
A Passive Learning Sensor Architecture for Multimodal Image Labeling: An Application for Social Robots

Abstract
:
1. Introduction
2. State-of-the-Art
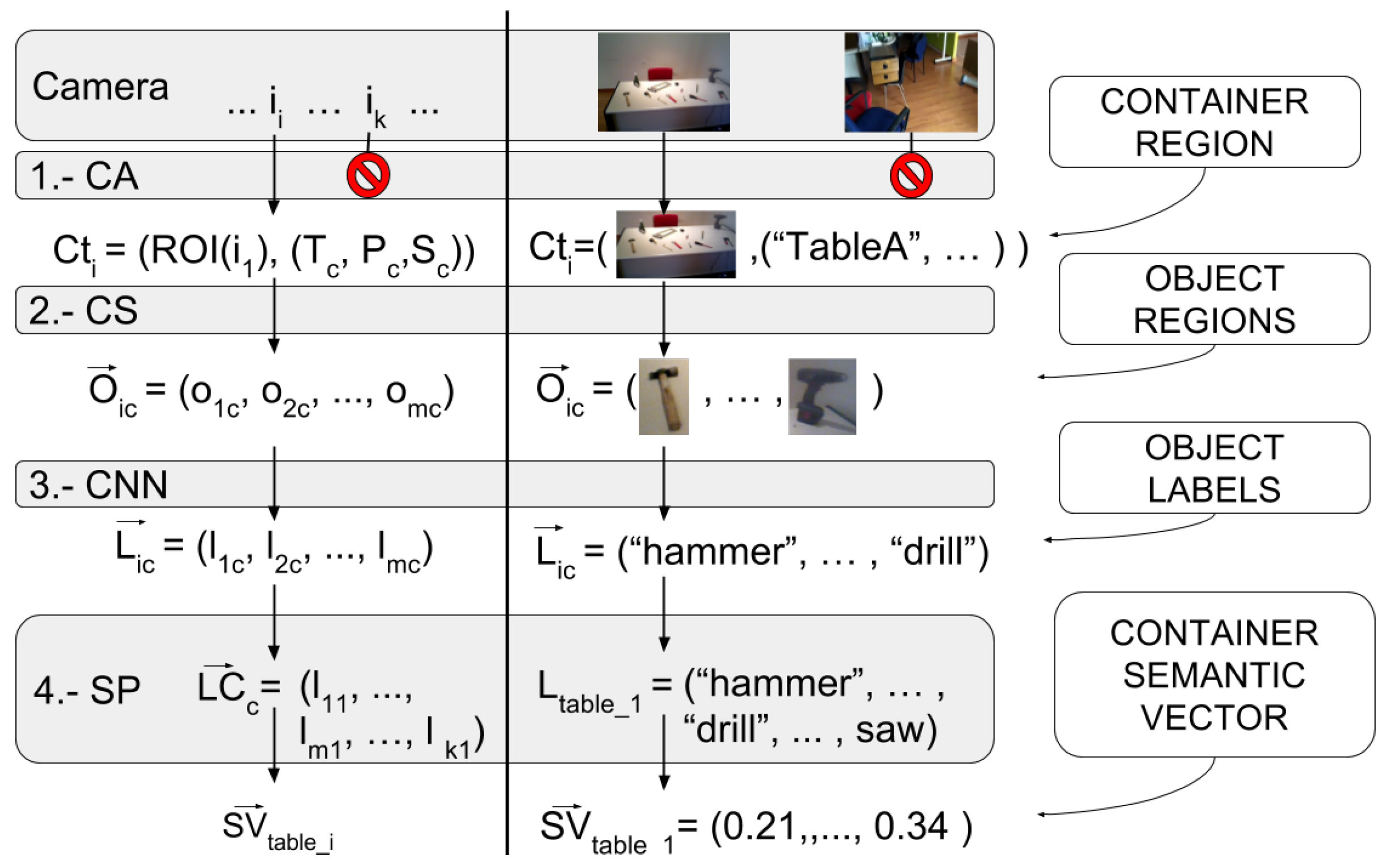
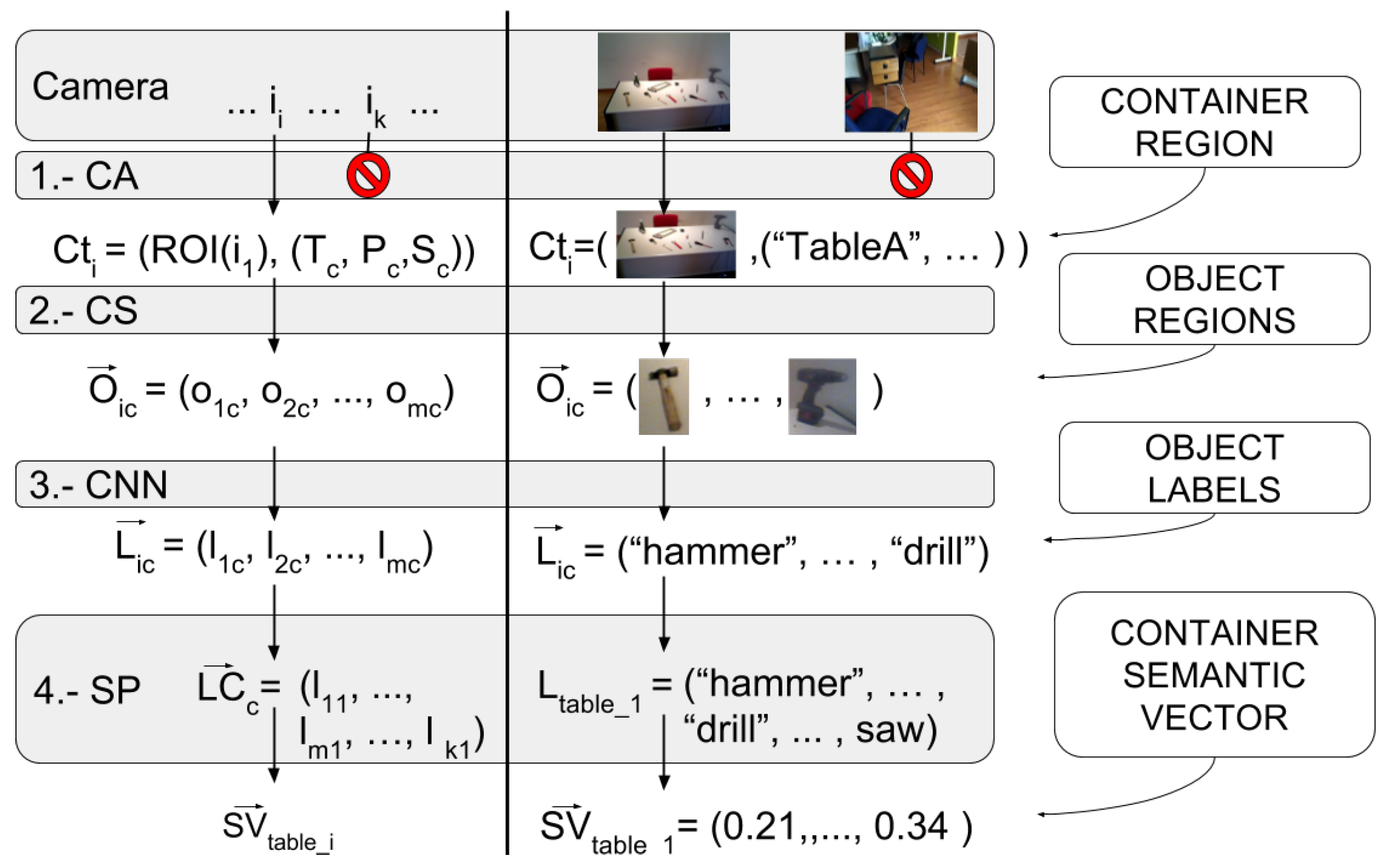
3. Passive Learning Sensor Architecture
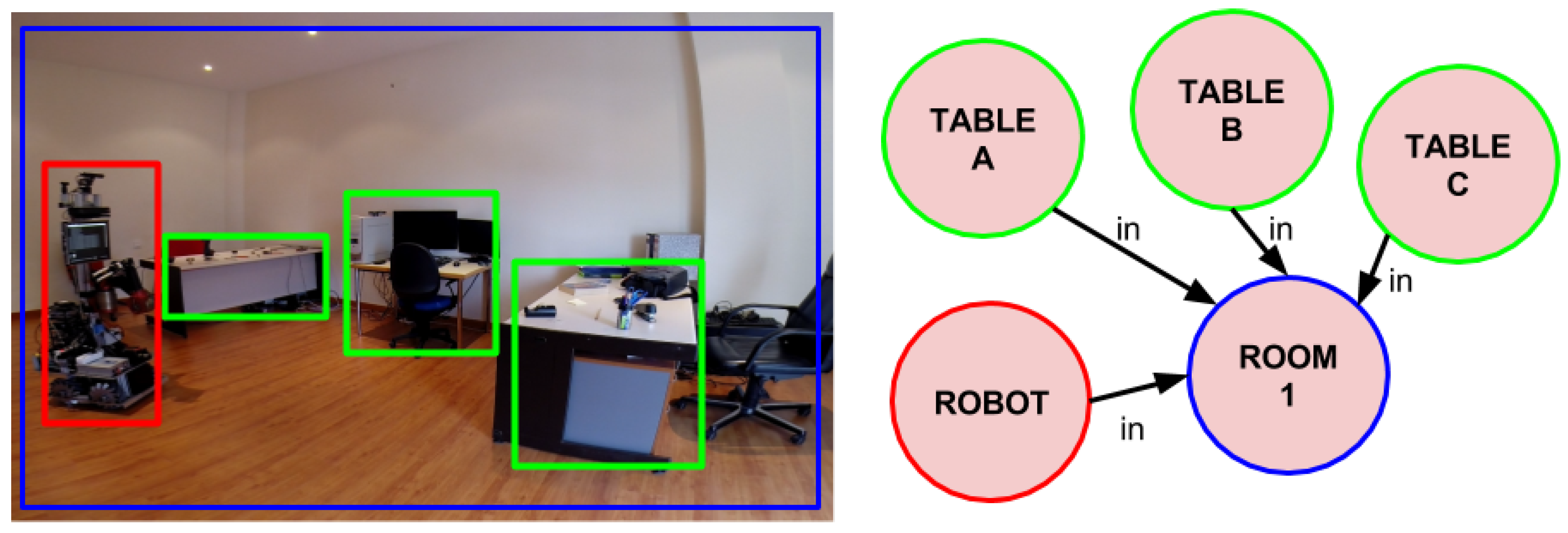
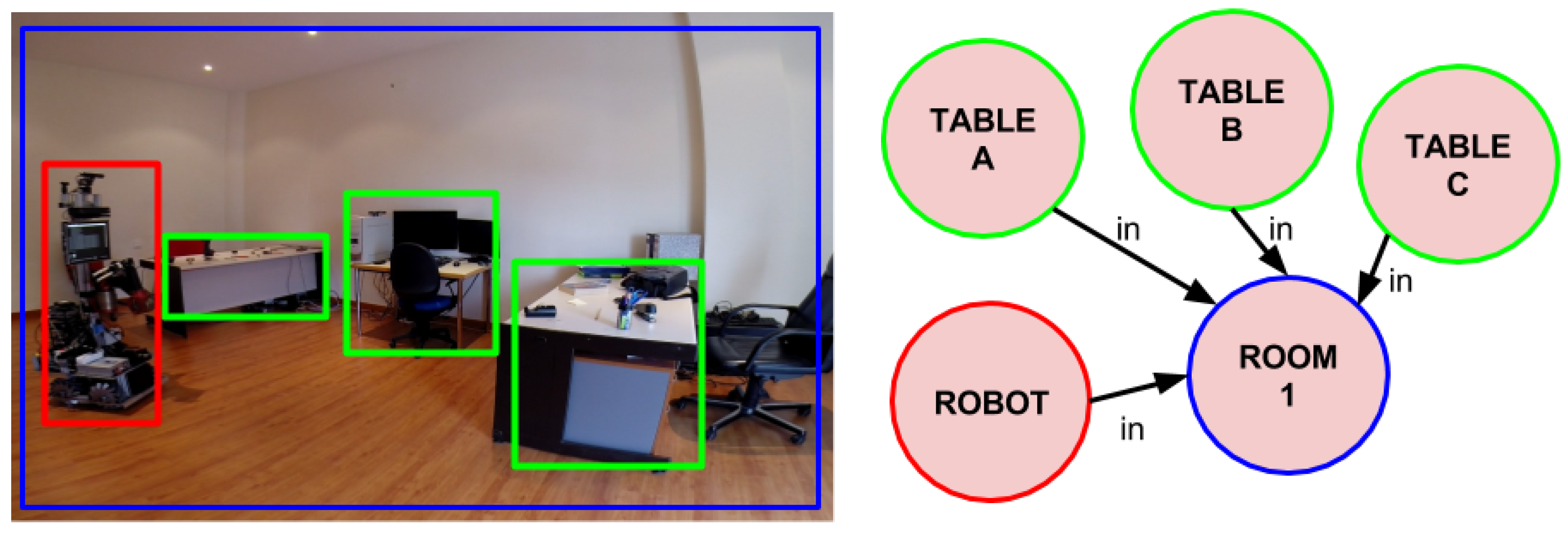
3.1. Cognitive Attention
3.2. Cognitive Subtraction
- Random sample consensus [20] is used to estimate the plane of the table using the point cloud of the scene acquired with the RGB-D camera. The border of the table is estimated using a convex hull of the 3D points laying within the table plane. Using this border information, an imaginary prism is created on top of the table. All the 3D points inside this prism are extracted and considered to belong to the unknown objects lying on the table.
- Different object point clouds are segmented using euclidean distance clustering [21]. A threshold distance to determine if points belong to the same object or to a new one is used (for the experiments conducted, 0.01 m).
- Candidate object point clouds are transformed to image coordinates and the image region corresponding to the object candidate is segmented.
