A Novel Weighted Clustering Algorithm Supported by a Distributed Architecture for D2D Enabled Content-Centric Networks




Abstract
1. Introduction
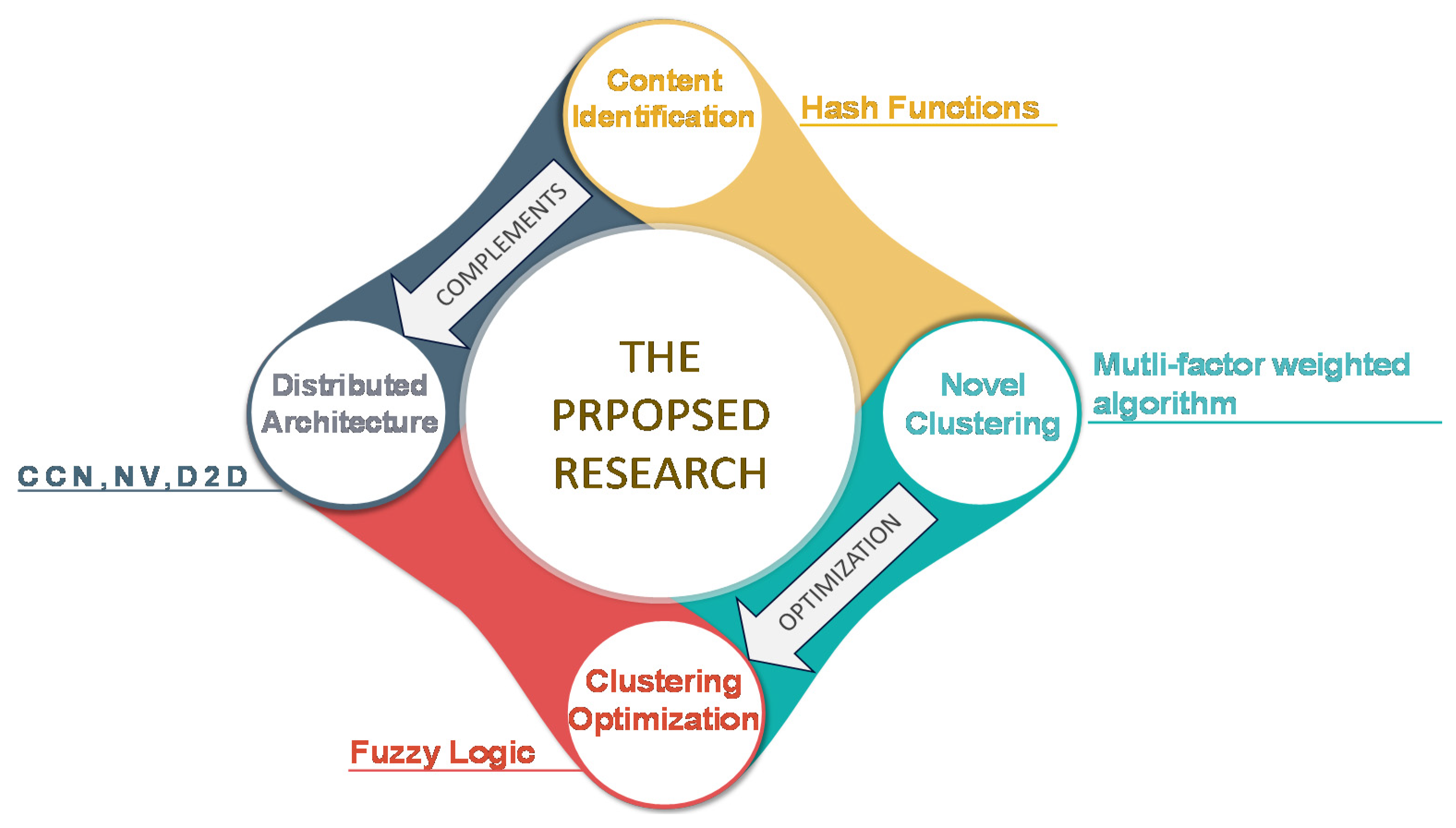
- A distributed architecture is proposed that is effectively supported by hash functions to identify the socially connected users. This is in contrast to the majority of the published works on D2D multicasting that do not consider distributed architecture along with content-identification.
- A novel multifactor weighted clustering has been proposed. The performance of the proposed algorithm is shown to be superior compared to five benchmarked algorithms. In addition, the weights of the algorithm can be adjusted to suit the system’s requirements. This flexibility in trading off the performance with respect to various parameters is not available for existing algorithms.
- The benchmarked algorithms are tested for throughput fairness which has not been reported in the literature on clustering. Moreover, different from the existing works, the impact of the number of clusters on the energy consumption and area spectral efficiency is also demonstrated.
- To the best of the author’s knowledge, reported work in the literature considers either the spatial distribution of users or users’ social ties for their respective clustering algorithms. We propose to include both to make the clustering process comprehensive and evaluate its impact on the system’s performance.
2. Related Work
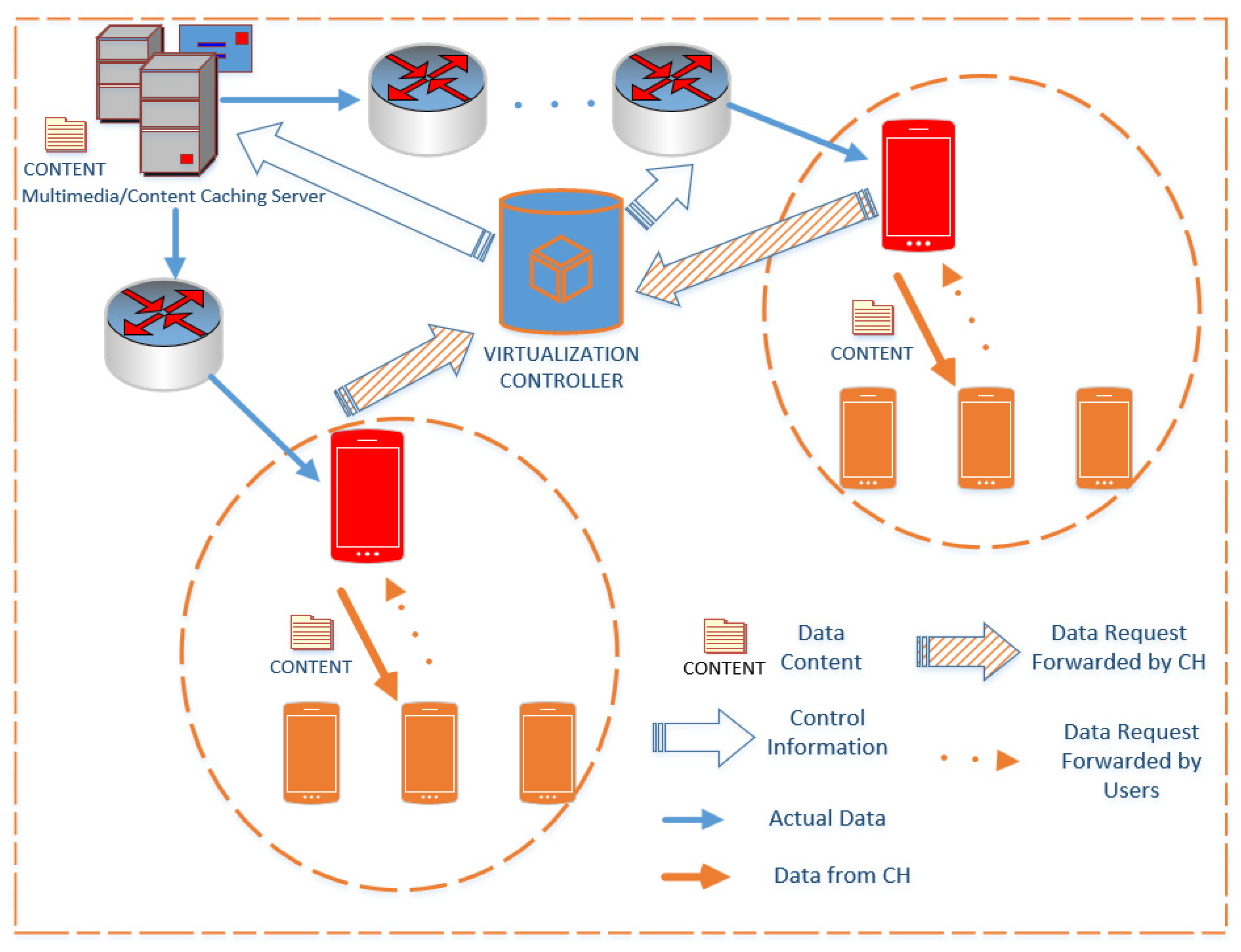
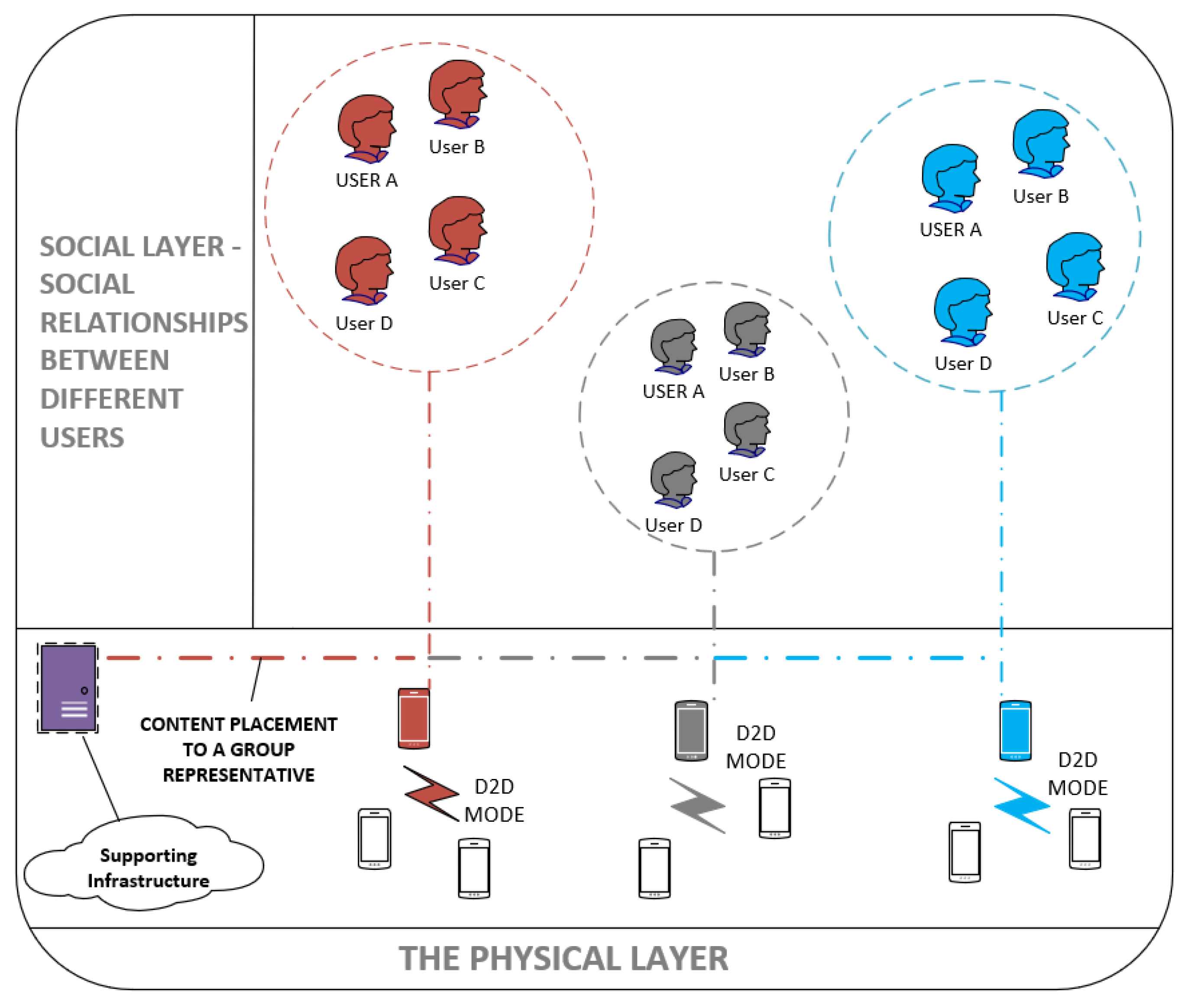
3. Proposed Distributed Architecture and Clustering Algorithm
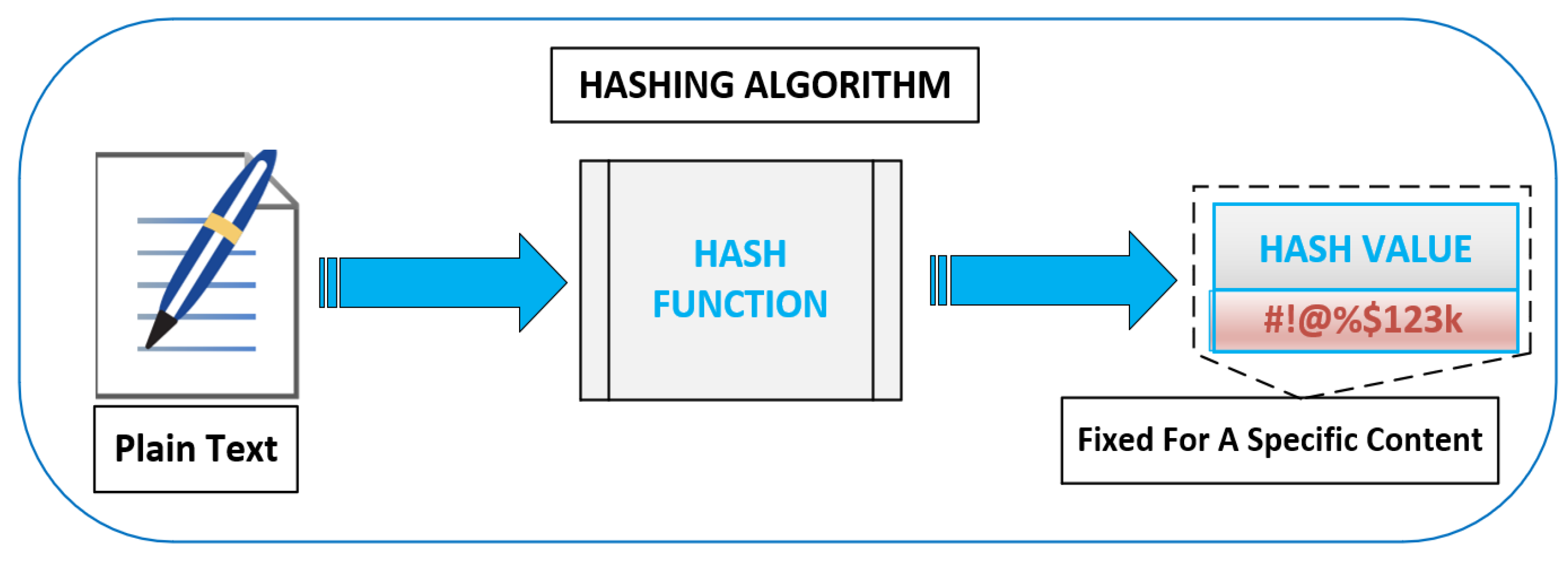
3.1. Content Identification Using Hash Functions
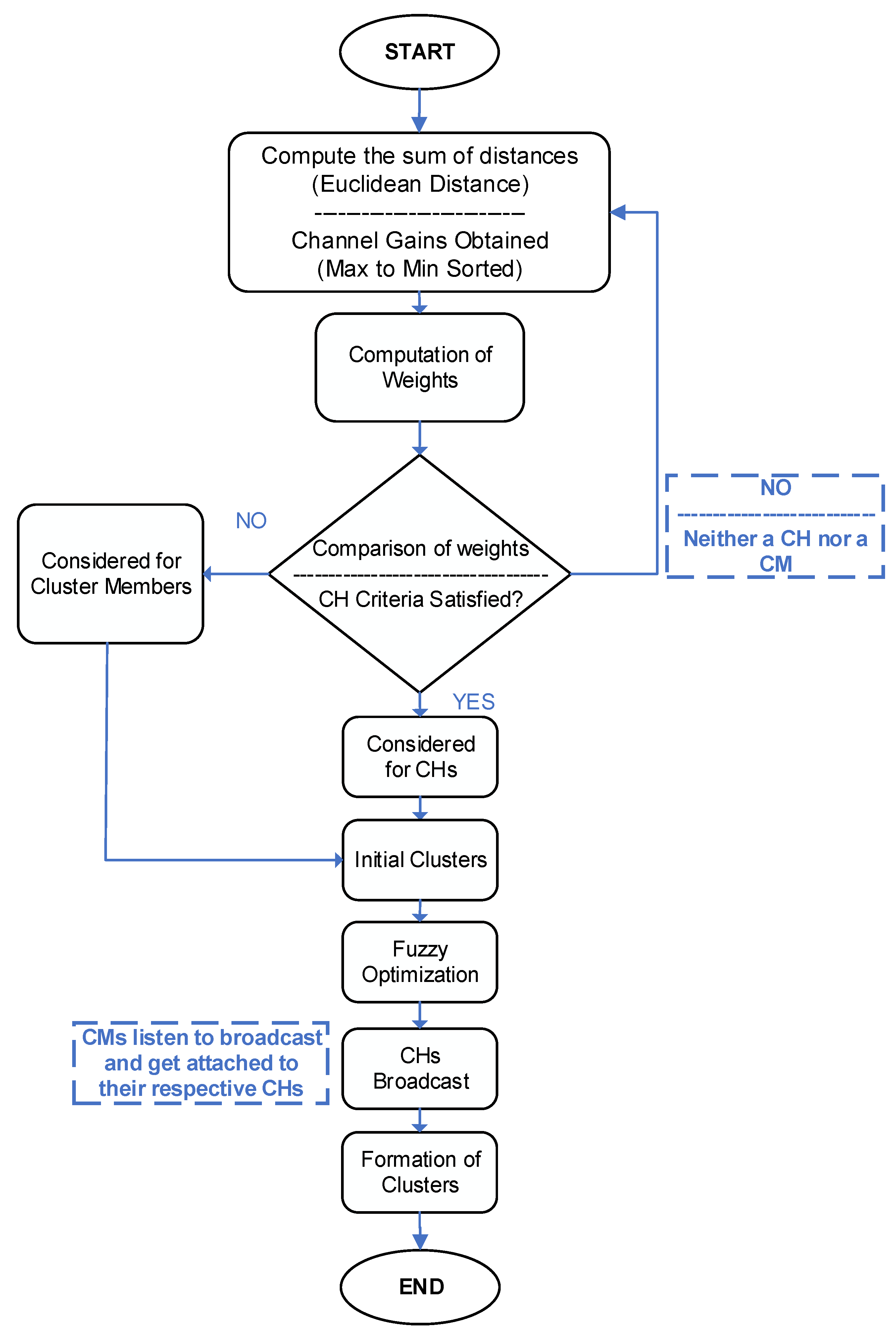
3.2. The Proposed Clustering Algorithm
3.2.1. Weighted Clustering Approach
3.2.2. Device Discovery
3.2.3. Clustering Metrics
- The Distance among the Nodes
- 2.
- Channel Conditions
3.2.4. Cluster Head Selection
3.2.5. Feature Scaling for the Clustering Metric
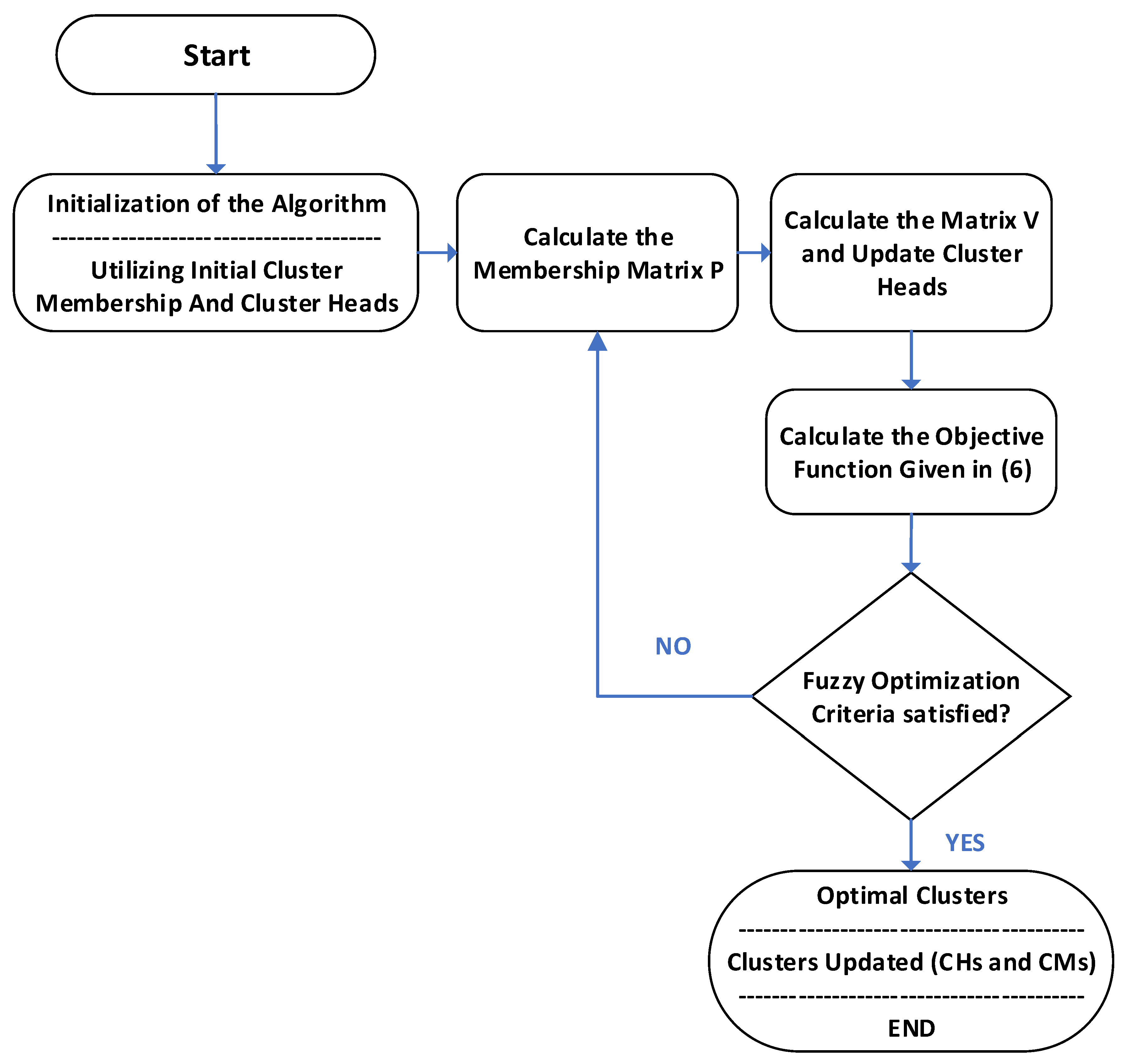
3.2.6. Fuzzy Optimization of Clustering
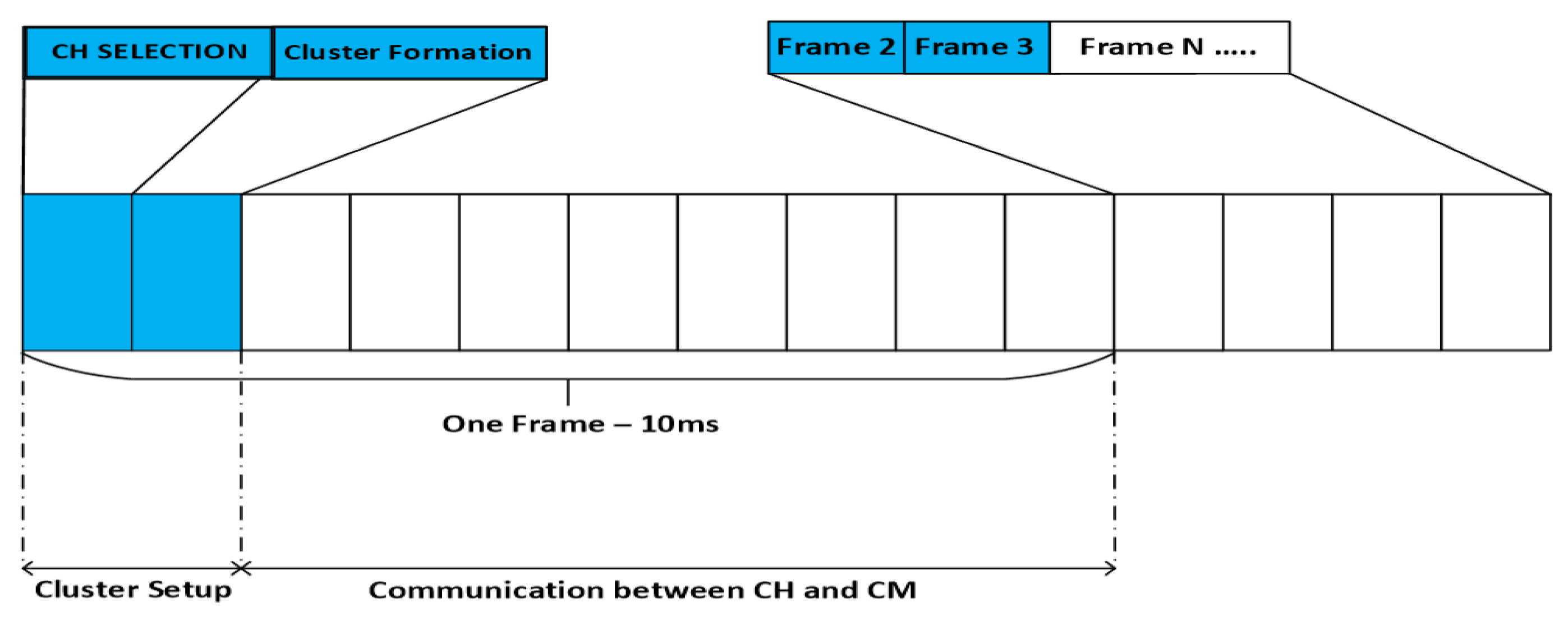
3.2.7. Communication
4. System Model and Simulation Setup
4.1. Mathematical Models for Performance Parameters
4.1.1. Achievable Rates for Cluster Head and Cluster Members
4.1.2. Energy Model
4.2. Simulation Setup
5. Results and Discussion
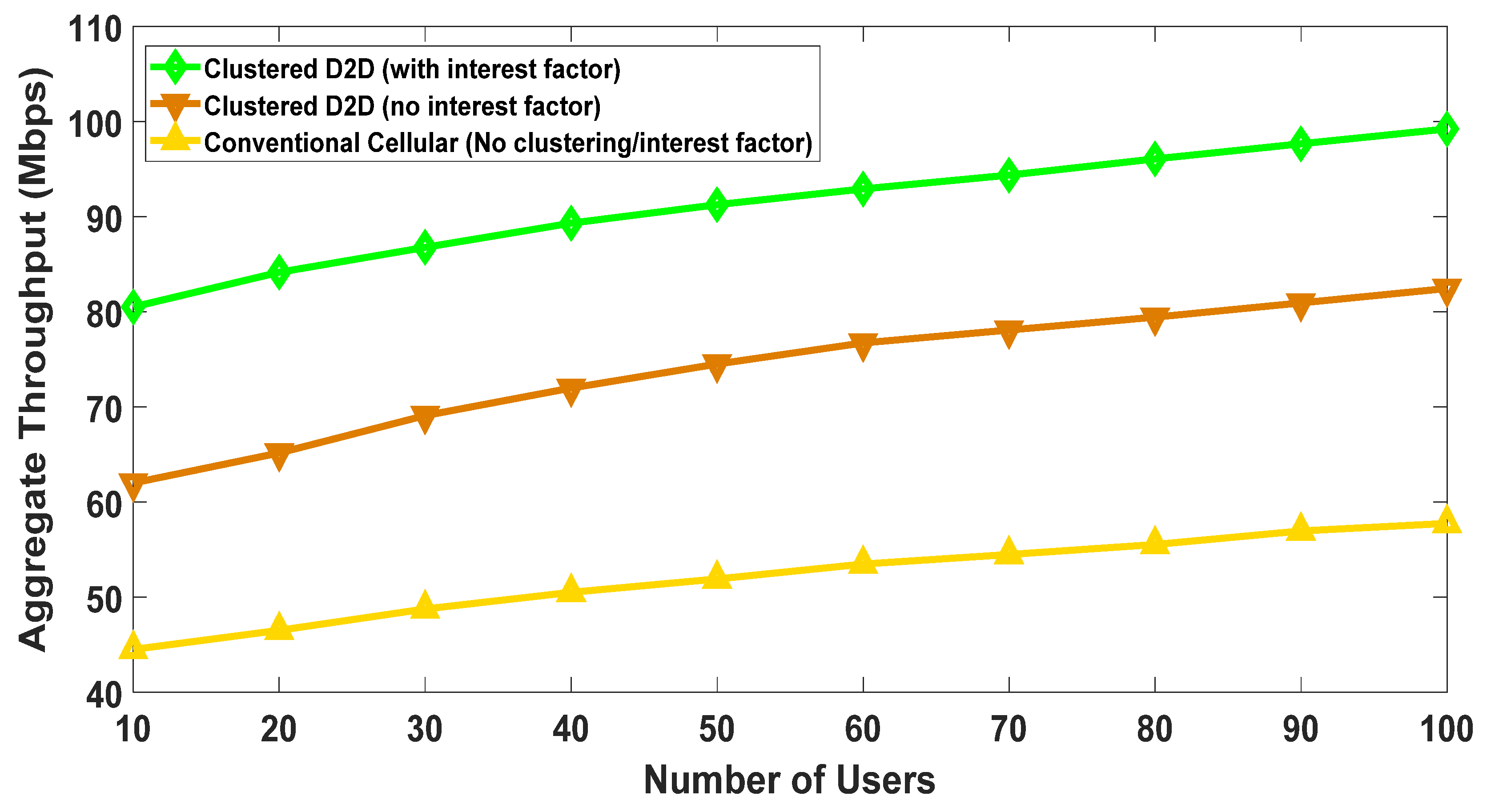
5.1. Impact of Clustering and Social-Interest
- Clustered D2D users with no interest factor
- Clustered D2D users with interest factor
5.2. Benchmarking against Existing Algorithms
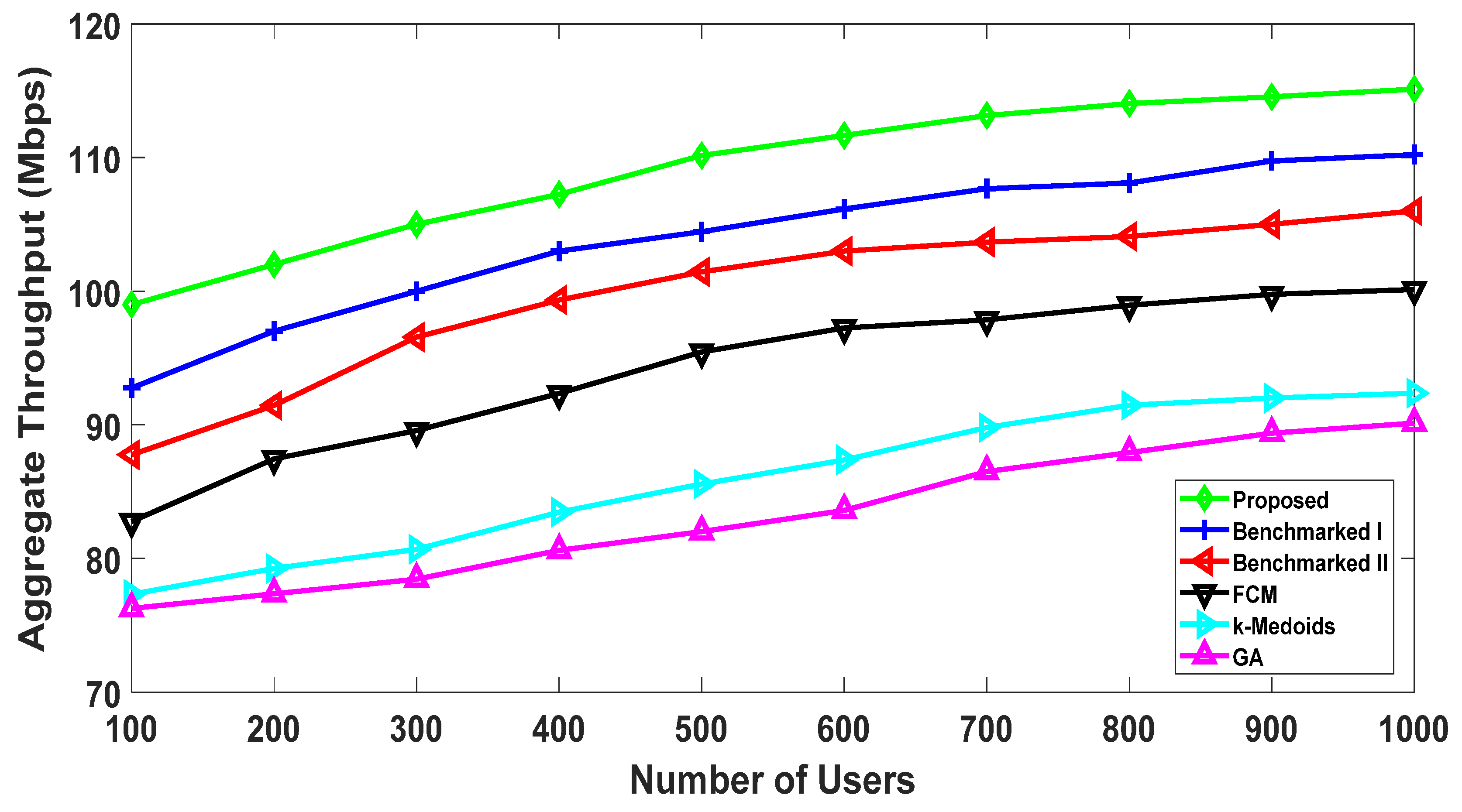
5.2.1. Throughput Comparison
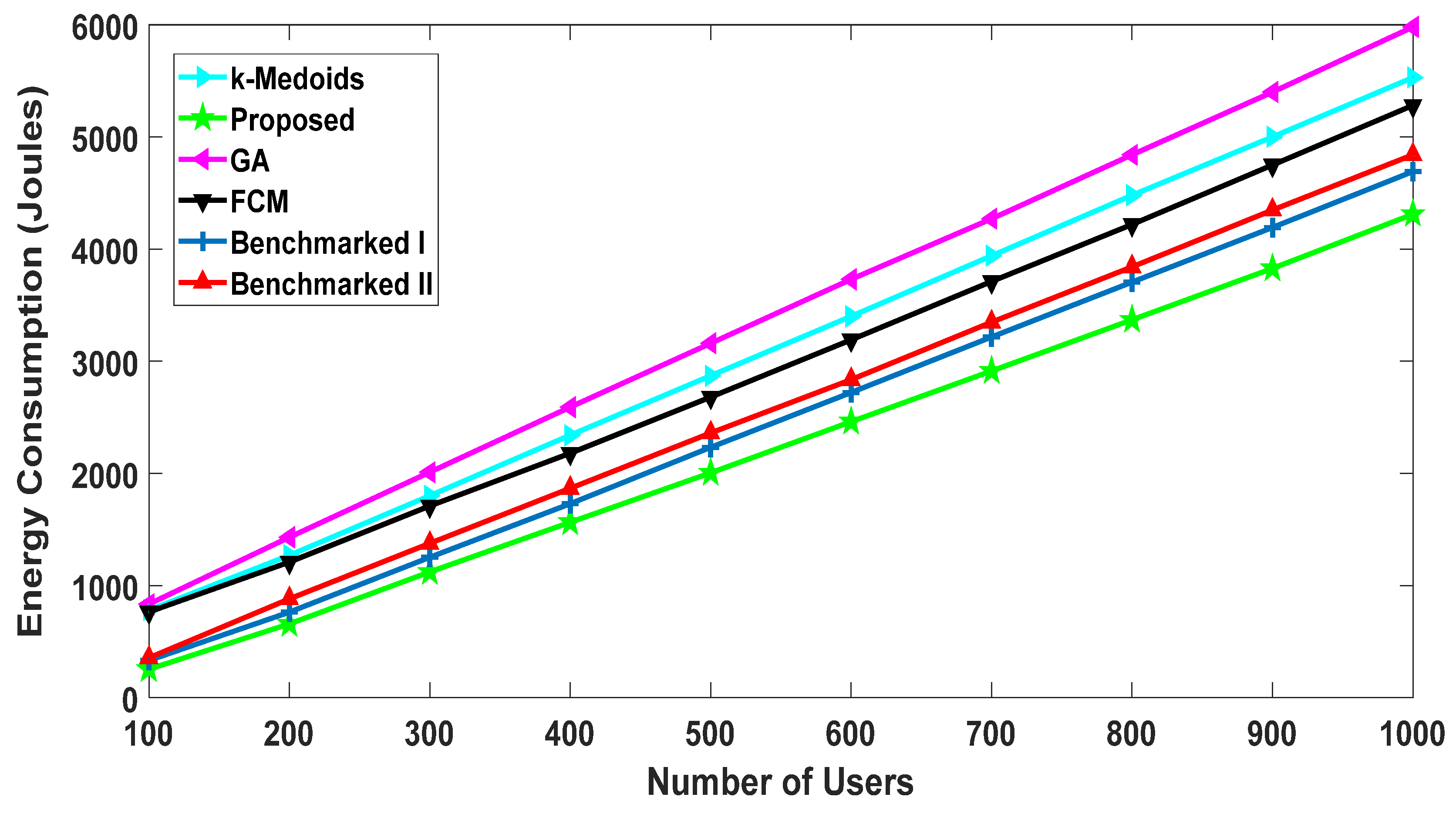
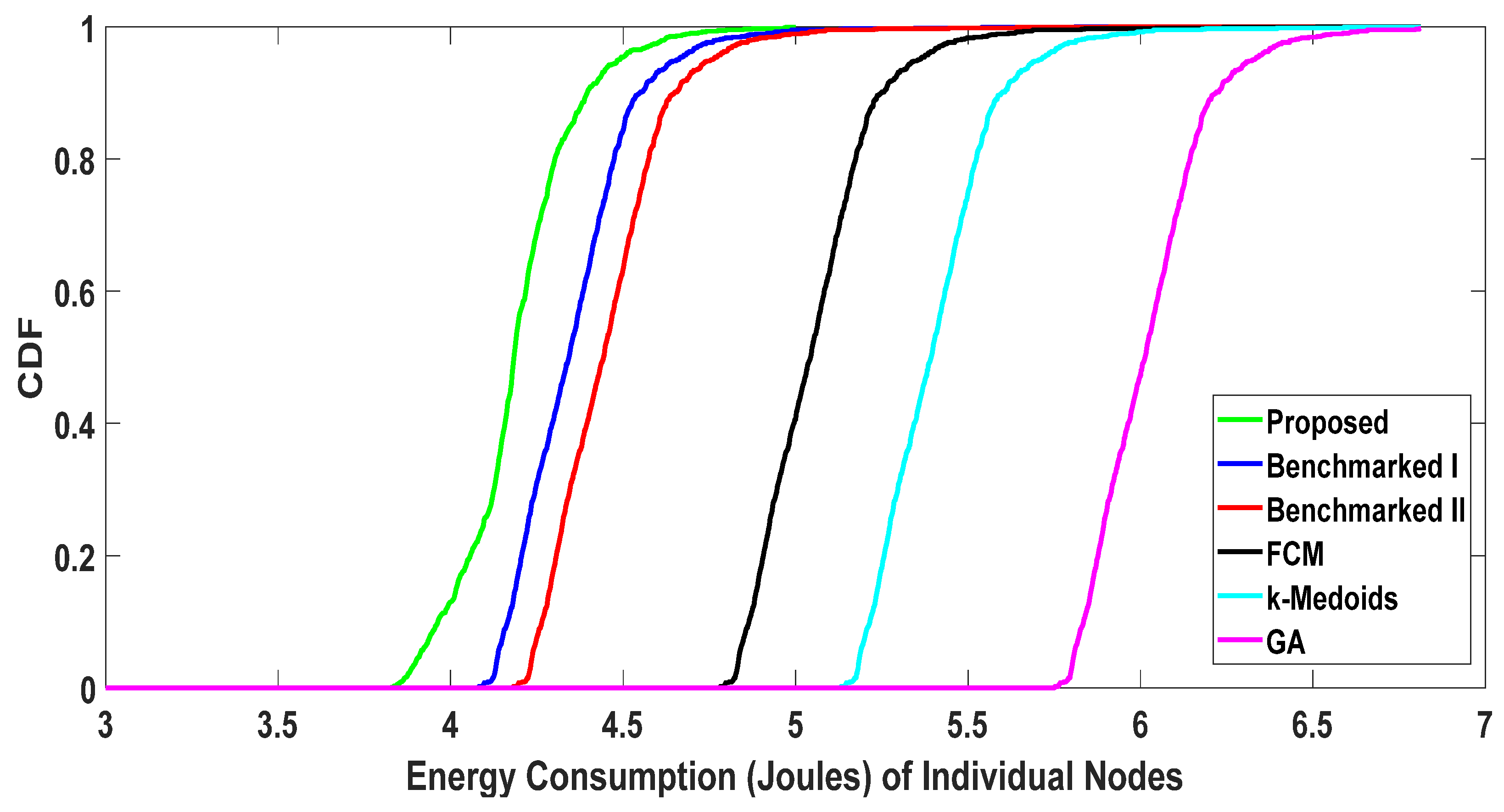
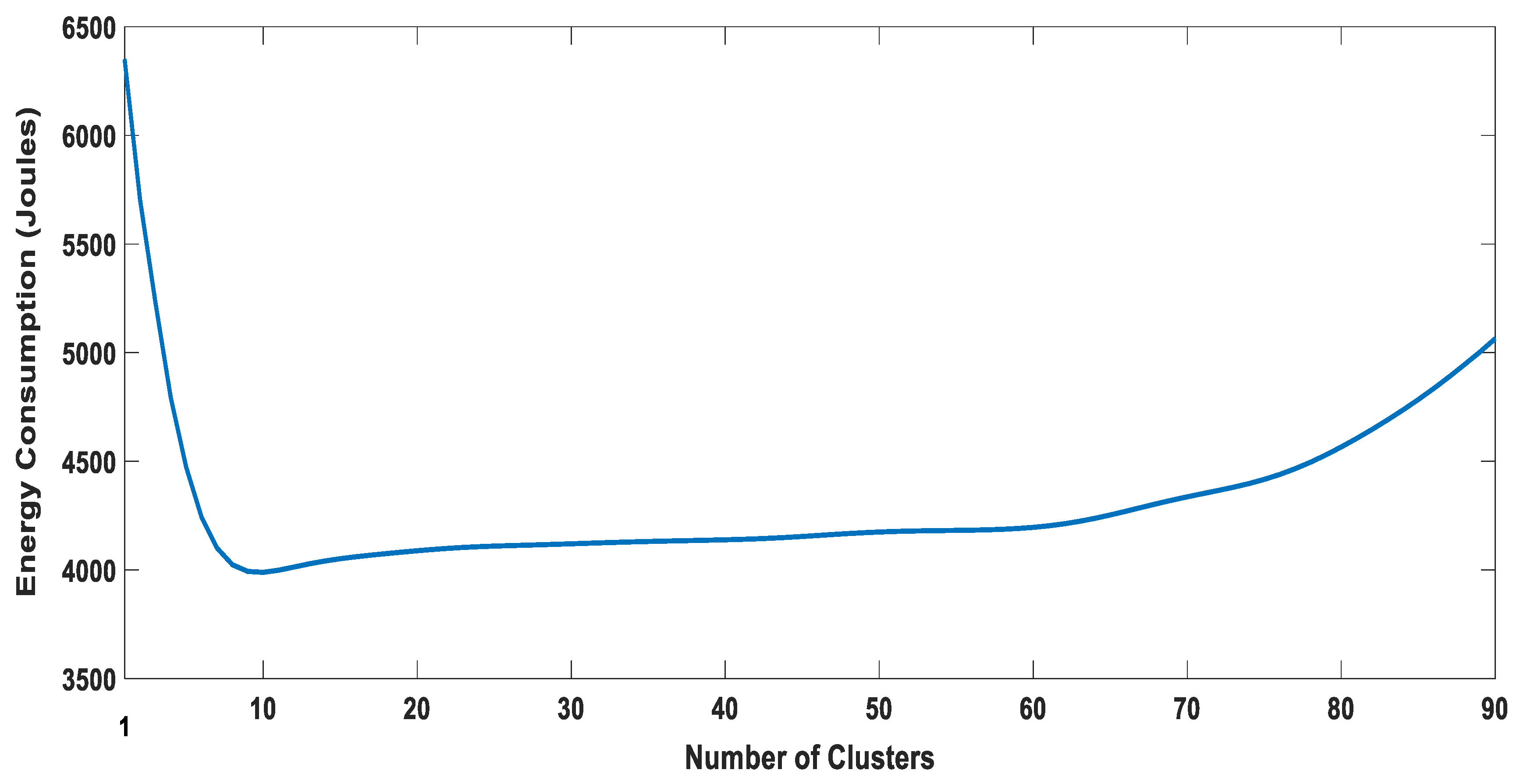
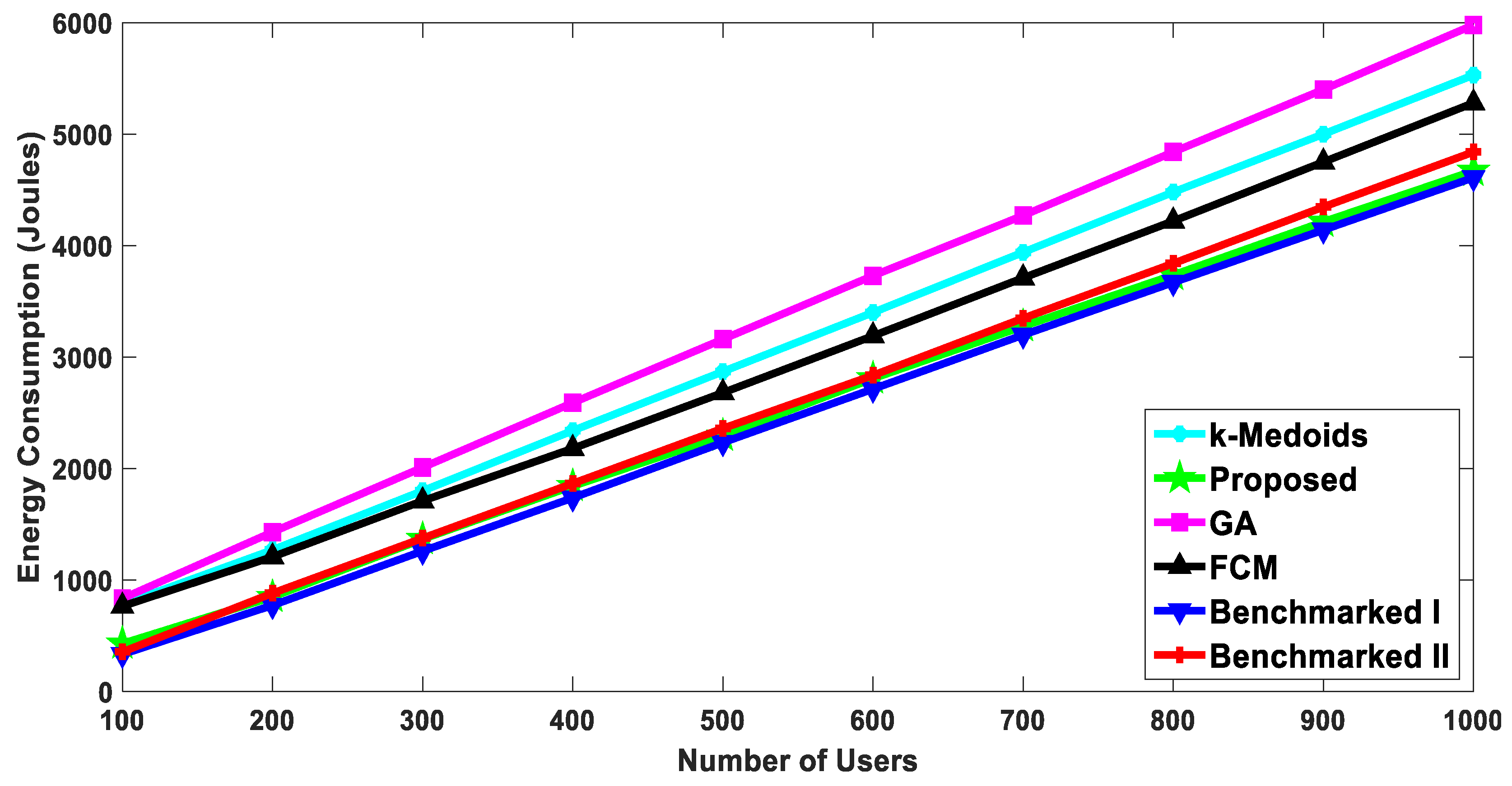
5.2.2. Energy Consumption of Users
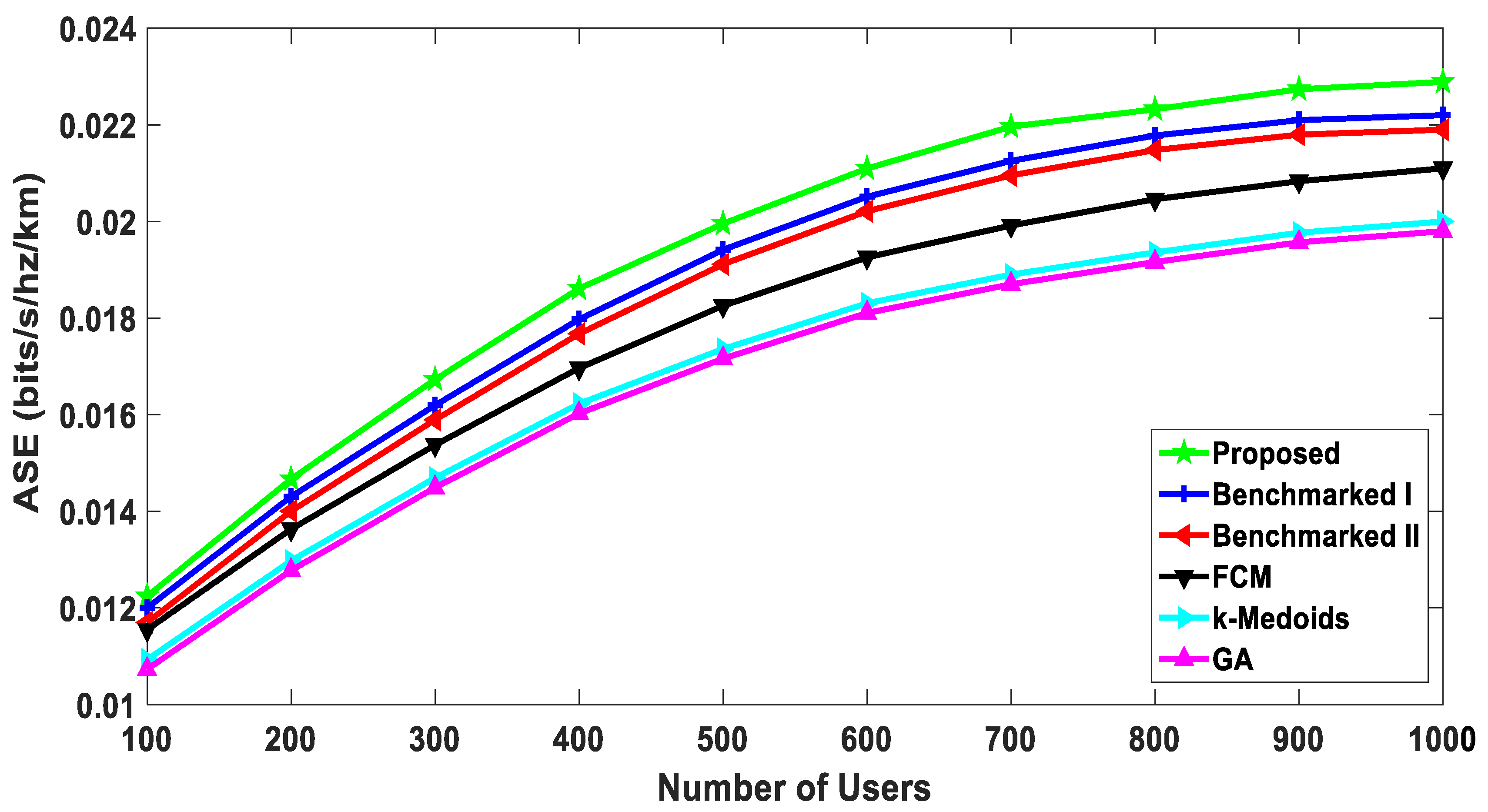
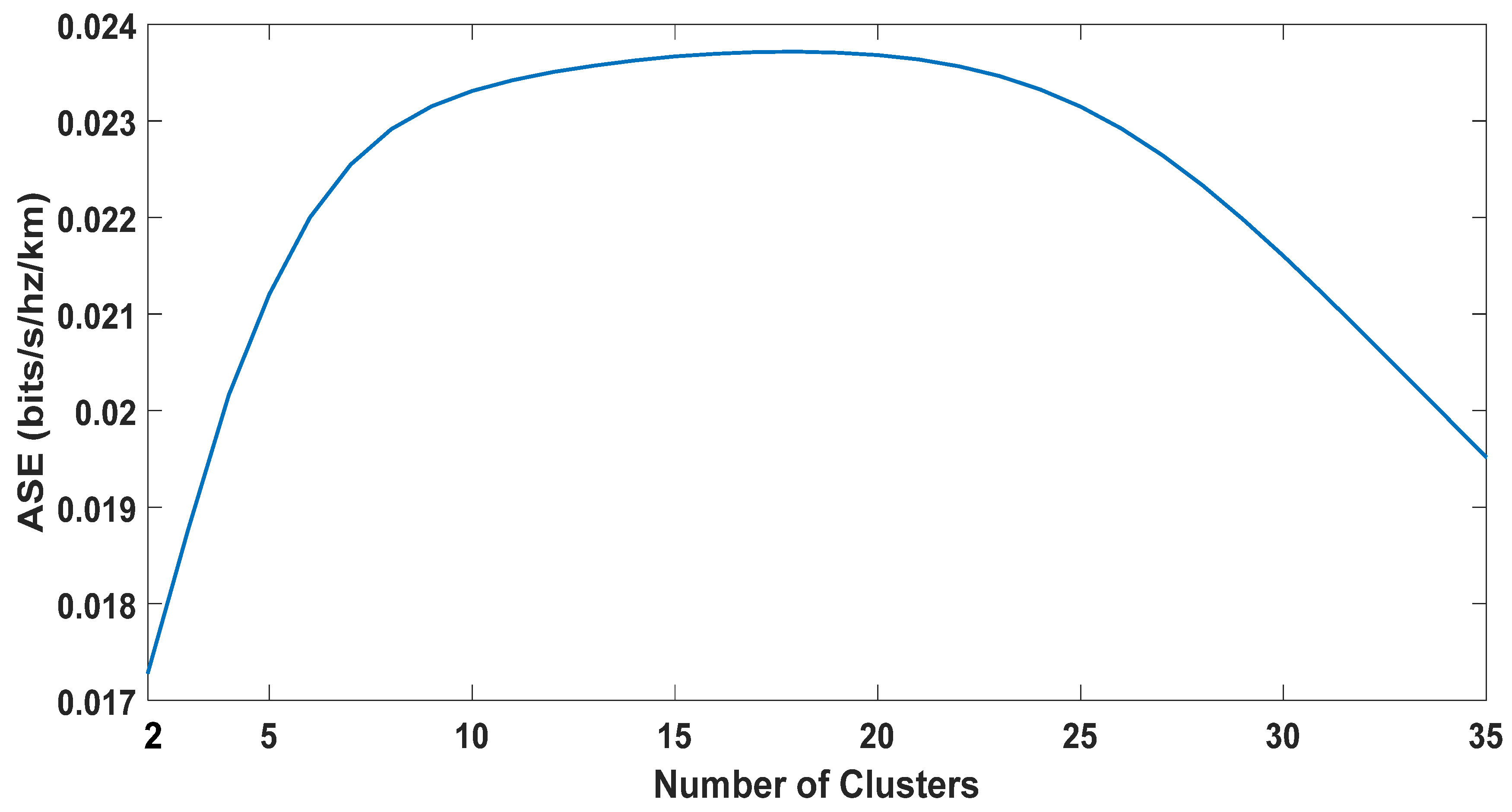
