Design of an Always-On Image Sensor Using an Analog Lightweight Convolutional Neural Network



Abstract
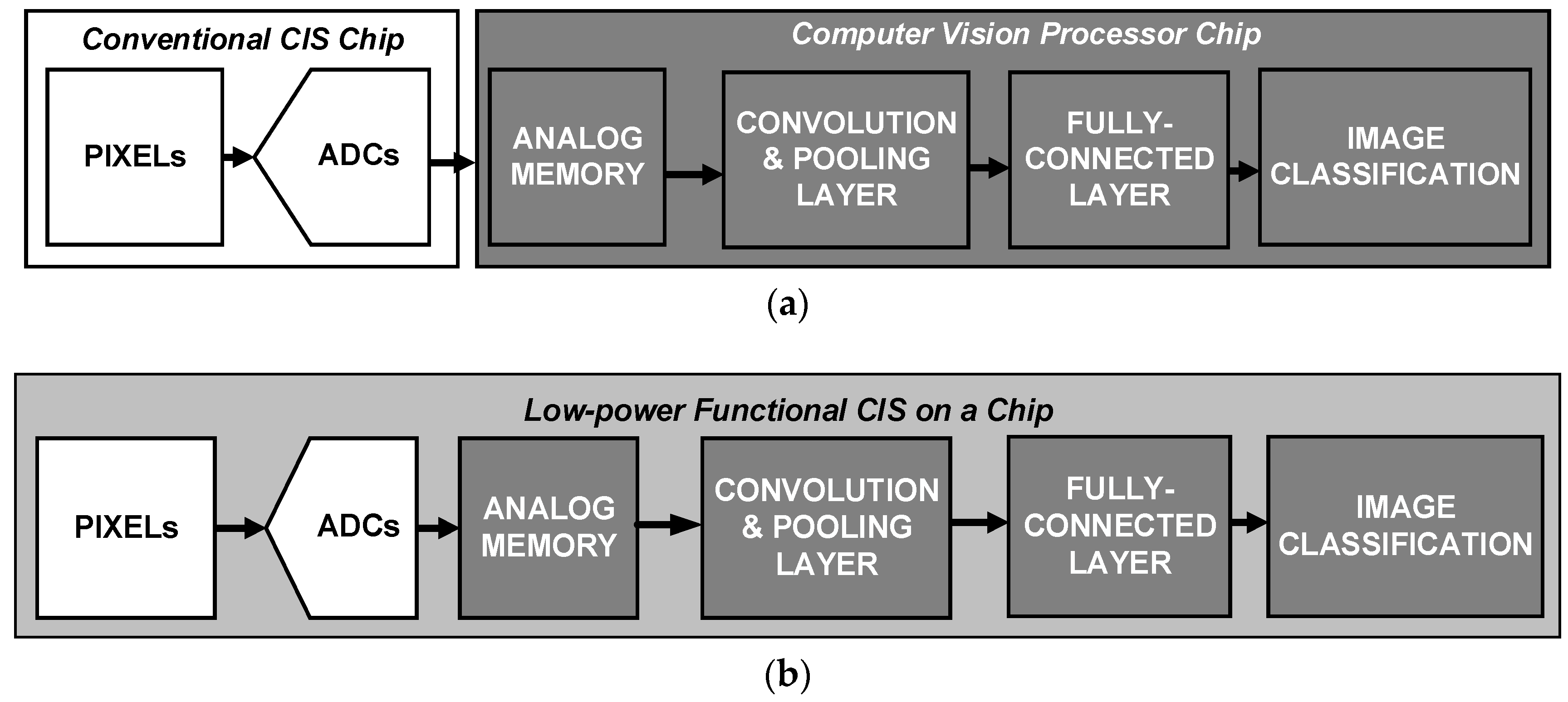
1. Introduction
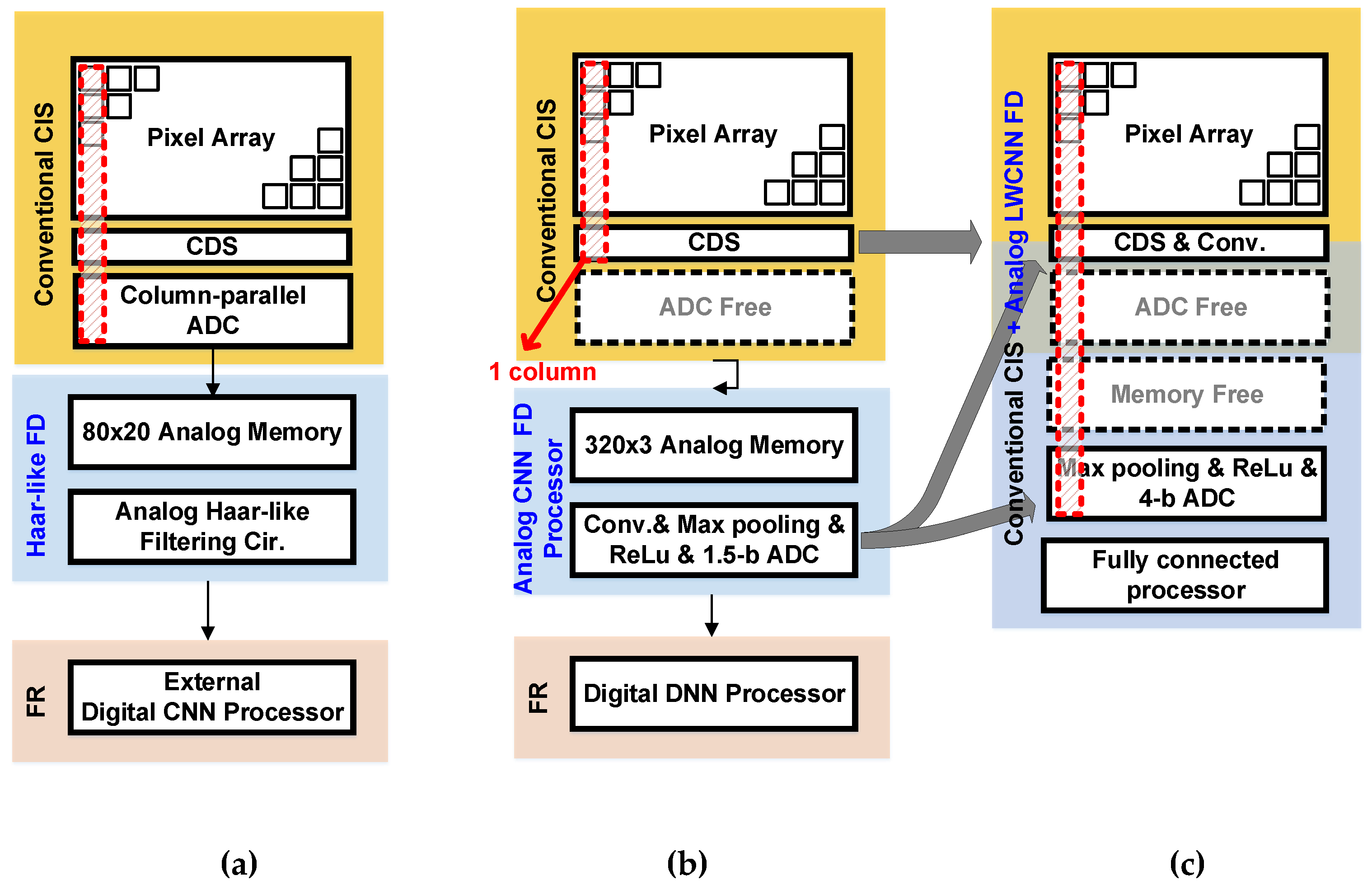
2. Design of the Proposed Functional CIS for Image Classification
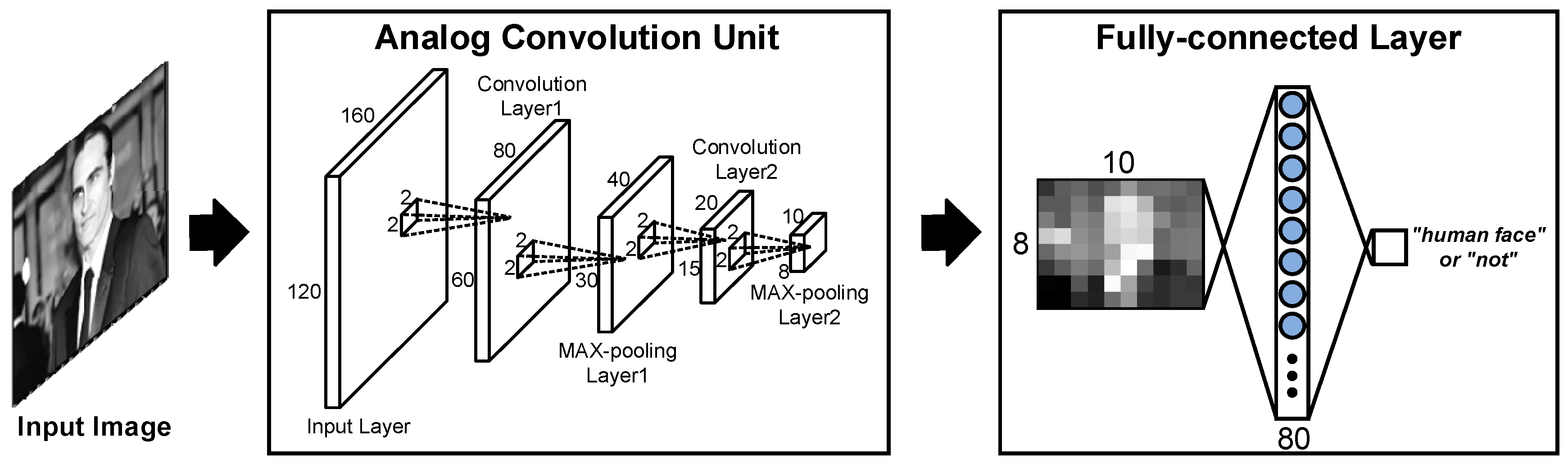
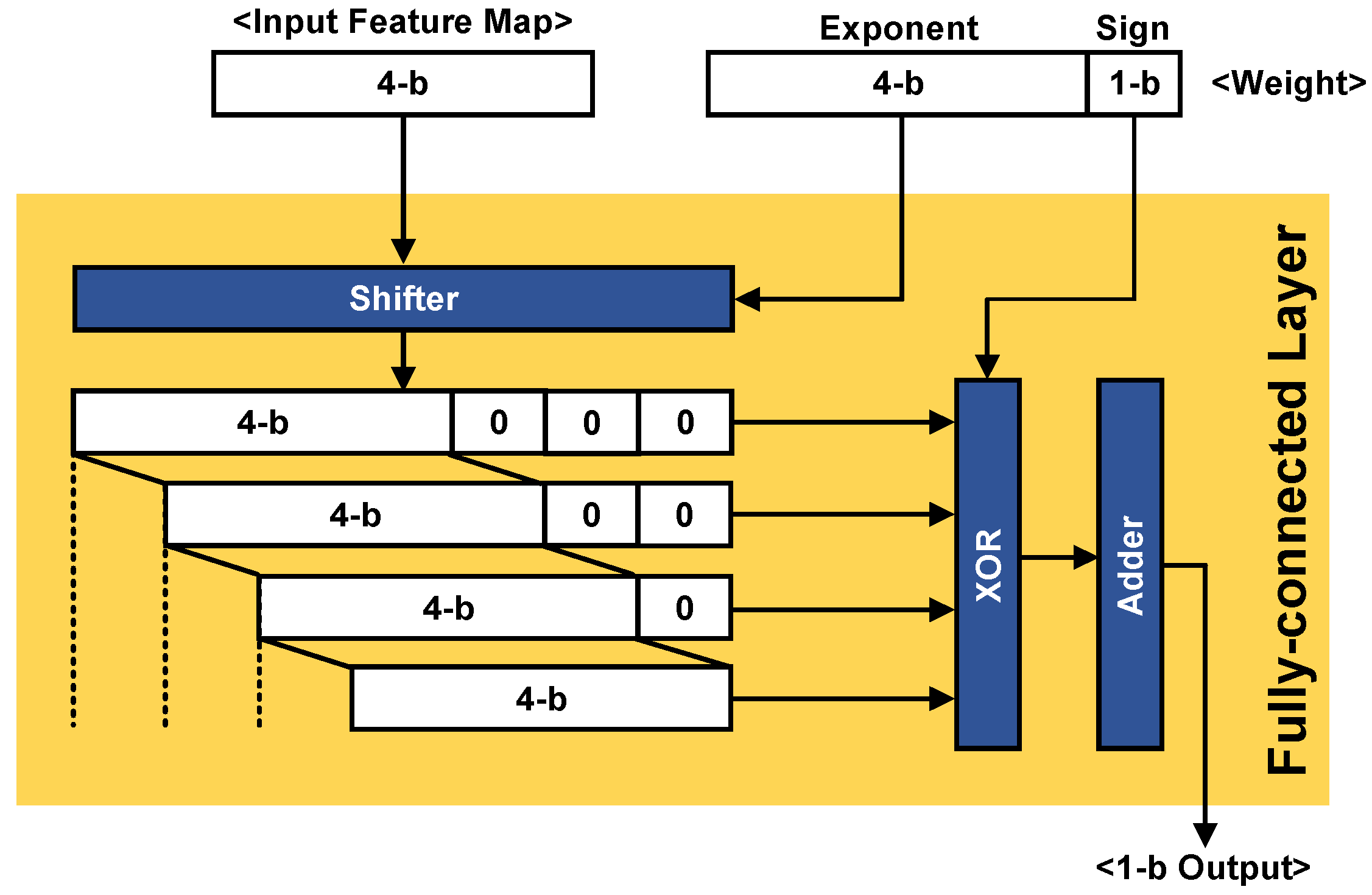
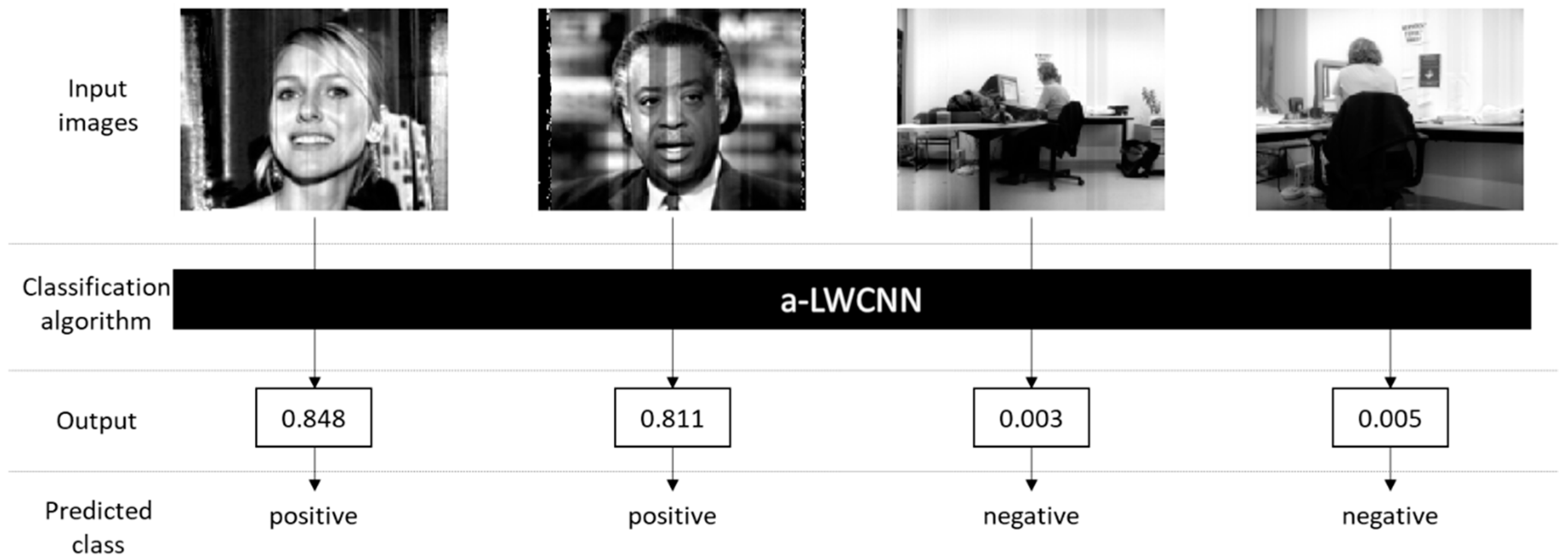
2.1. The Proposed Image Classification with the a-LWCNN Algorithm
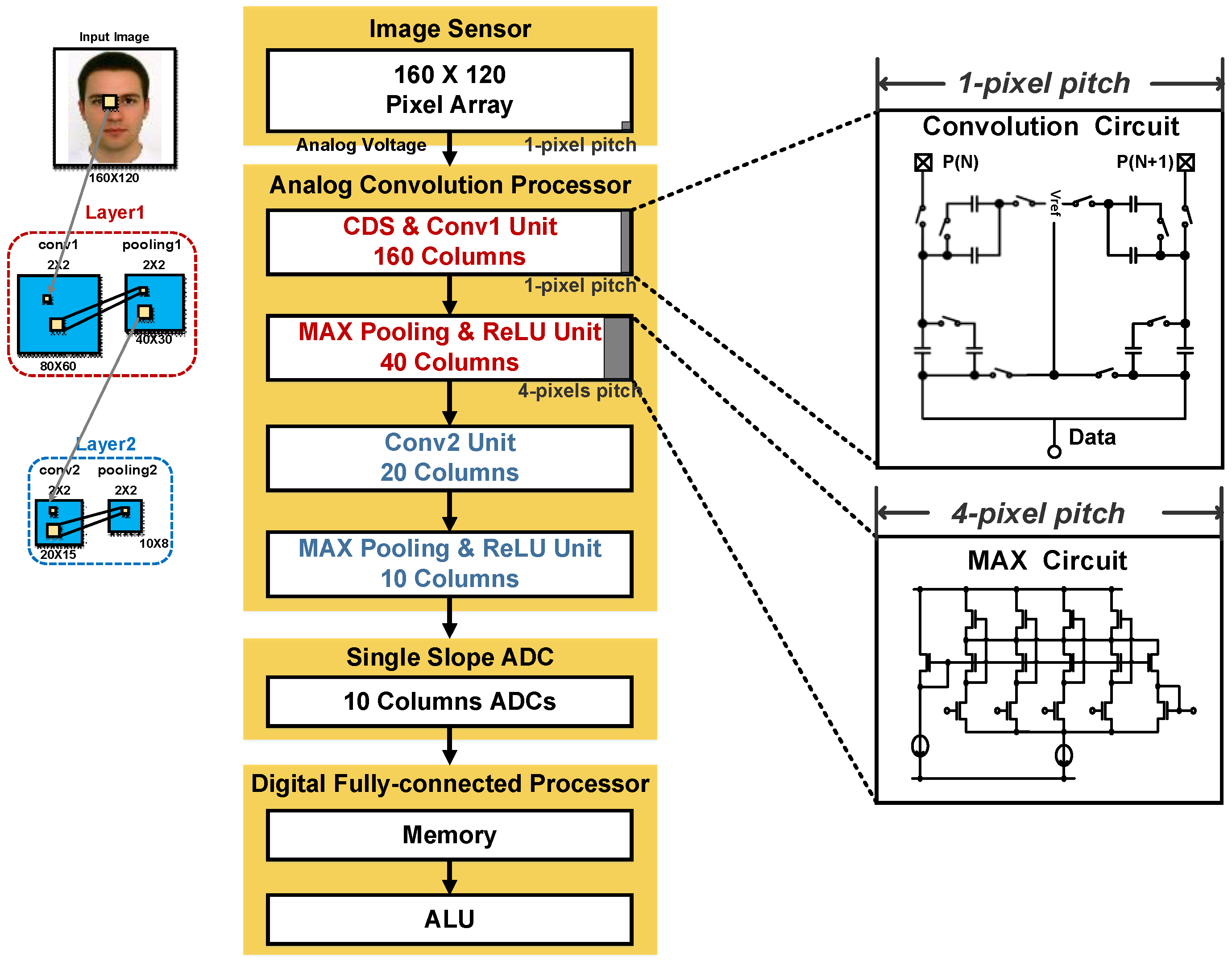
2.2. Overall Architecture of the Proposed CIS
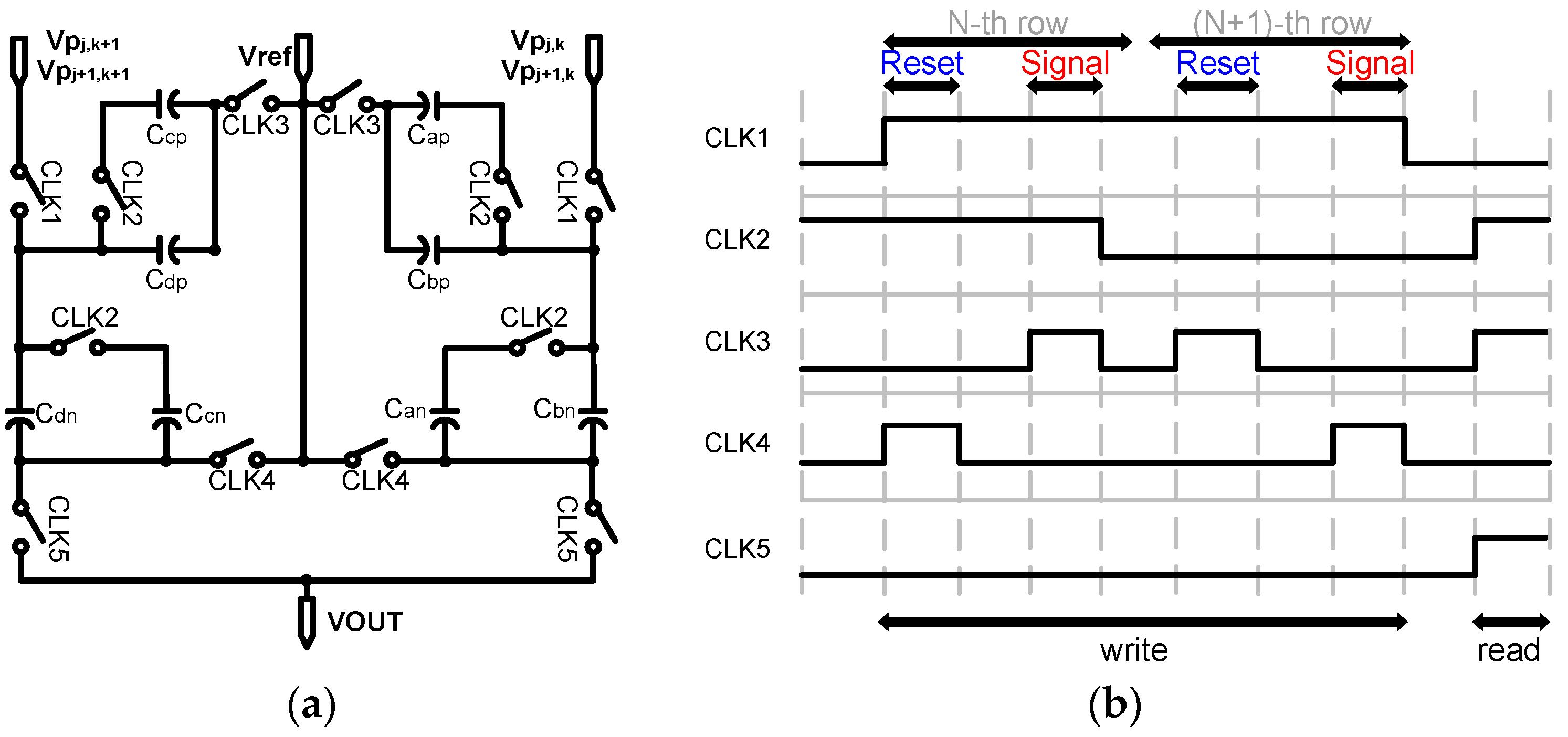
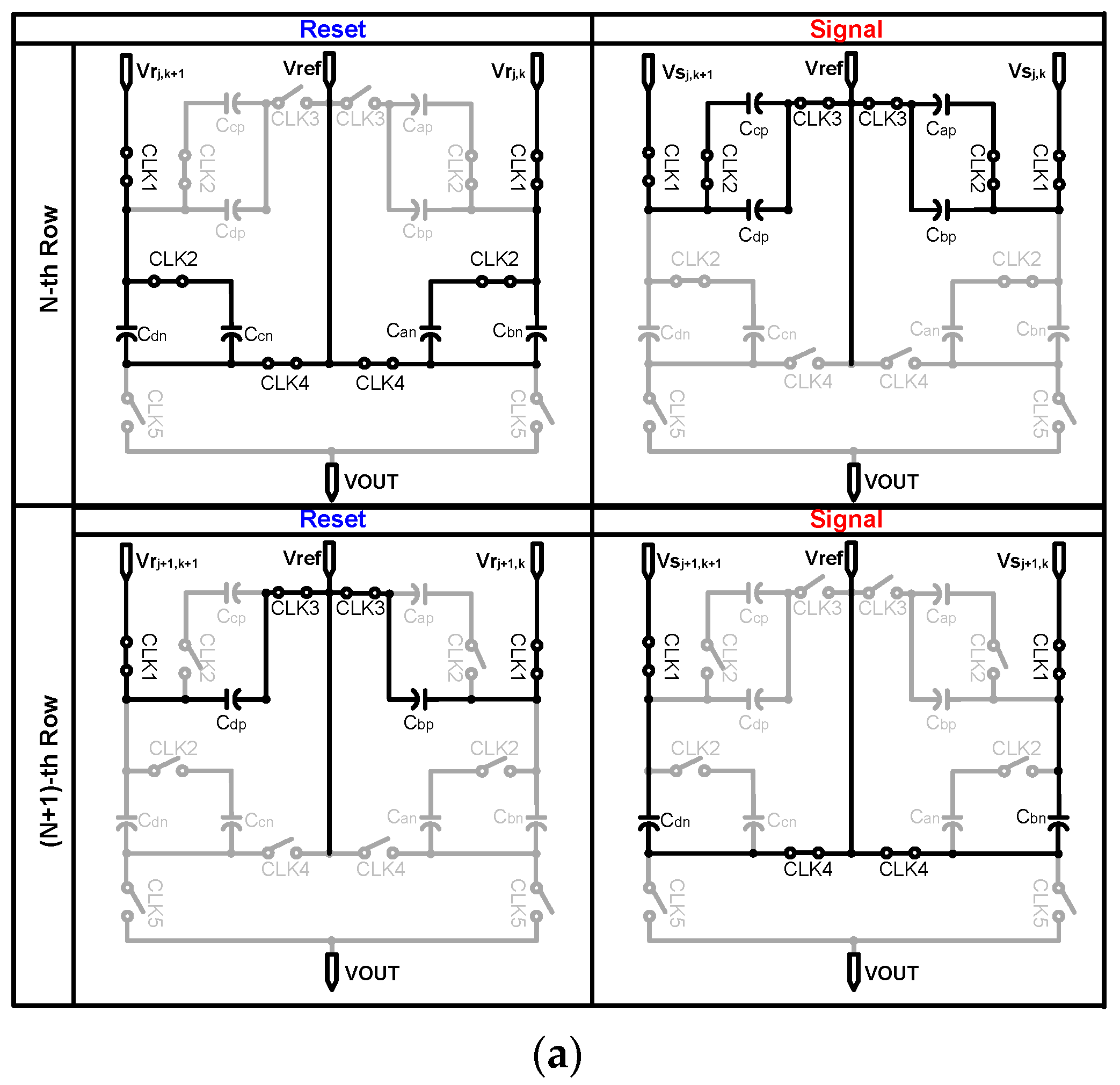
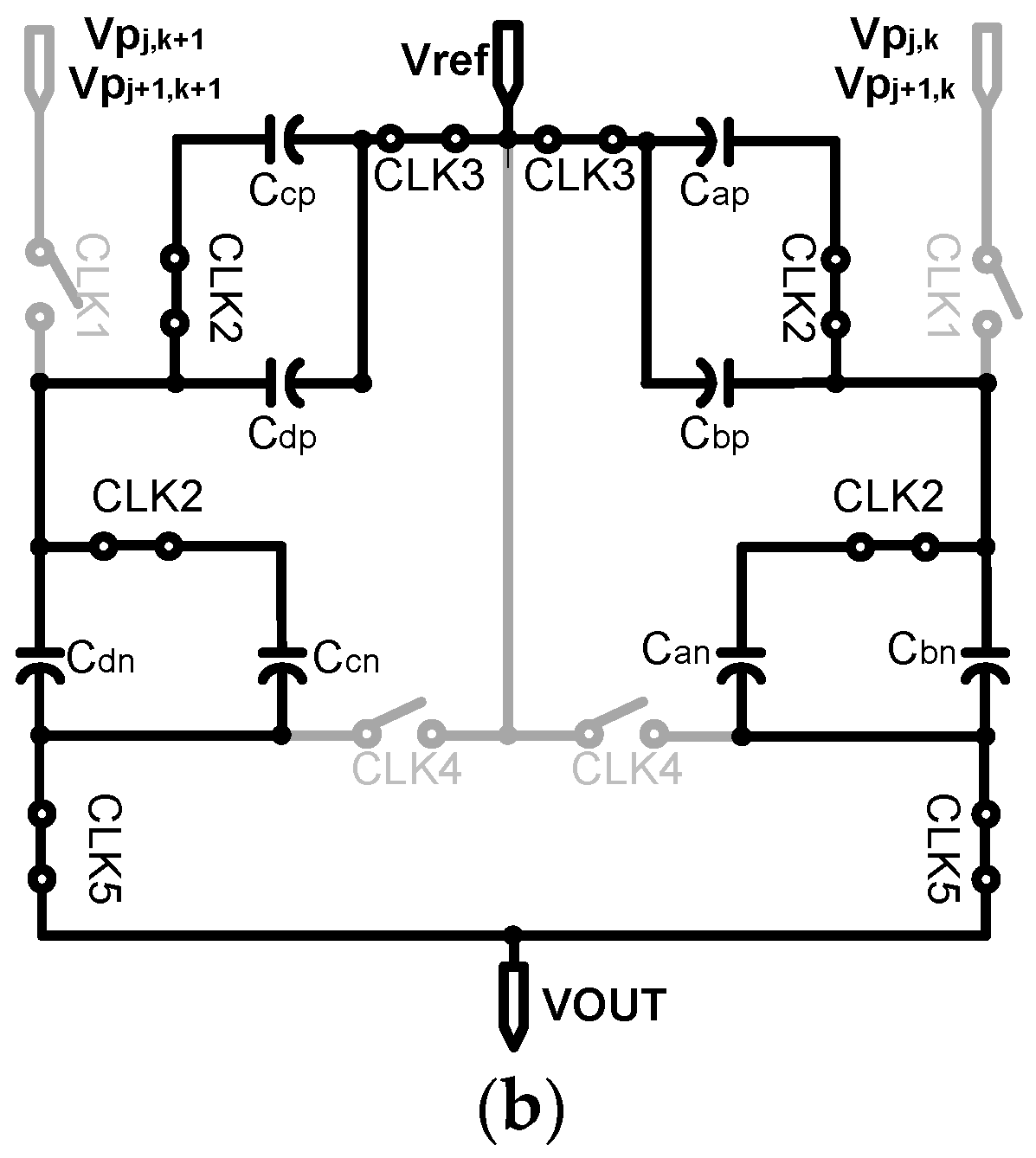
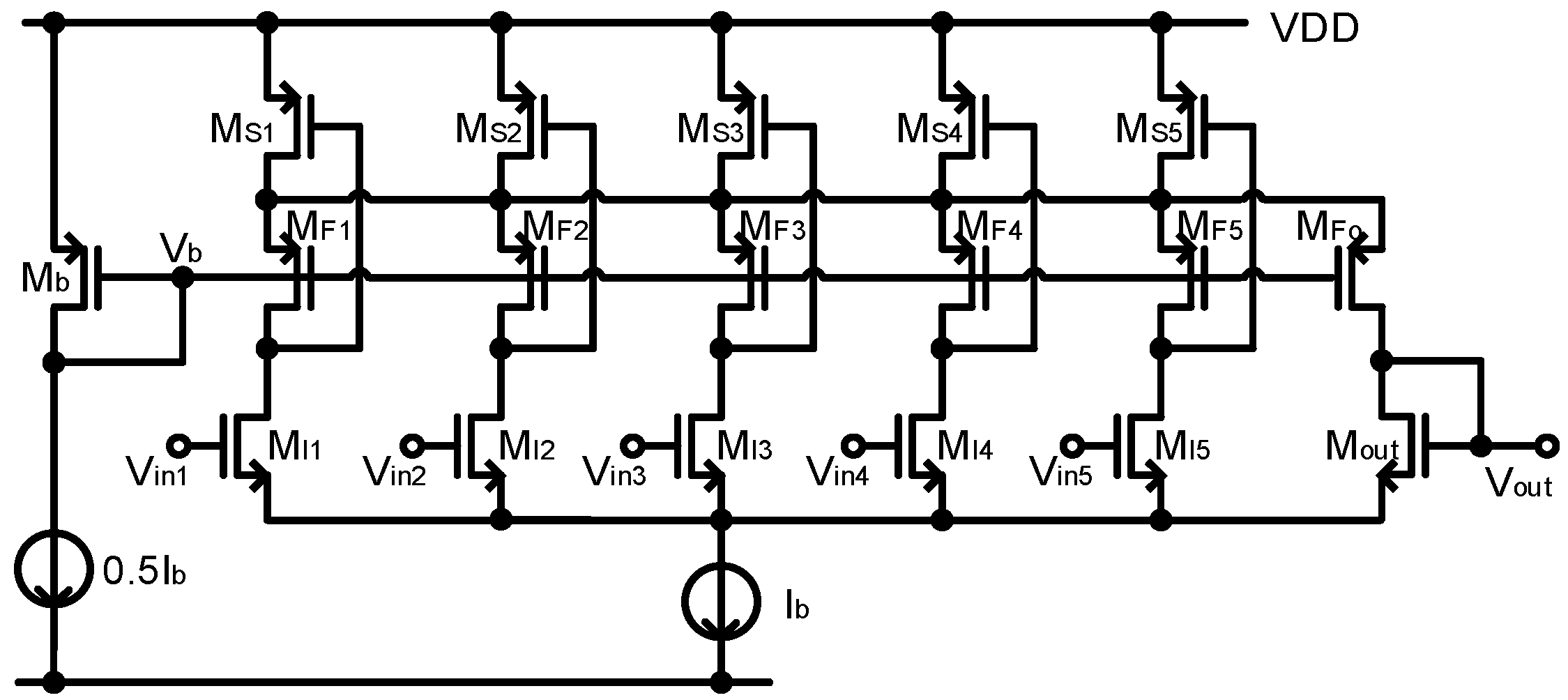
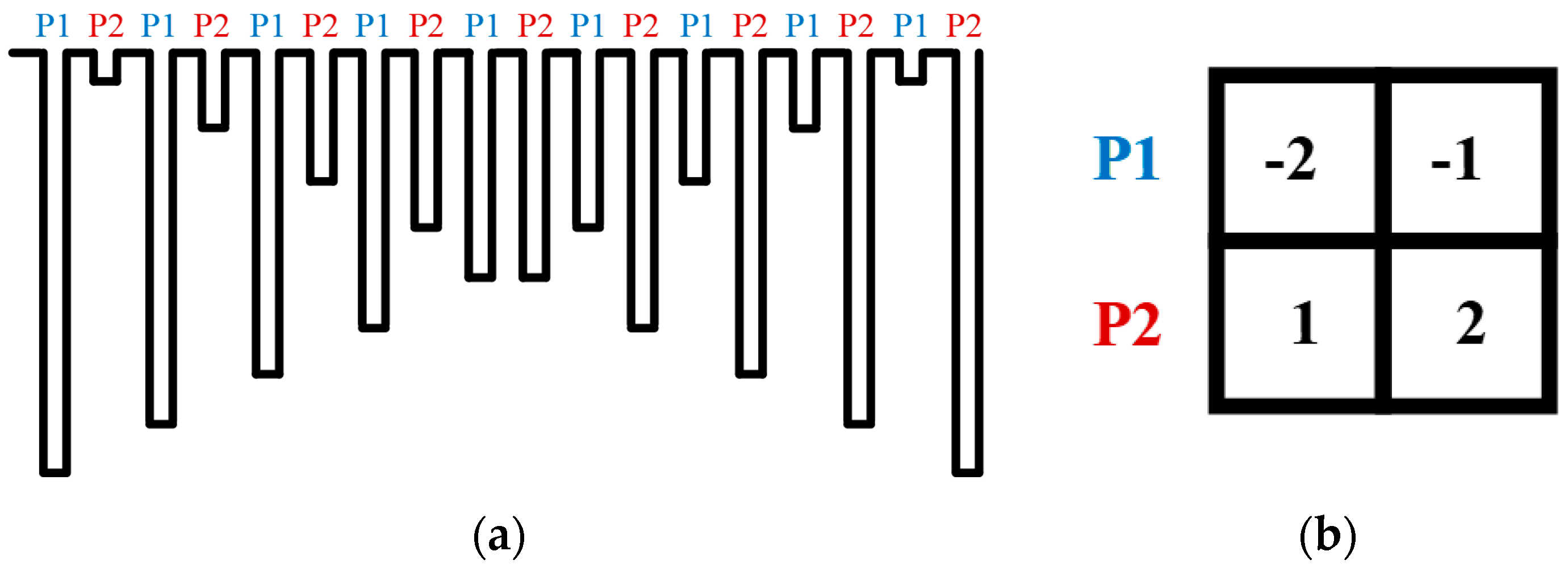
2.3. Detailed Building Blocks
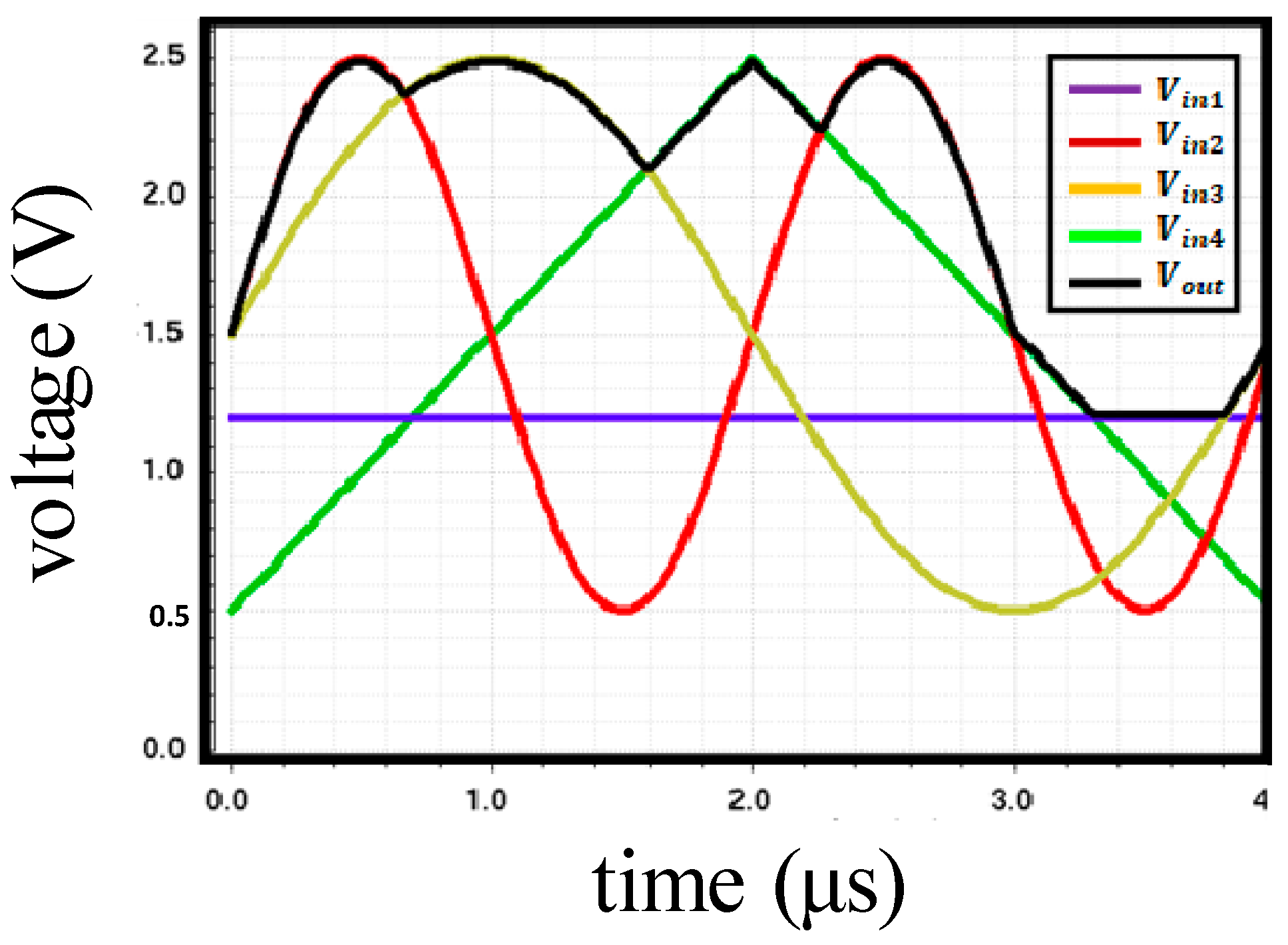
- First, is sampled onto and . As the output of the pixel changes from reset to signal, is stored in and ;
- By the row scanner, the pixel is changed from the nth row to the (n + 1)th row; is sampled only onto as the switch that is used to connect , and is opened by CLK2. Next, is sampled onto , and each of the four capacitors stores a different value. Similarly, the (k + 1)-column also performs this operation to store the values for and in , , , and ;
