Improving the Utility of the Tox21 Dataset by Deep Metadata Annotations and Constructing Reusable Benchmarked Chemical Reference Signatures


Abstract
1. Introduction
2. Results
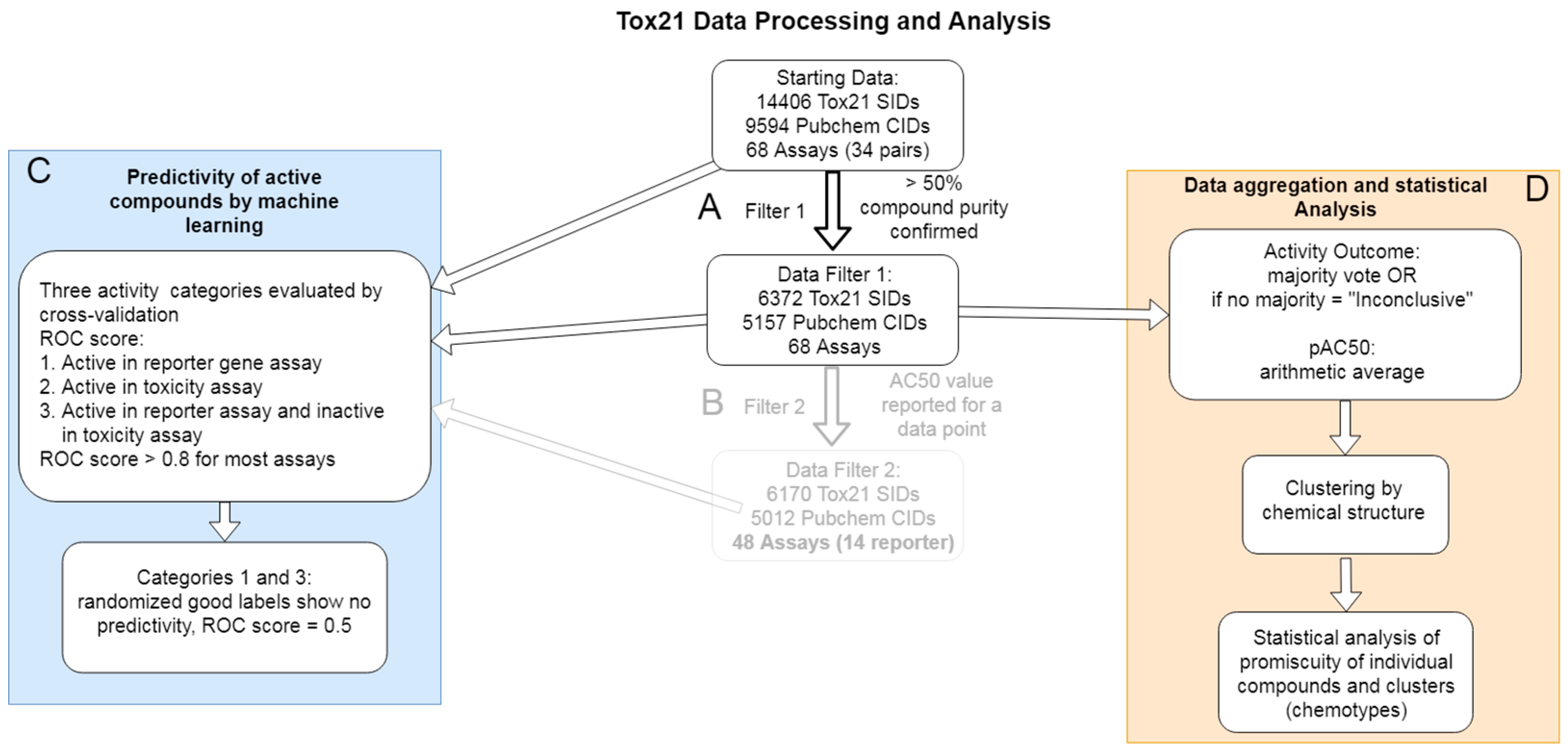
2.1. Data Annotation and Categorization
2.2. Data Cleaning and Aggregation of PubChem Activity Outcome Results
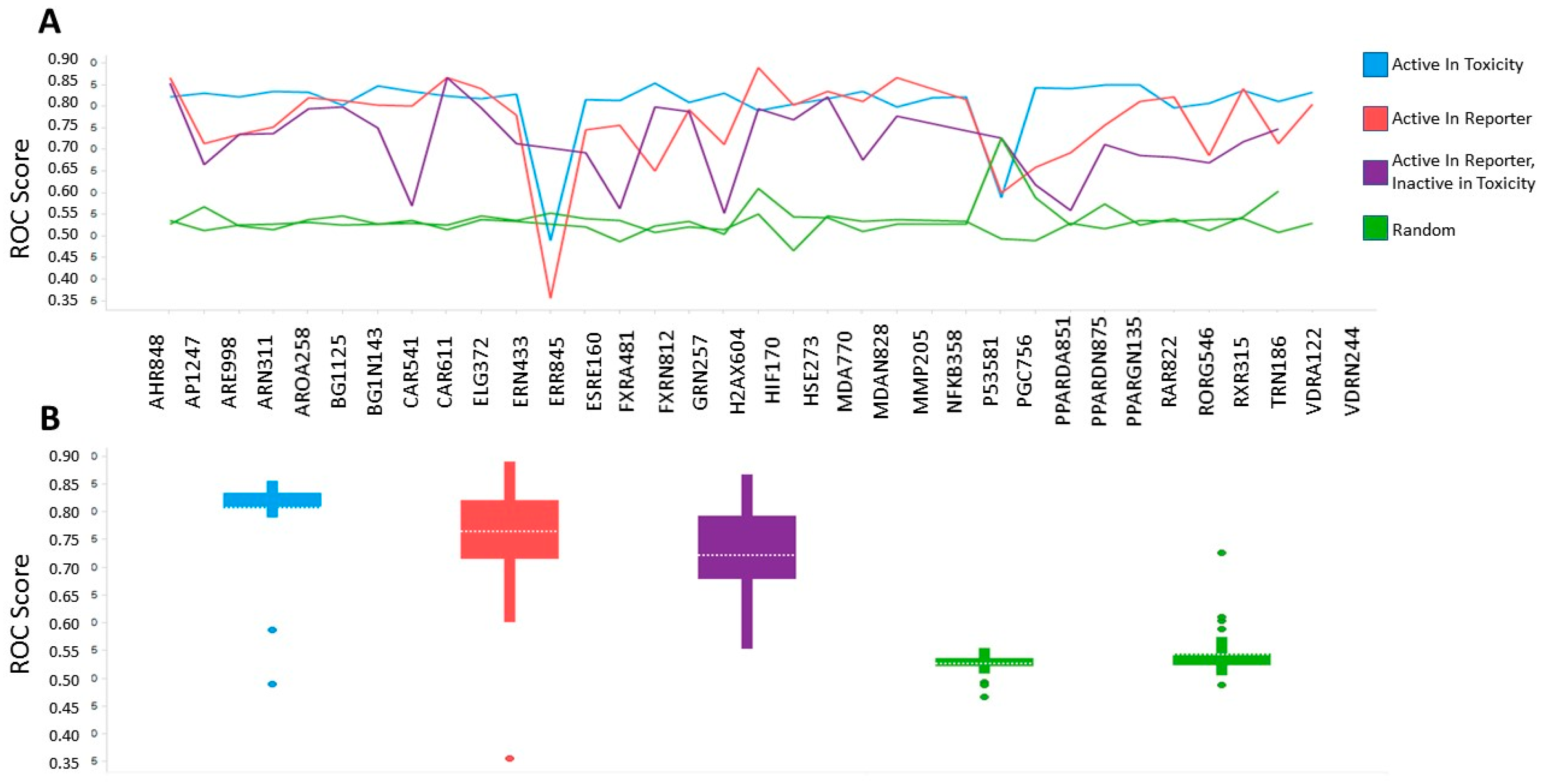
2.3. Benchmarking of Aggregate Tox21 Dataset by Machine Learning and Cross Validation
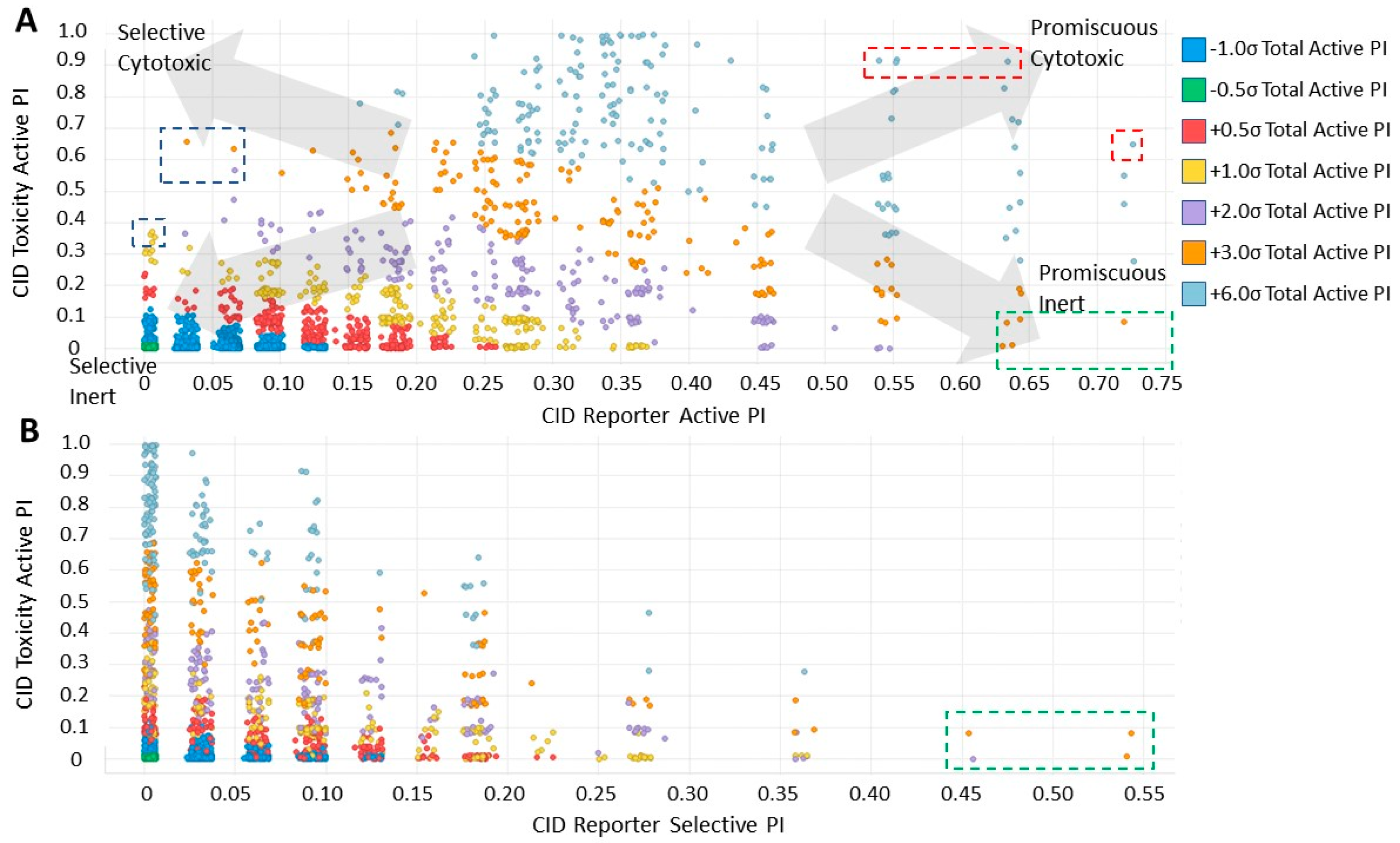
2.4. Analysis of Compound Promiscuity in the Tox21 Dataset
2.5. Cluster Promiscuity and Chemotype Analysis
3. Discussion
4. Materials and Methods
4.1. Tox21 Dataset Retrieval and Annotation
4.2. Data Cleaning
4.3. Machine Learning Classifiers and Cross Validation
4.4. Compound Structure Clustering
4.5. Classification of Promiscuity for Individual Compounds and Chemotypes
4.6. Characterization of Molecular Scaffolds and Features
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Collins, F.S.; Gray, G.M.; Bucher, J.R. Transforming environmental health protection. Science 2008, 319, 906–907. [Google Scholar] [CrossRef] [PubMed]
- Kavlock, R.J.; Austin, C.P.; Tice, R.R. Toxicity Testing in the 21st Century: Implications for Human Health Risk Assessment. Risk Anal. 2009, 29, 485–487. [Google Scholar] [CrossRef]
- Tice, R.R.; Austin, C.P.; Kavlock, R.J.; Bucher, J.R. Improving the human hazard characterization of chemicals: A Tox21 update. Environ. Health Perspect. 2013, 121, 756–765. [Google Scholar] [CrossRef] [PubMed]
- Thomas, R.S.; Paules, R.S.; Simeonov, A.; Fitzpatrick, S.C.; Crofton, K.M.; Casey, W.M.; Mendrick, D.L. The US Federal Tox21 Program: A strategic and operational plan for continued leadership. ALTEX 2018, 35, 163–168. [Google Scholar] [CrossRef] [PubMed]