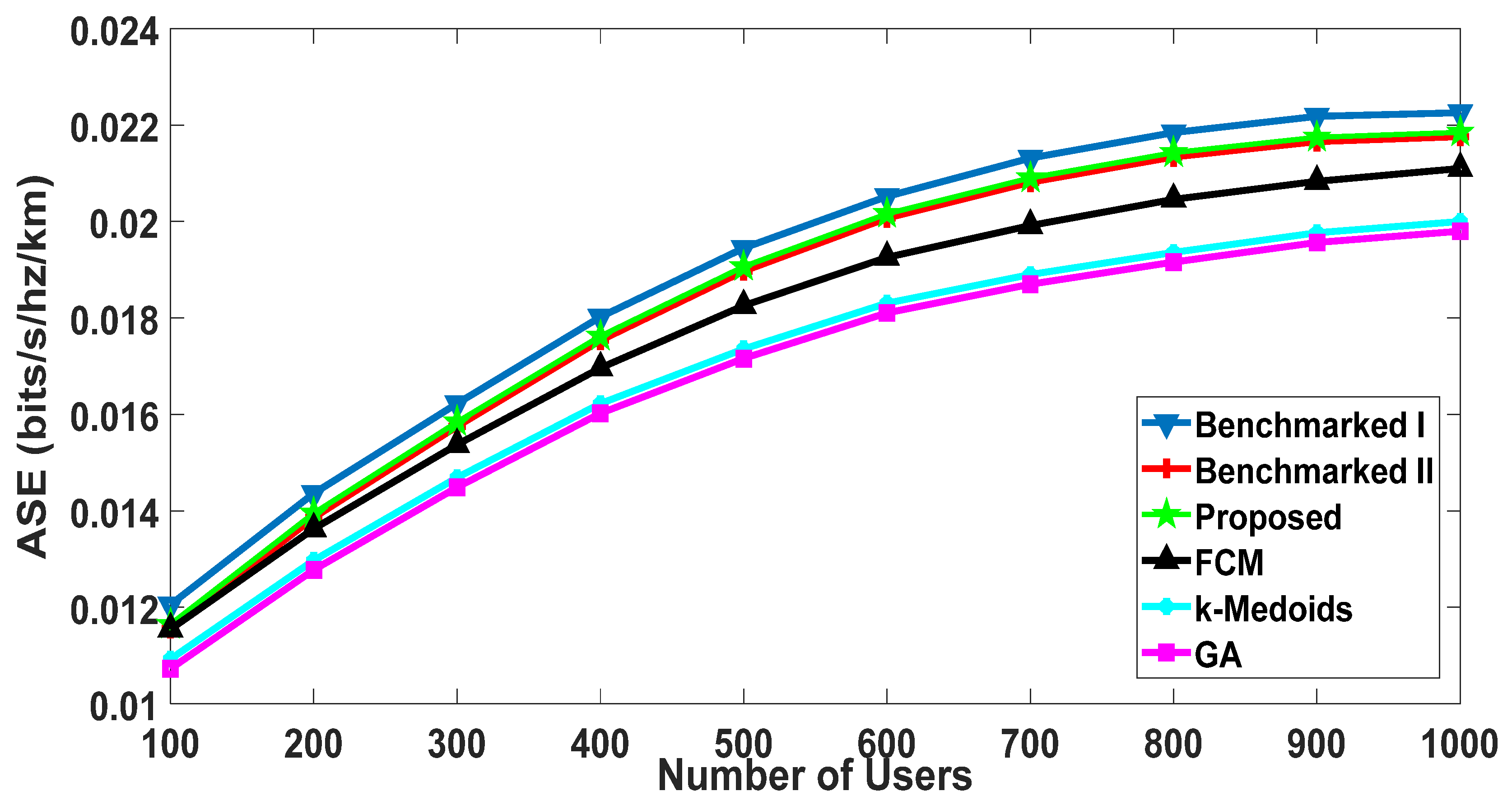
5.2.3. Area Spectral Efficiency
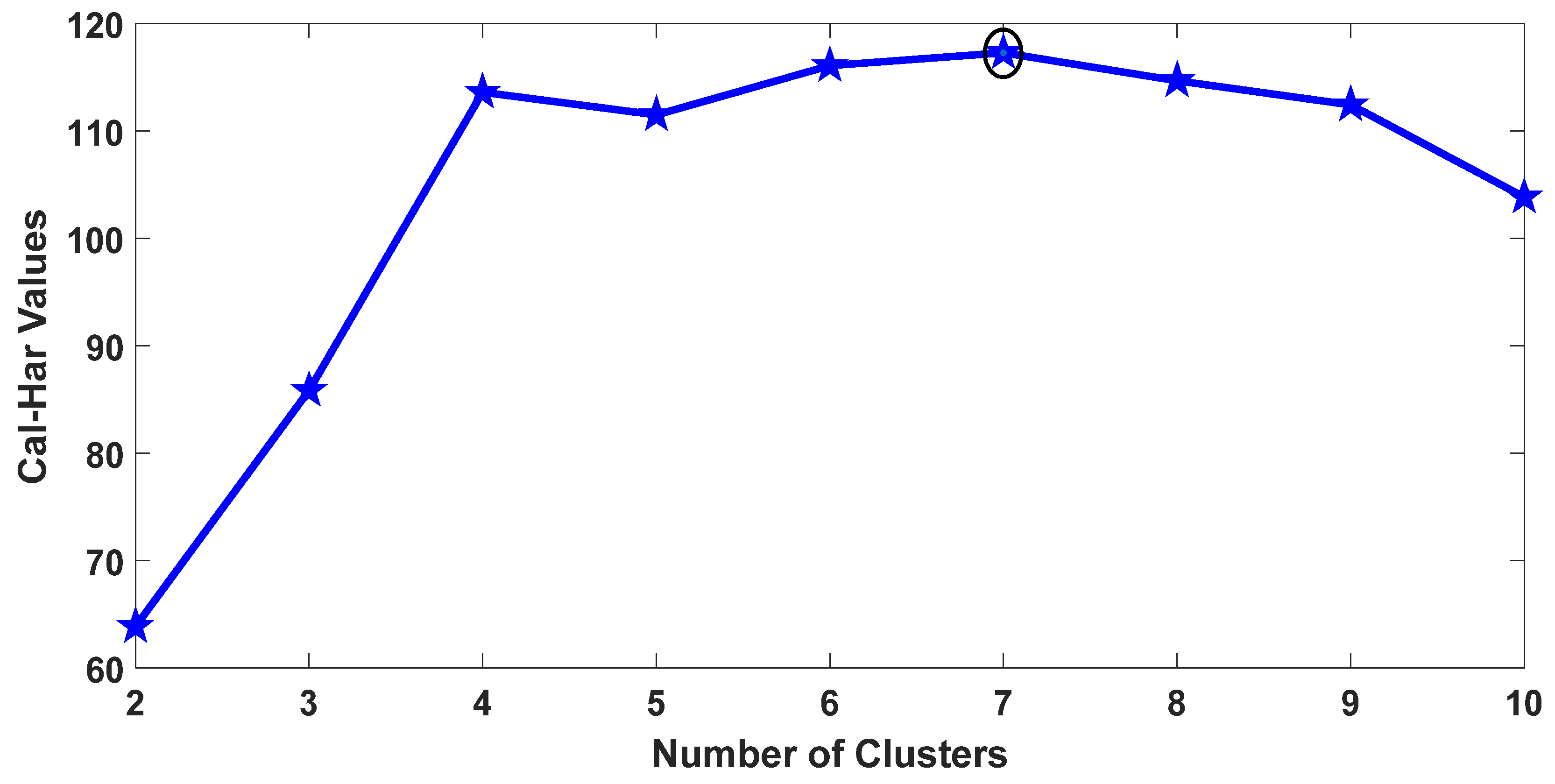
5.3. The Optimal Number of Clusters
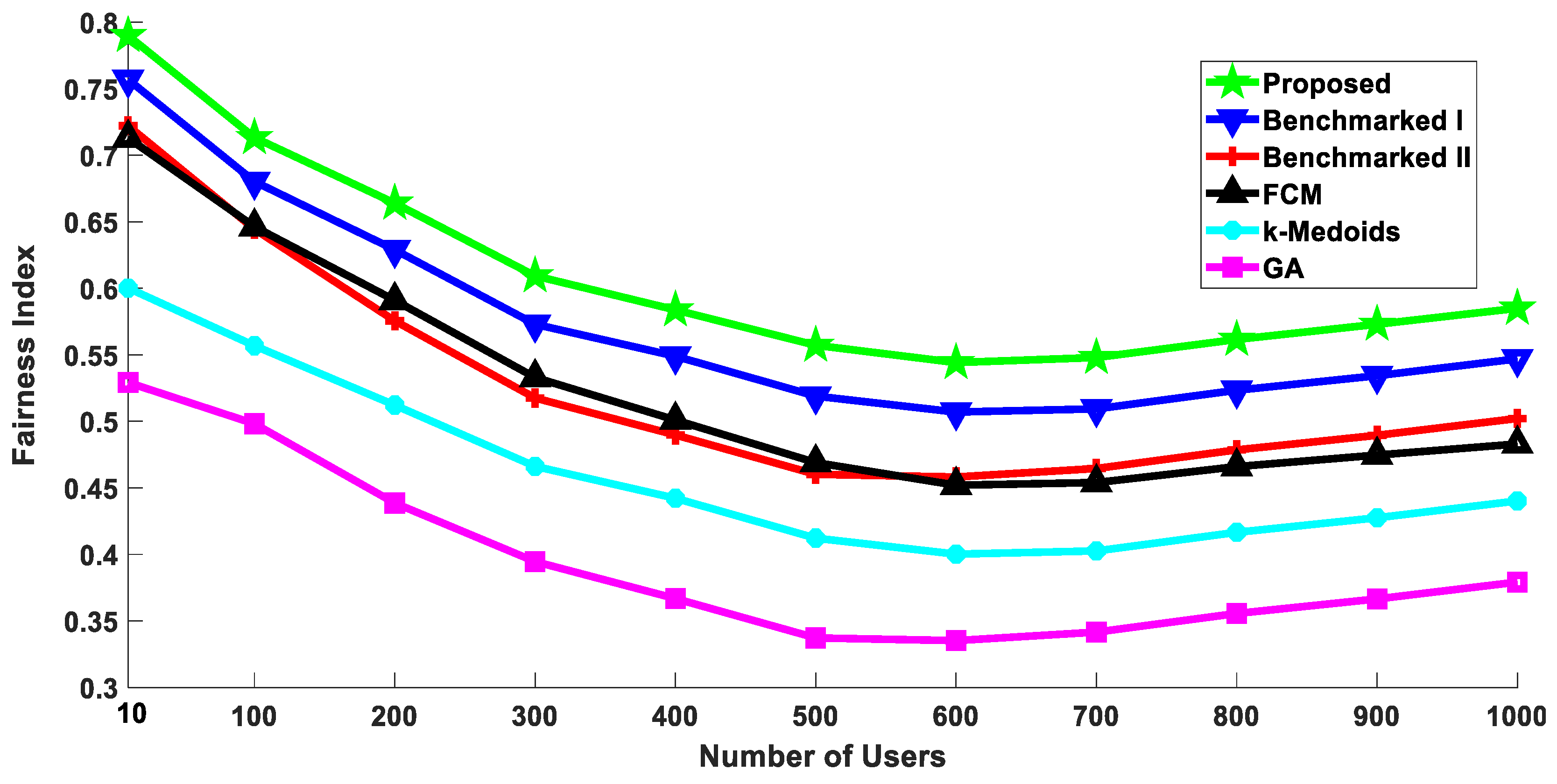
5.4. Throughput Fairness
5.5. The Trade-Off among Different Performance Parameters
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Penttinen, J.T. 3GPP Mobile Communications: LTE/SAE and LTE-A; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Benchaabene, Y.; Boujnah, N.; Zarai, F. 5G cellular: Survey on some challenging techniques. In Proceedings of the 2017 18th International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT), Taipei, Taiwan, 18–20 December 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Khan, M.F.; Yau, K.-L.A.; Noor, R.M.; Imran, M.A. Survey and taxonomy of clustering algorithms in 5G. J. Netw. Comput. Appl. 2020, 154, 102539. [Google Scholar] [CrossRef]
- Index, C.V.N. Global mobile data traffic forecast update, 2015–2020. In Cisco White Paper; Cisco: San Jose, CA, USA, 2016; p. 9. [Google Scholar]
- Ericsson, A. Ericsson Mobility Report: On the Pulse of the Networked Society; Tech. Rep. EAB-14; Ericsson: Stockholm, Sweden, 2015; p. 61078. [Google Scholar]
- Asadi, A.; Wang, Q.; Mancuso, V. A survey on device-to-device communication in cellular networks. IEEE Commun. Surv. Tutor. 2014, 16, 1801–1819. [Google Scholar] [CrossRef]
- Cao, Y.; Jiang, T.; Chen, X.; Zhang, J. Social-aware video multicast based on device-to-device communications. IEEE Trans. Mob. Comput. 2015, 15, 1528–1539. [Google Scholar] [CrossRef]
- Chang, Z.; Hu, Y.; Chen, Y.; Zeng, B. Cluster-oriented device-to-device multimedia communications: Joint power, bandwidth, and link selection optimization. IEEE Trans. Veh. Technol. 2017, 67, 1570–1581. [Google Scholar] [CrossRef]
- Feng, L.; Zhao, P.; Zhou, F.; Yin, M.; Yu, P.; Li, W.; Qiu, X. Resource allocation for 5G D2D multicast content sharing in social-aware cellular networks. IEEE Commun. Mag. 2018, 56, 112–118. [Google Scholar] [CrossRef]
- Jiang, J.; Zhang, S.; Li, B.; Li, B. Maximized cellular traffic offloading via device-to-device content sharing. IEEE J. Sel. Areas Commun. 2015, 34, 82–91. [Google Scholar] [CrossRef]
- Lin, P.; Khan, K.S.; Song, Q.; Jamalipour, A. Caching in heterogeneous ultradense 5G networks: A comprehensive cooperation approach. IEEE Veh. Technol. Mag. 2019, 14, 22–32. [Google Scholar] [CrossRef]
- Yang, L.; Wu, D.; Xu, S.; Zhang, G.; Cai, Y. Social-energy-aware user clustering for content sharing based on D2D multicast communications. IEEE Access 2018, 6, 36092–36104. [Google Scholar] [CrossRef]
- Aslam, S.; Alam, F.; Hasan, S.F.; Rashid, M. Performance Analysis of Clustering Algorithms for Content-Sharing Based D2D Enabled 5G Networks. In Proceedings of the 2019 29th International Telecommunication Networks and Applications Conference (ITNAC), Auckland, New Zealand, 27–29 November 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Akyildiz, I.F.; Nie, S.; Lin, S.-C.; Chandrasekaran, M. 5G roadmap: 10 key enabling technologies. Comput. Netw. 2016, 106, 17–48. [Google Scholar] [CrossRef]
