
RGB-D SLAM Based on Extended Bundle Adjustment with 2D and 3D Information

Abstract
:1. Introduction
2. Methodology
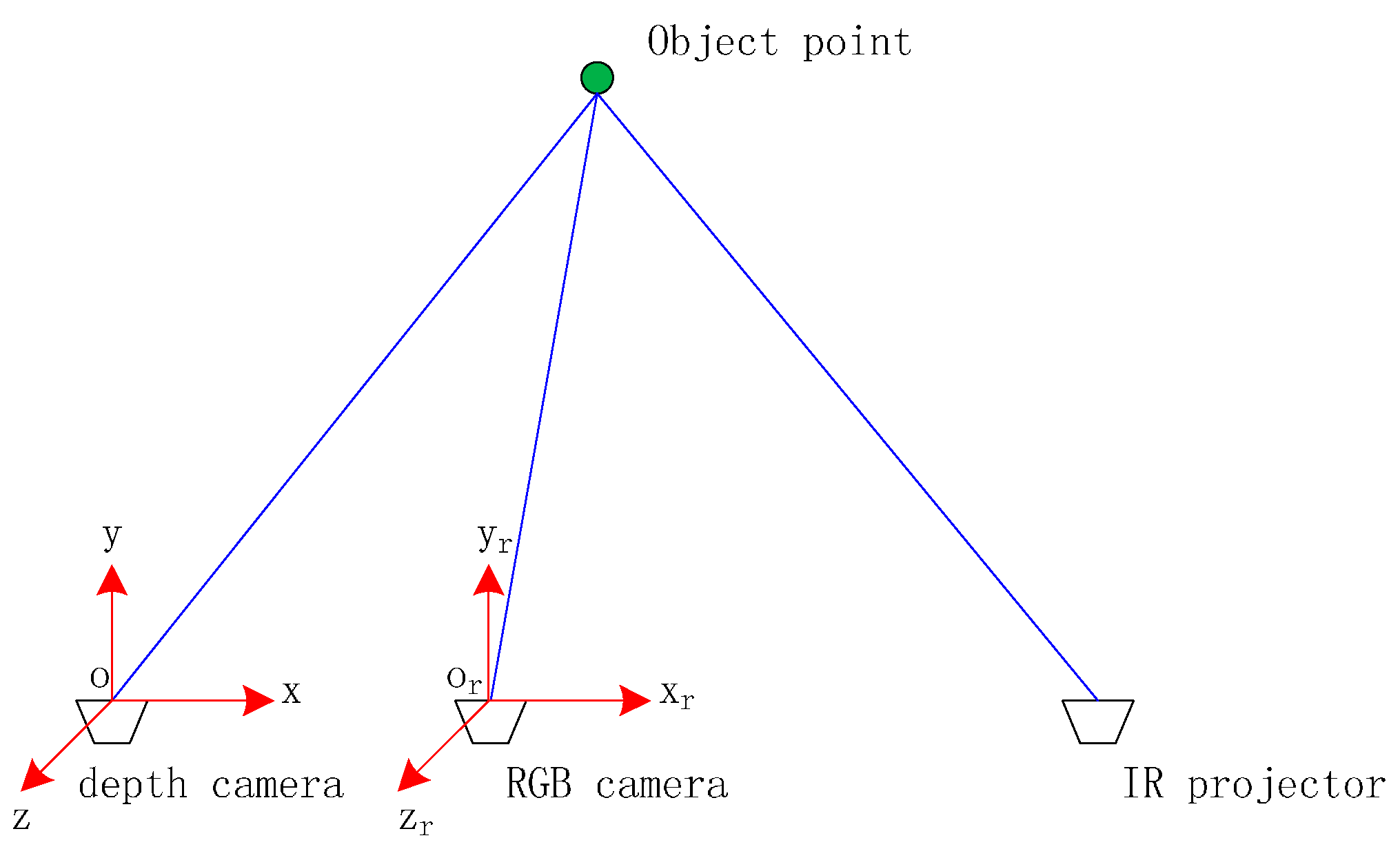
2.1. RGB Image and Depth Image Registration through Camera Calibration
2.2. 2D and 3D Feature Detection and Matching
2.3. Initial Exterior Orientation Calculation
2.4. Extended Bundle Adjustment with Image and Depth Measurements
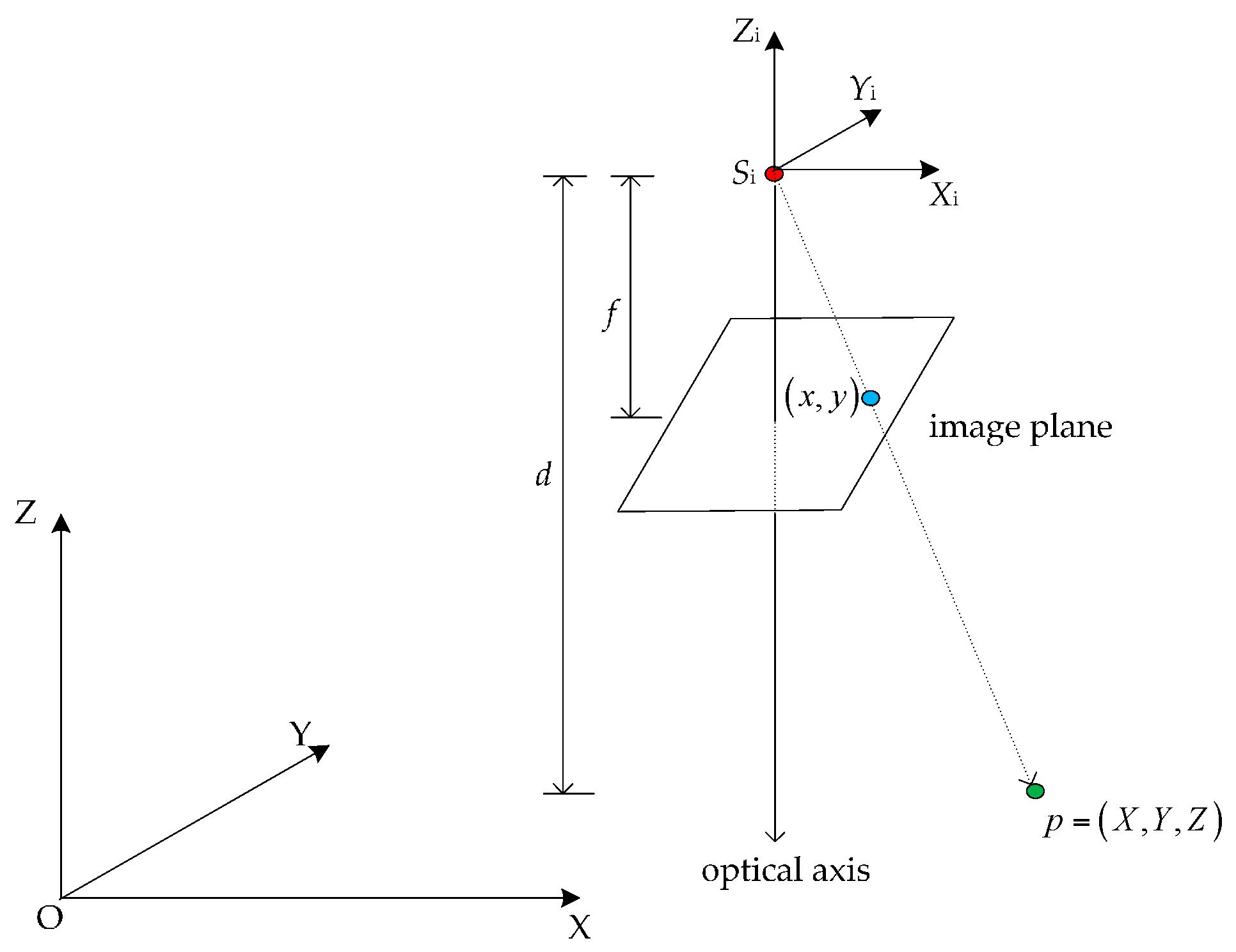
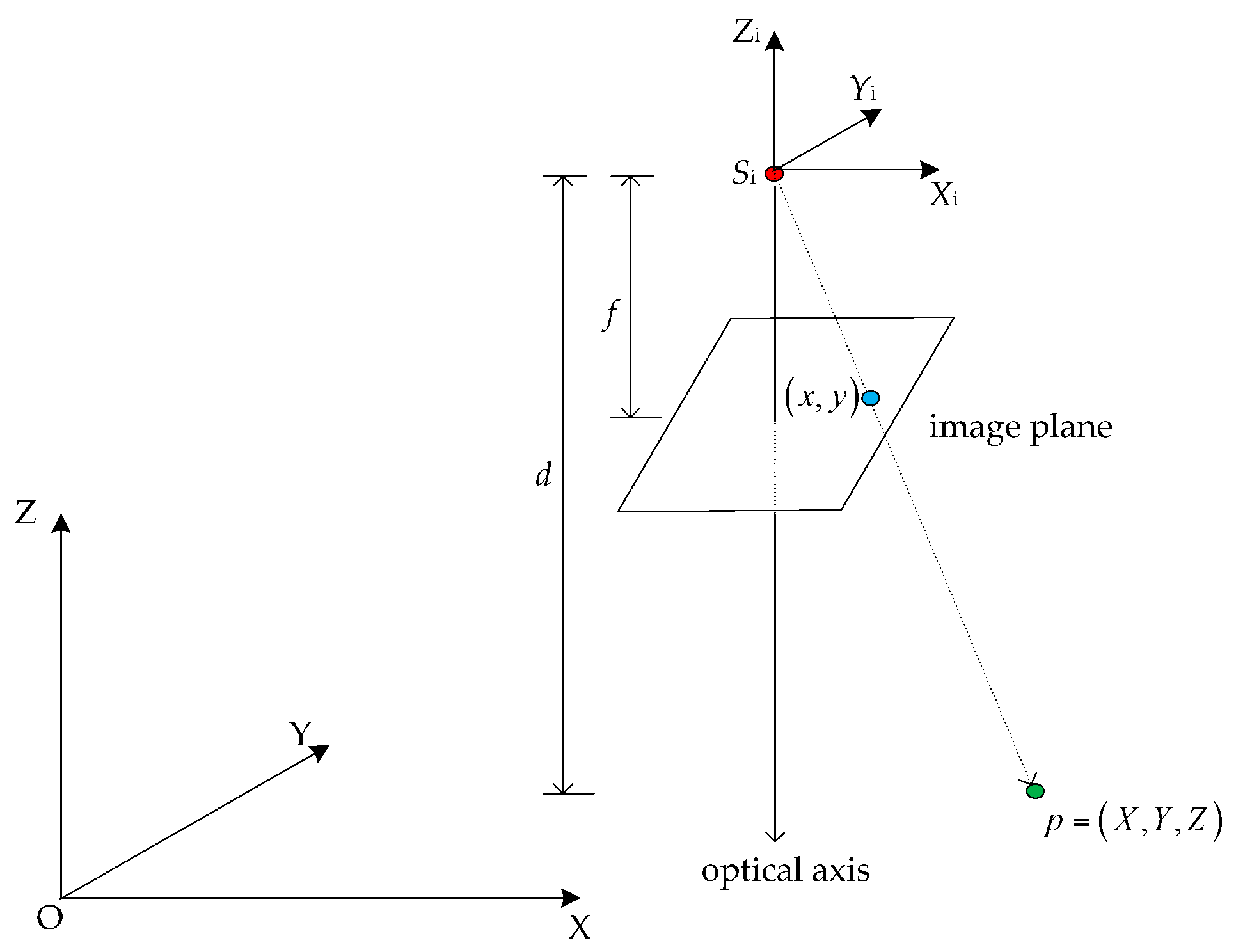
2.4.1. Projection Model
