Deep Learning Sensor Fusion for Autonomous Vehicle Perception and Localization: A Review




Abstract
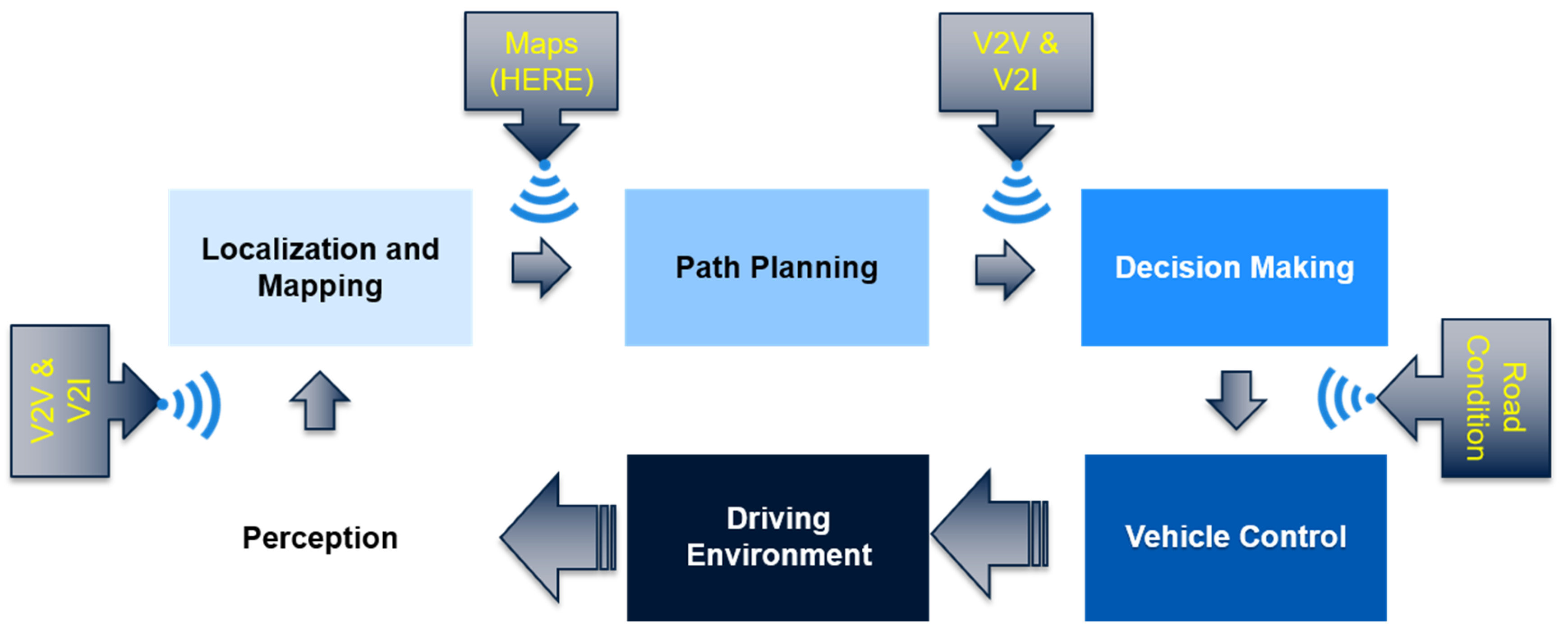
1. Introduction
2. Sensor Technology and Sensor Fusion Overview
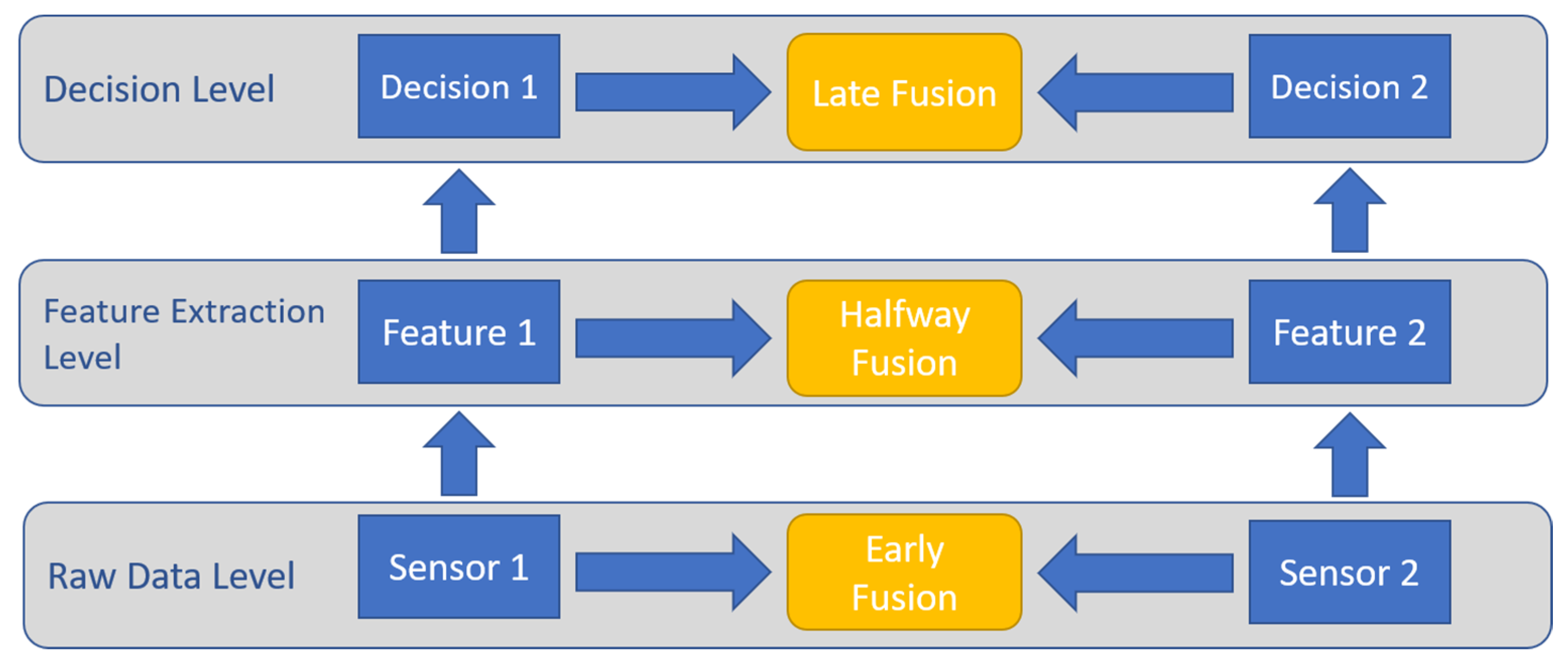
- Data in, data out: The input to the fusion network is raw sensor data, while the output is processed (typically enhanced) raw data.
- Data in, feature out: Raw data is integrated to produce a set of output features.
- Feature in, feature out: Where the input and output of the fusion network are feature vectors. This class is commonly referred to as either feature fusion, symbolic fusion, or information fusion.
- Feature in, decision out: As the name suggests, the input is a feature vector and the output is a decision. This class is more common in pattern recognition activities, where feature vectors are processed to be labeled.
- Decision in, decision out: Where both inputs and outputs are decisions, usually referred to as decision fusion networks.
2.1. Traditional Sensor Fusion Approaches
2.2. Deep Learning Sensor Fusion Approach
- Environmental perception, including vehicle detection, pedestrian detection, road surface detection, lane tracking, and road sign detection.
- Localization and mapping.
