
Multiscale Attention Fusion for Depth Map Super-Resolution Generative Adversarial Networks

Abstract
1. Introduction
2. Related Works
2.1. Conventional Color-Guided Depth Map Super-Resolution
2.2. Neural-Networks-Based Depth Map Super-Resolution
2.3. Generative Adversarial Network Based Color Image Super-Resolution
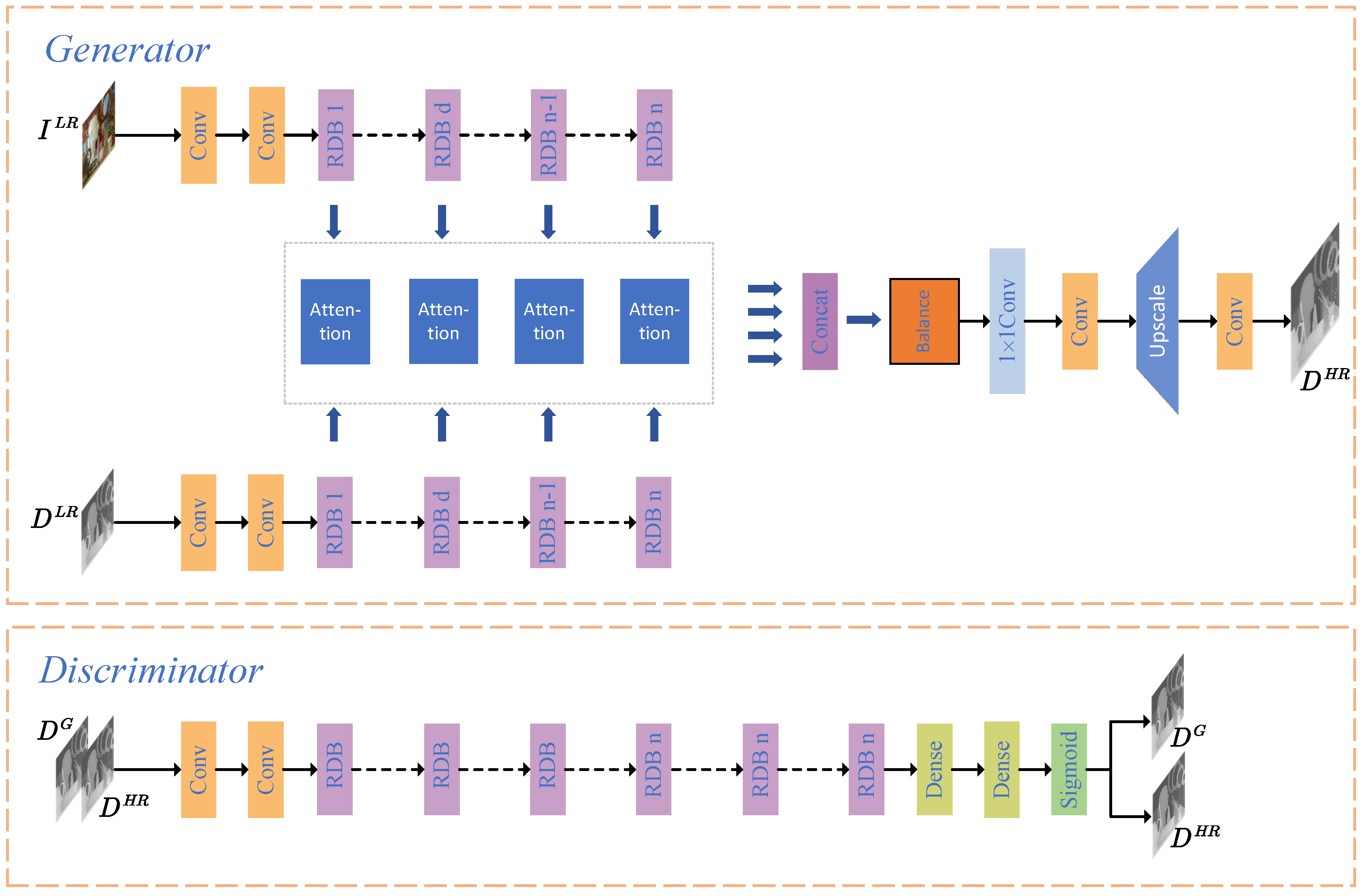
3. Multiscale Attention Fusion for Depth Map Super-Resolution Generative Adversarial Networks
3.1. Framework
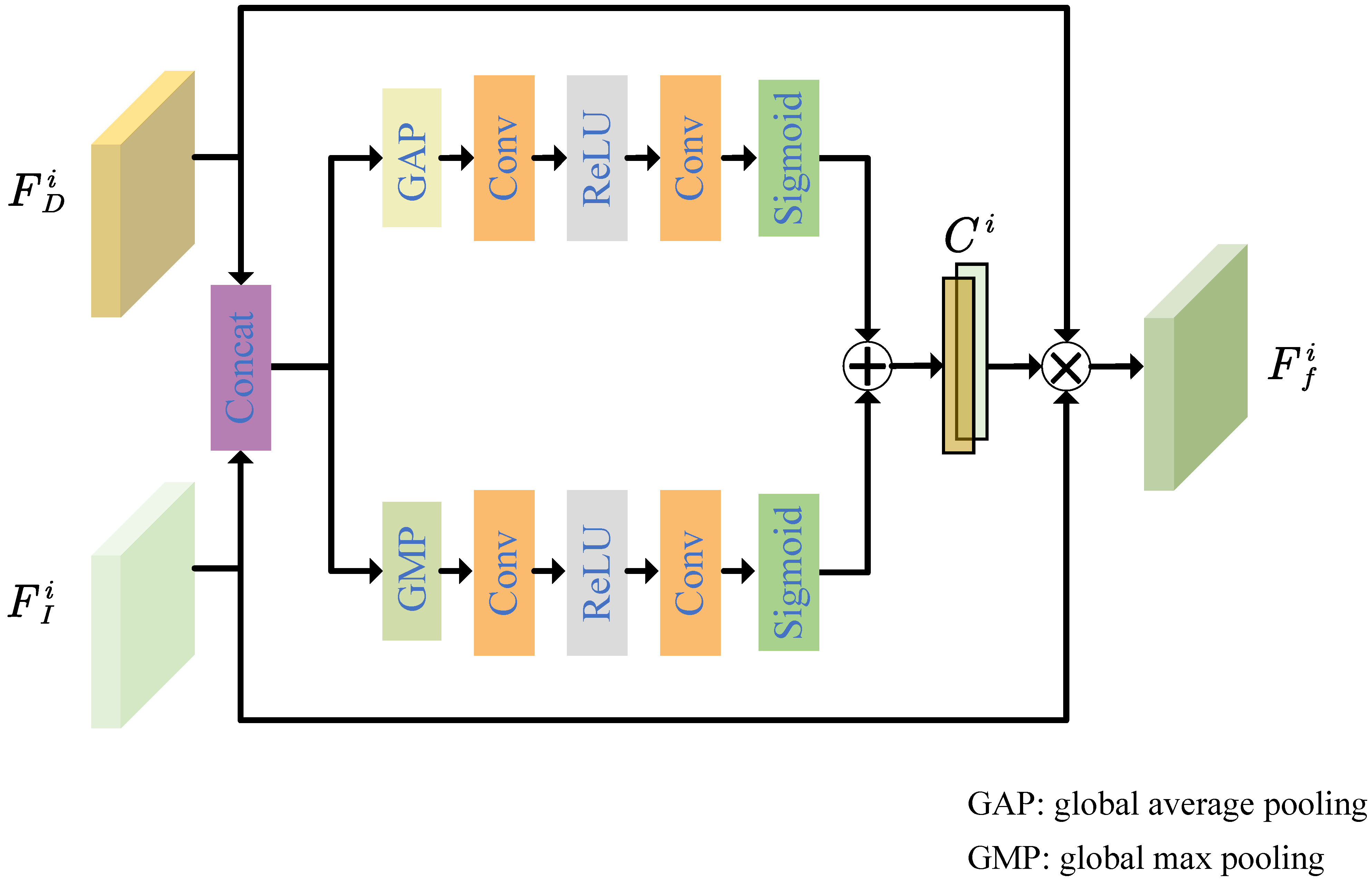
3.2. Hierarchical Color and Depth Attention Fusion Module
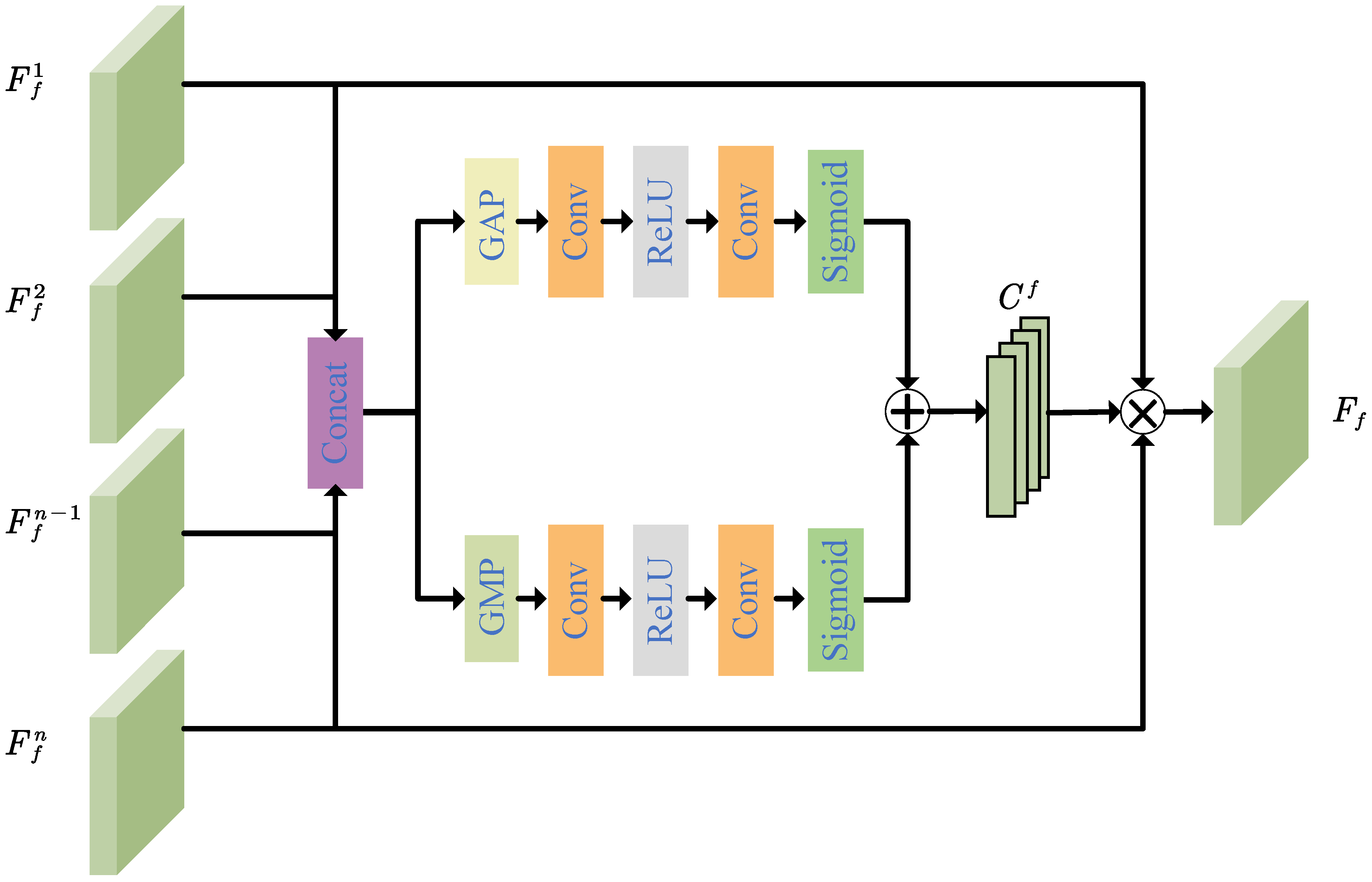
3.3. Multiscale Fused Feature Balance Module
3.4. Relativistic Standard Generative Adversarial Networks
4. Experimental Results
4.1. Parameter Setting
4.2. Datasets
- Training Datasets
- Testing Datasets
4.3. Evaluation Metrics
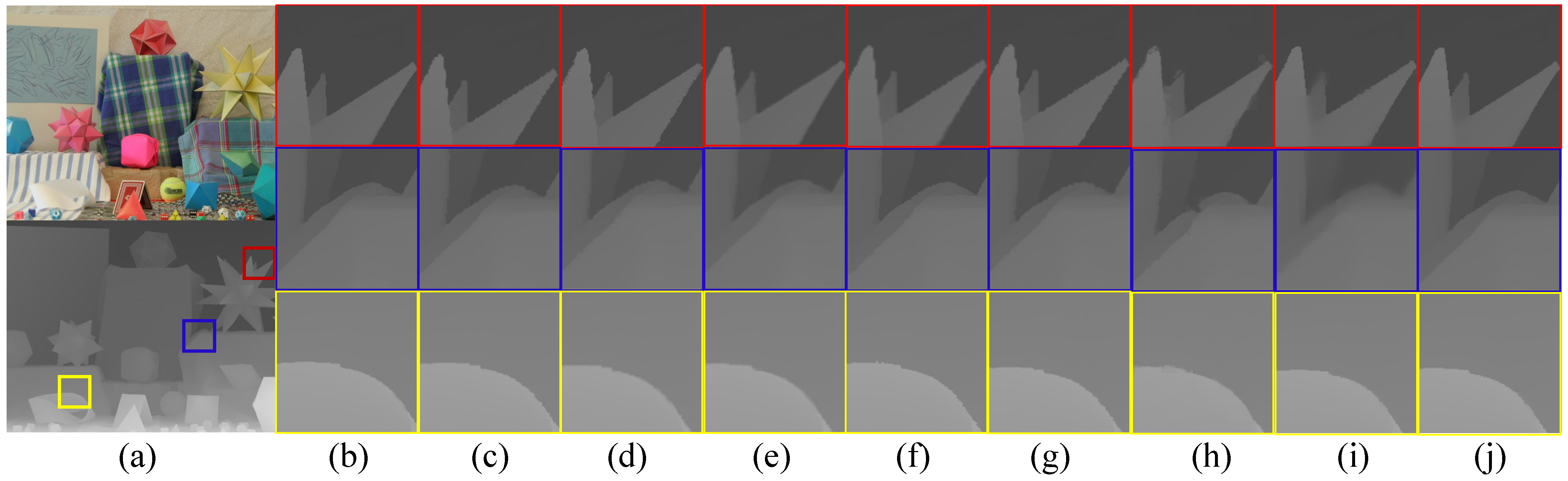
4.4. Comparison of Different Numbers of RDBs
4.5. Comparison of GAN Types
4.6. Comparison of Generator Losses
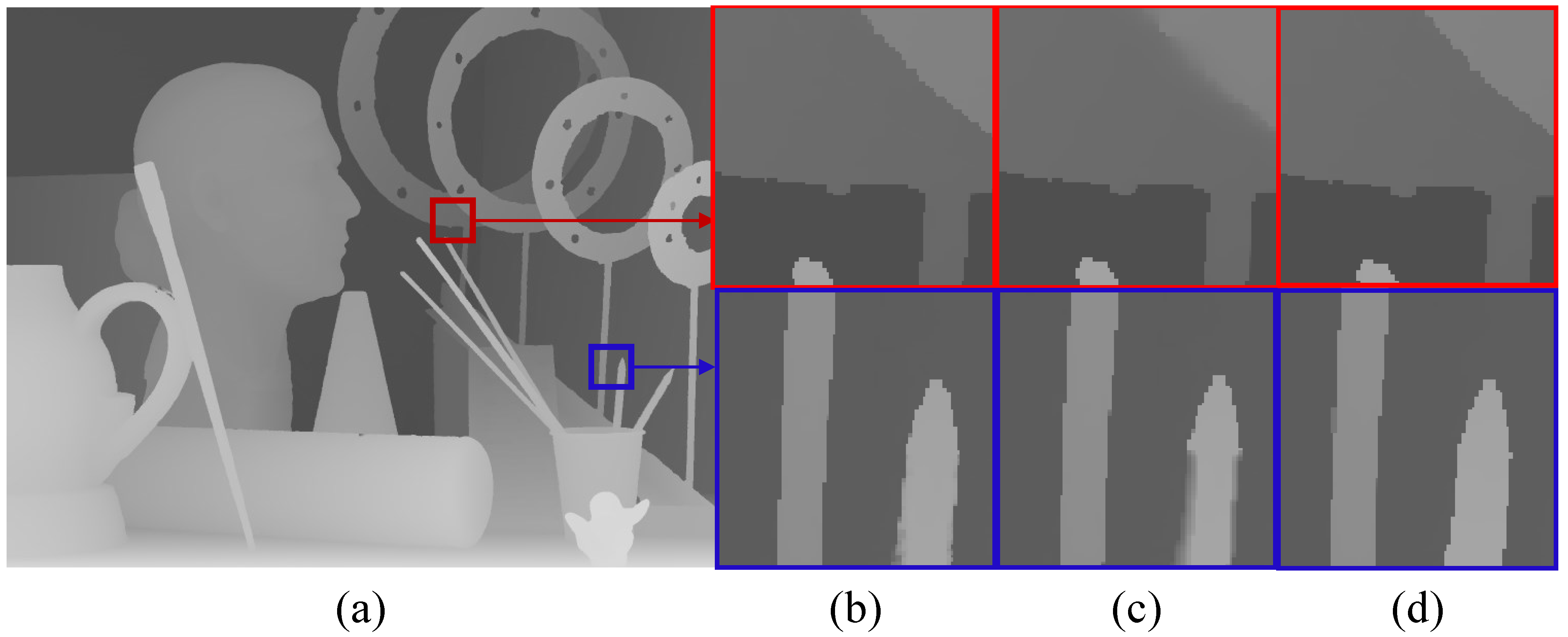
4.7. Experimental Results on Middlebury Datasets
4.8. Experimental Results on Real Datasets
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kopf, J.; Cohen, M.; Lischinski, D.; Uyttendaele, M. Joint Bilateral Upsampling. ACM Trans. Graph. 2007, 26, 96-es. [Google Scholar] [CrossRef]
- Diebel, J.; Thrun, S. An Application of Markov Random Fields to Range Sensing. In Proceedings of the 18th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 5–8 December 2005; pp. 291–298. [Google Scholar]
- Hui, T.W.; Loy, C.C.; Tang, X. Depth Map Super-Resolution by Deep Multi-Scale Guidance. In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9907, pp. 353–369. [Google Scholar] [CrossRef]
