
Identification of Cannabis sativa L. (hemp) Retailers by Means of Multivariate Analysis of Cannabinoids

 ,
,  , ,
, , 
Abstract
1. Introduction
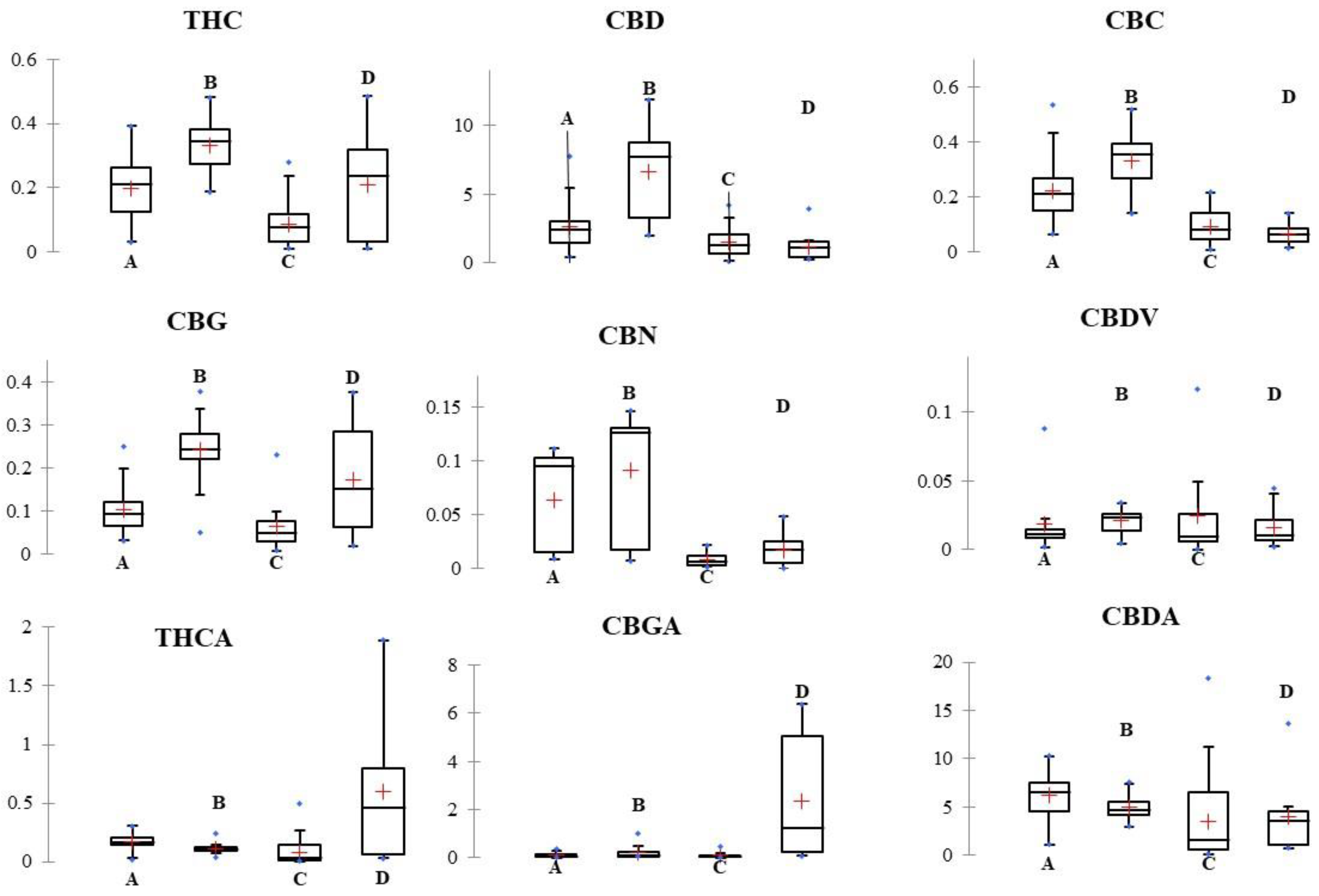
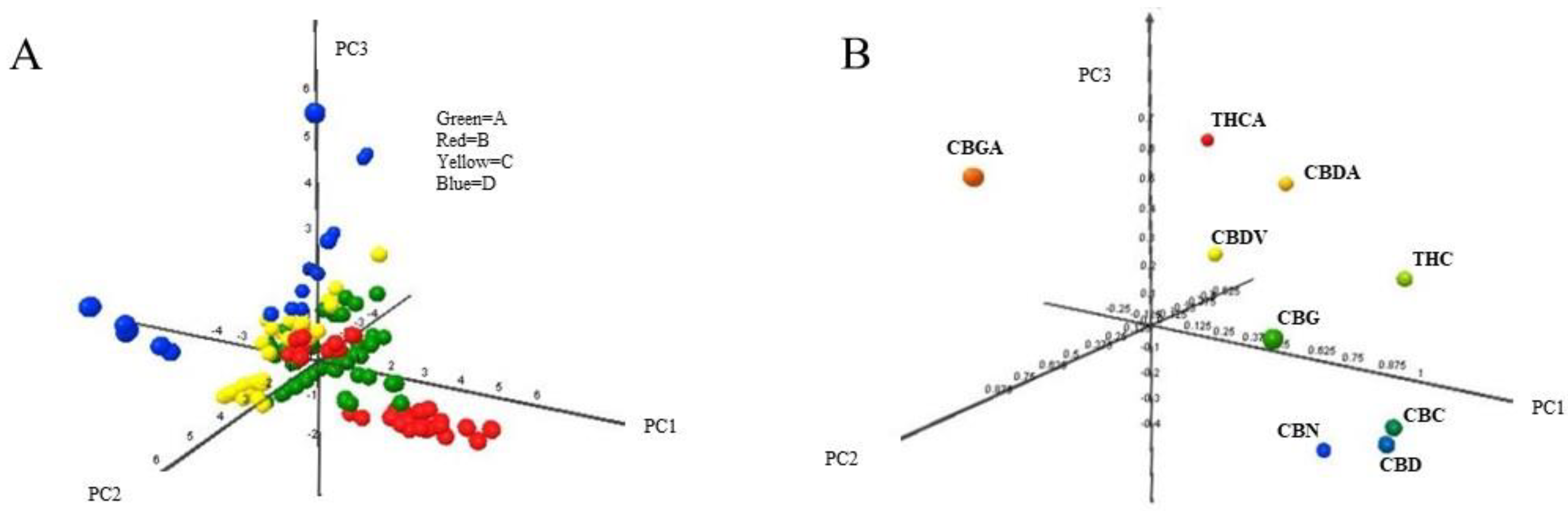
2. Results and Discussion
3. Materials and Methods
3.1. Sample Collection
3.2. Solvents and Chemicals
3.3. Sample Preparation
3.4. HPLC-MS/MS Analysis
3.5. Analytical Procedure Validation
3.6. Statistical Analysis
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Radwan, M.A.; Wanas, S.A.; Chandra, S.; ElSohly, M.A. Natural Cannabinoids of Cannabis and Methods of Analysis. In Cannabis sativa L.—Botany and Biotechnology; Chandra, S., Lata, H., ElSohly, M., Eds.; Springer: Cham, Switzerland, 2017; pp. 161–182. [Google Scholar]
- Pellati, F.; Brighenti, V.; Sperlea, J.; Marchetti, L.; Bertelli, D.; Benvenuti, S. New methods for the comprehensive analysis of bioactive compounds in Cannabis sativa L. (hemp). Molecules 2018, 23, 2639. [Google Scholar] [CrossRef] [PubMed]
- Bonini, S.A.; Premoli, M.; Tambaro, S.; Kumar, A.; Maccarinelli, G.; Memo, M.; Mastinu, A. Cannabis sativa: A comprehensive ethnopharmacological review of a medicinal plant with a long history. J. Ethnopharmacol. 2018, 227, 300–315. [Google Scholar] [CrossRef] [PubMed]
- Namdar, D.; Voet, H.; Ajjampura, V.; Nadarajan, S.; Mayzlish-Gati, E.; Mazuz, M.; Shalev, N.; Koltai, H. Terpenoids and Phytocannabinoids Co-Produced in Cannabis Sativa Strains Show Specific Interaction for Cell Cytotoxic Activity. Molecules 2019, 24, 3031. [Google Scholar] [CrossRef] [PubMed]
- Hazekamp, A.; Tejkalová, K.; Papadimitriou, S. Cannabis: From cultivar to chemovar II—A metabolomics approach to Cannabis classification. Cannabis Cannabinoid Res. 2016, 1, 202–215. [Google Scholar] [CrossRef]
- Mandrioli, M.; Tura, M.; Scotti, S.; Gallina Toschi, T. Fast Detection of 10 Cannabinoids by RP-HPLC-UV Method in Cannabis sativa L. Molecules 2019, 24, 2113. [Google Scholar] [CrossRef] [PubMed]
