Passenger Flow Forecasting in Metro Transfer Station Based on the Combination of Singular Spectrum Analysis and AdaBoost-Weighted Extreme Learning Machine


Abstract
1. Introduction
- Videos. The passenger flow videos are generally used to extract the passenger trajectories through image-processing techniques. The extracted data can help researchers to investigate and analyze passenger behaviors [9].
- Automatic Fare Collection (AFC) systems. Based on AFC systems, the passenger boarding and alighting information is recorded by the sensors in turnstiles automatically, and the recorded data is easy to access. The AFC systems are initially designed and employed to charge the passengers automatically. Since the AFC systems can also record some extra information of the passengers (i.e., personal identification, boarding/alighting time, boarding/alighting station, etc.), the AFC data has been used in the researches of transportation engineering. These studies are mainly focused on four fields: prediction of passenger flow [2,7,10,11,12], analysis of passenger flow patterns [13], investigation of passenger behaviors [14,15], and evaluation of metro networks [3,6].
- Parametric models. Due to a low computation complexity, parametric models are widely used in early studies—for instance, autoregressive integrated moving average (ARIMA) [17,18], Kalman filter (KF) [11], exponential smoothing (ES) [19], and so on. However, these models are sensitive to passenger flow patterns, since they are established based on the assumption of linearity.
- Nonparametric models. In order to capture the nonlinearity of passenger flow, the nonparametric models are introduced in subsequent researches, such as K-nearest neighbor (KNN) [20,21], support vector regression (SVR) [7,10], artificial neural network (ANN) [1,22], etc. The empirical results from these studies have suggested that the nonparametric models usually performed better than parametric models when the data size was large. It is owing to the ability of nonlinearity modeling.
- Hybrid models. The hybrid models are the combination of two or more individual methods. Due to both the linearity and nonlinearity of passenger flow, the hybrid models [2,23,24,25,26] are proposed to capture these two natures to increase the prediction accuracy. Both theoretical and empirical findings have demonstrated that the integration of different models can take full advantage of these models. Thus, this is an effective way to improve the predictive performance.
- Deep-learning models. Besides the aforementioned three kinds of models, according to the latest researches, the deep-learning methods have been introduced and developed in the passenger flow forecasting problem, including long short-term memory (LSTM) [12,16,27], deep belief network (DBN) [28], stacked autoencoders (SAE) [29], convolutional neural network (CNN) [12,30], etc. Due to the universal approximation capability of complex neural networks, the deep-learning models can approximate any nonlinear function in theory [24,31]. From the findings of these studies, deep-learning models usually show a superiority of high forecasting accuracy to parametric and nonparametric models. However, because of high computation complexity, the deep-learning models will require significant resources and training time [32]. In addition, these models are usually regraded as a “black box” [23] and lack interpretability of the results [32].
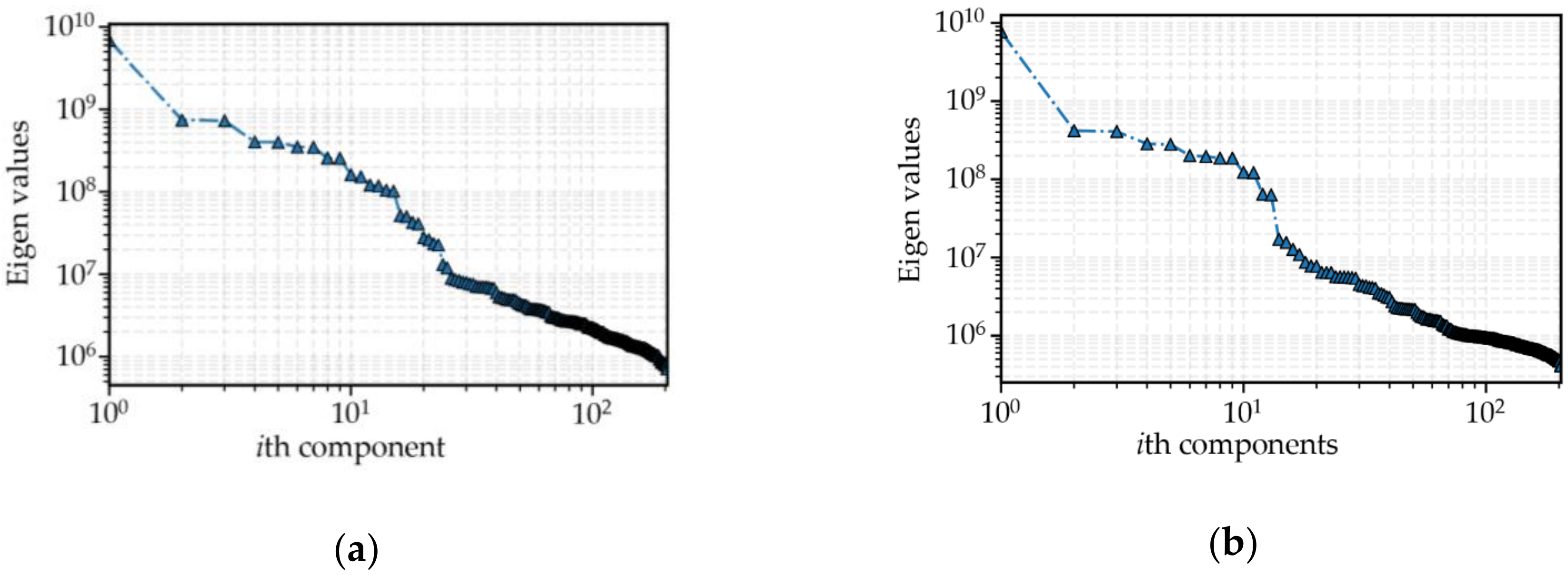
- The SSA approach is developed to decompose the original passenger into three components: trend, periodicity, and residue. Investigation of the three components can discover the inner characteristics of the original data.
- The ELM improved by AdaBoost (i.e., AWELM) is developed to forecast the three components. ELM, a neural network famous for fast computer speeds, is implemented, and the prediction performance is enhanced through AdaBoost ensemble learning. Thus, the hybrid model SSA-AWELM has the advantage of both accuracy and speediness for passenger flow forecasting.
- Multistep-ahead prediction of the passenger flow is established, which can offer more information of the future. A dataset collected from a metro AFC system is utilized to carry out the prediction tests and comparative analysis.
