


Quantification and Evolution of Online Public Opinion Heat Considering Interactive Behavior and Emotional Conflict


Abstract
1. Introduction
2. Literature Reviews
2.1. Online Public Opinion Dissemination
2.2. Interactive Behaviors in Online Public Opinion
2.3. Quantification of Public Opinion Heat
2.4. Social Media Data Analysis Based on Clustering Algorithms
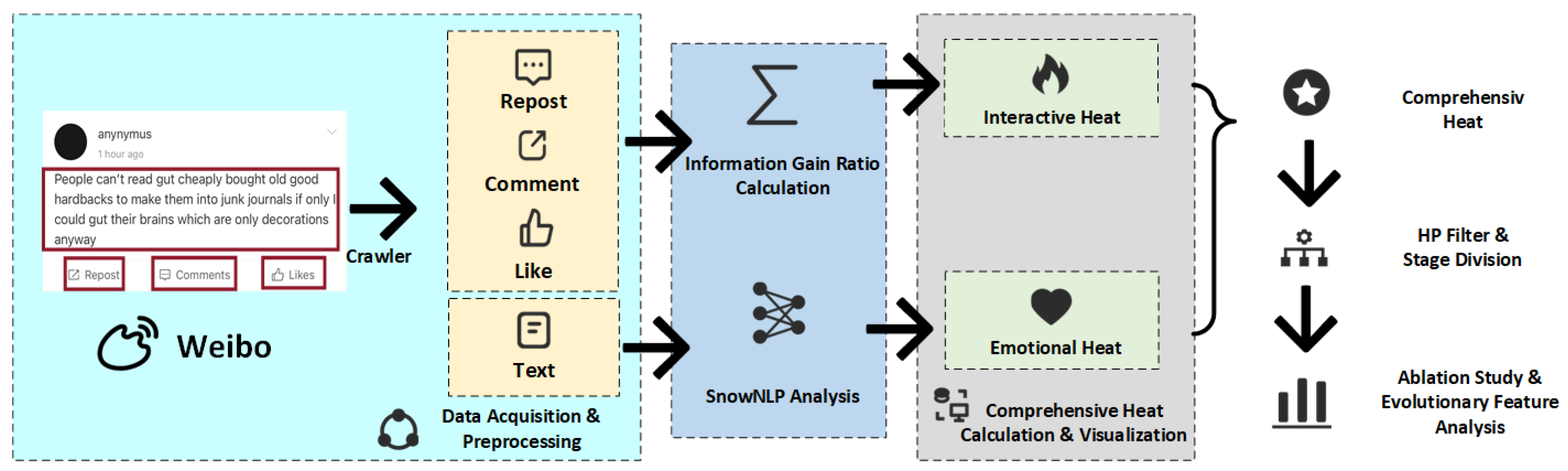
3. Construction of Public Opinion Heat Index Considering Interactive Behavior and Emotional Conflict
3.1. Construction of Public Opinion Heat Index Model Based on Interactive Behavior
3.1.1. Modeling of the Public Opinion Interaction Heat Index Based on Information Gain Ratio
3.1.2. Definition of the Public Opinion Interaction Heat Index
3.2. Construction of Public Opinion Heat Index Considering Emotional Conflict
3.3. Public Opinion Comprehensive Heat Index
4. Empirical Analysis
4.1. Dataset Description
4.2. Empirical Analysis of the Public Opinion Heat Index Model
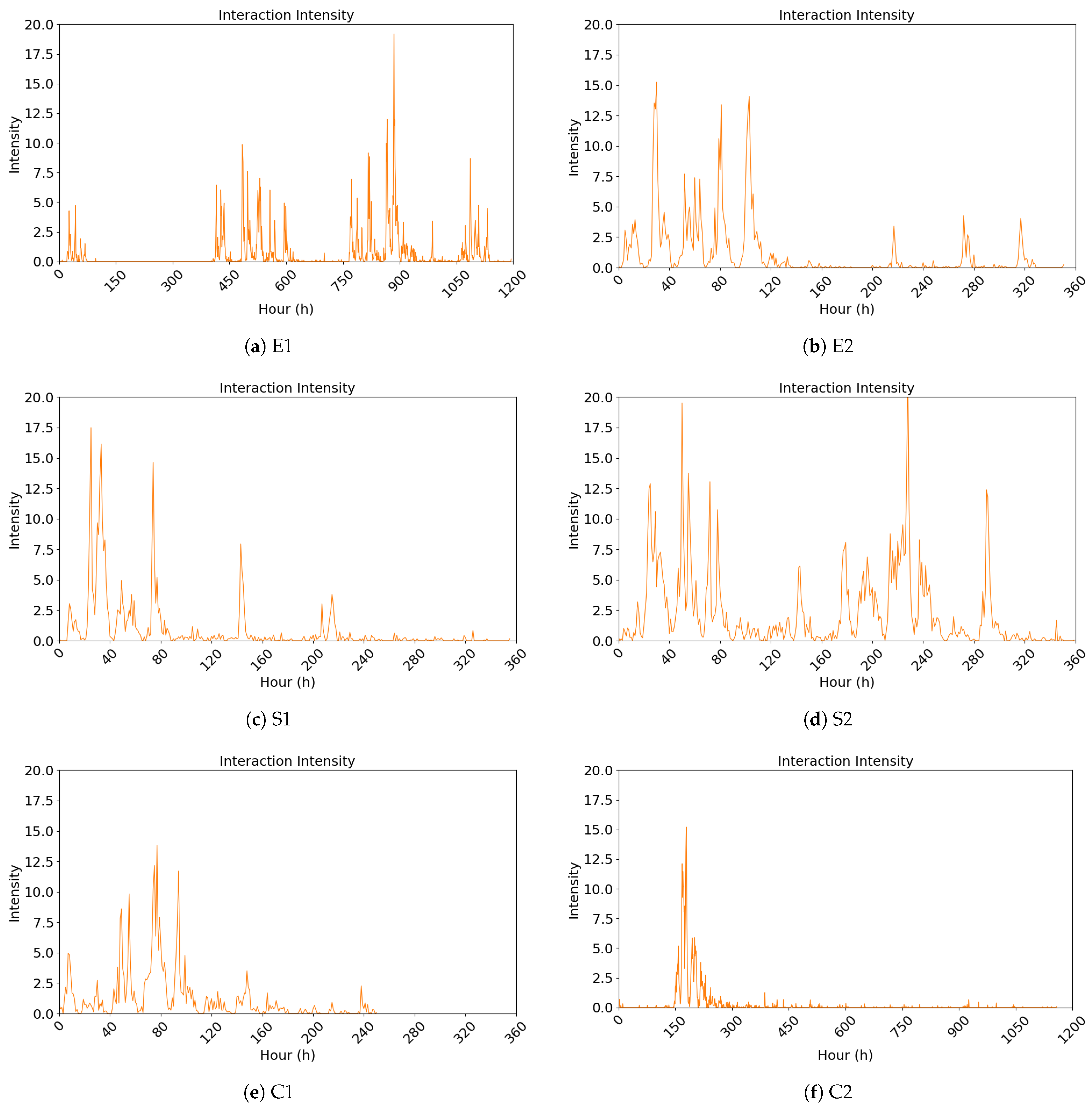
4.2.1. Analysis and Visualization of the Public Opinion Interaction Heat Index
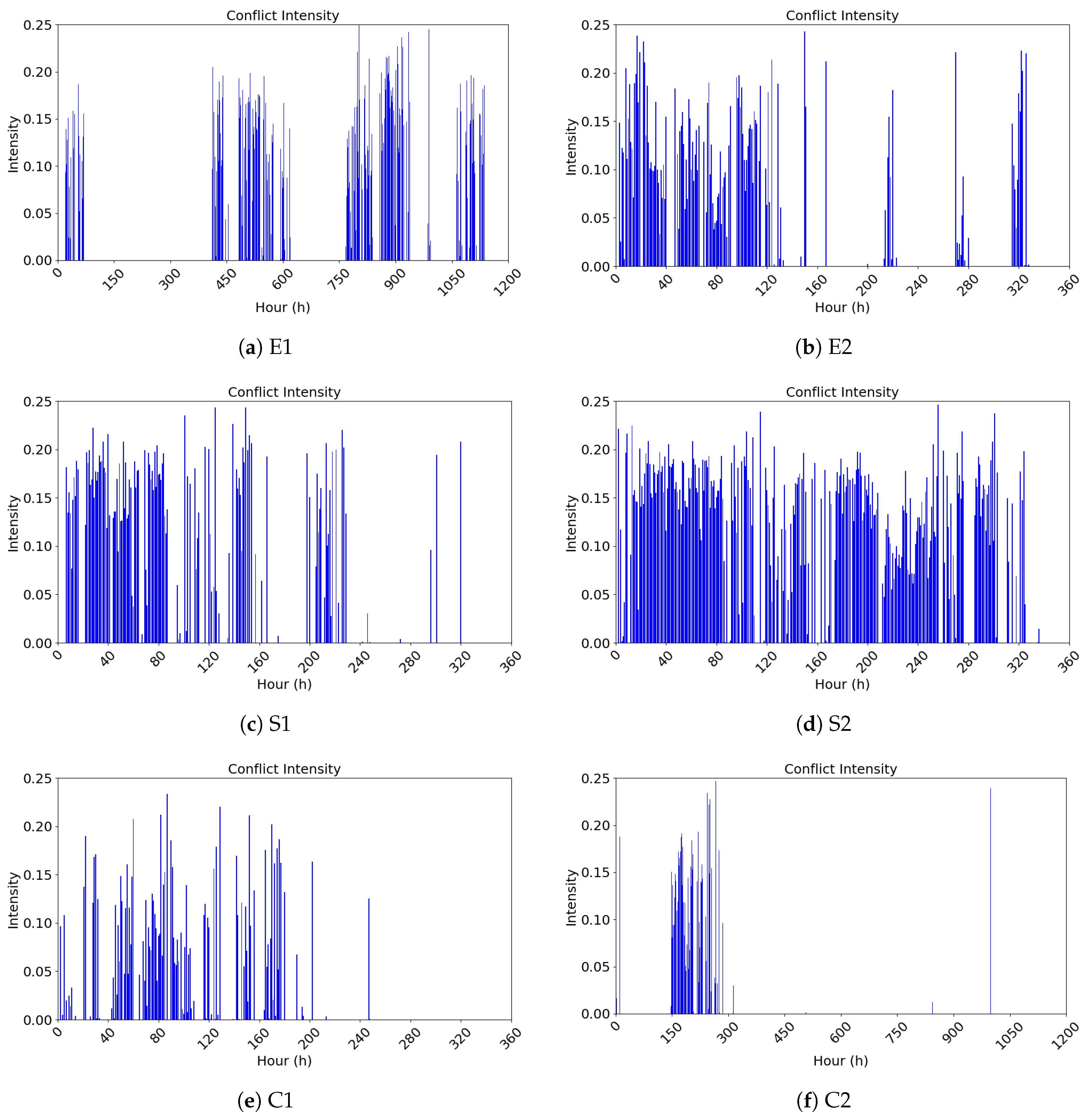
4.2.2. Analysis and Visualization of the Public Opinion Emotional Conflict Heat Index
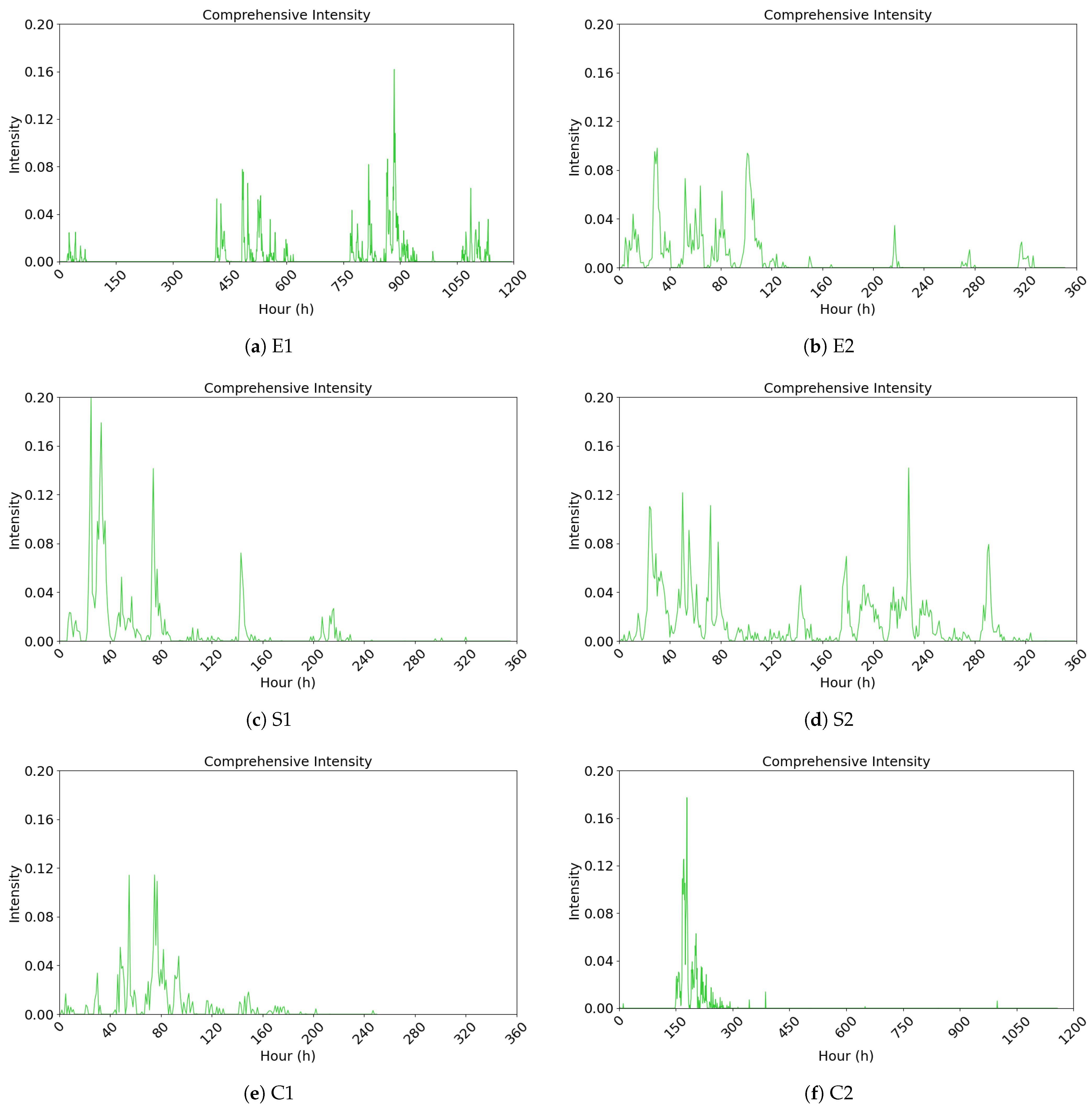
4.2.3. Analysis and Visualization of the Comprehensive Public Opinion Heat Index
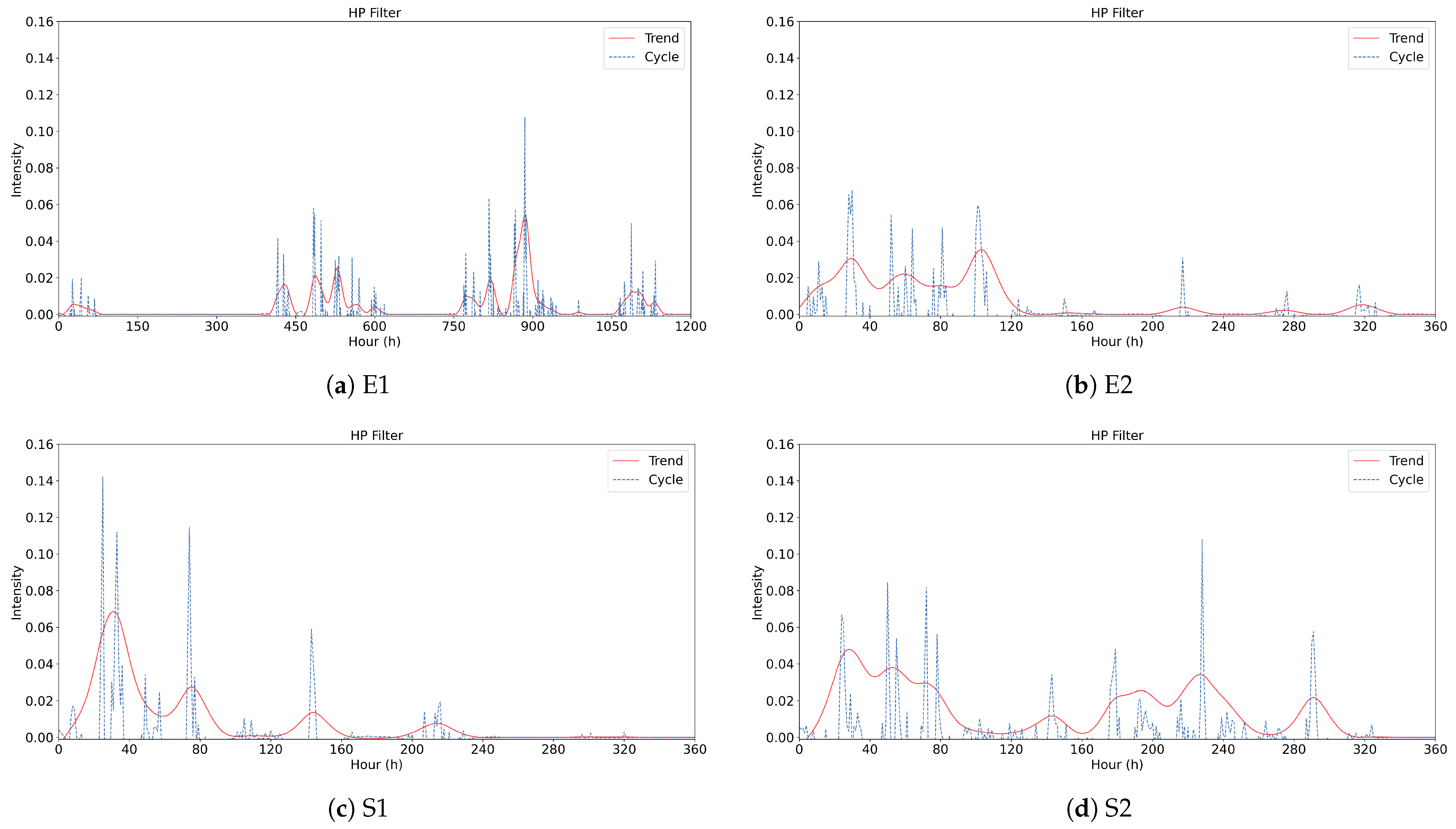
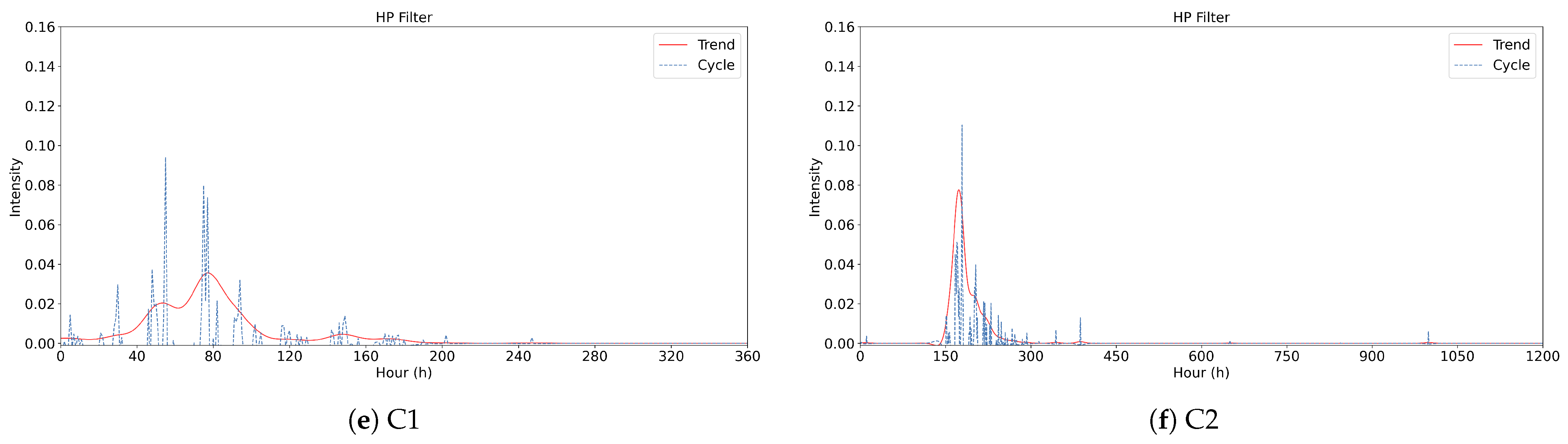
4.3. Dividing Online Public Opinion Evolution Stages Based on HP Filter
4.4. Robust K-Means and Stability Validation of Propagation Patterns
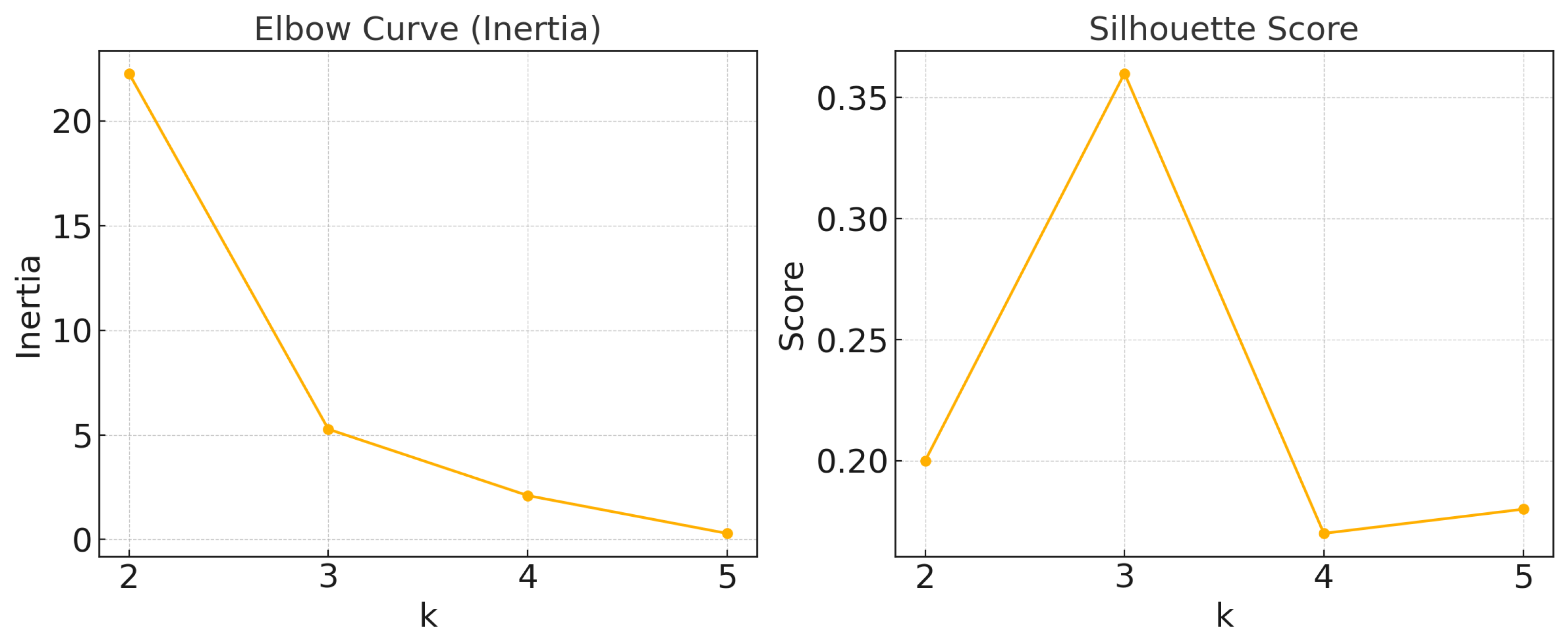
4.4.1. K-Means-Based Public Opinion Clustering
4.4.2. Robustness Testing and Validation
4.5. Ablation Study of Propagation Patterns Under External Interventions
4.5.1. Design and Results of the Ablation Study
4.5.2. Feature Analysis of Propagation Patterns Based on Ablation Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, H.; Noh, E.B.; Choi, S.H.; Zhao, B.; Nam, E.W. Determining public opinion of the COVID-19 pandemic in South Korea and Japan: Social network mining on twitter. Healthc. Inform. Res. 2020, 26, 335–343. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Li, Q.; Fu, P.; Yang, J.; Xu, C.; Cong, G.; Li, G. Public opinion polarization by individual revenue from the social preference theory. Int. J. Environ. Res. Public Health 2020, 17, 946. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Li, X. Quantitative research on the evolution stages of we-media network public opinion based on a logistic equation. Teh. Vjesn. 2021, 28, 983–993. [Google Scholar]
- Chen, M.; Du, W. The predicting public sentiment evolution on public emergencies under deep learning and internet of things. J. Supercomput. 2023, 79, 6452–6470. [Google Scholar] [CrossRef]
