
Potential Early Markers for Breast Cancer: A Proteomic Approach Comparing Saliva and Serum Samples in a Pilot Study


 , , , , and
, , , , and 
Abstract
1. Introduction
2. Results
2.1. Proteins Identified in Saliva Samples
2.2. Proteins Identified in Serum Samples
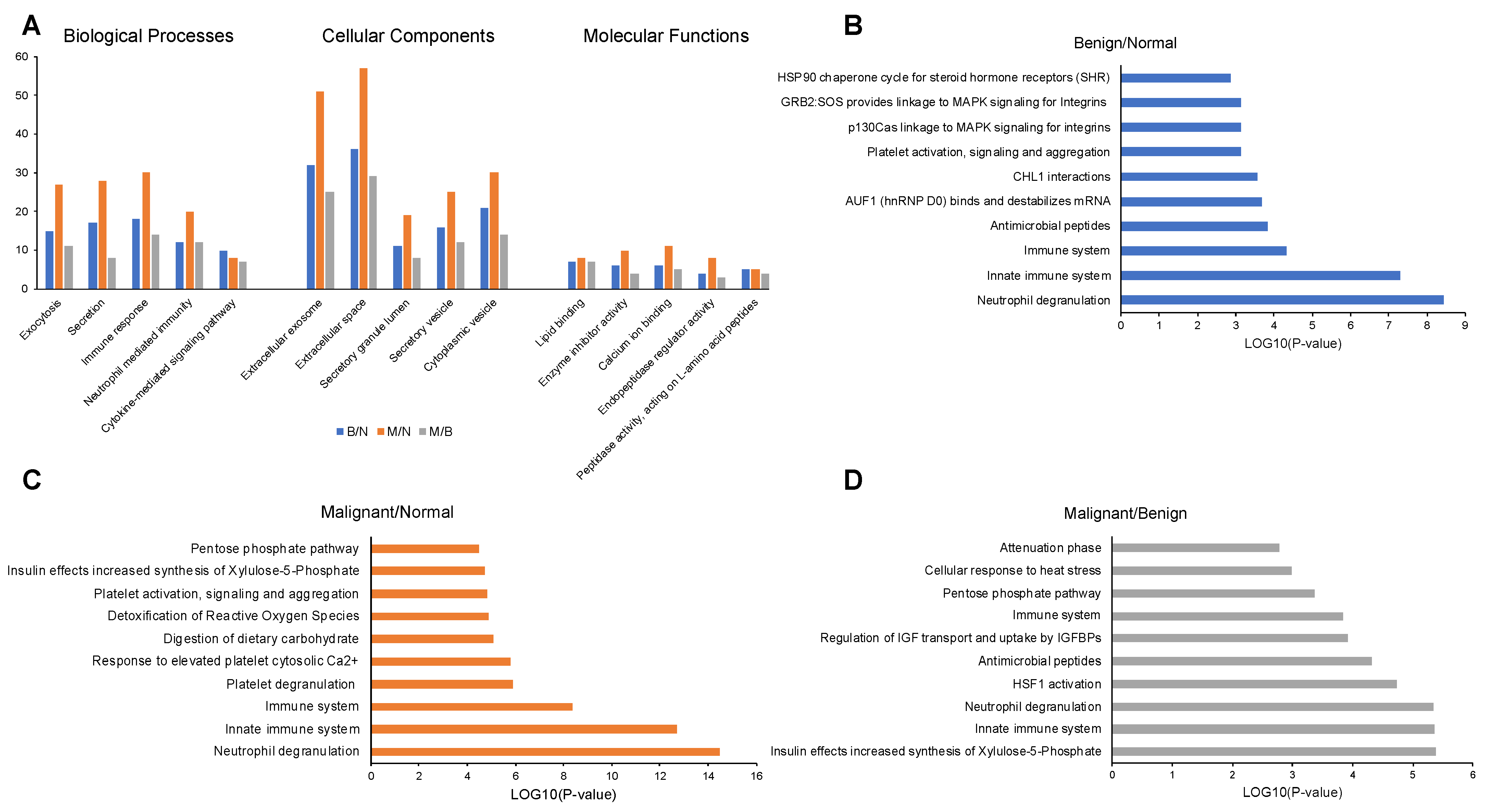
2.3. Enrichment Analysis of Proteins in Saliva Samples
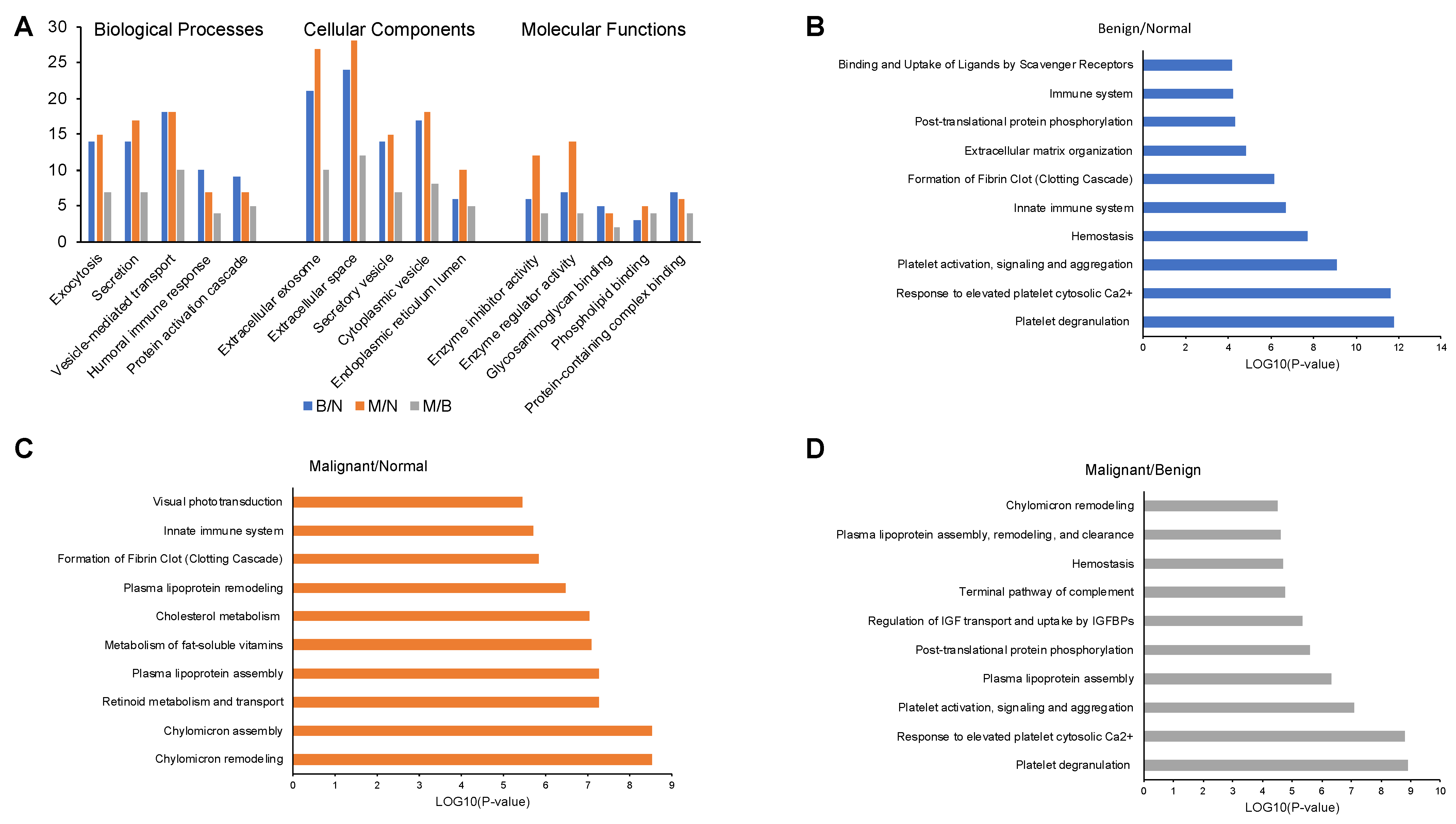
2.4. Enrichment Analysis of Proteins in Serum Samples
2.5. Protein-Protein Interaction (PPI) Networks for Proteins in Saliva
2.6. Protein–Protein Interaction Networks for Proteins in Serum
2.7. Protein Ratios across Serum and Saliva in B/N and M/N Groups
2.8. Prognostic Performance Analysis
3. Discussion
4. Materials and Methods
4.1. Study Subjects
4.2. Collection and Storage of Biological Samples
4.3. Sample Processing and Labeling Procedure for iTRAQ Analysis
4.4. Gene Set Over-Representation Analysis
4.5. Construction of Protein–Protein Interaction Network
4.6. Prognostic Performance Analysis
4.7. ROC Curve Analysis
4.8. Statistical Analyses
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Details on Experimental Procedures Involving iTRAQ Analysis
Appendix A.1.1. 2D-LC Separations
Appendix A.1.2. Mass Spectrometric (MS) Analysis
Appendix A.2. Database Search for Protein Identification and Quantitation
References
- Siegel, R.L.; Miller, K.D.; Fuchs, H.E.; Jemal, A. Cancer statistics, 2022. CA A Cancer J. Clin. 2022, 72, 7–33. [Google Scholar] [CrossRef]
- Kerlikowske, K.; Grady, D.; Rubin, S.M.; Sandrock, C.; Ernster, V.L. Efficacy of screening mammography. A me-ta-analysis. JAMA 1995, 273, 149–154. [Google Scholar] [CrossRef]
- Michaelson, J.S.; Halpern, E.; Kopans, D.B. Breast cancer: Computer simulation method for estimating optimal intervals for screening. Radiology 1999, 212, 551–560. [Google Scholar] [CrossRef]
- Kerlikowske, K.; Barclay, J. Outcomes of modern screening mammography. J. Natl. Cancer Inst. Monogr. 1997, 22, 105–111. [Google Scholar] [CrossRef]
- Elmore, J.G.; Barton, M.B.; Moceri, V.M.; Polk, S.; Arena, P.J.; Fletcher, S.W. Ten-year risk of false positive screening mammo-grams and clinical breast examinations. N. Eng. J. Med. 1998, 338, 1089–1096. [Google Scholar] [CrossRef] [PubMed]
- Wormwood, K.L.; Aslebagh, R.; Channaveerappa, D.; Dupree, E.J.; Borland, M.M.; Ryan, J.P.; Darie, C.C.; Woods, A.G. Salivary proteomics and biomarkers in neurology and psychiatry. Proteomics Clin. Appl. 2015, 9, 899–906. [Google Scholar] [CrossRef] [PubMed]
- Streckfus, C.F.; Bigler, L. Saliva as a diagnostic fluid. Oral Dis. 2002, 8, 69–76. [Google Scholar] [CrossRef]
- Nagler, R.M. Saliva as a tool for oral cancer diagnosis and prognosis. Oral Oncol. 2009, 45, 1006–1010. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Xiao, H.; Karlan, S.; Zhou, H.; Gross, J.; Elashoff, D.; Akin, D.; Yan, X.; Chia, D.; Karlan, B.; et al. Discovery and preclinical validation of salivary transcriptomic and proteomic biomarkers for the non-invasive detection of breast cancer. PLoS ONE 2010, 5, e15573. [Google Scholar] [CrossRef]
- Rapado-González, Ó.; Martínez-Reglero, C.; Salgado-Barreira, Á.; Takkouche, B.; López-López, R.; Suárez-Cunqueiro, M.M.; Muinelo-Romay, L. Salivary biomarkers for cancer diagnosis: A meta-analysis. Ann. Med. 2020, 52, 131–144. [Google Scholar] [CrossRef]
- Koopaie, M.; Kolahdooz, S.; Fatahzadeh, M.; Manifar, S. Salivary biomarkers in breast cancer diagnosis: A systematic re-view and diagnostic meta-analysis. Cancer Med. 2022, 11, 2644–2661. [Google Scholar] [CrossRef] [PubMed]
- Neagu, A.N.; Jayathirtha, M.; Whitham, D.; Mutsengi, P.; Sullivan, I.; Petre, B.A.; Darie, C.C. Proteomics-Based Identification of Dysregulated Proteins in Breast Cancer. Proteomes 2022, 10, 35. [Google Scholar] [CrossRef]
