Abstract
We describe the design and 3D sensing performance of an omnidirectional stereo (omnistereo) vision system applied to Micro Aerial Vehicles (MAVs). The proposed omnistereo sensor employs a monocular camera that is co-axially aligned with a pair of hyperboloidal mirrors (a vertically-folded catadioptric configuration). We show that this arrangement provides a compact solution for omnidirectional 3D perception while mounted on top of propeller-based MAVs (not capable of large payloads). The theoretical single viewpoint (SVP) constraint helps us derive analytical solutions for the sensor’s projective geometry and generate SVP-compliant panoramic images to compute 3D information from stereo correspondences (in a truly synchronous fashion). We perform an extensive analysis on various system characteristics such as its size, catadioptric spatial resolution, field-of-view. In addition, we pose a probabilistic model for the uncertainty estimation of 3D information from triangulation of back-projected rays. We validate the projection error of the design using both synthetic and real-life images against ground-truth data. Qualitatively, we show 3D point clouds (dense and sparse) resulting out of a single image captured from a real-life experiment. We expect the reproducibility of our sensor as its model parameters can be optimized to satisfy other catadioptric-based omnistereo vision under different circumstances.
1. Introduction
Micro aerial vehicles (MAVs), such as quadrotor helicopters, are popular platforms for unmanned aerial vehicle (UAV) research due to their structural simplicity, small form factor, vertical take-off and landing (VTOL) capability, and high omnidirectional maneuverability. In general, UAVs have plenty of military and civilian applications, such as target localization and tracking, 3-dimensional (3D) mapping, terrain and infrastructural inspection, disaster monitoring, environmental and traffic surveillance, search and rescue, deployment of instrumentation, and cinematography, among other uses. However, MAVs have size, payload, and on-board computation limitations, which involve the use of compact and lightweight sensors. The most commonly used perception sensors on MAVs are laser scanners and cameras in various configurations such as monocular, stereo, or omnidirectional. We present a vision-based omnidirectional stereo (omnistereo) sensor motivated by several aspects of MAV robotics.
1.1. Sensor Motivation
We justify the need for the proposed omnistereo sensor after observing two basic differences in the sensor requirements between MAVs and ground vehicles:
- Size and payload—In MAV applications, the sensor’s physical dimensions and weight are always a great concern due to payload constraints. Generally, MAVs require fewer and lighter sensors that are compactly designed, while larger robots (including high-payload UAVs) have greater freedom of sensor choice.
- Field-of-view (FOV)—Due to their omnidirectional motion model, MAVs require a simultaneous observation of the 3D surroundings. Conversely, most ground robots can safely rely upon narrow vision as their motion control on the plane is more stable.
1.2. Existing Range Sensors for MAVs
In addition to specifying our sensor requirements, it is important to note the most prevalent robot range sensors used today by MAVs and their limitations. For example, lightweight 2.5D laser scanners can accurately measure distances at fast rates, however, their instantaneous sensing is limited to plane sweeps, which in turn require the quadrotor to move vertically in order to generate 3D maps or to foresee obstacles and free space during navigation. More recently, 3D laser rangefinders and LiDARs are being developed, such as the sensor presented in [1], but this one is not compact enough for MAVs. Another disadvantage of laser-based technologies is their active sensing nature, which requires more power to operate and their measurements are more vulnerable to detection and corruption (e.g., due to dark/reflective surfaces) than vision-based solutions. Time-of-flight (ToF) cameras as well as red, green, blue plus depth (RGB-D) sensors like the Microsoft Kinect® are also very popular for robot navigation. They have been adopted for low-sunlight conditions and mainly indoor navigation of MAVs [2] due to its structured infrared light projection and short range sensing (under 5 m) [3]. Hence, a lightweight imaging system capable of instantly providing a large field of view (FOV) with acceptable resolutions is essential for MAV applications in 3D space. These state-of-the-art sensors’ pitfalls motivate the design and analysis of our omnistereo sensor.
1.3. Related Work
Using omnidirectional images alone and motion—like the approaches taken in [4,5]—have been proposed to map and localize a robot. Omnidirectional vision using a single mirror for the flight of large UAVs was first attempted in [6]. In [7], Hrabar proposed the use of traditional horizontal stereo-based obstacle avoidance and path planing for AUVs, but these techniques were only tested in a scaled-down air vehicle simulator (AVS). Omnidirectional catadioptric cameras can be aided by structured light such as the prototypes presented in [8] and more flexible configurations demonstrated in [9]. Alternatively, stereo cameras can provide passive, instantaneous 3D information for robot mapping and navigation (including UAVs [10]). Intuitively, omnidirectional stereo (omnistereo) can be achieved through circular arrangements of multiple perspective cameras with overlapping views. Higher resolution panoramas can be achieved by rotating a linear camera as presented in [11], but this approach suffers from motion blur in dynamic environments. We point the reader to [12] for a detailed study of multiple view geometry, and [13] for a compendium of geometric computer vision concepts. Instead, our solution to omnistereo vision consists of a ‘catadioptric’ system by employing cameras and mirrors [14].
Throughout the years, [15,16,17,18,19,20] are some of the works that have applied various omnistereo catadioptric configurations for ground mobile robots. Unfortunately, these systems are not compact since they use separate camera-mirror pairs, which are known to experience synchronization issues. In [21], Yi and Ahuja described a configuration using a mirror and a concave lens for omnistereo, but it rendered a very short baseline in comparison to the two-mirror configurations. Originally, Nayar and Peri [22] studied 9 possible folded-catadioptric configurations for a single-camera omnistereo imaging system. Eventually, a catadioptric system using two hyperbolic mirrors in a vertical configuration was implemented by He et al. [23]. Their omnistereo sensor provides a lengthy baseline at the expense of a very tall system. In the past [24], we developed a novel omnistereo catadioptric rig consisting of a perspective camera coaxially-aligned with two spherical mirrors of distinct radii (in a “folded" configuration). One caveat of spherical mirrors is their non-centrality; they do not satisfy the single effective viewpoint (SVP) constraint (discussed in Section 2.2) but rather a locus of viewpoints is obtained [25].
1.4. Proposed Sensor
We design a SVP-compliant omnistereo system based on the folded, catadioptric configuration with hyperboloidal mirrors. Our approach resembles the work of Jang, Kim, and Kweon [26], who first implemented an omnistereo system using a pair of hyperbolic mirrors and a single camera. However, their sensor’s characteristics were not studied in order to justify their design parameters and capabilities, which we do in our case.
It is true that an omnidirectional catadioptric system sacrifices spatial resolution on the imaging sensor (analyzed in Section 3.4). However, our sensor offers practical advantages such as reduced cost, acceptable weight, and truly-instantaneous pixel-disparity correspondences since the same single camera-lens operates for both views, so mis-synchronization issues do not exist. In fact, we believe we are the first to present a single-camera catadioptric omnistereo solution for MAVs. The initial geometry of our model was proposed in [27]. Now, we perform an extensive analysis of our model’s parameters (Section 2) involving its geometric projection (Section 3) that are obtained as a constrained numerical optimization solution devising the sensor’s real-life application to MAVs passive range sensing (Section 4). We also show how the panoramic images are obtained, where we find correspondences and triangulate 3D points for which an uncertainty model is introduced (Section 5). Finally, we present our experimental results and evaluation for 3D sensing with the proposed omnistereo sensor (Section 6), and we discuss the future direction of our work in Section 7.
2. Sensor Design
Figure 1 shows the single-camera catadioptric omnistereo vision system that we specifically design to be mounted on top of our micro quadrotors (manufactured by Ascending Technologies [28]). It consists of (1) one hyperboloid-planar mirror at the top; (2) one hyperboloidal mirror at the bottom; and (3) a high-resolution USB camera also at the bottom (inside the bottom mirror and looking up). The components are housed and supported by a (4) transparent tube or plastic standoffs (for the real-life prototype shown in Figure 13). The choice of the hyperboloidal reflectors owes to three reasons: it is one of the four non-degenerated conic shapes satisfying the SVP constraint [29]; it allows a wider vertical FOV than elliptical and planar mirrors; and it does not require a telescopic (orthographic) lens for imaging as with paraboloidal mirrors (so our system can be downsized). In addition, the planar part of mirror 1 works as a reflex mirror, which in part reduces distortion caused by dual conic reflections. Based on the SVP property, the system obtains two radial images of the omnidirectional views in the form of an inner and an outer ring as illustrated in Figure 2a,b). Nevertheless, the unique set of parameters describing the entire system categorizes it as a “global camera model" given by [13] because changing the value of any parameter in the model affects the overall projection function of visible light rays in the scene as well as other computational imaging factors such as depth resolution and overlapping field of view, which we attempt to optimize with the following design subsections. Please, refer to Appendix A for clarification on our symbolic notation.
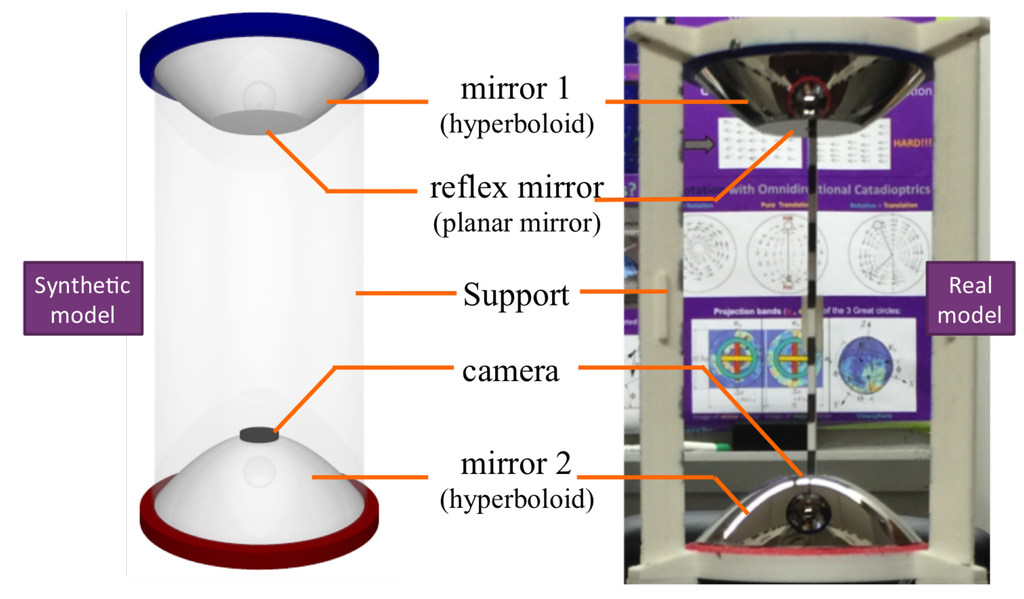
Figure 1.
Synthetic and real prototypes for the catadioptric single-camera omnistereo system.

Figure 13.
Real-life prototype of the omnistereo sensor.
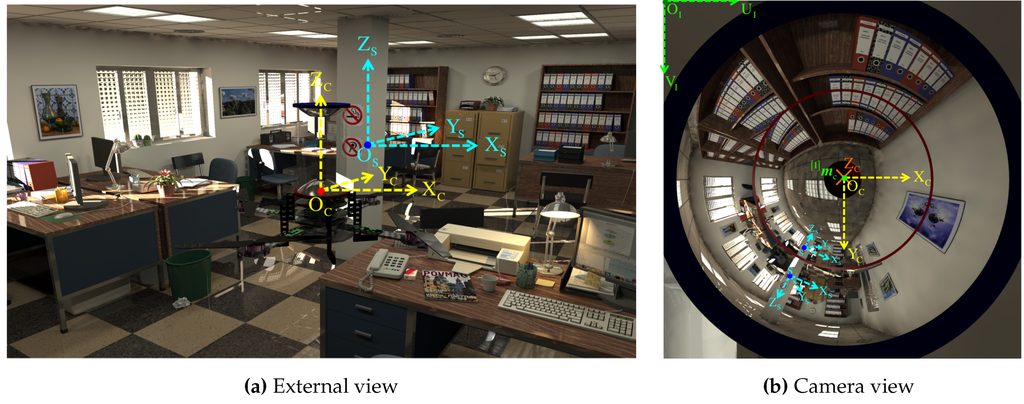
Figure 2.
Photo-realistic synthetic scene: (a) Side-view of the quadrotor with the omnistereo rig in an office environment; (b) the image captured by the system’s camera using this pose.