- Lynch, C.; Mackowiak, B.; Huang, R.; Li, L.; Heyward, S.; Sakamuru, S.; Wang, H.; Xia, M. Identification of Modulators That Activate the Constitutive Androstane Receptor from the Tox21 10K Compound Library. Toxicol. Sci. 2019, 167, 282–292. [Google Scholar] [CrossRef] [PubMed]
- Xia, M.; Huang, R.; Shi, Q.; Boyd, W.A.; Zhao, J.; Sun, N.; Rice, J.R.; Dunlap, P.E.; Hackstadt, A.J.; Bridge, M.F.; et al. Comprehensive Analyses and Prioritization of Tox21 10K Chemicals Affecting Mitochondrial Function by in-Depth Mechanistic Studies. Environ. Health Perspect. 2018, 126, 077010. [Google Scholar] [CrossRef]
- Attene-Ramos, M.S.; Huang, R.; Michael, S.; Witt, K.L.; Richard, A.; Tice, R.R.; Simeonov, A.; Austin, C.P.; Xia, M. Profiling of the Tox21 chemical collection for mitochondrial function to identify compounds that acutely decrease mitochondrial membrane potential. Environ. Health Perspect. 2015, 123, 49–56. [Google Scholar] [CrossRef]
- Lynch, C.; Sakamuru, S.; Huang, R.; Stavreva, D.A.; Varticovski, L.; Hager, G.L.; Judson, R.S.; Houck, K.A.; Kleinstreuer, N.C.; Casey, W.; et al. Identifying environmental chemicals as agonists of the androgen receptor by using a quantitative high-throughput screening platform. Toxicology 2017, 385, 48–58. [Google Scholar] [CrossRef] [PubMed]
- Kleinstreuer, N.C.; Ceger, P.; Watt, E.D.; Martin, M.; Houck, K.; Browne, P.; Thomas, R.S.; Casey, W.M.; Dix, D.J.; Allen, D.; et al. Development and Validation of a Computational Model for Androgen Receptor Activity. Chem. Res. Toxicol. 2017, 30, 946–964. [Google Scholar] [CrossRef]