- Streckfus, C.F.; Bigler, L.R.; Zwick, M. The use of surface-enhanced laser desorption/ionization time-of-flight mass spectrom-etry to detect putative breast cancer markers in saliva: A feasibility study. J. Oral Pathol. Med. 2006, 35, 292–300. [Google Scholar] [CrossRef] [PubMed]
- Delmonico, L.; Bravo, M.; Silvestre, R.T.; Ornellas, M.H.; De Azevedo, C.M.; Alves, G. Proteomic profile of saliva and plasma from women with impalpable breast lesions. Oncol. Lett. 2016, 12, 2145–2152. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Streckfus, C.F.; Storthz, K.A.; Bigler, L.; Dubinsky, W.P. A comparison of the proteomic expression in pooled saliva specimens from individuals diagnosed with ductal carcinoma of the breast with and without lymph node involvement. J. Oncol. 2009, 2009, 737619. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.W.; Wang, G.; Baek, S.J.; Shen, R.F. Comparative study of three proteomic quantitative methods, DIGE, cICAT, and iTRAQ, using 2D gel- or LC-MALDI TOF/TOF. J. Prot. Res. 2006, 5, 651–658. [Google Scholar] [CrossRef] [PubMed]
- Sur, T. iTRAQ, a New prospect of toxicogenomics. Int. J. Hum. Genet. 2013, 13, 33–40. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Lemeshow, S. Applied Logistic Regression, 2nd ed.; Chapter 5; John Wiley and Sons: New York, NY, USA, 2000; pp. 160–164. [Google Scholar]
- Veyssière, H.; Bidet, Y.; Penault-Llorca, F.; Radosevic-Robin, N.; Durando, X. Circulating proteins as predictive and prognostic biomarkers in breast cancer. Clin. Proteom. 2022, 19, 25. [Google Scholar] [CrossRef]
- Moon, P.G.; Lee, J.E.; Cho, Y.E.; Lee, S.J.; Chae, Y.S.; Jung, J.H.; Kim, I.S.; Park, H.Y.; Baek, M.C. Fibronectin on circulating extracellular vesicles as a liquid biopsy to detect breast cancer. Oncotarget 2016, 7, 40189–40199. [Google Scholar] [CrossRef]
- Cao, F.; Wang, K.; Zhu, R.; Hu, Y.W.; Fang, W.Z.; Ding, H.Z. Clinicopathological significance of reduced SPARCL1 expression in human breast cancer. Asian Pac. J. Cancer Prev. 2013, 14, 195–200. [Google Scholar] [CrossRef]
- Varvara, P.V.; Karaolanis, G.; Valavanis, C.; Stanc, G.; Tzaida, O.; Trihia, H.; Patapis, P.; Dimitroulis, D.; Perrea, D. gamma-H2AX: A potential biomarker in breast cancer. Tumour Biol. 2019, 41, 1010428319878536. [Google Scholar] [CrossRef] [PubMed]
- Sedelnikova, O.A.; Bonner, W.M. Gamma-H2AX in cancer cells: A potential biomarker for cancer diagnostics, prediction and recurrence. Cell Cycle 2006, 5, 2909–2913. [Google Scholar] [PubMed]
- Dai, D.N.; Li, Y.; Chen, B.; Du, Y.; Li, S.B.; Lu, S.X.; Zhao, Z.P.; Zhou, A.J.; Xue, N.; Xia, T.L.; et al. Elevated expression of CST1 promotes breast cancer progression and predicts a poor prognosis. J. Mol. Med. 2017, 95, 873–886. [Google Scholar] [CrossRef]
- Ponzetti, M.; Capulli, M.; Angelucci, A.; Ventura, L.; Monache, S.D.; Mercurio, C.; Calgani, A.; Sanità, P.; Teti, A.; Rucci, N. Non-conventional role of haemoglobin beta in breast malignancy. Br. J. Cancer 2017, 117, 994–1006. [Google Scholar] [CrossRef]
- Bonaventura, C.; Henkens, R.; Alayash, A.I.; Banerjee, S.; Crumbliss, A.L. Molecular controls of the oxygenation and redox reactions of hemoglobin. Antioxid. Redox Signal. 2013, 18, 2298–2313. [Google Scholar] [CrossRef]
- Janke, J.; Engeli, S.; Boschmann, M.; Adams, F.; Böhnke, J.; Luft, F.C.; Sharma, A.M.; Jordan, J. Retinol-binding protein 4 in human obesity. Diabetes 2006, 55, 2805–2810. [Google Scholar] [CrossRef] [PubMed]
- Jiao, C.; Cui, L.; Ma, A.; Li, N.; Si, H. Elevated Serum Levels of Retinol-Binding Protein 4 Are Associated with Breast Cancer Risk: A Case-Control Study. PLoS ONE 2016, 11, e0167498. [Google Scholar] [CrossRef] [PubMed]
- Fry, S.A.; Sinclair, J.; Timms, J.F.; Leathem, A.J.; Dwek, M.V. A targeted glycoproteomic approach identifies cadherin-5 as a novel biomarker of metastatic breast cancer. Cancer Lett. 2013, 328, 335–344. [Google Scholar] [CrossRef]