2.1. Model Parameters
In the configuration of Figure 3, mirror 1’s real or primary focus is , which is separated by a distance from its virtual or secondary focus, , at the bottom. Without loss of generality, we make both the camera’s pinhole and coincide with the origin of the camera’s coordinate system, . This way, the position of the primary focus, , can be referenced by vector in Cartesian coordinates with respect to the camera frame, . Similarly, the distance between the foci of mirror 2, and , is measured by . Here, we use the planar (reflex) mirror of radius and unit normal vector
in order to project the real camera’s pinhole located at as a virtual camera coinciding with the virtual focal point positioned at . We achieve this by setting as the symmetrical distance from the reflex mirror to and from the reflex mirror to . With respect to , mirror 2’s primary focus, , results in position . It yields the following expression for the reflective plane:
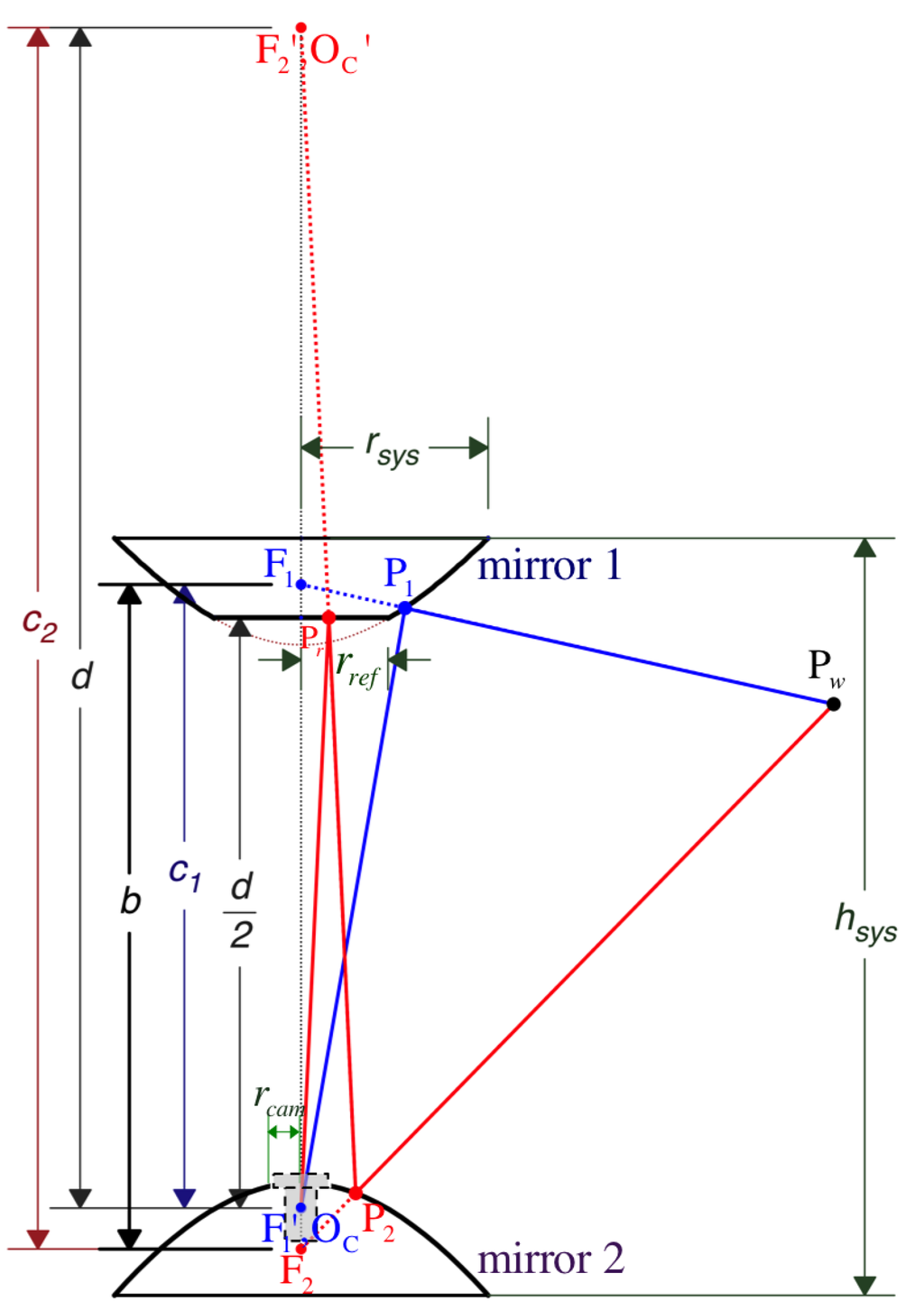
Figure 3.
Geometric model and observable design parameters.
The profile of each hyperboloid is determined by independent parameters and , respectively. Their reflective vertical field of view (vFOV) are indicated by angles and . They play an important role when designing the total vFOV of the system, , formally defined by Equation (54) and illustrated in Figure 5. Also importantly, while performing stereo vision, it is to consider angle , which measures the common (overlapping) vFOV of the omnistereo system. The camera’s nominal field of view and its opening radius also determine the physical areas of the mirrors that can be fully imaged. Theoretically, the mirrors’ vertical axis of symmetry (coaxial configuration) produces two image points that are radially collinear. This property is advantageous for the correspondence search during stereo sensing (Section 5) with a baseline measured as
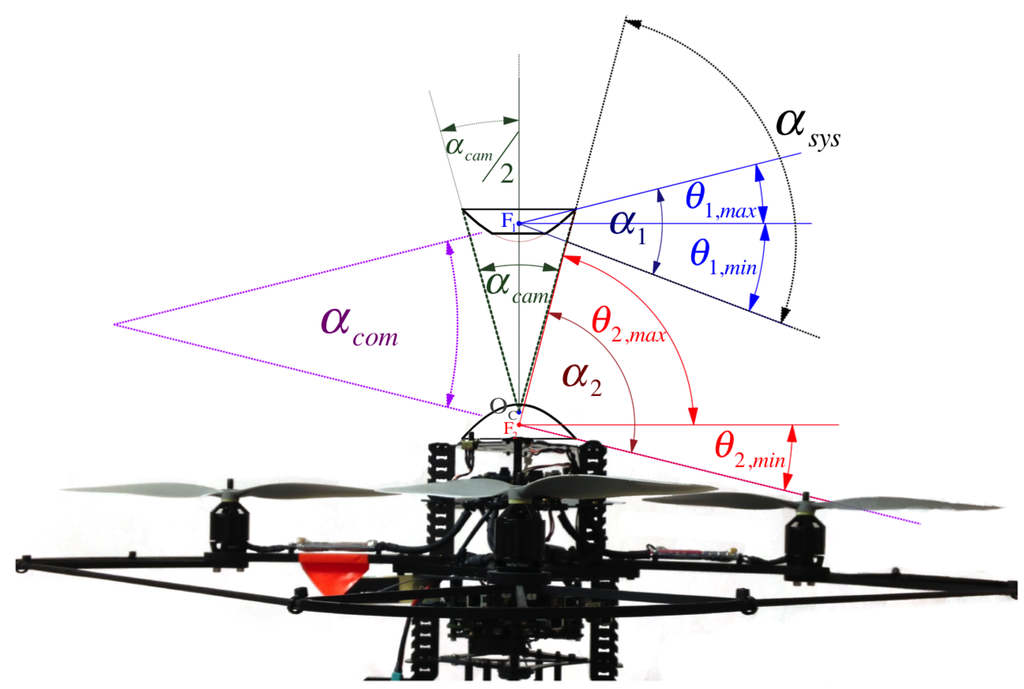
Figure 5.
Vertical Field of View (vFOV) angles: and are the individual angles of the mirrors formed by their respective elevation limits ; is the overall vFOV angle of the system; and measures the overlapping region conceived between and .
Among design parameters, we also include the total height of the system, , and weight , both being formulated in Section 2.3.
To summarize, the model has 6 primary design parameters given as a vector
in addition to by-product parameters such as
In Section 4, we perform a numerical optimization of the parameters in θ with the goal to maximize the baseline, b, required for life-size navigational stereopsis. At the same time, we restrict the overall size of the rig (Section 2.3) without sacrificing sensing performance characteristics such as vertical field of view, spatial resolution, and depth resolution. In the upcoming subsections, we first derive the analytical solutions for the forward projection problem in our coaxial stereo configuration as a whole. In Section 3.2, we derive the back-projection equations for lifting 2D image points into 3D space.
2.2. Single Viewpoint (SVP) Configuration for OmniStereo
As a central catadioptric system, its projection geometry must obey the existence of the so-called single effective viewpoint (SVP). While the SVP guarantees that true perspective geometry can always be recovered from the original image, it limits the selection of mirror profiles to a set of conics. Generally, a circular hyperboloid of revolution (about its axis of symmetry) conforms to the SVP constraint as demonstrated by Baker and Nayar in [30]. Since a hyperboloidal mirror has two foci, the effective viewpoint is the primary focus inside the physical mirror and the secondary (outer) focus is where the centre (pinhole) of the perspective camera should be placed for depicting a scene obeying the SVP configuration discussed in this section.
First of all, a hyperboloid i can be described by the following parametric equation:
where is the offset (shift) position of the focus along the Z-axis from the origin , and is the orthogonal distance to the axis of revolution / symmetry (i.e. the Z-axis) from a point on its surface.
In fact, the position of a valid point is constrained within the mirror’s physical surface of reflection, which is radially limited by and , such that:
and . Observe that the radius of the system is the upper bound for both mirrors (Figure 3). In addition, the hyperboloids profiled by Equation (5) must obey the following conical constraints:
k is a constant parameter (unit-less) inversely related to the mirror’s curvature or more precisely, the eccentricity of the conic. In fact, for hyperbolas, yet a plane is produced when or .
We devise as the set of all the reflection points with coordinates laying on the surface of the respective mirror i within bounds. Formally,
In our model, we describe both hyperboloidal mirrors, 1 and 2, with respect to the camera frame , which acts as the common origin of the coordinate system. Therefore,
Additionally, we define the function to find the corresponding component from a given r value as
where .
The inverse relation can be also implemented as
where , so a valid input z can be associated with both positive and negative solutions .
2.3. Rig Size
In the attempt to evaluate the overall system size, we consider the height and weight variables due to the primary design parameters, θ.
First, the height of the system, can be estimated from the functional relationships and defined in Equation (13), which can provide the respective component values at the out-most point on the mirror’s surface. More specifically, knowing , we get
where and .
The rig’s weight can be indicated by the total resulting mass of the main “tangible” components:
where the mass of the camera-lens combination is ; the mass of the support tube can be estimated from its cylindrical volume and material density , and the mass due to the mirrors
For computing the volume of the hyperboloidal shell, for mirror i, we apply a “ring method” of volume integration. By assuming all mirror material has the same wall thickness , we acquire by integrating the horizontal cross-sections area along the -axis. Each ring area depends on its outer and inner circumferences that vary according to radius for a given height z. Equation (14) establishes the functional relation , from which we only need its positive answer. We let A be the function that computes the ring area of constant thickness for a variable outer radius
We consider the definite integral evaluated in the z interval bounded by its height limits, which are correlated with its radial limits Equation (6) and can be obtained via the defined in Equation (13), such that
Then, we proceed to integrate Equation (18), so the shell volume for each hyperboloidal mirror is defined as
Finally, since the reflex mirror piece is just a solid cylinder of thickness , its volume is simply
3. Projective Geometry
3.1. Analytical Solutions to Projection (Forward)
Assuming a central catadioptric configuration for the mirrors and camera system (Section 2.2), we derive the closed-form solution to the imaging process (forward projection) for an observable point , positioned in three-dimensional Euclidean space, , with respect to the reference frame, , as vector . In addition, we assume all reference frames such as and have the same orientation as .
For mathematical stability, we must constrain that all projecting world points lie outside the mirror’s volume:
where is defined by Equation (14) and measures the horizontal range to .
is imaged at pixel position after its reflection as point on the hyperboloidal surface of mirror 1 (Figure 4). On the other hand, the second image point’s position, , due to reflection point on mirror 2 is rather obtained indirectly after an additional point is reflected at on the reflex mirror represented via Equation (32).
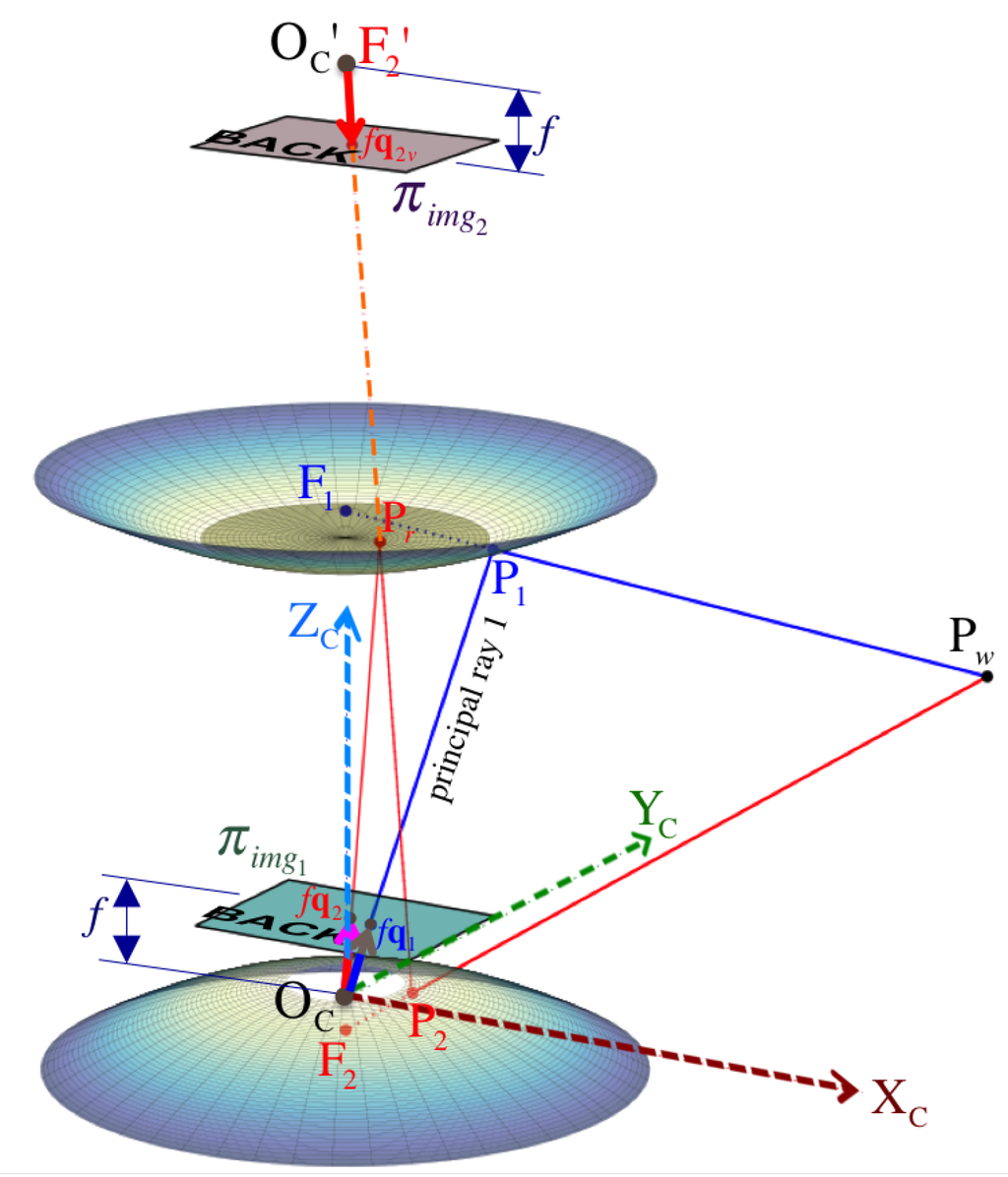
Figure 4.
Omnistereo projection of a 3D point to obtain image points and .
First, for ’s reflection point via mirror 1 at position vector , we use as the parametrization term for the line equation passing through toward with direction . The position of any point on this line is given by:
Substituting Equation (23) into Equation (11), we obtain:
in order to solve for , which turns out to be
where is the Euclidean norm between and mirror 1’s focus, .
In practice, we represent the reflection point’s position as a matrix-vector multiplication between the transformation matrix and the point’s position vector in homogeneous coordinates:
Note that ’s elevation angle, , must be bounded as
where and are the angular elevation limits for the real reflective area of the hyperboloid.