- Fischedick, J.T. Identification of Terpenoid Chemotypes Among High (−)-trans-Δ9-Tetrahydrocannabinol-Producing Cannabis sativa L. Cultivars. Cannabis Cannabinoid Res. 2017, 2, 34–47. [Google Scholar] [CrossRef] [PubMed]
- Fischedick, J.T.; Hazekamp, A.; Erkelens, T.; Choi, Y.H.; Verpoorte, R. Metabolic fingerprinting of Cannabis sativa L., cannabinoids and terpenoids for chemotaxonomic and drug standardization purposes. Phytochemistry 2010, 71, 2058–2073. [Google Scholar] [CrossRef] [PubMed]
- Mudge, E.M.; Murch, S.J.; Brown, P.N. Chemometric Analysis of Cannabinoids: Chemotaxonomy and Domestication Syndrome. Sci. Rep. 2018, 8, 13090. [Google Scholar] [CrossRef]
- Mudge, E.M.; Murch, S.J.; Brown, P.N. Leaner and greener analysis of cannabinoids. Anal. Bioanal. Chem. 2017, 409, 3153–3163. [Google Scholar] [CrossRef]
- Pertwee, R.G. Handbook of Cannabis; Oxford University Press: Oxford, UK, 2014. [Google Scholar]
- De Backer, B.; Debrus, B.; Lebrun, P.; Theunis, L.; Dubois, N.; Decock, L.; Verstraete, A.; Hubert, P.; Charlier, C. Innovative development and validation of an HPLC/DAD method for the qualitative and quantitative determination of major cannabinoids in cannabis plant material. J. Chromatogr. B 2009, 877, 4115–4124. [Google Scholar] [CrossRef]
- Wang, Y.-H.; Avula, B.; ElSohly, M.A.; Radwan, M.A.; Wang, M.; Wanas, A.S.; Mehmedic, Z.; Khan, I.A. Quantitative determination of Δ9-THC, CBG, CBD, their acid precursors and five other neutral cannabinoids by UHPLC-UV-MS. Planta Med. 2018, 84, 260–266. [Google Scholar] [CrossRef] [PubMed]
- Turi, C.E.; Finley, F.; Shipley, P.R.; Murch, S.J.; Brownet, P.N. Metabolomics for phytochemical discovery: Development of statistical approaches using a cranberry model system. J. Nat. Prod. 2015, 78, 953–966. [Google Scholar] [CrossRef] [PubMed]
- van Velzen, E.J.; Westerhuis, J.A.; van Duynhoven, J.P.; van Dorsten, F.A.; Hoefsloot, H.C.; Jacobs, D.M.; Smit, S.; Draijer, R.; Kroner, C.I.; Smilde, A.K. Multilevel data analysis of a crossover designed human nutritional intervention study. J. Proteome Res. 2008, 7, 4483–4491. [Google Scholar] [CrossRef] [PubMed]
