2.1. Background and Related Work
A frequently-used definition of data clustering considers it as the unsupervised classification of various observations (data) into specific groups [
5]. It emerges as a suitable approach for classifying big sensor data and potentially discovering hidden correlations among them. Data clustering has been applied in various diverse applications. Examples include recommender systems where users are grouped according to their preferences [
9] and healthcare applications classifying patients according to their medical history [
10]. There is a great variety of general-purpose clustering algorithms [
5], broadly segregated as centralized and distributed approaches. Centralized approaches may include partitioning (e.g.,
k-means [
11], CLARANS [
12]), hierarchical (e.g., BIRCH [
13], Chameleon [
14]), grid (e.g., STING [
15], WaveCluster [
16]) or density methods (e.g., DBSCAN [
17]), among others. Centralized approaches are usually simple to implement, but suffer from scaling issues with modern big sensory datasets. Distributed methods mainly implement MapReduce or some variation of parallel clustering. MapReduce approaches are modified versions of centralized algorithms like
k-means [
18], MR-DBSCAN [
19], DBCURE-MR [
20], etc. Parallel clustering methods [
21] typically consist of modified centralized algorithms, aiming at distributing their execution over multiple machines.
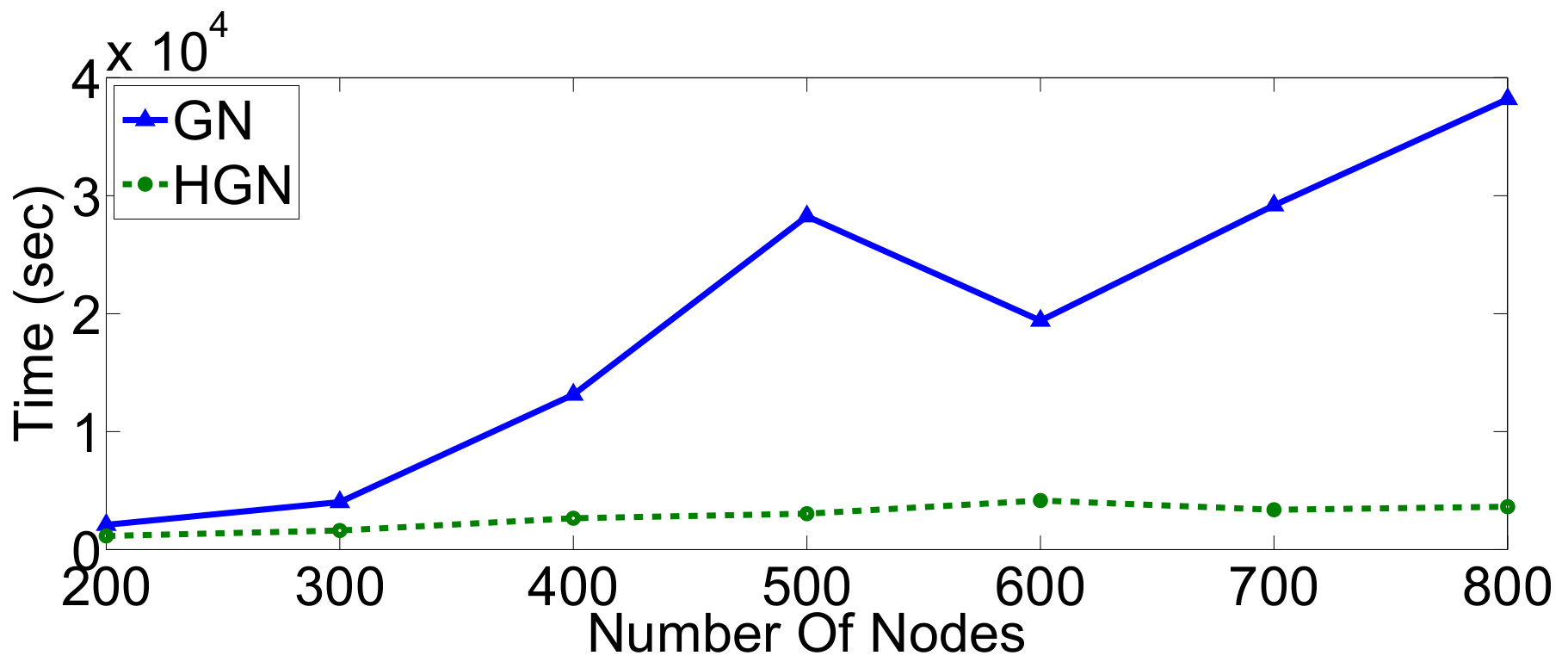
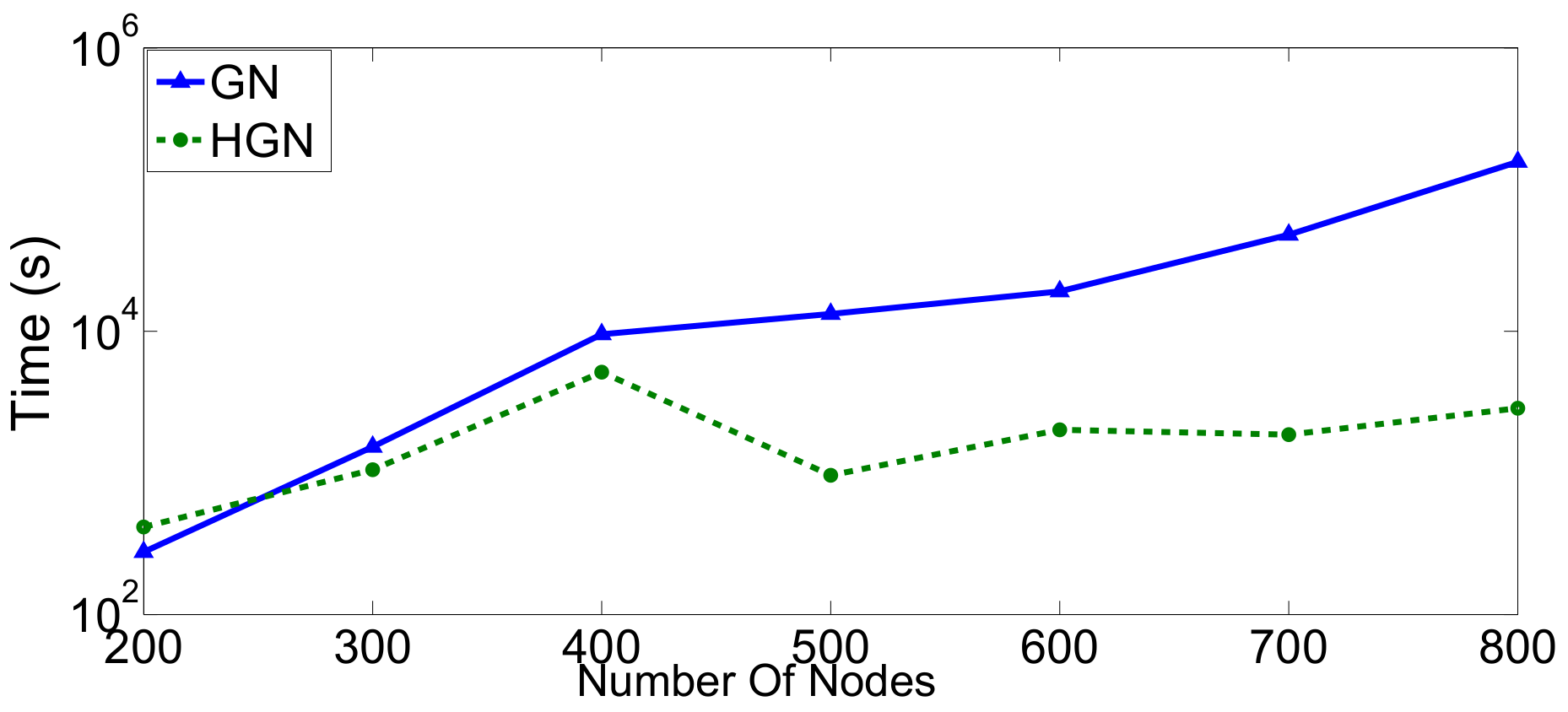
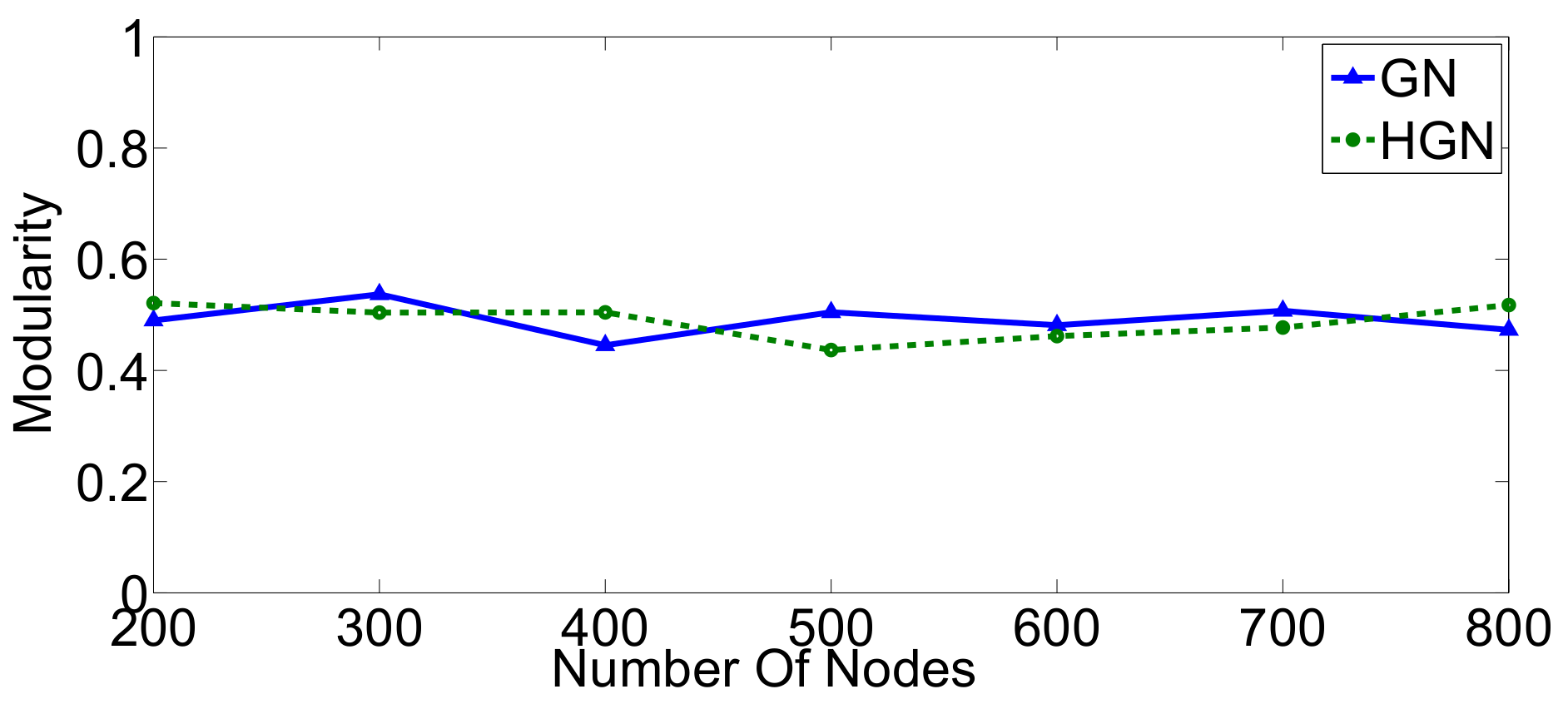
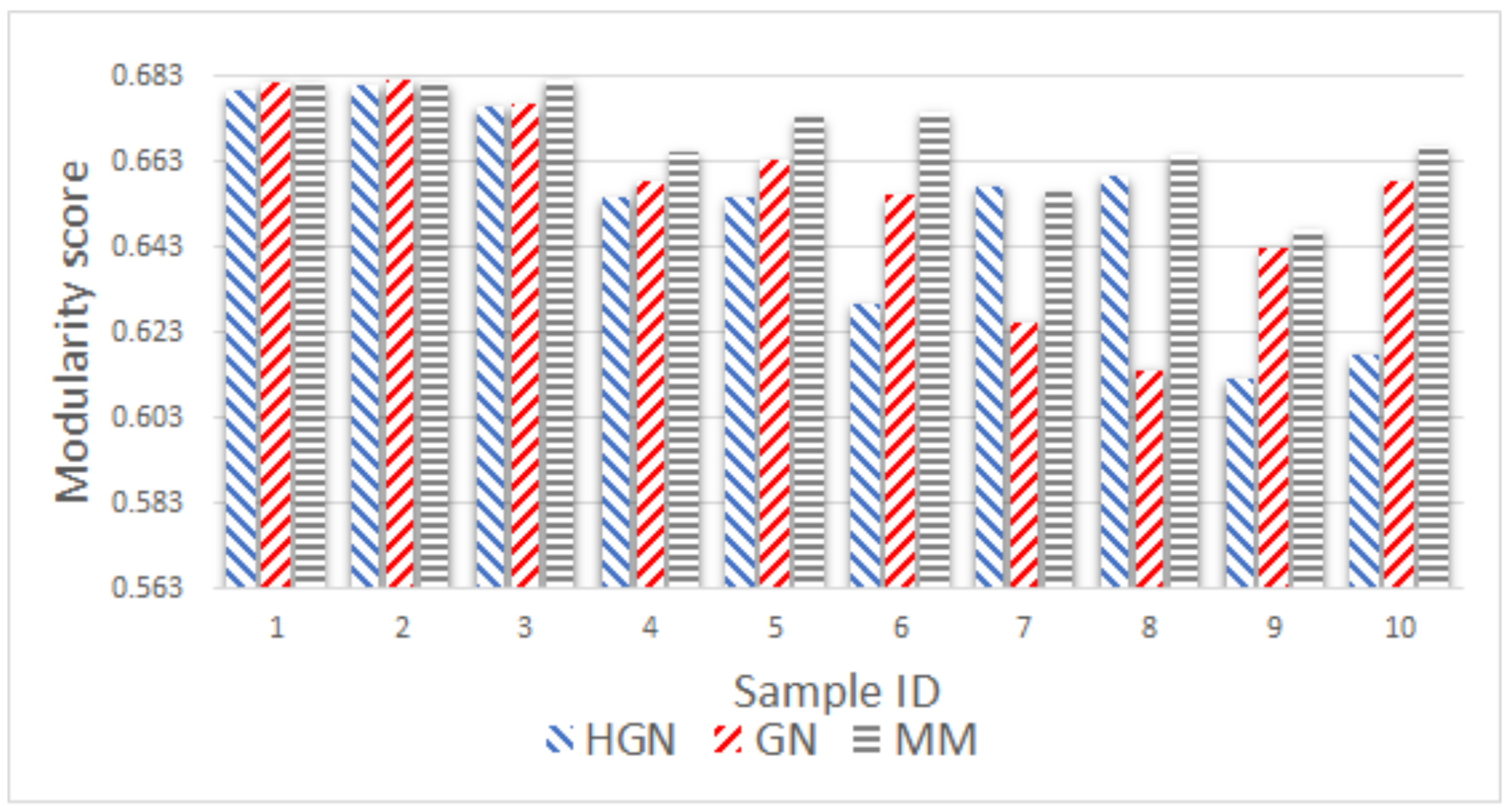
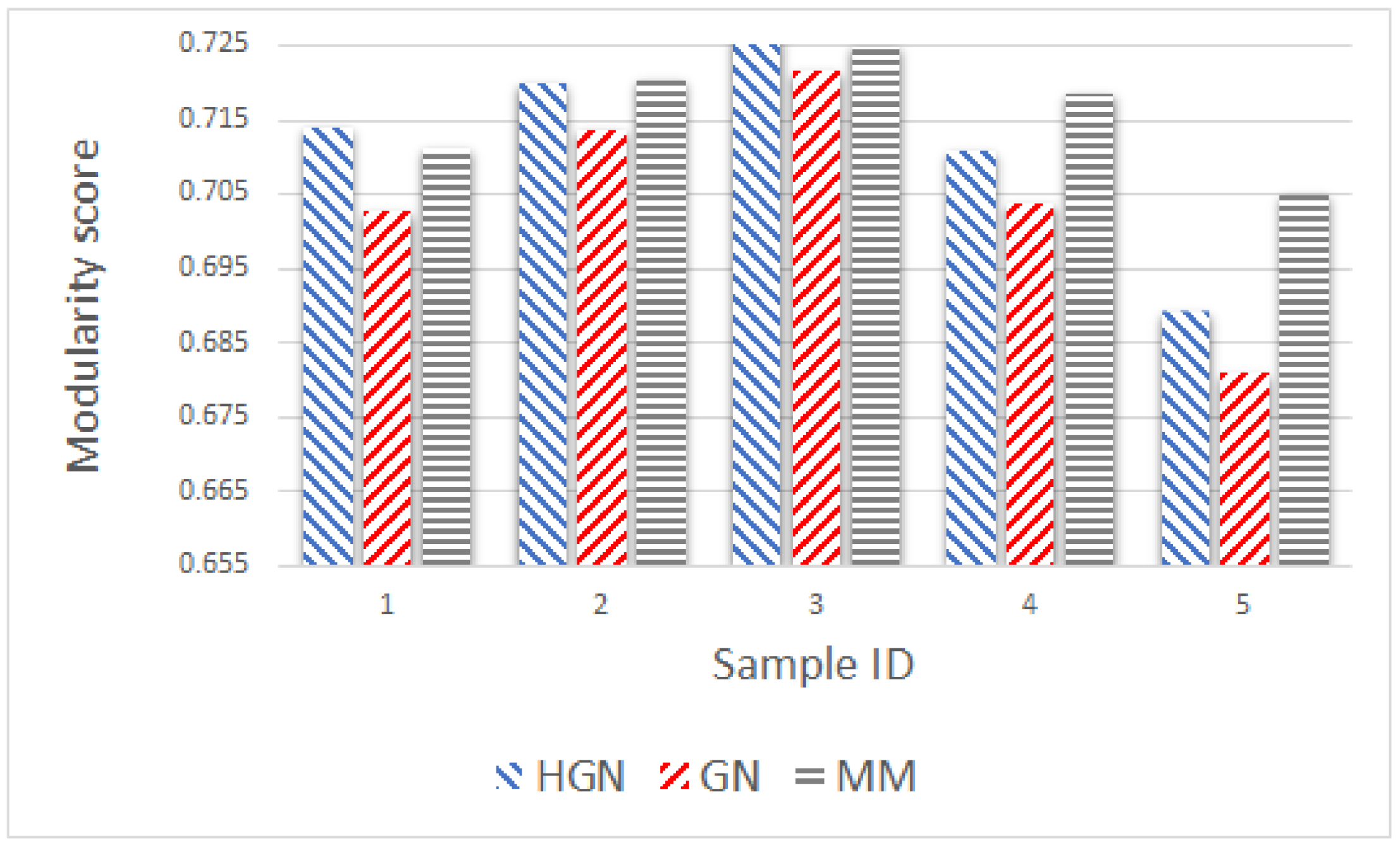
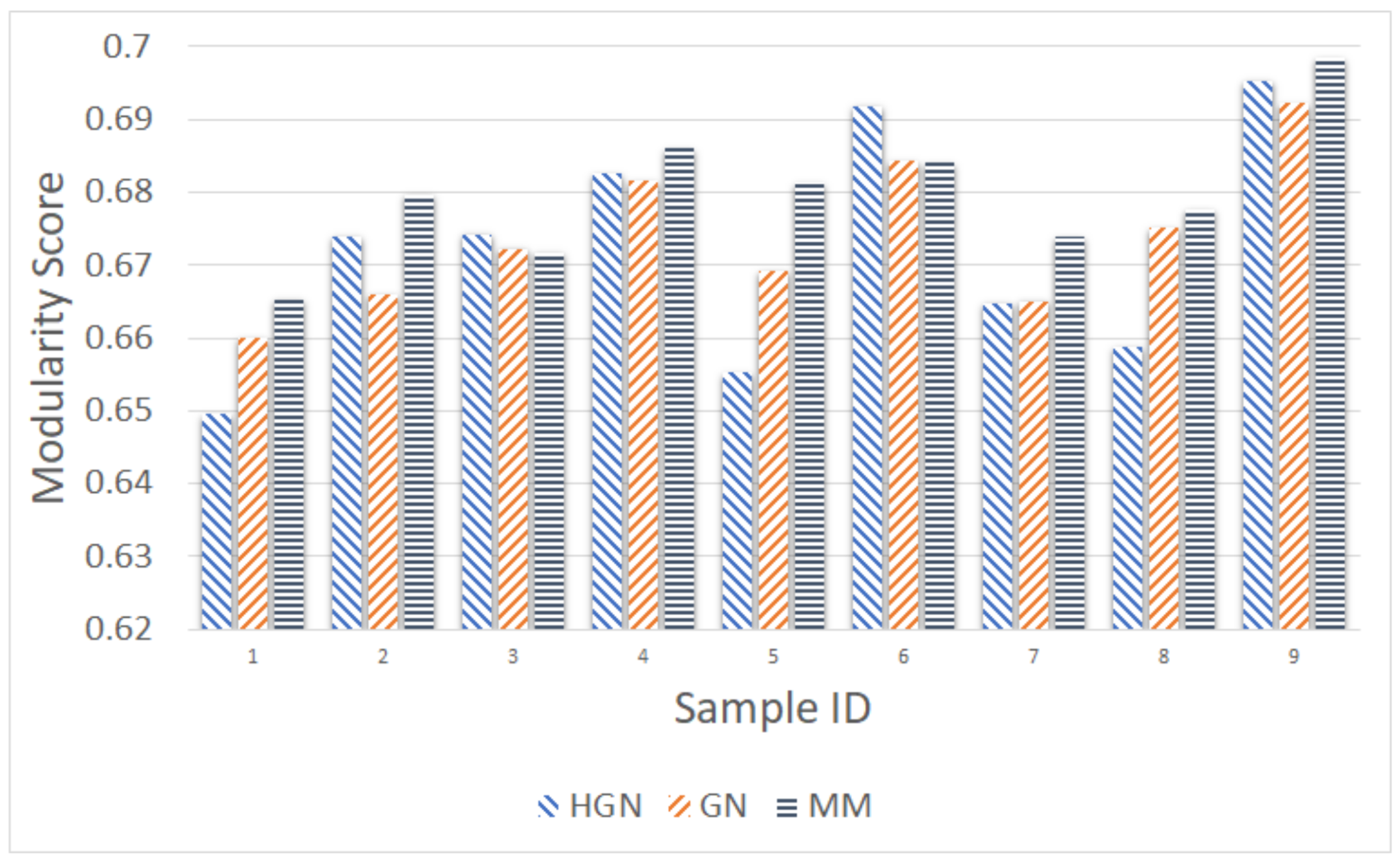
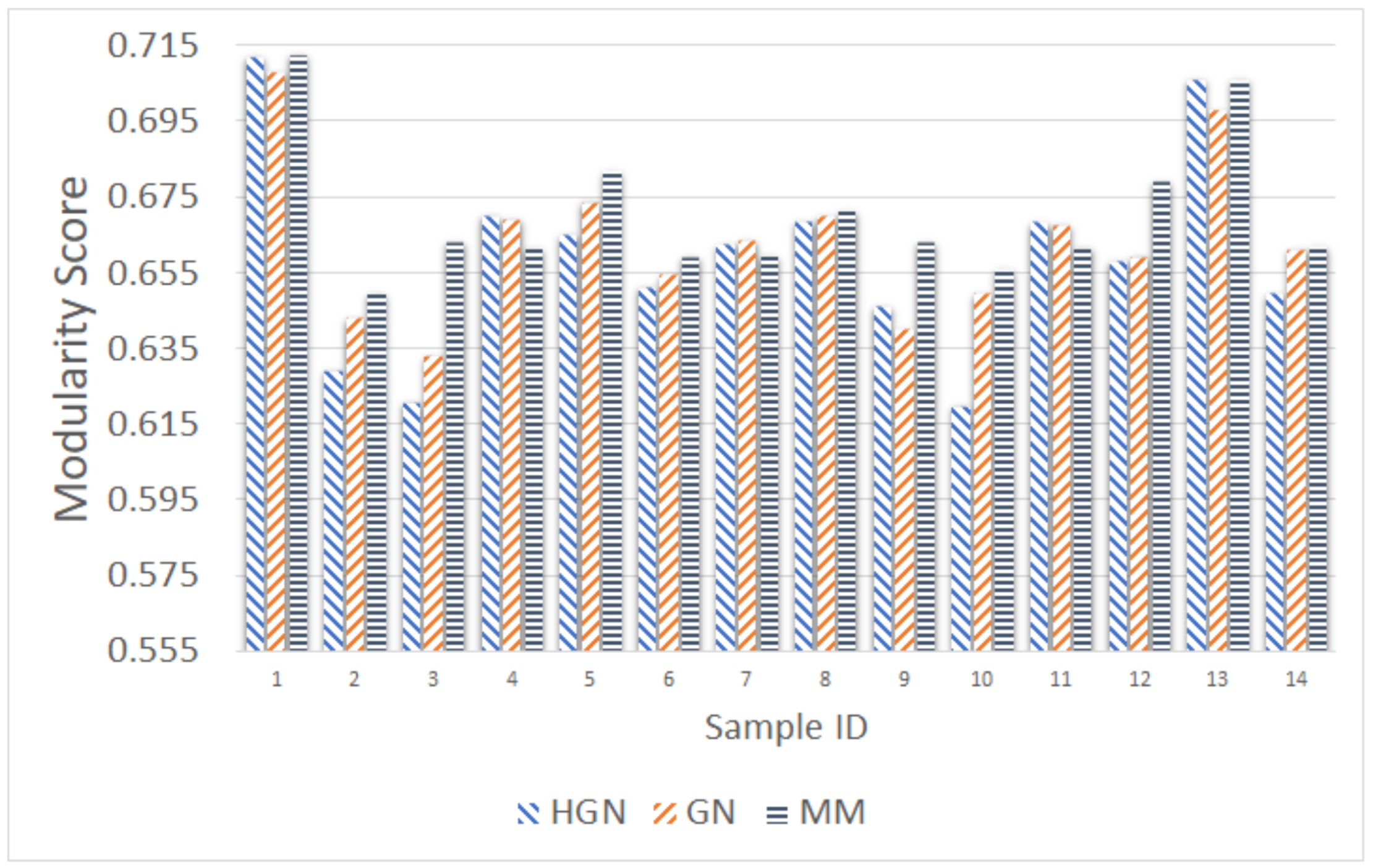
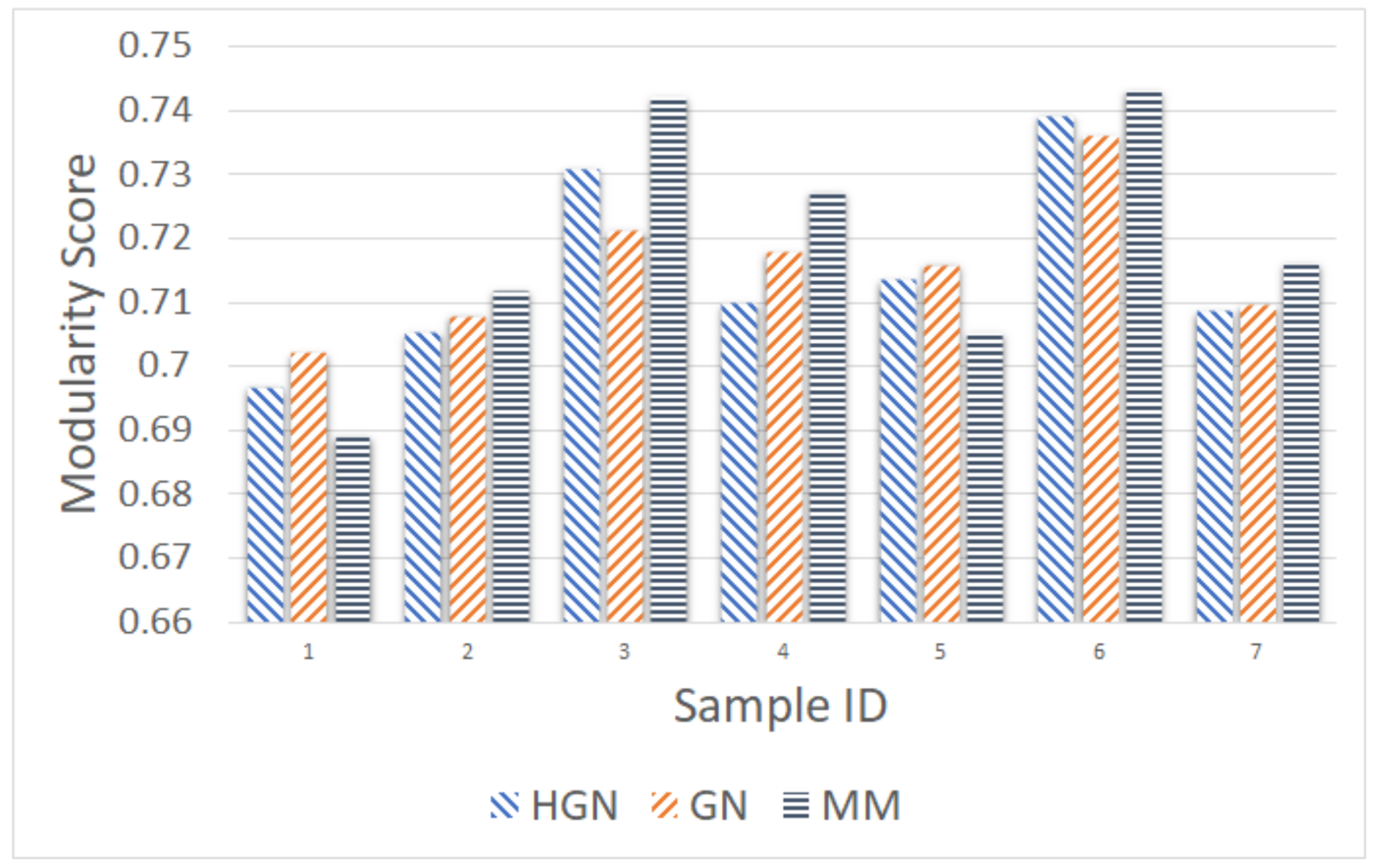
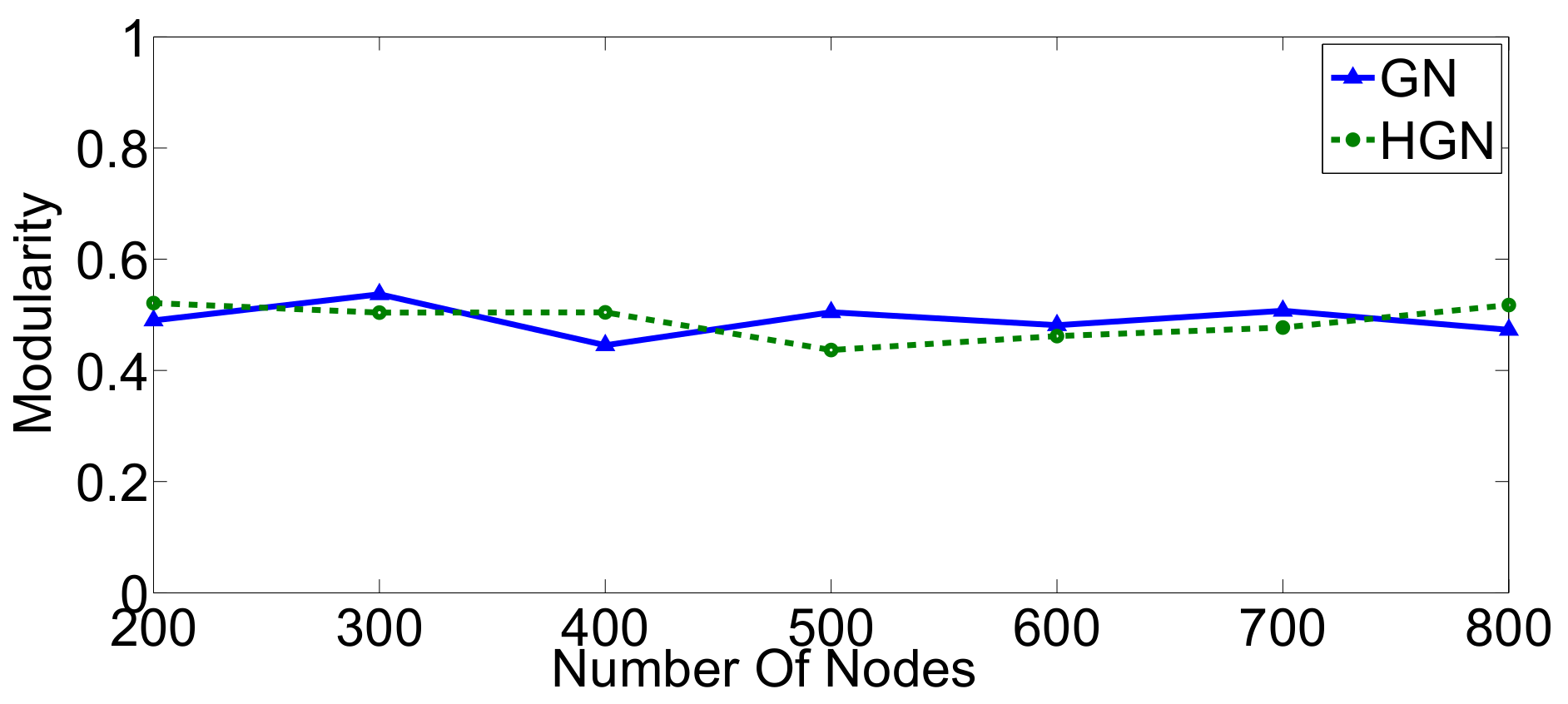
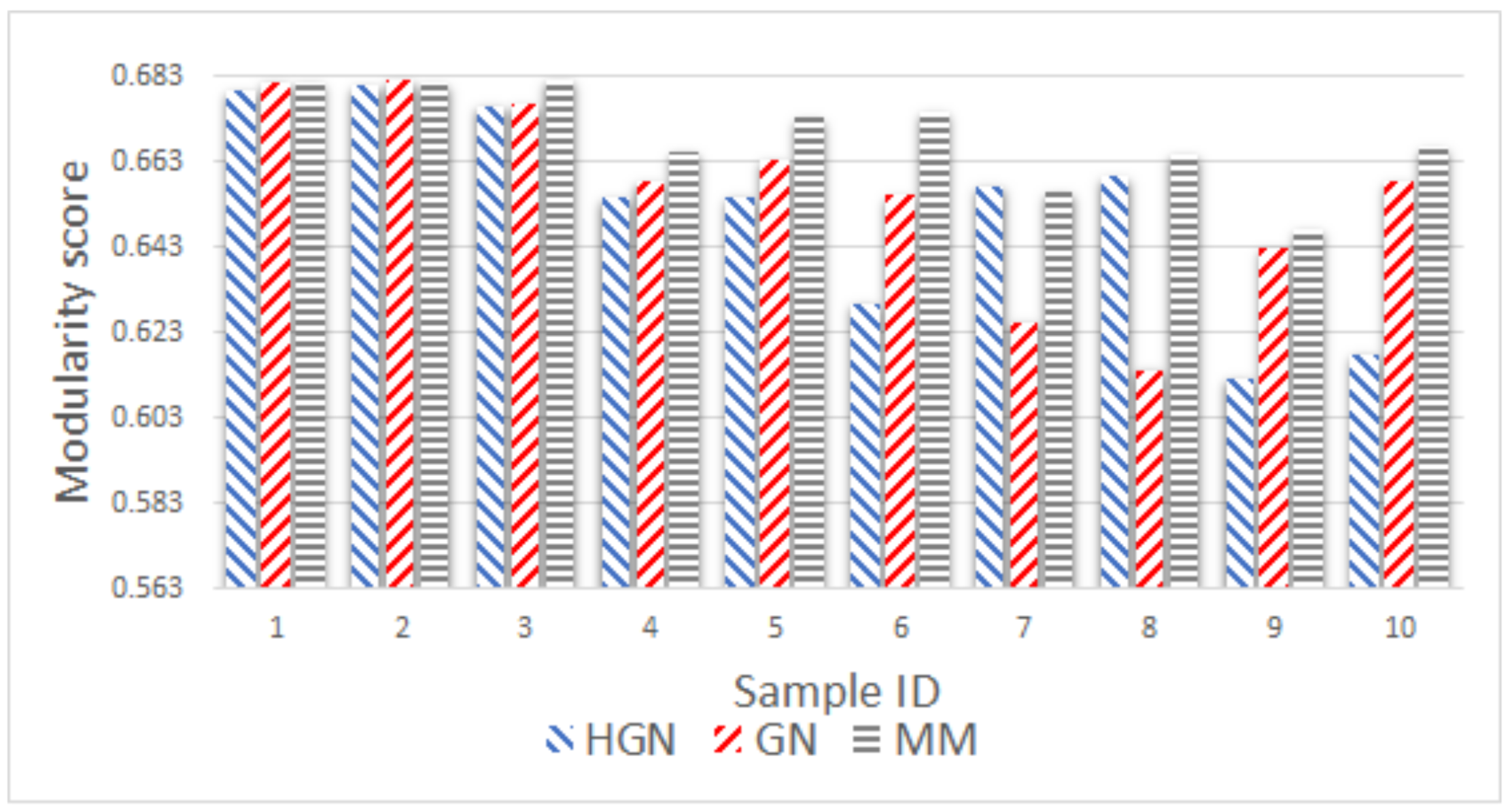
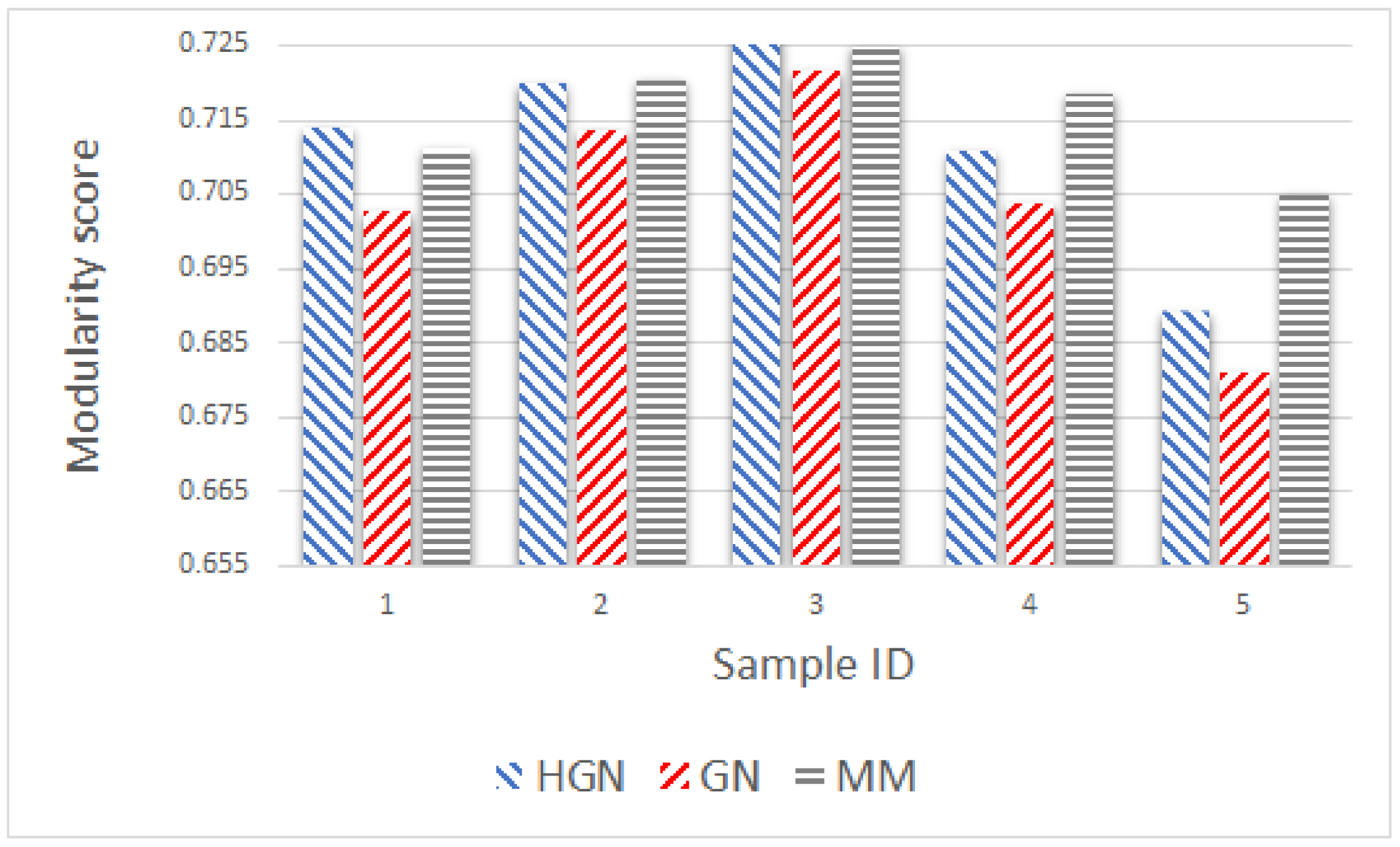
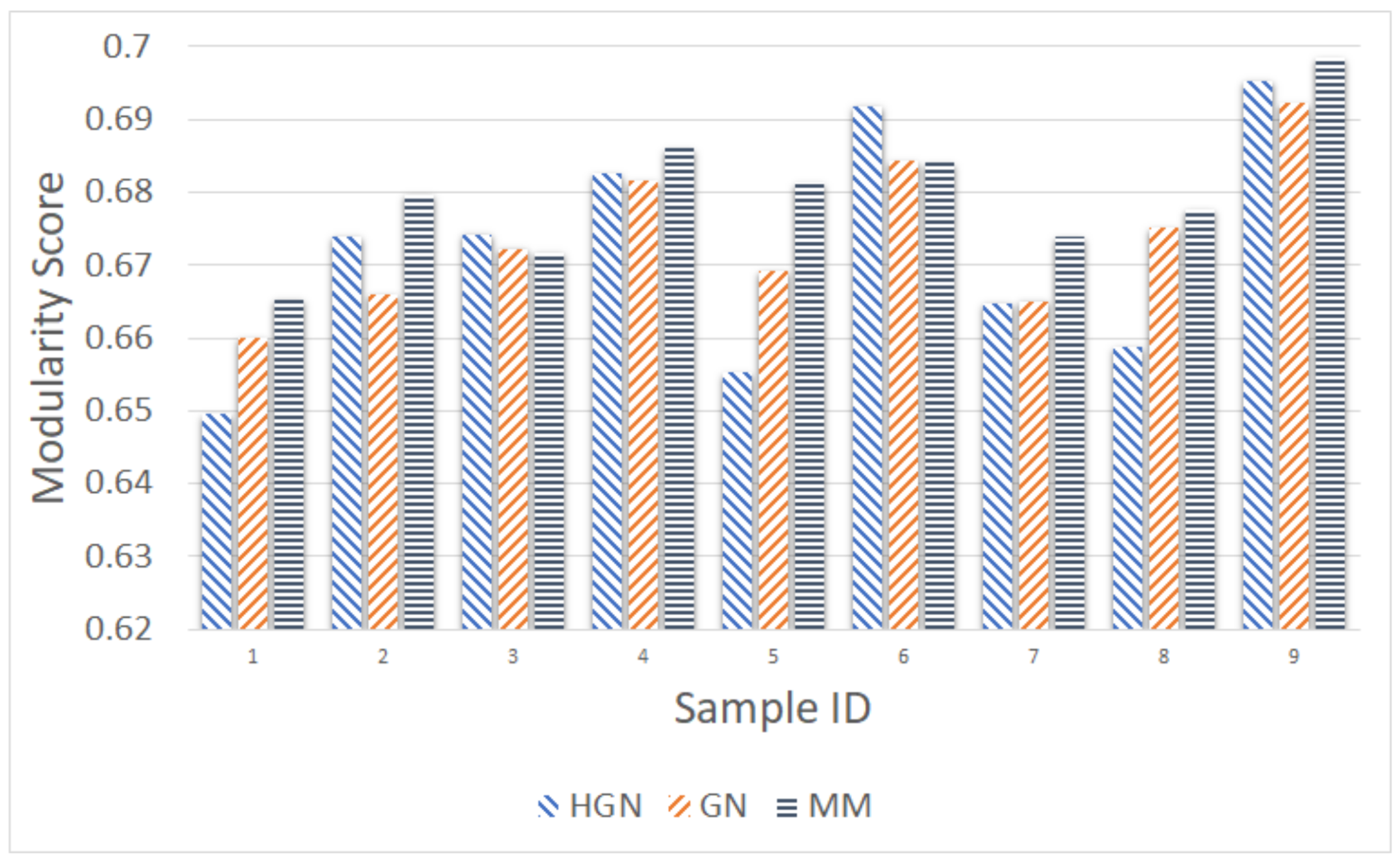
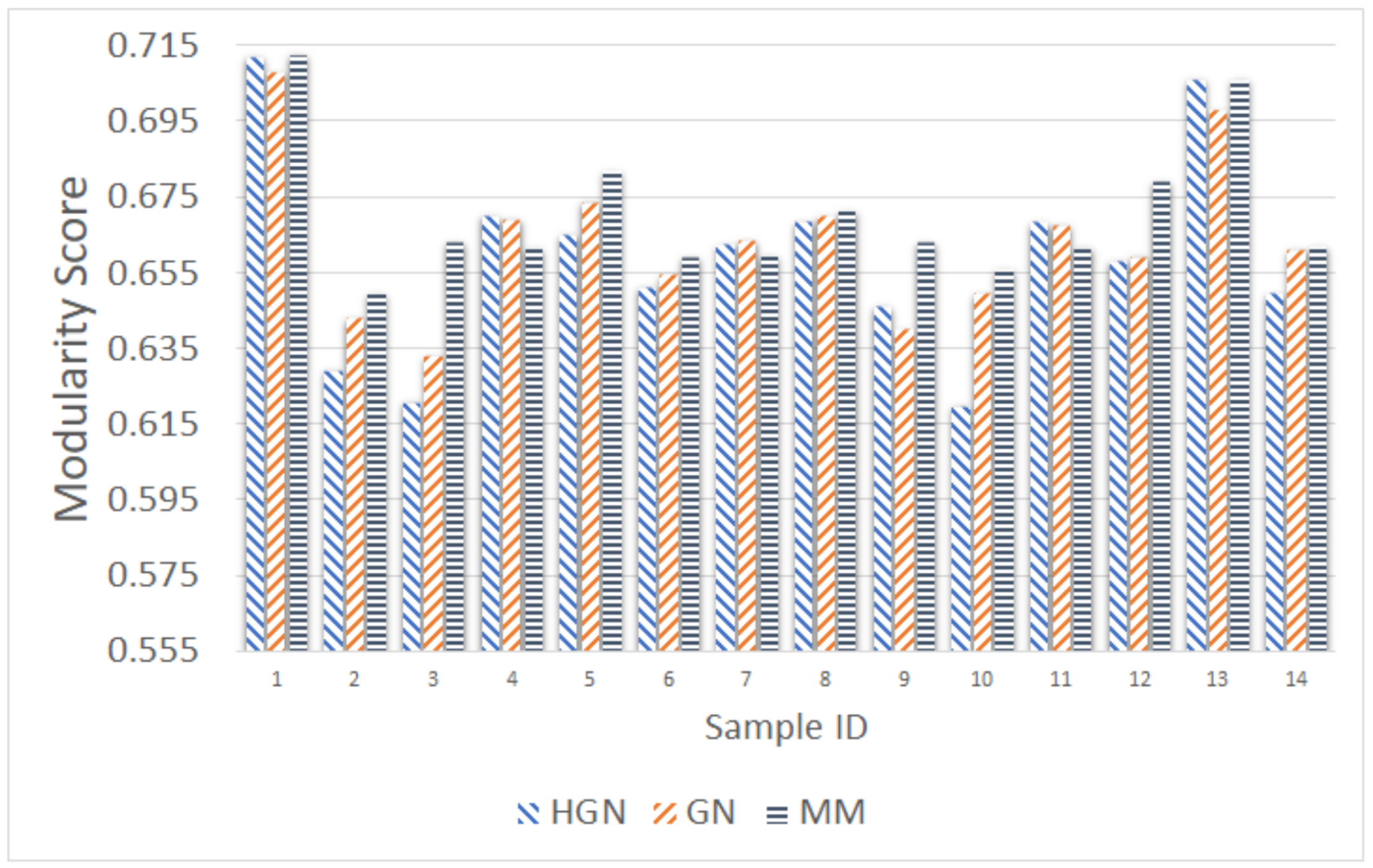
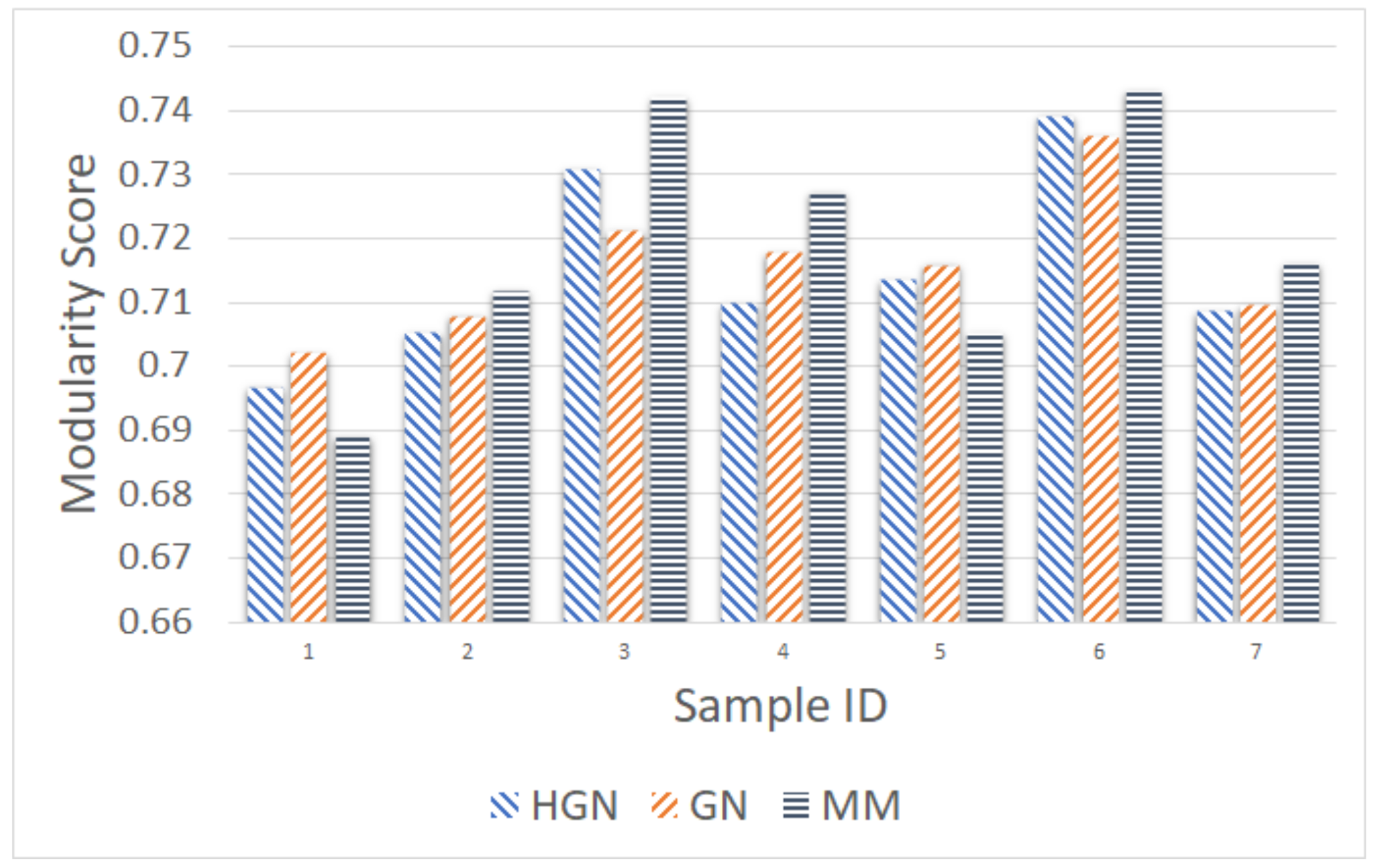