Finally, the reflection point with position can now be perspectively projected as a pixel point located at on the image. In fact, the entire imaging process of via mirror 1 can be expressed in homogeneous coordinates as:
where the scalar is the perspective normalizer that maps the principal ray passing through onto a point on the normalized projection plane . The traditional intrinsic matrix of the camera’s pinhole model is
in which and are based on the focal length f and the pixel dimension , s is the skew parameter, and is the optical center position on the image . Figure 4 illustrates the projection point on the respective image plane .
Similarly, we provide the analytical solution for the forward projection of via mirror 2 by first considering the position of reflection point :
where is similar to the transformation matrix , but obviously it now uses and
with direction vector’s norm
For completeness, note that the physical projection via mirror 2 is incident to the reflex mirror at
where according to Equation (2) in the theoretical model. Ultimately, ignoring any astigmatism and chromatic aberrations introduced by the reflex mirror, and because the same (and only) real camera with is used for imaging, we obtain the projected pixel position :
where is the perspective normalizer to find on the normalized projection plane, .
Due to planar mirroring via the reflex mirror, is used to change the coordinates of from onto the virtual camera frame, , located at . Hence,
where the unit normal vector of the reflex mirror plane, given in Equation (1), is mapped into its corresponding diagonal matrix , via the relationship:
It is convenient to define the forward projection functions and for a 3D point whose position vector is known with respect to and which is situated within the vertical field of view of mirror i (for ) indicated in Figure 5. Function maps to image point on frame , such that ,
In fact, is considered valid if it is located within the imaged radial bounds, such that:
where the frame of reference implies that its origin is the image center of the masked image (Figure 7). Therefore, the magnitude (norm) of any position in pixel space can be measured as
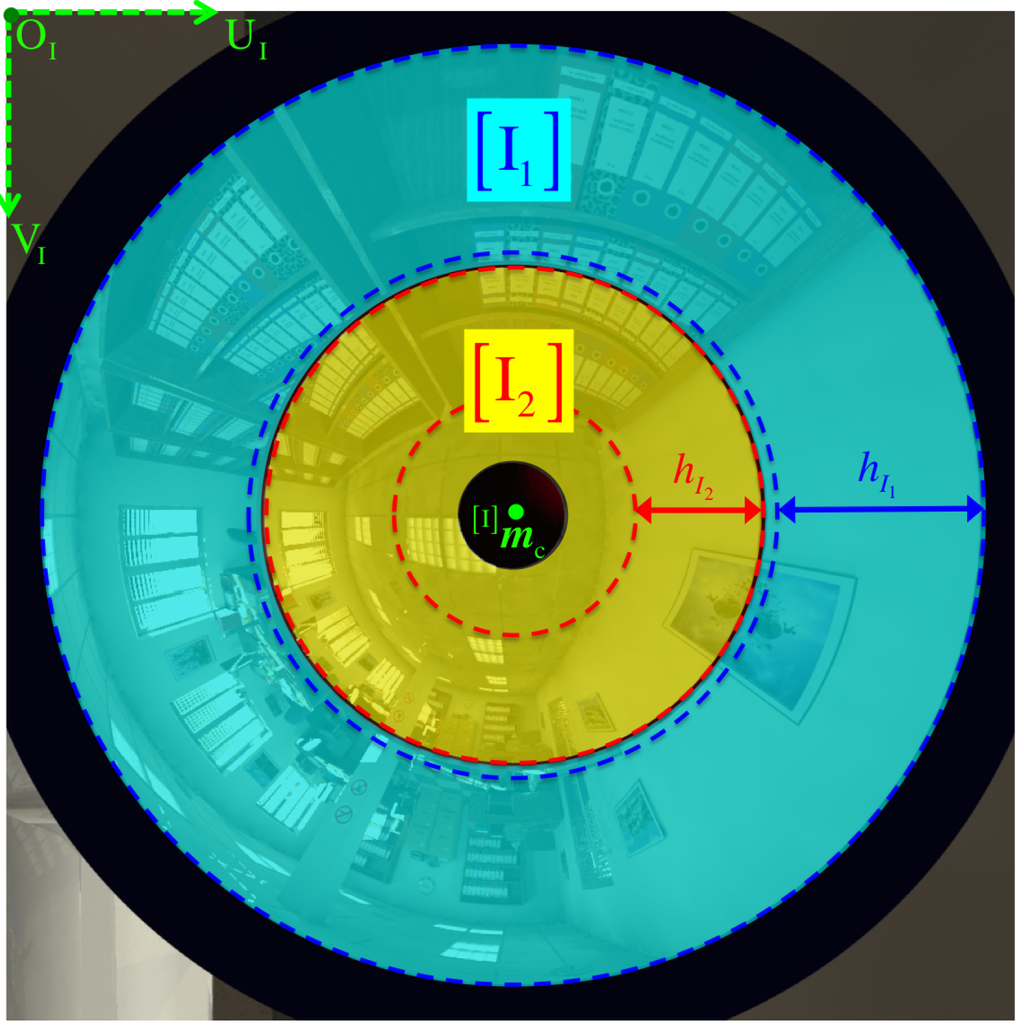
In particular, is the image radius obtained from the projection corresponding to a particular point coincident with the line of sight of the radial limit —it being either , , or as indicated by Equation (6).
3.2. Analytical Solutions to Back Projection
The back projection procedure establishes the relationship between the 2D position of a pixel point on the image and its corresponding 3D projective direction vector toward the observed point in the world.
Initially, the pixel point (imaged via mirror 1) is mapped as onto the normalized projection plane with coordinates by applying the inverse transformation of the camera intrinsic matrix Equation (28) as follows:
For simplicity, we assume no distortion parameters exist, so we can proceed with the lifting step along the principal ray that passes through three points: the camera’s pinhole , point on the projection plane, and the reflection point (Figure 4). The vector form of this line equation can be written as:
By substituting Equation (40) into Equation (11), we solve for the parameter , to get
where is the distance between and .
Given as the direction vector leaving focal point toward the world point . Through frame transformation , we get
for as the homogeneous form of Equation (40). In fact, provides the back-projected angles (elevation , azimuth ) from focus toward :
where is the norm of the back-projection vector up to the mirror surface.
Using the same approach, we lift a pixel point imaged via mirror 2. Because the virtual camera located at uses the same intrinsic matrix , we can safely back-project pixel to on the normalized projection plane as follows:
where the inverse transformation of the camera intrinsic matrix is given by Equation (28). Since the reflection matrix defined in Equation (34) is bidirectional due to the symmetric position of the reflex mirror about and , we can find the desired position of with respect to :
which is equivalent to .
In Figure 4, we can see the principal ray that passes through the virtual camera’s pinhole and the reflection point , so this line equation can be written as:
Solving for Equations (47) and (12), we get
where is the distance between the normalized projection point and the camera while considering Equation (46). Beware that the newly found location of is given with respect to the real camera frame, .
Again, we obtain the back-projection ray
in order to indicate the direction leaving from the primary focus toward through . Here, the corresponding elevation and azimuth angles are respectively given by
where is the magnitude of the direction vector from its reflection point .
Like done for the (forward) projection, it is convenient to define the back-projection functions and for lifting a 2D pixel point within radial bounds validated by Equation (37) to their angular components with respect to the respective foci frame (oriented like ) as indicated by Equations (43), (44), (50) and (51), such that ,
3.3. Field-of-View
The horizontal FOV is clearly 360° for both mirrors. In other words, azimuths ψ can be measured in the interval . As discussed previously, there exists a positive correlation between the vertical field of view (vFOV) angle of mirror i and its profile parameter , such that as (see Figure 9). As demonstrated in Figure 5, is physically bounded by its corresponding elevation angles: , . Both vFOV angles, and , are computed from their elevation limits as follows:
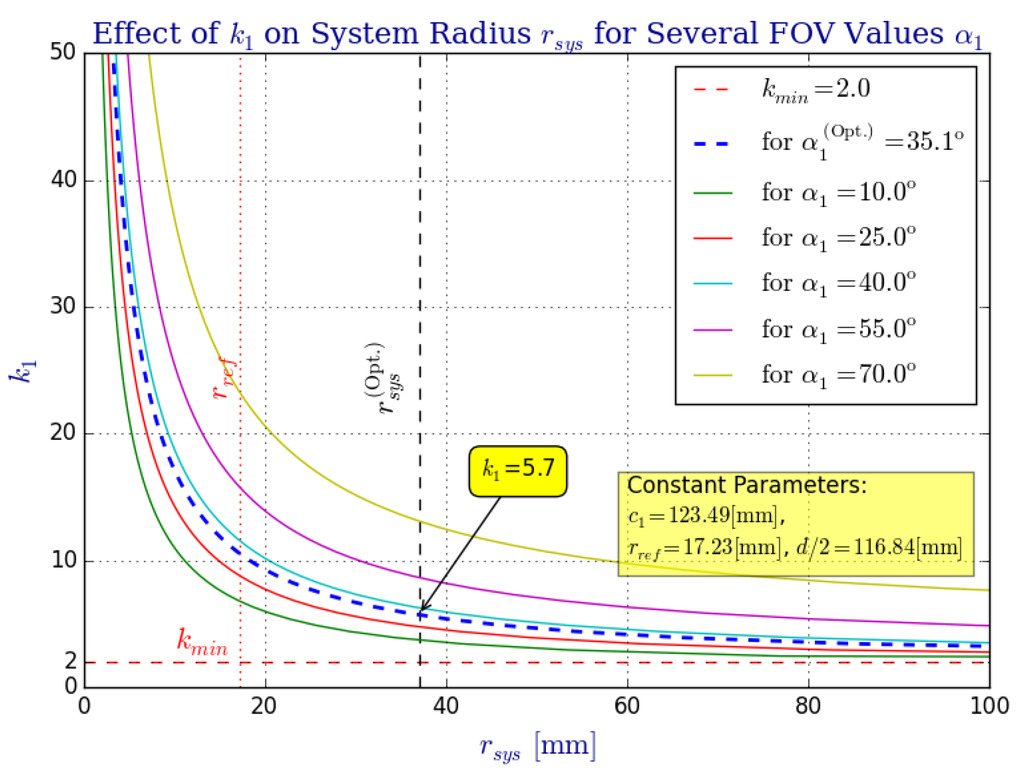
Figure 9.
The effect that parameter (showing mirror 1 only) has over the system radius for various values of the vertical field of view angle . In order to maintain a vertical field of view that is bounded by , the value of must change accordingly. Inherently, the system’s height, , and its mass, , are also affected by (see Section 2.3).
The overall vFOV of the system is also given from these elevation limits:
Figure 6 highlights the the so-called common vFOV angle, , for the stereo region of interest (SROI) where the same point can be seen from both mirrors so point correspondences can be found (Section 5). In our model, can be decided from the value of the three prevailing elevation angles (, , and ), such that:
where generally,
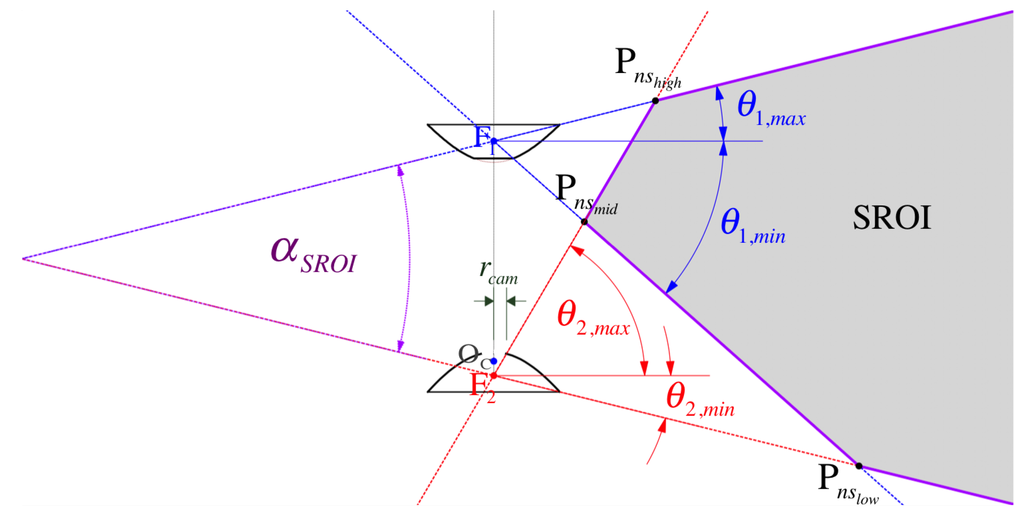
Figure 6.
A cross section of the SROI (shaded area) formed by the intersection of view rays for the limiting elevations . The nearest stereo () points are labeled , and since they are the vertices of the hull that near-bounds the set of usable points for depth computation from triangulation (Section 5.2). See Table 3 for the proposed sensor’s values.
The shaded area in Figure 6 illustrates the SROI that is far-bounded by the set of triangulated points found at the maximum range due to minimum disparity in the discrete case (refer to Figure 17), such that
where functions and , are provided in Equations (52) and (89).
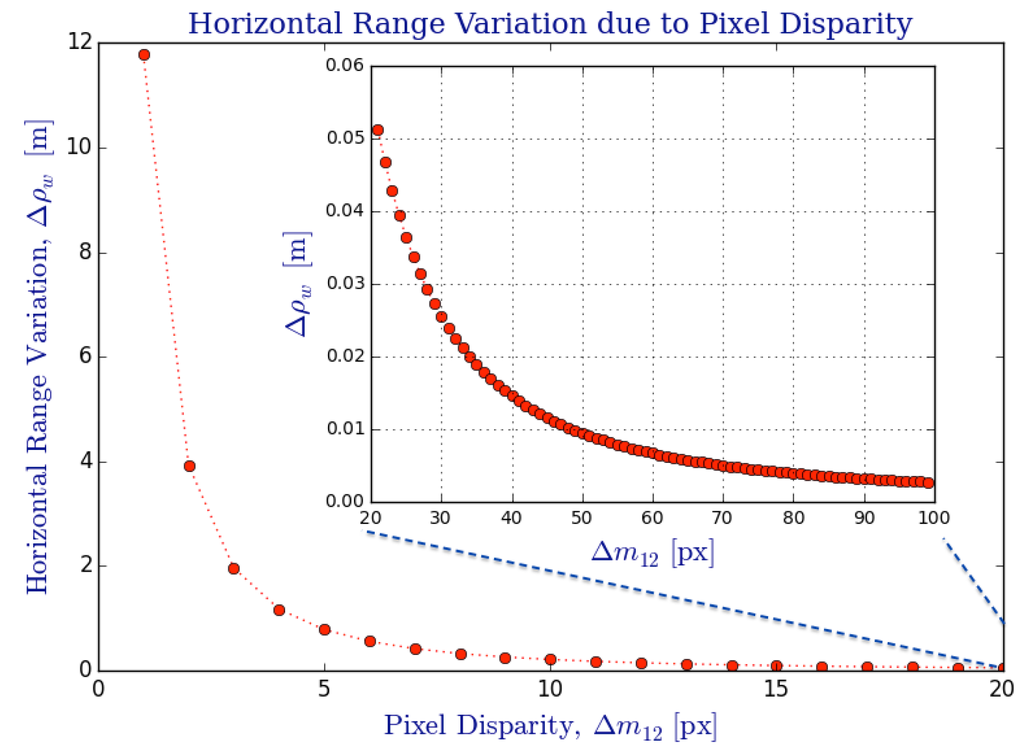
Figure 17.