2.4.2. Error Model
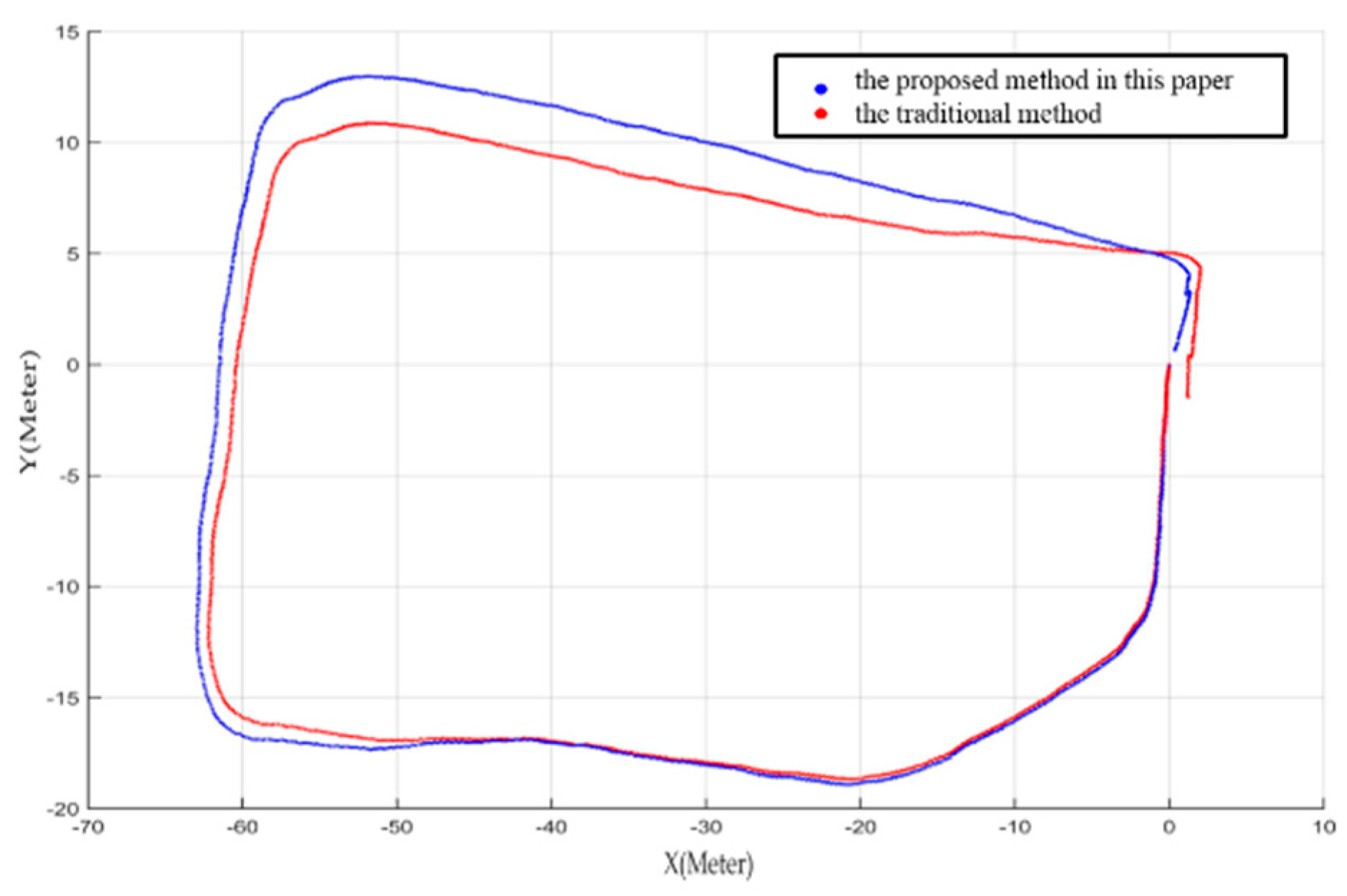
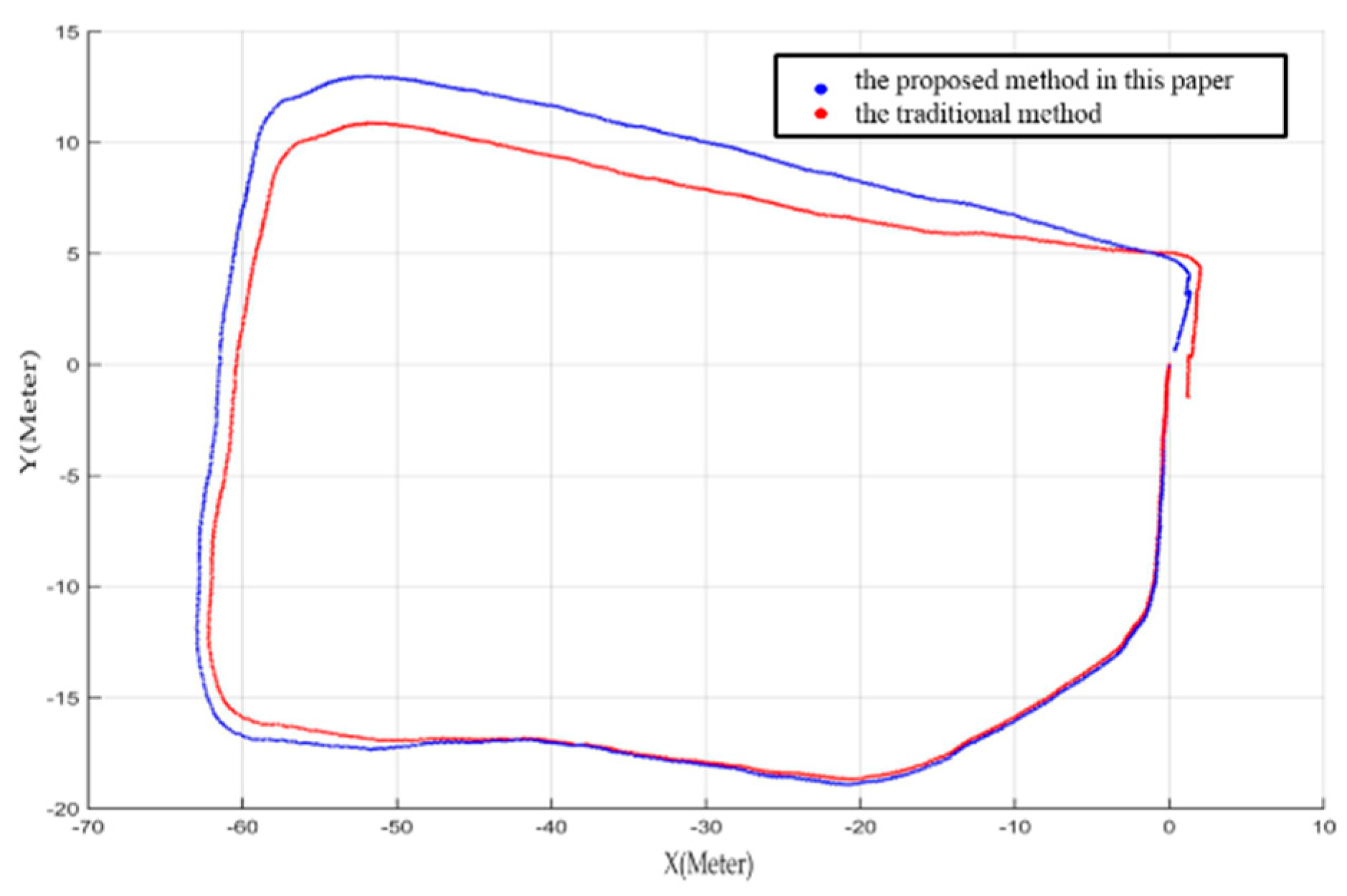
3. Experimental Results
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Dissanayake, M.W.M.G.; Newman, P.; Clark, S.; Durrant-Whyte, H.F.; Csorba, M.A. Solution to the simultaneous localization and map building (SLAM) problem. IEEE Trans. Robot. Autom. 2001, 17, 229–241. [Google Scholar] [CrossRef]
