1. Introduction
Recent advances in artificial intelligence and sensor technology have heightened the need for robots to perform assembly tasks autonomously. However, the applications in manufacturing remain a significant challenge, since traditional industrial robots deployed in production lines are pre-programmed for a specific task in a carefully structured environment. To overcome these challenges on different levels, the field of industrial robotics is now moving towards Human–Robot Collaboration (HRC) [
1,
2,
3,
4,
5,
6,
7]. In the area of HRC, Robot Learning from Demonstration (LfD) [
8] provides a natural and intuitive mechanism for humans to teach robots new skills without relying on professional knowledge. Robots first observe human demonstrations, then extract task-relevant features, derive the optimal policy between the world states and actions, finally reproduce and generalize tasks in different situations, and refine policy during practice [
9] (See
Figure 1).
Given that most current robotic assembly tasks in LfD [
10,
11,
12] are demonstrated by human hands, capturing human hand movements makes it a crucial step for robots to understand human intentions. Human hand movements are often treated as trajectories with capturing methods categorized into kinesthetic demonstration [
11], motion-sensor demonstration [
13,
14], and teleoperated demonstration [
15]. In kinesthetic demonstration, robots are guided by humans directly, without tackling correspondence problems owing to different kinematics and dynamics between each other [
13]. However, it relies heavily on the cooperative ability of industrial manipulators and fails when facing heavy objects or dangerous environments. Motion-sensor demonstration usually utilizes external markers [
13] or special equipment [
14], exhibiting flexibility compared to kinesthetic demonstration. Nevertheless, it relies on the illumination conditions and brings out correspondence problems when considering gesture imitation problems [
13]. Teleoperated demonstration, similar to kinesthetic demonstration, constructs a real-time interaction interface between humans and robots. Unfortunately, it relies on the teleoperation ability of the manipulators at an expensive cost. To overcome drawbacks mentioned above, research in [
16] has provided a promising path for capturing human hand movements by introducing a state-of-the-art Kinect FORTH system [
17], which is markerless and relatively insensitive to illumination conditions, obtaining the continuous and accurate poses of human hand articulations in near real-time. However, when facing occlusions with the human hand, the method has a poor performance. In this paper, based upon the Kinect FORTH system, we establish a vision capture system to acquire continuous human hand movements during the demonstration.
To encode human hand movements with task-oriented models, movement primitives (MPs) [
18] are well-established methods in robotics. Generally, movement primitive learning methods fall into two groups: one is based on probabilistic models [
11,
19,
20], the other is based on dynamical systems [
21,
22]. Probabilistic models commonly take the form of a Hidden Markov Model and Gaussian Mixture Regression (HMM-GMR) [
19], Gaussian Mixture Model and Gaussian Mixture Regression (GMM-GMR) [
11]. They use HMM and GMM to model joint probability distributions of multiple demonstration data and derive the desired trajectory using GMR. However, both HMM-GMR and GMM-GMR methods cannot adapt to new task situations. Recently, the Task-parametrized Gaussian Mixture Models (TP-GMMs) proposed in [
20] encapsulate task parameters into GMMs for adaptation to new situations encountered in robotic tasks. Nevertheless, TP-GMMs will fail when task parameters do not appear in the model during the learning process. Dynamical movement primitives (DMPs) [
21] are well-investigated methods under the category of dynamical systems. DMPs describe dynamical systems with a series of nonlinear differential equations equivalent to a linear spring system modulated by a nonlinear external force. However, DMPs only use one demonstration for learning which ones have suboptimal model parameters. The work [
22] proposes a combination method of Reinforcement Learning (RL) and DMPs to learn couplings across different control variables. Apart from two categories, the Mixture of Motor Primitives (MoMPs) [
23] and Probabilistic Movement Primitives (ProMPs) [
24] methods are new frameworks proposed in movement primitives learning. MoMPs use a gating network based on augmented states to activate different movement primitives and use mixed weights to generate new movements under new task situations. ProMPs represent movement primitives by hierarchical Bayesian models and generate movements with probability inference. Compared to DMPs, ProMPs can achieve this via-point generalization rather than start-points and end-points generalization in DMPs. However, ProMPs need a greater number of demonstrations to obtain reliable trajectory distributions. In this paper, since we tend to accomplish peg-in-hole tasks by generalizing start-points and end-points rather than via-points, movement primitives learning is achieved using DMPs. We adopt GMM-GMR to extract the optimal trajectory from multiple human demonstrations, then passed to DMPs for learning.
