Milk Source Identification and Milk Quality Estimation Using an Electronic Nose and Machine Learning Techniques





Abstract
1. Introduction
2. Materials and Methods
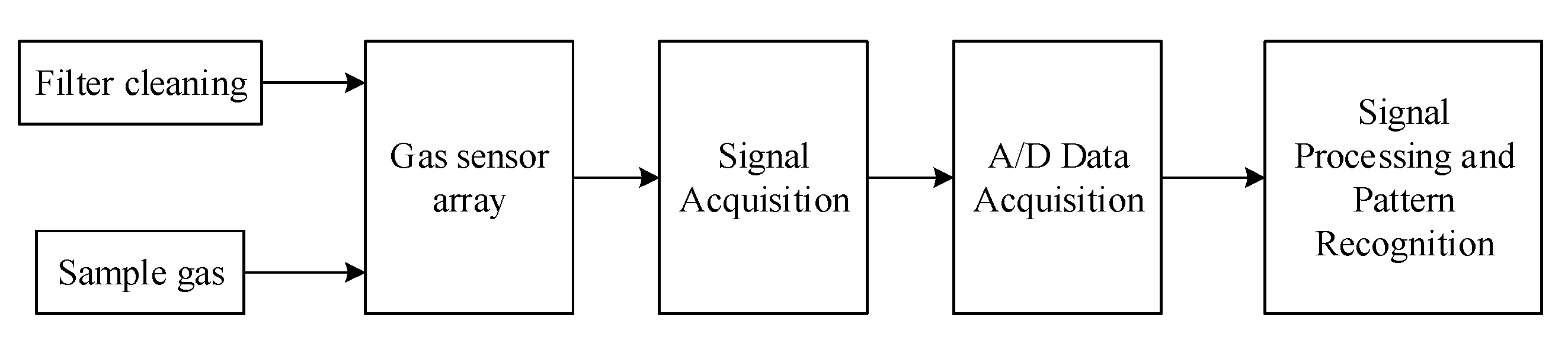
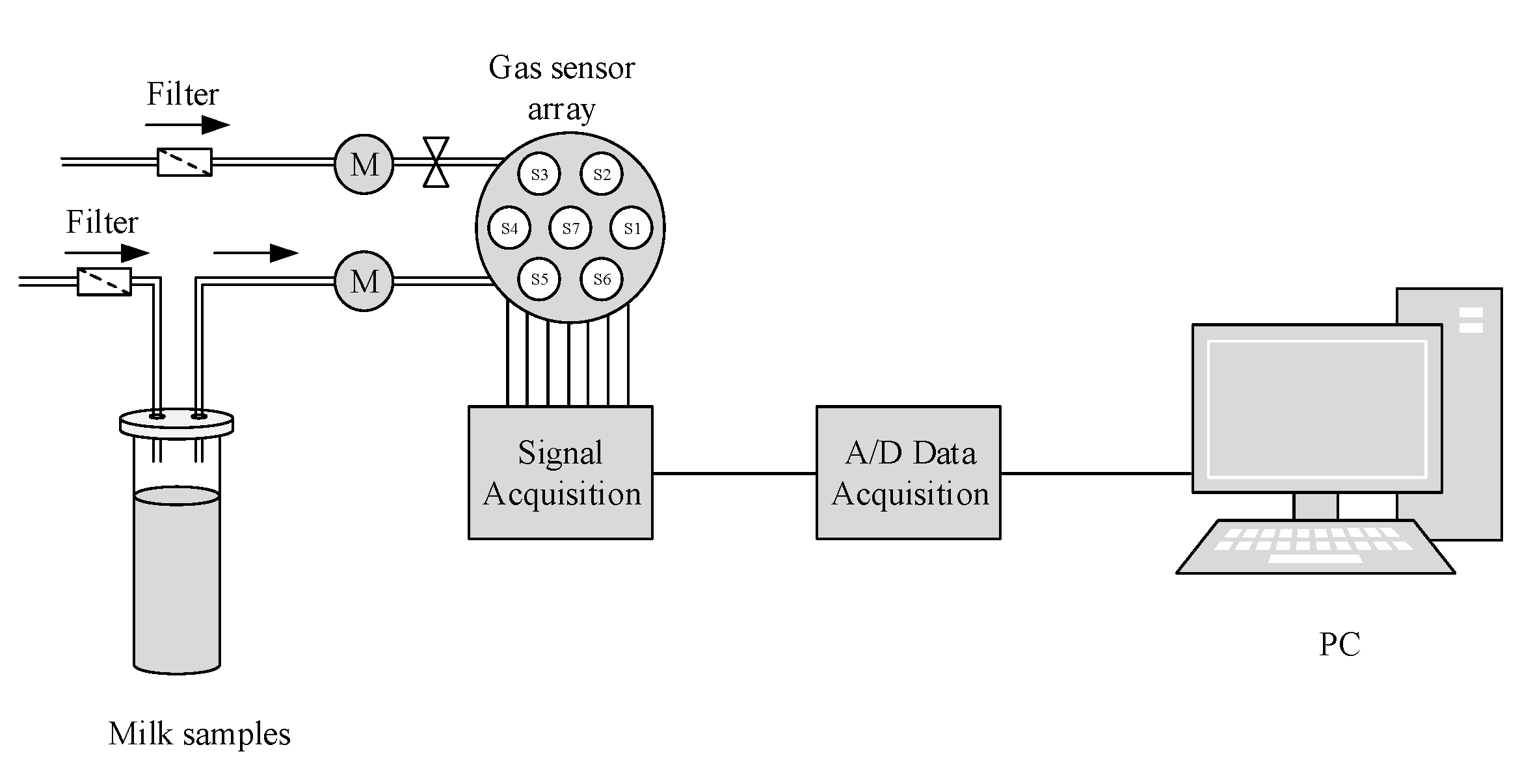
2.1. The Developed E-Nose
2.2. Milk Samples
2.2.1. DHI Analytical Data
2.2.2. E-Nose Measurements
2.3. Data Analysis
2.3.1. SVM
2.3.2. RF
2.3.3. LR
2.3.4. GBDT
2.3.5. XGBoost
3. Results and Discussion
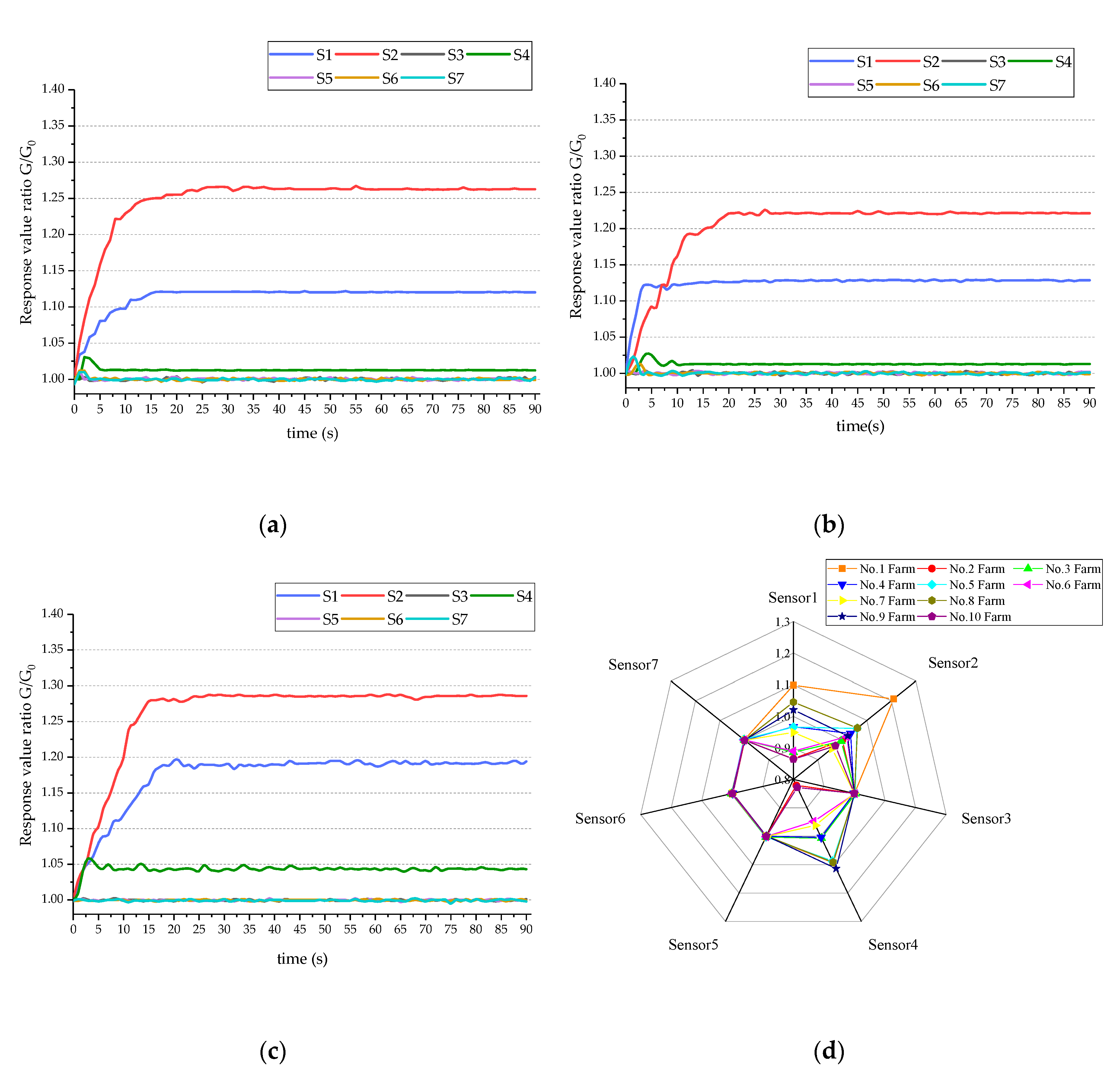
3.1. Response Curve and Radar Chart Analysis of E-Nose
3.2. Milk Source (Dairy Farm) Identification
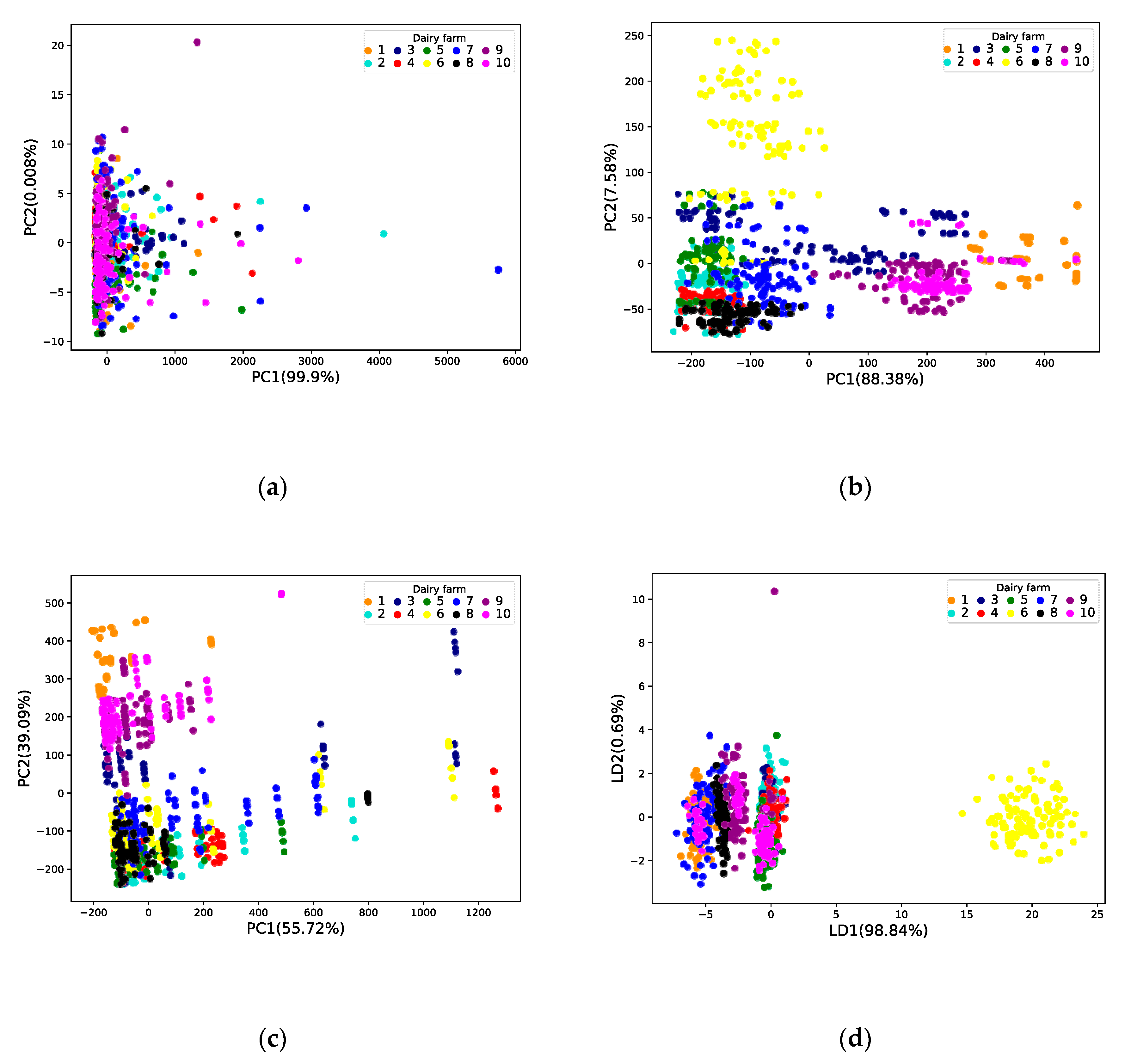
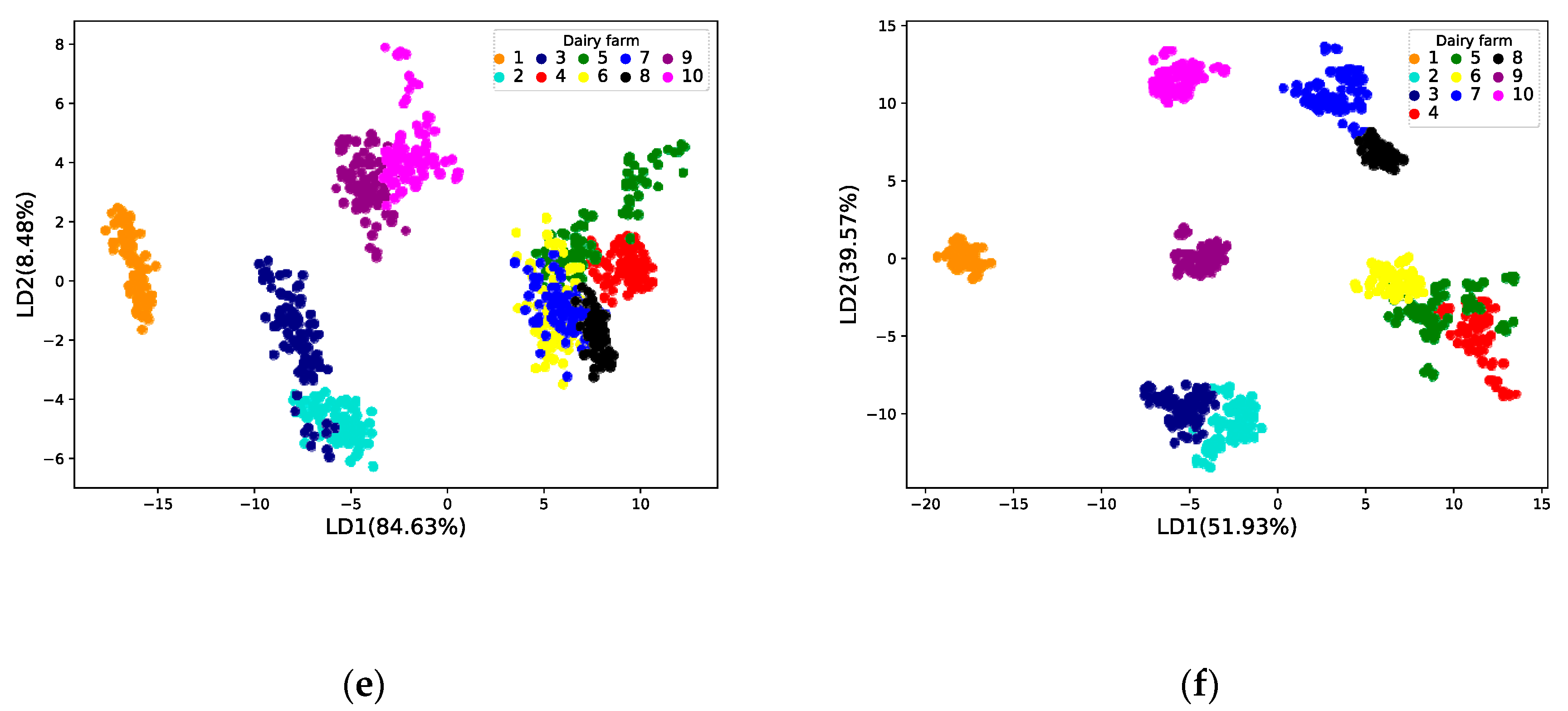
3.2.1. Results of Data Dimensionality Reduction
3.2.2. Model Validation and Analysis
3.3. Estimation Models of Milk Fat Content and Protein Content by E-Nose
3.3.1. Model Performance Indicators
- (1)
- Mean Absolute Error (MAE) calculated as:
- (2)
- Mean Squared Error (MSE) calculated as:
- (3)
- Coefficient of Determination, R2 calculated as:
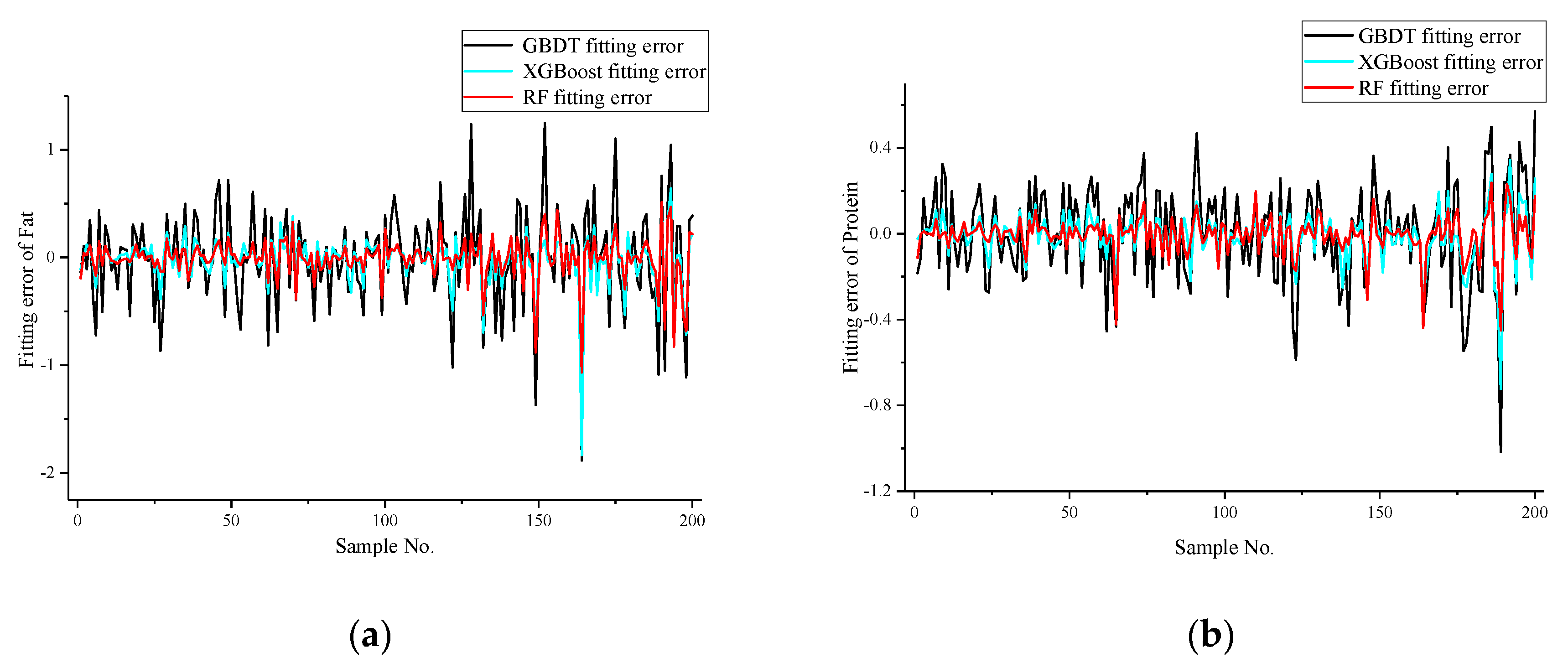
3.3.2. Comparison of Different Models
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, J.; Yang, M.; Cai, D.; Hao, Y.; Zhao, X.; Zhu, Y.; Zhu, H.; Yang, Z. Composition, coagulation characteristics, and cheese making capacity of yak milk. J. Food Sci. 2020, 103, 1276–1288. [Google Scholar] [CrossRef] [PubMed]
- Bilandzic, N.; Dokic, M.; Sedak, M.; Solomun, B.; Varenina, I.; Knezevic, Z.; Benic, M. Trace element levels in raw milk from northern and southern regions of Croatia. Food Chem. 2011, 127, 63–66. [Google Scholar] [CrossRef]