- Ye, X.; Duan, X.; Li, H. Depth Super-Resolution with Deep Edge-Inference Network and Edge-Guided Depth Filling. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1398–1402. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar] [CrossRef]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. In Proceedings of the Computer Vision—ECCV 2018 Workshops, Munich, Germany, 8–14 September 2018; pp. 63–79. [Google Scholar]
- Park, J.; Kim, H.; Tai, Y.-W.; Brown, M.S.; Kweon, I. High quality depth map upsampling for 3D-TOF cameras. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1623–1630. [Google Scholar] [CrossRef]
- Jeong, J.; Kim, J.; Jeon, G. Joint-adaptive bilateral depth map upsampling. Signal Process. Image Commun. 2014, 29, 506–513. [Google Scholar] [CrossRef]
- Liu, M.; Tuzel, O.; Taguchi, Y. Joint Geodesic Upsampling of Depth Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 169–176. [Google Scholar] [CrossRef]
- Min, D.; Lu, J.; Do, M.N. Depth Video Enhancement Based on Weighted Mode Filtering. IEEE Trans. Image Process. 2012, 21, 1176–1190. [Google Scholar] [CrossRef] [PubMed]
- Fu, M.; Zhou, W. Depth map super-resolution via extended weighted mode filtering. In Proceedings of the Visual Communications and Image Processing, Chengdu, China, 27–30 November 2016; pp. 1–4. [Google Scholar]
- Lo, K.; Wang, Y.F.; Hua, K. Edge-Preserving Depth Map Upsampling by Joint Trilateral Filter. IEEE Trans. Cybern. 2018, 48, 371–384. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Gong, L. Analysis and improvement of joint bilateral upsampling for depth image super-resolution. In Proceedings of the 2016 8th International Conference on Wireless Communications & Signal Processing (WCSP), Yangzhou, China, 13–15 October 2016; pp. 1–5. [Google Scholar]
