
A Kalman Filter-Based Localization Calibration Method Optimized by Reinforcement Learning and Information Matrix Fusion


Abstract
1. Introduction
2. Related Work
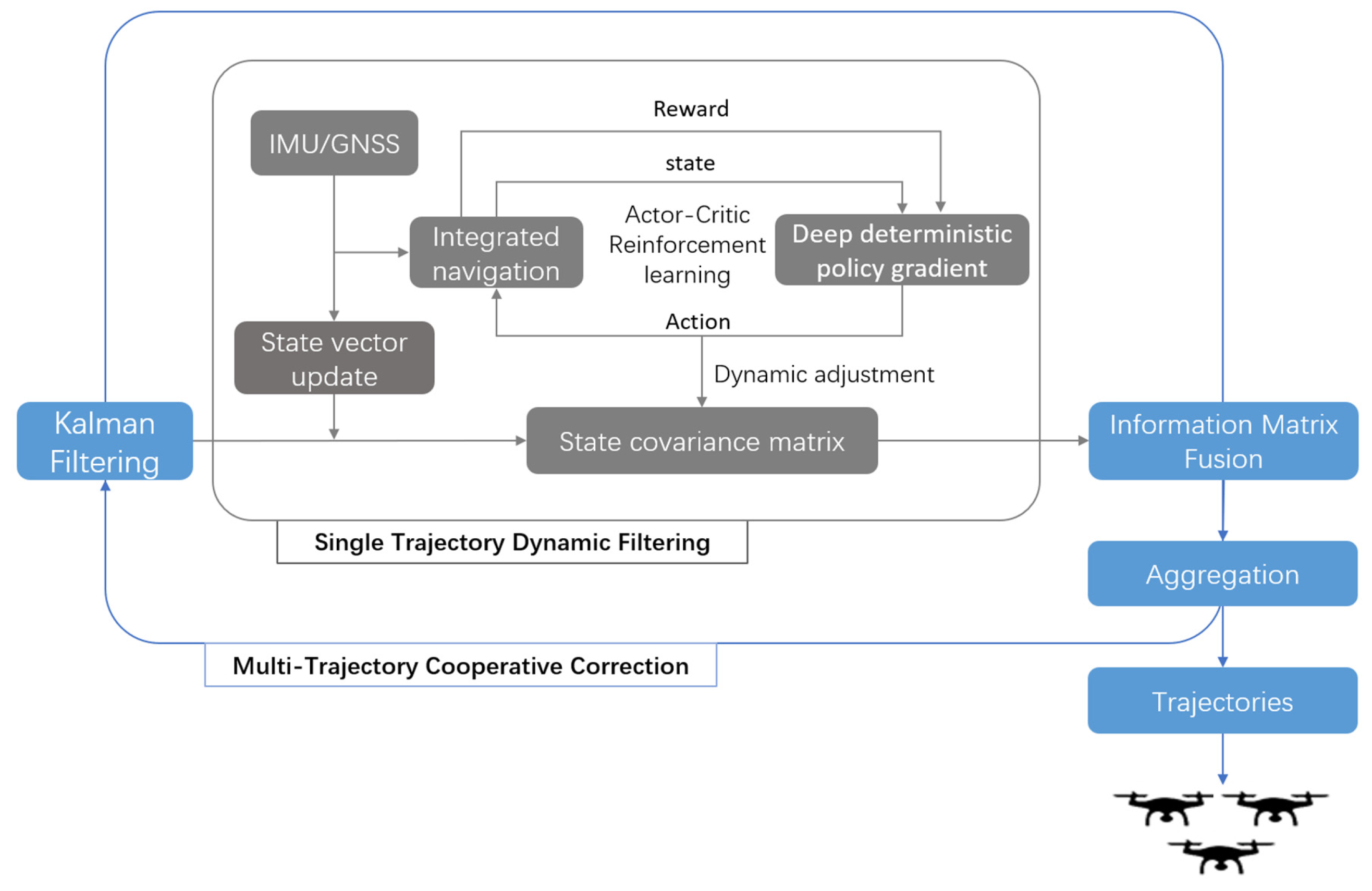
3. Methods
3.1. Reinforcement Learning-Driven Filter Parameter Optimization
3.2. Multi-Trajectory Information Fusion
4. Experiments and Results
4.1. Experimental Setup
4.2. Experimental Methods
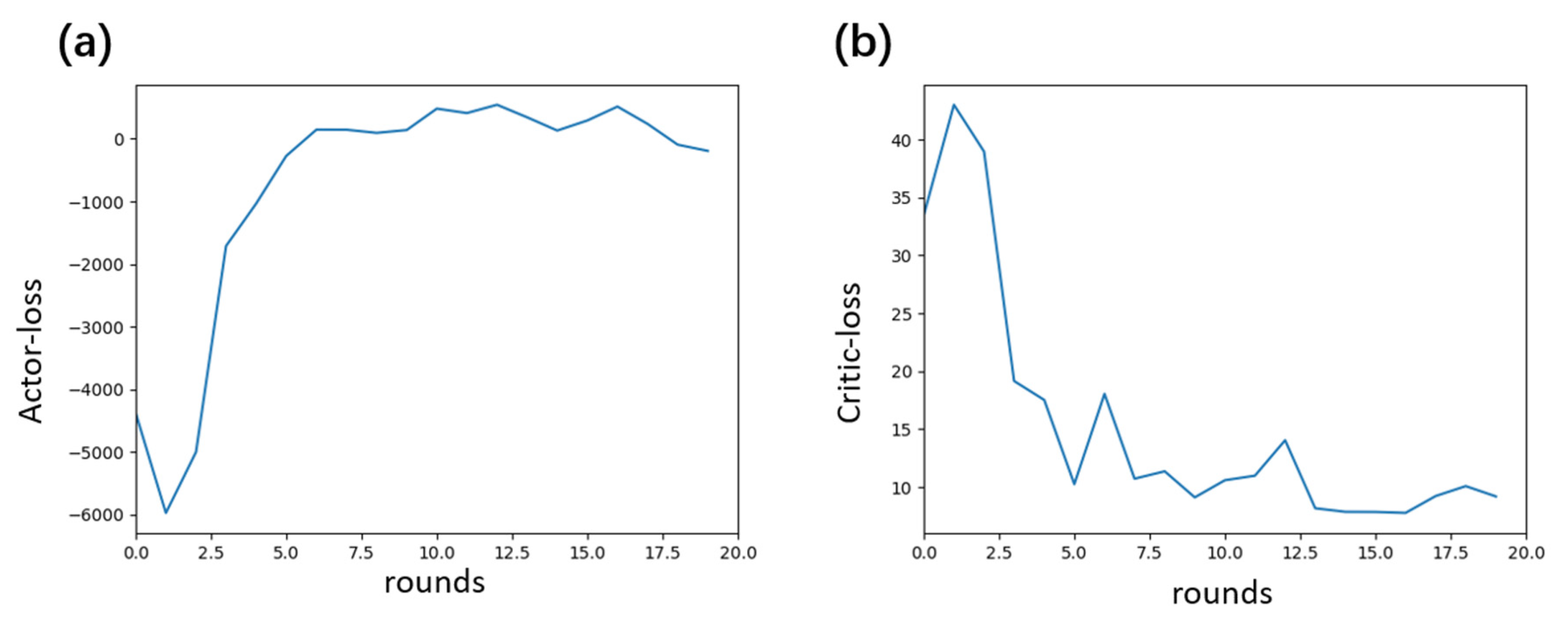
4.3. Evaluation of Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pereira, P.M.C.; da Silva, H.D.M.; Lima, C.M.G.S. Advancements in multipath mitigation for gnss receivers: Review of channel estimation techniques. Space Sci. Technol. 2025, 5, 0278. [Google Scholar] [CrossRef]
- Chen, W.; Zhang, C.; Peng, Y.; Yao, Y.; Cai, M.; Dong, D. Enhancing gnss positioning in urban canyon areas via a modified design matrix approach. IEEE Internet Things J. 2024, 11, 10252–10265. [Google Scholar] [CrossRef]
- Pai, K.R.; Marakala, N. A review on inertial navigational systems. In Proceedings of the 2016 International Conference on Electrical, Electronics, and Optimization Techniques (ICEEOT), Chennai, India, 3–5 March 2016; pp. 1682–1686. [Google Scholar] [CrossRef]
- Kalman, R.E. A new approach to linear filtering and prediction problems. Trans. ASME-Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Alsaggaf, A.U.; Saberi, M.; Berry, T.; Ebeigbe, D. Nonlinear kalman filtering in the absence of direct functional relationships between measurement and state. IEEE Control Syst. Lett. 2024, 8, 2865–2870. [Google Scholar] [CrossRef]
- Kou, E.; Haggenmiller, A. Extended kalman filter state estimation for autonomous competition robots. J. Stud. Res. 2023, 12, 1. [Google Scholar] [CrossRef]
- Wan, E.; Van Der Merwe, R. The unscented kalman filter for nonlinear estimation. In Proceedings of the IEEE 2000 Adaptive Systems for Signal Processing, Communications, and Control Symposium (Cat. No.00EX373), Lake Louise, AB, Canada, 1–4 October 2000; pp. 153–158. [Google Scholar] [CrossRef]
- Luo, J.; Wang, Z.; Chen, Y.; Wu, M.; Yang, Y. An improved unscented particle filter approach for multi-sensor fusion target tracking. Sensors 2020, 20, 6842. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, Y.; Xu, B.; Wu, Z.; Chambers, J.A. A new adaptive extended kalman filter for cooperative localization. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 353–368. [Google Scholar] [CrossRef]
- Akhlaghi, S.; Zhou, N.; Huang, Z. Adaptive adjustment of noise covariance in Kalman filter for dynamic state estimation. In Proceedings of the 2017 IEEE Power & Energy Society General Meeting, Chicago, IL, USA, 16–20 July 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2019, arXiv:1509.02971. [Google Scholar] [PubMed]
