Prediction Power on Cardiovascular Disease of Neuroimmune Guidance Cues Expression by Peripheral Blood Monocytes Determined by Machine-Learning Methods

 , , and
, , and
Abstract
1. Introduction
2. Results
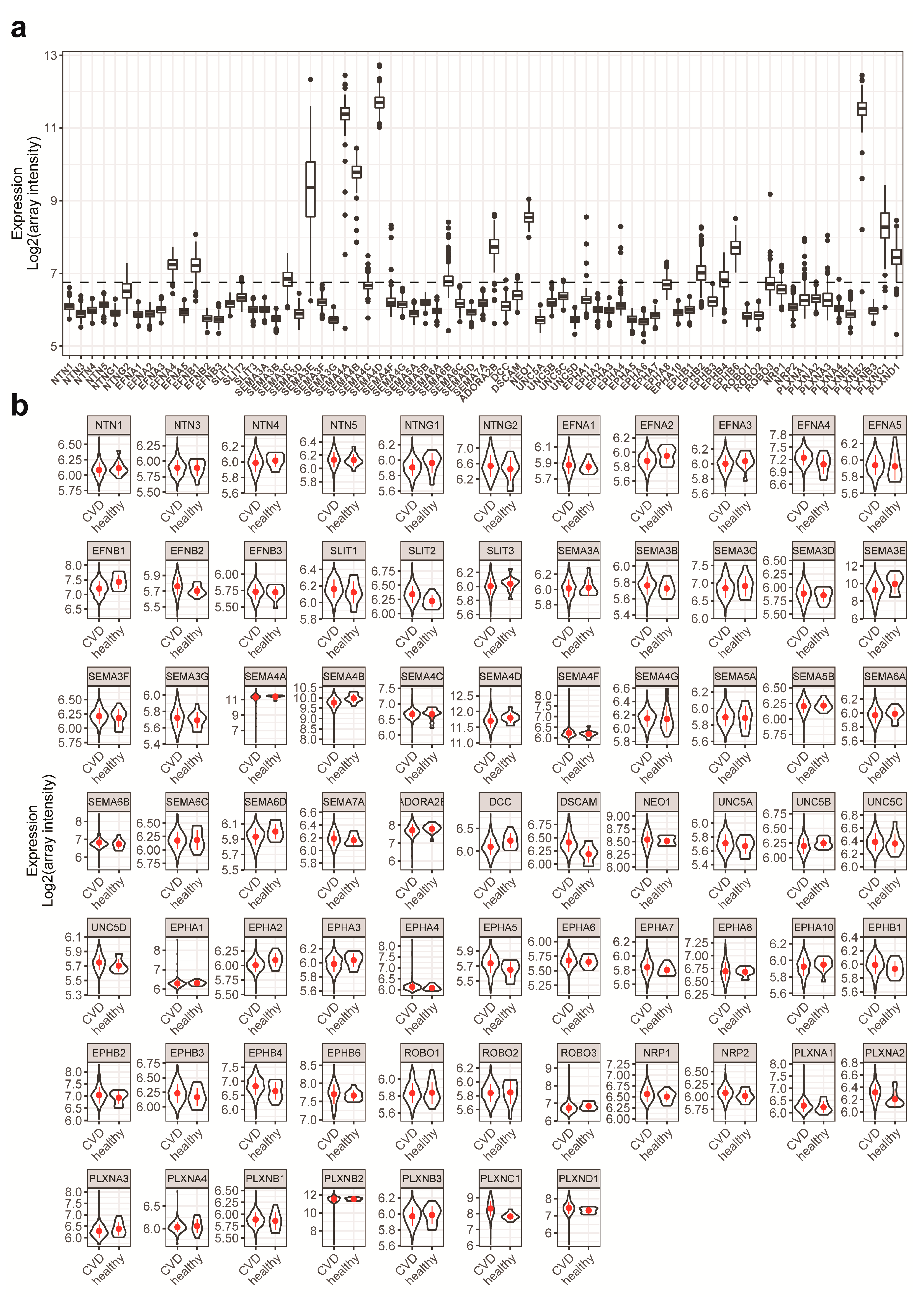
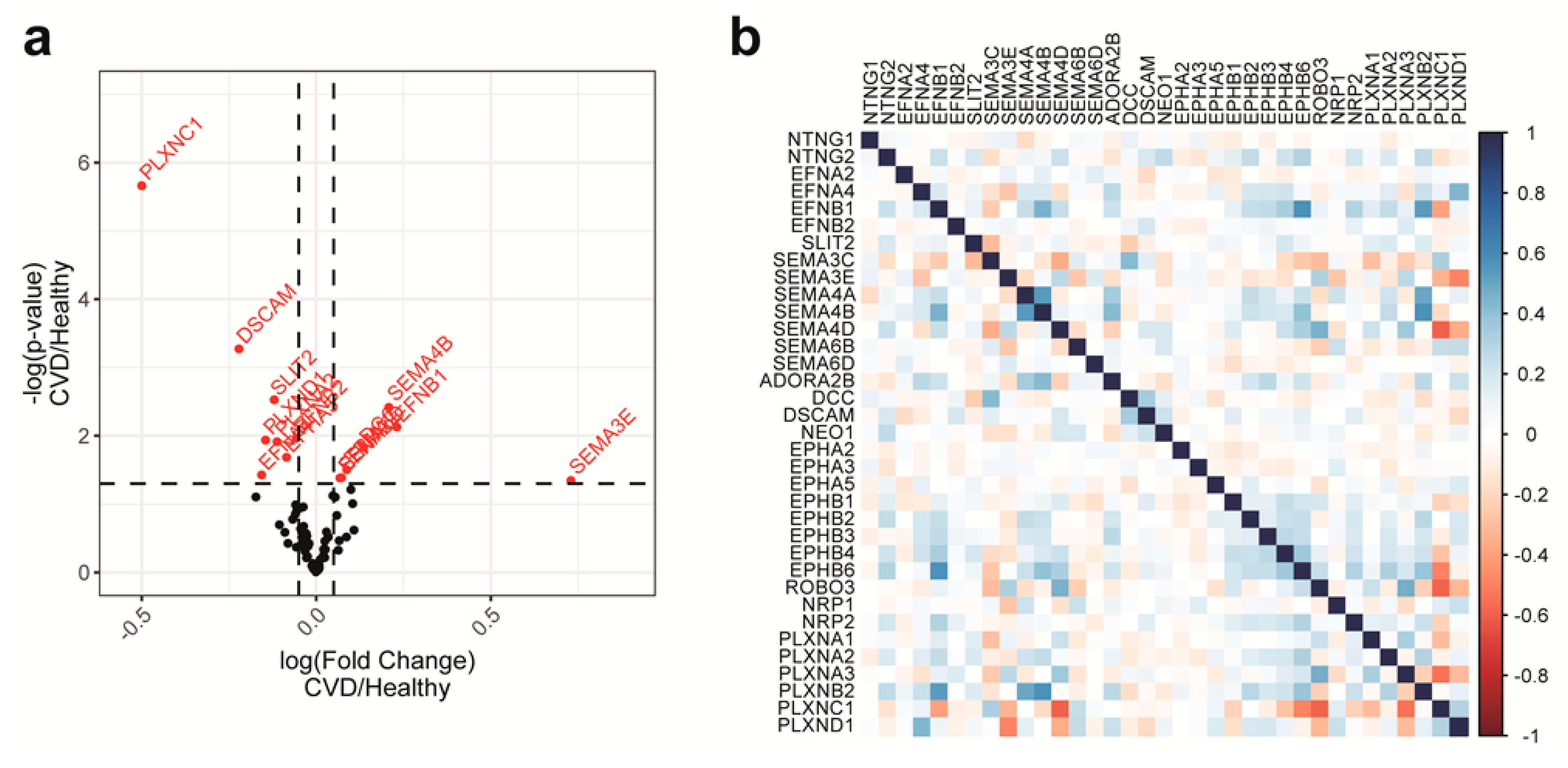
2.1. NGC Expressions in Monocytes and Feature Selections
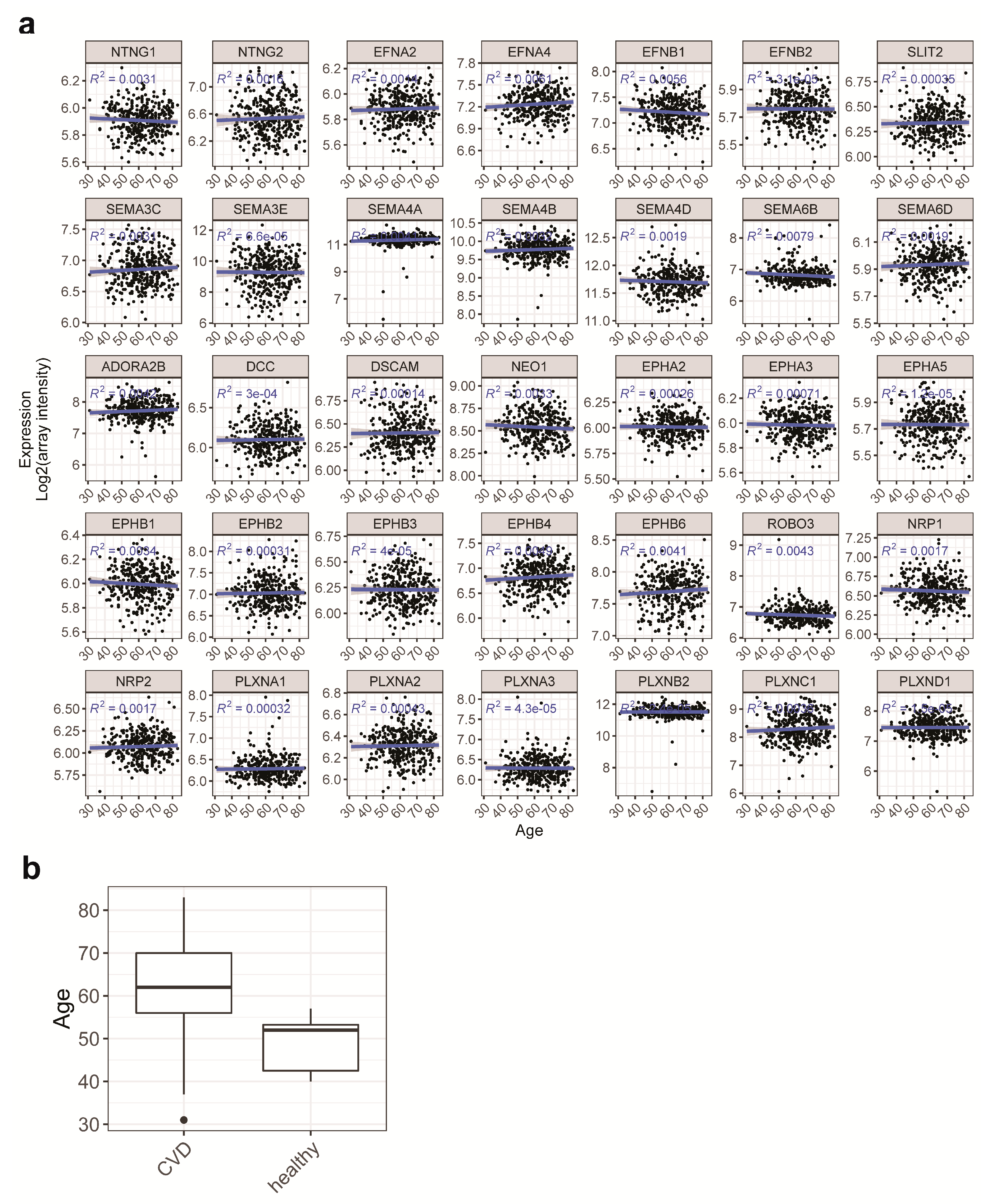
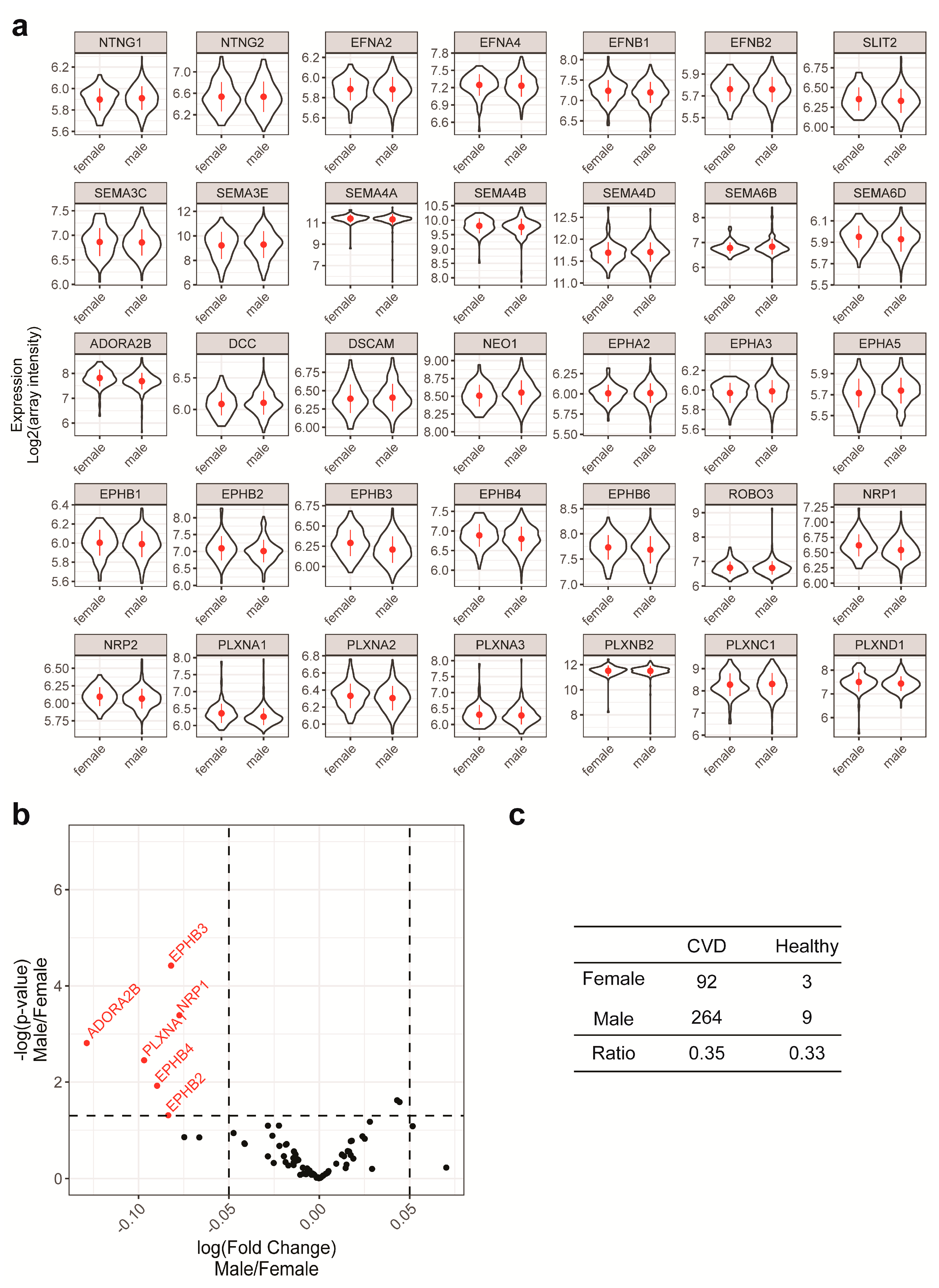
2.2. Gender and Age are Unlikely to be Confounding Factors in the Current Study
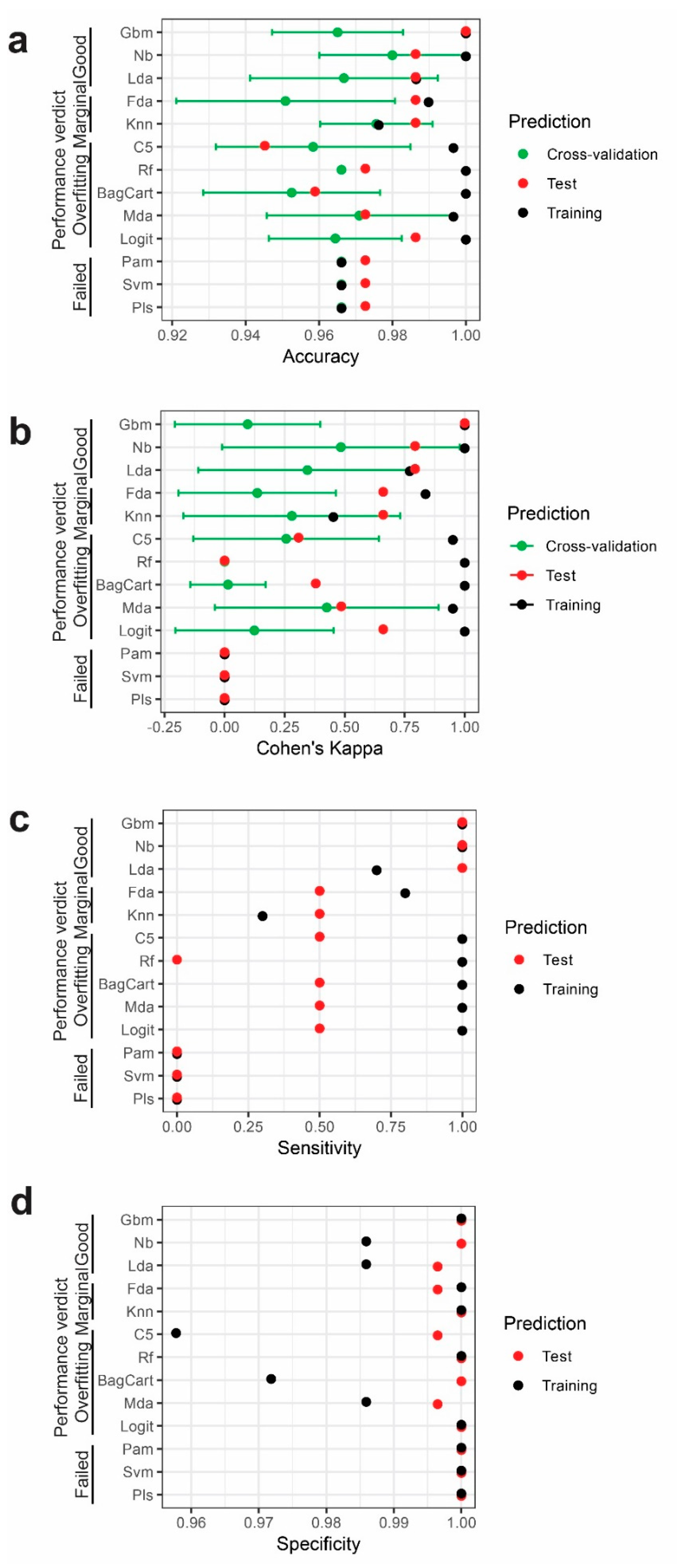
2.3. Performance of Different Models
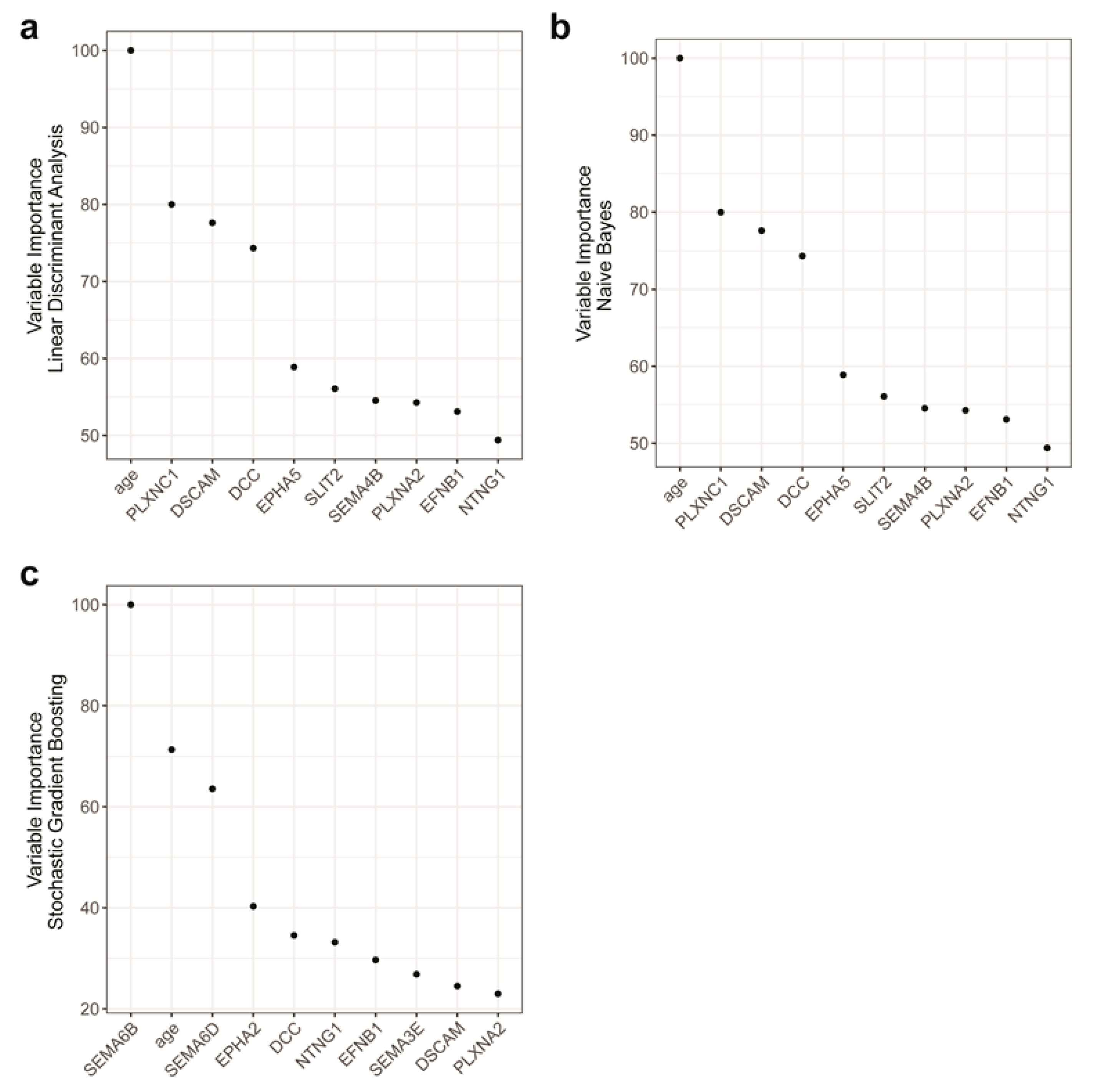
2.4. Features with the Most Importance in the Models
3. Discussion
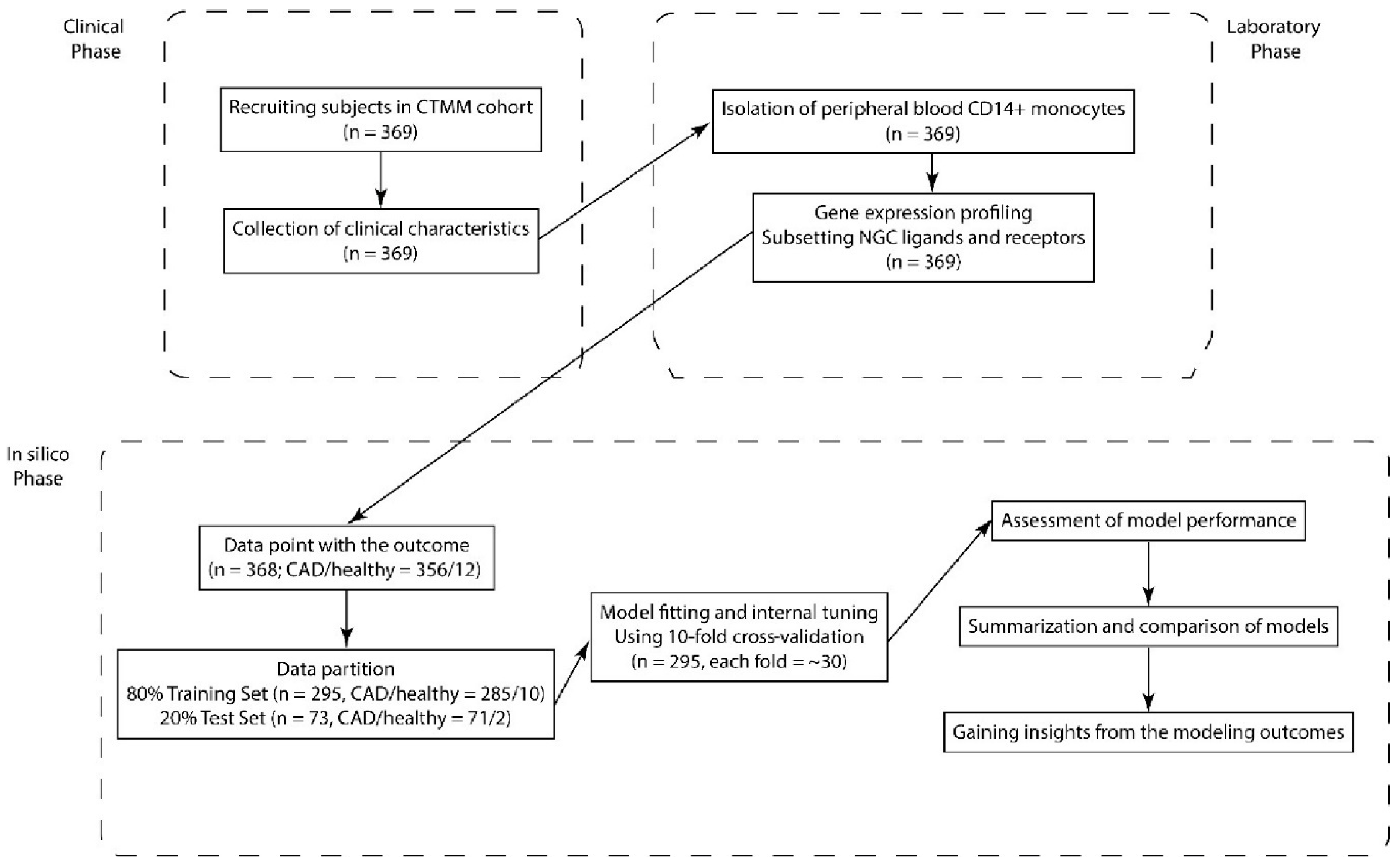
4. Materials and Methods
4.1. Study Population
4.2. Isolation of Peripheral Blood CD14-Positive Monocytes
4.3. RNA Isolation and Microarray Analysis
4.4. Statistical Analysis
4.5. Model Fitting and Assessment of Model Performance
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CVD | Cardiovascular diseases |
| NGC | Neuroimmune guidance cue |
| BMI | Body mass index |
| MI | Myocardial infarction |
| PTCA | Percutaneous transluminal coronary angioplasty |
| CABG | Coronary artery bypass graft |
| NYHA | New York Heart Association |
| Logit | Boosted Logistic Regression |
| Lda | Linear Discriminant Analysis |
| Pls | Partial Least Squares |
| Svm | Support Vector Machines |
| Pam | Nearest Shrunken Centroids |
| Mda | Mixture Discriminant Analysis |
| Fda | Flexible Discriminant Analysis |
| Knn | k-Nearest Neighbors |
| Nb | Naive Bayesian |
| BagCart | Bagged CART |
| Rf | Random Forest |
| Gbm | Random Forest |
| C5 | Single C5.0 Tree |
| STEMI | ST-elevation myocardial infarction |
References
- Frostegard, J. Immunity, atherosclerosis and cardiovascular disease. BMC Med. 2013, 11, 117. [Google Scholar] [CrossRef]
- Ross, R. Atherosclerosis--an inflammatory disease. N. Engl. J. Med. 1999, 340, 115–126. [Google Scholar] [CrossRef] [PubMed]
