Autonomous Scene Exploration for Robotics: A Conditional Random View-Sampling and Evaluation Using a Voxel-Sorting Mechanism for Efficient Ray Casting


Abstract
1. Introduction
- To make use of an efficient and updatable scene representation, i.e., OctoMap;
- To design a generator of plausible and feasible possible viewpoints, which increases the quality of the viewpoints that are tested, thus improving the quality of the exploration;
- To proposed a viewpoint evaluation methodology which sorts the voxels for which rays are cast, which enables the algorithm to skip a great number of tests and run very efficiently, thus allowing for more viewpoints to be tested for the same available time;
- To provide extensive results in which the automatic exploration system is categorized in terms of the efficiency of exploration, and compared against human explorers.
2. State of the Art
2.1. Spatial Data Representation
2.2. Intelligent Spatial Data Acquisition
2.3. 3D Object Reconstruction and Scene Exploration
2.4. Contributions beyond the State of the Art
3. Proposed Approach
3.1. Defining the Exploration Volume
3.2. Finding Unknown Space
3.3. View-Sampling
3.4. Generated Poses Evaluation
3.5. Voxel-Based Ray-Casting
| Algorithm 1: Voxel-Based Ray-Casting. |
 |
3.6. Pose Scoring
4. Results
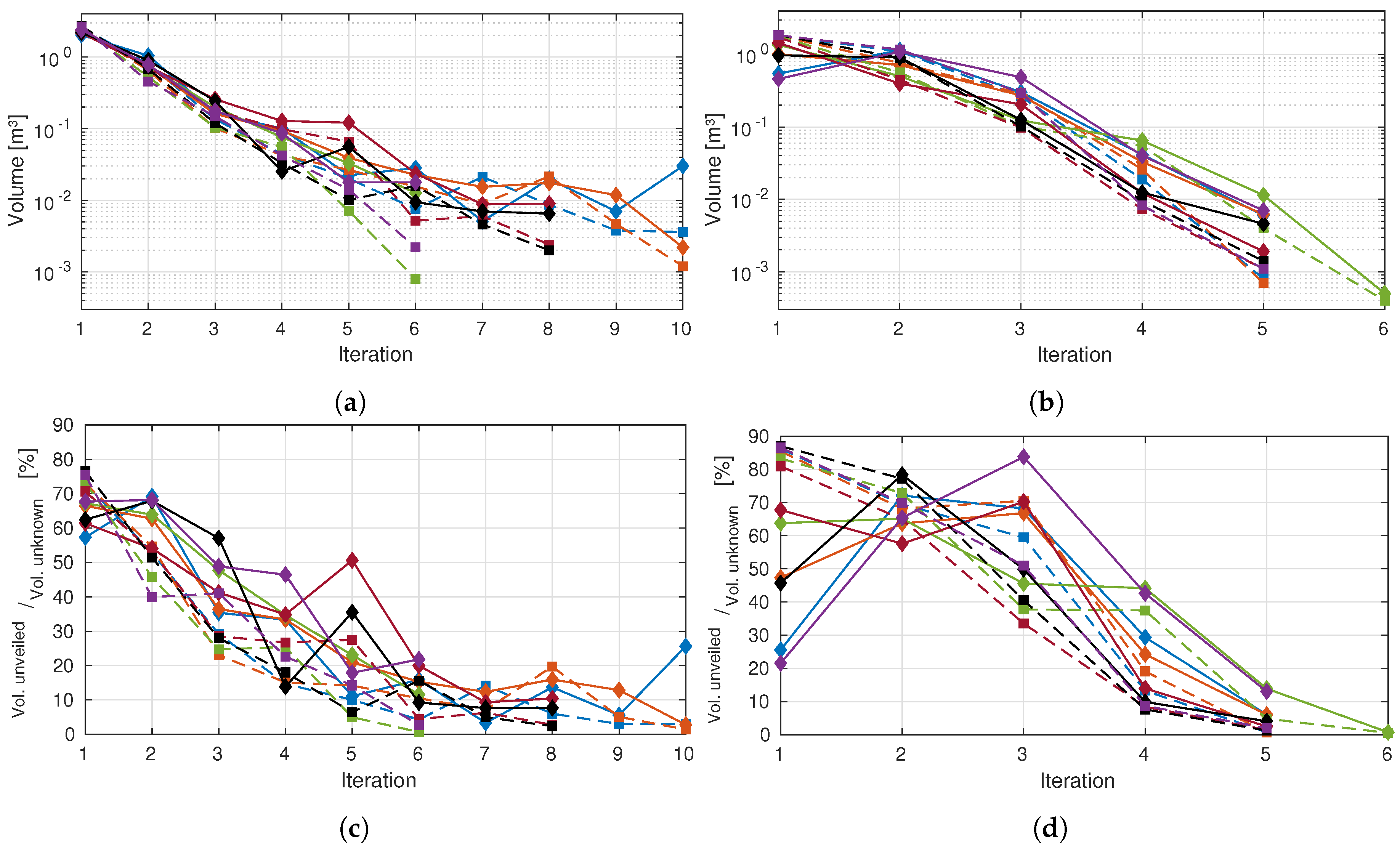
4.1. Test Scenario 1: Shelf and Cabinet
4.2. Test Scenario 2: Occluded Chair
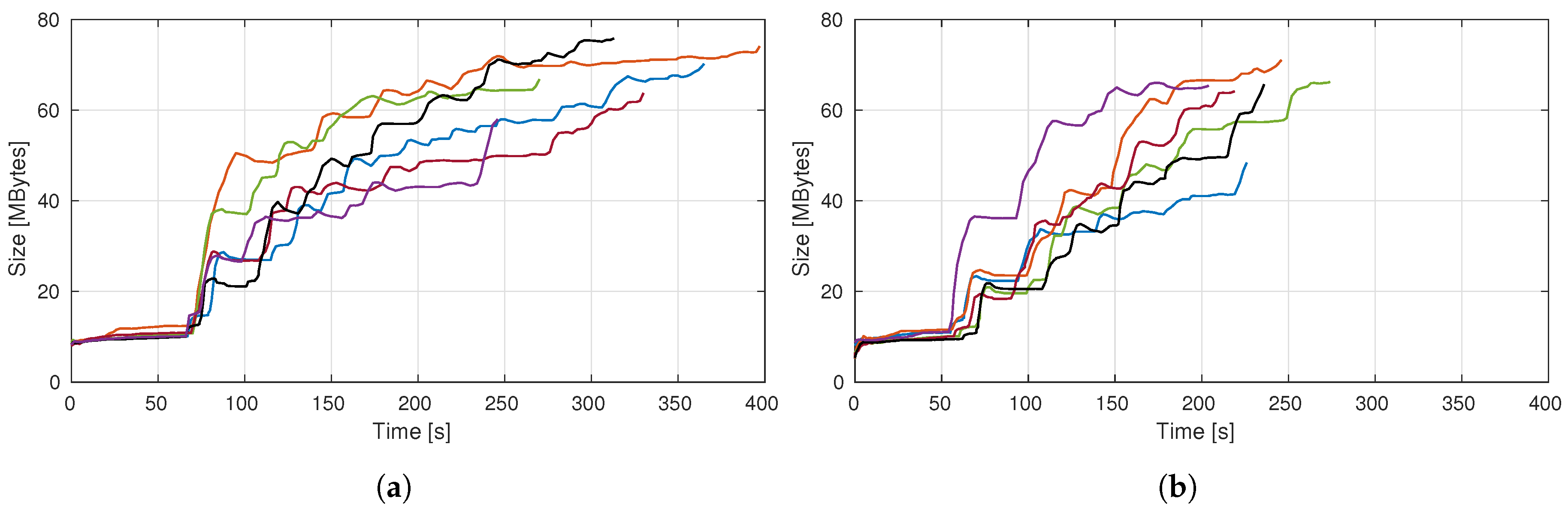
4.3. Experimental Analysis of the Autonomous Exploration Performance
4.4. Test Scenario 3: Industrial Application
4.5. Comparison between Automatic and Interactive Explorations
- SmObEx—Smart Object Exploration (https://github.com/lardemua/SmObEx)
- FANUC M6iB/6S Support and MoveIt Config (https://github.com/ros-industrial/fanuc/pull/264)
- OctoMap Tools (https://github.com/miguelriemoliveira/octomap_tools)
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| CPPS | Cyber-Physical Production Systems |
| DoF | Degrees of Freedom |
| FOV | Field of View |
| IoT | Internet of Things |
| LAR-UA | Laboratório de Automação e Robótica—University of Aveiro |
| NBV | Next Best View |
| OSPS | Open Scalable Production System |
| ROS | Robot Operating System |
References