- Ji, X. EUsers’ Sentiment Mining and Spreading Among Chinese Microblogs in the Context of Specific Events. Ph.D. Thesis, Nankai University, Tianjin, China, 2014. [Google Scholar]
- Tsirakis, N.; Poulopoulos, V.; Tsantilas, P.; Varlamis, I. Large scale opinion mining for social, news and blog data. J. Syst. Softw. 2017, 127, 237–248. [Google Scholar] [CrossRef]
- Bengesi, S.; Oladunni, T.; Olusegun, R.; Audu, H. A machine learning-sentiment analysis on monkeypox outbreak: An extensive dataset to show the polarity of public opinion from Twitter tweets. IEEE Access 2023, 11, 11811–11826. [Google Scholar] [CrossRef]
- Spence, P.R.; Lachlan, K.A.; Lin, X.; Del Greco, M. Variability in Twitter content across the stages of a natural disaster: Implications for crisis communication. Commun. Q. 2015, 63, 171–186. [Google Scholar] [CrossRef]
- Zhao, Y. Research of Several Key Issues of the Internet Public Opinion in China. In Proceedings of the 4th Multidisciplinary International Social Networks Conference, Bangkok, Thailand, 17–19 July 2017; pp. 1–6. [Google Scholar]
- QI, L.; LI, X.; CAO, S. A research on the evolution of net-mediated public sentiment in corporate social responsibility negative events and government-enterprise cooperation. Syst. Eng. Theory Pract. 2020, 40, 1793–1805. (In Chinese) [Google Scholar]
- Li, J. Research on the Evolution of Net-Mediated Public Sentiment of Online Financial Violations Based on Text Analysis. Ph.D. Thesis, Harbin Institute of Technology, Harbin, China, 2020. (In Chinese). [Google Scholar]
- He, J. A Study on Emergence and Diffusion of Hot Topics in Internet Group Communication. Ph.D. Thesis, Shanghai Jiao Tong University, Shanghai, China, 2019. (In Chinese). [Google Scholar]
- Hu, J. Structure Analysis and Predictive Modeling in Social Networks. Ph.D. Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2019. (In Chinese). [Google Scholar]
- Sun, Q. Empirical Research on Online Word-of-Mouth Propagation Network Structure Based on Social Network. Master’s Thesis, Huazhong University of Science & Technology, Wuhan, China, 2019. [Google Scholar]
- Wu, B.; Shen, H. Analyzing and predicting news popularity on Twitter. Int. J. Inf. Manag. 2015, 35, 702–711. [Google Scholar] [CrossRef]
- Dong, X. Research on the Influencing Factors of the Formation of Weibo Public Opinion Hot Events. Master’s Thesis, Jilin University, Changchun, China, 2020. [Google Scholar]
- Wu, Z.; Liao, J.; Zhang, L. Predicting on retweeting of hot topic tweets in microblog. In Proceedings of the 2013 5th IEEE International Conference on Broadband Network & Multimedia Technology, Guilin, China, 17–19 November 2013; pp. 119–123. [Google Scholar]
- Zhang, Y.S.; Zheng, J.; Tang, A.J. A Quantitative Evaluation Method of Micro-blog User Authority Based on Multi-Feature Fusion. Acta Electron. Sin. 2017, 45, 2800–2809. [Google Scholar]