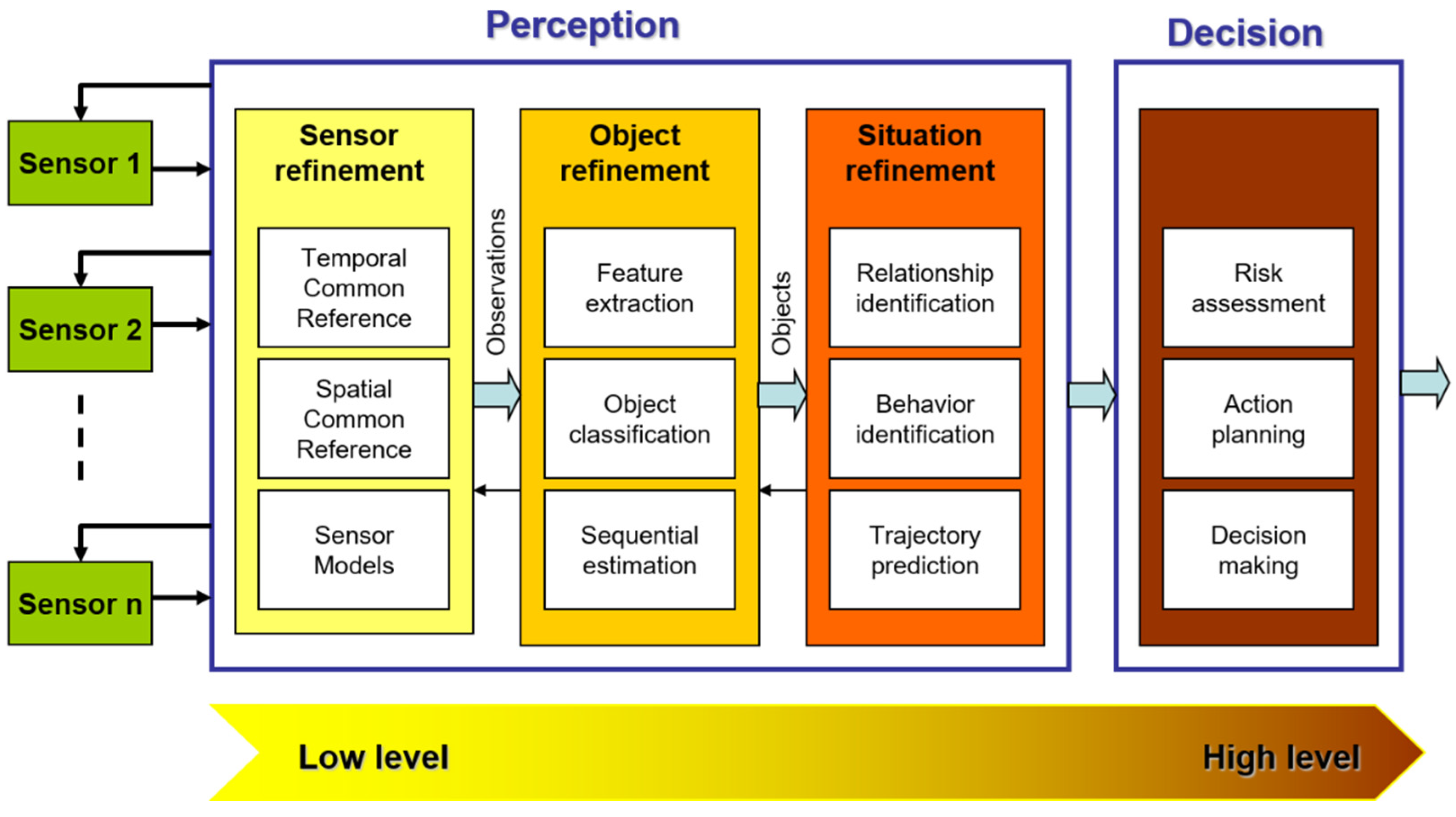
3. Environmental Perception: Local Dynamic Perception Map
- Input layer: This contains the data of the input image.
- Convolution layers: Convolution operation is performed in this layer to extract important features from the image.
- Pooling layers: Located between two convolution layers, which help in minimizing the computational cost by reducing some—but maintaining the most dominant—spatial information of the convoluted image.
- Fully connected layer: This serves as a classifier connecting all weights and neurons.
- Output layer: This stores the final output, which is the classification probability.
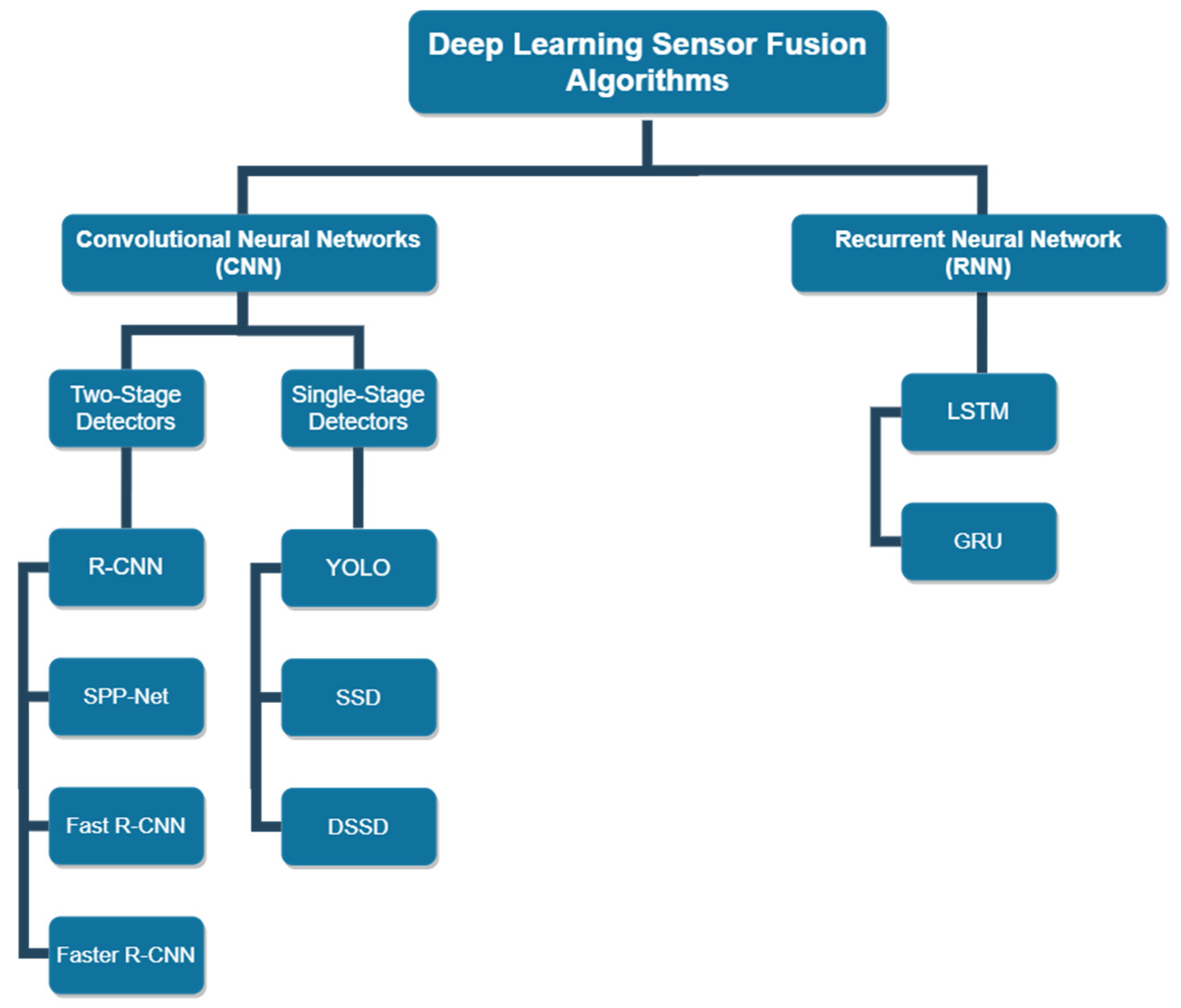
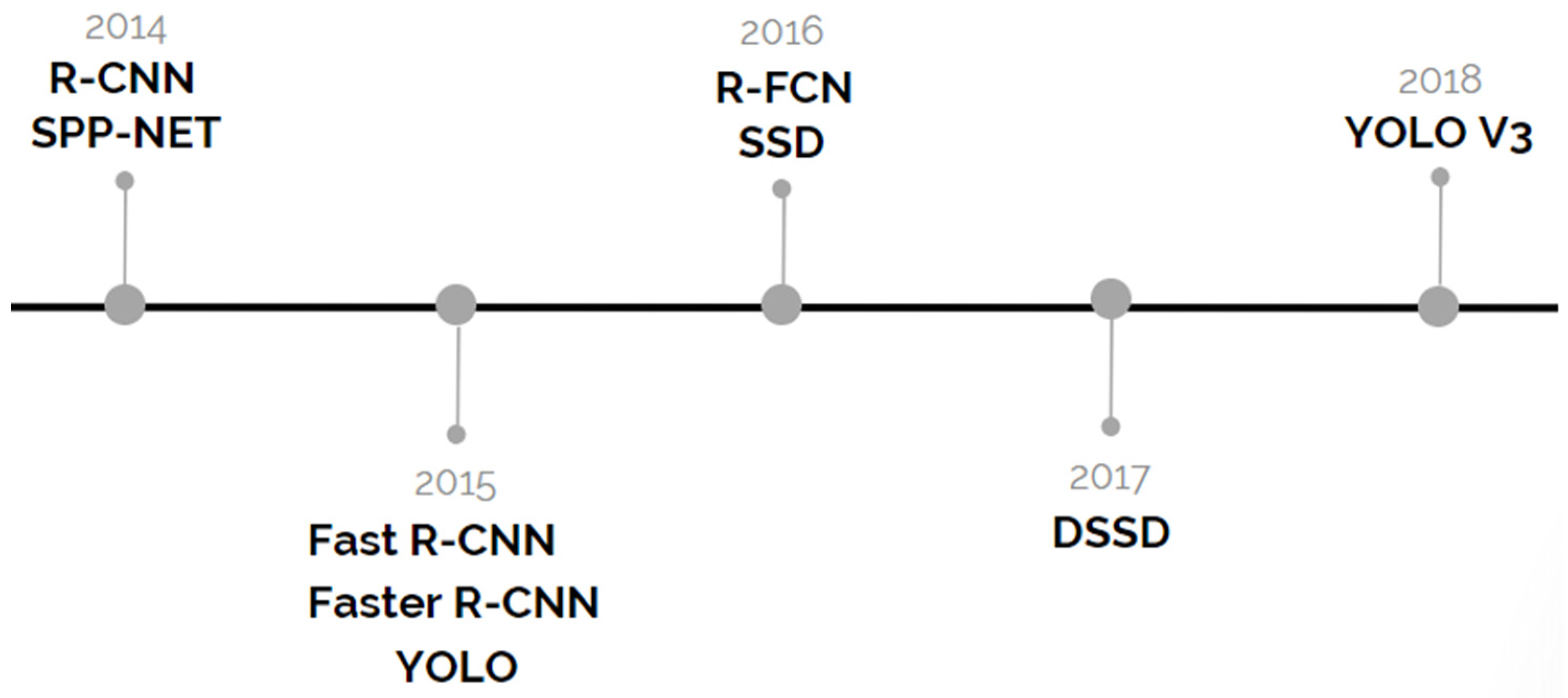
3.1. R-CNN
3.2. SPP-Net
3.3. Fast R-CNN
3.4. Faster R-CNN
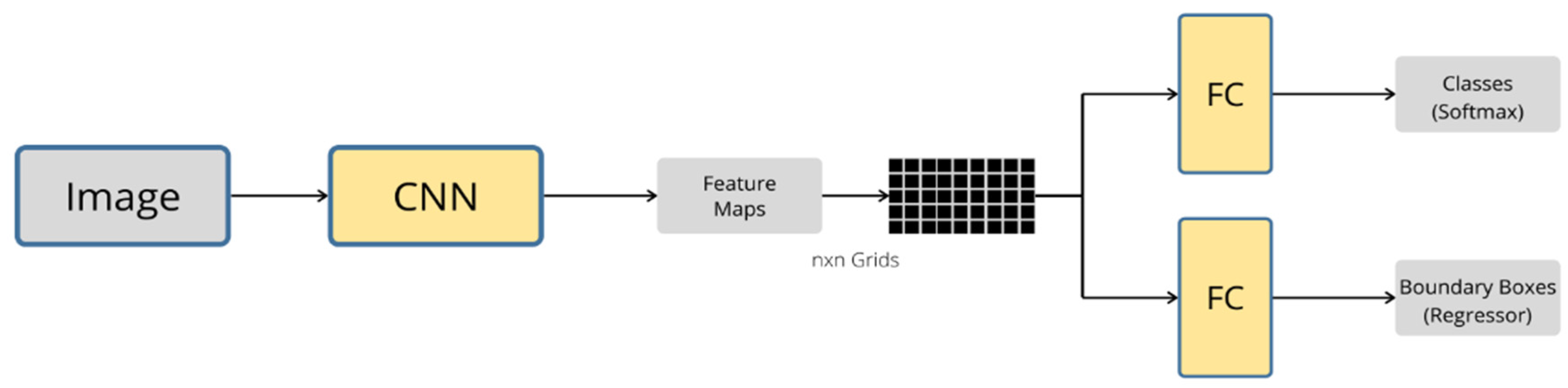
3.5. YOLO
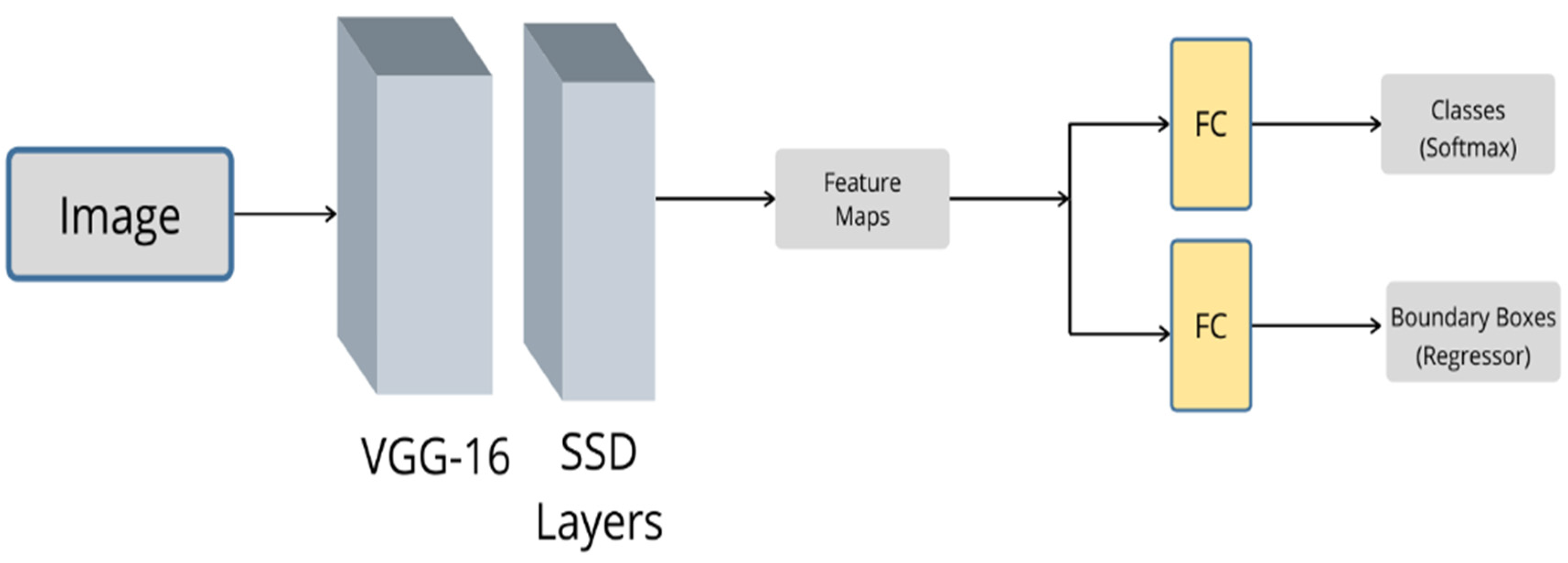
3.6. SSD
3.7. DSSD
4. Ego-Localization and Mapping
4.1. GNSS/IMU-Based Localization
4.2. Visual-Based Localization
4.2.1. Simultaneous Localization and Mapping (SLAM)
4.2.2. Visual Odometry (VO)
4.3. Map-Matching-Based Localization
5. Conclusions and Future Research Recommendations
5.1. Harsh Weather Conditions
5.2. Landmark Map-Matching
5.3. Deep Learning Algorithms for Localization