- Morgado, A.; Huq, K.M.S.; Mumtaz, S.; Rodriguez, J. A survey of 5G technologies: Regulatory, standardization and industrial perspectives. Digit. Commun. Netw. 2018, 4, 87–97. [Google Scholar] [CrossRef]
- Bega, D.; Gramaglia, M.; Bernardos Cano, C.J.; Banchs, A.; Costa-Perez, X. Toward the network of the future: From enabling technologies to 5G concepts. Trans. Emerg. Telecommun. Technol. 2017, 28, e3205. [Google Scholar] [CrossRef]
- Feng, Z.; Qiu, C.; Feng, Z.; Wei, Z.; Li, W.; Zhang, P. An effective approach to 5G: Wireless network virtualization. IEEE Commun. Mag. 2015, 53, 53–59. [Google Scholar] [CrossRef]
- Hossain, E.; Hasan, M. 5G cellular: Key enabling technologies and research challenges. IEEE Instrum. Meas. Mag. 2015, 18, 11–21. [Google Scholar] [CrossRef]
- Ateya, A.A.; Muthanna, A.; Makolkina, M.; Koucheryavy, A. Study of 5G services standardization: Specifications and requirements. In Proceedings of the 2018 10th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Moscow, Russia, 5–9 November 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Pérez, G.O.; Hernández, J.A.; Larrabeiti, D. Fronthaul network modeling and dimensioning meeting ultra-low latency requirements for 5G. IEEE/OSA J. Opt. Commun. Netw. 2018, 10, 573–581. [Google Scholar]
- Lien, S.-Y.; Shieh, S.-L.; Huang, Y.; Su, B.; Hsu, Y.-L.; Wei, H.-Y. 5G new radio: Waveform, frame structure, multiple access, and initial access. IEEE Commun. Mag. 2017, 55, 64–71. [Google Scholar] [CrossRef]
- Rappaport, T.S.; Sun, S.; Shafi, M. Investigation and comparison of 3GPP and NYUSIM channel models for 5G wireless communications. In Proceedings of the 2017 IEEE 86th Vehicular Technology Conference (VTC-Fall), Toronto, ON, Canada, 24–27 September 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Sanusi, I.O.; Nasr, K.M.; Moessner, K. Channel assignment and power control for D2D-enabled cellular networks. In Proceedings of the 2019 International Conference on Computing, Electronics & Communications Engineering (iCCECE), London, UK, 22–23 August 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Yang, P.; Zhang, N.; Zhang, S.; Yu, L.; Zhang, J.; Shen, X.S. Content popularity prediction towards location-aware mobile edge caching. IEEE Trans. Multimed. 2018, 21, 915–929. [Google Scholar] [CrossRef]
- Semenciuc, E.; Pastrav, A.; Palade, T.; Puschita, E. Performance evaluation of a Cloud-based QoS support mechanism. In Proceedings of the 2016 International Conference on Communications (COMM), Bucharest, Romania, 9–10 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Puschita, E.; Palade, T.; Moldovan, A.; Colda, R.; Vermesan, I. An innovative qos paradigm based on cognitive in-network management of resources for a future unified network architecture: I-name qos model. In Proceedings of the 2010 Second International Conference on Advances in Future Internet, Venice, Italy, 18–25 July 2010; IEEE: Piscataway, NJ, USA, 2010. [Google Scholar]
