1. Introduction
In practice, automated transaction facilities, such as automated teller machines (ATMs) and multifunctional counting machines, should be able to process various tasks, such as denomination determining, fitness classification, and counterfeit detection, with currencies from various countries and regions [
1]. Regarding banknote recognition, one of the most popular approaches is based on an image processing method, which has been considered an effective solution [
2,
3]. In this method, a recognition system captures an input banknote by using visible light sensors and determines its denomination based on the classification of the input direction of banknote.
Many studies involved in the classification of banknotes from different countries conducted experiments on separated image datasets of each country’s banknote. The method proposed by Gai et al. [
4] uses quaternion wavelet transform (QWT) and generalized Gaussian density (GGD) for feature extraction, and neural network (NN) for classification of banknote images from the United States (US), China, and Europe. In the method proposed by Pham et al. [
5], currency of the US dollar (USD), South African rand (ZR), Angolan kwanza (AOA), and Malawian kwacha (MWK) are recognized by a K-means-based classifier with the features extracted by principal component analysis (PCA) of the discriminative regions on banknote images. Using color features of hue, saturation, and value (HSV) model, Bhurke et al. [
6] proposed a Euclidian distance-based banknote recognition and built a graphical user interface (GUI) for displaying the results on the Indian rupee (INR), Australian dollar (AUD), Euro (EUR), Saudi Arabia riyal (SAR), and USD. There has also been research on USD, INR, and Korean won (KRW) from Kwon et al. [
7], however, they focused on banknote fitness classification.
Additionally, there have been studies on simultaneous recognition of multiple currencies from various countries. An NN was used as the combined classifier for two different types of banknote, the Cyprus Pound and Turkish Lira, in the study of Khashman and Sekeroglu [
8]. The two banknote types of USD and EUR are also recognized simultaneously in the method proposed by Rashid et al. [
9]. In this study, they conducted comparative experiments using three classification techniques. These are the support vector machine (SVM), artificial neural network (ANN), and hidden Markov model (HMM). The multi-currency classification method proposed by Youn et al. [
10] adopted multi-template correlation matching to determine the areas on banknote images used for recognition, such that they ensure high correlation among banknotes of the same types and poor correlation among those of different types. Rahman et al. [
11] proposed a linear discriminant analysis (LDA)-based recognition method using an edge histogram descriptor (EHD) for classifying banknotes of 14 denominations from four types of currencies including USD, EUR, Bangladeshi taka (BDT), and INR. Another four types of currencies from Japan, Italia, Spain, and France were previously classified in the research of Takeda et al. [