- Hansson, G.K.; Libby, P. The immune response in atherosclerosis: A double-edged sword. Nat. Rev. Immunol. 2006, 6, 508–519. [Google Scholar] [CrossRef] [PubMed]
- Lessner, S.M.; Prado, H.L.; Waller, E.K.; Galis, Z.S. Atherosclerotic lesions grow through recruitment and proliferation of circulating monocytes in a murine model. Am. J. Pathol. 2002, 160, 2145–2155. [Google Scholar] [CrossRef]
- Osterud, B.; Bjorklid, E. Role of monocytes in atherogenesis. Physiol. Rev. 2003, 83, 1069–1112. [Google Scholar] [CrossRef] [PubMed]
- Hansson, G.K. Inflammation, atherosclerosis, and coronary artery disease. N. Engl. J. Med. 2005, 352, 1685–1695. [Google Scholar] [CrossRef] [PubMed]
- Ley, K.; Miller, Y.I.; Hedrick, C.C. Monocyte and macrophage dynamics during atherogenesis. Arterioscler Thromb. Vasc. Biol. 2011, 31, 1506–1516. [Google Scholar] [CrossRef]
- Funk, S.D.; Orr, A.W. Ephs and ephrins resurface in inflammation, immunity, and atherosclerosis. Pharmacol. Res. 2013, 67, 42–52. [Google Scholar] [CrossRef]
- Mirakaj, V.; Rosenberger, P. Immunomodulatory Functions of Neuronal Guidance Proteins. Trends Immunol. 2017, 38, 444–456. [Google Scholar] [CrossRef]
- Zhang, H.; Vreeken, D.; Bruikman, C.S.; van Zonneveld, A.J.; van Gils, J.M. Understanding netrins and semaphorins in mature endothelial cell biology. Pharmacol. Res. 2018, 137, 1–10. [Google Scholar] [CrossRef]
- Ramkhelawon, B.Y.; Yang, J.M.; van Gils, B.; Hewing, K.J.; Rayner, S.; Parathath, L.; Guo, S.; Oldebeken, J.L.; Feig, E.A.; Moore, K.J. Hypoxia induces netrin-1 and Unc5b in atherosclerotic plaques: Mechanism for macrophage retention and survival. Arterioscler. Thromb. Vasc. Biol. 2013, 33, 1180–1188. [Google Scholar] [CrossRef] [PubMed]
- Hu, S.Y.; Liu, T.; You, J.; Heath, L.; Xu, X.; Zheng, A.; Wang, Y.; Wang, F.; Li, F.; Yang, Y.; et al. Vascular Semaphorin 7A Upregulation by Disturbed Flow Promotes Atherosclerosis Through Endothelial beta1 Integrin. Arterioscler. Thromb. Vasc. Biol. 2018, 38, 335–343. [Google Scholar] [CrossRef]