- Wu, Y.; Yao, S.; Yang, Y.; Zhou, T.; Qian, H.; Hu, H.; Hamalainen, M. Challenges of mobile social device caching. IEEE Access 2016, 4, 8938–8947. [Google Scholar] [CrossRef]
- Liang, C.; Yu, F.R.; Zhang, X. Information-centric network function virtualization over 5G mobile wireless networks. IEEE Netw. 2015, 29, 68–74. [Google Scholar] [CrossRef]
- Zhang, X.; Zhu, Q. Information-centric virtualization for software-defined statistical QoS provisioning over 5G multimedia big data wireless networks. IEEE J. Sel. Areas Commun. 2019, 37, 1721–1738. [Google Scholar] [CrossRef]
- Zhou, Z.; Gao, C.; Xu, C.; Zhang, Y.; Mumtaz, S.; Rodriguez, J. Social big-data-based content dissemination in internet of vehicles. IEEE Trans. Ind. Inform. 2017, 14, 768–777. [Google Scholar] [CrossRef]
- Zhou, Z.; Yu, H.; Xu, C.; Zhang, Y.; Mumtaz, S.; Rodriguez, J. Dependable content distribution in D2D-based cooperative vehicular networks: A big data-integrated coalition game approach. IEEE Trans. Intell. Transp. Syst. 2018, 19, 953–964. [Google Scholar] [CrossRef]
- Zhu, Y.; Qin, X.; Zhang, P. An efficient multicast clustering scheme for D2D assisted offloading in cellular networks. In Proceedings of the 2018 IEEE/CIC International Conference on Communications in China (ICCC), Beijing, China, 16–18 August 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Wu, D.; Yan, J.; Wang, H.; Wu, D.; Wang, R. Social attribute aware incentive mechanism for device-to-device video distribution. IEEE Trans. Multimed. 2017, 19, 1908–1920. [Google Scholar] [CrossRef]
- Asadi, A.; Mancuso, V. Network-assisted outband D2D-clustering in 5G cellular networks: Theory and practice. IEEE Trans. Mob. Comput. 2016, 16, 2246–2259. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, L.; Zhang, J. Energy efficiency of D2D multi-user cooperation. Sensors 2017, 17, 697. [Google Scholar] [CrossRef]
- Huang, H.; Liu, B.; Hu, M.; Tao, Y.; Xiang, W. User-information-aware D2D multicast file distribution mechanism. Sensors 2018, 18, 3389. [Google Scholar] [CrossRef]
- Rahman, M.A.; Lee, Y.; Koo, I. Energy-efficient power allocation and relay selection schemes for relay-assisted d2d communications in 5g wireless networks. Sensors 2018, 18, 2865. [Google Scholar] [CrossRef]
- Pizzi, S.; Rinaldi, F.; Molinaro, A.; Iera, A.; Araniti, G. Energy-Efficient Multicast Service Delivery Exploiting Single Frequency Device-To-Device Communications in 5G New Radio Systems. Sensors 2018, 18, 2205. [Google Scholar] [CrossRef]
