Activity Recognition Invariant to Sensor Orientation with Wearable Motion Sensors


Abstract
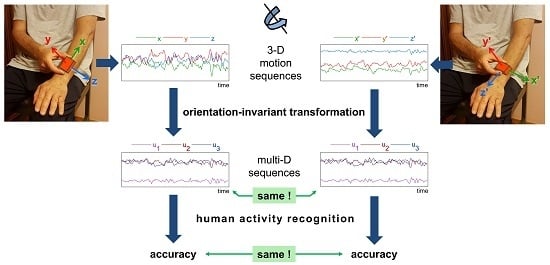
1. Introduction
2. Related Work
3. Invariance to Sensor Orientation
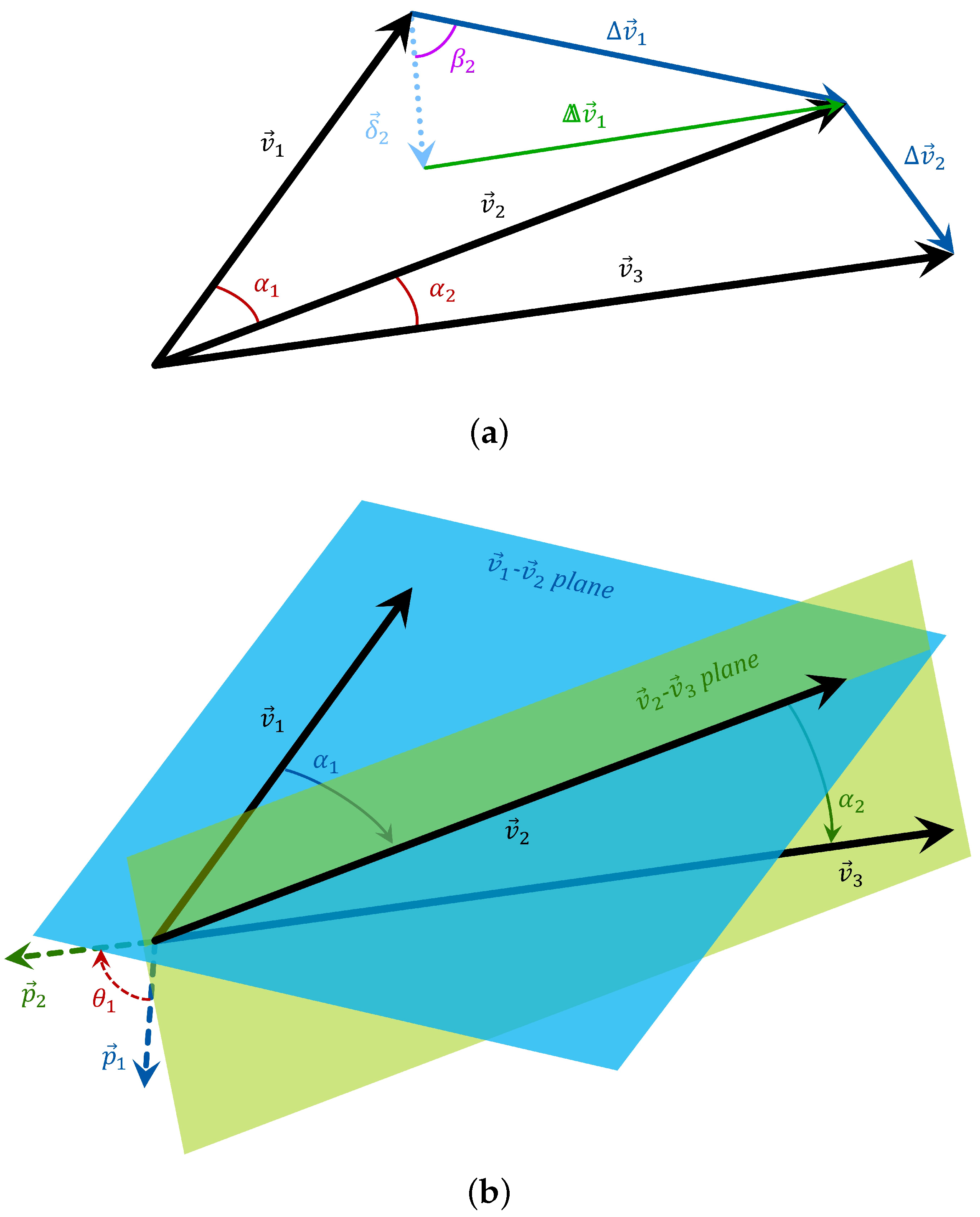
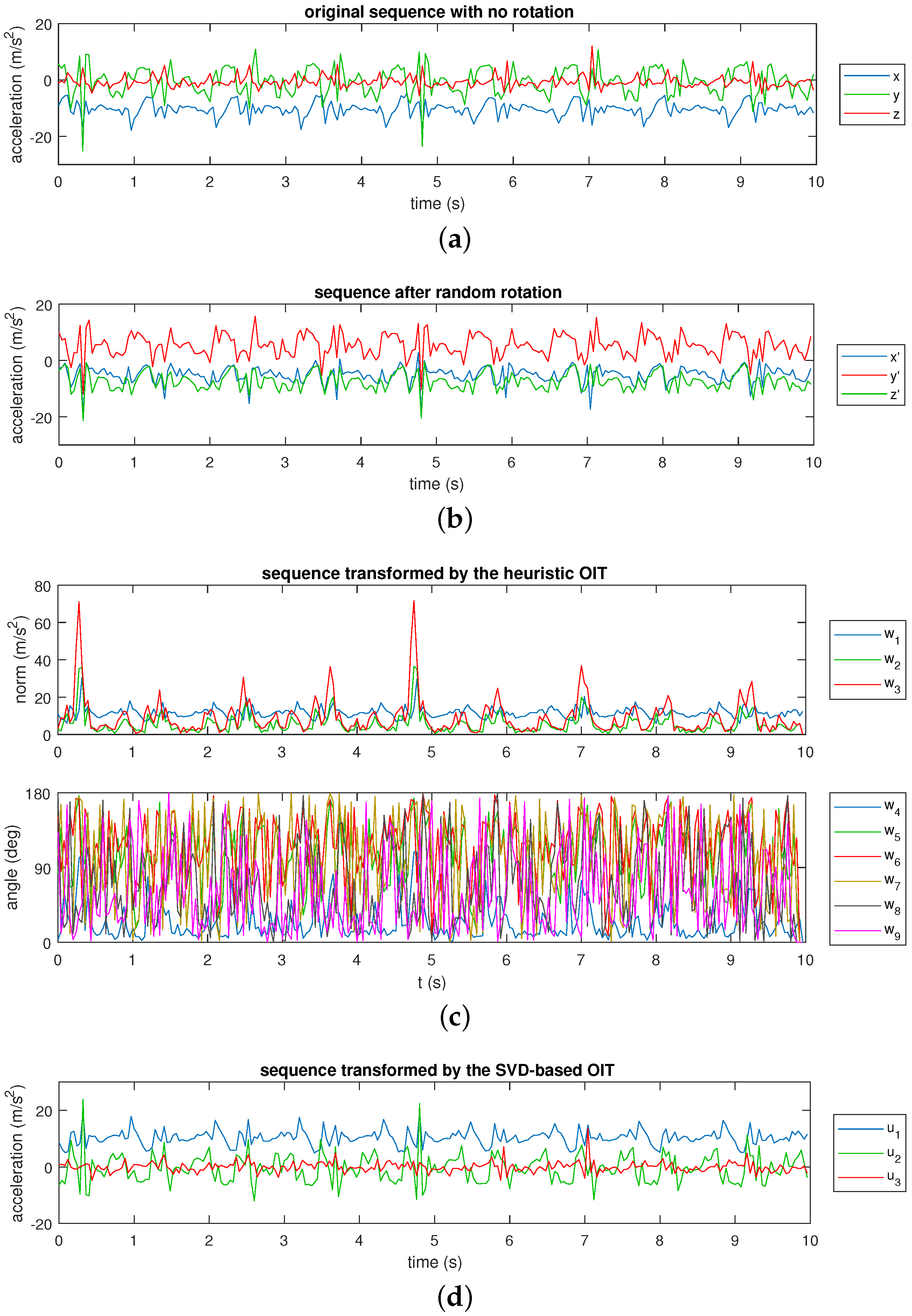
3.1. Heuristic Orientation-Invariant Transformation
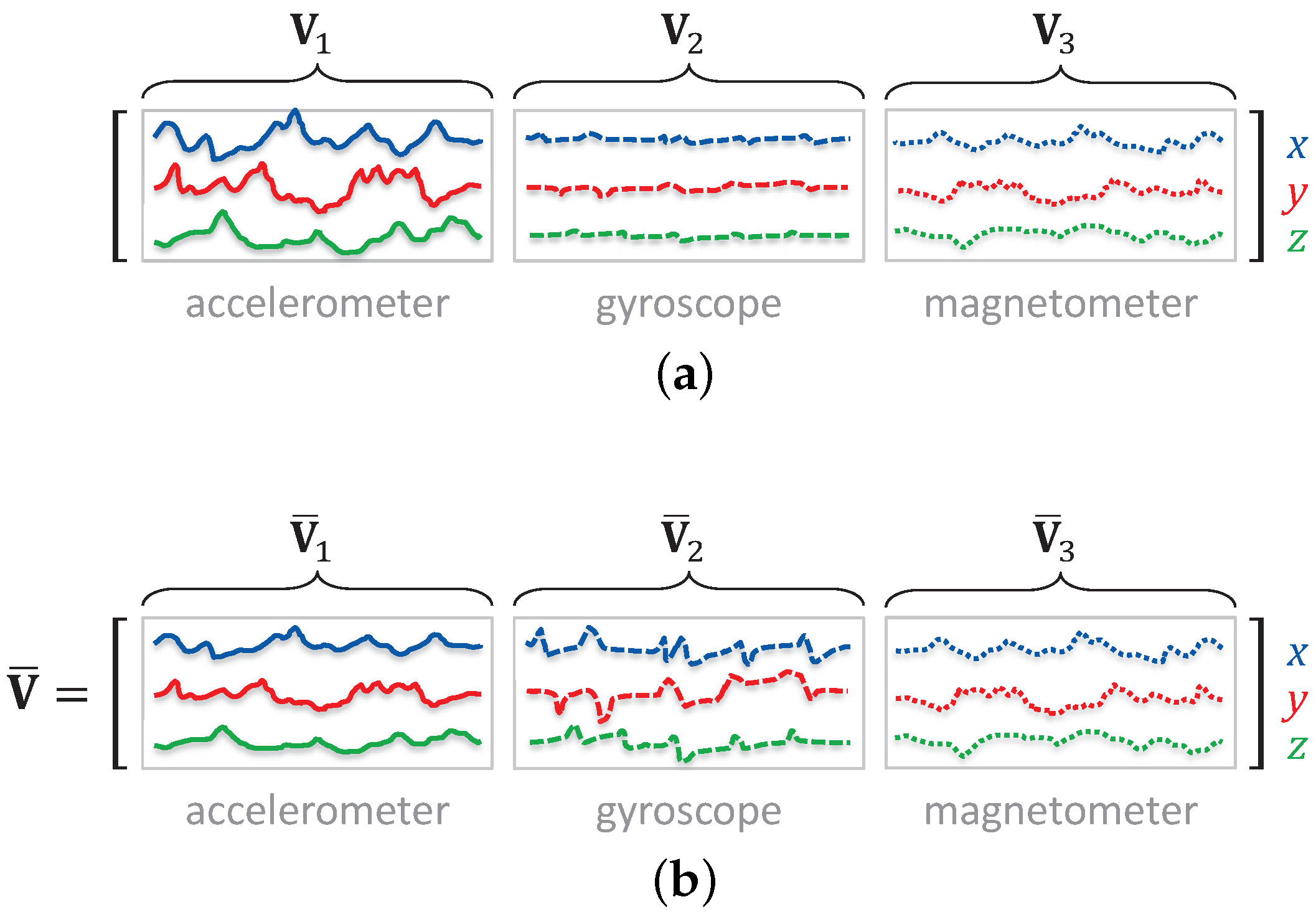
3.2. Orientation-Invariant Transformation Based on Singular Value Decomposition
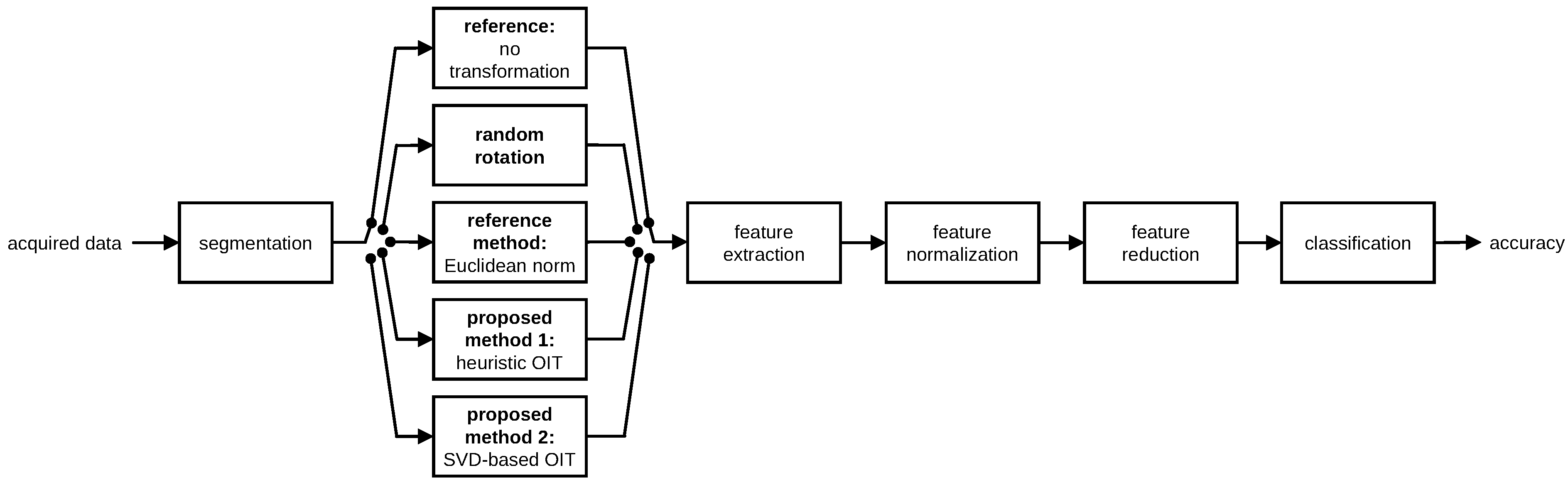
4. Experimental Methodology and Results
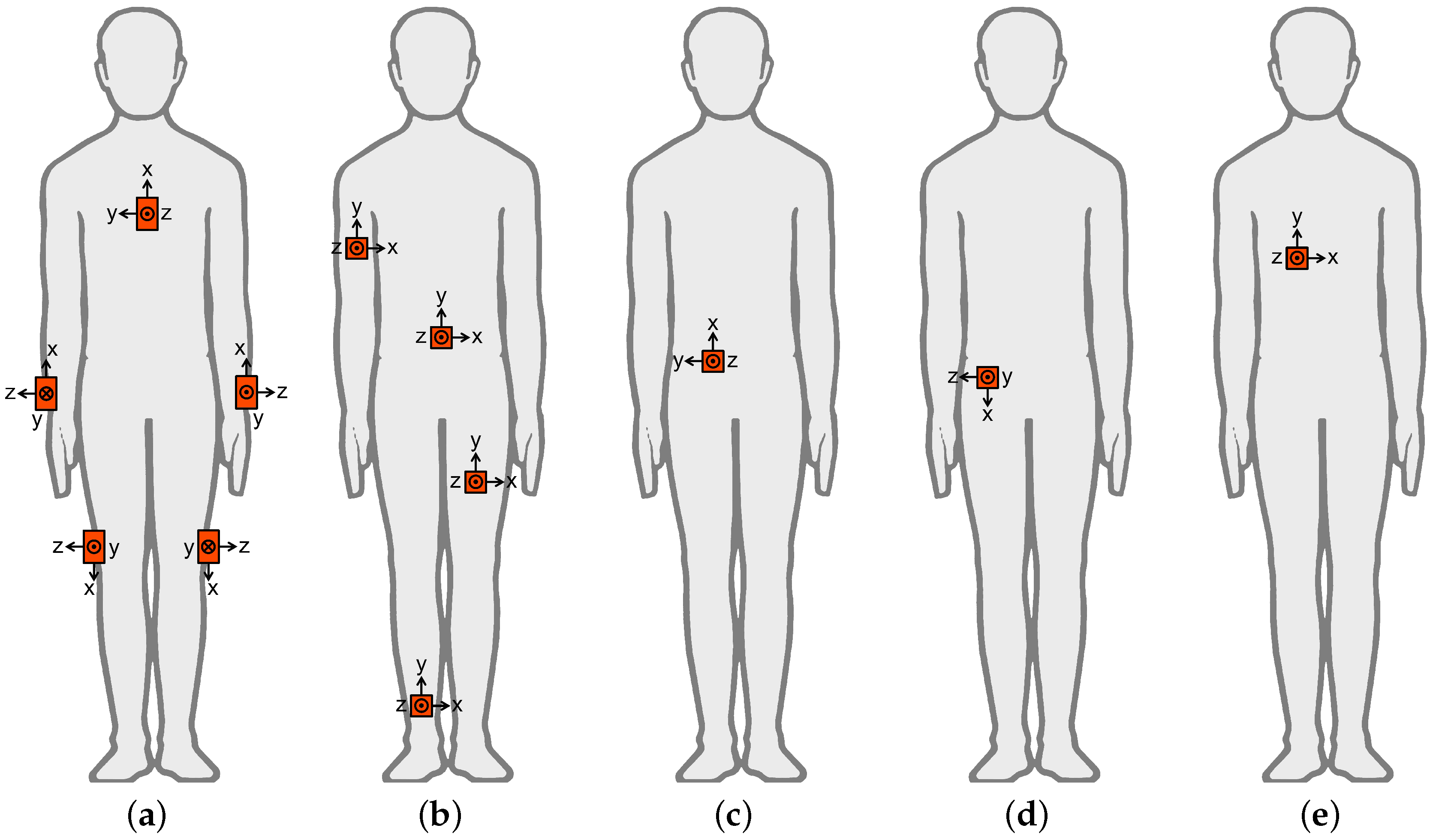
4.1. Datasets
4.2. Activity Recognition
4.2.1. Pre-Processing
- Reference case is the standard (ordinary) activity recognition scheme with fixed sensor positions and orientations. In this case, originally recorded sequences are used without applying any transformation.
- Random rotation case simulates the situation where each sensor unit is placed at a fixed position at any orientation. We use the original dataset by synthetically rotating the data to make a fair comparison between reference and random rotation cases. Tri-axial recordings of each sensor unit in each segment are randomly rotated in 3-D space to observe the performance of the system when the units are placed at random orientations. To this end, for each segment of each unit of a given dataset, we generate a random rotation matrix and pre-multiply each of the three-element measurement vectors belonging to that segment (for the accelerometer, gyroscope, and magnetometer if available) by this rotation matrix as . The rotation matrix is calculated from yaw, pitch, and roll angles that are randomly generated in the interval radians:Note that while all of the sensor types in the same unit are rotated in the same way for a given segment, each segment recorded from each sensor unit for each dataset is rotated differently (by a different random rotation matrix).
