Activity Recognition Invariant to Wearable Sensor Unit Orientation Using Differential Rotational Transformations Represented by Quaternions



Abstract

1. Introduction
2. Related Work
2.1. Transformation-Based Geometric Methods
2.2. Learning-Based Methods
2.3. Other Approaches
2.4. Discussion
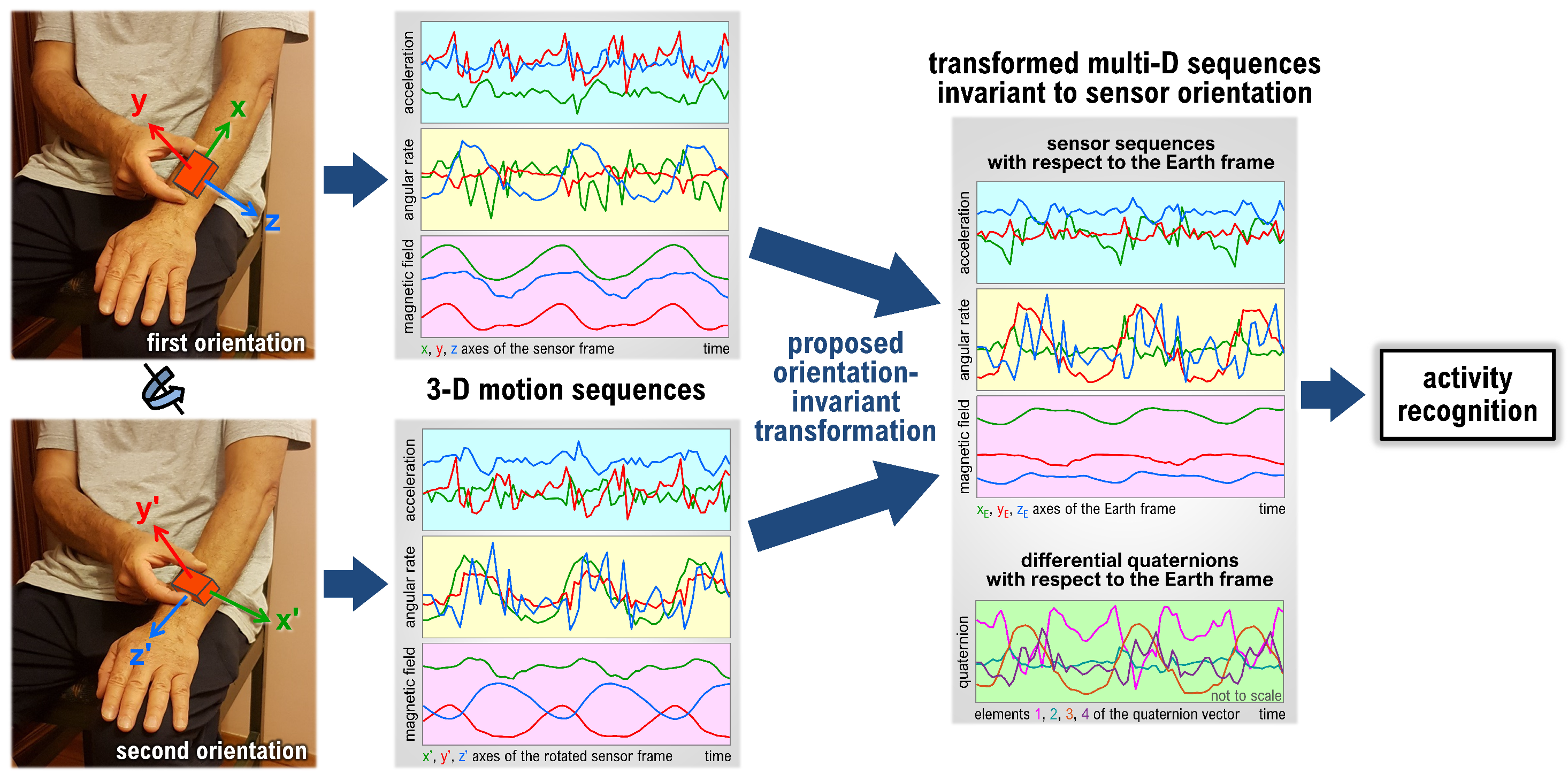
3. Proposed Methodology to Achieve Invariance to Sensor Unit Orientation
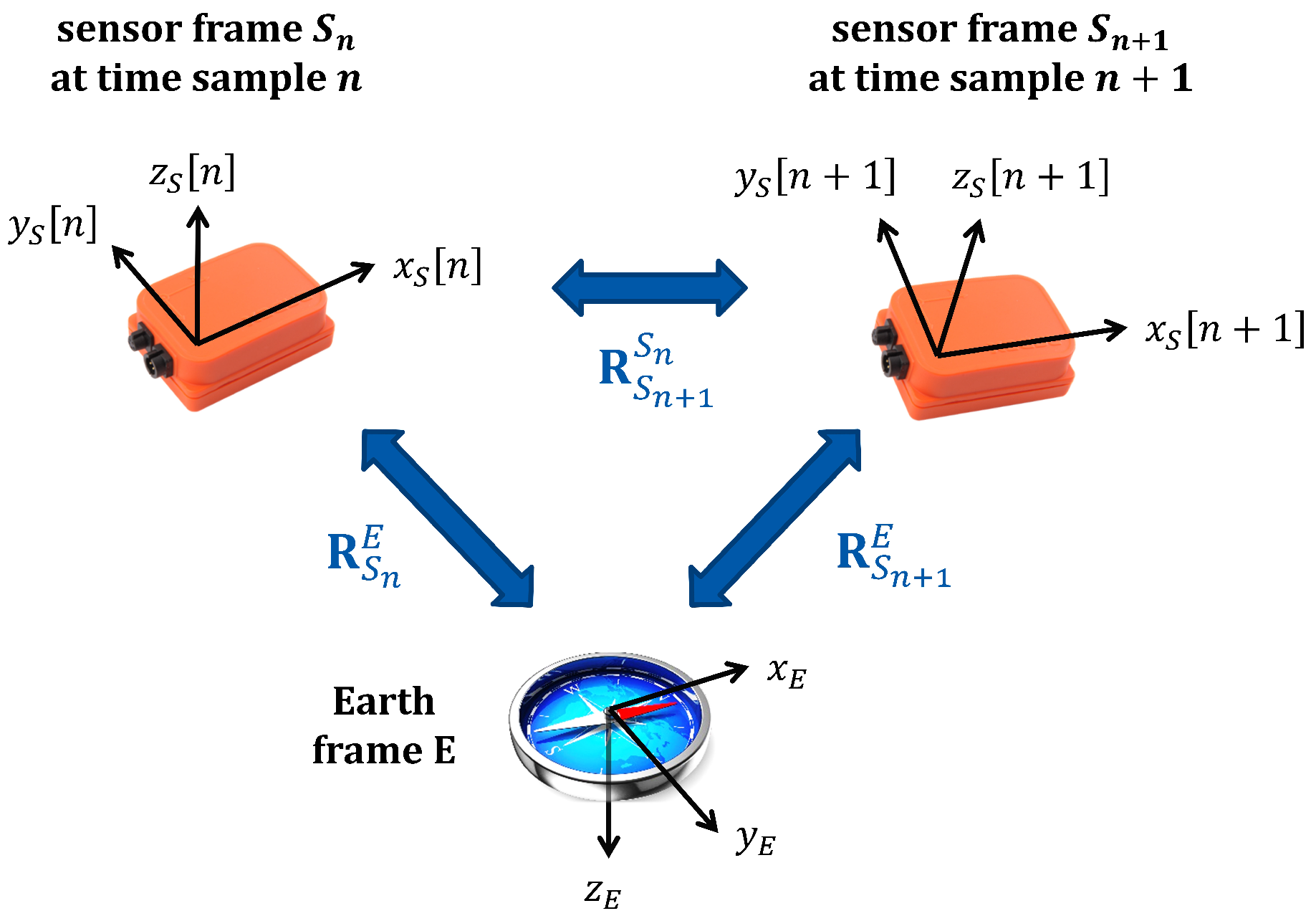
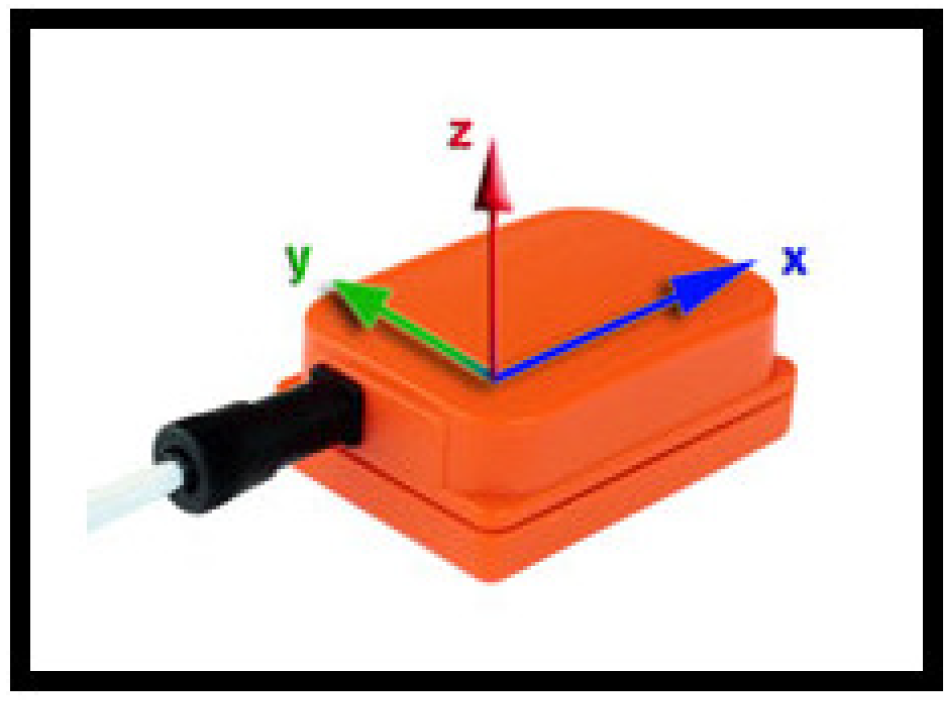
3.1. Estimation of Sensor Orientation
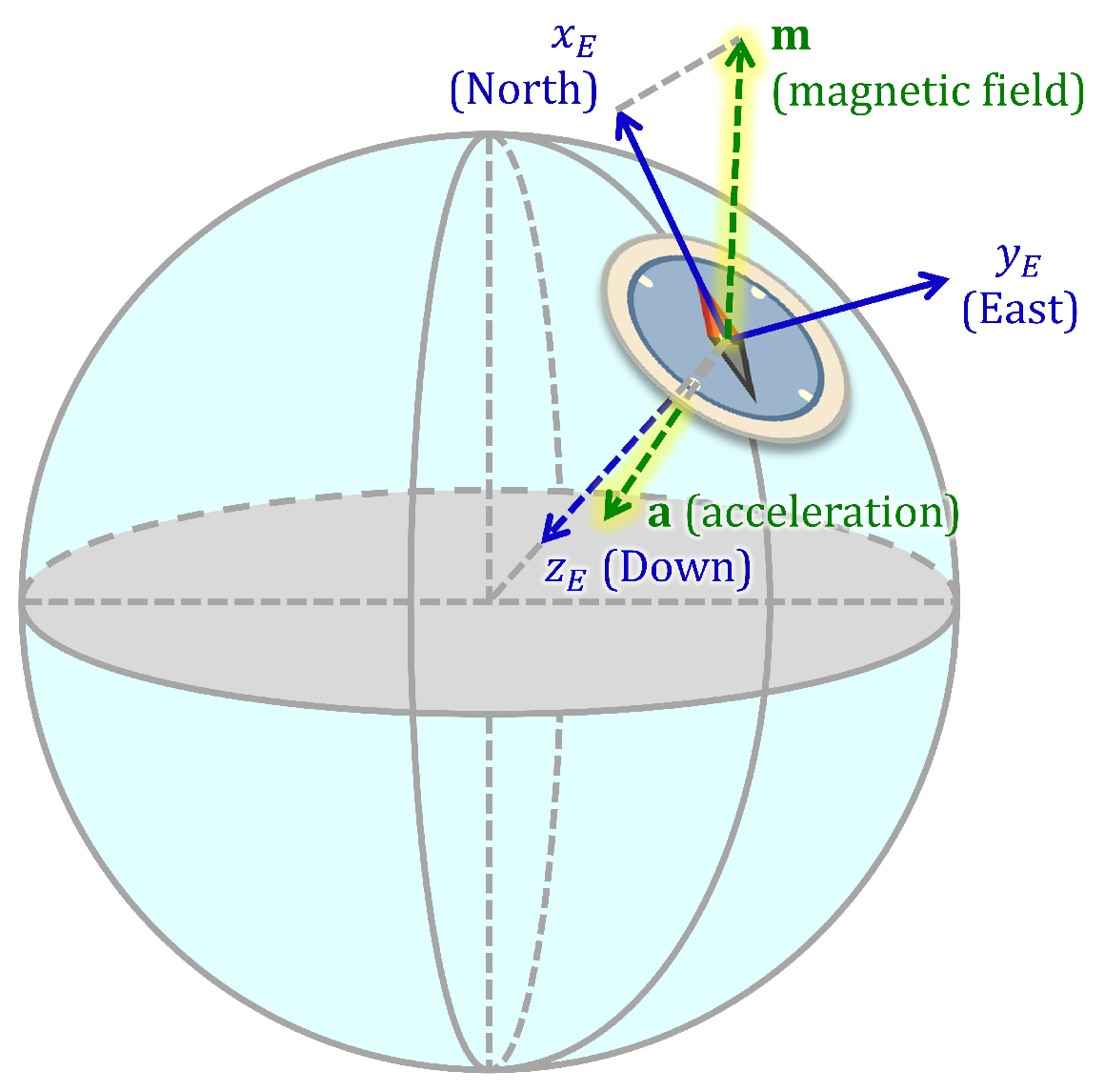
3.2. Sensor Signals with Respect to the Earth Frame
3.3. Differential Sensor Rotations with Respect to the Earth Frame
4. Comparative Evaluation of Proposed and Existing Methodology on Orientation Invariance for Activity Recognition
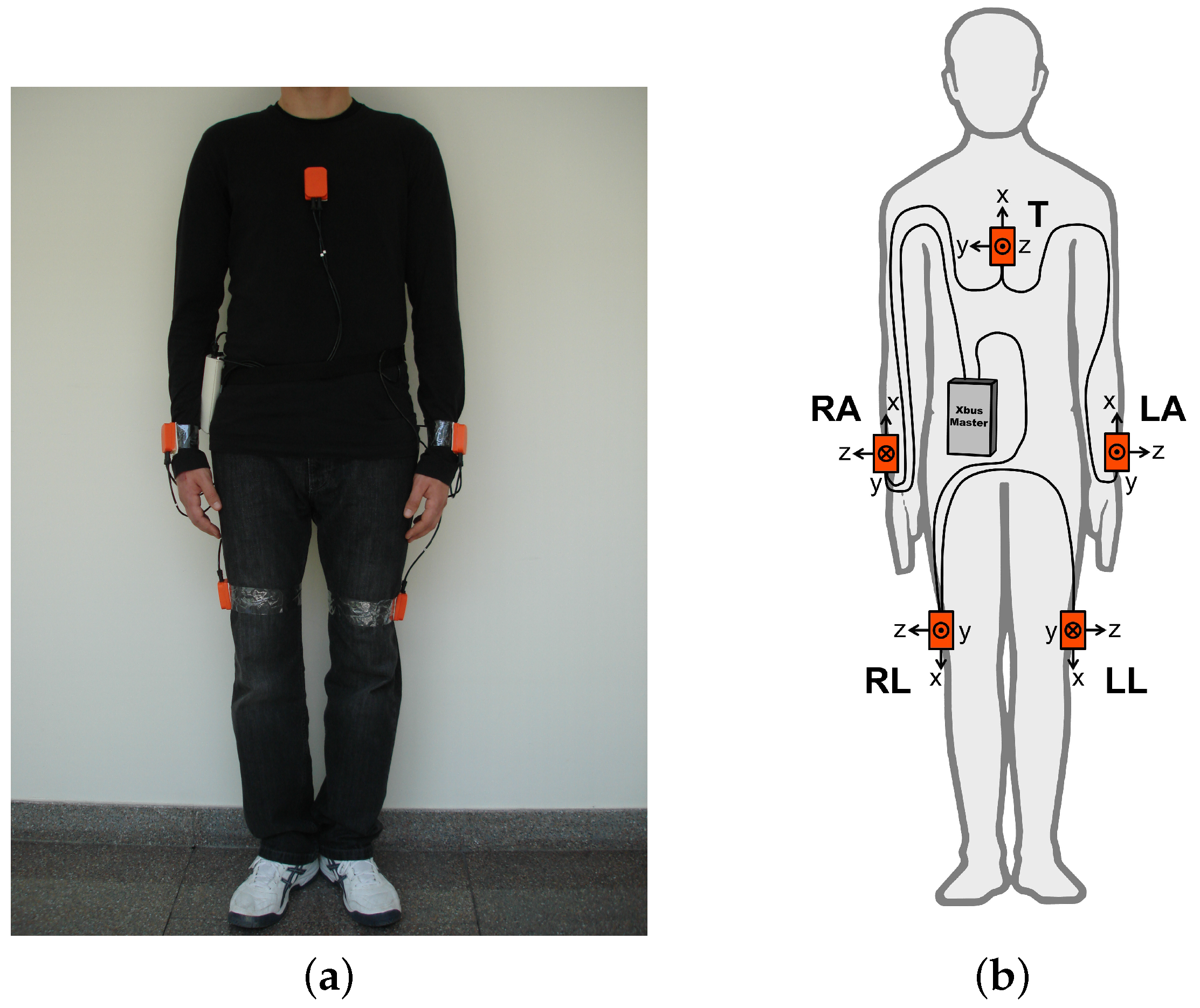
