1. Introduction
The recent adoption of innovative Internet of Things (IoT) technologies and products led to the evolution of several domains of critical infrastructures, including health, transportation, and utilities. Power grids, in particular, have been enhanced with Information and Communication Technologies (ICT) at operational and resiliency level with new smart functionalities, including real-time monitoring, smart management, smart customer billing, and provisioning of resources to normalize fluctuations and address unexpected events. Smart meters, phasor measurement units, smart relays, remote terminal units (RTUs), and Programmable Logic Controllers (PLCs) are only a few of the IoT devices that are utilized by energy operators in order to convert traditional power grids to smart grids.
However, the introduction of all these new IoT devices has side effects, including an increasing attack surface. According to the Cisco Annual Internet Report for 2018–2023 [
1], it is estimated that Distributed Denial of Service (DDoS) attacks will double to 15.4 million by 2023, which is expressed in 14% Compound Annual Growth Rate (CAGR). The statistics coming from the energy sector are also worrisome. According to LNS Research, 53% of industrial stakeholders have reported experiencing a cyberattack in the last 12 months [
2] and “76% of energy executives cited business interruption as the most impactful cyber loss scenario for their organization” [
3]. It is evident that even though the research on cybersecurity is progressing rapidly and the market stakeholders pursue the adoption of new cybersecurity products, cyber threats have an increasing trend.
The research community has provided innovative solutions to tackle cyber threats in the critical infrastructure and the energy domain, including intrusion detection systems and threat information sharing platforms that leverage Artificial Intelligence (AI) and modern cryptography techniques. The H2020-DS-SC7-2017 SPEAR: Secure and PrivatE smArt gRid project is a research project, funded by the European Commission, intends to provide a complete cybersecurity solution for modern smart grids by integrating AI-enabled anomaly detection, visual analytics, reputation schemes, forensic investigation frameworks, and deception mechanisms [
4].
Even though security mechanisms like signature-based and behavioral-based anomaly detection dominate in the cybersecurity domain, honeypots are emerging as an alternative strategy to trap intelligent cyberattackers that bypass traditional security measures. A first widely accepted definition of honeypots is provided by Spitzner [
5]: “A honeypot is a decoy computer resource whose value lies in being probed, attacked, or compromised.” Honeypots are deployed by organizations to disorient cyberattackers that target the infrastructure in production and persuade them to attack the honeypots rather than the real infrastructure. This can serve multiple purposes: either to prevent attacks against the valuable assets or to collect intelligence about the attacker’s activity. These deployment options are known as production and research honeypots, respectively [
6].
A major drawback of honeypots is that, during their operation, they reserve resources in a constant manner, regardless of the attacker’s activity, if any. Therefore, a large number of honeypots may lead to resource wastage, while a small number of honeypots may result to inefficient defenses to potential cyberattackers, thus resources are also wasted in this case as the invested resources do not accomplish their purpose. This practical quandary that security engineers face with honeypot orchestration is an active research issue, and game theory has been proposed to enable dynamic configuration of honeypots, by providing the optimal strategy for the defender, taking into account that the adversary is rational and tries to maximize his payoff. Our research aims to address the issue of honeypot orchestration by focusing on smart grid systems and considering their unique characteristics [
7].
1.1. Related Works & Motivation
Game theory and its potential applications have been thoroughly studied in the context of cyber security [
8] and honeypot deployment [
9,
10], although there is a lack of realistic schemes. The following paragraphs provide an overview of frameworks related to honeypot deployment and orchestration that were considered for our work.
Denial of Service (DoS) and Distributed DoS (DDoS) attack scenarios gain significant attention in the literature as their detection and mitigation is still an open research issue in the domain of cybersecurity. Thus, many of the existing game theory models focus on such type of attacks and provide specific strategies to confront such threats [
11]. In more detail, Ceker et al. [
12] have proposed a deception-based defense framework to tackle DoS attacks as well as threats that may employ unconventional stealth methods. The proposed framework provides a game-theoretical approach to model the interaction between the defender and the attacker, while a proactive deception mechanism is employed in this dynamic game to confuse the attacker about the defender’s profile. The deception mechanism is based on a Bayesian signaling game of incomplete information, and the perfect Bayesian Equilibrium is utilized as a solution of the proposed framework that takes into consideration resource constraints. The analytical results study the relation between invested resources, processing cost, and the desired security level. Even though the proposed game provides a dynamic framework that scales to other kinds of attacks, except DoS, it is highlighted by the authors that several limitations apply, one of them is that legitimate users may be blocked by the defender, while the defender cost is constant and could be converted to a dynamic function that reflects the implications of the decided actions in a more realistic way.
Wang et al. [
13] investigated the deployment of honeypots in an Advanced Metering Infrastructure (AMI), a typical network architecture utilized by Distribution System Operators (DSO) to obtain measurements from smart meters in the modern smart grid. The proposed game aims to address DDoS attacks in the aforementioned network topology, and to this aim, they introduce a Bayesian game model to find the equilibrium between legitimate users and attackers. An AMI network with four service providers, 10 honeypots, and two anti-honeypots is simulated via OPNET to obtain evaluation results, which indicate the optimal number of honeypots to be deployed with the given parameters when a balance between detection rate and energy consumption is achieved. It is also highlighted by the authors that the effectiveness of the defense strategy does not necessarily improve when more honeypots are deployed.
