
Genome-Wide Identification and Evolution of HECT Genes in Soybean

Abstract
:1. Introduction
2. Results
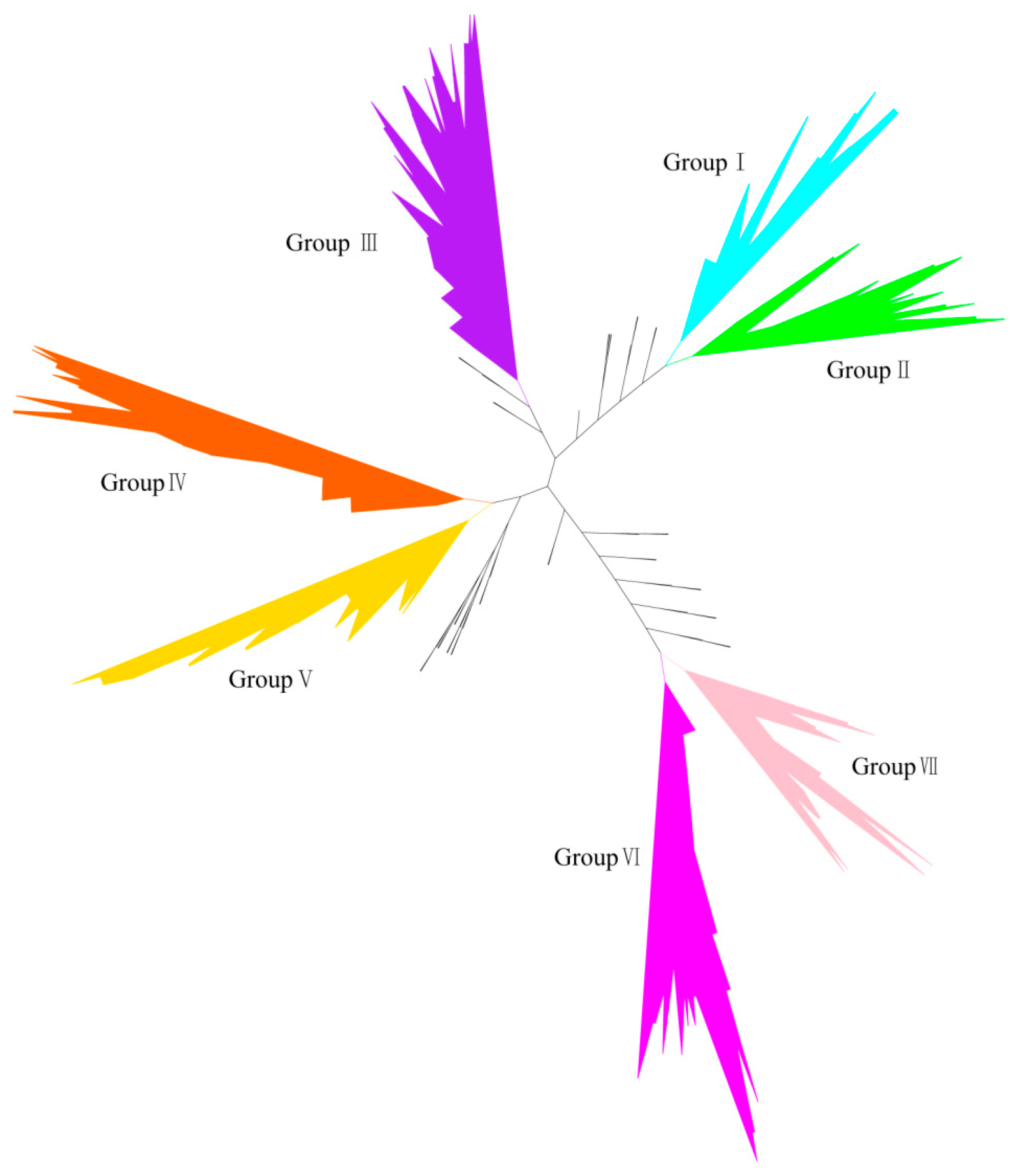
2.1. Identification of Homologous to the E6-Associated Protein (E6-AP) Carboxyl Terminus (HECT) Gene Family in Soybean

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gene Symbol | Gene Locus | Chromosome | Gene Start | Gene Stop | Amino Acids |
|---|---|---|---|---|---|
| Gma01 | Glyma02g38020 | 2 | 43347265 | 43364774 | 3649 |
| Gma02 | Glyma03g34650 | 3 | 42000995 | 42011419 | 973 |
| Gma03 | Glyma04g00530 | 4 | 285772 | 296292 | 1891 |
| Gma04 | Glyma04g10481 | 4 | 8701971 | 8719496 | 3680 |
| Gma05 | Glyma05g26360 | 5 | 32340858 | 32357248 | 3762 |
| Gma06 | Glyma06g00600 | 6 | 309849 | 320018 | 1895 |
| Gma07 | Glyma06g10360 | 6 | 7845196 | 7861448 | 3654 |
| Gma08 | Glyma07g36390 | 7 | 41782618 | 41798454 | 1026 |
| Gma09 | Glyma07g39546 | 7 | 44005949 | 44011941 | 867 |
| Gma10 | Glyma08g09270 | 8 | 6626148 | 6642483 | 3749 |
| Gma11 | Glyma10g05620 | 10 | 4408645 | 4417572 | 1557 |
| Gma12 | Glyma11g11490 | 11 | 8185583 | 8196786 | 1872 |
| Gma13 | Glyma12g03640 | 12 | 2443609 | 2454729 | 1877 |
| Gma14 | Glyma13g19981 | 13 | 23464333 | 23472965 | 1558 |
| Gma15 | Glyma14g36180 | 14 | 45377087 | 45394472 | 3652 |
| Gma16 | Glyma15g14591 | 15 | 11013042 | 11048953 | 1031 |
| Gma17 | Glyma17g01210 | 17 | 704329 | 710650 | 867 |
| Gma18 | Glyma17g04180 | 17 | 2781543 | 2800188 | 1026 |
| Gma19 | Glyma19g37310 | 19 | 44504837 | 44515898 | 1157 |
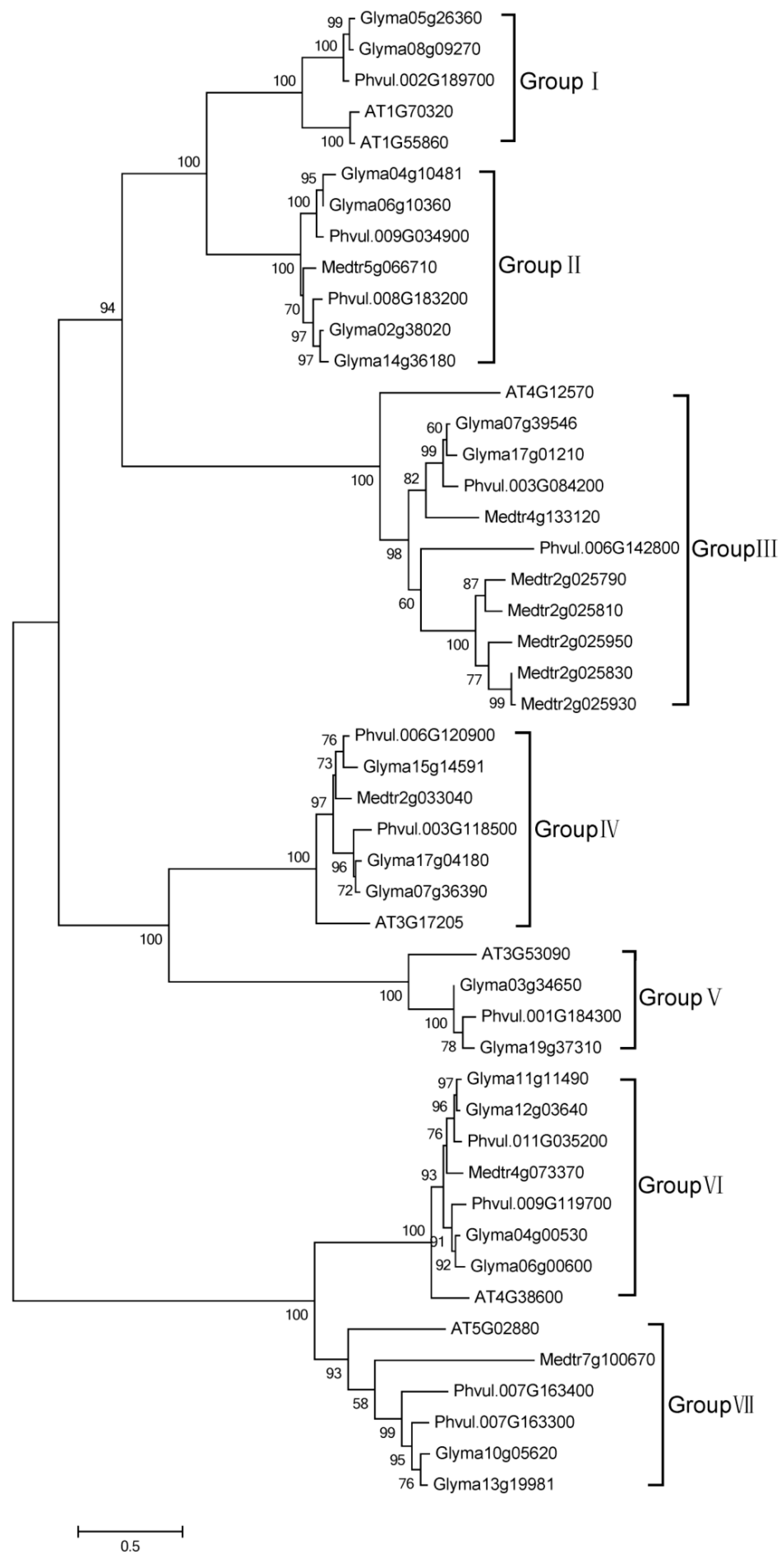
2.2. Phylogenetic Analysis of HECT Genes in Soybean
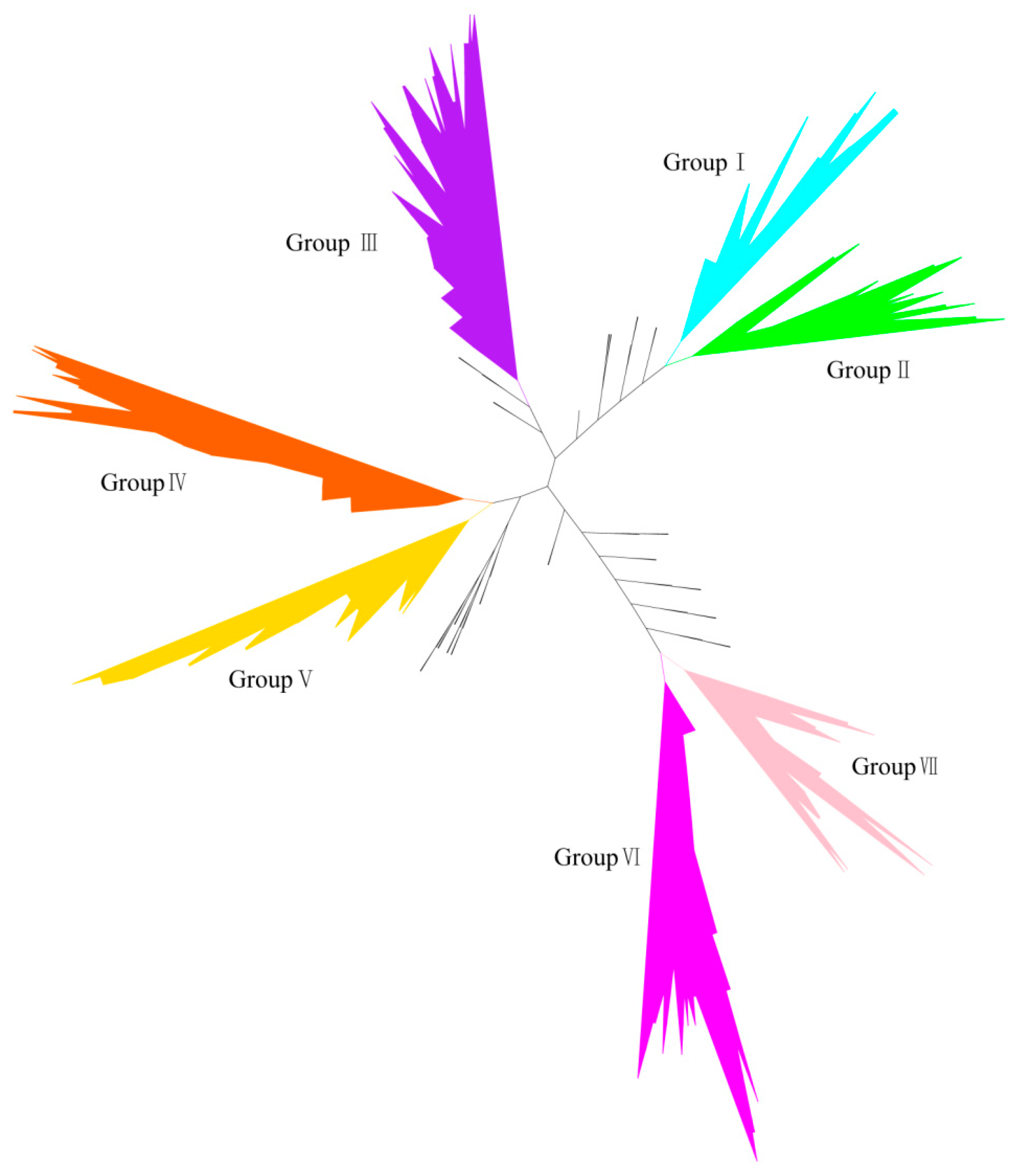
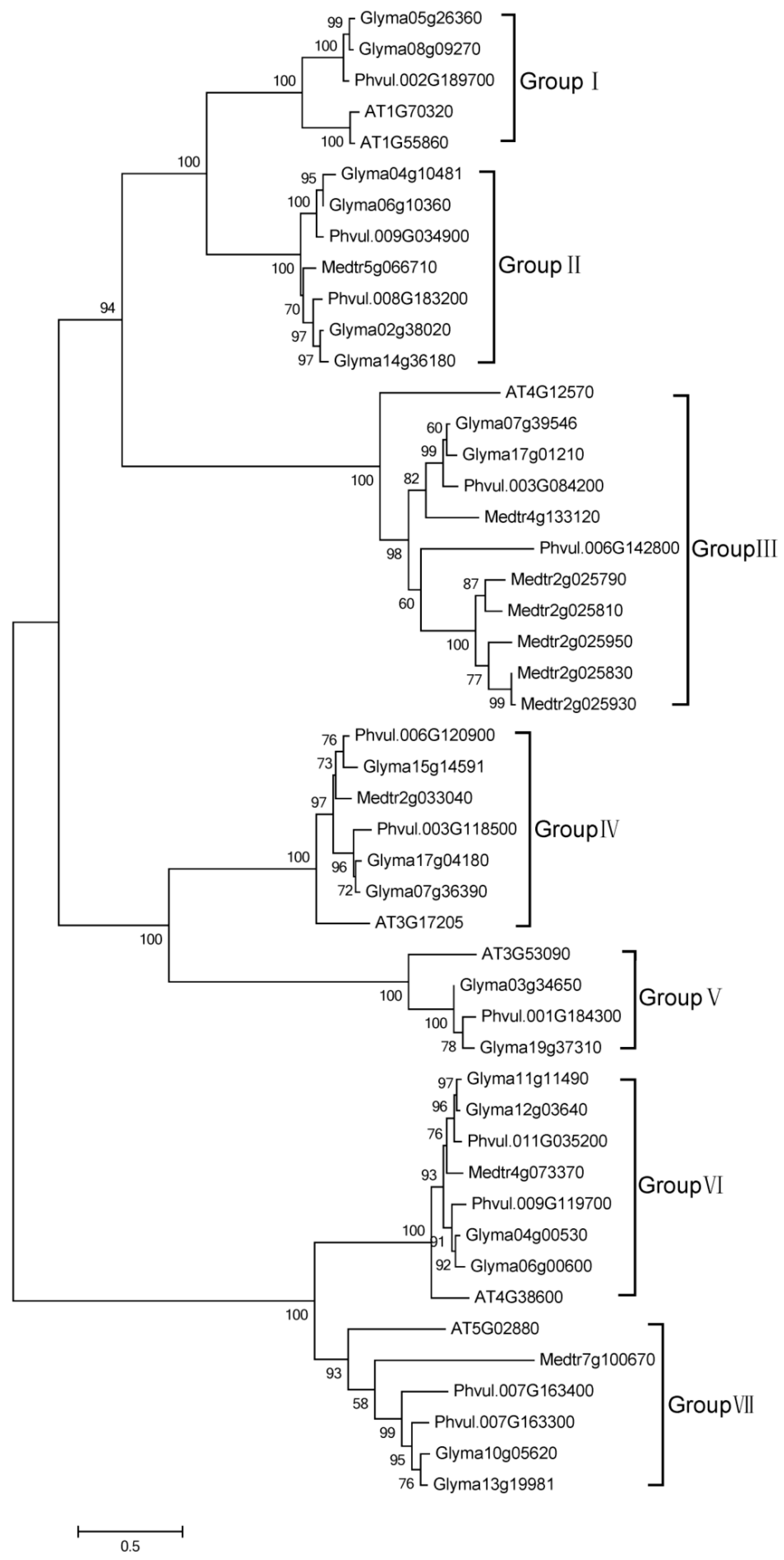
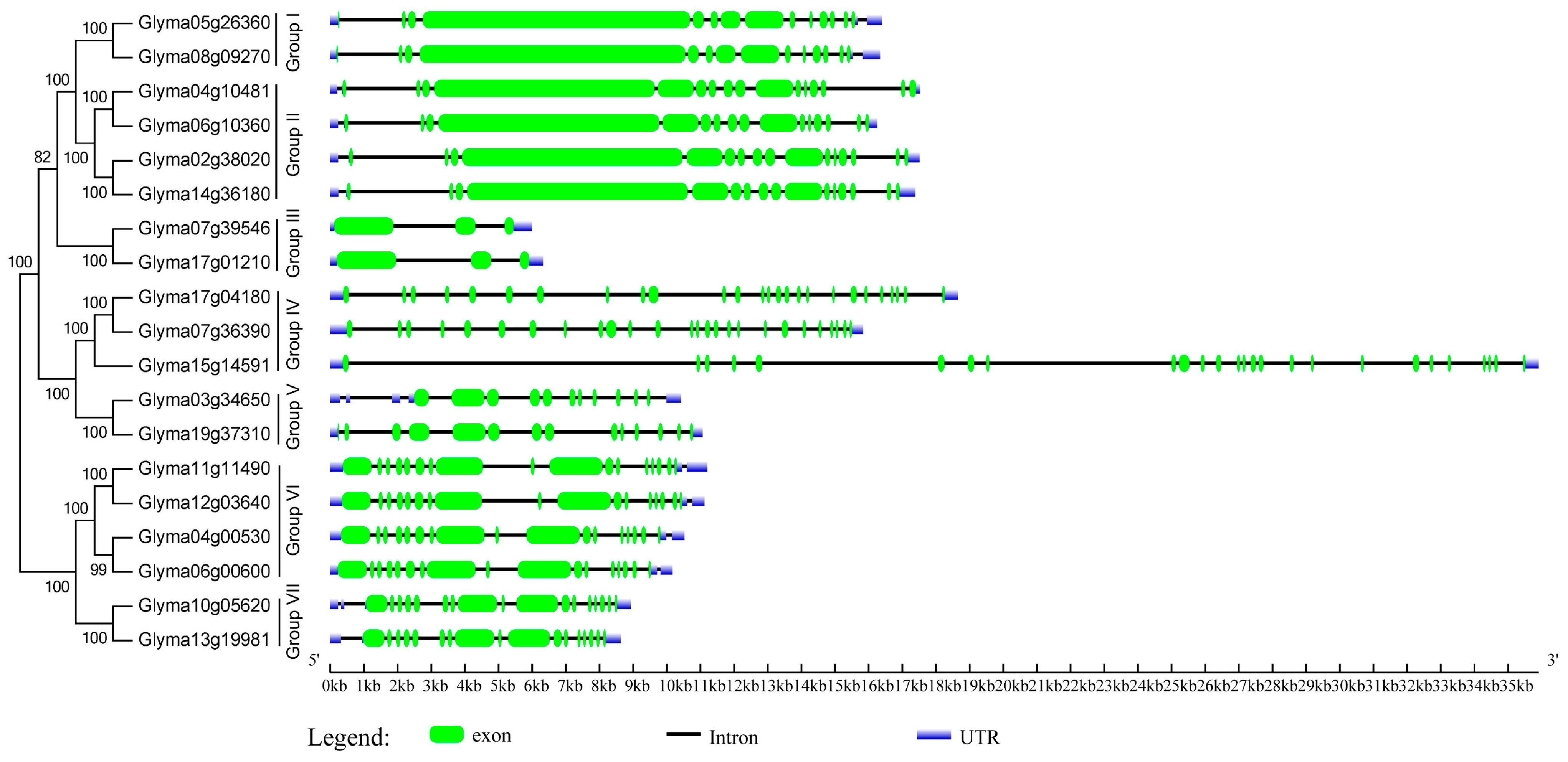
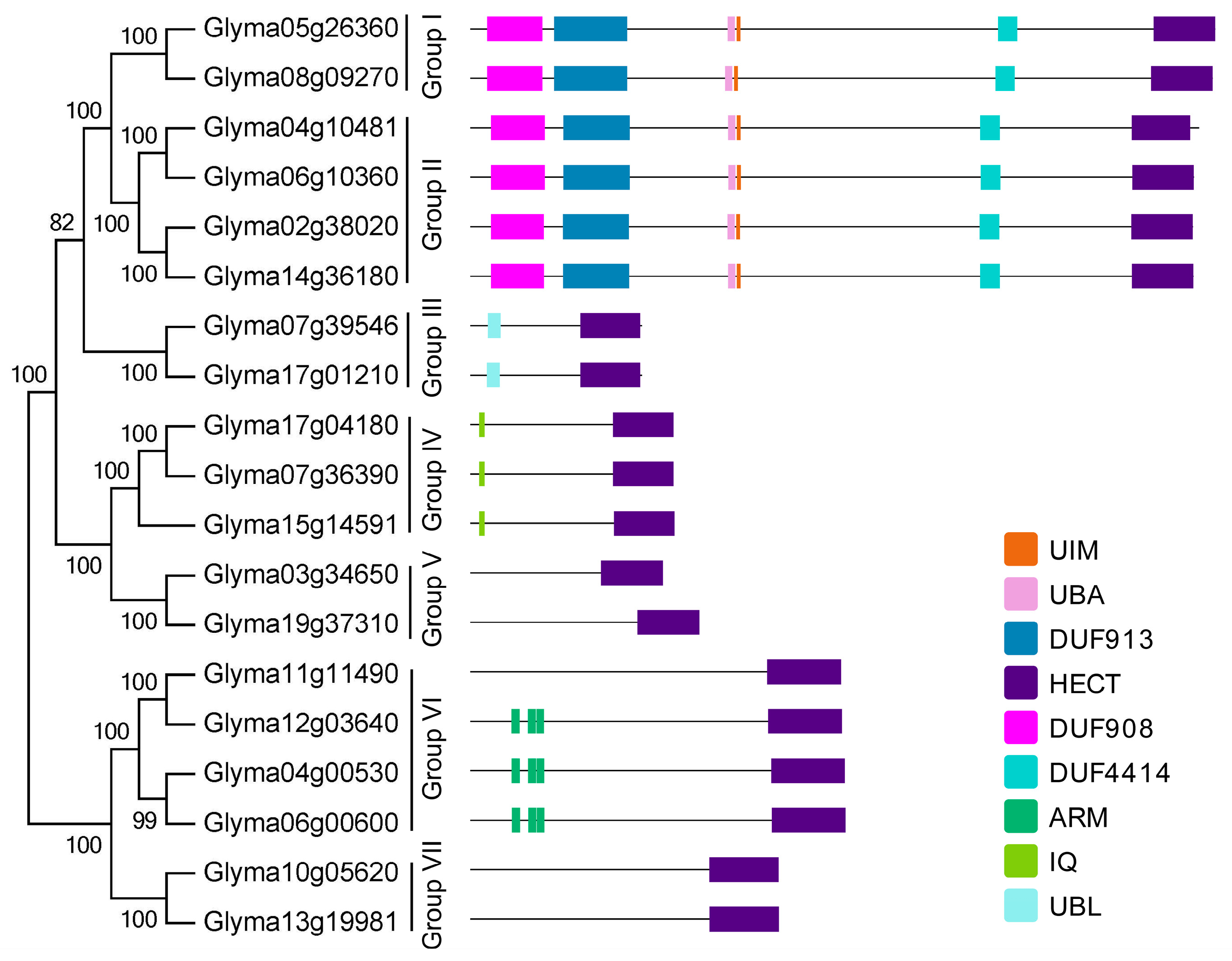
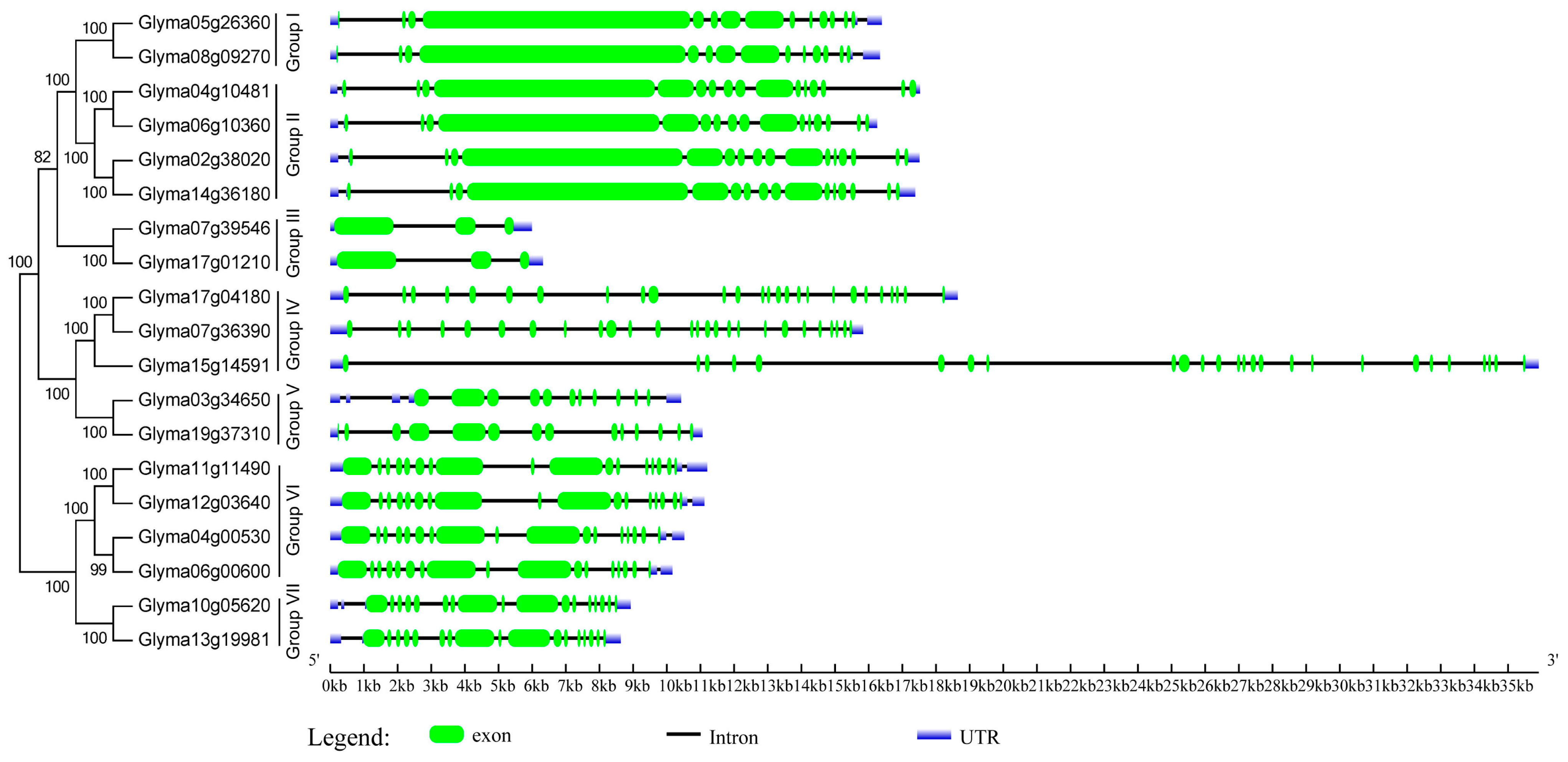
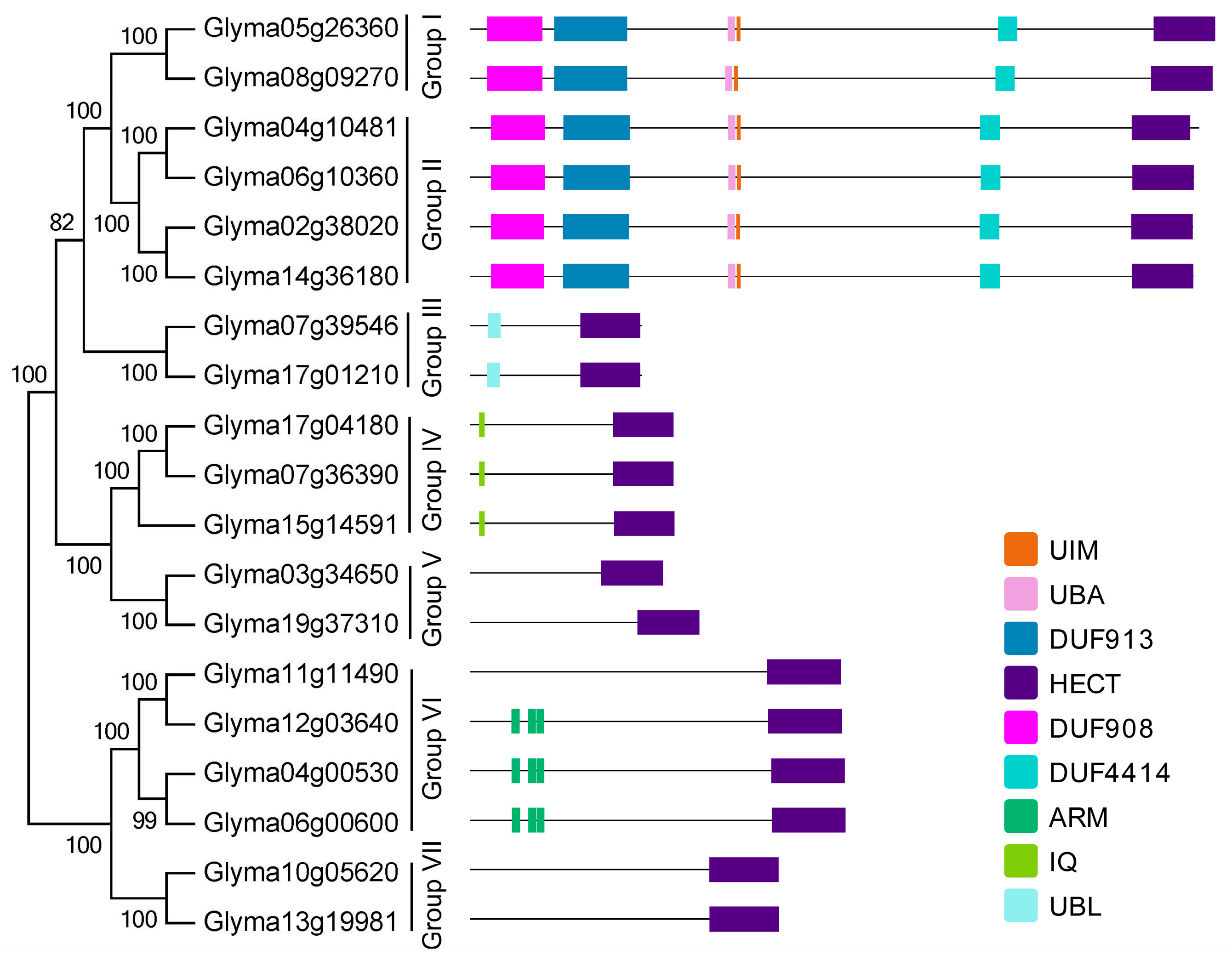
2.3. Domain Architecture and Exon-Intron Structure of the Soybean HECT Genes
2.4. Chromosome Location and Duplication of Soybean HECT Genes
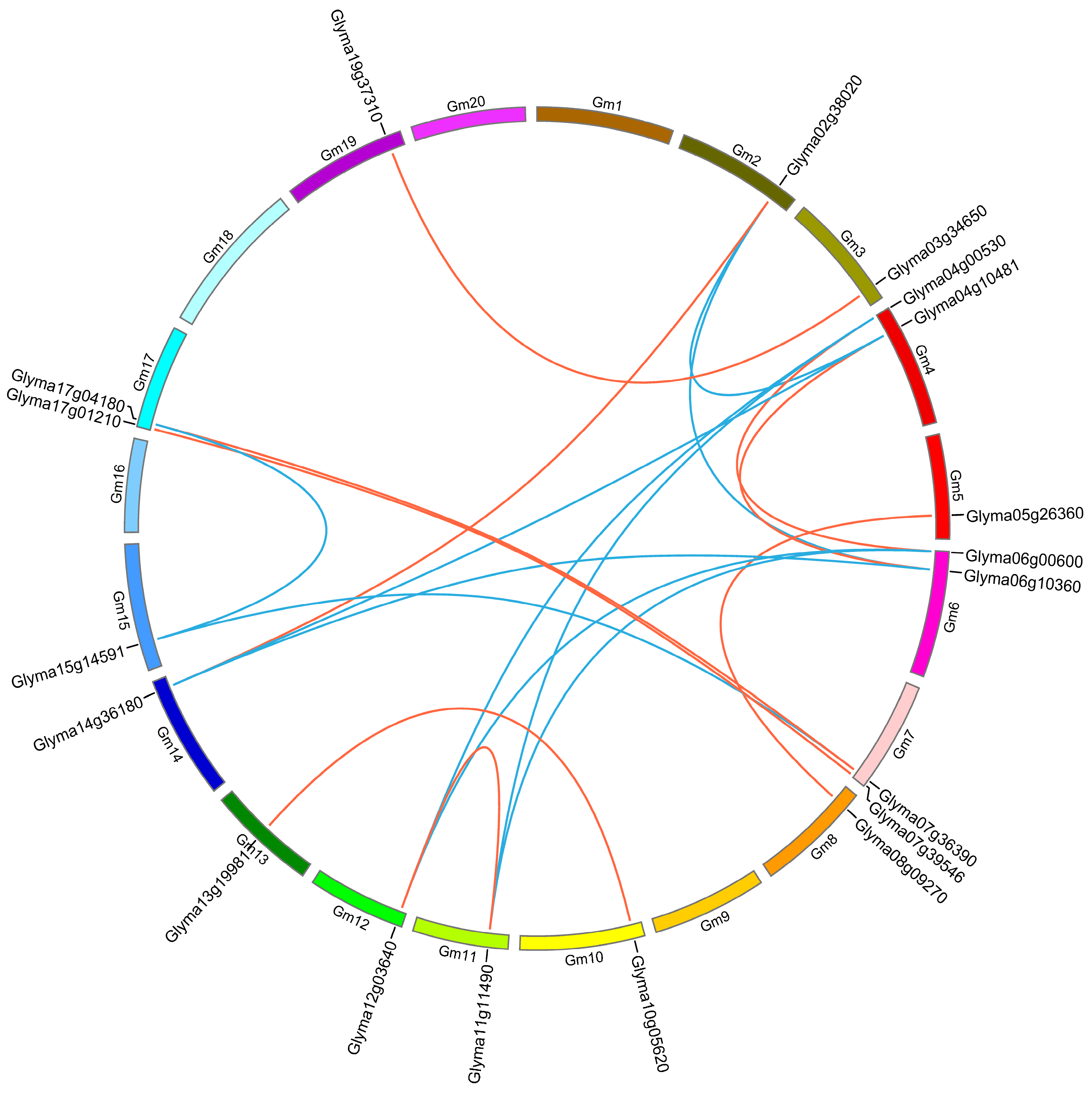
| Group | Gene Locus 1 | Gene Locus 2 | Ka | Ks | Ka/Ks | Mya |
|---|---|---|---|---|---|---|
| I | Glyma05g26360 | Glyma08g09270 | 0.02 | 0.08 | 0.25 | 6.56 |
| II | Glyma02g38020 | Glyma04g10481 | 0.1 | 0.51 | 0.2 | 41.8 |