4.1. Dataset
Sitting (A), standing (A), lying on back and on right side (A and A), ascending and descending stairs (A and A), standing still in an elevator (A), moving around in an elevator (A), walking in a parking lot (A), walking on a treadmill in flat and inclined positions at a speed of (A and A), running on a treadmill at a speed of (A), exercising on a stepper (A), exercising on a cross trainer (A), cycling on an exercise bike in horizontal and vertical positions (A and A), rowing (A), jumping (A), and playing basketball (A).
4.2. Description of the Proposed and Existing Methodology on Orientation Invariance
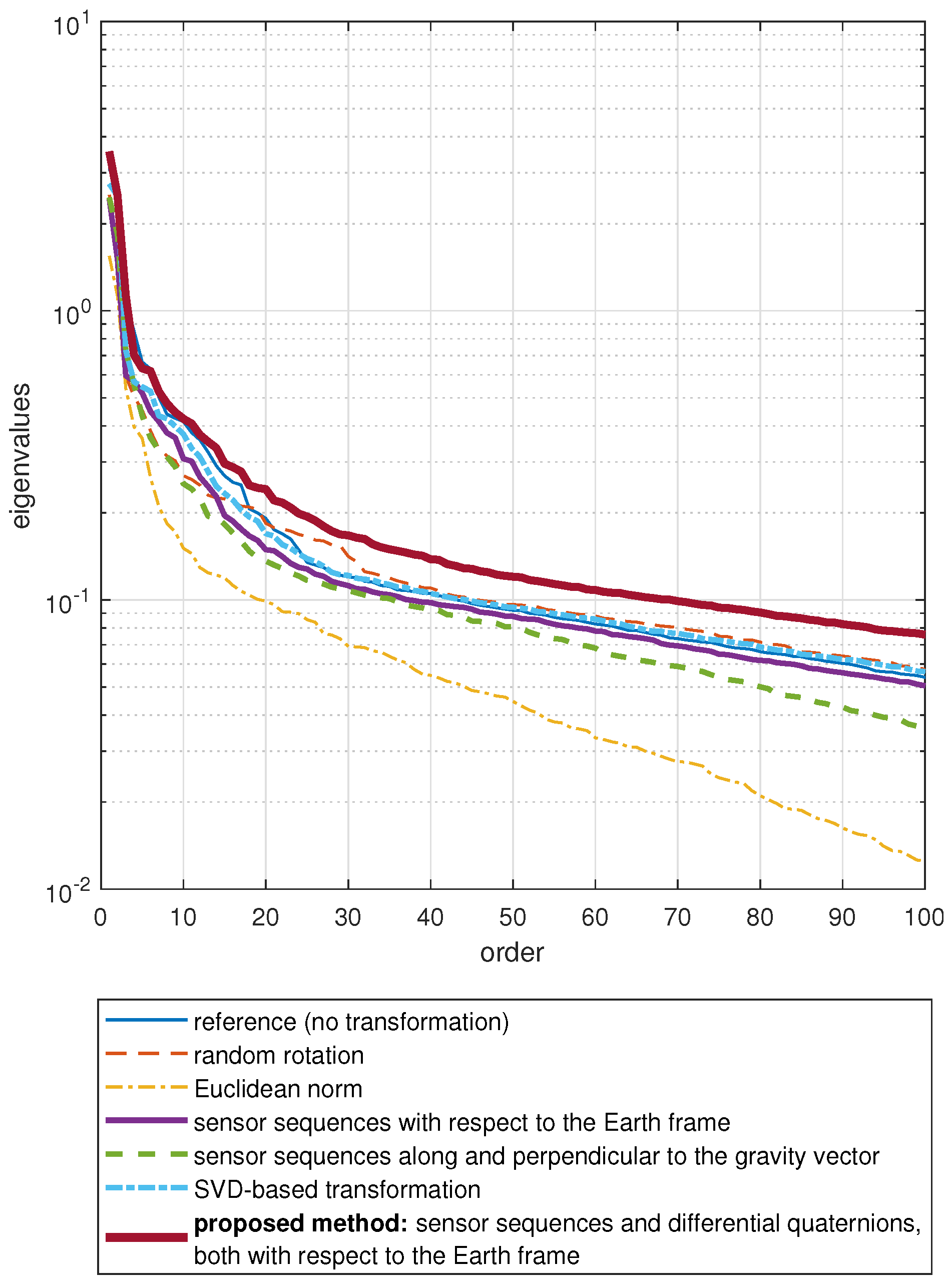
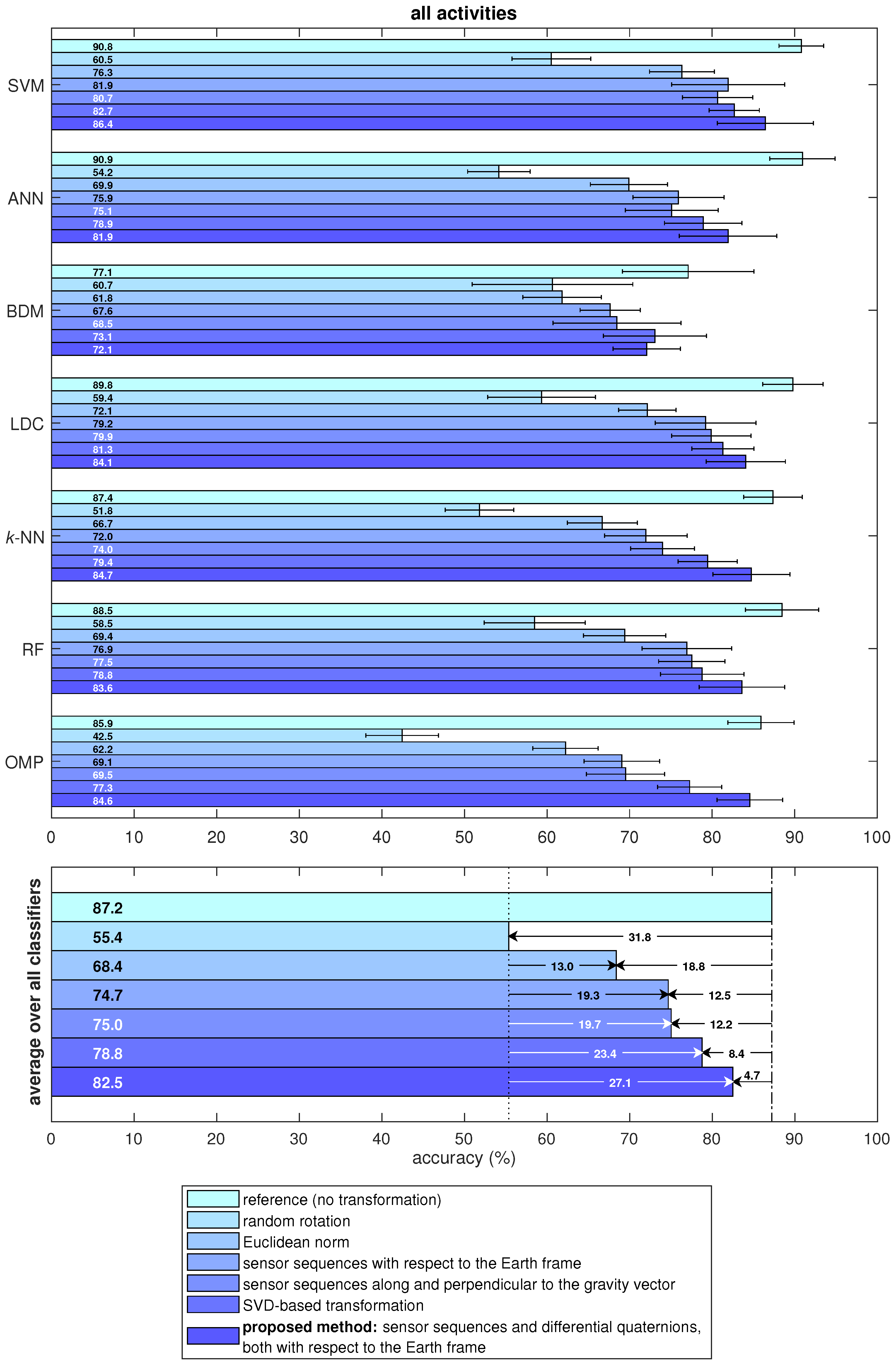
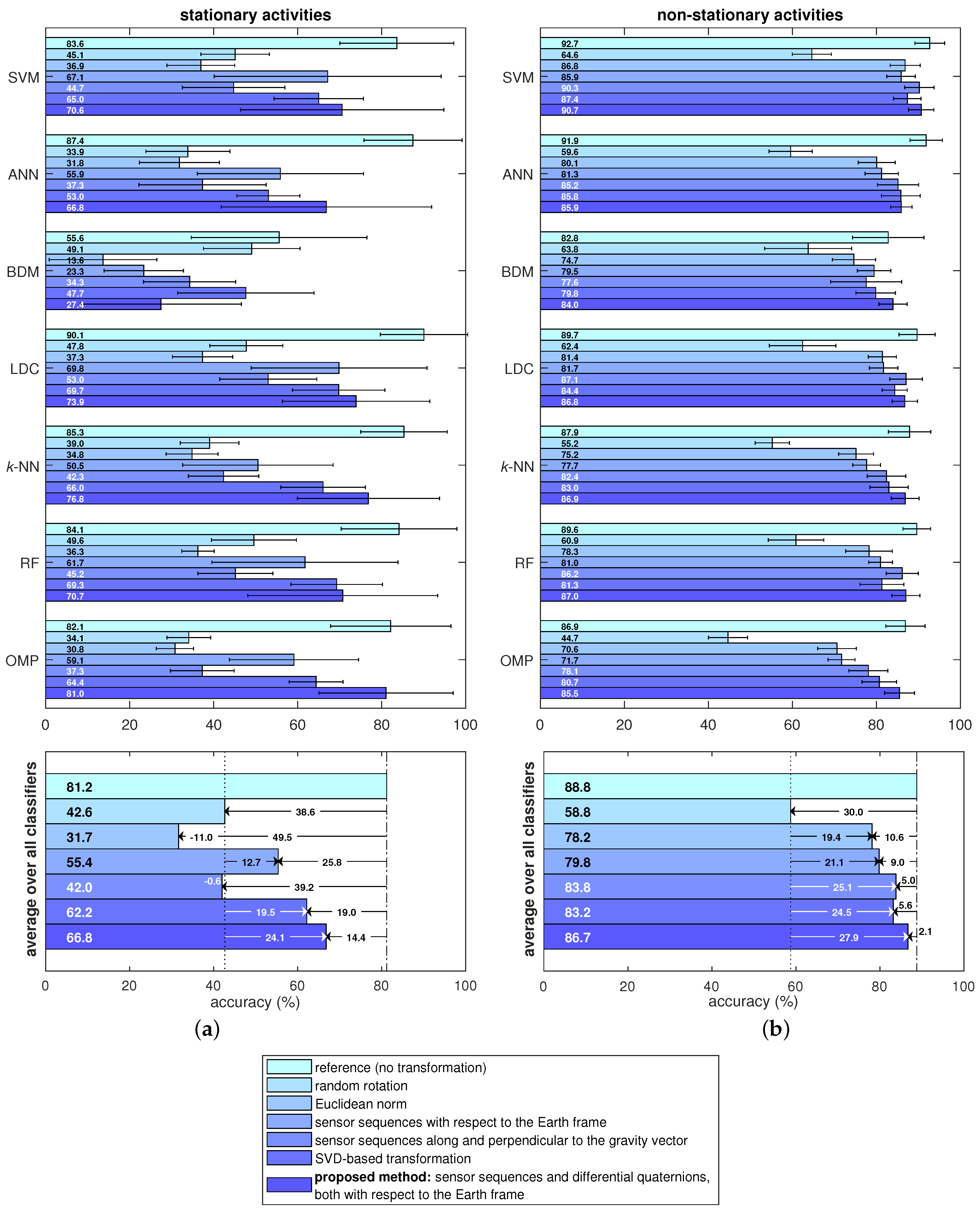