- In the read phase, reference voltage is applied in one direction to average the four pixel values stored in each of the capacitors. The final voltage at the output of the convolution circuit is ideally as given by Equation (1):
3. Experimental Results
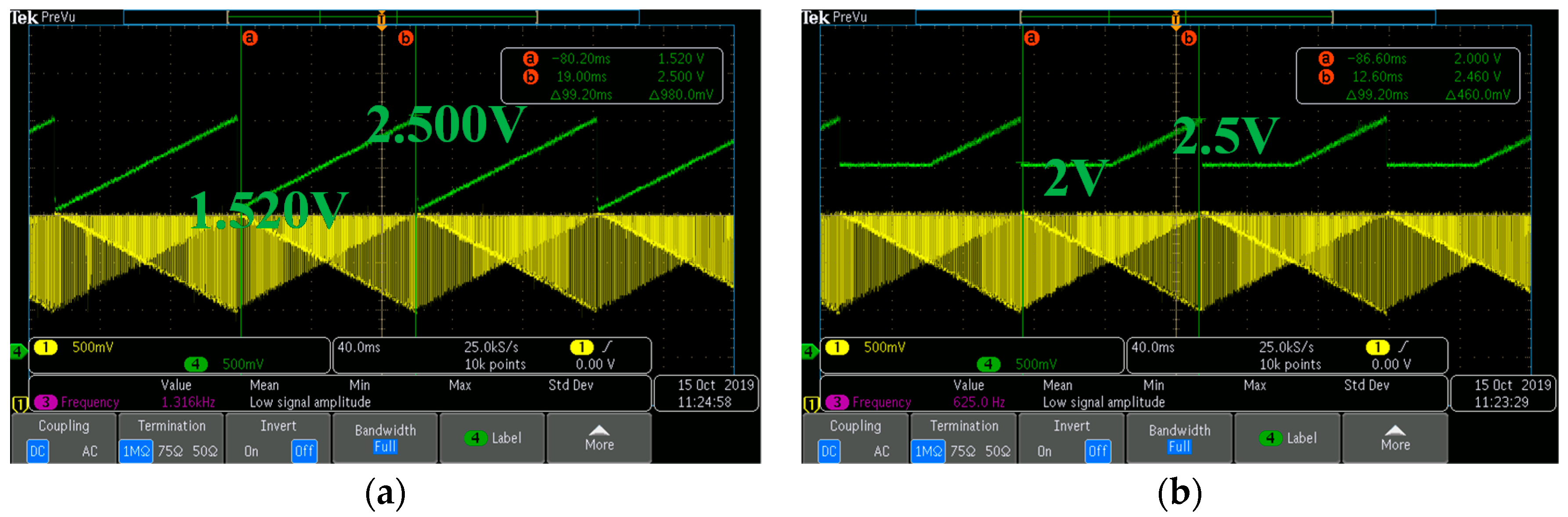
3.1. Chip Measurement Results
3.2. Classification Results
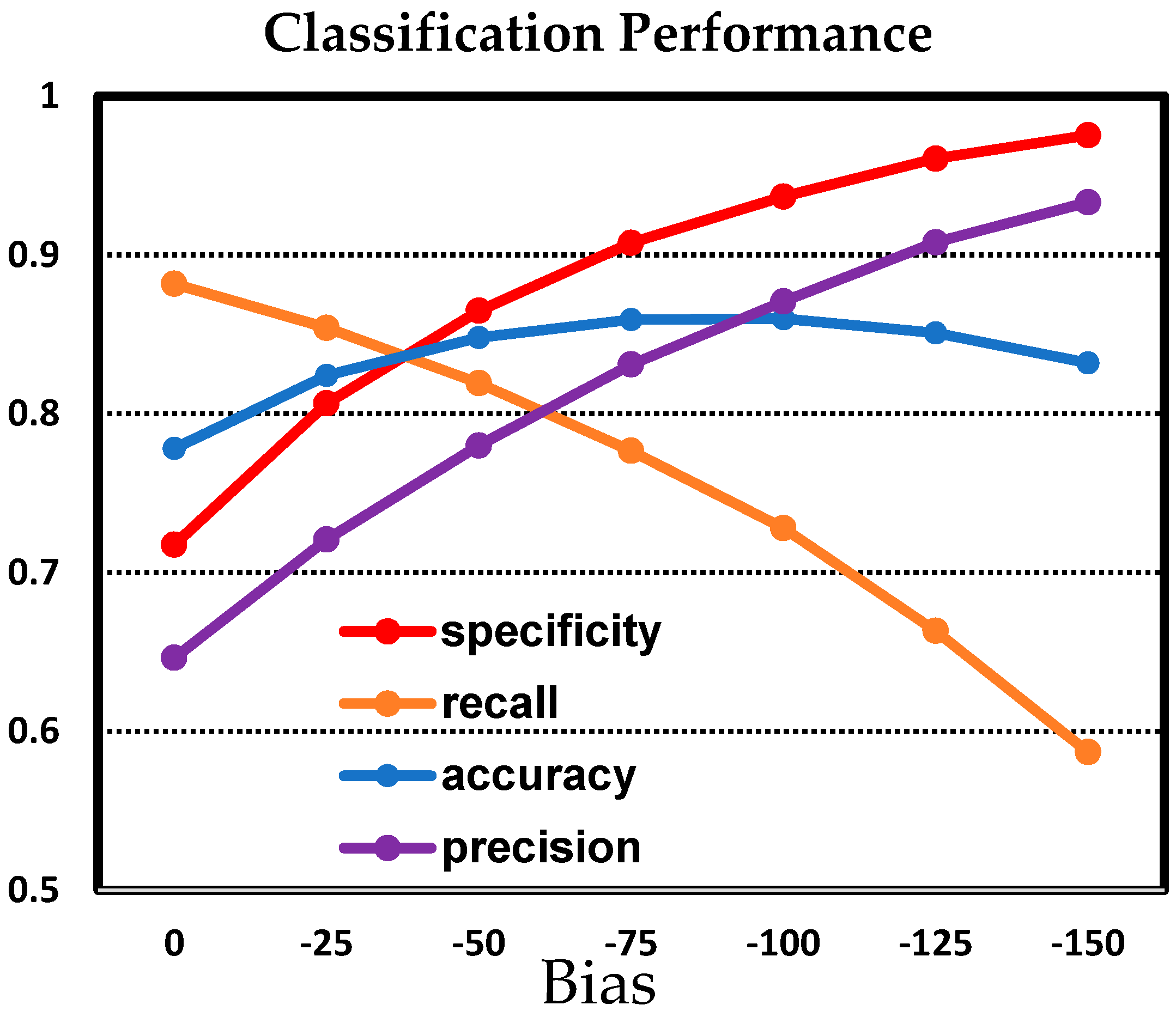
3.3. Discussion
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Evans, D. The Internet of Things—How the Next Evolution of the Internet Is Changing Everything, White Paper; Cisco IBSG: San Jose, CA, USA, 2011; p. 111. [Google Scholar]
- Fernandez, E.; Jimenez, D. Face recognition for authentication on mobile devices. Image Vis. Comput. 2016, 55, 31–33. [Google Scholar] [CrossRef]
- Fathy, M.E.; Patel, V.M.; Chellappa, R. Face-based active authentication on mobile devices. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 1687–1691. [Google Scholar]
- Park, K.; Song, M.; Kim, S.Y. The design of a single-bit CMOS image sensor for iris recognition applications. Sensors 2018, 18, 669. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.; Shin, J.; Kang, D.; Park, D. Always-on CMOS image sensor for mobile and wearable devices. IEEE J. Solid State Circuits 2016, 51, 130–140. [Google Scholar] [CrossRef]