- Citti, C.; Linciano, P.; Panseri, S.; Vezzalini, F.; Forni, F.; Vandelli, M.A.; Cannazza, G. Cannabinoid profiling of hemp seed oil by liquid chromatography coupled to high-resolution mass spectrometry. Front. Plant Sci. 2019, 10, 120. [Google Scholar] [CrossRef] [PubMed]
- Ross, S.A.; Mehmedic, Z.; Murphy, T.P.; Elsohly, M.A. GC-MS analysis of the total δ9-thc content of both drug-and fiber-type cannabis seeds. J. Anal. Toxicol. 2000, 24, 715–717. [Google Scholar] [CrossRef] [PubMed]
- Gagne, S.J.; Stout, J.M.; Liu, E.; Boubakir, Z.; Clark, S.M.; Page, J.E. Identification of olivetolic acid cyclase from Cannabis sativa reveals a unique catalytic route to plant polyketides. Proc. Natl. Acad. Sci. USA 2012, 109, 12811–12816. [Google Scholar] [CrossRef] [PubMed]
- Fellermeier, M.; Zenk, M.H. Prenylation of olivetolate by a hemp transferase yields cannabigerolic acid, the precursor of tetrahydrocannabinol. FEBS Lett. 1998, 427, 283–285. [Google Scholar] [CrossRef]
- Sirikantaramas, S.; Morimoto, S.; Shoyama, Y.; Ishikawa, Y.; Wada, Y.; Shoyama, Y. The Gene Controlling Marijuana Psychoactivity molecular cloning and heterologous expression of ?1-tetrahydrocannabinolic acid synthase from Cannabis sativa L. J. Biol. Chem. 2004, 279, 39767–39774. [Google Scholar] [CrossRef]
- Taura, F.; Morimoto, S.; Shoyama, Y.; Mechoulam, R. Cannabidiolic-acid synthase, the chemotype-determining enzyme in the fiber-type Cannabis sativa. FEBS Lett. 2007, 581, 2929–2934. [Google Scholar] [CrossRef]
- Faberi, A.; Marianella, R.S.; Fuselli, F.; La Mantia, A.; Ciardiello, F.; Montesano, C.; Mascini, M.; Sergi, M.; Compagnone, D. Fatty acid composition and ?13C of bulk and individual fatty acids as marker for authenticating Italian PDO/PGI extra virgin olive oils by means of isotopic ratio mass spectrometry. J. Mass Spectrom. 2014, 49, 840–849. [Google Scholar] [CrossRef]
- Rocchi, R.; Mascini, M.; Faberi, A.; Sergi, M.; Compagnone, D.; Di Martino, V.; Carradori, S.; Pittia, P. Comparison of IRMS, GC-MS and E-Nose data for the discrimination of saffron samples with different origin, process and age. Food Control 2019, 106736. [Google Scholar] [CrossRef]