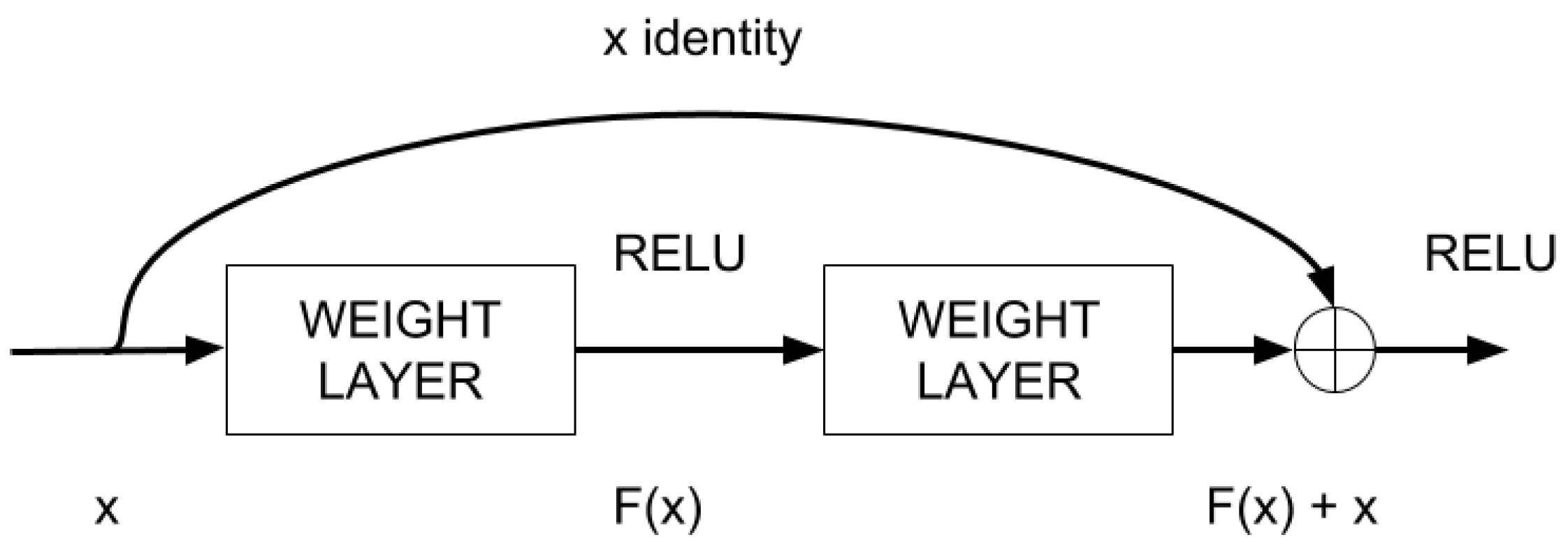
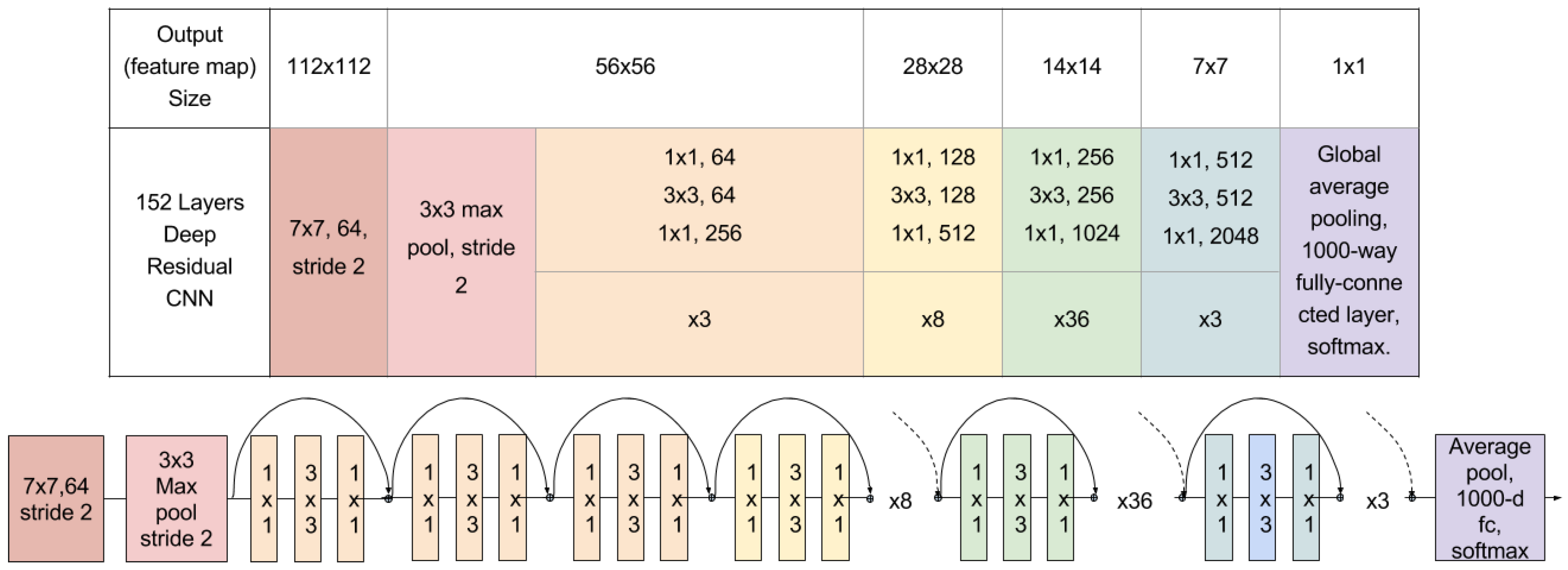
3.3. CNN Classification Step
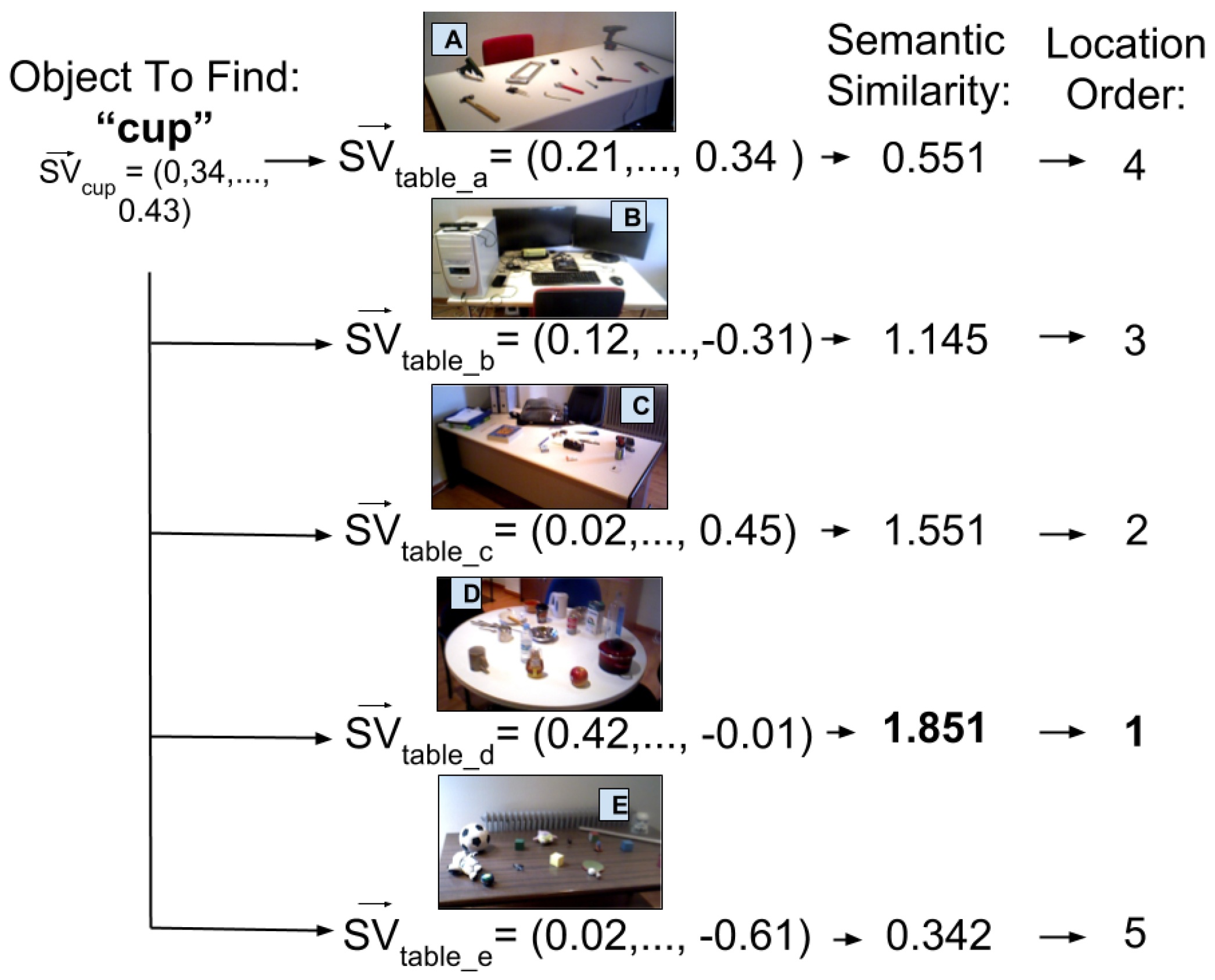
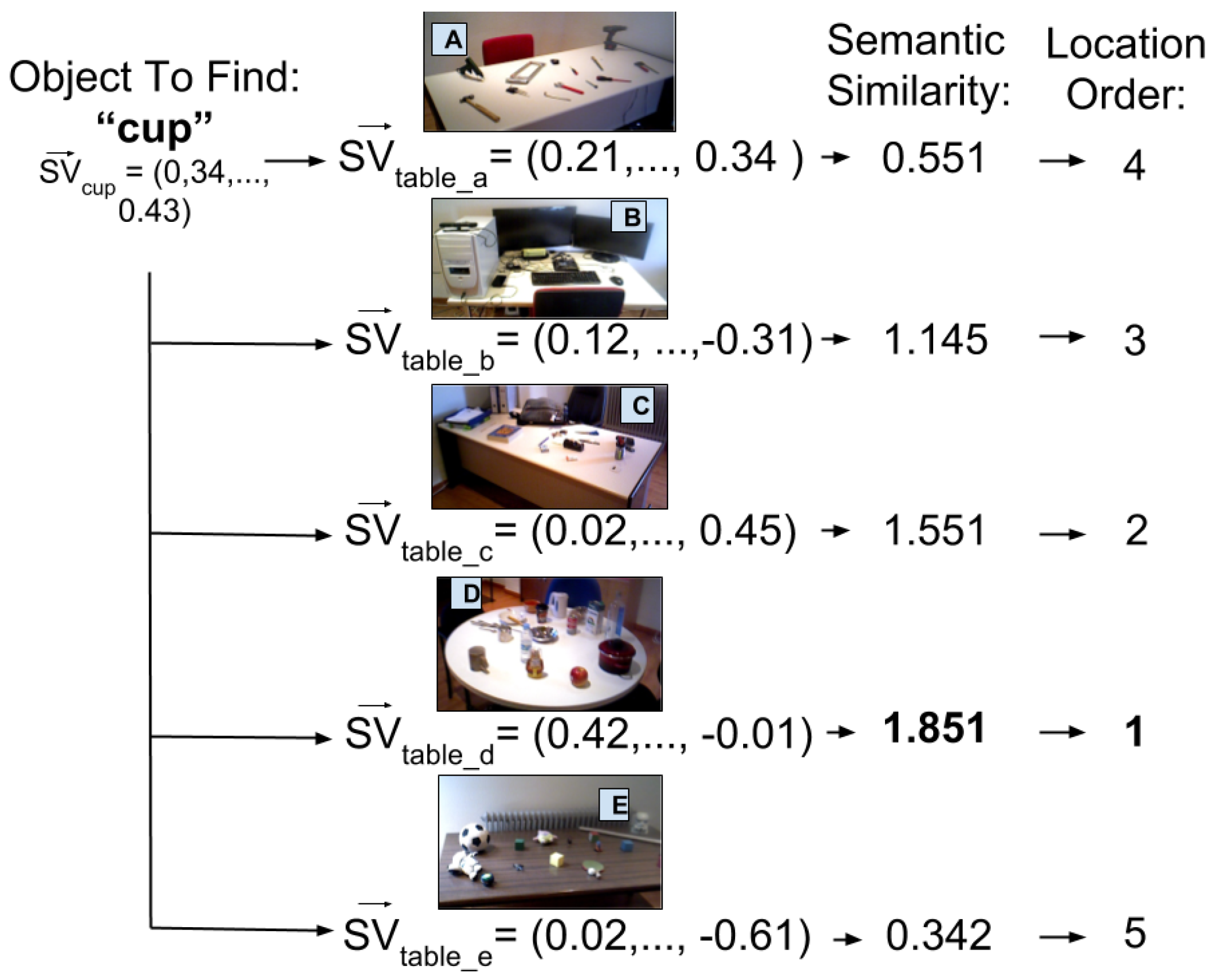
3.4. Semantic Processing
4. Experiments
- GoogleNet [25] is a 22 layers deep network (27 if pooling is taken into account) that makes use of “inception modules” which basically act as multiple convolution filter inputs, that are processed on the same source, while pooling at the same time. Another training of this network but without relighting data-augmentation was also tested (GoogleNet2).
- AlexNet, by Krizhevsky et al. [26], consists of eight layers, of which five are convolutional layers, with some of them being followed by maxpooling layers. The other three layers are fully-connected layers with a final 1000-way softmax.
- Very Deep Convolutional Networks by Simonyan et al., presented in [27] (VGG16) consist of a series of thirteen convolutional layers (also with maxpool in between), followed by three fully connected layers.