- Kim, C.; Bong, K.; Hong, I.; Lee, K.; Choi, S.; Yoo, H. An ultra-low-power and mixed-mode event-driven face detection SoC for always-on mobile applications. In Proceedings of the IEEE European Solid State Circuits Conference, Leuven, Belgium, 11–14 September 2017; pp. 255–258. [Google Scholar]
- Jeon, D.; Dong, Q.; Kim, Y.; Wang, X.; Chen, S.; Yu, H.; Blaauw, D.; Sylvester, D. A 23-mW face recognition processor with mostly-read 5T memory in 40-nm CMOS. IEEE J. Solid State Circuits 2017, 52, 1628–1642. [Google Scholar] [CrossRef]
- Tsai, A.; Ou, Y.; Hsu, L.; Wang, J. Efficient and effective multi-person and multi-angle face recognition based on deep CNN architecture. In Proceedings of the International Conference on Orange Technologies (ICOT), Bali, Indonesia, 23–26 October 2018; pp. 1–4. [Google Scholar]
- Ahamed, H.; Alam, I.; Islam, M.M. HOG-CNN based real time face recognition. In Proceedings of the International Conference on Advancement in Electrical and Electronic Engineering (ICAEEE), Gazipur, Bangladesh, 22–24 November 2018; pp. 1–4. [Google Scholar]
- Goetschalckx, K.; Moons, B.; Lauwereins, S.; Andraud, M.; Verhelst, M. Optimized hierarchical cascaded processing. IEEE J. Emerg. Sel. Top. Circuits Syst. 2018, 8, 884–894. [Google Scholar] [CrossRef]