- Klaren, W.D.; Ring, C.; Harris, M.A.; Thompson, C.M.; Borghoff, S.; Sipes, N.S.; Hsieh, J.-H.; Auerbach, S.S.; Rager, J.E. Identifying Attributes that Influence In Vitro-to-In Vivo Concordance by Comparing In Vitro Tox21 Bioactivity versus In Vivo DrugMatrix Transcriptomic Responses across 130 Chemicals. Toxicol. Sci. 2018, 167, 157–171. [Google Scholar] [CrossRef] [PubMed]
- Sipes, N.S.; Wambaugh, J.F.; Pearce, R.; Auerbach, S.S.; Wetmore, B.A.; Hsieh, J.H.; Shapiro, A.J.; Svoboda, D.; Devito, M.J.; Ferguson, S.S. An Intuitive Approach for Predicting Potential Human Health Risk with the Tox21 10k Library. Environ. Sci. Technol. 2017, 51, 10786–10796. [Google Scholar] [CrossRef]
- Zang, Q.; Mansouri, K.; Williams, A.J.; Judson, R.S.; Allen, D.G.; Casey, W.M.; Kleinstreuer, N.C. In Silico Prediction of Physicochemical Properties of Environmental Chemicals Using Molecular Fingerprints and Machine Learning. J. Chem. Inf. Model. 2017, 57, 36–49. [Google Scholar] [CrossRef] [PubMed]
- Judson, R.; Houck, K.; Martin, M.; Richard, A.M.; Knudsen, T.B.; Shah, I.; Little, S.; Wambaugh, J.; Setzer, R.W.; Kothiya, P.; et al. Analysis of the effects of cell stress and cytotoxicity on in vitro assay activity across a diverse chemical and assay space. Toxicol. Sci. 2016, 153, 409. [Google Scholar] [CrossRef] [PubMed]
- Richard, A.M.; Judson, R.S.; Houck, K.A.; Grulke, C.M.; Volarath, P.; Thillainadarajah, I.; Yang, C.; Rathman, J.; Martin, M.T.; Wambaugh, J.F.; et al. ToxCast Chemical Landscape: Paving the Road to 21st Century Toxicology. Chem. Res. Toxicol. 2016, 29, 1225–1251. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Mansouri, K.; Judson, R.S.; Martin, M.T.; Hong, H.; Chen, M.; Xu, X.; Thomas, R.S.; Shah, I. Predicting hepatotoxicity using ToxCast in vitro bioactivity and chemical structure. Chem. Res. Toxicol. 2015, 28, 738–751. [Google Scholar] [CrossRef]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, Ij.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef]