- Regions with Convolutional Neural Network (R-CNN) [28] performs localization and classification of the objects in the image. It generates category-independent region proposals, then a convolutional network extracts a fixed-length feature vector from each region and finally the third module, which is a set of class-specific linear SVMs, scores each feature vector. Since it performs localization by itself, no previous segmentation step is added to this network.
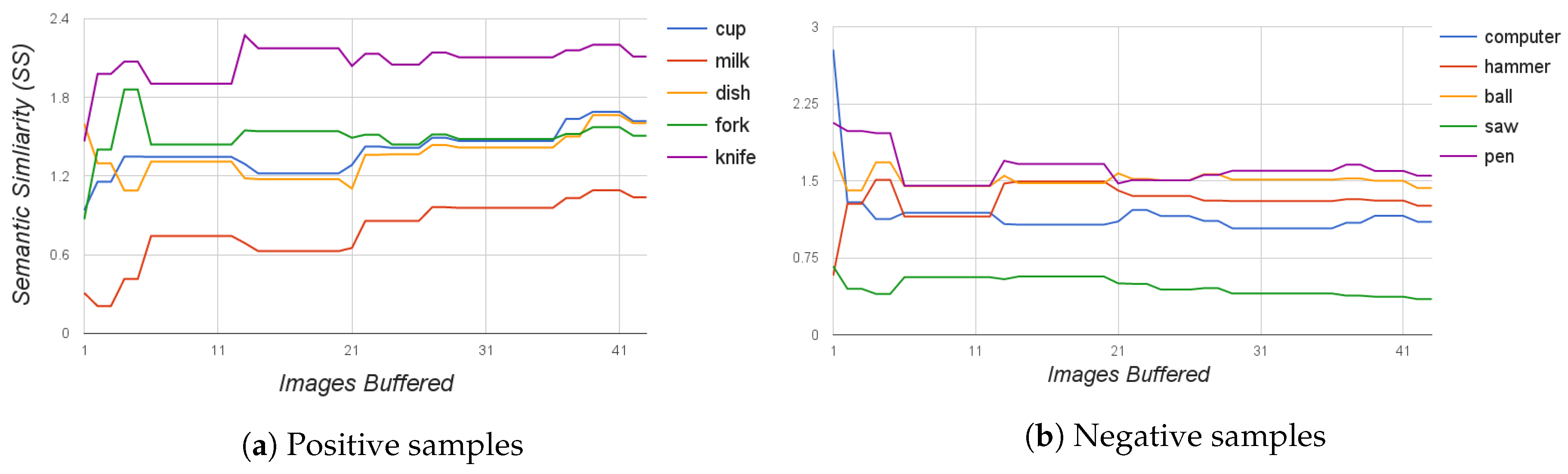
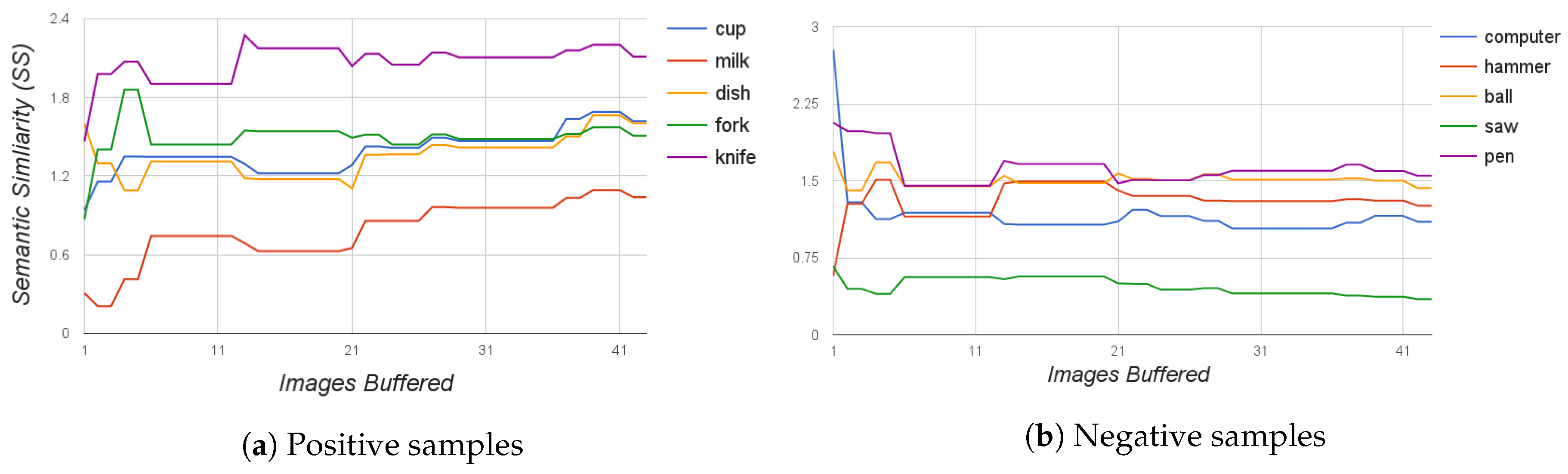
4.1. Tests on Image Buffering
4.2. Cognitive Attention Tests
4.3. Tests with Networks with Generic ImageNet Training
4.4. Tests with Networks with Fine-Tuned Training Datasets
- GoogLeNet2_ft: this model is the ImageNet trained GoogLeNet2 model with a retrain on the last full-connected layer for 138 classes.
- VGG16_fc1: is VGG16 fine-tuned on 1000 categories by simply training on new images.
- VGG16_fc2: uses the VGG16 model but retraining the last fully-connected layers on 136 categories.
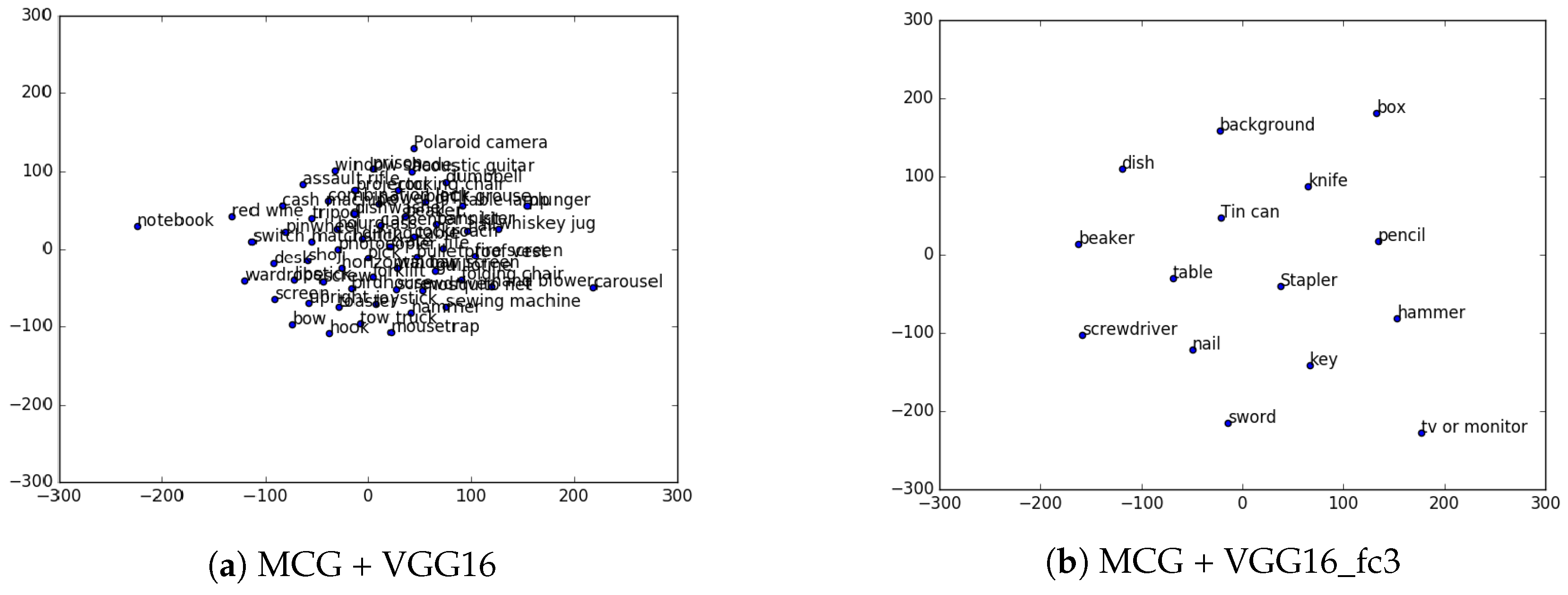
- VGG16_fc3: is VGG16 fine-tuned on 44 categories by changing the last fully-connected layer.