Variation of horizontal range, , due to change in pixel disparity on the omnidirectional image, . There exists a “nonlinear & inverse” relation between the change in depth from triangulation () and the number of disparity pixels () available from the omnistereo image pair , which are exclusive subspaces of .
The SROI is near-bounded (to the -axis of radial symmetry) by its vertices , and , which result from the following ray-intersection cases:
- (a)
- (b)
- (c)
By assuming a radial symmetry on the camera’s field of view , it should allow for a complete view of the mirror surface at its outmost diameter of according to Equation (6). Substantially, as depicted in Figure 6, is upper-bounded by the camera hole radius selected according to Equation (78). The following inequality constraint emerges
where the respective functions are defined in Equation (13).
Our specific viewing requirements when mounting the omnidirectional sensor along the central axis of the quadrotor ensure that objects located at 15 cm under the rig’s base and at 1 meter away (from the central axis) can be viewed. Thus, angles and should only be large enough as to avoid occlusions from the MAV’s propellers (Figure 5) and to produce inner and outer ring images at a useful ratio (Figure 7).
3.4. Spatial Resolution
The resolution of the images acquired by our system are not space invariant. In fact, an omnidirectional camera producing spatial resolution-invariant images can only be obtained through a non-analytical function of the mirror profile as shown in [31]. In this section, we study the effect our design has on its spatial resolution as it depends on position parameters like d and introduced in Section 2.1 as well as a direct dependency on the characteristics (e.g., focal length f) of the camera obtaining the image.
Let be the spatial resolution for a conventional perspective camera as defined by Baker and Nayar in [25,29]. It measures the ratio between the infinitesimal solid angle d (usually measured in steradians) that is directed toward a point at an angle (formed with the optical axis ) and the infinitesimal element of image area d that d subtends (as shown in Figure 8). Accordingly, we have:
whose behavior tends to decrease as , so higher resolution areas on the sensor plane continuously increase the farther away they get from the optical center imaged at . For ease of visualization, we plot only the u pixel coordinates corresponding to the 2D spatial resolution , which is obtained by projecting the solid angle Ω onto a planar angle (the apex angle in 2D of the solid cone of view). This yields , and we reduce the image area into its circular diameter with . Generally, our conversion from 3D spatial resolution η in units to 2D proceeds as follows:
where . More specifically, Equation (59) is manipulated to provide as the indicative of spatial resolution toward any specific point in the mirror, according to Equation (8), as follows:
where is the radial length defined in Equation (6) and its associated coordinate, f is the camera’s focal length, and the design parameters d and that relate to the position of the mirror focal points with respect to the camera frame .
Figure 8.
The spatial resolution for a central catadioptric sensor is the ratio between an infinitesimal image area dA and its corresponding solid angle d that views a point . (Note: infinitesimal elements are exaggerated in the figure for better visualization.)
Thus, for a conventional perspective camera, grows as due to the foreshortening effect that stretches the image representation around the sensor plane’s periphery where spatial information gets collected onto a larger number of pixels. Therefore, image areas farther from the optical axis are considered to have higher spatial resolutions.
Baker and Nayar also defined the resolution, , of a catadioptric sensor in order to quantify the view of the world or d, an infinitesimal element of the solid angle subtended by the mirror’s effective viewpoint , which is consequently imaged onto a pixel area d. Again, here we provide the resolution according to our model:
for our mirror-perspective camera configuration, where is the origin of coordinates as shown in Figure 8 and is given in Equation (61).
As demonstrated by the plot of Figure 12 in Section 4.2.2, grows accordingly towards the periphery of each mirror (the equatorial region). This aspect of our sensor design is very important because it indicates that the common field of view, , where stereo vision is employed (Section 5), is imaged at a relatively higher resolution than the unused polar regions closer to the optical axis (the axis).
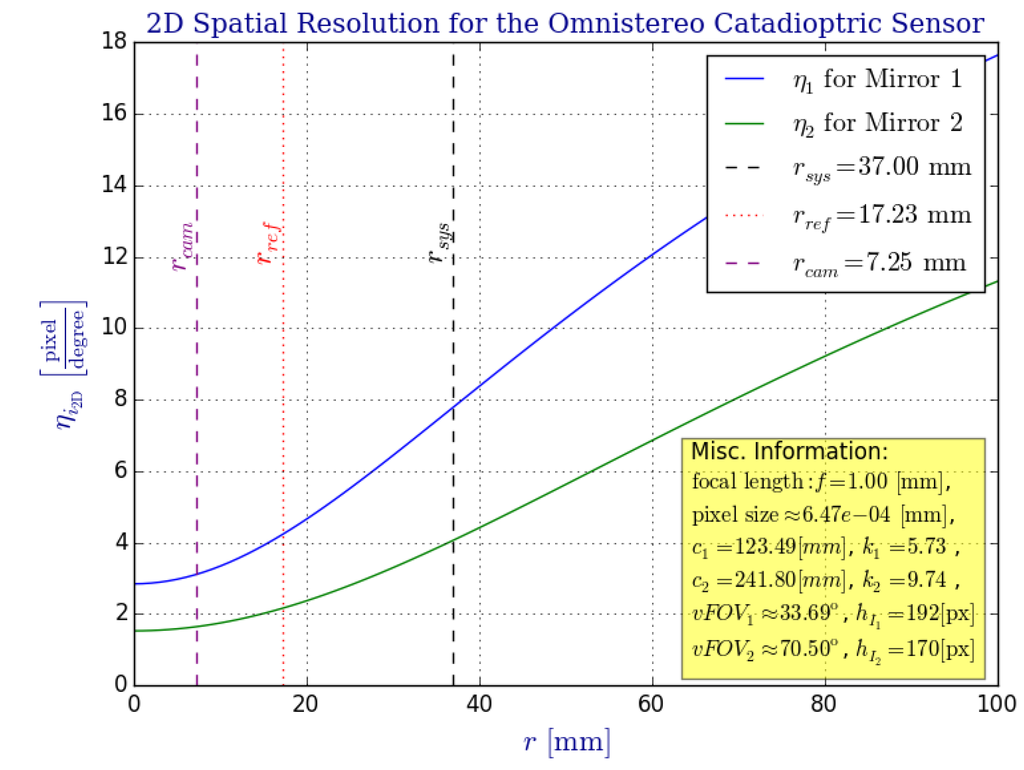
Figure 12.
Using the formula given in Equation (60), we plot the 2D version of the spatial resolution of our proposed omnistereo catadioptric sensor (37-radius rig). Both resolutions and increase towards the equatorial region where they are physically limited by . This verifies the spatial resolution theory given in [29], and it justifies our coaxial configuration useful for omnistereo sensing within the SROI indicated in Figure 6.
If we modify by substituting with its equivalent function defined in Equation (14), using mirror 1 for example, we get:
which is an inherent indicative of how the resolution for a reflection point increases with (Figure 11). Conversely, the smaller the parameter gets (related to eccentricity as discussed in Section 2.2), the flatter the mirror becomes, so its resolution resembles more that of the perspective camera alone. Mathematically, .
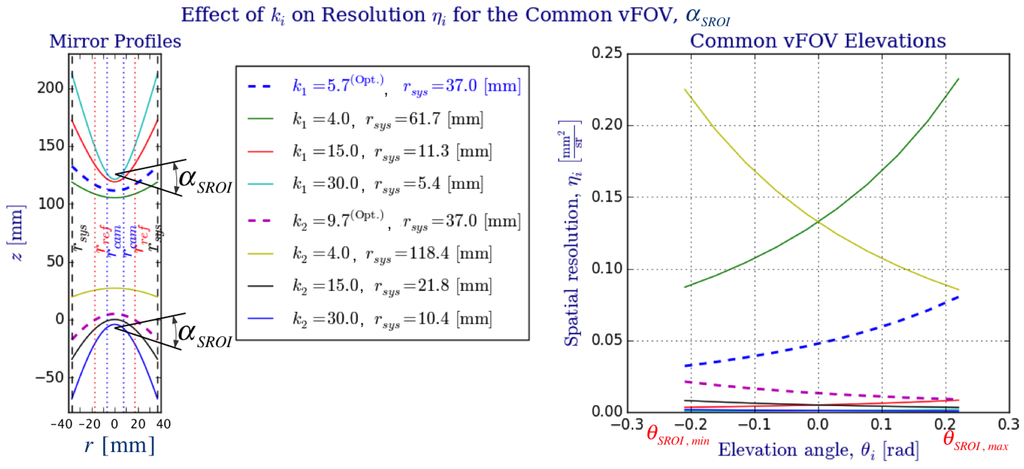
Figure 11.
Comparison of values and their effect on spatial resolution for . For the big rig, the optimal focal dimensions and (from Table 1) were used as well as the angular span on the common vertical FOV, . Although resolution for the optimal values of could be improved by employing smaller k values (lower curvature profiles indicated on the left plot of the figure), this would in turn increase the system radius, , as to maintain (Figure 9). As expected, the plot on the right help us appreciate how the spatial resolutions, , increase towards the equatorial regions ( and ).
As shown in Figure 9, a smaller would require a wider radius in order to achieve the same omnidirectional vertical field of view, . Even worse, in order to image such a wider reflector, either the camera’s field of view, , would have to increase (by decreasing the focal length f and perhaps requiring a larger camera hole and sensor size), or the distance between the effective pinhole and the viewpoint would have to increase accordingly. Another consequence is the effect on the baseline b, which must change in order to maintain the same vertical field of view (Figure 10). As a result, the depth resolution of the stereo system would suffer as well.
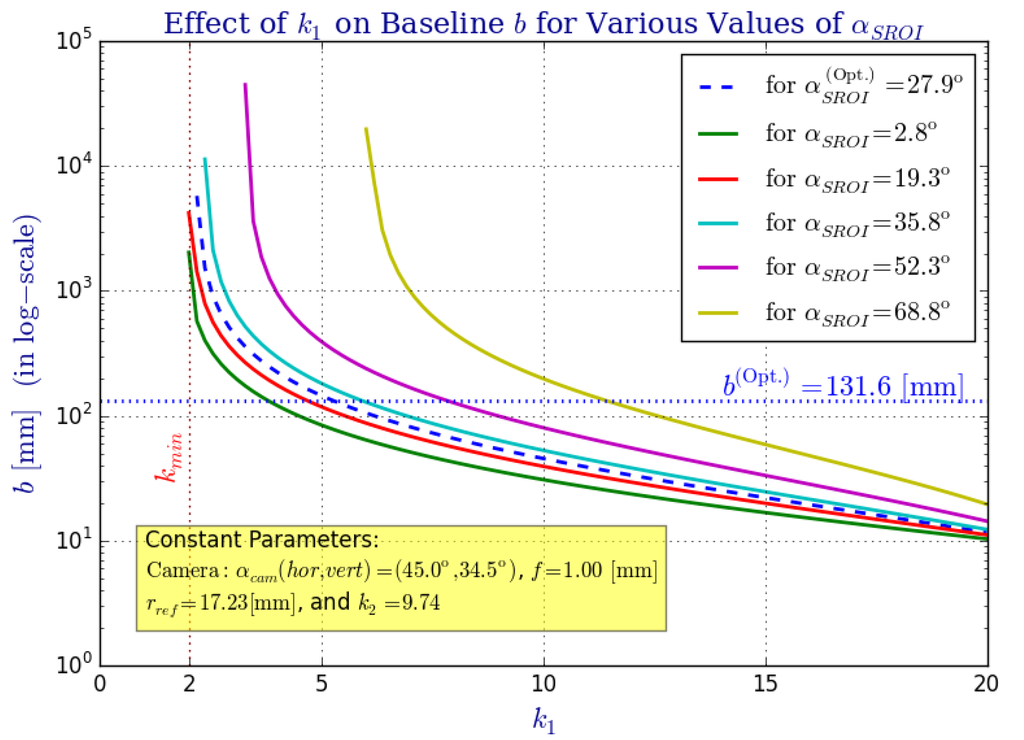
Figure 10.
The effect that parameter has over the omnistereo system’s baseline b for several common FOV angles () and a fixed camera with . An inverse relationship exists between k and b as plotted here (using a logarithmic scale for the vertical axis). Intuitively, the flatter the mirror gets (), the farther must be translated in order to fit within the camera’s view, , causing b to increase.
4. Parameter Optimization and Prototyping
The nonlinear nature of this system makes it very difficult to balance among its desirable performance aspects. The optimal vector of design parameters, , can be found by posing a constrained maximization problem for the objective function
which measures the baseline according to Equation (3). Indeed, the optimization problem is subject to the set of constraints C, which we enumerate in Section 4.1. Formally,
where is the 6-dimensional solution space for given in Equation (4) as .
4.1. Optimization Constraints
We discuss the constraints that the proposed omnistereo sensor is subject to. Overall, we mainly take the following into account:
- (a)
- geometrical constraints — including SVP and reflex constraints described by Equations (11), (12) and (2);
- (b)
- physical constraints — the rig’s dimensions, which include the mirrors radii as well as by-product parameters such as system height and mass ;
- (c)
- performance constraints — the spatial resolution and range from triangulation determined by parameters , , and ; the desired viewing angles for an optimal SROI field of view, .