- Tamsma, A.; Kurtz, F.E.; Bright, R.S.; Pallansch, M.J. Contribution of milk fat to the flavor of milk. J. Dairy Sci. 1969, 52, 1910–1913. [Google Scholar] [CrossRef]
- Kinsella, J.E.; Patton, S.; Dimick, P.S. The flavor potential of milk fat. A review of its chemical nature and biochemical origin. J. Am. Oil Chem. Soc. 1967, 44, 449–454. [Google Scholar] [CrossRef]
- Forss, D.A. Mechanisms of formation of aroma compounds in milk and milk products. J. Dairy Res. 1979, 46, 691–706. [Google Scholar] [CrossRef]
- Mcgorrin, R.J. Flavor analysis of dairy products. ACS Symp. Ser. 2007, 971, 23–49. [Google Scholar] [CrossRef]
- Keenan, T.W.; Lindsay, R.C. Evidence for a dimethyl sulfide precursor in milk. J. Dairy Sci. 1968, 51, 112–114. [Google Scholar] [CrossRef]
- Faulkner, H.; O’Callaghan, T.F.; McAuliffe, S.; Hennessy, D.; Stanton, C.; O’Sullivan, M.G.; Kerry, J.P.; Kilcawley, K.N. Effect of different forage types on the volatile and sensory properties of bovine milk. J. Dairy Sci. 2018, 101, 1034–1047. [Google Scholar] [CrossRef]
- Kuhn, J.; Considine, T.; Singh, H. Interactions of milk proteins and volatile flavor compounds: Implications in the development of protein foods. J. Food Sci. 2006, 71, 72–82. [Google Scholar] [CrossRef]
