1. Introduction
With the development of society, mobile robots are playing an increasingly important role in modern life. Mobile robots can autonomously move and operate according to different assigned tasks and have been widely used in the military, medical, manufacturing, entertainment, logistics and other fields [
1,
2,
3]. The path planning problem is a hot topic in the field of robotics research. It requires robots to find an optimal or suboptimal path from the starting position to the target position according to some specific performance index (such as distance, time, etc) in a working environment with obstacles [
4,
5].
Path planning problems are generally divided into global path planning and local path planning. In global path planning, a path search is carried out in a known environment. On the contrary, local path planning is relatively complex because the environment may be partially or completely unknown. According to the information of obstacles, the working environment of the robot can be divided into the fully known environment, partly known environment, completely unknown environment and dynamic environment [
6]. The quality of robot path planning can be evaluated according to path length, path smoothness, energy consumption or risk degree [
7].
According to the different stages of the path planning algorithm development, the algorithms can be divided into two categories: fast-exploring random tree method [
8], artificial potential field method [
9], the visible method [
10], A* algorithm [
11] as representative traditional algorithms. Intelligent algorithms represented by genetic algorithm [
12], ant colony algorithm [
13], particle swarm algorithm [
14], immune cloning algorithm [
15]. In [
8], Janson theoretically proved that the use of deterministic low-dispersion sampling plan usually makes the RRT algorithm display superior performance. In [
9], Yu proposed an improved artificial potential field method. This method uses the strength of the potential field instead of the force vector to plan the path of the mobile robot. This method can better realize the path planning of the mobile robot in a dynamic environment. In [
10], Blasi first proposed a real-time collision avoidance algorithm based on visibility graph method. The algorithm solves the optimization problem through a piecewise linear path with the smallest cost. In [
11], Le proposed an improved A* algorithm. The algorithm can automatically generate path points to improve the path coverage of the robot. These traditional path planning algorithms are light and small, with less calculation and easy to understand. Such algorithms are often used for small-scale maps with fewer obstacles. However, these traditional path planning algorithms are not suitable for large-scale maps or maps with many obstacles, and it is easy to fall into a locally optimal solution. In [
12], Park proposed a new multi-population genetic algorithm. The algorithm can solve complex communication problems and multi-label feature selection problems. In [
13], Beschi used an ant colony algorithm to solve complex motion planning problems after discretizing the task space. In [
14], Strąk proposed a discrete particle swarm optimization algorithm to solve the dynamic traveling salesman problem. The algorithm can automatically set the parameter values of the discrete particle swarm optimization algorithm. Simulation results show that the algorithm is suitable for large-scale dynamic traveling salesman problems. Aiming at the multi-objective optimization problem, reference [
15] proposed an immune cloning algorithm based on the reference direction method. The algorithm uses the reference direction method to guide the selection and cloning of active populations. The simulation results show that the algorithm still has strong competitiveness in complex environments. Compared with traditional algorithms, these intelligent algorithms are suitable for both small-scale maps and large-scale maps. They can be used for both global path planning and local path planning, and can effectively avoid local optimal solution problems.
This article uses the genetic algorithm to study path planning. The genetic algorithm is designed according to the evolutionary laws of organisms in Nature. This algorithm is a randomized search method that simulates natural selection theory and biological genetic mechanisms. Because the genetic algorithm has the advantages of strong robustness and parallelism, it is widely used in path planning. Forrest [
16] summarized the standard genetic algorithm (SGA) proposed by Holland and pointed out that SGA has the advantages of flexible search and strong scalability. However, SGA also has disadvantages such as low quality of convergent individuals, many iterations required for convergence, easy to fall into local optimal solutions, and poor population diversity. Hu Jun et al. [
17] initialized the population by introducing chaotic sequences and a heuristic method based on environmental knowledge to improve the quality of the initial population. However, this method is very slow at generating individuals in a multi-obstacle environment and may even fail to produce effective individuals. Shi et al. [
18] proposed a new coding method based on projecting two-dimensional data to one-dimensional data. This coding method can reduce the computational complexity of the algorithm model. However, this coding method can only generate fixed-length codes. This will affect the quality of the generated path. This encoding method is also not suitable for large-scale maps. Guo et al. [
19] proposed an improved genetic algorithm (IGA) by improving the crossover mutation operator of SGA. Compared with SGA, IGA can converge faster. However, the quality of convergent individuals is not good, and the shortcomings of poor population diversity are still not significantly improved. Based on the apoptosis theory proposed by Yigong, Zhang et al. [
20] improved the selection operator of SGA. Then they proposed the programmed cell death evolutionary algorithm (PCDA). Compared with SGA, PCDA has improved performance indexes such as program running time, iterations required for convergence, individual quality of convergence, and population diversity. However, there is also the problem that population diversity drops sharply in the middle and late iteration.
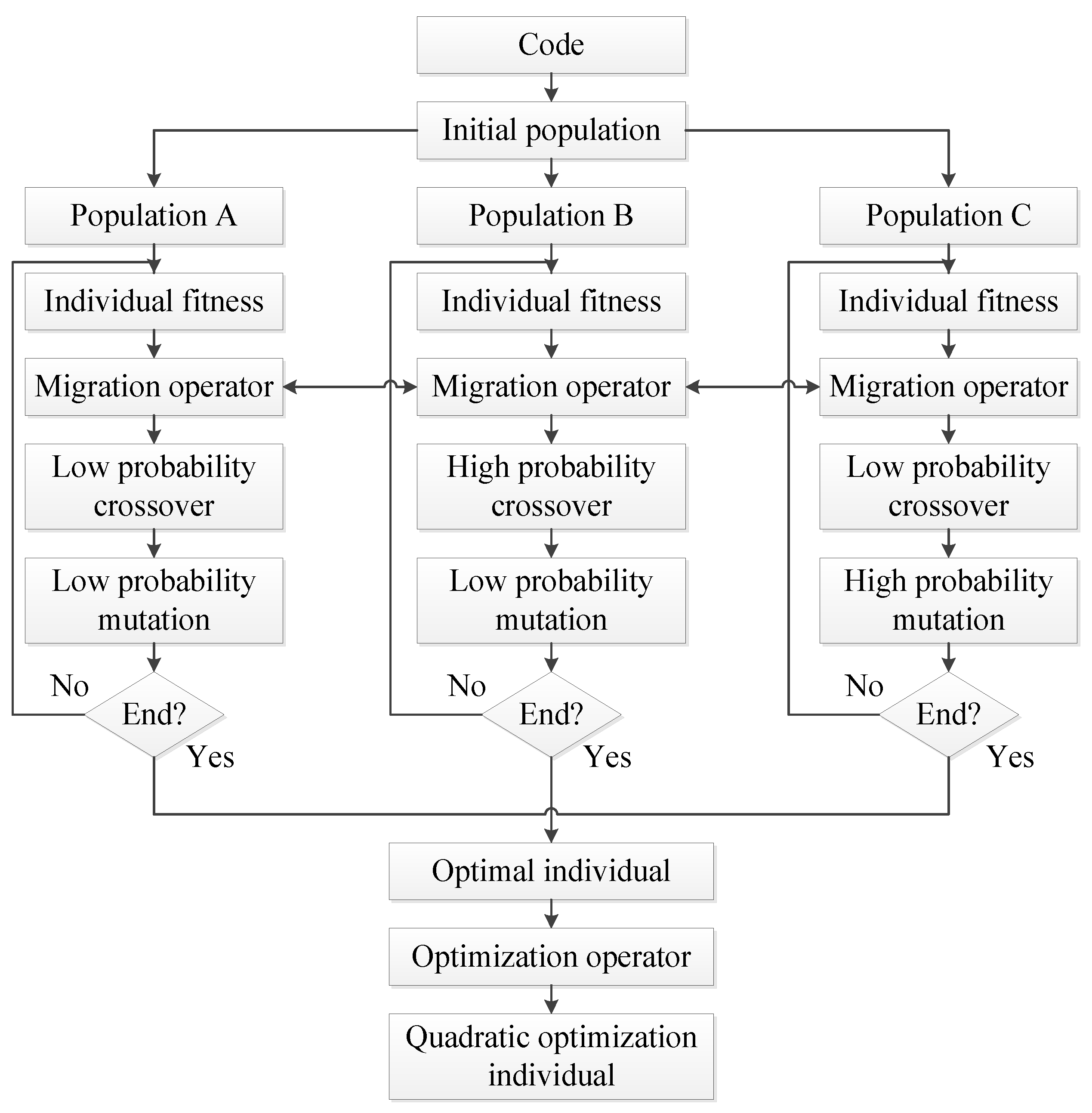
Through the above analysis, this paper proposes a path planning method based on the multi-population migration genetic algorithm (MPMGA). This paper makes the following innovations and contributions: (1) A new algorithm framework is proposed to enhance the parallelism of the algorithm. (2) Compared with other algorithms, MPMGA can be used for both global static path planning and local dynamic path planning and MPMGA shows good performance in both. (3) Compared with other algorithms, MPMGA has better feasibility and effectiveness in actual maps and good applicability in simulation maps. (4) No matter what the scale of the map and no matter how the obstacles are distributed, MPMGA can always generate high-quality and effective planning paths. (5) MPMGA proposes migration operators and optimization operators. The migration operator can speed up the algorithm convergence speed and enhance the diversity of the population. Optimization operators can further improve the quality of convergent individuals. (6) MPMGA improves the population initialization process, crossover operator and mutation operator. MPMGA improves the quality of the initial population by improving the population initialization process. MPMGA further enhances the global search ability of the algorithm by improving the crossover operator. MPMGA further enhances the local search ability of the algorithm by improving the mutation operator.
The remainder of this paper is organized as follows:
Section 2 introduces the algorithm framework of MPMGA.
