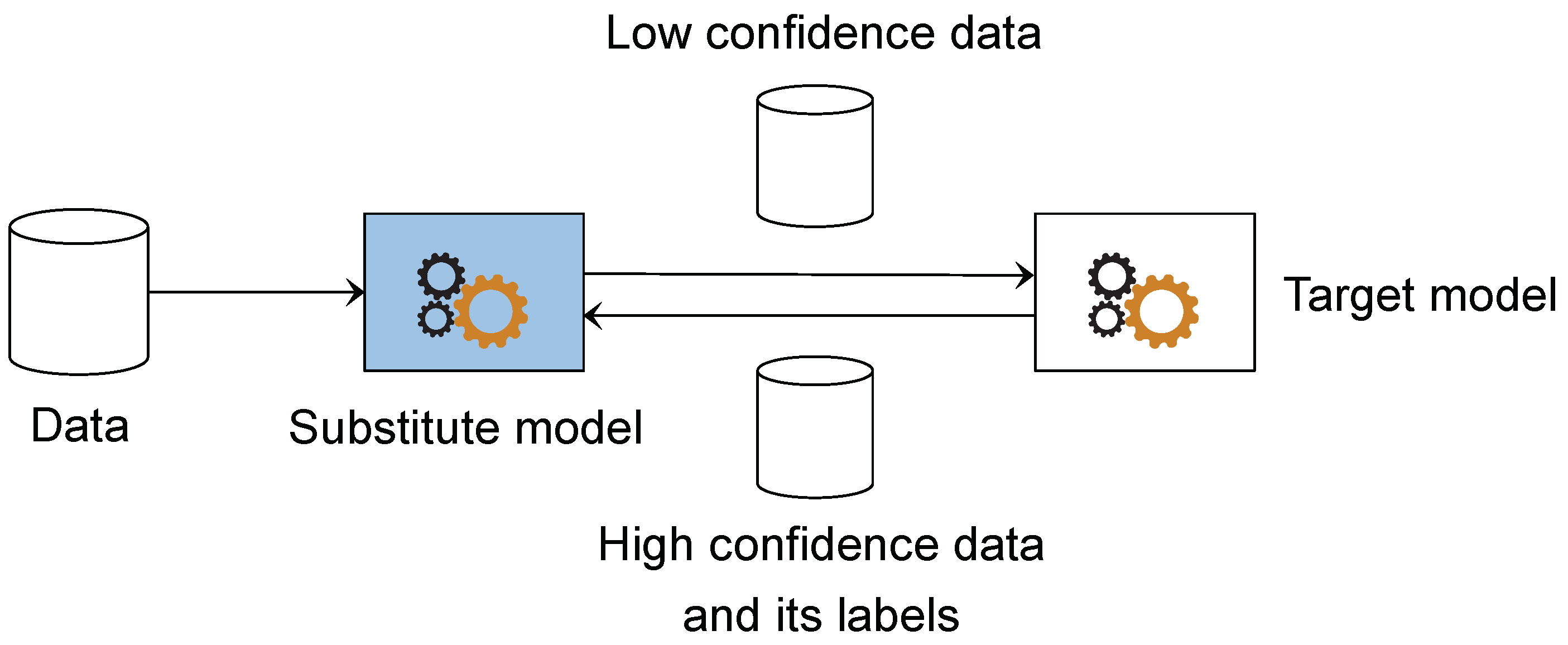
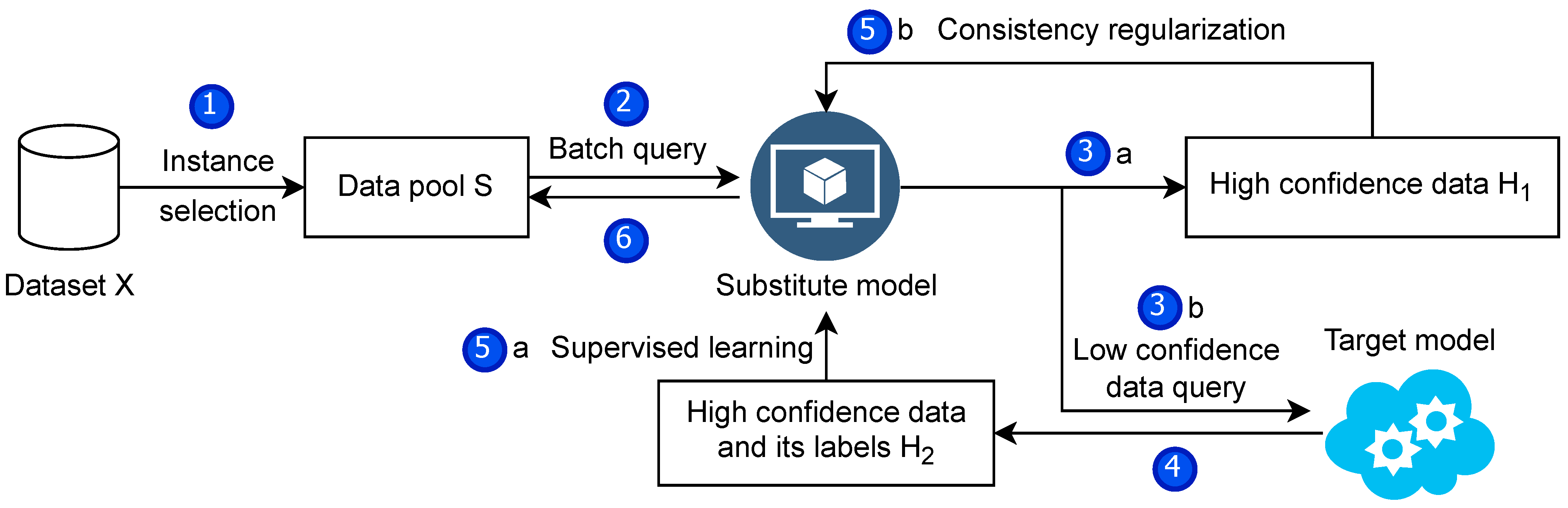
5.1. Experimental Setup
Evaluation metric. We define the purpose of the model extraction attack as obtaining the target model decision capability as much as possible, i.e., the substitute model should be as close as possible to or even exceed the performance of the target model on the test dataset, and this is carried out because we stand for a practical point of view and want the extracted model to have more satisfactory usability. Thus, we use such an evaluation metric—the ratio of the substitute model to the target model in test accuracy, as shown in the following equation, where
is the substitute model and
f is the target model. This is different from the way some papers evaluate extraction attacks, Ref. [
3] is more concerned with the proximity of the substitute model to the target model and how similar they behave on the data individuals; Ref. [
11] is more concerned with the ability of the adversarial sample made using the substitute model to deceive the target model. They are more concerned with the indicator of the transferability of adversarial samples:
Target models and their data selection. We use Microsoft’s Azure Custom Vision image recognition service, allowing users to build, deploy, and improve their own image identifier models. Image identifiers apply labels to images based on detected visual features, with each label representing a classification or object. We randomly selected 5000 image data from the training datasets of Intel-image and Fashion-MNIST, respectively, ensured a balanced number of data in each category, and trained two separate models using the service as targets for the attack. The models were trained on the platform for a few minutes. We needed to gain knowledge of the model architecture, weights, and hyperparameters. We could not change the models after training; only queries and the models would return output vectors. The trained model also gives the accuracy, which is 94.7% and 91% on the two datasets, respectively.
Substitute models and their data selection. The substitute model is based on Squee-zenet [
32], a lightweight model that maximizes the speed of operations without losing network performance while reducing network parameters.