- Kagermann, H.; Lukas, W.D.; Wahlster, W. Industrie 4.0: Mit dem Internet der Dinge auf dem Weg zur 4. industriellen Revolution. VDI Nachrichten 2011, 13, 3–4. [Google Scholar]
- Jazdi, N. Cyber physical systems in the context of Industry 4.0. In Proceedings of the AQTR 2014: 2014 IEEE International Conference on Automation, Quality and Testing, Robotics, Cluj-Napoca, Romania, 22–24 May 2014; pp. 1–4. [Google Scholar]
- Arrais, R.; Oliveira, M.; Toscano, C.; Veiga, G. A mobile robot based sensing approach for assessing spatial inconsistencies of a logistic system. J. Manuf. Syst. 2017, 43, 129–138. [Google Scholar] [CrossRef]
- Wu, C.; Schulz, E.; Speekenbrink, M.; Nelson, J.; Meder, B. Generalization guides human exploration in vast decision spaces. Nat. Hum. Behav. 2018, 2. [Google Scholar] [CrossRef]
- Rauscher, G.; Dube, D.; Zell, A. A Comparison of 3D Sensors for Wheeled Mobile Robots. Intel. Auto. Syst. 2016, 302, 29–41. [Google Scholar] [CrossRef]
- Jiang, G.; Yin, L.; Jin, S.; Tian, C.; Ma, X.; Ou, Y. A Simultaneous Localization and Mapping (SLAM) Framework for 2.5D Map Building Based on Low-Cost LiDAR and Vision Fusion. Appl. Sci. 2019, 9, 2105. [Google Scholar] [CrossRef]
- Gu, J.; Cao, Q.; Huang, Y. Rapid Traversability Assessment in 2.5D Grid-based Map on Rough Terrain. Int. J. Adv. Robot. Syst. 2008, 5, 40. [Google Scholar] [CrossRef]
- Douillard, B.; Underwood, J.; Melkumyan, N.; Singh, S.; Vasudevan, S.; Brunner, C.; Quadros, A. Hybrid elevation maps: 3D surface models for segmentation. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 1532–1538. [Google Scholar]
- Pfaff, P.; Burgard, W. An Efficient Extension of Elevation Maps for Outdoor Terrain Mapping. In Field and Service Robotics; Springer: Berlin/Heidelberg, Germany, 2006; Volume 25, pp. 195–206. [Google Scholar]
- Kong, S.; Shi, F.; Wang, C.; Xu, C. Point Cloud Generation From Multiple Angles of Voxel Grids. IEEE Access 2019, 7, 160436–160448. [Google Scholar] [CrossRef]
- Sauze, C.; Neal, M. A Raycast Approach to Collision Avoidance in Sailing Robots. Available online: https://pure.aber.ac.uk/portal/en/publications/a-raycast-approach-to-collision-avoidance-in-sailing-robots(eda63719-ed5c-4aa1-b128-0f92f9930247).html (accessed on 1 August 2020).