Section 3 introduces the modeling method of the two-dimensional space environment and the preprocessing process for irregular obstacles. In
Section 4, we introduce the various aspects of MPMGA in detail, including encoding methods, population initialization process, cross mutation operator, migration operator, etc. In
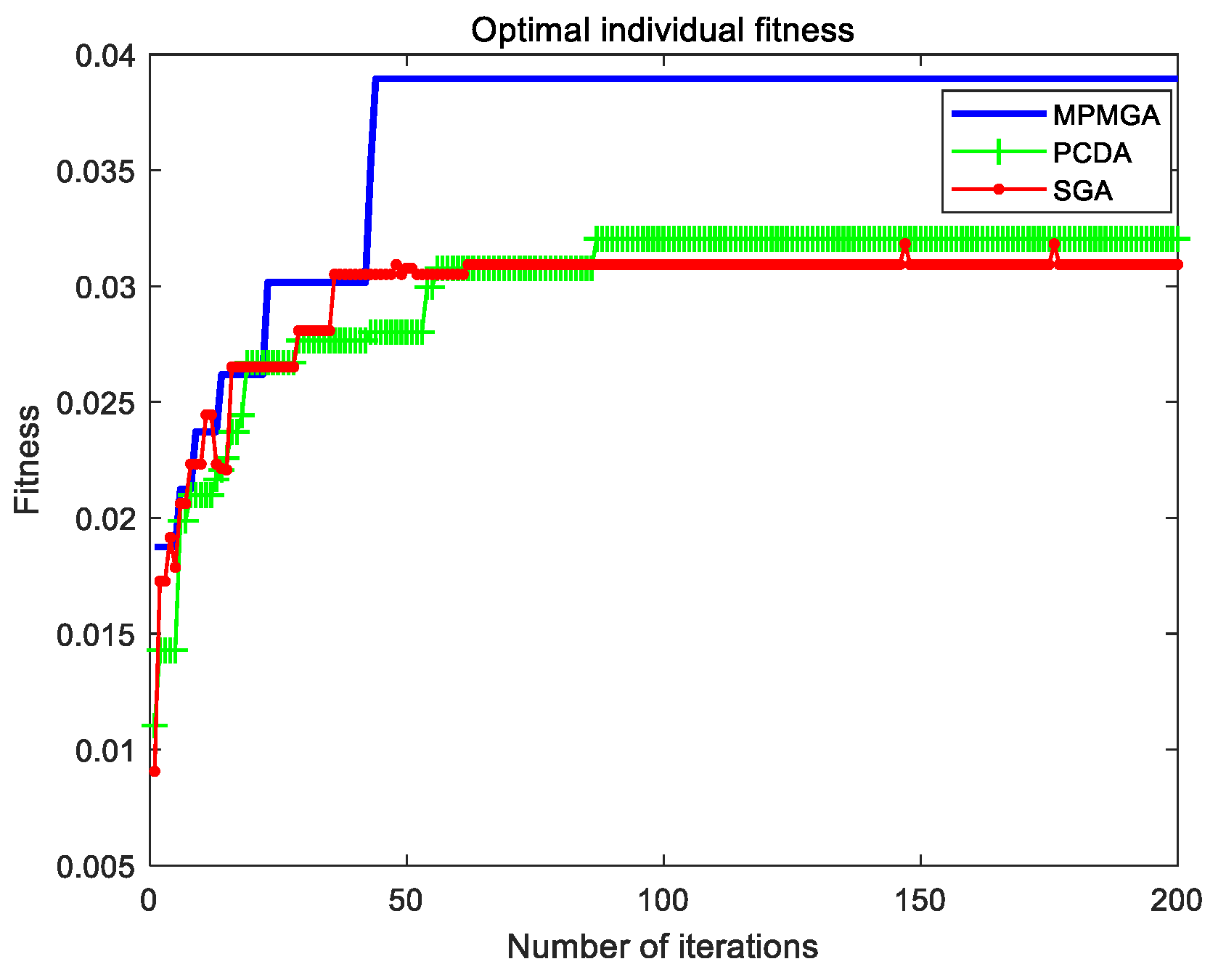
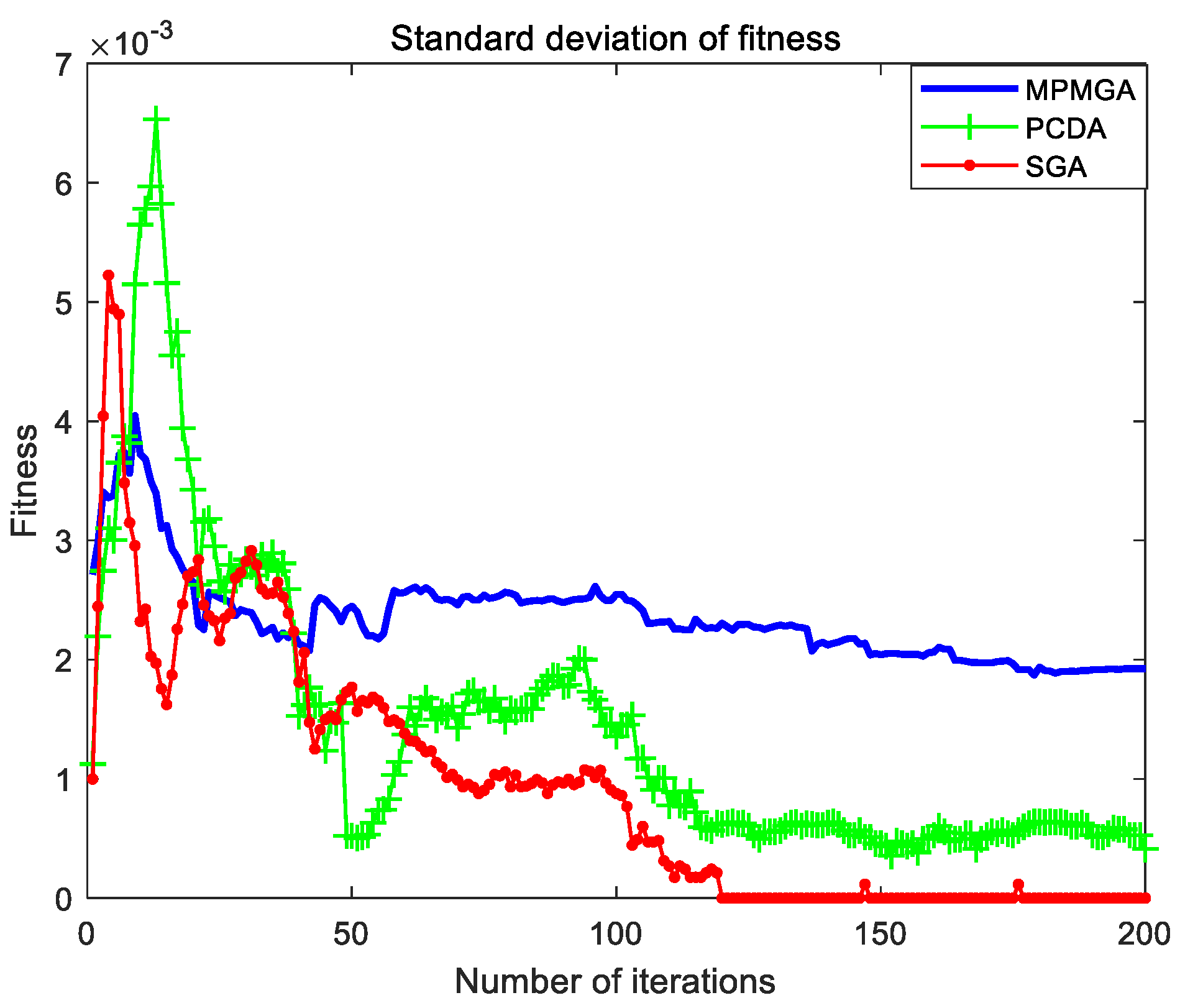
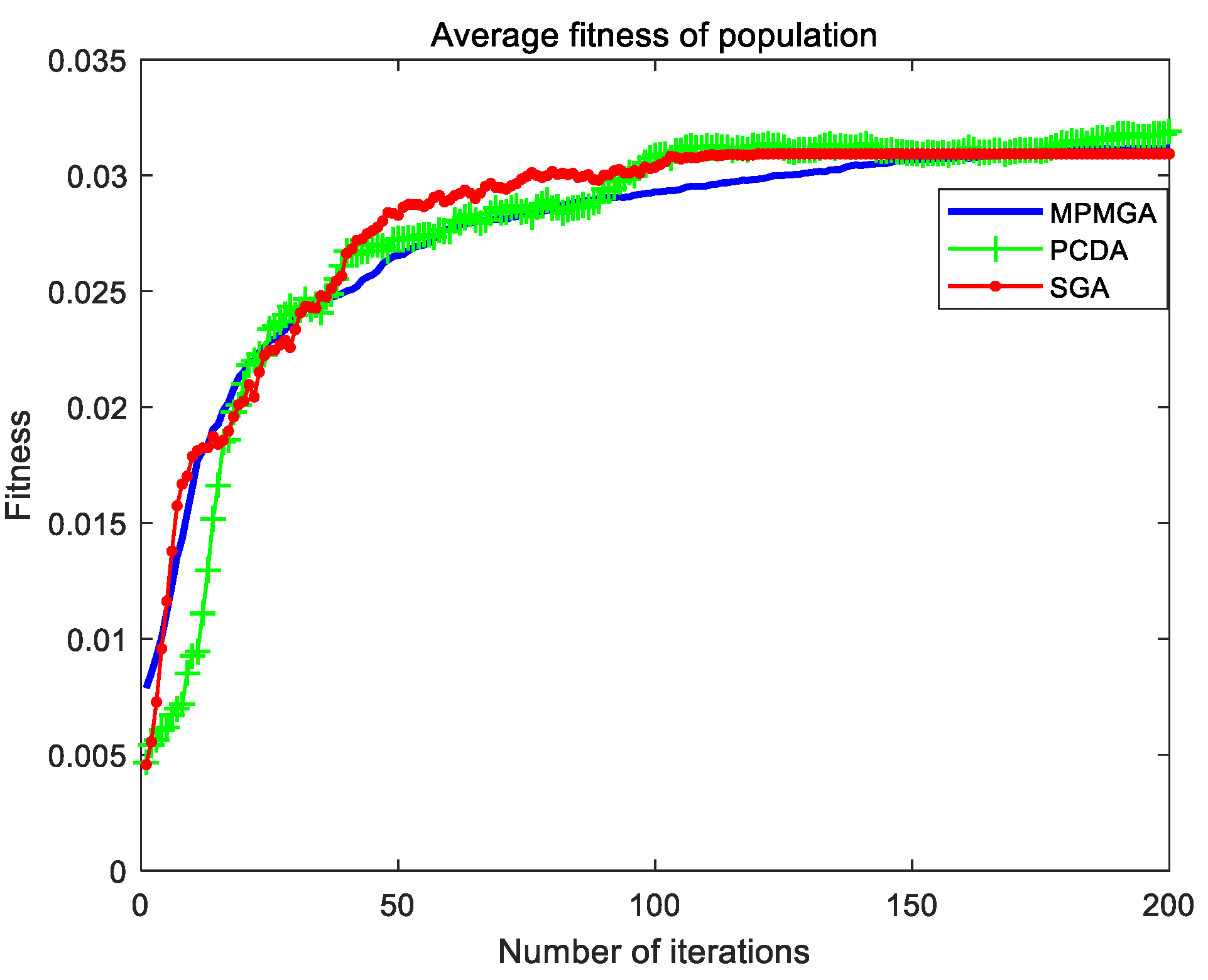
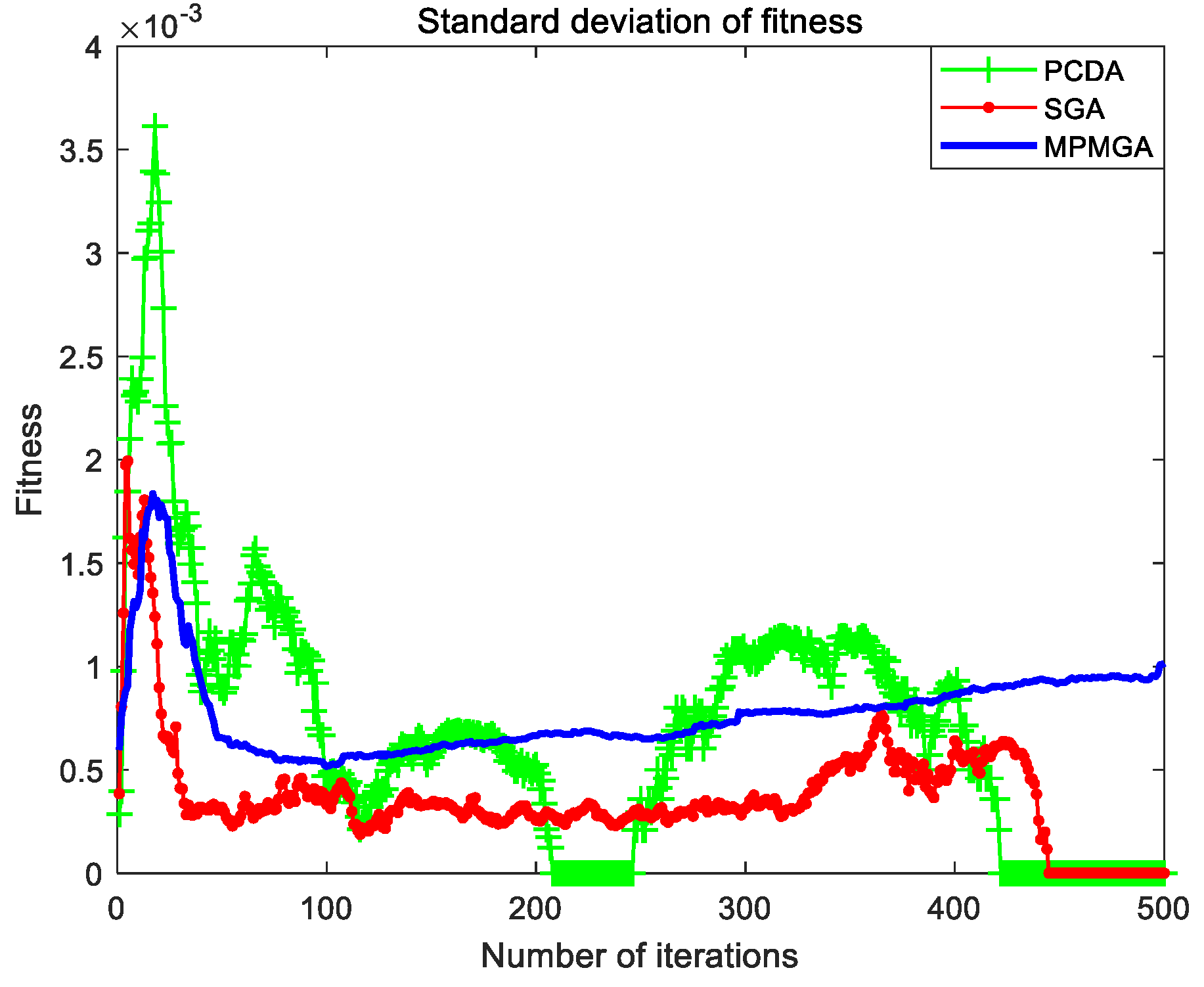