- Euclidean norm method takes the Euclidean norm of each 3-D sensor sequence at each time sample, and uses only the norms (as functions of the time sample) in classification. This is indeed a basic but proper OIT technique, which corresponds to the first dimension of the transformed signal, , in the heuristic OIT. It has been used in some studies to obtain a scalar quantity as a feature [41], to achieve orientation invariance in the simplest possible way [17,42], or to incorporate additional information such as the energy expenditure estimate of the subject [43]. Taking the Euclidean norm reduces the number of axes by a factor of three.
- Proposed method 1 corresponds to the heuristic OIT technique. The time-domain sequence contained in each segment of each tri-axial sensor in each unit is transformed to yield a 9-D orientation-invariant time-domain sequence. As a consequence, dimensionality of the time-domain data increases by a factor of three (from three to nine). We also consider taking only the first three or the first six elements of the transformation. (Throughout this article, all of the nine elements of the heuristic OIT are considered unless stated otherwise.)
- Proposed method 2 corresponds to the SVD-based OIT. A single transformation is calculated for all the sensor types in each sensor unit, again independently for each time segment, as explained in Section 3.2. The dimensionality is not affected by this transformation, unlike the Euclidean norm method and proposed method 1.
4.2.2. Classification and Cross Validation
- Bayesian Decision Making (BDM): To train a BDM classifier, for each activity class a multi-variate Gaussian distribution is fitted using the training feature vectors of that class by using maximum likelihood estimation. This process involves estimating the mean vector and the covariance matrix for each class. Then, for a given test vector, its conditional probability, conditioned on the class information (i.e., the probability given that it belongs to a particular class) can be calculated. The class that maximizes this probability is selected according to the maximum a posteriori (MAP) decision rule [44,45].
- k-Nearest-Neighbor (k-NN): The k-NN classifier requires storing training vectors. A test vector is classified by using majority voting on the classes of the k nearest training vectors to the test vector in terms of the Euclidean distance, where k is a parameter that takes integer values [44,45]. In this study, k values ranging from 1 to 30 have been considered for all cases, cross-validation techniques, and datasets. The value is found to be suitable and is used throughout this work.
- Support Vector Machines (SVM): The SVM is a binary classifier in which the feature space is separated into two classes by an optimal hyperplane that has the maximum margin [45]. In case the original feature space may not be linearly separable, it can be implicitly and nonlinearly mapped to a higher-dimensional space by using a kernel function, which represents a measure of similarity between two data vectors and . There are two commonly used kernels: the Gaussian radial basis function (RBF), , and the linear kernel, . In this study, we use the former, which is equivalent to mapping the feature space to a Hilbert space of infinite dimensionality. The reason for this choice is that there is no need to consider the linear kernel if the RBF kernel is used with optimized parameters [46], which is the case here. Then, binary classification is performed according to which side of the hyperplane the test vector resides on. To use the SVM with more than two classes, a one-versus-one approach is followed where a binary SVM classifier is trained for each class pair. A test vector is classified with all pairs of classifiers and the classifier with the highest confidence makes the class decision [47]. The MATLAB toolbox LibSVM is used for the implementation [48]. The two parameters of the SVM classifier, C and , are optimized jointly over all five cases, both cross-validation techniques, and all five datasets. The parameter C is the penalty parameter of the optimization problem of the SVM classifier (see Equation (1) in [49]) and is the parameter of the Gaussian RBF kernel described above. A two-level grid search is used to determine the parameter pair that performs the best over all cases, cross-validation techniques, and datasets. In the coarse grid, the parameters are selected as and the best parameter pair is found to be . Then, a finer grid around on the set , with reveals the best parameter pair , which is used in all five cases, cross-validation techniques, and datasets considered in this study.
- Artificial Neural Networks (ANN): An ANN consists of neurons, each of which produces an output that is a nonlinear function (called the activation function) of a weighted linear combination of multiple inputs and a constant. In this study, the sigmoid function, , is used as the activation function [45]. A multi-layer ANN consists of several layers of neurons. The inputs to the first layer are the elements of the feature vector. In the last layer, a neuron is allocated to each of the K classes. The number of hidden-layer neurons is selected as the nearest integer to , depending on the number of classes K. (As a rule of thumb, each class is assumed to have two linearly separable subclasses. Then, the number of neurons in the hidden layer is selected as the average of the optimistic and pessimistic cases. In the former, neurons are required to have the hyperplanes intersect at different positions, whereas in the latter, neurons are required for parallel hyperplanes [50].) Training an ANN can be implemented in various ways and determines the weights of the linear combination for each neuron. The desired output is one for the neuron corresponding to the class of the input vector and zero for the output neurons of the other classes. The back-propagation algorithm is used for training, which iteratively minimizes the errors in the neuron outputs in the least-squares sense, starting from the last layer and proceeding backwards [51]. The weights are initialized with a uniform random distribution in and the learning rate is chosen as 0.3. An adaptive stopping criterion is used, which terminates the algorithm at the ith epoch (that is, when each training vector has been used exactly i times) if , where is the average of the sum of the squared errors over all the training vectors in the last layer’s outputs at the ith epoch. In other words, the algorithm stops when the errors at (any of) the last 10 epochs are not significantly smaller than the error at the 11th epoch from the end. In classification, a test vector is given as the input to the ANN and the output neuron with the maximum output indicates the class decision.
