 0 to 14. A total of 7139 samples are available (after pre-processing the vertical acceleration calculation, packaged in 150 and half-segment overlap), corresponding to 4990 for training and 2149 for testing.
- In the last layer of the neural network it is necessary to expand the number of neurons by two in order to be able to identify the 17 subjects available in the database after adding the new data. The activation function remains “softmax” since the purpose of identification is the same.
4.3.2. Performing User Identification with Gyroscope Extra Data
4.3.3. Changing the Window Size for Data Analysis
4.3.4. Identification of Users in Other Activities
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Simon, K. Digital 2019: Global Internet Use Accelerates. Available online: https://wearesocial.com/blog/2019/01/digital-2019-global-internet-use-accelerates (accessed on 17 November 2019).
- Irfan, A. How much Data is Generated Every Minute [Infographic]. Available online: https://www.socialmediatoday.com/news/how-much-data-is-generated-every-minuteinfographic-1/525692/ (accessed on 18 November 2019).
- Sztyler, T.; Stuckenschmidt, H. On-body localization of wearable devices: An investigation of position-aware activity recognition. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, Australia, 14–19 March 2016; pp. 1–9. Available online: https://ieeexplore.ieee.org/abstract/document/7456521 (accessed on 21 October 2019).
- De Marsico, M.; Nappi, M.; Proença, H.P. Gait recognition: The wearable solution. In Human Recognition in Unconstrained Environments: Using Computer Vision, Pattern Recognition and Machine Learning Methods for Biometrics; Academic Press: Cambrigde, MA, USA, 2017; pp. 177–195. [Google Scholar]
- Marsico, M.D.; Mecca, A. A survey on gait recognition via wearable sensors. ACM Comput. Surv. 2019, 52, 1–39. [Google Scholar] [CrossRef]
- Prakash, C.; Kumar, R.; Mittal, N. Recent developments in human gait research: Parameters, approaches, applications, machine learning techniques, datasets and challenges. Artif. Intell. Rev. 2018, 49, 1–40. [Google Scholar] [CrossRef]
- Deb, S.; Yang, Y.O.; Chua, M.C.H.; Tian, J. Gait identification using a new time-warped similarity metric based on smartphone inertial signals. J. Ambient Intell. Humaniz. Comput. 2020, 11, 1–13. [Google Scholar] [CrossRef]
- Mäntyjärvi, J.; Lindholm, M.; Vildjiounaite, E.; Mäkelä, S.M.; Ailisto, H. Identifying users of portable Devices from gait pattern with accelerometers. In Proceedings of the (ICASSP ‘05), IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 23 March 2005; IEEE: New York, NY, USA, 2005; pp. 973–976. [Google Scholar]
- Gafurov, D.; Snekkenes, E.; Bours, P. Gait authentication and identification using wearable accelerometer sensor. In Proceedings of the 2007 IEEE Workshop on Automatic Identification Advanced Technologies, Alghero, Italy, 7–8 June 2007; pp. 220–225. [Google Scholar] [CrossRef]
- Thang, H.M.; Viet, V.Q.; Dinh Thuc, N.; Choi, D. Gait identification using accelerometer on mobile phone. In Proceedings of the 2012 International Conference on Control, Automation and Information Sciences, ICCAIS, Ho Chi Minh City, Vietnam, 26–29 November 2012; IEEE: New York, NY, USA, 2012; pp. 344–348. [Google Scholar]
- Cola, G.; Avvenuti, M.; Vecchio, A. Real-time identification using gait pattern analysis on a standalone wearable accelerometer. Comput. J. 2017, 60, 1173–1186. [Google Scholar] [CrossRef]
- Sun, F.; Zang, W.; Gravina, R.; Fortino, G.; Li, Y. Gait-based identification for elderly users in wearable healthcare systems. Inf. Fus. 2020, 53, 134–144. [Google Scholar] [CrossRef]
- Sprager, S.; Zazula, D. A cumulant-based method for gait identification using accelerometer data with principal component analysis and support vector machine. WSEAS Trans. Signal Process. 2009, 5, 369–378. [Google Scholar]
- Nickel, C.; Brandt, H.; Busch, C. Classification of acceleration data for biometric gait recognition on mobile devices. BIOSIG 2011 Proc. Int. Conf. Biom. Spec. Interest Group 2011, 191, 57–66. [Google Scholar]
- Nickel, C.; Busch, C.; Rangarajan, S.; Möbius, M. Using hidden Markov models for accelerometer-based biometric gait recognition. In Proceedings of the 2011 IEEE 7th International Colloquium on Signal Processing and its Applications (CSPA), Penang, Malaysia, 4–6 March 2011; IEEE: New York, NY, USA, 2011; pp. 58–63. [Google Scholar]
- Nickel, C.; Wirtl, T.; Busch, C. Authentication of smartphone users based on the way they walk using k-NN algorithm. In Proceedings of the 2012 Eighth International Conference on Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP), Piraeus, Greece, 18–20 July 2012; IEEE: New York, NY, USA, 2012; pp. 16–20. [Google Scholar]
- Huan, Z.; Chen, X.; Lv, S.; Geng, H. Gait Recognition of Acceleration Sensor for Smart Phone Based on Multiple Classifier Fusion. Math. Probl. Eng. 2019, 2019. [Google Scholar] [CrossRef]
- Gadaleta, M.; Rossi, M. Idnet: Smartphone-based gait recognition with convolutional neural networks. Pattern Recognit. 2018, 74, 25–37. [Google Scholar] [CrossRef]
- Giorgi, G.; Martinelli, F.; Saracino, A.; Sheikhalishahi, M. Try walking in my shoes, if you can: Accurate gait recognition through deep learning. In International Conference on Computer Safety, Reliability, and Security; Springer: Cham, Switzerland, 2017; pp. 384–395. [Google Scholar]
- Giorgi, G.; Martinelli, F.; Saracino, A.; Sheikhalishahi, M. Walking through the deep: Gait analysis for user authentication through deep learning. In IFIP International Conference on ICT Systems Security and Privacy Protection; Springer: Cham, Switzerland, 2018; pp. 62–76. [Google Scholar]
- Zou, Q.; Wang, Y.; Wang, Q.; Zhao, Y.; Li, Q. Deep Learning-Based Gait Recognition Using Smartphones in the Wild. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3197–3212. [Google Scholar] [CrossRef]
- Fernandez-Lopez, P.; Liu-Jimenez, J.; Kiyokawa, K.; Wu, Y.; Sanchez-Reillo, R. Recurrent neural network for inertial gait user recognition in smartphones. Sensors 2019, 19, 4054. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. Available online: https://www.bioinf.jku.at/publications/older/2604.pdf (accessed on 15 February 2020). [CrossRef] [PubMed]
- Olah, C. Understanding LSTM Networks. Github—Colah’s Blog. Available online: http://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 16 February 2020).
