1. Introduction
Compared with information provided by a single sensor image, multi-sensor images can supply additional information with feature complementarity for complex and complete scene representations and improved visual understanding. By integrating useful information from different sensor images, we can generate a single composite image, which is informative and suitable for follow-up processing and decision-making. In particular, infrared and visible image fusion is an indispensable branch that plays an important role in military and civilian applications [
1] and has been used to enhance the performance in terms of human visual perception, object detection, and target recognition [
2,
3,
4,
5,
6,
7,
8].
Visible sensors can capture reflected light to provide background details, such as vegetation, texture, area, and soil with high spatial resolution because they operate in the same waveband that can be recognized by human vision [
9]. However, under unsatisfactory light conditions, scene information is lost. By contrast, infrared sensors map thermal radiation emitted from objects to gray images; therefore, these sensors exhibit unique advantages in overcoming adverse light conditions and highlighting thermal targets, such as pedestrians and vehicles. Nevertheless, due to limitations of hardware and environments, infrared images are often accompanied by blurred details, serious noise, and considerably low resolution. These limitations encourage the fusion of infrared and visible images to produce a single image, which can simultaneously highlight thermal radiation for target detection and reserve texture information for characterization of appearance.
According to different representations and applications, the fusion process can be conducted at the following three levels [
10]: pixel, feature, and symbol levels. Pixel-level fusion is on the lowest level and fuses different physical parameters. Feature-level fusion involves feature descriptor, probability variables, and object labels. Symbol-level fusion uses high abstraction of information, such as representative symbols or decisions, for fusion. The focus of this paper is on pixel level. From another perspective, existing infrared and visible image fusion methods are divided into eight categories according to their corresponding theories [
1], including multi-scale transform-based methods [
11,
12], sparse representation-based methods [
13,
14], neural network-based methods [
15,
16], subspace-based methods [
17,
18], saliency-based methods [
19,
20], hybrid methods [
21,
22], deep learning-based methods [
23,
24], and other fusion methods [
10,
25].
Despite the notable progress of image fusion, fusing infrared and visible images of different resolutions remains a challenging task. Infrared images constantly suffer from considerably lower resolution compared with visible images. Under this condition, if existing methods are applied to fusing source images, then eliminating resolution differences, through downsampling visible images or upsampling infrared images as an example, is the first problem to solve. As shown in
Figure 1, to intuitively illustrate the fusion process, we take a typical image pair and a typical fusion method, such as hybrid multi-scale decomposition (HMSD) [
26], as an example. In procedure (a), the visible image is downsampled before using as a source image for fusion, and the fused image is upsampled considering consistency and comparability. Although the fused image can be forcibly converted into high resolution, the discarded high-quality texture information in the visible image caused by downsampling operation by image processing cannot be retrieved from the viewpoint of information theory; hence, the clarity of the fused image is not improved. In procedure (c), the original infrared image is upsampled to high resolution before fusion. As shown in the figure, upsampling results in blur and inaccuracy in the infrared image, which is also fused into the resulting image; hence, the fused image in procedure (c) is accompanied by serious noise. In addition, the principle of existing fusion rules typically focuses on preserving texture details in source images. This condition may be problematic in the fusion of infrared and visible images because infrared thermal radiation information is characterized by pixel intensities and usually contains few texture details that may fail to be fused in the resulting image. However, such information is often crucial to highlight the targets. This can be shown in procedures (a) and (c), in which the fused image loses the property of high contrast similar to that in the infrared image, submerging the target in the clutter background.
To address the above-mentioned challenges, in this paper, we propose a new algorithm termed as Different Resolution Total Variation (DRTV) for infrared and visible image fusion. In particular, we formulate the fusion problem as a convex optimization problem characterized by total variation model and seek the optimal fused image that minimizes an energy function. This formulation accepts different resolutions of infrared and visible images. The energy consists of a data fidelity term and a regularization term. The data fidelity term constrains that the downsampled fused image should present similar pixel intensities with the original infrared image. The regularization term ensures that the gradient distribution in the visible image can be transferred into the fused image. The two terms can guarantee that our fusion result contains the thermal radiation information from the infrared image and the texture details from the visible image. To optimize the solution procedure, we apply the fast iterative shrinkage-thresholding algorithm (FISTA) [
27] framework to accelerate convergence, e.g., the convergence speed is increased to
with
k being the iteration number. Owing to the preceding causes, the cost for acquiring high-quality infrared and visible fused images can be considerably reduced, thereby providing substantial benefit to military equipment and civilian industries relying on infrared and visible image fusion. For intuitive comparison,
Figure 1b shows the fused result of DRTV on the same source image pair, where we zoom in a small region in the red box for clear comparison.
