Heuristic Approaches for Enhancing the Privacy of the Leader in IoT Networks


Abstract
1. Introduction
1.1. Background
1.2. Our Contributions
- An optimization problem of removing k edges to minimize the closeness value of the leader and its complexity analysis.
- A greedy algorithm to solve the proposed optimization problem in polynomial time and theoretical proof of the lower bound of its solution.
- An effective pruning algorithm—UpdateCloseness for computing closeness value after removing an edge.
- Experimental evaluation of the efficiency and accuracy of the proposed algorithms.
- An optimization problem of removing k edges to maximize the closeness rank of the leader and its complexity analysis.
- An approximation algorithm (GSA) combing greedy algorithm and simulated annealing algorithm to solve the proposed optimization problem in polynomial time.
- An effective pruning algorithm—FastTopRank for computing closeness rank of the high ranking nodes.
- Experimental evaluation of the efficiency and accuracy of the proposed algorithms.
2. Preliminaries
2.1. Basic Notation
2.2. Related Work
2.2.1. Closeness Algorithm
2.2.2. Topic
- As shown in Rochat’s work [21], harmonic centrality only performs a little better in the unconnected network. However, usually the Internet of Things needs to be connected. Hence, differing from Crescenzi’s work [19], we choose closeness centrality as the measurement of identifying the importance of a node.
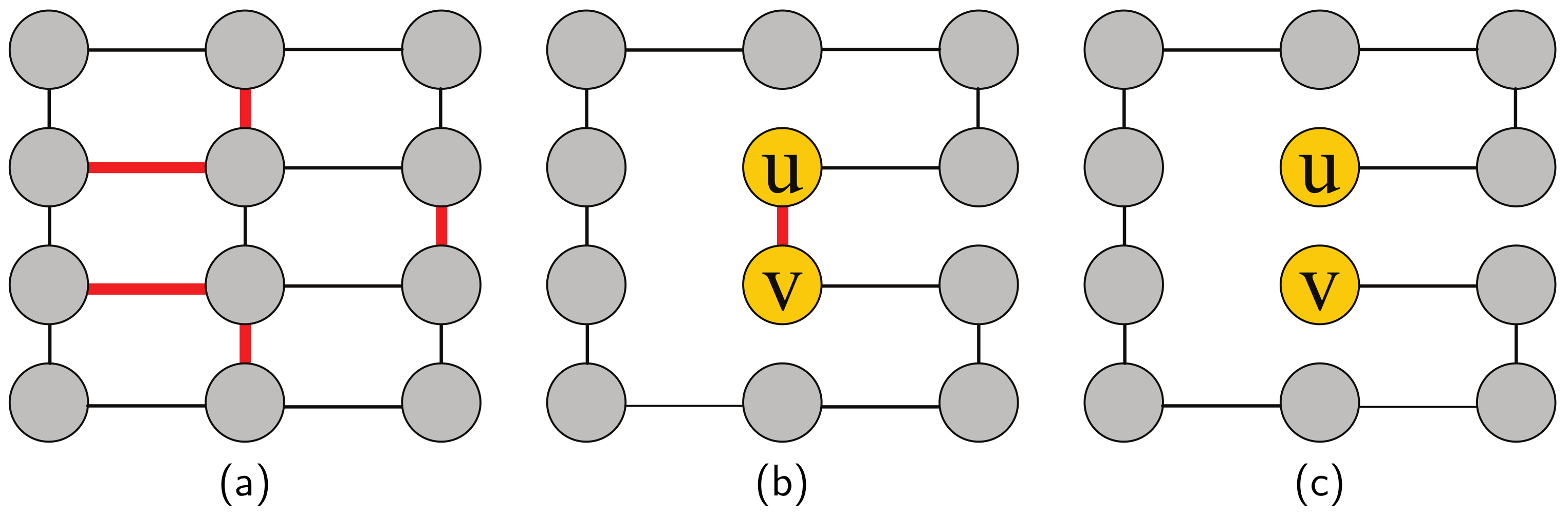
- We extend the selection range of the removing edges from the neighbors of the target node to the entire network despite the extra time cost.
3. Problem Definition
3.1. Theoretical Definition
3.2. Complexity Analysis
- At first, we choose a set of edges , and . After removing the set of edges , there is a Hamiltonian cycle in the modified network .
- Secondly, for the leader u in the Hamiltonian cycle, there are two edges and after removing one of these two edges, the target network M is obtained and the closeness value of the leaderu, .