- Wang, D.; Xu, J.; Duan, C.; Wu, Y.; Sun, J. An Improved Algorithm for User Influence Evaluation Based on PageRank. J. Harbin Inst. Technol. 2018, 50, 60–67. (In Chinese) [Google Scholar]
- Cha, M.; Haddadi, H.; Benevenuto, F.; Gummadi, K. Measuring user influence in twitter: The million follower fallacy. In Proceedings of the International AAAI Conference on Web and Social Media, Washington, DC, USA, 23–26 May 2010; Volume 4, pp. 10–17. [Google Scholar]
- Lu, J.; Wan, W. Identification of key nodes in microblog networks. Etri J. 2016, 38, 52–61. [Google Scholar] [CrossRef]
- Alp, Z.Z.; Öğüdücü, Ş.G. Identifying topical influencers on twitter based on user behavior and network topology. Knowl.-Based Syst. 2018, 141, 211–221. [Google Scholar]
- Yi, X.; Han, Y.; Wang, X. The Evaluation of Online Social Network’s Nodes Influence Based on User’s Attribute and Behavior. In Frontiers in Internet Technologies; Su, J., Zhao, B., Sun, Z., Wang, X., Wang, F., Xu, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 9–20. [Google Scholar]
- Liu, R. Research on User Influence of Weibo Specific Topic Domain Based on Interaction Relationship. Master’s Thesis, Chongqing University of Posts and Telecommunications, Chongqing, China, 2019. [Google Scholar]
- Weng, J.; Lim, E.P.; Jiang, J.; He, Q. Twitterrank: Finding topic-sensitive influential twitterers. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, New York, NY, USA, 4–6 February 2010; pp. 261–270. [Google Scholar]
- Wu, J.; Sha, Y.; Li, R.; Liang, Q.; Jiang, B.; Tan, J.; Wang, B. Identification of influential users based on topic-behavior influence tree in social networks. In Proceedings of the Natural Language Processing and Chinese Computing: 6th CCF International Conference, NLPCC 2017, Dalian, China, 8–12 November 2017; Proceedings 6. Springer: Berlin/Heidelberg, Germany, 2018; pp. 477–489. [Google Scholar]
- Zhou, D.H.; Han, W.B. DiffRank: A Novel Information Propagation Detection Algorithm in Social Networks. Chin. J. Comput. 2014, 37, 884–893. (In Chinese) [Google Scholar]
- Tatar, A.; De Amorim, M.D.; Fdida, S.; Antoniadis, P. A survey on predicting the popularity of web content. J. Internet Serv. Appl. 2014, 5, 1–20. [Google Scholar] [CrossRef]
- Szabo, G.; Huberman, B.A. Predicting the popularity of online content. Commun. ACM 2010, 53, 80–88. [Google Scholar] [CrossRef]
- Cha, M.; Kwak, H.; Rodriguez, P.; Ahn, Y.Y.; Moon, S. I tube, you tube, everybody tubes: Analyzing the world’s largest user generated content video system. In Proceedings of the 7th ACM SIGCOMM Conference on Internet Measurement, San Diego, CA, USA, 24–26 October 2007; pp. 1–14. [Google Scholar]
- Pinto, H.; Almeida, J.M.; Gonçalves, M.A. Using early view patterns to predict the popularity of youtube videos. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013; pp. 365–374. [Google Scholar]