For multistep robotic assembly tasks like peg-in-hole [
25] and chair assembly [
26,
27], encoding whole movements with one movement primitive is unrealistic. Whole movements are supposed to be represented by a sequence of movement primitives explaining human demonstrations, and after movement segmentation, robots can reuse and reorder the same set of movement primitives to accomplish similar but different robotic tasks without external demonstrations. Previous work in movement segmentation including methods based on heuristic [
12] and unsupervised learning [
26,
27]. Heuristic-based methods utilize the prior knowledge of robot kinematic and dynamics properties. In [
12], zero-crossing velocity (ZCV) is used for movement segmentation in robotic assembly tasks. However, ZCV usually leads to sub-optimal segmentation results. In contrast, unsupervised learning methods cluster similar movements with minimum prior knowledge. HMMs are popular methods in this context. However, the number of unobservable states needs to be chosen in advance. To tackle the problems, recent work in [
26] has used the Beta Process Autoregressive HMM (BP-AR-HMM) algorithm [
28] with potentially infinite states, which can be shared and switched between each other. Further, in [
27], the Probabilistic Segmentation (ProbS) algorithm is proposed to improve a given segmentation concurrently through the Expectation Maximum (EM) [
29] algorithm. Nevertheless, both BP-AR-HMM and ProbS need a time-consuming iterative procedure, reducing segmentation efficiency. In this paper, we propose a threshold-based heuristic segmentation algorithm to segment complete movements into different movement primitives automatically. Compared to ZCV [
12], we can obtain better segmentation results and achieve fast segmentation with no need for a large amount of training time compared to BP-AR-HMM [
26].
Despite learning movement primitives from human demonstrations, goal configuration learning [
30,
31,
32] concerning spatial relationships between task-relevant objects need to be considered. The work in [
31] proposes a novel Visuospatial Skill Learning (VSL) method with the ability to learn from observing human demonstrations directly with only visual inputs. VSL learns goal configurations from only one multioperation demonstration with minimum prior knowledge and generalizes the learned goal configurations under new situations maintaining the task execution order. Trajectory-generation with this method is equation-based, and further research in [
32] combines DMPs to acquire human-like trajectories. However, VSL will sometimes fail when occlusions occur during the task execution process. For instance, in robotic jigsaw tasks [
31], after the robot picks and places the first jigsaw based on the generalized goal configurations in advance, then it will determine the next pick-and-place points for the second jigsaw during the task execution process. If task-relevant objects are occluded by the robot body, the VSL method will not find accurate pick-and-place points. In this paper, aiming at fundamental peg-in-hole tasks, we propose an improved VSL algorithm with modifications to [
32] by defining peg-in-hole observations and offsets to learn goal configurations from observing human demonstration directly. Only one complete multioperation demonstration is required for learning, and robots can generalize goal configurations under new task situations following the task execution order. Through the improved VSL algorithm, we can generalize all the actual 3D pick-and-place points with only one image captured before the robot executes peg-in-hole tasks, and the peg-in-hole objects and base are fixed during the task execution process, so the occlusion problems will not occur.
A workflow diagram of the proposed task-learning strategy can be seen in
Figure 2. The strategy consists of two phases: the demonstration and learning phase, and the reproduction and generalization phase, with the robot skill library conducting their interactions.
During the demonstration and learning phase, we demonstrate pick-and-place operations of a blue object multiple times as basic trajectory components in peg-in-hole tasks. We track human hand centroid movements by the Kinect FORTH system and segment complete movements into three phases represented by different movement primitives using the proposed heuristic segmentation algorithm. For each segmented movement primitive, we adopt GMM-GMR to derive the optimal trajectory from multiple demonstrations, learn with DMPs and store into the robot skill library for trajectory generalization. Subsequently, we record the video of a single multioperation demonstration in peg-in-hole tasks and use the improved VSL algorithm for goal configuration learning. The task execution order and learned goal configurations from the demonstration are stored into the robot skill library for goal configurations generalization.