- Random rotation: This case is considered to assess the accuracy of the standard activity recognition scheme (without any orientation-invariant transformation) when the sensor units are oriented randomly at their fixed positions. Instead of recording a new dataset with random sensor orientations, we randomly rotate the original data to make a fair comparison with the reference case. For this purpose, we randomly generate a rotational transformation:where yaw, pitch, roll angles are independent and uniformly distributed in the interval radians. For each time segment of each sensor unit (see Section 4.3 for segmentation), we generate a different matrix and pre-multiply each of the three tri-axial sequences of that unit by the random rotation matrix corresponding to that segment of the unit: . In this way, we simulate the situation where each sensor unit is placed at a possibly different random orientation in each time segment.
- Euclidean norm method: The Euclidean norm of the components of the sensor sequences are taken at each time sample and used instead of using the original tri-axial sequences. As reviewed in Section 2, this technique has been used in activity recognition to achieve sensor orientation invariance [10,11,12] or as an additional feature as in [13,14,15,16,48,49].
- Sequences along and perpendicular to the gravity vector: In this method, the acceleration sequence in each time segment is averaged over time to approximately calculate the direction of the gravity vector. Then, for each sensor type, the sensor sequence’s amplitude in this direction and the magnitude that is perpendicular to this direction are taken. This method has been used in [17,18,19] to achieve orientation invariance.