4. Approach
4.1. Approximation Algorithm for LCVMIN Problem
4.1.1. Greedy Algorithm
| Algorithm 1: GreedyReduction. |
 |
4.1.2. The Approximation Ratio of the Greedy Algorithm
4.1.3. Example of the UpdateCloseness Algorithm
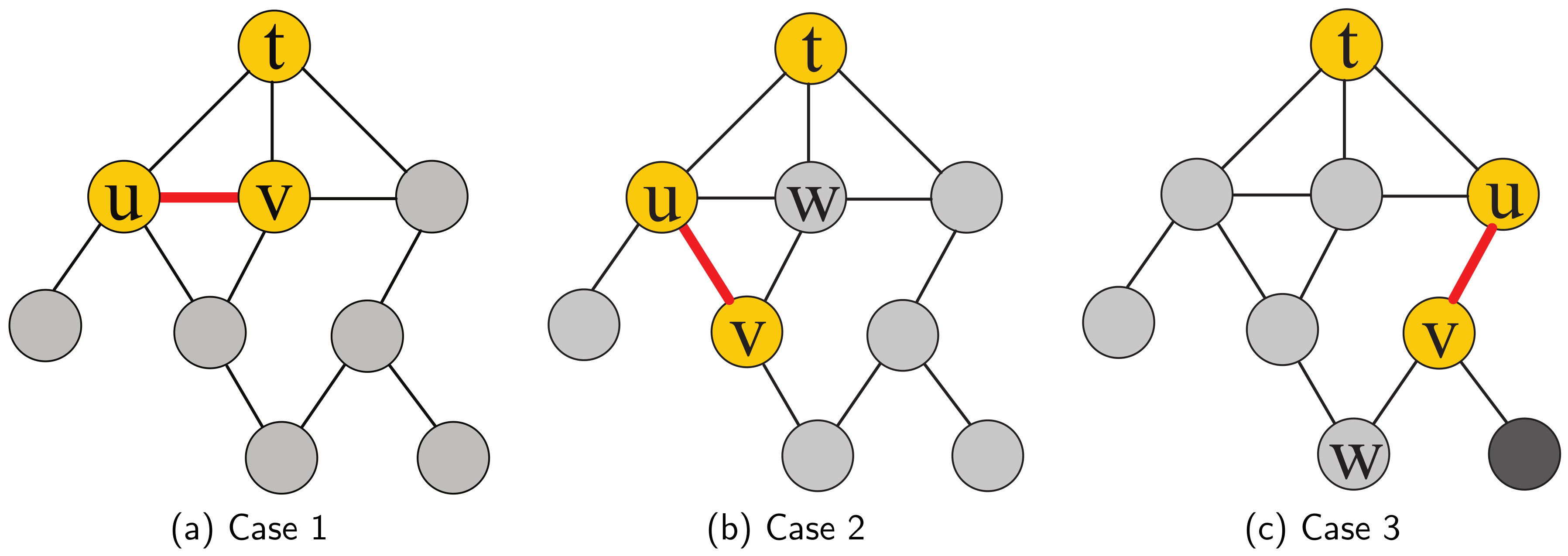
- : Since the ends of the removed edge e, u and v are at the same level of the bfs tree, it will not influence the shortest paths from t to all other nodes, i.e., .
- and : Assume that for , there exists a shortest path in . Since after removing the edge , there still exists a shortest path which has the same length, i.e., as shown in Figure 3b. Hence, it will not influence the shortest paths from t to all other nodes, i.e., .
4.1.4. UpdateCloseness Algorithm
| Algorithm 2: UpdateCloseness. |
 |
| Algorithm 3: FindAffectSet. |
 |
4.1.5. Time Complexity Analysis
4.2. Approximation Algorithm for LCRMAX Problem (GSA)
| Algorithm 4: Greedy and Simulated Annealing algorithm (GSA). |
 |
| Algorithm 5: Simulated Annealing algorithm. |
 |
4.2.1. The Reason for Proposing this Heuristic Method
4.2.2. FastTopRank Algorithm
| Algorithm 6: FastTopRank algorithm. |
 |
| Algorithm 7: Level-based lower bound for undirected graphs |
 |
| Algorithm 8: Neighborhood-based lower bound for undirected graphs |
 |
5. Experiment
5.1. Dataset
- Random network, which is generated by the Erdos–Renyi model [23]. The generated network can be denoted as with n nodes and p connection probability. This kind of network is denoted as ER.
- Small-world network, which is generated by the Watts–Strogatz model [24]. The generated graph can be denoted as with n nodes, k average degree and p rewiring edge probability. This kind of network is denoted as WS.
- Scale-free network, which is generated by the Barabási–Albert model [25]. The generated graph can be denoted as with n nodes and m edges to connect a new node with existing nodes. This kind of network is denoted as BA.