- Patmore, S.; Dhami, S.P.S.; O’Sullivan, J.M. Von Willebrand factor and cancer; metastasis and coagulopathies. J. Thromb. Haemost. 2020, 18, 2444–2456. [Google Scholar] [CrossRef]
- Dhami, S.P.S.; Patmore, S.; Comerford, C.; Byrne, C.M.; Cavanagh, B.; Castle, J.; Kirwan, C.C.; Kenny, M.; Schoen, I.; O’Donnell, J.S.; et al. Breast cancer cells mediate endothelial cell activation, promoting von Willebrand factor release, tumor adhesion, and transendothelial migration. J. Thromb. Haemost. 2022, 20, 2350–2365. [Google Scholar] [CrossRef]
- Opstal-van Winden, A.W.; Krop, E.J.; Kåredal, M.H.; Gast, M.C.; Lindh, C.H.; Jeppsson, M.C.; Jönsson, B.A.; Grobbee, D.E.; Peeters, P.H.; Beijnen, J.H.; et al. Searching for early breast cancer biomarkers by serum protein profiling of pre-diagnostic serum; a nested case-control study. BMC Cancer 2011, 11, 381. [Google Scholar] [CrossRef] [PubMed]
- Mei, J.; Hao, L.; Liu, X.; Sun, G.; Xu, R.; Wang, H.; Liu, C. Comprehensive analysis of peroxiredoxins expression profiles and prognostic values in breast cancer. Biomark. Res. 2019, 7, 16. [Google Scholar] [CrossRef] [PubMed]
- Kori, M.; Ozdemir, G.E.; Arga, K.Y.; Sinha, R. A Pan-Cancer Atlas of Differentially Interacting Hallmarks of Cancer Proteins. J. Pers Med. 2022, 12, 1919. [Google Scholar] [CrossRef]
- Sinha, I.; Karagoz, K.; Fogle, R.L.; Hollenbeak, C.S.; Zea, A.H.; Arga, K.Y.; Stanley, A.E.; Hawkes, W.C.; Sinha, R. “Omics” of Selenium Biology: A Prospective Study of Plasma Proteome Network Before and After Selenized-Yeast Supplementation in Healthy Men. OMICS 2016, 20, 202–213. [Google Scholar] [CrossRef]
- Sinha, I.; Goel, R.; Bitzer, Z.T.; Trushin, N.; Liao, J.; Sinha, R. Evaluating electronic cigarette cytotoxicity and inflammatory responses in vitro. Tob. Induc. Dis. 2022, 20, 45. [Google Scholar] [CrossRef]
- Kamburov, A.; Stelzl, U.; Lehrach, H.; Herwig, R. The ConsensusPathDB interaction database: 2013 update. Nucleic Acids Res. 2013, 41, D793–D800. [Google Scholar] [CrossRef]
- Kanehisa, M.; Furumichi, M.; Tanabe, M.; Sato, Y.; Morishima, K. KEGG: New perspectives on genomes, pathways, diseases and drugs. Nucleic Acids Res. 2017, 45, D353–D361. [Google Scholar] [CrossRef] [PubMed]
- Croft, D.; O’Kelly, G.; Wu, G.; Haw, R.; Gillespie, M.; Matthews, L.; Caudy, M.; Garapati, P.; Gopinath, G.; Jassal, B.; et al. Reactome: A database of reactions, pathways and biological processes. Nucleic Acids Res. 2011, 39, D691–D697. [Google Scholar] [CrossRef]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene ontology: Tool for the unification of biology. The Gene Ontology Consortium. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef]
- Oughtred, R.; Stark, C.; Breitkreutz, B.J.; Rust, J.; Boucher, L.; Chang, C.; Kolas, N.; O’Donnell, L.; Leung, G.; McAdam, R.; et al. The BioGRID interaction database: 2019 update. Nucleic Acids Res. 2019, 47, D529–D541. [Google Scholar] [CrossRef]
- Shannon, P.; Markiel, A.; Ozier, O.; Baliga, N.S.; Wang, J.T.; Ramage, D.; Amin, N.; Schwikowski, B.; Ideker, T. Cytoscape: A software environment for integrated models of biomolecular interaction networks. Genome Res. 2003, 13, 2498–2504. [Google Scholar] [CrossRef] [PubMed]
- Aguirre-Gamboa, R.; Gomez-Rueda, H.; Martínez-Ledesma, E.; Martínez-Torteya, A.; Chacolla-Huaringa, R.; Rodriguez-Barrientos, A.; Tamez-Peña, J.G.; Treviño, V. SurvExpress: An online biomarker validation tool and database for cancer gene expression data using survival analysis. PLoS ONE 2013, 8, e74250. [Google Scholar] [CrossRef] [PubMed]
- Gulfidan, G.; Turanli, B.; Beklen, H.; Sinha, R.; Arga, K.Y. Pan-cancer mapping of differential protein-protein interactions. Sci. Rep. 2020, 10, 3272. [Google Scholar] [CrossRef] [PubMed]
- Therneau, T. A Package for Survival Analysis in R. R Package Version 3.3-1. 2022. Available online: https://CRAN.R-project.org/package=survival (accessed on 21 July 2022).