- Zhu, L.; Stalker, T.J.; Fong, K.P.; Jiang, H.; Tran, A.; Crichton, I.; Lee, E.K.; Neeves, K.B.; Maloney, S.F.; Kikutani, H.; et al. Disruption of SEMA4D ameliorates platelet hypersensitivity in dyslipidemia and confers protection against the development of atherosclerosis. Arterioscler. Thromb. Vasc. Biol. 2009, 29, 1039–1045. [Google Scholar] [CrossRef] [PubMed]
- Wanschel, A.; Seibert, T.; Hewing, B.; Ramkhelawon, B.; Ray, T.D.; Van Gils, J.M.; Rayner, K.J.; Feig, J.E.; O’Brien, E.R.; Fisher, E.A.; et al. Neuroimmune guidance cue Semaphorin 3E is expressed in atherosclerotic plaques and regulates macrophage retention. Arterioscler. Thromb. Vasc. Biol. 2013, 33, 886–893. [Google Scholar] [CrossRef]
- Van Gils, J.M.; Derby, M.C.; Fernandes, L.R.; Ramkhelawon, B.; Ray, T.D.; Rayner, K.J.; Parathath, S.; Distel, E.; Feig, J.L.; Alvarez-Leite, J.I.; et al. The neuroimmune guidance cue netrin-1 promotes atherosclerosis by inhibiting the emigration of macrophages from plaques. Nat. Immunol. 2012, 13, 136–143. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Rao, S.; Shen, G.Q.; Li, L.; Moliterno, D.J.; Newby, L.K.; Rogers, W.J.; Cannata, R.; Zirzow, E.; Elston, R.C.; et al. Premature myocardial infarction novel susceptibility locus on chromosome 1P34-36 identified by genomewide linkage analysis. Am. J. Hum. Genet. 2004, 74, 262–271. [Google Scholar] [CrossRef]
- Ghosh, S.; Vivar, J.; Nelson, C.P.; Willenborg, C.; Segre, A.V.; Makinen, V.P.; Nikpay, M.; Erdmann, J.; Blankenberg, S.; O’Donnell, C.; et al. Systems Genetics Analysis of Genome-Wide Association Study Reveals Novel Associations Between Key Biological Processes and Coronary Artery Disease. Arterioscler. Thromb. Vasc. Biol. 2015, 35, 1712–1722. [Google Scholar] [CrossRef]