- Montemerlo, M.; Thrun, S.; Koller, D.; Wegbreit, B. FastSLAM: A factored solution to the simultaneous localization and mapping problem. In Proceedings of the 18th National Conference on Artificial Intelligence, Edmonton, Canada, 28 July–1 August 2002; pp. 593–598.
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- Bailey, T.; Durrant-Whyte, H. Simultaneous localization and mapping (SLAM): Part II. IEEE Robot. Autom. Mag. 2006, 13, 108–117. [Google Scholar] [CrossRef]
- Cheng, Y.; Maimone, M.W.; Matthies, L. Visual odometry on the Mars exploration rovers—A tool to ensure accurate driving and science imaging. IEEE Robot. Autom. Mag. 2006, 13, 54–62. [Google Scholar] [CrossRef]
- Maimone, M.; Cheng, Y.; Matthies, L. Two years of visual odometry on the mars exploration rovers: Field reports. J. Field Robot. 2007, 24, 169–186. [Google Scholar] [CrossRef]
- Di, K.; Xu, F.; Wang, J.; Agarwal, S.; Brodyagina, E.; Li, R.; Matthies, L. Photogrammetric processing of rover imagery of the 2003 Mars Exploration Rover mission. ISPRS J. Photogramm. Remote Sens. 2008, 63, 181–201. [Google Scholar] [CrossRef]
- Wang, B.F.; Zhou, J.L.; Tang, G.S. Research on visual localization method of lunar rover. Sci. China Inf. Sci. 2014, 44, 452–260. [Google Scholar]
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. KinectFusion: Real-time 3D reconstruction and interaction using a moving depth camera. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, New York, NY, USA, 16–19 October 2011; pp. 559–568.