- Sumi, N.; Baba, A.; Moshnyaga, V.G. Effect of computation offload on performance and energy consumption of mobile face recognition. In Proceedings of the 2014 IEEE Workshop on Signal Processing Systems (SiPS), Belfast, UK, 20–22 October 2014; pp. 1–7. [Google Scholar]
- Bong, K.; Choi, S.; Kim, C.; Han, D.; Yoo, H. A low-power convolutional neural network face recognition processor and a CIS integrated with always-on face detector. IEEE J. Solid State Circuits 2018, 53, 115–123. [Google Scholar] [CrossRef]
- Kim, J.; Kim, C.; Kim, K.; Yoo, H. An ultra-low-power analog-digital hybrid CNN face recognition processor integrated with a CIS for always-on mobile devices. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar]
- Lecun, M.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Stateline, NV, USA, 3–8 December 2012; pp. 1–9. [Google Scholar]
- Schwarz, M.; Schulz, H.; Behnke, S. RGB-D object recognition and pose estimation based on pre-trained convolutional neural network features. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1329–1335. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G.E. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face recognition: A convolutional neural-network approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef] [PubMed]
- Park, I.; Park, C.; Cheon, J.; Chae, Y. 76 mW 500 fps VGA CMOS image sensor with time-stretched single-slope ADCs achieving 1.95e− random noise. In Proceedings of the 2019 IEEE International Solid-State Circuits Conference—(ISSCC), San Francisco, CA, USA, 17–21 February 2019; pp. 100–102. [Google Scholar]
- Park, K.; Jin, M.; Kim, S.Y.; Song, M. Design of a high speed CMOS image sensor with a hybrid single-slope column ADC and a finite state machine. In Proceedings of the 2017 International SoC Design Conference (ISOCC), Seoul, Korea, 5–8 November 2017; pp. 95–96. [Google Scholar]
- Park, K.; Kim, S.Y. Low-power column counter with a logical-shift algorithm for CMOS image sensors. Electron. Lett. 2020, 56, 232–234. [Google Scholar] [CrossRef]
- Kim, D.; Song, M.; Choe, B.; Kim, S.Y. A multi-resolution mode CMOS image sensor with a novel two-step single-slope ADC for intelligent surveillance systems. Sensors 2017, 17, 1497. [Google Scholar] [CrossRef] [PubMed]
- Shin, M.; Kim, J.; Kim, M.; Jo, Y.; Kwon, O. A 1.92-mega pixel cmos image sensor with column-parallel low-power and area efficient SA-ADCs. IEEE Trans. Electron Devices 2012, 59, 1693–1700. [Google Scholar] [CrossRef]
