1. Introduction
Modern training, entertainment and education applications make extensive use of autonomously controlled virtual agents or physical robots. In these applications, the agents must display complex intelligent behaviors that, until recently, were only shown by humans. Driving simulations, for example, require having vehicles moving in a realistic way in the simulation, while interacting with other virtual agents as well as humans. Likewise, computer games require artificial characters or opponents that display complex intelligent behaviors to enhance the entertainment factor of the games. Manually creating those complex behaviors is usually expensive. For example, the artificial intelligence for the two virtual characters in the game
Façade [
1] took more than five person-years to develop. Additionally, the required knowledge to create these behaviors is often tacit. In other words, humans that are proficient in the task at hand have difficulties articulating this knowledge in an effective manner so that it can be included into the agent’s behavior. For example, when asked how hard to apply the brakes in a car when approaching a traffic light, most human practitioners would be unable to find appropriate words to describe the experience. On the other hand, showing how to do it is much easier.
Another example comes from the United States Department of Defense, which was one of the first official institutions to recognize the value of intelligent virtual agents that could reliably act as intelligent opponents, friendly forces and neutral bystanders in training simulations. The availability of such agents permitted them to avoid using human experts, a scarce and expensive resource, who had been used to manually control such entities in past training sessions. Semi-Automated Forces (SAF) were the first attempt at developing such software agents, where simulated enemy and friendly entities inhabit the virtual training environment and act to combat or support war-fighters in training sessions. Recent advances in the closely related area of Computer-Generated Forces (CGF) indicate important progress in simulating behaviors that are more complex, but at the cost of operational efficiency. However, CGF models are still very difficult to build, validate and maintain.
An attractive and promising alternative to handcrafting behaviors is to automatically generate them through machine learning techniques. The problem of automatically generating behaviors has been studied in artificial intelligence at least from two different perspectives. The first one is Reinforcement Learning (RL), which focuses on learning from experimentation. The second one is Learning from Observation (LfO), focusing on learning by observing sample traces of the behavior to be learned. Reinforcement Learning is by far the better known and studied of the two, but presents several open problems like scalability and generalization. Furthermore, RL does not lend itself to learn human-like behaviors, given its inherent nature toward optimization. We believe that LfO offers a promising and computationally tractable approach to achieve human-like behaviors with high fidelity, at an affordable cost, and with a reasonable level of generalization. Although LfO has already shown some success in learning behaviors requiring tacit knowledge, many open problems remain in the field.
Some of the early work on the field refers to a technique called programming by demonstration. For example, Bauer [
2] showed how to make use of knowledge about variables, inputs, instructions and procedures in order to learn programs, which basically amounts to learning strategies to perform abstract computations by demonstration. Programing by demonstration has also been especially popular in robotics [
3]. Another early mention of LfO comes from Michalski et al. [
4], who define it merely as unsupervised learning. Gonzalez et al. [
5] discussed LfO at length, but provided no formalization nor suggested an approach to realize it algorithmically. More extensive work on the more general LfO subject came nearly simultaneously but independently from Sammut et al. [
6] and Sidani [
7]. Fernlund et al. [
8] used LfO to build agents capable of driving a simulated automobile in a city environment. Pomerleau [
9] developed the Autonomous Land Vehicle in a Neural Network (ALVINN) system that trained neural networks from observations of a road-following automobile in the real world. Moriarty and Gonzalez [
10] used neural networks to carry out LfO for computer games. Könik and Laird [
11] introduced LfO in complex domains with the State, Operator and Result (SOAR) system, by using inductive logic programming techniques. Other significant work done under the label of learning from demonstration has emerged recently in the Case-Based Reasoning community. For example, Floyd et al. [
12] present an approach to learn how to play RoboSoccer by observing the play of other teams. Ontañón et al. [
13] use learning from demonstration for real-time strategy games in the context of Case-Based Planning. Another related area is that of Inverse Reinforcement Learning [
14], where the focus is on reconstructing the reward function given optimal behavior (i.e., given a policy, or a set of trajectories). One of the main problems here is that different reward functions may correspond to the observed behavior, and heuristics need to be devised to consider only those families of reward functions that are interesting. In this paper, we present an approach to LfO based on Probabilistic Finite Automata (PFAs). PFAs are interesting because, in addition to learning a model of the desired behavior, they can also assess the probability that a certain behavior was generated by a given PFA. For that reason, given a training set consisting of traces with observations that come from an agent exhibiting different behaviors, PFAs can be used for two different tasks. The first one is behavioral recognition: a PFA can be trained from the traces of each one of these behaviors (one PFA per different behavior). Then, given a new, unseen, behavioral trace from another agent, these PFAs can be used to assess the probability that this new behavior has been produced by each one of them. Assuming that each PFA is a good model of each of the behaviors of interest, this effectively corresponds to identifying which of the initial set of behaviors was exhibited by the new agent. The second one is behavioral cloning: by training a PFA with the traces corresponding to the desired behavior, such a PFA can be used to recreate this behavior in a new, unseen, situation. The notion of BC was first introduced in [
15] to refer to a form of imitation learning whose motivation is to build a model of the behavior of a human.