5.4. Issues to Solve: Cybersecurity, Reliability, and Repeatability
Funding
Conflicts of Interest
References
- Singh, S. Critical Reasons for Crashes Investigated in the National Motor Vehicle Crash Causation Survey. Traffic Safety Facts Crash Stats. Report No. DOT HS 812 115; National Center for Statistics and Analysis: Washington, DC, USA, 2015.
- Olia, A.; Abdelgawad, H.; Abdulhai, B.; Razavi, S.N. Assessing the Potential Impacts of Connected Vehicles: Mobility, Environmental, and Safety Perspectives. J. Intell. Transp. Syst. 2016, 20, 229–243. [Google Scholar] [CrossRef]
- Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles (J3016 Ground Vehicle Standard)—SAE Mobilus. Available online: https://saemobilus.sae.org/content/j3016_201806 (accessed on 23 October 2019).
- Learn More About General Motors’ Approach to Safely Putting Self-Driving Cars on the Roads in 2019. Available online: https://www.gm.com/our-stories/self-driving-cars.html (accessed on 23 October 2019).
- Autopilot. Available online: https://www.tesla.com/autopilot (accessed on 23 October 2019).
- BMW Group, Intel and Mobileye Team Up to Bring Fully Autonomous Driving to Streets by 2021. Available online: https://newsroom.intel.com/news-releases/intel-bmw-group-mobileye-autonomous-driving/ (accessed on 23 October 2019).