- R-CNN_m: is using the pretrained R-CNN with bounding boxes (region proposals) given by MCG instead of Selective Search.
5. Conclusions and Future Work
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| AGM | Active Grammar Model |
| API | Application Programming Interface |
| CA | Cognitive Attention |
| CNN | Convolutional Neural Network |
| CS | Cognitive Subtraction |
| DNN | Deep Neural Network |
| FLOP | Floating Point Operations |
| GPU | Graphic Process Unit |
| ILSVRC | ImageNet Large-Scale Visual Recognition Challenge |
| MCG | Multiscale Combinatorial Grouping |
| PLSA | Passive Learning Sensor Architecture |
| R-CNN | Regions with Convolutional Neural Networks |
| RELU | Rectifier Linear Unit |
| RGB-D | Red Green Blue Depth |
| ROI | Region Of Interest |
| SIFT | Scale Invariant Feature Transform |
| SP | Semantic Processing step |
| SV | Semantic Vector |
| SVM | Support Vector Machine |
| TH | Top-Hat |
| t-SNE | t-distributed Stochastic Neighbor Embedding |
| VGG | Visual Geometry Group |
| VOC | Visual Object Challenge |
References
- Kita, Y.; Kanehiro, F.; Ueshiba, T.; Kita, N. Strategy for Folding Clothing on the Basis of Deformable Models. In Proceedings of the 11th International Conference on Image Analysis and Recognition (ICIAR 2014), Vilamoura, Portugal, 22–24 October 2014; Campilho, A., Kamel, M., Eds.; Springer: Cham, Switzerland, 2014. Part II. pp. 442–452. [Google Scholar]
- Doty, K.L.; Harrison, R.R. Sweep Strategies for a Sensory-Driven, Behavior-Based Vacuum Cleaning Agent. In Proceedings of the AAAI 1993 Fall Symposium Series, Raleigh, NC, USA, 22–24 October 1993; pp. 1–6.
- Bollini, M.; Tellex, S.; Thompson, T.; Roy, N.; Rus, D. Interpreting and Executing Recipes with a Cooking Robot. In Proceedings of the 13th International Symposium on Experimental Robotics, Quebec City, QC, Canada, 18–21 June 2012; Desai, P.J., Dudek, G., Khatib, O., Kumar, V., Eds.; Springer: Heidelberg, Germany, 2013; pp. 481–495. [Google Scholar]
- Khosravi, P.; Ghapanchi, A.H. Investigating the effectiveness of technologies applied to assist seniors: A systematic literature review. Int. J. Med. Inform. 2016, 85, 17–26. [Google Scholar] [CrossRef] [PubMed]
- Kidd, C.D.; Orr, R.; Abowd, G.D.; Atkeson, C.G.; Essa, I.A.; MacIntyre, B.; Mynatt, E.; Starner, T.E.; Newstetter, W. The Aware Home: A Living Laboratory for Ubiquitous Computing Research. In Proceedings of the Second International Workshop on Cooperative Buildings, Integrating Information, Organizations, and Architecture (CoBuild’99), Pittsburgh, PA, USA, 1–2 October 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 191–198. [Google Scholar]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep neural networks for object detection. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2553–2561.
- Manso, L.J. Perception as Stochastic Grammar-Based Sampling on Dynamic Graph Spaces. Ph.D. Thesis, University of Extremadura, Badajoz, Spain, 2013. [Google Scholar]
- Woodman, G.F.; Chun, M.M. The role of working memory and long-term memory in visual search. Vis. Cognit. 2006, 14, 808–830. [Google Scholar] [CrossRef]
- Rangel, J.C.; Cazorla, M.; García-Varea, I.; Martínez-Gómez, J.; Élisa, F.; Sebban, M. Scene classification based on semantic labeling. Adv. Robot. 2016, 30, 758–769. [Google Scholar] [CrossRef]
- Gutierrez, M.A.; Banchs, R.E.; D’Haro, L.F. Perceptive Parallel Processes Coordinating Geometry and Texture. In Proceedings of the Workshop on Multimodal Semantics for Robotics Systems (MuSRobS) and International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015.
- Aydemir, A.; Pronobis, A.; Göbelbecker, M.; Jensfelt, P. Active Visual Object Search in Unknown Environments Using Uncertain Semantics. IEEE Trans. Robot. 2013, 29, 986–1002. [Google Scholar] [CrossRef]
- Saidi, F.; Stasse, O.; Yokoi, K.; Kanehirot, F. Online object search with a humanoid robot. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 1677–1682.
- Elfring, J.; Jansen, S.; van de Molengraft, R.; Steinbuch, M. Active Object Search Exploiting Probabilistic Object–Object Relations. In RoboCup 2013: Robot World Cup XVII; Behnke, S., Veloso, M., Visser, A., Xiong, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 13–24. [Google Scholar]
- Sjö, K.; López, D.G.; Paul, C.; Jensfelt, P.; Kragic, D. Object search and localization for an indoor mobile robot. CIT J. Comput. Inf. Technol. 2009, 17, 67–80. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Manso, L.J.; Calderita, L.V.; Bustos, P.; Bandera, A. Use and Advances in the Active Grammar-based Modeling Architecture. In Proceedings of the International Workshop on Physical Agents 2016, Malaga, Spain, 16–17 June 2016; pp. 31–36.
- Milliez, G.; Warnier, M.; Clodic, A.; Alami, R. A framework for endowing an interactive robot with reasoning capabilities about perspective-taking and belief management. In Proceedings of the 23rd IEEE International Symposium on Robot and Human Interactive Communication, Edinburgh, UK, 25–29 August 2014; pp. 1103–1109.