The perspective provided by our work is general enough to deal with significant applications such as masquerade detection in computer intrusion, analysis of the task performed by the user in some e-learning activity, classification and prediction of the user behavior in a web user interaction process and, more generally, Activity Recognition (AR). The aim of AR is to recognize the actions and tasks of one or several agents taking as input a sequence of observations of their actions and the state of the environment. Most research in AR concentrates on the recognition of human activities. One goal of Human Activity Recognition (HAR) is to provide information on a user’s behavior that allows computing systems to proactively assist users with their tasks (see [
16] for a detailed overview on the subject). Hidden Markov Models are widely used tools for prediction in the context of HAR. Successful applications of these machines include important applications like speech recognition [
17] and DNA sequence alignment [
18].
The remainder of this paper is organized as follows. In
Section 2, we introduce our proposed LfO framework, we explain how this framework can be used for BC and BR, and we propose a set of evaluation metrics to assess the performance of the approach. Then, in
Section 3, we report on the experiments conducted in the context of a simulated learning environment (a virtual Roomba vacuum cleaner robot). Finally, concluding remarks and future work ideas are presented in
Section 4.
2. Methodology
The key idea in Learning from Observation is that there is a learner that observes one or several agents performing a task in a given environment, and records the agent’s behavior in the form of traces. Then, those traces are used by the learner to generalize the observed behavior and replicate it in other similar situations. Most LfO work assumes that the learner does not have access to a description of the task during learning, and thus, the features of the task and the way it is achieved must be learned purely through unobtrusive observation of the behavior of the agent.
Let B be the behavior (by, behavior, we mean the control mechanism, policy, or algorithm that an agent or a learner uses to determine which actions to execute over time) of an agent A. Our formalization is founded on the principle that behavior can be modeled as a stochastic process, and its elements as random variables dependent on time. Our model includes the following variables (we use the following convention: if X is a variable, then we use a calligraphic to denote the set of values it can take, and lower case to denote specific values it takes.): the state of the environment, the unobservable internal state of the agent and the perceptible action that the agent executes. We interpret the agent’s behavior as a discrete-time process (which can be either deterministic or stochastic), with state space . is a multidimensional variable that captures the state of the agent at time t, i.e, a description of the environment, the internal state and the action performed at time t.
The observed behavior of an agent in a particular execution defines a
trace T of observations:
, where
and
represent the specific perception of the environment and action of the agent at time
t. The pair of variables
and
represents the
observation of the agent
A. We assume that the random variables
and
are multidimensional discrete variables. Under this statistical model, we distinguish three types of behaviors [
19]: Type 1 (that includes strict imitation behavior) corresponding to a process that only depends on time (independent of previous states and actions); Type 2 (reactive behavior), where
may only depend on the time
t, the present state
and the non-observable internal state
; and Type 3 (planned behavior) for the case in which the action
depends on the time
t, on the non-observable internal state
, and on any of the previous states
and actions
.
When a behavior does not explicitly depend on time, we say that it is a stationary behavior. In addition, we distinguish between deterministic and stochastic behavior.