During the reproduction and generalization phase, the robot reproduces and generalizes different peg-in-hole tasks under new task situations with images captured under the Kinect view. Based upon previously learned goal configurations, we can obtain actual pick-and-place points through the improved VSL algorithm, then pass them to DMPs for trajectory generalization. Trajectory segments of each phase are finally connected to complete trajectories following the task execution order for robots to accomplish peg-in-hole tasks.
To summarize, the main contributions of this paper are as follows:
We establish a markerless vision capture system based on the Kinect FORTH System to track continuous human hand centroid movements and develop a threshold-based heuristic movement segmentation algorithm to segment human hand movements into different movement primitives automatically with no need for a large amount of training time.
We adopt the GMM-GMR method to derive the optimal trajectory encapsulating sufficient human features and utilize DMPs to learn for trajectory generalization, the generated trajectories exhibit satisfactory smoothness and similarity with respect to human demonstrations.
We propose an improved VSL algorithm enabling robots to learn goal configurations directly from the video of only one multioperation demonstration and generalize them under new task situations, the generated goal configurations reflect the actual pick-and-place points of peg-in-hole tasks exactly.
The remainder of this paper is organized as follows.
Section 2 details the overall task-learning methodology, and
Section 3 presents the experiment study for a series of peg-in-hole robotic assembly tasks.
Section 4 analyzes the experimental results and summarizes the advantages and disadvantages of the proposed strategy, and finally, we conclude the paper and discuss future directions in
Section 5.
2. Methodology
The emphasis of this paper lies in allowing robots to learn and generalize robotic assembly tasks autonomously from human demonstrations, without taking into account gesture imitation [
13] and obstacle avoidance problems. Hence, we assume that the learned human hand movements can directly apply to the end-effector, and task-relevant objects involved will not collide and interfere with each other during task execution. The orientation of the end-effector is fixed, using XYZ positions to accomplish peg-in-hole tasks.
2.1. Data Acquisition and Preprocessing from Markerless Demonstrations
The Kinect FORTH system [
17] merely relies on markerless visual data acquired from the Kinect sensor to track 3D positions, orientations and full articulations of a human hand robustly and accurately. In this work, we choose human hand centroid point as the tracking point with trajectory coordinate sets
from
N demonstrations stored as the original data. The trajectory data are then transformed to the base frame of the robot based on hand-eye calibration. To reduce the noise generated from illuminations and occlusions of the vision capture system, we apply a Moving Average Filter (MAF) with a window width
n set experimentally to ensure satisfactory smoothness and minimum distortion loss of trajectories. Multiple demonstrations usually have different timesteps, we thus utilize Cubic Spline Interpolation (CSI) to normalize trajectories to the same timesteps.