- Tox21 Data Browser. Available online: https://tripod.nih.gov/tox21 (accessed on 22 April 2019).
- Koleti, A.; Terryn, R.; Stathias, V.; Chung, C.; Cooper, D.J.; Turner, J.P.; Vidovic, D.; Forlin, M.; Kelley, T.T.; D’Urso, A.; et al. Data Portal for the Library of Integrated Network-based Cellular Signatures (LINCS) program: integrated access to diverse large-scale cellular perturbation response data. Nucleic Acids Res. 2018, 46, D558–D566. [Google Scholar] [CrossRef]
- Brandizi, M.; Singh, A.; Rawlings, C.; Hassani-Pak, K. Towards FAIRer Biological Knowledge Networks Using a Hybrid Linked Data and Graph Database Approach. J. Integr. Bioinform. 2018, 15, 20180023. [Google Scholar] [CrossRef]
- Boeckhout, M.; Zielhuis, G.A.; Bredenoord, A.L. The FAIR guiding principles for data stewardship: Fair enough? Eur. J. Hum. Genet. 2018, 26, 931–936. [Google Scholar] [CrossRef]
- Stathias, V.; Koleti, A.; Vidović, D.; Cooper, D.J.; Jagodnik, K.M.; Terryn, R.; Forlin, M.; Chung, C.; Torre, D.; Ayad, N.; et al. Sustainable data and metadata management at the BD2K-LINCS Data Coordination and Integration Center. Sci. Data 2018, 5, 180117. [Google Scholar] [CrossRef]
- Keenan, A.B.; Jenkins, S.L.; Jagodnik, K.M.; Koplev, S.; He, E.; Torre, D.; Wang, Z.; Dohlman, A.B.; Silverstein, M.C.; Lachmann, A.; et al. The Library of Integrated Network-Based Cellular Signatures NIH Program: System-Level Cataloging of Human Cells Response to Perturbations. Cell Syst. 2018, 6, 13–24. [Google Scholar] [CrossRef]