12]. In this multi-national currency recognition method, the NN was also used as the classifier for the banknote feature extracted by genetic algorithm (GA)-based optimized masks. A dataset consist of 150 denominations of banknotes from 23 countries were used for assessing the performance of HMM-based paper currency recognition proposed by Hassanpour and Farahabadi [
13].
The NN has been used as the classifier in many previous studies because of its effectiveness in the solution of the multiclass classification in the banknote recognition problem [
4,
8,
9,
12,
14,
15,
16,
17,
18,
19]. The network model can be either learning vector quantization (LVQ)-based [
14,
15,
16,
17] or multi-layered perceptron (MLP)-based [
4,
8,
9,
12,
18,
19]. In these studies, features from banknote images are extracted by various methods, such as wavelet transform [
4], pixel averaging [
8], scale-invariant feature transform (SIFT) [
9], symmetrical masks on banknote images [
12,
19], edge feature extraction [
14,
18], and PCA feature extraction [
15,
17]; and subsequently fed into the NN for determination of denomination or input direction. The recent banknote detection and recognition methods aiming to visual impaired users used speeded up robust feature (SURF) for feature extraction [
20,
21]. Because the banknotes in these studies were captured by camera mounted on sunglasses, the problems of rotation, scaling and illumination changes can be handled by the robustness of SURF for geometric and photometric variation as well as speed improvement [
20].
Recently, convolutional neural network (CNN) algorithms have been emerging and playing an important role in the development of deep learning and artificial intelligent technology. Since the first introduction by LeCun et al. in the review research of handwritten character recognition [
22,
23], CNN has been adopted for solving various problems, such as image classification for the ImageNet large-scale visual recognition challenge (ILSVRC) contest [
24,
25], arrow-read marker [
26], traffic sign recognition [
27], and multi-sensor-based person recognition [
28]. However, there is little previous research conducted on banknote recognition using CNN. Recently, Ke et al. proposed banknote image defect recognition using CNN [
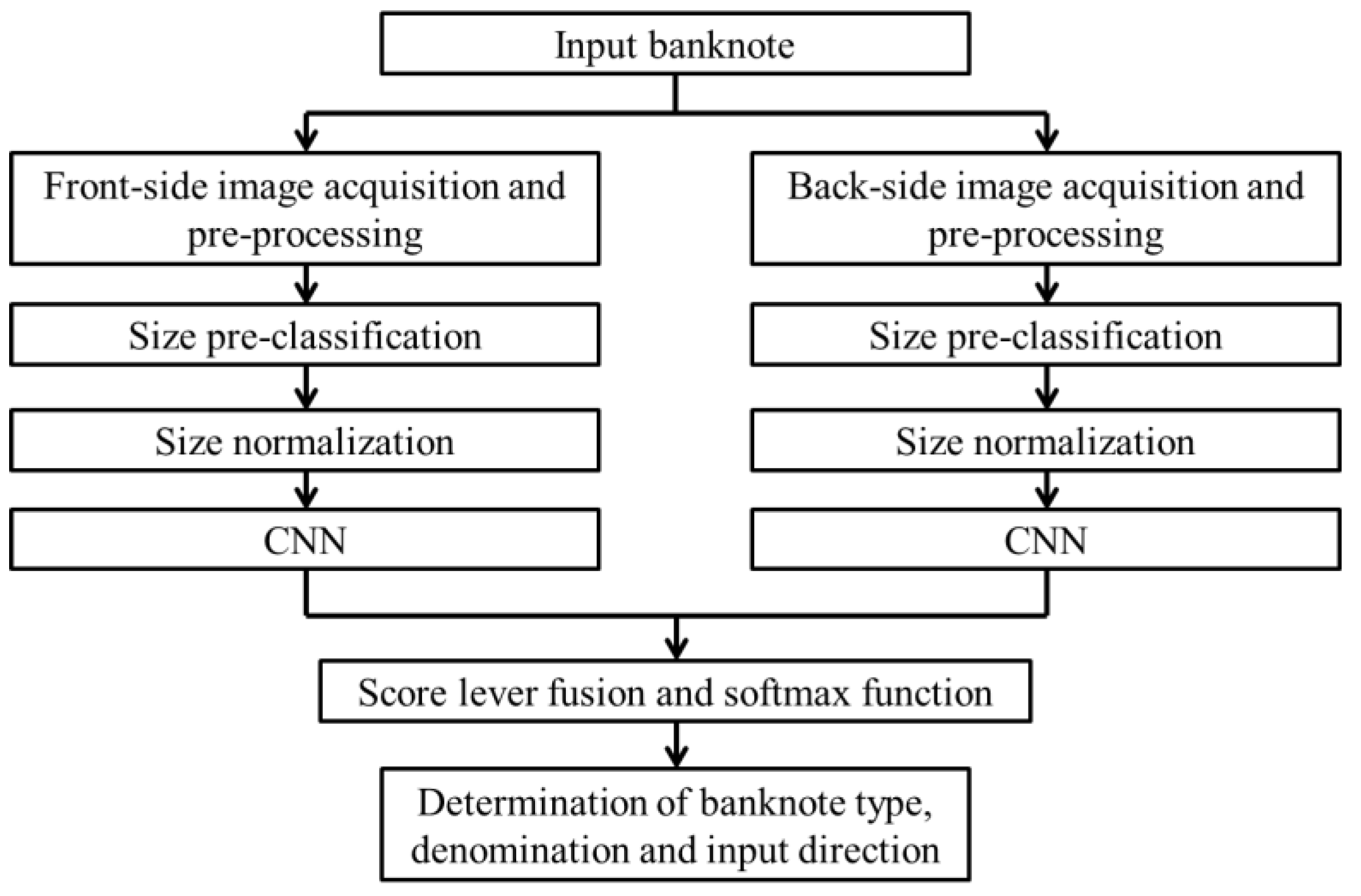
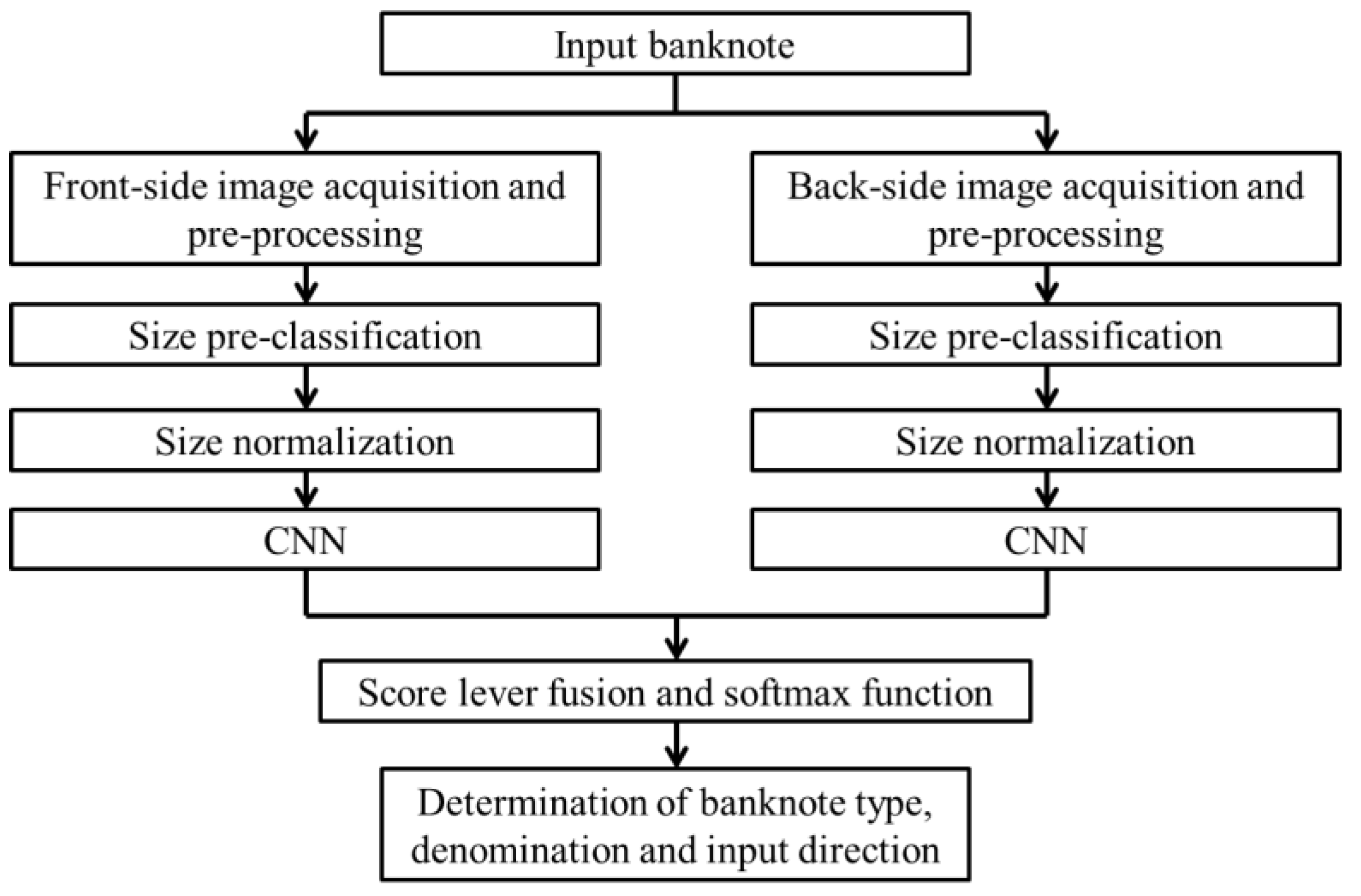
29], however, they focused only on ink dot recognition in a banknote image defect and did not specify which type of banknote was used in the experimental dataset. To overcome these shortcomings, we propose CNN-based recognition of banknote images captured by visible-light line sensors. Owing to the advantage of deep learning by a convolutional network, our proposed method is designed to simultaneously classify banknote from multiple countries. To reduce the complexity of the classifier, first, we perform the size pre-classification of banknote. The pre-classified banknote is subsequently normalized in size and input into the CNN classifier.
