Integrate Point-Cloud Segmentation with 3D LiDAR Scan-Matching for Mobile Robot Localization and Mapping

Abstract
1. Introduction
2. Related Work
3. Methodology
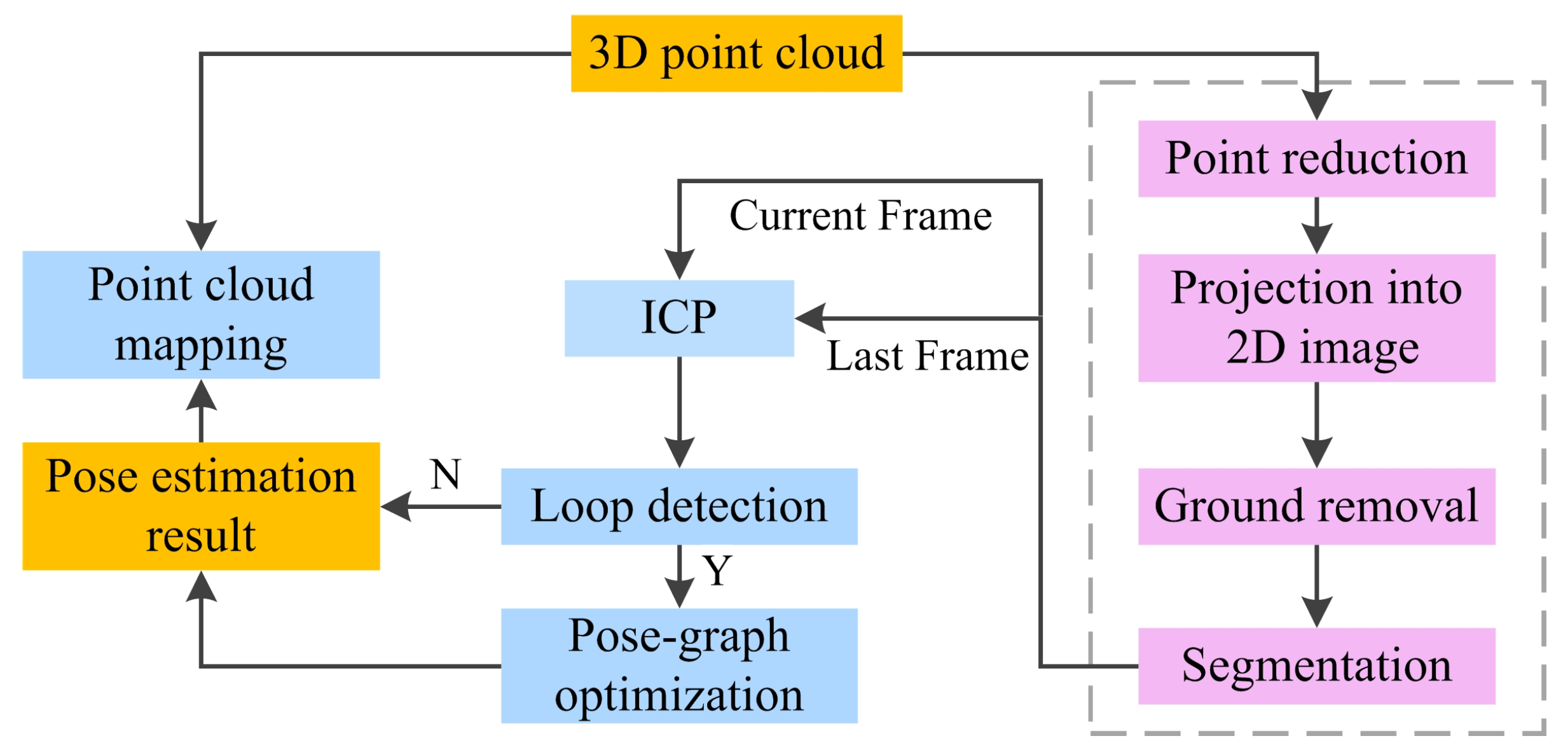
3.1. System Overview
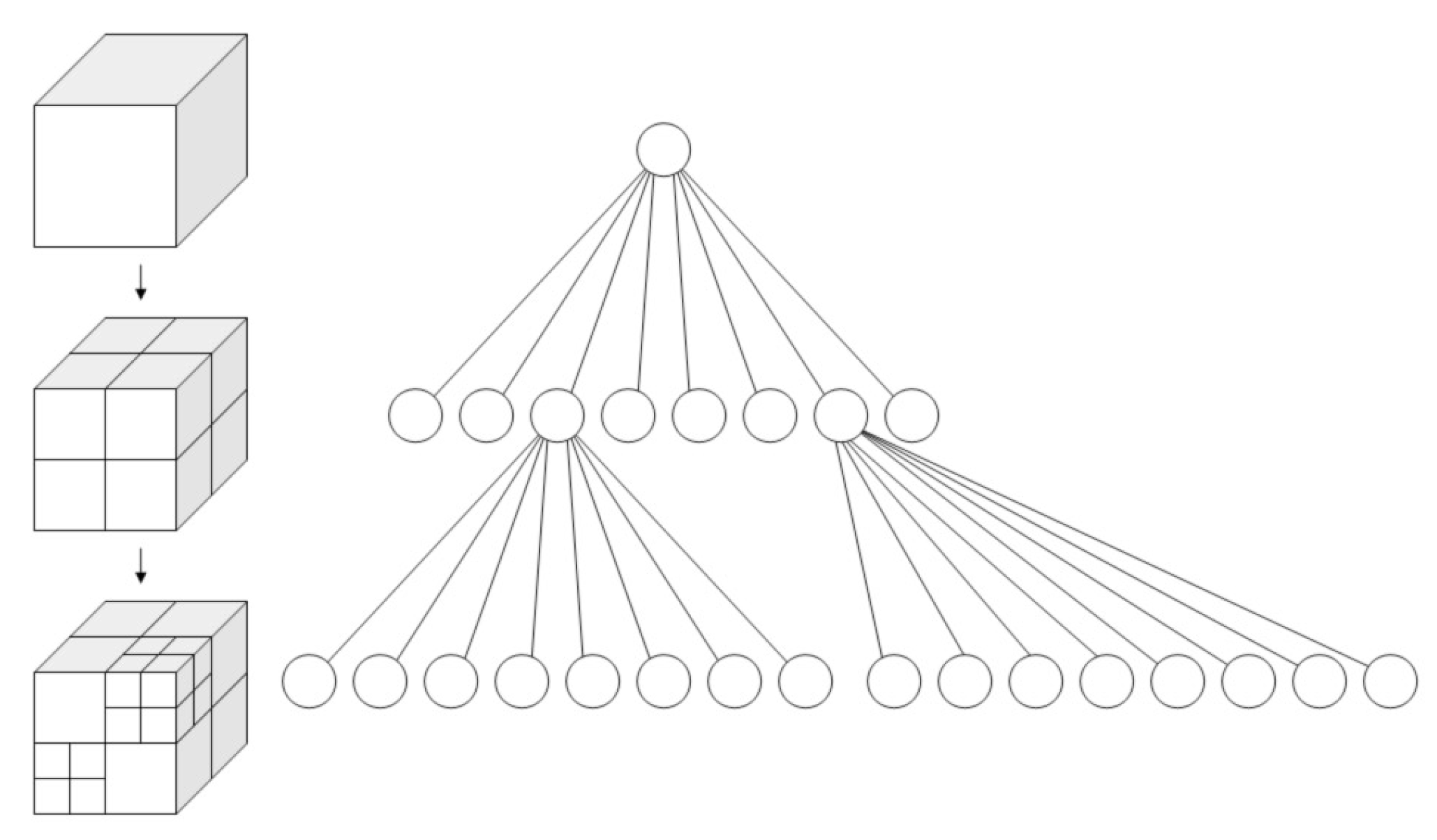
3.2. Point Reduction
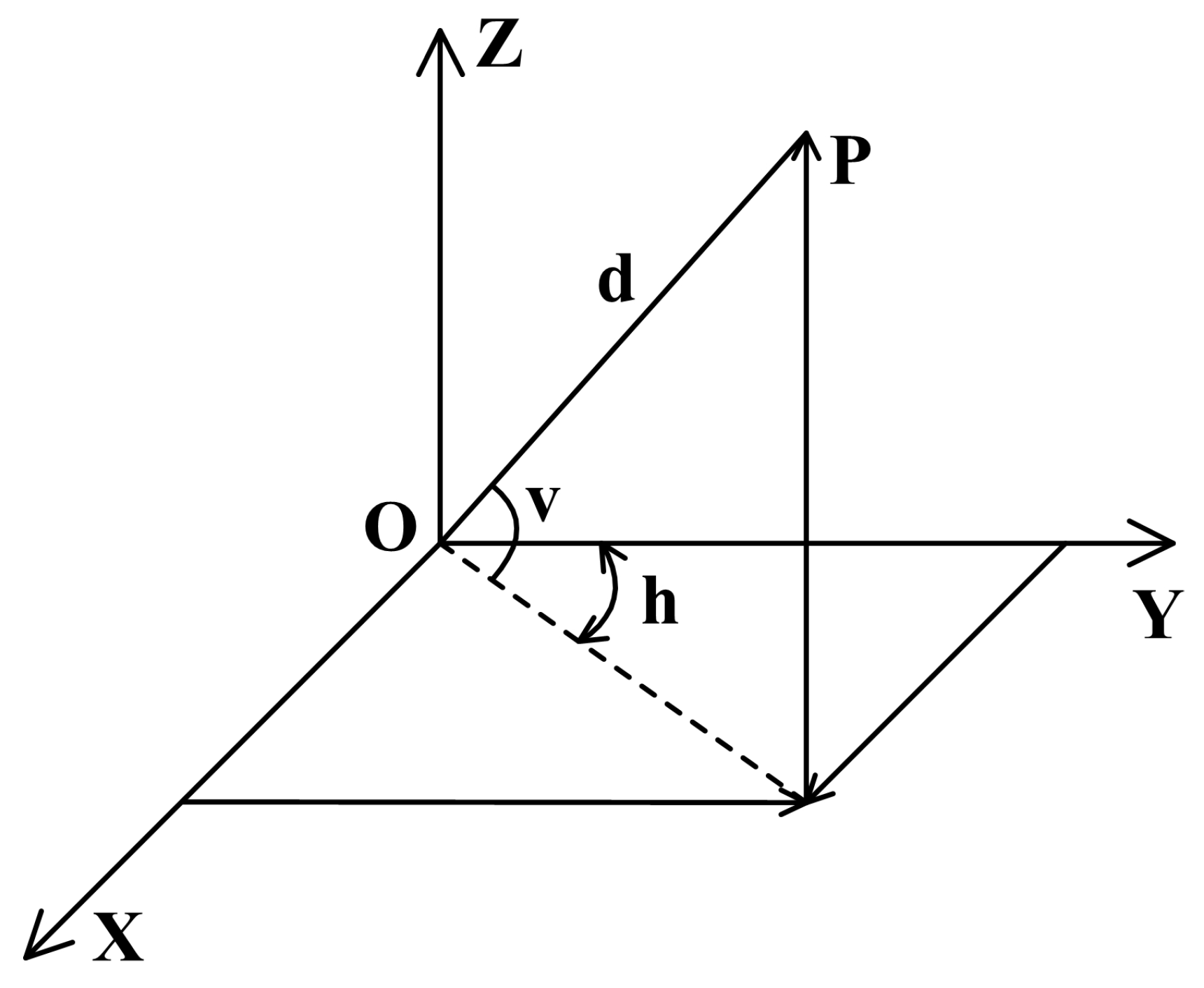
3.3. Projection into 2D Range Image
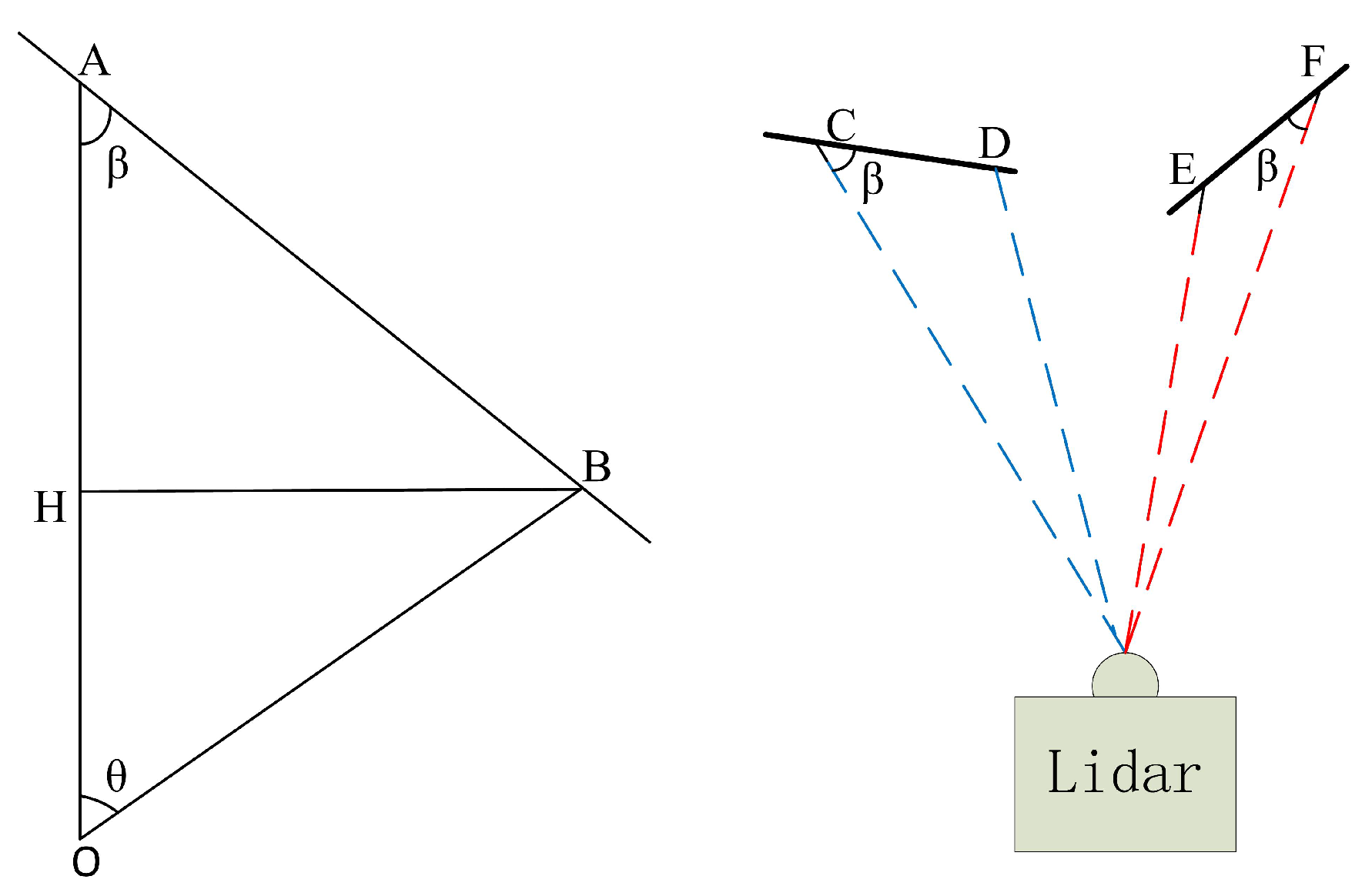
3.4. Ground Removal
| Algorithm 1 Ground points extraction |
| Input: Range image R, ground angle threshold , Label=1, windowsize |
| Output: L |
|
3.5. Segmentation
| Algorithm 2 Segmentation |
| Input: Range image , segmentation threshold , Label=1 |
| Output: L |
|
3.6. ICP and 6D SLAM
4. Experimental Results
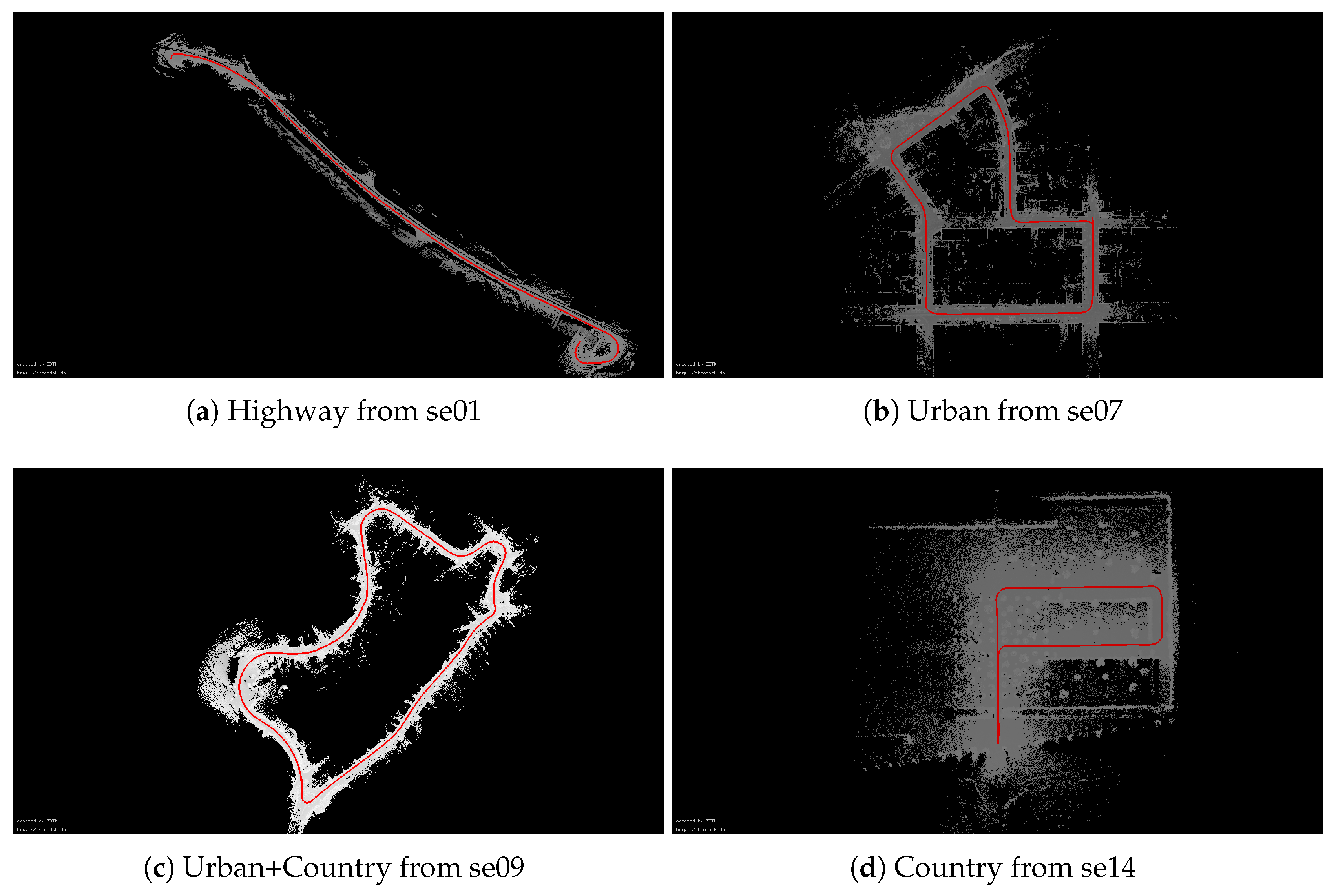
4.1. Experimental Platform and Evaluation Method
4.2. Results
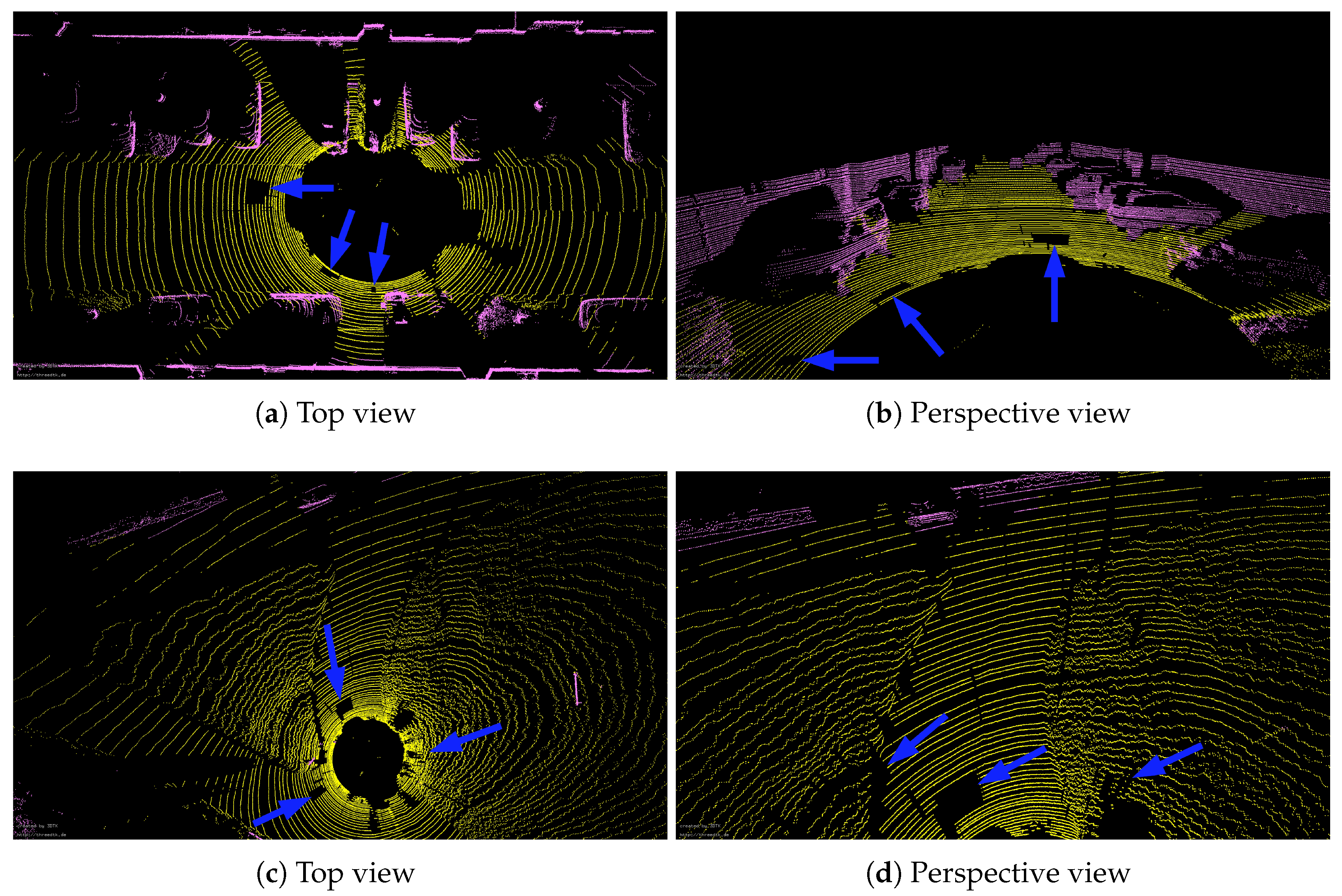
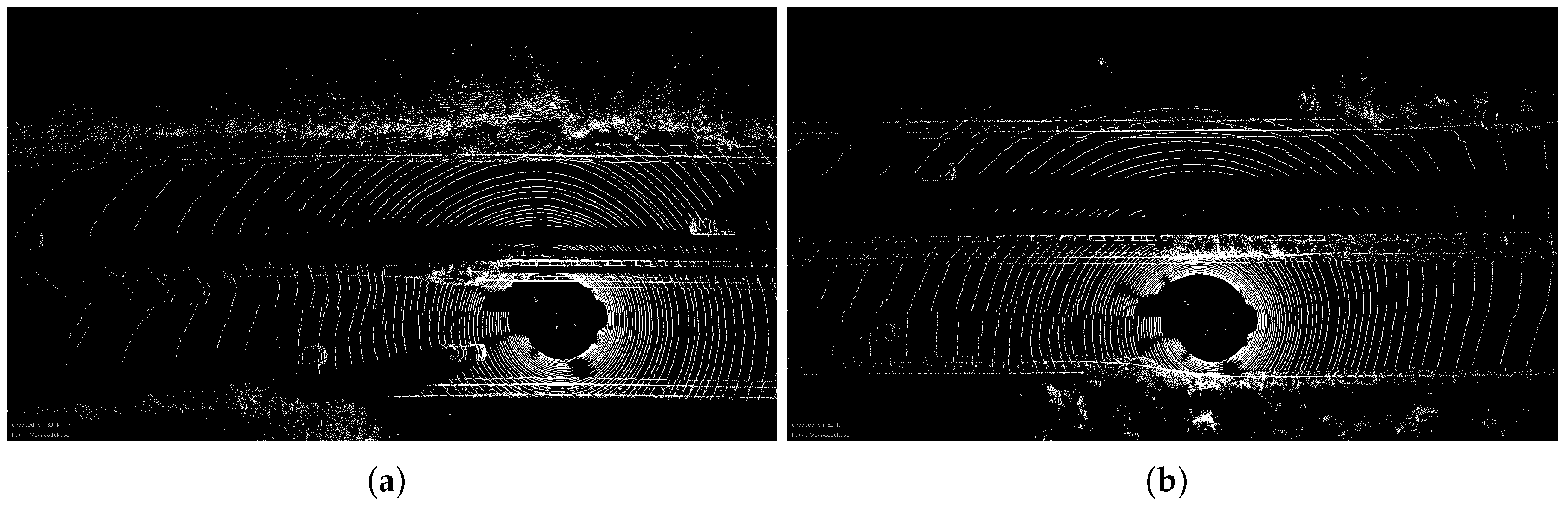
4.2.1. Ground Points Removal
4.2.2. Segmentation
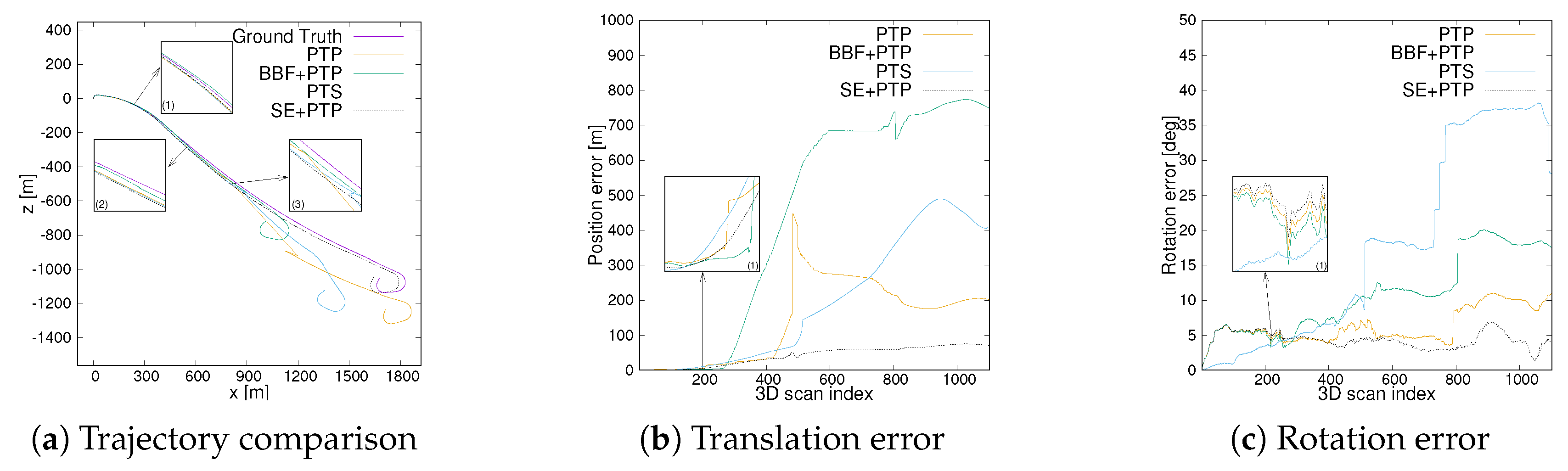
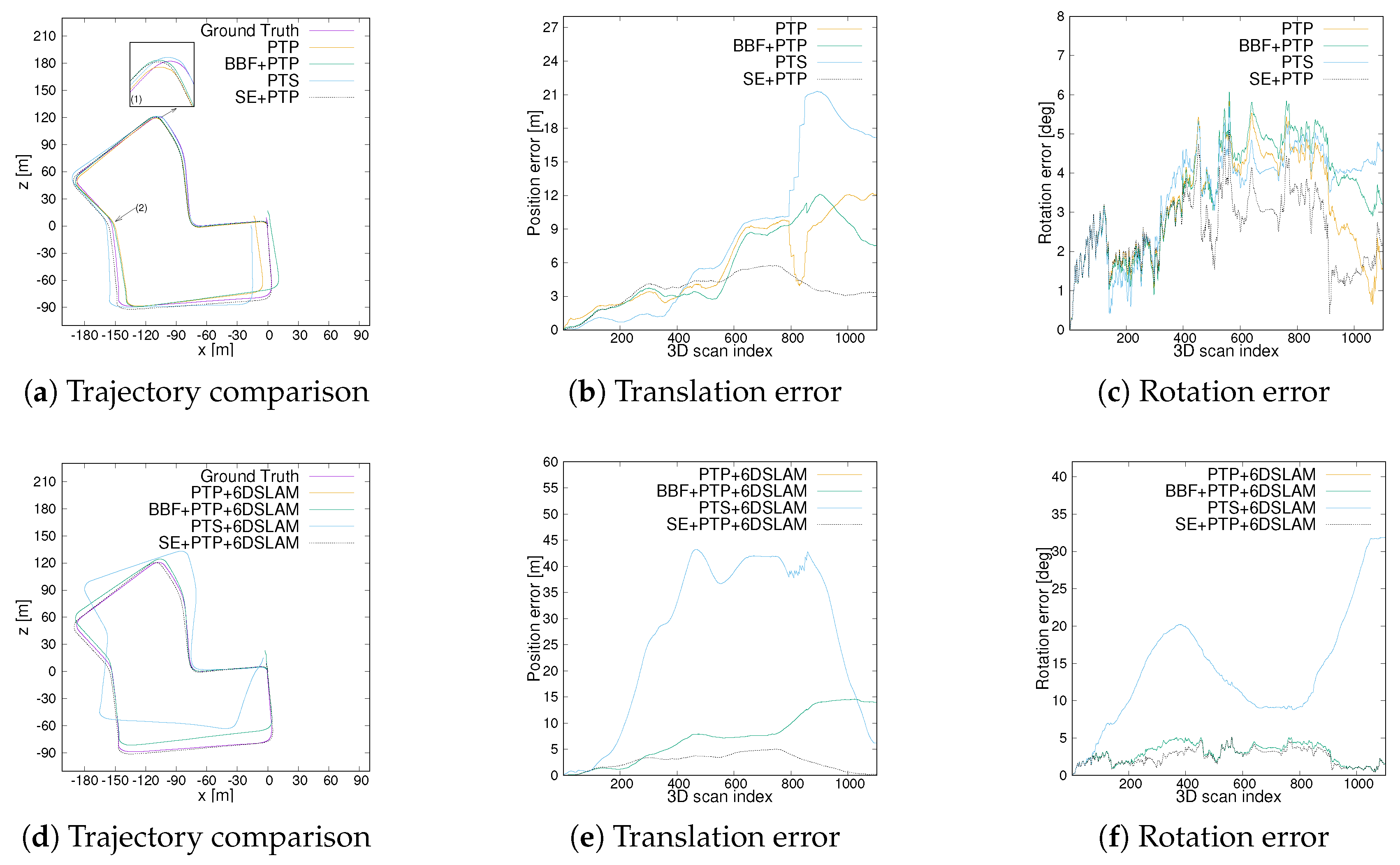
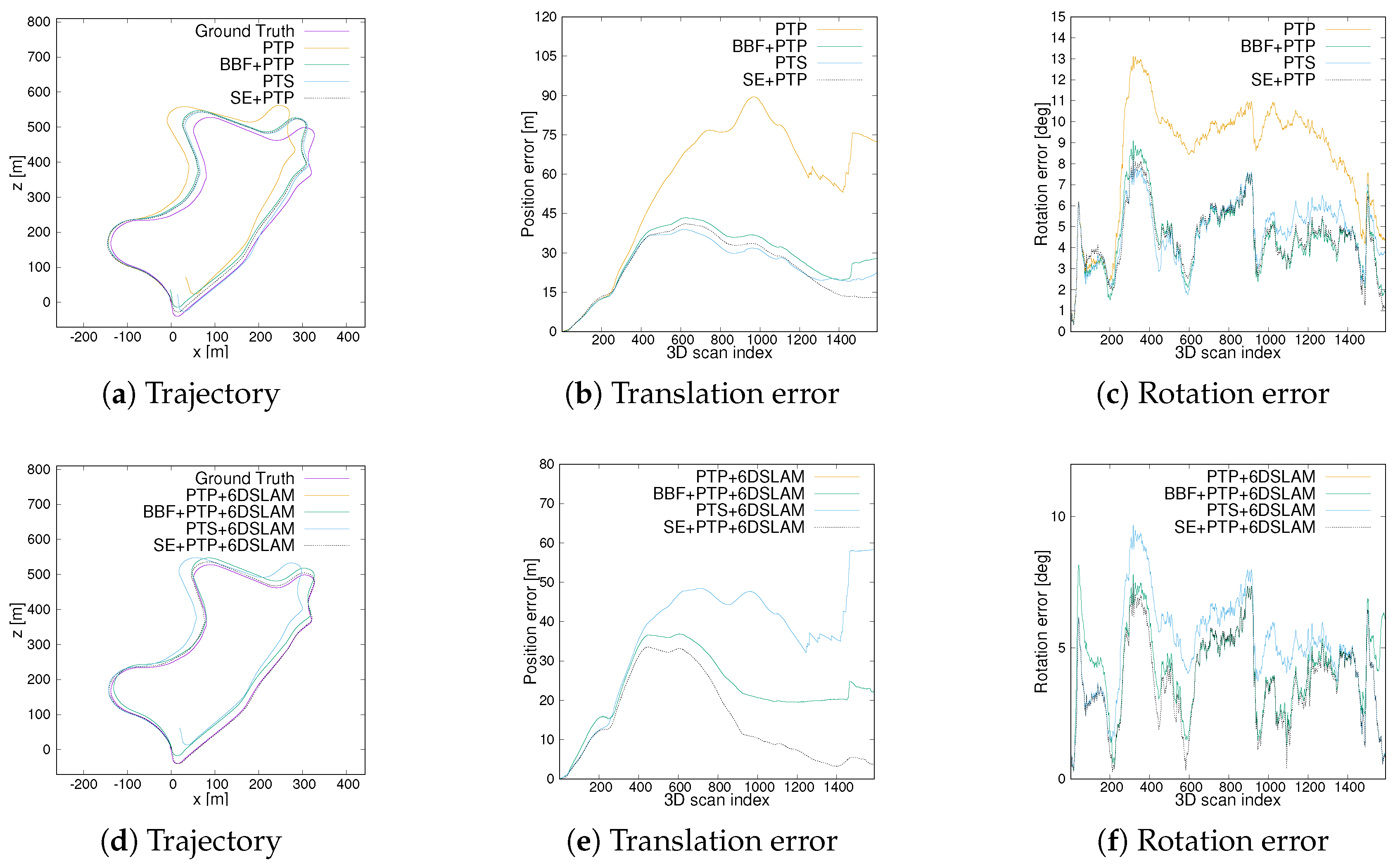
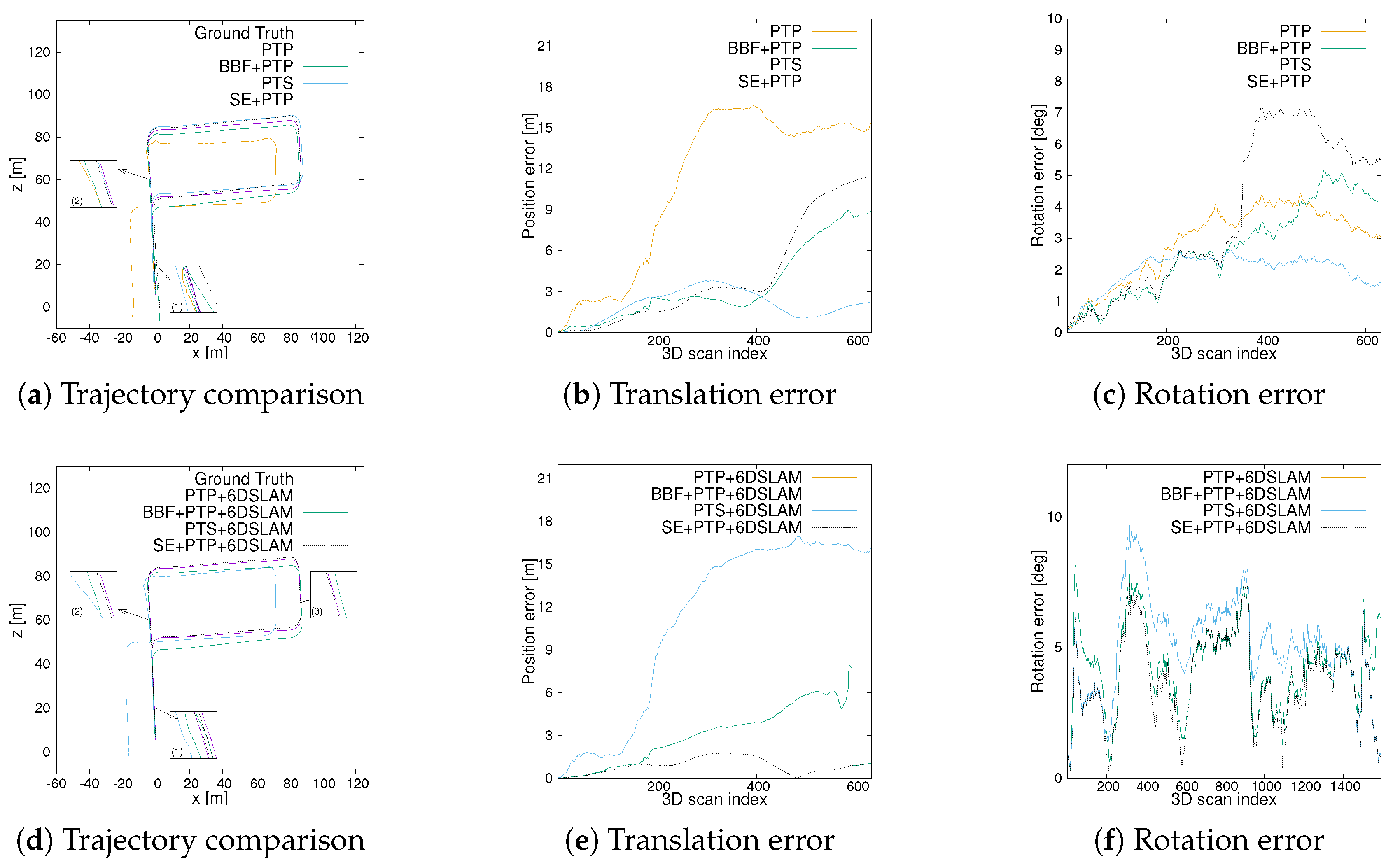