5.2. Closeness Value Case Results
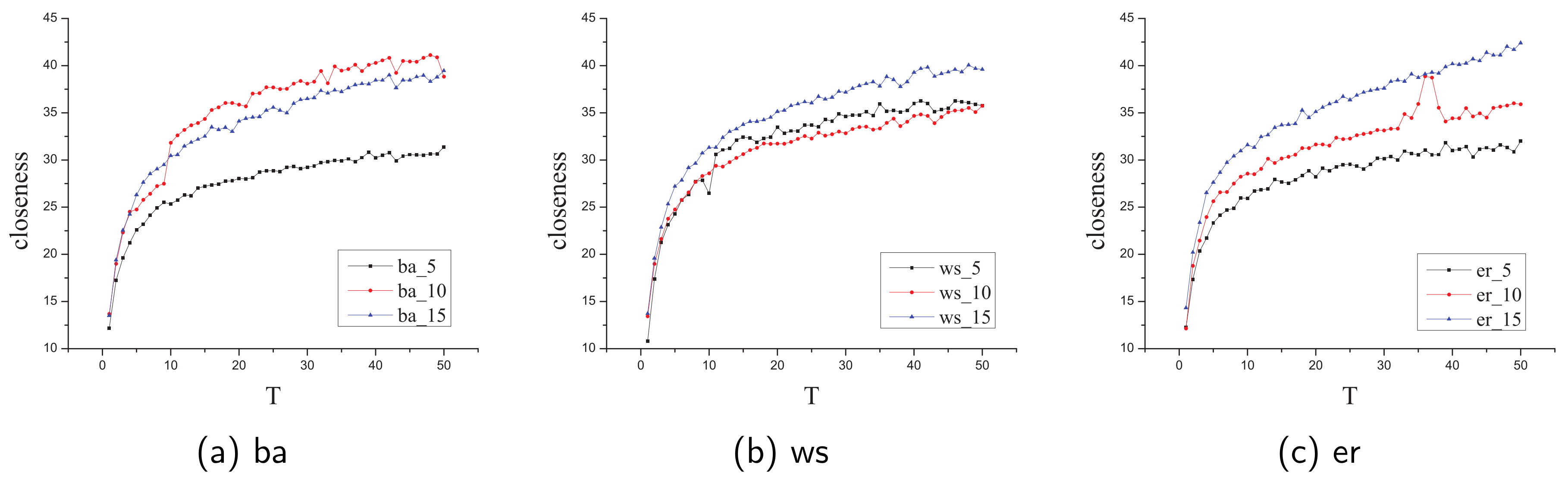
5.2.1. Evaluate UpdateCloseness Algorithm
- First, randomly generate networks in different size and kinds (BA, WS and ER). Then, randomly choose the node and a removed edge in the chosen network, then calculate the closeness value by BFS and UpdateCloseness for each time. We choose the average times by repeating it for 5000 times.
- First, choose some real-life complex networks as the datasets. Then, randomly choose the node and a removed edge in the chosen network, then calculate the closeness value by BFS and UpdateCloseness for each time. We choose the average times by repeating it for 5000 times.