Compared to the previous studies, our proposed method is novel in the following:
- (1)
This is the first approach to adopt CNN for multi-national banknote classification. We performed intensive training on the CNN using a huge number of banknote images obtained through data augmentation based on the images of six national currencies having 62 denominations, which makes our method robust for a variety of banknote images.
- (2)
Considering the size characteristics of a conventional banknote image, we use a size normalized image whose width is larger than height for input to CNN. This is different from the previous methods of CNN-based object detection and recognition using the square-shaped input. In addition, in our method, the input banknote is captured on both sides, and we use score level fusion method to combine the CNN output scores of the front and back images to enhance recognition accuracy.
- (3)
Our recognition system can simultaneously classify banknotes from six national currencies: Chinese yuan (CNY), EUR, Japanese yen (JPY), KRW, Russian ruble (RUB), and USD. Because the input banknote image is recognized by denomination and direction, the number of classes is increased significantly. To reduce the complexity, we pre-classify the type of banknote by size, and adopt separated CNN classifiers for the size classes of the banknote in our system.
- (4)
We made our database of multi-national currencies and trained CNN model public such that other researchers can compare and evaluate its performance.
A summary comparison between our research and previous studies is given in
Table 1. In
Section 2, we present the details of the proposed multi-national banknote recognition method. Experimental results and conclusions drawn are presented in
Section 3 and
Section 4 of this paper, respectively.
3. Experimental Results