- Maegher, D. Octree Encoding: A New Technique for the Representation, Manipulation and Display of Arbitrary 3-D Objects by Computer. Available online: https://searchworks.stanford.edu/view/4621957 (accessed on 1 August 2020).
- Han, S. Towards Efficient Implementation of an Octree for a Large 3D Point Cloud. Sensors 2018, 18, 4398. [Google Scholar] [CrossRef]
- Elseberg, J.; Borrmann, D.; Nüchter, A. One billion points in the cloud – an octree for efficient processing of 3D laser scans. ISPRS J. Photogramm. Remote Sens. 2013, 76, 76–88. [Google Scholar] [CrossRef]
- Elseberg, J.; Borrmann, D.; Nuchter, A. Efficient processing of large 3D point clouds. In Proceedings of the 2011 XXIII International Symposium on Information, Communication and Automation Technologies, Sarajevo, Bosnia and Herzegovina, 27–29 October 2011; pp. 1–7. [Google Scholar]
- Canelhas, D.R.; Stoyanov, T.; Lilienthal, A.J. A Survey of Voxel Interpolation Methods and an Evaluation of Their Impact on Volumetric Map-Based Visual Odometry. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3637–3643. [Google Scholar]
- Hornung, A.; Wurm, K.M.; Bennewitz, M.; Stachniss, C.; Burgard, W. OctoMap: An efficient probabilistic 3D mapping framework based on octrees. Auton. Robots 2013, 34, 189–206. [Google Scholar] [CrossRef]
- Kriegel, S. Autonomous 3D Modeling of Unknown Objects for Active Scene Exploration. Ph.D. Thesis, Technische Universität München (TUM), München, Germany, 2015. [Google Scholar]
- Konolige, K. Improved Occupancy Grids for Map Building. Auton. Robots 1997, 4, 351–367. [Google Scholar] [CrossRef]
- Faria, M.; Ferreira, A.S.; Pérez-Leon, H.; Maza, I.; Viguria, A. Autonomous 3D Exploration of Large Structures Using an UAV Equipped with a 2D LIDAR. Sensors 2019, 19, 4849. [Google Scholar] [CrossRef] [PubMed]
- Brito Junior, A.; Goncalves, L.; Tho, G.; De O Cavalcanti, A. A simple sketch for 3D scanning based on a rotating platform and a Web camera. In Proceedings of the XV Brazilian Symposium on Computer Graphics and Image Processing, Fortaleza, Brazil, 7–10 October 2002; p. 406. [Google Scholar]
- Gedicke, T.; Günther, M.; Hertzberg, J. FLAP for CAOS: Forward-Looking Active Perception for Clutter-Aware Object Search. Available online: https://www.sciencedirect.com/science/article/pii/S2405896316309946 (accessed on 1 August 2020).