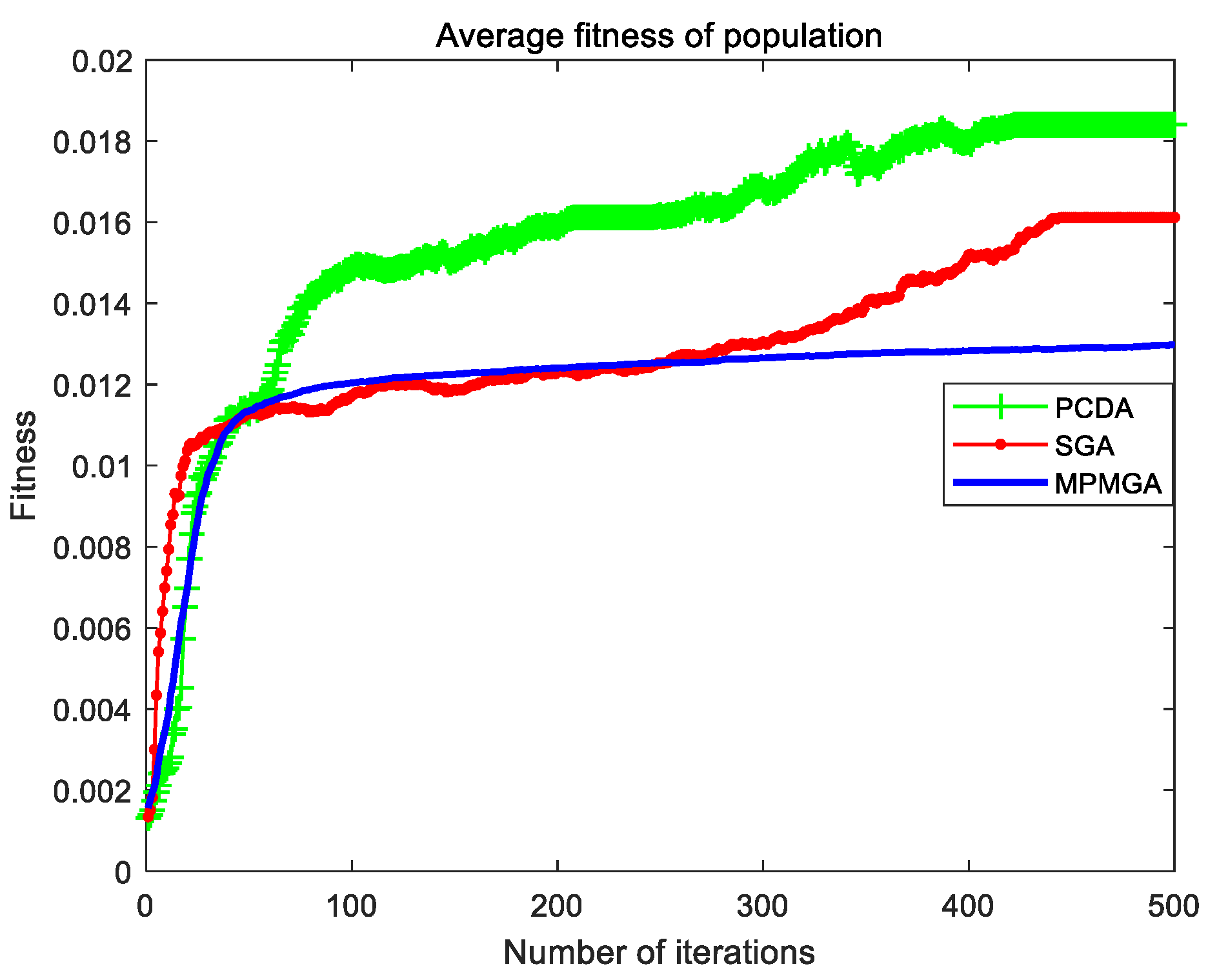
Section 5, we compare the performance of each algorithm and the quality of path planning of each algorithm in two different scale simulation maps through simulation programs. We analyze in detail the reasons why each algorithm produces good or poor performance. In
Section 6, we summarize the entire paper and discuss the applicability and problems of MPMGA on a real mobile robot. According to these issues and limitations, we discuss future work.
