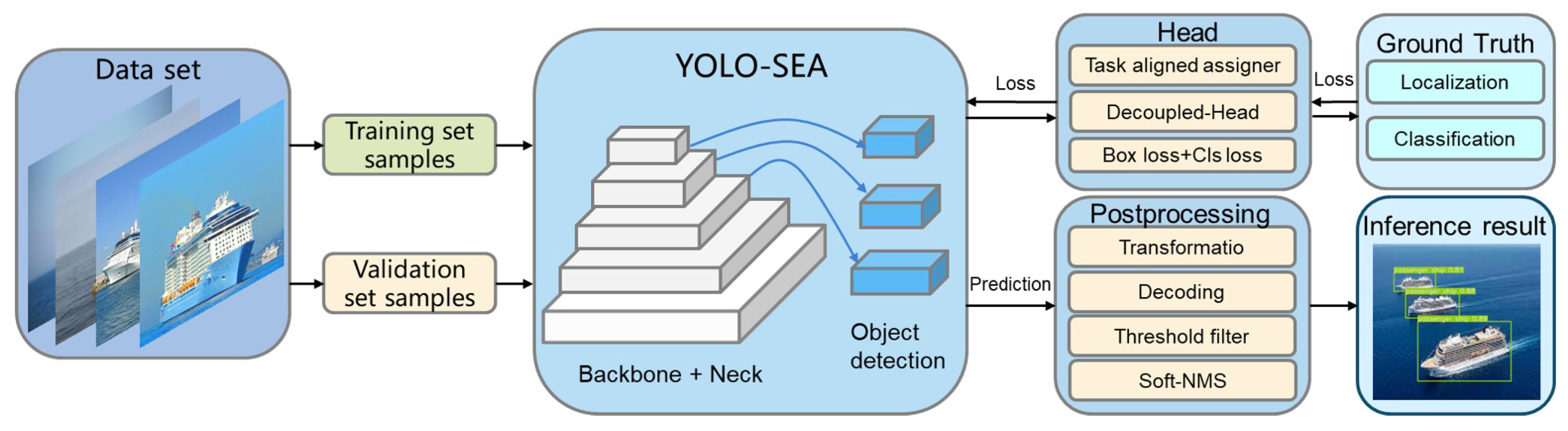
1. Introduction
As global attention to marine resource exploitation, environmental conservation, maritime safety, and the protection of maritime interests continues to grow, ocean monitoring and management are encountering increasingly complex challenges. Maritime environments contain a diverse range of dynamic targets—such as naval vessels, fishing boats, cargo ships, and offshore structures—characterized by significant variation in shape, scale, and motion patterns. This diversity presents substantial difficulties for accurate detection and localization. Robust and efficient detection of multi-class maritime targets is not only crucial for enhancing global maritime traffic safety, emergency response, and resource management but also provides essential technological support for national and international marine governance and strategic decision-making [
1].
The dynamic and unpredictable nature of the marine environment complicates detection tasks. Factors like wave motion, variable lighting, sea fog, and adverse weather degrade visual quality, reducing the reliability of traditional detection algorithms [
2]. Additionally, differences between nearshore and offshore scenes, static and moving targets, and imbalanced target classes require more adaptable detection solutions [
3]. Developing advanced models for accurate multi-scale, multi-class, and multi-object detection in complex marine conditions is therefore crucial. Advancements in this area will accelerate smart maritime technologies and autonomous navigation while supporting sustainable ocean resource use and enhancing global maritime security.
Conventional techniques employ convolutional templates to extract feature information from images, utilizing methods such as HOG [
4] (Histogram of Oriented Gradients) and SIFT [
5] (Scale-Invariant Feature Transform). These features are subsequently integrated with classifiers—notably, Support Vector Machine (SVM) [
6]—to facilitate target classification and recognition. Building on this, studies have combined HOG [
7] features with SVM classifiers for marine oil spill detection, enhancing low-altitude monitoring accuracy and enabling all-weather offshore surveillance. Other works have developed SVM-based frameworks [
8] to extract key ship defect features for effective prediction of vessel detention events.
Recent advances in computer vision, image analysis, and pattern recognition have been driven by significant progress in artificial intelligence [
9], especially in computational power, large-scale data collection, and deep learning optimization. These advancements have led to improved accuracy and efficiency in maritime target detection. Deep learning-based recognition technologies, particularly convolutional neural network models like SSD (Single-Shot MultiBox Detector), Faster R-CNN (Faster Region-based Convolutional Neural Network), and YOLO (You Only Look Once) have become the standard for target detection due to their superior capabilities and wide applicability. To meet the real-time recognition demands of complex marine environments, extensive experiments have been conducted using these models to continuously improve detection accuracy, computational efficiency, and generalization. A convolutional neural network model integrating multiple strategies [
10] was developed for ship target detection. Experimental results show that the model outperforms mainstream methods such as SSD and Faster R-CNN in detection accuracy. Cross-polarized C-band SAR (Synthetic Aperture Radar) images [
11] have been utilized to implement Faster R-CNN, RetinaNet, and single-stage detectors on various ResNet backbones, enabling performance and adaptability comparisons across detection frameworks. A Faster R-CNN-based [
12] approach integrates dilated and group convolutions into a multi-scale feature extraction module and optimizes the classification strategy, improving the robustness and accuracy of unmanned surface-vessel obstacle detection. To address reduced detection accuracy under sea-fog conditions, a method combining dehazing preprocessing with an SSD-based detection model [
13] has been proposed, enhancing maritime vessel detection in adverse weather environments.
Convolutional neural networks such as the YOLO [
14] model serve as the basis for deep learning algorithms. The YOLOv2 network, combined with the SELU (Scaled Exponential Linear Unit) activation function [
15], achieves excellent detection accuracy and speed for small ship detection. An improved YOLOv3-Tiny detection method [
16] was proposed based on a feature pyramid network, enhancing detection accuracy through feature fusion. This method integrates the second scale output layer with the fourth DBL (Conv + BatchNorm + LeakyReLU) output and introduces a 52 × 52 scale output, improving accuracy while maintaining detection speed, with results validated on a self-built dataset. An improved YOLOv3 model [
17] introduces new anchor-setting methods and a cross-PANet structure with focal loss, boosting sea target detection accuracy. However, its performance still depends on anchor settings, limiting generalization. In the feature fusion module of YOLOv4, a convolutional attention module [
18] is introduced to weight channel and spatial features, significantly improving maritime target detection accuracy. An improved YOLOv5 model incorporates weighted clustering for data processing and introduces a BN (Batch Normalization) scaling factor for lightweight implementation [
19], boosting real-time ship detection performance. Despite its high accuracy and robustness, the recall rate for small targets remains to be improved. An improved YOLOv5 model [
20] incorporates weighted clustering for data processing and introduces a BN scaling factor for lightweight implementation, boosting real-time ship detection performance. Despite its high accuracy and robustness, the recall rate for small targets remains to be improved.