- Katrakazas, C.; Quddus, M.; Chen, W.-H.; Deka, L. Real-time motion planning methods for autonomous on-road driving: State-of-the-art and future research directions. Transp. Res. Part C Emerg. Technol. 2015, 60, 416–442. [Google Scholar] [CrossRef]
- Pendleton, S.; Andersen, H.; Du, X.; Shen, X.; Meghjani, M.; Eng, Y.; Rus, D.; Ang, M. Perception, Planning, Control, and Coordination for Autonomous Vehicles. Machines 2017, 5, 6. [Google Scholar] [CrossRef]
- Kaviani, S.; O’Brien, M.; Van Brummelen, J.; Najjaran, H.; Michelson, D. INS/GPS localization for reliable cooperative driving. In Proceedings of the 2016 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), Vancouver, BC, Canada, 15–18 May 2016; pp. 1–4. [Google Scholar]
- Kato, S.; Tsugawa, S.; Tokuda, K.; Matsui, T.; Fujii, H. Vehicle control algorithms for cooperative driving with automated vehicles and intervehicle communications. IEEE Trans. Intell. Transp. Syst. 2002, 3, 155–161. [Google Scholar] [CrossRef]
- Chen, X.; Chen, Y.; Najjaran, H. 3D object classification with point convolution network. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 783–788. [Google Scholar]
- Siegwart, R.; Nourbakhsh, I.R.; Scaramuzza, D. Introduction to Autonomous Mobile Robots; MIT Press: Cambridge, MA, USA, 2011; ISBN 978-0-262-01535-6. [Google Scholar]
- Pirník, R.; Hruboš, M.; Nemec, D.; Mravec, T.; Božek, P. Integration of Inertial Sensor Data into Control of the Mobile Platform. In Proceedings of the 2015 Federated Conference on Software Development and Object Technologies; Janech, J., Kostolny, J., Gratkowski, T., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 271–282. [Google Scholar]
- Božek, P.; Bezák, P.; Nikitin, Y.; Fedorko, G.; Fabian, M. Increasing the production system productivity using inertial navigation. Manuf. Technol. 2015, 15, 274–278. [Google Scholar] [CrossRef]
- Aubert, D.; Brémond, R.; Cord, A.; Dumont, E.; Gruyer, D.; Hautière, N.; Nicolle, P.; Tarel, J.P.; Boucher, V.; Charbonnier, P.; et al. Digital imaging for assessing and improving highway visibility. In Proceedings of the Transport Research Arena 2014 (TRA 2014), Paris, France, 14–17 April 2014; pp. 14–17. [Google Scholar]
- Cord, A.; Gimonet, N. Detecting Unfocused Raindrops: In-Vehicle Multipurpose Cameras. IEEE Robot. Autom. Mag. 2014, 21, 49–56. [Google Scholar] [CrossRef]
- Cord, A.; Aubert, D. Process and Device for Detection of Drops in a Digital Image and Computer Program for Executing This Method. U.S. Patent US9058643B2, 16 June 2015. [Google Scholar]
- Hu, X.; Rodríguez, F.S.A.; Gepperth, A. A multi-modal system for road detection and segmentation. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; pp. 1365–1370. [Google Scholar]
- Xiao, L.; Wang, R.; Dai, B.; Fang, Y.; Liu, D.; Wu, T. Hybrid conditional random field based camera-LIDAR fusion for road detection. Inf. Sci. 2018, 432, 543–558. [Google Scholar] [CrossRef]
- Shinzato, P.Y.; Wolf, D.F.; Stiller, C. Road terrain detection: Avoiding common obstacle detection assumptions using sensor fusion. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; IEEE: Dearborn, MI, USA, 2014; pp. 687–692. [Google Scholar]
- Choi, E.J.; Park, D.J. Human detection using image fusion of thermal and visible image with new joint bilateral filter. In Proceedings of the 5th International Conference on Computer Sciences and Convergence Information Technology, Seoul, Korea, 30 November–2 December 2010; pp. 882–885. [Google Scholar]
- Torresan, H.; Turgeon, B.; Ibarra-Castanedo, C.; Hebert, P.; Maldague, X.P. Advanced surveillance systems: Combining video and thermal imagery for pedestrian detection. Presented at the SPIE, Orlando, FL, USA, 13–15 April 2004; SPIE: Bellingham, WA, USA, 2004. [Google Scholar] [CrossRef]
- Mees, O.; Eitel, A.; Burgard, W. Choosing smartly: Adaptive multimodal fusion for object detection in changing environments. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; IEEE: Daejeon, Korea, 2016; pp. 151–156. [Google Scholar]
- Vandersteegen, M.; Van Beeck, K.; Goedemé, T. Real-Time Multispectral Pedestrian Detection with a Single-Pass Deep Neural Network. In Image Analysis and Recognition; Campilho, A., Karray, F., ter Haar Romeny, B., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 10882, pp. 419–426. ISBN 978-3-319-92999-6. [Google Scholar]
- Fritsche, P.; Zeise, B.; Hemme, P.; Wagner, B. Fusion of radar, LiDAR and thermal information for hazard detection in low visibility environments. In Proceedings of the 2017 IEEE International Symposium on Safety, Security and Rescue Robotics (SSRR), Shanghai, China, 11–13 October 2017; pp. 96–101. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D Object Detection Network for Autonomous Driving. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); IEEE: Honolulu, HI, USA, 2017; pp. 6526–6534. [Google Scholar]
- Wang, S.; Deng, Z.; Yin, G. An Accurate GPS-IMU/DR Data Fusion Method for Driverless Car Based on a Set of Predictive Models and Grid Constraints. Sensors 2016, 16, 280. [Google Scholar] [CrossRef]
- Saadeddin, K.; Abdel-Hafez, M.F.; Jaradat, M.A.; Jarrah, M.A. Performance enhancement of low-cost, high-accuracy, state estimation for vehicle collision prevention system using ANFIS. Mech. Syst. Signal Process. 2013, 41, 239–253. [Google Scholar] [CrossRef]
- Moutarde, F.; Bresson, G.; Li, Y.; Joly, C. Vehicle absolute ego-localization from vision, using only pre-existing geo-referenced panoramas. In Proceedings of the Reliability and Statistics in Transportation and Communications, Riga, Latvia, 16–19 October 2019. [Google Scholar]
- Bresson, G.; Yu, L.; Joly, C.; Moutarde, F. Urban Localization with Street Views using a Convolutional Neural Network for End-to-End Camera Pose Regression. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1199–1204. [Google Scholar]
- Bresson, G.; Rahal, M.-C.; Gruyer, D.; Revilloud, M.; Alsayed, Z. A cooperative fusion architecture for robust localization: Application to autonomous driving. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 859–866. [Google Scholar]
- Gruyer, D.; Belaroussi, R.; Revilloud, M. Accurate lateral positioning from map data and road marking detection. Expert Syst. Appl. 2016, 43, 1–8. [Google Scholar] [CrossRef]
- Gruyer, D.; Magnier, V.; Hamdi, K.; Claussmann, L.; Orfila, O.; Rakotonirainy, A. Perception, information processing and modeling: Critical stages for autonomous driving applications. Annu. Rev. Control 2017, 44, 323–341. [Google Scholar] [CrossRef]
- Schlosser, J.; Chow, C.K.; Kira, Z. Fusing LIDAR and images for pedestrian detection using convolutional neural networks. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; IEEE: Stockholm, Sweden, 2016; pp. 2198–2205. [Google Scholar]
- Melotti, G.; Premebida, C.; Gonçalves, N.M.D.S.; Nunes, U.J.; Faria, D.R. Multimodal CNN Pedestrian Classification: A Study on Combining LIDAR and Camera Data. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; IEEE: Maui, HI, USA, 2018; pp. 3138–3143. [Google Scholar]
- Labayrade, R.; Gruyer, D.; Royere, C.; Perrollaz, M.; Aubert, D. Obstacle Detection Based on Fusion between Stereovision and 2D Laser Scanner. In Mobile Robots: Perception & Navigation; Kolski, S., Ed.; Pro Literatur Verlag: Augsburg, Germany, 2007. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D. Multispectral Deep Neural Networks for Pedestrian Detection. arXiv 2016, arXiv:1611.02644. [Google Scholar]
- Hou, Y.-L.; Song, Y.; Hao, X.; Shen, Y.; Qian, M.; Chen, H. Multispectral pedestrian detection based on deep convolutional neural networks. Infrared Phys. Technol. 2018, 94, 69–77. [Google Scholar] [CrossRef]
- Wagner, J.; Fischer, V.; Herman, M.; Behnke, S. Multispectral Pedestrian Detection using Deep Fusion Convolutional Neural Networks. In Proceedings of the ESANN, Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Lee, Y.; Bui, T.D.; Shin, J. Pedestrian Detection based on Deep Fusion Network using Feature Correlation. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; IEEE: Honolulu, HI, USA, 2018; pp. 694–699. [Google Scholar]
- Zheng, Y.; Izzat, I.H.; Ziaee, S. GFD-SSD: Gated Fusion Double SSD for Multispectral Pedestrian Detection. arXiv 2019, arXiv:1903.06999. [Google Scholar]
- Shopovska, I.; Jovanov, L.; Philips, W. Deep Visible and Thermal Image Fusion for Enhanced Pedestrian Visibility. Sensors 2019, 19, 3727. [Google Scholar] [CrossRef]
- Gu, S.; Lu, T.; Zhang, Y.; Alvarez, J.M.; Yang, J.; Kong, H. 3-D LiDAR + Monocular Camera: An Inverse-Depth-Induced Fusion Framework for Urban Road Detection. IEEE Trans. Intell. Veh. 2018, 3, 351–360. [Google Scholar] [CrossRef]
- Yang, F.; Yang, J.; Jin, Z.; Wang, H. A Fusion Model for Road Detection based on Deep Learning and Fully Connected CRF. In Proceedings of the 2018 13th Annual Conference on System of Systems Engineering (SoSE), Paris, France, 19–22 June 2018; IEEE: Paris, France, 2018; pp. 29–36. [Google Scholar]
- Lv, X.; Liu, Z.; Xin, J.; Zheng, N. A Novel Approach for Detecting Road Based on Two-Stream Fusion Fully Convolutional Network. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; IEEE: Changshu, China, 2018; pp. 1464–1469. [Google Scholar]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. LIDAR-Camera Fusion for Road Detection Using Fully Convolutional Neural Networks. Robot. Auton. Syst. 2019, 111, 125–131. [Google Scholar] [CrossRef]
- Zhang, Y.; Morel, O.; Blanchon, M.; Seulin, R.; Rastgoo, M.; Sidibé, D. Exploration of Deep Learning-based Multimodal Fusion for Semantic Road Scene Segmentation. In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications; SCITEPRESS—Science and Technology Publications: Prague, Czech Republic, 2019; pp. 336–343. [Google Scholar]
- Kato, T.; Ninomiya, Y.; Masaki, I. An obstacle detection method by fusion of radar and motion stereo. IEEE Trans. Intell. Transp. Syst. 2002, 3, 182–188. [Google Scholar] [CrossRef]
- Bertozzi, M.; Bombini, L.; Cerri, P.; Medici, P.; Antonello, P.C.; Miglietta, M. Obstacle detection and classification fusing radar and vision. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 608–613. [Google Scholar]