- Van der Harst, P.; Verweij, N. Identification of 64 Novel Genetic Loci Provides an Expanded View on the Genetic Architecture of Coronary Artery Disease. Circ. Res. 2018, 122, 433–443. [Google Scholar] [CrossRef]
- Casamassimi, A.; Federico, A.; Rienzo, M.; Esposito, S.; Ciccodicola, A. Transcriptome Profiling in Human Diseases: New Advances and Perspectives. Int. J. Mol. Sci. 2017, 18, 1652. [Google Scholar] [CrossRef]
- Hoefer, I.E.; Sels, J.W.; Jukema, J.W.; Bergheanu, S.; Biessen, E.; McClellan, E.; Daemen, M.; Doevendans, P.; de Groot, P.; Hillaert, M.; et al. Circulating cells as predictors of secondary manifestations of cardiovascular disease: Design of the CIRCULATING CELLS study. Clin. Res. Cardiol. 2013, 102, 847–856. [Google Scholar] [CrossRef]
- Thomas, G.D.; Hamers, A.A.J.; Nakao, C.; Marcovecchio, P.; Taylor, A.M.; McSkimming, C.; Nguyen, A.T.; McNamara, C.A.; Hedrick, C.C. Human Blood Monocyte Subsets: A New Gating Strategy Defined Using Cell Surface Markers Identified by Mass Cytometry. Arterioscler. Thromb. Vasc. Biol. 2017, 37, 1548–1558. [Google Scholar] [CrossRef] [PubMed]
- Moroni, F.; Ammirati, E.; Norata, G.D.; Magnoni, M.; Camici, P.G. The Role of Monocytes and Macrophages in Human Atherosclerosis, Plaque Neoangiogenesis, and Atherothrombosis. Mediat. Inflamm. 2019, 2019, 7434376. [Google Scholar] [CrossRef] [PubMed]
- Rogacev, K.S.; Cremers, B.; Zawada, A.M.; Seiler, S.; Binder, N.; Ege, P.; Grosse-Dunker, G.; Heisel, I.; Hornof, F.; Jeken, J.; et al. CD14++CD16+ monocytes independently predict cardiovascular events: A cohort study of 951 patients referred for elective coronary angiography. J. Am. Coll. Cardiol. 2012, 60, 1512–1520. [Google Scholar] [CrossRef]
- Holmes, S.; Downs, A.M.; Fosberry, A.; Hayes, P.D.; Michalovich, D.; Murdoch, P.; Moores, K.; Fox, J.; Deen, K.; Pettman, G.; et al. Sema7A is a potent monocyte stimulator. Scand. J. Immunol. 2002, 56, 270–275. [Google Scholar] [CrossRef] [PubMed]