- Foote, T. tf: The transform library. In Proceedings of the 2013 IEEE International Conference on Technologies for Practical Robot Applications (TePRA), Woburn, MA, USA, 22–23 April 2013; pp. 1–6.
- Cotterill, R.M. Cooperation of the basal ganglia, cerebellum, sensory cerebrum and hippocampus: Possible implications for cognition, consciousness, intelligence and creativity. Prog. Neurobiol. 2001, 64, 1–33. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data Clustering: A Review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
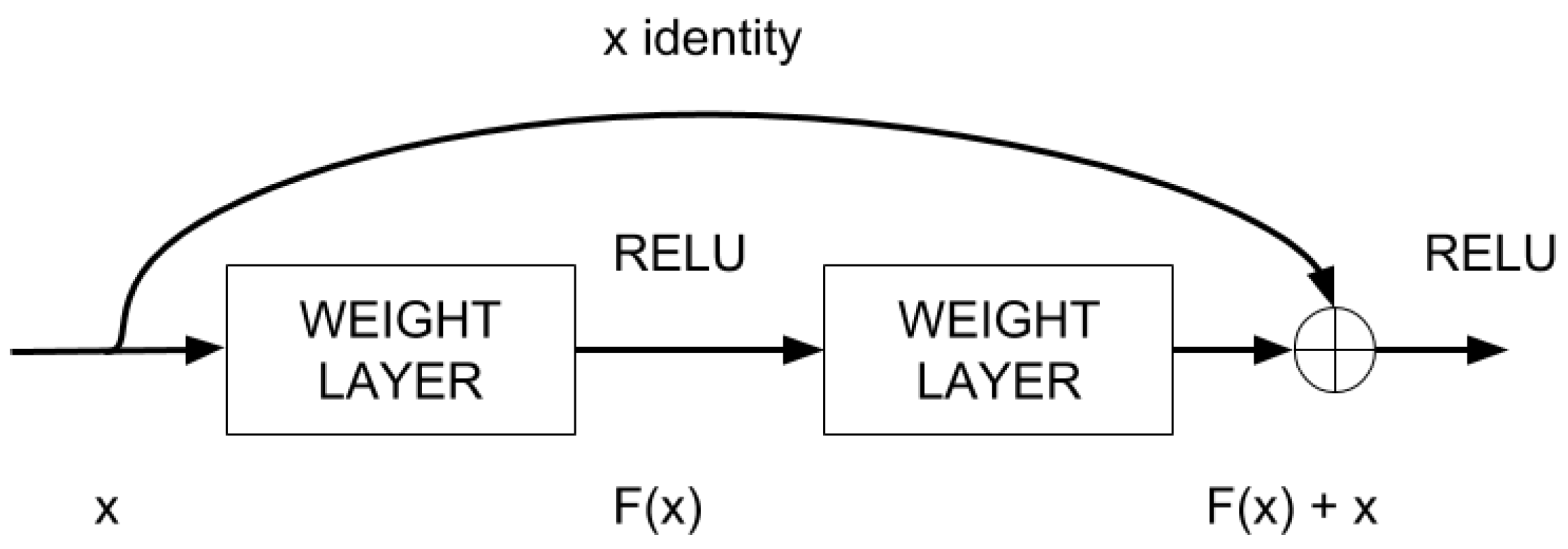
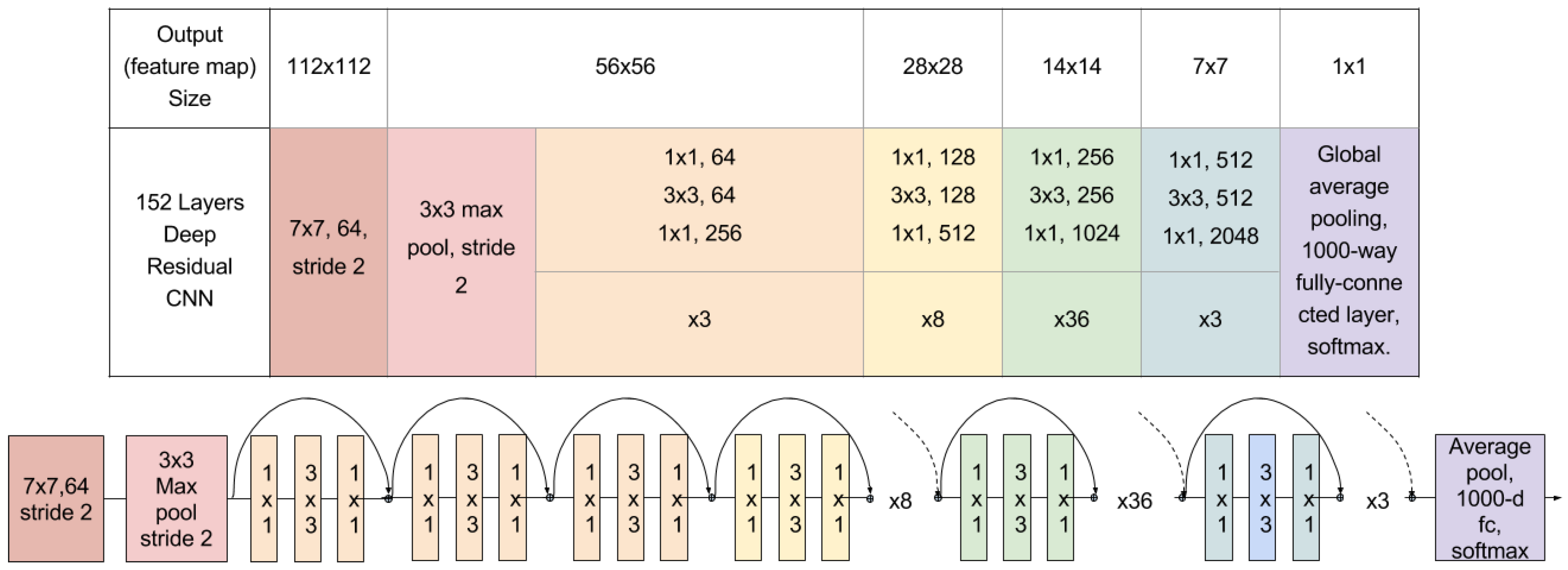
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814.
- Mikolov, T.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013.
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105.