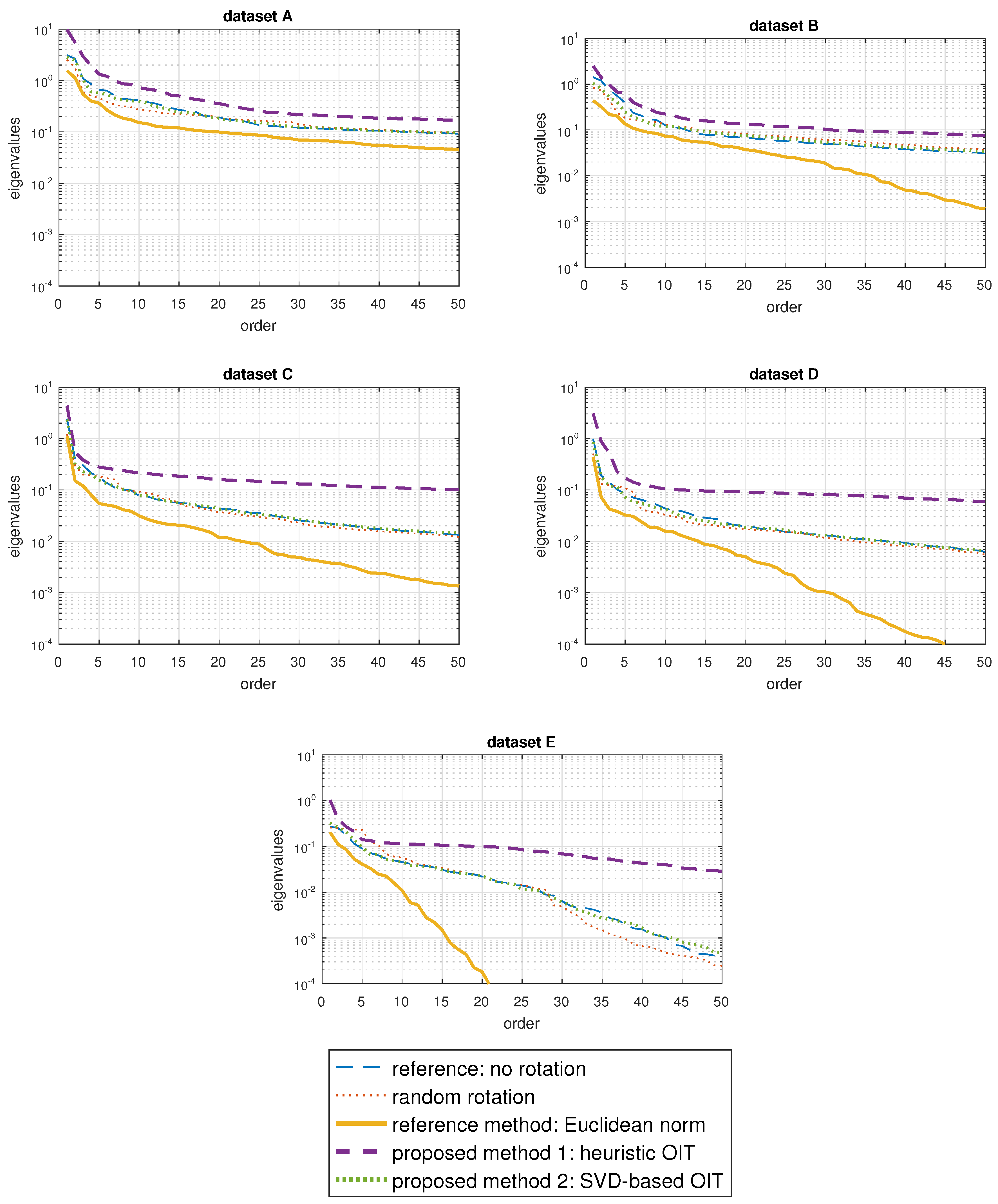
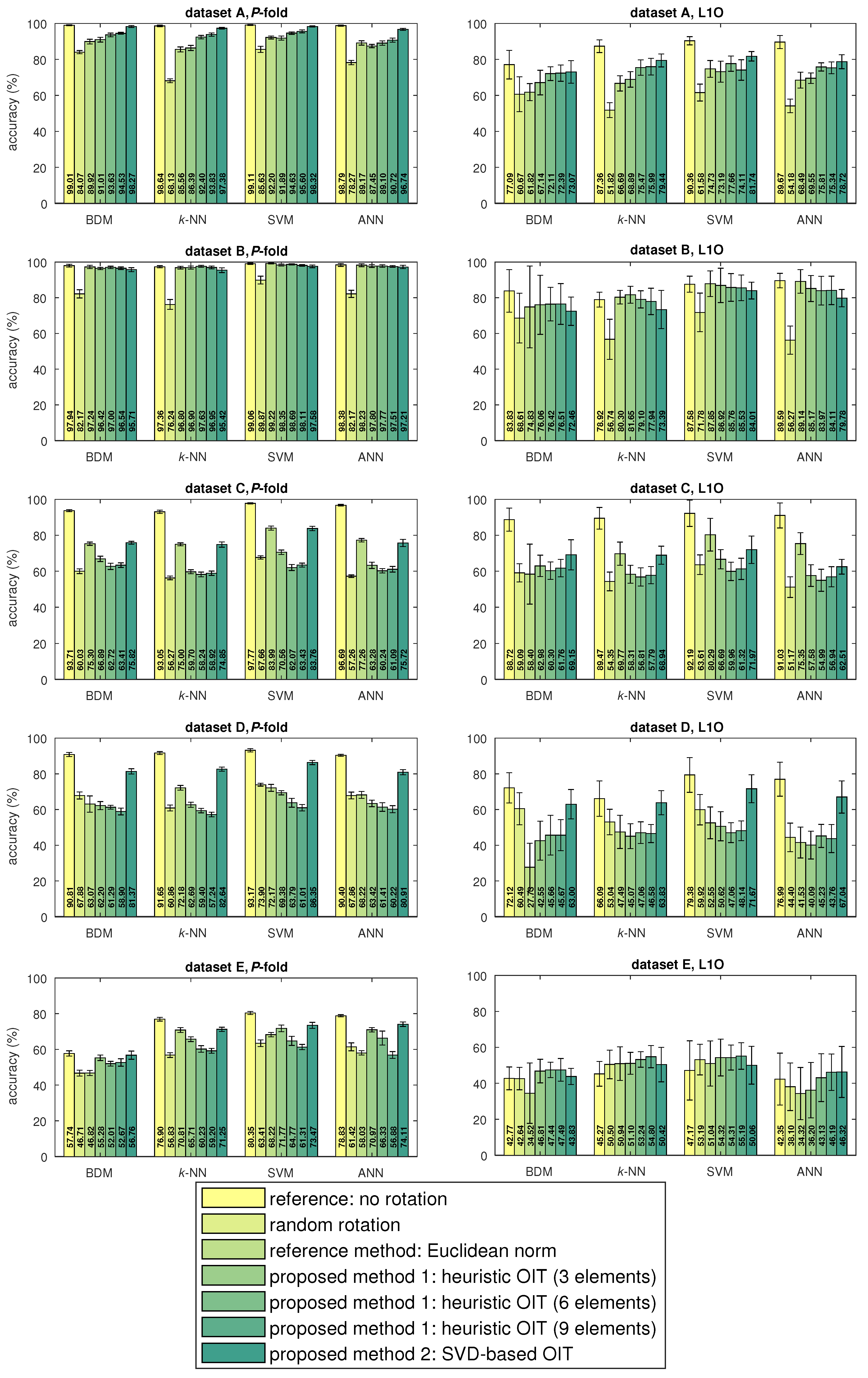
4.3. Results
5. Discussion
6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| OIT | Orientation-Invariant Transformation |
| SVD | Singular Value Decomposition |
| BDM | Bayesian Decision Making |
| k-NN | k-Nearest Neighbor |
| SVM | Support Vector Machines |
| ANN | Artificial Neural Networks |
| PCA | Principal Component Analysis |
| DFT | Discrete Fourier Transform |
| RBF | Radial Basis Function |
| MAP | maximum a posteriori |
| L1O | Leave One Out |
References
- Preece, S.J.; Goulermas, J.Y.; Kenney, L.P.J.; Howard, D.; Meijer, K.; Crompton, R. Activity identification using body-mounted sensors—A review of classification techniques. Physiol. Meas. 2009, 30, R1–R33. [Google Scholar] [CrossRef] [PubMed]
- Yürür, O.; Liu, C.H.; Moreno, W. A survey of context-aware middleware designs for human activity recognition. IEEE Commun. Mag. 2014, 52, 24–31. [Google Scholar] [CrossRef]
- Shoaib, M.B.; Bosch, S.; İncel, O.D.; Scholten, H.H.; Paul, J.M. A survey of online activity recognition using mobile phones. Sensors 2015, 15, 2059–2085. [Google Scholar] [CrossRef] [PubMed]
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Ur Rehman, M.H.; Liew, C.S.; Teh, Y.W.; Shuja, J.; Daghighi, B. Mining personal data using smartphones and wearable devices: A survey. Sensors 2015, 15, 4430–4469. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Hoey, J.; Nugent, C.D.; Cook, D.J.; Yu, Z. Sensor-based activity recognition. IEEE Trans. Syst. Man Cybern. Part C 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. 2014, 46, 33. [Google Scholar] [CrossRef]
- Kunze, K.; Lukowicz, P. Sensor placement variations in wearable activity recognition. IEEE Pervasive Comput. 2014, 13, 32–41. [Google Scholar] [CrossRef]
- Rodrigues, J.L.; Gonçalves, N.; Costa, S.; Soares, F. Stereotyped movement recognition in children with ASD. Sens. Actuators A 2013, 202, 162–169. [Google Scholar] [CrossRef]
- Banos, O.; Toth, M.A.; Damas, M.; Pomares, H.; Rojas, I. Dealing with the effects of sensor displacement in wearable activity recognition. Sensors 2014, 14, 9995–10023. [Google Scholar] [CrossRef] [PubMed]
- Altun, K.; Barshan, B. Daily and Sports Activities Dataset. In UCI Machine Learning Repository; University of California, Irvine, School of Information and Computer Sciences: Irvine, CA, USA, 2013; Available online: http://archive.ics.uci.edu/ml/datasets/Daily+and+Sports+Activities (accessed on 9 August 2017).
- Morales, J.; Akopian, D. Physical activity recognition by smartphones, a survey. Biocybern. Biomed. Eng. 2017, 37, 388–400. [Google Scholar] [CrossRef]
- Yang, J. Toward physical activity diary: Motion recognition using simple acceleration features with mobile phones. In Proceedings of the 1st International Workshop on Interactive Multimedia for Consumer Electronics, Beijing, China, 23 October 2009; pp. 1–10. [Google Scholar]
- Henpraserttae, A.; Thiemjarus, S.; Marukatat, S. Accurate activity recognition using a mobile phone regardless of device orientation and location. In Proceedings of the International Conference on Body Sensor Networks, Dallas, TX, USA, 23–25 May 2011; pp. 41–46. [Google Scholar]
- Attal, F.; Mohammed, S.; Dedabrishvili, M.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. Physical human activity recognition using wearable sensors. Sensors 2015, 15, 31314–31338. [Google Scholar] [CrossRef] [PubMed]
- Morales, J.; Akopian, D.; Agaian, S. Human activity recognition by smartphones regardless of device orientation. In Proceedings of the SPIE-IS&T Electronic Imaging: Mobile Devices and Multimedia: Enabling Technologies, Algorithms, and Applications, San Francisco, CA, USA, 18 February 2014; pp. 90300I:1–90300I:12. [Google Scholar]
- Sun, L.; Zhang, D.; Li, B.; Guo, B.; Li, S. Activity recognition on an accelerometer embedded mobile phone with varying positions and orientations. In Lecture Notes in Computer Science, Proceedings of the Ubiquitous Intelligence and Computing, Xi’an, China, 26–29 October 2010; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6406, pp. 548–562. [Google Scholar]