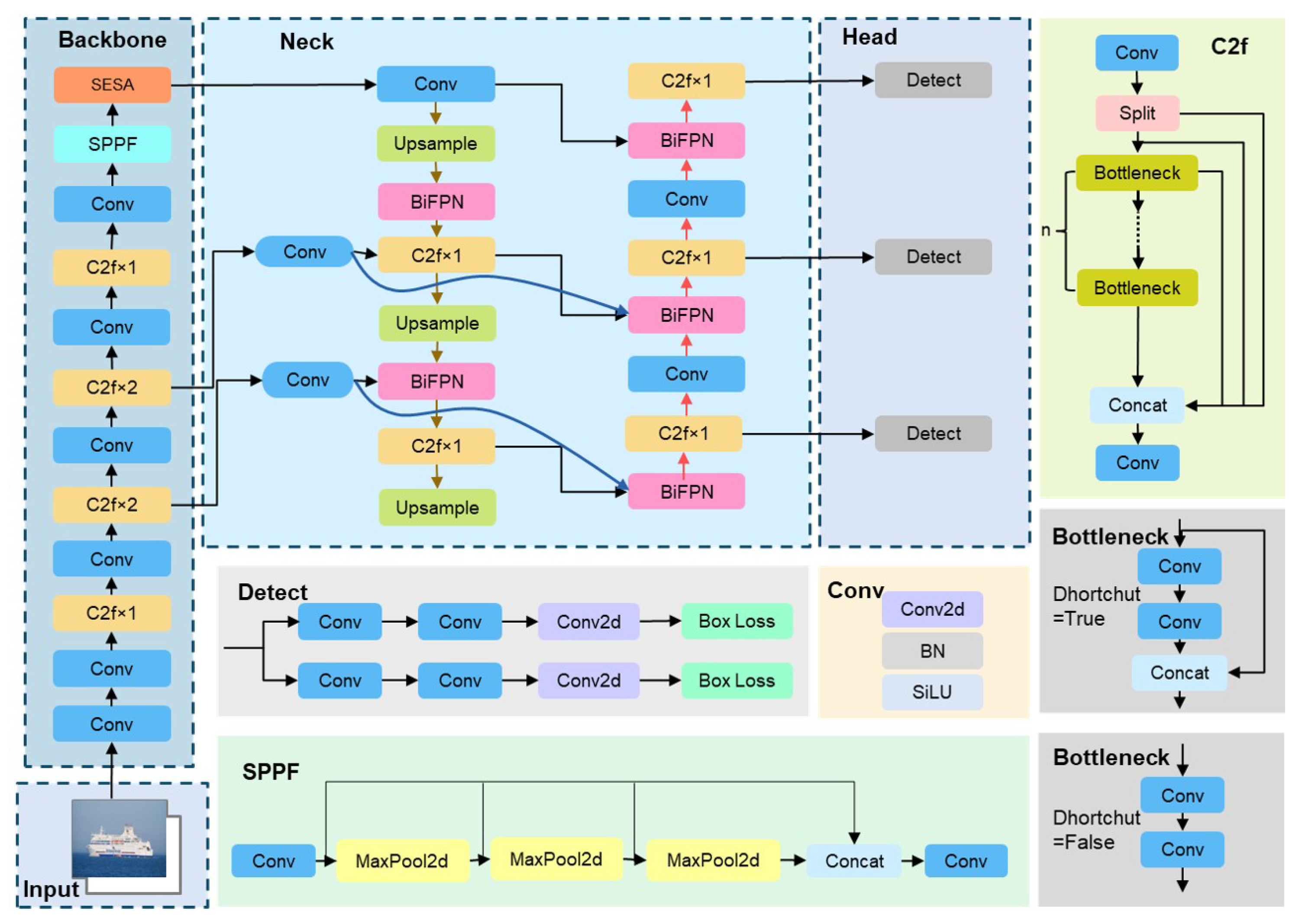
To improve target detection accuracy and generalization capacity in complicated maritime situations, this work suggests an enhanced YOLOv8 algorithm for multi-category, multi-target, and multi-scale high-precision detection at sea. The following are the primary contributions:
The dataset encompasses a range of marine objects, including common ships, buoys, lighthouses, and aircraft operating on the sea surface. It features eight distinct target categories characterized by significant diversity and variety. This approach aligns more closely with the complexity of the actual offshore maritime environment compared to a traditional single-ship dataset.
The backbone network integrates the SESA (SimAM-Enhanced SENetV2 Attention) fusion attention module, which combines the parameter-free feature modeling mechanism of the Simple, Parameter-Free Attention Module (SimAM) with the channel-adaptive weight adjustment of Squeeze-and-Excitation Network Version 2 (SENetV2) across the three dimensions of channel, height, and width. It also examines the spatial distribution of features and the significance of the channel. This synergistic mechanism effectively captures key features of multi-scale and multi-category targets in complex maritime scenes, enhancing their differentiation and expression capabilities. This leads to increased detection accuracy and robustness, along with a more thorough and reliable target sensing capability.