Relations between multi-dimensional or other types of data observations can be represented via a data graph, where data correspond to nodes and links between them represent their inter-relations. Data clustering using the data graph model resembles node clustering emerging in community detection in networks. The latter has become a prominent field of cross-disciplinary research. Three main classes of methodologies can be identified, namely division based, label propagation based and modularity optimization. The first suggests removing edges of the analyzed network according to specific rules, resulting in various connected components, each corresponding to a different community. The most popular representative of this category is the Girvan–Newman (GN) algorithm, which removes edges according to the EBC metric. The main observation exploited by the GN approach is that the number of edges connecting members within a community (intra-edges) is significantly greater than the number of edges connecting nodes belonging in different communities (inter-edges). These inter-community edges demonstrate a bridge-like property, and therefore, they tend to have large EBC values. Thus, removing such edges will lead to revealing the emerging communities in the network. The GN algorithm exhibits slow computational speed, since the process of EBC computation-ordering-removal of high-EBC value edges has a significant cost, and it needs to be repeatedly applied. Furthermore, in GN, the number of targeted communities is pre-specified. Modularity optimization methods typically exhibit better performance when the number of communities is unknown. Modularity is a measure used to evaluate the partition of a network in communities. It quantifies the number of edges that exist inside the communities relative to a random distribution of the total number of edges over the network. The mathematical expression of modularity is:
, where
m is the total number of edges in the network,
k is the number of communities,
denotes the set of nodes in the
l-th community,
is the adjacency matrix from which
is obtained, corresponding to the actual number of edges between nodes
, and
is the degree of node
i. A large modularity score, where
, indicates well-connected communities, meaning that the edges inside the communities are more than those connecting different ones. Modularity optimization methods aim to find the partition of the network into communities that maximizes the total modularity score, summed over all communities. Since the problem of determining the best partition according to modularity is an NP-hard problem [
22], methods aiming at Modularity Maximization (MM) apply heuristics to achieve communities, each yielding individually high modularity score and, thus, cumulatively, a high modularity value, in a reasonable amount of time.