- Ballabio, D. A MATLAB toolbox for Principal Component Analysis and unsupervised exploration of data structure. Chemometr. Intell. Lab. Syst. 2015, 149, 1–9. [Google Scholar] [CrossRef]
- Ballabio, D.; Consonni, V. Classification tools in chemistry. Part 1: Linear models. PLS-DA. Anal. Methods 2013, 5, 3790–3798. [Google Scholar] [CrossRef]
- Stanimirova, I.; Daszykowski, M.; Walczak, B. Dealing with missing values and outliers in principal component analysis. Talanta 2007, 72, 172–178. [Google Scholar] [CrossRef] [PubMed]
- Broséus, J.; Vallat, M.; Esseiva, P. Multi-class differentiation of cannabis seedlings in a forensic context. Chemometr. Intell. Lab. Syst. 2011, 107, 343–350. [Google Scholar] [CrossRef]
- Barker, M.; Rayens, W. Partial least squares for discrimination. J. Chemom. 2003, 17, 166–173. [Google Scholar] [CrossRef]
Sample Availability: Hemp samples studied are available from the authors. |



{kind=link}
{kind=link}
| Retailer | № of Samples | Region | City | Label |
|---|---|---|---|---|
| A | 63 | Lombardy | Milan | A1–63 |
| B | 43 | Lombardy | Mantova | B1–43 |
| C | 38 | Lazio | Pomezia | C1–38 |
| D | 17 | Abruzzo | Tortoreto | D1–17 |
| Cannabinoids | THC | CBD | CBC | CBG | CBN | CBDV | THCA | CBGA | CBDA |
|---|---|---|---|---|---|---|---|---|---|
| THC | 1.00 | 0.80 | 0.81 | 0.61 | 0.50 | 0.19 | 0.34 | −0.16 | 0.46 |
| CBD | 0.80 | 1.00 | 0.91 | 0.68 | 0.64 | 0.20 | −0.17 | −0.17 | 0.21 |
| CBC | 0.81 | 0.91 | 1.00 | 0.65 | 0.60 | 0.19 | −0.19 | −0.23 | 0.35 |
| CBG | 0.61 | 0.68 | 0.65 | 1.00 | 0.31 | 0.12 | −0.17 | 0.44 | 0.19 |
| CBN | 0.50 | 0.64 | 0.60 | 0.31 | 1.00 | −0.03 | −0.03 | −0.25 | 0.11 |
| CBDV | 0.19 | 0.20 | 0.19 | 0.12 | −0.03 | 1.00 | −0.01 | −0.04 | 0.19 |
| THCA | 0.34 | −0.17 | −0.19 | −0.17 | −0.03 | −0.01 | 1.00 | 0.01 | 0.18 |
| CBGA | −0.16 | −0.17 | −0.23 | 0.44 | −0.25 | −0.04 | 0.01 | 1.00 | −0.04 |
| CBDA | 0.46 | 0.21 | 0.35 | 0.19 | 0.11 | 0.19 | 0.18 | −0.04 | 1.00 |
| PLS-DA results | |||