In our study, experiments using the proposed method were conducted on a multi-national banknote image database containing images from six national currencies: CNY, EUR, JPY, KRW, RUB, and USD. A total of 64,668 images were captured from both sides of 32,334 banknotes belonging to 62 currency denominations from six countries. The number of classes is four times the number of denominations because of the inclusion of four directions; therefore, there are 248 classes of banknote to be classified in our study. In
Table 3, we give the details, number of images, and classes (denominations and directions) of each country’s banknote in the dataset. In comparison with the multi-national databases used in the previous work, our experimental database contains more numbers of national currencies and denominations than those of the previous studies in [
10,
11,
12], and more number of images than that of [
13], as shown in
Table 4. Examples of banknote images of CNY, JPY, KRW, RUB, and USD are shown in
Figure 6. EUR banknote image examples are given in
Figure 3. We made our database of multi-national currencies and trained CNN model public through [
37], such that other researchers can compare and evaluate its performance.
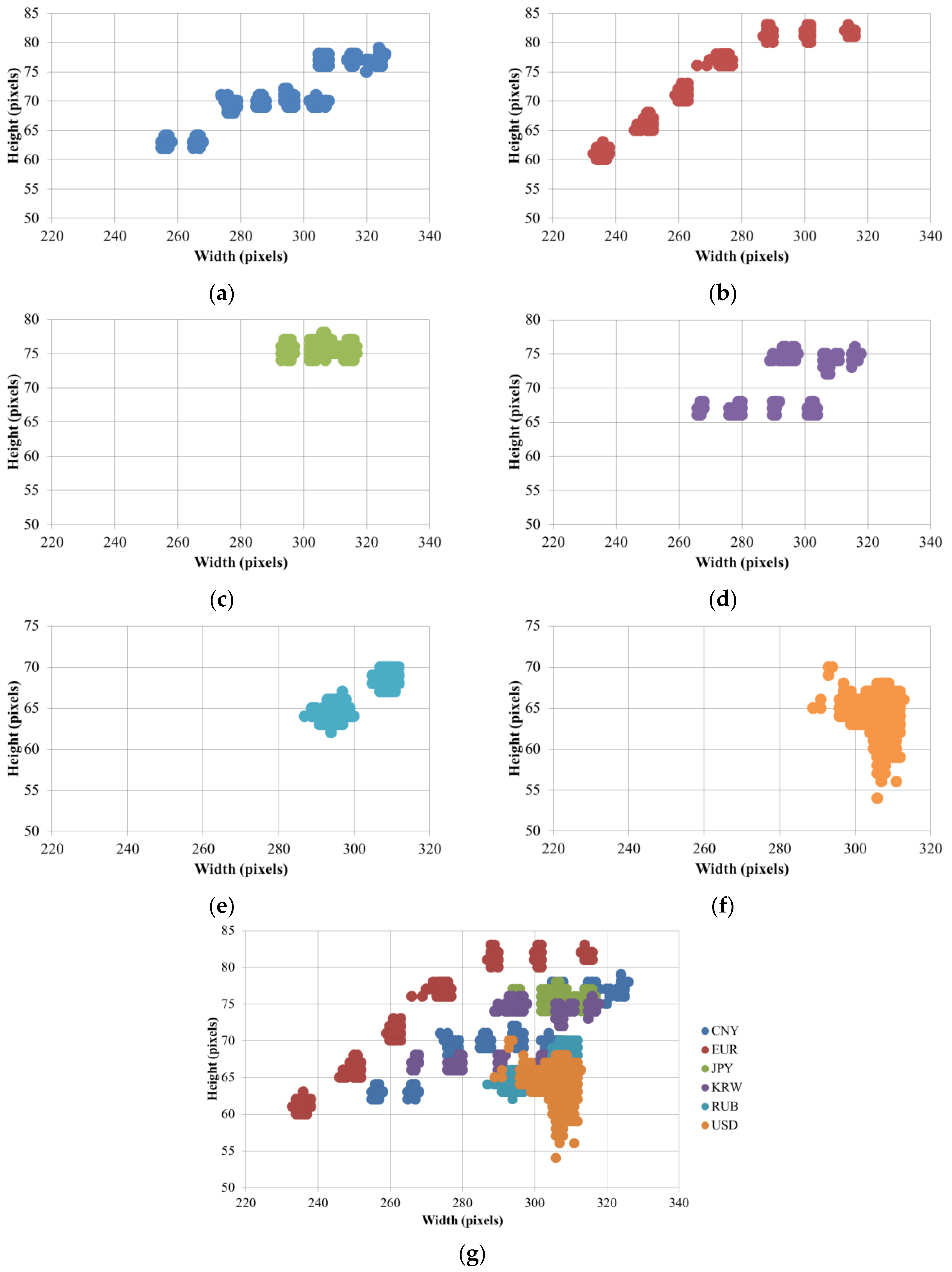
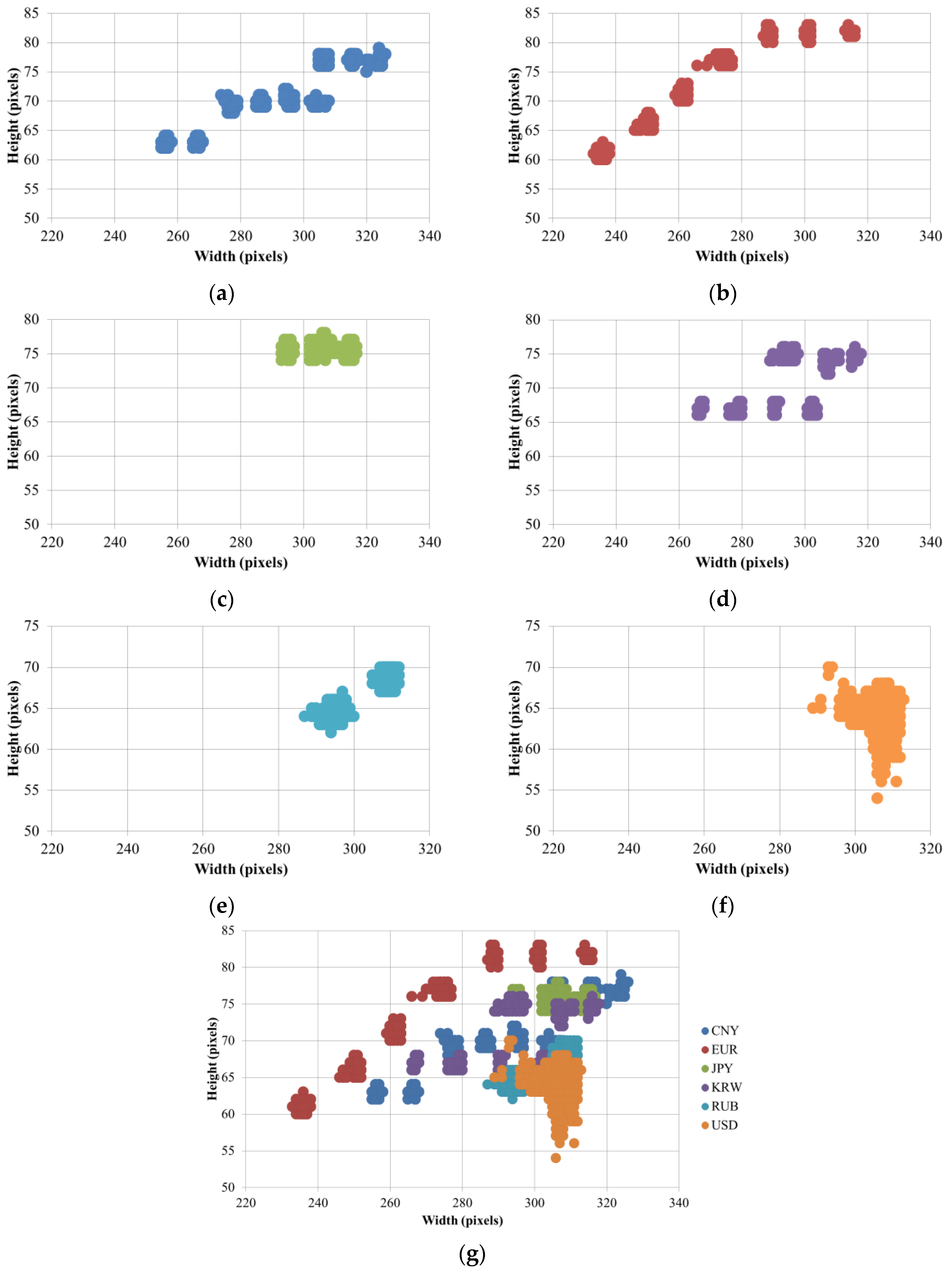
In the first experiment, we investigated the size information of banknote images for size pre-classification. Based on the size distributions shown in
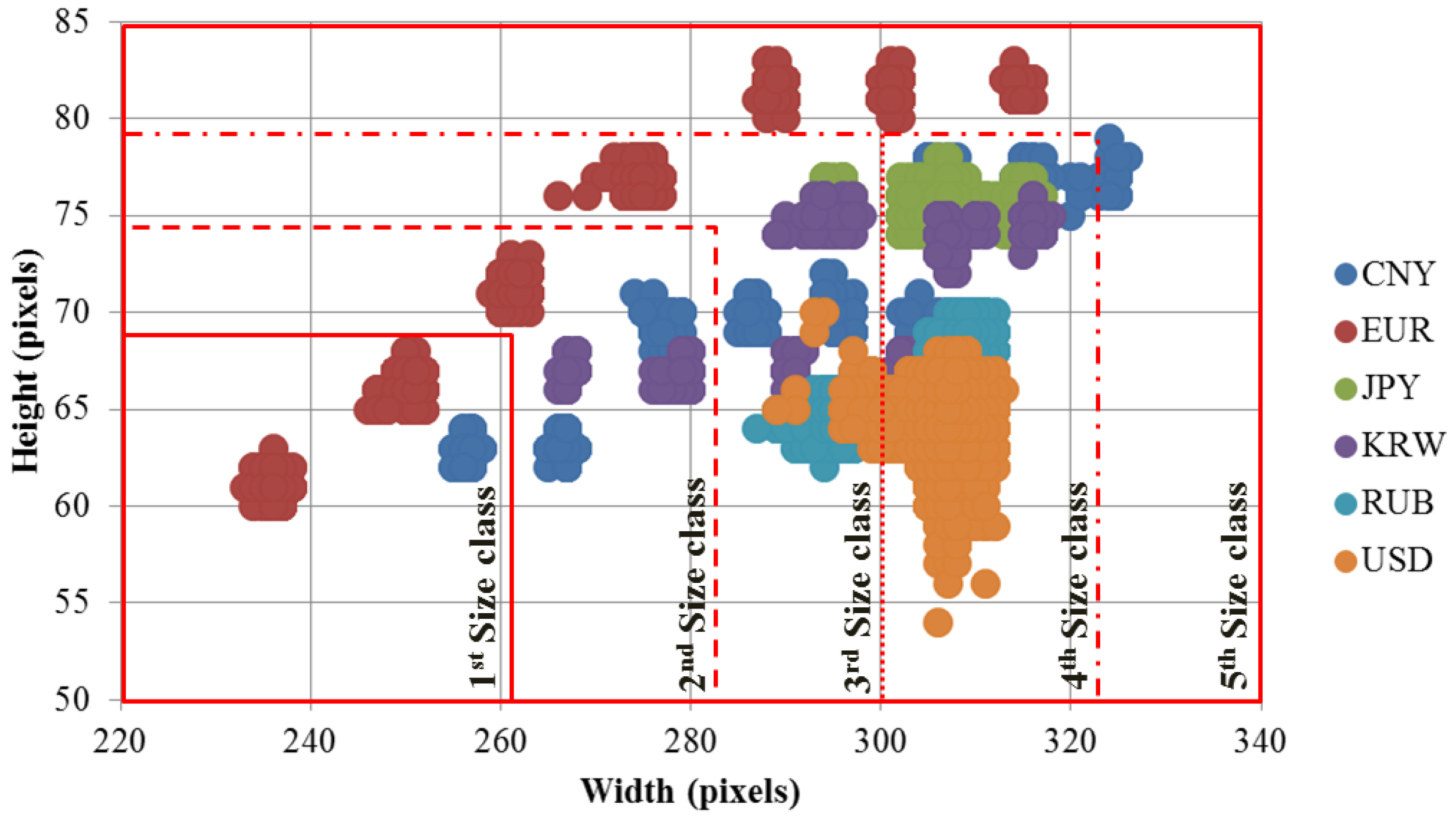
Figure 4, we defined five size classes in an ascending order of heights and widths of banknote region segmented images, considering the separation and overlapping of banknote type sizes.
Figure 7 illustrates the definition of size class boundaries defined on size distribution scatter plots. It can be seen from the
