1. Introduction
With the rapid development of mobile phones and digital video recorders, the number of videos has grown explosively. For example, over 300 h of video data are uploaded every minute on YouTube [
1]. Due to this explosive growth of videos, people cannot manually process and extract useful information from the video data quickly and accurately. Therefore, how to automatically recognize and analyze the contents of a video has attracted widespread attention in the computer vision community and has rapidly become a significant research topic.
Video action recognition aims to use machine learning techniques to automatically identify human action in the video sequences, which has excellent academic value and broad application prospects, such as in video retrieval [
2], intelligent human-machine interfaces [
3], intelligent video surveillance [
4], and autonomous driving vehicles [
5]. However, due to the different motion speeds, pose changes, appearance variations, and camera views of human action in videos, action recognition remains a challenging task [
5,
6].
The key step in video action recognition is extracting the effective spatiotemporal features where the spatial feature is mainly used to describe the global scene configuration and the appearance of objects in a single frame of the video, while the temporal feature is extracted to represent motion cues among multiple frames over time. In recent years, many video action recognition methods have been proposed, which can be mainly divided into two categories [
7]: hand-crafted feature-based action recognition [
8,
9], and deep learning network-based action recognition [
10,
11]. Hand-crafted feature-based methods usually detect key spatiotemporal points in the video and then represent these points with local descriptors, while deep learning-based methods utilize multilayers to automatically and progressively extract high-level features from raw input. Compared to hand-crafted feature-based methods, deep learning-based methods can achieve considerably better action recognition performance because they can learn more discriminative representations of videos. Hence, deep learning-based action recognition methods have attracted increasing attention recently.
Deep convolutional neural networks (CNNs) have been widely applied in the field of static image understanding, and they have achieved remarkable results in many practical tasks, e.g., image classification [
12], object detection [
13], and semantic segmentation [
11]. Hence, many researchers have tried to introduce CNNs pretrained on images to directly learn the features from the individual video frames and then fuse the features of all frames into one feature vector as the representation of the video [
14,
15]. However, learning the features from individual frames for video representation does not fully exploit the temporal information across consecutive frames, which limits the performance of the video analysis tasks, e.g., dynamic scene recognition [
16] and action recognition [
7,
14,
15]. To address this limitation, two-stream CNN-based [
17] and 3D CNN-based [
7,
18] deep learning approaches were proposed, and they rapidly became the two mainstream architectures for video action recognition.
Two-stream CNNs [
17] capture the appearance and motion information of the video by applying two CNN architectures separately, which can gain good performance for video action recognition and has the merit of high calculation efficiency. However, it integrates the spatial and temporal information by late fusing the softmax predictions of two CNN models, which fails to fully learn intrinsic spatiotemporal features of the video [
19]. To mitigate this problem, Feichtenhofer et al. [
19] proposed spatiotemporal multiplier networks by adopting a cross-stream residual connection, which can learn more effective spatiotemporal features. Specifically, they introduced the multiplicative motion gating function into residual networks to construct a two-steam architecture that can ensure that the appearance and motion features interact with each other in the process of network learning.
3D CNNs [
18,
20] utilize 3D convolution filters and 3D pooling operations to capture the spatiotemporal features from the stacked video frame volumes. Some research has shown that 3D convolutions are a superior approach for extracting both spatial and temporal activations of a video. However, executing deep 3D CNNs leads to high computational time and memory demand [
21]. Hence, Qiu et al. [
7] presented pseudo3D residual networks (P3D ResNets) to simulate 3D convolutions by building the P3D blocks in the residual networks, which is an economical and effective method to replace 3D convolutions.
In this paper, we propose a novel architecture named the spatiotemporal interaction residual network with pseudo3D (STINP) for video action recognition.
Figure 1 shows the framework of STINP. The contributions of the STINP are as follows: (1) By introducing a pseudo3D block into two-branch architectures, the proposed STINP can effectively combine the advantages of two-stream and 3D architecture so that it can simultaneously and effectively extract temporal and spatial video information. (2) By employing the multiplicative function to combine the spatial and temporal branches, the STINP can make the learned temporal and spatial representations directly impact each other in the earlier learning stage of the network, and the representations are directly integrated into the final output layer. (3) In the spatial branch of the STINP, 1D temporal convolutions combined with 2D spatial convolutions are added in the residual units by adopting the pseudo3D structure, which aims to learn the interactive cues among the neighboring frames to further improve the effectiveness of the proposed STINP for action recognition tasks.