- O’Connor, B.P.; Eun, S.Y.; Ye, Z.; Zozulya, A.L.; Lich, J.D.; Moore, C.B.; Iocca, H.A.; Roney, K.E.; Holl, E.K.; Wu, Q.P.; et al. Semaphorin 6D regulates the late phase of CD4+ T cell primary immune responses. Proc. Natl. Acad. Sci. USA 2008, 105, 13015–13020. [Google Scholar] [CrossRef] [PubMed]
- Mukai, M.; Suruga, N.; Saeki, N.; Ogawa, K. EphA receptors and ephrin-A ligands are upregulated by monocytic differentiation/maturation and promote cell adhesion and protrusion formation in HL60 monocytes. BMC Cell Biol. 2017, 18, 28. [Google Scholar] [CrossRef]
- Saeki, N.; Nishino, S.; Shimizu, T.; Ogawa, K. EphA2 promotes cell adhesion and spreading of monocyte and monocyte/macrophage cell lines on integrin ligand-coated surfaces. Cell Adh. Migr. 2015, 9, 469–482. [Google Scholar] [CrossRef]
- Jiang, H.; Li, X.; Zhang, X.; Liu, Y.; Huang, S.; Wang, X. EphA2 knockdown attenuates atherosclerotic lesion development in ApoE(-/-) mice. Cardiovasc. Pathol. 2014, 23, 169–174. [Google Scholar] [CrossRef]
- Zawadzki, M.; Krzystek-Korpacka, M.; Gamian, A.; Witkiewicz, W. Serum cytokines in early prediction of anastomotic leakage following low anterior resection. Wideochir. Inne Tech. Maloinwazyjne 2018, 13, 33–43. [Google Scholar] [CrossRef]
- Shimanuki, M.; Imanishi, Y.; Sato, Y.; Nakahara, N.; Totsuka, D.; Sato, E.; Iguchi, S.; Sato, Y.; Soma, K.; Araki, Y.; et al. Pretreatment monocyte counts and neutrophil counts predict the risk for febrile neutropenia in patients undergoing TPF chemotherapy for head and neck squamous cell carcinoma. Oncotarget 2018, 9, 18970–18984. [Google Scholar] [CrossRef]
- Machado, G.P.; Araujo, G.N.; Carpes, C.K.; Lech, M.; Mariani, S.; Valle, F.H.; Bergoli, L.C.C.; Goncalves, S.C.; Wainstein, R.V.; Wainstein, M.V. Comparison of neutrophil-to-lymphocyte ratio and mean platelet volume in the prediction of adverse events after primary percutaneous coronary intervention in patients with ST-elevation myocardial infarction. Atherosclerosis 2018, 274, 212–217. [Google Scholar] [CrossRef] [PubMed]