- Bhattacharya, S.; Nurmi, P.; Hammerla, N.; Plötz, T. Using unlabeled data in a sparse-coding framework for human activity recognition. Pervasive Mob. Comput. 2014, 15, 242–262. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; İncel, Ö.D.; Scholten, H.; Havinga, J.M. Fusion of smartphone motion sensors for physical activity recognition. Sensors 2014, 14, 10146–10176. [Google Scholar] [CrossRef] [PubMed]
- De, D.; Bharti, P.; Das, S.K.; Chellappan, S. Multimodal wearable sensing for fine-grained activity recognition in healthcare. IEEE Internet Comput. 2015, 19, 26–35. [Google Scholar] [CrossRef]
- Hur, T.; Bang, J.; Kim, D.; Banos, O.; Lee, S. Smartphone location-independent physical activity recognition based on transportation natural vibration analysis. Sensors 2017, 17, 931. [Google Scholar] [CrossRef] [PubMed]
- Janidarmian, M.; Fekr, A.R.; Radecka, K.; Zilic, Z. A comprehensive analysis on wearable acceleration sensors in human activity recognition. Sensors 2017, 17, 529. [Google Scholar] [CrossRef] [PubMed]
- Thiemjarus, S. A device-orientation independent method for activity recognition. In Proceedings of the International Conference on Body Sensor Networks, Biopolis, Singapore, 7–9 June 2010; pp. 19–23. [Google Scholar]
- Ustev, Y.E.; İncel, Ö.D.; Ersoy, C. User, device and orientation independent human activity recognition on mobile phones: Challenges and a proposal. In Proceedings of the ACM Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; pp. 1427–1436. [Google Scholar]
- Kunze, K.; Lukowicz, P. Dealing with sensor displacement in motion-based onbody activity recognition systems. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Korea, 21–24 September 2008; pp. 20–29. [Google Scholar]
- Förster, K.; Roggen, D.; Troster, G. Unsupervised classifier self-calibration through repeated context occurrences: Is there robustness against sensor displacement to gain? In Proceedings of the International Symposium on Wearable Computers, Linz, Austria, 4–7 September 2009; pp. 77–84. [Google Scholar]
- Vlachos, M.; Gunopulos, D.; Das, G. Rotation invariant distance measures for trajectories. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 707–712. [Google Scholar]
- Moon, T.K.; Stirling, W.C. Mathematical Methods and Algorithms for Signal Processing; Prentice Hall: New Jersey, NJ, USA, 2000; Chapter 7; p. 369. [Google Scholar]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef]
- Seçer, G.; Barshan, B. Improvements in deterministic error modeling and calibration of inertial sensors and magnetometers. Sens. Actuators A 2016, 247, 522–538. [Google Scholar] [CrossRef]
- Ugulino, W.; Cardador, D.; Vega, K.; Velloso, E.; Milidiú, R.; Fuks, H. Wearable Computing: Classification of Body Postures and Movements (PUC-Rio) Data Set. In UCI Machine Learning Repository; University of California, Irvine, School of Information and Computer Sciences: Irvine, CA, USA, 2013. [Google Scholar]
- Reyes-Oritz, J.L.; Anguita, D.; Ghio, A.; Oneto, L.; Parra, X. Human Activity Recognition Using Smartphones Data Set. In UCI Machine Learning Repository; University of California, Irvine, School of Information and Computer Sciences: Irvine, CA, USA, 2012. [Google Scholar]
- Zhang, M.; Sawchuk, A.A. USC-HAD: A daily activity dataset for ubiquitous activity recognition using wearable sensors. In Proceedings of the ACM International Conference on Ubiquitous Computing Workshop on Situation, Activity, and Goal Awareness, Pittsburgh, PA, USA, 5–8 September 2012; pp. 1036–1043. [Google Scholar]
- Casale, P.; Pujol, O.; Redeva, P. Human activity recognition from accelerometer data using a wearable device. In Pattern Recognition and Image Analysis, Lecture Notes in Computer Science, Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Gran Canaria, Spain, 8–10 June 2011; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6669, pp. 289–296. [Google Scholar]
- Altun, K.; Barshan, B.; Tunçel, O. Comparative study on classifying human activities with miniature inertial and magnetic sensors. Pattern Recognit. 2010, 43, 3605–3620. [Google Scholar] [CrossRef]
- Barshan, B.; Yüksek, M.C. Recognizing daily and sports activities in two open source machine learning environments using body-worn sensor units. Comput. J. 2014, 57, 1649–1667. [Google Scholar] [CrossRef]
- Xsens Technologies, B.V. MTi, MTx, and XM-B User Manual and Technical Documentation; Xsens: Enschede, The Netherlands, 2017. [Google Scholar]