- Zuo, Y.; Wu, Q.; Zhang, J.; An, P. Explicit Edge Inconsistency Evaluation Model for Color-Guided Depth Map Enhancement. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 439–453. [Google Scholar] [CrossRef]
- Lu, J.; Min, D.; Pahwa, R.S.; Do, M.N. A revisit to MRF-based depth map super-resolution and enhancement. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 985–988. [Google Scholar] [CrossRef]
- Mac Aodha, O.; Campbell, N.D.F.; Nair, A.; Brostow, G.J. Patch Based Synthesis for Single Depth Image Super-Resolution. In Computer Vision—ECCV 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 71–84. [Google Scholar]
- Xie, J.; Feris, R.S.; Sun, M. Edge-Guided Single Depth Image Super Resolution. IEEE Trans. Image Process. 2016, 25, 428–438. [Google Scholar] [CrossRef] [PubMed]
- Lo, K.; Hua, K.; Wang, Y.F. Depth map super-resolution via Markov Random Fields without texture-copying artifacts. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 1414–1418. [Google Scholar]
- Li, J.; Lu, Z.; Zeng, G.; Gan, R.; Zha, H. Similarity-Aware Patchwork Assembly for Depth Image Super-resolution. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3374–3381. [Google Scholar]
- Li, Y.; Xue, T.; Sun, L.; Liu, J. Joint Example-Based Depth Map Super-Resolution. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, VIC, Australia, 9–13 July 2012; pp. 152–157. [Google Scholar] [CrossRef]
- Ferstl, D.; Rüther, M.; Bischof, H. Variational Depth Superresolution Using Example-Based Edge Representations. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 513–521. [Google Scholar]