3. Method
The STINP is proposed based on ResNets. In this section, we first review ResNets, and then we give the details of the spatial branch and temporal branch of the STINP, respectively, and the method of integrating these two branches.
3.1. Residual Network
In recent years, it has been proven that the depth of the network is a crucial factor for optimizing network performance. In general, a deeper network architecture is beneficial for achieving good image classification task results. Hence, many very deep networks have been designed, such as networks with depths of sixteen [
44], twenty-two [
45], or thirty [
46]. However, as the depth of the network increases, the problems of vanishing and exploding gradient are magnified, and the accuracy of the model degrades rapidly after it reaches the saturated point [
12]. To solve the problem of vanishing and exploding gradient, residual networks (ResNets) [
12] were proposed.
ResNets employ residual units to learn the residual representation of the input signal. Residual units include the bottleneck building blocks, residual connections, and batch normalization layers. The bottleneck architectures consist of the convolution (1 × 1, 3 × 3, and 1 × 1) layers, and the residual connection adds a skip/shortcut connection to address the vanishing/exploding gradient problem. The residual learning block in ResNets is defined as:
where
and
are the input and output data of the
residual unit,
is a function that is used to learn the residual map,
represents the convolution filter, and
represents the rectified linear units (
ReLU) function.
Although ResNets have obtained good performance for various image classification tasks, they cannot achieve very satisfactory results when they are directly adopted for action recognition in video. This is because ResNets cannot learn the temporal information of the video. Therefore, to simultaneously learn the spatial and temporal cues in the video for action recognition, we propose the STINP, which includes two branches: spatial branch and temporal branch. Both branches are constructed based on ResNets architecture.
3.2. Spatial Branch
Generally, the categories of actions are associated with the appearances of objects and scenes appearing in the video [
23]. For instance, in subway stations, people often crowd or walk, while in a bookstore, people usually move slowly, stand up, or read a book. Hence, to capture the cues from the objects and the scene in the video and obtain the potential interaction information among the consecutive frames, we designed the spatial branch in the proposed STINP.