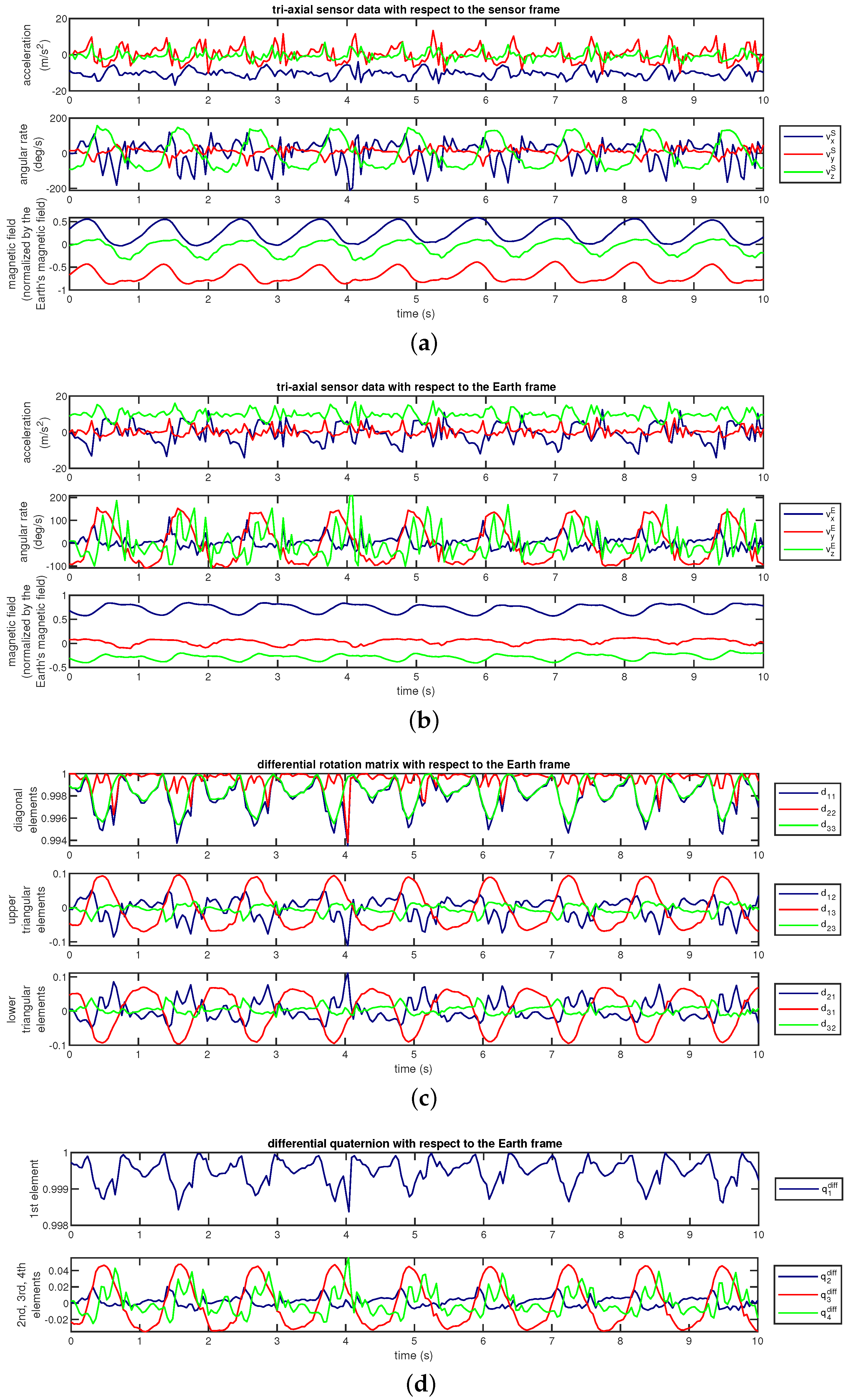
- Sensor sequences with respect to the Earth frame: We transform the sensor sequences into the Earth frame using the estimated sensor orientations, as described by Equation (1). This method has been used in [22] to achieve invariance to sensor orientation in activity recognition.As an example, Figure 7a shows the accelerometer, gyroscope, and magnetometer data acquired during activity A and Figure 7b shows the same sequences transformed into the Earth frame. We observe that the magnetic field with respect to the Earth frame does not significantly vary over time because the Earth’s magnetic field is nearly constant in the Earth frame provided that there are no external magnetic sources in the vicinity of the sensor unit.
- Proposed method: sensor sequences and differential quaternions, both with respect to the Earth frame: We calculate the differential rotation matrix with respect to the Earth frame for each sensor unit at each time sample n, as explained in Section 3.3. This rotation matrix representation is quite redundant because it has nine elements while any 3D rotation can be represented by only three angles. Since the representation by three angles has a singularity problem, we represent the differential rotation compactly by a four-element quaternion aswhere are the elements of [50]. The vector is called differential quaternion with respect to the Earth frame (the dependence of the elements of and on n has been dropped from the notation for simplicity). In the classification process, we use each element of as a function of n, as well as the sensor sequences with respect to the Earth frame. Hence, there are four time sequences for the differential quaternion in addition to the three axes each of accelerometer, gyroscope, and magnetometer data for each of the five sensor units. Therefore, the transformed data comprises sequences in total.We have observed that the joint use of the sensor sequences and differential quaternions, both with respect to the Earth frame, achieves the highest activity recognition accuracy compared to the other combinations. Representing rotational transformations by rotation matrices instead of quaternions degrades the accuracy. Omitting magnetometer sequences with respect to the Earth frame causes a slight reduction in the accuracy. Activity recognition results of the various different approaches that we have implemented are not presented in this article for brevity, and can be found in [51].Figure 7c shows the nine elements of the differential rotation matrix with respect to the Earth frame over time, which are calculated based on the sensor data shown in Figure 7a. Figure 7d shows the elements of the differential quaternion as a function of n. The almost periodic nature of the sensor sequences (Figure 7a) is preserved in and (Figure 7c,d). The differential rotation is calculated between two consecutive time samples that are only a fraction of a second apart, hence the amplitudes of the elements of and do not vary much. Since differential rotations involve small rotation angles (close to 0), the matrices are close to the identity matrix because they can be expressed as the product of three rotation matrices as in Equation (6) where each of the basic rotation matrices (as well as their product) is close to because of the small angles. Hence, the diagonal elements which are close to one and the upper- and lower-diagonal elements which are close to zero are plotted separately in Figure 7c for better visualization. When is close to , the vectors calculated by using Equation (7) are close to , as observed in Figure 7d.
4.3. Activity Recognition and Classifiers
- Support Vector Machines (SVM): The feature space is nonlinearly mapped to a higher-dimensional space by using a kernel function and divided into regions by hyperplanes. In this study, the kernel is selected to be a Gaussian radial basis function with parameter because it can perform at least as accurately as the linear kernel if the parameters of the SVM are optimized [53]. To extend the binary SVM to more than two classes, a binary SVM classifier is trained for each class pair, and the decision is made according to the classifier with the highest confidence level [54]. The penalty parameter C (see Equation (1) in [55]) and the kernel parameter are jointly optimized over all the data transformation techniques by performing a two-level grid search. The optimal parameter values in the coarse grid are obtained as . Then, a finer grid is constructed around as with and the optimal parameter values found by searching the fine grid, , are used in SVM throughout this study. The SVM classifier is implemented by using the MATLAB toolbox LibSVM [56].
- Artificial Neural Networks (ANN): We use three layers of neurons, where each neuron has a sigmoid output function [57]. The number of neurons in the first (input) and the third (output) layers are as many as the reduced number of features, F, and the number of classes, K, respectively. The number of neurons in the second (or hidden) layer is selected as the integer nearest to the average of and , with the former expression corresponding to the optimistic case where the hyperplanes intersect at different positions and the latter corresponding to the pessimistic case where the hyperplanes are parallel to each other. The weights of the linear combination in each neuron are initialized randomly in the interval and during the training phase, they are updated by the back-propagation algorithm [58]. The learning rate is selected as 0.3. The algorithm is terminated when the amount of error reduction (if any) compared to the average of the last 10 epochs is less than 0.01. The ANN has a scalar output for each class. A given test feature vector is fed to the input and the class corresponding to the largest output is selected.
- Bayesian Decision Making (BDM): In the training phase, a multi-variate Gaussian distribution with an arbitrary covariance matrix is fitted to the training feature vectors of each class. Based on maximum likelihood estimation, the mean vector is estimated as the arithmetic mean of the feature vectors and the covariance matrix is estimated as the sample covariance matrix for each class. In the test phase, for each class, the test vector’s conditional probability given that it is associated with that class is calculated. The class that has the maximum conditional probability is selected according to the maximum a posteriori decision rule [52,57].
