Study on the Classification Performance of Underwater Sonar Image Classification Based on Convolutional Neural Networks for Detecting a Submerged Human Body †


Abstract
1. Introduction
1.1. The Necessity of Submerged Body Detection
1.2. Deep Learning
1.3. Paper Contents
- Experiments were carried out to acquire underwater sonar images for the study of the submerged body detection method. Mainly, we obtained the experimental data in both clean and turbid water environments.
- Through the case study to validate the robust submerged body detection, the reasonable classification performance of sonar images including a submerged body was obtained using a CNN-based deep learning model.
- The most important thing in this study is to confirm the feasibility of applying a deep learning model only with CKI to a field image of the seaside. For that, we prepared the training data by using image processing techniques that can realize general and polarized noise by background. With this possibility, indoor testbed data alone will provide a starting point for considering various field robotic applications.
2. Convolutional Neural Network
2.1. CNN Architecture
2.2. Definition of Convolution Layer
2.3. AlexNet
2.4. GoogLeNet
3. Image Pre-Processing for Deep Learning
3.1. Uncommon Sensor Images
3.2. Noise Generation
3.3. Image Preparation for Training
4. Experimental Results
4.1. Image DataSets
4.2. Model Setup and Learning
4.3. Classification Results
4.4. Re-Training
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Francisco, F.; Jan, S. Detection of Visual Signatures of Marine Mammals and Fish within Marine Renewable Energy Farms using Multibeam Imaging Sonar. J. Mar. Sci. Eng. 2019, 7, 22. [Google Scholar] [CrossRef]
- Lee, S. Deep Learning of Submerged Body Images from 2D Sonar Sensor based on Convolutional Neural Network. In Proceedings of the 2017 IEEE Underwater Technology (UT), Busan, Korea, 21–24 February 2017. [Google Scholar]
- Kang, H. Identification of Underwater Objects using Sonar Image. J. Inst. Electron. Inf. Eng. 2016, 53, 91–98. [Google Scholar]
- Cho, H.; Gu, J.; Joe, H.; Asada, A.; Yu, S.C. Acoustic beam profile-based rapid underwater object detection for an imaging sonar. J. Mar. Sci. Technol. 2015, 20, 180–197. [Google Scholar] [CrossRef]
- Purcell, M.; Gallo, D.; Packard, G.; Dennett, M.; Rothenbeck, M.; Sherrell, A.; Pascaud, S. Use of REMUS 6000 AUVs in the search for the Air France Flight 447. In Proceedings of the OCEANS’11 MTS/IEEE KONA, Waikoloa, HI, USA, 19–22 September 2011; pp. 1–7. [Google Scholar]
- Reed, S.; Petillot, Y.; Bell, J. An automatic approach to the detection and extraction of mine features in sidescan sonar. IEEE J. Ocean. Eng. 2003, 28, 90–105. [Google Scholar] [CrossRef]
- Williams, D.P.; Groen, J. A fast physics-based, environmentally adaptive underwater object detection algorithm. In Proceedings of the OCEANS, Santander, Spain, 6–9 June 2011; pp. 1–7. [Google Scholar]
- Galceran, E.; Djapic, V.; Carreras, M.; Williams, D.P. A real-time underwater object detection algorithm for multi-beam forward looking sonar. IFAC Proc. Vol. 2012, 45, 306–311. [Google Scholar] [CrossRef]