- Nitta, Y. High-speed digital double sampling with analog CDS on column parallel ADC architecture for low-noise active pixel sensor. In Proceedings of the 2006 IEEE International Solid State Circuits Conference—Digest of Technical Papers, San Francisco, CA, USA, 6–9 February 2006; pp. 2024–2031. [Google Scholar]
- Soleimani, M.; Khoei, A.; Hadidi, K.; Nia, S.K. Design of high-speed high-precision voltage-mode MAX-MIN circuits with low area and low power consumption. In Proceedings of the 2009 European Conference on Circuit Theory and Design, Antalya, Turkey, 23–27 August 2009; pp. 351–354. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning internal representations by error propagation. Parallel Distrib. Process. 1986, 1, 318–362. [Google Scholar]
- Bengio, Y. Practical recommendations for gradient-based training of deep architectures. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 437–478. [Google Scholar]
- Alvarez, S.A. An Exact Analytical Relation among Recall, Precision, and Classification Accuracy in Information Retrieval; Technical Report; Computer Science Department, Boston College: Chestnut Hill, MA, USA, 2002. [Google Scholar]
- Buckland, M.; Gey, F. The relationship between Recall and Precision. J. Am. Soc. Inf. Sci. 1994, 45, 12–19. [Google Scholar] [CrossRef]
- Unal, I. Defining an optimal cut-point value in ROC analysis: An alternative approach. Comput. Math. Methods Med. 2017, 2017, 3762651. [Google Scholar] [CrossRef] [PubMed]
- Cevik, I.; Huang, X.; Yu, H.; Yan, M.; Ay, S.U. An ultra-low power CMOS image sensor with on-chip energy harvesting and power management capability. Sensors 2015, 15, 5531–5554. [Google Scholar] [CrossRef] [PubMed]
- Choi, B.-S.; Shin, E.; Bae, M.; Kim, S.-H.; Lee, J.; Seo, S.-H. A low-power CMOS image sensor based on variable frame rate operation. J. Semicond. Technol. Sci. 2017, 17, 854–861. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Process Tech. | 0.11 μm 1P4M CIS Process |
|---|---|
| Chip Size | 5.90 mm × 5.24 mm(30.92 mm2) |
| Core Size | 2.93 mm × 2.61 mm(7.65 mm2) |
| Resolution | QQVGA (160 × 120) |
| Pixel type | 4T-APS |
| Supply voltages | 3.3 V (Analog)/1.5 (Digital) |
| Power consumption | 0.96 mW @ 60 fps/1.12 mW @ 120 fps |
| Maximum Frame rate | 120 fps |
| Actual | Predicted | Positive | Negative |
|---|---|---|---|
| Positive | 72 | 28 | |
| Negative | 4 | 196 | |
| JSSC’18 [12] | ISCAS’19 [13] | This Work | |
|---|---|---|---|