- Keras. Available online: https://keras.io (accessed on 17 January 2020).
- Sztyler, T. Sensor Data Collector. Available online: https://github.com/sztyler/sensordatacollector (accessed on 24 February 2020).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Memory Units in LSTM Layers | Number of Hidden Layers | Number of Neurons in Hidden Layers | Number of Trainable Parameters | Accuracy Test Execution 1 | Accuracy Test Execution 2 | Accuracy Test Execution 3 | Training Time |
|---|---|---|---|---|---|---|---|---|
| 1 | 50 and 100 | 2 | 100 and 90 | 91.355 | 97.86% | 98.14% | 96.76% | ~29 min |
| 2 | 50 and 100 | 2 | 100 and 60 | 87.875 | 96.13% | 96.87% | 97.45% | ~30 min |
| 3 | 50 and 100 | 3 | 100, 90, and 60 | 96.365 | 96.34% | 95.33% | 95.18% | ~31 min |
| 4 | 50 and 100 | 3 | 100, 60, and 30 | 89.255 | 96.29% | 95.49% | 96.12% | ~32 min |
| 5 | 100 and 100 | 2 | 100 and 90 | 141.755 | 97.88% | 97.61% | 97.24% | ~37 min |
| Seed Group Test | Accuracy for Configuration ID 1 LSTM (50–100) and 90–100 | Accuracy for Configuration ID 5 LSTM (100–100) and 90–100 |
|---|---|---|
| 10 | Mean: 97.82% Variance: 0.861 | Mean: 98.35% Variance: 0.299 |
| 20 | Mean: 96.23% Variance: 0.98 | Mean: 97.61% Variance: 0.667 |
| 40 | Mean: 97.08% Variance: 0.612 | Mean: 98.15% Variance: 0.425 |
| 50 | Mean: 96.76% Variance: 0.774 | Mean: 96.97% Variance: 0.746 |
| Configuration ID 5 | Accuracy in Test Data with Chest Sensor | Mean Accuracy |
| 95.39% | 95.793% | |
| 96.12% | ||
| 95.88% |
| Used Variables | Accuracy in Test Data |
|---|---|
| Only acceleration data | 95.85% |
| Only gyroscope data | 93.55% |
| Both acc and gyro’s data | 97.95% |
| Packet Data Size | Equivalent Time of Each Packet | Number of Train Data | Number of Test Data | Accuracy in Test Data | Training Time |
|---|---|---|---|---|---|
| 300 | 6 s | 2481 | 1075 | 98.14% | 48.3 min |
| 250 | 5 s | 2983 | 1291 | 97.90% | 34.2 min |
| 200 | 4 s | 3735 | 1613 | 96.40% | 32.7 min |
| 150 | 3 s | 4990 | 2149 | 98.09% | 35.56 min |
| 100 | 2 s | 7498 | 3223 | 95.03% | 32.4 min |
| 50 | 1 s | 15,022 | 6448 | 93.24% | 32.6 min |
| 20 | 0.4 s | 18,797 | 8063 | 80.14% | 33.1 min |
| 12 | 0.24 s | 31,322 | 13,440 | 68.58% | 33.3 min |
| Activities | Number of Data Train/Test | Training Time | Accuracy in Test Data |
|---|---|---|---|
| Climb stairs | 3622/1560 | ~26 min | 90.06% |
| Run | 4883/2101 | ~35 min | 87.91% |
| Jump | 538/239 | ~3.5 min | 90.79% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peinado-Contreras, A.; Munoz-Organero, M. Gait-Based Identification Using Deep Recurrent Neural Networks and Acceleration Patterns. Sensors 2020, 20, 6900. https://doi.org/10.3390/s20236900
Peinado-Contreras A, Munoz-Organero M. Gait-Based Identification Using Deep Recurrent Neural Networks and Acceleration Patterns. Sensors. 2020; 20(23):6900. https://doi.org/10.3390/s20236900
Chicago/Turabian StylePeinado-Contreras, Angel, and Mario Munoz-Organero. 2020. "Gait-Based Identification Using Deep Recurrent Neural Networks and Acceleration Patterns" Sensors 20, no. 23: 6900. https://doi.org/10.3390/s20236900
APA StylePeinado-Contreras, A., & Munoz-Organero, M. (2020). Gait-Based Identification Using Deep Recurrent Neural Networks and Acceleration Patterns. Sensors, 20(23), 6900. https://doi.org/10.3390/s20236900