1. Introduction
As befits one of the most crucial problems in robotics, SLAM has received much attention for the past two decades and opened up many new vistas for autonomous robots, alongside numerous proposed approaches and schemes for implementing it, which fall into three categories by sensing modality: Laser SLAM, visual SLAM, and visual-inertial SLAM. Laser SLAM preponderated in the early stages of the development of SLAM by virtue of its high precision, long range, and capacity for obstacle avoidance. Notwithstanding its advantages, its scale in size and weight means its application is confined to platforms allowing a limited load and a capacity enough for carrying a laser scanner, which therefore circumscribes the application range and agility of the platform. Being cost-effective, lightweight, and efficient in energy consumption, cameras, or vision-based sensors in general, are in the ascendant, which is also attributed to its informative representation of geometry in a single image caught on camera. A desirable consequence of images being abundant in information is the capacity to retrieve previously registered scenes, known as scene recognition, so as to perform loop closure to curb drift in estimates.
For a vision-based SLAM system or those reliant mainly on visual perception, four components are deemed indispensable, including visual tracking, filtering/optimization, loop closure, and mapping, each of which holds systemic effects on the overall performance of a system and to which various solutions have been conceived, implemented, and experimented. Approaches to tracking visual cues can be categorized into such two classes as feature-based and direct methods according to how they implement data association. Feature-based methods rely on the descriptors of features extracted in images to associate image points appearing across several images, and points existing in more than one images can then be used to estimate poses with stability due to the invariance of descriptors. Apart from