| Glyma02g38020 | Glyma06g10360 | 0.09 | 0.49 | 0.18 | 40.16 | |
| Glyma02g38020 | Glyma14g36180 | 0.02 | 0.09 | 0.22 | 7.38 | |
| Glyma04g10481 | Glyma06g10360 | 0.04 | 0.09 | 0.44 | 7.38 | |
| Glyma04g10481 | Glyma14g36180 | 0.1 | 0.5 | 0.2 | 40.98 | |
| Glyma06g10360 | Glyma14g36180 | 0.09 | 0.49 | 0.18 | 40.16 | |
| III | Glyma07g39546 | Glyma17g01210 | 0.03 | 0.14 | 0.21 | 11.48 |
| IV | Glyma07g36390 | Glyma15g14591 | 0.09 | 0.4 | 0.23 | 32.79 |
| Glyma07g36390 | Glyma17g04180 | 0.02 | 0.09 | 0.22 | 7.38 | |
| Glyma15g14591 | Glyma17g04180 | 0.1 | 0.42 | 0.24 | 34.43 | |
| V | Glyma03g34650 | Glyma19g37310 | 0.03 | 0.07 | 0.43 | 5.74 |
| VI | Glyma04g00530 | Glyma06g00600 | 0.03 | 0.09 | 0.33 | 7.38 |
| Glyma04g00530 | Glyma11g11490 | 0.07 | 0.55 | 0.13 | 45.08 | |
| Glyma04g00530 | Glyma12g03640 | 0.07 | 0.52 | 0.13 | 42.62 | |
| Glyma06g00600 | Glyma11g11490 | 0.09 | 0.55 | 0.16 | 45.08 | |
| Glyma06g00600 | Glyma12g03640 | 0.08 | 0.51 | 0.16 | 41.8 | |
| Glyma11g11490 | Glyma12g03640 | 0.02 | 0.08 | 0.25 | 6.56 | |
| VII | Glyma10g05620 | Glyma13g19981 | 0.03 | 0.1 | 0.3 | 8.2 |
2.5. Conserved Residues in the HECT Domain
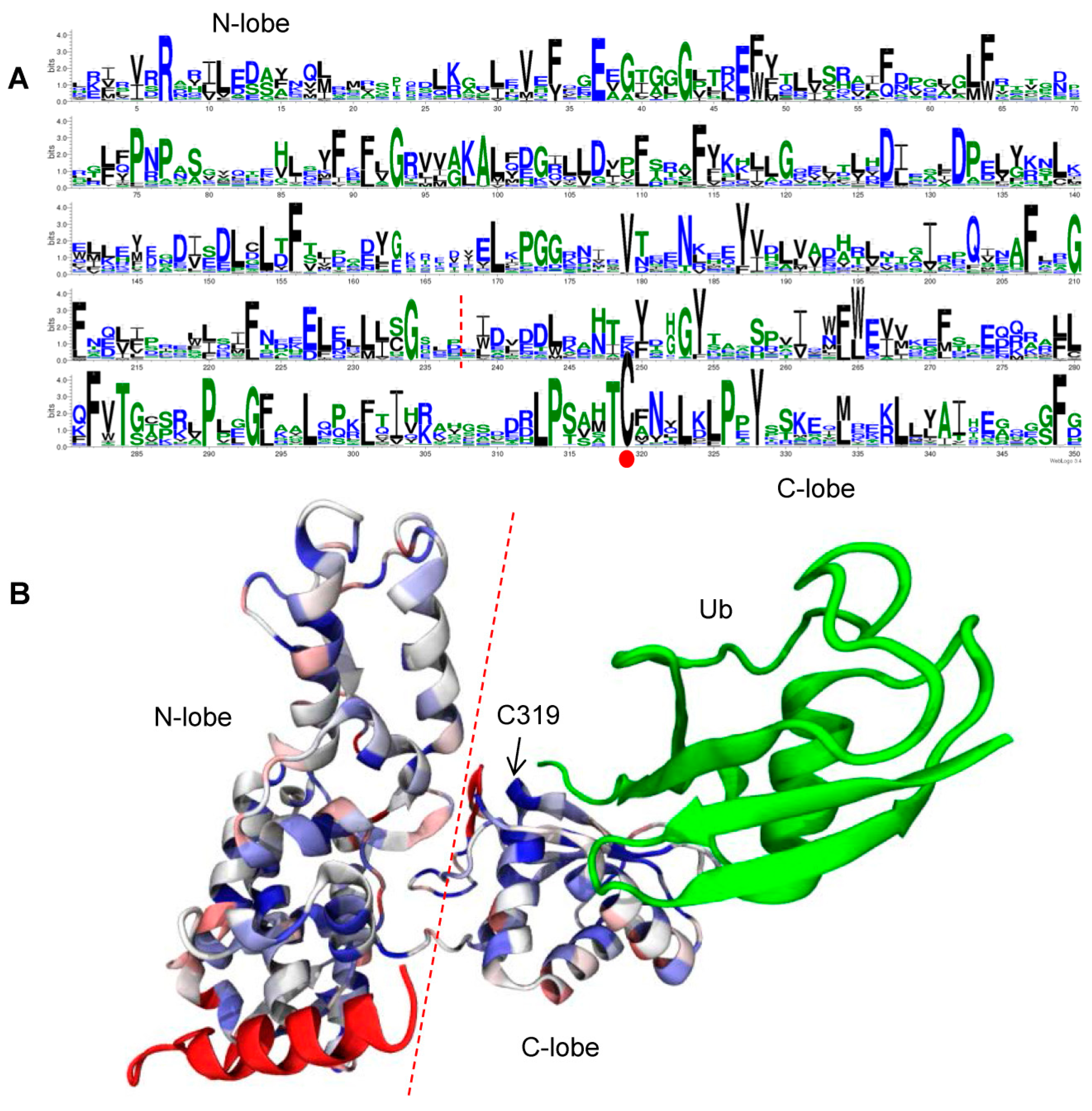
2.6. Expression Patterns of Soybean HECT Genes

3. Discussion
4. Experimental Section
4.1. Identification of HECT Genes in Soybean
4.2. Phylogenetic Analysis and Gene Structure
4.3. Chromosome Location and Duplication
4.4. Calculation of Synonymous (Ks) and Nonsynonymous Substitution (Ka) to Date Duplication Events
4.5. Logos of HECT Domains and Three-Dimensional Representations of Domain Alignment
4.6. Expression Analyses
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Wang, F.; Deng, X.W. Plant ubiquitin-proteasome pathway and its role in gibberellin signaling. Cell Res. 2011, 21, 1286–1294. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Stone, S.L. E3 ubiquitin ligases and abscisic acid signaling. Plant Signal. Behav. 2011, 6, 344–348. [Google Scholar] [CrossRef] [PubMed]