The promising and innovative concept of Software-Defined Networks (SDN) is adopted in [
14] to propose a game-theoretic framework that estimates the optimal strategies for both defenders and attackers, considering the balance between energy consumption and detection rate. As highlighted by the authors, the centralized nature of SDN makes the architecture susceptible to (D)DoS attacks, and the proposed model aims to deploy a defense mechanism against such attacks. Moreover, anti-honeypot attacks and pseudo-honeypot game strategies are introduced in this research to model and tackle DDoS attacks, respectively, resulting in several Bayesian Nash solutions. To evaluate the proposed model, a realistic testbed was constructed with hosts, attackers, and OpenFlow switches. The experimental results outperform in terms of performance in energy consumption and detection rate.
Al-Shaer et al. [
15] proposed a different approach, compared to the previously mentioned references, that is based on the hypergame theory. The main motives of this perspective are the capabilities that are offered in terms of defense strategies for both proactive and reactive approaches as well as the limited contribution in the literature regarding mature and well-structured mathematical frameworks listing the hypergame concept. In the proposed work, an attack–defense model is structured with subjective beliefs in a dynamic environment, in which the defender tries to manipulate the attacker’s belief utilizing deception techniques. Hypergame theory provides the ability to estimate the decision of each player and the impact that the uncertainty has on the expected utility. The deception model is studied by modeling a Stochastic Petri Net and the results deliver insightful findings that relate the perceptions by different players (i.e., an attacker or a defender) with their chosen optimal strategies and the corresponding utilities.
A Partially Observable Stochastic Game (POSG) was introduced in [
16] that applies in situations where each player has partial information about the environment. In particular, the authors develop a POSG-based game theoretic framework to optimize honeypot deployment that assumes literal movement of the attacker in a computer network. The attacker and the defender are placed on a graph, in which nodes represent network hosts and the edges represent attacks against other hosts, with each attack incurring an associated cost. In this context, the attacker tries iteratively to attack hosts, while the defender chooses the edges that will act as honeypots. The experimental results prove that the POSG model was able to generate near-optimal deployment strategies as well as realistic and scalable networks of multiple hosts.
The authors of [
17,
18] proposed a game-theoretic framework that focuses on Cyber-Physical system (CPS) honeypots, with both low and high interaction. The proposed model is specifically used to deploy defensive mechanisms against Advanced Persistent Threats (APTs) in CPS and considers limited resources for honeypot allocation and human analysis as well as incomplete information for the players. Simulation results prove that the proposed model succeeds to maximize the defender’s payoff and provides multiple Bayesian equilibria.
The authors of [
19,
20] used game theory to study various attacks and defense scenarios in networks with honeypots. Specifically, they utilize a Bayesian model to adequately reflect the defender’s imperfect knowledge of user behavior (i.e., normal or malicious), thus forming a Bayesian signaling game of incomplete information. A one-shot game model is presented in order to determine how the defender should react to different user behaviors. Moreover, the authors provided a repeated version of this game that enables the players to update their opinions under a Bayes rule. Finally, mathematical analysis, as well as simulations, are used to find the equilibria and further evaluate the model. The results suggest that when the defender is facing attacks with high frequency, the best action is to massively deploy honeypots. Otherwise, in the case of low-frequency attacks, the defender can mix up their strategy.
Finally, Bilinski et al. in [
21] investigated the Nash Equilibrium (NE) of a honeynet system, in which the defender aims to protect a number of network hosts and has a fixed set of resources, therefore can defend only a limited number of hosts. On the contrary, the attacker can attack a specific number of hosts concurrently, although no cost is incurred to the adversary for each attack. In this context, the attacker is considered the winner if they attack a real host and not a honeypot, otherwise the defender wins. The analysis of the proposed model concludes that the value of a host is inversely proportional to the probability of the host to being attacked. However, certain limitations are remarked, including the fact that the attacker’s activity is not limited by a cost function and that the proposed game assumes that the attacker wins the game if it attacks any host which is not a honeypot as well as that the number of served real devices is fixed, despite the fact that limited resources have been assumed. Finally, a similar scenario has been investigated in [
22], assuming though that the defender has complete information about the attacker’s payoff, a cost function for the attacker, and fixed number of served real devices, which has led to the formulation of a Stackelberg game. Moreover, in contrast in [
21], the payoff of the attacker has been considered to be an increasing function of the number of attacked real devices.