- Linear Discriminant Classifier (LDC): This classifier is the same as BDM except that the average of the covariance matrices individually calculated for each class is used for all of the classes. Since the Gaussian distributions fitted to the different classes have different mean vectors but the same covariance matrix in this case, the classes have identical probability density functions centered at different points in the feature space. Hence, the classes are linearly separated from each other, and the decision boundaries in the feature space are hyperplanes [57].
- k-Nearest Neighbor (k-NN): The training phase consists only of storing the training vectors with their class labels. In the classification phase, the class corresponding to the majority of the k training vectors that are closest to the test vector in terms of the Euclidean distance is selected [57]. The parameter k is chosen as because it is suitable among the k values ranging from 1 to 30.
- Random Forest (RF): A random forest classifier is a combination of multiple decision trees [59]. In the training phase, each decision tree is trained by randomly and independently sampling the training data. Normalized information gain is used as the splitting criterion at each node. In the classification phase, the decisions of the trees are combined by using majority voting. The number of decision trees is selected as 100 because we have observed that using a larger number of trees does not significantly improve the accuracy while increasing the computational cost considerably.
- Orthogonal Matching Pursuit (OMP): The training phase consists of only storing the training vectors with their class labels. In the classification phase, each test vector is represented as a linear combination of a very small portion of the training vectors with a bounded error, which is called the sparse representation. The vectors in the representation are selected iteratively by using the OMP algorithm [60] where an additional training vector is selected at each iteration. The algorithm terminates when the desired representation error level is reached, which is selected to be . Then, a residual for each class is calculated as the representation error when the test vector is represented as a linear combination of the training vectors of only that class, and the class with the minimum residual error is selected.
4.4. Comparative Evaluation Results
4.5. Run Time Analysis
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| SVM | Support Vector Machines |
| PCA | Principal Component Analysis |
| 1-NN | One-Nearest-Neighbor |
| SVD | Singular Value Decomposition |
| DFT | Discrete Fourier Transformation |
| ANN | Artificial Neural Networks |
| BDM | Bayesian Decision Making |
| LDC | Linear Discriminant Classifier |
| k-NN | k-Nearest Neighbor |
| RF | Random Forest |
| OMP | Orthogonal Matching Pursuit |
| L1O | Leave-One-Subject-Out |
Appendix A. Sensor Unit Orientation Estimation
References
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Rawassizadeh, R.; Price, B.A.; Marian, P. Wearables: Has the age of smartwatches finally arrived? Commun. ACM 2015, 58, 45–47. [Google Scholar] [CrossRef]
- Mortazavi, B.; Nemati, E.; VanderWall, K.; Flores-Rodriguez, H.G.; Cai, J.Y.J.; Lucier, J.; Arash, N.; Sarrafzadeh, M. Can smartwatches replace smartphones for posture tracking? Sensors 2015, 15, 26783–26800. [Google Scholar] [CrossRef] [PubMed]
- Darwish, A.; Hassanien, A.E. Wearable and implantable wireless sensor network solutions for healthcare monitoring. Sensors 2011, 11, 5561–5595. [Google Scholar] [CrossRef] [PubMed]
- Pantelopoulos, A.; Bourbakis, N.G. A survey on wearable sensor-based systems for health monitoring and prognosis. IEEE Trans. Syst. Man Cybern. Part C 2010, 40, 1–12. [Google Scholar] [CrossRef]
- Yurtman, A.; Barshan, B. Human activity recognition using tag-based radio frequency localization. Appl. Artif. Intell. 2016, 30, 153–179. [Google Scholar] [CrossRef]
- Yurtman, A.; Barshan, B. Automated evaluation of physical therapy exercises using multi-template dynamic time warping on wearable sensor signals. Comput. Methods Progr. Biomed. 2014, 117, 189–207. [Google Scholar] [CrossRef] [PubMed]
- Seçer, G.; Barshan, B. Improvements in deterministic error modeling and calibration of inertial sensors and magnetometers. Sens. Actuators A Phys. 2016, 247, 522–538. [Google Scholar] [CrossRef]
- Morales, J.; Akopian, D. Physical activity recognition by smartphones, a survey. Biocybern. Biomed. Eng. 2017, 37, 388–400. [Google Scholar] [CrossRef]
- Kunze, K.; Lukowicz, P. Sensor placement variations in wearable activity recognition. IEEE Pervasive Comput. 2014, 13, 32–41. [Google Scholar] [CrossRef]
- Reddy, S.; Mun, M.; Burke, J.; Estrin, D.; Hansen, M.; Srivastava, M. Using mobile phones to determine transportation modes. ACM Trans. Sens. Netw. 2010, 6, 13. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Nurmi, P.; Hammerla, N.; Plötz, T. Using unlabeled data in a sparse-coding framework for human activity recognition. Pervasive Mob. Comput. 2014, 15, 242–262. [Google Scholar] [CrossRef]
- Sun, L.; Zhang, D.; Li, B.; Guo, B.; Li, S. Activity recognition on an accelerometer embedded mobile phone with varying positions and orientations. In Lecture Notes in Computer Science, Proceedings of the 7th International Conference on Ubiquitous Intelligence and Computing, Xi’an, China, 26–29 October 2010; Yu, Z., Liscano, R., Chen, G., Zhang, D., Zhou, X., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6406, pp. 548–562. [Google Scholar]
- Shoaib, M.; Bosch, S.; İncel, Ö.D.; Scholten, H.; Havinga, J.M. Fusion of smartphone motion sensors for physical activity recognition. Sensors 2014, 14, 10146–10176. [Google Scholar] [CrossRef] [PubMed]
- Janidarmian, M.; Fekr, A.R.; Radecka, K.; Zilic, Z. A comprehensive analysis on wearable acceleration sensors in human activity recognition. Sensors 2017, 17, 529. [Google Scholar] [CrossRef] [PubMed]
- Siirtola, P.; Röning, J. Recognizing human activities user-independently on smartphones based on accelerometer data. Int. J. Interact. Multimed. Artif. Intell. 2012, 1, 38–45. [Google Scholar] [CrossRef]
- Yang, Y. Toward physical activity diary: Motion recognition using simple acceleration features with mobile phones. In Proceedings of the 1st International Workshop on Interactive Multimedia for Consumer Electronics, Beijing, China, 23 October 2009; pp. 1–10. [Google Scholar]
- Lu, H.; Yang, J.; Liu, Z.; Lane, N.D.; Choudhury, T.; Campbell, A.T. The Jigsaw continuous sensing engine for mobile phone applications. In Proceedings of the 8th ACM Conference on Embedded Networked Sensor Systems, Zürich, Switzerland, 3–5 November 2010; pp. 71–84. [Google Scholar]
- Wang, N.; Redmond, S.J.; Ambikairajah, E.; Celler, B.G.; Lovell, N.H. Can triaxial accelerometry accurately recognize inclined walking terrains? IEEE Trans. Biomed. Eng. 2010, 57, 2506–2516. [Google Scholar] [CrossRef] [PubMed]
- Henpraserttae, A.; Thiemjarus, S.; Marukatat, S. Accurate activity recognition using a mobile phone regardless of device orientation and location. In Proceedings of the International Conference on Body Sensor Networks, Dallas, TX, USA, 23–25 May 2011; pp. 41–46. [Google Scholar]
- Chavarriaga, R.; Bayati, H.; Millán, J.D. Unsupervised adaptation for acceleration-based activity recognition: Robustness to sensor displacement and rotation. Pers. Ubiquitous Comput. 2011, 17, 479–490. [Google Scholar] [CrossRef]