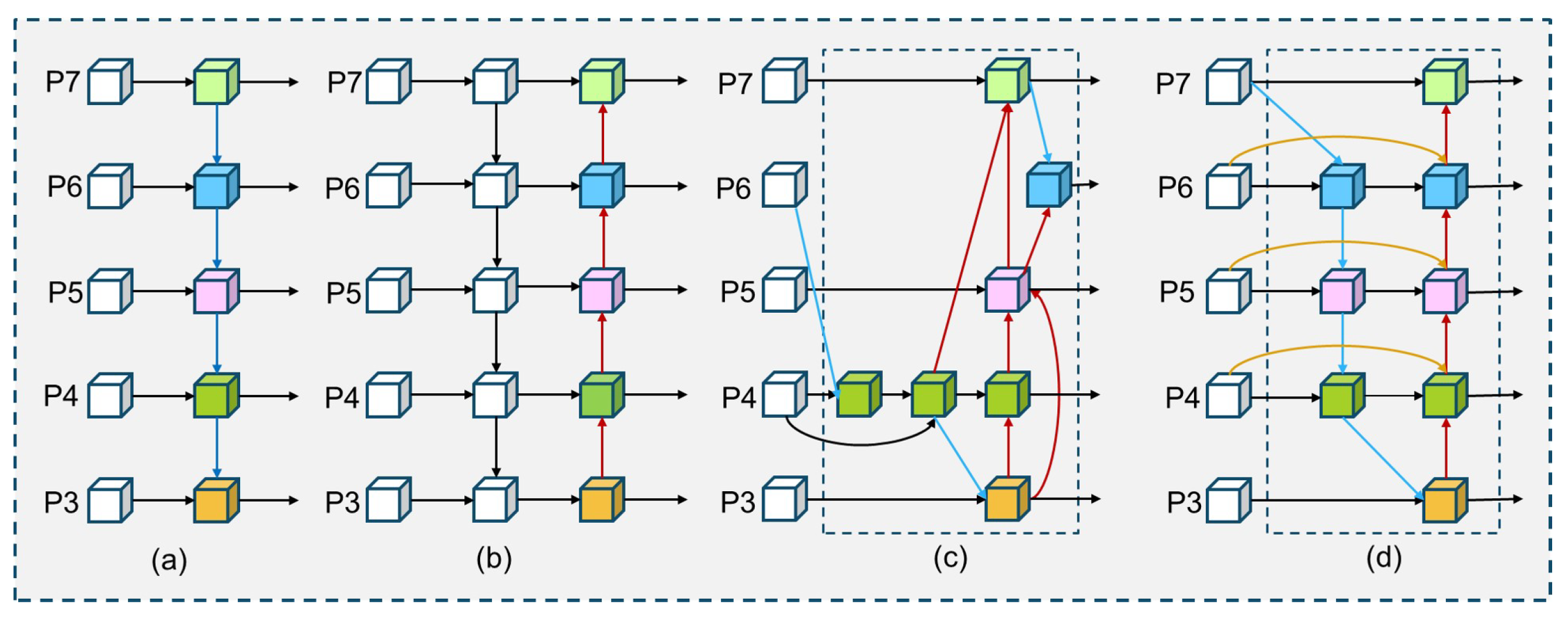
The neck section presents an enhanced fusion model utilizing a Bidirectional Feature Pyramid Network (BiFPN). This model facilitates information interoperability across feature levels through the weighted fusion of diverse scale feature information via bidirectional cross-scale connections. It strengthens the integration of high-level semantics with low-level detail features, thereby significantly improving the detection accuracy of multi-scale targets in complex environments.
Soft Non-Maximum Suppression (Soft-NMS) utilizes weight attenuation to dynamically modify the confidence levels of candidate boxes based on their overlap rather than outright rejection, thereby preserving more valid information. This substantially enhances the average accuracy of current object detection algorithms in the detection of multiple overlapping objects.
A test dataset was created to assess the detection model’s performance under various severe weather conditions, including three scenarios: rainy weather, hazy weather, and low-light environments.
The remainder of this paper is organized as follows:
Section 2 provides a comprehensive description of the proposed methodological improvements.
Section 3 subsequently presents extensive experimental validation, including ablation studies and generalization tests, along with comparative performance analyses against existing approaches. Finally,
Section 4 concludes the study by summarizing key findings and outlining potential directions for future research in this domain.
3. Experiments
3.1. Experimental Environment and Dataset
3.1.1. Experimental Environment
The experimental environment utilizes the Ubuntu 18.04.2 LTS operating system and a GPU network featuring an NVIDIA GeForce RTX 4090 Ti, which has 10 GB of video memory for experimental operations. The software environment consists of PyTorch v2.4.1 operating on the Ubuntu 20.04 system. The input image is standardized to 640 × 640, and the number of epochs is established at 300 during the training process. This study employs stochastic gradient descent (SGD) with a learning rate of 0.01 and a momentum of 0.01 for network optimization. This paper employs default parameters for training during the experiments.
3.1.2. Dataset Acquisition
This study verifies the performance of YOLO-SEA using a dataset of 1934 images sourced from the Roboflow website. The dataset encompasses eight categories: aircraft carriers, buoys, freighters, fishing boats, helicopters, lighthouses, passenger ships, and warships. These categories are selected based on their typicality in maritime environments, visual distinguishability, and the availability of sufficient annotated samples, ensuring a balanced class distribution conducive to effective model training and evaluation. The images are randomly partitioned into training, validation, and test sets in a 7:2:1 ratio. Labeling is conducted utilizing LabelMe.
Table 1 presents the details of the dataset.
3.2. Evaluation Models
The YOLOv8 model comprises five versions: YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, and YOLOv8x. The network characteristics remain consistent; however, there are variations in network depth and width. Experiments could theoretically be conducted using any of these versions. This study primarily focuses on the smallest version of the model, YOLOv8n, due to limitations in computational resources.
This paper evaluates the detection capability of YOLO-SEA using model size, detection speed per image, precision (P), recall (R), F1 score, mAP@0.5, mAP@0.5:0.95, and additional metrics. Evaluation metrics are defined based on specific parameters: true positives (TPs) refer to instances where the prediction accurately identifies a positive class, false positives (FPs) refer to instances where the prediction inaccurately identifies a positive class, and false negatives (FNs) refer to instances where the prediction inaccurately identifies a negative class. The ratio of their intersection to concatenation, known as the Intersection over Union (IoU), reflects the percentage of overlap between the bounding box and the true box.
3.2.1. Precision and Recall
Equation (
14) illustrates that precision [
36] is determined by the ratio of positively predicted samples to the total number of observed samples.
The recall rate is defined as the proportion of positive predictor samples accurately identified by the model relative to the total number of positive samples available. Equation (
15) calculates the recall rate.
Precision–recall curves (P-R curves) serve as effective representations of visualization model performance. The study by Boyd et al. [
37] presented recall on the x-axis and precision on the y-axis in its plots.