2.1. LfO Models
In this article, we model only stationary behaviors of Types 2 and 3 that do not explicitly depend on the internal state. Moreover, we limit the “window” of knowledge in the case of planned behavior to one previous observation (our methodology could be easily extended to allow a larger memory, with the obvious drawback of an increased number of features). This gives rise to three possibilities for the current action
:
depends only on current state (Model 1);
depends on previous and current state: (Model 2);
depends on previous and current state: , and on previous action (Model 3).
An example of the kind of information available for each of the three models is presented in
Table 1, where each row represents a training example, and columns represent features. The last column (
Class) is the action to be performed, which is what our models try to predict.
Note that some of the actual strategies employed by the agents in our experiments exhibit more complex dependencies (see
Section 3.2), but the model of the behavior learned by our approach is restricted to one of the three models presented above.
2.2. Machine Learning Tools
We describe in this section the kind of learning machines that we propose for modeling reactive and planned behaviors. Note that the only information we have is a trace with pairs (state, action): we do not know if the trace was produced by a deterministic or a stochastic agent, or whether it uses an internal state. However, we would like to have a mechanism that predicts, in each state, the action to perform.
If the learned strategy is a deterministic one, this can be done via a classifier, using more or less features depending on the model (see
Table 1). We experimented with a decision tree (DT) algorithm [
20], a probabilistic neural network (PNN) [
21], the
k Nearest Neighbour (kNN) algorithm, the RProp algorithm for multilayer feedforward networks [
22] and the Naive Bayes (NB) algorithm. On the other hand, for training stochastic models, we propose the use of PFAs, which we describe below.
PFAs were introduced in the 1960s by Rabin (see [
23]) and are still used in several fields of science and technology for modeling stochastic processes in applications such as DNA sequencing analysis, image and speech recognition, human activity recognition and environmental problems, among others. The reader is referred to the work of Dupont et al. [
24] for an overview of the basic properties of PFAs and a presentation of their relation with other Markovian models.
Formally, a PFA is a 5-tuple
, where Σ is a finite alphabet (that is, a discrete set of symbols),
Q is a finite collection of states,
is a function defining the transition probability (i.e.,
is the probability of emission of symbol
a while transitioning to state
from state
q),
is the initial state probability function and
is the final state probability function. In addition, the following functions, defined over words
and state paths
, must be probability distributions (Equation (
1) when using final probabilities and Equation (
2) otherwise):
This implies in particular that the two following functions are probability distributions over
:
Note that
is the probability of generating word
α and
is the probability of generating a word with prefix
α. Here,
is the extension of function
to words with the obvious meaning: the probability of reaching state
from state
q while generating word
α (the reader is referred to the work of Dupont et al. [
24] for a detailed explanation of Equations (
3) and (
4)). In many real situations, we are interested in PFAs with no final probabilities, and in this case we use Equation (
4).
2.3. Training a Probabilistic Finite Automaton
We propose to train a PFA to model an unknown behavior by observing its trace T. To this end, we define the alphabet Σ of automaton to be the set of all actions that the agent can perform. The state space Q depends on the model: it is either (Model 1), or (Model 2) or (Model 3).
Training the automaton from a trace consists of determining the transition probability function values and the initial probability values (we opted for a model with no final probabilities). For any state , let be the number of occurrences of symbol q in trace T. In the case of Model 1, , for Model 2, if , then , and for Model 3, if , then . Similarly, we define and for and as follows:
Note that, in the case of Models 2 and 3,
is zero by definition if the last element of state
q is different than the first element of state
. Next, we estimate the values of
ι and
with the following formulas (we use Laplace smoothing to avoid zero values in the testing phase for elements that never appeared in training):
It is easy to see that
, the probability of performing the action
a when in state
q, defined as
, becomes
(see [
24] for a survey on learnings PFAs).
2.4. Evaluation Metrics
In the case of BR, the goal is to identify which was the strategy employed by an agent A using the learning trace that the agent produced. To this end, we train a PFA for each available planned strategy, we compute the value and return , where and . The value of depends on the amount M of memory used: for Model 1, for Model 2 and for Model 3.