2. Materials and Methods
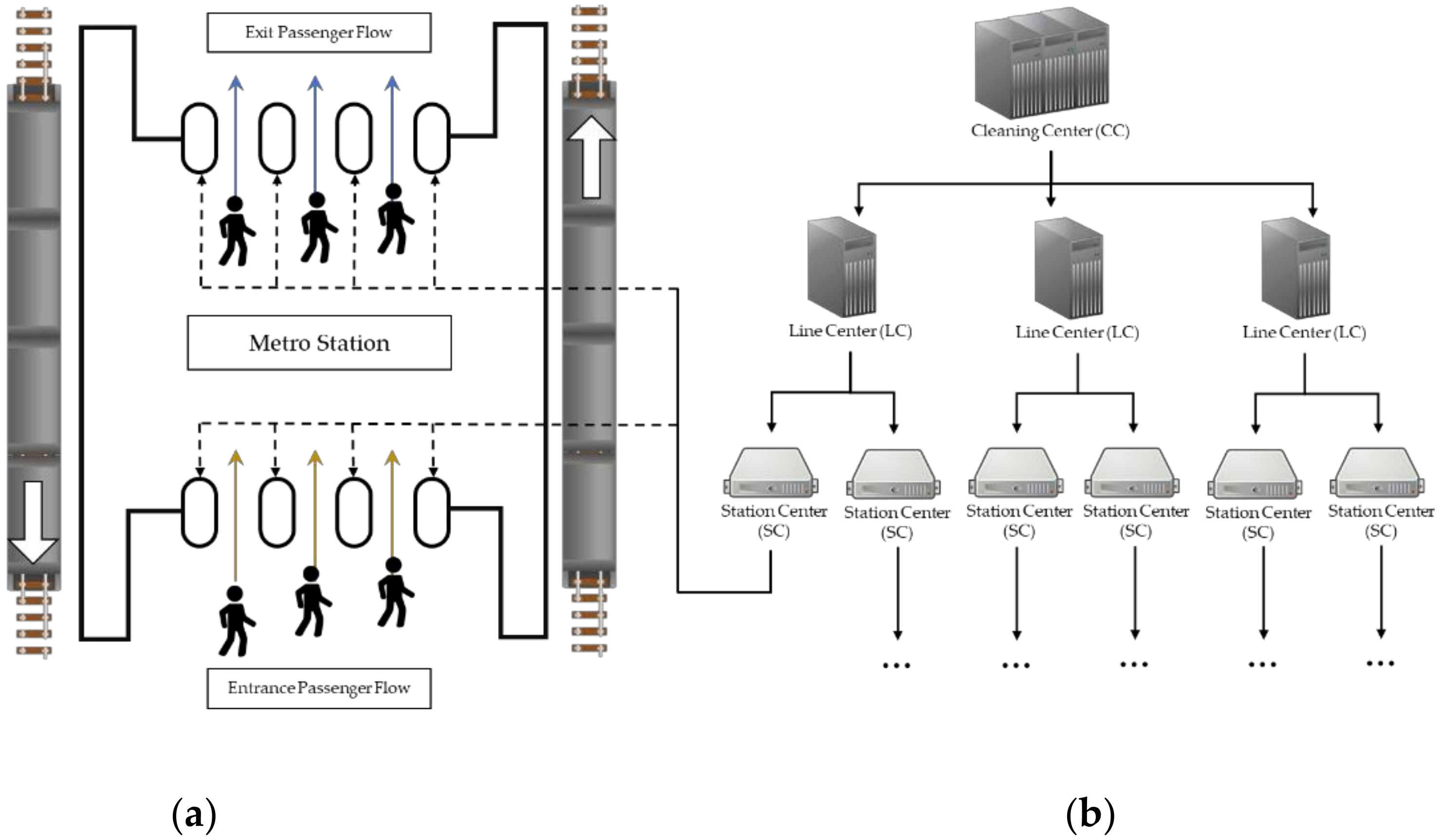
2.1. Automatic Fare Collection Systems
2.2. Passenger Flow Forecasting Problem
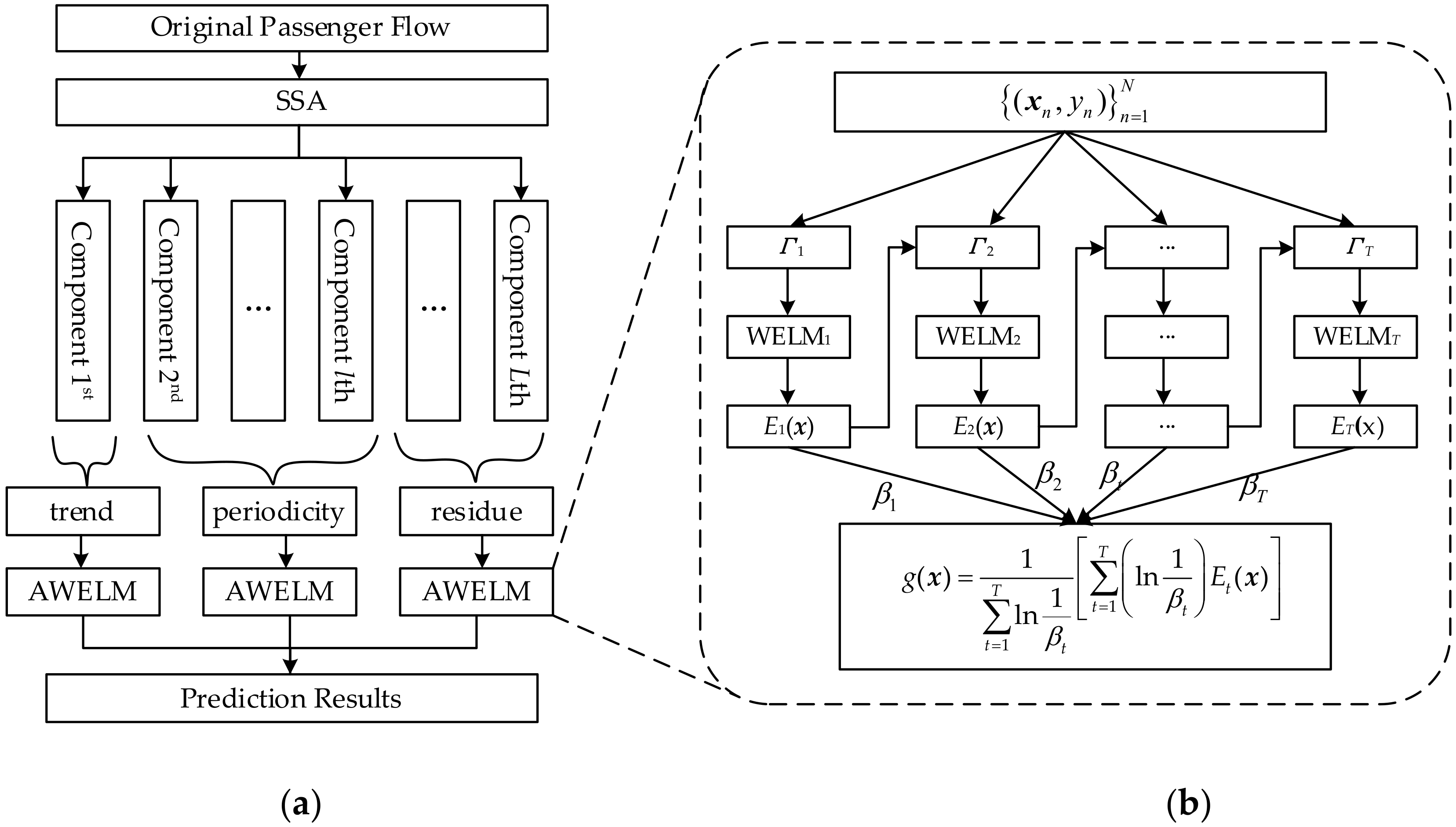
2.3. The Proposed Hybrid Model
2.3.1. Singular Spectrum Analysis
2.3.2. AdaBoost Ensemble Learning
2.3.3. Weighted Extreme Learning Machine
2.3.4. The Hybrid Model
3. Empirical Study
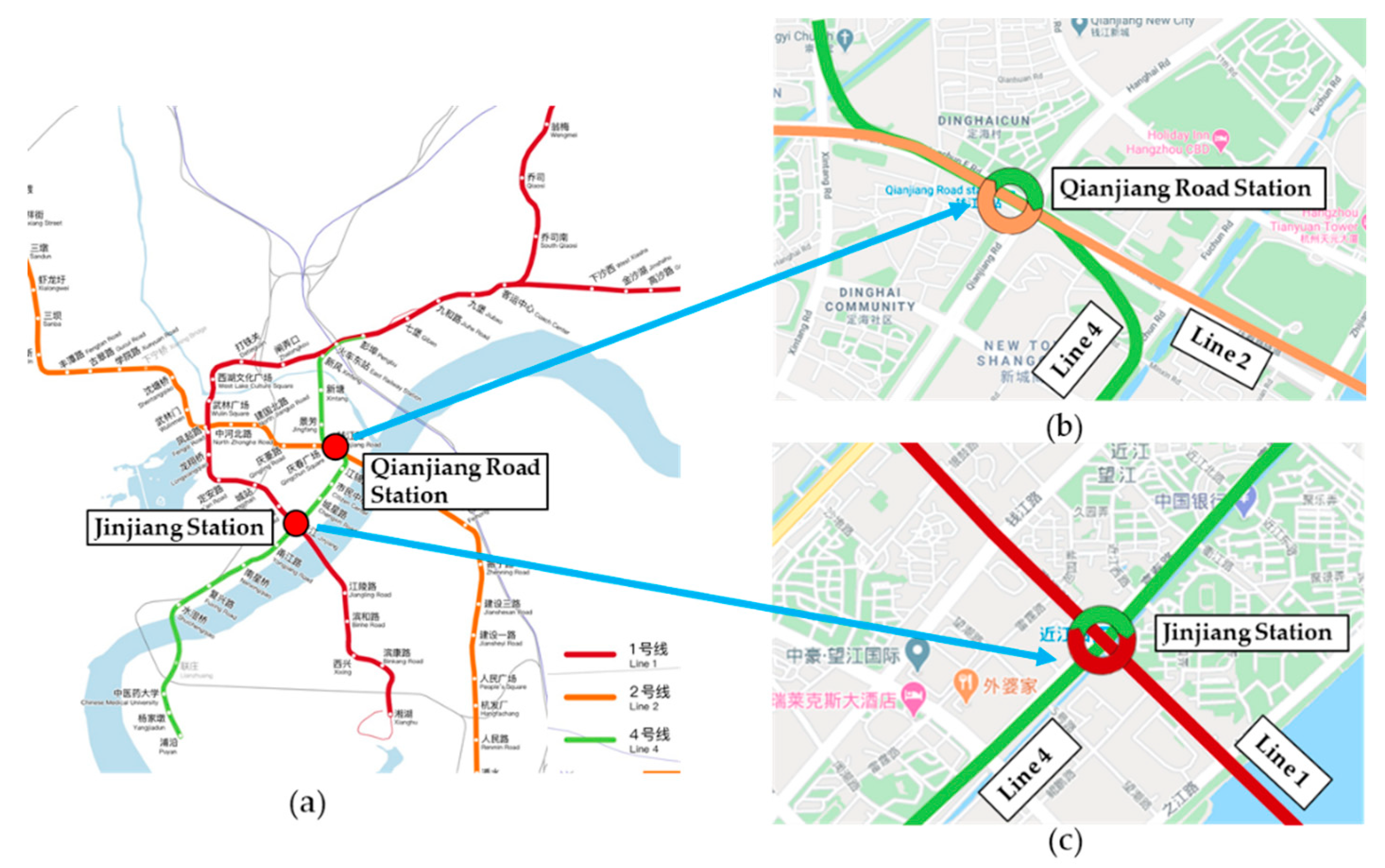
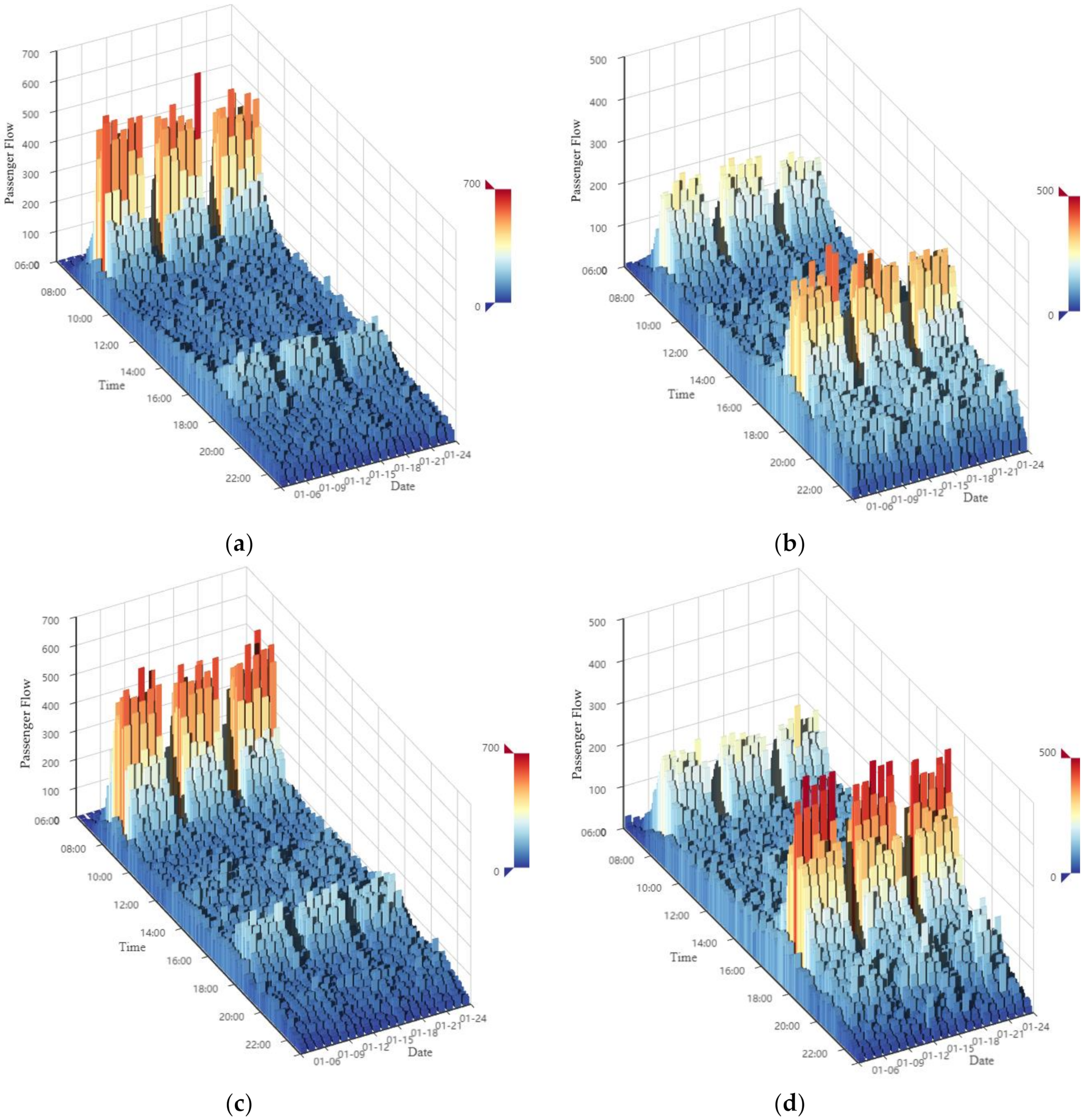
3.1. Data Collection
3.2. Data Preprocessing
3.3. Comparison Models and Evaluation Measures
- ARIMA: ARIMA is a classical statistical model for time series forecasting. It is widely used to predict traffic flow and passenger flow in early studies [17]. The performance of ARIMA is affected by three parameters: autoregressive order p, difference order d, and moving average order q. Generally, d is set based on the stationarity test, and the p and q are selected from the range of [0,12] based on the Bayesian information criterion (BIC) [51].
- ANN: Due to the ability of nonlinearity, the ANN model is widely used in time series modeling, including passenger flow forecasting. A typical ANN model consists of three parts: one input layer, one hidden layer, and one output layer and optimized through a back-propagation algorithm (thus, it also aliased as BPNN). In this study, the ANN model is optimized by a stochastic Adam algorithm with a mean square error (MSE) loss of function. The learning rate is set as 0.001, the batch-size is 256, and the epochs is 1000.
- LSTM: As a prevalent deep-learning model for time series modeling, the well-designed LSTM units replace traditional neurons in a hidden layer, which can assist the LSTM model to capture the temporal characteristics. This model has also been developed to predict the passenger flow. The parameters are set identically to the ANN model.
- ELM: The ELM model has been elaborated in Section 2.3.3.; the individual ELM model is utilized to forecast the passenger flow as a comparison.
- AWELM: The AWELM is combined by AdaBoost and WELM, which has been represented in Section 2.3.3. and Section 2.3.4.