the relatively high computational cost of extracting features and descriptors, one of the penalties to feature-based methods is their lack of resistance to texture-less views. The descriptor, dependent on features being identifiable, does not contain the amount of information enough to perform data association. Direct methods, however, eschew this problem by direct exploitation of changes in illumination and by minimization of photometric errors rather than geometric ones, thereby being more impervious to scarcity of texture as well as driving down computational consumption since they don’t have to describe features. The concept behind every formulations of estimation is probabilistic modelling with noisy measurements as input to estimate certain parameters. Typical models are based on maximum a posterior (MAP) in which the final estimates maximize the a posteriori probability given existent measurements. For pure visual SLAM, the probabilistic model is usually based on Maximum Likelihood (ML) in the absence of prediction models. Earlier SLAM schemes estimate states mainly in a filtering way in which the prior parameters are always marginalized out to focus merely on current states for containment of computation, i.e., all the previous states are fixed, which is bound to affect precision. Recently nonlinear optimization-based methodology has begun to gain ground among scholars alongside increases in the performance of hardware and decreases in its cost. Due to the sparsity inherent in the Hessian matrix of BA (Bundle Adjustment), the computational complexity of estimation in SLAM is lighter than would be conceived. By benefiting from the sparsity and properly assigning tasks among several parallels and with existent optimization modules including Ceres, g2o, iSAM, and gtsam which have been leveraged across many platforms of navigation, optimization-based systems can run smoothly within reasonable time but still need to marginalize out older states to restrict the number of keyframes. The factor graph based on fast incremental matrix factorization, on the other hand, allows for a more accurate and efficient solution by virtue of recalculating only the matrix entries in need of change, whereby the system can considerably slash computation while holding the whole trajectory.