- Ustev, Y.E.; İncel, Ö.D.; Ersoy, C. User, device and orientation independent human activity recognition on mobile phones: Challenges and a proposal. In Proceedings of the ACM Conference on Pervasive and Ubiquitous Computing, Zürich, Switzerland, 8–12 September 2013; pp. 1427–1436. [Google Scholar]
- Morales, J.; Akopian, D.; Agaian, S. Human activity recognition by smartphones regardless of device orientation. In Proceedings of the SPIE-IS&T Electronic Imaging: Mobile Devices and Multimedia: Enabling Technologies, Algorithms, and Applications, San Francisco, CA, USA, 18 February 2014; Creutzburg, R., Akopian, D., Eds.; SPIE: Bellingham, WA, USA; IS&T: Springfield, VA, USA, 2014; Volume 9030, pp. 90300I-1–90300I-12. [Google Scholar]
- Banos, O.; Toth, M.A.; Damas, M.; Pomares, H.; Rojas, I. Dealing with the effects of sensor displacement in wearable activity recognition. Sensors 2014, 14, 9995–10023. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.B.; Nguyen, M.N.; San, P.P.; Li, X.L.; Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. In Proceedings of the 24th International Conference on Artificial Intelligence (IJCAI’15), Buenos Aires, Argentina, 25–31 July 2015; pp. 3995–4001. [Google Scholar]
- Alsheikh, M.A.; Selim, A.; Niyato, D.; Doyle, L.; Lin, S.; Tan, H.-P. Deep activity recognition models with triaxial accelerometers. In Proceedings of the Workshop at the Thirtieth AAAI Conference on Artificial Intelligence: Artificial Intelligence Applied to Assistive Technologies and Smart Environments, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Ravi, D.; Wong, C.; Lo, B.; Yang, G. A deep learning approach to on-node sensor data analytics for mobile or wearable devices. IEEE J. Biomed. Health 2017, 21, 56–64. [Google Scholar] [CrossRef] [PubMed]
- Thiemjarus, S. A device-orientation independent method for activity recognition. In Proceedings of the International Conference on Body Sensor Networks, Biopolis, Singapore, 7–9 June 2010; pp. 19–23. [Google Scholar]
- Jiang, M.; Shang, H.; Wang, Z.; Li, H.; Wang, Y. A method to deal with installation errors of wearable accelerometers for human activity recognition. Physiol. Meas. 2011, 32, 347–358. [Google Scholar] [CrossRef] [PubMed]
- Kunze, K.; Lukowicz, P. Dealing with sensor displacement in motion-based onbody activity recognition systems. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Korea, 21–24 September 2008; pp. 20–29. [Google Scholar]
- Förster, K.; Roggen, D.; Troster, G. Unsupervised classifier self-calibration through repeated context occurrences: Is there robustness against sensor displacement to gain? In Proceedings of the International Symposium on Wearable Computers, Linz, Austria, 4–7 September 2009; pp. 77–84. [Google Scholar]
- Bachmann, E.R.; Yun, X.; Brumfield, A. Limitations of attitude estimation algorithms for inertial/magnetic sensor modules. IEEE Robot. Autom. Mag. 2007, 14, 76–87. [Google Scholar] [CrossRef]
- Ghasemi-Moghadam, S.; Homaeinezhad, M.R. Attitude determination by combining arrays of MEMS accelerometers, gyros, and magnetometers via quaternion-based complementary filter. Int. J. Numer. Model. Electron. Netw. Devices Fields 2018, 31, 1–24. [Google Scholar] [CrossRef]
- Yurtman, A.; Barshan, B. Activity recognition invariant to sensor orientation with wearable motion sensors. Sensors 2017, 17, 1838. [Google Scholar] [CrossRef] [PubMed]
- Yurtman, A.; Barshan, B. Recognizing activities of daily living regardless of wearable device orientation. In Proceedings of the Fifth International Symposium on Engineering, Artificial Intelligence, and Applications, Book of Abstracts, Kyrenia, Turkish Republic of Northern Cyprus, 1–3 November 2017; pp. 22–23. [Google Scholar]
- Yurtman, A.; Barshan, B. Classifying daily activities regardless of wearable motion sensor orientation. In Proceedings of the Eleventh International Conference on Advances in Computer-Human Interactions (ACHI), Rome, Italy, 25–29 March 2018. [Google Scholar]
- Zhong, Y.; Deng, Y. Sensor orientation invariant mobile gait biometrics. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 29 September–2 October 2014; pp. 1–8. [Google Scholar]
- Barshan, B.; Yurtman, A. Investigating inter-subject and inter-activity variations in activity recognition using wearable motion sensors. Comput. J. 2016, 59, 1345–1362. [Google Scholar] [CrossRef]
- Cai, G.; Chen, B.M.; Lee, T.H. Chapter 2: On Coordinate Systems and Transformations. In Unmanned Rotorcraft Systems; Springer: London, UK, 2011; pp. 23–34. [Google Scholar]
- Comotti, D. Orientation Estimation Based on Gauss-Newton Method and Implementation of a Quaternion Complementary Filter; Technical Report; Department of Computer Science and Engineering, University of Bergamo: Bergamo, Italy, 2011; Available online: https://storage.googleapis.com/google-code-archive-downloads/v2/code.google.com/9dof-orientation-estimation/GaussNewton_QuaternionComplemFilter_V13.pdf (accessed on 16 August 2018).
- Spong, M.W.; Hutchinson, S.; Vidyasagar, M. Section 2.3: On Rotational Transformations. In Robot Modeling and Control; John Wiley & Sons: New York, NY, USA, 2006; pp. 4–48. [Google Scholar]
- Chen, C.-T. Section 3.4: On Similarity Transformation. In Linear System Theory and Design; Oxford University Press: New York, NY, USA, 1999; pp. 53–55. [Google Scholar]
- Altun, K.; Barshan, B. Daily and Sports Activities Dataset. In UCI Machine Learning Repository; School of Information and Computer Sciences, University of California, Irvine: Irvine, CA, USA, 2013; Available online: http://archive.ics.uci.edu/ml/datasets/Daily+and+Sports+Activities (accessed on 16 August 2018).
- Xsens Technologies B.V. MTi, MTx, and XM-B User Manual and Technical Documentation; Xsens: Enschede, The Netherlands, 2018; Available online: http://www.xsens.com (accessed on 16 August 2018).
- Altun, K.; Barshan, B.; Tunçel, O. Comparative study on classifying human activities with miniature inertial and magnetic sensors. Pattern Recognit. 2010, 43, 3605–3620. [Google Scholar] [CrossRef]
- Barshan, B.; Yüksek, M.C. Recognizing daily and sports activities in two open source machine learning environments using body-worn sensor units. Comput. J. 2014, 57, 1649–1667. [Google Scholar] [CrossRef]
- Altun, K.; Barshan, B. Human activity recognition using inertial/magnetic sensor units. In Lecture Notes in Computer Science, Proceedings of the International Workshop on Human Behaviour Understanding, Istanbul, Turkey, 22 August 2010; Salah, A.A., Gevers, T., Sebe, N., Vinciarelli, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6219, pp. 38–51. [Google Scholar]
- Rulsch, M.; Busse, J.; Struck, M.; Weigand, C. Method for daily-life movement classification of elderly people. Biomed. Eng. 2012, 57, 1071–1074. [Google Scholar] [CrossRef] [PubMed]
- Özdemir, A.T.; Barshan, B. Detecting falls with wearable sensors using machine learning techniques. Sensors 2014, 14, 10691–10708. [Google Scholar] [CrossRef] [PubMed]
- Diebel, J. Representing Attitude: Euler Angles, Unit Quaternions, and Rotation Vectors; Technical Report; Department of Aeronautics and Astronautics, Stanford University: Stanford, CA, USA, 2006; Available online: http://www.swarthmore.edu/NatSci/mzucker1/papers/diebel2006attitude.pdf (accessed on 16 August 2018).