4. Results Analysis
4.1. Analysis of SSA Decomposition
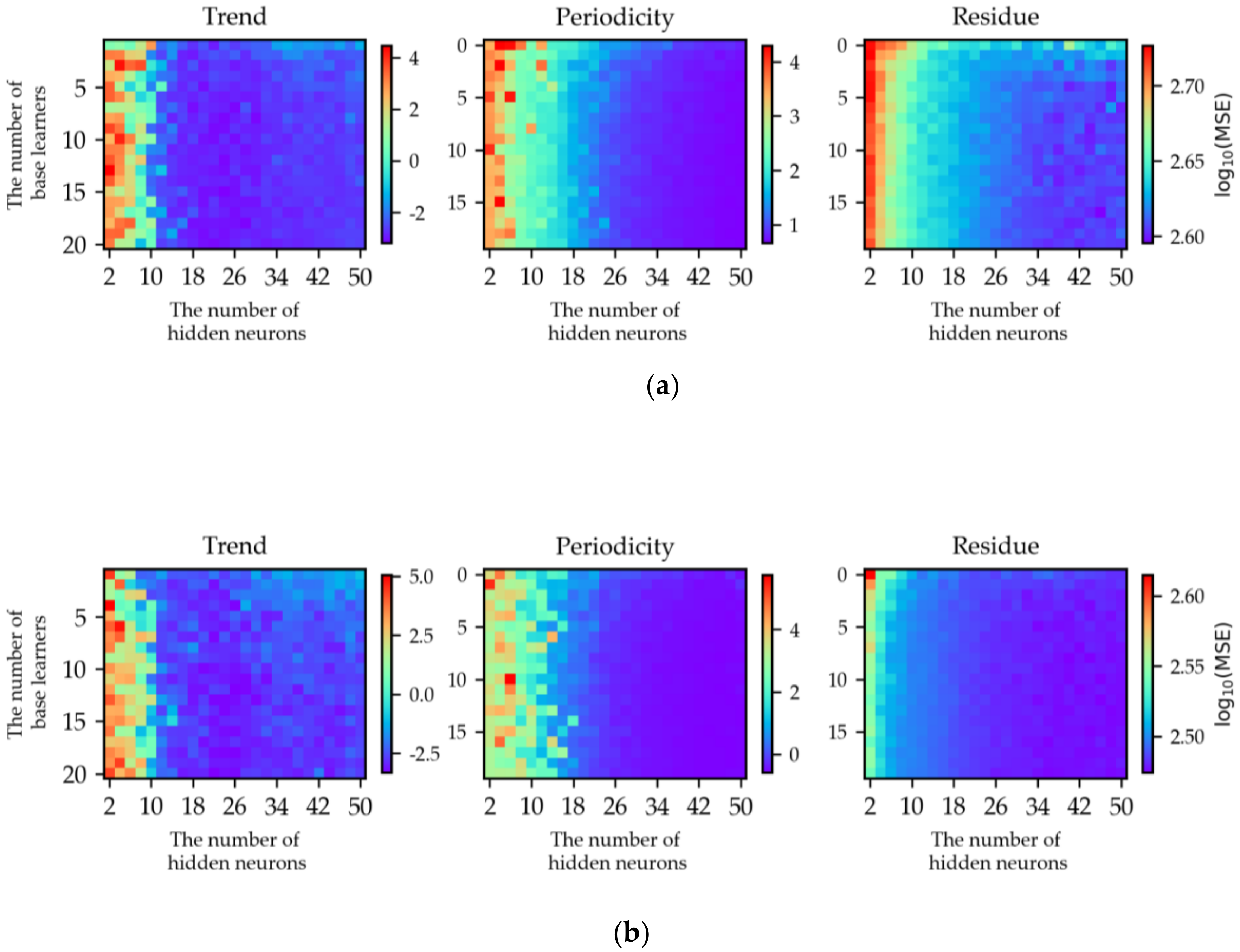
4.2. Analysis of Hyper-Parameters
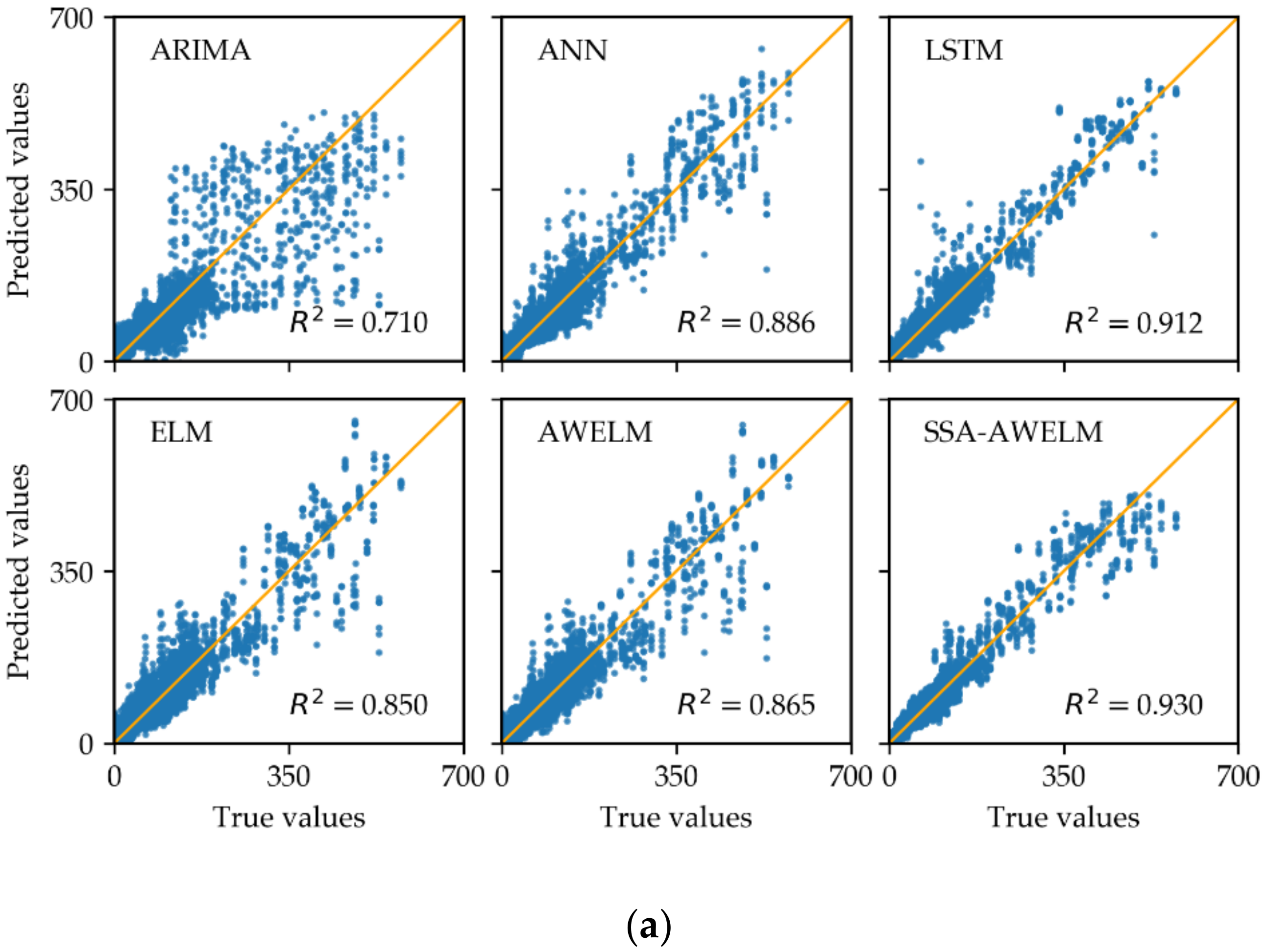
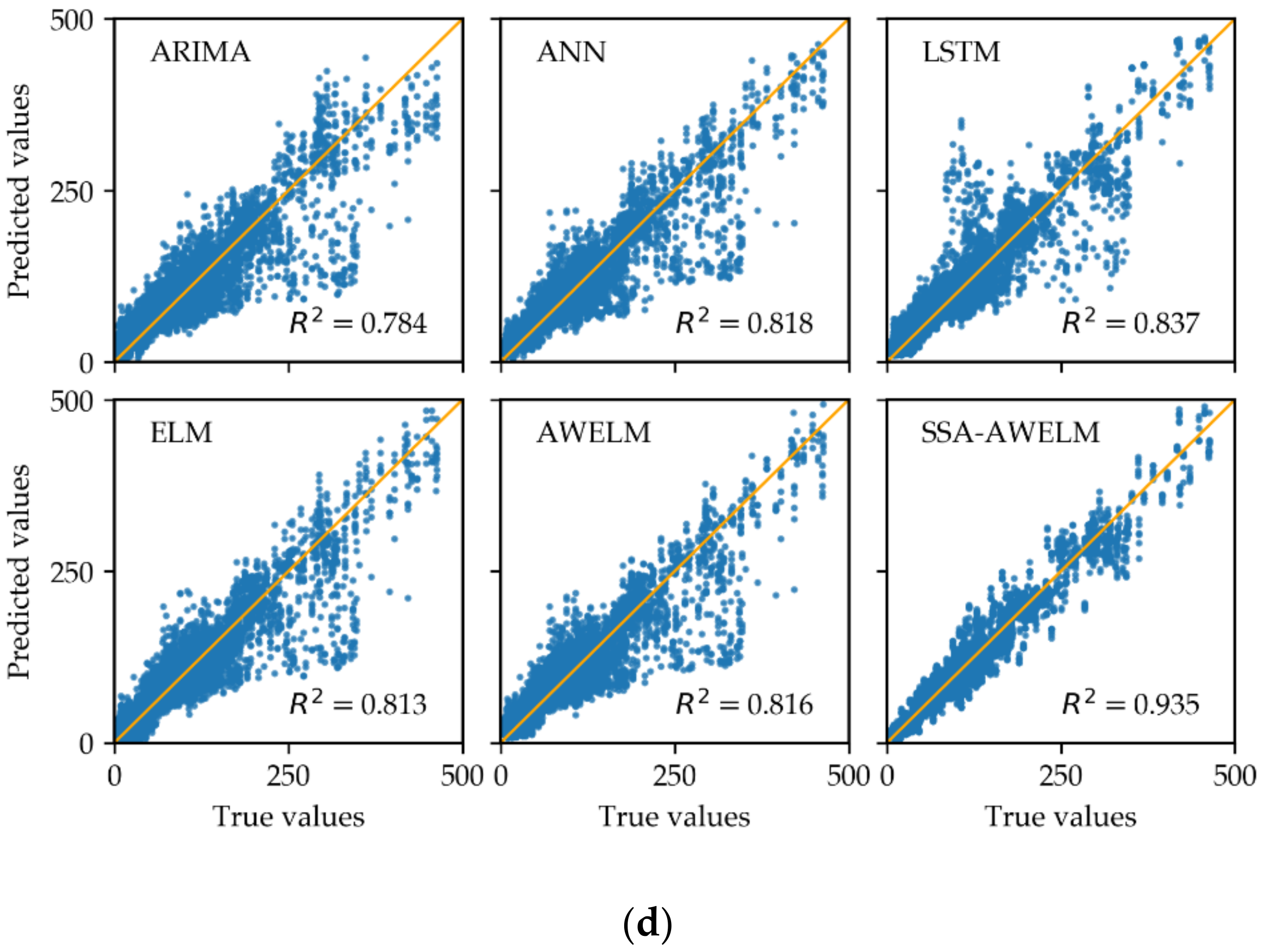
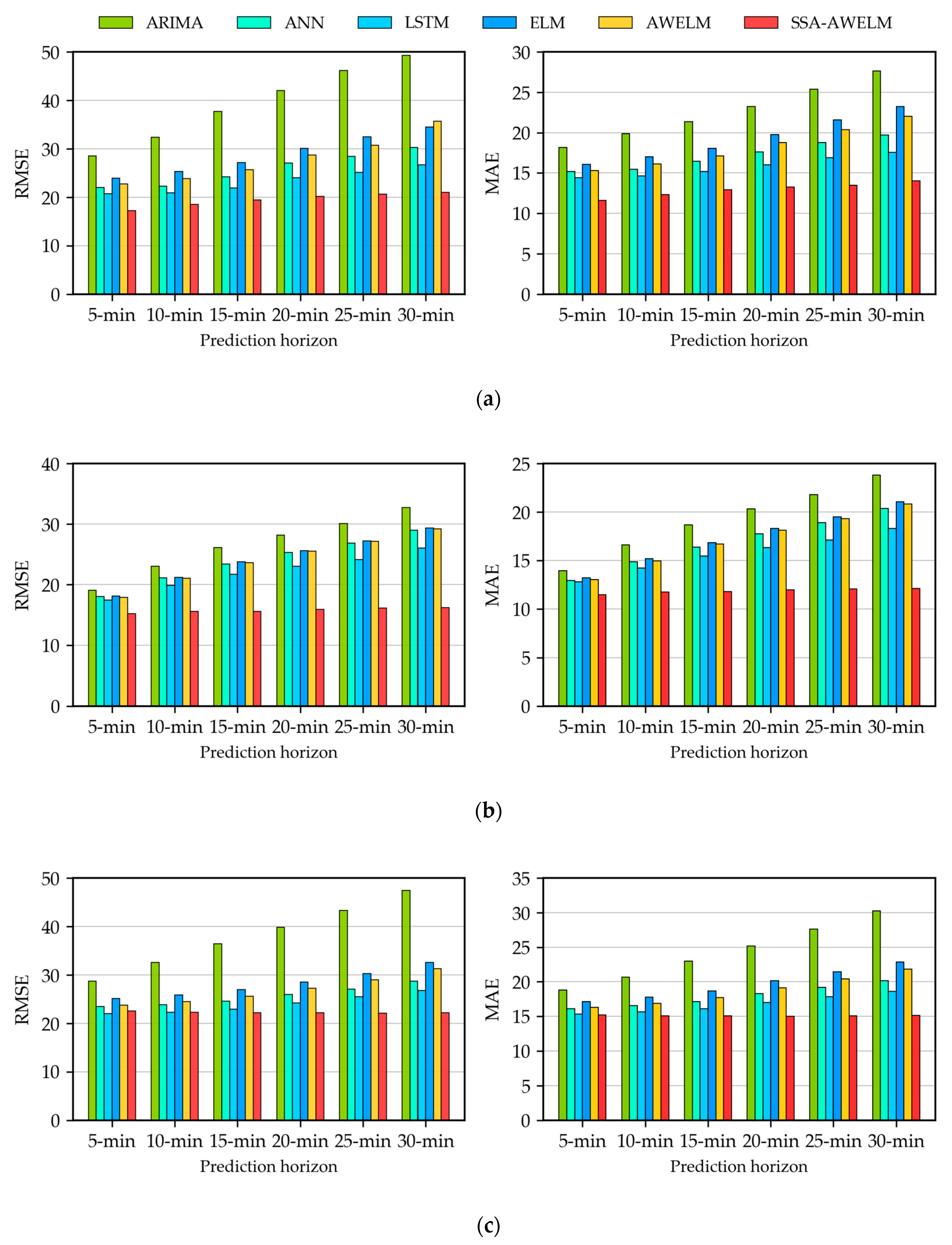
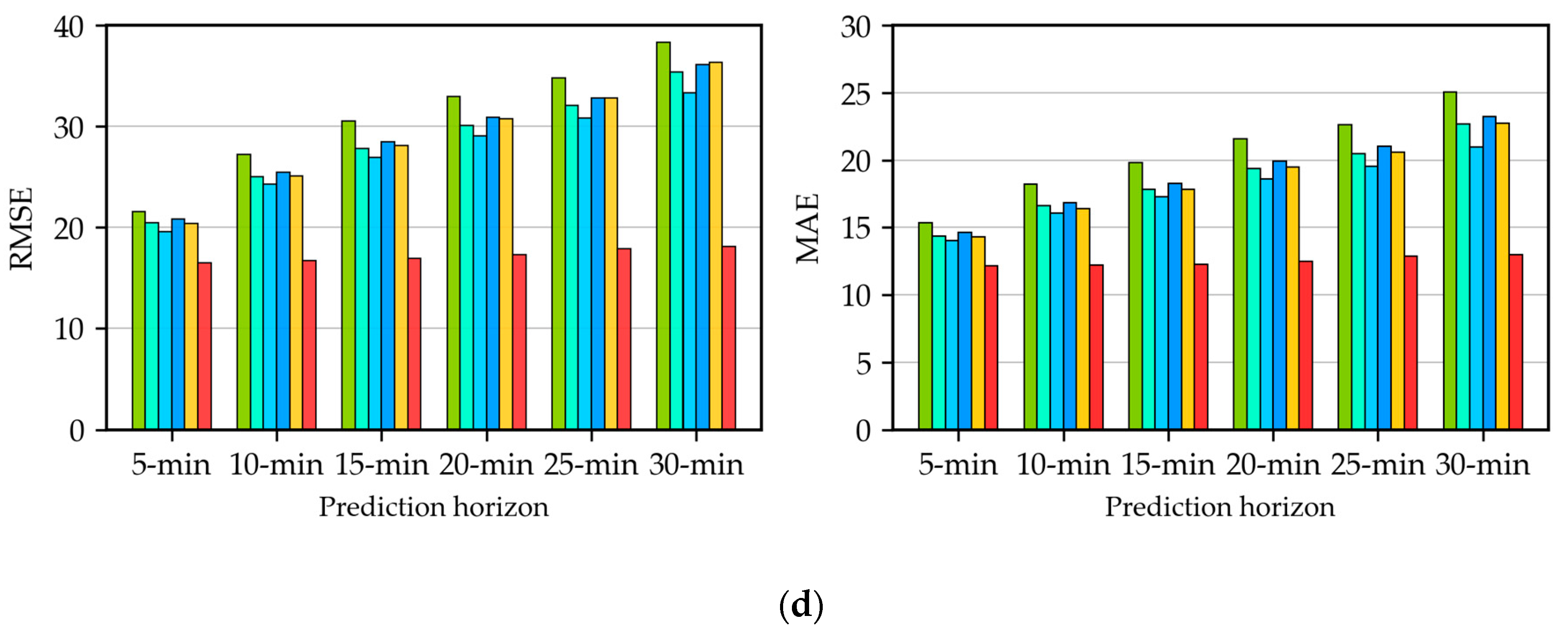
4.3. Analysis of Forecasting Results
4.4. Analysis of Multistep-Ahead Forecasting
5. Conclusions
- The SSA approach can get an insight into the inner characteristics of the passenger flow. The trend represents the overall tendency, the periodicity represents the variants within a day, and the residue represents noise.
- The AWELM model, which is combined by AdaBoost and WELM, are developed to make a more accurate and faster prediction for each component. Compared to the state-of-the-art model LSTM, the propose model has improved upon the performance by 22% and saved time by 84%, on average.
- From the results of the evaluation measures and DM statistical test, the proposed model SSA-AWELM can reduce the cumulative errors during the multistep-ahead prediction. These findings have demonstrated that the SSA-AWELM is a robust model for passenger flow forecasting.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Component | Hyper-Parameters | Testing Cases | |||
|---|---|---|---|---|---|---|
| Exit Passenger Flow of Q.R. Sta. | Entrance Passenger Flow of Q.R. Sta. | Exit Passenger Flow of J. Sta. | Entrance Passenger Flow of J. Sta. | |||
| ARIMA | - | p, d, q | 10,0,3 | 8,0,7 | 6,0,10 | 6,0,9 |
| ANN | - | H | 24 | 24 | 26 | 34 |
| LSTM | - | H | 40 | 34 | 28 | 22 |
| ELM | - | H | 50 | 50 | 42 | 42 |
| AWELM | - | H, T | 50,13 | 50,5 | 50,8 | 42,16 |
| SSA-AWELM | trend | H, T | 24,15 | 22,20 | 22,13 | 24,11 |
| periodicity | H, T | 50,19 | 50,15 | 46,15 | 48,11 | |
| remainder | H, T | 46,17 | 44,9 | 40,8 | 48,10 | |
| Models | Training Time (Seconds) | |||
|---|---|---|---|---|
| Exit Passenger Flow of Q.R. Sta. | Entrance Passenger Flow of Q.R. Sta. | Exit Passenger Flow of J. Sta. | Entrance Passenger Flow of J. Sta. | |
| ARIMA | ~10.1 | ~8.9 | ~12.8 | ~11.0 |
| ANN | ~2.9 | ~1.6 | ~3.6 | ~2.4 |
| LSTM | ~54.0 | ~51.8 | ~51.0 | ~55.0 |
| ELM | <1 | <1 | <1 | <1 |
| AWELM | ~4.6 | ~1.7 | ~2.9 | ~4.1 |
| SSA-AWELM | ~9.6 | ~8.8 | ~8.2 | ~7.8 |
References
- Gallo, M.; De Luca, G.; D’Acierno, L.; Botte, M. Artificial neural networks for forecasting passenger flows on metro lines. Sensors 2019, 19, 3424. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.; Wen, D.; Li, X.; Chen, D.; Lv, H.; Zhang, J.; Gao, P. Empirical mode decomposition based long short-term memory neural network forecasting model for the short-term metro passenger flow. PLoS ONE 2019, 14, e0222365. [Google Scholar] [CrossRef] [PubMed]
- Lin, P.; Weng, J.; Fu, Y.; Alivanistos, D.; Yin, B. Study on the topology and dynamics of the rail transit network based on automatic fare collection data. Phys. A Stat. Mech. Appl. 2020, 545. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, S.; Zhang, Z.; Zou, K.; Shu, Z. Characteristics on hub networks of urban rail transit networks. Phys. A Stat. Mech. Appl. 2016, 447, 502–507. [Google Scholar] [CrossRef]