- Garbaras, A.; Skipityte, R.; Meliaschenia, A.; Senchenko, T.; Smoliak, T.; Ivanko, M.; Sapolaite, J.; Ezerinskis, Z.; Remeikis, V. Region dependent C-13, N-15, O-18 isotope ratios in the cow milk. Lith. J. Phys. 2018, 58, 277–282. [Google Scholar] [CrossRef]
- Valenti, B.; Biondi, L.; Campidonico, L.; Bontempo, L.; Luciano, G.; Di, P.F.; Copani, V.; Ziller, L.; Camin, F. Changes in stable isotope ratios in PDO cheese related to the area of production and green forage availability. The case study of Pecorino Siciliano. Rapid Commun. Mass Spectrom. 2017, 31, 737–744. [Google Scholar] [CrossRef] [PubMed]
- Tenori, L.; Santucci, C.; Meoni, G.; Morrocchi, V.; Matteucci, G.; Luchinat, C. NMR metabolomic fingerprinting distinguishes milk from different farms. Food Res. Int. 2018, 113, 131–139. [Google Scholar] [CrossRef] [PubMed]
- de la Roza-Delgado, B.; Garrido-Varo, A.; Soldado, A.; Arrojo, A.G.; Valdes, M.C.; Maroto, F.; Perez-Marin, D. Matching portable NIRS instruments for in situ monitoring indicators of milk composition. Food Control 2017, 76, 74–81. [Google Scholar] [CrossRef]
- Yusof, N.H.; Sani, N.A.; Hannan, F.; Jamil, M.S.; Zubairi, S.I. Rapid microbial detection model system in UHT milk products using poly (L-Lactic Acid) (PLLA) thin film. Sains Malays. 2018, 47, 2677–2683. [Google Scholar] [CrossRef]
- Hernandez-Falcon, T.A.; Monter-Arciniega, A.; Cruz-Cansino, N.D.; Alanis-Garcia, E.; Rodriguez-Serrano, G.M.; Castaneda-Ovando, A.; Garcia-Garibay, M.; Ramirez-Moreno, E.; Jaimez-Ordaz, J. Effect of thermoultrasound on aflatoxin M-1 levels, physicochemical and microbiological properties of milk during storage. Ultrason. Sonochem. 2018, 48, 396–403. [Google Scholar] [CrossRef]