In practice, we use the values
to measure the distance between the behavior
B exhibited by agent
A (through the learning trace
T) and the behavior
of the strategy modeled by automaton
by computing the negative log-probability:
This value can be interpreted as a Monte Carlo approximation of the crossed entropy between behaviors
B and
, known in the literature as Vapnik’s risk (see [
19]). Obviously, maximizing
is the same as minimizing
and for practical reasons (in order to avoid underflow and because adding is faster than multiplying), we use distances instead of probabilities.
In the case of BC, we are interested in assessing the quality of the models proposed (that is, we would like to know how well does the cloned agent behave on previously unseen data). For this purpose, we use two different metrics, which we detail below.
Predictive Accuracy. This is a standard measure for classification tasks. Let be the model trained by one of the learning algorithms using the trace obtained by observing an agent A (that follows a certain strategy) on a fixed set of maps. This model can be either deterministic (in which case, there is only one possible action at any point in time) or stochastic (the action is chosen randomly according to some probability distribution).
Now, let
be the trace of the agent
A on a different previously unseen map. The predictive accuracy
is measured as follows:
where
represents the action predicted by the model
for the state
, possibly knowing previous state and action. If
is a stochastic model,
is a random variable over
with the probability distribution
, where
for Model 1,
for Model 2 and
for Model 3.
Monte Carlo Distance. To assess the adequacy of a model
in reproducing the behavior of an agent
A, we propose a Monte Carlo-like measure based on estimating the crossed entropy between the probability distributions associated with both the model
and the agent
A. More concretely, let
be a trace generated (the model predicts the next action, but the next state is given by the actual configuration of the map; in the case that it is impossible to perform a certain action because of an obstacle, the agent does not change its location) according to model
on a fixed map (different than the one used in training), and let
be the trace generated by the agent on the same map. We define the Monte Carlo distance between model
and agent
A as follows (estimated through traces
T and
):
where
and
(depending on the model used, we may store into our observations information about previous state and action). Here,
means the indicator function of set
. The previous measure in Equation (
7) is obviously empirical. For large enough traces, it approximates the true cross entropy between the behavior corresponding to model
and the behavior exhibited by agent
A. Using Laplace smoothing, the previous formula becomes:
3. Experiments