Figure 1 shows that the fused image generated by our DRTV, i.e.,
Figure 1b, is clearer with less noise compared with
Figure 1a,c due to the forced resolution conversion. In addition, our fusion result looks like a super-resolved infrared image, which preserves the property of high contrast in the infrared image, clearly highlighting the target.
The contributions of this paper include the following two aspects. On the one hand, the proposed DRTV makes a breakthrough in fusing visible and infrared images of different resolutions, which can considerably prevent loss of texture information caused by compression or blur and inaccuracy due to forced upsampling, without expenses on upgrading hardware devices. On the other hand, the fused images obtained by DRTV visually benefit from rich texture information; simultaneously, the thermal targets are easily detected. By changing the regularization parameter in our model, we can subjectively adjust the visual similarity between the fused image and visible/infrared image.
The remainder of this paper is organized as follows.
Section 2 describes the problem statement and formulation for infrared and visible image fusion.
Section 3 provides the optimization strategy of our algorithm. In
Section 4, we compare DRTV with several state-of-the-art methods on publicly available datasets and analyze the results. Conclusions and future works are presented in
Section 5.
2. Problem Statement and Formulation
We denote the visible image of size and the infrared image of size , where c is a constant denoting the ratio between the infrared image resolution and the resolution of the visible image. denotes the fused image. Note that the size of is rather than .
Our goal for the given and is to fuse them to generate a high-resolution fused image, which should virtually retain important information in source images, e.g., thermal radiation information in the infrared image, and texture features in the visible image.
2.1. Data Fidelity Term
Previous methods generally apply a restriction on source images, in which visible and infrared images should share the same resolution. When this restriction is not satisfied, downsampling the visible image is one solution, but the information translated into the fused image also is similarly limited. Employing the upsampled infrared image as the prior knowledge to maintain thermal radiation information is another solution. However, thermal information after upsampling is constantly blurred and inaccurate. If we constrain fused information to follow the blurred source, then the fused result is even less accurate. Therefore, we assume in this study that the fused image after downsampling possesses similar pixel intensities to the original infrared image. Least squares fitting is used to model this relationship:
where
denotes the Frobenius norm of matrix, which is defined as
.
denotes the downsampling operator of the nearest interpolation. If the high-resolution image is defined as
and the downsampled image is
, then the operator
can be denoted as
, where
represents rounding the data to the nearest integer.
is a data fidelity term. According to the preceding constraint, the thermal target remains prominent in the fused image.
2.2. Regularization Term
The regularization term is essentially the prior knowledge used to avoid overfitting of least squares. One requirement is to allow thermal targets in the fused image to remain noticeable. Additional detailed appearance information in the visible image is expected to be preserved in the fused result. The direct approach is to constrain similar pixel intensity distribution in the fused and visible image. However, the same constraint is applied in , and pixel intensity distributions of infrared and visible images considerably vary due to their different manifestations. Therefore, this approach is contradictory, and we attempt to search another feature to characterize appearance information in the visible image.
According to the human visual perception system, image edges and textures are abundant when the spatial frequency is large. Moreover, the spatial frequency is a metric based on gradient distribution. Understanding that the detailed appearance information is basically represented by gradient distribution of the image is easy. On the basis of this observation, we require that the fused image should present similar gradients with the visible image, which is represented by the
norm (
):
where ∇ is the gradient operator and
should be as small as possible.
By using
to represent the image gradient at pixel (
) and
to denote the pixel of the
i-th row and
j-th column in the image, we obtain the following:
If i is the last row of the image, then we set . Similarly, if j is the last column, then we set .
We now consider the
norm in
. Given that the image intensities are often piece-wise smooth across the image domain, their gradients tend to be sparse, and the non-zero elements usually correspond to the boundaries [
28,
29]. For constraining the fused image to exhibit similar pixel gradient distribution with the visible image, the differences of gradients between the images should be as sparse as possible; that is, the number of non-zero entries of gradient difference should be as small as possible. This condition is theoretically equivalent to minimizing the
norm of gradient difference, i.e.,
. However, we must traverse all cases to obtain the
norm of a matrix; hence, obtaining the
norm is non-deterministic polynomial-time hard (NP-hard). Fortunately, for vectors, the
norm is the optimal convex approximation of the
norm and can be easily solved. The restricted isometry condition [
30] also theoretically guarantees the exact recovery of sparse solution by
norm. For a vector
, the
norm is defined as
. Specifically, if the energy function is the
norm of the gradient, it is a total variation model [
10,
31]. If
is calculated by a norm of vectors, we can directly set the
norm as
norm. However, in Equation (
2),
is the norm of the matrix. For the matrix
, if the optimal convex approximation of vectors above is to be applied, the norm of the matrix should be equal to the sum of absolute values of all elements. Note that
is a norm on the gradient and the discrete isotropic TV-norm [
32], i.e.,
is defined by the sum of gradients of all elements, which is defined as:
where
is a matrix of size
. It motivates us to convert the minimization of the
norm to that of the TV-norm.