Following the design model described throughout Section 2, we now list the pertaining linear and nonlinear constraints that compose the set C. We disjoint the linear constraints in a subset and the non-linear constraints subset , so . Within each subset, we generalize equality constraints as functions that obey
whereas inequality functions satisfy
4.1.1. Linear Constraints
We have only setup linear inequalities for constraints in . Specifically, we require the following:
- g1:
- In order to set the position of below the origin of the pinhole camera frame , the focal distance of mirror 2 must be larger than d (distance between and ),
- g2:
- Because the hyperboloidal mirror should reflect light towards its effective viewpoint without being occluded by the reflex mirror, mirror 1’s focal distance, , needs to exceed the placement of the reflex mirror,
- g3:
- The empirical constraintpertains our rig dimensions in order to assign a greater curvature to mirror 2’s profile (located a the bottom), so its view is directed toward the equatorial region rather than up. Complementarily, this constraint flattens mirror 1’s profile, so it can possess a greater view of the ground. This curvature inequality allows the SROI to be bounded by a wider vertical field of view when the sensor must be mounted above the MAV’s propellers as depicted in Figure 5.
4.1.2. Non-Linear Constraints
For the non-linear design constraints, we establish the following inequalities:
- g4:
- The AscTec Pelican quadrotor has a maximum payload of 650 (according to the manufacturer specifications [28]). Therefore, we must satisfy the system mass computed via Equation (16), such that
- g5:
- Similarly, we limit the system’s height obtained with Equation (15) by a height limit ,For example, we set for the 37-radius rig.
- g6:
- The origin of coordinates for the camera frame is set at its viewpoint, . In order to fit the camera enclosure under mirror 2, it is realistic to position the focus on the vertical transverse axis at more than 5 away from :where is defined in Equation (10), and pertains to Equation (5).
Next, we determine the bounds for the limiting angles that partake in the computation of the system’s vertical field of view , which is based on equation Equation (54). Our application has specific viewing requirements that can be achieved with the following application conditions:
- g7:
- Let be an acceptable upper-bound for angle , such that
- g8:
- Because we desire a larger view towards the ground from mirror 1, we empirically set as a lower-bound for the minimum elevation ,
- g9:
- In order to avoid occlusions with the MAV’s propellers while being capable to image objects located about 5 under the rig’s base and 20 away (horizontally) from the central axis, we limit mirror 2’s lowest angle by a lower-bound ,
Finally, we restrict the radius of the system, , to be identical for both hypeboloids by satisfying the following equality condition:
- h1:
- With functions and defined in Equation (14), we setwhere we imply that using Equation (13). Thus, the entire function composition for this equality becomes
4.2. Optimal Results
Applying the aforementioned constraints (Section 4.1) and using an iterative nonlinear optimization method such as one of the surveyed in [32], a bounded solution vector converges to the the values shown in Table 1 for two rig sizes. Table 2 contains the by-product parameters corresponding to the dimensions listed in Table 1.

Table 1.
Optimal System Design Parameters.
Table 2.
By-product Length Parameters.
As Figure 3 illustrates, a realistic dimension for the radius of the camera hole, , must consider the maximum value between a physical micro-lens radius () and the radius for an unoccluded field of view of the camera imaging the complete surface of mirror 1. Practically,
For both rigs, the expected vertical field of views are according to Equation (54), and using Equation (55). Note that may be actually limited by the camera hole radius, so in reality , and . For the big rig, Table 3 shows the nearest vertices of the SROI that result from these angles (Figure 6).
Table 3.
Near Vertices of the SROI for the Big Rig.
4.2.1. Optimality of Parameters and
Finally, we study the effect parameter has over the system radius (Figure 9), the omnistereo baseline b (Figure 10), and the spatial resolution (Figure 11 and Figure 12). Figure 9 addresses the relation between and radius (recall the rig size specified in Section 2.3). In Figure 11, it can be seen that for the same , realistic values for fall in the range , and the vertical field of view as , which is expected according to the SVP property specified in Section 2.2. In fact, the left part of Figure 11 also demonstrates the necessary to maintain for various values of .
Figure 10 shows the inverse relationship between values of and the baseline, b, as we attempt to fit the view of a wider/narrower mirror profile (due to ) on the constant camera field of view, . In order to make a fair comparison, let
for which we find its new focal length while solving for the new and . Provided with a function such that , we perform the analysis for a given and shown in Figure 10. Given the baseline function defined in Equation (64), the following implication holds true:
Notice that , and d are kept constant through this last analysis, and we ignore possible occlusions from the reflex mirror fixed at .
4.2.2. Spatial Resolution Optimality
In this section, we compare the sensor’s spatial resolution, , defined in Section 3.4 for the optimal parameters listed in Table 1 (for the big rig, only). In Figure 12, we verify how both resolutions and increase towards the equatorial region according to the spatial resolution theory presented in [29]. Indeed, the increase in spatial resolution within the SROI that covers the equatorial region (as indicated in Figure 6) justifies our model’s coaxial configuration intended for omnistereo applications.
In Figure 11, we compare the effect on for various mirror profiles, which depend directly on . We illustrate the change in curvature due to parameters and and also show (in the legend) the respective achieving a common vFOV of as for the optimal parameters of the big rig. From this plot, we appreciate the compromise due to optimal parameters, and , for a realistic system size due to and a suitable range of spatial resolutions, , within the SROI.
4.3. Prototypes
We validate our design with both synthetic and real-life models.
4.3.1. Synthetic Prototype (Simulation)
After converging to an optimal solution , we employ these parameters (Table 1) to describe synthetic models using POV-Ray, an open-source ray-tracer. We render 3D scenes via the camera of the synthetic omnistereo sensor like the example shown in Figure 2b. The simulation stage plays two important roles in our investigation:
- (1)
- to acquire ground-truth 3D-scene information in order to evaluate the computed range by the omnistereo system (as explained in Section 5); and
- (2)
- to provide an almost accurate geometrical representation of the model by discounting some real-life computer vision artifacts such as assembly misalignments, glare from the support tube (motivating the use of standoffs on the real prototype), as well as the camera’s shallow depth-of-field. All of these artifacts can affect the quality of the real-life results shown in Section 6.
4.3.2. Real-Life Prototypes
We have also produced two physical prototypes that can be installed on the Pelican quadrotor (made by Ascending Technologies [28]). Figure 13a shows the rig constructed with hyperboloidal mirrors of , and a Logitech® HD Pro Webcam C910 camera capable of (2592 × 1944) pixel images at 15∼20 FPS. We decided to skip the use of the acrylic glass tube to separate the mirrors at the specified distance, and instead we constructed a lighter 3-standoff mount in order to avoid glare and cross-reflections. This support was designed in 3D-CAD and printed for assembly. The three areas of occlusion due to the 3-wide standoffs are non-invasive for the purpose of omnidirectional sensing and can be ignored with simple masks during image processing. In fact, we stamped fiducial markers to the vertical standoffs to aid with the panoramas generation (Section 5.1) and future calibration methods. To image the entire surface of mirror 1, we require a camera with a (minimum) field of view of , which is achieved by . In practice, as noted by Equation (78), microlenses measure around . Therefore, we set , as a safe specification to fit a standard microlens through the opening of mirror 2 as shown in Figure 3.
Recall that is limited by the maximum 650-payload that the AscTec Pelican quadrotor is capable of flying with (according to the manufacturer specifications [28]). The camera with lens weights approximately 25. A cylindrical tube made of acrylic has an average density gcm, whereas the mirrors machined out of brass have a density gcm. Empirically, we verify a close estimate of the entire system’s mass, such that for the big rig, and for the small rig.
5. 3D Sensing from Omnistereo Images
Stereo vision from point correspondences on images at distinct locations is a popular method for obtaining 3D range information via triangulation. Techniques for image point matching are generally divided between dense (area-based scanning [32]) and sparse (feature description [33]) approaches. Due to parallax, the disparity in point positions for objects close to the vision system must be larger than for objects that are farther away. As illustrated in Figure 6, the nearsightedness of the sensor is determined mainly by the common observable space (a.k.a. SROI) acquired by the limiting elevation angles of the mirrors (Section 3.3). In addition, we will see next (Section 5.2) that the baseline b also plays a major role in range computation.
Due to our model’s coaxial configuration, we could scan for pixel correspondences radially between a given pair of warped images like in the approach taken by similar works such as [34]. However, it seems more convenient to work on a rectified image space, such as with panoramic images, where the search for correspondences can be performed using any of the various existing methods for perspective stereo views. Hence, we first demonstrate how these rectified panoramic images are produced (Section 5.1) and used for establishing point correspondences. Then, we proceed to study our triangulation method for the range computation from a given set of point correspondences (Section 5.2). Last, we show preliminary 3D point clouds as the outcome from such procedure.
5.1. Panoramic Images
Figure 14 illustrates how we form the respective panoramic image out of its warped omnidirectional image . As illustrated in Figure 7, is simply the region of interest out of the full image where projection occurs via mirror i. However, we can safely refer to because it will never be the case that projections via different mirrors overlap on the same pixel position . In a few words, we obtain a panorama by reverse-mapping each discretized 3D point to its projected pixel coordinates on according to Section 3.2.
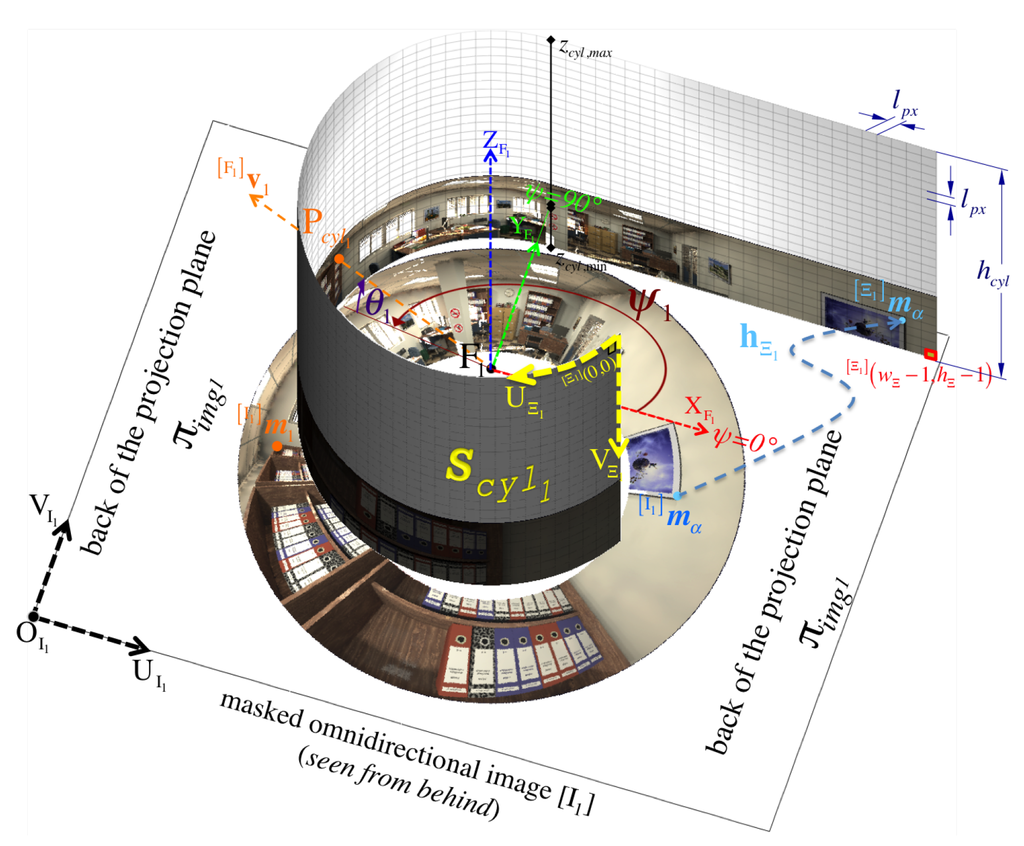
Figure 14.
An example for the formation of panoramic image out of the omnidirectional image (showing only the masked region of interest on the back of image plane ). Any particular ray, indicated by its elevation and azimuth such as that is directed towards the focus must traverse the projection cylinder at point . More abstractly, the figure also shows how a pixel position on the panoramic pixel space gets mapped from its corresponding pixel position via function defined in Equation (85). Although not up to scale, it’s crucial to notice the relative orientation between and the back of the projection plane where the omnidirectional image is found.
More thoroughly, for , is the set of all valid 3D points that lie on an imaginary unit cylinder centered along the Z-axis and positioned with respect to the mirror’s primary focus . Recall that the radius of a unit cylinder is , so its circumference becomes . Noticed that the imaging ratio, , illustrated in Figure 7 provides a way of inferring the scale between pairs of point correspondences. However, we achieve conforming scales among both panoramic representations by simply setting both cylinders to an equal height , which is determined from the system’s elevation limits, , since they partake in the measurement of the system’s vertical field of view given by Equation (54). Hence, we obtain
Consequently, to achieve panoramic images of the same dimensions by maintaining a true aspect ratio , it suffices to indicate either the width (number of columns) or the height (number of rows) as number of pixels. Here, we propose a custom method for resolving the panoramic image dimensions by setting the equality for the length of an individual “square” pixel in the cylinder (behaving like a panoramic camera sensor):
For instance, if the width is given, then the height is simply .
To increase the processing speed for each panoramic image , we fill up its corresponding look-up-table LUT of size that encodes the mapping for each panoramic pixel coordinates to its respective projection on the distorted image . Each pixel gets associated with its cylinder’s 3D point positioned at , which can inherently be indicated by its elevation and azimuth (relative to the mirror’s primary focus ) as illustrated in Figure 4. Thus, the ray of a particular 3D point directed about must pass through in order to get imaged as pixel .
Since the circumference of the cylinder, , is discretized with respect to the number of pixel columns or width , we use the pixel length as the factor to obtain the arc length spanned by the azimuth out of a given coordinate on the panoramic image. Generally,
or simply for the unit cylinder case.
An order reversal in the columns of the panorama is performed by Equation (82) because we account for the relative position between and the projection plane . For , Figure 14 depicts the unrolling of the cylindrical panoramic image onto a planar panoramic image. However, note that is shown from above (or its back) in Figure 14, so the panorama visualization places the viewer inside the cylinder at .