- Miao, Y.; Zentgraf, U. A HECT E3 ubiquitin ligase negatively regulates Arabidopsis leaf senescence through degradation of the transcription factor WRKY53. Plant J. 2010, 63, 179–188. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.T.; Kim, K.P.; Lledias, F.; Kisselev, A.F.; Scaglione, K.M.; Skowyra, D.; Gygi, S.P.; Goldberg, A.L. Certain pairs of ubiquitin-conjugating enzymes (E2s) and ubiquitin-protein ligases (E3s) synthesize nondegradable forked ubiquitin chains containing all possible isopeptide linkages. J. Biol. Chem. 2007, 282, 17375–17386. [Google Scholar] [CrossRef]
- Moon, J.; Parry, G.; Estelle, M. The ubiquitin-proteasome pathway and plant development. Plant Cell 2004, 16, 3181–3195. [Google Scholar] [CrossRef] [PubMed]
- El Refy, A.; Perazza, D.; Zekraoui, L.; Valay, J.G.; Bechtold, N.; Brown, S.; Hulskamp, M.; Herzog, M.; Bonneville, J.M. The Arabidopsis KAKTUS gene encodes a HECT protein and controls the number of endoreduplication cycles. Mol. Genet. Genomics 2003, 270, 403–414. [Google Scholar] [CrossRef]
- Downes, B.P.; Stupar, R.M.; Gingerich, D.J.; Vierstra, R.D. The HECT ubiquitin-protein ligase (UPL) family in Arabidopsis: UPL3 has a specific role in trichome development. Plant J. 2003, 35, 729–742. [Google Scholar]
- Stone, S.L. The role of ubiquitin and the 26S proteasome in plant abiotic stress signaling. Front. Plant Sci. 2014, 5, 135. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Cheng, D.; Peng, J.; Pickart, C.M. Molecular determinants of polyubiquitin linkage selection by an HECT ubiquitin ligase. EMBO J. 2006, 25, 1710–1719. [Google Scholar]
- Wang, M.; Pickart, C.M. Different HECT domain ubiquitin ligases employ distinct mechanisms of polyubiquitin chain synthesis. EMBO J. 2005, 24, 4324–4333. [Google Scholar] [CrossRef] [PubMed]
- Scheffner, M.; Nuber, U.; Huibregtse, J.M. Protein ubiquitination involving an E1–E2–E3 enzyme ubiquitin thioester cascade. Nature 1995, 373, 81–83. [Google Scholar] [CrossRef] [PubMed]
- Huibregtse, J.M.; Scheffner, M.; Beaudenon, S.; Howley, P.M. A family of proteins structurally and functionally related to the E6-AP ubiquitin-protein ligase. Proc. Natl. Acad. Sci. USA 1995, 92, 2563–2567. [Google Scholar] [CrossRef]
- Guzman, P. ATLs and BTLs, plant-specific and general eukaryotic structurally-related E3 ubiquitin ligases. Plant Sci. 2014, 215–216, 69–75. [Google Scholar] [CrossRef]