- Du, X.; Ang, M.H.; Rus, D. Car detection for autonomous vehicle: LIDAR and vision fusion approach through deep learning framework. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: Vancouver, BC, Canada, 2017; pp. 749–754. [Google Scholar]
- Valente, M.; Joly, C.; de La Fortelle, A. Deep Sensor Fusion for Real-Time Odometry Estimation. arXiv 2019, arXiv:1908.00524. [Google Scholar]
- Alatise, M.B.; Hancke, G.P. Pose Estimation of a Mobile Robot Based on Fusion of IMU Data and Vision Data Using an Extended Kalman Filter. Sensors 2017, 17, 2164. [Google Scholar] [CrossRef] [PubMed]
- Bresson, G.; Alsayed, Z.; Yu, L.; Glaser, S. Simultaneous Localization and Mapping: A Survey of Current Trends in Autonomous Driving. IEEE Trans. Intell. Veh. 2017, 2, 194–220. [Google Scholar] [CrossRef]
- Jaradat, M.A.K.; Abdel-Hafez, M.F. Non-Linear Autoregressive Delay-Dependent INS/GPS Navigation System Using Neural Networks. IEEE Sens. J. 2017, 17, 1105–1115. [Google Scholar] [CrossRef]
- Rohani, M.; Gingras, D.; Gruyer, D. A Novel Approach for Improved Vehicular Positioning Using Cooperative Map Matching and Dynamic Base Station DGPS Concept. IEEE Trans. Intell. Transp. Syst. 2016, 17, 230–239. [Google Scholar] [CrossRef]
- Hall, D.L.; Llinas, J. An Introduction to Multisensor Data Fusion. Proc. IEEE 1997, 85, 18. [Google Scholar] [CrossRef]
- Bhateja, V.; Patel, H.; Krishn, A.; Sahu, A.; Lay-Ekuakille, A. Multimodal Medical Image Sensor Fusion Framework Using Cascade of Wavelet and Contourlet Transform Domains. IEEE Sens. J. 2015, 15, 6783–6790. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Q.; Wang, Y. Remote Sensing Image Fusion Based on Two-stream Fusion Network. Inf. Fusion 2019. [Google Scholar] [CrossRef]
- Smaili, C.; Najjar, M.E.E.; Charpillet, F. Multi-sensor Fusion Method Using Dynamic Bayesian Network for Precise Vehicle Localization and Road Matching. In Proceedings of the 19th IEEE International Conference on Tools with Artificial Intelligence (ICTAI 2007), Patras, Greece, 29–31 October 2007; Volume 1, pp. 146–151. [Google Scholar]
- Dasarathy, B.V. Sensor fusion potential exploitation-innovative architectures and illustrative applications. Proc. IEEE 1997, 85, 24–38. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schuetz, C.; Rosenbaum, L.; Hertlein, H.; Glaeser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multi-modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2019. [Google Scholar] [CrossRef]
- Malviya, A.; Bhirud, S.G. Wavelet based multi-focus image fusion. In Proceedings of the 2009 International Conference on Methods and Models in Computer Science (ICM2CS), Delhi, India, 14–15 December 2009; pp. 1–6. [Google Scholar]
- Guan, D.; Cao, Y.; Yang, J.; Cao, Y.; Yang, M.Y. Fusion of multispectral data through illumination-aware deep neural networks for pedestrian detection. Inf. Fusion 2019, 50, 148–157. [Google Scholar] [CrossRef]
- Castanedo, F. A Review of Data Fusion Techniques. Sci. World J. 2013, 2013, 1–19. [Google Scholar] [CrossRef]
- Pires, I.; Garcia, N.; Pombo, N.; Flórez-Revuelta, F. From Data Acquisition to Data Fusion: A Comprehensive Review and a Roadmap for the Identification of Activities of Daily Living Using Mobile Devices. Sensors 2016, 16, 184. [Google Scholar] [CrossRef]
- Van Brummelen, J.; O’Brien, M.; Gruyer, D.; Najjaran, H. Autonomous vehicle perception: The technology of today and tomorrow. Transp. Res. Part C Emerg. Technol. 2018, 89, 384–406. [Google Scholar] [CrossRef]
- Santoso, F.; Garratt, M.A.; Anavatti, S.G. Visual–Inertial Navigation Systems for Aerial Robotics: Sensor Fusion and Technology. IEEE Trans. Autom. Sci. Eng. 2017, 14, 260–275. [Google Scholar] [CrossRef]
- Jaradat, M.A.K.; Abdel-Hafez, M.F. Enhanced, Delay Dependent, Intelligent Fusion for INS/GPS Navigation System. IEEE Sens. J. 2014, 14, 1545–1554. [Google Scholar] [CrossRef]
- Alkhawaja, F.; Jaradat, M.; Romdhane, L. Techniques of Indoor Positioning Systems (IPS): A Survey. In Proceedings of the 2019 Advances in Science and Engineering Technology International Conferences (ASET), Dubai, UAE, 26 March–10 April 2019; pp. 1–8. [Google Scholar]
- Luo, R.C.; Chang, C.-C. Multisensor Fusion and Integration: A Review on Approaches and Its Applications in Mechatronics. IEEE Trans. Ind. Inform. 2012, 8, 49–60. [Google Scholar] [CrossRef]
- Khaleghi, B.; Khamis, A.; Karray, F.O.; Razavi, S.N. Multisensor data fusion: A review of the state-of-the-art. Inf. Fusion 2013, 14, 28–44. [Google Scholar] [CrossRef]
- Nagla, K.S.; Uddin, M.; Singh, D. Multisensor Data Fusion and Integration for Mobile Robots: A Review. IAES Int. J. Robot. Autom. IJRA 2014, 3, 131–138. [Google Scholar] [CrossRef]
- Vincke, B.; Lambert, A.; Gruyera, D.; Elouardi, A.; Seignez, E. Static and dynamic fusion for outdoor vehicle localization. In Proceedings of the 2010 11th International Conference on Control Automation Robotics Vision, Singapore, 7–10 December 2010; pp. 437–442. [Google Scholar]
- Kueviakoe, K.; Wang, Z.; Lambert, A.; Frenoux, E.; Tarroux, P. Localization of a Vehicle: A Dynamic Interval Constraint Satisfaction Problem-Based Approach. Available online: https://www.hindawi.com/journals/js/2018/3769058/ (accessed on 11 May 2020).
- Wang, Z.; Lambert, A. A Reliable and Low Cost Vehicle Localization Approach Using Interval Analysis. In Proceedings of the 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress(DASC/PiCom/DataCom/CyberSciTech), Athens, Greece, 12–15 August 2018; pp. 480–487. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Ouyang, W.; Wang, X.; Zeng, X.; Qiu, S.; Luo, P.; Tian, Y.; Li, H.; Yang, S.; Wang, Z.; Loy, C.-C.; et al. DeepID-Net: Deformable Deep Convolutional Neural Networks for Object Detection. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3D Object Detection for Autonomous Driving. In Proceedings of the Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Yan, S.; Teng, Y.; Smith, J.S.; Zhang, B. Driver behavior recognition based on deep convolutional neural networks. In Proceedings of the 2016 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Changsha, China, 13–15 August 2016; pp. 636–641. [Google Scholar]
- Zhao, Y.; Li, J.; Yu, L. A deep learning ensemble approach for crude oil price forecasting. Energy Econ. 2017, 66, 9–16. [Google Scholar] [CrossRef]
- Matsugu, M.; Mori, K.; Mitari, Y.; Kaneda, Y. Subject independent facial expression recognition with robust face detection using a convolutional neural network. Neural Netw. 2003, 16, 555–559. [Google Scholar] [CrossRef]
- Gao, H.; Cheng, B.; Wang, J.; Li, K.; Zhao, J.; Li, D. Object Classification Using CNN-Based Fusion of Vision and LIDAR in Autonomous Vehicle Environment. IEEE Trans. Ind. Inform. 2018, 14, 4224–4231. [Google Scholar] [CrossRef]
- Melotti, G.; Asvadi, A.; Premebida, C. CNN-LIDAR pedestrian classification: Combining range and reflectance data. In Proceedings of the 2018 IEEE International Conference on Vehicular Electronics and Safety (ICVES), Madrid, Spain, 12–14 September 2018; IEEE: Madrid, Spain, 2018; pp. 1–6. [Google Scholar]
- Xiong, W.; Wu, L.; Alleva, F.; Droppo, J.; Huang, X.; Stolcke, A. The Microsoft 2017 Conversational Speech Recognition System. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5934–5938. [Google Scholar]
- Mao, J.; Xu, W.; Yang, Y.; Wang, J.; Huang, Z.; Yuille, A. Deep Captioning with Multimodal Recurrent Neural Networks (m-RNN). arXiv 2014, arXiv:1412.6632. [Google Scholar]
- Shi, H.; Xu, M.; Li, R. Deep Learning for Household Load Forecasting—A Novel Pooling Deep RNN. IEEE Trans. Smart Grid 2018, 9, 5271–5280. [Google Scholar] [CrossRef]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very Deep Convolutional Networks for Text Classification. arXiv 2016, arXiv:1606.01781. [Google Scholar]
- Hongliang, C.; Xiaona, Q. The Video Recommendation System Based on DBN. In Proceedings of the 2015 IEEE International Conference on Computer and Information Technology; Ubiquitous Computing and Communications; Dependable, Autonomic and Secure Computing; Pervasive Intelligence and Computing, Liverpool, UK, 26–28 October 2015; pp. 1016–1021. [Google Scholar] [CrossRef]
- Sazal, M.M.R.; Biswas, S.K.; Amin, M.F.; Murase, K. Bangla handwritten character recognition using deep belief network. In Proceedings of the 2013 International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 13–15 February 2014; pp. 1–5. [Google Scholar]
- Mohamed, A.; Dahl, G.; Hinton, G. Deep belief networks for phone recognition. In Proceedings of the NIPS Workshop on Deep Learning for Speech Recognition and Related Applications; MIT Press: Whister, BC, Canada, 2009; Volume 1, p. 39. [Google Scholar]
- Hinton, G.E. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G.E. Using very deep autoencoders for content-based image retrieval. In Proceedings of the ESANN, Bruges, Belgium, 27–29 April 2011. [Google Scholar]
- Lu, X.; Tsao, Y.; Matsuda, S.; Hori, C. Speech enhancement based on deep denoising autoencoder. In Proceedings of the Annual Conference of International Speech Communication Association; INTERSPEECH, Lyon, France, 25–29 August 2013; pp. 436–440. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems—Volume 1; Curran Associates Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: Piscataway, NJ, USA, 2015; pp. 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:150601497. [Google Scholar] [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-aware faster R-CNN for robust multispectral pedestrian detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef]
- Kim, J.H.; Batchuluun, G.; Park, K.R. Pedestrian detection based on faster R-CNN in nighttime by fusing deep convolutional features of successive images. Expert Syst. Appl. 2018, 114, 15–33. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:150602640. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:180402767. [Google Scholar]
- Asvadi, A.; Garrote, L.; Premebida, C.; Peixoto, P.J.; Nunes, U. Multimodal vehicle detection: Fusing 3D-LIDAR and color camera data. Pattern Recognit. Lett. 2018, 115, 20–29. [Google Scholar] [CrossRef]
- Wang, H.; Lou, X.; Cai, Y.; Li, Y.; Chen, L. Real-Time Vehicle Detection Algorithm Based on Vision and Lidar Point Cloud Fusion. Available online: https://www.hindawi.com/journals/js/2019/8473980/ (accessed on 18 August 2019).