- Visser, U.; Abeyruwan, S.; Vempati, U.; Smith, R.P.; Lemmon, V.; Schürer, S.C. BioAssay Ontology (BAO): A semantic description of bioassays and high-throughput screening results. BMC Bioinform. 2011, 12, 257. [Google Scholar] [CrossRef]
- Abeyruwan, S.; Vempati, U.D.; Küçük-McGinty, H.; Visser, U.; Koleti, A.; Mir, A.; Sakurai, K.; Chung, C.; Bittker, J.A.; Clemons, P.A.; et al. Evolving BioAssay Ontology (BAO): modularization, integration and applications. J. Biomed. Semant. 2014, 5, S5. [Google Scholar] [CrossRef] [PubMed]
- Zander Balderud, L.; Murray, D.; Larsson, N.; Vempati, U.; Schürer, S.C.; Bjäreland, M.; Engkvist, O. Using the BioAssay Ontology for Analyzing High-Throughput Screening Data. J. Biomol. Screen. 2014, 20, 402–415. [Google Scholar] [CrossRef][Green Version]
- Vempati, U.D.; Przydzial, M.J.; Chung, C.; Abeyruwan, S.; Mir, A.; Sakurai, K.; Visser, U.; Lemmon, V.P.; Schürer, S.C. Formalization, annotation and analysis of diverse drug and probe screening assay datasets using the BioAssay Ontology (BAO). PLoS ONE 2012, 7, e49198. [Google Scholar] [CrossRef]
- LINCS Data Portal (LDP). Available online: http://lincsportal.ccs.miami.edu/dcic-portal (accessed on 22 April 2019).
- Aggregated Tox21 Bioactivity Data. Available online: http://identifiers.org/lincs.data/EDG-1016 (accessed on 22 April 2019).
- iCSS ToxCast Dashboard. Available online: https://actor.epa.gov/dashboard (accessed on 22 April 2019).
- Sarntivijai, S.; Lin, Y.; Xiang, Z.; Meehan, T.F.; Diehl, A.D.; Vempati, U.D.; Schürer, S.C.; Pang, C.; Malone, J.; Parkinson, H.; et al. CLO: The cell line ontology. J. Biomed. Semant. 2014, 5, 37. [Google Scholar] [CrossRef] [PubMed]
- Shukla, S.J.; Huang, R.; Austin, C.P.; Xia, M. The future of toxicity testing: A focus on in vitro methods using a quantitative high-throughput screening platform. Drug Discov. Today 2010, 15, 997–1007. [Google Scholar] [CrossRef] [PubMed]