- Robin, X.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.C.; Müller, M. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef] [PubMed]
- Fogle, R.L.; Hollenbeak, C.S.; Stanley, B.A.; Vary, T.C.; Kimball, S.R.; Lynch, C.J. Functional proteomic analysis reveals sex-dependent differences in structural and energy-producing myocardial proteins in rat model of alcoholic cardiomyopathy. Physiol. Genomics 2011, 43, 346–356. [Google Scholar] [CrossRef][Green Version]
- Fox, J.; Weisberg, S. An R Companion to Applied Regression, 3rd ed.; SAGE Publishing: Thousand Oaks, CA, USA, 2019. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accession # | UniProt ID | Gene ID | Protein Name | B/N | M/N | M/B | Runs | Peptides (95%) | AUC (%) |
|---|---|---|---|---|---|---|---|---|---|
| 189083772 | GELS | GSN | Gelsolin isoform b | 0.71 | 0.62 | 0.98 | 4 | 13 | 97.37 |
| 4502101 | ANXA1 | ANXA1 | Annexin A1 | 0.56 | 0.28 | 0.54 | 4 | 12 | 97.23 |
| 157412247 | RUSC1 | RUSC1 | RUN and SH3 domain-containing protein 1 isoform b | 0.23 | 0.69 | 1.61 | 2 | 1 | 97.09 |
| 190341024 | SPRL1 | SPARCL1 | SPARC-like protein 1 isoform 1 precursor | 0.15 | 0.44 | 2.02 | 2 | 3 | 96.53 |
| 58331204 | RN150 | RNF150 | RING finger protein 150 precursor | 0.30 | 2.30 | 7.76 | 2 | 1 | 95.93 |
| 4504253 | H2AX | H2AFX | Histone H2AX | 1.16 | 0.50 | 0.39 | 2 | 5 | 93.68 |
| 19882251 | CYTN | CST1 | Cystatin-SN precursor | 1.09 | 1.94 | 1.96 | 8 | 140 | 93.07 |
| 807066348 | FINC | FN1 | Fibronectin isoform 11 preproprotein | 1.97 | 0.99 | 0.56 | 6 | 14 | 93.05 |
| 23110942 | PSA5 | PSMA5 | Proteasome subunit alpha type-5 isoform 1 | 0.27 | 0.56 | 2.05 | 2 | 3 | 92.87 |
| 578822814 | A2MG | A2M | Alpha-2-macroglobulin isoform X1 | 0.99 | 3.21 | 4.52 | 2 | 54 | 92.39 |
| 66932947 | A2MG | A2M | Alpha-2-macroglobulin precursor | 0.83 | 0.57 | 0.84 | 6 | 54 | 92.39 |
| 58219024 | LEG1H | LEG1 | Protein LEG1 homolog precursor | 2.51 | 1.71 | 0.63 | 8 | 53 | 91.10 |
| 4503105 | CYTT | CST2 | Cystatin-SA precursor | 1.35 | 1.73 | 1.82 | 8 | 43 | 90.65 |
| 94967023 | DAB2P | DAB2IP | Disabled homolog 2-interacting protein isoform 1 | 3.36 | 1.64 | 0.48 | 2 | 1 | 90.03 |
| 4506041 | PRELP | PRELP | Prolargin precursor | 0.13 | 0.33 | 2.52 | 2 | 1 | 89.87 |
| 4503109 | CYTS | CST4 | Cystatin-S precursor | 1.71 | 2.73 | 1.58 | 8 | 105 | 89.74 |
| 4826898 | PROF1 | PFN1 | Profilin-1 | 0.84 | 0.69 | 0.75 | 8 | 9 | 88.24 |
| 20070125 | PDIA1 | P4HB | Protein disulfide-isomerase precursor | 0.75 | 0.67 | 0.87 | 8 | 21 | 87.90 |
| 10280622 | AMY2B | AMY2B | Alpha-amylase 2B precursor | 1.86 | 3.27 | 1.63 | 8 | 765 | 87.89 |
| 22538465 | PSB3 | PSMB3 | Proteasome subunit beta type-3 | 0.95 | 0.20 | 0.31 | 4 | 1 | 87.87 |
| 32455266 | PRDX1 | PRDX1 | Peroxiredoxin-1 | 0.68 | 0.65 | 0.88 | 8 | 8 | 87.56 |
| 31657142 | ITA | ITGA1 | Integrin alpha-1 precursor | 0.11 | 0.45 | 4.25 | 2 | 1 | 86.93 |
| 4505763 | PGK | PGK1 | Phosphoglycerate kinase 1 | 0.72 | 0.71 | 0.89 | 8 | 19 | 86.28 |
| 767959648 | NUDT5 | NUDT5 | ADP-sugar pyrophosphatase isoform X2 | 0.43 | 0.36 | 0.82 | 2 | 1 | 83.99 |
| 119395754 | K2C5 | KRT5 | Keratin, type II cytoskeletal 5 | 0.97 | 0.41 | 0.37 | 4 | 16 | 83.71 |
| 74272287 | MMP9 | MMP9 | Matrix metalloproteinase-9 preproprotein | 0.95 | 0.48 | 0.67 | 8 | 11 | 83.20 |
| 767909532 | PIGR | PIGR | Polymeric immunoglobulin receptor isoform X1 | 1.82 | 3.07 | 1.47 | 8 | 125 | 83.20 |
| 767979880 | CATG | CTSG | Cathepsin G isoform X1 | 0.72 | 0.41 | 0.49 | 8 | 6 | 83.01 |
| 767922296 | FAM3D | FAM3D | Protein FAM3D isoform X2 | 4.16 | 1.41 | 0.29 | 4 | 2 | 82.75 |
| 395132469 | CAH6 | CA6 | Carbonic anhydrase 6 isoform 2 precursor | 3.00 | 2.94 | 1.15 | 8 | 36 | 82.20 |
| 4503143 | CATD | CTSD | Cathepsin D preproprotein | 1.82 | 1.77 | 1.12 | 8 | 9 | 82.09 |
| 157168362 | PNPH | PNP | Purine nucleoside phosphorylase | 0.54 | 0.33 | 0.53 | 4 | 8 | 81.62 |
| 4504259 | H2B1L | HIST1H2BL | Histone H2B type 1-L | 1.02 | 0.39 | 0.36 | 2 | 7 | 81.51 |
| 4758950 | PPIB | PPIB | Peptidyl-prolyl cis-trans isomerase B precursor | 1.66 | 1.24 | 0.82 | 8 | 7 | 80.99 |