- Cabrera, V.E.; Barrientos-Blanco, J.A.; Delgado, H.; Fadul-Pacheco, L. Symposium review: Real-time continuous decision making using big data on dairy farms. J. Dairy Sci. 2020, 103, 3856–3866. [Google Scholar] [CrossRef]
- Cui, S.; Inocente, E.A.A.; Acosta, N.; Keener, H.M.; Zhu, H.; Ling, P.P. Development of fast e-nose system for early-stage diagnosis of aphid-stressed tomato plants. Sensors 2019, 19, 3480. [Google Scholar] [CrossRef]
- Yang, B.; Qi, L.; Wang, M.; Hussain, S.; Wang, H.; Wang, B.; Ning, J. Cross-category tea polyphenols evaluation model based on feature fusion of electronic nose and hyperspectral imagery. Sensors 2020, 20, 50. [Google Scholar] [CrossRef]
- Liu, H.; Li, Q.; Yan, B.; Zhang, L.; Gu, Y. Bionic electronic nose based on MOS sensors array and machine learning algorithms used for wine properties detection. Sensors 2019, 19, 45. [Google Scholar] [CrossRef]
- Gursoy, O.; Somervuo, P.; Alatossava, T. Preliminary study of ion mobility based electronic nose MGD-1 for discrimination of hard cheeses. J. Food Eng. 2009, 92, 202–207. [Google Scholar] [CrossRef]
- Cevoli, C.; Cerretani, L.; Gori, A.; Caboni, M.F.; Toschi, T.G.; Fabbri, A. Classification of Pecorino cheeses using electronic nose combined with artificial neural network and comparison with GC-MS analysis of volatile compounds. Food Chem. 2011, 129, 1315–1319. [Google Scholar] [CrossRef] [PubMed]