- Duplan, V.; Rivas, S. E3 ubiquitin-ligases and their target proteins during the regulation of plant innate immunity. Front. Plant Sci. 2014, 5, 42. [Google Scholar] [CrossRef]
- Chen, L.; Hellmann, H. Plant E3 ligases: Flexible enzymes in a sessile world. Mol. Plant 2013, 6, 1388–1404. [Google Scholar] [CrossRef] [PubMed]
- Yee, D.; Goring, D.R. The diversity of plant U-box E3 ubiquitin ligases: From upstream activators to downstream target substrates. J. Exp. Bot. 2009, 60, 1109–1121. [Google Scholar] [CrossRef] [PubMed]
- Craig, A.; Ewan, R.; Mesmar, J.; Gudipati, V.; Sadanandom, A. E3 ubiquitin ligases and plant innate immunity. J. Exp. Bot. 2009, 60, 1123–1132. [Google Scholar]
- Qin, F.; Sakuma, Y.; Tran, L.S.; Maruyama, K.; Kidokoro, S.; Fujita, Y.; Fujita, M.; Umezawa, T.; Sawano, Y.; Miyazono, K.; et al. Arabidopsis DREB2A-interacting proteins function as RING E3 ligases and negatively regulate plant drought stress-responsive gene expression. Plant Cell 2008, 20, 1693–1707. [Google Scholar] [CrossRef] [PubMed]
- Schwechheimer, C.; Calderon Villalobos, L.I. Cullin-containing E3 ubiquitin ligases in plant development. Curr. Opin. Plant Biol. 2004, 7, 677–686. [Google Scholar] [CrossRef] [PubMed]
- Mach, J. Ubiquitin ligation RINGs twice: Redundant control of plant processes by E3 ubiquitin ligases. Plant Cell 2008, 20, 1424. [Google Scholar] [CrossRef]
- Maspero, E.; Valentini, E.; Mari, S.; Cecatiello, V.; Soffientini, P.; Pasqualato, S.; Polo, S. Structure of a ubiquitin-loaded HECT ligase reveals the molecular basis for catalytic priming. Nat. Struct. Mol. Biol. 2013, 20, 696–701. [Google Scholar]
- Marin, I. Evolution of plant HECT ubiquitin ligases. PLoS ONE 2013, 8, e68536. [Google Scholar] [CrossRef]
- Grau-Bove, X.; Sebe-Pedros, A.; Ruiz-Trillo, I. A genomic survey of HECT ubiquitin ligases in eukaryotes reveals independent expansions of the HECT system in several lineages. Genome Biol. Evol. 2013, 5, 833–847. [Google Scholar] [CrossRef] [PubMed]
- Kamadurai, H.B.; Qiu, Y.; Deng, A.; Harrison, J.S.; Macdonald, C.; Actis, M.; Rodrigues, P.; Miller, D.J.; Souphron, J.; Lewis, S.M. Mechanism of ubiquitin ligation and lysine prioritization by a HECT E3. Elife 2013, 2, e00828. [Google Scholar] [CrossRef]