- Hu, Y. Research on the Analysis and Prediction of Popularity Evolution in Social Networks. Ph.D. Thesis, University of Science and Technology Beijing, Beijing, China, 2018. (In Chinese). [Google Scholar]
- Adnan, M.M.J.; Hemmje, M.L.; Kaufmann, M.A. Social Media Mining to Study Social User Group by Visualizing Tweet Clusters using Word2Vec, PCA and K-Means. In Proceedings of the BIRDS+ WEPIR@ CHIIR, Canberra, Australia, 19 March 2021; pp. 40–51. [Google Scholar]
- Alsayat, A.; El-Sayed, H. Social media analysis using optimized K-Means clustering. In Proceedings of the 2016 IEEE 14th International Conference on Software Engineering Research, Management and Applications (SERA), Towson, MD, USA, 8–10 June 2016; pp. 61–66. [Google Scholar]
- Zul, M.I.; Yulia, F.; Nurmalasari, D. Social media sentiment analysis using K-means and naïve bayes algorithm. In Proceedings of the 2018 2nd International Conference on Electrical Engineering and Informatics (ICon EEI), Batam, Indonesia, 16–17 October 2018; pp. 24–29. [Google Scholar]
- Madhuri, K.; Rao, M.K.S. Social Media Analysis using Optimized K-Means Clustering. Int. J. Trend Sci. Res. Dev. 2019, 3, 953–957. [Google Scholar] [CrossRef]
- Qi, M.; Zhao, J.; Feng, Y. An optimized public opinion communication system in social media networks based on K-means cluster analysis. Heliyon 2024, 10, e40033. [Google Scholar] [CrossRef]
- Rosso, P.; Bosco, C.; Damiano, R.; Patti, V.; Cambria, E. Emotion and sentiment in social and expressive media: Introduction to the special issue. Inf. Process. Manag. 2016, 52, 1–4. [Google Scholar] [CrossRef]
- Wang, P. Study on Social Network Information Dissemination Prediction Based on User Features. Master’s Thesis, Chongqing University, Chongqing, China, 2019. (In Chinese). [Google Scholar]
- Feng, J. Research on Event Prediction of Social Network Events Based on Text Analysis. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2018. [Google Scholar]
- Bollen, J.; Mao, H.; Zeng, X. Twitter mood predicts the stock market. J. Comput. Sci. 2011, 2, 1–8. [Google Scholar] [CrossRef]
- Liu, C.; Tian, Y.; Shi, Y.; Huang, Z.; Shao, Y. An analysis of public topics and sentiments based on social media during the COVID-19 Omicron Variant outbreak in Shanghai 2022. Comput. Urban Sci. 2024, 4, 19. [Google Scholar] [CrossRef]
- AL-Sharuee, M.T.; Liu, F.; Pratama, M. Sentiment analysis: Dynamic and temporal clustering of product reviews. Appl. Intell. 2021, 51, 51–70. [Google Scholar] [CrossRef]
- Asur, S.; Huberman, B.A.; Szabo, G.; Wang, C. Trends in social media: Persistence and decay. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Catalonia, Spain, 17–21 July 2011; Volume 5, pp. 434–437. [Google Scholar]