- Bougrini, M.; Tahri, K.; Haddi, Z.; El Bari, N.; Llobet, E.; Jaffrezic-Renault, N.; Bouchikhi, B. Aging time and brand determination of pasteurized milk using a multisensor e-nose combined with a voltammetric e-tongue. Mater. Sci. Eng. C—Mater. 2014, 45, 348–358. [Google Scholar] [CrossRef] [PubMed]
- Tong, L.; Yi, H.; Wang, J.; Pan, M.; Chi, X.; Hao, H.; Ai, N. Effect of preheating treatment before defatting on the flavor quality of skim milk. Molecules 2019, 24, 2824. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, F.; Wang, L.; Niu, Y.; Xiao, Z. Evaluation of the synergism among volatile compounds in Oolong tea infusion by odour threshold with sensory analysis and E-nose. Food Chem. 2017, 221, 1484–1490. [Google Scholar] [CrossRef]
- Ghasemi-Varnamkhasti, M.; Mohammad-Razdari, A.; Yoosefian, S.H.; Izadi, Z.; Siadat, M. Aging discrimination of French cheese types based on the optimization of an electronic nose using multivariate computational approaches combined with response surface method (RSM). LWT—Food Sci. Technol. 2019, 111, 85–98. [Google Scholar] [CrossRef]
- Sivalingam, D.; Rayappan, J.B.B. Development of e-nose prototype for raw milk quality discrimination. Milchwiss.—Milk Sci. Int. 2012, 67, 381–385. [Google Scholar] [CrossRef]
- Jensen, R.G. The composition of bovine milk lipids: January 1995 to December 2000. J. Dairy Sci. 2002, 85, 295–350. [Google Scholar] [CrossRef]