Similarly, the elevation angle is inferred out the row or coordinate, which is scaled to its cylindrical representation by . Recall that both cylinders have the same height, , computed by Equation (80). By taking into account any row offset from the maximum height position, , of the cylinder, we get
Given these angles and assuming coaxial alignment, we evaluate the positon vector for a point on the panoramic cylinder with respect to the camera frame :
where cancels out for a unit cylinder. The direction equations Equations (82) and (83) leading to Equation (84) as a process:
, which is eventually used as the input argument to Equation (36) in order to determine pixel via the mapping function ,
Stereo Matching on Panoramas
We understand that the algorithm chosen for finding matches is crucial to attain correct pixel disparity results. We refer the reader to [35] for a detailed survey of stereo correspondence methods. After comparing various block matching algorithms, we were able to obtain acceptable disparity maps with the semi-global block matching (SGBM) method introduced by [36], which can find subpixel matches in real time. As a result of this stereo block matcher among the pair of panoramic images , we get the dense disparity map visualized as an image in Figure 15 and Figure 21a. Note that valid disparity values must be positive and they are given with respect to the reference image, in this case, . In addition, recall that no stereo matching algorithm (as far as we are aware) is totally immune to mismatches due to several well-known reasons in the literature such as ambiguity of cyclic patterns.

Figure 15.
For the synthetic omnidirectional image shown in Figure 2b, we generate its pair of panoramic images using the procedure explained in Section 5.1. Note that we only work on the SROI (shown here) to perform a semi-global block match between the panoramas as indicated in Section 5.1.1. The resulting disparity map, , is visualized at the bottom as a gray-scale panoramic image normalized about its 256 intensity levels, where brighter colors imply larger disparity values. To distinguish the relative vertical view of both panoramas, we have annotated the row position of the zero-elevation.
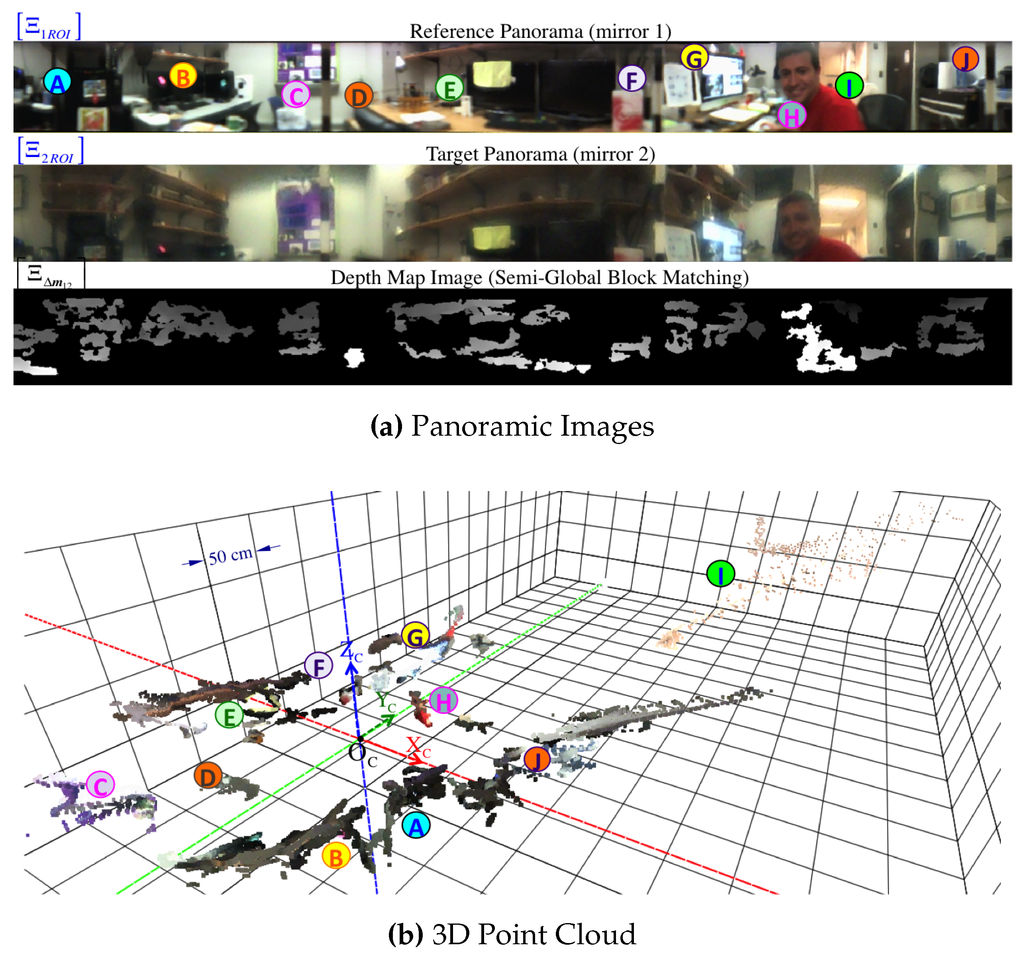
Figure 21.
Real-life experiment using the 37-radius prototype and a single 2592 × 1944 pixels image where the rig was positioned in the middle of the room observed in Figure 13a. Some landmarks of the scene are annotated as following: Ⓐ appliances, Ⓑ monitors and shelf, Ⓒ back wall, Ⓓ chair, Ⓔ monitors and shelf,Ⓕ book, Ⓖ monitors, Ⓗ person, Ⓘ hallway, Ⓙ supplies. For the point cloud, the grid size is 0.50 m in all directions and points are thickened for clarity.
An advantage of the block (window) search for correspondences is that it can be narrowed along epipolar lines. Unlike the traditional horizontal stereo configuration, our system captures panoramic images whose views differ in a vertical fashion. As shown in [14], the unwrapped panoramas contain vertical, parallel epipolar lines that facilitate the pixel correlation search. Thus, given a pixel position on the reference panorama and its disparity value , we can resolve the correspondence pixel coordinate on the target image, , by simply offsetting the v-coordinate with the disparity value:
5.2. Range from Triangulation
Recall the duality that states a point as the intersection of a pair of lines. Regardless of the correspondence search technique employed, such as block stereo matching between panoramas (Section 5.1.1) or feature detection directly on , we can resolve for . From Equations (42) and (49), we obtain the respective pair of back-projected rays , emanating from their respective physical viewpoints, and , which are separated by baseline b. We can compute elevation angles and using equations Equations (43) and (50). Then, we can triangulate the back-projected rays in order to calculate the horizontal range defined in Equation (22), as follows:
Finally, we obtain the 3D position of :
where is the common azimuthal angle (on the XY-plane) for coplanar rays, so it can be determined either by Equation (44) or Equation (51). Functionally, we define the “naive” intersection function that implements Equations (87) and (88) such that
where θ is the model parameters vector defined in Equation (4) and can be omitted when calling this function because the model parameters should not change (ideally).
5.2.1. Common Perpendicular Midpoint Triangulation Method
Because the coplanarity of these rays cannot be guaranteed (skew rays case), a better triangulation approximation while considering coaxial misalignments is to find the midpoint of their common perpendicular line segment (as attempted in [23]). As illustrated in Figure 16, we define the common perpendicular line segment as the parametrized vector , for the unit vector normal to the back-projected rays, and , such that:
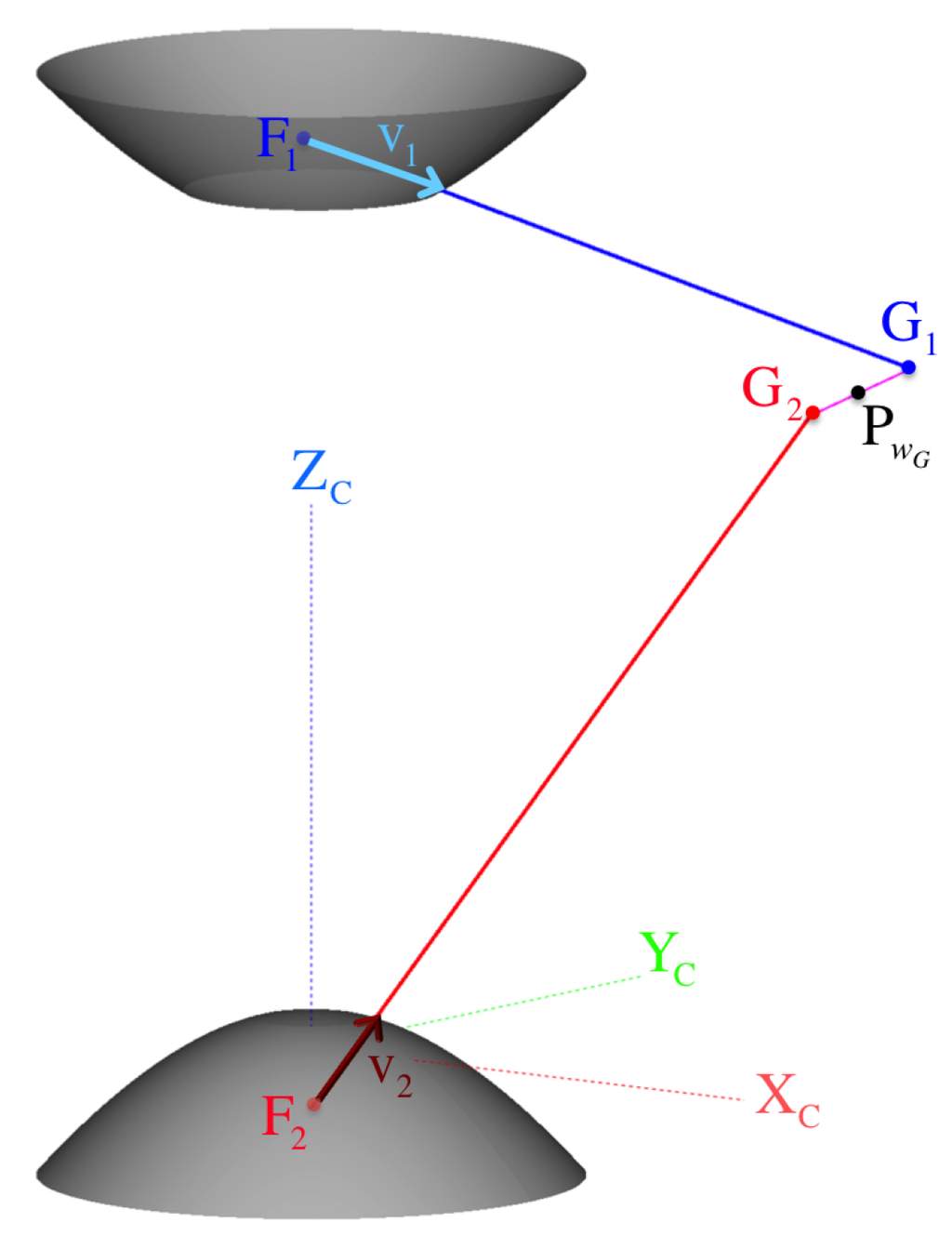
Figure 16.
The more realistic case of skew back-projection rays approximates the triangulated point by getting the midpoint on the common perpendicular line segment . Note that the visualized skew rays were formed from a pixel correspondence pair and by offsetting the coordinate by 15 pixels.
If the rays are not parallel (), we can compute the “exact” solution, , of the well-determined linear matrix equation
It follows that the location of the midpoint on the common perpendicular with respect to the common frame is
5.2.2. Range Variation
Before we introduce an uncertainty model for triangulation (Section 5.3), we briefly analyze how range varies according to the possible combinations of pixel correspondences, on the image . Here, we demonstrate how a radial variation of discretized pixel disparities, , affects the 3D position of a point obtained from triangulation (Section 5.2). Figure 17 demonstrates the nonlinear characteristics of the variation in horizontal range, , from the discrete relation between pixel positions and their respective back-projected (direction) rays obtained from and triangulated via function defined in Equation (89). It can be observed that the horizontal range variation, , increases quadratically as , which is the minimum discrete pixel disparity, which provides a maximum horizontal range (computed analytically). The main plot of Figure 17 shows the small disparity values in the interval , whereas the subplot is a zoomed-in extension of the large disparity cases in the interval .
The current analysis is an indicative that triangulation error (e.g., due to false pixel correspondences) may have a severe effect on range accuracy that increases quadratically with distance as it can be appreciated with the 8 variation on the disparity interval . Also, observe the example of Figure 20 for a reconstructed point cloud, where this range sensing characteristic is more noticeable for faraway points. In fact, the following uncertainty model provides a probabilistic framework for the triangulation error (uncertainty) that agrees with the current numerical claims.
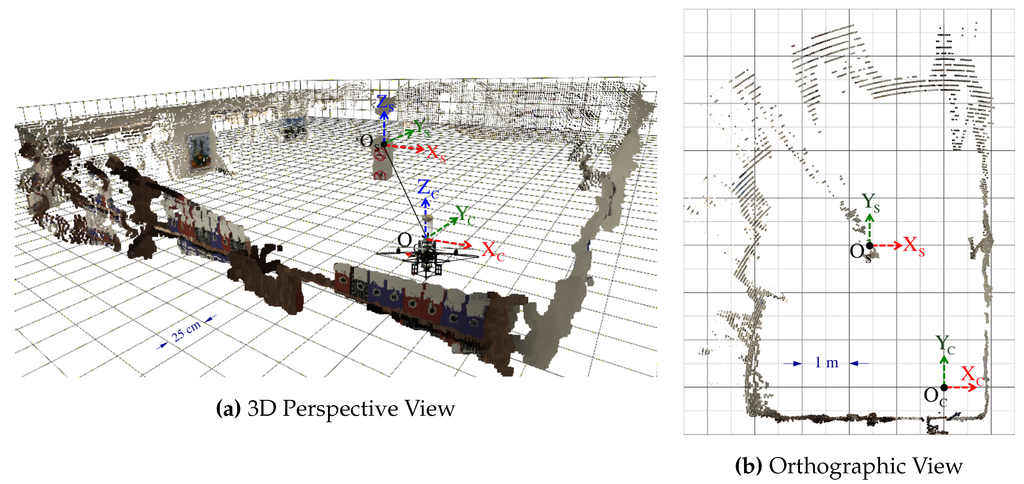
Figure 20.
A 3-D dense point cloud computed out of the synthetic model that rendered the omnidirectional image shown in Figure 2b. Pixel correspondences are established via the panoramic depth map visualized in Figure 15. The 3D point triangulation implements the common perpendicular midpoint method indicated in Section 5.2.1. The position of the omnistereo sensor mounted on the quadrotor is annotated as frame with respect to the scene’s coordinates frame . (a) 3D visualization of the point cloud (the quadrotor with the omnistereo rig has been added for visualization only); (b) Orthographic projection of the point cloud to the -plane of the visualization grid.
5.3. Triangulation Uncertainty Model
Let be the vector-valued function that computes the 3D coordinates of point with respect to as the common perpendicular midpoint defined in Equation (92). We express this triangulation function component-wise as follows:
where is composed by the pixel coordinates of the correspondence upon which to base the triangulation (Section 5.2).