- Yurtman, A.; Barshan, B. Choosing Sensory Data Type and Rotational Representation for Activity Recognition Invariant to Wearable Sensor Orientation Using Differential Rotational Transformations; Technical Report; Department of Electrical and Electronics Engineering, Bilkent University: Ankara, Turkey, 2018. [Google Scholar]
- Webb, A. Statistical Pattern Recognition; John Wiley & Sons: New York, NY, USA, 2002. [Google Scholar]
- Keerthi, S.S.; Lin, C.-J. Asymptotic behaviors of support vector machines with Gaussian kernel. Neural Comput. 2003, 15, 1667–1689. [Google Scholar] [CrossRef] [PubMed]
- Duan, K.-B.; Keerthi, S.S. Which is the best multiclass SVM method? An empirical study. In Lecture Notes in Computer Science, Proceedings of the 6th International Workshop on Multiple Classifier Systems, Seaside, CA, USA, 13–15 June 2005; Nikunj, C.O., Polikar, R., Kittler, J., Roli, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3541, pp. 278–285. [Google Scholar]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification; Technical Report; Department of Computer Science, National Taiwan University: Taipei, Taiwan, 2003. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; John Wiley & Sons: New York, NY, USA, 2000. [Google Scholar]
- Haykin, S. Neural Networks: A Comprehensive Foundation, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 1998. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Elsevier: Cambridge, MA, USA, 2016. [Google Scholar]
- Pati, Y.C.; Rezaiifar, R.; Krishnaprasad, P.S. Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition. In Proceedings of the 27th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–3 November 1993; pp. 40–44. [Google Scholar]
- Wang, L.; Cheng, L.; Zhao, G. Machine Learning for Human Motion Analysis: Theory and Practice; IGI Global: Hershey, PA, USA, 2000. [Google Scholar]
- Rawassizadeh, R.; Pierson, T.J.; Peterson, R.; Kotz, D. NoCloud: Exploring network disconnection through on-device data analysis. IEEE Pervasive Comput. 2018, 17, 64–74. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Estimated Labels | True Labels | Total | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | A9 | A10 | A11 | A12 | A13 | A14 | A15 | A16 | A17 | A18 | A19 | |||||
| A | 286 | 1 | 68 | 20 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 383 | |||
| A | 0 | 330 | 0 | 0 | 0 | 0 | 26 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 357 | |||
| A | 81 | 0 | 372 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 453 | |||
| A | 1 | 0 | 0 | 367 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 368 | |||
| A | 0 | 0 | 0 | 0 | 477 | 0 | 0 | 2 | 11 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 503 | |||
| A | 0 | 0 | 0 | 0 | 0 | 453 | 2 | 5 | 0 | 0 | 0 | 0 | 6 | 0 | 0 | 0 | 0 | 42 | 0 | 508 | |||
| A | 97 | 102 | 33 | 83 | 0 | 0 | 354 | 61 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 730 | |||
| A | 15 | 47 | 6 | 10 | 1 | 27 | 90 | 409 | 1 | 0 | 1 | 0 | 9 | 2 | 2 | 0 | 0 | 0 | 8 | 628 | |||
| A | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 1 | 416 | 19 | 4 | 0 | 36 | 0 | 0 | 1 | 0 | 0 | 0 | 479 | |||
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 13 | 354 | 84 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 451 | |||
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 38 | 105 | 374 | 0 | 11 | 0 | 0 | 0 | 0 | 0 | 0 | 528 | |||
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 480 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 480 | |||
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 2 | 5 | 0 | 399 | 7 | 0 | 0 | 0 | 0 | 1 | 416 | |||
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 19 | 471 | 0 | 0 | 0 | 0 | 0 | 490 | |||
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 478 | 1 | 0 | 0 | 0 | 479 | |||
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 477 | 0 | 0 | 0 | 477 | |||
| A | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 480 | 0 | 1 | 482 | |||
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 438 | 0 | 439 | |||
| A | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 469 | 469 | |||
| total | 480 | 480 | 480 | 480 | 480 | 480 | 480 | 480 | 480 | 480 | 480 | 480 | 480 | 480 | 480 | 480 | 480 | 480 | 480 | 9120 | |||
| accuracy (%) | 59.6 | 68.8 | 77.5 | 76.5 | 99.4 | 94.4 | 73.8 | 85.2 | 86.7 | 73.8 | 77.9 | 100.0 | 83.1 | 98.1 | 99.6 | 99.4 | 100.0 | 91.3 | 97.7 | 86.5 (overall) | |||
| 70.6 | 90.7 | ||||||||||||||||||||||
| (for stationary activities) | (for non-stationary activities) | ||||||||||||||||||||||
| Data Transformation Technique | Run Time (ms) |
|---|---|
| Euclidean norm | 0.69 |
| sensor sequences with respect to the Earth frame | 56.25 |
| sensor sequences along and perpendicular to the gravity vector | 1.09 |
| SVD-based transformation | 8.94 |
| proposed method: sensor sequences and differential | 61.08 |
| quaternions, both with respect to the Earth frame |
| Classifier | Reference (No Transformation) | Random Rotation | Euclidean Norm | Sensor Sequences with Respect to the Earth Frame | Sensor Sequences Along and Perpendicular to the Gravity Vector | SVD-Based Transformation | Proposed Method: Sensor Sequences and Differential Quaternions, Both with Respect to the Earth Frame | |
|---|---|---|---|---|---|---|---|---|
| (a) total run time (s) | SVM | 6.42 | 14.20 | 7.22 | 11.71 | 8.19 | 6.24 | 10.05 |
| ANN | 7.37 | 8.49 | 8.54 | 6.58 | 12.04 | 7.91 | 6.14 | |
| BDM | 1.67 | 1.61 | 1.59 | 1.55 | 2.12 | 1.48 | 1.69 | |
| LDC | 1.10 | 0.87 | 0.84 | 1.52 | 0.84 | 0.93 | 1.51 | |
| k-NN | 0.24 | 0.12 | 0.12 | 0.21 | 0.19 | 0.12 | 0.22 | |
| RF | 16.81 | 22.51 | 26.40 | 24.34 | 19.05 | 19.71 | 23.98 | |
| OMP | 1018.27 | 798.90 | 92.32 | 99.41 | 96.48 | 75.18 | 114.68 | |
| (b) training time (s) | SVM | 6.01 | 13.39 | 6.61 | 10.31 | 7.58 | 5.36 | 8.60 |
| ANN | 7.35 | 8.47 | 8.52 | 6.57 | 12.01 | 7.89 | 6.12 | |
| BDM | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | |
| LDC | 0.33 | 0.23 | 0.22 | 0.38 | 0.22 | 0.26 | 0.33 | |
| k-NN | – | – | – | – | – | – | – | |
| RF | 15.20 | 20.90 | 24.11 | 21.75 | 17.45 | 17.87 | 21.25 | |
| OMP | – | – | – | – | – | – | – | |
| (c) classification time (ms) | SVM | 0.26 | 0.60 | 0.42 | 0.39 | 0.40 | 0.24 | 0.31 |
| ANN | 0.02 | 0.02 | 0.01 | 0.01 | 0.02 | 0.01 | 0.01 | |
| BDM | 1.46 | 1.41 | 1.39 | 1.35 | 1.85 | 1.29 | 1.47 | |
| LDC | 0.04 | 0.03 | 0.03 | 0.05 | 0.03 | 0.03 | 0.04 | |
| k-NN | 0.21 | 0.11 | 0.11 | 0.19 | 0.16 | 0.11 | 0.19 | |
| RF | 0.71 | 0.73 | 0.99 | 0.83 | 0.72 | 0.74 | 0.87 | |
| OMP | 892.55 | 700.17 | 80.55 | 86.38 | 84.20 | 65.43 | 99.69 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yurtman, A.; Barshan, B.; Fidan, B. Activity Recognition Invariant to Wearable Sensor Unit Orientation Using Differential Rotational Transformations Represented by Quaternions. Sensors 2018, 18, 2725. https://doi.org/10.3390/s18082725
Yurtman A, Barshan B, Fidan B. Activity Recognition Invariant to Wearable Sensor Unit Orientation Using Differential Rotational Transformations Represented by Quaternions. Sensors. 2018; 18(8):2725. https://doi.org/10.3390/s18082725
Chicago/Turabian StyleYurtman, Aras, Billur Barshan, and Barış Fidan. 2018. "Activity Recognition Invariant to Wearable Sensor Unit Orientation Using Differential Rotational Transformations Represented by Quaternions" Sensors 18, no. 8: 2725. https://doi.org/10.3390/s18082725
APA StyleYurtman, A., Barshan, B., & Fidan, B. (2018). Activity Recognition Invariant to Wearable Sensor Unit Orientation Using Differential Rotational Transformations Represented by Quaternions. Sensors, 18(8), 2725. https://doi.org/10.3390/s18082725