- Liu, Z.Q.; Song, R. Reliability analysis of Guangzhou rail transit with complex network theory. J. Transp. Syst. Eng. Inf. Technol. 2010, 10, 194–200. [Google Scholar]
- Du, Z.; Tang, J.; Qi, Y.; Wang, Y.; Han, C.; Yang, Y. Identifying critical nodes in metro network considering topological potential: A case study in Shenzhen city—China. Phys. A Stat. Mech. Appl. 2020, 539. [Google Scholar] [CrossRef]
- Tang, L.; Zhao, Y.; Cabrera, J.; Ma, J.; Tsui, K.L. Forecasting Short-Term Passenger Flow: An Empirical Study on Shenzhen Metro. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3613–3622. [Google Scholar] [CrossRef]
- Danfeng, Y.; Jing, W. Subway Passenger Flow Forecasting with Multi-Station and External Factors. IEEE Access 2019, 7, 57415–57423. [Google Scholar] [CrossRef]
- Ding, X.; Liu, Z.; Xu, H. The passenger flow status identification based on image and WiFi detection for urban rail transit stations. J. Vis. Commun. Image Represent. 2019, 58, 119–129. [Google Scholar] [CrossRef]
- Liu, S.; Yao, E. Holiday passenger flow forecasting based on the modified least-square support vector machine for the metro system. J. Transp. Eng. 2017, 143. [Google Scholar] [CrossRef]
- Jiao, P.; Li, R.; Sun, T.; Hou, Z.; Ibrahim, A. Three Revised Kalman Filtering Models for Short-Term Rail Transit Passenger Flow Prediction. Math. Probl. Eng. 2016, 2016, 1–10. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Z.; Jia, R.; Deep, P.F. A deep learning based architecture for metro passenger flow prediction. Transp. Res. Part C Emerg. Technol. 2019, 101, 18–34. [Google Scholar] [CrossRef]
- Fu, X.; Gu, Y. Impact of a New Metro Line: Analysis of Metro Passenger Flow and Travel Time Based on Smart Card Data. J. Adv. Transp. 2018, 2018. [Google Scholar] [CrossRef]
- Tavassoli, A.; Mesbah, M.; Shobeirinejad, A. Modelling passenger waiting time using large-scale automatic fare collection data: An Australian case study. Transp. Res. Part F Traffic Psychol. Behav. 2018, 58, 500–510. [Google Scholar] [CrossRef]
- Xu, X.; Xie, L.; Li, H.; Qin, L. Learning the route choice behavior of subway passengers from AFC data. Expert Syst. Appl. 2018, 95, 324–332. [Google Scholar] [CrossRef]
- Hao, S.; Lee, D.H.; Zhao, D. Sequence to sequence learning with attention mechanism for short-term passenger flow prediction in large-scale metro system. Transp. Res. Part C Emerg. Technol. 2019, 107, 287–300. [Google Scholar] [CrossRef]
- Lee, S.; Fambro, D.B. Application of subset autoregressive integrated moving average model for short-term freeway traffic volume forecasting. Transp. Res. Rec. 1999, 179–188. [Google Scholar] [CrossRef]
- Milenković, M.; Švadlenka, L.; Melichar, V.; Bojović, N.; Avramović, Z. SARIMA modelling approach for railway passenger flow forecasting. Transport 2018, 33, 1113–1120. [Google Scholar] [CrossRef]
- Wang, Y.H.; Jin, J.; Li, M. Forecasting the section passenger flow of the subway based on exponential smoothing. Appl. Mech. Mat. 2013, 409–410, 1315–1319. [Google Scholar] [CrossRef]