3. Environment Modeling
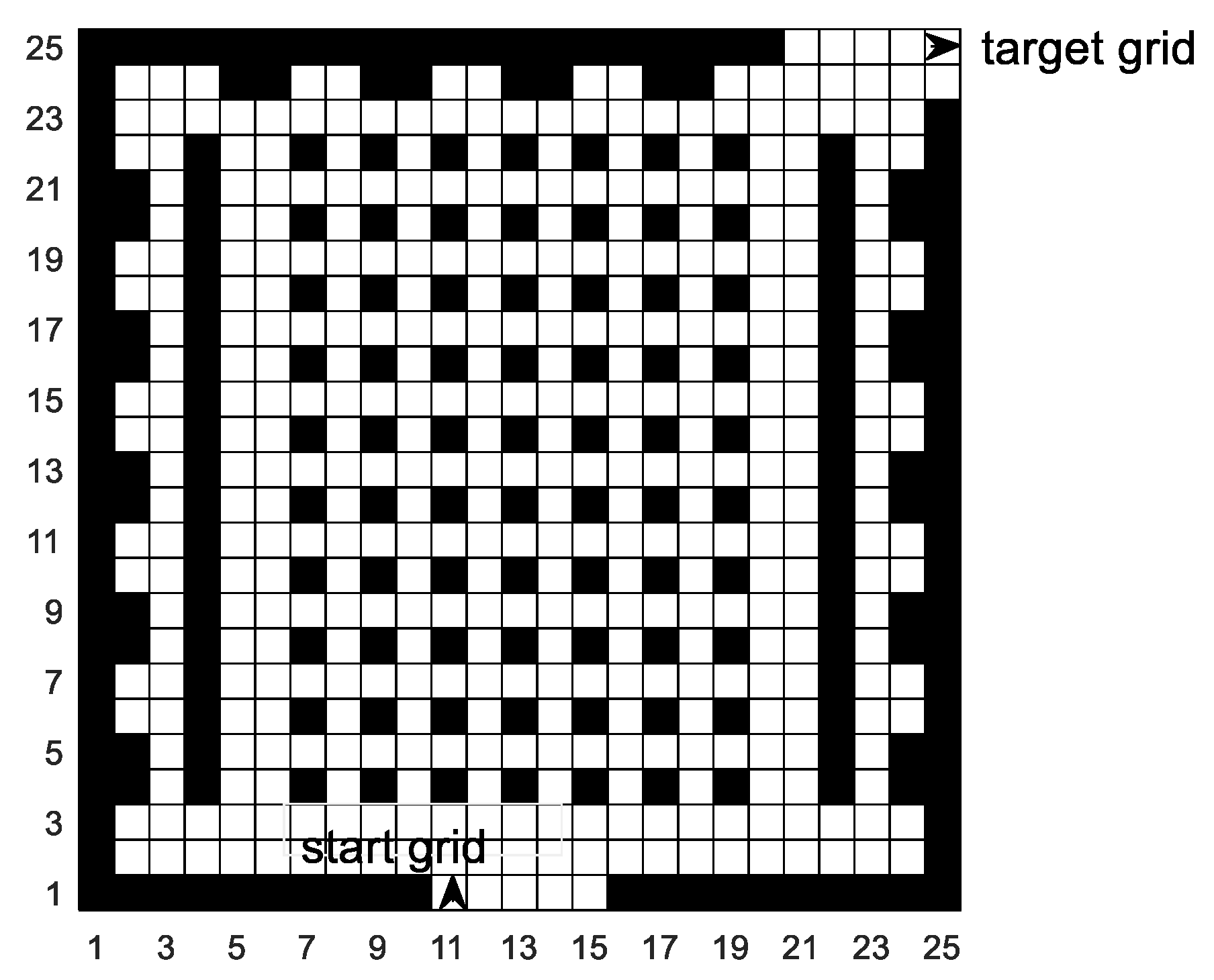
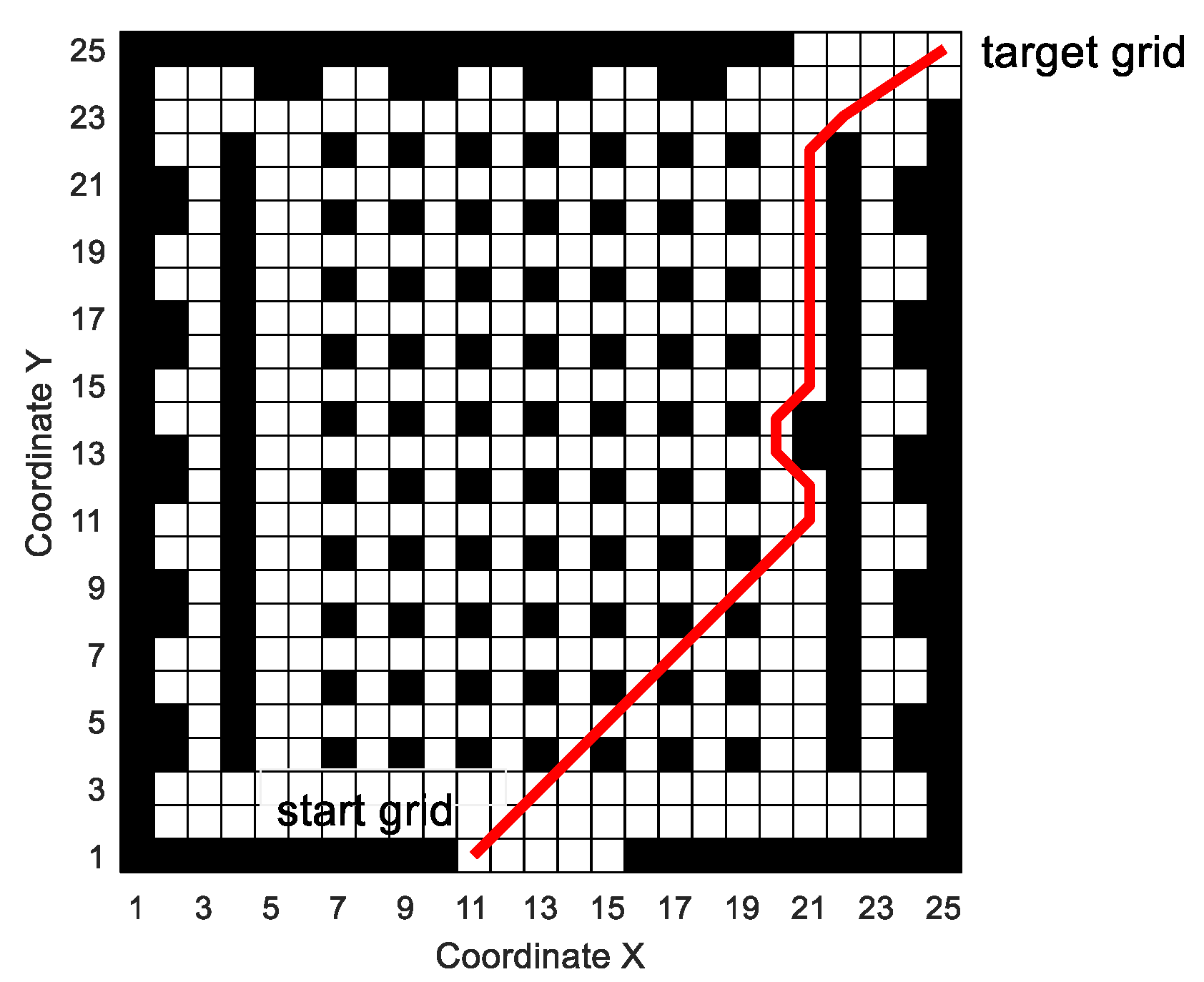
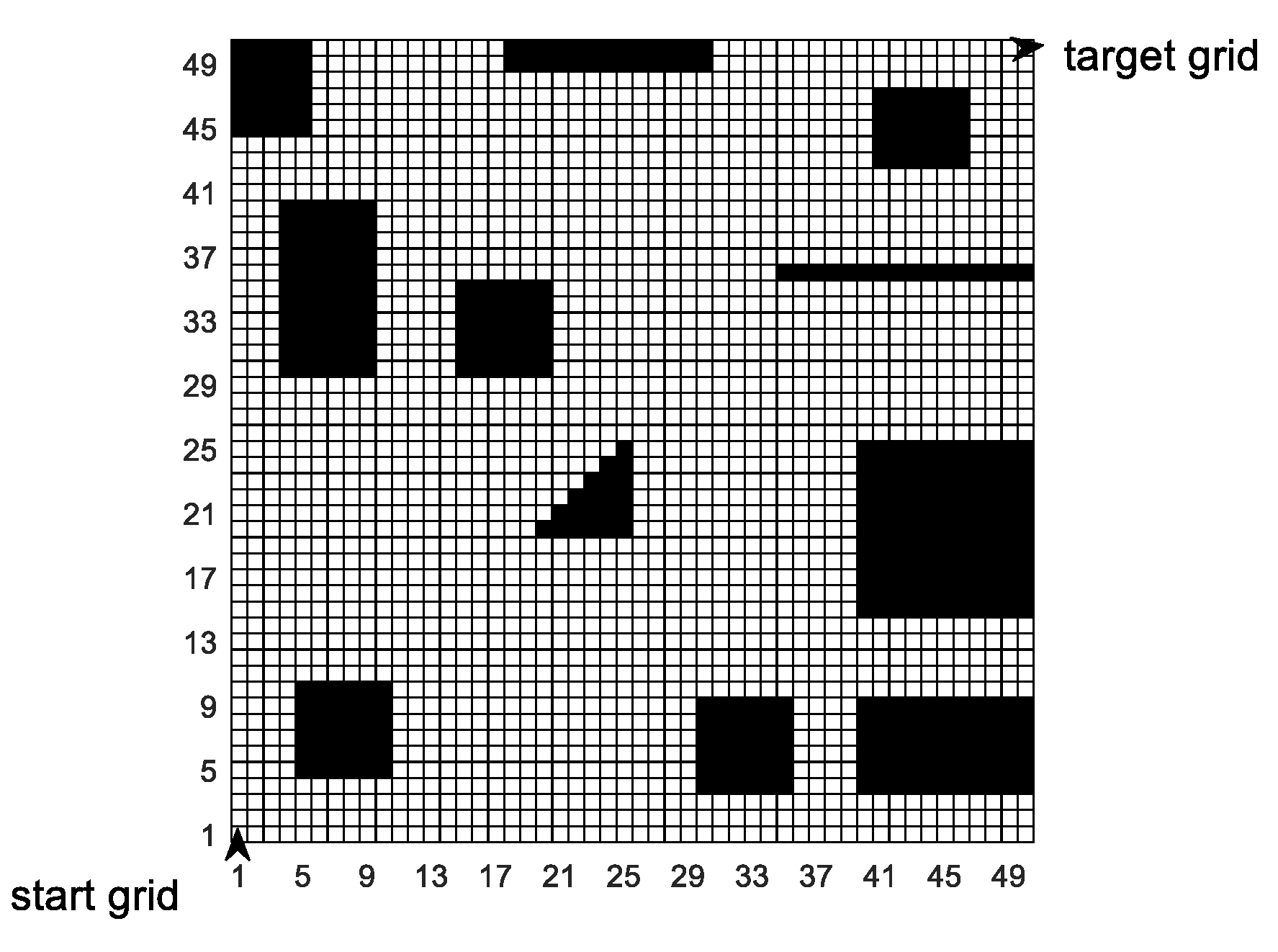
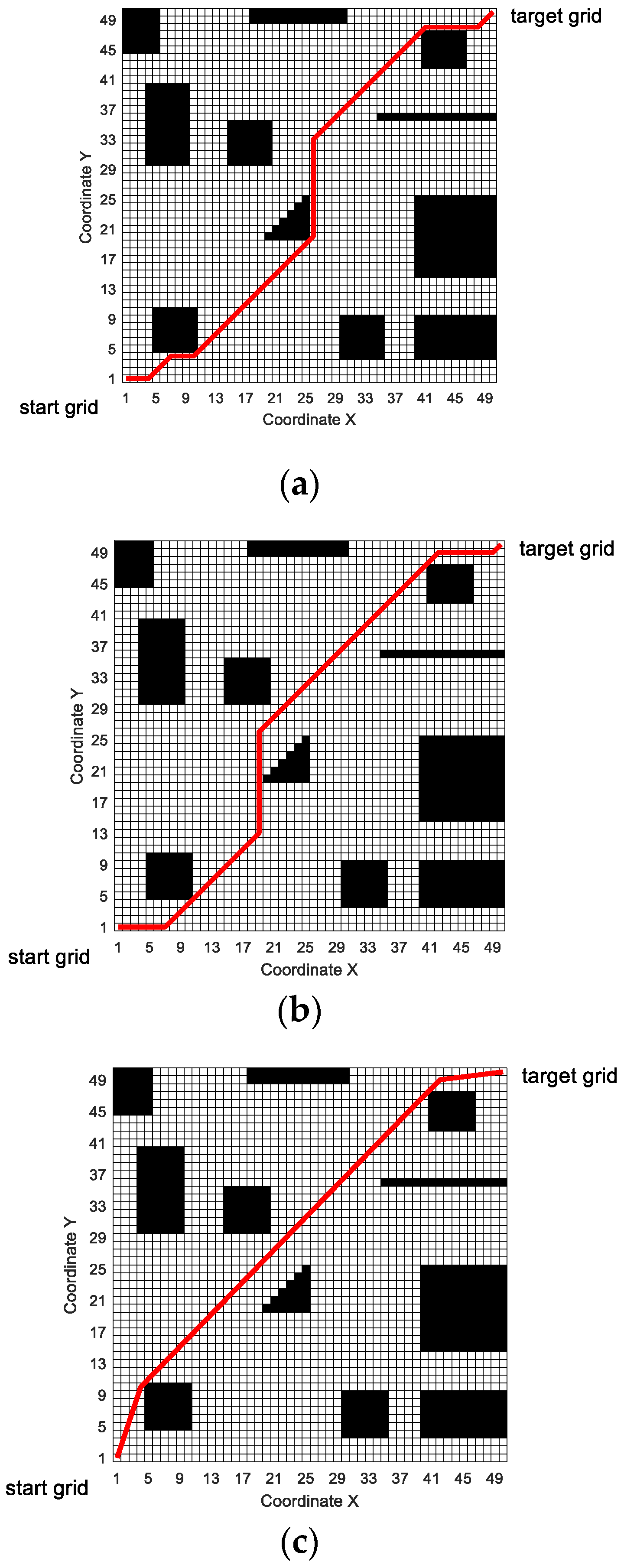
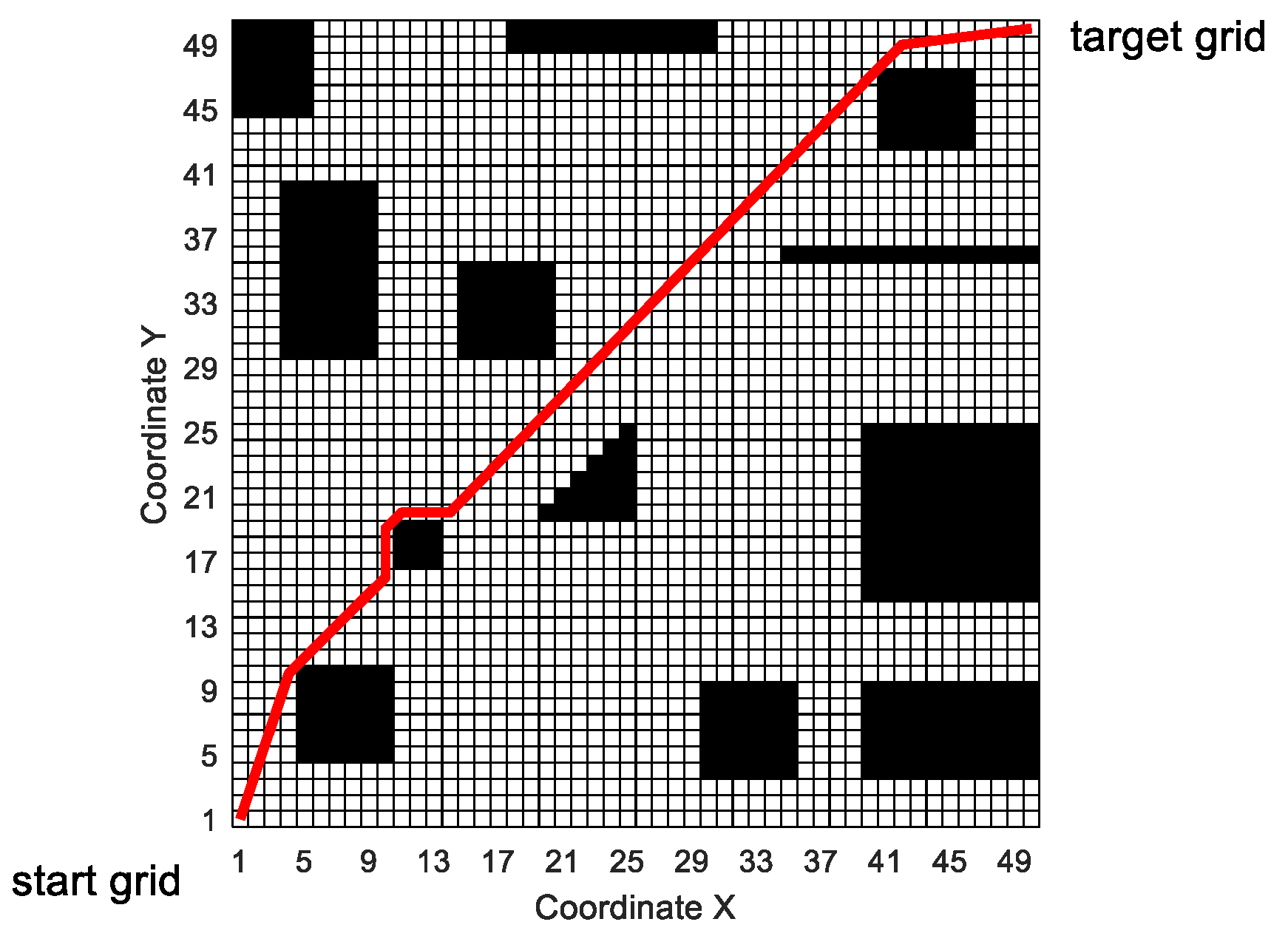
In this paper, the grid method is used to build the environment model. The grid method is a method that divides the two-dimensional workspace of mobile robots into several grids of the same size. As shown in
Figure 2, the entire two-dimensional workspace is divided into a 20 × 20 grid map by using the grid method. In the grid map, the numbers are 0, 1, 2, 3, 4...399 from left to right and bottom to top. The white grid represents the feasible area, and the black grid represents the infeasible area, i.e., the obstacle area. Grid coordinates are represented by grid center points.
The corresponding relationship between grid number and grid coordinate is
Equation (1) converts grid numbers into grid coordinates and Equation (2) converts grid coordinates into grid numbers. In the Equations (1) and (2), p is the grid number, (x,y) is the coordinate point corresponding to the grid, N is the grid number per row, mod is the remainder operation, and fix is the rounding operation.
To improve the security of the grid map and the efficiency of the algorithm, the following preprocessing is required:
- (1)
The mobile robot is equivalent to the mass point, and the obstacle is expanded. The expansion size is the sum of the radius and reserved safety distance of the mobile robot.
- (2)
If the obstacle is irregular, the grid is marked in black, where the obstacle is located.
- (3)
If all eight directions of a white grid are black grids, this white grid is also marked as a black grid.
4. Algorithm Design
4.1. Coding Mode
Common coding methods include binary coding, gray coding, floating-point coding, real coding, permutation coding, etc. In this paper, variable-length real-number coding is used. Variable-length real-number coding refers to real-number coding with a variable chromosome length (as shown in
Figure 3).