4.2.3. Comparison of Trajectory Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lin, Y.; Gao, F.; Qin, T.; Gao, W.; Liu, T.; Wu, W.; Yang, Z.; Shen, S. Autonomous aerial navigation using monocular visual inertial fusion. IEEE Intell. Transp. Syst. Mag. 2018, 35, 23–51. [Google Scholar] [CrossRef]
- Pinies, P.; Lupton, T.; Sukkarieh, S.; Tardos, J.D. Inertial aiding of inverse depth SLAM using a monocular camera. In Proceedings of the IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 2797–2802. [Google Scholar]
- Tong, C.H.; Barfoot, T.D. Gaussian process gaussnewton for 3d laser-based visual odometry. In Proceedings of the IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 5204–5211. [Google Scholar]
- Barfoot, T.D.; McManus, C.; Anderson, S.; Dong, H.; Beerepoot, E.; Tong, C.H.; Furgale, P.; Gammell, J.D.; Enright, J. Into darkness: Visual navigation based on a lidar-intensity-image pipeline. Robot. Res. 2016, 114, 487–504. [Google Scholar]
- Yang, J.; Li, H.; Campbell, D.; Jia, Y. Go-ICP: A Globally Optimal Solution to 3D ICP Point-Set Registration. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2241–2254. [Google Scholar] [CrossRef] [PubMed]