- Maspero, E.; Mari, S.; Valentini, E.; Musacchio, A.; Fish, A.; Pasqualato, S.; Polo, S. Structure of the HECT:ubiquitin complex and its role in ubiquitin chain elongation. EMBO Rep. 2011, 12, 342–349. [Google Scholar]
- Kim, H.C.; Steffen, A.M.; Oldham, M.L.; Chen, J.; Huibregtse, J.M. Structure and function of a HECT domain ubiquitin-binding site. EMBO Rep. 2011, 12, 334–341. [Google Scholar] [CrossRef]
- Rotin, D.; Kumar, S. Physiological functions of the HECT family of ubiquitin ligases. Nat. Rev. Mol. Cell Biol. 2009, 10, 398–409. [Google Scholar] [CrossRef] [PubMed]
- Schmutz, J.; Cannon, S.B.; Schlueter, J.; Ma, J.; Mitros, T.; Nelson, W.; Hyten, D.L.; Song, Q.; Thelen, J.J.; Cheng, J.; et al. Genome sequence of the palaeopolyploid soybean. Nature 2010, 463, 178–183. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Wu, N.; Song, W.; Yin, G.; Qin, Y.; Yan, Y.; Hu, Y. Soybean (Glycine max) expansin gene superfamily origins: segmental and tandem duplication events followed by divergent selection among subfamilies. BMC Plant Biol. 2014, 14, 93. [Google Scholar]
- Cannon, S.B.; Mitra, A.; Baumgarten, A.; Young, N.D.; May, G. The roles of segmental and tandem gene duplication in the evolution of large gene families in Arabidopsis thaliana. BMC Plant Biol. 2004, 4, 10. [Google Scholar]
- Lee, T.H.; Tang, H.; Wang, X.; Paterson, A.H. PGDD: A database of gene and genome duplication in plants. Nucleic Acids Res. 2013, 41, 1152–1158. [Google Scholar] [CrossRef]
- Crooks, G.E.; Hon, G.; Chandonia, J.M.; Brenner, S.E. WebLogo: A sequence logo generator. Genome Res. 2004, 14, 1188–1190. [Google Scholar]
- Severin, A.J.; Woody, J.L.; Bolon, Y.T.; Joseph, B.; Diers, B.W.; Farmer, A.D.; Muehlbauer, G.J.; Nelson, R.T.; Grant, D.; Specht, J.E. RNA-Seq Atlas of Glycine max: A guide to the soybean transcriptome. BMC Plant Biol. 2010, 10, 160. [Google Scholar] [CrossRef]
- Patra, B.; Pattanaik, S.; Yuan, L. Ubiquitin protein ligase 3 mediates the proteasomal degradation of GLABROUS 3 and ENHANCER OF GLABROUS 3, regulators of trichome development and flavonoid biosynthesis in Arabidopsis. Plant J. 2013, 74, 435–447. [Google Scholar] [CrossRef] [PubMed]
- Kong, H.; Landherr, L.L.; Frohlich, M.W.; Leebens-Mack, J.; Ma, H.; dePamphilis, C.W. Patterns of gene duplication in the plant SKP1 gene family in angiosperms: Evidence for multiple mechanisms of rapid gene birth. Plant J. 2007, 50, 873–885. [Google Scholar]