- Dou, J.; Fang, J.; Li, T.; Xue, J. Boosting CNN-Based Pedestrian Detection via 3D LiDAR Fusion in Autonomous Driving. In Proceedings of the Image and Graphics; Zhao, Y., Kong, X., Taubman, D., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 3–13. [Google Scholar]
- Han, J.; Liao, Y.; Zhang, J.; Wang, S.; Li, S. Target Fusion Detection of LiDAR and Camera Based on the Improved YOLO Algorithm. Mathematics 2018, 6, 213. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Kim, J.; Choi, J.; Kim, Y.; Koh, J.; Chung, C.C.; Choi, J.W. Robust Camera Lidar Sensor Fusion Via Deep Gated Information Fusion Network. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; IEEE: Changshu, China, 2018; pp. 1620–1625. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature Fusion Single Shot Multibox Detector. arXiv 2017, arXiv:171200960. [Google Scholar]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:abs/1701.06659. [Google Scholar]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2722–2730. [Google Scholar]
- Kim, Y.-H.; Jang, J.-I.; Yun, S. End-to-end deep learning for autonomous navigation of mobile robot. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 12–14 January 2018; pp. 1–6. [Google Scholar]
- Pfeiffer, M.; Schaeuble, M.; Nieto, J.; Siegwart, R.; Cadena, C. From perception to decision: A data-driven approach to end-to-end motion planning for autonomous ground robots. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1527–1533. [Google Scholar]
- Qazizada, M.E.; Pivarčiová, E. Mobile Robot Controlling Possibilities of Inertial Navigation System. Procedia Eng. 2016, 149, 404–413. [Google Scholar] [CrossRef]
- Caron, F.; Duflos, E.; Pomorski, D.; Vanheeghe, P. GPS/IMU data fusion using multisensor Kalman filtering: Introduction of contextual aspects. Inf. Fusion 2006, 7, 221–230. [Google Scholar] [CrossRef]
- Qi, H.; Moore, J.B. Direct Kalman filtering approach for GPS/INS integration. IEEE Trans. Aerosp. Electron. Syst. 2002, 38, 687–693. [Google Scholar] [CrossRef]
- Wang, G.; Han, Y.; Chen, J.; Wang, S.; Zhang, Z.; Du, N.; Zheng, Y. A GNSS/INS Integrated Navigation Algorithm Based on Kalman Filter. IFAC-Pap. 2018, 51, 232–237. [Google Scholar] [CrossRef]
- Wan, E.A.; Merwe, R.V.D. The unscented Kalman filter for nonlinear estimation. In Proceedings of the IEEE 2000 Adaptive Systems for Signal Processing, Communications, and Control Symposium (Cat. No.00EX373), Lake Louise, AB, Canada, 4 October 2000; pp. 153–158. [Google Scholar]
- Ndjeng Ndjeng, A.; Gruyer, D.; Glaser, S.; Lambert, A. Low cost IMU–Odometer–GPS ego localization for unusual maneuvers. Inf. Fusion 2011, 12, 264–274. [Google Scholar] [CrossRef]
- Bacha, A.R.A.; Gruyer, D.; Lambert, A. OKPS: A Reactive/Cooperative Multi-Sensors Data Fusion Approach Designed for Robust Vehicle Localization. Positioning 2015, 7, 1–20. [Google Scholar] [CrossRef]
- Noureldin, A.; El-Shafie, A.; Bayoumi, M. GPS/INS integration utilizing dynamic neural networks for vehicular navigation. Inf. Fusion 2011, 12, 48–57. [Google Scholar] [CrossRef]
- Dai, H.; Bian, H.; Wang, R.; Ma, H. An INS/GNSS integrated navigation in GNSS denied environment using recurrent neural network. Def. Technol. 2019. [Google Scholar] [CrossRef]
- Kim, H.-U.; Bae, T.-S. Deep Learning-Based GNSS Network-Based Real-Time Kinematic Improvement for Autonomous Ground Vehicle Navigation. J. Sens. 2019. [Google Scholar] [CrossRef]
- Jiang, C.; Chen, Y.; Chen, S.; Bo, Y.; Li, W.; Tian, W.; Guo, J. A Mixed Deep Recurrent Neural Network for MEMS Gyroscope Noise Suppressing. Electronics 2019, 8, 181. [Google Scholar] [CrossRef]
- Singandhupe, A.; La, H.M. A Review of SLAM Techniques and Security in Autonomous Driving. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 602–607. [Google Scholar]
- The KITTI Vision Benchmark Suite. Available online: http://www.cvlibs.net/datasets/kitti/eval_odometry.php (accessed on 12 May 2020).
- Magnier, V. Multi-Sensor Data Fusion for the Estimation of the Navigable Space for the Autonomous Vehicle; University Paris Saclay and Renault: Versailles, France, 2018. [Google Scholar]
- Kaneko, M.; Iwami, K.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Mask-SLAM: Robust Feature-Based Monocular SLAM by Masking Using Semantic Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 371–3718. [Google Scholar]
- Xiao, L.; Wang, J.; Qiu, X.; Rong, Z.; Zou, X. Dynamic-SLAM: Semantic monocular visual localization and mapping based on deep learning in dynamic environment. Robot. Auton. Syst. 2019, 117, 1–16. [Google Scholar] [CrossRef]
- Yu, C.; Liu, Z.; Liu, X.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments. 2018 IEEERSJ Int. Conf. Intell. Robots Syst. IROS 2018, 1168–1174. [Google Scholar] [CrossRef]
- Farrokhsiar, M.; Najjaran, H. A Velocity-Based Rao-Blackwellized Particle Filter Approach to Monocular vSLAM. J. Intell. Learn. Syst. Appl. 2011, 3, 113–121. [Google Scholar] [CrossRef]
- Tateno, K.; Tombari, F.; Laina, I.; Navab, N. CNN-SLAM: Real-Time Dense Monocular SLAM with Learned Depth Prediction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6565–6574. [Google Scholar]
- Laidlow, T.; Czarnowski, J.; Leutenegger, S. DeepFusion: Real-Time Dense 3D Reconstruction for Monocular SLAM using Single-View Depth and Gradient Predictions. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4068–4074. [Google Scholar]
- Lee, S.J.; Choi, H.; Hwang, S.S. Real-time Depth Estimation Using Recurrent CNN with Sparse Depth Cues for SLAM System. Int. J. Control Autom. Syst. 2020, 18, 206–216. [Google Scholar] [CrossRef]
- Kuznietsov, Y.; Stuckler, J.; Leibe, B. Semi-Supervised Deep Learning for Monocular Depth Map Prediction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2215–2223. [Google Scholar]
- Cvišić, I.; Ćesić, J.; Marković, I.; Petrović, I. SOFT-SLAM: Computationally efficient stereo visual simultaneous localization and mapping for autonomous unmanned aerial vehicles. J. Field Robot. 2018, 35, 578–595. [Google Scholar] [CrossRef]
- Lenac, K.; Ćesić, J.; Marković, I.; Petrović, I. Exactly sparse delayed state filter on Lie groups for long-term pose graph SLAM. Int. J. Robot. Res. 2018, 37, 585–610. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Engel, J.; Stückler, J.; Cremers, D. Large-scale direct SLAM with stereo cameras. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 1935–1942. [Google Scholar]
- Deschaud, J.-E. IMLS-SLAM: Scan-to-Model Matching Based on 3D Data. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2480–2485. [Google Scholar]
- Neuhaus, F.; Koß, T.; Kohnen, R.; Paulus, D. MC2SLAM: Real-Time Inertial Lidar Odometry Using Two-Scan Motion Compensation. In Proceedings of the Pattern Recognition; Brox, T., Bruhn, A., Fritz, M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 60–72. [Google Scholar]
- Ji, K.; Chen, H.; Di, H.; Gong, J.; Xiong, G.; Qi, J.; Yi, T. CPFG-SLAM:a Robust Simultaneous Localization and Mapping based on LIDAR in Off-Road Environment. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 650–655. [Google Scholar]
- Behley, J.; Stachniss, C. Efficient Surfel-Based SLAM using 3D Laser Range Data in Urban Environments. In Robotics: Science and System XIV; Carnegie Mellon University: Pittsburgh, PA, USA, 2018. [Google Scholar]
- Hou, Y.; Zhang, H.; Zhou, S. Convolutional neural network-based image representation for visual loop closure detection. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 2238–2245. [Google Scholar]
- Merrill, N.; Huang, G. Lightweight Unsupervised Deep Loop Closure. arXiv 2018, arXiv:180507703. [Google Scholar]
- Kang, R.; Shi, J.; Li, X.; Liu, Y.; Liu, X. DF-SLAM: A Deep-Learning Enhanced Visual SLAM System based on Deep Local Features. arXiv 2019, arXiv:190107223. [Google Scholar]
- Parisotto, E.; Chaplot, D.S.; Zhang, J.; Salakhutdinov, R. Global Pose Estimation with an Attention-based Recurrent Network. arXiv 2018, arXiv:180206857. [Google Scholar]
- Yousif, K.; Bab-Hadiashar, A.; Hoseinnezhad, R. An Overview to Visual Odometry and Visual SLAM: Applications to Mobile Robotics. Intell. Ind. Syst. 2015, 1, 289–311. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. Visual-lidar odometry and mapping: Low-drift, robust, and fast. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 2174–2181. [Google Scholar]