- Ren, Z.; Wang, L.; Bi, L. Robust GICP-Based 3D LiDAR SLAM for Underground Mining Environment. Sensors 2019, 19, 2915. [Google Scholar] [CrossRef] [PubMed]
- Besl, P.J.; McKay, N.D. A Method for Registration of 3D Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Segal, A.; Haehnel, D.; Thrun, S. Generalized-ICP. In Proceedings of the Robotics: Science and Systems, Zurich, Switzerland, 25–28 June 2009; Volume 2, p. 435. [Google Scholar]
- Zhou, Q.Y.; Park, J.; Koltun, V. Fast global registration. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 766–782. [Google Scholar]
- Zhang, J.; Singh, S. LOAM: Lidar Odometry and Mapping in Real-time. In Proceedings of the Robotics: Science and Systems, Cambridge, CA, USA, 12–16 July 2014; pp. 1–9. [Google Scholar]
- Zaganidis, A.; Sun, L.; Duckett, T.; Cielniak, G. Integrating Deep Semantic Segmentation into 3D Point Cloud Registration. IEEE Robot. Autom. Lett. 2018, 3, 2942–2949. [Google Scholar] [CrossRef]
- Stoyanov, T.; Magnusson, M.; Lilienthal, A.J. Point Set Registration through Minimization of the L2 Distance between 3D-NDT Models. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 5196–5201. [Google Scholar]