At the same time, computing network metrics in large graphs, such as the length of shortest paths between node pairs or the EBC values needed in GN, is rather costly. By embedding the network in a low dimensional space via assigning each node coordinates can aid in accomplishing the computations more efficiently. The hyperbolic space is known to be a suitable choice when it comes to large graphs that represent various complex/social networks. This is because such graphs have been conjectured to have an underlying hyperbolic geometry [
23]. There are several approaches for hyperbolic network embedding in the literature [
24], such as Rigel [
25], greedy [
24] and Hypermap [
26]. In this paper, we rely on Rigel embedding. The latter maps the network graph in hyperbolic space via multi-dimensional scaling. Rigel assumes the hyperboloid model of the
n-dimensional hyperbolic space [
25]. In this model of hyperbolic geometry, the distance between two points with coordinates
,
, is given by:
In the above distance formula,
is the Euclidean norm and
the inner product. The solutions (
) of Equation (
1) are denoted as hyperbolic distances in the hyperboloid model.
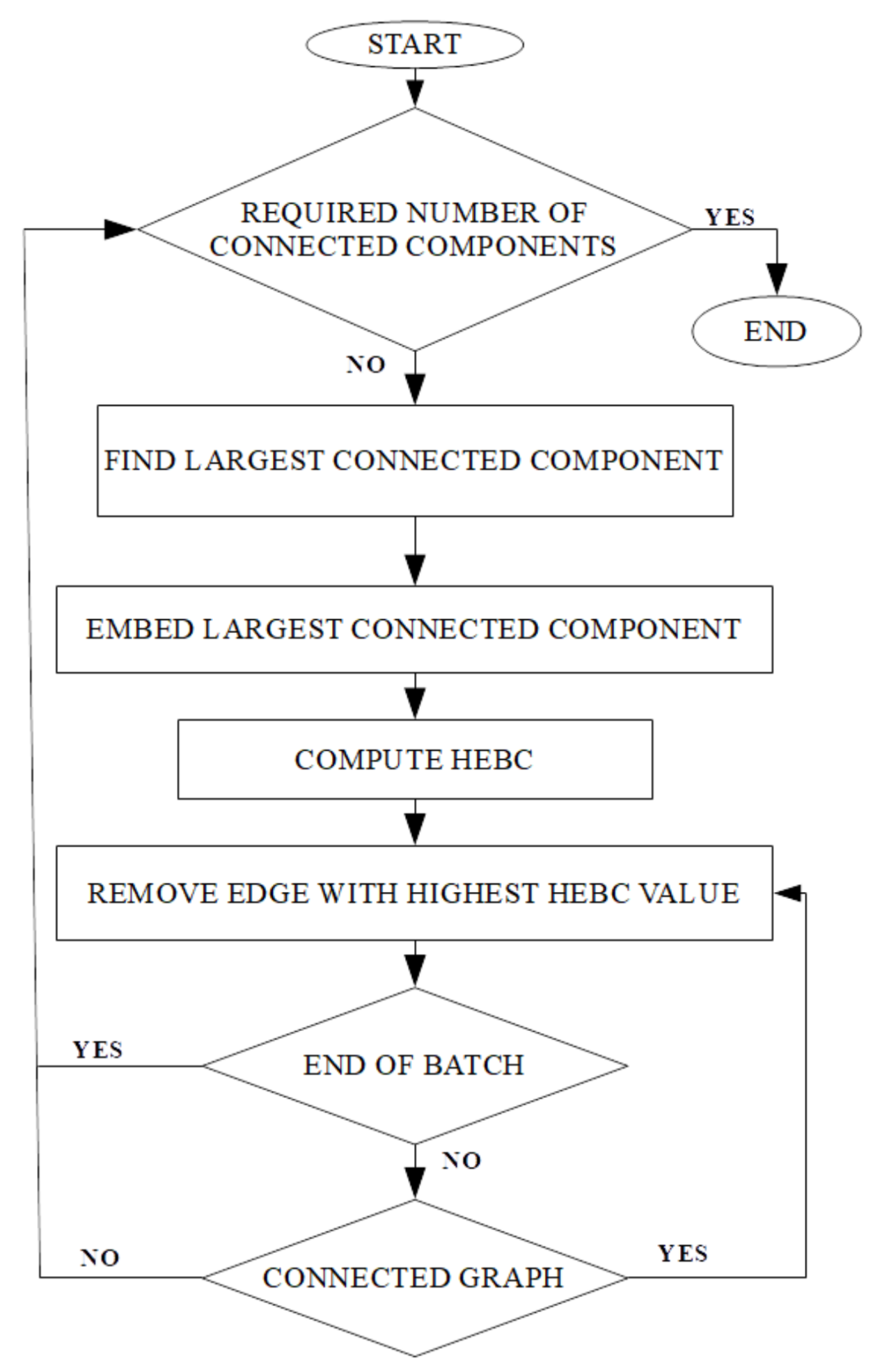
In brief, Rigel operates as follows. Assume a network with
N nodes. Rigel defines a special subset of
nodes, termed landmarks, which are used as reference points. The bootstrapping step computes the proper hyperbolic coordinates of each landmark as solutions of a global optimization problem, in which the distances for all pairs of landmarks in the hyperboloid match as closely as possible their corresponding distances in the original graph measured in hops. The hyperbolic coordinates of the rest of the nodes are computed according to the coordinates of the landmarks, hence their name, so that each node’s hyperbolic distances to all landmarks are as close as possible to their corresponding hop distances in the original graph. The selection of landmarks is key, and several strategies for appropriate selection of landmark nodes are provided in [
27]. Furthermore, the accuracy of Rigel increases as the dimension of hyperbolic space increases. The number of landmarks should be equal to, or even higher than the dimension of the embedding space [
25]. Consequently, avoiding the computation of shortest paths for all possible node pairs and leveraging on Rigel’s properties reduce the time complexity to simple algebraic calculations of distance. This allows for faster computation of HEBC, yielding faster community detection.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}