- Dalen, G.; Rachah, A.; Norstebo, H.; Schukken, Y.H.; Reksen, O. Dynamics of somatic cell count patterns as a proxy for transmission of mastitis pathogens. J. Dairy Sci. 2019, 102, 11349–11358. [Google Scholar] [CrossRef]
- Guinn, J.M.; Nolan, D.T.; Krawczel, P.D.; Petersson-Wolfe, C.S.; Pighetti, G.M.; Stone, A.E.; Ward, S.H.; Bewley, J.M.; Costa, J.H.C. Comparing dairy farm milk yield and components, somatic cell score, and reproductive performance among United States regions using summer to winter ratios. J. Dairy Sci. 2019, 102, 11777–11785. [Google Scholar] [CrossRef]
- Benedet, A.; Franzoi, M.; Penasa, M.; Pellattiero, E.; De Marchi, M. Prediction of blood metabolites from milk mid-infrared spectra in early-lactation cows. J. Dairy Sci. 2019, 102, 11298–11307. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Atzberger, C.; Guerif, M.; Baret, F.; Werner, W. Comparative analysis of three chemometric techniques for the spectroradiometric assessment of canopy chlorophyll content in winter wheat. Comput. Electron. Agric. 2010, 73, 165–173. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, W.; Yan, X.; Zhao, Z.; Hong, H.; Bui, D.; Pradhan, B. Spatial prediction of landslide susceptibility using data mining-based kernel logistic regression, naive Bayes and RBFNetwork models for the Long County area (China). Bull. Eng. Geol. Environ. 2019, 78, 247–266. [Google Scholar] [CrossRef]
- Semanjski, I.; Gautama, S. Smart city mobility application-gradient boosting trees for mobility prediction and analysis based on crowdsourced data. Sensors 2015, 15, 15974–15987. [Google Scholar] [CrossRef]