- Guaricci, A.I.; Lorenzoni, V.; Guglielmo, M.; Mushtaq, S.; Muscogiuri, G.; Cademartiri, F.; Rabbat, M.; Andreini, D.; Serviddio, G.; Gaibazzi, N.; et al. Prognostic relevance of subclinical coronary and carotid atherosclerosis in a diabetic and nondiabetic asymptomatic population. Clin. Cardiol. 2018, 41, 769–777. [Google Scholar] [CrossRef] [PubMed]
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B.; the R Core Team; et al. Caret: Classification and Regression Training. R Package Version 6.0-80. 2018. Available online: https://CRAN.R-project.org/package=caret (accessed on 1 September 2020).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clinical Characteristics | All | CVD | Healthy |
|---|---|---|---|
| Demographic data | |||
| Number (male/female) | 368 (273/95) | 356 (264/92) | 12 (9/3) |
| Age | 61.8 (±10.4) | 62.2 (±10.3) | 49.2 (±6.3) |
| BMI | 27.3 (±4.3) | 27.4 (±4.3) | 23.7 (±2.3) |
| Coronary risk factors | |||
| Hypertension | 231 (63%) | 231 (65%) | 0 (0%) |
| Hypercholesterolemia | 70 (19%) | 65 (18%) | 5 (42%) |
| Diabetes | 77 (21%) | 77 (22%) | 0 (0%) |
| Current smoker | 73 (20%) | 73 (21%) | 0 (0%) |
| Family MI history | 141 (39%) | 137 (39%) | 4 (33%) |
| Previous MI | 112 (30%) | 112 (31%) | 0 (0%) |
| Positive family history | 157 (43%) | 152 (43%) | 5 (42%) |
| Therapeutic decision | |||
| PTCA | 130 (35%) | 130 (37%) | 0 (0%) |
| CABG | 32 (9%) | 32 (9%) | 0 (0%) |
| NYHA Classification | |||
| NYHA Class I | 248 (67%) | 236 (66%) | 12 (1%) |
| NYHA Class II | 78 (21%) | 78 (22%) | 0 (0%) |
| NYHA Class III | 26 (7%) | 26 (7%) | 0 (0%) |
| NYHA Class IV | 16 (4%) | 16 (4%) | 0 (0%) |
| Current medication | |||
| β-blocker | 228 (69%) | 228 (72%) | 0 (0%) |
| Ca-antagonist | 95 (29%) | 95 (30%) | 0 (0%) |
| Aspirin | 260 (79%) | 260 (82%) | 0 (0%) |
| Vitamin K antagonist | 29 (9%) | 29 (9%) | 0 (0%) |
| Low molecular weight heparin | 10 (3%) | 10 (3%) | 0 (0%) |