| samples | 161 | ||
| variables | 9 | ||
| classes | 4 | ||
| component in model | 8 | ||
| explained variance (%) | 100% | ||
| error rate CL 1 | 0.05 | ||
| error rate CV 2 | 0.06 | ||
| Retailer | Specificity | Sensitivity | Precision |
| Fitting | |||
| A | 1.00 | 0.86 | 1.00 |
| B | 1.00 | 0.88 | 1.00 |
| C | 0.88 | 1.00 | 0.72 |
| D | 1.00 | 0.94 | 1.00 |
| Cross-Validation | |||
| A | 1.00 | 0.86 | 1.00 |
| B | 0.98 | 0.88 | 0.95 |
| C | 0.89 | 0.95 | 0.72 |
| D | 1.00 | 1.00 | 1.00 |
| Fitting | |||||
| real/predicted | A | B | C | D | |
| A | 54 | 0 | 9 | 0 | 86% |
| B | 0 | 38 | 5 | 0 | 88% |
| C | 0 | 0 | 38 | 0 | 100% |
| D | 0 | 0 | 1 | 16 | 94% |
| Total | 92% | ||||
| Cross-Validation | |||||
| real/predicted | A | B | C | D | |
| A | 54 | 0 | 9 | 0 | 86% |
| B | 0 | 38 | 5 | 0 | 88% |
| C | 0 | 2 | 36 | 0 | 95% |
| D | 0 | 0 | 0 | 17 | 100% |
| Total | 92% | ||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Palmieri, S.; Mascini, M.; Ricci, A.; Fanti, F.; Ottaviani, C.; Lo Sterzo, C.; Sergi, M. Identification of Cannabis sativa L. (hemp) Retailers by Means of Multivariate Analysis of Cannabinoids. Molecules 2019, 24, 3602. https://doi.org/10.3390/molecules24193602
Palmieri S, Mascini M, Ricci A, Fanti F, Ottaviani C, Lo Sterzo C, Sergi M. Identification of Cannabis sativa L. (hemp) Retailers by Means of Multivariate Analysis of Cannabinoids. Molecules. 2019; 24(19):3602. https://doi.org/10.3390/molecules24193602
Chicago/Turabian StylePalmieri, Sara, Marcello Mascini, Antonella Ricci, Federico Fanti, Chiara Ottaviani, Claudio Lo Sterzo, and Manuel Sergi. 2019. "Identification of Cannabis sativa L. (hemp) Retailers by Means of Multivariate Analysis of Cannabinoids" Molecules 24, no. 19: 3602. https://doi.org/10.3390/molecules24193602
APA StylePalmieri, S., Mascini, M., Ricci, A., Fanti, F., Ottaviani, C., Lo Sterzo, C., & Sergi, M. (2019). Identification of Cannabis sativa L. (hemp) Retailers by Means of Multivariate Analysis of Cannabinoids. Molecules, 24(19), 3602. https://doi.org/10.3390/molecules24193602