In addition, another important advantage of the regularization based on
is its insensitivity to outliers, which always correspond to sharp edges in image processing. Therefore, we use
to define
as follows:
2.3. Formulation of the Fusion Problem
Taking comprehensive consideration of
and
, positive regularization parameter
is introduced herein to control the trade-off between the data fidelity term and the regularization term. Then, the fusion problem can be expressed as follows:
which is equivalent to:
Thus far, the fusion problem is converted to solve the fused image
in Equation (
8), which minimizes the energy function
.
3. Optimization
The optimization problem (
8) is clearly a convex optimization problem; therefore, a global optimal solution that minimizes
exists. In our model, the data fidelity term is smooth, while the regularization term is non-smooth; thus, we can conclude that problem (
8) is in the form of:
where
f is a smooth convex function, of which the gradient is Lipschitz continuous, and
g is a continuous, but possibly non-smooth, convex function. Specifically,
The iterative shrinkage-thresholding algorithm (ISTA) [
33] can be used to resolve the preceding problem. Although ISTA can solve general convex optimization problems, its convergence rate is proven to be only
with
k being the iteration number. For optimizing the slow convergence of ISTA,
Beck and
Teboulle proposed FISTA [
27]. Its convergence rate can be improved to
. The iterative step in FISTA can be rewritten as follows:
We denote
as the inverse operation of
and set
, where
L is a Lipschitz constant of
, which can be set as 1 herein. By approximating
with
in the FISTA framework, the formula (
11) then can be rewritten as:
According to the standard FISTA framework, we can optimize Equation (
8) by using Algorithm 1. From the iteration process, each iterate of FISTA depends on the previous two iterates and not only on the last iterate as in ISTA. Therefore, FISTA can achieve a fast convergence rate.
| Algorithm 1: FISTA framework for DRTV. |
- Input:
, , , , - Output:
- 1:
fortoMaxiterationdo; - 2:
; - 3:
; solved by Algorithm 2; - 4:
; - 5:
; - 6:
end for; - 7:
is obtained as in the last iteration.
|
To solve the optimization problem in Line 3 in Algorithm 1, we set
. Then, we obtain the following minimization problem:
The minimization problem in Equation (
13) is the problem of total variation (TV) minimization [
31], and
can be updated by
. The first term reflects that
should be similar to
in terms of content. The second term, i.e., the TV term, is a constraint on the piece-wise smoothness of
. The smooth constraint has been proven to allow the existence of step edges; hence, the boundary is not blurred when minimizing the energy function [
34].
We follow the standard procedure [
32,
35] for solving the TV minimization problem in Equation (
13) and summarize the entire procedure in Algorithm 2. The convergence rate is also considerably superior to other methods based on gradient projection. Refer to [
32] for the detailed derivation. For ease of understanding, we use the same symbol notations as those in [
36]. The linear operator is defined as:
. The corresponding inverse operator is presented as follows:
, where
,
.
is a projection operator to ensure
,
, and
.
| Algorithm 2: TV minimization. |
- Input:
, , , , , - Output:
- 1:
fortoMaxiterationdo; - 2:
; - 3:
; - 4:
; - 5:
end for; - 6:
; - 7:
.
|
4. Experimental Results
In this section, we conduct experiments on publicly available datasets in comparison with several state-of-the-art methods to verify the effectiveness of our DRTV. We first introduce the testing data and compare methods and evaluation metrics. Then, we report the experimental results, followed by parameter analysis and computational cost comparison. All experiments are performed on a laptop with 1.9 GHz Intel Core i3 4030 CPU, 8 GB RAM, and Matlab code.
