Visual Sorting of Express Parcels Based on Multi-Task Deep Learning



Abstract
1. Introduction
2. Sorting Method for Express Parcels in Complex Scenes
2.1. Overall Framework
2.2. Lightweight Object Detection Network
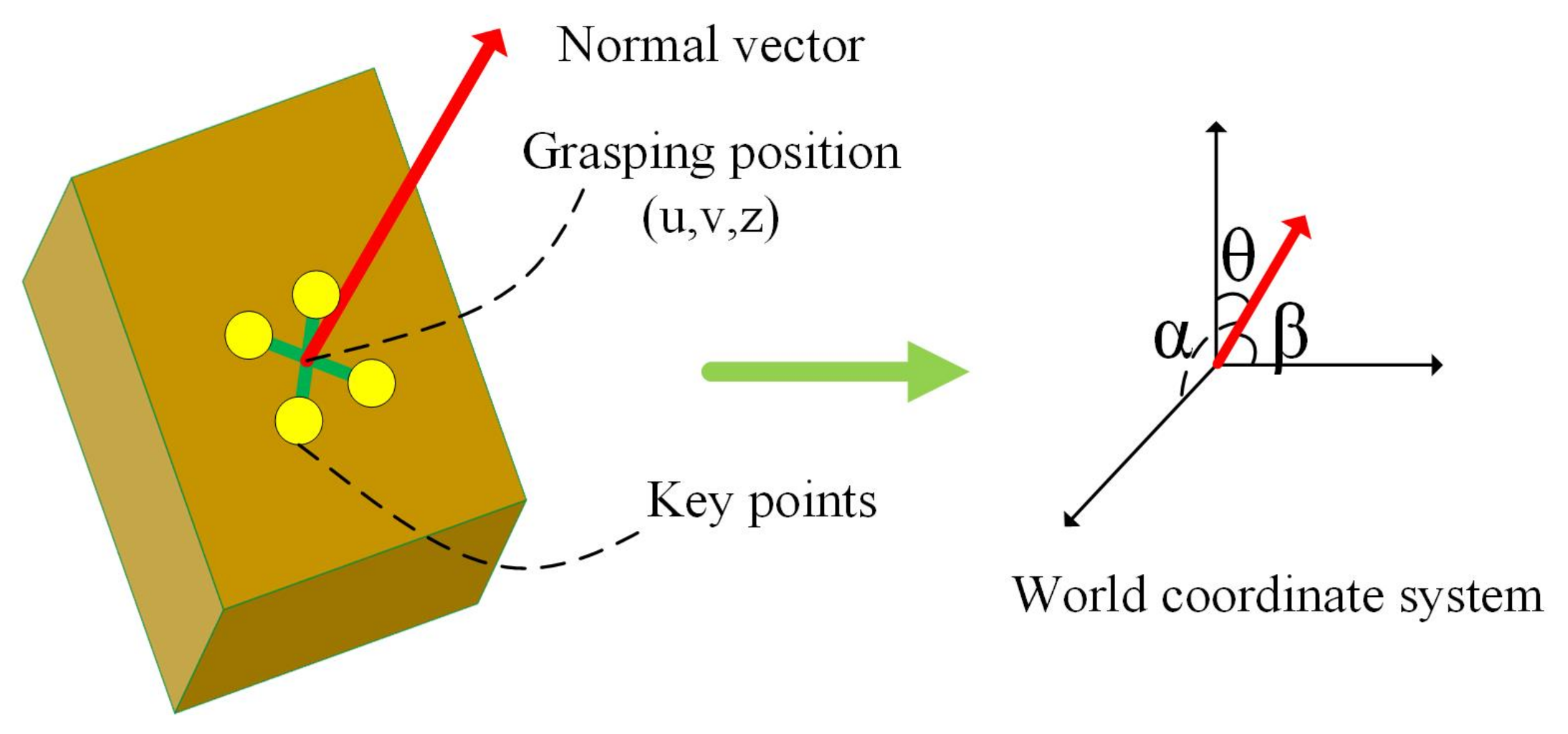
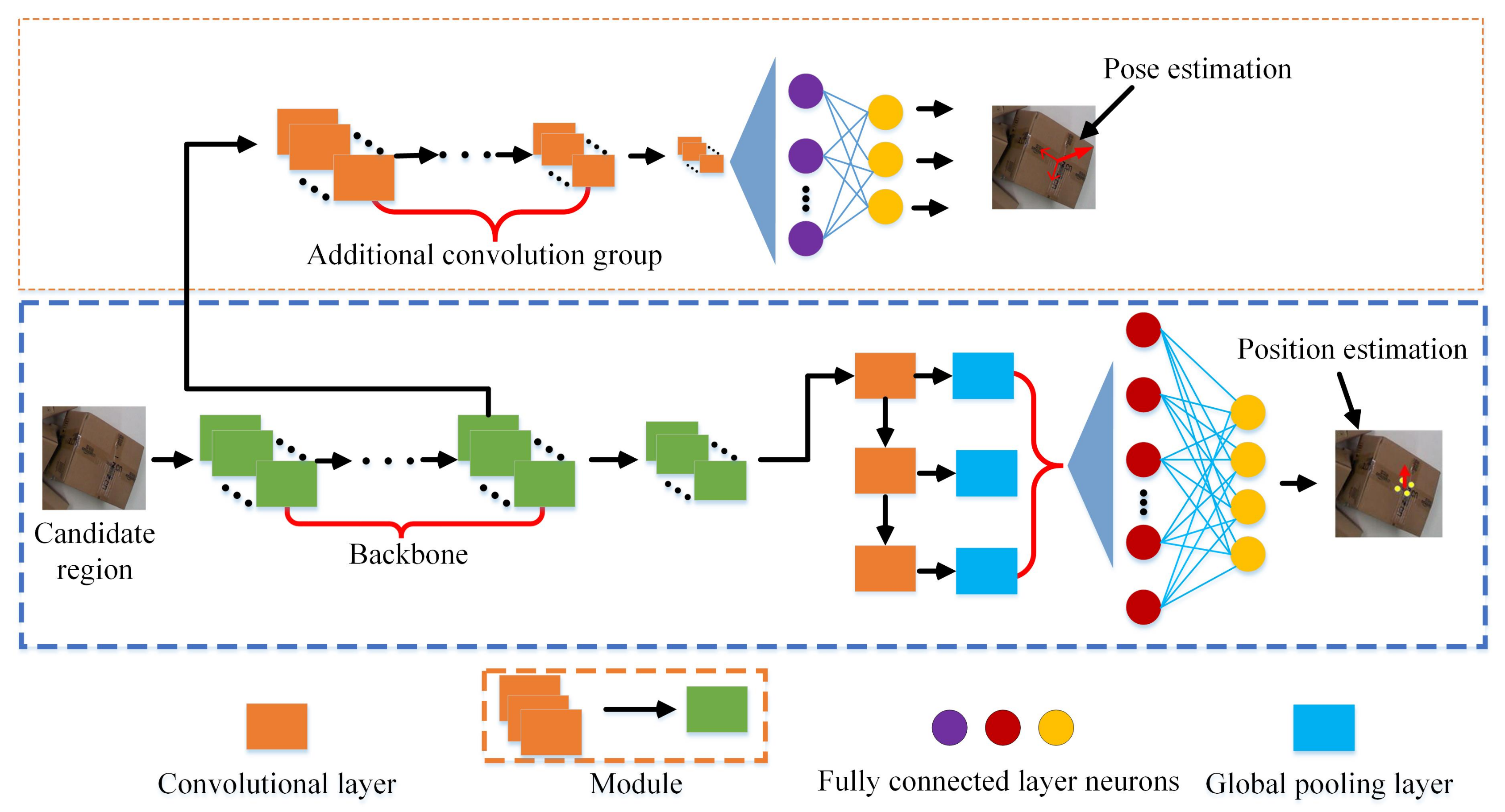
2.3. Multi-Task Optimal Sorting Position and Pose Estimation Network
3. Experiment and Analysis
3.1. Experiment on Object Detection
3.2. Experiment on Multi-Task Optimal Sorting Network
3.3. Robot Sorting Experiment
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sansoni, G.; Bellandi, P.; Leoni, F.; Docchio, F. Optoranger: A 3D pattern matching method for bin picking applications. Opt. Lasers Eng. 2014, 54, 222–231. [Google Scholar] [CrossRef]
- Wu, C.H.; Jiang, S.Y.; Song, K.T. CAD-based pose estimation for random bin-picking of multiple objects using a RGB-D camera. In Proceedings of the 2015 15th International Conference on Control, Automation and Systems (ICCAS), Busan, Korea, 13–16 October 2015. [Google Scholar]
- Song, K.T.; Wu, C.H.; Jiang, S.Y. CAD-based Pose Estimation Design for Random Bin Picking using a RGB-D Camera. J. Intell. Robot. Syst. 2017, 87, 455–470. [Google Scholar] [CrossRef]
- Schwarz, M.; Milan, A.; Lenz, C.; Munoz, A.; Periyasamy, A.S.; Schreiber, M.; Schüller, S.; Behnke, S. NimbRo picking: Versatile part handling for warehouse automation. In Proceedings of the IEEE International Conference on Robotics & Automation, Singapore, 29 May–3 June 2017. [Google Scholar]
- Pomerleau, F.; Colas, F.; Siegwart, R. A review of point cloud registration algorithms for mobile robotics. Found. Trends Robot. 2015, 4, 1–104. [Google Scholar] [CrossRef]
- Kumra, S.; Kanan, C. Robotic grasp detection using deep convolutional neural networks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Lenz, I.; Lee, H.; Saxena, A. Deep learning for detecting robotic grasps. Int. J. Robot. Res. 2015, 34, 705–724. [Google Scholar] [CrossRef]