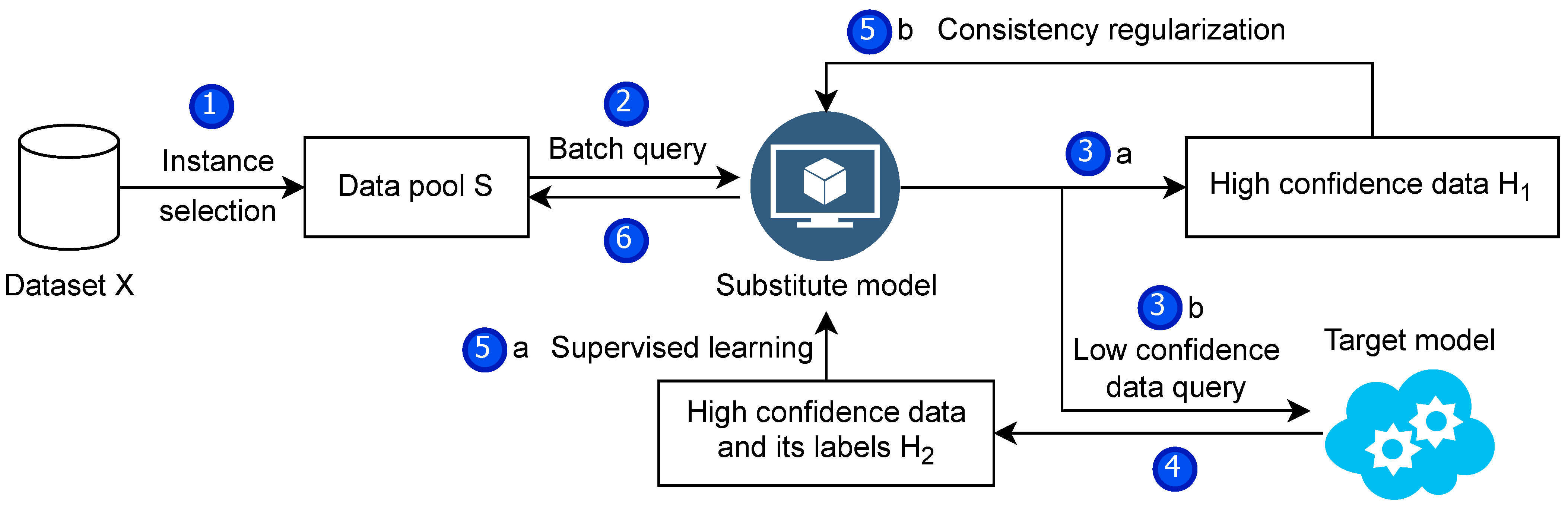
As we discussed in the threat model regarding the attacker’s capabilities, an attacker can collect a dataset of waiting queries for the target model oriented to that task based on the knowledge of the task the model is oriented to. We consider the following two types of data relevant to the target model’s task for the training dataset of the substitute model.
The first type of data comes from the validation set of Intel-image and part of the test dataset of Fashion-MNIST with 7301 data and 10,000 data, respectively. We strictly partitioned the datasets to ensure that the partial data from the validation set of Intel-image and the test dataset of Fashion-MNIST do not intersect with the training dataset of the two target models and the test dataset to be used later, respectively.
The second type of data comes from the image data relevant to the target model task we searched using Google. Some keywords relevant to the task are searched on Google. These include the specific type of data used by the target model and some other keywords relevant to the task. After the search, the images displayed by Google are obtained. Then, these data are downloaded using a bulk download tool. For an attacker, searching for specific data with Google is a better option than finding data from some large datasets because the desired data can be easily found, and the data quality is not low. We experimentally query the target model with a small portion of the Google search data to see how much data can be classified with high confidence by the target model. Using our metric for measuring model confidence, the percentage of high confidence classifications by the two target models for the two datasets obtained from the search is shown in
Table 1. With the high percentage of high-confidence data in the table, the target models are very receptive to the data obtained from these searches. This indicates that the data searched with Google are usable, which is consistent with our direct observation that we found the data searched by Google to be of higher quality.
In our experiments, we considered two substitute model training datasets using a combination of the above two types of task-relevant data for each of the two target models.