- Ugulino, W.; Cardador, D.; Vega, K.; Velloso, E.; Milidiú, R.; Fuks, H. Wearable computing: Accelerometers’ data classification of body postures and movements. In Lecture Notes in Computer Science/Lecture Notes in Artificial Intelligence, Proceedings of the 21st Brazilian Symposium on Artificial Intelligence: Advances in Artificial Intelligence, Curitiba, Brasil, 20–25 October 2012; Springer: Berlin/Heidelberg, Germany, 2010; Volume 7589, pp. 52–61. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Oritz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the 21th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2013; pp. 437–442. [Google Scholar]
- Casale, P.; Pujol, O.; Redeva, P. Personalization and user verification in wearable systems using biometric walking patterns. Pers. Ubiquitous Comput. 2012, 16, 563–580. [Google Scholar] [CrossRef]
- Rulsch, M.; Busse, J.; Struck, M.; Weigand, C. Method for daily-life movement classification of elderly people. Biomed. Eng. 2012, 57, 1071–1074. [Google Scholar] [CrossRef] [PubMed]
- Álvarez de la Concepción, M.Á.; Soria Morillo, L.M.; Álvarez García, J.A.; González-Abril, L. Mobile activity recognition and fall detection system for elderly people using Ameva algorithm. Pervasive Mob. Comput. 2017, 34, 3–13. [Google Scholar] [CrossRef]
- Bouten, C.V.C.; Koekkoek, K.T.M.; Verduin, M.; Kodde, R.; Janssen, J.D. A triaxial accelerometer and portable data processing unit for the assessment of daily physical activity. IEEE Trans. Biomed. Eng. 1997, 44, 136–147. [Google Scholar] [CrossRef] [PubMed]
- Webb, A. Statistical Pattern Recognition; John Wiley & Sons: New York, NY, USA, 2002. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; John Wiley & Sons: New York, NY, USA, 2000. [Google Scholar]
- Keerthi, S.S.; Lin, C.-J. Asymptotic behaviors of support vector machines with Gaussian kernel. Neural Comput. 2003, 15, 1667–1689. [Google Scholar] [CrossRef] [PubMed]
- Duan, K.B.; Keerthi, S.S. Which is the best multiclass SVM method? An empirical study. In Multiple Classifier Systems, Lecture Notes in Computer Science, Proceedings of the 6th International Workshop, Seaside, CA, USA, 13–15 June 2005; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3541, pp. 278–285. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification; Technical Report; Department of Computer Science, National Taiwan University: Taipei, Taiwan, 2003. [Google Scholar]
- Zurada, J.M. Introduction to Artificial Neural Networks; St. Paul: West Publishing Company: Dakota Country, MN, USA, 1992; Volume 8. [Google Scholar]
- Haykin, S. Neural Networks: A Comprehensive Foundation, 2nd ed.; Prentice Hall: New Jersey, NJ, USA, 1998. [Google Scholar]
- Barshan, B.; Yurtman, A. Investigating inter-subject and inter-activity variations in activity recognition using wearable motion sensors. Comput. J. 2016, 59, 1345–1362. [Google Scholar]
- Aggarwal, J.K.; Ryoo, M.S. Human activity analysis: A review. ACM Comput. Surv. 2011, 43, 16. [Google Scholar] [CrossRef]
- Ngo, T.T.; Makihara, Y.; Nagahara, H.; Mukaigawa, Y.; Yagi, Y. The largest inertial sensor-based gait database and performance evaluation of gait-based personal authentication. Pattern Recognit. 2014, 47, 228–237. [Google Scholar] [CrossRef]
- Yurtman, A.; Barshan, B. Automated evaluation of physical therapy exercises using multi-template dynamic time warping on wearable sensor signals. Comput. Methods Progr. Biomed. 2014, 117, 189–207. [Google Scholar] [CrossRef] [PubMed]
- Özdemir, A.T.; Barshan, B. Detecting falls with wearable sensors using machine learning techniques. Sensors 2014, 14, 10691–10708. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | A [11] | B [31] | C [32] | D [33] | E [34] |
|---|---|---|---|---|---|
| no. of subjects | 8 | 4 | 30 | 14 | 15 |
| no. of activities | 19 | 5 | 6 | 12 | 7 |