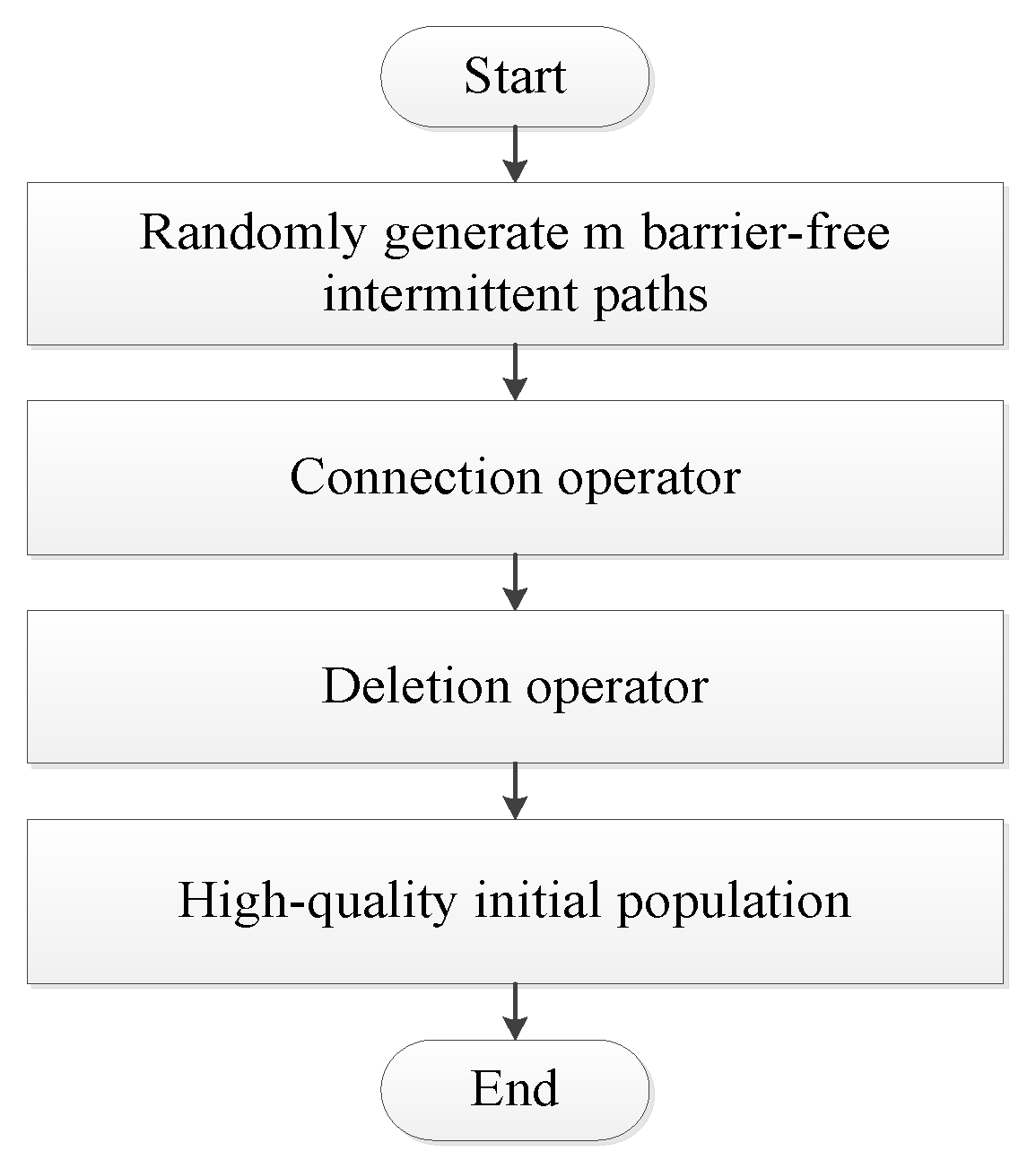
4.2. Initial Population
The barrier-free intermittent path refers to a path that selects a series of free grids between the starting point and the target point and does not require continuity between the grids [
21]. Based on the barrier-free intermittent path, this paper connects the barrier-free intermittent path into a barrier-free continuous path through the connection operator. Then we use the deletion operator to delete the circular partial path in the barrier-free continuous path; thus, we can generate high-quality initial populations. The connection operator refers to an operator that connects a barrier-free intermittent path into a barrier-free continuous path (as shown in
Figure 4). For example 0,60 is a barrier-free intermittent path. It becomes a barrier-free continuous path such as 0, 20, 40, 60, after the operation of the connection operator. The connection method is the intermediate value insertion method. i.e., if two adjacent path points in a path are not continuous, the middle grid of the connection line between two path points is inserted into the middle of two path points. If the inserted grid is an obstacle grid, we replace the obstacle grid with a free grid around the obstacle grid. Then we repeat the insertion process in such a loop until the entire path becomes a barrier-free continuous path.
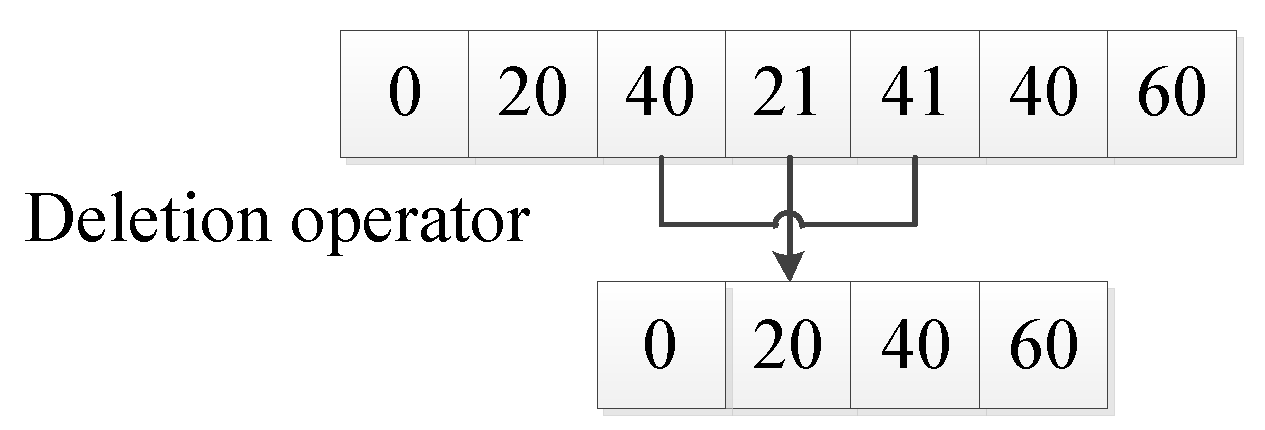
The deletion operator refers to an operator that deletes a circular partial path in a barrier-free continuous path. For example: in paths 0, 20, 40, 21, 41, 40, 60, paths 21, 41, 40 are circular partial paths; then, the path after using the deletion operator is: 0, 20, 40, 60.The deletion operator deletes the circular partial path by removing any repeated path point and the partial path between repeated path points in the barrier-free continuous path (as shown in
Figure 5).
The generation process of the initial population is shown in
Figure 6.
4.3. Fitness Function
Fitness is often used to evaluate the quality of path individuals. High fitness implies good individual quality. Compared with the traditional single-objective optimization, this paper comprehensively considers two factors: path length and path smoothness. In the form of a weighted sum, the multi-objective optimization problem is transformed into a single-objective optimization problem. The fitness function is defined as follows:
where
fitness is the total fitness function,
f1 is the fitness function of the path length,
f2 is the fitness function of the path smoothness, and
α and
β are the weights of the two fitness functions.
f1 and
f2 are defined as follows:
where
path is the length of the path,
smoothness is the smoothness of the path and
c is a precision coefficient and
c is a fixed constant. By adjusting
c,
f2 and
f1 can be controlled to maintain the same order of magnitude.
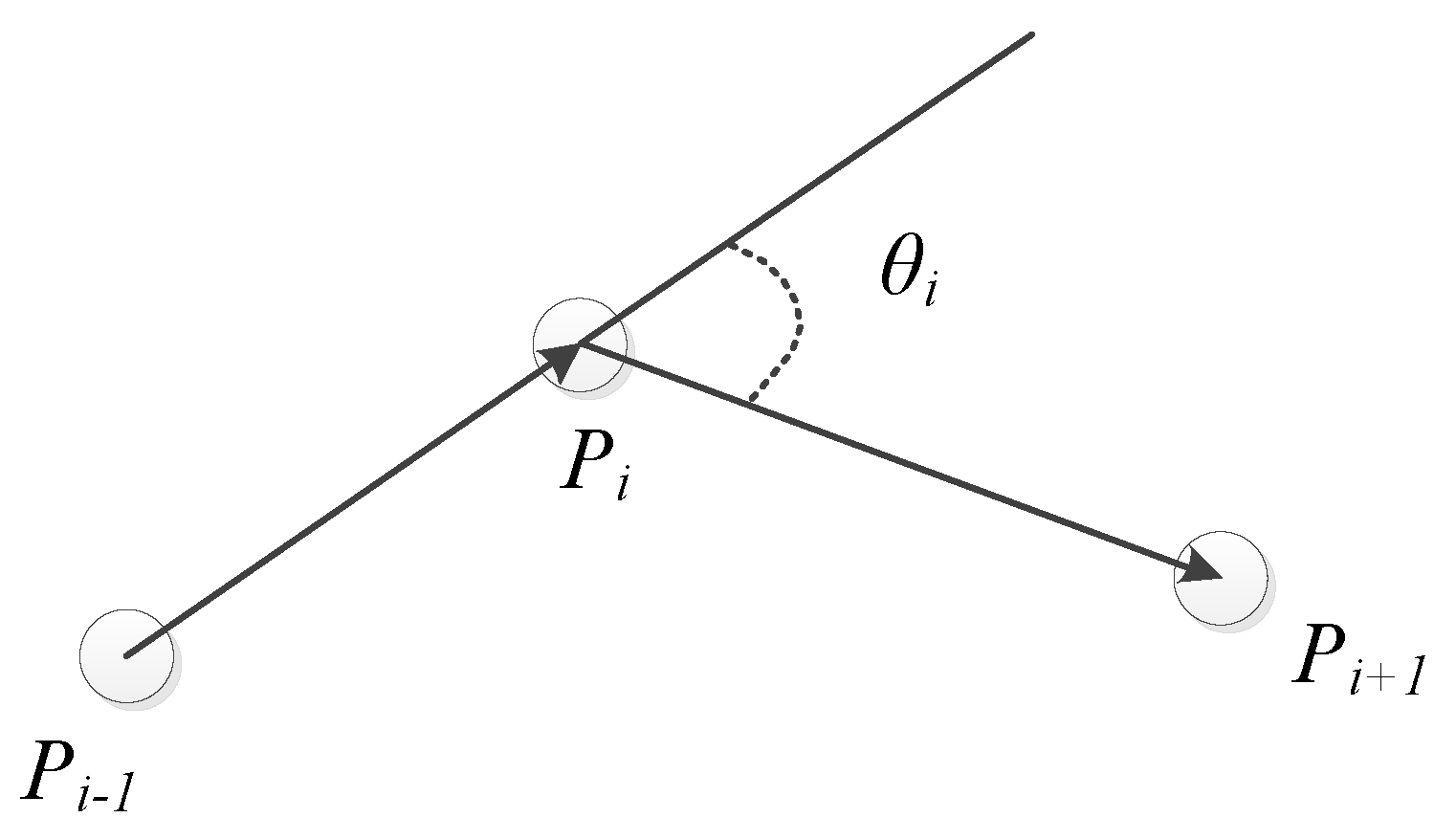
Assuming that a specific route is composed of n waypoints, the coordinate of the i-th waypoint is
Pi(xi,yi) and the coordinate of the i + 1 th waypoint is
Pi+1(xi+1,yi+1); then, the path length can be expressed as:
Suppose that there are three continuous path points
Pi−1, Pi, Pi + 1, and two path segments among the three path points:
Pi−1Pi, PiPi + 1. Let
θi be the rotation angle between the two path segments and
αi be the included angle between the two path segments, i.e.,
π−θi, as shown in
Figure 7.