- Sarmiento, A.; Murrieta, R.; Hutchinson, S. An efficient strategy for rapidly finding an object in a polygonal world. In Proceedings of the 2003 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2003), Las Vegas, NV, USA, 27–31 October 2003; Volume 2, pp. 1153–1158. [Google Scholar]
- Blodow, N.; Goron, L.C.; Marton, Z.C.; Pangercic, D.; Ruhr, T.; Tenorth, M.; Beetz, M. Autonomous semantic mapping for robots performing everyday manipulation tasks in kitchen environments. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, 5 December 2011; pp. 4263–4270. [Google Scholar]
- Dornhege, C.; Kleiner, A. A frontier-void-based approach for autonomous exploration in 3d. In Proceedings of the 2011 IEEE International Symposium on Safety, Security, and Rescue Robotics, Kyoto, Japan, 1–5 November 2011; pp. 351–356. [Google Scholar]
- Isler, S.; Sabzevari, R.; Delmerico, J.; Scaramuzza, D. An information gain formulation for active volumetric 3D reconstruction. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 3477–3484. [Google Scholar]
- Yervilla-Herrera, H.; Vasquez-Gomez, J.I.; Murrieta-Cid, R.; Becerra, I.; Sucar, L.E. Optimal motion planning and stopping test for 3-D object reconstruction. Intel. Serv. Robot. 2018, 12, 103–123. [Google Scholar] [CrossRef]
- Kriegel, S.; Brucker, M.; Marton, Z.C.; Bodenmuller, T.; Suppa, M. Combining object modeling and recognition for active scene exploration. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 2384–2391. [Google Scholar]
- Wang, C.; Wang, J.; Li, C.; Ho, D.; Cheng, J.; Yan, T.; Meng, L.; Meng, M.Q.H. Safe and Robust Mobile Robot Navigation in Uneven Indoor Environments. Sensors 2019, 19, 2993. [Google Scholar] [CrossRef] [PubMed]
- Hepp, B.; Dey, D.; Sinha, S.N.; Kapoor, A.; Joshi, N.; Hilliges, O. Learn-to-Score: Efficient 3D Scene Exploration by Predicting View Utility. In Computer Vision–ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11219, pp. 455–472. [Google Scholar]
- Bajcsy, R.; Aloimonos, Y.; Tsotsos, J. Revisiting Active Perception. Auton. Robots 2016, 42, 177–196. [Google Scholar] [CrossRef] [PubMed]
- Kulich, M.; Kubalík, J.; Přeučil, L. An Integrated Approach to Goal Selection in Mobile Robot Exploration. Sensors 2019, 19, 1400. [Google Scholar] [CrossRef]
- Coleman, D.; Sucan, I.; Chitta, S.; Correll, N. Reducing the Barrier to Entry of Complex Robotic Software: A MoveIt! Case Study. Available online: https://arxiv.org/abs/1404.3785 (accessed on 1 August 2020).