| Technology | Samsung 65 nm | Samsung 65 nm | Dongbu 110 nm |
| Algorithm | FD: Haar-like FR: Digital CNN | FD and FR: Analog–Digital Hybrid CNN | FD: Analog-CNN |
| Accuracy | 97% | 96.18% | 89.33% |
| Resolution | QVGA | QVGA | QQVGA |
| Conv. Power | 24–96 μW 1 | 10.17–18.75 μW 2 | 1.46 μW 2 |
| Total Power | 0.62 mW @ 1 fps 3 | 0.62 mW @ 1 fps 3 | 0.16 mW @ 1 fps 4 |
| 0.96 mW @ 60 fps | |||
| 1.12 mW @ 120 fps |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J.; Lee, S.; Son, Y.; Kim, S.Y. Design of an Always-On Image Sensor Using an Analog Lightweight Convolutional Neural Network. Sensors 2020, 20, 3101. https://doi.org/10.3390/s20113101
Choi J, Lee S, Son Y, Kim SY. Design of an Always-On Image Sensor Using an Analog Lightweight Convolutional Neural Network. Sensors. 2020; 20(11):3101. https://doi.org/10.3390/s20113101
Chicago/Turabian StyleChoi, Jaihyuk, Sungjae Lee, Youngdoo Son, and Soo Youn Kim. 2020. "Design of an Always-On Image Sensor Using an Analog Lightweight Convolutional Neural Network" Sensors 20, no. 11: 3101. https://doi.org/10.3390/s20113101
APA StyleChoi, J., Lee, S., Son, Y., & Kim, S. Y. (2020). Design of an Always-On Image Sensor Using an Analog Lightweight Convolutional Neural Network. Sensors, 20(11), 3101. https://doi.org/10.3390/s20113101