We have run our experiments with a simulator of a simplified version of a Roomba (iRobot, Bedford, MA, USA), which is a series of autonomous robotic vacuum cleaners sold by iRobot (According to the company’s website (
http://www.irobot.com), iRobot Corporation is an American advanced technology company founded in 1990 by Massachusetts Institute of Technology roboticists. More than 14 million home robots have been sold worldwide. Roomba was introduced in 2002). The original Roomba vacuum cleaner uses a set of basic sensors in order to perform its tasks. For instance, it is able to change direction whenever it encounters an obstacle. It uses two independently operating wheels that allow 360 degree turns in place. Additionally, it can adapt to perform other more creative tasks using an embedded computer in conjunction with the Roomba Open Interface.
3.1. Training Maps
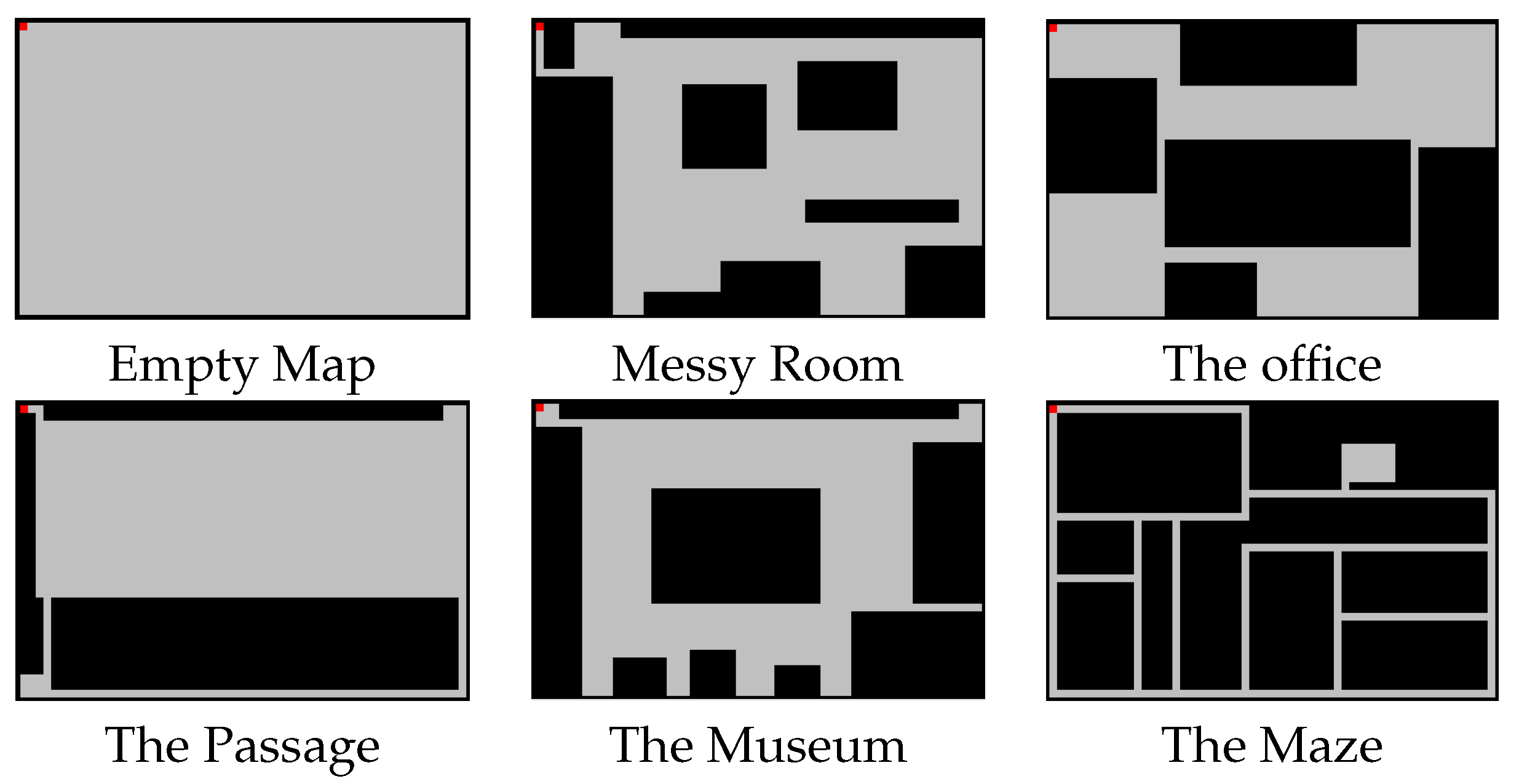
The environment in which the agent moves is a 40 × 60 rectangle surrounded by walls, which may contain all sorts of obstacles. For testing, we have randomly generated obstacles on an empty map. Below, we briefly explain the six maps used in the training phase (they are visually represented in
Figure 1). Each of them is meant to represent a real-life situation, as indicated by their title.
Empty Map. The empty map consists of a big empty room with no obstacles.
Messy Room. The messy room simulates an untidy teenager bedroom, with all sorts of obstacles on the floor, and with a narrow entry corridor that makes the access to the room even more challenging for any “hostile intruder”.
The Office. The office map simulates a space in which several rooms are connected to each other by small passages. In this case, obstacles are representing big furniture such as office desks or storage cabinets.
The Passage. The highlight of this map is an intricate pathway that leads to a small room. The main room is big and does not have any obstacle in it.
The Museum. This map is intended to simulate a room from a museum, with the main sculpture in the center, and with several other sculptures on the four sides of the room, separated by small spaces.
The Maze. In this map, there are many narrow pathways with the same width as the agent. It also contains a little room, which is difficult to find.
3.2. Agent Strategies
In our experiments, the simulation time is discrete, and, at each time step, the agent can take one out of these four actions: up, down, left and right, with their intuitive effect. The agent perceives the world through the input variable X having four different binary components (up, down, left, right), each one of them identifying what the vacuum cleaner can see in each direction (obstacle, no obstacle). We have designed a series of strategies with different complexities. When describing a strategy, we must define the behavior of the agent in a certain situation (its state ) that depends on the configuration of obstacles in its vicinity (prefix Rnd is used for stochastic strategies).