The inertial measurement unit (IMU), light in weight, size, and price, and often in the form of a MEMS (Micro-Electro-Mechanical System), has been gaining in popularity as a source of inertial information complementary to vision since it recovers poses from motion itself and permits rendering observable the metric scale of monocular vision and the direction of gravity whereas visual constraints, in reverse, given accurate data association, can check error accumulation in the integration of IMU measurements (angular velocity, acceleration). The fusion of visual and inertial information began with loosely-coupled mechanisms and has now transitioned into tightly-coupled ones. The procedure of propagating and predicting states with inertial measurements between two consecutive frames and later using a visual image (or several) as an observation to update estimates is characteristic of loosely-coupled mechanisms which are straightforward but fall short of gratifying decision because they fail to take into account the correlation between the two types of data, as opposed to which, tightly-coupled ones fare better by incorporating variables specific to vision (the coordinates of landmarks) and those to inertia (gyroscope and accelerometer biases) into the whole set of optimization states, which in essence utilizes the complementary attribute to a greater extent. To ameliorate the additional computational expense incurred by the introduction of inertial constraints into the optimization graph, in which case the Hessian matrix is no longer as sparse as that of purely visual models, pre-integration on manifold may be adopted to reduce calculation for optimization and bias correction.
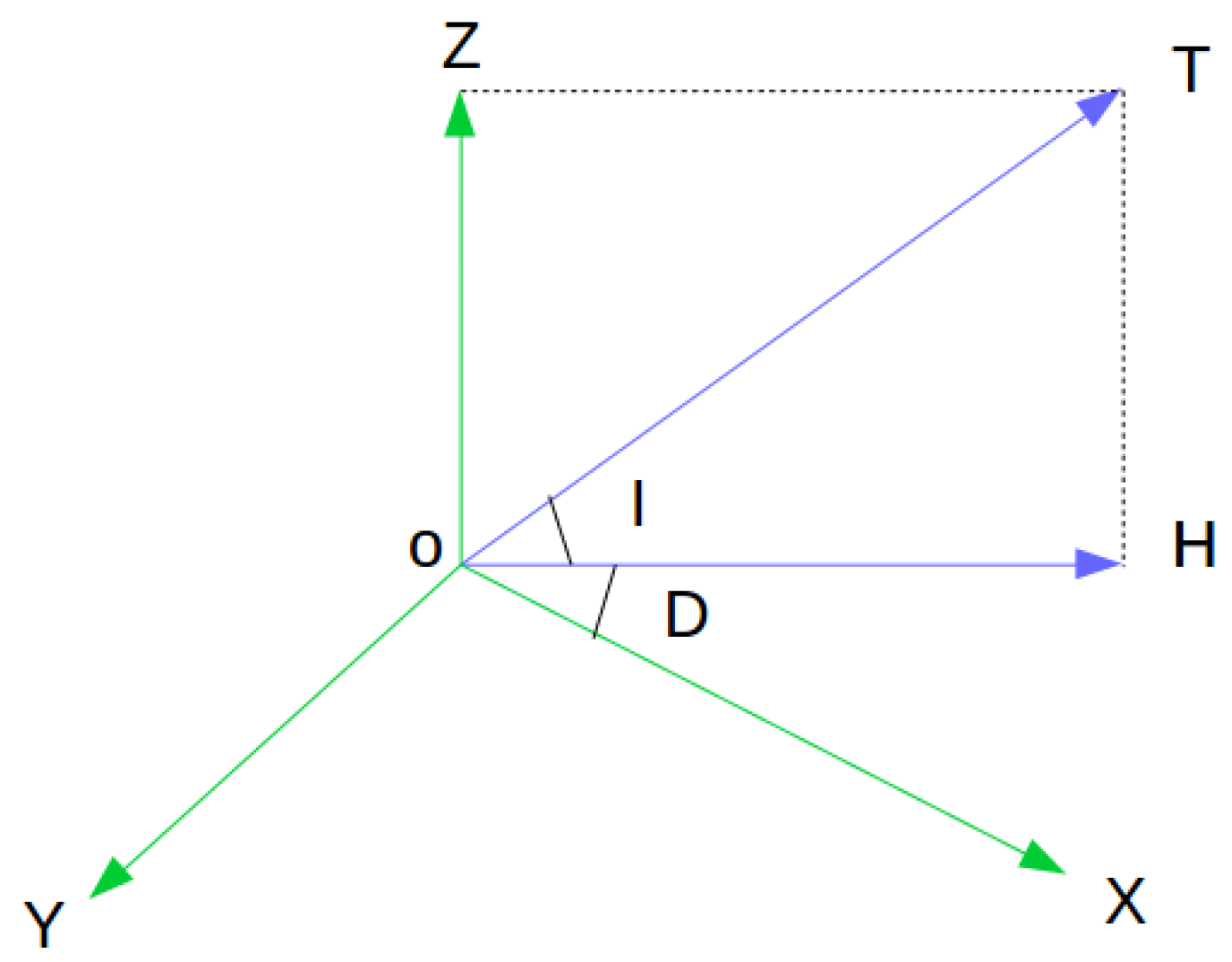