- Fan, J.; Wang, X.; Wu, L.; Zhou, H.; Zhang, F.; Yu, X.; Lu, X.; Xiang, Y. Comparison of Support Vector Machine and Extreme Gradient Boosting for predicting daily global solar radiation using temperature and precipitation in humid subtropical climates: A case study in China. Energy Convers. Manag. 2018, 164, 102–111. [Google Scholar] [CrossRef]
- Li, Q.; Yu, X.; Xu, L.; Gao, J. Novel method for the producing area identification of Zhongning Goji berries by electronic nose. Food Chem. 2017, 221, 1113–1119. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Sensor | Sensitive Substance |
|---|---|---|
| 1 | TGS2600 | Polluting gas |
| 2 | TGS822 | Volatile substances of alcohol and organic solvents |
| 3 | TGS2611 | Methane gas |
| 4 | TGS826 | Ammonia |
| 5 | TGS2602 | Volatile organic compounds (VOC), benzene |
| 6 | TGS832 | Freon gas |
| 7 | TGS2620 | Alcohol, carbon monoxide, other volatile organic vapors |
| Features | SVM | RF | LR | ||||
|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | ||
| DHI | PCA | 19.50 | 15.50 | 17.63 | 18.50 | 19.88 | 18.00 |
| LDA | 57.75 | 58.50 | 52.13 | 53.50 | 53.38 | 56.00 | |
| E-nose | PCA | 56.25 | 59.50 | 71.62 | 70.50 | 62.00 | 65.00 |
| LDA | 85.75 | 85.00 | 82.13 | 80.50 | 84.38 | 81.50 | |
| Fusion | PCA | 41.50 | 45.00 | 53.38 | 51.50 | 39.75 | 34.50 |
| LDA | 95.50 | 95.00 | 92.50 | 94.00 | 93.50 | 92.50 | |
| Model | Training Set | Testing Set | ||||