| 6005942 | TERA | VCP | Transitional endoplasmic reticulum ATPase | 1.61 | 0.59 | 0.36 | 6 | 9 | 80.69 |
| 32189392 | PRDX2 | PRDX2 | Peroxiredoxin-2 | 0.65 | 0.59 | 1.00 | 8 | 7 | 80.24 |
| 34419635 | HSP76 | HSPA6 | Heat shock 70 kDa protein 6 | 1.39 | 0.42 | 0.30 | 2 | 6 | 79.02 |
| 66912162 | H2B2F | H2BC18 | Histone H2B type 2-F isoform a | 0.36 | 0.33 | 0.63 | 6 | 7 | 78.99 |
| 8393956 | SPB13 | SERPINB13 | Serpin B13 isoform 2 | 0.45 | 0.58 | 1.51 | 6 | 8 | 78.79 |
| 4885165 | CYTA | CSTA | Cystatin-A | 0.35 | 0.50 | 1.20 | 8 | 13 | 78.59 |
| 767969637 | PLGT3 | POGLUT3 | Protein O-glucosyltransferase 3 isoform X1 | 2.44 | 3.34 | 1.36 | 2 | 1 | 76.93 |
| 4557581 | FABP5 | FABP5 | Fatty acid-binding protein, epidermal | 0.58 | 0.71 | 1.07 | 8 | 18 | 76.03 |
| 4504309 | H4 | HIST1H4C | Histone H4 | 0.96 | 0.43 | 0.34 | 8 | 6 | 75.67 |
| 4502107 | ANXA5 | ANXA5 | Annexin A5 | 0.68 | 0.27 | 0.40 | 2 | 1 | 74.55 |
| 11496281 | KLK13 | KLK13 | Kallikrein-13 precursor | 1.41 | 1.17 | 0.45 | 6 | 4 | 74.51 |
| 530412176 | K1C10 | KRT10 | Keratin, type I cytoskeletal 10 isoform X1 | 0.91 | 0.35 | 0.34 | 8 | 17 | 73.38 |
| 38016911 | STOM | STOM | Erythrocyte band 7 integral membrane protein isoform a (stomatin isoform a) | 3.21 | 4.06 | 1.26 | 2 | 1 | 72.54 |
| 5729877 | HSP7C | HSPA8 | Heat shock cognate 71 kDa protein isoform 1 | 0.71 | 0.66 | 0.86 | 8 | 21 | 72.46 |
| 119703753 | K2C6B | KRT6B | Keratin, type II cytoskeletal 6B | 0.26 | 0.77 | 2.90 | 4 | 24 | 71.90 |
| 767968230 | MYO7A | MYO7A | Unconventional myosin-VIIa isoform X11 | 0.5 | 1.57 | 3.08 | 2 | 2 | 71.69 |
| 5031857 | LDHA | LDHA | L-lactate dehydrogenase A chain isoform 1 | 0.92 | 0.67 | 0.84 | 8 | 20 | 71.52 |
| 53793688 | H32 | H3C15 | Histone H3.2 | 1.19 | 0.7 | 0.57 | 6 | 1 | 71.31 |
| 4506179 | PSA1 | PSMA1 | Proteasome subunit alpha type-1 isoform 2 | 0.39 | 0.87 | 2.22 | 4 | 1 | 71.04 |
| 21071008 | TCO1 | TCN1 | Transcobalamin-1 precursor | 1.09 | 1.80 | 1.30 | 8 | 16 | 70.72 |
| 4504183 | GSTP1 | GSTP1 | Glutathione S-transferase P | 0.48 | 0.59 | 1.09 | 8 | 27 | 70.68 |
| 5032059 | S10AC | S100A12 | Protein S100-A12 | 1.30 | 0.52 | 0.39 | 4 | 2 | 70.61 |
| 4504251 | H2A2A | H2AC18 | Histone H2A type 2-A | 0.75 | 0.54 | 0.77 | 6 | 5 | 70.34 |
| 5902134 | COR1A | CORO1A | Coronin-1A | 1.01 | 0.51 | 0.57 | 8 | 8 | 70.30 |
| 5803187 | TALDO | TALDO1 | Transaldolase | 0.90 | 0.53 | 0.61 | 8 | 14 | 69.63 |
| 194248072 | HS71A | HSPA1A | Heat shock 70 kDa protein 1A | 0.61 | 0.81 | 1.25 | 8 | 34 | 69.37 |
| 115387104 | AL9A1 | ALDH9A1 | 4-trimethylaminobutyraldehyde dehydrogenase | 0.67 | 0.85 | 1.23 | 8 | 5 | 68.33 |
| 5031863 | LG3BP | LGALS3BP | Galectin-3-binding protein precursor | 1.88 | 1.94 | 1.11 | 8 | 12 | 68.07 |
| 4557485 | CERU | CP | Ceruloplasmin precursor | 0.53 | 0.99 | 2.22 | 2 | 16 | 67.22 |
| 13325075 | QSOX1 | QSOX1 | Sulfhydryl oxidase 1 isoform a precursor | 8.00 | 7.74 | 1.14 | 2 | 4 | 66.46 |
| 14211875 | ISK7 | SPINK7 | Serine protease inhibitor Kazal-type 7 precursor | 1.00 | 0.36 | 0.53 | 4 | 1 | 66.16 |
| 604723334 | PRPC | PRH1 | Salivary acidic proline-rich phosphoprotein 1/2 isoform b | 0.12 | 0.34 | 0.32 | 2 | 58 | 66.13 |
| 7661678 | RAP1B | RAP1B | Ras-related protein Rap-1b isoform 1 precursor | 4.77 | 1.73 | 0.88 | 2 | 1 | 65.41 |
| 4757952 | CDC42 | CDC42 | Cell division control protein 42 homolog isoform 1 precursor | 0.51 | 0.51 | 0.98 | 6 | 2 | 65.13 |
| 4501987 | AFAM | AFM | Afamin precursor | 0.06 | 0.7 | 4.57 | 2 | 2 | 63.81 |
| 119395750 | K2C1 | KRT1 | Keratin, type II cytoskeletal 1 | 0.30 | 0.28 | 0.74 | 2 | 15 | 63.79 |
| 15055535 | BPIB2 | BPIFB2 | BPI fold-containing family B member 2 precursor | 1.73 | 1.94 | 1.21 | 8 | 34 | 62.36 |
| 9966777 | RETN | RETN | Resistin precursor | 1.38 | 2.87 | 1.91 | 4 | 2 | 62.34 |
| 31542986 | ITLN1 | ITLN1 | Intelectin-1 precursor | 6.64 | 2.70 | 0.40 | 2 | 2 | 62.13 |
| 5454052 | 1433S | SFN | 14-3-3 protein sigma | 0.67 | 0.81 | 1.30 | 8 | 26 | 60.75 |