Figure 7 that the banknote images from national currencies consisting of multiple-size notes such as CNY, EUR, EUR, JPY and KRW can be pre-classified into different size classes. The detail description of banknote classes in each size class is given in
Table 5. It can be seen from
Table 5 that the third and fourth size classes consist of the most numbers of classes in comparison to the other size classes. The reason is as follows: From
Figure 4 and
Figure 7, we can see that USD’s size distribution overlaps with several size groups of banknotes from other countries. Because of this fact, we included 68 classes of USD in both the third and fourth size classes, and consequently, the numbers of classes in these two size classes were increased.
The performance of our proposed method was measured by conducting a two-fold cross-validation method. To do so, we randomly divided the dataset into each size class shown in
Table 5, into two subsets, one for training and another one for testing, and repeated the processes with alternating these two subsets. In the cases of the CNY, EUR, JPY, and KRW banknotes, we performed data augmentation for expanding and generalizing the datasets because the numbers of images for these four kinds of banknotes are relatively smaller than those for RUB and USD. For data augmentation, we randomly cropped the original image in the dataset in the range of 1~5 pixels on the four boundaries. The numbers of images in CNY, EUR, JPY, and KRW datasets were multiple by the factor of 20, 3, 10 and 24, respectively, for being relatively similar to that of RUB dataset. These augmented data were used for training, and based on this scheme of data augmentation, the unbalance of training dataset of each country’s banknote can be reduced. We also list the number of images in each country’s banknote dataset after performing data augmentation in