4.1. Dataset
The publicly available image dataset TNO Human Factors, which contains multispectral night images of different military scenarios, is used for performance evaluation. We select 20 infrared/visible images with different types of scenes for testing: airplane_in_trees, helicopter, nato_camp_sequence, Farm, house_with_3_men, Kaptein_01, Kaptein_1123, Marne_02, Marne_03, Marne_11, Movie_01, Duine_7408, heather, house, Kaptein_1654, man_in_doorway, Movie_12, Movie_18, Movie_24, and Reek.
Notably, visible and infrared images in the dataset are of the same resolution. As in real-world applications, the infrared images often present considerably low resolution. Here, we downsample the infrared images in our testing data for the experimental conditions to approximate the real-world situation. Therefore, all infrared source images present a low resolution (e.g., ratio
c described in
Section 2 is fixed to 2). We do not need image registration [
37,
38,
39,
40,
41,
42] before fusion because the source image pairs are all aligned.
We compare our DRTV with six state-of-the-art fusion methods, including pyramid transform-based methods such as Laplacian pyramid (LP) [
43] and ratio of low-pass pyramid (RP) [
44], multi-scale transform-based method such as HMSD [
26]), edge-preserving decomposition-based method such as cross-bilateral filter (CBF) [
45], subspace-based method such as directional discrete cosine transform and principal component analysis (DDCTPCA) [
46], and total variation-based method such as gradient transfer fusion (GTF) [
10]. Parameters in these methods are set by default as suggested in the original papers.
4.2. Evaluation Metrics
In numerous cases, the visual differences between fused results are insufficiently significant; therefore, fusion methods should be evaluated comprehensively from different perspectives. At present, evaluations are mainly divided into two directions: subjective evaluation and objective evaluation.
Subjective evaluation relies on human eyes and concentrates on the perception of details, contrast, sharpness, and target highlighting. While the quality of image is also affected by other factors, our eyes are insensitive to such factors. Numerous types of objective evaluation, which are mainly based on information theory, structural similarity, image gradients, and statistics, are available. Objective evaluation is consistent with human visual perception system and subject to experimental conditions.
The first two metrics, i.e., standard deviation (
) [
47] and entropy (
) [
48], are only dependent on the fused image. The three remaining metrics, i.e. mutual information (
) [
49], structural similarity index measure (
) [
50] and Peak signal-to-noise ratio (
) [
51], are determined by the fused and source images. In this paper, if the resolution of the fused image
is higher than that of the source image
(either the infrared image
or the visible image
), then we must downsample the fused image first and then calculate the metrics.
- (1)
is a statistical concept reflecting distribution and contrast.
is mathematically defined as follows:
where
is the mean value of
. Areas with high contrast are more likely to attract attention. Therefore, a large
means that the fused image is improved.
- (2)
The
of the fused image can measure the amount of information contained in it and is mathematically defined as:
where
L is the number of gray levels and
is the normalized histogram of the corresponding gray level. When the
is large, additional information is contained in the fused image, and the performance of the fusion method is improved. However,
is conventionally used as an auxiliary metric because it may be influenced by noise.
- (3)
is used to measure the amount of information transmitted from the source image to the fused image.
is defined as follows:
where
and
respectively represent the amount of information transmitted from the infrared image and the visible image to the fused image.
between two random variables can be calculated by the Kullback–Leibler metric:
where
and
respectively represent the edge histograms of
and
.
is the joint histogram of
and
. A large
metric means that considerable information is transferred from source images to the fused image, thereby indicating good fusion performance.
- (4)
To model image loss and distribution,
was proposed by Wang et al. [
52] as a universal image quality index based on structural similarity. The formula of the index is as follows:
In the formula above, to measure the structural similarity between source image
and fused image
,
is calculated and it mainly consists of three components: similarities of light, contrast and structure information, denoted as
,
and
, respectively. The image patches of source image
and fused image
in a sliding window are respectively denoted by
a and
x. The specific definitions of the three components are as follows:
where
and
indicate the mean values of image patches
a and
x, respectively, reflecting brightness information;
and
represent
, reflecting contrast information;
denotes the covariance of source and fused images, reflecting the similarity of structure information;
,
, and
are positive parameters used to avoid unstable phenomenon. Specifically, when
, the index is equivalent to the universal image quality index [
53]. Thus, for all source and fused images, the index measure
is defined as follows:
where
and
indicate structural similarities between visible/infrared and fused images, respectively.
- (5)
is used to reflect the distortion by the fusion operation and is defined by the ratio of peak value power and noise power in the generated fused image:
where
r denotes the peak value of the fused image and
denotes the the mean square error between the fused image and source images. The larger the
, the less distortion the fusion method produces.