3.2.2. F1 Score
The F1 score [
36] provides an accurate evaluation of algorithm performance by considering both precision and recall. Equation (
16) illustrates the calculation of the F1 score.
In image recognition tasks, the F1 score serves as a metric for assessing an algorithm’s capability in target detection. This paper utilizes the F1 score as the primary metric for assessing model efficacy.
3.2.3. Average Precision mAP
The area beneath the precision–recall curve is equivalent to the average precision (AP) and can be computed using the subsequent equation.
Mean accuracy precision [
36] (mAP) serves as a comprehensive metric for evaluating the detection performance of a model, derived from a weighted average of the average precision (AP) values across each sample category.
In Equation (
18),
denotes the average precision value for class index
i, and
N represents the total number of classes in the training dataset. Setting the intersection over union (IoU) threshold to 0.5 results in the average precision being referred to as mAP@0.5. Conversely, when the IoU value ranges from 0.5 to 0.95, the average precision is denoted as mAP@0.5:0.95.
3.3. Optimal Decision-Making Experiments for SimAM Addition
This experiment assessed the impact of integrating the SimAM attention mechanism into the YOLOv8 architecture with SENetV2 and BiFPN frameworks. SimAM (Simple Attention Module) is a lightweight channel attention mechanism that enhances feature representation without adding extra convolution operations. In the experiments, SimAM was combined with SENetV2 to form the SESA module, incorporated into both the backbone and head layers, to evaluate its impact on model performance. The results show that integrating SimAM with SENetV2 (SESA) increased mAP@0.5 to 86.3%, significantly outperforming the original YOLOv8n model. This improvement is mainly due to SimAM’s ability to adaptively highlight important channel features during feature extraction while suppressing irrelevant ones. As a parameter-free method, SimAM avoids additional convolution operations, leading to no significant increase in inference time while enhancing accuracy.
The study also analyzed the effects of incorporating SimAM into various detection layers: small-object, large-object, and neck layers. The detection outcomes of incorporating SimAM at different positions are summarized in
Table 2. The results show that applying SimAM only to the small-object layer achieved an mAP@0.5 of 83.7%, indicating some benefit in small-object detection but not fully optimizing the feature representation. When applied to the large-object layer, the mAP@0.5 remained the same, suggesting minimal improvement for large objects, which already have robust feature representations. Applying SimAM to the neck layer resulted in a decrease in mAP@0.5 to 82.5%, likely due to redundant attention computations across layers, leading to excessive filtering and reduced performance. The best results were achieved by incorporating SimAM into the backbone layer, which enhanced detection accuracy with minimal computational cost. This approach is particularly effective for multi-scale, multi-object detection in marine environments, where adaptability is essential.
3.4. Ablation Experiments
The proposed enhancements—the SESA fusion attention mechanism, BiFPN, and Soft-NMS—were validated via ablation experiments, illustrating their substantial impact in terms of improving the performance of the baseline YOLOv8 model. The “✓” symbol denotes the application of a specific evaluation method.
Table 3 indicates that YOLOv8-n functions as the baseline for these experiments. The findings indicate that each enhancement significantly influences detection accuracy, recall, mAP@0.5, mAP@0.5:0.95, FLOPs, and model parameters, with especially marked improvements in the mAP metrics.
The introduction of the SESA module markedly improved the feature representation capability of Model B. The SESA module enhances the model’s sensitivity to essential features while mitigating redundancy via an inter-channel information recalibration mechanism. The mAP@0.5 improved from 82.4% to 84.2%, while mAP@0.5:0.95 increased to 56.8%. The number of model parametersincreased to 3,028,792, while the FLOPs remained at 8.2 G, demonstrating that SESA significantly enhances detection accuracy without additional computational costs.
The BiFPN module’s introduction enhanced Model C’s performance in multi-scale feature fusion, particularly improving small object detection. This module enhances feature integration via efficient bidirectional pathways and an adaptive weight allocation mechanism, achieving an mAP@0.5 of 84.1% and an mAP@0.5:0.95 of 54.9%. The number of parameters was reduced to 2,789,572, while the computational load remained at 8.2 G, illustrating the module’s capacity to improve performance without compromising with respect to a lightweight model structure.
The integration of Soft-NMS into Model D substantially reduced false detections associated with traditional NMS in high-overlap situations. The adjustment resulted in a significant enhancement in performance, with the mAP@0.5 increasing to 85.0% and mAP@0.5:0.95 rising to 57.6%. The increase in FLOPs to 8.9G was accompanied by a notable enhancement in detection performance in dense scenes due to the implementation of this post-processing strategy, resulting in an effective balance between accuracy and efficiency.
The incorporation of Soft-NMS into Model D significantly diminished false detections linked to conventional NMS in scenarios with high overlap. The adjustment led to a notable improvement in performance, with the mAP@0.5 increasing to 85.0% and mAP@0.5:0.95 rising to 57.6%. The increase in FLOPs to 8.9 G resulted in a significant improvement in detection performance in dense scenes, which is attributable to the application of this post-processing strategy, thereby achieving a balance between accuracy and efficiency.
3.5. Comparison of the Overall Performance of YOLO-SEA and YOLOv8n
Table 4 presents a detailed performance comparison between the YOLOv8n model and the YOLO-SEA model introduced in this study. The enhanced algorithm demonstrates superior performance compared to YOLOv8 in terms of average mAP accuracy, achieving improvements of 5.4% in mAP@0.5 and 7.2% in mAP@0.5:0.95 for YOLO-SEA. The enhanced model algorithm exhibits marginally reduced parameters and lighter weights in terms of model space complexity, while the FLOPs remain consistent with those of the original model. The enhanced model demonstrates increased accuracy with a comparatively low parameter count while maintaining real-time inference speed. The denser fusion paths, broader receptive fields, and enhanced contextual information offer adequate feature support for detection processes, thereby improving target localization and classification, particularly in complex background scenarios.