Table 3. Training and testing experiments were performed by using the MATLAB implementation of CNN [
38] on a desktop computer equipped with an Intel
® Core™ i7-6700 CPU @ 3.40 GHz [
39], 64 GB memory, and an NVIDIA GeForce GTX TITAN X graphics card with 3072 CUDA cores, and 12 GB GDDR5 memory [
40].
In the CNN training experiments, we trained five separate network models for classifying banknotes in each of five size classes, and repeated it twice for two-fold cross-validation. The training method used in this research is stochastic gradient descend (SGD), or on-line gradient descent [
30], which updates the network weights based on one data point at a time. Network training parameters were selected as follows: the learning process iterated over 100 epochs, with the initial learning rate of 0.01 and reduced by 10% at every 33 epochs; the probability of dropout in the second fully connected layer is set to 65%.
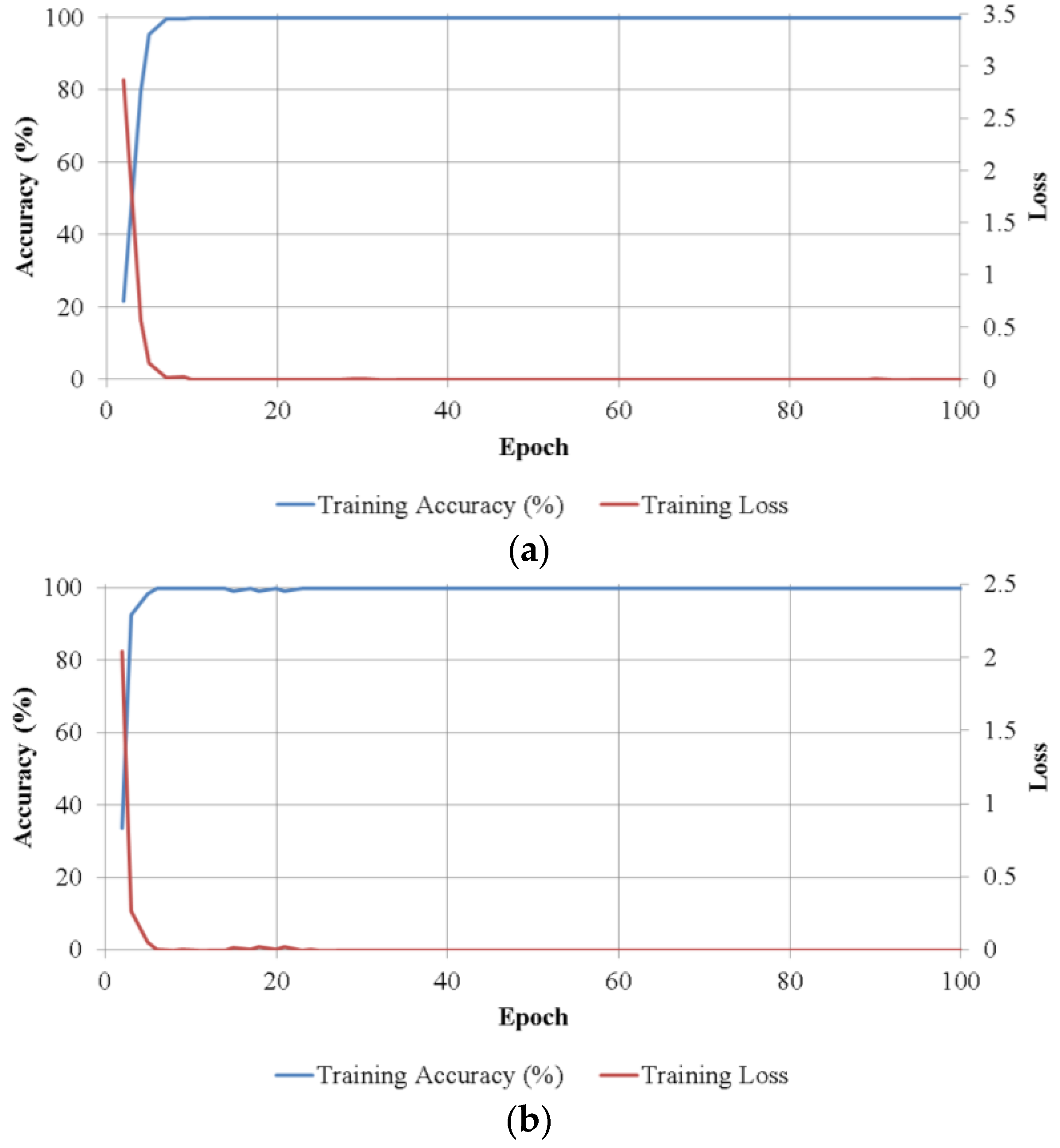
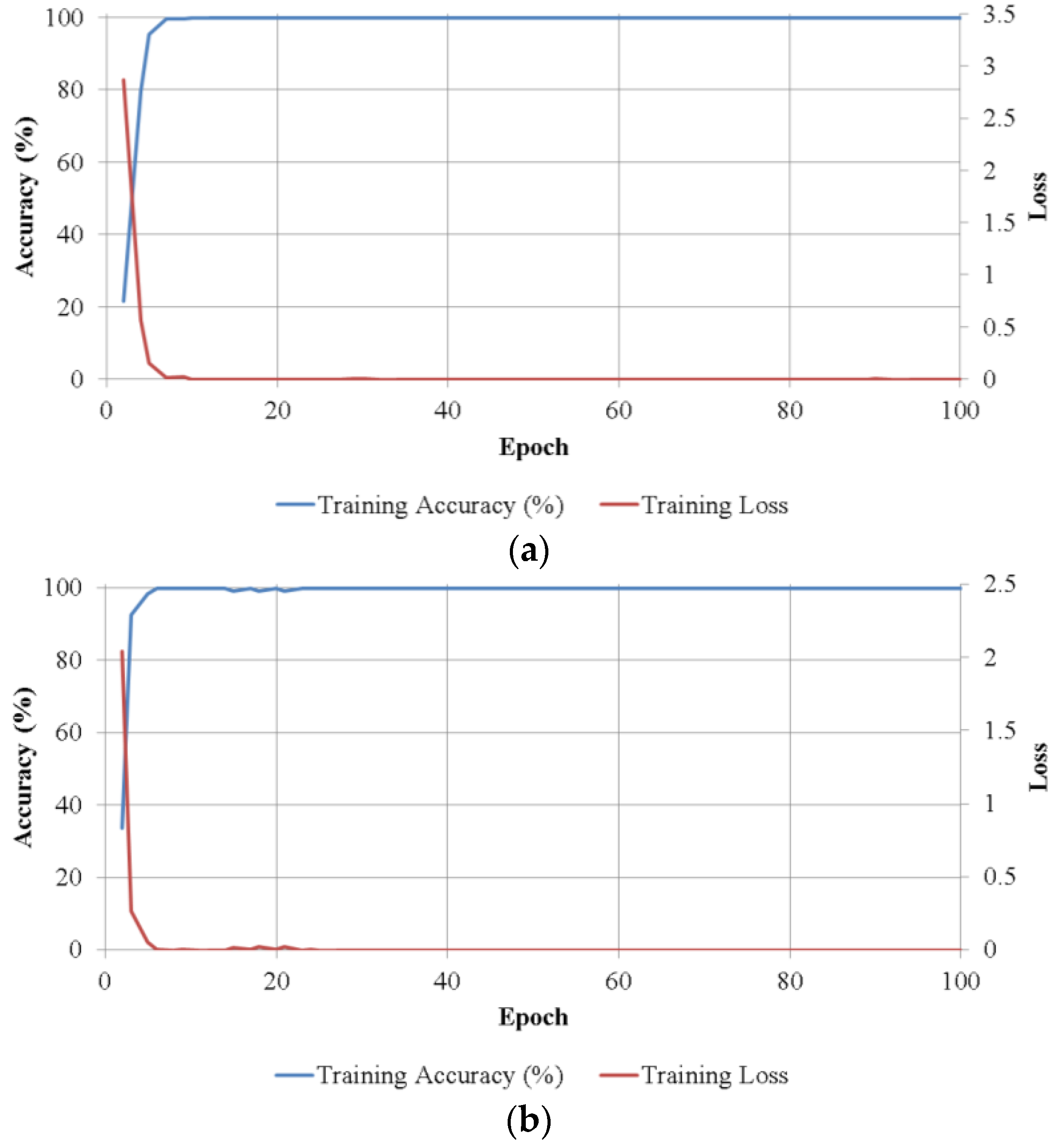
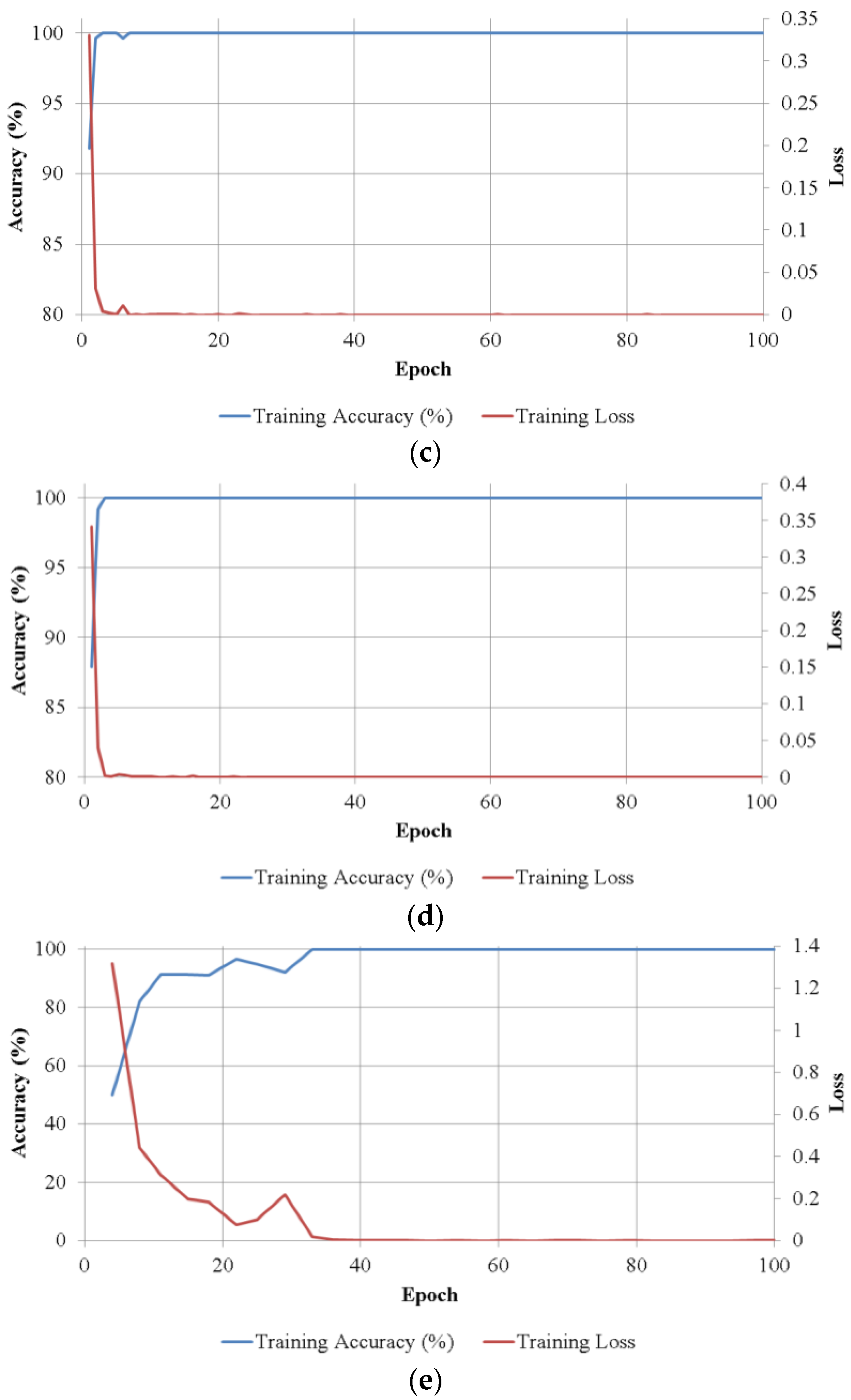
Figure 8 shows the training convergence graphs of the average batch loss and classification accuracy values of the two trainings in two-fold cross-validation according to the epoch number on each size class. As shown in
Figure 8, in all cases, accuracies increased and loss curve approaches zero with the increment of training epochs.
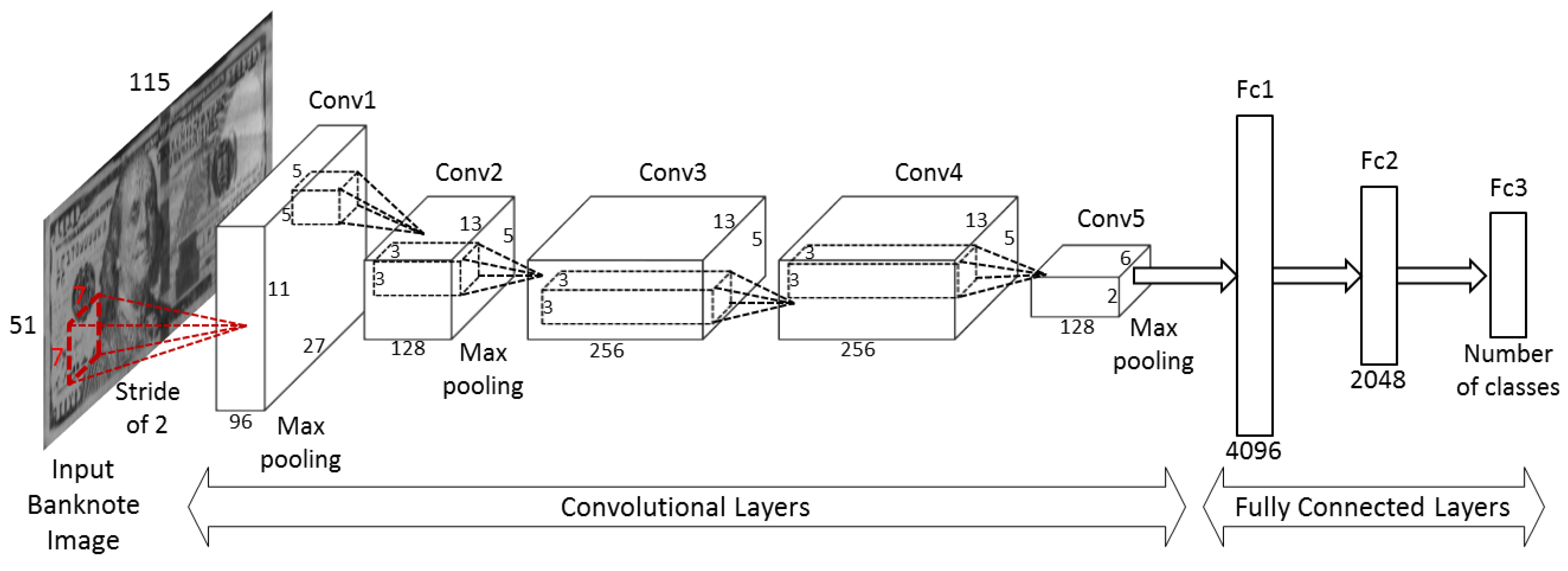
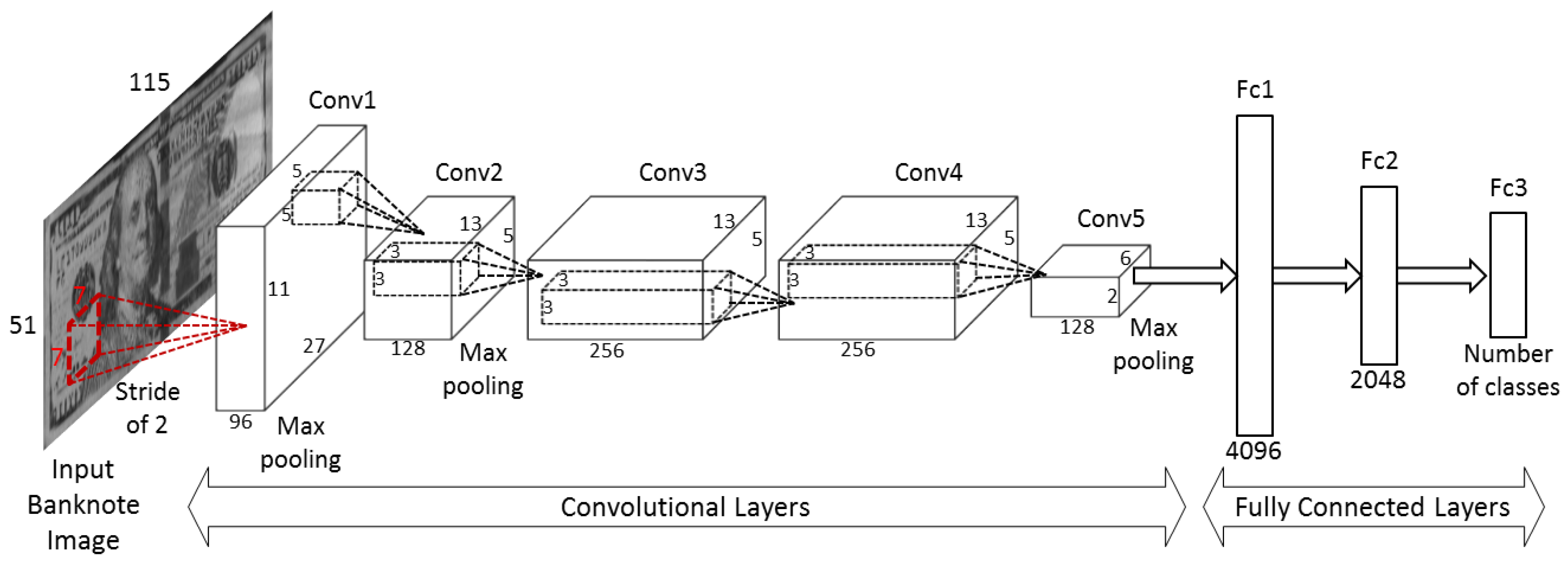
Figure 9 shows the 96 trained filters in the first convolutional layers of the CNN models obtained by two trainings of two-fold cross-validation on each size class. The original size of each filter is 7 × 7 pixels as shown in
Table 2. For visualization purpose, we resized each filter with the factor of 5 and scaled the original real values of filter weights to the range of gray scale images (0 to 255 of unsigned integer type).