- Rogers, D.; Hahn, M. Extended-Connectivity Fingerprints. J. Chem. Inf. Model. 2010, 50, 742–754. [Google Scholar] [CrossRef]
- Auld, D.S.; Inglese, J. Interferences with Luciferase Reporter Enzymes Assay Guidance Manual. Assay Guid. Man. [Internet] 2016, 1, 1–14. [Google Scholar]
- Auld, D.S.; Lovell, S.; Thorne, N.; Lea, W.A.; Maloney, D.J.; Shen, M.; Rai, G.; Battaile, K.P.; Thomas, C.J.; Simeonov, A.; et al. Molecular basis for the high-affinity binding and stabilization of firefly luciferase by PTC124. Proc. Natl. Acad. Sci. USA 2010, 107, 4878. [Google Scholar] [CrossRef] [PubMed]
- Kirsner, R.S.; Froelich, C.W. Soaps and detergents: Understanding their composition and effect. Ostomy. Wound. Manag. 1998, 44, 62S–69S. [Google Scholar] [PubMed]
- Kohno, Y.; Fukuzaki, K.; Kitahara, K.; Koja, T. Anti-tremor activity of talipexole produced by selective dopamine D2 receptor stimulation in cynomolgus monkeys with unilateral lesions in the ventromedial tegmentum. Eur. J. Pharmacol. 1997, 319, 197–205. [Google Scholar] [CrossRef]
- Schneider, S.; Hawkins, T.; Rosander, M.; Vaghjiani, G.; Chambreau, S.; Drake, G. Ionic Liquids as Hypergolic Fuels. Energy Fuels 2008, 22, 2871–2872. [Google Scholar] [CrossRef]
- Hayyan, M.; Mjalli, F.S.; Hashim, M.A.; AlNashef, I.M.; Mei, T.X. Investigating the electrochemical windows of ionic liquids. J. Ind. Eng. Chem. 2013, 19, 106–112. [Google Scholar] [CrossRef]
- Austin, C.P.; Brady, L.S.; Insel, T.R.; Collins, F.S. NIH Molecular Libraries Initiative. Science 2004, 306, 1138. [Google Scholar] [CrossRef] [PubMed]
- PDSP–Psychoactive Drug Screening Program. Available online: https://pdspdb.unc.edu/pdspWeb (accessed on 22 April 2019).