- Xie, J.; Feris, R.S.; Yu, S.; Sun, M. Joint Super Resolution and Denoising From a Single Depth Image. IEEE Trans. Multimed. 2015, 17, 1525–1537. [Google Scholar] [CrossRef]
- Kiechle, M.; Hawe, S.; Kleinsteuber, M. A Joint Intensity and Depth Co-sparse Analysis Model for Depth Map Super-resolution. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1545–1552. [Google Scholar]
- Zhang, Y.; Zhang, Y.; Dai, Q. Single depth image super resolution via a dual sparsity model. In Proceedings of the 2015 IEEE International Conference on Multimedia Expo Workshops (ICMEW), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Zheng, H.; Bouzerdoum, A.; Phung, S.L. Depth image super-resolution using internal and external information. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 1206–1210. [Google Scholar]
- Wang, Z.; Ye, X.; Sun, B.; Yang, J.; Xu, R.; Li, H. Depth upsampling based on deep edge-aware learning. Pattern Recognit. 2020, 103, 107274. [Google Scholar] [CrossRef]
- Zuo, Y.; Fang, Y.; An, P.; Shang, X.; Yang, J. Frequency-Dependent Depth Map Enhancement via Iterative Depth-Guided Affine Transformation and Intensity-Guided Refinement. IEEE Trans. Multimed. 2021, 23, 772–783. [Google Scholar] [CrossRef]
- Zuo, Y.; Fang, Y.; Yang, Y.; Shang, X.; Wang, B. Residual dense network for intensity-guided depth map enhancement. Inf. Sci. 2019, 495, 52–64. [Google Scholar] [CrossRef]
- Denton, E.L.; Chintala, S.; Szlam, A.; Fergus, R. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks. In Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; 2015; Volume 8, Available online: https://proceedings.neurips.cc/paper/2015/hash/aa169b49b583a2b5af89203c2b78c67c-Abstract.html (accessed on 16 May 2023).