| ADP receptor blocker | 168 (51%) | 168 (53%) | 0 (0%) |
| ACE inhibitor | 116 (35%) | 116 (36%) | 0 (0%) |
| ATII receptor blocker | 71 (22%) | 71 (22%) | 0 (0%) |
| Diuretic | 76 (23%) | 76 (24%) | 0 (0%) |
| Statins | 252 (77%) | 252 (79%) | 0 (0%) |
| Model Name | Abbreviation | Type | Best Tuning Parameter (Tuning Range) | R Package Dependency |
|---|---|---|---|---|
| Boosted Logistic Regression | Logit | Linear | Number of iterations = 41 (11, 101) | “caTools” |
| Linear Discriminant Analysis | Lda | Linear | NA | “MASS” |
| Partial Least Squares | Pls | Linear | Number of components = 1 (1, 10) | “pls” |
| Support Vector Machines | Svm | Nonlinear | Cost = 0.25 (2 × 10−2, 2 × 10−7) | “kernlab” |
| Nearest Shrunken Centroids | Pam | Linear | Threshold = 0 (0, 25) | “pamr” |
| Mixture Discriminant Analysis | Mda | Nonlinear | Subclasses = 11 (2, 16) | “mda” |
| Flexible Discriminant Analysis | Fda | Nonlinear | Degree = 4 (1, 5); Number of pruning = 5 (2, 5) | “earth”, “mda” |
| k-Nearest Neighbors | Knn | Nonlinear | Number of neighbors = 5 (5, 23) | “class” |
| Naive Bayesian | Nb | Nonlinear | Laplace correction = 1 (1, 3); Kernal function = FALSE (FALSE, TRUE); Bandwidth Adjustment = 1 (1, 3) | “naivebayes” |
| Bagged CART | BagCart | Tree/Rule-based | NA | “ipred”, “plyr”, “e1071” |
| Random Forest | Rf | Tree/Rule-based | Number of random parameters = 2 (2, 37) | “randomForest” |
| Stochastic Gradient Boosting | Gbm | Tree/Rule-based | Interaction depth = 1 (1, 7); Number of trees = 450 (100, 1000); Shrinkage = 0.1 (0.01, 0.1); Min terminal node size = 5 (5, 7) | “gbm”, “plyr” |
| Single C5.0 Tree | C5 | Tree/Rule-based | NA | “C50”, “plyr” |
| Training | Reference | Test | Reference | |||
|---|---|---|---|---|---|---|
| Model | Prediction | CVD | Healthy | Prediction | CVD | Healthy |
| Linear Discriminant | CVD | 284 | 3 | CVD | 70 | 0 |
| Analysis | Healthy | 1 | 7 | Healthy | 1 | 2 |
| Naive Bayesian | CVD | 285 | 0 | CVD | 70 | 0 |