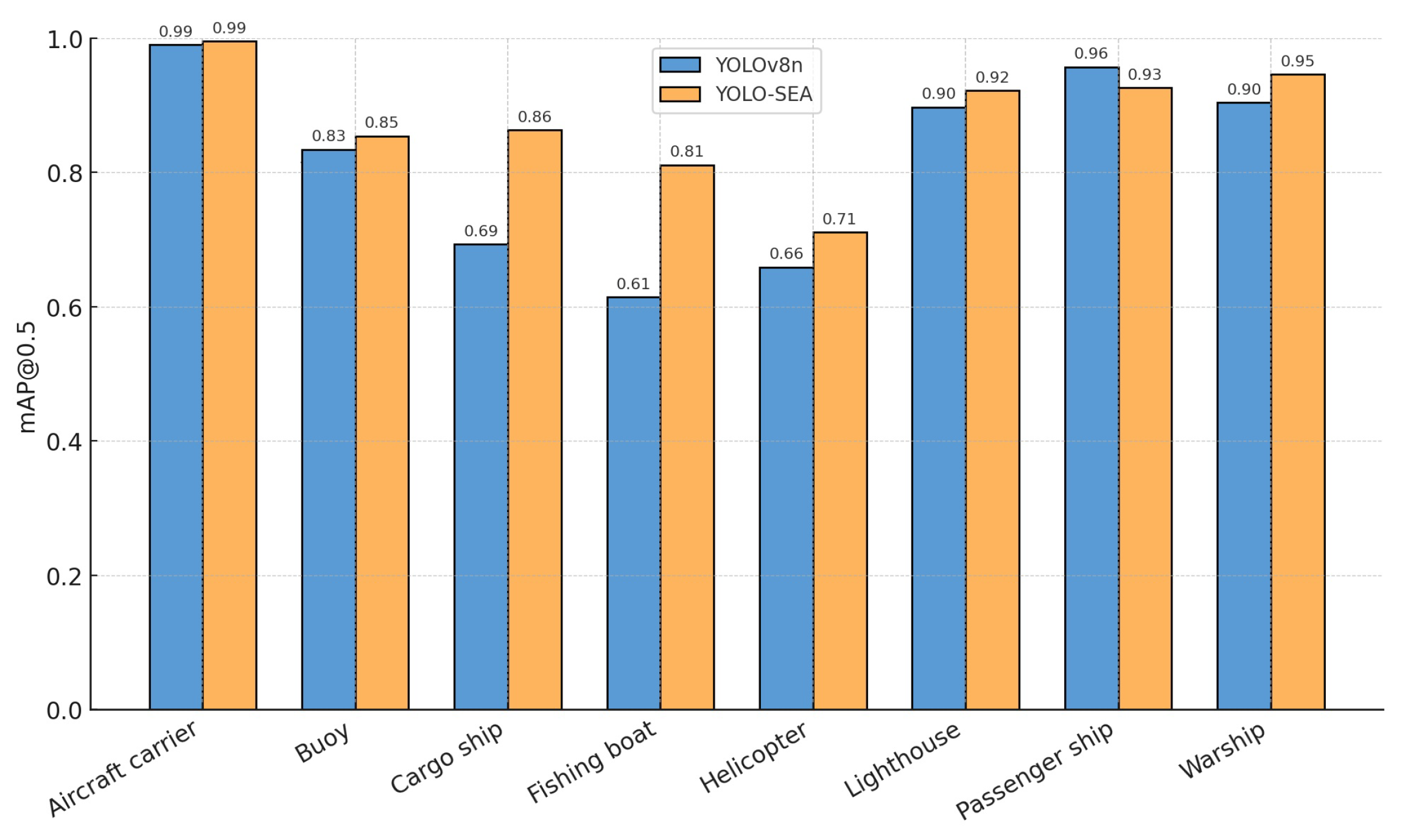
Figure 8 presents the mAP@0.5 for eight classes within the test set, contrasting YOLO-SEA with YOLOv8n. The proposed model demonstrates improvements across all categories, with the most notable enhancements in the cargo ship and fishing boat classes. The experimental results indicate that the enhanced model produces detection regions that better correspond to the actual object boundaries, improving the accuracy of multi-class object detection and localization in maritime environments.
This paper visualizes and analyzes the detection results to evaluate the effectiveness of the YOLO-SEA model in identifying various categories of objects at sea.
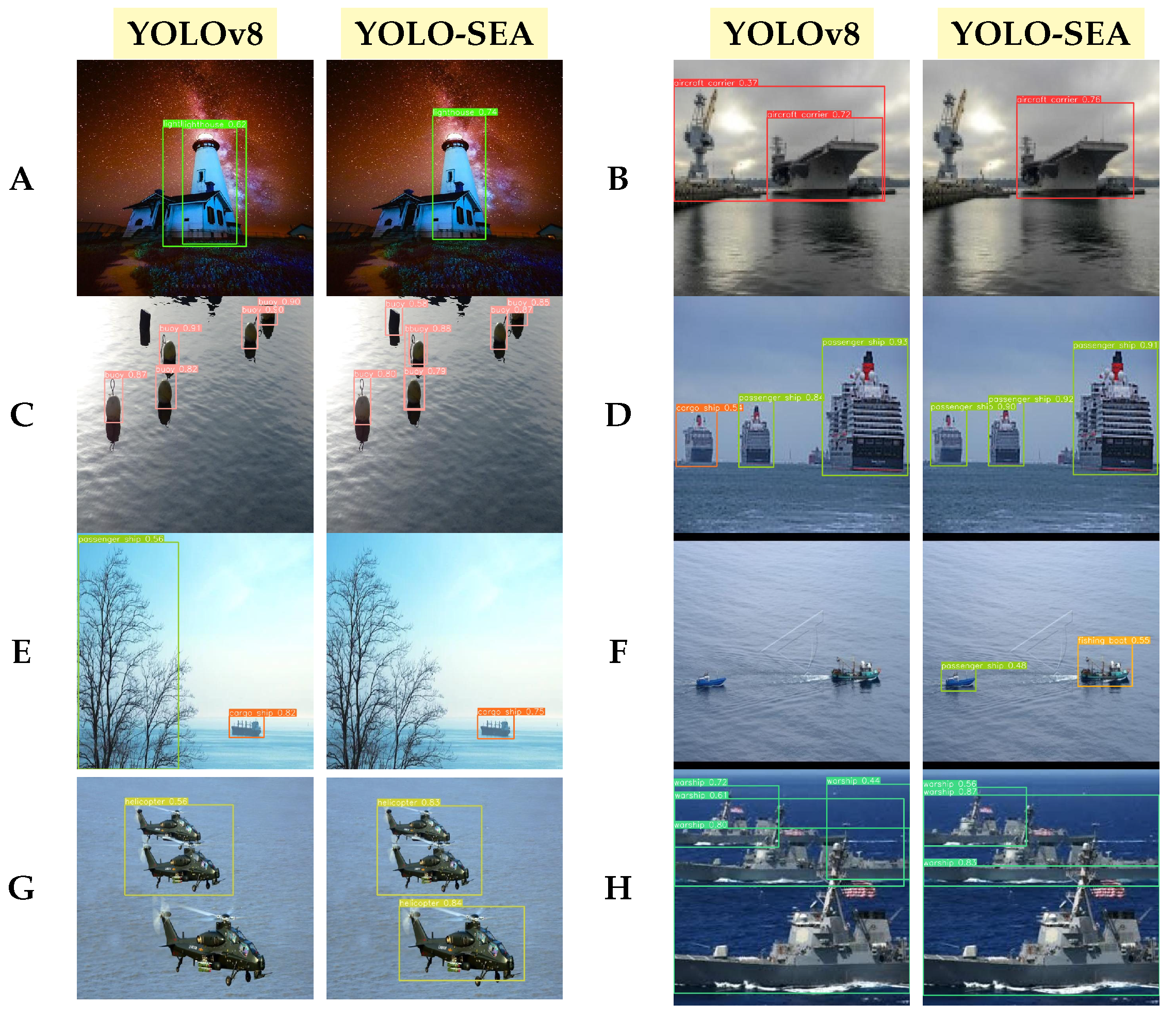
Figure 9 presents a comparative analysis of the detection performance between the YOLO-SEA model and the original YOLOv8 across various maritime scenarios. Analysis of various scenarios indicates that YOLO-SEA surpasses YOLOv8 in target differentiation, false detection management, omission correction, and the detection of small targets against complex backgrounds. In scenario (A), YOLOv8 misclassifies a house as a lighthouse, achieving a recognition accuracy of 62%. In contrast, YOLO-SEA effectively eliminates interfering targets and accurately identifies a lighthouse with a recognition accuracy of 74%. This demonstrates YOLO-SEA’s superior classification capability in complex backgrounds compared to the original YOLOv8.
In scene (B), YOLOv8 mistakenly identifies other objects as aircraft carriers, with a recognition accuracy of 72%, but false detections persist. YOLO-SEA improves recognition accuracy to 76%, successfully identifying the aircraft carrier and demonstrating its stronger target feature extraction. Scene (C) showcases YOLO-SEA’s advantage in detecting small targets. While YOLOv8 misses the buoys, YOLO-SEA correctly detects all of them, proving its robustness in small object detection. In scene (D), YOLOv8 misidentifies a passenger ship as a cargo ship, but YOLO-SEA accurately classifies the vessel, achieving over 90% accuracy and showcasing better stability in distinguishing similar targets.
Scene (E) reveals that YOLOv8, though accurate with cargo ships, mistakenly classifies an adjacent tree, causing detection ambiguity. YOLO-SEA maintains correct cargo ship recognition while improving target boundary precision. Scene (F) highlights YOLO-SEA’s capability to detect small targets at a distance, whereas YOLOv8 fails to spot a fishing boat. YOLO-SEA excels in detecting low-resolution features in complex scenes. Scene (G) emphasizes YOLO-SEA’s multi-target detection strength, outperforming YOLOv8, which fails to detect a helicopter in a multi-target setting. YOLO-SEA achieves over 80% accuracy. In scene (H), YOLOv8 struggles with redundant detection frames for warships, whereas YOLO-SEA eliminates redundancy and boosts recognition accuracy. Overall, YOLO-SEA, enhanced by improved modules, excels in maritime object detection, providing an efficient solution for complex surveillance tasks.