- Redmon, J.; Angelova, A. Real-time grasp detection using convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 25–30 May 2015. [Google Scholar]
- Jiang, Y.; Stephen, M.; Ashutosh, S. Efficient grasping from rgbd images: Learning using a new rectangle representation. In Proceedings of the 2011 IEEE International conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011. [Google Scholar]
- Zhang, H.; Lan, X.; Zhou, X.; Tian, Z.; Zhang, Y. Visual Manipulation Relationship Network for Autonomous Robotics. In Proceedings of the 2018 IEEE-RAS 18th International Conference on Humanoid Robots (Humanoids), Beijing, China, 6–9 November 2018. [Google Scholar]
- Andy, Z.; Shuran, S.; Kuan-Ting, Y.; Elliott, D.; Alberto, R. Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Long, J.; Evan, S.; Trevor, D. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Nguyen, A.; Kanoulas, D.; Caldwell, D.G.; Tsagarakis, N.G. Object-based affordances detection with convolutional neural networks and dense conditional random fields. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Lafferty, J.; Andrew, M.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the 18th International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001. [Google Scholar]
- Do, T.; Anh, N.; Ian, R. Affordancenet: An end-to-end deep learning approach for object affordance detection. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018. [Google Scholar]
- Kaiming, H.; Georgia, G.; Piotr, D. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Shao, Q.; Hu, J.; Wang, W.; Fang, Y.; Ma, J. Suction Grasp Region Prediction Using Self-supervised Learning for Object Picking in Dense Clutter. In Proceedings of the 2019 IEEE 5th International Conference on Mechatronics System and Robots (ICMSR), Singapore, 3–5 May 2019. [Google Scholar]