Merging inertial and visual information leads to the angles of pitch and roll being observable with the last dimension of attitude, namely yaw, still unobservable and bound to drift over time. It is conceivable that high accuracy in yawing estimation can bolster the overall precision as every pose is estimated partly based on previous estimates and is therefore affected by their yaw angles. The magnetometer has long been employed in the field of navigation, often in combination with other types of apparatus such as an IMU. The magnetometer, as its name reveals, is a type of sensors that measure magnetic density in a magnetic field, especially the Earth’s magnetic field (EMF), one of the Geophysical Fields of the Earth (GFE) including the Earth’s Gravitational Field (EGF). It has been used in a wide range of commercial and military applications, mostly for directional information [
1], whereas another way of using it for motion estimation is through measuring magnetic field gradients so as to acquire velocity information as in [
2] which formulated a sensing suite consisting of a vision sensor and a MIMU (Magneto-Inertial Measurement Unit) that, on the presupposition of stationary and non-uniform magnetic field surroundings (particularly indoor environments), can render the body speed observable. The said two manners of employing the magnetometer imply that for this sensor there is a dichotomy in how to process its readings between outdoor and indoor scenarios, and it will not be straightforward to reconcile them.
However, little research has been done about integrating visual-inertial frameworks with magnetic observation that could ably suppress the cumulative azimuth error and further facilitate navigation. It seems that the magnetometer is not so much appealing for scholars in the area of SLAM as it ought to be. What keeps magnetometers from being adopted might be its liability to magnetic disturbance. Ubiquitous sources magnetic interference from ferrous metals and even from the platform itself would entail the system both growing in size and demanding more intricate handling. Since applications of SLAM are always towards compactness and generality, the magnetometer has remained out of favour.