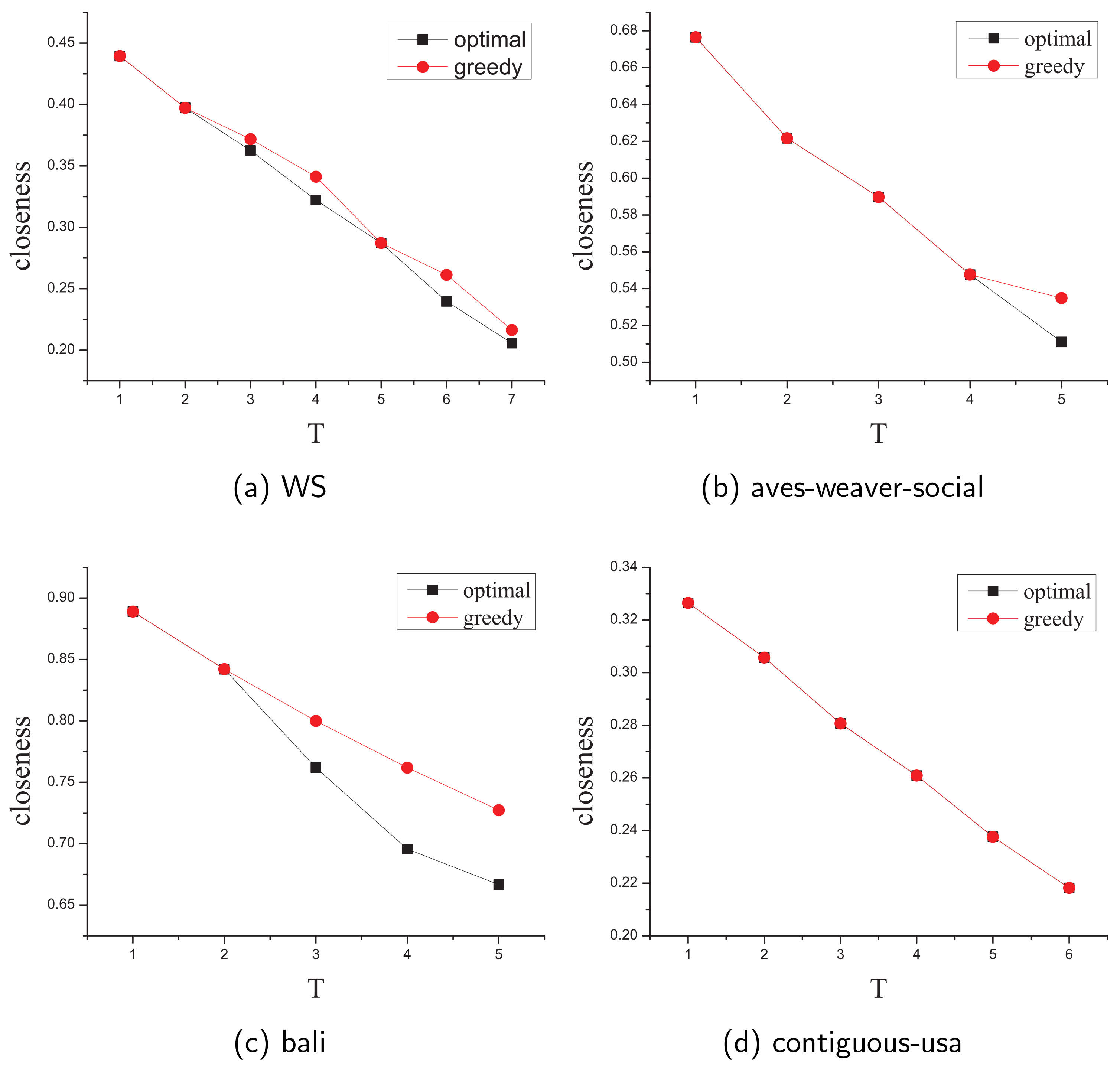
5.2.2. Compare Greedy Solution with the Optimal Solution
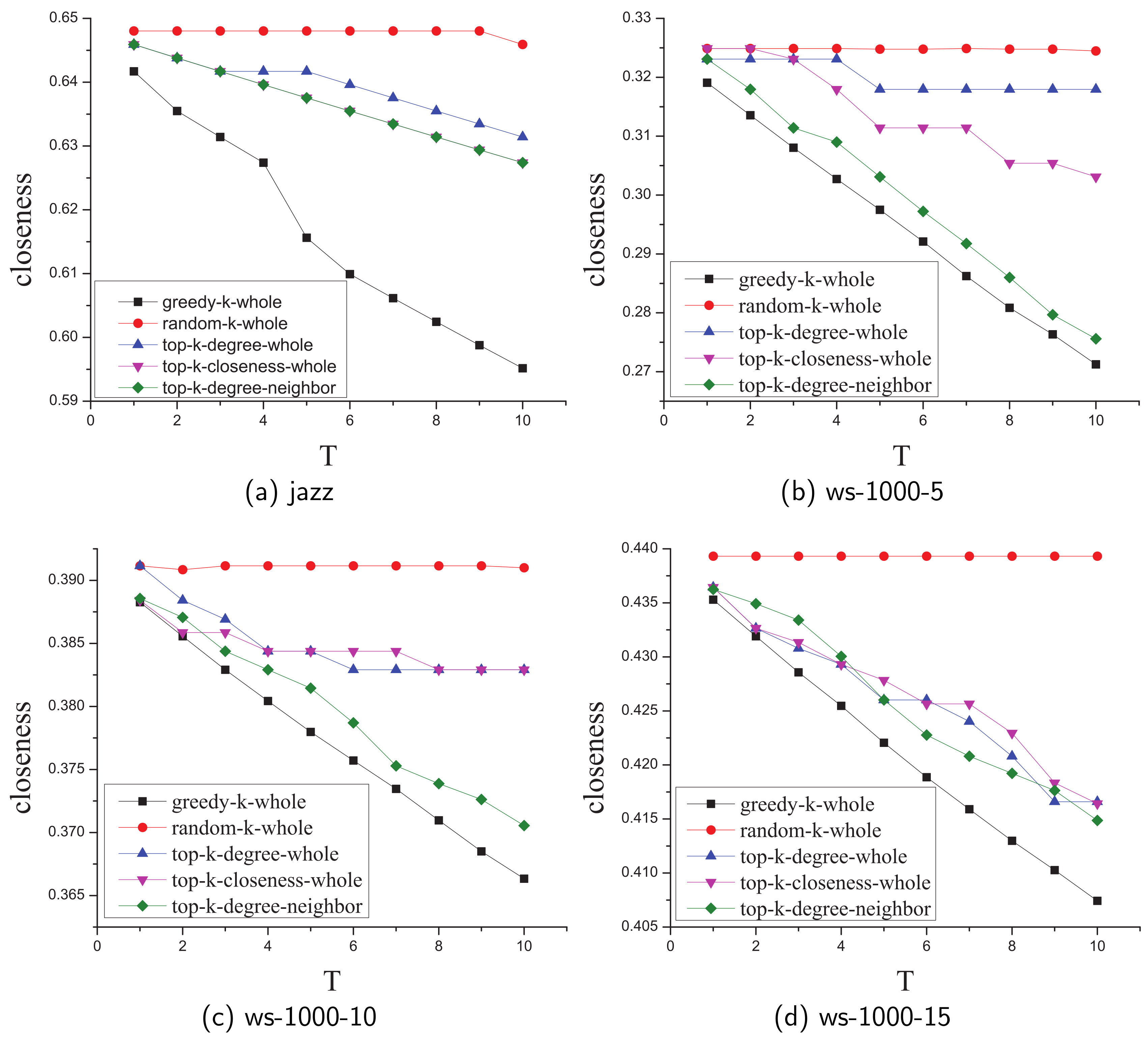
5.2.3. Compare Approximate Greedy Algorithm with Other Baseline Algorithms
- Random: randomly and uniformly select k edges in the whole network.
- Top-k degree: choose k edges with the highest degree sum.
- Top-k closeness: choose k edges with the highest closeness value sum.
- Top-k neighbor degree: choose k edges in the neighbor of the leader node with the highest degree.