1.2. Contribution
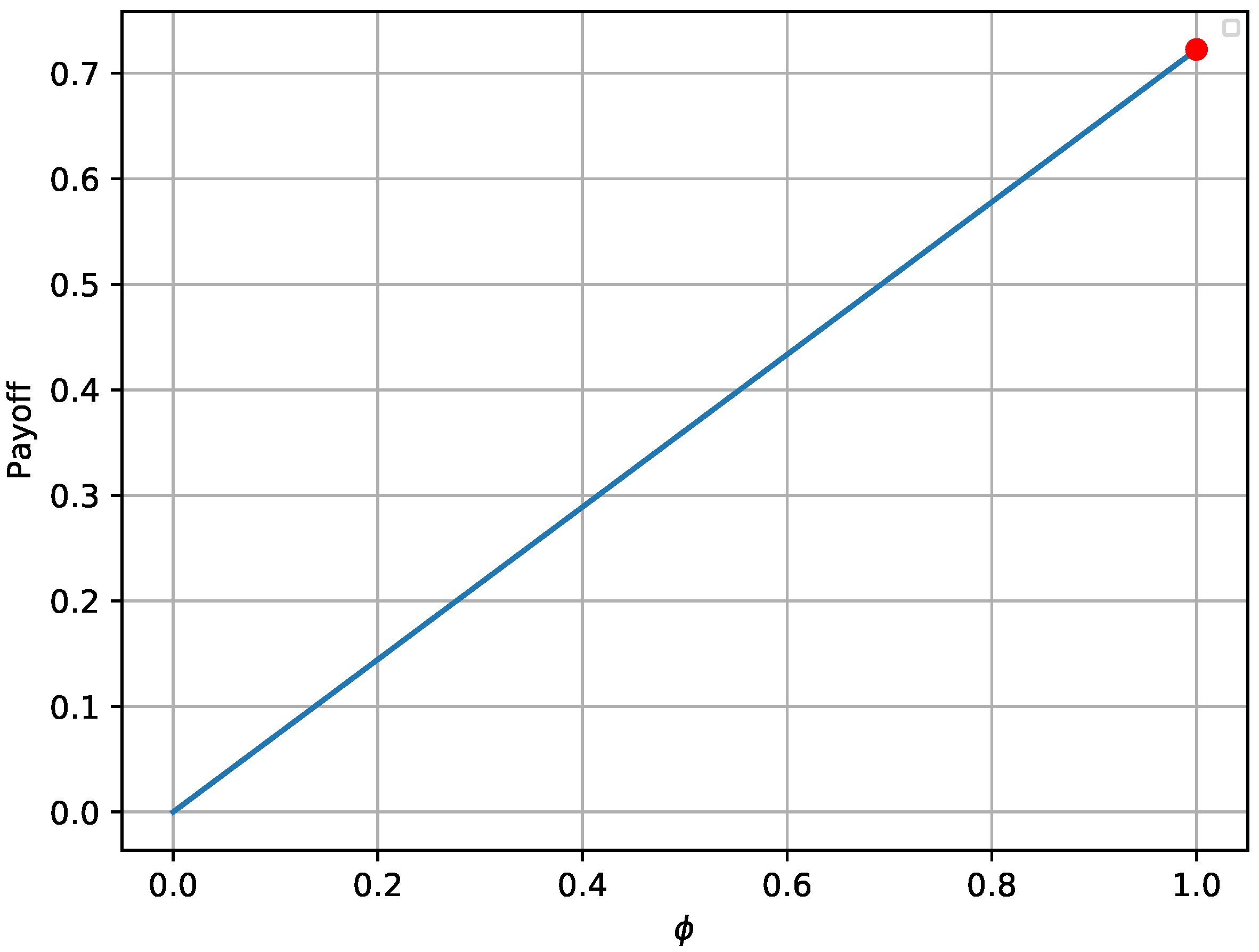
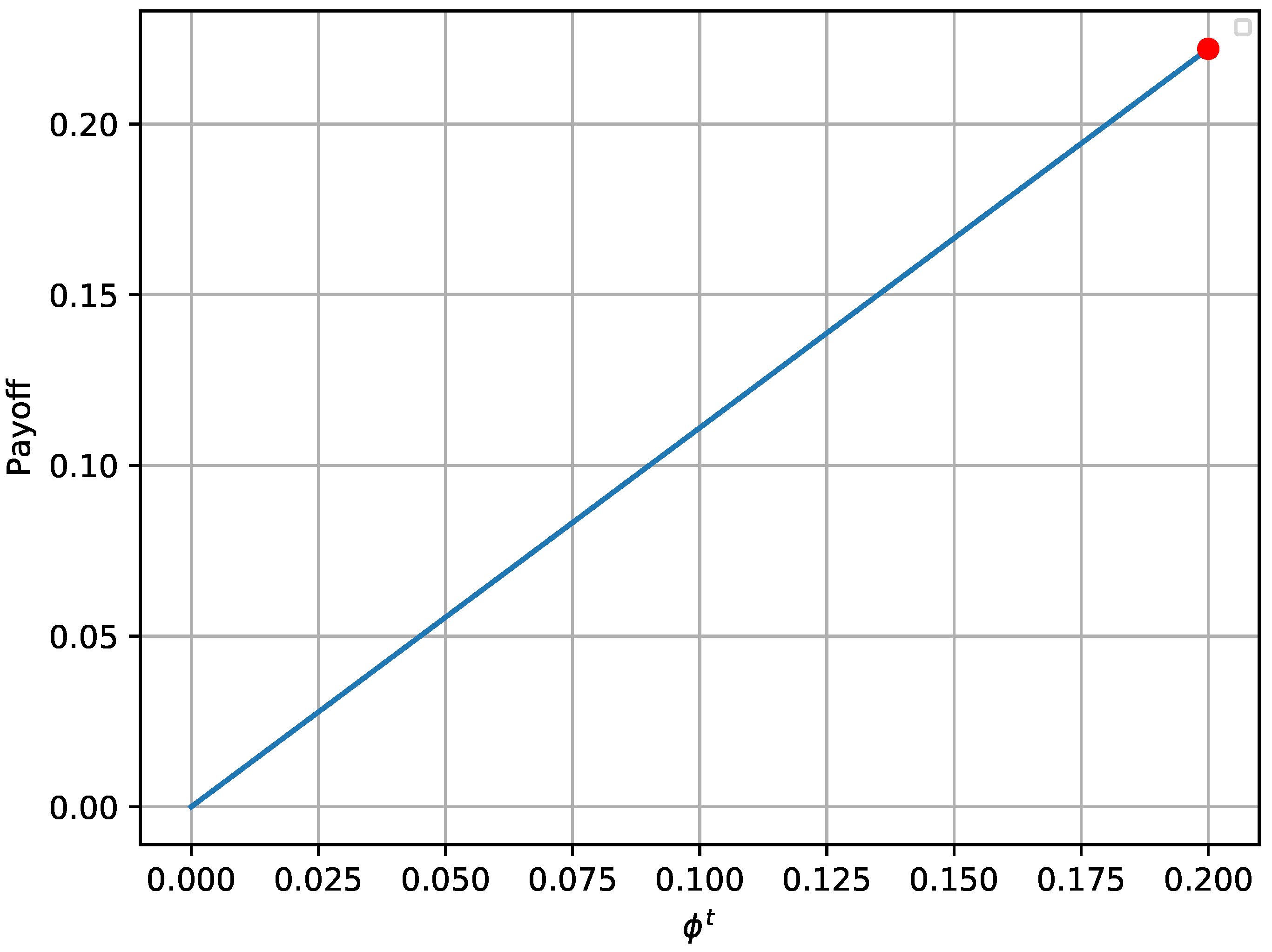
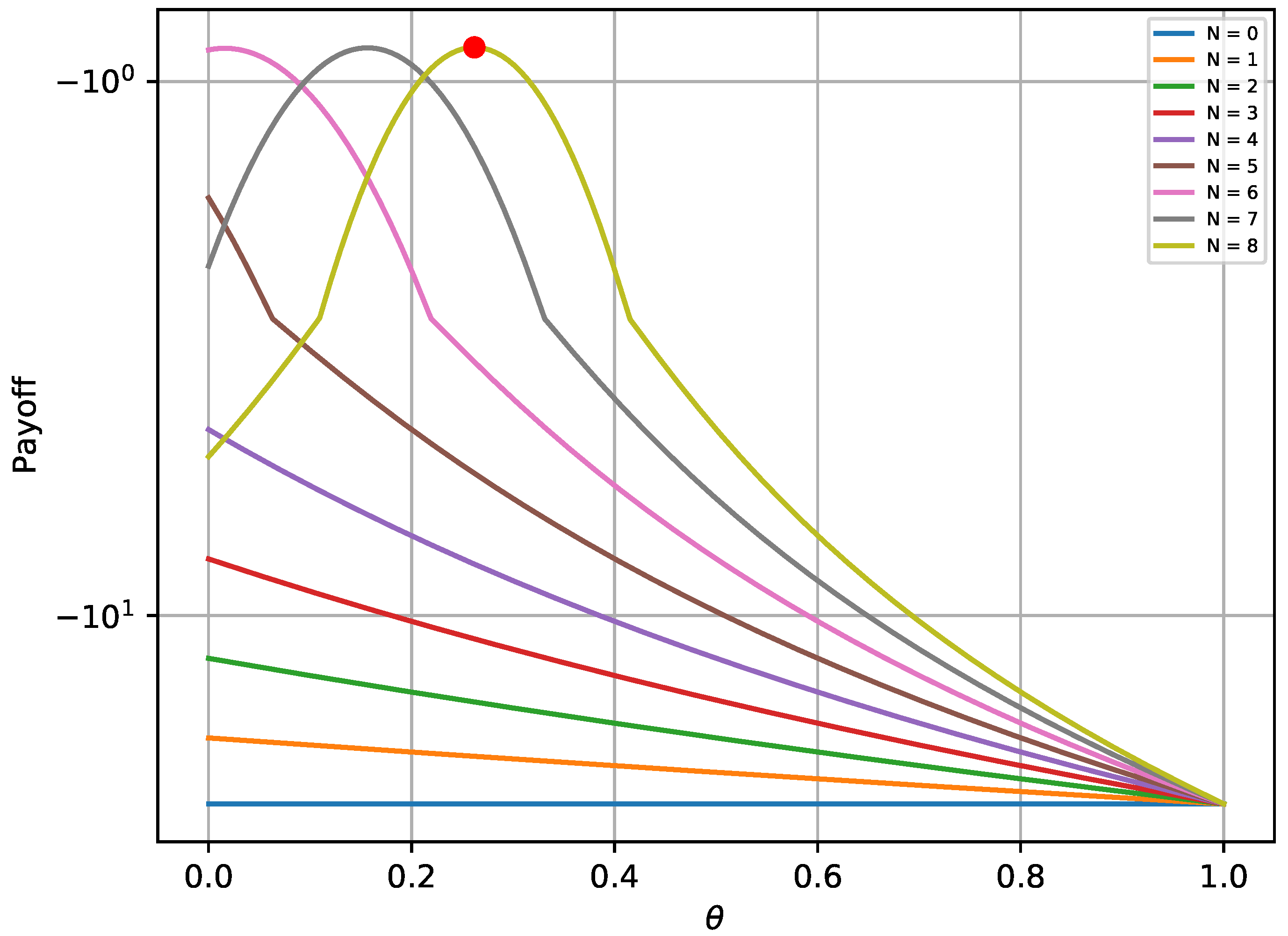
In this paper, game theory is used to model the interaction between an attacker and a defender, who makes use of honeypots to mitigate the impact of attacks within a smart grid. Taking into account the trade-off between connectivity and security, which is an important challenge in the smart grid, a novel framework is proposed according to which the defender has the option to periodically substitute part of the real devices with honeypots, e.g., for a portion of time, with the aim to deceive the attacker. More specifically, the defender optimizes the number of connected real devices and honeypots, taking into account the attacker’s preferences. First, we focus on one encounter between the attacker and the defender, which is solved by using the concept of NE. Moreover, an alternative optimization framework is proposed for the case that the NE does not exist. Next, we extend the analysis considering a more sophisticated attacker, who randomizes its strategy, by attacking a random number of hosts, while also considering a repeated game and uncertainty about the attacker’s payoff parameters. In this case, the interaction between the attacker and the defender is modeled as a multi-stage Bayesian game and the Bayesian NE is derived. Moreover, a rule to update the defender’s belief about the type of the attacker is also provided. Finally, simulation results are provided to illustrate the effectiveness of the proposed framework.