4.3. Results and Analysis
To maintain a considerable amount of information in source images, we select the strategy of upsampling infrared images rather than downsampling visible images for the comparison methods before fusion, that is, e.g., the procedure (c) in
Figure 1. Our DRTV involves only one parameter
, which we set to 50 as its default value.
We first conducted several qualitative comparisons of different methods on four typical image pairs, including
airplane_in_trees,
Kaptein_01,
nato_camp_sequence, and
sandpath, as shown in
Figure 2. Compared with other six fusion methods, DRTV considerably improves the resolution of the fused images and does not suffer from strong noise caused by upsampling infrared images before fusion. Although the resolution of infrared images is only half of that of visible images, DRTV allows preservation of additional detailed texture information, which benefits from the downsampling operator in
and the
norm of gradient differences in
, in visible images. Furthermore, the fused results generated by our DRTV are similar to high-resolution infrared images with detailed scene representations, which are beneficial for detecting and recognizing potential targets.
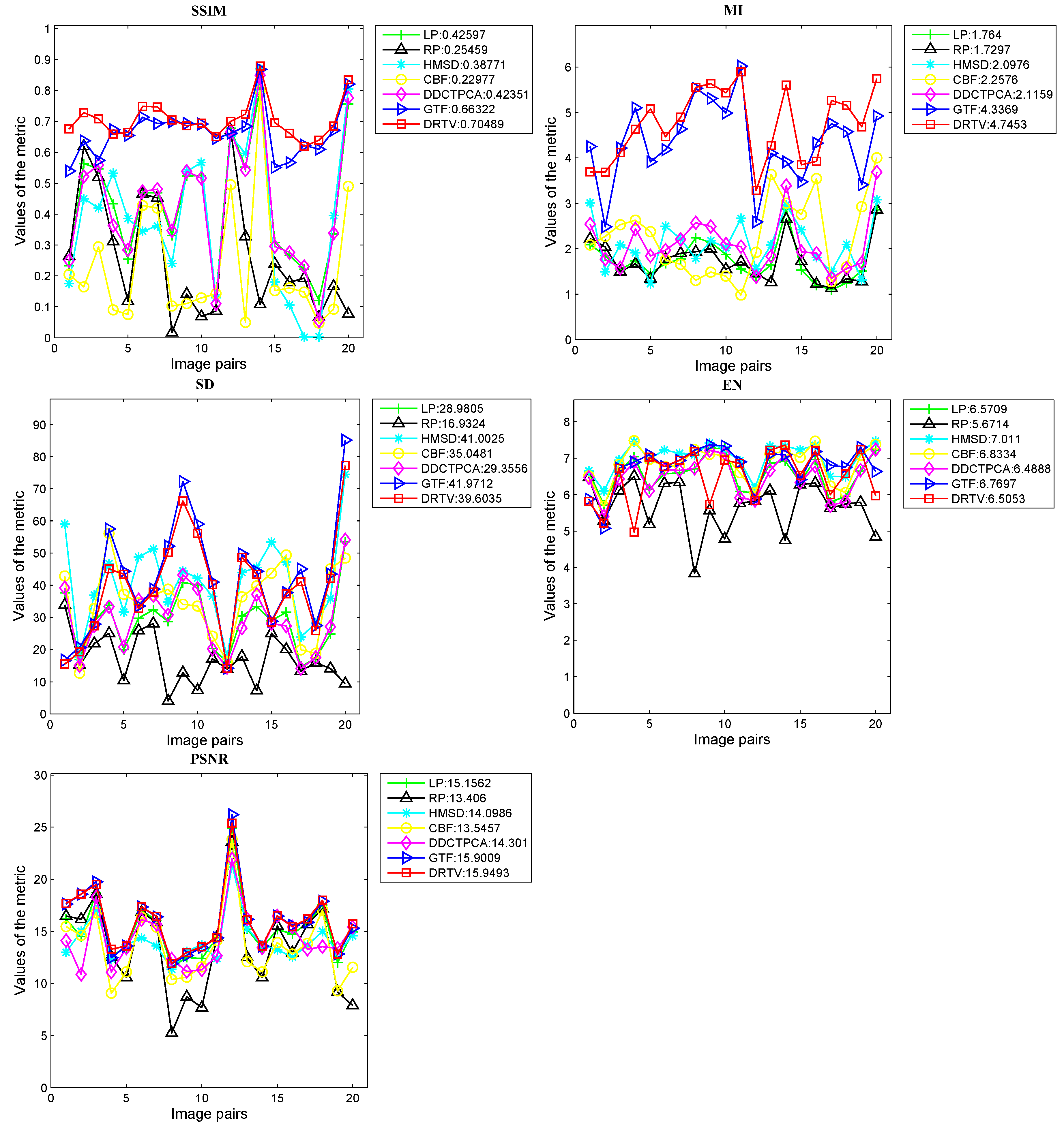
Next, we provide quantitative comparisons on the total dataset with the following five metrics described in the last section:
,
,
,
and
. The results are shown in
Figure 3. For the metrics
,
and
, our DRTV can generate the largest average values and exhibits the best performance on 17, 15 and 9 image pairs, respectively. For the metric
, DRTV can produce comparable results. Meanwhile, our method for the metric
does not achieve the best results, which can be explained as follows. Entropy is defined as a measure of uncertainty. When the probability of each gray value is evenly distributed, the uncertainty and the entropy are both large. For our DRTV, we constrain the fused image and the infrared image to present similar intensity distribution to facilitate discrimination of the thermal target by human eyes. Therefore, our fusion result maintained the intensity distribution of the original infrared image, where the gray value is unevenly distributed as that in the visible image, leading to a small
value.