5.3. Closeness Rank Case Results
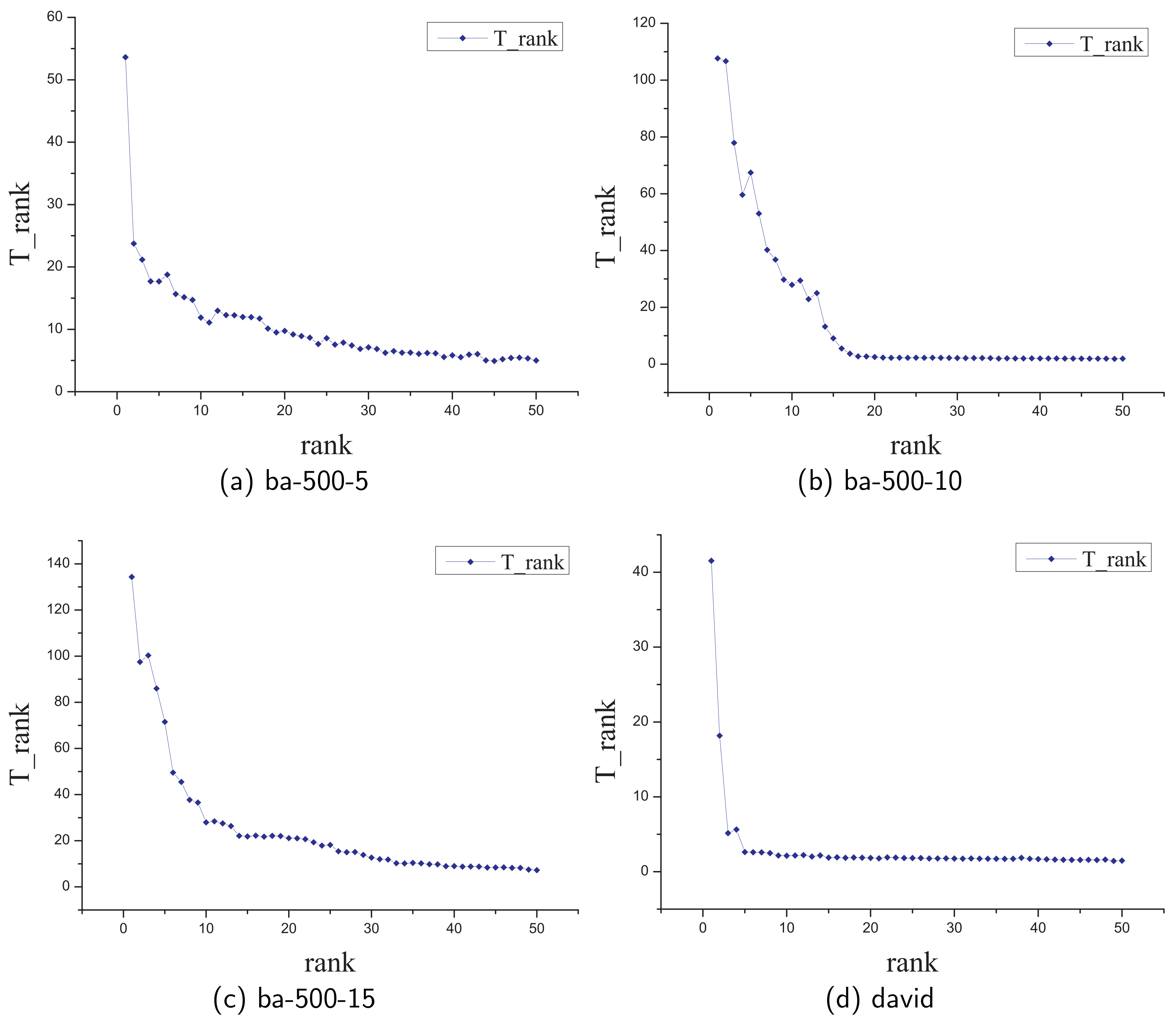
5.3.1. Evaluate FastTopRank Algorithm
5.3.2. Compare the Solution of GSA Algorithm with the Optimal Solution
5.3.3. Compare GSA Algorithm with Other Baseline Algorithms
- Greedy Neighbor: the greedy algorithm that chooses the neighbor edges that maximize the closeness rank each time.
- Top-k degree: choose k edges with the highest degree sum.
- Top-k closeness: choose k edges with the highest closeness value sum.