The first substitute model training dataset consists of two types of task-relevant data. The ratio of the number of the two types is related to the percentage of the target model’s high confidence classification of the dataset obtained from the search in
Table 1. This is handled this way because we are more concerned with the role of high-confidence data, and we want the substitute model to classify the high-confidence data of the target model with high confidence. Thus, we need to ensure that the number of data classified with high confidence by the target model is approximately equal in both relevant data types. At the same time, it can be assumed that the target model will classify a high percentage of the first data type with high confidence. The first substitute model training dataset is shown in
Table 2.
The second substitute model training dataset consists of only the second type of data described above, i.e., using only task-relevant image data searched with Google. For Intel-image, the training dataset of the substitute model is 9149 data searched with Google. For Fashion-MNIST, the training data set of the substitute model is 30,626 data searched with Google. For Intel-image and Fashion-MNIST, the second substitute model training dataset is identified with and , respectively.
The reason for considering the above two substitute model training datasets is that we want to explore the effect of data with different degrees of relevance to the target model task on the attack effectiveness. The effect of the attack is confirmed using the evaluation metrics described above. The first substitute model training dataset is more relevant to the target model task compared to the second substitute model training dataset.
To minimize queries and to be consistent with our proposed scheme, the substitute models are trained using five substitute epochs. Using the updated dataset, the substitute model is trained for 100 epochs in each epoch.
5.2. Experimental Results
- (1)
Effect of data with different degrees of correlation
As we described, for Intel-image and Fashion-MNIST, the substitute models use two training datasets, respectively.
is more relevant to the target model task than
, and
is more relevant to the target model task than
.