4.4. Parameter Analysis
Only one parameter is presented in our proposed method, i.e., the regularized parameter
, which controls the trade-off between
and
. When
is small, the fused image preserves additional thermal radiation information in the infrared image, allowing the visual effect to be highly similar to the infrared image. Conversely, when
is sufficiently large, the texture information in the visible image remains in the fused image to a large extent; hence, the fused image is similar to the visible image. When
, the fused image is the original visible image. To analyze the influence of parameter
on fusion performance in detail, we test different values of
on two image pairs, including
nato_camp_sequence and
lake. We gradually increase the value of
and observe the changes of the fused images.
Figure 4 and
Figure 5 show the changes of the fused images of the two image pairs when
is fixed to 1, 10, 50, 100, 200, and 500.
As
changes from 1 to 500, the fence and hill around the house in
Figure 4 gradually appear. In addition, the outline of the chimney in the bottom left corner becomes gradually clear. For the results in
Figure 5, the most evident change is that the texture of vegetation on the river is clearly delineated, and the chair is gradually separated from the road. Thus, we can conclude that texture features in the fused image gradually become clear as the value of
increases.
By contrast, we can observe that, in
Figure 5, when
is smaller than 200, the pedestrian in
nato_camp_sequence is legible, and the gray distribution of the house in the bottom left corner is similar to that in the infrared image. Meanwhile, when
is set as 500, the pedestrian’s thermal radiation information is completely lost in the fused image and the house is similar to that in the visible image. In
Figure 5, the word “AUTO” in the upper right corner gradually disappears in the fused image as
changes from 1 to 500. Therefore, we conclude that, as
increases, thermal radiation information becomes gradually lost in the fused image. This finding is also the flexibility and advantage offered by our method. By adjusting the value of parameter