1.3. Structure
The rest of the paper is organized as follows. The system model for the strategies and payoffs of the attacker and the defender is introduced in
Section 2. In
Section 3, the NE in the case of a one-shot game is derived, while the case that the NE does not exist is also discussed. In
Section 4, the results of
Section 3 are extended to the case of repeated games with uncertainty about the type of the attacker. Simulation results are given and discussed in
Section 5. Finally, conclusions are summarized in
Section 6.
2. System Model
A defending system is considered within a smart grid, hereinafter termed as a defender, that protects a collection of hosts from a potential attacker by using honeypots, which are able to detect unauthorized accesses, collect evidence, and help hide the real devices [
13]. The honeypots are designed to mimic common services of the smart grid, including Industrial Control System (ICS) devices, smart meters, and smart appliances, among others [
7].
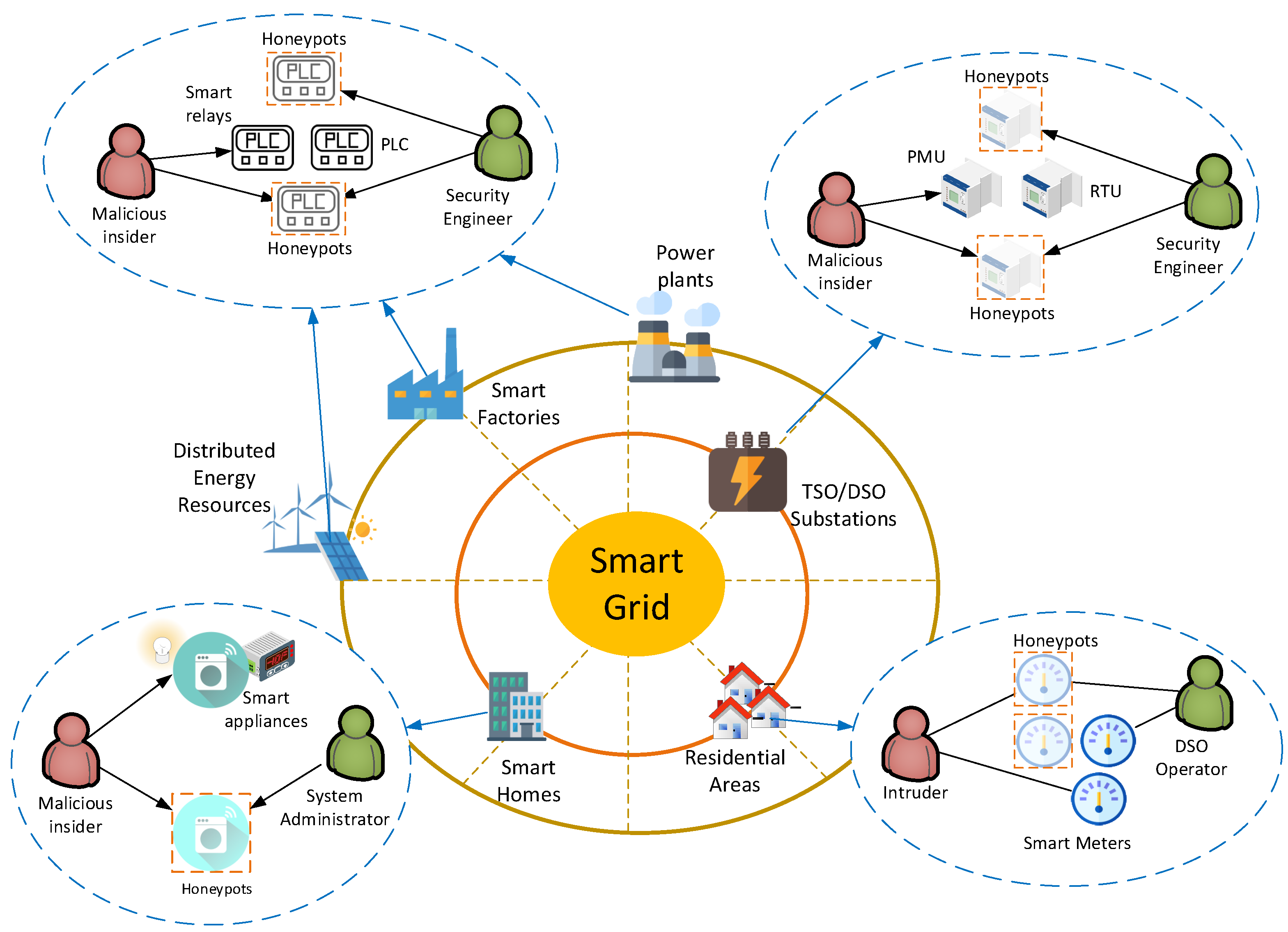
Figure 1 depicts the most common locations of attack threats and honeypots as well as real-life applications of the proposed model. In more detail, honeypots could be deployed in Supervisory Control and Data Acquisition (SCADA) networks, located in smart factories, power plants, and Distributed Energy Resources (DERs), to mimic various ICS devices, including Programmable Logic Controllers (PLCs), sensors, and smart relays, among others [
23]. Moreover, honeypots could be deployed in substations owned by Transmission System Operators (TSO) or Distribution System Operators (DSO) to emulate more advanced ICS devices, including Remote Terminal Units (RTUs) and Phasor Measurement Units (PMUs). Finally, honeypots could be applicable in smart buildings to emulate smart appliances and energy meters or in Advanced Metering Infrastructures (AMIs), operated by DSOs, to emulate smart meters [
24]. It is assumed that the defender has a fixed set of resources and, as a result, is only able to defend a limited number of hosts [
21].