- Mitchell, T.M. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Tao, Q.; Zhuang, S.; Huan, L.; Zhouguo, C. Learning to Rank for Evolution Trend Evaluation of Online Public Opinion Events. J. Comput. Res. Dev. 2020, 57, 2490–2500. [Google Scholar]
- Murtagh, F.; Legendre, P. Ward’s hierarchical agglomerative clustering method: Which algorithms implement Ward’s criterion? J. Classif. 2014, 31, 274–295. [Google Scholar] [CrossRef]
- Li, T.; Rezaeipanah, A.; El Din, E.M.T. An ensemble agglomerative hierarchical clustering algorithm based on clusters clustering technique and the novel similarity measurement. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 3828–3842. [Google Scholar] [CrossRef]
- Ikotun, A.M.; Ezugwu, A.E.; Abualigah, L.; Abuhaija, B.; Heming, J. K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data. Inf. Sci. 2023, 622, 178–210. [Google Scholar] [CrossRef]
- Chaudhry, M.; Shafi, I.; Mahnoor, M.; Vargas, D.L.R.; Thompson, E.B.; Ashraf, I. A systematic literature review on identifying patterns using unsupervised clustering algorithms: A data mining perspective. Symmetry 2023, 15, 1679. [Google Scholar] [CrossRef]
- Maharana, K.; Mondal, S.; Nemade, B. A review: Data pre-processing and data augmentation techniques. Glob. Transit. Proc. 2022, 3, 91–99. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Dalmaijer, E.S.; Nord, C.L.; Astle, D.E. Statistical power for cluster analysis. BMC Bioinform. 2022, 23, 205. [Google Scholar] [CrossRef]
- Batool, F.; Hennig, C. Clustering with the average silhouette width. Comput. Stat. Data Anal. 2021, 158, 107190. [Google Scholar] [CrossRef]
- Sangiorgio, E.; Di Marco, N.; Etta, G.; Cinelli, M.; Cerqueti, R.; Quattrociocchi, W. Evaluating the effect of viral posts on social media engagement. Sci. Rep. 2025, 15, 639. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Cheng, H.; Liu, Q.; Tan, S. The delayed and combinatorial response of online public opinion to the real world: An inquiry into news texts during the COVID-19 era. Humanit. Soc. Sci. Commun. 2024, 11, 1–18. [Google Scholar] [CrossRef]
- Miao, H.; Miao, H. Evaluation of Public Opinion Influence of Emergencies and Identification of Its Main Driving Factors:Based on the Analysis from the Dimension of Event Classification. J. Beijing Univ. Aeronaut. Astronaut. Sci. Ed. 2023, 36, 92–102. [Google Scholar]
- Li, Z.; Tang, X.; Hong, Z. Collective attention dynamic induced by novelty decay. Eur. Phys. J. B 2022, 95, 132. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, X.; Liu, W.; Li, P. Spatiotemporal pattern evolution and influencing factors of online public opinion—Evidence from the early-stage of COVID-19 in China. Heliyon 2023, 9, e20080. [Google Scholar] [CrossRef] [PubMed]