- Shi, R.; Wang, B.; Shi, F.; Piao, D.; Hu, J. A Design of D2D-Clustering Algorithm for Group D2D Communication. In Proceedings of the International Conference on Communications and Networking in China, Shanghai, China, 29 November–1 December 2019; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Wu, Y.; Wu, D.; Yang, L.; Shi, X.; Ao, L.; Fu, Q. Matching-coalition based cluster formation for D2D multicast content sharing. IEEE Access 2019, 7, 73913–73928. [Google Scholar] [CrossRef]
- Wang, Y.; Zhu, Q. Performance analysis of clustered device-to-device networks using matern cluster process. Wirel. Netw. 2019, 25, 4849–4858. [Google Scholar] [CrossRef]
- Zhou, L.; Wu, Y.; Yu, H. A Two-Layer, Energy-Efficient Approach for Joint Power Control and Uplink–Downlink Channel Allocation in D2D Communication. Sensors 2020, 20, 3285. [Google Scholar] [CrossRef]
- Padmavathi, P.; Eswaramurthy, V.; Revathi, J. Fuzzy Social Spider Optimization Algorithm for Fuzzy Clustering Analysis. In Proceedings of the 2018 International Conference on Current Trends towards Converging Technologies (ICCTCT), Coimbatore, India, 1–3 March 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Khan, A.A.; Abolhasan, M.; Ni, W.; Lipman, J.; Jamalipour, A. A hybrid-fuzzy logic guided genetic algorithm (H-FLGA) approach for resource optimization in 5G VANETs. IEEE Trans. Veh. Technol. 2019, 68, 6964–6974. [Google Scholar] [CrossRef]
- Cardoso, E.; Silva, K.; Francês, R. Intelligent handover procedure for heterogeneous LTE networks using fuzzy logic. In Proceedings of the 2017 13th International Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain, 26–30 June 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Alhammadi, A.; Roslee, M.; Alias, M.Y.; Shayea, I.; Alriah, S.; Abas, A.B. Advanced handover self-optimization approach for 4G/5G HetNets using weighted fuzzy logic control. In Proceedings of the 2019 15th International Conference on Telecommunications (ConTEL), Graz, Austria, 3–5 July 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Kim, D.; Kim, J.-h.; Moon, C.; Choi, J.; Yeom, I. Efficient content delivery in mobile ad-hoc networks using CCN. Ad Hoc Netw. 2016, 36, 81–99. [Google Scholar] [CrossRef]
- Wang, Q.; Chen, D.; Zhang, N.; Qin, Z.; Qin, Z. LACS: A lightweight label-based access control scheme in IoT-based 5G caching context. IEEE Access 2017, 5, 4018–4027. [Google Scholar] [CrossRef]
- Fritter, M.; Ould-Khessal, N.; Fazackerley, S.; Lawrence, R. Experimental evaluation of hash function performance on embedded devices. In Proceedings of the 2018 IEEE Canadian Conference on Electrical & Computer Engineering (CCECE), Quebec City, QC, Canada, 13–16 May 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Varna, A.L.; Wu, M. Modeling and analysis of content identification. In Proceedings of the 2009 IEEE International Conference on Multimedia and Expo, New York, NY, USA, 28 June–3 July 2009; IEEE: Piscataway, NJ, USA, 2009. [Google Scholar]