Considering the proposed system model, the corresponding attack model ensembles a wide range of attack scenarios, especially those that target specific vulnerable network assets and in which the adversary has to choose between assets in the operational environment and honeypots. In more detail, DoS attacks are very common in smart grid applications and include a variety of attacks, such as buffer overflow, flooding, and amplification attacks, among others, that aim to render a remote service inaccessible to legitimate users. By its definition, the proposed system model aggregates possible multiple adversaries to a single entity, therefore the attack model also considers DDoS attacks, where multiple systems launch orchestrated attacks against a single host. Finally, False Data Injection Attacks (FDIAs) can also be considered for the attack model as they target specific assets in a smart grid. FDIAs aim to tamper control systems with falsified data that can manipulate the decision of automation systems, with severe consequences ranging from the destruction of smart grid equipment to grid fluctuations, instabilities, and financial loses [
25].
Let denote the total number of hosts within a block of IP addresses, with the value of N being controlled by the defender. Additionally to the total number of hosts, the defender can also control which of them are used by real devices and honeypots, with the aim to mitigate the impact of potential attacks without unnecessarily increasing the related costs. It is highlighted that in the considered scenario, the defender has the option to increase the number of honeypots by disconnecting real devices (each of which for a portion of time), if this further assists on further mitigating the impact of potential attacks. This approach aims at exploring the potential security gains of “hiding” some of the real devices and substituting them with honeypots. In general, the defender’s decision is affected by several parameters, such as the deployment costs; the benefit of capturing an attack with a honeypot; the cost of having a number of real devices under attack; and the trade-off between increasing the number of real devices that are connected to the smart grid at each time slot, the level of security, which increases with the number of utilized honeypots, and the implementation cost.
The attacker set of strategies determines whether or not to attack a host. Thus, the attacker’s decision depends on the trade-off between the benefit acquired when attacking a real device and the cost of attacking a honeypot.
For the
t-th interval, let
be equal to 1 when the
i-th host is used by a real device and equal to
when it is used by a honeypot. On the other hand, regarding the set of strategies of the attacker, let
be equal to 1 when the attacker attacks the
j-th host and equal to 0 when the
j-th host is not attacked. For the sake of clarity, the notation is given in
Table 1.
According to the aforementioned trade-off for the attacker’s side, the attacker’s payoff is given by
where
are the non-negative weights that correspond to the impact that the number of attacked real devices; the number of attacked honeypots and the total number of attacks has on its payoff; and
f is an increasing function of
, i.e., the number of attacked real devices, and a decreasing function of
, i.e., the number of attacked honeypots. Moreover, the total number of attacks, i.e.,
, also introduces extra cost to the attacker’s payoff due to the implementation cost and the general increase of the probability of the attacker to reveal information about their identity and action. For example, assuming that the aforementioned terms have a linear impact on the attacker’s payoff,
could be written as
On the other hand, the defender’s payoff is given by
where
are the non-negative weights that correspond to the impact that the number of attacked real devices, the number of attacked honeypots, the number of real devices that are not served, and the total number of used hosts has on its payoff, and
g is an increasing function of
and a decreasing function of the absolute value of
. Moreover, the total number of hosts also introduces an extra cost. Next, it is assumed that the terms coupled with
,
, and
have a linear impact on the attacker’s payoff. Moreover, it is considered that the level of satisfaction of the defender gradually gets saturated as more real devices are served, i.e., the defender’s payoff is a concave function, hereinafter modeled by square function, of the number of real devices that are not served. Thus,
could be written as
As it has already been mentioned, if a smart grid device is attacked, this might have several negative consequences, such as the disruption of the normal operation of the electricity grid and financial loss. For example, when the attacks target the dynamic energy management (DEM) system [
26], they might lead to the under/overestimation of the energy consumption and, thus, monetary loss in energy trading. This is reflected to the first term of the payoff function of the defender. More specifically,
can be seen as a function of the average cost,
, of under- or overestimating the energy demand of the attacked device, assuming that the later corresponds to an energy consumer. Furthermore, assuming that the DEM management operation is implemented over two stages—the unit-commitment and economic-dispatch stages—the utility generates and reserves the energy supply based on the estimated energy demand of the consumers, while if the energy supply was underestimated, the utility needs to buy the energy difference between the actual and the generated energies in the economic dispatch stage to prevent the undersupply situation [
27]. In this case, the cost of under- or overestimating the energy demand of the attacked devices is given by [
27,
28,
29]
where
is the probability density function of the actual energy consumption,
is the mean energy demand of the
i-th device,
is the maximum energy consumption, and
and
are the energy prices in the unit commitment and economic dispatch stages, respectively. On the other hand, the isolated use of some devices could lead to a nonlinear increase of the energy cost, e.g., when a local energy generator is used [
30], which is taken into account by the third term of the defender’s payoff.