2.2. Heuristic Movement Segmentation Algorithm
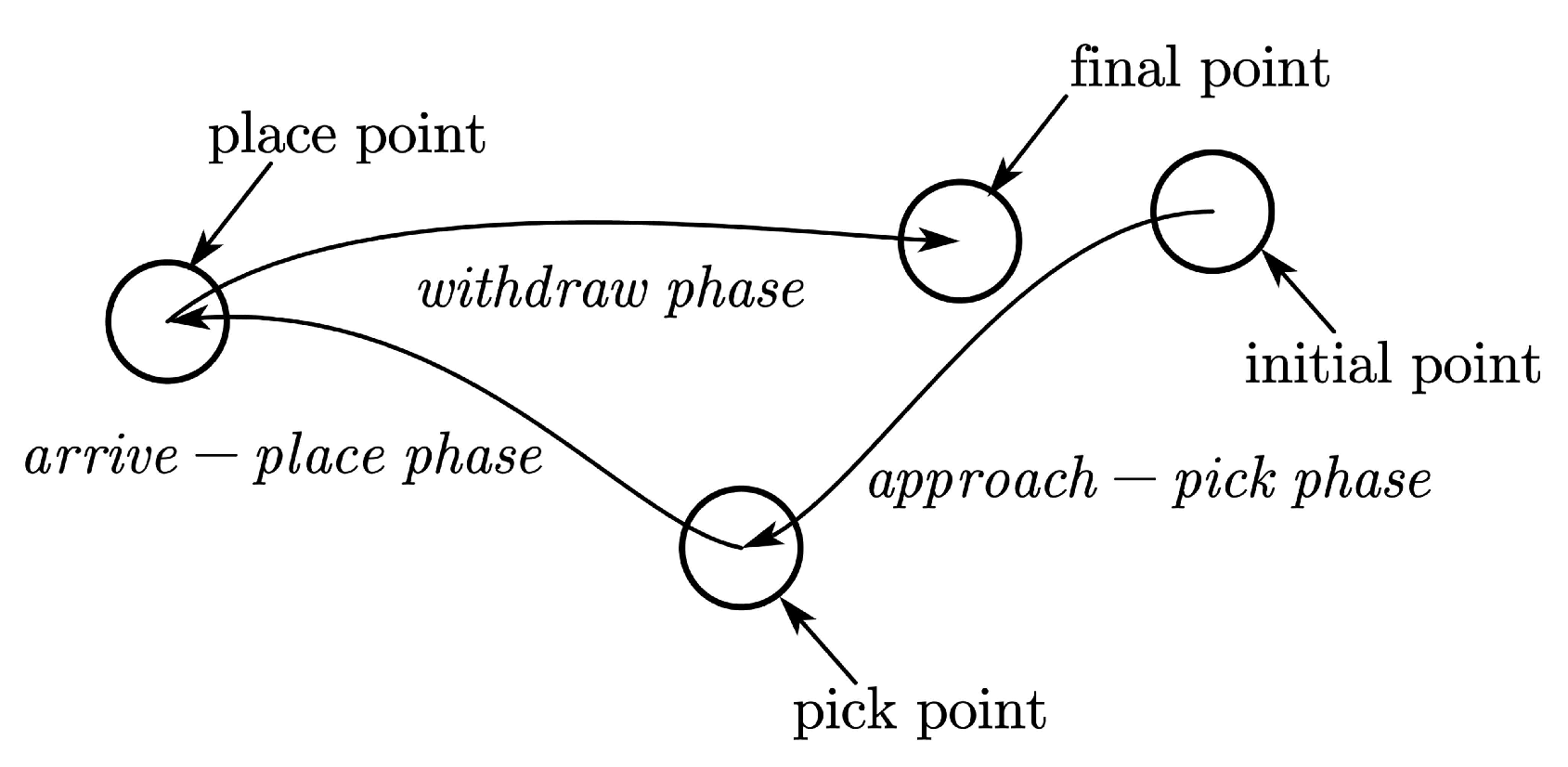
Generally, we represent whole human hand movements in basic pick-and-place operations of peg-in-hole tasks with three phases, as shown in
Figure 3.
The approach-pick phase, during which the human moves his hand from an initial point, approaches a pick point just before he makes contact with the object and grasps it.
The arrive-place phase, during which the human grasps the object from a pick point and arrives at a place point just before he releases the object.
The withdraw phase, during which the human releases the object from a place point and returns to a final point.
Inspired by research on vision-based action recognition [
33] that possible Grasp and Release points may occur at the local lowest points of human hand palm motions, we propose a heuristic segmentation algorithm based on human hand centroid velocities, as depicted in Algorithm 1.
| Algorithm 1 Heuristic Movement Segmentation Algorithm. |
| Input: Human hand centroid trajectory coordinates |
| |
| Output: Segmentation points set of pick-and-place operations |
| |
- 1:
for to N do - 2:
for each Cartesian dimension do - 3:
Calculate velocities by the differential process; - 4:
Smooth velocities using MAF twice and normalize velocities using CSI; - 5:
end for - 6:
Calculate the square sum of velocities in all Cartesian dimensions and normalize the results
|
| within the range ; |
- 7:
Initialization:
|
- 8:
- 9:
- 10:
- 11:
if then - 12:
; - 13:
end if - 14:
- 15:
- 16:
- 17:
if then - 18:
- 19:
else - 20:
if then - 21:
- 22:
else - 23:
; - 24:
end if - 25:
end if - 26:
end for - 27:
Return:
|
| |
For each trajectory in N demonstrations, we first calculate velocities in each Cartesian dimension by the differential process. Considering large velocity fluctuation during the human demonstration, we applied MAF twice to smooth velocities and normalize to the same timesteps by CSI. The velocity square sum is calculated and normalized within the range .