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Huang, X.; Li, Y.; Poursaeed, O.; Hopcroft, J.; Belongie, S. Stacked Generative Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1866–1875. [Google Scholar] [CrossRef]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar] [CrossRef]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Hirschmuller, H.; Scharstein, D. Evaluation of Cost Functions for Stereo Matching. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Butler, D.J.; Wulff, J.; Stanley, G.B.; Black, M.J. A naturalistic open source movie for optical flow evaluation. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012. Part IV, LNCS 7577. pp. 611–625. [Google Scholar]
- MVD. Multi-View Video Plus Depth MVD Format for Advanced 3D Video Systems. In Document Joint Video Team (JVT) of ISO/IEC MPEG ITU-T VCEG, and JVT-W100; MVD: Online, 2007. [Google Scholar]
- Ferstl, D.; Reinbacher, C.; Ranftl, R.; Ruether, M.; Bischof, H. Image Guided Depth Upsampling Using Anisotropic Total Generalized Variation. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 993–1000. [Google Scholar] [CrossRef]
- Liu, Y.; Gu, K.; Wang, S.; Zhao, D.; Gao, W. Blind Quality Assessment of Camera Images Based on Low-Level and High-Level Statistical Features. IEEE Trans. Multimed. 2019, 21, 135–146. [Google Scholar] [CrossRef]
- Hu, R.; Liu, Y.; Gu, K.; Min, X.; Zhai, G. Toward a No-Reference Quality Metric for Camera-Captured Images. IEEE Trans. Cybern. 2023, 53, 3651–3664. [Google Scholar] [CrossRef] [PubMed]
- Chan, D.; Buisman, H.; Theobalt, C.; Thrun, S. A Noise-Aware Filter for Real-Time Depth Upsampling. In Proceedings of the Workshop on Multi-Camera and Multi-Modal Sensor Fusion Algorithms and Applications—M2SFA2 2008, Marseille, France, 18 October 2008; pp. 1–12. [Google Scholar]
- Liu, J.; Gong, X. Guided Depth Enhancement via Anisotropic Diffusion. In Proceedings of the Pacific-Rim Conference on Multimedia, Nanjing, China, 13–16 December 2013; Springer: Berlin/Heidelberg, Germnay, 2013; pp. 408–417. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar] [CrossRef]
- Liu, W.; Chen, X.; Yang, J.; Wu, Q. Robust Color Guided Depth Map Restoration. IEEE Trans. Image Process. 2017, 26, 315–327. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Huang, J.; Ahuja, N.; Yang, M. Deep Joint Image Filtering. In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 154–169. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Art | Book | Moebius | Reindeer | Laundry | Dolls | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | |
| RDB_10 | 1.19 | 2.40 | 3.13 | 3.84 | 0.79 | 1.26 | 1.58 | 2.31 | 0.52 | 0.81 | 1.27 | 1.69 | 1.45 | 1.71 | 2.48 | 3.35 | 1.32 | 1.75 | 2.16 | 3.09 | 0.87 | 1.13 | 1.37 | 1.69 |
| RDB_16 | 0.81 | 2.15 | 2.81 | 3.47 | 0.49 | 0.94 | 1.30 | 1.83 | 0.29 | 0.58 | 0.95 | 1.52 | 1.28 | 1.49 | 2.18 | 3.03 | 1.11 | 1.47 | 1.96 | 2.80 | 0.61 | 0.84 | 1.03 | 1.46 |
| RDB_20 | 0.79 | 2.13 | 2.78 | 3.43 | 0.46 | 0.91 | 1.27 | 1.80 | 0.26 | 0.55 | 0.90 | 1.48 | 1.24 | 1.45 | 2.16 | 2.98 | 1.06 | 1.45 | 1.92 | 2.78 | 0.59 | 0.82 | 0.98 | 1.43 |