Moreover, it is highlighted that the different terms of the players’ payoff do not necessarily correspond to direct monetary loss or gain, but also reflect the potential impact of security risks on the reliable operation of the smart grid, which has an indirect effect on financial loss. Furthermore, it is noted that many of our results could easily be generalized assuming different functions for both and .
6. Conclusions
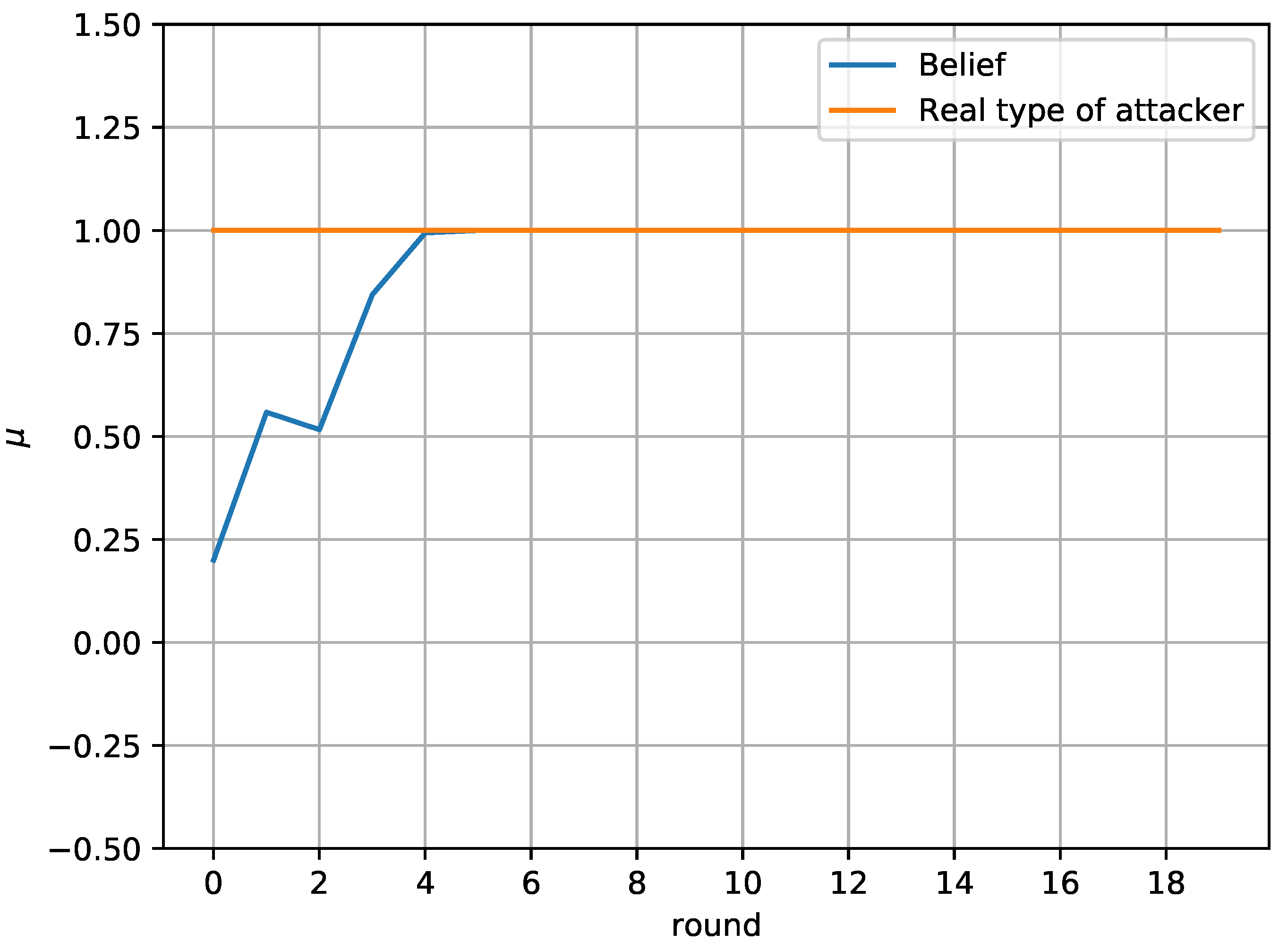
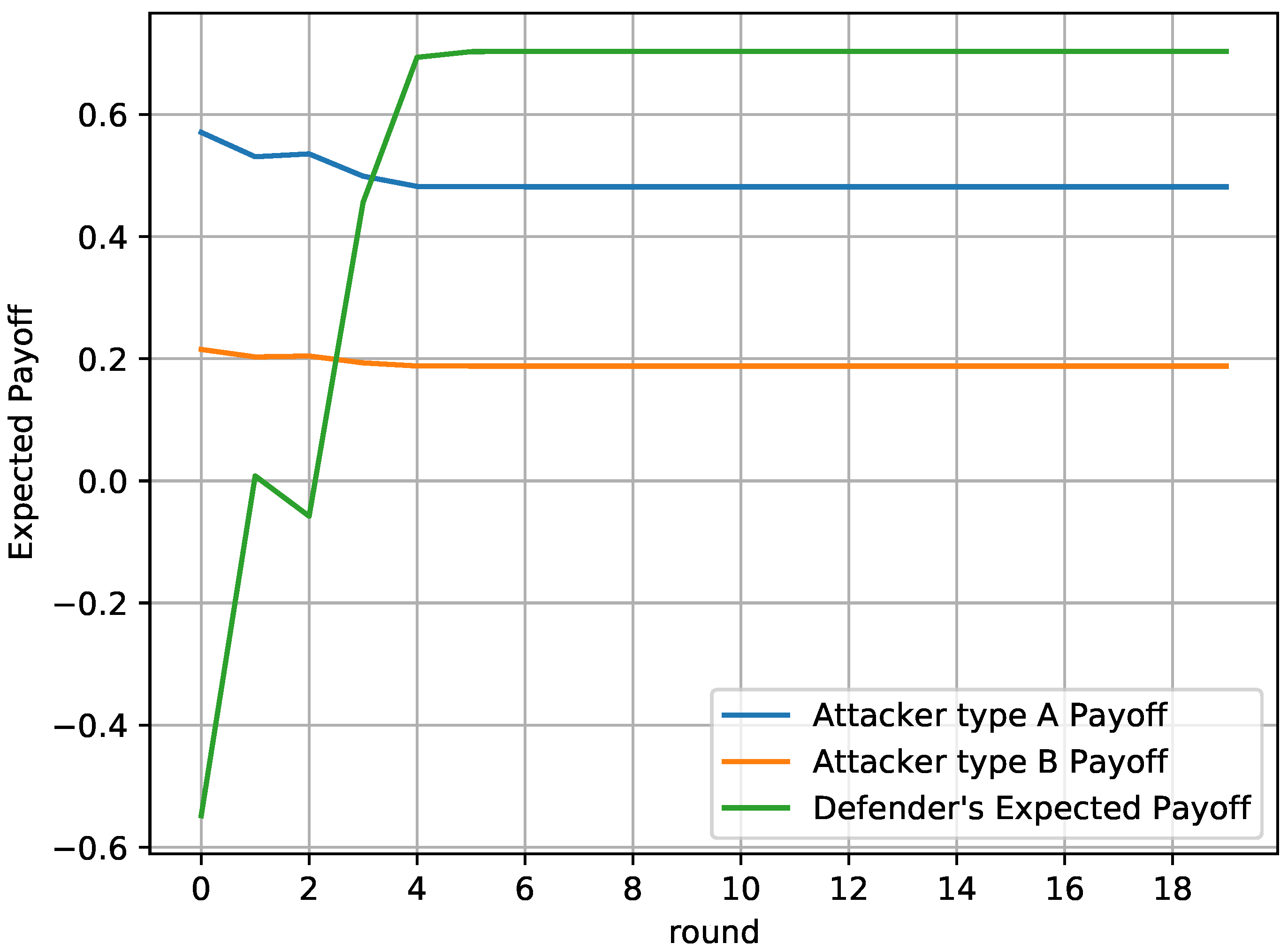
In this paper, the efficient use of honeypots has been considered with the aim of mitigating the impact of attacks to smart grid infrastructure. More specifically, the interaction of an attacker and a defender has been investigated, who both aim at maximizing their payoffs by optimizing the deployment of attacks and honeypots, respectively. Two different games have been considered, namely, a one-shot one with perfect knowledge of the players’ payoff and a repeated one with uncertainty about the payoff of the attacker. The Nash Equilibrium and the Bayesian Nash Equilibrium have been derived for the first and the second game, respectively, as well as the corresponding conditions, while the Equilibria uniqueness has been proved. Moreover, an alternative framework has also been provided for the case that an Equilibrium does not exist, which can be seen as the optimization of the worst-case scenario, as it is based on the maximization of the lowest value the attacker can force the defender to receive when they know the defender’s action. Simulation results validated the analytical results of the equilibrium for both the attacker and the defender, for both games. Furthermore, the derived solution for case that the equilibrium does not exist has also also been evaluated. Finally, concerning the repeated game, it has been shown that the defender successfully identifies the attacker’s type, thus maximizing its payoff throughout the game.
The proposed theoretical framework in the considered analysis facilitates the investigation of the potential benefits of using honeypots to enhance security in smart grids and creates opportunities for future research on this topic. For example, the use of more complicated payoffs can be explored, taking into account the particularities of different case studies. Moreover, further research is also needed in order to specify the long-term monetary gain of capturing attacks of a certain type by the utilized honeypots. Finally, the results can be extended to the case of more than two attackers types, while also considering uncertainty for the type of the defender.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}