Without loss of generality, we model a multivariate Gaussian uncertainty model for triangulation, so that the position vector of any world point is centered at its mean with a covariance matrix :
However, since is a non-linear vector-valued function, we linearize it by approximation to a first-order Taylor expansion and we use its Jacobian matrix to propagate the uncertainty (covariance) as in the linear case as follows:
where the Jacobian matrix for the triangulation function is
and the covariance matrix of the pixel arguments being
where we assume for the standard deviation of each pixel coordinate in the discretized pixel space. The complete symbolic solution of is too involved to appear in this manuscript. However, in Figure 18, we show the top-view of the covariance ellipsoid drawn at a three- level for a point triangulated nearly around . Figure 19 visualizes uncertainty ellipsoids drawn at a one- level for several triangulation ranges. We refer the reader to the end of Section 6.3 where we validate the safety of this 1 pixel deviation assumption through experimental results using subpixel precision.
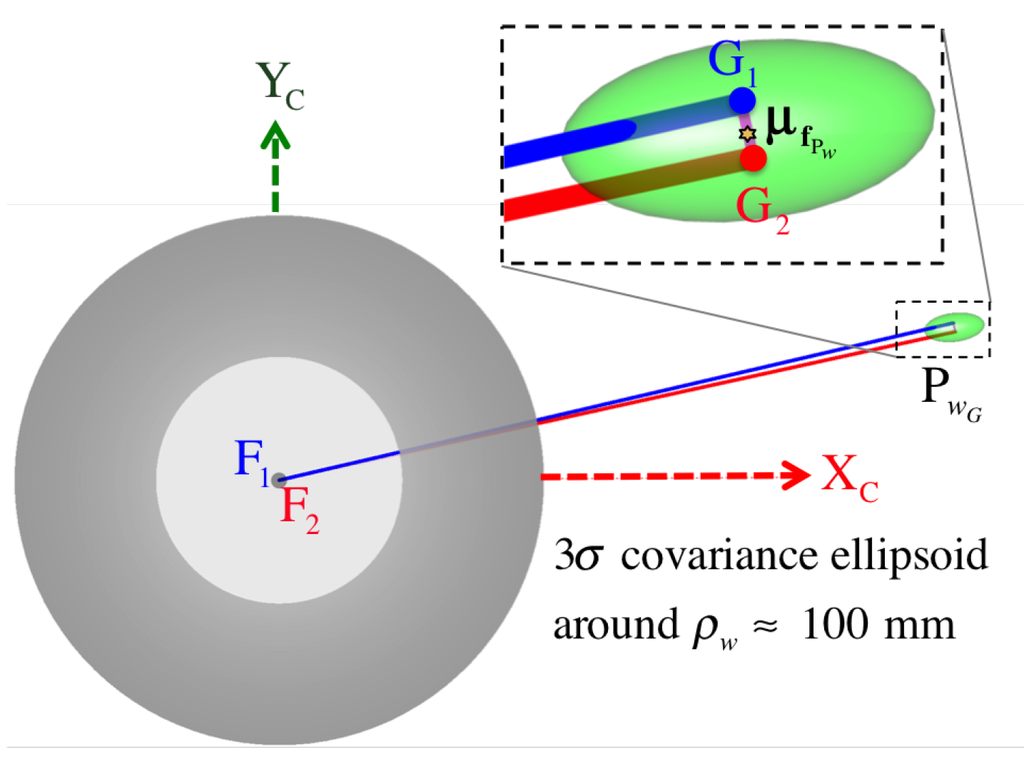
Figure 18.
Top-view of the three-sigma level ellipsoid for the triangulation uncertainty of a pixel pair with an assumed standard deviation .
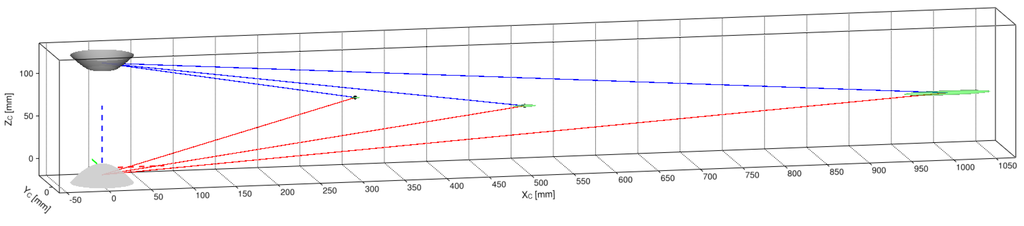
Figure 19.
Uncertainty ellipsoids for triangulated points at ranges .
6. Experiment Results
In this section, we demonstrate the capabilities of the omnistereo sensor to provide 3D information either as dense point clouds or as for the registration of sparse 2D features and 3D points. We also evaluate the precision of both projection and triangulation of a few detected corners from a chessboard whose various 3D poses are given as ground-truth.
6.1. Dense 3D Point Clouds
By implementing the process described in Section 5, we begin by visualizing the dense point-cloud obtained from the omnidirectional synthetic image given in Figure 2b, whose actual size is 1280 × 960 pixels. The associated panoramic images, , were obtained using function defined in Equation (85) and are shown in Figure 15. Pixel correspondences on the panoramic representations are mapped via into their respective image positions . Then, these are triangulated with given in Equation (93), resulting in the set (cloud) of color 3D points visualized in Figure 20. Here, the synthetic scene (Figure 2a) is for a room 5.0 wide (along its -axis), 8.0 long (along its -axis), and 2.5 high (along its -axis). With respect to the scene center of coordinates, , the catadioptric omnistereo sensor, , is positioned at in meters.
We also present results from a real experiment using the prototype described in Section 4.3.2 and shown in Figure 13a. The panoramic images and dense point cloud shown in Figure 21 are obtained by implementing the pertinent functions described throughout this manuscript and by holding the SVP assumption of an ideal configuration. We provide these qualitative results as preliminary proof of concept for the proposed sensor after employing a calibration procedure based on the generalized unified model proposed in [37].
6.2. Sparse 3D Points from Features
Using the SURF feature detector and descriptors [38], Figure 22 demonstrates 44 correct matches that are triangulated with Equation (93). Sparse 3D points can be useful for applications of visual odometry where the sensor changes poses and those registered point features can be matched against new images. Please, refer to [39] for a tutorial on visual odometry.
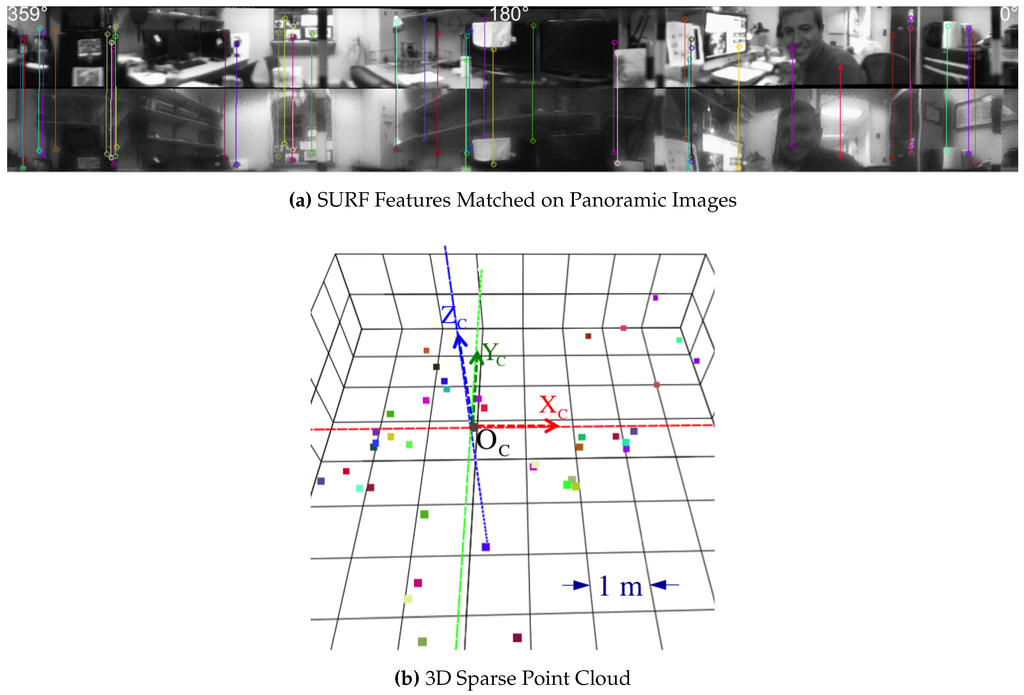
Figure 22.
Sparse point correspondences for the real-life image from Figure 13b. Point correspondences are identifiable by random colors that persist in both the panoramic image and the respective triangulated 3D points (scaled-up for visualization).
6.3. Triangulation Evaluation
6.3.1. Evaluation of Synthetic Rig
Due to the unstructured nature of the dense point clouds previously discussed, we proceed to triangulate sets of sparse 3D points whose positions with respect to the omnistereo sensor camera frame, , are known in advance. We synthesize a calibration chessboard pattern containing square cells for various predetermined poses . Since the sensor is assumed to be rotationally symmetric, it suffices to experiment with groups of chessboard patterns situated at a given horizontal range. A total of 3D points are available for each range group. Each corner point’s position is found with respect to via the frame transformation for all indices .
Figure 23 shows the set of detected corner points on the image from the group of patterns set to a range of . We adjust the pattern’s cell sizes accordingly so its points can be safely discerned by an automated corner detector [35]. We systematically establish correspondences of pattern points on the omnidirectional image, and proceed to triangulate with Equation (93). For each range group of points, we compute the root-mean-square of the 3D position errors (RMSE) between the observed (triangulated) points and the true (known) points that were used to describe the ray-traced image. Table 4 compiles the RMSE results and the standard deviation (SD) for some group of patterns whose frames , are located at specified horizontal ranges away from .
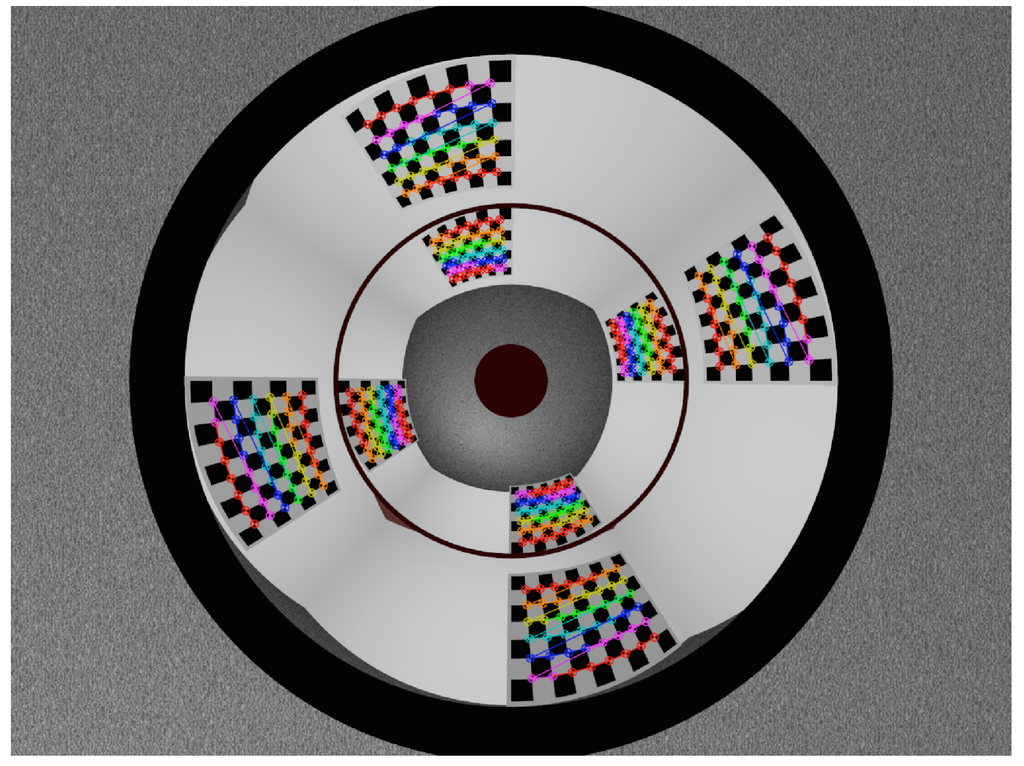
Figure 23.
Example of sparse point correspondences detected with subpixel precision from corners on the chessboard patterns around the omnistereo sensor. The size of the rendered images for this experiment is 1280 × 960 pixels. For this example’s patterns, the square cell size is 140. The RMSE for this set of points at is approximately 15 (Table 4).
Table 4.
Results of RMSE from Synthetic Triangulation Experiment.
We notice that for all the 3D points in the synthetic patterns, we obtained an average error of with a standard deviation for the subpixel detection of corners on the image versus their theoretical values obtained from defined in Equation (36). This last experiment helps us validate the pessimistic choice of for the discrete pixel space in the triangulation uncertainty model proposed in Section 5.3.
6.3.2. Evaluation of Real-Life Rig
The following experiment uses different poses of a real chessboard pattern with corner points where the square cell size is . As done in Section 6.3.1, the evaluated error is the Euclidean norms between the triangulated points and the ground-truth positions of the chessboard posses captured via a motion capture system. The RMSE for all projected points in this set of chessboard patterns is 2.5 with a standard deviation of 1.5 . The RMSE for all triangulated points in this set is 3.5 with a standard deviation of 1.4. Figure 24 visually confirms the proximity of the triangulated chessboard poses against the ground-truth pose information.