The multi-target detection task requires the model to identify and localize multiple targets simultaneously, with the complex maritime environment adding to the detection challenges. Experimental results show that YOLOv8 suffers from issues like leakage detection, false detections, and overlapping anchor frames in multi-target scenarios. When targets are close or the background is cluttered, some targets are missed, leading to leakage detection. Additionally, similar targets are often misclassified, reducing accuracy. YOLOv8 also struggles with multiple detection frames for a single target, complicating processing. As shown in
Figure 10, YOLO-SEA improves target differentiation and reduces misdetections by optimizing feature extraction and fusion, while Soft-NMS removes redundant frames, enhancing detection accuracy and stability. Key improvements include a shallow information-dense fusion module for better small target feature learning and multi-scale feature fusion to handle varying target sizes. This optimization boosts target differentiation in complex backgrounds, improving detection robustness. YOLO-SEA outperforms YOLOv8 in detecting small targets, managing multi-target occlusions, and adapting to complex environments, providing a more stable and efficient solution for maritime multi-target detection.
3.6. Evaluation of the Model’s Performance Across Various Weather Conditions
The marine environment is intricate and variable, presenting significant challenges for the accurate detection of ships, buoys, and other marine objects under adverse weather conditions. Obtaining a substantial quantity of high-quality images in adverse weather conditions within the actual marine environment presents significant challenges. This paper employs an artificial synthesis method to generate images of maritime objects across various weather conditions to evaluate the detection model’s performance. This paper synthesizes three typical severe weather scenarios—rain, fog, and low light—to create a hybrid weather test set. The YOLO-SEA model is subsequently evaluated using the test set to systematically analyze the impact of various severe weather conditions on maritime object detection performance. The experimental results elucidate the model’s adaptability in complex marine environments and serve as a reference for enhancing the robustness of maritime object detection. This content provides a detailed description of the image synthesis process across various weather conditions.
Synthesis of rain images: The rain layer exhibits various tilt angles. We integrate rainfall patterns with tilt angles of
degrees, 0 degrees, and 45 degrees into the preprocessed images of maritime objects to synthesize ship images under rainy conditions. The equation for synthesized rain is expressed as follows:
where
represents the initial input image,
denotes the generated simulated raindrop effect image, and
is the blending weight that regulates the impact of the raindrop effect on the final image. Typically,
assumes values between 0 and 1, with lower values indicating a more pronounced raindrop effect. This study establishes
to equilibrate the original image with the raindrop effect, thereby aligning the simulation outcomes more closely with actual rainy-day conditions.
Figure 11a presents an example of a synthesized image depicting a rainy day.