- Shireman, E.M.; Steinley, D.; Sher, K. Sex differences in the latent class structure of alcohol use disorder: Does (dis) aggregation of indicators matter? Exp. Clin. Psychopharmacol. 2015, 23, 291. [Google Scholar] [CrossRef]
- Žnidaršič, A.; Ferligoj, A.; Doreian, P. Non-response in social networks: The impact of different non-response treatments on the stability of blockmodels. Soc. Netw. 2012, 34, 438–450. [Google Scholar] [CrossRef]
- Yang, B.; Shang, K.k.; Small, M.; Chao, N. Information overload: How hot topics distract from news—COVID-19 spread in the US. Natl. Sci. Open 2023, 2, 20220051. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Gitau, M.W.; Pai, N.; Daggupati, P. Hydrologic and water quality models: Performance measures and evaluation criteria. Trans. ASABE 2015, 58, 1763–1785. [Google Scholar]
- Liu, H. Official social media and its impact on public behavior during the first wave of COVID-19 in China. BMC Public Health 2022, 22, 428. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Yang, S.; An, X. Opinion leaders and crisis communication during the COVID-19 pandemic: A study of theme evolution and emotional impact on Twitter. Digit. Health 2024, 10, 20552076241234619. [Google Scholar] [CrossRef]
- Sun, D.; Li, Y. Influence of Strategic Crisis Communication on Public Perceptions during Public Health Crises: Insights from YouTube Chinese Media. Behav. Sci. 2024, 14, 91. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Zhang, T.; Ye, Z.; Chen, K.; Kuijp, J.v.d.; Sun, X.; Han, G.; Zhao, Y.; Liu, Y.; Huang, L. Public anxiety through various stages of COVID-19 coping: Evidence from China. PLoS ONE 2022, 17, e0270229. [Google Scholar] [CrossRef]
- Yang, Z. Construction of a Multi-Subject Collaborative Governance Mechanism for Network Public Opinion in Emergencies. Adv. Soc. Sci. 2023, 12, 2174. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Event ID | Event | Date |
|---|---|---|---|
| Enterprise Survival | E1 | “Dong Bei Yu Jie” Livestream Sales Failure | 4 September 2024–24 October 2024 |
| E2 | “Crazy Xiao Yang” Livestreaming Meicheng Mooncakes | 14 September 2024–29 September 2024 | |
| Social Livelihood | S1 | 315 Sausage Scandal | 15 March 2024–25 March 2024 |
| S2 | Oil Tanker Mixing Edible Oil Incident | 2 July 2024–21 August 2024 | |
| Culture and Sports | C1 | Li Ziqi’s Comeback | 12 November 2024–27 November 2024 |
| C2 | Wu Liufang Incident | 22 November 2024–8 December 2024 |
| Quantitative Feature | Definition and Explanation |
|---|---|
| Number of Peaks | The total count of major peaks appearing in the comprehensive intensity curve (red line), used to determine whether the event undergoes multiple outbreaks. |
| Time of First Peak | The hour at which the first major peak occurs, indicating how quickly the event reaches its initial peak within the dissemination timeline. |