- Yu, B.; Song, X.; Guan, F.; Yang, Z.; Yao, B. K-Nearest Neighbor Model for Multiple-Time-Step Prediction of Short-Term Traffic Condition. J. Transp. Eng. 2016, 142. [Google Scholar] [CrossRef]
- Cai, P.; Wang, Y.; Lu, G.; Chen, P.; Ding, C.; Sun, J. A spatiotemporal correlative k-nearest neighbor model for short-term traffic multistep forecasting. Transp. Res. Part C. Emerg. Technol. 2016, 62, 21–34. [Google Scholar] [CrossRef]
- Tsai, T.H.; Lee, C.K.; Wei, C.H. Neural network based temporal feature models for short-term railway passenger demand forecasting. Expert Syst. Appl. 2009, 36, 3728–3736. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Y.; Haghani, A. A hybrid short-term traffic flow forecasting method based on spectral analysis and statistical volatility model. Transp. Res. Part C Emerg. Technol. 2014, 43, 65–78. [Google Scholar] [CrossRef]
- Zeng, D.; Xu, J.; Gu, J.; Liu, L.; Xu, G. Short term traffic flow prediction using hybrid ARIMA and ANN models. In Proceedings of the 2008 Workshop on Power Electronics and Intelligent Transportation System (PEITS 2008), Guangzhou, China, 2–3 August 2008; pp. 621–625. [Google Scholar] [CrossRef]
- Sun, Y.; Leng, B.; Guan, W. A novel wavelet-SVM short-time passenger flow prediction in Beijing subway system. Neurocomputing 2015, 166, 109–121. [Google Scholar] [CrossRef]
- Wei, Y.; Chen, M.C. Forecasting the short-term metro passenger flow with empirical mode decomposition and neural networks. Transp. Res. Part C Emerg. Technol. 2012, 21, 148–162. [Google Scholar] [CrossRef]
- Yang, D.; Chen, K.; Yang, M.; Zhao, X. Urban rail transit passenger flow forecast based on LSTM with enhanced long-term features. IET Intell. Transp. Syst. 2019, 13, 1475–1482. [Google Scholar] [CrossRef]
- Bai, Y.; Sun, Z.; Zeng, B.; Deng, J.; Li, C. A multi-pattern deep fusion model for short-term bus passenger flow forecasting. Appl. Soft Comput. J. 2017, 58, 669–680. [Google Scholar] [CrossRef]
- Liu, L.; Chen, R.C. A novel passenger flow prediction model using deep learning methods. Transp. Res. Part C Emerg. Technol. 2017, 84, 74–91. [Google Scholar] [CrossRef]
- Ma, X.; Dai, Z.; He, Z.; Ma, J.; Wang, Y.; Wang, Y. Learning traffic as images: A deep convolutional neural network for large-scale transportation network speed prediction. Sensors 2017, 17, 818. [Google Scholar] [CrossRef]
- Yang, C.; Guo, Z.; Xian, L. Time series data prediction based on sequence to sequence model. IOP Conf. Ser. Mat. Sci. Eng. 2019, 692. [Google Scholar] [CrossRef]
- Li, W.; Wang, J.; Fan, R.; Zhang, Y.; Guo, Q.; Siddique, C.; Ban, X. (Jeff). Short-term traffic state prediction from latent structures: Accuracy vs. efficiency. Transp. Res. Part C Emerg. Technol. 2020, 111, 72–90. [Google Scholar] [CrossRef]
- Liu, R.; Wang, Y.; Zhou, H.; Qian, Z. Short-Term Passenger Flow Prediction Based on Wavelet Transform and Kernel Extreme Learning Machine. IEEE Access 2019, 7, 158025–158034. [Google Scholar] [CrossRef]