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Meyer, F. Contrast feature extraction. In Analyse Quantitative des Microstructures en Sciences des Materiaux, Biologie et Medecine; Cherman, J.L., Ed.; Rieder: Stuttgart, Germany, 1977; p. 374. [Google Scholar]
- Pont-Tuset, J.; Arbelaez, P.; Barron, J.; Marques, F.; Malik, J. Multiscale Combinatorial Grouping for Image Segmentation and Object Proposal Generation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 128–140. [Google Scholar] [CrossRef] [PubMed]
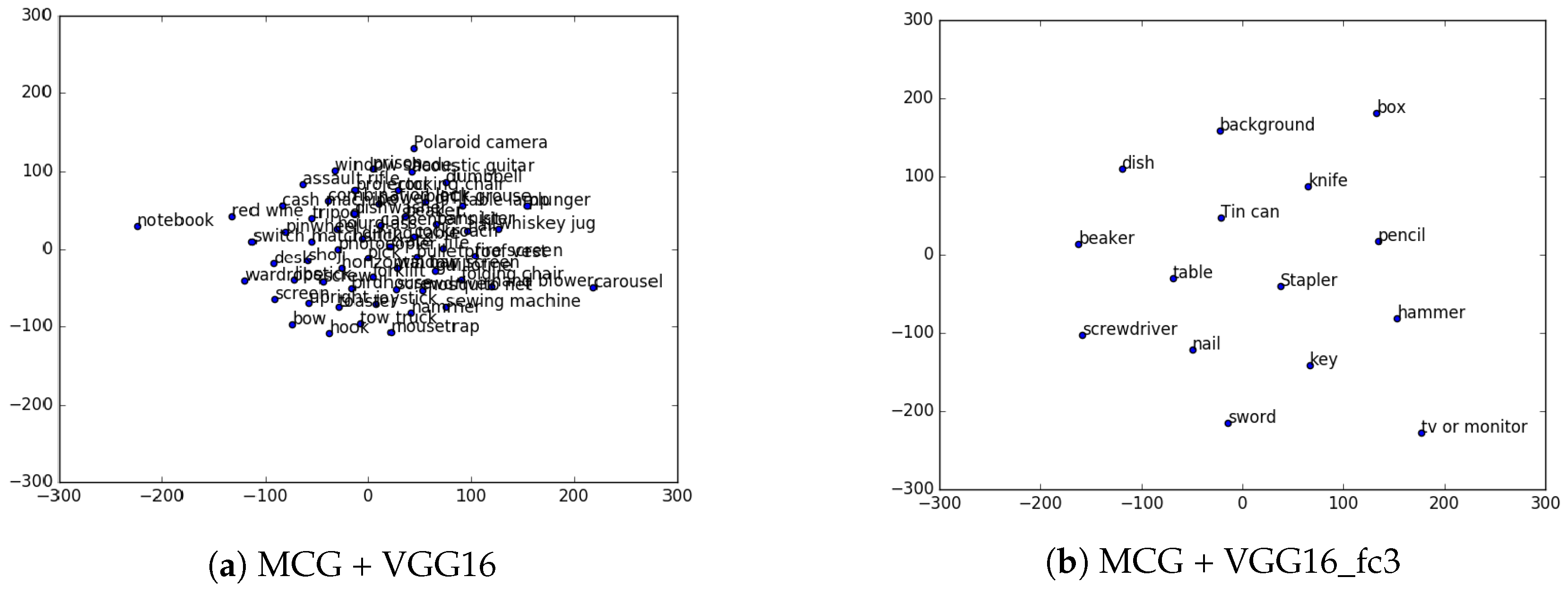
- Van der Maaten, L.; Hinton, G. Visualizing non-metric similarities in multiple maps. Mach. Learn. 2012, 87, 33–55. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Full Image | Cognitive Attention |
|---|---|---|
| PLSA (no semantics) | 0.4 | 0.65 |
| TH + GoogLeNet | 0.35 | 0.35 |
| TH + GoogLeNet2 | 0.35 | 0.35 |
| TH + AlexNet | 0.2 | 0.35 |
| TH + VGG16 | 0.55 | 0.6 |
| Method | Direct Match | Semantic Processing |
|---|---|---|
| PLSA | 0.65 | 0.75 |
| TH + GoogleNet | 0.35 | 0.45 |
| TH + GoogleNet2 | 0.35 | 0.45 |
| TH + AlexNet | 0.35 | 0.1 |
| TH + VGG16 | 0.6 | 0.6 |
| MCG + GoogleNet | 0.5 | 0.5 |
| MCG + AlexNet | 0.15 | 0.25 |
| MCG + ResNet | 0.55 | 0.55 |
| MCG + VGG16 | 0.55 | 0.45 |
| CS + GoogleNet | 0.45 | 0.5 |
| CS + GoogleNet2 | 0.6 | 0.65 |
| CS + AlexNet | 0.2 | 0.25 |
| CS + VGG16 | 0.45 | 0.45 |
| R-CNN | 0.4 | 0.0 |
| Method | Direct Match | Semantic Processing |
|---|---|---|
| PLSA | 0.65 | 0.75 |
| TH + VGG16_fc1 | 0.5 | 0.4 |
| TH + VGG16_fc2 | 0.65 | 0.45 |
| TH + VGG16_fc3 | 0.4 | 0.4 |
| TH + GoogleNet2_ft | 0.35 | 0.6 |
| MCG + VGG16_fc1 | 0.5 | 0.4 |
| MCG + VGG16_fc2 | 0.55 | 0.55 |
| MCG + VGG16_fc3 | 0.55 | 0.4 |
| MCG + GoogleNet2_ft | 0.35 | 0.4 |
| CS + VGG16_fc1 | 0.65 | 0.6 |
| CS + VGG16_fc2 | 0.6 | 0.5 |
| CS + VGG16_fc3 | 0.5 | 0.5 |
| CS + GoogleNet2_ft | 0.45 | 0.4 |
| R-CNN_m | 0.35 | 0.2 |
| Method | Table A | Table B | Table C | Table D | Table E |
|---|---|---|---|---|---|
| MCG + VGG16 | 0.6014 | 0.3906 | 0.37714 | 0.33766 | 0.4097 |
| MCG + VGG16_fc1 | 0.19741 | 0.23967 | 0.19976 | 0.21568 | 0.28264 |
| MCG + VGG16_fc2 | 0.18415 | 0.22191 | 0.18938 | 0.17405 | 0.24179 |
| MCG + VGG16_fc3 | 0.2178 | 0.19943 | 0.18505 | 0.20464 | 0.23815 |
| MCG + GoogLeNet2 | 0.28346 | 0.2965 | 0.24557 | 0.2136 | 0.36935 |
| MCG + GoogLeNet2_ft | 0.18915 | 0.19017 | 0.18314 | 0.18309 | 0.32282 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gutiérrez, M.A.; Manso, L.J.; Pandya, H.; Núñez, P. A Passive Learning Sensor Architecture for Multimodal Image Labeling: An Application for Social Robots. Sensors 2017, 17, 353. https://doi.org/10.3390/s17020353
Gutiérrez MA, Manso LJ, Pandya H, Núñez P. A Passive Learning Sensor Architecture for Multimodal Image Labeling: An Application for Social Robots. Sensors. 2017; 17(2):353. https://doi.org/10.3390/s17020353
Chicago/Turabian StyleGutiérrez, Marco A., Luis J. Manso, Harit Pandya, and Pedro Núñez. 2017. "A Passive Learning Sensor Architecture for Multimodal Image Labeling: An Application for Social Robots" Sensors 17, no. 2: 353. https://doi.org/10.3390/s17020353
APA StyleGutiérrez, M. A., Manso, L. J., Pandya, H., & Núñez, P. (2017). A Passive Learning Sensor Architecture for Multimodal Image Labeling: An Application for Social Robots. Sensors, 17(2), 353. https://doi.org/10.3390/s17020353