- Melekhov, I.; Ylioinas, J.; Kannala, J.; Rahtu, E. Relative Camera Pose Estimation Using Convolutional Neural Networks. arXiv 2017, arXiv:170201381. [Google Scholar]
- Mohanty, V.; Agrawal, S.; Datta, S.; Ghosh, A.; Sharma, V.D.; Chakravarty, D. DeepVO: A Deep Learning approach for Monocular Visual Odometry. arXiv 2016, arXiv:161106069. [Google Scholar]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks. IEEE Int. Conf. Robot. Autom. ICRA 2017, 2043–2050. [Google Scholar] [CrossRef]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. End-to-end, sequence-to-sequence probabilistic visual odometry through deep neural networks. Int. J. Robot. Res. 2018, 37, 513–542. [Google Scholar] [CrossRef]
- Graeter, J.; Wilczynski, A.; Lauer, M. LIMO: Lidar-Monocular Visual Odometry. arXiv 2018, arXiv:180707524. [Google Scholar]
- Zhu, J. Image Gradient-based Joint Direct Visual Odometry for Stereo Camera. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17, Melbourne, Australia, 19–25 August 2017; pp. 4558–4564. [Google Scholar]
- Kovalenko, D.; Korobkin, M.; Minin, A. Sensor Aware Lidar Odometry. arXiv 2020, arXiv:190709167. [Google Scholar]
- Dias, N.; Laureano, G. Accurate Stereo Visual Odometry Based on Keypoint Selection. In Proceedings of the 2019 Latin American Robotics Symposium (LARS), 2019 Brazilian Symposium on Robotics (SBR) and 2019 Workshop on Robotics in Education (WRE), Rio Grande, Brazil, 23–25 October 2019; pp. 74–79. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised Learning of Depth and Ego-Motion from Video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6612–6619. [Google Scholar]
- Li, R.; Wang, S.; Long, Z.; Gu, D. UnDeepVO: Monocular Visual Odometry through Unsupervised Deep Learning. arXiv 2018, arXiv:170906841. [Google Scholar]
- Yang, N.; Stumberg, L.V.; Wang, R.; Cremers, D. D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry. arXiv 2020, arXiv:2003.01060. [Google Scholar]
- Chen, D. Semi-Supervised Deep Learning Framework for Monocular Visual Odometry. 2019. [Google Scholar]
- Valada, A.; Radwan, N.; Burgard, W. Deep Auxiliary Learning for Visual Localization and Odometry. arXiv 2018, arXiv:180303642. [Google Scholar]
- Kent, L. HERE Introduces HD Maps for Highly Automated Vehicle Testing. Available online: https://360.here.com/2015/07/20/here-introduces-hd-maps-for-highly-automated-vehicle-testing/ (accessed on 15 October 2019).
- Lu, W.; Zhou, Y.; Wan, G.; Hou, S.; Song, S. L3-Net: Towards Learning Based LiDAR Localization for Autonomous Driving. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–21 June 2019; pp. 6382–6391. [Google Scholar]
- Vaquero, V.; Fischer, K.; Moreno-Noguer, F.; Sanfeliu, A.; Milz, S. Improving Map Re-localization with Deep “Movable” Objects Segmentation on 3D LiDAR Point Clouds. arXiv 2019, arXiv:191003336. [Google Scholar]
- Bijelic, M.; Mannan, F.; Gruber, T.; Ritter, W.; Dietmayer, K.; Heide, F. Seeing Through Fog Without Seeing Fog: Deep Sensor Fusion in the Absence of Labeled Training Data. arXiv 2019, arXiv:190208913. [Google Scholar]
- Ritter, W.; Bijelic, M.; Gruber, T.; Kutila, M.; Holzhüter, H. DENSE: Environment Perception in Bad Weather—First Results. In Proceedings of the Electronic Components and Systems for Automotive Applications; Langheim, J., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 143–159. [Google Scholar]
- Sefati, M.; Daum, M.; Sondermann, B.; Kreisköther, K.D.; Kampker, A. Improving vehicle localization using semantic and pole-like landmarks. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 13–19. [Google Scholar]
- Fang, J.; Wang, Z.; Zhang, H.; Zong, W. Self-localization of Intelligent Vehicles Based on Environmental Contours. In Proceedings of the 2018 3rd International Conference on Advanced Robotics and Mechatronics (ICARM), Singapore, 18–20 July 2018; pp. 624–629. [Google Scholar]
- DOrazio, L.; Conci, N.; Stoffella, F. Exploitation of road signalling for localization refinement of autonomous vehicles. In Proceedings of the 2018 International Conference of Electrical and Electronic Technologies for Automotive, Milan, Italy, 9–11 July 2018; pp. 1–6. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Chen, X.; Chen, Y.; Gupta, K.; Zhou, J.; Najjaran, H. SliceNet: A proficient model for real-time 3D shape-based recognition. Neurocomputing 2018, 316, 144–155. [Google Scholar] [CrossRef]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust Physical-World Attacks on Deep Learning Models. arXiv 2018, arXiv:170708945. [Google Scholar]
- Komkov, S.; Petiushko, A. AdvHat: Real-world adversarial attack on ArcFace Face ID system. arXiv 2019, arXiv:190808705. [Google Scholar]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images. arXiv 2015, arXiv:14121897. [Google Scholar]
- Heaven, D. Why deep-learning AIs are so easy to fool. Nature 2019, 574, 163–166. [Google Scholar] [CrossRef]
- Vialatte, J.-C.; Leduc-Primeau, F. A Study of Deep Learning Robustness against Computation Failures. arXiv 2017, arXiv:170405396. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | AV Application | Fused Sensors | Limitations without Fusion | Fusion Advantages |
|---|---|---|---|---|
| [34,35,36] | Pedestrian Detection | Vision and LiDAR | Sensitive to illumination quality; Night vision difficulties by vision camera only Low resolution of LiDAR 3D scene reconstruction when used alone. | Ability to measure depth and range, with less computational power; Improvements in extreme weather conditions (fog and rain) |
| [37,38,39,40,41,42] | Pedestrian Detection | Vision and Infrared | Night vision difficulties with vision camera only; Thermal cameras lose fine details of objects due to their limited resolution. | Robustness to lighting effects and nighttime detection; Infrared camera provides distinct silhouettes of objects; Ability to operate in bad weather conditions. |
| [43,44,45,46] | Road Detection | Vision and LiDAR | Illumination and lighting conditions; High computational cost for vision depth measurements; Limited resolution and range measurements by LiDAR; Sparse and unorganized point cloud LiDAR data | Road scene geometry measurements (depth) while maintaining rich color information; Calibration of scattered LiDAR point cloud with the image |
| [47] | Road Detection | Vision and Polarization camera | Sensitive to lighting conditions; Lack of color information | Polarized images enhance scene understanding, especially with reflective surfaces. |
| [48,49,50] | Vehicle Detection Lane Detection | Vision and Radar | Low resolution of radar. Camera needs special lenses, arrangements, and heavy computation to measure distance. | Measure distance accurately; Performs well in bad weather conditions; Camera is well suited for lane detection applications |
| [51] | Visual Odometry | 2D Laser scanner and Vision | 2D scanners can miss detection of objects in complex environments; 2D images are insufficient for capturing all the features of the 3D world. | Fusion of vision and 2D scanners can replace the need for 3D LiDAR, and hence reduce price and computation load. |
| [52,53] | SLAM | Vision and Inertial Measurement Unit | Illumination and lighting conditions by the camera; Camera suffers blur due to fast movement; Drifting error for IMU | Improved accuracy with less computational load; Robustness against vision noise, and corrective for IMU drifts. |
| [54] | Navigation | GPS and INS | GPS outage in denied and canyon areas; Drift in INS readings | Continuous navigation; Correction in INS readings |
| [32,55] | Ego Positioning | Map, vision, GPS, INS | GPS outage; INS drifts; HD map accuracy; Visibility of road markings | Accurate lateral positioning through road marking detection and HD map matching. |
| Algorithm | Characteristics | Advantages | Disadvantages | Applications Areas | Level of Fusion |
|---|---|---|---|---|---|
| Statistical Methods | Utilized to enhance data imputation using a statistical model to model the sensory information [64,67] | Can handle unknown correlations; Tolerant [68,69] | Limited to linear estimators; Computation complexity is high [65] | Estimation | Low [70] |