- Malhotra, J.; Bakal, J. A survey and comparative study of data deduplication techniques. In Proceedings of the 2015 International Conference on Pervasive Computing (ICPC), Pune, India, 8–10 January 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Padhi, M.; Chaudhari, R. An optimized pipelined architecture of SHA-256 hash function. In Proceedings of the 2017 7th International Symposium on Embedded Computing and System Design (ISED), Durgapur, India, 18–20 December 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Qiuyun, X.; Ligang, H.; Qiming, L.; Shuqin, G.; Jinhui, W. The Verification of SHA-256 IP using a semi-automatic UVM platform. In Proceedings of the 2017 13th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Yangzhou, China, 20–22 October 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Jaffry, S.; Zaidi, S.K.; Shah, S.T.; Hasan, S.F.; Gui, X. D2D neighborhood discovery by a mobile device. In Proceedings of the ICC 2019-2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Wang, Y.; Li, Y.; Wang, W.; Song, M. A locality-based mobile caching policy for D2D-based content sharing network. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Lin, X.; Andrews, J.G.; Ghosh, A. Spectrum sharing for device-to-device communication in cellular networks. IEEE Trans. Wirel. Commun. 2014, 13, 6727–6740. [Google Scholar] [CrossRef]
- Mancuso, V.; Asadi, A.; Jacko, P. Tie-breaking can maximize fairness without sacrificing throughput in D2D-assisted networks. In Proceedings of the 2016 IEEE 17th International Symposium on a World of Wireless, Mobile and Multimedia Networks (WoWMoM), Coimbra, Portugal, 21–24 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Kuerbis, M.; Balasubramanya, N.M.; Lampe, L.; Lampe, A. On the use of channel models and channel estimation techniques for massive MIMO systems. In Proceedings of the 2016 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Wimmer, H.; Powell, L. Principle component analysis for feature reduction and data preprocessing in data science. In Proceedings of the Conference on Information Systems Applied Research, Las Vegas, NV, USA, 6–9 November 2016. [Google Scholar]
- Obaid, H.S.; Dheyab, S.A.; Sabry, S.S. The Impact of Data Pre-Processing Techniques and Dimensionality Reduction on the Accuracy of Machine Learning. In Proceedings of the 2019 9th Annual Information Technology, Electromechanical Engineering and Microelectronics Conference (IEMECON), Jaipur, India, 13–15 March 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Runkler, T.A.; Katz, C. Fuzzy clustering by particle swarm optimization. In Proceedings of the 2006 IEEE International Conference on Fuzzy Systems, Vancouver, BC, Canada, 16–21 July 2006; IEEE: Piscataway, NJ, USA, 2006. [Google Scholar]
- Antonopoulos, A.; Verikoukis, C. Multi-player game theoretic MAC strategies for energy efficient data dissemination. IEEE Trans. Wirel. Commun. 2013, 13, 592–603. [Google Scholar] [CrossRef]
- Antonopoulos, A.; Kartsakli, E.; Verikoukis, C. Game theoretic D2D content dissemination in 4G cellular networks. IEEE Commun. Mag. 2014, 52, 125–132. [Google Scholar] [CrossRef]