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the 10th IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Basel, Switzerland, 26–29 October 2011; pp. 127–136.
- Khoshelham, K.; Elberink, S. Accuracy and resolution of kinect depth data for indoor mapping applications. Sensor 2012, 12, 1437–1454. [Google Scholar] [CrossRef] [PubMed]
- Smisek, J.; Jancosek, M.; Pajdla, T. 3D with Kinect. In Consumer Depth Cameras for Computer Vision; Springer: London, UK, 2011; pp. 1154–1160. [Google Scholar]
- Daniel, H.C.; Kannala, J.; Heikkil, J. Joint depth and color camera calibration with distortion correction. IEEE Trans. Softw. Eng. 2012, 34, 2058–2064. [Google Scholar]
- Butkiewicz, T. Low-cost coastal mapping using Kinect v2 time-of-flight cameras. In Proceedings of the IEEE Oceanic Engineering Society (OCEANS), St. John’s, NL, Canada, 14–19 September 2014; pp. 1–9.
- Fankhauser, P.; Bloesch, M.; Rodriguez, D.; Kaestner, R.; Hutter, M.; Siegwart, R. Kinect v2 for mobile robot navigation: Evaluation and modeling. In Proceedings of the 2015 IEEE International Conference on Advanced Robotics (ICAR), Istanbul, Turkey, 27–31 July 2015; pp. 388–394.
- Lee, S.; Ho, Y. Real-time stereo view generation using kinect depth camera. In Proceedings of Asia-Pacific Singal and Information Processing Association Annual Summit and Conference, Xi’an, China, 18–21 October 2011; pp. 1–4.
- Chen, X.M.; Jiang, L.T.; Ying, R.D. Research of 3D reconstruction and filtering algorithm based on depth information of Kinect. Appl. Res. Comput. 2013, 4, 1216–1218. [Google Scholar]
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.; Fox, D. RGB-D mapping: Using kinect-style depth cameras for dense 3D modeling of indoor environments. Int. J. Robot. Res. 2012, 31, 647–663. [Google Scholar] [CrossRef]
- Huang, A.S.; Bachrach, A.; Henry, P.; Krainin, M.; Maturana, D.; Fox, D.; Roy, N. Visual odometry and mapping for autonomous flight using an RGB-D camera. In Proceedings of the 15th International Symposium on Robotics Research (ISRR), Flagstaff, AZ, USA, 28 August–1 September 2011.
- Endres, F.; Hess, J.; Sturm, J.; Cremers, D.; Burgard, W. 3-D mapping with an RGB-D camera. IEEE Trans. Robot. 2014, 30, 177–187. [Google Scholar] [CrossRef]
- Hu, G.; Huang, S.; Zhao, L.; Alempijevic, A.; Dissanayake, G. A robust RGB-D SLAM algorithm. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 1714–1719.
- Kerl, C.; Sturm, J.; Cremers, D. Dense visual SLAM for RGB-D cameras. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 2100–2106.
- Maier, R.; Sturm, J.; Cremers, D. Submap-based bundle adjustment for 3D reconstruction from RGB-D data. In Proceedings of the 36th German Conference on Pattern Recognition, Münster, Germany, 2–5 September 2014; pp. 54–65.
- Dryanovski, I.; Valenti, R.G.; Xiao, J. Fast visual odometry and mapping from RGB-D data. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 2305–2310.
- Whelan, T.; Kaess, M.; Johannsson, H.; Fallon, M.; Leonard, J.J.; McDonald, J. Real-time large-scale dense RGB-D SLAM with volumetric fusion. Int. J. Robot. Res. 2015, 34, 598–626. [Google Scholar] [CrossRef]
- Heredia, M.; Endres, F.; Burgard, W.; Sanz, R. Fast and Robust Feature Matching for RGB-D Based Localization. 2015. Available online: http://arxiv.org/abs/ 1502.00500 (accessed on 11 August 2016).