, users can conveniently control the similarity of the fused image to the infrared image or the visible image.
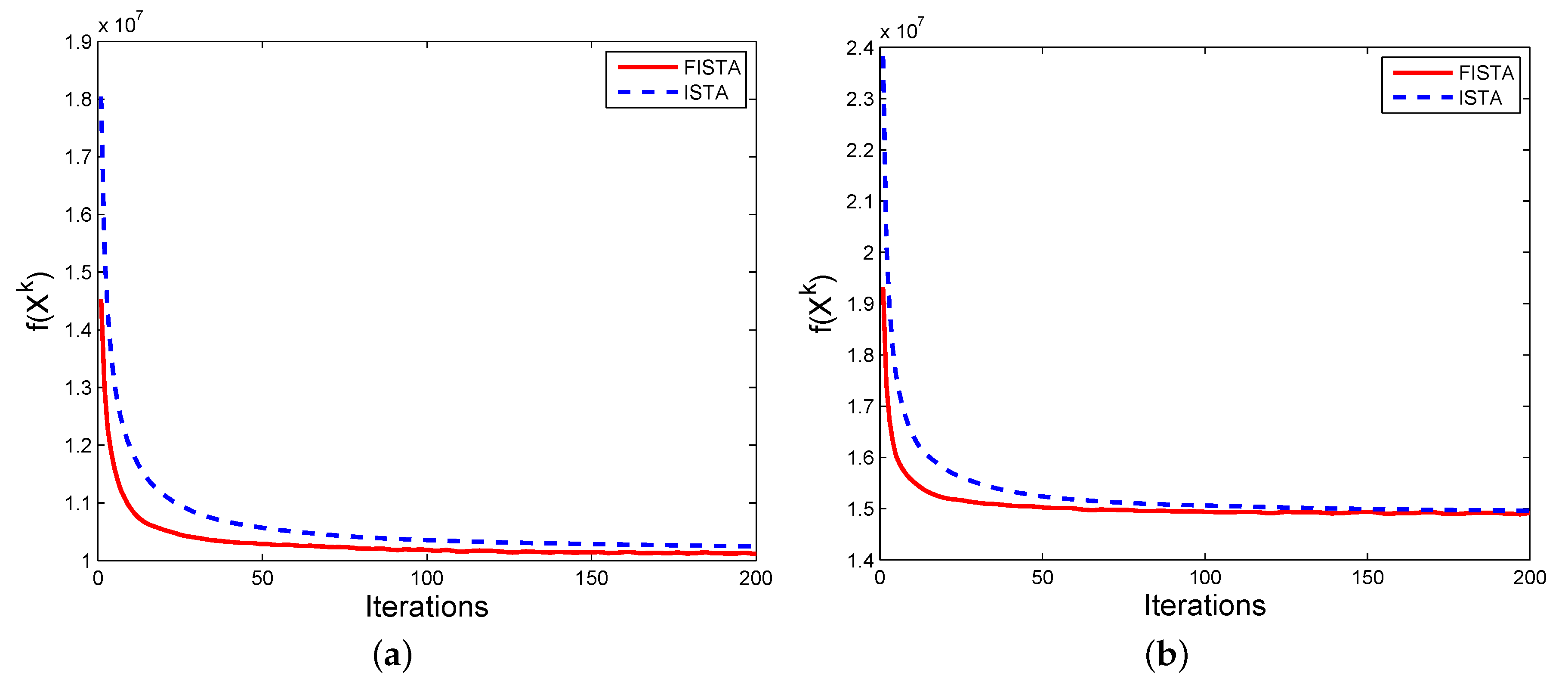
4.5. Computational Cost Comparison
Given that the FISTA framework is introduced in our model to accelerate the convergence rate, to evaluate it, we compare the model solved by FISTA framework and that solved by the previous variational model, ISTA. The convergence rate is observed through the value of
. The objective function
is denoted by
in Equation (
8) and
denotes the fused image obtained by the
k-th iteration.
Figure 6 demonstrates the convergence rate comparison corresponding to two image pairs in
Figure 2, e.g.,
airplane and
Kaptein_01, as an example. Inheriting the advantage of the FISTA framework, our method typically converges only after 20 to 50 iterations while the method based on ISTA often converges in 70 to 90 iterations. Additional iterations will increase the computational cost without substantial performance gain. To stop the iteration automatically by the value of
, we apply the residual ratio of
to stop the iteration process. The residual ratio (
) is defined as:
During the iteration process, the iteration is stopped when the value of is less than a predefined threshold and in our method, and the threshold is set as empirically.
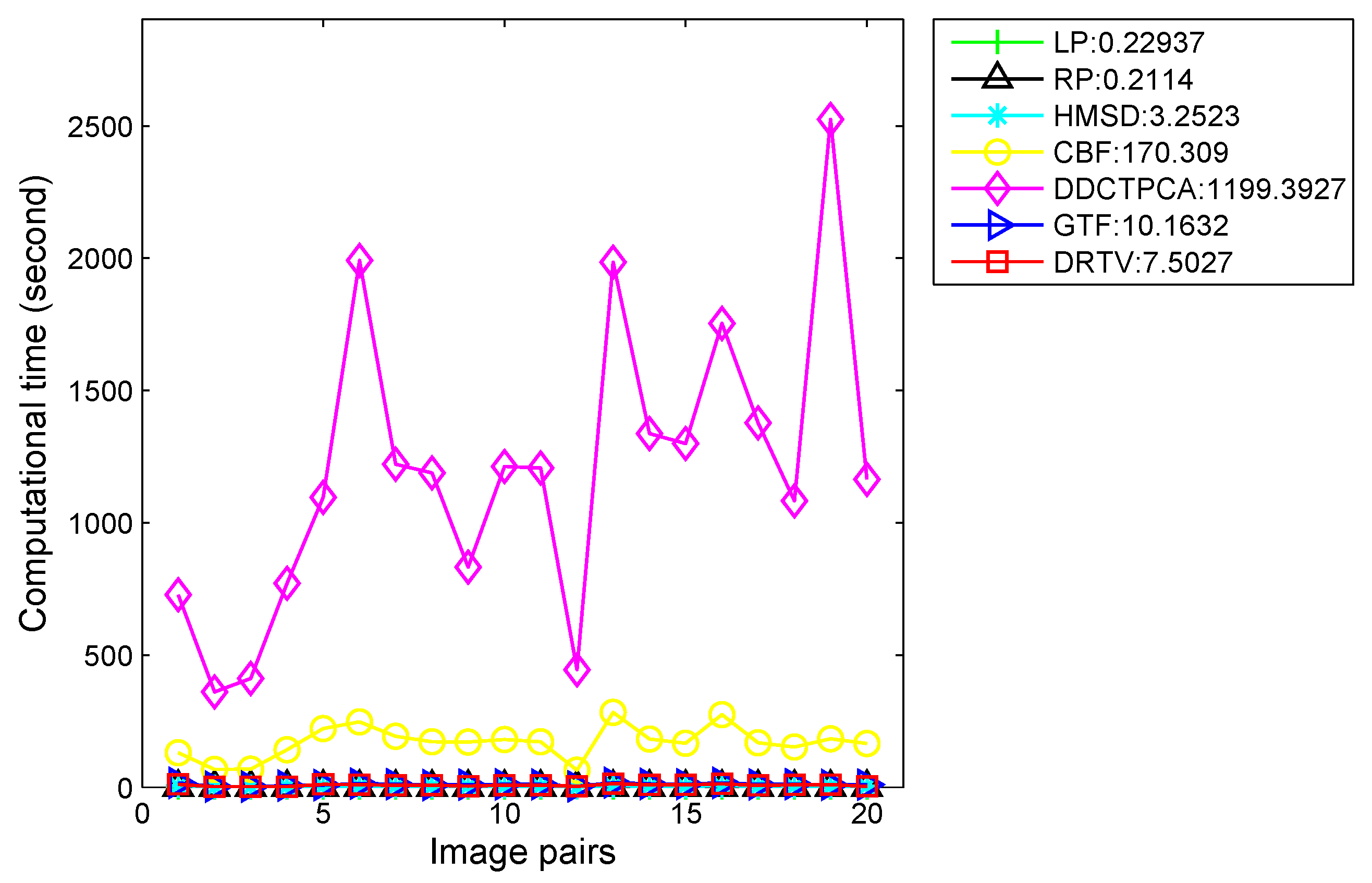
To evaluate the efficiency of our proposed method, we compare our method with six other methods in terms of runtime. The computational costs of seven methods on 20 image pairs are shown in
Figure 7, and the average runtime of seven algorithms are reported in the legend. In DDCTPCA, the source images are divided into many non-overlapping square blocks and there are eight directional modes to be performed on each block. All the coefficients in eight modes are used for fusion. Thus, the process of obtaining and fusing the coefficients for all the blocks takes up most of the runtime. Therefore, the runtime has a lot to do with the number of blocks, i.e., the size of source images. This