- Ronneberger, O.; Philipp, F.; Thomas, B. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; Nassir, N., Hornegger, J., Wells, W.M., Eds.; Springer International Publishing: Berlin, Germany, 2015. [Google Scholar]
- Xing, H.; Xiao-Ping, L. Robotic sorting method in complex scene based on deep neural network. J. Beijing Univ. Posts Telecommun. 2019, 42, 22–28. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Joseph, R.; Santosh, D.; Ross, G.; Ali, F. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Redmon, J.; Ali, F. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wen, W.; Wu, C.; Wang, Y.; Chen, Y.; Li, H. Learning structured sparsity in deep neural networks. Advances in neural information processing systems. arXiv 2016, arXiv:1608.03665. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Han, S.; Huizi, M.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Du, X.; Cai, Y.; Lu, T.; Wang, S.; Yan, Z. A robotic grasping method based on deep learning. Robot 2017, 39, 820–837. [Google Scholar]
- Horaud, R.; Fadi, D. Hand-eye calibration. Int. J. Robot. Res. 1995, 14, 195–210. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Detection Feature Map | Size of Feature Map () | Size of the Preset Bounding Box () | Number of Preset Bounding Boxes |
|---|---|---|---|
| feature map1 | 13 × 13 | (116 × 90); (156 × 198); (373 × 326) | 13 × 13 × 3 |
| feature map2 | 26 × 26 | (30 × 61); (62 × 45); (59 × 119) | 26 × 26 × 3 |
| feature map3 | 52 × 52 | (10 × 13); (16 × 30); (33 × 23) | 52 × 52 × 3 |
| Hyperparameters | Value |
|---|---|
| batch size | 8 |
| base learning rate | 0.01 |
| learning rate decay | 2000, 4000 |
| rate of learning rate change | 0.1 |
| maximum iterations | 8000 |
| momentum | 0.9 |
| weight decay | 0.0005 |
| Model | MAP(%) | Parameter Amount (MB) | Parameter Reduction (%) | Inference Time (s) | Time Reduction (%) |