We gather that despite the magnetometer’s weaknesses, outdoor environments might still be in accord with its characteristics with appropriate measures taken, and therein lies the main motivation of the paper.
In this paper, we present a visual-inertial-magnetic system of navigation based on graph optimization that, apart from visual and inertial measurements, utilizes the geomagnetic field to restrain drift in yaw. From devising the scheme to verifying its superiority, the following tasks have been followed through along the way:
Exhaustive mathematic deductions have been made to support the proposed system theoretically and mathematically, embodying observation models, least squares problems concerned with initialization, the novel optimization framework that fuses visual-inertial-magnetic information, and a novel way of loop-closure formulation aimed at enhancing the robustness to false loops.
A complete and reliable procedure of initialization for visual-inertial-magnetic navigation systems is presented.
An effective and efficient optimization using visual-inertial-magnetic measurements as observation is established.
A suite of sensors and a CPU with other hardware, capable of data acquisition and real-time operation, has been assembled.
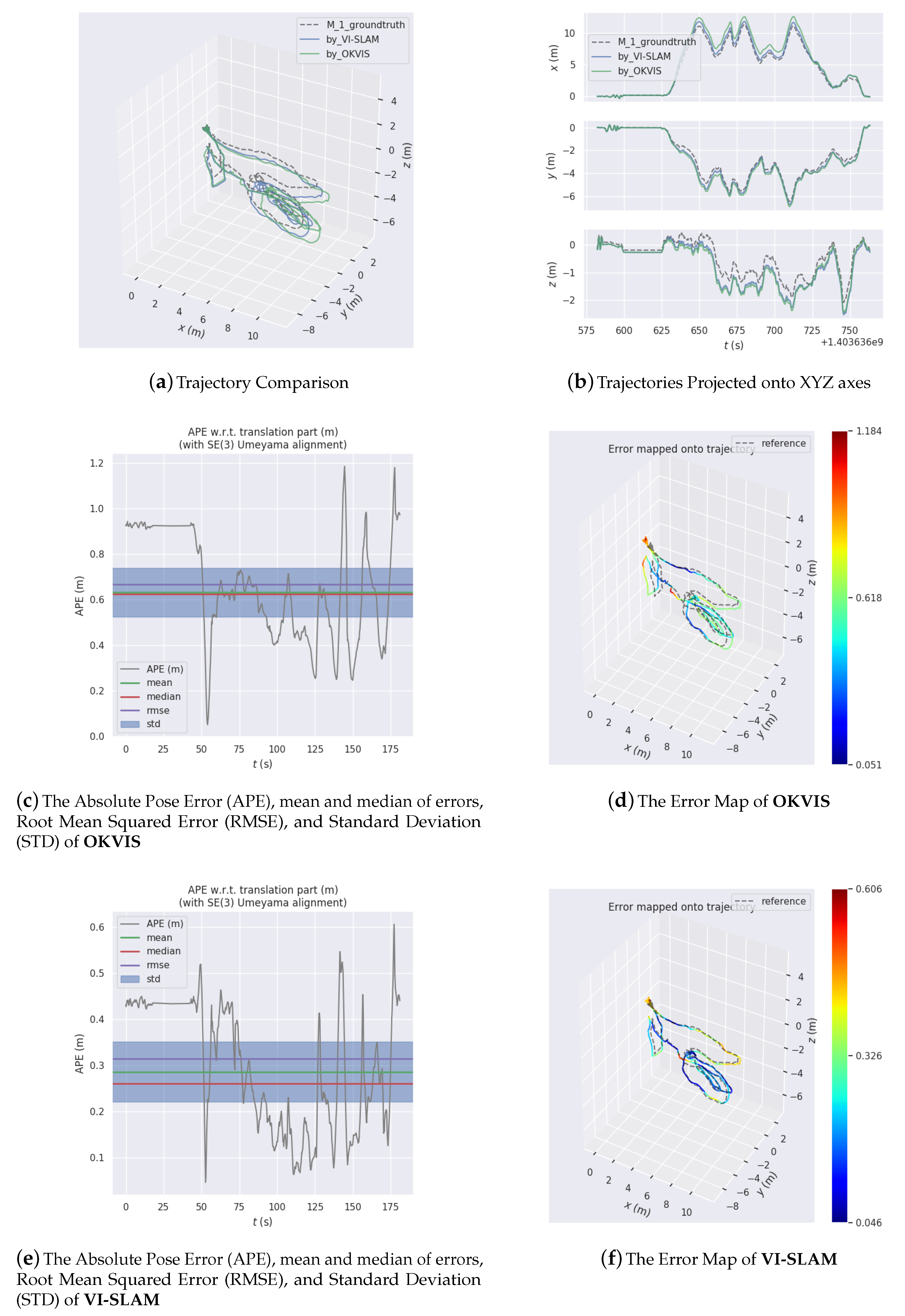
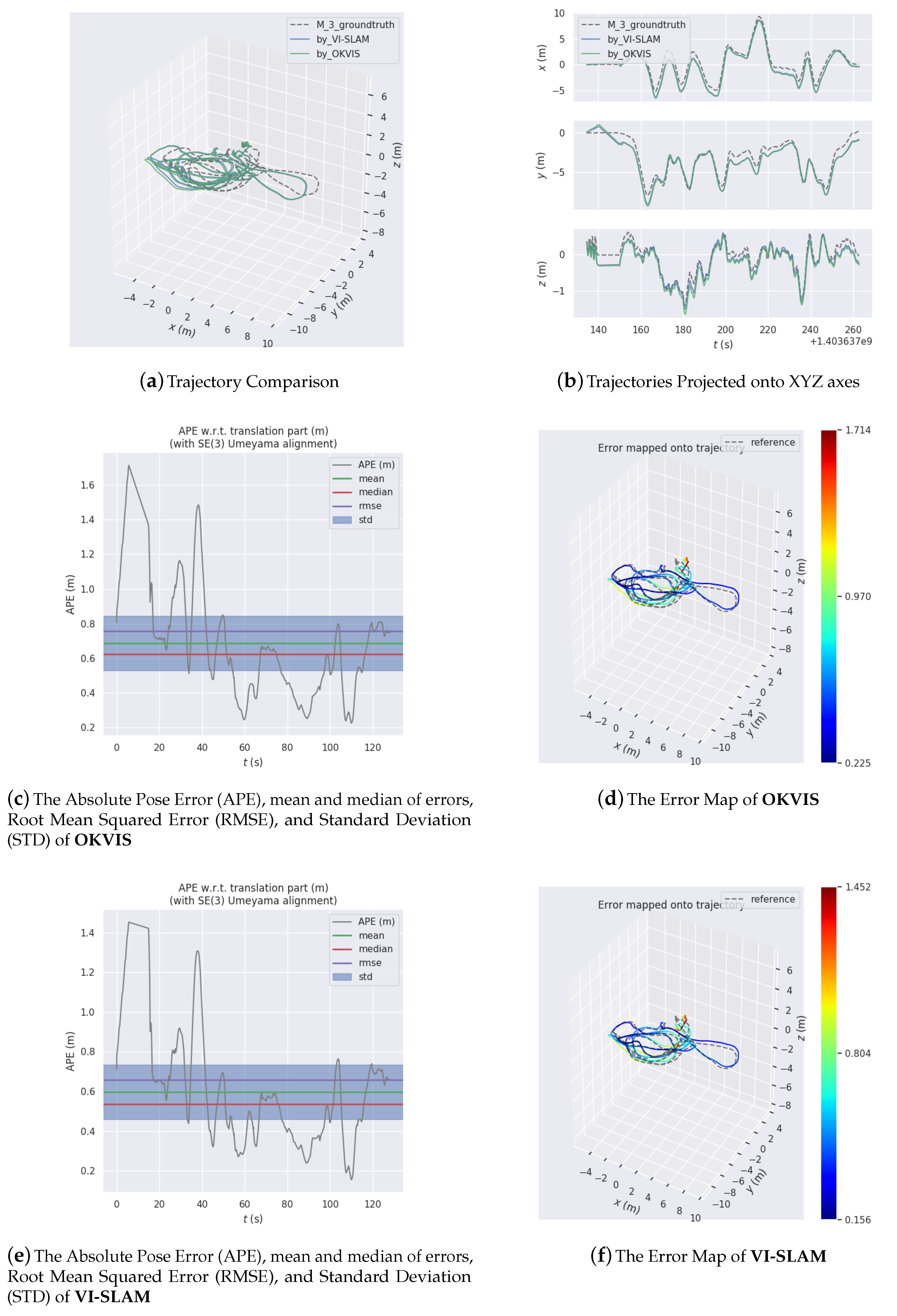
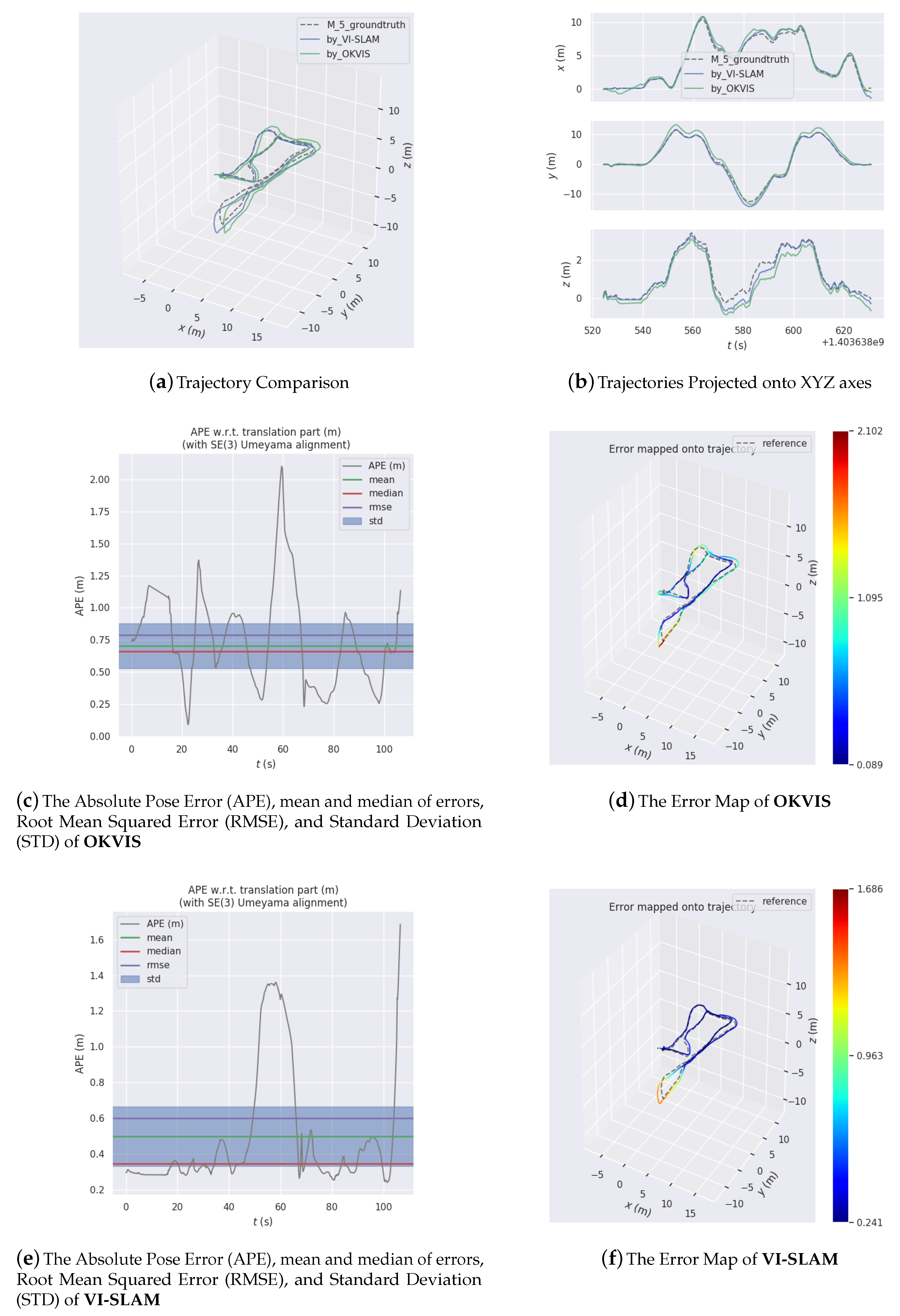
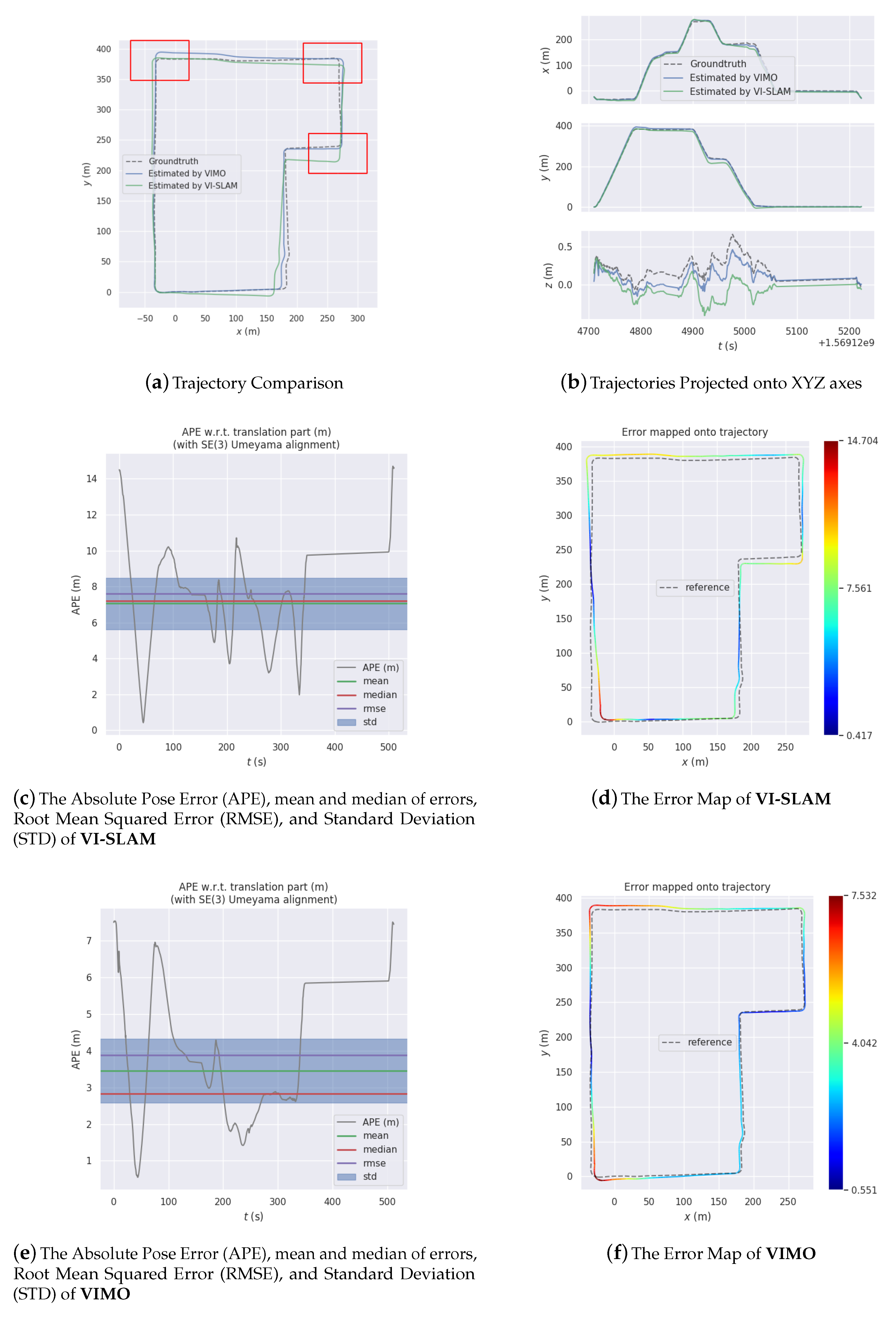
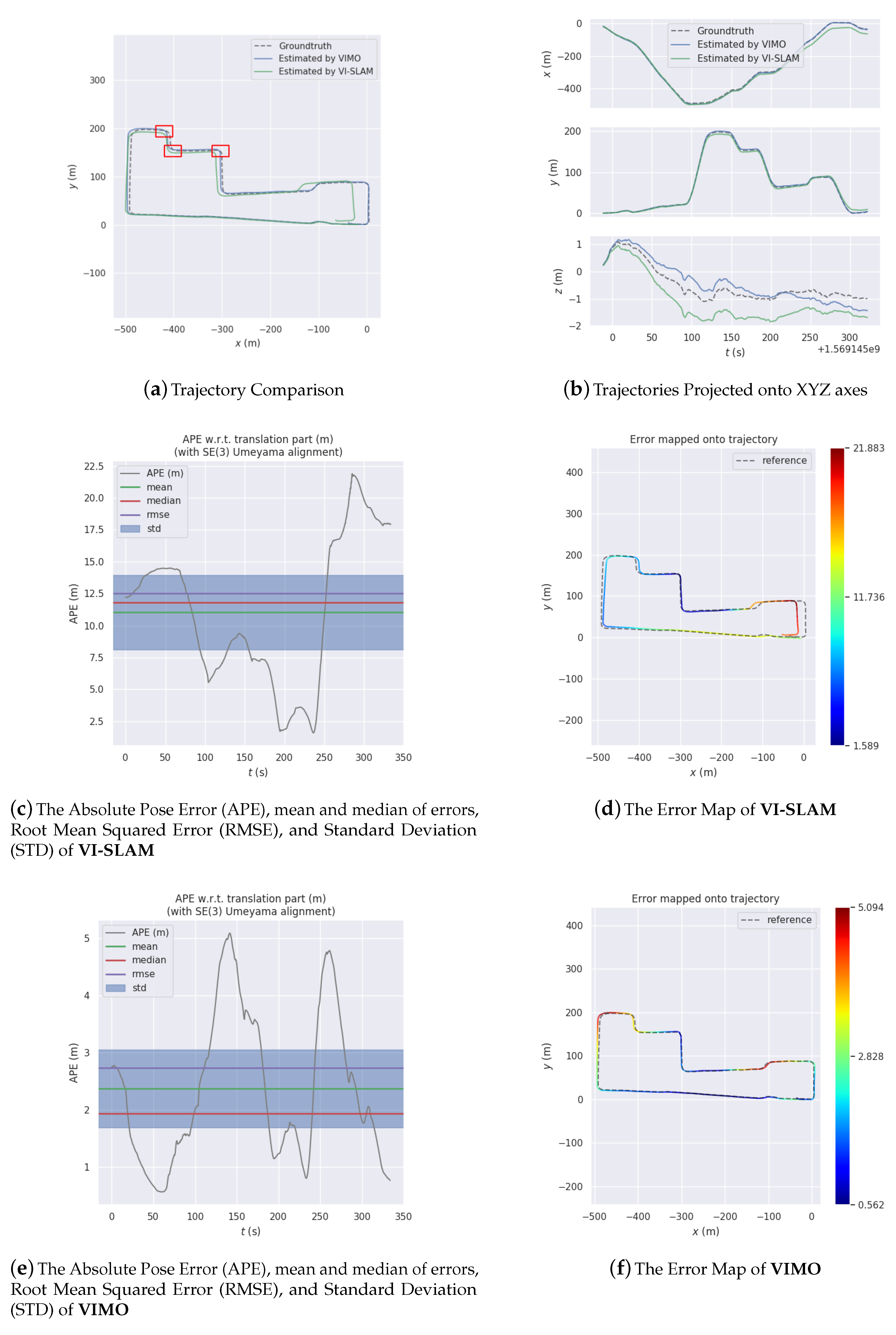
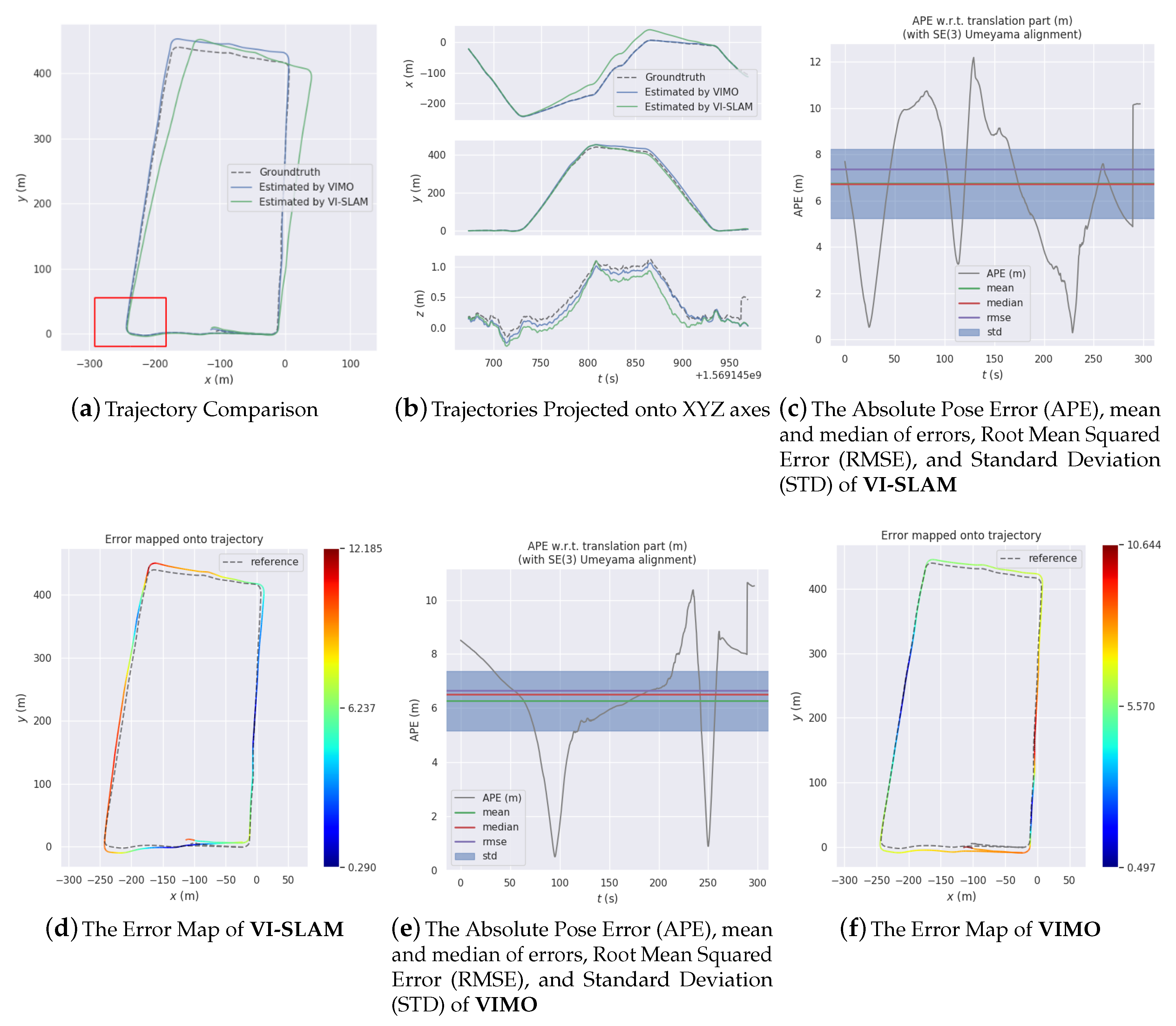
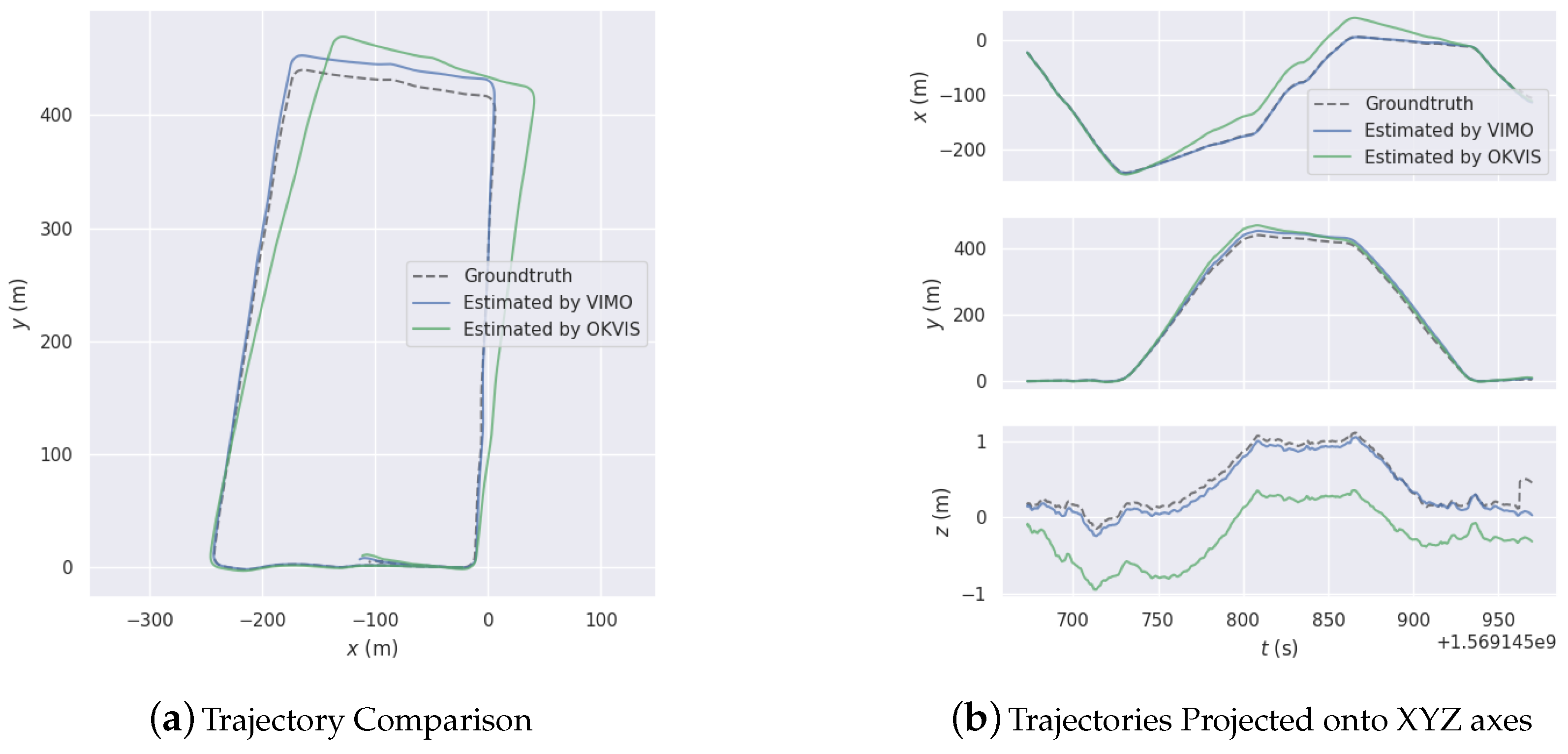
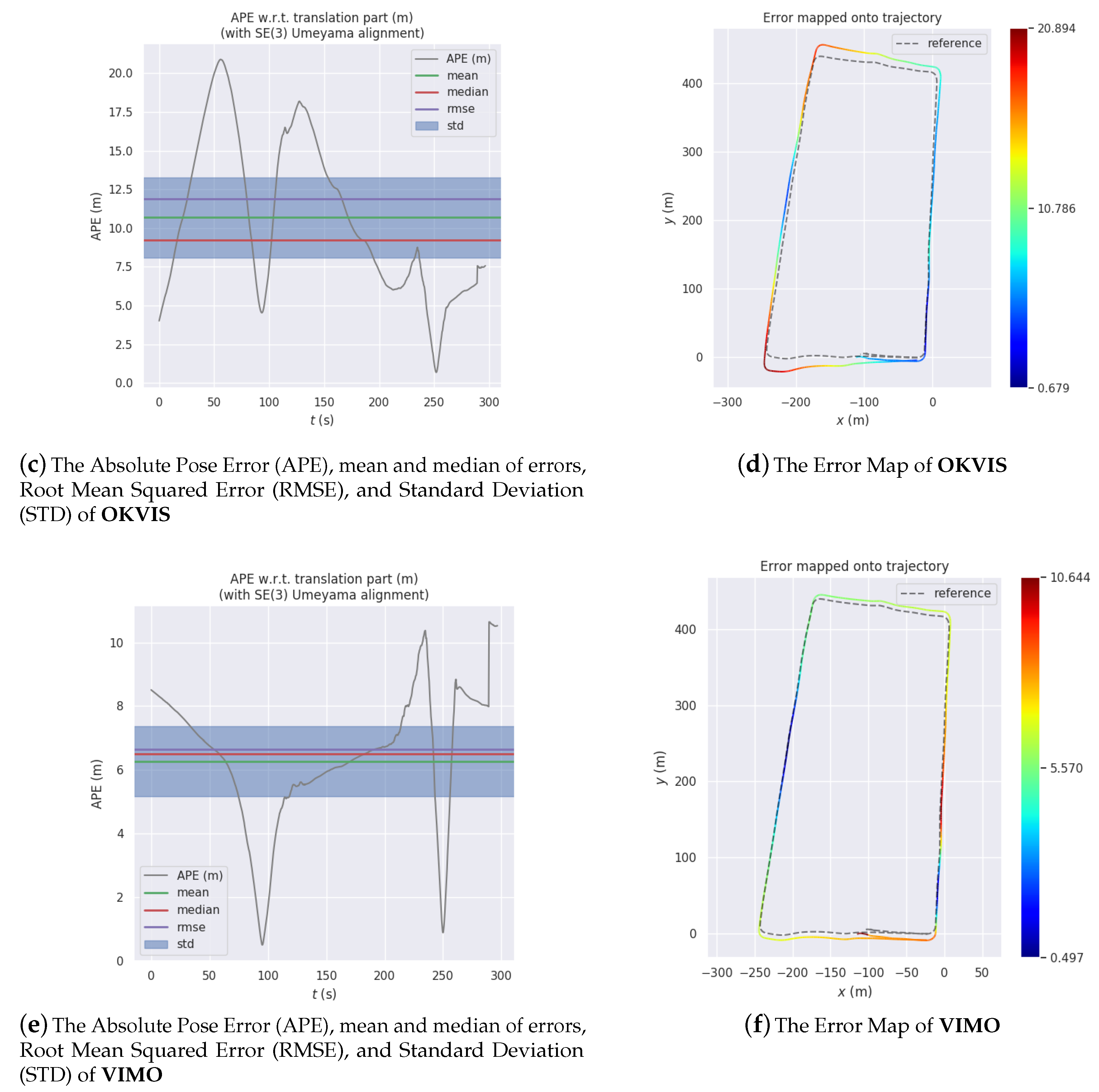
The system has been tried and tested on several datasets collected in large-scale outdoor environments. Analysis and comparison of the experiment results attest to the feasibility, efficacy, and excellence of the proposed system.