There are:
where Equations (10)–(12) use the inverse cosine function to calculate angle
αi between the two path segments. Equations (7)–(8) calculate the slope of the two path segments. Due to the inherent defects of the inverse cosine function, in Equation (9), the value of rotation angle
θi is discussed by using the relationship between the slopes of the two path segments.
Path smoothness is a penalty set according to the value of rotation angle
θi. The smoothness of the path can be measured by
smoothness as follows:
In Equation (13), a larger the rotation angle θi corresponds to a greater smoothness value of the path, which indicates that the path is not smooth. In addition, when the value of θi is too large, the mobile robot has great challenges in terms of energy consumption and safety, so it must be given a high penalty.
4.4. Migration Operator
Common selection strategies include roulette selection, elite selection, tournament selection, truncation selection, etc. However, there are some problems in these selection strategies, such as serious homogenization, easy convergence to local optimal solutions and loss of population diversity. The most prominent problem is the serious homogenization phenomenon. The phenomenon of homogenization implies that as the number of iterations increases, a particular individual will appear in large numbers in the population. The phenomenon of homogeneity will make the effect of the crossover operator gradually decrease as the number of iterations increases. When the entire population is composed of the same individuals, the crossover operator is completely invalid.
Based on the ideas of population mobility and social division of labor proposed in the reference [
22,
23,
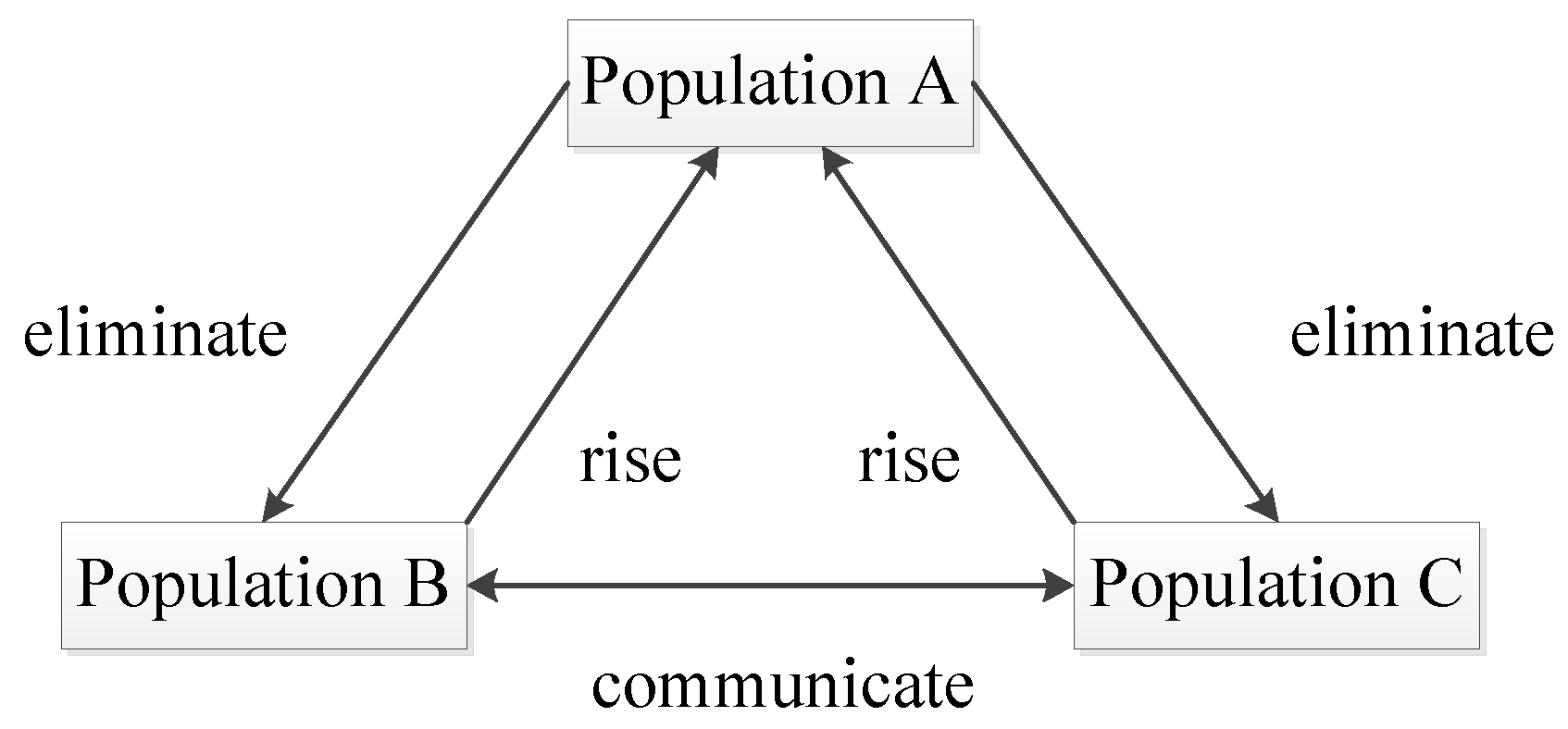
24], this paper proposes a migration operator. The migration operator refers to a comprehensive mechanism that assigns different functions to different small populations, maintains normal communication among different small populations and ensures that high-quality individuals in ordinary populations rise to high-quality populations and inferior individuals in high-quality populations sink to ordinary populations. The migration process of the migration operator is shown in
Figure 8.
In
Figure 8, three small populations are given different functions by setting different crossover rates and mutation rates. By giving population A low crossover rate and low mutation rate. We make population A well preserve high-quality individuals. This way can prevent the loss or destruction of high-quality individuals. Therefore, population A is designated as a high-quality population. By giving population B high crossover rate and low mutation rate and giving population C low crossover rate and high mutation rate. We make population B and population C act as resource banks. This way can provide many crossover and mutation individuals and is conducive to expanding the solution space search coverage. Hence, we designate population B and population C as ordinary populations.
In the migration process of
Figure 8, several high-quality individuals in population B and population C rose to population A to be preserved, and a part of the poor individuals in population A were eliminated into population B and population C to act as raw materials for crossover or mutation. The latter process can play the role of waste utilization. In addition, a certain individual communication mechanism has been maintained between population B and population C to break the gap between the two populations.
In summary, the migration operator has the advantages of accelerating the convergence rate, increasing the population diversity, breaking the local optimal solution and solving the serious homogenization of the population individual in the middle and late iterations.
4.5. Crossover Operator
The crossover operator is an operator that generates new individuals through the crossover recombination of two individuals. Common crossover operations include single-point crossover, multipoint crossover, uniform crossover, etc. Reference [
25] uses a single-point crossover method and notes that single-point crossover is more efficient and easier to implement than other crossover methods.
Single-point crossover randomly selects any path point with the same grid number in the two paths and exchanges the chromosome fragments after the selected path point to form two new individuals. This crossover method is also called homologous single-point crossover [
26].
This paper proposes a heterologous single-point crossover based on the homologous single-point crossover and adopts the individual reception method proposed in the reference [
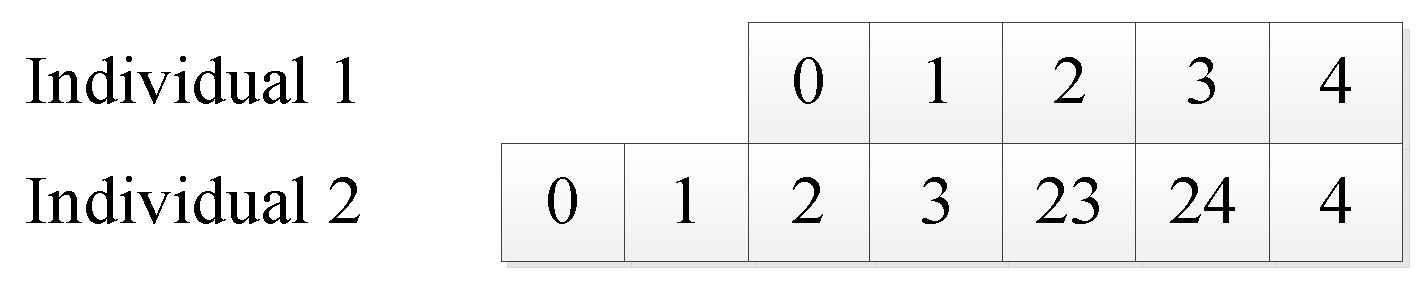
27]. If the individual after crossover is better than the individual before crossover, then the individual after crossover is accepted. If the individual after crossover is worse than the individual before crossover, then the individual before crossover is accepted. The heterogeneous single-point crossover operator no longer looks for a common path point with identical grid numbers but finds a pair of path points that satisfy the condition that the two new paths are still continuous after the crossing. Such a group of path points must satisfy two conditions:
- (1)
The grid corresponding to the i-th path point in the first path and the grid corresponding to the j + 1-th path point in the second path are continuous.
- (2)
The grid corresponding to the i + 1-th path point in the first path and the grid corresponding to the j-th path point in the second path are continuous.