- Oprea, T.I.; Bologa, C.G.; Brunak, S.; Campbell, A.; Gan, G.N.; Gaulton, A.; Gomez, S.M.; Guha, R.; Hersey, A.; Holmes, J.; et al. Unexplored therapeutic opportunities in the human genome. Nat. Rev. Drug Discov. 2018, 17, 317. [Google Scholar] [CrossRef] [PubMed]
- Illuminating the Druggable Genome. Available online: https://druggablegenome.net/ (accessed on 22 April 2019).
- Russo, D.P.; Zhu, H. Accessing the High-Throughput Screening Data Landscape. Methods Mol. Biol. 2016, 1473, 153–159. [Google Scholar]
- Subramanian, A.; Narayan, R.; Corsello, S.M.; Peck, D.D.; Natoli, T.E.; Lu, X.; Gould, J.; Davis, J.F.; Tubelli, A.A.; Asiedu, J.K.; et al. A Next Generation Connectivity Map: L1000 Platform and the First 1,000,000 Profiles. Cell 2017, 171, 1437–1452. [Google Scholar] [CrossRef]
- Bioassay Ontology. Available online: http://bioassayontology.org/ (accessed on 22 April 2019).
- Tox21 Assays. Available online: https://tripod.nih.gov/tox/apps/assays/assays.jsp (accessed on 22 April 2019).
- Tox21 Samples. Available online: https://tripod.nih.gov/tox21/samples (accessed on 22 April 2019).
- Gene Ontology Consortium, G.O. The Gene Ontology (GO) project in 2006. Nucleic Acids Res. 2006, 34, D322–D326. [Google Scholar] [CrossRef]
- The Gene Ontology Consortium Expansion of the Gene Ontology knowledgebase and resources. Nucleic Acids Res. 2017, 45, D331–D338. [CrossRef]
- Schürer, S.C.; Vempati, U.; Smith, R.; Southern, M.; Lemmon, V. BioAssay Ontology Annotations Facilitate Cross-Analysis of Diverse High-Throughput Screening Data Sets. J. Biomol. Screen. 2011, 16, 415–426. [Google Scholar] [CrossRef] [PubMed]
Sample Availability: Samples of the compounds are available from the authors of the original data (Tox21 program members), notated as members of the Tox21 10k library |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set Number | Compounds Tested | Number of Assays * | Total Data Points |
|---|---|---|---|
| Set 1 | 5157 | 22 | 113,454 |
| Set 2 | 3354 | 42 | 140,868 |
| Set 3 | 63 | 4 | 252 |
| Total Unique | 5157 | 68 | 254,574 |
| Total Data Pairs ** | 127,287 |
| Compounds with High Toxicity z-Scores | ||
|---|---|---|
| Sample compound 1 | Sample compound 2 | Sample compound 3 |
 PubChem CID: 91505 Toxicity PI fraction: 0.36 Toxicity z-score: +2.0 |  PubChem CID: 132519 Toxicity PI fraction: 0.36 Toxicity z-score: +2.0 |  PubChem CID: 458426 Toxicity PI fraction: 0.63 Toxicity z-score: +6.0 |
| Compounds with High Toxicity and Reporter z-Scores | ||
| Sample compound 1 | Sample compound 2 | Sample compound 3 |