- Yaacoub, E.; Kubbar, O. Energy-efficient device-to-device communications in LTE public safety networks. In Proceedings of the 2012 IEEE Globecom Workshops, Anaheim, CA, USA, 3–7 December 2012; IEEE: Piscataway, NJ, USA, 2012. [Google Scholar]
- Ometov, A.; Orsino, A.; Militano, L.; Moltchanov, D.; Araniti, G.; Olshannikova, E.; Fodor, G.; Andreev, S.; Olsson, T.; Iera, A. Toward trusted, social-aware D2D connectivity: Bridging across the technology and sociality realms. IEEE Wirel. Commun. 2016, 23, 103–111. [Google Scholar] [CrossRef]
- Łukasik, S.; Kowalski, P.A.; Charytanowicz, M.; Kulczycki, P. Clustering using flower pollination algorithm and Calinski-Harabasz index. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- 3rd Generation Partnership Project (3GPP). 3GPP TR 25.814 3GPP TSG RAN Physical Layer Aspects for Evolved UTRA, v7. 1.0; 3GPP: Sophia Antipolis, France, 2006. [Google Scholar]
- Mahmud, K.; Inoue, M.; Murakami, H.; Hasegawa, M.; Morikawa, H. Energy consumption measurement of wireless interfaces in multi-service user terminals for heterogeneous wireless networks. IEICE Trans. Commun. 2005, 88, 1097–1110. [Google Scholar] [CrossRef]
- Tulu, M.M.; Hou, R.; Li, C.; Amentie, M.D. Cluster head selection method for content-centric mobile social network in 5G. IET Commun. 2017, 12, 402–408. [Google Scholar] [CrossRef]
- Kazez, A.C.; Girici, T. Clustering-based device-to-device cache placement. Ad Hoc Netw. 2019, 84, 170–177. [Google Scholar] [CrossRef]
- Jung, H.; Lee, I.-H. Coverage probability and area spectral efficiency of clustered linear unmanned vehicle sensor networks. Sensors 2017, 17, 2550. [Google Scholar] [CrossRef] [PubMed]
- Cheng, H.T.; Zhuang, W. An optimization framework for balancing throughput and fairness in wireless networks with QoS support. IEEE Trans. Wirel. Commun. 2008, 7, 584–593. [Google Scholar] [CrossRef]
- Huaizhou, S.; Prasad, R.V.; Onur, E.; Niemegeers, I. Fairness in wireless networks: Issues, measures and challenges. IEEE Commun. Surv. Tutor. 2013, 16, 5–24. [Google Scholar] [CrossRef]
- Seppälä, J.; Koskela, T.; Chen, T.; Hakola, S. Network controlled device-to-device (D2D) and cluster multicast concept for LTE and LTE-A networks. In Proceedings of the 2011 IEEE Wireless Communications and Networking Conference, Cancun, Quintana Roo, Mexico, 28–31 March 2011; IEEE: Piscataway, NJ, USA, 2011. [Google Scholar]
- Jain, R.K.; Chiu, D.-M.W.; Hawe, W.R. A Quantitative Measure of Fairness and Discrimination; Eastern Research Laboratory, Digital Equipment Corporation: Hudson, MA, USA, 1984. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research | Year | Distributed Architecture | Performance Parameters | |||
|---|---|---|---|---|---|---|
| Throughput | Energy Consumption | ASE (Area Spectral Efficiency) | Fairness | |||
| Asadi et al. [34] | 2016 | × | ✓ | ✓ | × | ✓ |
| Zhang et al. [35] | 2017 | × | × | ✓ | × | × |