| 530417837 | BPIA2 | BPIFA2 | BPI fold-containing family A member 2 isoform X1 | 0.58 | 1.34 | 2.23 | 8 | 35 | 60.74 |
| 767924143 | TKT | TKT | Transketolase isoform X1 | 0.94 | 0.59 | 0.68 | 8 | 12 | 60.69 |
| 295986608 | IGLL5 | IGLL5 | Immunoglobulin lambda-like polypeptide 5 isoform 1 | 1.10 | 1.97 | 1.64 | 8 | 29 | 60.47 |
| 74271845 | A2ML1 | A2ML1 | Alpha-2-macroglobulin-like protein 1 isoform 1 precursor | 0.29 | 0.54 | 1.99 | 2 | 57 | 60.33 |
| 189458821 | TGM3 | TGM3 | Protein-glutamine gamma-glutamyltransferase E | 0.67 | 0.39 | 0.54 | 8 | 30 | 60.18 |
| 768031399 | ARSA | ARSA | Arylsulfatase A isoform X1 | 0.70 | 0.18 | 0.46 | 2 | 1 | 59.63 |
| 145279222 | C251 | WDR66 | WD repeat-containing protein 66 isoform 1 | 6.47 | 4.25 | 0.73 | 2 | 1 | 59.13 |
| 301172750 | MUC5B | MUC5B | Mucin-5B precursor | 2.39 | 1.97 | 0.96 | 8 | 145 | 59.04 |
| 42794752 | ACSL3 | ACSL3 | Long-chain-fatty-acid--CoA ligase 3 | 2.81 | 0.17 | 0.10 | 2 | 1 | 58.55 |
| 4503107 | CYTC | CST3 | Cystatin-C precursor | 1.45 | 2.06 | 1.55 | 8 | 15 | 58.06 |
| 4506925 | SH3L1 | SH3BGRL | SH3 domain-binding glutamic acid-rich-like protein | 1.26 | 0.27 | 0.47 | 2 | 3 | 57.54 |
| 768038036 | SH3L1 | SH3BGRL | SH3 domain-binding glutamic acid-rich-like protein isoform X2 | 0.41 | 0.89 | 3.14 | 4 | 2 | 57.54 |
| 114199475 | VPS41 | VPS41 | Vacuolar protein sorting-associated protein 41 homolog isoform 1 | 1.59 | 1.82 | 0.90 | 6 | 1 | 57.30 |
| 120433590 | ACBP | DBI | Acyl-CoA-binding protein isoform 3 | 1.27 | 0.58 | 0.52 | 2 | 2 | 57.22 |
| 767950128 | DEF3 | DEFA3 | Neutrophil defensin 3 isoform X1 | 0.78 | 0.46 | 0.57 | 8 | 4 | 57.20 |
| 767910129 | S10A8 | S100A8 | Protein S100-A8 isoform c | 2.24 | 0.38 | 0.19 | 2 | 13 | 56.94 |
| 300244562 | CRIS3 | CRISP3 | Cysteine-rich secretory protein 3 isoform 2 precursor | 1.20 | 1.48 | 1.33 | 8 | 9 | 56.57 |
| 158937236 | PSA | NPEPPS | Puromycin-sensitive aminopeptidase | 0.23 | 0.92 | 4.40 | 2 | 11 | 56.15 |
| 153251272 | CPPED | CPPED1 | Serine/threonine-protein phosphatase CPPED1 isoform b | 0.43 | 0.25 | 0.58 | 2 | 1 | 56.14 |
| 40549418 | PERL | LPO | Lactoperoxidase isoform 1 preproprotein | 1.11 | 1.61 | 1.42 | 8 | 41 | 55.98 |
| 331999954 | K2C4 | KRT4 | Keratin, type II cytoskeletal 4 | 0.37 | 0.37 | 0.96 | 8 | 20 | 55.60 |
| 767903808 | AMY1B | AMY1B | Alpha-amylase 1B precursor | 2.86 | 3.20 | 1.13 | 8 | 932 | 55.60 |
| 507588248 | ACTN2 | ACTN2 | Alpha-actinin-2 isoform 2 | 0.81 | 7.97 | 5.96 | 2 | 2 | 55.50 |
| 45827734 | SPR1A | SPRR1A | Cornifin-A | 0.84 | 1.24 | 1.69 | 6 | 4 | 55.32 |
| 4502085 | AMYP | AMY2A | Pancreatic alpha-amylase precursor | 1.94 | 2.29 | 1.12 | 6 | 654 | 55.08 |
| 4502337 | ZA2G | AZGP1 | Zinc-alpha-2-glycoprotein precursor | 1.40 | 2.14 | 1.56 | 8 | 46 | 54.01 |
| 50659080 | AACT | SERPINA3 | Alpha-1-antichymotrypsin precursor | 1.19 | 1.76 | 1.20 | 8 | 5 | 52.28 |
| 71361688 | PRTN3 | PRTN3 | Myeloblastin precursor | 0.40 | 0.33 | 0.80 | 4 | 11 | 51.42 |
| 767939339 | ILEU | SERPINB1 | Leukocyte elastase inhibitor isoform X1 | 0.71 | 0.65 | 1.13 | 6 | 17 | 51.19 |
| 767939343 | ILEU | SERPINB1 | Leukocyte elastase inhibitor isoform X2 | 0.60 | 0.84 | 1.33 | 2 | 17 | 51.19 |
| 7706635 | CRNN | CRNN | Cornulin | 0.55 | 0.38 | 0.76 | 8 | 20 | 50.71 |
| 4504529 | HIS1 | HTN1 | Histatin-1 precursor | 0.07 | 0.90 | 3.21 | 4 | 11 | 50.08 |
| 4507725 | TTHY | TTR | Transthyretin precursor | 0.43 | 1.31 | 3.02 | 2 | 3 | 49.84 |
| 40068518 | 6PG | PGD | 6-phosphogluconate dehydrogenase, decarboxylating isoform 1 | 0.50 | 0.44 | 0.93 | 2 | 24 | 49.00 |
| 751130505 | 6PGD | PGD | 6-phosphogluconate dehydrogenase, decarboxylating isoform 2 | 0.45 | 0.31 | 0.69 | 2 | 22 | 49.00 |
| 4507261 | STAT | STATH | Statherin isoform a precursor | 2.18 | 7.20 | 0.98 | 8 | 119 | 36.72 |
| Accession # | UniProt ID | Gene ID | Protein Name | B/N | M/N | M/B | Runs | Peptides (95%) | AUC (%) |
|---|---|---|---|---|---|---|---|---|---|
| 4502443 | DYST | DST | Dystonin isoform 1e precursor | 3.65 | 1.93 | 0.52 | 2 | 2 | 95.80 |