- Chen, M.C.; Wei, Y. Exploring time variants for short-term passenger flow. J. Trans. Geogr. 2011, 19, 488–498. [Google Scholar] [CrossRef]
- Qin, L.; Li, W.; Li, S. Effective passenger flow forecasting using STL and ESN based on two improvement strategies. Neurocomputing 2019, 356, 244–256. [Google Scholar] [CrossRef]
- Chen, D.; Zhang, J.; Jiang, S. Forecasting the Short-Term Metro Ridership with Seasonal and Trend Decomposition Using Loess and LSTM Neural Networks. IEEE Access 2020, 8, 91181–91187. [Google Scholar] [CrossRef]
- Mao, X.; Shang, P. Multivariate singular spectrum analysis for traffic time series. Phys. A Stat. Mech. Appl. 2019, 526, 1–13. [Google Scholar] [CrossRef]
- Shang, Q.; Lin, C.; Yang, Z.; Bing, Q.; Zhou, X. A hybrid short-term traffic flow prediction model based on singular spectrum analysis and kernel extreme learning machine. PLoS ONE 2016, 11. [Google Scholar] [CrossRef]
- Guo, F.; Krishnan, R.; Polak, J. A computationally efficient two-stage method for short-term traffic prediction on urban roads. Transp. Plan. Technol. 2013, 36, 62–75. [Google Scholar] [CrossRef]
- Qiu, H.; Zhang, N.; Xu, W.; He, T. Research of Architecture on Rail Transit’s AFC System. Urb. Rapid Rail Transit 2014, 27, 86–89. [Google Scholar] [CrossRef]
- Taieb, S.B. and Hyndman, R.J. Recursive and Direct Multi-Step Forecasting: The Best of Both Worlds; Monash Econometrics and Business Statistics Working Papers; Monash University: Melbourne, Australia, 2012. [Google Scholar]
- Bontempi, G.; Ben Taieb, S.; Le Borgne, Y.A. Machine learning strategies for time series forecasting. In Lecture Notes in Business Information Processing, LNBIP; Springer: Berlin/Heidelberg, Germany, 2013; Volume 138, pp. 62–77. [Google Scholar] [CrossRef]
- Golyandina, N.; Nekrutkin, V.V.; Zhigljavsky, A.A. Analysis of Time Series Structure: SSA and Related Techniques; Monographs on Statistics and Applied Probability; Chapman & Hall/CRC: Boca Raton, FL, USA, 2001; Volume 90, ISBN 1584881941. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a New Boosting Algorithm. In Proceedings of the 13th International Conference on Machine Learning, Bari, Italy, 3–6 July 1996; pp. 148–156. [Google Scholar]
- Drucker, H. Improving regressors using boosting techniques. In Proceedings of the 14th International Conference on Machine Learning, San Francisco, CA, USA, 8–12 July 1997; pp. 107–115. [Google Scholar]
- Solomatine, D.P.; Shrestha, D.L. AdaBoost.RT: A boosting algorithm for regression problems. In Proceedings of the 2004 IEEE International Conference on Neural Networks, Budapest, Hungary, 25–29 July 2004; pp. 1163–1168. [Google Scholar] [CrossRef]
- Shrestha, D.L.; Solomatine, D.P. Experiments with AdaBoost.RT, an improved boosting scheme for regression. Neural Comput. 2006, 18, 1678–1710. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Conference on Neural Networks, Budapest, Hungary, 25–29 July 2004; pp. 985–990. [Google Scholar] [CrossRef]
- Tianchi, A. The AI Challenge of Urban Computing. Available online: https://tianchi.aliyun.com/competition/entrance/231712/information (accessed on 20 February 2020).