- Top-k neighbor degree: choose k edges in the neighbor of the leader node with the highest degree.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Elmazi, D.; Cuka, M.; Ikeda, M.; Barolli, L. Effect of Size of Giant Component for actor node selection in WSANs: A comparison study. Concurr. Comput. Pract. Exp. 2019. [Google Scholar] [CrossRef]
- Zhou, B.; Pei, J.; Luk, W. A brief survey on anonymization techniques for privacy preserving publishing of social network data. ACM Sigkdd Explor. Newsl. 2008, 10, 12–22. [Google Scholar] [CrossRef]
- Waniek, M.; Michalak, T.P.; Wooldridge, M.J.; Rahwan, T. Hiding individuals and communities in a social network. Nat. Hum. Behav. 2018, 2, 139. [Google Scholar] [CrossRef]
- Beauchamp, M.A. An improved index of centrality. Behav. Sci. 1965, 10, 161–163. [Google Scholar] [CrossRef] [PubMed]
- Berno, B. Network formation with closeness incentives. In Networks, Topology and Dynamics; Springer: Berlin/Heidelberg, Germany, 2009; pp. 95–109. [Google Scholar]
- Okamoto, K.; Chen, W.; Li, X.Y. Ranking of Closeness Centrality for Large-Scale Social Networks; Springer: Berlin/Heidelberg, Germany, 2008; pp. 186–195. [Google Scholar]
- Bergamini, E.; Borassi, M.; Crescenzi, P.; Marino, A.; Meyerhenke, H. Computing top-k closeness centrality faster in unweighted graphs. In Proceedings of the Eighteenth Workshop on Algorithm Engineering and Experiments (ALENEX), Arlington, VA, USA, 10 January 2016; pp. 68–80. [Google Scholar]
- Borassi, M.; Crescenzi, P.; Marino, A. Fast and simple computation of top-k closeness centralities. arXiv 2015, arXiv:1507.01490. [Google Scholar]
- Le Merrer, E.; Le Scouarnec, N.; Trédan, G. Heuristical top-k: Fast estimation of centralities in complex networks. Inf. Process. Lett. 2014, 114, 432–436. [Google Scholar] [CrossRef]
- Olsen, P.W.; Labouseur, A.G.; Hwang, J.H. Efficient top-k closeness centrality search. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering (ICDE), Chicago, IL, USA, 31 March–4 April 2014; pp. 196–207. [Google Scholar]
- Saxena, A.; Gera, R.; Iyengar, S. A heuristic approach to estimate nodes’ closeness rank using the properties of real world networks. Soc. Netw. Anal. Min. 2019, 9, 3. [Google Scholar] [CrossRef]
- Bisenius, P.; Bergamin, E.; Angriman, E.; Meyerhenke, H. Computing top-k closeness centrality in fully-dynamic graphs. In Proceedings of the Twentieth Workshop on Algorithm Engineering and Experiments (ALENEX), New Orleans, LA, USA, 7–8 January 2018; pp. 21–35. [Google Scholar]
- Tong, H.; Prakash, B.A.; Eliassi-Rad, T.; Faloutsos, M.; Faloutsos, C. Gelling, and melting, large graphs by edge manipulation. In Proceedings of the 21st ACM international conference on Information and knowledge management, Maui, HI, USA, 29 October–2 November 2012; pp. 245–254. [Google Scholar]
- Santos, E.E.; Korah, J.; Murugappan, V.; Subramanian, S. Efficient anytime anywhere algorithms for closeness centrality in large and dynamic graphs. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Chicago, IL, USA, 23–27 May 2016; pp. 1821–1830. [Google Scholar]
- Sariyuce, A.E.; Kaya, K.; Saule, E.; Catalyurek, U.V. Incremental algorithms for network management and analysis based on closeness centrality. arXiv 2013, arXiv:1303.0422. [Google Scholar]
- Kas, M.; Carley, K.M.; Carley, L.R. Incremental closeness centrality for dynamically changing social networks. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Niagara, ON, Canada, 25–28 August 2013; pp. 1250–1258. [Google Scholar]
- Yen, C.C.; Yeh, M.Y.; Chen, M.S. An efficient approach to updating closeness centrality and average path length in dynamic networks. In Proceedings of the IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 867–876. [Google Scholar]
- Shaw, M.E. Group structure and the behavior of individuals in small groups. J. Psychol. 1954, 38, 139–149. [Google Scholar] [CrossRef]
- Crescenzi, P.; D’angelo, G.; Severini, L.; Velaj, Y. Greedily improving our own closeness centrality in a network. ACM Trans. Knowl. Discov. Data 2016, 11, 9. [Google Scholar] [CrossRef]
- Marchiori, M.; Latora, V. Harmony in the small-world. Phys. A Stat. Mech. Its Appl. 2000, 285, 539–546. [Google Scholar] [CrossRef]
- Rochat, Y. Closeness Centrality Extended to Unconnected Graphs: the Harmonic Centrality Index. Available online: http://infoscience.epfl.ch/record/200525 (accessed on 15 June 2019).
- Nemhauser, G.L.; Wolsey, L.A.; Fisher, M.L. An analysis of approximations for maximizing submodular set functions—I. Math. Program. 1978, 14, 265–294. [Google Scholar] [CrossRef]
- Erds, P.; Rényi, A. On random graphs I. Publ. Math. Debr. 1959, 6, 290–297. [Google Scholar]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’networks. Nature 1998, 393, 440. [Google Scholar] [CrossRef] [PubMed]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed]
- Kunegis, J. Konect: The koblenz network collection. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1343–1350. [Google Scholar]
- Leskovec, J.; Krevl, A. SNAP Datasets: Stanford Large Network Dataset Collection. Available online: http://snap.stanford.edu/data (accessed on 30 June 2019).