- Liu, H.; Ye, Q.; Wang, H.; Chen, L.; Yang, J. A Precise and Robust Segmentation-Based Lidar Localization System for Automated Urban Driving. Remote Sens. 2019, 11, 1348. [Google Scholar] [CrossRef]
- Opromolla, R.; Fasano, G.; Grassi, M.; Savvaris, A.; Moccia, A. PCA-Based Line Detection from Range Data for Mapping and Localization-Aiding of UAVs. Int. J. Aerosp. Eng. 2017, 38, 1–14. [Google Scholar] [CrossRef]
- Durrant-Whyte, H.; Bailey, T. Simultaneous Localization and Mapping (SLAM): Part I the essential algorithms. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- Grisetti, G.; Kummerle, R.; Stachniss, C.; Burgard, W. A Tutorial on GraphBased SLAM. IEEE Intell. Transp. Syst. Mag. 2010, 4, 31–43. [Google Scholar] [CrossRef]
- Rusu, R.; Cousins, S. 3D is here: Point Cloud Library (PCL). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Na, K.; Byun, J.; Roh, M.; Seo, B. The ground segmentation of 3D LIDAR point cloud with the optimized region merging. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 2–6 December 2013; pp. 445–450. [Google Scholar]
- Luo, Z.; Mohrenschildt, M.; Habibi, S. A Probability Occupancy Grid Based Approach for Real-Time LiDAR Ground Segmentation. IEEE Trans. Intell. Transp. Syst. 2019, 1–13. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B. LeGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar]
- Pomares, A.; Martínez, J.; Mandow, A.; Martinez, M.; Moran, M.; Morales, J. Ground Extraction from 3D Lidar Point Clouds with the Classification Learner App. In Proceedings of the 26th Mediterranean Conference on Control and Automation (MED), Zadar, Croatia, 19–22 June 2018; pp. 400–405. [Google Scholar]
- Hackel, T.; Wegner, J.D.; Schindler, K. Fast Semantic Segmentation of 3d Point Clouds with Strongly Varying Density. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 177–184. [Google Scholar] [CrossRef]
- Velas, M.; Spanel, M.; Hradis, M.; Herout, A. CNN for Very Fast Ground Segmentation in Velodyne Lidar Data. In Proceedings of the 2018 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Torres Vedras, Portugal, 25–27 April 2018; pp. 97–103. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Huhle, B.; Magnusson, M.; Strasser, W.; Lilienthal, A.J. Registration of colored 3D point clouds with a Kernel-based extension to the normal distributions transform. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008; pp. 4025–4030. [Google Scholar]
- Nüchter, A.; Wulf, O.; Lingemann, K.; Hertzberg, J.; Wagner, B.; Surmann, H. 3D mapping with semantic knowledge. In Robot Soccer World Cup; Springer: Berlin, Germany, 2005; pp. 335–346. [Google Scholar]
- Zaganidis, A.; Magnusson, M.; Duckett, T.; Cielniak, G. Semantic-assisted 3d normal distributions transform for scan registration in environments with limited structure. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- PiniÉs, P.; TardÓs, J.D. Large-Scale SLAM Building Conditionally Independent Local Maps: Application to Monocular Vision. IEEE Trans. Robot. 2008, 24, 1094–1106. [Google Scholar] [CrossRef]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved Techniques for Grid Mapping With Rao-Blackwellized Particle Filters. IEEE Trans. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef]
- Olofsson, B.; Antonsson, J.; Kortier, H.G.; Bernhardsson, B.; Robertsson, A.; Johansson, R. Sensor fusion for robotic workspace state estimation. IEEE/ASME Trans. Mechatronics 2016, 21, 2236–2248. [Google Scholar] [CrossRef]
- Wang, K.; Liu, Y.; Li, L. A Simple and Parallel Algorithm for Real-Time Robot Localization by Fusing Monocular Vision and Odometry/AHRS Sensors. IEEE/ASME Trans. Mechatronics 2014, 19, 1447–1457. [Google Scholar] [CrossRef]
- Borrmann, D.; Elseberg, J.; Lingemann, K.; Nüchter, A.; Hertzberg, J. Globally consistent 3D mapping with scan matching. Robot. Auton. Syst. 2008, 56, 130–142. [Google Scholar] [CrossRef]
- Elseberg, J.; Borrmann, D.; Nüchter, A. One billion points in the cloud—An octree for efficient processing of 3D laser scans. Int. J. Photogramm. Remote. Sens. 2013, 76, 76–88. [Google Scholar] [CrossRef]
- Bogoslavskyi, I.; Stachniss, C. Fast range image-based segmentation of sparse 3D laser scans for online operation. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 163–169. [Google Scholar]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Nüchter, A.; Lingemann, K. 6D SLAM Software. Available online: http://slam6d.sourceforge.net/ (accessed on 31 December 2019).