|---|---|---|---|---|---|---|
| MAE | MSE | R2 | MAE | MSE | R2 | |
| GBDT | 0.3267 | 0.1907 | 0.7201 | 0.3245 | 0.1926 | 0.7172 |
| XGBoost | 0.1063 | 0.0241 | 0.9645 | 0.1487 | 0.0573 | 0.9158 |
| RF | 0.1046 | 0.0253 | 0.9627 | 0.1253 | 0.0410 | 0.9399 |
| Model | Training Set | Testing Set | ||||
|---|---|---|---|---|---|---|
| MAE | MSE | R2 | MAE | MSE | R2 | |
| GBDT | 0.1773 | 0.0498 | 0.7003 | 0.1770 | 0.0501 | 0.6985 |
| XGBoost | 0.0616 | 0.0071 | 0.9572 | 0.0766 | 0.0123 | 0.9257 |
| RF | 0.0488 | 0.0052 | 0.9687 | 0.0607 | 0.0116 | 0.9301 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mu, F.; Gu, Y.; Zhang, J.; Zhang, L. Milk Source Identification and Milk Quality Estimation Using an Electronic Nose and Machine Learning Techniques. Sensors 2020, 20, 4238. https://doi.org/10.3390/s20154238
Mu F, Gu Y, Zhang J, Zhang L. Milk Source Identification and Milk Quality Estimation Using an Electronic Nose and Machine Learning Techniques. Sensors. 2020; 20(15):4238. https://doi.org/10.3390/s20154238
Chicago/Turabian StyleMu, Fanglin, Yu Gu, Jie Zhang, and Lei Zhang. 2020. "Milk Source Identification and Milk Quality Estimation Using an Electronic Nose and Machine Learning Techniques" Sensors 20, no. 15: 4238. https://doi.org/10.3390/s20154238
APA StyleMu, F., Gu, Y., Zhang, J., & Zhang, L. (2020). Milk Source Identification and Milk Quality Estimation Using an Electronic Nose and Machine Learning Techniques. Sensors, 20(15), 4238. https://doi.org/10.3390/s20154238