Such a set of path points
i, j is the cross path point for which the heterogeneous single point cross operator is looking. The two new individuals obtained by crossing the chromosome segment after the
i-th path point in the first path and the chromosome segment after the
j-th path point in the second path are still unobstructed continuous paths (as shown in
Figure 9).
The cross-path point searched by the heterologous single-point crossover operator includes the cross-path points searched by the homologous single-point crossover operator. So the homologous single-point crossover operator is a special case of the heterologous single-point crossover operator.
4.6. Mutation Operator
MPMGA proposes the single-gene segment mutation and uses a simulated annealing algorithm to improve the receiving method of mutant individuals. Single-gene segment mutation refers to the mutation way of mutating a specific gene segment rather than mutating a certain gene point (as shown in
Figure 10). i.e., it mutates a random gene segment. Specific operation is to randomly delete a specific gene segment on the individual and then use the connection operator to repair the damaged individual. Single-gene segment mutation ensures the continuity and accessibility of the individual after the mutation. Single-gene segment mutation greatly improves the quality of the mutation and enhances the ability to explore the solution space.
Compared with the method of full reception or optimal reception, the simulated annealing algorithm is more flexible for receiving mutated individuals. When the mutant individual is better than the original individual, the mutant individual will be accepted. When the mutant individual is worse than the original individual, the mutant individual will be accepted with a certain probability. The advantage is that it can consider the retention of high-quality individuals and give some tolerance to inferior individuals to expand the diversity of the population.
Assume that the individual before mutation is represented as
old, the individual after mutation is represented as
new, and
fitness() represents the fitness of an individual. Then, the simulated annealing algorithm receives the mutation individual probability equation as follows:
In Equation (15), T is the current temperature and a is a parameter. In equation (16), p(new) is the probability of receiving the mutated individual. In Equation (17), c1 is the initial temperature, w is the temperature decay rate and t is the current number of iterations. Obviously, when the number of iterations t increases, temperature T will decrease and the tolerance for individuals who become worse after mutation will decrease. Until a certain generation, the algorithm will no longer tolerate individuals who become worse after mutation.
4.7. Optimization Operator
The initial population will converge to the optimal individual through several iterations. Then the optimization operator performs the second optimization based on the optimal individual. This paper adopts the deletion point method to design the optimization operator (as shown in
Figure 11). The deletion point method refers to the method of deleting redundant path points in the barrier-free continuous path so that the barrier-free continuous path becomes a barrier-free discontinuous path again. This barrier-free discontinuous path is a safe path with great performance indicators. The difference between the optimization operator and the previous deletion operator is that the deletion operator deletes the circular path in the unobstructed continuous path. After the deletion, it is still an unobstructed continuous path. But the optimization operator deletes the redundant path points in the unobstructed continuous path. The path after deletion is the barrier-free discontinuous path. Assuming that the path
path contains n path points,
path(i) represents the grid number corresponding to the
i-th path point in the
path path, and the optimization operator design steps are as follows:
- (1)
Initialize i = 1, j = i + 1, the list table is empty, add path (i) to the list.
- (2)
Determine whether j is equal to n. If they are equal, add path (j) to the list and go to step (4). If they are not equal, go to step (3).
- (3)
Determine whether the connection line between i-th path point and j + 1-th path points passes through the obstacle grid. If it does not pass, then j = j + 1 and go to step (2). If it passes, then i = j and add path (i) to the list; then, go to step (3) again.
- (4)
Output the grid number in the list.
It is known from the optimization operator design steps. The grid number in the list table is the optimized result of the optimization operator.
6. Conclusions
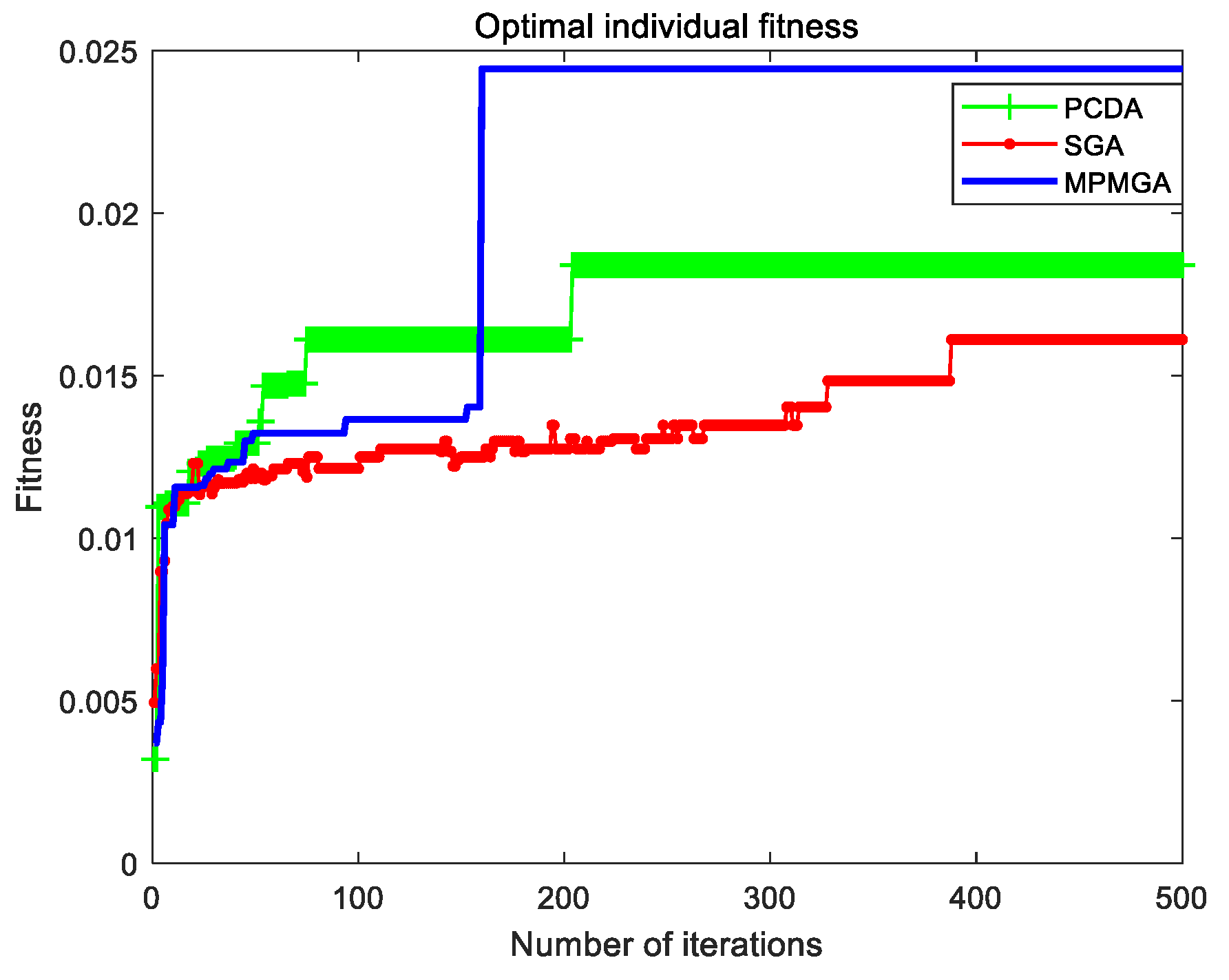
In this paper, a multi-population migration genetic algorithm is proposed, and the framework and operators of the standard genetic algorithm are improved. In terms of framework, the algorithm proposes a parallel interactive framework. This framework has good parallelism and robustness. Especially when there are many individuals in the initial population, and the performance of a single processor is limited. A parallel interactive framework can divide a large population into several small populations, and each small population is equipped with a processor. The data among the small populations interacts through the bus, which can greatly reduce the running time of the program. Even if a processor fails and some data are lost, the impact on the algorithm is relatively limited. In terms of operators, the algorithm proposes a migration operator and an optimization operator. The migration operator replaces the selection system of the selection operator by the migration system, and the optimization operator performs the second optimization of the convergent optimal individual. In addition, the algorithm also improves the population’s initialization process, crossover operator, and mutation operator. By using the new operators or improving the original operators, the algorithm breaks the local optimal solution, solves the phenomenon of serious homogenization of population individuals, accelerates the convergence speed of the algorithm and improves the quality of convergent individuals. The simulation results show that MPMGA is not only suitable for simulation maps of various scales and various obstacle distributions, but also has superior performance. But the MPMGA program takes too long time to run.
In fact, if we consider implementing MPMGA on a real mobile robot, MPMGA may face the following problems: First, in actual large-scale scenarios, the MPMGA program takes a long time to run. Although MPMGA has excellent performance in large-scale maps, the long program running time limits the application of MPMGA in actual large-scale scenarios. Second, MPMGA is not sensitive to unknown environments. It means MPMGA does not consider how to generate a high-quality path in an unknown environment. We know that the map environment is unknown in many actual scenarios. In this case, the application of MPMGA has been greatly restricted. Third, MPMGA does not consider the preprocessing process of grid maps more comprehensively. This may cause MPMGA to fail to generate feasible paths in actual maps with a large number of irregular obstacles.
In the future, we need to do four aspects: First, we need to reduce the running time of the program. On the one hand, we can compress map models or simplify map models. On the other hand, we can improve the population’s initialization process. Second, we need to enhance the application capabilities of algorithms in different environments. MPMGA can perform static global path planning; it can also effectively deal with sudden threats and perform local path re-planning. However, the global or local path planning in an unknown environment is not considered. Therefore, global or local path planning in an unknown environment can also be used as the next research content. Third, we need to consider the preprocessing process of grid maps more comprehensively. We can use adaptive grid map method. In other words, the grid size in the grid map is no longer fixed. The size of the grid is automatically adjusted according to the size of the mobile robot and obstacles. The adaptive grid map method can effectively deal with the actual map with a large number of irregular obstacles. Fourth, we consider applying MPMGA on actual mobile robots. Mobile robots can obtain information about obstacles in the surrounding environment through visual sensors to generate electronic maps. We need to use the grid environment modeling method and map preprocessing process given in
Section 3 to process the electronic map. After processing the electronic map, we get a grid map that algorithm can run. Then we can run the MPMGA program on the grid map to generate the actual path we need.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}