- Sun, Y.; Zhang, G.; Yin, H. Passenger flow prediction of subway transfer stations based on nonparametric regression model. Discret. Dyn. Nat. Soc. 2014, 2014, 1–8. [Google Scholar] [CrossRef]
- Harvey, A.C. Forecasting, Structural Time Series Models and the Kalman Filter; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Diebold, F.X. Comparing Predictive Accuracy, Twenty Years Later: A Personal Perspective on the Use and Abuse of Diebold-Mariano Tests. SSRN Electr. J. 2013. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, J.; Gao, Y. A hybrid short-term electricity price forecasting framework: Cuckoo search-based feature selection with singular spectrum analysis and SVM. Energy Econ. 2019, 81, 899–913. [Google Scholar] [CrossRef]












| Field | Description | |
|---|---|---|
| 1 | Time | Passenger boarding or alighting time |
| 2 | Line ID | Number assigned to every metro line |
| 3 | Station ID | Number assigned to every metro station |
| 4 | Device ID | Number assigned to every turnstile |
| 5 | Status | Boarding or alighting: 0 represents alighting, and 1 represents boarding |
| 6 | User ID | Personal identification information |
| 7 | Pay Type | Ticket type |
| Time | Line ID | Station ID | Device ID | Status | User ID | Pay Type | |
|---|---|---|---|---|---|---|---|
| 1 | 2019-01-01 06:00:00 | B | 15 | 759 | 1 | Baecf*** | 1 |
| 2 | 2019-01-01 06:00:00 | B | 32 | 1558 | 1 | Da226*** | 3 |
| 3 | 2019-01-01 06:00:01 | B | 8 | 402 | 1 | Bb8e6*** | 1 |
| 4 | 2019-01-01 06:00:02 | B | 32 | 1562 | 1 | C03b9*** | 2 |
| 5 | 2019-01-01 06:00:02 | B | 9 | 446 | 0 | Be9c9*** | 1 |
| Model | Exit Passenger Flow of Q.R. Sta. | Entrance Passenger Flow of Q.R. Sta. | Exit Passenger Flow of J. Sta. | Entrance Passenger Flow of J. Sta. | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | |
| ARIMA | 40.01 | 22.60 | 26.90 | 19.19 | 38.55 | 24.23 | 31.37 | 20.44 |
| ANN | 25.88 | 17.18 | 24.21 | 16.86 | 25.67 | 17.92 | 28.87 | 18.56 |
| LSTM | 23.34 | 15.78 | 22.24 | 15.69 | 24.01 | 16.76 | 27.71 | 17.74 |
| ELM | 29.14 | 19.28 | 24.49 | 17.35 | 28.32 | 19.67 | 29.52 | 18.98 |
| AWELM | 28.22 | 18.28 | 24.35 | 17.15 | 27.00 | 18.71 | 29.37 | 18.55 |
| SSA-AWELM | 19.53 | 12.93 | 15.77 | 11.84 | 22.24 | 15.10 | 17.25 | 12.49 |
| Prediction Horizon | Case: Exit Passenger Flow of Q.R. Sta. | ||||
| ARIMA | ANN | LSTM | ELM | AWELM | |
| 5-min | −6.90 *** | −5.32 *** | −2.51 ** | −5.54 *** | −5.07 *** |
| 10-min | −5.58 *** | −3.75 *** | −1.88 * | −4.95 *** | −4.77 *** |
| 15-min | −4.72 *** | −5.00 *** | −1.24 | −4.98 *** | −4.91 *** |
| 20-min | −4.13 *** | −3.29 *** | −1.77 * | −4.45 *** | −3.84 *** |
| 25-min | −3.95 *** | −3.36 *** | −1.45 | −5.06 *** | −4.39 *** |
| 30-min | −3.78 *** | −3.00 *** | −1.42 | −4.98 *** | −4.33 *** |
| Case: Entrance Passenger Flow of Q.R. Sta. | |||||
| ARIMA | ANN | LSTM | ELM | AWELM | |
| 5-min | −7.60 *** | −5.90 *** | −6.25 *** | −6.22 *** | −5.95 *** |
| 10-min | −6.62 *** | −5.34 *** | −5.00 *** | −5.59 *** | −5.49 *** |
| 15-min | −6.90 *** | −5.71 *** | −5.14 *** | −6.07 *** | −6.06 *** |
| 20-min | −7.23 *** | −6.20 *** | −5.42 *** | −6.75 *** | −6.68 *** |
| 25-min | −7.42 *** | −6.52 *** | −5.75 *** | −7.23 *** | −7.07 *** |
| 30-min | −7.15 *** | −6.37 *** | −6.06 *** | −6.96 *** | −6.78 *** |
| Case: Exit Passenger Flow of J. Sta. | |||||
| ARIMA | ANN | LSTM | ELM | AWELM | |
| 5-min | −6.07 *** | −1.18 | 0.99 | −2.29 ** | −1.57 |
| 10-min | −5.80 *** | −2.31 ** | 0.15 | −3.45 *** | −2.71 *** |
| 15-min | −5.82 *** | −3.24 *** | −0.62 | −4.45 *** | −3.95 *** |
| 20-min | −5.52 *** | −4.13 *** | −1.59 | −4.94 *** | −4.80 *** |
| 25-min | −5.13 *** | −4.24 *** | −2.51 ** | −4.69 *** | −5.18 *** |
| 30-min | −4.68 *** | −4.61 *** | −2.72 *** | −4.89 *** | −5.11 *** |
| Case: Entrance passenger flow of J. Sta. | |||||
| ARIMA | ANN | LSTM | ELM | AWELM | |
| 5-min | −6.16 *** | −5.02 *** | −4.66 *** | −5.63 *** | −5.15 *** |
| 10-min | −4.87 *** | −3.96 *** | −3.75 *** | −4.02 *** | −3.84 *** |
| 15-min | −4.64 *** | −3.82 *** | −3.67 *** | −3.88 *** | −3.74 *** |
| 20-min | −4.67 *** | −3.96 *** | −3.66 *** | −4.01 *** | −3.93 *** |
| 25-min | −4.54 *** | −4.14 *** | −3.48 *** | −4.07 *** | −4.01 *** |
| 30-min | −4.51 *** | −4.25 *** | −3.60 *** | −4.18 *** | −4.13 *** |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, W.; Wang, W.; Zhao, D. Passenger Flow Forecasting in Metro Transfer Station Based on the Combination of Singular Spectrum Analysis and AdaBoost-Weighted Extreme Learning Machine. Sensors 2020, 20, 3555. https://doi.org/10.3390/s20123555
Zhou W, Wang W, Zhao D. Passenger Flow Forecasting in Metro Transfer Station Based on the Combination of Singular Spectrum Analysis and AdaBoost-Weighted Extreme Learning Machine. Sensors. 2020; 20(12):3555. https://doi.org/10.3390/s20123555
Chicago/Turabian StyleZhou, Wei, Wei Wang, and De Zhao. 2020. "Passenger Flow Forecasting in Metro Transfer Station Based on the Combination of Singular Spectrum Analysis and AdaBoost-Weighted Extreme Learning Machine" Sensors 20, no. 12: 3555. https://doi.org/10.3390/s20123555
APA StyleZhou, W., Wang, W., & Zhao, D. (2020). Passenger Flow Forecasting in Metro Transfer Station Based on the Combination of Singular Spectrum Analysis and AdaBoost-Weighted Extreme Learning Machine. Sensors, 20(12), 3555. https://doi.org/10.3390/s20123555