2. Related Work
Since [
3] came out, large numbers of well-designed systems [
4,
5,
6,
7,
8] have swollen the ranks of SLAM schemes. Copious studies have been done on visual-inertial SLAM along with various applications that have since been on a continuum to full maturity [
9,
10,
11]. Until today, scholars are still endeavoring to bring it to perfection with novel ideas and approaches [
12,
13,
14,
15,
16]. Incipient methods fuse inertial and visual measurements loosely where the two types of information are processed, filtered, and used for estimation all separately [
17]. In overcoming the notorious inconsistency of loosely-coupled approaches, researchers have come to appreciate that the advantages of fusing tightly, such as improved consistency [
18,
19]. Whether sources of information are amalgamated loosely or tightly, filtering mechanisms hold more likelihood to arrive at a suboptimal solution in the wake of linearizing all previous states. In break with traditional filter-based methods, non-linear optimization employed in SLAM has been deemed more desirable with its high precision and tolerable computational requirements. Reference [
20] copes with holding on to and optimizing an entire trajectory by what the authors call ‘full smoothing’, but the ever increasing complexity in line with the incremental map and trajectory largely limits its applicability. Reference [
21] is generally recognized as one of most early mature systems using non-linear optimization based on sliding window and marginalization for containment of problem size. To make a virtue of escalated computation due to the addition of inertial measurements, reference [
22] proposes what is called the IMU preintegration technique that integrates on manifold a segment of measurements between two time points with the Jacobian matrices maintained for correction. In that way, changes in linearization will not need complete re-integration but a few minor adjustments with respect to the Jacobian matrices as long as they are not too large.