Because ResNets can efficiently and effectively extract the features from the images (frames), we utilize it as the underlying architecture of the spatial branch. Specifically, we add the appropriate temporal convolution filters in the “bottleneck” building block of the original ResNets model to enhance the network for capturing not only the appearance features from the single frames but also the interaction features among the adjacent frames. To achieve this, we build our spatial branch by adopting the work in Ref. [
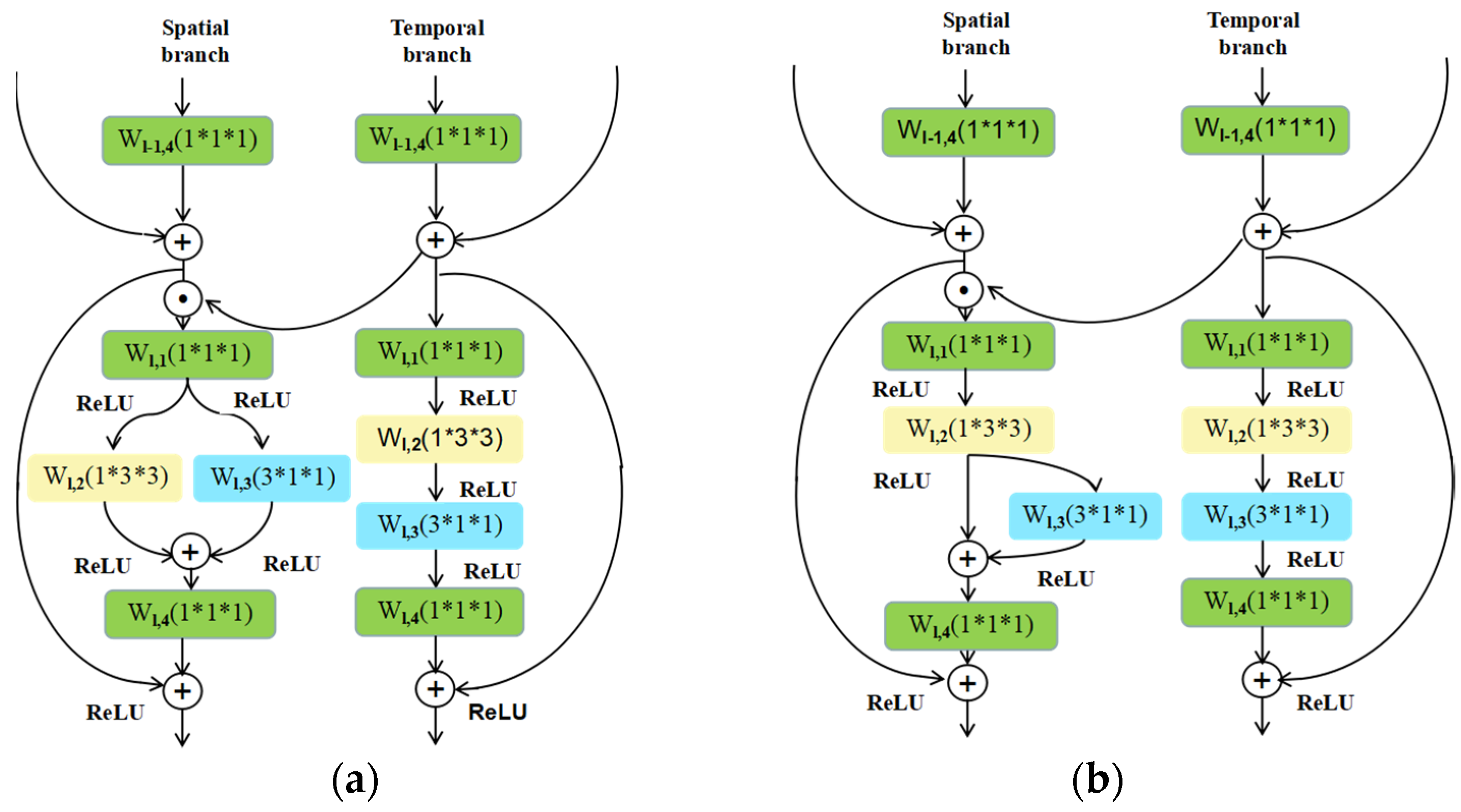
7]. That is, we simulate 3D convolutions with 2D convolutional filters in the spatial domain, plus 1D convolutional filters in the temporal domain to obtain the connections on neighbor feature maps. The different combinations of 2D and 1D convolutional filters yield different performances. Hence, we developed two variant structures of the spatial branch in the proposed STINP and we named the STINP with these two different appearance branches as STINP-1 and STINP-2, respectively.
Spatial branch in STINP-1: the 2D convolutional filter (
cf2) and 1D convolutional filter (
cf1) are parallelly combined, which can ensure that both the 2D and 1D convolutional filters directly influence the output of the spatial branch, while they do not directly affect each other. This combination can be expressed as:
Spatial branch in STINP-2: the 2D convolutional filter (
cf2) and 1D convolutional filter (
cf1) are fused by Equation (3), which can ensure that they directly affect each other and directly affect the final output of the spatial branch separately and simultaneously.
In Equations (2) and (3),
and
are the input and output data of the
residual unit, and
denotes the
ReLU. The detailed structures of the spatial branches in STINP-1 and STINP-2 are shown in
Figure 2a,b, respectively.
From Equations (2) and (3), we find that the 2D filter and 1D filter influence the output of each layer of the spatial branch regardless of whether they affect each other. Therefore, regardless of which combination approach we take, we can evidently and directly use the appearance features from single frames and interaction features among several frames in the process of network learning, which is beneficial for improving the performance of action recognition.
Although our spatial branch is proposed by referring to Ref. [
7], our STINP
has two obvious differences compared with the P3D ResNets [
7]. First, the pipeline of the P3D ResNets consists of only one branch, but the proposed STINP includes two branches (spatial
branch and temporal branch). Second, when comparing our spatial branch
developed based on P3D blocks with the P3D ResNets, the inputs of the P3D
ResNets and our spatial branch are not the same. Specifically, the P3D ResNets learn the features from the RGB frames, while our proposed spatial branch learns the features from the motion feature maps scaled RGB frames (shown by ⊙ in
Figure 1 and
Figure 2).