Synthesis of haze images: Haze is a prevalent adverse weather phenomenon encountered in maritime transportation. The atmospheric scattering theory posits that haze primarily results from the scattering of particles present in the atmosphere. Haze significantly diminishes image quality in the process of detecting objects at sea. To accurately replicate real sea conditions, the atmospheric scattering model [
38] is employed to synthesize the haze image. Synthesized fog is expressed as follows:
In this formula,
denotes the synthesized dense haze image,
signifies the original image,
indicates medium transmittance, and
represents global atmospheric light. The dielectric transmittance (
) exhibits an exponential decay concerning the propagation distance of light, as described by
, where
represents the scattering factor attributed to atmospheric particles and
denotes the distance to the target object. Adjusting the atmospheric scattering factor (
) allows for the generation of varying degrees of haze in images of maritime objects. In this experiment,
takes values of
.
Figure 11b presents an example of a synthesized haze image.
The synthesis of low-light images indicates that low-light conditions at sea can cause blurring of a ship’s silhouette, potentially leading to confusion with coastal buildings and complicating detection efforts. Retinex theory posits that an image can be represented as the product of light and reflectivity. The formula is presented as follows:
In this context,
, where
represents the image domain, and the low-light image (
) is derived by multiplying the reflectance image (
) by the illumination image (
). A low-light environment diminishes brightness and contrast and results in a loss of detail. This paper employs the gamma transform (
) to simulate low-light conditions, with
representing the attenuation coefficient that regulates the extent of brightness attenuation.
.
Figure 11c presents an example of a synthesized low-light image.
This experiment employs YOLOv8n as a baseline comparison model, training it on original natural images and testing it with mixed-weather images to evaluate the impact of severe weather conditions on detection performance for maritime objects.
Table 5 illustrates that the detection performance on mixed severe-weather test images is notably diminished, with the original YOLOv8 model underperforming compared to our proposed YOLO-SEA model across multiple evaluation metrics. The YOLO-SEA model demonstrates the ability to mitigate specific environmental disturbances in mixed severe-weather test images, achieving enhanced ship detection accuracy while reducing the model’s parameter count relative to the original YOLOv8 model.
To evaluate the detection performance of the models across various environments, we present examples of maritime object detection under differing weather conditions for each model. This analysis assesses the relevance of the models in practical maritime contexts.
Figure 12 presents the detection outcomes of YOLOv8n and the YOLO-SEA model introduced in this study across various weather conditions, encompassing both the original images and the detection results influenced by environmental factors.
Figure 12a,b illustrate that images before and following processing exhibit minimal impact on larger targets during moderate rainfall, whereas smaller targets are more susceptible to disturbances caused by raindrops from various angles. Our model demonstrates superior performance in minimizing leakage and false detection compared to the original YOLOv8 model, resulting in a notable enhancement in overall detection efficacy despite the persistence of some leakage instances.
Figure 12c,d illustrate that varying concentrations of haze impact ship detection differently. In conditions of thin haze, the false detection rate is elevated (as observed in scene (c)). Conversely, as haze concentration increases, detection accuracy declines, particularly resulting in the omission of small target ships due to haze occlusion. The original YOLOv8 model demonstrates significant limitations in detecting targets under haze conditions, with
, whereas the YOLO-SEA model retains the ability to recognize target objects in high-haze environments. Despite a lower confidence level, YOLO-SEA offers more precise target location information.
The impact of varying lighting conditions on ship detection is notably pronounced in low-light environments.
Figure 12e,f illustrate that an increase in the low-light parameter correlates with a decrease in image contrast, leading to less distinct ship features. This reduction in prominence adversely impacts the model’s capacity to identify detailed features, thereby compromising detection outcomes. At
, the original YOLOv8 model demonstrates significant limitations in object detection, whereas the YOLO-SEA model maintains effective target identification. Furthermore, the localization capability of YOLO-SEA surpasses that of YOLOv8, even though an increase in
results in a reduction in detections and an elevated risk of misdetection. In comparison to the original YOLOv8 model, YOLO-SEA exhibits enhanced robustness in detecting ships across various complex environments. Compared to the original YOLOv8 model, YOLO-SEA demonstrates enhanced robustness and improved accuracy in recognizing ship categories and positional information, as evidenced by both quantitative results and detection examples.
3.7. Comparison of the Performance of Leading Algorithms
This paper conducts a comprehensive evaluation of the detection performance of the YOLO-SEA model by comparing it with Faster R-CNN, SSD, RT-DETR, and various models from the YOLO series. As shown in
Table 6, the tabular data indicates that YOLO-SEA demonstrates superior performance compared to existing models regarding detection accuracy (mAP@0.5 and mAP@0.5:0.95), particularly in the detection of small targets and complex backgrounds. YOLO-SEA achieves a favorable balance between the number of parameters and computational effort, enhancing its potential for practical applications, particularly in resource-intensive scenarios. There remain areas of concern, particularly regarding the optimization of lightweight design and computational efficiency, which could facilitate future improvements.
Conventional target detection models Faster R-CNN and SSD exhibit detection accuracies of 78.6 and 80.8, respectively—significantly lower than that of YOLO-SEA. Their reliance on Region Proposal Network (RPN) or Anchor-Based methods renders them susceptible to interference in complex backgrounds and results in substantial computational demands, complicating the fulfillment of real-time detection requirements. RT-DETR utilizes the Transformer architecture, known for its effective global feature extraction. However, its parameter count of 32 million and its 103.5 billion FLOPs result in significant computational overhead, surpassing the requirements for real-time applications. In contrast, YOLO-SEA employs only 2.8 million parameters and 8.1 billion FLOPs, resulting in a substantial reduction in computational resource consumption while achieving enhanced detection accuracy, particularly for small targets and complex backgrounds, demonstrating clear advantages.
The YOLO-series models are widely used for real-time object detection due to their lightweight design and high efficiency. Among them, YOLOv7 achieved a mAP@0.5 of 83.1, while YOLOv6 obtained a mAP@0.5:0.95 of 54.5. However, these gains came with increased computational complexity. For instance, YOLOv5 has a computational load of 16.0 GFLOPs, whereas YOLOv7 reaches 105.2 GFLOPs. Despite improved accuracy, their high computational cost limits their use in resource-constrained environments. YOLOv8, with a reduced count of 8.2 GFLOPs, still lags behind YOLO-SEA in detection accuracy. YOLO-SEA improves feature extraction through the SESA fusion attention module and uses BiFPN for effective feature fusion, achieving superior performance within the same computational limits.