| Maximum Amplitude | The highest observed intensity value throughout the entire dissemination process, reflecting the strongest level of public attention or discussion. |
| Decay Time | The time interval from the first peak to the first trough, illustrating how quickly the trend transitions from an increasing phase to a decreasing phase. |
| Peak Emotional Conflict | The maximum variance in the emotional conflict index, capturing the greatest level of divergence or polarization in user sentiments during the event. |
| Overall Duration | The total time span from when intensity first rises notably above the baseline until it returns to baseline, reflecting how long the event remains in public view. |
| Event ID | ||||||
|---|---|---|---|---|---|---|
| E1 | 13 | 28 | 0.551 | 432 | 4.975 | 1103 |
| E2 | 8 | 29 | 3.047 | 16 | 3.567 | 290 |
| S1 | 4 | 54 | 2.0348 | 53 | 1.843 | 117 |
| S2 | 2 | 173 | 7.761 | 151 | 7.877 | 214 |
| C1 | 5 | 31 | 6.864 | 28 | 5.711 | 183 |
| C2 | 7 | 28 | 4.789 | 15 | 3.273 | 263 |
| k | K-Means | Ward | ||
|---|---|---|---|---|
| Inertia | Silhouette | Silhouette | CH | |
| 2 | 22.27 | 0.20 | 0.39 | 4.10 |
| 3 | 5.27 | 0.36 | 0.36 | 8.74 |
| 4 | 2.10 | 0.17 | 0.18 | 10.74 |
| 5 | 0.29 | 0.18 | 0.18 | 10.74 |
| Event | K-Means | Ward | Patterns |
|---|---|---|---|
| E1 | C | 1 | Long-tail |
| E2 | B | 3 | Normal burst |
| S1 | B | 3 | Normal burst |
| S2 | A | 2 | Extreme burst |
| C1 | B | 3 | Normal burst |
| C2 | B | 3 | Normal burst |
| Event | First Intervention | Second Intervention | ||
|---|---|---|---|---|
| Date | Description | Date | Description | |
| E1 | 24 September 2024 | Market Supervision Bureau of Benxi Manchu Autonomous County informs that the sweet potato vermicelli of “Dong Bei Yu Jie” has “no detectable sweet potato ingredients and detectable cassava ingredients”, and the other indexes are in line with food safety standards. | 30 September 2024 | “Dong Bei Yu Jie” issued an apology statement, saying that it has been sent to the national standard quality inspection department testing, and promised to all users a full refund. |
| E2 | 17 September 2024 | Hefei High-tech Zone Market Supervision Bureau informed that “Crazy Xiao Yang” is suspected of misleading consumers with goods behavior and has filed for investigation. | 19 September 2024 | Caixin.com disclosed that “Crazy Xiao Yang” invited Hong Kong star Eric Tsang during a live broadcast and used “Hong Kong big brand” and “Michelin master modulation” to mislead consumers. |
| S1 | 20 March 2024 | The Public Opinion Monitoring System (POMS) released a 315 exposure list and heat analysis, pointing out that “sausage” has become the hottest exposed food, driving a subsequent trend of public opinion. | 23 March 2024 | Titanium Media and other platforms published expert scientific articles to calm the controversy from the perspective of industry standards and nutritional value, effectively eliminating some misunderstandings. |