Another property of visual-inertial SLAM that comes to scholar’s attention is its initialization and what its does is to work out several parameters describing the system’s initial states and sensors’ relation. Sfm calls for enough motion to be reliable while estimation of gravity’s direction is better off under stationary condition. This contradiction suggests that visual-inertial initialization can not be trifled with. Reference [
23] proposes a deterministic closed-form method that can recover gravity’s direction and scalar factor, but fails to take cognizance of IMU biases, making the system less stable than it would otherwise be. Reference [
17] estimates not only IMU biases but velocity using an EFK but the convergence takes long. Reference [
24] initializes system on the assumption that MAVs take off flat with as small inclination as possible, which is, of necessity, unlikely to be the case in practice. Reference [
25], much like [
24], relies on alignment with gravity at the beginning to initialize. In [
26,
27], initialization does not calculate gyroscope biases, derogating from the precision.
As it develops, SLAM has begun to go beyond passively observing surroundings to actively exploring environments so as to gain coverage, hence the name ‘active SLAM’ [
28]. So-called active SLAM integrates SLAM itself with path planing. Using this technique, a system covers an area autonomously while performing plain SLAM.
Reference [
29] is aimed at solving active SLAM problems where coverage is required and certain constraints are imposed. With that end in view, reference [
29] proposes a solution to it that focuses on minimization and area coverage within an MPC (Model Predictive Control) framework. It uses a sub-map joining method to improve both effectiveness and efficiency. The D-opt MPC problem is resolved with recourse to a graph topology and convex optimization and the SQP method is employed to address the coverage problem.The main contribution of [
29] is it presents a new method capable of generating a sound collision-free trajectory so as to better perform coverage tasks than many other systems do.
Reference [
30] presents an effective indoor navigation system for the Fetch robot. The main idea is founded on sub-mapping and DeepLCD and the system is implemented using Cartographer and AMCL (adaptive Monte Carlo localization). The main method comprises mapping and on-line localization modules and sequential sub-maps are generated by fusing data from a 2D laser scanner and a RGBD camera. AMCL is used to perform accurate localization according to image matching results. Not only the localization system itself but novel evaluation methods for it are presented in the paper and by using it the robustness and accuracy of the system is demonstrated.
Reference [
31] presents a navigation method whereby a flying robot is able to explore and map an underground mine without collision. Simulations have verified that the system performs as well as the authors expected whether the robot is circling above flat or sloping ground. The authors also claim in the paper that the system is as simple as it is reliable.
6. Visual-Inertial-Magnetic Initialization
The initialization of monocular visual inertial odometry is as crucial as it is intricate, on account of its precarious structure. Futile or incomplete initialization spell trouble for the entire system. On the one hand, monocular vision calls for a certain length of translation long enough to reflect the depths of key points, on the other hand, the projection of gravity onto the body frame can only be calculated when there’s no extra acceleration other than gravity.
This section intends to present and lay out a novel and efficacious procedure of initialization. As drawn out in
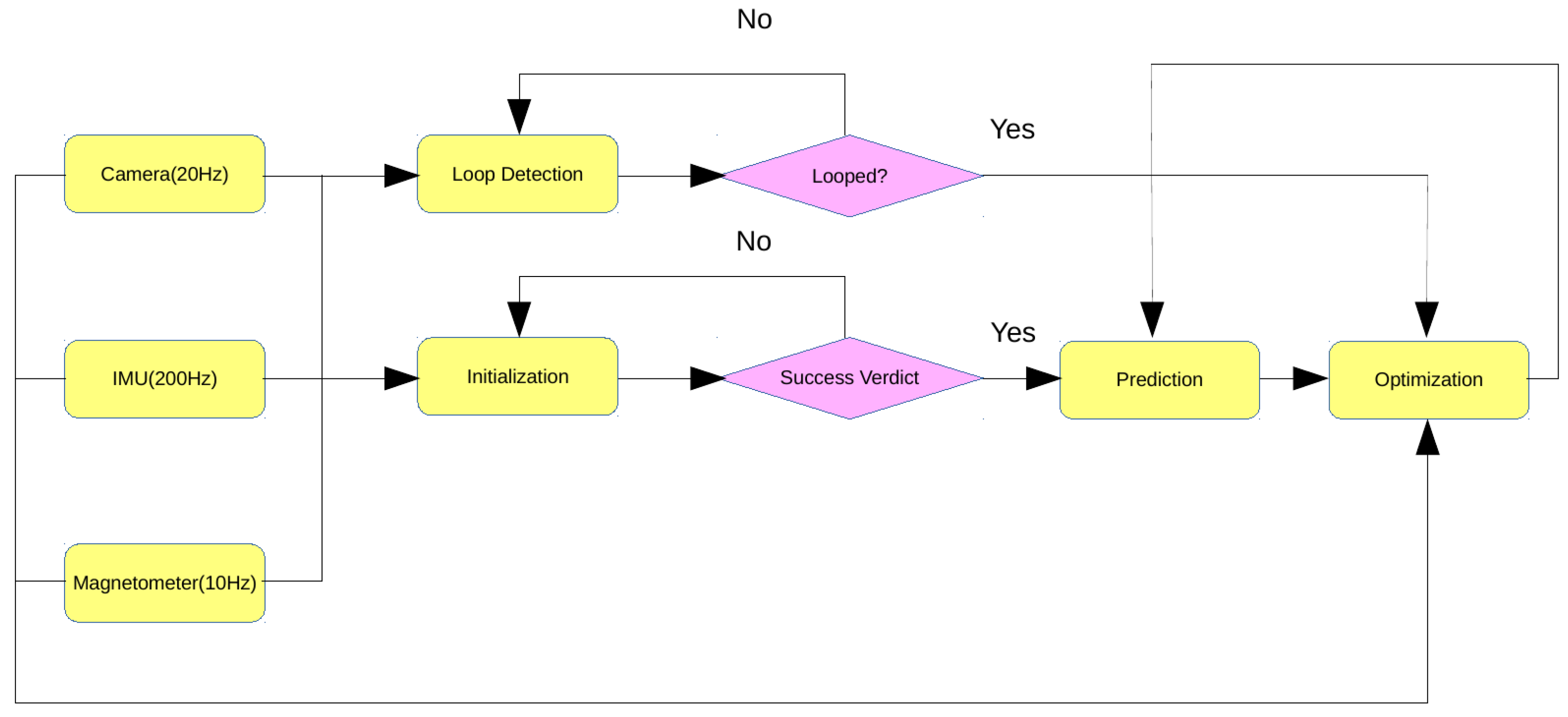
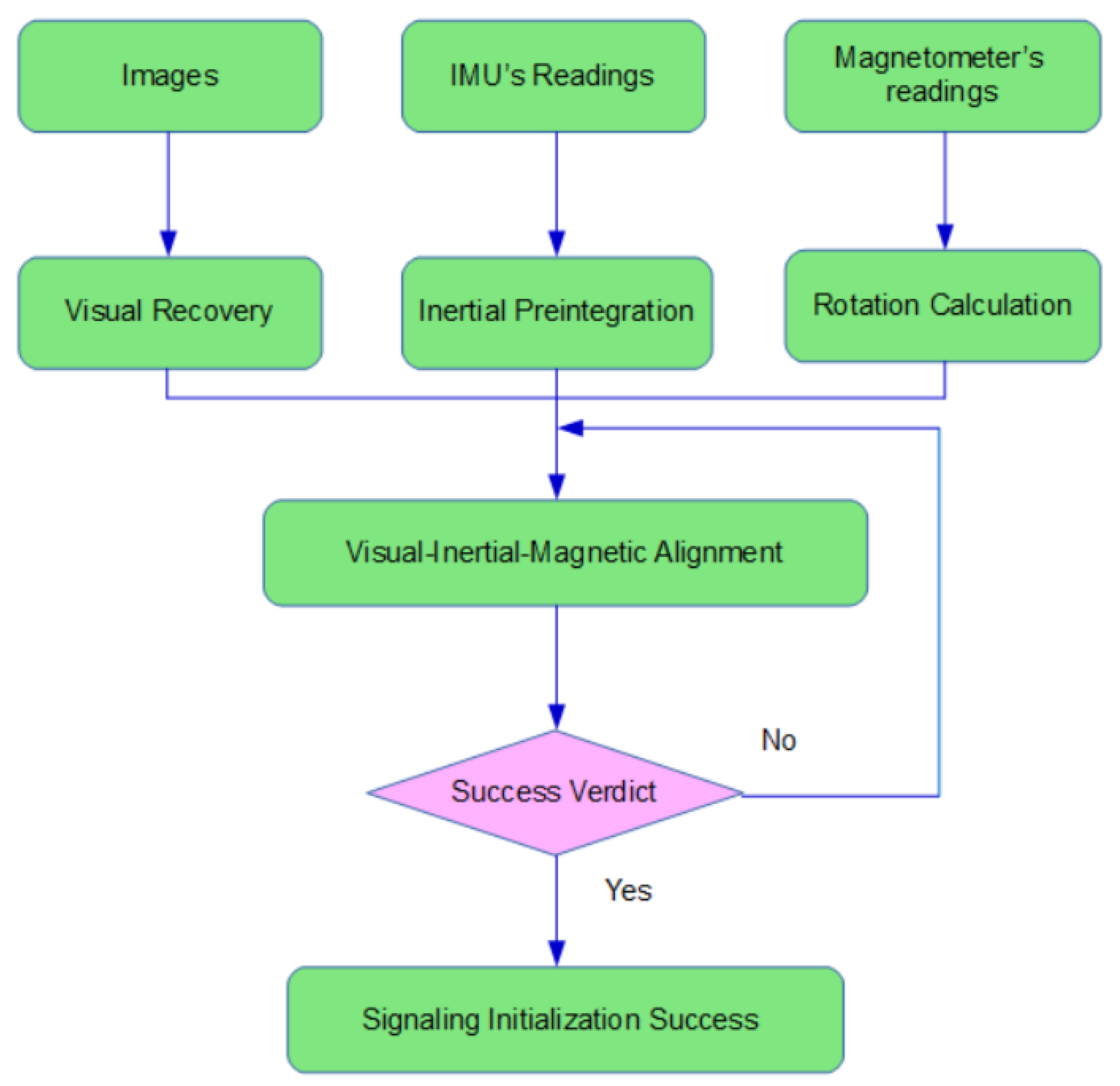