- Rossi, R.A.; Ahmed, N.K. The Network Data Repository with Interactive Graph Analytics and Visualization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Krebs, V.E. Mapping networks of terrorist cells. Connections 2002, 24, 43–52. [Google Scholar]
- Trnka, M.; Cerny, T. On security level usage in context-aware role-based access control. In Proceedings of the 31st Annual ACM Symposium on Applied Computing, Pisa, Italy, 4–8 April 2016; pp. 1192–1195. [Google Scholar]
- Kayes, A.; Han, J.; Rahayu, W.; Dillon, T.; Islam, M.S.; Colman, A. A policy model and framework for context-aware access control to information resources. Comput. J. 2018, 62, 670–705. [Google Scholar] [CrossRef]
- Colombo, P.; Ferrari, E. Enhancing NoSQL datastores with fine-grained context-aware access control: A preliminary study on MongoDB. Int. J. Cloud Comput. 2017, 6, 292–305. [Google Scholar] [CrossRef]
- Kayes, A.; Rahayu, W.; Dillon, T.; Chang, E.; Han, J. Context-aware access control with imprecise context characterization for cloud-based data resources. Future Gener. Comput. Syst. 2019, 93, 237–255. [Google Scholar] [CrossRef]
- Cheng, C.; Lu, R.; Petzoldt, A.; Takagi, T. Securing the Internet of Things in a quantum world. IEEE Commun. Mag. 2017, 55, 116–120. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scheme | Edges Updated | Measurement | Selection Range | Hidden Effect | Solution Goal |
|---|---|---|---|---|---|
| Waniek [3] | Addition and Deletion | Degree Centrality [18] | Neighbors | Yes | Value |
| Crescenzi [19] | Addition | Harmonic Centrality [20] | Neighbors | No | Value |
| Our work | Deletion | Closeness Centrality [4] | Entire Network | Yes | Value and Rank |
| Delete Edges | Closeness Value (Optimal) | Closeness Rank (Optimal) | Closeness Rank (Greedy) |
|---|---|---|---|
| 1 | 0.89 | 1 | 1 |
| 2 | 0.84 | 1 | 1 |
| 3 | 0.76 | 1 | 1 |
| 4 | 0.69 | 1 | 1 |
| 5 | 0.66 | 6 | 1 |
| Network | Network Type | ||
|---|---|---|---|
| WTC [29] | 36 | 64 | Terrorist Network |
| bali | 17 | 63 | Terrorist Network |
| moreno-rhesus | 16 | 69 | Animal Social Network |
| aves-weaver-social | 24 | 62 | Animal Social Network |
| Dolphins | 62 | 159 | Animal Social Network |
| ContiguousUSA | 49 | 107 | Infrastructure Network |
| david | 112 | 425 | Lexical Network |
| Jazz | 198 | 2742 | Collaboration Network |
| arenas-email | 1133 | 5451 | Communication Network |
| arenas-pgp | 10,680 | 24,316 | Interaction Network |
| as-caida | 26,475 | 106,762 | Internet Network |
| ucidata-gama | 16 | 58 | Social Network |
| moreno-taro | 22 | 39 | Social Network |
| moreno-beach | 37 | 105 | Social Network |
| moreno-oz | 217 | 1839 | Social Network |
| FB-tvshow | 3892 | 17,262 | Social Network |
| FB-politician | 5908 | 41,729 | Social Network |
| FB-government | 7057 | 89,455 | Social Network |
| Network | Speed up Ratio | ||
|---|---|---|---|
| arenas-email | 1133 | 5451 | 26.52 |
| FB-tvshow | 3892 | 17,262 | 28.95 |
| FB-politician | 5908 | 41,729 | 32.59 |
| FB-government | 7057 | 89,455 | 36.15 |
| arenas-pgp | 10,680 | 24,316 | 32.24 |
| as-caida | 26,475 | 106,762 | 31.46 |
| Network | Min Appro Ratio | ||
|---|---|---|---|
| WTC | 36 | 64 | 0.9632 |
| bali | 17 | 63 | 0.9130 |
| aves-weaver-social | 24 | 62 | 0.9556 |
| moreno-rhesus | 16 | 69 | 0.9200 |
| moreno-beach | 37 | 105 | 1.0000 |
| moreno-taro | 22 | 39 | 0.8852 |
| dolphins | 62 | 159 | 0.9600 |
| contiguous-usa | 49 | 107 | 1.0000 |
| ucidata-gama | 16 | 58 | 0.9231 |
| Random graph | 30 | 55 | 0.8511 |
| Scale-free | 30 | 56 | 0.9437 |
| Small-world | 30 | 60 | 0.9174 |
| Network | ||
|---|---|---|
| Jazz | 198 | 2742 |
| moreno-oz | 217 | 1839 |
| david | 112 | 425 |