Models YOLOv9 to YOLOv12 focused on reducing model size and complexity. While YOLOv9 showed a reduction in parameters and computational load, it still fell short of YOLO-SEA by 2.9 and 2.7 points in mAP@0.5 and mAP@0.5:0.95, respectively, indicating that lightweight optimizations can compromise accuracy. In contrast, YOLO-SEA strikes a better balance. YOLOv10 and YOLOv11 improved detection accuracy but still did not surpass YOLO-SEA, despite similar computational complexity, demonstrating YOLO-SEA’s superior feature representation. Although YOLOv11 and YOLOv12 offered slight improvements in the number of parameters and FLOPs, they still did not exceed the performance of YOLO-SEA, which offers an optimal balance between accuracy and efficiency.
YOLO-SEA stands out for balancing detection accuracy, computational efficiency, and model size, excelling particularly in small object detection and complex backgrounds. Compared to other YOLO models, YOLO-SEA significantly reduces computational resource consumption while outperforming previous versions, especially in the mAP@0.5:0.95 metric, with a notable score of 60.8. While it lags behind YOLOv9, YOLOv11, and YOLOv12 in terms of lightweight design, this gap presents opportunities for future optimization. Techniques such as pruning and knowledge distillation could further reduce the model size while maintaining precision, enhancing YOLO-SEA’s competitiveness in real-world applications.
3.8. Experiments on Generalizability
To evaluate the generalization ability and effectiveness of the YOLO-SEA model in maritime object detection, comparative experiments were conducted using the publicly available
6_class_final [
39] dataset. Two commonly utilized metrics, mAP@0.5 and mAP@0.5:0.95, were chosen to evaluate detection performance. As shown in
Table 7, YOLO-SEA attained an mAP@0.5 of 81.7% and an mAP@0.5:0.95 of 61.6%, indicating a notable enhancement compared to the baseline YOLOv8n, which recorded an mAP@0.5 of 78.8% and an mAP@0.5:0.95 of 58.4%. This enhancement demonstrates that the proposed model exhibits superior performance in detecting objects across different scales, providing more accurate feature extraction while sustaining high detection accuracy in intricate maritime environments. It exhibited enhanced adaptability in identifying small objects and medium-to-large vessels. In the
Fish-b (torpedo boat) and
Warship categories, YOLO-SEA attained detection accuracies of 90.5% and 84.8%, respectively, exceeding YOLOv8n’s performance (89.7% and 77.2%) and surpassing all other models in the
Warship category, thereby demonstrating its enhanced feature extraction capabilities. Furthermore, in the
Container and
Cruise categories, YOLO-SEA achieved detection accuracies of 71.3% and 97.2%, respectively, demonstrating significant enhancements compared to YOLOv8n, which recorded accuracies of 58.1% and 95.3%. It notably surpassed all YOLO-series and RT-DETR models in container detection, demonstrating enhanced generalization ability in identifying complex ship categories. YOLO-SEA achieved overall mAP@0.5 and mAP@0.5:0.95 scores of 81.7% and 61.6%, respectively, demonstrating superior performance compared to all other evaluated models, thereby confirming its effective detection capability in maritime contexts.
While YOLO-SEA excels in numerous categories, opportunities for optimization remain within specific areas. In category A, the mAP of YOLO-SEA is 51.6%, showing a minor improvement over YOLOv8n, at 50.6%, yet remaining below YOLOv11, which stands at 55.0%. This phenomenon may be associated with the smaller size and greater environmental disturbance of the targets in this category, which limits the model’s ability to learn their features. The RT-DETR series of models demonstrates superior performance in certain categories, such as Cruisers, with RT-DETR-l achieving 99.3% accuracy compared to YOLO-SEA’s 99.1%. This indicates that the RT-DETR models remain competitive in specific large target categories. In the future, YOLO-SEA can be optimized to improve its detection capabilities in complex environments with small targets, and its adaptability for specific categories can be enhanced to further elevate its overall detection performance. YOLO-SEA demonstrates a strong generalization ability in marine environments, effectively adapting to various target detection tasks. It achieves high detection accuracy while remaining lightweight, offering a reliable solution for maritime surveillance, safety, and intelligent shipping.
4. Conclusions
This paper proposes YOLO-SEA, a high-precision, multi-class maritime object detection algorithm optimized for multi-target, multi-scale, and multi-category detection, particularly in complex marine environments. The model incorporates the SESA fusion attention mechanism within the backbone network, effectively integrating the advantages of both approaches in feature modeling. SENetV2 enhances global and contextual information by utilizing adaptive channel weights, whereas SimAM effectively captures essential features across both spatial and channel dimensions. The complementary synergy of the two enhances SESA’s ability to perceive key information while effectively suppressing redundant features, thereby significantly improving feature expression capability and detection accuracy.
The weighted bidirectional feature pyramid network (BiFPN) is employed to enhance feature fusion. The structure of the target object is tailored to align with maritime scenarios, thereby improving the detection capability for small targets. Additionally, target localization is refined using Soft-NMS to increase recall rates and detection stability. Experiments indicate that YOLO-SEA achieves a detection accuracy of mAP@0.5 = 88.2% on the dataset utilized in this study, surpassing that of the original model, YOLOv8-n, while also demonstrating consistent detection performance across various severe weather conditions. Furthermore, generalizability experiments conducted on various ocean-related datasets indicate that YOLO-SEA surpasses current mainstream methods regarding detection accuracy and computational efficiency, thereby exhibiting enhanced robustness and adaptability. YOLO-SEA effectively balances model compression and detection performance, making it appropriate for offshore mobile devices with constrained computational resources. It offers efficient and reliable detection solutions for ship monitoring, maritime cruising, and emergency rescue scenarios. Future work will focus on the design of a more lightweight model, the improvement of small object detection accuracy, and further validation and optimization of the model’s performance under more complex maritime environments to broaden its practical applicability. In addition, we plan to expand the dataset to include additional categories such as engineering ships and offshore vessels, thereby enhancing the model’s ability to recognize a wider variety of maritime targets and improving its adaptability in diverse real-world scenarios.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