| Yang et al. [12] | 2018 | × | × | ✓ | × | × |
| Huang et al. [36] | 2018 | × | ✓ | × | × | × |
| Rahman et al. [37] | 2018 | × | × | ✓ | × | × |
| Pizzi et al. [38] | 2019 | × | ✓ | × | × | × |
| Aslam et al. [13] | 2019 | × | ✓ | ✓ | ✓ | × |
| Shi et al. [39] | 2019 | × | × | ✓ | × | × |
| Wu et al. [40] | 2019 | × | ✓ | × | × | × |
| Wang et al. [41] | 2019 | × | × | × | ✓ | × |
| Zhou et al. [42] | 2020 | × | × | ✓ | ✓ | × |
| Our Proposal | 2020 | ✓ | ✓ | ✓ | ✓ | ✓ |
| Symbol | Representation |
|---|---|
| Set comprises of all the users | |
| Index of cluster member | |
| Cluster Head | |
| Achievable Rate of when receiving the contents from the Base Station (BS) | |
| Signal-to-Noise Ratio of a | |
| Noise Spectral Density | |
| Bandwidth of the Transmission Channel | |
| Channel Gain between the BS and the | |
| Transmit Power of the BS | |
| Achievable Rate of cluster member | |
| Channel Gain between the cluster member and | |
| Transmit Power of the | |
| File Size (size of the demanded content) | |
| Power consumed by the CH to receive the contents from BS | |
| Power consumed by the cluster member to receive the content from cluster head (CH) |
| Parameters | Value |
|---|---|
| Simulation Platform | MATLAB |
| Channel Model | Rayleigh Distributed |
| User Placement | Uniformly Distributed |
| Node Density | 100 to 1000 |
| Cluster Size | Variable |
| Number of Clusters | Variable |
| Transmit Power of CH | 1.425 Joules/s |
| Power required to receive data from BS | 1.8 Joules/s |
| Power required to receive data from CH | 0.925 Joules/s |
| Content Considered | A file of size 100 kBits |
| Classical benchmarked Schemes | K-Medoids (KM), Genetic Algorithm (GA) and Fuzzy C-Means (FCM) |
| State-of-the-art benchmarked Schemes | Proposed in [69]. (referred in this document as benchmarked I) Proposed in [70]. (referred in this document as benchmarked II) |
| Number of Simulation Runs | 10,000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aslam, S.; Alam, F.; Hasan, S.F.; Rashid, M. A Novel Weighted Clustering Algorithm Supported by a Distributed Architecture for D2D Enabled Content-Centric Networks. Sensors 2020, 20, 5509. https://doi.org/10.3390/s20195509
Aslam S, Alam F, Hasan SF, Rashid M. A Novel Weighted Clustering Algorithm Supported by a Distributed Architecture for D2D Enabled Content-Centric Networks. Sensors. 2020; 20(19):5509. https://doi.org/10.3390/s20195509
Chicago/Turabian StyleAslam, Saad, Fakhrul Alam, Syed Faraz Hasan, and Mohammad Rashid. 2020. "A Novel Weighted Clustering Algorithm Supported by a Distributed Architecture for D2D Enabled Content-Centric Networks" Sensors 20, no. 19: 5509. https://doi.org/10.3390/s20195509
APA StyleAslam, S., Alam, F., Hasan, S. F., & Rashid, M. (2020). A Novel Weighted Clustering Algorithm Supported by a Distributed Architecture for D2D Enabled Content-Centric Networks. Sensors, 20(19), 5509. https://doi.org/10.3390/s20195509