- Song, H.R.; Choi, W.S.; Kim, H.D. Depth-aided robust localization approach for relative navigation using RGB-depth camera and LiDAR sensor. In Proceedings of the 2014 International Conference on Control, Automation and Information Sciences (ICCAIS), Gwangju, Germany, 2–5 December 2014; pp. 105–110.
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Wu, C.C. SiftGPU: A GPU Implementation of Scale Invariant Feature Transform (SIFT). Available online: http://cs.unc.edu/~ccwu/siftgpu (accessed on 1 April 2015).
- Steder, B.; Rusu, R.B.; Konolige, K.; Burgard, W. Point feature extraction on 3D range scans taking into account object boundaries. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, Beijing, 9–13 May 2011; pp. 2601–2608.
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217.
- Hänsch, R.; Hellwich, O.; Weber, T. Comparison of 3D interest point detectors and descriptors for point cloud fusion. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 3, 57–64. [Google Scholar] [CrossRef]
- Eggert, D.W.; Lorusso, A.; Fisher, R.B. Estimating 3-D rigid body transformations: A comparison of four major algorithms. Mach. Vis. Appl. 1997, 9, 272–290. [Google Scholar] [CrossRef]
- Arun, K.S.; Huang, T.S.; Blostein, S.D. Least-squares fitting of two 3-D point sets. IEEE Trans. Patt. Anal. Mach. Intell. 1987, 9, 698–700. [Google Scholar] [CrossRef]
- Triggs, B.; McLauchlan, P.F.; Hartley, R.I.; Fitzgibbon, A.W. Bundle adjustment—A modern synthesis. In Vision Algorithms: Theory & Practice; Springer: Heidelberg, Germany, 1999; pp. 298–372. [Google Scholar]
- Wang, Z.Z. Principles of Photogrammetry with Remote Sensing; House of Surveying and Mapping: Beijing, China, 1990. [Google Scholar]
- Pirker, K.; Rüther, M.; Schweighofer, G.; Bischof, H. GPSlam: Marrying sparse geometric and dense probabilistic visual mapping. In Proceedings of the 22nd British Machine Vision Conference, Dundee, Scotland, 29 August–2 September 2011.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| fx | fy | x0 | y0 | k1 | k2 | k3 | p1 | p2 | |
|---|---|---|---|---|---|---|---|---|---|
| Depth | 519.95 | 519.55 | 315.82 | 238.71 | 0.04810 | 0.19281 | 0.0 | 0.00458 | 0.00014 |
| RGB | 584.35 | 584.33 | 317.97 | 252.80 | 0.10585 | 0.27096 | 0.0 | 0.00504 | 0.00166 |
| Rotation Angles (degree) | −0.00079 | −0.00084 | −0.00541 |
| Translation Vector (mm) | −25.59983 | 0.16700 | −0.40571 |
| Calculated Length (m) | Error | |
|---|---|---|
| Our method | 45.82 | 2.45% |
| Traditional method | 44.99 | 4.22% |
| Closure Error(m) | Error | |
|---|---|---|
| Our method | 4.56 | 2.48% |
| Traditional method | 7.05 | 3.84% |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di, K.; Zhao, Q.; Wan, W.; Wang, Y.; Gao, Y. RGB-D SLAM Based on Extended Bundle Adjustment with 2D and 3D Information. Sensors 2016, 16, 1285. https://doi.org/10.3390/s16081285
Di K, Zhao Q, Wan W, Wang Y, Gao Y. RGB-D SLAM Based on Extended Bundle Adjustment with 2D and 3D Information. Sensors. 2016; 16(8):1285. https://doi.org/10.3390/s16081285
Chicago/Turabian StyleDi, Kaichang, Qiang Zhao, Wenhui Wan, Yexin Wang, and Yunjun Gao. 2016. "RGB-D SLAM Based on Extended Bundle Adjustment with 2D and 3D Information" Sensors 16, no. 8: 1285. https://doi.org/10.3390/s16081285
APA StyleDi, K., Zhao, Q., Wan, W., Wang, Y., & Gao, Y. (2016). RGB-D SLAM Based on Extended Bundle Adjustment with 2D and 3D Information. Sensors, 16(8), 1285. https://doi.org/10.3390/s16081285