- Gao, X.; Luo, H.; Ning, B.; Zhao, F.; Bao, L.; Gong, Y.; Xiao, Y.; Jiang, J. Rl-akf: An adaptive kalman filter navigation algorithm based on reinforcement learning for ground vehicles. Remote Sens. 2020, 12, 1704. [Google Scholar] [CrossRef]
- Julier, S.; Uhlmann, J.K. General Decentralized Data Fusion with Covariance Intersection (CI). In Handbook of Multisensor Data Fusion, Theroy and Practice; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar] [CrossRef]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. In Proceedings of the 13th International Conference on Neural Information Processing Systems (NIPS’99), Denver, CO, USA, 29 November–4 December 1999; MIT Press: Cambridge, MA, USA, 1999; pp. 1057–1063. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Jaradat, M.A.K.; Abdel-Hafez, M.F. Enhanced, delay dependent, intelligent fusion for ins/gps navigation system. IEEE Sens. J. 2014, 14, 1545–1554. [Google Scholar] [CrossRef]
- Ni, S.; Li, S.; Xie, Y.; Deng, D. Overview of gnss/ins ultra-tight integrated navigation. J. Natl. Univ. Def. Technol. 2023, 45, 48–59. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, Z. Motion measurement using inertial sensors, ultrasonic sensors, and magnetometers with extended kalman filter for data fusion. IEEE Sens. J. 2012, 12, 943–953. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhou, X.; Wang, C.; Zhao, W.; Wu, G.; Jiang, T.; Wang, M. Adaptive robust federal kalman filter for multisensor fusion positioning systems of intelligent vehicles. IEEE Sens. J. 2024, 24, 17269–17281. [Google Scholar] [CrossRef]
- Gao, B.; Gao, S.; Zhong, Y.; Hu, G.; Gu, C. Interacting multiple model estimation-based adaptive robust unscented Kalman filter. Int. J. Control Autom. Syst. 2017, 15, 2013–2025. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, J.; Hu, G.; Zhong, Y. Set-Membership Based Hybrid Kalman Filter for Nonlinear State Estimation under Systematic Uncertainty. Sensors 2020, 20, 627. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Gao, B.; Hu, G.; Zhong, Y.; Zhu, X. Cubature Kalman Filter With Both Adaptability and Robustness for Tightly-Coupled GNSS/INS Integration. IEEE Sens. J. 2021, 21, 14997–15011. [Google Scholar] [CrossRef]
- Cohen, N.; Klein, I. Inertial navigation meets deep learning: A survey of current trends and future directions. Results Eng. 2024, 24, 103565. [Google Scholar] [CrossRef]
- Jwo, D.-J.; Biswal, A.; Mir, I.A. Artificial neural networks for navigation systems: A review of recent research. Appl. Sci. 2023, 13, 4475. [Google Scholar] [CrossRef]