- Reis, R.; Diniz, F.; Mizioka, L.; Yamasaki, R.; Lemos, G.; Quintiães, M.; Menezes, R.; Caldas, N.; Vita, R.; Schultz, R.; et al. FASTEN: EU-Brazil cooperation in IoT for manufacturing. The Embraer use. MATEC Web Conf. EDP Sci. 2019, 304, 04007. [Google Scholar] [CrossRef]
- Kuffner, J.; LaValle, S. RRT-connect: An efficient approach to single-query path planning. In Proceedings of the 2000 ICRA. Millennium Conference, IEEE International Conference on Robotics and Automation, Symposia Proceedings, San Francisco, CA, USA, 24–28 April 2000; Volume 2, pp. 995–1001. [Google Scholar]
- Arrais, R.; Veiga, G.; Ribeiro, T.T.; Oliveira, D.; Fernandes, R.; Conceição, A.G.S.; Farias, P. Application of the Open Scalable Production System to Machine Tending of Additive Manufacturing Operations by a Mobile Manipulator. In Proceedings of the EPIA Conference on Artificial Intelligence, Vila Real, Portugal, 3–6 September 2019; pp. 345–356. [Google Scholar]
- Toscano, C.; Arrais, R.; Veiga, G. Enhancement of industrial logistic systems with semantic 3D representations for mobile manipulators. In Proceedings of the Iberian Robotics Conference, Seville, Spain, 22–24 November 2017; pp. 617–628. [Google Scholar]
- Moreno, F.A.; Monroy, J.; Ruiz-Sarmiento, J.R.; Galindo, C.; Gonzalez-Jimenez, J. Automatic Waypoint Generation to Improve Robot Navigation Through Narrow Spaces. Sensors 2020, 20, 240. [Google Scholar] [CrossRef]
- Cepeda, J.S.; Chaimowicz, L.; Soto, R.; Gordillo, J.L.; Alanís-Reyes, E.A.; Carrillo-Arce, L.C. A Behavior-Based Strategy for Single and Multi-Robot Autonomous Exploration. Sensors 2012, 12, 12772–12797. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, H.; Huang, C. A Novel RGB-D SLAM Algorithm Based on Cloud Robotics. Sensors 2019, 19, 5288. [Google Scholar] [CrossRef]
- Jeong, J.; Yoon, T.S.; Park, J.B. Towards a Meaningful 3D Map Using a 3D Lidar and a Camera. Sensors 2018, 18, 2571. [Google Scholar] [CrossRef] [PubMed]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Exploration Volume [m³] | Number of Iterations | Total Distance [m] | ||
|---|---|---|---|---|---|
| Mean | Standard Deviation | Mean | Standard Deviation | ||
| Shelf and Cabinet | 3.531 | 8.00 | 1.789 | 8.525 | 1.084 |
| Occluded Chair | 2.140 | 5.17 | 0.408 | 6.365 | 1.089 |
| Subject | Point Cloud View | Volumetric View | ||
|---|---|---|---|---|
| Iterations | % Volume Unknown | Iterations | % Volume Unknown | |
| 1 | 5 | 7.6 | 4 | 2.5 |
| 2 | 6 | 9.8 | 7 | 5.0 |
| 3 | 6 | 8.9 | 5 | 6.7 |
| 4 | 4 | 7.8 | 6 | 7.0 |
| 5 | 7 | 8.0 | 3 | 4.5 |
| 6 | 8 | 13.6 | 5 | 7.9 |
| 7 | 8 | 50.6 | 8 | 15.5 |
| Robot | Human | |||
|---|---|---|---|---|
| Mean | Standard Deviation | Mean | Standard Deviation | |
| Distance [m/iteration] | 1.240 | 0.136 | 0.840 | 0.317 |
| Rotation [°/iteration] | 127.633 | 22.633 | 91.910 | 28.906 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santos, J.; Oliveira, M.; Arrais, R.; Veiga, G. Autonomous Scene Exploration for Robotics: A Conditional Random View-Sampling and Evaluation Using a Voxel-Sorting Mechanism for Efficient Ray Casting. Sensors 2020, 20, 4331. https://doi.org/10.3390/s20154331
Santos J, Oliveira M, Arrais R, Veiga G. Autonomous Scene Exploration for Robotics: A Conditional Random View-Sampling and Evaluation Using a Voxel-Sorting Mechanism for Efficient Ray Casting. Sensors. 2020; 20(15):4331. https://doi.org/10.3390/s20154331
Chicago/Turabian StyleSantos, João, Miguel Oliveira, Rafael Arrais, and Germano Veiga. 2020. "Autonomous Scene Exploration for Robotics: A Conditional Random View-Sampling and Evaluation Using a Voxel-Sorting Mechanism for Efficient Ray Casting" Sensors 20, no. 15: 4331. https://doi.org/10.3390/s20154331
APA StyleSantos, J., Oliveira, M., Arrais, R., & Veiga, G. (2020). Autonomous Scene Exploration for Robotics: A Conditional Random View-Sampling and Evaluation Using a Voxel-Sorting Mechanism for Efficient Ray Casting. Sensors, 20(15), 4331. https://doi.org/10.3390/s20154331