- Gu, Z.; Steinmetz, L.M.; Gu, X.; Scharfe, C.; Davis, R.W.; Li, W.H. Role of duplicate genes in genetic robustness against null mutations. Nature 2003, 421, 63–66. [Google Scholar] [CrossRef]
- Bowers, J.E.; Chapman, B.A.; Rong, J.; Paterson, A.H. Unravelling angiosperm genome evolution by phylogenetic analysis of chromosomal duplication events. Nature 2003, 422, 433–438. [Google Scholar]
- Finn, R.D.; Bateman, A.; Clements, J.; Coggill, P.; Eberhardt, R.Y.; Eddy, S.R.; Heger, A.; Hetherington, K.; Holm, L.; Mistry, J.; et al. Pfam: The protein families database. Nucleic Acids Res. 2014, 42, D222–D230. [Google Scholar] [CrossRef] [PubMed]
- Punta, M.; Coggill, P.C.; Eberhardt, R.Y.; Mistry, J.; Tate, J.; Boursnell, C.; Pang, N.; Forslund, K.; Ceric, G.; Clements, J.; et al. The Pfam protein families database. Nucleic Acids Res. 2012, 40, D290–D301. [Google Scholar] [CrossRef] [PubMed]
- Finn, R.D.; Clements, J.; Eddy, S.R. HMMER web server: Interactive sequence similarity searching. Nucleic Acids Res. 2011, 39, W29–W37. [Google Scholar] [CrossRef] [PubMed]
- Eddy, S.R. Accelerated profile HMM searches. PLoS Comput. Biol. 2011, 7, e1002195. [Google Scholar] [CrossRef] [PubMed]
- Camacho, C.; Coulouris, G.; Avagyan, V.; Ma, N.; Papadopoulos, J.; Bealer, K.; Madden, T.L. BLAST+: Architecture and applications. BMC Bioinform. 2009, 10, 421. [Google Scholar] [CrossRef]
- Jones, P.; Binns, D.; Chang, H.Y.; Fraser, M.; Li, W.; McAnulla, C.; McWilliam, H.; Maslen, J.; Mitchell, A.; Nuka, G.; et al. InterProScan 5: Genome-scale protein function classification. Bioinformatics 2014, 30, 1236–1240. [Google Scholar] [CrossRef] [PubMed]
- Sigrist, C.J.; de Castro, E.; Cerutti, L.; Cuche, B.A.; Hulo, N.; Bridge, A.; Bougueleret, L.; Xenarios, I. New and continuing developments at PROSITE. Nucleic Acids Res. 2013, 41, D344–D347. [Google Scholar] [CrossRef]
- Letunic, I.; Doerks, T.; Bork, P. SMART 7: Recent updates to the protein domain annotation resource. Nucleic Acids Res. 2012, 40, D302–D305. [Google Scholar] [CrossRef] [PubMed]