is the reason why the runtime of DDCTPCA is oscillating, while, in our method, we formulate the problem as a convex optimization problem characterized by total variation model and sizes of source images have less effects on computational cost. This finding demonstrates that our method can achieve comparable efficiency.
5. Conclusions and Future Work
In this paper, we proposed a method for fusing infrared and visible images of different resolutions called DRTV. The fusion process is similar to conducting infrared image super-resolution, which simultaneously integrates the texture detail information in the visible image. The quantitative comparisons on several metrics with six state-of-the-art fusion methods demonstrate that our method can not only keep more detailed information in the source images, but also considerably reduce noise in the results caused by upsampling infrared images before fusion which typically occurs in existing methods. The fused image can also retain the thermal radiation information to a large extent, thereby benefiting fusion-based target detection and recognition systems.
In our objective function, we have used the first-order TV to preserve the texture detail information in the visible image. The first-order TV performs well in preserving edges of object in the piecewise constant image compared with other total variational models. However, it will produce staircase effects. For the purpose of eliminating the staircase effect in the first-order TV model, high-order models have been proposed by modifying the TV regularizer in the first order variational model to other regularizers and have shown promising performance, e.g., the TGV regularizer in [
54], the bounded Hessian regularizer together with an edge diffusivity function in [
55], Laplacian regularizer and regularizers combining the aforementioned regularizers with the TV regularizer [
56]. Thus, it deserves attention to modify our model with high-order variational models to remove staircase effects in the follow-up work.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