| RDB_22 | 0.78 | 2.10 | 2.76 | 3.39 | 0.44 | 0.89 | 1.25 | 1.79 | 0.23 | 0.52 | 0.87 | 1.46 | 1.21 | 1.42 | 2.15 | 2.97 | 1.03 | 1.44 | 1.90 | 2.75 | 0.56 | 0.81 | 0.96 | 1.38 |
| Algorithm | Art | Book | Moebius | Reindeer | Laundry | Dolls | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | |
| GAN | 0.96 | 2.37 | 3.02 | 3.68 | 0.61 | 1.25 | 1.58 | 2.19 | 0.46 | 0.73 | 1.21 | 1.74 | 1.50 | 1.81 | 2.49 | 3.27 | 1.45 | 1.75 | 2.32 | 3.33 | 0.92 | 1.14 | 1.49 | 1.87 |
| RGAN | 0.81 | 2.15 | 2.81 | 3.47 | 0.49 | 0.94 | 1.30 | 1.83 | 0.29 | 0.58 | 0.95 | 1.52 | 1.28 | 1.49 | 2.18 | 3.03 | 1.11 | 1.47 | 1.96 | 2.80 | 0.61 | 0.84 | 1.03 | 1.46 |
| Algorithm | Art | Book | Moebius | Reindeer | Laundry | Dolls | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | |
| MSE | 0.79 | 2.13 | 2.75 | 3.42 | 0.48 | 0.91 | 1.26 | 1.80 | 0.25 | 0.54 | 0.93 | 1.48 | 1.21 | 1.46 | 2.13 | 3.00 | 1.06 | 1.45 | 1.92 | 2.77 | 0.58 | 0.81 | 1.01 | 1.44 |
| MSE + Edge | 0.81 | 2.15 | 2.81 | 3.47 | 0.49 | 0.94 | 1.30 | 1.83 | 0.29 | 0.58 | 0.95 | 1.52 | 1.28 | 1.49 | 2.18 | 3.03 | 1.11 | 1.47 | 1.96 | 2.80 | 0.61 | 0.84 | 1.03 | 1.46 |
| Algorithm | Art | Book | Moebius | Reindeer | Laundry | Dolls | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | |
| JBU [1] | 3.49 | 5.08 | 6.26 | 9.74 | 1.78 | 2.50 | 2.97 | 5.44 | 1.50 | 2.14 | 2.99 | 4.29 | 2.46 | 3.29 | 4.08 | 5.86 | 2.42 | 3.08 | 4.12 | 5.84 | 1.38 | 1.77 | 2.43 | 3.30 |
| NAF [40] | 3.52 | 5.10 | 6.39 | 10.45 | 1.85 | 2.44 | 3.03 | 5.76 | 1.51 | 2.27 | 3.01 | 4.38 | 2.48 | 3.36 | 4.49 | 6.34 | 2.49 | 3.13 | 4.44 | 6.20 | 1.45 | 1.96 | 2.83 | 3.51 |
| AD [41] | 4.16 | 4.88 | 6.65 | 9.71 | 1.66 | 2.23 | 2.95 | 5.28 | 1.44 | 2.15 | 3.11 | 4.40 | 2.59 | 3.35 | 4.51 | 6.37 | 2.51 | 3.17 | 4.25 | 5.96 | 1.31 | 1.80 | 2.69 | 3.59 |
| MRF [2] | 3.74 | 4.75 | 6.48 | 9.92 | 1.73 | 2.35 | 3.17 | 5.34 | 1.40 | 2.11 | 3.17 | 4.48 | 2.58 | 3.29 | 4.41 | 6.26 | 2.54 | 3.17 | 4.19 | 5.92 | 1.32 | 1.79 | 2.66 | 3.55 |
| GIF [42] | 3.15 | 4.11 | 5.73 | 8.53 | 1.41 | 2.03 | 2.58 | 3.67 | 1.15 | 1.65 | 2.58 | 4.12 | 2.19 | 2.98 | 4.44 | 6.58 | 1.88 | 2.60 | 4.02 | 5.89 | 1.18 | 1.67 | 2.10 | 3.24 |
| SRF [43] | 2.65 | 3.89 | 5.51 | 8.24 | 1.06 | 1.62 | 2.38 | 3.41 | 0.90 | 1.37 | 2.06 | 2.99 | 1.95 | 2.84 | 4.10 | 5.97 | 1.61 | 2.40 | 3.50 | 5.24 | 1.14 | 1.39 | 1.98 | 2.79 |
| Edge [44] | 2.58 | 3.24 | 4.30 | 6.03 | 1.21 | 1.52 | 1.93 | 2.60 | 0.86 | 1.27 | 1.99 | 2.68 | 1.96 | 2.89 | 3.58 | 3.99 | 1.62 | 2.39 | 3.22 | 4.29 | 1.12 | 1.32 | 1.51 | 2.20 |
| JESR [20] | 2.63 | 3.66 | 5.13 | 7.05 | 1.05 | 1.59 | 1.83 | 2.91 | 0.87 | 1.21 | 1.59 | 2.24 | 1.95 | 2.69 | 3.55 | 4.88 | 1.61 | 2.34 | 2.84 | 4.44 | 1.13 | 1.32 | 1.67 | 2.25 |
| JGF [9] | 3.08 | 3.94 | 5.25 | 7.13 | 1.32 | 1.82 | 2.38 | 3.49 | 1.14 | 1.59 | 2.34 | 3.47 | 2.17 | 2.78 | 3.50 | 4.46 | 1.87 | 2.59 | 3.68 | 5.24 | 1.13 | 1.50 | 1.98 | 2.71 |
| TGV [37] | 2.60 | 3.34 | 4.10 | 6.43 | 1.20 | 1.47 | 1.82 | 2.63 | 0.82 | 1.22 | 1.64 | 2.41 | 1.80 | 2.71 | 3.15 | 4.60 | 1.61 | 2.39 | 2.64 | 4.17 | 1.01 | 1.31 | 1.61 | 2.22 |