With the trained CNN models, we measured the classification accuracies on the multi-national currency datasets. In the first experiment, we conducted the testing process of two-fold cross-validation separately on each dataset. We also compared the performance of the proposed method with that of the method in the previous study [
5] using two-fold cross-validation. When using the previous method in [
5], classification scores were selected as the matching distances between banknote’s feature vector to the trained K-means centroids of banknote classes [
5], and the score fusion method was also the SUM rule as shown in Equation (7). The comparative experimental results of the two-fold testing processes on the five banknote size classes are given in
Table 6. The average testing accuracies were calculated based on the number of accurately classified samples on each testing subset of the two-fold cross-validation method as follow [
41]:
where
ACC is the average testing accuracy,
GA1 and
GA2 are the number of correctly recognized samples (genuine acceptance cases of banknotes) in the first and second testing subsets, respectively, and
N is the total number of the samples in the dataset.
In the final testing experiment, we tested the recognition accuracy of the overall workflow of the proposed method as shown in
Figure 1. First, the banknote images in each testing subsets were pre-classified into five size classes according to their size information as shown in
Table 5. Banknote features were subsequently extracted and used for classification of national currency, denomination, and input direction by using the corresponding CNN model of the pre-classified size class. These overall testing results are also shown in
Table 6. With the average testing accuracy, we evaluated the performance of the proposed method in comparison to the accuracies reported for multi-national banknote recognition methods used in previous works [
12,
13], as shown in
Table 7.
It can be seen from
Table 6 that the proposed method correctly classifies banknotes from multiple countries in all test experiment cases. In the cases of the third and fourth size classes, our CNN-based method outperformed the previous study’s method in terms of higher recognition accuracy. From
Table 7, we can see that although the number of banknote images in our experimental database were greater than that in other studies of [
12,
13], and consisted of more classes than that in [
12], the proposed CNN-based multi-national banknote classification method outperforms the previous methods [
12,
13], in term of higher reported recognition accuracies.
Examples of classification error cases when using the previous method are shown in
Figure 10, in which both side images of misclassified banknotes were presented with the upper images are the original captured banknote images and the lower images was banknote region segmented image of the upper one.
It can be seen from
Figure 10 that Case 1 consists of banknote images captured from a creased banknote that caused a loss of information when performing sub-sampling on images in the method from [
5]; and Case 2 was from a severely bleached and damaged banknote. Both cases are from USD dataset which is included in the third and fourth size classes. The physical damage on these banknotes caused the misclassification when using the previous method in [
5]. However, when using CNN, all the cases were correctly recognized, due to the robustness of CNN to the quality of captured images [
26].











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}