- Belcher, E.O.; Lynn, D.C. Acoustic near-video-quality images for work in turbid water. In Proceedings of the Underwater Intervention, Houston, TX, USA, 24–26 January 2000. [Google Scholar]
- Lee, Y.; Kim, T.G.; Choi, H.T. Preliminary study on a framework for imaging sonar based underwater object recognition. In Proceedings of the 10th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Jeju, Korea, 30 October–2 November 2013; pp. 517–520. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C.; Bekaert, P. Color Balance and Fusion for Underwater Image Enhancement. IEEE Trans. Image Process. 2018, 27, 379–393. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G.E. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Alex, K.; Ilya, S.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the NIPS, Lake Tahoe, CA, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Lee, S.; Park, B.; Kim, A. A Deep Learning based Submerged Body Classification Using Underwater Imaging Sonar. In Proceedings of the 16th International Conference on Ubiquitous Robots, Jeju, Korea, 24–27 June 2019; Volume 20, pp. 106–112. [Google Scholar]
- Cadieu, C.F.; Hong, H.; Yamins, D.L.K.; Pinto, N.; Ardila, D.; Solomon, E.A.; Majaj, N.J.; DiCarlo, J.J. Deep Neural Networks Rival the Representation of Primate IT Cortex for Core Visual Object Recognition. PLoS Comput. Biol. 2014, 10, 1–18. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
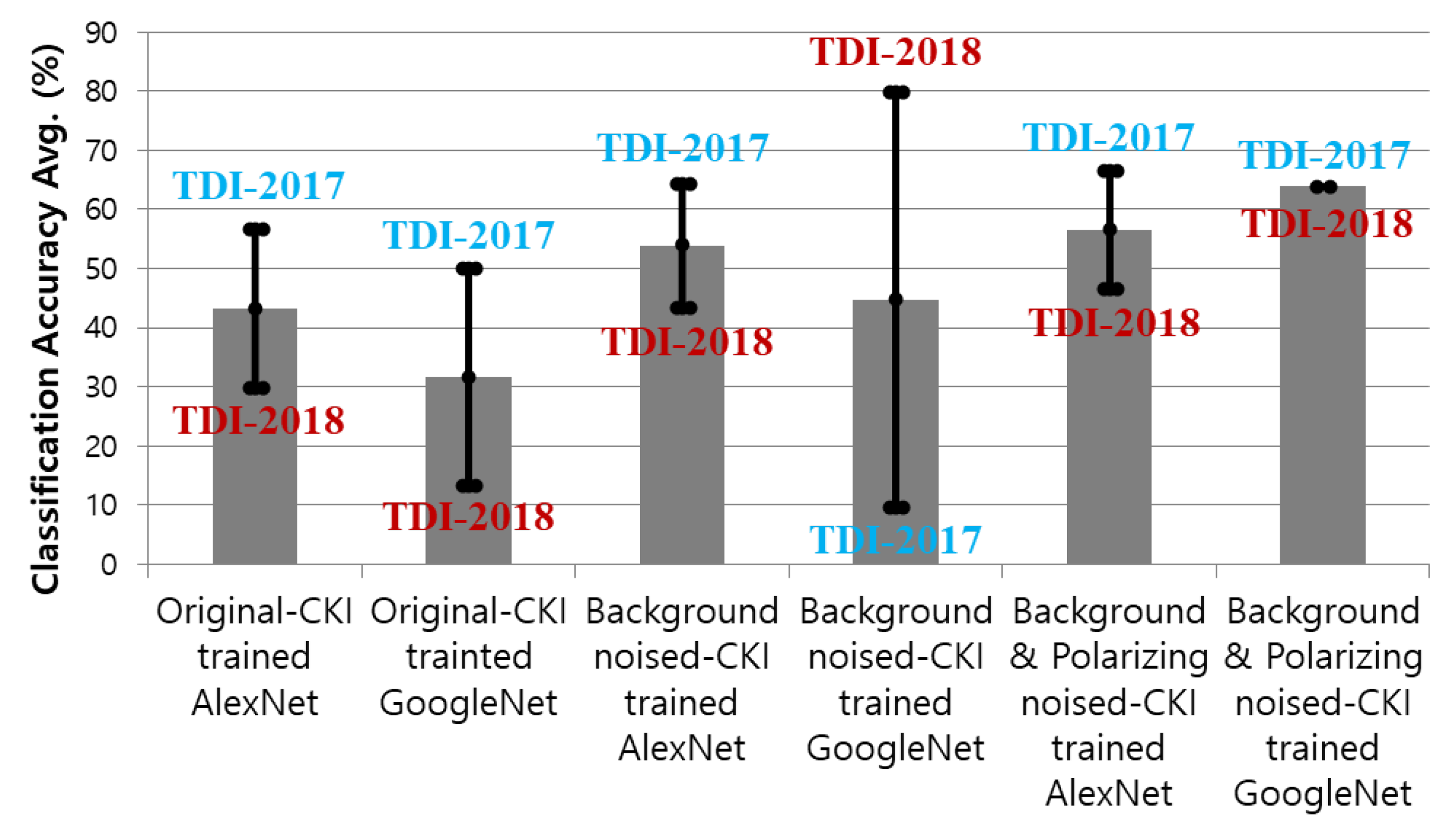
| Models | TDI-2017 | TDI-2018 | Averages |
|---|---|---|---|
| Original-CKI trained AlexNet | 56.6 | 30 | 43.3 |
| Original-CKI trained GoogleNet | 50 | 13.3 | 31.6 |
| Background noised-CKI trained AlexNet | 64.4 | 43.3 | 53.8 |
| Background noised-CKI trained GoogleNet | 9.6 | 80 | 44.8 |
| Background & Polarizing noised- | 66.6 | 46.6 | 56.6 |
| CKI trained AlexNet | |||
| Background & Polarizing noised- | 63.8 | 63.8 | 63.8 |
| CKI trained GoogleNet |
| Models | TDI-2017 | TDI-2018 | Averages |
|---|---|---|---|
| Background & Polarizing Lv.1 noised- | 63.8 | 63.8 | 63.8 |
| CKI trained GoogleNet | |||
| Background & Polarizing Lv.2 noised- | 80 | 70 | 75 |
| CKI trained GoogleNet | |||
| Background & Polarizing Lv.3 noised- | 83.3 | 100 | 91.6 |
| CKI trained GoogleNet |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, H.-T.; Lee, E.-H.; Lee, S. Study on the Classification Performance of Underwater Sonar Image Classification Based on Convolutional Neural Networks for Detecting a Submerged Human Body. Sensors 2020, 20, 94. https://doi.org/10.3390/s20010094
Nguyen H-T, Lee E-H, Lee S. Study on the Classification Performance of Underwater Sonar Image Classification Based on Convolutional Neural Networks for Detecting a Submerged Human Body. Sensors. 2020; 20(1):94. https://doi.org/10.3390/s20010094
Chicago/Turabian StyleNguyen, Huu-Thu, Eon-Ho Lee, and Sejin Lee. 2020. "Study on the Classification Performance of Underwater Sonar Image Classification Based on Convolutional Neural Networks for Detecting a Submerged Human Body" Sensors 20, no. 1: 94. https://doi.org/10.3390/s20010094
APA StyleNguyen, H.-T., Lee, E.-H., & Lee, S. (2020). Study on the Classification Performance of Underwater Sonar Image Classification Based on Convolutional Neural Networks for Detecting a Submerged Human Body. Sensors, 20(1), 94. https://doi.org/10.3390/s20010094