- Geiger, A.; Lenz, P.; Urtasum, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- May, S.; Droeschel, D.; Holz, D.; Fuchs, S.; Malis, E.; Nüchter, A.; Hertzberg, J. Three dimensional mapping with time of flight cameras. J. Field Robot. 2009, 26, 934–965. [Google Scholar] [CrossRef]
- Cvišić, I.; Ćesić, J.; Marković, I.; Petrović, I. SOFT-SLAM: Computationally Efficient Stereo Visual SLAM for Autonomous UAVs. J. Field Robot. 2017, 35, 578–595. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | se01(Highway) | se07(Urban) | se09(Urban+Country) | se14(Country) | ||||
|---|---|---|---|---|---|---|---|---|
| tabs [m] | rabs [deg] | tabs [m] | rabs [deg] | tabs [m] | rabs [deg] | tabs [m] | rabs [deg] | |
| PTP | 183.8600 | 6.7351 | 7.0136 | 3.4204 | 61.6887 | 8.8175 | 12.3578 | 3.1265 |
| BBF+PTP | 543.1686 | 12.0947 | 6.7612 | 3.7937 | 30.5351 | 4.8372 | 4.3729 | 3.0239 |
| PTS | 261.8181 | 22.4791 | 10.9247 | 3.6953 | 27.0114 | 5.0372 | 2.3129 | 2.0502 |
| SE+PTP | 49.0841 | 4.4752 | 3.8886 | 2.7021 | 27.4586 | 4.7811 | 5.5984 | 4.4430 |
| PTP+6DSLAM | n.a. | n.a. | 30.5522 | 15.9400 | 39.4745 | 5.4160 | 12.6070 | 1.6986 |
| BBF+PTP+6DSLAM | n.a. | n.a. | 8.6707 | 3.2422 | 24.7700 | 4.5936 | 3.5380 | 1.6498 |
| PTS+6DSLAM | n.a. | n.a. | 30.5522 | 15.9400 | 39.4745 | 5.4160 | 12.6070 | 1.6986 |
| SE+PTP+6DSLAM | n.a. | n.a. | 3.0454 | 2.6856 | 18.5825 | 4.1382 | 1.0114 | 0.8563 |
| Sequences | Number of Scans | PTP(s) | BBF+PTP(s) | PTS(s) | SE+PTP(s) |
|---|---|---|---|---|---|
| se01 | 1101 | 534.9202 | 235.6870 | 1518.7555 | 351.6523 |
| se07 | 1101 | 256.9504 | 199.3139 | 962.3334 | 191.0013 |
| se09 | 1591 | 592.2633 | 368.2708 | 2000.6465 | 311.0511 |
| se14 | 631 | 242.4361 | 183.1523 | 774.3427 | 132.9431 |
| Method | se01(Highway) | se07(Urban) | se09(Urban+Country) | se14(Country) | ||||
|---|---|---|---|---|---|---|---|---|
| trel [%] | rrel [deg] | trel [%] | rrel [deg] | trel [%] | rrel [deg] | trel [%] | rrel [deg] | |
| PTS | 12.0361 | 0.0245 | 3.1390 | 0.0151 | 4.2922 | 0.0198 | 1.4128 | 0.0101 |
| SE+PTP | 3.9835 | 0.0080 | 1.5691 | 0.0136 | 4.1093 | 0.0189 | 3.0411 | 0.0301 |
| BBF+PTP+6DSLAM | 34.0821 | 0.0127 | 2.8382 | 0.0182 | 4.4884 | 0.0201 | 2.1407 | 0.0122 |
| SE+PTP+6DSLAM | 3.9835 | 0.0080 | 1.4075 | 0.0131 | 3.9607 | 0.0183 | 0.9815 | 0.0143 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Du, S.; Li, G.; Li, H. Integrate Point-Cloud Segmentation with 3D LiDAR Scan-Matching for Mobile Robot Localization and Mapping. Sensors 2020, 20, 237. https://doi.org/10.3390/s20010237
Li X, Du S, Li G, Li H. Integrate Point-Cloud Segmentation with 3D LiDAR Scan-Matching for Mobile Robot Localization and Mapping. Sensors. 2020; 20(1):237. https://doi.org/10.3390/s20010237
Chicago/Turabian StyleLi, Xuyou, Shitong Du, Guangchun Li, and Haoyu Li. 2020. "Integrate Point-Cloud Segmentation with 3D LiDAR Scan-Matching for Mobile Robot Localization and Mapping" Sensors 20, no. 1: 237. https://doi.org/10.3390/s20010237
APA StyleLi, X., Du, S., Li, G., & Li, H. (2020). Integrate Point-Cloud Segmentation with 3D LiDAR Scan-Matching for Mobile Robot Localization and Mapping. Sensors, 20(1), 237. https://doi.org/10.3390/s20010237