- Wei, X.; Li, J.; Feng, K.; Zhang, D.; Li, P.; Zhao, L.; Jiao, Y. A mixed optimization method based on adaptive kalman filter and wavelet neural network for ins/gps during gps outages. IEEE Access 2021, 9, 47875–47886. [Google Scholar] [CrossRef]
- Liu, H.; Li, K.; Fu, Q.; Yuan, L. Research on integrated navigation algorithm based on radial basis function neural network. J. Phys. Conf. Ser. 2021, 1961, 012031. [Google Scholar] [CrossRef]
- Li, S.; Mikhaylov, M.; Mikhaylov, N.; Pany, T. Deep learning based kalman filter for gnss/ins integration: Neural network architecture and feature selection. In Proceedings of the 2023 International Conference on Localization and GNSS (ICL-GNSS), Castellón, Spain, 6–8 June 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar] [CrossRef]
- Xia, J.; Gao, S.; Zhong, Y.; Qi, X.; Li, G.; Liu, Y. Moving-window-based adaptive fitting H-infinity filter for the nonlinear system disturbance. IEEE Access 2020, 8, 76143–76157. [Google Scholar] [CrossRef]
- Gao, S.; Wei, W.; Zhong, Y.; Subic, A. Sage windowing and random weighting adaptive filtering method for kinematic model error. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 1488–1500. [Google Scholar] [CrossRef]
- Song, I.Y.; Jeon, M.; Shin, V. Efficient multisensor fusion with sliding window Kalman filtering for discrete-time uncertain systems with delays. IET Signal Process. 2012, 6, 446–455. [Google Scholar] [CrossRef]
- Han, Y.; Wei, C.; Li, R.; Wang, J.; Yu, H. A novel cooperative localization method based on imu and uwb. Sensors 2020, 20, 467. [Google Scholar] [CrossRef] [PubMed]
- Kang, X.; Wang, D.; Shao, Y.; Ma, M.; Zhang, T. An efficient hybrid multi-station tdoa and single-station aoa localization method. IEEE Trans. Wirel. Commun. 2023, 22, 5657–5670. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Gao, S.; Zhong, Y.; Shirinzadeh, B. Random weighting estimation for fusion of multi-dimensional position data. Inf. Sci. 2010, 180, 4999–5007. [Google Scholar] [CrossRef]
- Gao, S.; Zhong, Y.; Li, W. Random Weighting Method for Multisensor Data Fusion. IEEE Sens. J. 2011, 11, 1955–1961. [Google Scholar] [CrossRef]
- Hu, G.; Gao, S.; Zhong, Y.; Gao, B.; Subic, A. Matrix weighted multisensor data fusion for INS/GNSS/CNS integration. Proc. Inst. Mech. Eng. Part G J. Aerosp. Eng. 2016, 230, 1011–1026. [Google Scholar] [CrossRef]
- Li, G.; Knoop, V.L.; van Lint, H. How predictable are macroscopic traffic states: A perspective of uncertainty quantification. Transp. B Transp. Dyn. 2024, 12, 2314766. [Google Scholar] [CrossRef]