- Wilson, D.; Pethica, R.; Zhou, Y.; Talbot, C.; Vogel, C.; Madera, M.; Chothia, C.; Gough, J. SUPERFAMILY—Sophisticated comparative genomics, data mining, visualization and phylogeny. Nucleic Acids Res. 2009, 37, D380–D386. [Google Scholar]
- Mi, H.; Muruganujan, A.; Thomas, P.D. PANTHER in 2013: Modeling the evolution of gene function, and other gene attributes, in the context of phylogenetic trees. Nucleic Acids Res. 2013, 41, D377–D386. [Google Scholar] [CrossRef] [PubMed]
- Lees, J.G.; Lee, D.; Studer, R.A.; Dawson, N.L.; Sillitoe, I.; Das, S.; Yeats, C.; Dessailly, B.H.; Rentzsch, R.; Orengo, C.A. Gene3D: Multi-domain annotations for protein sequence and comparative genome analysis. Nucleic Acids Res. 2014, 42, D240–D245. [Google Scholar]
- Edgar, R.C. MUSCLE: Multiple sequence alignment with high accuracy and high throughput. Nucleic Acids Res. 2004, 32, 1792–1797. [Google Scholar] [CrossRef]
- Kuraku, S.; Zmasek, C.M.; Nishimura, O.; Katoh, K. aLeaves facilitates on-demand exploration of metazoan gene family trees on MAFFT sequence alignment server with enhanced interactivity. Nucleic Acids Res. 2013, 41, W22–W28. [Google Scholar] [CrossRef] [PubMed]
- Katoh, K.; Standley, D.M. MAFFT multiple sequence alignment software version 7: Improvements in performance and usability. Mol. Biol. Evol. 2013, 30, 772–780. [Google Scholar] [CrossRef] [PubMed]
- Capella-Gutierrez, S.; Silla-Martinez, J.M.; Gabaldon, T. trimAl: A tool for automated alignment trimming in large-scale phylogenetic analyses. Bioinformatics 2009, 25, 1972–1973. [Google Scholar] [CrossRef] [PubMed]
- Darriba, D.; Taboada, G.L.; Doallo, R.; Posada, D. ProtTest 3: Fast selection of best-fit models of protein evolution. Bioinformatics 2011, 27, 1164–1165. [Google Scholar]
- Guindon, S.; Dufayard, J.F.; Lefort, V.; Anisimova, M.; Hordijk, W.; Gascuel, O. New algorithms and methods to estimate maximum-likelihood phylogenies: Assessing the performance of PhyML 3.0. Syst. Biol. 2010, 59, 307–321. [Google Scholar] [CrossRef]
- Letunic, I.; Bork, P. Interactive Tree Of Life v2: Online annotation and display of phylogenetic trees made easy. Nucleic Acids Res. 2011, 39, W475–W478. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Gao, S.; Lercher, M.J.; Hu, S.; Chen, W.H. EvolView, an online tool for visualizing, annotating and managing phylogenetic trees. Nucleic Acids Res. 2012, 40, W569–W572. [Google Scholar]