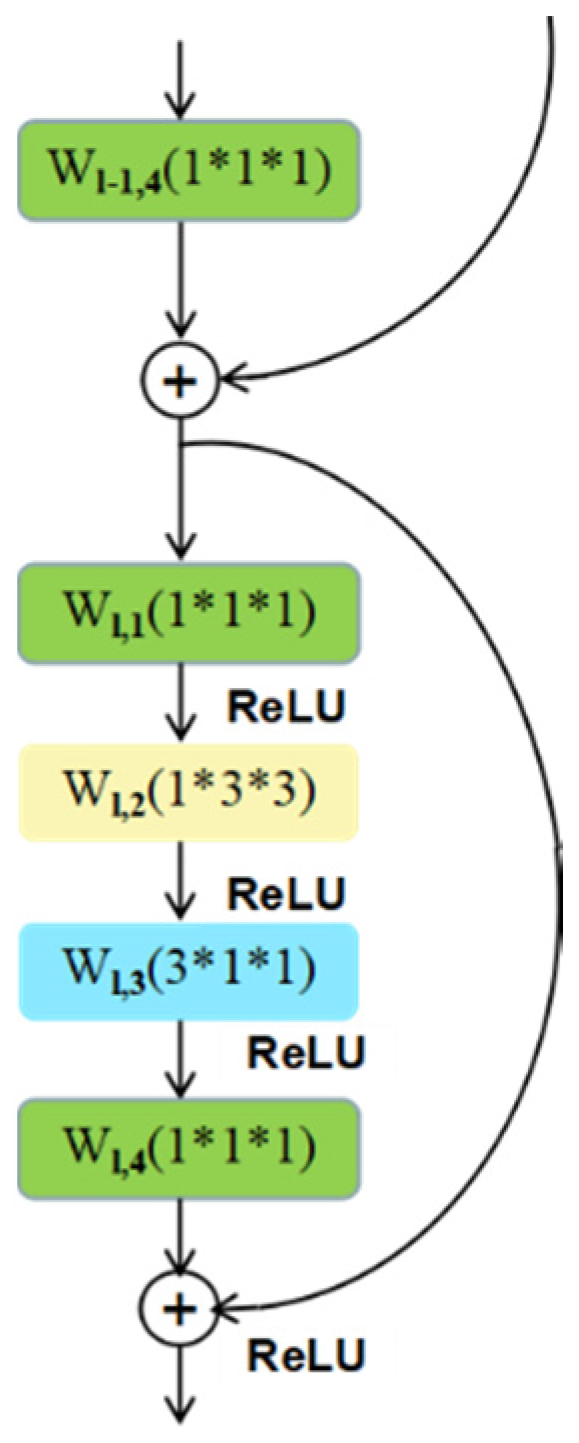
3.3. Temporal Branch
Motion features in the video can provide crucial information for action recognition and can be represented by extracting dynamic changes among the continuous frames. Optical flow [
17] is a classical and effective motion representation method in the field of video processing. Therefore, we employ the precomputed optical flow images as the input of the temporal branch of the STINP. Specifically, we cascade a 2D spatial convolutional filter (
cf2) and 1D temporal convolutional filter (
cf1) in the “bottleneck” building block of the ResNets to learn the abstract immediate motion information from the single optical flow image and fuse them to capture long-time motion information from the continuous optical flow images. The temporal branch is shown in
Figure 3 and can be expressed as:
where
and
are the input and output data of the
residual unit, and
denotes the
ReLU.
3.4. Combination of the Spatial and Temporal Branches
To effectively and simultaneously learn the appearance representation from single frames, interaction features among several frames, and the motion representation from the optical flow images, we integrate the spatial branch and temporal branch into the STINP.
Many integration approaches have been proposed, such as fusing softmax layers [
47] and max pooling operations on the output feature maps of each branch [
19]. These approaches cannot fully gain the spatiotemporal features because of the late fusion. Hence, we utilize multiplication to fuse the spatial branch and temporal branch, as shown in
Figure 4. Specifically, the output of the last residual unit in the temporal branch is used to multiply the input of the current residual unit in the spatial branch. The motion feature maps are used to weight the appearance feature maps pixel by pixel. The advantage of the multiplication fusion operator is twofold: (1) a multiplication fusion operator can make the spatial and temporal branches interact with each other in each residual unit during the process of the network learning, which avoids the drawback of late fusion; (2) and a multiplication fusion operator can use the motion feature to weight the appearance feature to prevent the appearance representation learning from dominating the network learning, which is beneficial to action recognition because the motion information is generally more discriminative for categorizing action [
19].









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}