Walk. The agent always performs the same action in a given state. As an example, a possible strategy could be to go Right whenever there are no obstacles, and Up whenever there is only one obstacle to the right (stationary deterministic behavior of Type 2, it only depends on current state ).
Rnd_Walk. In this strategy, the next move is selected randomly from the set of available moves. For example, an agent that has obstacles to the right and to the left can only move Up or Down, but there is no predefined choice between those two (stationary stochastic behavior of Type 2, it only depends on current state ).
Crash. In this strategy, the agent should perform the same action as in the previous time step (if possible). Whenever it encounters a new obstacle in its way, the agent must choose a certain predefined action. Therefore, it needs to have information about its previous action in order to know where to move (stationary deterministic behavior of Type 3, it depends on current state and previous action ).
Rnd_Crash. This strategy allows the agent to take a random direction when it crashes with an obstacle. The main difference with the Rnd_Walk is that in Rnd_Crash the agent does not change direction if it does not encounter an obstacle in its way (stationary stochastic behavior of Type 3, it depends on current state and previous action ).
ZigZag. It consists of different vertical movements in two possible directions, avoiding the obstacles. It has an internal state that tells the robot if it should advance towards the left or the right side with this vertical movements: it initially goes towards the right side, and once it reaches one of the right corners, the internal state changes so that the robot will start moving toward the left side (stationary deterministic behavior of Type 3, it depends on current state , previous action and internal state ).
Rnd_ZigZag. This strategy is similar to the previous one, with the only difference that, once it reaches a corner, the internal state could either change its value or not, and this is randomly assigned (stationary stochastic behavior of Type 3, it depends on current state , previous action and internal state ).
3.3. Trace and Performance Evaluation
We work with an agent represented by a simplified version of a Roomba robot. In our implementation, although it is possible for the agent to start anywhere, the traces we generate are always with the agent starting in the top-left corner of the map. We use the strategies explained in
Section 3.2 and the maps described in
Section 3.1. For each of the six strategies, we have generated six traces of 1500 time steps (one for each map) and merged them together into one single trace, which was used as training data.
3.4. Behavioral Recognition Experimentation
In order to determine whether our approach leads to a correct identification of the agent’s strategy, we performed the following experiment. First, we generated 100 random maps (each of them having a total of 150 obstacles). Then, we generated a family of traces (each of them of 1500 time steps) for each pair strategy/map:
and we computed the log-normalized distance
between the observation trace
and the automaton
(see Equation (
5)). The average value
of these distances is reported in
Table 2, in the
-th cell.
Our system classifies the testing task represented by column n as being generated by the automaton such that (minimizing distance maximizes trace probability). The smallest value of each column is marked in bold.
Analysis of the results indicates that the PFA recognition system is able to correctly identify the three random strategies (Rnd_Walk, Rnd_Crash and Rnd_ZigZag). However, the system most often fails when recognizing the respective underlying deterministic strategies (Walk, Crash and ZigZag). In addition, note that the deterministic versions of the random behaviors Crash and ZigZag are not confused with each other but each of them is most of the times classified by the system as its corresponding non-deterministic version (Crash is classified as Rnd_Crash and ZigZag as Rnd_ZigZag for all three models). Moreover, Walk is, on average, correctly classified by Models 2 and 3.
In
Table 3, we present the confusion matrix. This is a specific table layout that allows the visualization of the performance of a supervised learning algorithm (see [
16]). The numerical value
placed in the
-th cell of this matrix is the empirical probability of the
n-th task to be classified as the
m-th task, that is, the percentage of the learning traces produced using strategy
n that are recognized as being produced by strategy
m. More precisely,
The diagonal of this matrix reflects the empirical probabilities of right classification and the sum of the other rows different from the diagonal element is the probability of error.
We observe that this second table confirms the conclusions of the first one, with one notable exception: Models 2 and 3 seem to be more prone to confuse the Walk strategy with Rnd_Crash, while Model 1 is the one with highest rates of success. Note that the percentage of right classification is not negligible for deterministic strategies of Type 3 (around 0.20 in the case of Crash for all three models, and between 0.16 and 0.39 for ZigZag).
3.5. Behavioral Cloning Experimentation
As in the case of BR, we used a single trace containing 9000 time steps for each strategy to train our models. For testing, we used the same set of 100 randomly generated maps.