| 105990532 | APOB | APOB | Apolipoprotein B-100 precursor | 0.93 | 0.93 | 1.04 | 8 | 456 | 95.42 |
| 4504349 | HBB | HBB | Hemoglobin subunit beta | 0.78 | 1.97 | 2.04 | 6 | 5 | 93.73 |
| 4557871 | TRFE | TF | Serotransferrin precursor | 0.25 | 0.19 | 0.77 | 2 | 38 | 93.59 |
| 55743122 | RET4 | RBP4 | Retinol-binding protein 4 precursor | 1.40 | 1.48 | 1.03 | 8 | 54 | 93.48 |
| 936697130 | PROS | PROS1 | Vitamin K-dependent protein S isoform 1 precursor | 0.78 | 1.04 | 1.28 | 8 | 20 | 93.48 |
| 578822814 | A2MG | A2M | Alpha-2-macroglobulin isoform X1 | 0.96 | 0.94 | 0.97 | 8 | 684 | 92.39 |
| 767989245 | CADH5 | CDH5 | Cadherin-5 isoform X1 | 1.50 | 1.18 | 0.80 | 8 | 5 | 91.60 |
| 89191868 | VWF | VWF | Von Willebrand factor preproprotein | 1.57 | 0.90 | 0.59 | 8 | 17 | 91.58 |
| 73858570 | IC1 | SERPING1 | Plasma protease C1 inhibitor precursor | 0.90 | 0.76 | 0.89 | 8 | 54 | 88.63 |
| 530366456 | C4BPA | C4BPA | C4b-binding protein alpha chain isoform X1 | 0.66 | 0.87 | 1.29 | 8 | 16 | 86.41 |
| 7669550 | VINC | VCL | Vinculin isoform meta-VCL | 0.61 | 1.75 | 2.86 | 2 | 2 | 85.53 |
| 45580688 | CO7 | C7 | Complement component C7 precursor | 0.98 | 0.72 | 0.68 | 8 | 61 | 85.14 |
| 4503143 | CATD | CTSD | Cathepsin D preproprotein | 0.35 | 0.72 | 2.03 | 2 | 1 | 82.09 |
| 767934633 | CO6 | C6 | Complement component C6 isoform X4 | 1.60 | 1.32 | 0.79 | 8 | 58 | 81.67 |
| 115298678 | CO3 | C3 | Complement C3 preproprotein | 0.97 | 0.95 | 0.96 | 8 | 809 | 80.78 |
| 32189392 | PRDX2 | PRDX2 | Peroxiredoxin-2 | 1.89 | 2.16 | 1.11 | 6 | 9 | 80.24 |
| 530416417 | APOC1 | APOC1 | Apolipoprotein C-I isoform a precursor | 0.59 | 0.28 | 0.36 | 8 | 3 | 76.02 |
| 32130518 | APOC2 | APOC2 | Apolipoprotein C-II precursor | 0.69 | 0.69 | 1.06 | 8 | 23 | 75.30 |
| 15811782 | GPKOW | GPKOW | G-patch domain and KOW motifs-containing protein | 1.1 | 0.19 | 0.17 | 2 | 2 | 74.64 |
| 223671861 | PROP | CFP | Properdin precursor | 1.40 | 1.33 | 0.90 | 8 | 11 | 73.84 |
| 38016947 | CO5 | C5 | Complement C5 isoform 1 preproprotein | 0.68 | 0.75 | 1.08 | 6 | 73 | 72.95 |
| 40548420 | COL11 | COLEC11 | Collectin-11 isoform b | 0.31 | 0.55 | 1.73 | 2 | 2 | 72.86 |
| 73858566 | HEP2 | SERPIND1 | Heparin cofactor 2 precursor | 0.64 | 0.54 | 0.78 | 8 | 30 | 71.61 |
| 167857790 | A1AG1 | ORM1 | Alpha-1-acid glycoprotein 1 precursor | 2.39 | 3.47 | 1.31 | 8 | 88 | 69.22 |
| 21071030 | A1BG | A1BG | Alpha-1B-glycoprotein precursor | 1.66 | 1.54 | 0.93 | 8 | 183 | 67.10 |
| 514239916 | CO8B | C8B | Complement component C8 beta chain isoform 1 preproprotein | 0.58 | 0.54 | 1.00 | 6 | 26 | 66.92 |
| 4557321 | APOA1 | APOA1 | Apolipoprotein A-I isoform 1 preproprotein | 0.96 | 0.91 | 0.94 | 8 | 202 | 66.64 |
| 530375762 | CPN2 | CPN2 | Carboxypeptidase N subunit 2 isoform X1 | 0.88 | 0.74 | 0.83 | 8 | 18 | 66.55 |
| 16418467 | A2GL | LRG1 | Leucine-rich alpha-2-glycoprotein precursor | 1.26 | 1.49 | 1.17 | 8 | 26 | 66.10 |
| 4501987 | AFAM | AFM | Afamin precursor | 1.43 | 0.97 | 0.67 | 8 | 67 | 63.81 |
| 4502419 | BLVRB | BLVRB | Flavin reductase (NADPH) | 0.94 | 3.13 | 3.31 | 2 | 1 | 62.79 |
| 11321561 | HEMO | HPX | Hemopexin precursor | 0.92 | 0.97 | 0.99 | 8 | 347 | 62.75 |
| 73858564 | CBG | SERPINA6 | Corticosteroid-binding globulin precursor | 0.71 | 0.60 | 0.83 | 8 | 13 | 62.28 |
| 4505047 | LUM | LUM | Lumican precursor | 1.82 | 1.40 | 0.79 | 8 | 25 | 61.56 |
| 4503689 | FIBA | FGA | Fibrinogen alpha chain isoform alpha-E preproprotein | 1.37 | 2.03 | 1.34 | 8 | 23 | 61.18 |
| 4504893 | KNG1 | KNG1 | Kininogen-1 isoform 2 precursor | 1.21 | 0.83 | 0.7 | 8 | 102 | 59.04 |
| 8923909 | ERBIN | ERBIN | Erbin isoform 2 | 2.26 | 0.78 | 0.34 | 2 | 1 | 58.76 |
| 33350932 | DYHC1 | DYNC1H1 | Cytoplasmic dynein 1 heavy chain 1 | 0.22 | 0.37 | 1.64 | 2 | 2 | 57.99 |
| 573459745 | KAIN | SERPINA4 | Kallistatin isoform 2 precursor | 0.67 | 0.64 | 0.91 | 8 | 20 | 57.95 |
| 530365618 | CD5L | CD5L | CD5 antigen-like isoform X1 | 1.32 | 1.65 | 1.73 | 6 | 4 | 56.55 |
| 60499001 | SOX | PIPOX | Peroxisomal sarcosine oxidase | 0.35 | 0.23 | 0.66 | 2 | 1 | 55.97 |