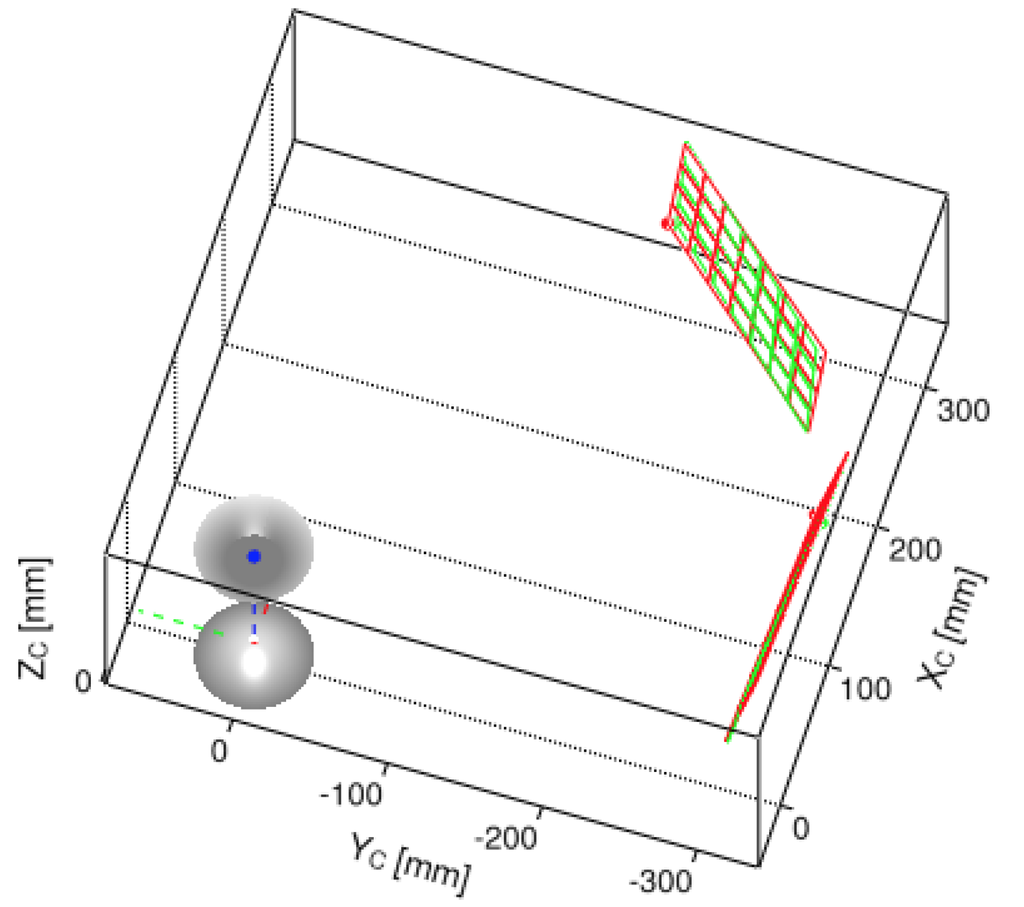
Figure 24.
Visualization of estimated 3D poses for some chessboard patterns using the real-life omnistereo rig. Color annotations: ground-truth poses (green), estimated triangulated poses (red).
7. Discussion and Future Work
The portable aspect of the proposed omnistereo sensor is one of its greatest advantages, as discussed in the introduction section. The total weight of the big rig using 37-radius mirrors is about 550, so it can be carried by the AscTec Pelican quadrotor under its payload limitations of 650. The mirror profiles maximize the stereo baseline while obeying the various design constraints such as size and field of view. Currently, the mirrors are custom-manufactured out of brass using CNC machining. However, it is possible to reduce the system’s weight dramatically by employing lighter materials.
In reality, it is almost impossible to assemble a perfect imaging system that fulfills the SVP assumption and avoids the triangulation uncertainty studied in Section 5.3 on top of the error already introduced by any feature matching technique. The coaxial misalignment of the folded mirrors-camera system, defocus blur of the lens, and the inauspicious glare from the support tube are all practical caveats we need to overcome for better 3D sensing tasks. As described in the text for the real-life rig, we have avoided the traditional use of a support cylinder in order to workaround the cross-reflections and glare issues. Possible vibrations caused by the robot dynamics are reduced by vibration pads placed on the sensor-body interface. Details about our tentative calibration method for vertically-folded omnistereo systems has not been included in the current study since we would like the reader’s attention to be devoted to the sensor characteristics defended by this analysis.
Our ongoing research is also focusing on the development of efficient software algorithms for real-time 3D pose estimation from point clouds. Bear in mind that all the experimental results demonstrated in this manuscript rely upon a single camera snapshot. We understand that the narrow vertical field-of-view where stereo vision operates is a limiting factor for dense scene reconstruction from a single image, so we have also considered non-optimal geometries for the quadrotor’s view. In fact, increasing the region of interest for stereo (SROI) while maintaining the wide baseline implies an enlargement of each mirror’s radius. We believe that our omnidirectional system is more advantageous than forward-looking sensors because it can provide a robust pose estimation by extracting 3D point features from all around the scene at once. As in our past work [24], fusing multiple modalities (e.g., stereo and optical-flow) is a possibility in order to resolve the scale-factor problem inherent while performing structure from motion over the non-stereo regions of each mirror (near the poles).
In this work, we performed an extensive study of the proposed omnistereo sensor’s properties, such as its spatial resolution and triangulation uncertainty. We validated the projection accuracy of the synthetic model (the ideal case) where 3D points in the world are given exactly. In order to validate the precision of the real sensor, we require a perfectly constructed and assembled device so point projections can be accepted as the ultimate truth. This is hard to achieve at a low-cost prototyping stage. Although we acquired ground-truth 3D points via a position capture system alone, we deem this insufficient to validate the imaging accuracy of the real sensor because the precision of the calibration method is truly what is being accounted for. For reproducibility purposes, source code is available for the implementation of the theoretical omnistereo model, optimization, plots and figures presented in this analysis [40].
Acknowledgments
This work was supported in part by U.S. Army Research Office grantNo. W911NF-09-1-0565, U.S. National Science Foundation grant No. IIS-0644127, and a Ford Foundation Pre-doctoral Fellowship awarded to Carlos Jaramillo.
Author Contributions
The work presented in this paper is a collaborative development by all of the authors. C. Jaramillo wrote this manuscript, carried out all the experiments and conceived the extensive analysis of the omnistereo sensor studied here. R.G. Valenti contributed with the analytical derivation of various equations and manuscript revisions. L. Guo established the geometrical model and rules for the constrained optimization of design parameters. J. Xiao funded and guided this entire study and helped with revisions.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Symbolic Notation
a point where post-subscript i as a unique identifier. | |
a reference frame or image space with origin . | |
The position vector of with respect to reference frame . | |
for homogeneous coordinates. | |
a 2D point or pixel position on image frame . | |
the magnitude (Euclidean norm) of . | |
A unit vector so . | |
a matrix, or in homogeneous coordinates. | |
a scalar-valued function that outputs some s. | |
a vector-valued function for the computation of . |
All coordinate systems obey the right-hand rule unless otherwise indicated.
References
- Marani, R.; Renò, V.; Nitti, M.; D’Orazio, T.; Stella, E. A Compact 3D Omnidirectional Range Sensor of High Resolution for Robust Reconstruction of Environments. Sensors 2015, 15, 2283–2308. [Google Scholar] [CrossRef]
- Valenti, R.G.; Dryanovski, I.; Jaramillo, C.; Strom, D.P.; Xiao, J. Autonomous quadrotor flight using onboard RGB-D visual odometry. In Proceedings of the International Conference on Robotics and Automation (ICRA 2014), Hong Kong, China, 31 May–7 June 2014; pp. 5233–5238.
- Khoshelham, K.; Elberink, S.O. Accuracy and resolution of Kinect depth data for indoor mapping applications. Sensors 2012, 12, 1437–1454. [Google Scholar] [CrossRef] [PubMed]
- Payá, L.; Fernández, L.; Gil, A.; Reinoso, O. Map building and monte carlo localization using global appearance of omnidirectional images. Sensors 2010, 10, 11468–11497. [Google Scholar] [CrossRef] [PubMed]
- Berenguer, Y.; Payá, L.; Ballesta, M.; Reinoso, O. Position Estimation and Local Mapping Using Omnidirectional Images and Global Appearance Descriptors. Sensors 2015, 15, 26368–26395. [Google Scholar] [CrossRef] [PubMed]
- Hrabar, S.; Sukhatme, G. Omnidirectional vision for an autonomous helicopter. In Proceedings of the International Conference on Robotics and Automation (ICRA), Taipei, Taiwan, 14–19 September 2003; pp. 3602–3609.
- Hrabar, S. 3D path planning and stereo-based obstacle avoidance for rotorcraft UAVs. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Nice, France, 22–26 September 2008; pp. 807–814.
- Orghidan, R.; Mouaddib, E.M.; Salvi, J. Omnidirectional depth computation from a single image. In Proceedings of the IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 1222–1227.
- Paniagua, C.; Puig, L.; Guerrero, J.J. Omnidirectional structured light in a flexible configuration. Sensors 2013, 13, 13903–13916. [Google Scholar] [CrossRef] [PubMed]
- Byrne, J.; Cosgrove, M.; Mehra, R. Stereo based obstacle detection for an unmanned air vehicle. In Proceedings of the International Conference on Robotics and Automation, Orlando, FL, USA, 15–19 May 2006.
- Smadja, L.; Benosman, R.; Devars, J. Hybrid stereo configurations through a cylindrical sensor calibration. Mach. Vis. Appl. 2006, 17, 251–264. [Google Scholar] [CrossRef]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Volume 2, Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Sturm, P.; Ramalingam, S.; Tardif, J.P.; Gasparini, S.; Barreto, J.P. Camera models and fundamental concepts used in geometric computer vision. Found. Trends®Comput. Graph. Vis. 2010, 6, 1–183. [Google Scholar] [CrossRef]
- Gluckman, J.; Nayar, S.K.; Thoresz, K.J. Real-Time Omnidirectional and Panoramic Stereo. Comput. Vis. Image Underst. 1998. [Google Scholar]
- Koyasu, H.; Miura, J.; Shirai, Y. Realtime omnidirectional stereo for obstacle detection and tracking in dynamic environments. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Maui, HI, USA, 29 October–3 November 2001; Volume 1, pp. 31–36.
- Bajcsy, R.; Lin, S.S. High resolution catadioptric omni-directional stereo sensor for robot vision. In Proceedings of the 2003 IEEE International Conference on Robotics and Automation, Taipei, Taiwan, 14–19 September 2003; pp. 1694–1699.
- Cabral, E.E.; de Souza, J.C.J.; Hunold, M.C. Omnidirectional stereo vision with a hyperbolic double lobed mirror. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR), Cambridge, UK, 23–26 August 2004; pp. 0–3.
- Su, L.; Zhu, F. Design of a novel stereo vision navigation system for mobile robots. In Proceedings of the IEEE Robotics and Biomimetics (ROBIO), Hong Kong, China, 5–9 July 2005; pp. 611–614.
- Mouaddib, E.M.; Sagawa, R. Stereovision with a single camera and multiple mirrors. In Proceedings of the International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 800–805.
- Schönbein, M.; Kitt, B.; Lauer, M. Environmental Perception for Intelligent Vehicles Using Catadioptric Stereo Vision Systems. In Proceedings of the European Conference on Mobile Robots (ECMR), Örebro, Sweden, 7–9 September 2011; pp. 1–6.
- Yi, S.; Ahuja, N. An Omnidirectional Stereo Vision System Using a Single Camera. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 861–865.
- Nayar, S.K.; Peri, V. Folded catadioptric cameras. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999; pp. 217–223.
- He, L.; Luo, C.; Zhu, F.; Hao, Y. Stereo Matching and 3D Reconstruction via an Omnidirectional Stereo Sensor. In Motion Planning; Number 60575024; In-Tech Education and Publishing: Vienna, Austria, 2008; pp. 123–142. [Google Scholar]
- Labutov, I.; Jaramillo, C.; Xiao, J. Generating near-spherical range panoramas by fusing optical flow and stereo from a single-camera folded catadioptric rig. Mach. Vis. Appl. 2011, 24, 1–12. [Google Scholar] [CrossRef]
- Swaminathan, R.; Grossberg, M.D.; Nayar, S.K. Caustics of catadioptric cameras. In Proceedings of the Eighth IEEE International Conference on Computer Vision (ICCV 2001), Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 2–9.
- Jang, G.; Kim, S.; Kweon, I. Single camera catadioptric stereo system. In Proceedings of the Workshop on Omnidirectional Vision, Camera Networks and Nonclassical Cameras (OMNIVIS2005), Beijing, China, 21 October 2005.
- Jaramillo, C.; Guo, L.; Xiao, J. A Single-Camera Omni-Stereo Vision System for 3D Perception of Micro Aerial Vehicles (MAVs). In Proceedings of the IEEE Conference on Industrial Electronics and Applications (ICIEA), Melbourne, Australia, 19–21 June 2013; Volume 10016.
- Ascending Technologies (AscTec). Available online: http://www.asctec.de/en/uav-uas-drones-rpas-roav/ (accessed on 23 May 2014).
- Baker, S.; Nayar, S.K. A theory of single-viewpoint catadioptric image formation. Int. J. Comput. Vis. 1999, 35, 175–196. [Google Scholar] [CrossRef]
- Nayar, S.K.; Baker, S. Catadioptric Image Formation. In Proceedings of the 1997 DARPA Image Understanding Workshop, New Orleans, LA, USA, May 1997; pp. 1431–1437.
- Gaspar, J.; Deccó, C.; Okamoto, J.J.; Santos-Victor, J.; Sistemas, I.D.; Pais, A.R.; Brazil, S.P. Constant resolution omnidirectional cameras. In Proceedings of the OMNIVIS’02 Workshop on Omni-directional Vision, Copenhagen, Denmark, 2 June 2002.
- Forsgren, A.; Gill, P.; Wright, M. Interior Methods for Nonlinear Optimization. Soc. Ind. Appl. Math. (SIAM Rev.) 2002, 44, 525–597. [Google Scholar] [CrossRef]
- Tuytelaars, T.T.; Mikolajczyk, K. Local Invariant Feature Detectors- A Survey. Found. Trends® in Comput. Graph. Vis. 2008, 3, 177–280. [Google Scholar] [CrossRef]
- Spacek, L. Coaxial Omnidirectional Stereopsis. Computer Vision-ECCV 2004; Springer Berlin Heidelberg: Berlin, Heidelberg, 2004; pp. 354–365. [Google Scholar]
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer vision with the OpenCV library; O’Reilly Media, Inc.: Sebastopol, California, 2008. [Google Scholar]
- Hirschmüller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Xiang, Z.; Dai, X.; Gong, X. Noncentral catadioptric camera calibration using a generalized unified model. Opt. Lett. 2013, 38, 1367–1369. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Vangool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Scaramuzza, D.; Fraundorfer, F. Visual Odometry Part 1: The First 30 Years and Fundamentals. IEEE Robot. Autom. Mag. 2011, 18, 80–92. [Google Scholar] [CrossRef]
- Source Code Repository. Available online: https://github.com/ubuntuslave/omnistereo_sensor_design (accessed on 5 February 2016).
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).