3.5.1. Predictive Accuracy
The numbers in the three tables of
Table 4 represent average values of the predictive accuracy (see Equation (
6)) computed for each of the randomly generated maps. Note that the only stochastic model is the PFA.
Analyzing the results, we can see that our hierarchy of models behaves as expected: Type 3 behavior is very well captured by Model 3 (the one that uses information about both previous state and previous action), while Type 2 deterministic behavior is better explained by Model 1 (in which we only take into account the current state). Note that, even though, intuitively, the more info we have the best we can predict, in the case of Type 2 behavior, using this extra information can do more harm than good. Another anticipated result that was experimentally confirmed is that Model 1 would be very good in predicting the Walk strategy because the agent always performs the same action in a given state. A surprising conclusion that can be drawn is that, while Rnd_Walk should be the most unpredictable strategy of all, in the case of Models 2 and 3, most of our classifiers have even worse accuracy for the Walk strategy. It is worth noting the high accuracy rates of Model 3 for Rnd_Crash, Rnd_ZigZag and ZigZag, all Type 3 strategies. Furthermore, this model gives somewhat lower but still satisfactory prediction rates for the Crash strategy.
A PFA is the best option when predicting the behavior of Walk and Zigzag strategies (both in their deterministic and stochastic versions) using a minimal amount of memory. In addition, although, intuitively, a stochastic model should be better than a deterministic one in describing the behavior of a random process. According to the predictive accuracy metric, the advantage of using PFAs apparently has to do more with the amount of memory used and not with the nature of the underlying process.
3.5.2. Monte Carlo Distance
Predictive accuracy, however, is not a very good metric for BC when behaviors are non-deterministic. Consider, for example, the extreme case of cloning a random agent. Using the predictive accuracy metric, the highest accuracy a learning agent could expect is 0.25 (if there are four possible actions), even when the behavior is perfectly cloned. Thus, the Monte Carlo distance metric is a more adequate metric when comparing stochastic behaviors.
We used the same set of 100 randomly generated maps. For each of the classifiers (DT, PNN, KNN, RProp, NB) and, for each of the six predefined strategies (
Walk,
Rnd_Walk,
Crash,
Rnd_Crash,
ZigZag,
Rnd_ZigZag), we generated the trace
T produced by an agent whose next action is dictated by the classifier on each of the randomly generated maps (each trace would contain at most 1500 observations). Note that, since the strategy is a learned one, it could happen that the action suggested by the model is not feasible (for example, the model says to go up even if there is an obstacle in that direction). Therefore, one may end up having empty traces (marked by a dash in
Table 5). On the other hand, we generated the trace
of each of the six predefined strategies on those maps (in this case, all traces have 1500 observations). In
Table 5, we present the average of
for each pair classifier/strategy (see Equation (
8)). For stochastic models, the next action, instead of being predefined, is obtained by sampling according to the probability distribution given by the trained model.
According to this metric, PFAs are globally the best tool when less information is used (Models 1 and 2), being outperformed by DTs in the case in which the model of the learner also takes into consideration the previous action (Model 3). Note that PFAs are mostly better than other classifiers when learning random strategies. One surprising conclusion that can be drawn is that NB seem to be the best tool for the Walk strategy when the learner is allowed to use knowledge about the past (Models 2 and 3).
Finally, for each model, each strategy and each machine learning tool, we report the number of times the given tool was the best one. Since we have 100 different maps, this number is always between 0 and 100. In the case of equal Monte Carlo distance score, we assigned a corresponding fraction to each of the ‘winning’ models. For example, if there are three tools with the same score, each of them receives 1/3 points for that particular map (therefore, we end up having real numbers other than integers).
Table 6 confirms PFAs as being the best tool in the case of Model 1, this time even for the
Crash strategy. In the case of Model 2, it is the best overall tool and the most reliable one for random strategies. In addition, note that the frequency with which it returns the best score is very close to the NB one for
Walk and to the DT one for
Zigzag. Again, it is the the third model where its use does not pay off, being outperformed by DTs when the strategy to be cloned is of Type 3.


 ,
, 

{kind=link}