An initialization step is then performed to establish segmentation points set and auxiliary points set . Considering movement switching may occur at the local minima, we find all the local minimum of velocities and add them into the local minimum points set using the FindLocalMins function with velocities , the start point and the end point as input. To eliminate local minimum points caused by human hand quiver rather than movements switching, we determine a threshold experimentally and use the ThresholdElimination function to update the local minimum points set by eliminating those local minimum points whose corresponding velocities are above the threshold. Meanwhile, the FindIntersection function expands the threshold value to a line with the same timesteps as velocities and find the intersection points between each other, the points are then rounded off and added into the intersection points set . For the first intersection point , we calculate the distance between the start point and the first local minimum point . If the distance of the former is less than the latter, we delete the first intersection point using the DeleteFirstIndex function to update the intersection points set . That is to say, if a threshold-based intersection occurs at a moment closer to the start point, we select the start point as the first segment point.
After updating and , we traverse elements in to calculate distances between each other, the FindMinIndex function finds the corresponding indexes of the minimum distance in and adds them into the minimum distance index set . Finally, the segmentation points set can be obtained from , based on heuristic rules. Specifically, we add and the first index from to construct the approach-pick phase . Then, the second index and the third index from are added to the arrive-place phase . The withdraw phase is constructed based on the length of . If the length is less than 5, that is, there are no intersections in the withdraw phase, we thus add the fourth index from and to the withdraw phase . If not, there are two cases to consider. The first case is that if the last point of is greater than of the last from , we add the fourth index from and the last point of to . The meaning is that there is no switching of movements that occurs after the last intersection point, thus making it the end point of the withdraw phase. The other case occurs when the human quivers his hand at the end of the withdraw phase with the local minimum points detected, the fourth index and the last index are added to as a consequence. The output segmentation points set is used to index the whole trajectories of N demonstrations and store them into different movement primitives separately for movement primitives learning.
2.3. Optimal Demonstration Trajectroy Extraction Using GMM-GMR
After segmentation,
N trajectories in the same phase usually have different durations. We adopt the Dynamical Time Warping (DTW) [
34] method for time alignment. Considering the aligned dataset
with
N matrixes of
dimensionality.
T is the identical duration of multiple demonstrations after alignment,
t is the timestep index of each demonstration and
is the corresponding Cartesian positions of human hand centroid. The dataset can be modelled by GMM through a mixture of
K Gaussian components with dimensionality
as follows:
The parameters
of GMM define the number, prior, mean and covariance matrix of Gaussian components, respectively. We select the optimal number
K using the BIC criteria [
35]. The parameters
of each component are estimated iteratively using the expectation-maximization (EM) algorithm [
29]. EM is a method suitable for parameters estimation with hidden variables, however, it is sensitive to initial values, getting trapped into a local minimum easily. As a consequence, k-means clustering method is applied to initialize parameters for iteration.
After updating parameters
, we apply GMR to generate a desired trajectory. For each Gaussian component, the mean and covariance matrix are separated as follows:
The temporal values
are then used as the input data to estimate the conditional expectation
and covariance
:
The mixing coefficient
is defined:
and the overall expectation
and covariance
are:
The datasets are treated as the extracted optimal trajectory using GMM-GMR and passed to DMPs as input for subsequent learning.
2.4. Trajectory Learning and Generalization Using DMPs
DMPs encode discrete and rhythmic movements with linear differential equations modulated by nonlinear functions. In this paper, we focus on discrete movements and encode each degree of freedom (DOF) in Cartesian space with a separated DMP described by the canonical system:
and the transformation system:
where
is the time constant,
x is the phase variable indicates the movement evolution,
determines the decay rate.
y defines the position,
are respectively velocity and acceleration intermediate variables.
and
are constants set to be critically damped.