| FB-tvshow | 3892 | 17,262 |
| FB-politician | 5908 | 41,729 |
| arenas-email | 1133 | 5451 |
| BA-5 | 1100 | 5475 |
| BA-10 | 1000 | 9900 |
| BA-15 | 1000 | 14,775 |
| ER-5 | 1000 | 5025 |
| ER-10 | 1000 | 10,029 |
| ER-15 | 1000 | 14,917 |
| WS-5 | 1000 | 5000 |
| WS-10 | 1100 | 10,000 |
| WS-15 | 1100 | 15,000 |
| Aves-Weaver-Social | Dolphins | Moreno_Rhesus | |||||||
|---|---|---|---|---|---|---|---|---|---|
| k | Optimal | Greedy | GSA | Optimal | Greedy | GSA | Optimal | Greedy | GSA |
| 1 | 1 | 1 | 1 | 3 | 3 | 3 | 1 | 1 | 1 |
| 2 | 1 | 1 | 1 | 10 | 6 | 10 | 6 | 5 | 6 |
| 3 | 1 | 1 | 1 | 23 | 17 | 23 | 10 | 8 | 10 |
| 4 | 1 | 1 | 1 | 36 | 36 | 36 | 10 | 10 | 10 |
| 5 | 5 | 1 | 5 | 50 | 50 | 50 | 13 | 11 | 13 |
| k | Greedy | GSA | Top-k-Degree | Top-k-Closeness | Top-k-Neighbor |
|---|---|---|---|---|---|
| 5 | 2 | 2 | 1 | 1 | 1 |
| 6 | 2 | 2 | 1 | 1 | 1 |
| 7 | 2 | 2 | 1 | 1 | 1 |
| 8 | 3 | 4 | 1 | 1 | 1 |
| 9 | 5 | 6 | 1 | 1 | 1 |
| 10 | 5 | 6 | 1 | 1 | 2 |
| 11 | 5 | 6 | 1 | 1 | 2 |
| 12 | 6 | 8 | 1 | 1 | 2 |
| 13 | 8 | 9 | 1 | 1 | 2 |
| 14 | 9 | 9 | 1 | 1 | 2 |
| 15 | 10 | 10 | 1 | 1 | 2 |
| 16 | 13 | 20 | 1 | 1 | 3 |
| 17 | 17 | 19 | 1 | 1 | 5 |
| 18 | 19 | 23 | 1 | 1 | 5 |
| 19 | 22 | 25 | 1 | 1 | 5 |
| 20 | 24 | 32 | 1 | 1 | 5 |
| 21 | 30 | 35 | 1 | 1 | 5 |
| 22 | 35 | 39 | 1 | 1 | 5 |
| 23 | 38 | 39 | 1 | 1 | 8 |
| 24 | 46 | 52 | 2 | 1 | 10 |
| 25 | 52 | 54 | 2 | 1 | 10 |
| 26 | 54 | 62 | 3 | 1 | 11 |
| 27 | 63 | 65 | 3 | 1 | 19 |
| 28 | 67 | 73 | 3 | 1 | 20 |
| k | Greedy | GSA | Top-k-Degree | Top-k-Closeness | Top-k-Neighbor |
|---|---|---|---|---|---|
| 3 | 2 | 6 | 1 | 1 | 2 |
| 4 | 6 | 6 | 2 | 2 | 6 |
| 5 | 12 | 22 | 6 | 6 | 6 |
| 6 | 30 | 30 | 11 | 11 | 11 |
| 7 | 33 | 33 | 20 | 20 | 21 |
| 8 | 42 | 42 | 30 | 30 | 29 |
| 9 | 61 | 61 | 33 | 33 | 33 |
| 10 | 70 | 94 | 42 | 42 | 42 |
| 11 | 94 | 111 | 42 | 52 | 52 |
| 12 | 111 | 111 | 42 | 61 | 70 |
| 13 | 119 | 124 | 52 | 78 | 78 |
| 14 | 122 | 128 | 61 | 77 | 95 |
| 15 | 140 | 140 | 78 | 77 | 111 |
| 16 | 140 | 143 | 77 | 77 | 118 |
| 17 | 144 | 144 | 77 | 77 | 124 |
| 18 | 145 | 146 | 77 | 77 | 135 |
| 19 | 148 | 148 | 77 | 77 | 138 |
| k | Greedy | GSA | Top-k-Degree | Top-k-Closeness | Top-k-Neighbor |
|---|---|---|---|---|---|
| 4 | 6 | 8 | 1 | 1 | 1 |
| 5 | 10 | 10 | 1 | 1 | 2 |
| 6 | 11 | 11 | 1 | 1 | 6 |
| 7 | 14 | 19 | 1 | 2 | 6 |
| 8 | 26 | 36 | 1 | 1 | 9 |
| 9 | 35 | 37 | 1 | 6 | 11 |
| 10 | 40 | 40 | 1 | 10 | 17 |
| 11 | 54 | 60 | 4 | 16 | 33 |
| 12 | 65 | 77 | 10 | 16 | 37 |
| 13 | 89 | 104 | 11 | 16 | 47 |
| 14 | 88 | 104 | 11 | 24 | 55 |
| 15 | 111 | 118 | 10 | 24 | 65 |
| 16 | 129 | 156 | 26 | 37 | 77 |
| 17 | 162 | 177 | 33 | 40 | 88 |
| 18 | 177 | 181 | 33 | 55 | 112 |
| 19 | 184 | 186 | 33 | 65 | 141 |
| 20 | 189 | 192 | 37 | 73 | 156 |
| 21 | 195 | 197 | 47 | 73 | 179 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, J.; Wu, G.; Shuai, J.; Zhang, Z.; Wang, Z.; Ren, Y. Heuristic Approaches for Enhancing the Privacy of the Leader in IoT Networks. Sensors 2019, 19, 3886. https://doi.org/10.3390/s19183886
Ji J, Wu G, Shuai J, Zhang Z, Wang Z, Ren Y. Heuristic Approaches for Enhancing the Privacy of the Leader in IoT Networks. Sensors. 2019; 19(18):3886. https://doi.org/10.3390/s19183886
Chicago/Turabian StyleJi, Jie, Guohua Wu, Jinguo Shuai, Zhen Zhang, Zhen Wang, and Yizhi Ren. 2019. "Heuristic Approaches for Enhancing the Privacy of the Leader in IoT Networks" Sensors 19, no. 18: 3886. https://doi.org/10.3390/s19183886
APA StyleJi, J., Wu, G., Shuai, J., Zhang, Z., Wang, Z., & Ren, Y. (2019). Heuristic Approaches for Enhancing the Privacy of the Leader in IoT Networks. Sensors, 19(18), 3886. https://doi.org/10.3390/s19183886