 PubChem CID: 5709754 Toxicity PI fraction: 0.91 Reporter PI fraction: 0.55 Toxicity z-score: +6.0 Reporter z-score: +6.0 |  PubChem CID: 10578 Toxicity PI fraction: 0.91 Reporter PI fraction: 0.64 Toxicity z-score: +6.0 Reporter z-score: +6.0 |  PubChem CID: 636362 Toxicity PI fraction: 0.64 Reporter PI fraction: 0.7 Toxicity z-score: +6.0 Reporter z-score: +6.0 |
| Compounds with High Reporter z-Scores | ||
| Sample compound 1 | Sample compound 2 | Sample compound 3 |
 PubChem CID: 443375 Reporter PI fraction: 0.64 Reporter z-score: +6.0 |  PubChem CID: 6764 Reporter PI fraction: 0.64 Reporter z-score: +6.0 |  PubChem CID: 157917 Reporter PI fraction: 0.73 Reporter z-score: +6.0 |
| Compounds with High Reporter Selective z-Scores | ||
| Sample compound 1 | Sample compound 2 | Sample compound 3 |
 PubChem CID: 443375 Selective PI fraction: 0.56 Selective z-score: +6.0 |  PubChem CID: 65620 Selective PI fraction: 0.56 Selective z-score: +6.0 |  PubChem CID: 42725 Selective PI fraction: 0.46 Selective z-score: +6.0 |
| Compounds in Cluster 53 (Figure 4B Annotated) | ||
| Sample compound 1 | Sample compound 2 | Sample compound 3 |
 PubChem CID: 11219835 * Reporter PI fraction: 0.18 Cluster avg. reporter PI: 0.20 |  PubChem CID: 68706 Reporter PI fraction: 0.00 Cluster avg. toxicity PI: 0.16 |  PubChem CID: 3059 Reporter PI fraction: 0.09 Cluster avg. selective PI: 0.17 |
| Compounds in Cluster 251 (Figure 4A Annotated) | ||
| Sample compound 1 | Sample compound 2 | Sample compound 3 |
 PubChem CID: 31204 Toxicity PI fraction: 0.88 Cluster avg. reporter PI: 0.22 |  PubChem CID: 5374 Toxicity PI fraction: 0.00 Cluster avg. toxicity PI: 0.55 |  PubChem CID: 16213711 Toxicity PI fraction: 0.00 Cluster avg. selective PI: 0.02 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cooper, D.J.; Schürer, S. Improving the Utility of the Tox21 Dataset by Deep Metadata Annotations and Constructing Reusable Benchmarked Chemical Reference Signatures. Molecules 2019, 24, 1604. https://doi.org/10.3390/molecules24081604
Cooper DJ, Schürer S. Improving the Utility of the Tox21 Dataset by Deep Metadata Annotations and Constructing Reusable Benchmarked Chemical Reference Signatures. Molecules. 2019; 24(8):1604. https://doi.org/10.3390/molecules24081604
Chicago/Turabian StyleCooper, Daniel J., and Stephan Schürer. 2019. "Improving the Utility of the Tox21 Dataset by Deep Metadata Annotations and Constructing Reusable Benchmarked Chemical Reference Signatures" Molecules 24, no. 8: 1604. https://doi.org/10.3390/molecules24081604
APA StyleCooper, D. J., & Schürer, S. (2019). Improving the Utility of the Tox21 Dataset by Deep Metadata Annotations and Constructing Reusable Benchmarked Chemical Reference Signatures. Molecules, 24(8), 1604. https://doi.org/10.3390/molecules24081604