| S2 | 6 July 2024 | China Agri-Industries Group issued a letter in response to “the quality of the brand involved is qualified” and cooperated with the investigation, trying to stabilize market confidence. | 9 July 2024 | Food Safety Office of the State Council and other seven ministries and commissions held a special meeting, set up a joint investigation team to investigate the whole chain, and informed that no other similar problems were found; the enterprises and personnel involved were to be punished. |
| C1 | 13 November 2024 | CBNData interview: Li Ziqi revealed that the comeback is a temporary decision; in the past three years, she visited more than 100 intangible-heritage inheritors and will focus on cultural innovation in the future. | 16 November 2024 | On the first anniversary of the Zhejiang Rui’an Dongyuan Wooden Character Printing Cultural Research Institute and the launch of the Cultural IP Strategic Alliance, Li Ziqi was appointed “Cultural Communication Ambassador” and appeared at the ceremony. |
| C2 | 24 November 2024 | After being banned for violating Weibo rules, the account was unbanned hours later, gaining over 1.2 million followers the same day, raising questions about the platform’s enforcement standards. | 27 November 2024 | The United Daily News published a commentary pointing out that the incident reflected the conflict between retired athletes’ career development and societal expectations, triggering a broader social discussion. |
| Event | Full Data | Excluding First Intervention | Excluding Second Intervention | Excluding All Interventions |
|---|---|---|---|---|
| E1 | 0.87 | 0.71 | 0.89 | 0.88 |
| E2 | 0.87 | 0.92 | 0.88 | 0.89 |
| S1 | 0.92 | 0.92 | 0.82 | 0.93 |
| S2 | 0.86 | 0.91 | 0.56 | 0.70 |
| C1 | 0.85 | 0.23 | 0.81 | 0.25 |
| C2 | 0.83 | 0.85 | 0.76 | 0.79 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Z.; Wang, D.; Li, Z. Quantification and Evolution of Online Public Opinion Heat Considering Interactive Behavior and Emotional Conflict. Entropy 2025, 27, 701. https://doi.org/10.3390/e27070701
Sun Z, Wang D, Li Z. Quantification and Evolution of Online Public Opinion Heat Considering Interactive Behavior and Emotional Conflict. Entropy. 2025; 27(7):701. https://doi.org/10.3390/e27070701
Chicago/Turabian StyleSun, Zhengyi, Deyao Wang, and Zhaohui Li. 2025. "Quantification and Evolution of Online Public Opinion Heat Considering Interactive Behavior and Emotional Conflict" Entropy 27, no. 7: 701. https://doi.org/10.3390/e27070701
APA StyleSun, Z., Wang, D., & Li, Z. (2025). Quantification and Evolution of Online Public Opinion Heat Considering Interactive Behavior and Emotional Conflict. Entropy, 27(7), 701. https://doi.org/10.3390/e27070701