| Probabilistic Methods | Based on probability representation for the sensory information [64] | Uncertainty in the provided information is handled. handles nonlinear systems (particle filter, UKF, …) | Requires prior knowledge of systems model and data | Estimation/Classification | Low→Medium [70] |
| Knowledge-based Theory Methods | Utilizes computational intelligence approaches inspired by human intelligence mechanisms. [71] | Handles Uncertainty and imprecision; Ability to handle complex nonlinear systems [72] | Depends on the expertise knowledge and extraction of knowledge | Classification/Decision | Medium→High [70] |
| Evidence Reasoning Methods | Depends on the Dempster combination mechanism to implement the model [71] | Uncertainty degree is assigned to the provided information. Identification of conflicting situation. Modeling of complex assumption | High computation complexity. Require assumption of evidence. | Decision | High [70] |
| Interval Analysis theory | Shares the operating space in intervals [73]. Constraint satisfaction problem [74,75] | Guaranty integrity. Ability to handle complex nonlinear systems | Discretization of the operating space. High computation complexity. | Estimation | Low |
| DL Algorithm | Description | Applications |
|---|---|---|
| Convolutional Neural Network (CNN) | A feedforward network with convolution layers and pooling layers. CNN is very powerful in finding the relationship among image pixels. | Computer Vision [82,83,84]; Speech Recognition [85] |
| Recurrent Neural Network (RNN) | A class of feedback networks that uses previous output samples to predict new data sample. RNN deals with sequential data; both the input and output can be a sequence of data. | Image Caption [86]; Data Forecasting [87]; Natural Language Processing [88] |
| Deep Belief Net (DBN) | Multilayer generative energy-based model with a visible input layer and multiple hidden layers. DBN assigns probabilistic values to its model parameters. | Collaborative Filtering [89]; Handwritten Character Recognition [90]; acoustic modeling [91] |
| Autoencoders (AE) | A class of neural network that tends to learn the representation of data in an unsupervised manner. AE consists of an encoder and decoder, and it can be trained through minimizing the differences between the input and output. | Dimensionality Reduction [92]; Image Retrieval [93]; Data Denoising [94] |
| R-CNN | SPP-Net | Fast R-CNN | Faster R-CNN | |
|---|---|---|---|---|
| Training time (In hours) | 84 | 25 | 9.5 | NA |
| Speedup with respect to R-CNN | 1× | 3.4× | 8.8× | NA |
| Testing rate (Seconds/Image) | 47 | 2.3 | 0.3 | 0.2 |
| Speedup with respect to R-CNN | 1× | 20× | 146× | 235× |
| Method | Accuracy | Cost | Computational Load | External Effect | Data Size |
|---|---|---|---|---|---|
| GPS/IMU | Low | Medium | Low | Signal outage | Low |
| GPS/INS/LiDAR/Camera | High | Medium | Medium | Map accuracy | High |
| SLAM | High | Low | High | Illumination | High |
| Visual Odometry | Medium | Low | High | Illumination | High |
| Map-Based Matching | Very High | Medium | Very high | Map change | Very High |
| Date | Reference | Method | Translation | Rotation | Runtime | Sensor |
|---|---|---|---|---|---|---|
| 2017 | [138] | SOFT-SLAM 2 | 0.65% | 0.0014 | 0.1 s | Stereo |
| 2018 | [139] | LG-SLAM | 0.82% | 0.0020 | 0.2 s | Stereo |
| 2017 | [140] | ORB-SLAM2 | 1.15% | 0.0027 | 0.06 s | Stereo |
| 2015 | [141] | S-LSD-SLAM | 1.20% | 0.0033 | 0.07 s | Stereo |
| 2018 | [142] | IMLS-SLAM | 0.69% | 0.0018 | 1.25 s | LIDAR |
| 2018 | [143] | MC2SLAM | 0.69% | 0.0016 | 0.1 s | LIDAR |
| 2018 | [144] | CPFG-slam | 0.87% | 0.0025 | 0.03 s | LIDAR |
| 2018 | [145] | SuMa | 1.39% | 0.0034 | 0.1 s | LIDAR |
| Year | Reference | Contribution of Deep Learning | Description | Architecture | Testing Datasets | Runtime |
|---|---|---|---|---|---|---|
| 2018 | [130] | Semantic Segmentation | Semantic segmentation produces a mask and the feature points on the mask are excluded. | DeepLab V2 | CARLA | - |
| 2019 | [148] | Feature Descriptors | Replace handcrafted descriptors with learned feature descriptors. | TFeat | EuRoC/TUM | 90 ms |
| 2018 | [132] | Semantic Segmentation | Semantic segmentation reduces the effect of dynamic objects and is used to build a dense map. | SegNet | TUM/Real Environment | 76.5 ms |
| 2019 | [131] | Semantic Segmentation | SSD Network is used to detect dynamic objects. The selection tracking algorithm is used to eliminate dynamic objects and a missed detection compensation algorithm is used for improvements. | SSD | TUM/KITTI | 45 ms |
| 2018 | [149] | Pose Estimation | End-to-end trained model that consist of a local pose estimation model, pose selection module, and graph optimization process. | FlowNet DTC | Viz-Doom simulated maze | - |
| 2018 | [147] | Loop Closure | Compact unsupervised loop closure algorithm that is based on convolutional autoencoders. | Autoencoders | KITTI | - |
| 2019 | [135] | Depth Estimation | Real time algorithm that is able to reconstruct dense depth maps from RGB images. | U-Net | ICL-NUIMTUM RGB | 94 ms |
| 2020 | [136] | Depth Estimation | A recurrent CNN network that is used to process spatial and temporal information for map depth estimation. | Convolutional GRU (U-Net) | KITTI | 80 ms |
| Date | Reference | Method | Translation | Rotation | Runtime | Sensors |
|---|---|---|---|---|---|---|
| 2015 | [151] | V-LOAM | 0.54% | 0.0013 | 0.1 s | MC + LIDAR |
| 2019 | [143] | MC2SLAM | 0.69% | 0.0016 | 0.1 s | IMU + LIDAR |
| 2018 | [156] | LIMO2_GP | 0.84% | 0.0022 | 0.2 s | MC + LIDAR |
| 2017 | [157] | GDVO | 0.86% | 0.0031 | 0.09 s | SC |
| 2018 | [156] | LIMO | 0.93% | 0.0026 | 0.2 s | MC + LIDAR |
| 2018 | [156] | LiViOdo | 1.22% | 0.0042 | 0.5 s | MC + LIDAR |
| 2019 | [158] | SALO | 1.37% | 0.0051 | 0.6 s | LIDAR |
| 2019 | [159] | KLTVO | 2.86% | 0.0044 | 0.1 s | SC |
| Year | Reference | Description | Architecture | Testing Datasets | Learning Model |
|---|---|---|---|---|---|
| 2017 | [155] | End-to-end algorithm for finding poses directly from RGB images using deep recurrent convolutional neural networks. | CNN-LSTM | KITTI | Supervised |
| 2019 | [163] | Encode-regress network that produces 6-Degree of Freedom (DoF) poses without the need of depth maps. | ERNet | KITTI | Semi-Supervised |
| 2016 | [153] | Two parallel CNN networks are connected at the end by fully connected layers to generate the required pose. | AlexNet | KITTI | Supervised |
| 2017 | [160] | An end-to-end algorithm that uses single-view depth and multi-view pose for camera depth and motion estimation. | DispNet | KITTI | Unsupervised |
| 2017 | [152] | An approach that generates a 7-dimensional relative camera pose orientation and position vector. | AlexNet with SPP | DTU | Supervised |
| 2018 | [161] | Pose and dense depth map estimation with an absolute scale. This generates 6 DoF poses from unlabeled stereo images. | VGG-16 and Encoder-Decoder | KITTI | Unsupervised |
| 2020 | [162] | The algorithm uses deep networks for depth, pose, and uncertainty estimation of monocular odometry. | U-Net (DepthNet and PoseNet) | KITTI EuROC MAV | Unsupervised |
| 2018 | [164] | A global pose regression and relative pose estimation framework. The network takes two monocular frames and regresses the 6 DoF poses with inter-task correlation. | ResNet-50 | Microsoft 7-Scenes Cambridge Landmarks | Supervised |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fayyad, J.; Jaradat, M.A.; Gruyer, D.; Najjaran, H. Deep Learning Sensor Fusion for Autonomous Vehicle Perception and Localization: A Review. Sensors 2020, 20, 4220. https://doi.org/10.3390/s20154220
Fayyad J, Jaradat MA, Gruyer D, Najjaran H. Deep Learning Sensor Fusion for Autonomous Vehicle Perception and Localization: A Review. Sensors. 2020; 20(15):4220. https://doi.org/10.3390/s20154220
Chicago/Turabian StyleFayyad, Jamil, Mohammad A. Jaradat, Dominique Gruyer, and Homayoun Najjaran. 2020. "Deep Learning Sensor Fusion for Autonomous Vehicle Perception and Localization: A Review" Sensors 20, no. 15: 4220. https://doi.org/10.3390/s20154220
APA StyleFayyad, J., Jaradat, M. A., Gruyer, D., & Najjaran, H. (2020). Deep Learning Sensor Fusion for Autonomous Vehicle Perception and Localization: A Review. Sensors, 20(15), 4220. https://doi.org/10.3390/s20154220