- Solà, J. Quaternion kinematics for the error-state Kalman filter. arXiv 2017, arXiv:1711.02508. [Google Scholar] [CrossRef]
- Xu, W.; Cai, Y.; He, D.; Lin, J.; Zhang, F. FAST-LIO2: Fast Direct LiDAR-Inertial Odometry. IEEE Trans. Robot. 2022, 38, 2053–2073. [Google Scholar] [CrossRef]
- Titterton, D.H.; Weston, J.L. Strapdown Inertial Navigation Technology, 2nd ed.; Institution of Engineering and Technology: Stevenage, UK, 2004. [Google Scholar]
- Vettori, S.; Lorenzo, D.; Peeters, B.; Luczak, M.; Chatzi, E. An adaptive-noise augmented kalman filter approach for input-state estimation in structural dynamics. Mech. Syst. Signal Process. 2023, 184, 109654. [Google Scholar] [CrossRef]
- Dong, Y.; Kwan, K.; Arslan, T. Enhanced pedestrian trajectory reconstruction using bidirectional extended kalman filter and automatic refinement. In Proceedings of the 2024 14th International Conference on Indoor Positioning and Indoor Navigation (IPIN), Kowloon, Hong Kong, 14–17 October 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, X.; He, F.; Zheng, T. An LSTM-based trajectory estimation algorithm for non-cooperative maneuvering flight vehicles. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 8821–8826. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Filtering Method | Average Error on Training Data (m) | Average Error on Test Data (m) |
|---|---|---|
| Raw GNSS | 9.0915 | 9.8605 |
| EKF | 2.7469 | 2.9337 |
| ANKF | 2.6414 | 2.8140 |
| BEKF | 2.4125 | 2.7037 |
| LSTM-based | 2.4767 | 2.5836 |
| RL-AKF | 2.5756 | 2.6932 |
| RL-IMKF | 2.3141 | 2.4221 |
| M | Position Error (m) |
|---|---|
| 1 | 2.6679 |
| 2 | 2.6373 |
| 3 | 2.6655 |
| 4 | 2.1202 |
| 5 | 2.0767 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Xu, Q.; Sun, M.; Zhu, X. A Kalman Filter-Based Localization Calibration Method Optimized by Reinforcement Learning and Information Matrix Fusion. Entropy 2025, 27, 821. https://doi.org/10.3390/e27080821
Huang Z, Xu Q, Sun M, Zhu X. A Kalman Filter-Based Localization Calibration Method Optimized by Reinforcement Learning and Information Matrix Fusion. Entropy. 2025; 27(8):821. https://doi.org/10.3390/e27080821
Chicago/Turabian StyleHuang, Zijia, Qiushi Xu, Menghao Sun, and Xuzhen Zhu. 2025. "A Kalman Filter-Based Localization Calibration Method Optimized by Reinforcement Learning and Information Matrix Fusion" Entropy 27, no. 8: 821. https://doi.org/10.3390/e27080821
APA StyleHuang, Z., Xu, Q., Sun, M., & Zhu, X. (2025). A Kalman Filter-Based Localization Calibration Method Optimized by Reinforcement Learning and Information Matrix Fusion. Entropy, 27(8), 821. https://doi.org/10.3390/e27080821