G is the target position of the movement.
For trajectory learning,
f is a nonlinear function represented by a linear combination of
normalized radial basis functions
as follows:
where
denotes mixture weights,
is the start point,
and
are respectively the width and center of basis functions distributing along the phase variable
x with equal spacing. The weights
can be learned through the locally weighted regression (LWR) method [
21].
After learning, trajectory generalization is achieved with DMPs by adapting new start position
and target position
, then computing
using Equation (
10) , finally integrating the transformation system using Equation (
9) to generate desired trajectories for task execution.
2.5. Goal Configuration Learning and Generalization Using the Improved VSL Algorithm
Formally, we represent the goal configuration learning process as a tuple:
where
determines the number of pick-and-place operations involved in peg-in-hole tasks.
defines image sequences of the world under the camera view with
and
denote respectively the demonstration phase and the generalization phase.
U and
V are resolution parameters.
are image sequences of observations holding the essential parts of the world described by observation frames
.
determine rectangle areas in 2D images with resolution parameters
and
. In this work, we define pre-pick observation and peg-in-hole observation sequences
for modifications to the original VSL method [
32]. In particular,
are images captured just before the human approaches task-relevant objects and grasps them, and
are images captured after the human accomplishes each peg-in-hole operation with task-relevant objects stabilized in their own positions. The observation sequences can be obtained from the video easily and robustly to achieve accurate and stable goal configuration generalization.
are output goal configurations of the generalization phase. In this work, goal configurations are equivalent to actual pick-and-place points of peg-in-hole tasks with
, the previously segmented and learned movement primitives set. Based upon representations above, the implementation of the improved VSL algorithm is detailed in Algorithm 2.
To initialize,
are set according to objects maximum size. The initial points
and the final points
are set the same for each peg-in-hole operation. Meanwhile, the pick offsets
and peg-in-hole offsets
are set experimentally for adaption to peg-in-hole tasks. During the demonstration phase,
are a sequence of pre-action and post-action images obtained via key frame extraction from the video. We utilize RecordPrePickObs and RecordPegInHoleObs functions to obtain
and
respectively. Image substracting and thresholding methods are performed with morphological erosion and dilation processed to extract pixel centers and add to observation sequences under observation frames
and
. During the generalization phase,
are new task situations captured under the camera view for each operation. Subsequently, the FindBestMatch function finds best matched feature point pairs
exploiting image matching methods. We adopt the Speeded Up Robust Features (SURF) algorithm [
36] to match features along with the M-estimator Sample Consensus (MSAC) algorithm [
37] to reject error matching pairs and calculate the homography matrix. Subsequently, the FindPickPoint and FindPlacePoint function transform pixel centers of
and
to those in
as pick-and-place points
under the image plane. Further, we transform those points to actual 3D pick-and-place points
under the robot base frame using the Transform function based on hand-eye calibration with
and
added. Finally, based upon previously segmented and learned movement primitives as well as goal configurations generalized from previous steps, robots are able to accomplish peg-in-hole tasks under new situations using functions PickObject, PlaceObject, and Return. To illustrate the relationships between trajectory learning and goal configuration-learning from these functions, we take the PickObject function as an example and the functions PlaceObject and Return are run in the same way. Specifically, the PickObject function utilizes the initial points
set fixed for each peg-in-hole operation and the generalized pick points
for each peg-in-hole operation as query points for the trajectory learned with DMPs in the approach-pick phase (i.e.,
) to generalize new trajectories under new task situations for each peg-in-hole operation.
| Algorithm 2 The Improved VSL Algorithm for Robotic Peg-in-Hole Tasks. |
- Input:
- Output:
- 1:
Initialization:
|
| |
- 2:
\\ The Demonstration Phase - 3:
for to do - 4:
; - 5:
; - 6:
end for - 7:
\\ The Generalization Phase - 8:
for to do - 9:
; - 10:
; - 11:
; - 12:
; - 13:
; - 14:
; - 15:
; - 16:
; - 17:
; - 18:
end for
|















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}