- Guo, A.Y.; Zhu, Q.H.; Chen, X.; Luo, J.C. GSDS: A gene structure display server. Yi Chuan 2007, 29, 1023–1026. [Google Scholar]
- Chen, X.; Chen, Z.; Zhao, H.; Zhao, Y.; Cheng, B.; Xiang, Y. Genome-wide analysis of soybean HD-Zip gene family and expression profiling under salinity and drought treatments. PLoS ONE 2014, 9, e87156. [Google Scholar]
- Krzywinski, M.; Schein, J.; Birol, I.; Connors, J.; Gascoyne, R.; Horsman, D.; Jones, S.J.; Marra, M.A. Circos: An information aesthetic for comparative genomics. Genome Res. 2009, 19, 1639–1645. [Google Scholar]
- Yang, Z. PAML 4: Phylogenetic analysis by maximum likelihood. Mol. Biol. Evol. 2007, 24, 1586–1591. [Google Scholar] [CrossRef] [PubMed]
- Lynch, M.; Conery, J.S. The evolutionary fate and consequences of duplicate genes. Science 2000, 290, 1151–1155. [Google Scholar] [CrossRef] [PubMed]
- Roberts, E.; Eargle, J.; Wright, D.; Luthey-Schulten, Z. MultiSeq: Unifying sequence and structure data for evolutionary analysis. BMC Bioinform. 2006, 7, 382. [Google Scholar] [CrossRef]
- Humphrey, W.; Dalke, A.; Schulten, K. VMD: Visual molecular dynamics. J. Mol. Graph. 1996, 14, 33–38. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, X.; Wang, C.; Rahman, S.U.; Wang, Y.; Wang, A.; Tao, S. Genome-Wide Identification and Evolution of HECT Genes in Soybean. Int. J. Mol. Sci. 2015, 16, 8517-8535. https://doi.org/10.3390/ijms16048517
Meng X, Wang C, Rahman SU, Wang Y, Wang A, Tao S. Genome-Wide Identification and Evolution of HECT Genes in Soybean. International Journal of Molecular Sciences. 2015; 16(4):8517-8535. https://doi.org/10.3390/ijms16048517
Chicago/Turabian StyleMeng, Xianwen, Chen Wang, Siddiq Ur Rahman, Yaxu Wang, Ailan Wang, and Shiheng Tao. 2015. "Genome-Wide Identification and Evolution of HECT Genes in Soybean" International Journal of Molecular Sciences 16, no. 4: 8517-8535. https://doi.org/10.3390/ijms16048517
APA StyleMeng, X., Wang, C., Rahman, S. U., Wang, Y., Wang, A., & Tao, S. (2015). Genome-Wide Identification and Evolution of HECT Genes in Soybean. International Journal of Molecular Sciences, 16(4), 8517-8535. https://doi.org/10.3390/ijms16048517