| activities | sitting (A), standing (A), lying on back and on right side (A, A), ascending and descending stairs (A, A), standing still in an elevator (A), moving around in an elevator (A), walking in a parking lot (A), walking on a treadmill in flat and inclined positions at a speed of 4 km/h (A, A), running on a treadmill at a speed of 8 km/h (A), exercising on a stepper (A), exercising on a cross trainer (A), cycling on an exercise bike in horizontal and vertical positions (A, A), rowing (A), jumping (A), and playing basketball (A) | sitting down (B), standing up (B), standing (B), walking (B), and sitting (B) | walking (C), ascending stairs (C), descending stairs (C), sitting (C), standing (C), and lying (C) | walking (D), walking left and right (D and D), ascending and descending stairs (D, D), running forward (D), jumping (D), sitting (D), standing (D, sleeping (D), ascending and descending in an elevator (D, D) | working at a computer (E), standing up–walking–ascending/descending stairs (E), standing (E), walking (E), ascending/descending stairs (E), walking and talking with someone (E), talking while standing (E) |
| no. of non-stationary | 15 | 3 | 3 | 9 | 4 |
| activities | A–A | B, B, B | C–C | D–D, D, D | E, E–E |
| no. of units | 5 | 4 | 1 | 1 | 1 |
| no. of axes per unit | 9 | 3 | 6 | 6 | 3 |
| unit positions | torso | waist | waist | front right hip | chest |
| right and left arm | left thigh | ||||
| right and left leg | right ankle | ||||
| right upper arm | |||||
| accelerometer | accelerometer | accelerometer | accelerometer | accelerometer | |
| sensor types | gyroscope | gyroscope | gyroscope | ||
| magnetometer | (of smartphone) | ||||
| dataset duration (h) | 13 | 8 | 7 | 7 | 10 |
| sampling rate (Hz) | 25 | 8 | 50 | 100 | 52 |
| no. of segments | 9120 | 4130 | 10,299 | 5353 | 7345 |
| (50% overlap) | |||||
| segment length (s) | 5 | 5 | 2.56 | 5 | 5 |
| no. of features | |||||
| (for the reference case, | 1170 | 276 | 234 | 156 | 78 |
| with no transformation) |
| Method | Dataset | ||||
|---|---|---|---|---|---|
| A | B | C | D | E | |
| Euclidean norm | 6.597 | 2.338 | 5.515 | 4.123 | 3.513 |
| proposed method 1: heuristic OIT (3 elements) | 28.928 | 2.226 | 6.574 | 5.954 | 2.763 |
| proposed method 1: heuristic OIT (6 elements) | 191.406 | 10.096 | 44.059 | 49.240 | 21.005 |
| proposed method 1: heuristic OIT (9 elements) | 369.243 | 17.503 | 84.239 | 91.445 | 38.670 |
| proposed method 2: SVD-based OIT | 70.034 | 4.122 | 20.434 | 59.737 | 8.325 |
| Reference | Euclidean Norm | Random Rotation | Proposed Method 1 | Proposed Method 2 | Reference | Euclidean Norm | Random Rotation | Proposed Method 1 | Proposed Method 2 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Classifier | P-Fold | L1O | |||||||||
| runtime (s) | BDM | 1.312 | 1.617 | 1.303 | 1.292 | 1.309 | 1.628 | 1.612 | 1.688 | 2.588 | 2.384 |
| k-NN | 0.149 | 0.156 | 0.157 | 0.155 | 0.153 | 0.175 | 0.172 | 0.185 | 0.424 | 0.259 | |
| SVM | 13.238 | 36.050 | 12.230 | 30.504 | 13.645 | 12.074 | 28.420 | 11.700 | 34.525 | 17.495 | |
| ANN | 8.754 | 12.796 | 13.850 | 14.482 | 10.118 | 7.992 | 9.326 | 9.131 | 11.353 | 9.326 | |
| training time (s) | BDM | 0.009 | 0.010 | 0.008 | 0.009 | 0.009 | 0.009 | 0.009 | 0.009 | 0.014 | 0.013 |
| k-NN | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | |
| SVM | 12.839 | 30.186 | 11.681 | 29.891 | 13.219 | 11.636 | 27.521 | 11.056 | 33.580 | 16.811 | |
| ANN | 8.561 | 12.773 | 13.826 | 14.448 | 10.095 | 7.966 | 9.299 | 9.104 | 11.313 | 9.299 | |
| classification time (ms) | BDM | 1.424 | 1.757 | 1.416 | 1.403 | 1.421 | 1.417 | 1.404 | 1.469 | 2.253 | 2.075 |
| k-NN | 0.159 | 0.166 | 0.168 | 0.166 | 0.163 | 0.150 | 0.147 | 0.159 | 0.367 | 0.222 | |
| SVM | 0.307 | 0.722 | 0.478 | 0.522 | 0.342 | 0.285 | 0.690 | 0.463 | 0.659 | 0.451 | |
| ANN | 0.019 | 0.018 | 0.020 | 0.026 | 0.017 | 0.017 | 0.017 | 0.017 | 0.025 | 0.018 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yurtman, A.; Barshan, B. Activity Recognition Invariant to Sensor Orientation with Wearable Motion Sensors. Sensors 2017, 17, 1838. https://doi.org/10.3390/s17081838
Yurtman A, Barshan B. Activity Recognition Invariant to Sensor Orientation with Wearable Motion Sensors. Sensors. 2017; 17(8):1838. https://doi.org/10.3390/s17081838
Chicago/Turabian StyleYurtman, Aras, and Billur Barshan. 2017. "Activity Recognition Invariant to Sensor Orientation with Wearable Motion Sensors" Sensors 17, no. 8: 1838. https://doi.org/10.3390/s17081838
APA StyleYurtman, A., & Barshan, B. (2017). Activity Recognition Invariant to Sensor Orientation with Wearable Motion Sensors. Sensors, 17(8), 1838. https://doi.org/10.3390/s17081838