| Healthy | 0 | 10 | Healthy | 1 | 2 | |
| Stochastic Gradient Boosting | CVD | 285 | 0 | CVD | 71 | 0 |
| Healthy | 0 | 10 | Healthy | 0 | 2 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Bredewold, E.O.W.; Vreeken, D.; Duijs, J.M.G.J.; de Boer, H.C.; Kraaijeveld, A.O.; Jukema, J.W.; Pijls, N.H.; Waltenberger, J.; Biessen, E.A.L.; et al. Prediction Power on Cardiovascular Disease of Neuroimmune Guidance Cues Expression by Peripheral Blood Monocytes Determined by Machine-Learning Methods. Int. J. Mol. Sci. 2020, 21, 6364. https://doi.org/10.3390/ijms21176364
Zhang H, Bredewold EOW, Vreeken D, Duijs JMGJ, de Boer HC, Kraaijeveld AO, Jukema JW, Pijls NH, Waltenberger J, Biessen EAL, et al. Prediction Power on Cardiovascular Disease of Neuroimmune Guidance Cues Expression by Peripheral Blood Monocytes Determined by Machine-Learning Methods. International Journal of Molecular Sciences. 2020; 21(17):6364. https://doi.org/10.3390/ijms21176364
Chicago/Turabian StyleZhang, Huayu, Edwin O. W. Bredewold, Dianne Vreeken, Jacques. M. G. J. Duijs, Hetty C. de Boer, Adriaan O. Kraaijeveld, J. Wouter Jukema, Nico H. Pijls, Johannes Waltenberger, Erik A.L. Biessen, and et al. 2020. "Prediction Power on Cardiovascular Disease of Neuroimmune Guidance Cues Expression by Peripheral Blood Monocytes Determined by Machine-Learning Methods" International Journal of Molecular Sciences 21, no. 17: 6364. https://doi.org/10.3390/ijms21176364
APA StyleZhang, H., Bredewold, E. O. W., Vreeken, D., Duijs, J. M. G. J., de Boer, H. C., Kraaijeveld, A. O., Jukema, J. W., Pijls, N. H., Waltenberger, J., Biessen, E. A. L., van der Veer, E. P., van Zonneveld, A. J., & van Gils, J. M. (2020). Prediction Power on Cardiovascular Disease of Neuroimmune Guidance Cues Expression by Peripheral Blood Monocytes Determined by Machine-Learning Methods. International Journal of Molecular Sciences, 21(17), 6364. https://doi.org/10.3390/ijms21176364