| SRCNN [45] | 2.63 | 3.53 | 5.34 | 7.68 | 1.20 | 1.47 | 1.84 | 2.84 | 0.86 | 1.20 | 1.87 | 2.67 | 2.07 | 2.78 | 3.54 | 4.86 | 1.67 | 2.18 | 2.78 | 4.49 | 1.15 | 1.33 | 1.66 | 2.64 |
| SRGAN [5] | 2.02 | 3.57 | 4.25 | 5.90 | 1.08 | 1.43 | 1.85 | 2.79 | 0.78 | 1.23 | 1.60 | 2.38 | 1.86 | 2.68 | 3.43 | 4.37 | 1.54 | 2.06 | 2.75 | 3.96 | 1.16 | 1.37 | 1.64 | 2.21 |
| ESRGAN [6] | 1.76 | 3.29 | 3.86 | 5.49 | 0.75 | 1.37 | 1.69 | 2.58 | 0.65 | 1.01 | 1.42 | 2.12 | 1.73 | 2.51 | 3.19 | 4.08 | 1.45 | 1.99 | 2.52 | 3.72 | 0.97 | 1.25 | 1.48 | 2.02 |
| DJIF [46] | 1.83 | 3.46 | 4.07 | 4.70 | 0.77 | 1.50 | 1.78 | 2.61 | 0.56 | 1.04 | 1.47 | 2.09 | 2.15 | 2.59 | 3.24 | 4.12 | 2.04 | 2.23 | 2.86 | 3.88 | 0.91 | 1.16 | 1.45 | 1.94 |
| DSR [26] | 1.41 | 3.03 | 3.59 | 4.02 | 0.63 | 1.36 | 1.62 | 2.38 | 0.48 | 0.85 | 1.29 | 1.94 | 1.52 | 1.98 | 2.82 | 3.89 | 1.64 | 1.97 | 2.41 | 3.56 | 0.86 | 1.04 | 1.27 | 1.77 |
| CGN [27] | 1.27 | 2.91 | 3.46 | 3.88 | 0.68 | 1.25 | 1.55 | 2.16 | 0.33 | 0.79 | 1.13 | 1.71 | 1.49 | 1.70 | 2.65 | 3.62 | 1.48 | 1.72 | 2.35 | 3.19 | 0.75 | 1.02 | 1.25 | 1.73 |
| Ours | 0.81 | 2.15 | 2.81 | 3.47 | 0.49 | 0.94 | 1.30 | 1.83 | 0.29 | 0.58 | 0.95 | 1.52 | 1.28 | 1.49 | 2.18 | 3.03 | 1.11 | 1.47 | 1.96 | 2.80 | 0.61 | 0.84 | 1.03 | 1.46 |
| Algorithm | Art | Book | Moebius | Reindeer | Laundry | Dolls | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | 2× | 4× | 8× | 16× | |
| JBU [1] | 0.72 | 1.13 | 1.95 | 3.47 | 0.30 | 0.41 | 0.69 | 1.21 | 0.31 | 0.41 | 0.69 | 1.24 | 0.53 | 0.65 | 0.94 | 2.06 | 0.43 | 0.64 | 1.12 | 2.03 | 0.33 | 0.44 | 0.63 | 1.18 |
| NAF [40] | 0.72 | 1.24 | 1.98 | 3.68 | 0.30 | 0.40 | 0.67 | 1.24 | 0.31 | 0.41 | 0.61 | 1.26 | 0.54 | 0.65 | 0.98 | 2.04 | 0.45 | 0.69 | 1.13 | 2.01 | 0.31 | 0.45 | 0.66 | 1.27 |
| AD [41] | 0.75 | 1.22 | 2.06 | 4.29 | 0.33 | 0.45 | 0.85 | 1.54 | 0.35 | 0.45 | 0.74 | 1.56 | 0.50 | 0.64 | 1.09 | 2.17 | 0.48 | 0.70 | 1.05 | 2.75 | 0.38 | 0.47 | 0.81 | 1.40 |
| MRF [2] | 0.80 | 1.29 | 2.15 | 4.25 | 0.36 | 0.47 | 0.86 | 1.58 | 0.37 | 0.43 | 0.70 | 1.50 | 0.52 | 0.62 | 1.04 | 1.96 | 0.51 | 0.79 | 1.10 | 2.29 | 0.30 | 0.46 | 0.88 | 1.35 |
| GIF [42] | 0.63 | 1.01 | 1.70 | 3.46 | 0.22 | 0.35 | 0.58 | 1.14 | 0.23 | 0.37 | 0.59 | 1.16 | 0.42 | 0.53 | 0.88 | 1.80 | 0.38 | 0.52 | 0.95 | 1.90 | 0.28 | 0.35 | 0.56 | 1.13 |
| SRF [43] | 0.46 | 0.97 | 1.83 | 3.44 | 0.15 | 0.32 | 0.59 | 1.12 | 0.14 | 0.32 | 0.51 | 1.10 | 0.30 | 0.55 | 1.04 | 1.85 | 0.23 | 0.54 | 1.06 | 1.99 | 0.20 | 0.35 | 0.56 | 1.13 |
| Edge [44] | 0.41 | 0.65 | 1.03 | 2.11 | 0.17 | 0.30 | 0.56 | 1.03 | 0.18 | 0.29 | 0.51 | 1.10 | 0.20 | 0.37 | 0.63 | 1.28 | 0.17 | 0.32 | 0.54 | 1.14 | 0.16 | 0.31 | 0.56 | 1.05 |
| JESR [20] | 0.45 | 0.76 | 1.51 | 2.98 | 0.15 | 0.27 | 0.48 | 0.90 | 0.16 | 0.30 | 0.44 | 1.01 | 0.31 | 0.47 | 0.69 | 1.42 | 0.23 | 0.50 | 0.96 | 1.47 | 0.20 | 0.32 | 0.51 | 0.92 |
| JGF [9] | 0.29 | 0.47 | 0.78 | 1.54 | 0.15 | 0.24 | 0.43 | 0.81 | 0.15 | 0.25 | 0.46 | 0.80 | 0.23 | 0.38 | 0.64 | 1.09 | 0.21 | 0.36 | 0.64 | 1.20 | 0.19 | 0.33 | 0.59 | 1.06 |