|---|---|---|---|---|---|
| YOLOv3 (Baseline) | 98.75 | 58.67 | — | 0.0161 | — |
| YOLOv3 (10%Pruned) | 97.28 | 57.76 | 1.55 | 0.0158 | 1.82 |
| YOLOv3 (20%Pruned) | 97.25 | 54.55 | 7.21 | 0.0156 | 3.11 |
| YOLOv3 (40%Pruned) | 96.58 | 38.78 | 33.9 | 0.0131 | 18.63 |
| YOLOv3 (60%Pruned) | 65.34 | 20.67 | 64.8 | 0.0103 | 36.02 |
| YOLOv3 (80%Pruned) | 20.26 | 6.36 | 89.2 | 0.0101 | 37.28 |
| Sparse Weight | Pruning Ratio | MAP (%) | Inference Time (s) |
|---|---|---|---|
| fixed 0.0005 | 20% | 93.43 | 0.0156 |
| fixed 0.0005 | 40% | 90.84 | 0.0132 |
| fixed 0.001 | 20% | 91.98 | 0.0155 |
| fixed 0.001 | 40% | 89.67 | 0.0131 |
| (, ) | 20% | 97.25 | 0.0156 |
| (, ) | 40% | 96.58 | 0.0131 |
| Structure | Detection Accuracy (%) | Inference Time in CPU (s) | Inference Time in GPU (s) |
|---|---|---|---|
| end-to-end + single-task | 93.62 | 0.2572 | 0.01674 |
| cascaded + single-task | 95.86 | 0.3836 | 0.02607 |
| cascaded + multi-task | 98.34 | 0.4258 | 0.03127 |
| end-to-end + multi-task | 97.53 | 0.2764 | 0.01833 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, S.; Liu, X.; Han, X.; Wang, G.; Wu, S. Visual Sorting of Express Parcels Based on Multi-Task Deep Learning. Sensors 2020, 20, 6785. https://doi.org/10.3390/s20236785
Han S, Liu X, Han X, Wang G, Wu S. Visual Sorting of Express Parcels Based on Multi-Task Deep Learning. Sensors. 2020; 20(23):6785. https://doi.org/10.3390/s20236785
Chicago/Turabian StyleHan, Song, Xiaoping Liu, Xing Han, Gang Wang, and Shaobo Wu. 2020. "Visual Sorting of Express Parcels Based on Multi-Task Deep Learning" Sensors 20, no. 23: 6785. https://doi.org/10.3390/s20236785
APA StyleHan, S., Liu, X., Han, X., Wang, G., & Wu, S. (2020). Visual Sorting of Express Parcels Based on Multi-Task Deep Learning. Sensors, 20(23), 6785. https://doi.org/10.3390/s20236785