| 767975372 | CE290 | CEP290 | Centrosomal protein of 290 kDa isoform X6 | 2.83 | 2.81 | 0.98 | 2 | 3 | 55.70 |
| 40317626 | TSP1 | THBS1 | Thrombospondin-1 precursor | 0.56 | 0.76 | 1.30 | 6 | 30 | 55.48 |
| 767985152 | TSP1 | THBS1 | Thrombospondin-1 isoform X2 | 0.55 | 0.30 | 0.58 | 2 | 29 | 55.48 |
| 767953771 | MED30 | MED30 | Mediator of RNA polymerase II transcription subunit 30 isoform 3 | 0.52 | 0.28 | 0.82 | 6 | 4 | 54.62 |
| 4502337 | ZA2G | AZGP1 | Zinc-alpha-2-glycoprotein precursor | 1.04 | 1.36 | 1.22 | 8 | 67 | 54.01 |
| 156523970 | FETUA | AHSG | Alpha-2-HS-glycoprotein preproprotein | 1.71 | 1.34 | 0.86 | 8 | 149 | 52.63 |
| 205277441 | THBG | SERPINA7 | Thyroxine-binding globulin precursor | 0.66 | 0.60 | 0.80 | 8 | 20 | 52.62 |
| 189163530 | A1AT | SERPINA1 | Alpha-1-antitrypsin precursor | 0.12 | 0.08 | 0.77 | 2 | 1 | 52.04 |
| 4502149 | APOA2 | APOA2 | Apolipoprotein A-II preproprotein | 0.90 | 0.50 | 0.50 | 8 | 119 | 51.83 |
| 190194360 | PCD20 | PCDH20 | Protocadherin-20 precursor | 0.62 | 2.74 | 4.41 | 2 | 1 | 51.39 |
| 530374534 | HRG | HRG | Histidine-rich glycoprotein isoform X1 | 0.77 | 1.04 | 1.36 | 2 | 49 | 50.77 |
| 4507725 | TTHY | TTR | Transthyretin precursor | 1.47 | 1.31 | 0.97 | 8 | 134 | 49.84 |
| 4885399 | SMC3 | SMC3 | Structural maintenance of chromosomes protein 3 | 0.69 | 0.31 | 0.45 | 2 | 1 | 49.08 |
| 153266841 | APOH | APOH | Beta-2-glycoprotein 1 precursor | 1.58 | 1.75 | 1.09 | 8 | 124 | 45.16 |
| Subject ID | Age | Diagnosis | Subject ID | Age | Diagnosis | Subject ID | Age | Diagnosis |
|---|---|---|---|---|---|---|---|---|
| N1 | 41 | NAD | B1 | 53 | Fibroadenoma | M1 | 75 | Invasive ductal carcinoma, Grade II, ER+/PR+/HER2- |
| N2 | 54 | NAD | B2 | 46 | Ductal ectasia | M2 | 64 | Invasive ductal carcinoma, Grade I, ER+/PR+/HER2- |
| N3 | 50 | NAD | B3 | 59 | Ductal hyperplasia; microcalcifications associated with benign ducts | M3 | 43 | Invasive ductal carcinoma, Grade II, ER+/PR+/HER2- |
| N4 | 47 | NAD | B4 | 52 | Benign fibroepithelial lesion | M4 | 71 | Invasive ductal carcinoma, Grade II, ER+/PR+/HER2- |
| N5 | 63 | NAD | B5 | 38 | Ductal hyperplasia | M5 | 68 | Invasive ductal carcinoma, Grade III, ER+/PR-/HER2- |
| N6 | 52 | NAD | B6 | 44 | Stromal fibrosis | M6 | 51 | Invasive ductal carcinoma, Grade III, ER-/PR-/HER2- |
| N7 | 48 | NAD | B7 | 64 | Atypical lobular dysplasia | M7 | 49 | Invasive ductal carcinoma, Grade II, ER+/PR+/HER2- |
| N8 | 65 | NAD | B8 | 52 | Ductal hyperplasia | M8 | 49 | Invasive ductal carcinoma, Grade II, ER+/PR+/HER2- |
| Mean ± SD | 52.5 ± 8.1 | Mean ± SD | 51 ± 8.3 | Mean ± SD | 58.8 ± 12.1 | |||
| Range | 41–65 | Range | 38–64 | Range | 43–75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sinha, I.; Fogle, R.L.; Gulfidan, G.; Stanley, A.E.; Walter, V.; Hollenbeak, C.S.; Arga, K.Y.; Sinha, R. Potential Early Markers for Breast Cancer: A Proteomic Approach Comparing Saliva and Serum Samples in a Pilot Study. Int. J. Mol. Sci. 2023, 24, 4164. https://doi.org/10.3390/ijms24044164
Sinha I, Fogle RL, Gulfidan G, Stanley AE, Walter V, Hollenbeak CS, Arga KY, Sinha R. Potential Early Markers for Breast Cancer: A Proteomic Approach Comparing Saliva and Serum Samples in a Pilot Study. International Journal of Molecular Sciences. 2023; 24(4):4164. https://doi.org/10.3390/ijms24044164
Chicago/Turabian StyleSinha, Indu, Rachel L. Fogle, Gizem Gulfidan, Anne E. Stanley, Vonn Walter, Christopher S. Hollenbeak, Kazim Y. Arga, and Raghu Sinha. 2023. "Potential Early Markers for Breast Cancer: A Proteomic Approach Comparing Saliva and Serum Samples in a Pilot Study" International Journal of Molecular Sciences 24, no. 4: 4164. https://doi.org/10.3390/ijms24044164
APA StyleSinha, I., Fogle, R. L., Gulfidan, G., Stanley, A. E., Walter, V., Hollenbeak, C. S., Arga, K. Y., & Sinha, R. (2023). Potential Early Markers for Breast Cancer: A Proteomic Approach Comparing Saliva and Serum Samples in a Pilot Study. International Journal of Molecular Sciences, 24(4), 4164. https://doi.org/10.3390/ijms24044164