| TGV [37] | 0.45 | 0.65 | 1.17 | 2.30 | 0.18 | 0.27 | 0.42 | 0.82 | 0.18 | 0.29 | 0.49 | 0.90 | 0.32 | 0.49 | 1.03 | 3.05 | 0.31 | 0.55 | 1.22 | 3.37 | 0.21 | 0.33 | 0.70 | 2.20 |
| SRCNN [45] | 0.22 | 0.53 | 0.77 | 2.13 | 0.09 | 0.22 | 0.40 | 0.79 | 0.10 | 0.22 | 0.42 | 0.89 | 0.32 | 0.47 | 0.68 | 1.77 | 0.24 | 0.50 | 0.96 | 1.54 | 0.23 | 0.33 | 0.57 | 1.09 |
| SRGAN [5] | 0.19 | 0.48 | 0.70 | 2.05 | 0.16 | 0.28 | 0.40 | 0.74 | 0.15 | 0.26 | 0.47 | 0.81 | 0.27 | 0.46 | 0.65 | 1.19 | 0.28 | 0.44 | 0.60 | 1.15 | 0.20 | 0.31 | 0.53 | 0.88 |
| ESRGAN [6] | 0.15 | 0.36 | 0.62 | 1.69 | 0.14 | 0.21 | 0.37 | 0.65 | 0.14 | 0.23 | 0.42 | 0.76 | 0.24 | 0.43 | 0.60 | 1.08 | 0.23 | 0.39 | 0.52 | 1.08 | 0.15 | 0.27 | 0.48 | 0.75 |
| DJIF [46] | 0.16 | 0.38 | 0.68 | 1.83 | 0.18 | 0.25 | 0.39 | 0.68 | 0.19 | 0.22 | 0.40 | 0.73 | 0.23 | 0.39 | 0.52 | 1.04 | 0.20 | 0.30 | 0.53 | 1.12 | 0.18 | 0.28 | 0.45 | 0.79 |
| DSR [26] | 0.13 | 0.31 | 0.57 | 1.46 | 0.15 | 0.22 | 0.34 | 0.61 | 0.12 | 0.20 | 0.37 | 0.66 | 0.21 | 0.37 | 0.50 | 0.96 | 0.15 | 0.28 | 0.46 | 1.07 | 0.15 | 0.24 | 0.42 | 0.69 |
| CGN [27] | 0.11 | 0.25 | 0.48 | 1.39 | 0.12 | 0.18 | 0.30 | 0.57 | 0.13 | 0.18 | 0.35 | 0.62 | 0.18 | 0.35 | 0.46 | 0.83 | 0.12 | 0.26 | 0.43 | 1.05 | 0.14 | 0.23 | 0.40 | 0.65 |
| Ours | 0.09 | 0.23 | 0.42 | 1.25 | 0.09 | 0.14 | 0.25 | 0.48 | 0.10 | 0.15 | 0.26 | 0.47 | 0.12 | 0.24 | 0.39 | 0.67 | 0.11 | 0.21 | 0.38 | 0.94 | 0.08 | 0.18 | 0.33 | 0.61 |
| Books | Devil | Shark | |
|---|---|---|---|
| Bicubic | 16.23 | 17.78 | 16.66 |
| JGF [9] | 17.39 | 19.02 | 18.17 |
| TGV [37] | 12.80 | 14.97 | 15.53 |
| SRGAN [5] | 11.76 | 12.80 | 13.92 |
| ESRGAN [6] | 10.44 | 12.16 | 13.03 |
| DJIF [46] | 10.85 | 11.63 | 13.50 |
| DSR [26] | 10.32 | 10.41 | 12.59 |
| CGN [27] | 10.01 | 10.23 | 11.87 |
| Ours | 9.69 | 9.14 | 11.44 |
| Doorflowers | PoznanStreet | PoznanCarpark | |
|---|---|---|---|
| Bicubic | 38.12 | 45.09 | 35.15 |
| JGF [9] | 38.36 | 45.28 | 35.13 |
| TGV [37] | 38.42 | 45.50 | 35.18 |
| SRGAN [5] | 39.95 | 45.67 | 36.60 |
| ESRGAN [6] | 40.81 | 47.73 | 38.09 |
| DJIF [46] | 40.67 | 47.69 | 38.26 |
| DSR [26] | 41.38 | 48.33 | 39.21 |
| CGN [27] | 41.80 | 48.72 | 39.66 |
| Ours | 41.95 | 49.11 | 39.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, D.; Fan, X.; Gao, W. Multiscale Attention Fusion for Depth Map Super-Resolution Generative Adversarial Networks. Entropy 2023, 25, 836. https://doi.org/10.3390/e25060836
Xu D, Fan X, Gao W. Multiscale Attention Fusion for Depth Map Super-Resolution Generative Adversarial Networks. Entropy. 2023; 25(6):836. https://doi.org/10.3390/e25060836
Chicago/Turabian StyleXu, Dan, Xiaopeng Fan, and Wen Gao. 2023. "Multiscale Attention Fusion for Depth Map Super-Resolution Generative Adversarial Networks" Entropy 25, no. 6: 836. https://doi.org/10.3390/e25060836
APA StyleXu, D., Fan, X., & Gao, W. (2023). Multiscale Attention Fusion for Depth Map Super-Resolution Generative Adversarial Networks. Entropy, 25(6), 836. https://doi.org/10.3390/e25060836