Section 2, successful initialization is a prerequisite for the system to start off properly. How accurate the initial parameters are estimated will play a huge part in how stably and smoothly the system operates. The involvement of magnetometers introduces extra parameters to be determined, namely the initial magnetic bearing. The proposed method delivers visual-inertial-magnetic initialization with efficacy and credibility assured in some measure by deciding whether or not it is initialized successfully through a set of specific criteria.
Figure 3 illustrates the procedure of initialization.
As opposed to VI-SLAM, the system uses magnetic information as rotation constraint during visual recovery with the intention of expediting the initialization process and enhancing its precision.
6.1. Visual Recovery and Rotation Calculation through Magnetism
The task the visual module undertakes is estimating the relative transformation with respect to the first frame by vision itself. Using a monocular camera without depth information indicates the first step is to extract from two selected images the essential or homography matrix which can be decomposed to recover the transformation between the images. The two images for recovering poses are selected if there’s enough parallax between them. The essential matrix is better at computing poses if the camera’s moved, whereas if it is only rotated without translation the homography matrix fare better. The problem is there’s no way of establishing whether or not the camera’s moved because either pure rotation or translation causes parallax between two images. For better robustness, we compute and decompose both of them and check through whose transformation the reprojection is smaller to decide to use which matrix. Key points tracked in the two images are triangulated to determine depths if there’s sufficient translation between them. Those 3D key points are then utilized to execute PnP (Perspective-n-Point) on all the intervening key frames under the auspices of BA (Bundle Adjustment).
Magnetic information is also exploited for rotation estimation by incorporating its measurements into the BA problem as extra cost functions in Equation (
42).
where
denotes magnetometer’s
kth frame and
is the rotation from magnetometer’s frame to body’s frame.
6.2. Visual-Inertial-Magnetic Alignment
Before alignment, gyroscope biases need to be worked out. The reason why only gyroscope biases are computed is because attitude holds much more influence on pose estimation as its estimates dictate whether gravity can be rightly projected onto the body frame. By solving Equation (
43) through least squares, gyroscope biases
can be obtained:
where
is the rotational preintegration and
is its partial derivative with respect to gyroscope biases.
Section 4.2 lays out how to maintain this partial derivative.
where
,
,
, and
are the scalar factor, velocity, and the vector of gravity to be determined. Obviously,
and
come from the visual recovery module. Every combination of adjacent images and the preintegration in-between forms a set of equations like (
44), stacking up into a least squares problem.
The process described above is merely visual-inertial alignment after which the z-axis of the world frame is aligned with the vector of gravity, velocity states projected onto the world frame, and key points’ depths scaled to proper size. The next step is to align the magnetometer with the world frame by making its projection on the plane of the world frame parallel with the x-axis.
After the complete alignment, the world frame’s z-axis is parallel with the direction of gravity and x-axis with magnetic north.
6.3. Initialization Completion Verdict
It is not beyond the bounds of possibility that parameters initialized could be dubious. A common case explaining this phenomenon is when the system keeps moving in one direction at a constant speed, not administering sufficient excitation to IMU.
Inspired by [
32,
33], we examines initialization’s efficacy by reviewing estimation error that links in to a degree with the uncertainty of the initialization system.
With the estimation error satisfactorily low, the system will be notified and go to the optimization stage.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}