Table 3 shows this part of the experiment. We can find that the degree of data relevant to the task affects the performance of the substitute model, and the substitute model trained with data more relevant to the target model task performs better—not to mention that some papers use completely irrelevant data, which is a big waste because queries are paid for.
- (2)
The important role of high confidence data
First, our method of evaluating model confidence is valid. In the experiments, the softmax function is applied to the output of the substitute model to calculate the probability, following the practice of existing work. When a component of the output after the action is greater than or equal to 0.9, the model is considered confidential in classifying that data. To demonstrate the validity of this measure, one can look at the training data of the untrained substitute model based on the pre-trained model SqueezeNet for classification confidence. Both figures in
Figure 5 show the data filtered by the above measure of model confidence, clustered at a specific location of the components of the model output. These two classes of images correspond to exactly two classes of images. This demonstrates the usability of this method for measuring model confidence.
Second, the model trained with high confidence data only performs better on the test dataset than the model trained with all confidence data, as shown in
Table 4.
- (3)
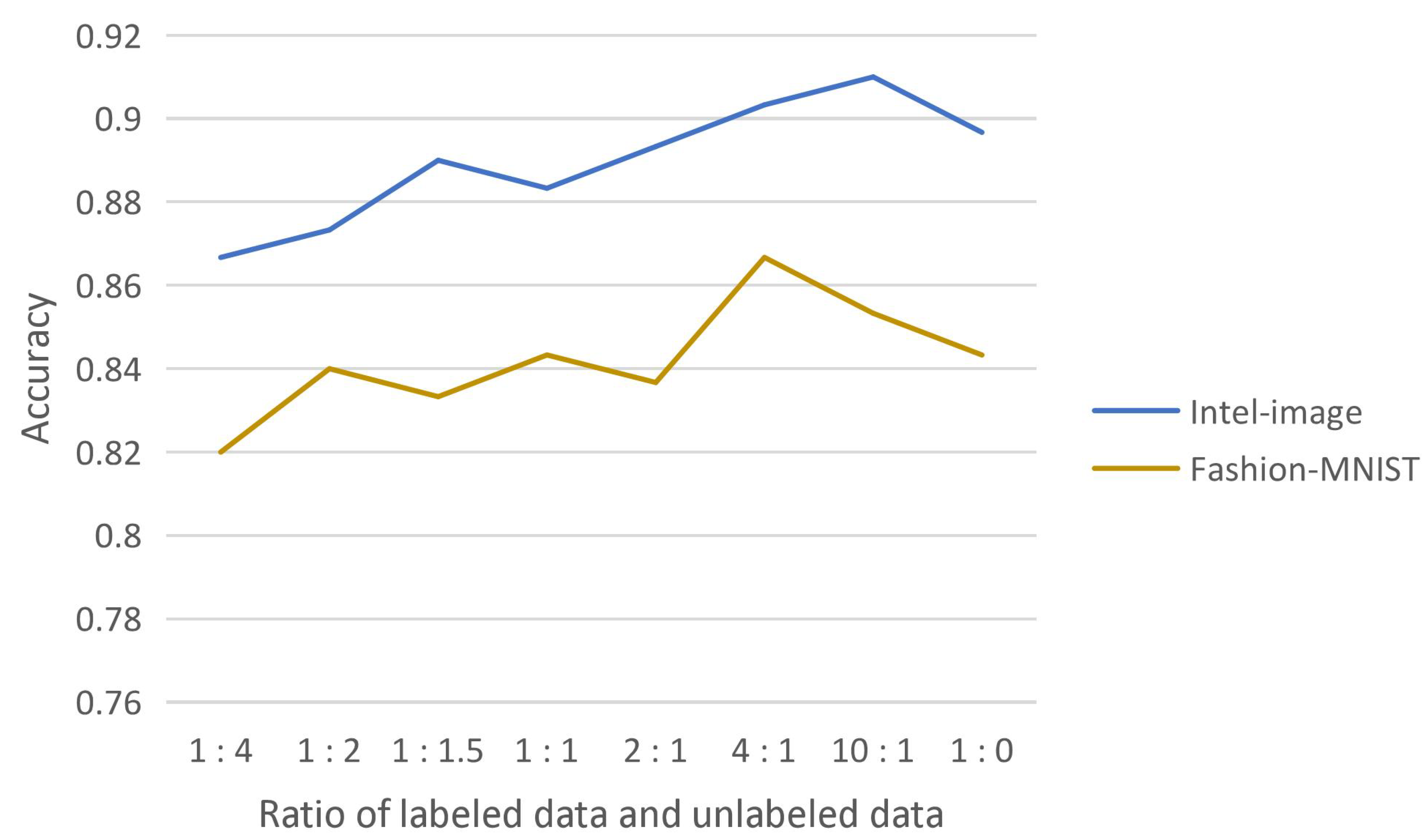
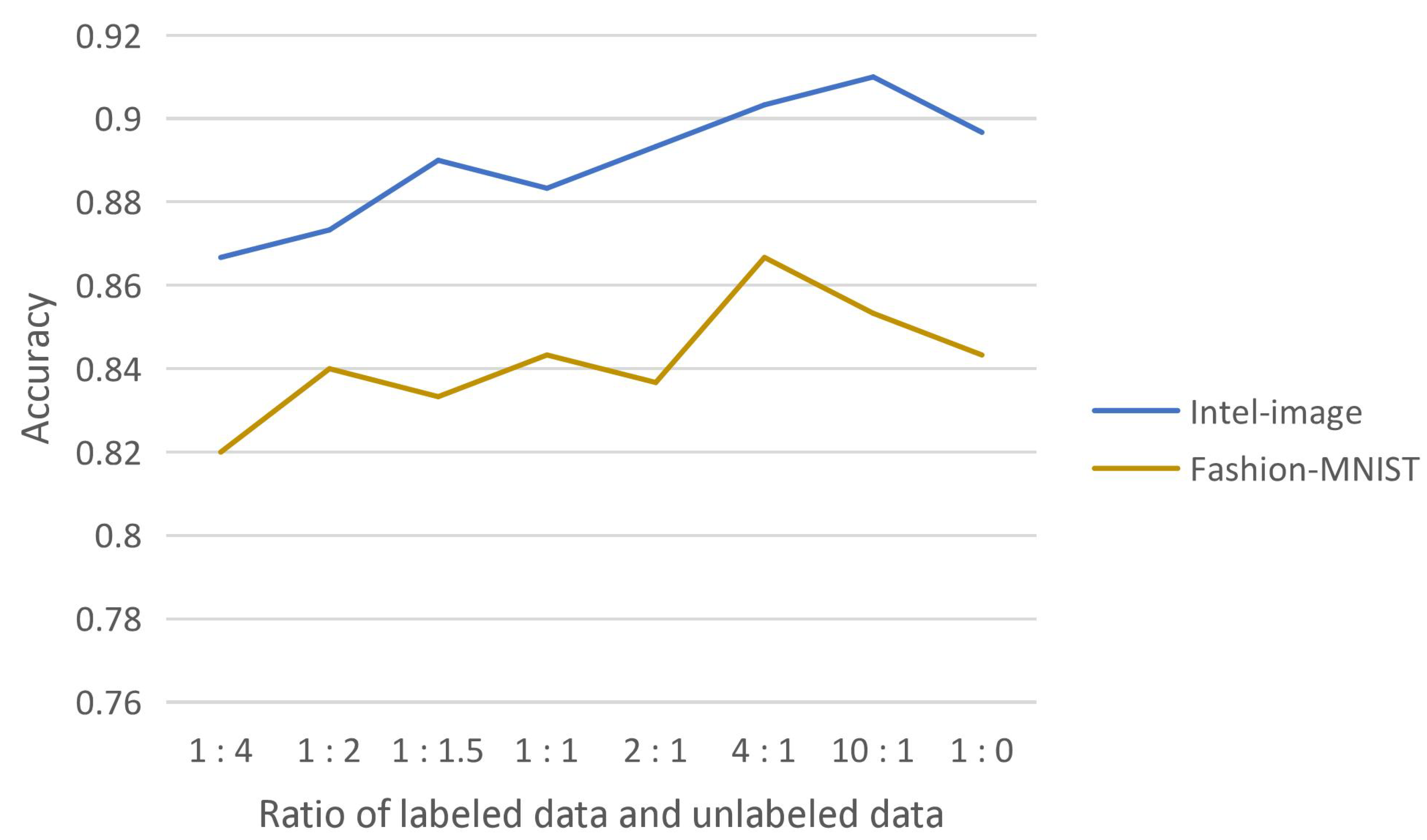
Effect of the ratio of labeled and unlabeled data
We experimentally demonstrate the effectiveness of introducing consistency regularization into the model extraction attack, which fully uses the substitute model’s high-confidence data while reducing the query to the target model. The substitute model effectively learns from this unlabeled data. The substitute model trained by adding this part of unlabeled data obtained the highest test accuracy compared to the substitute model trained with high-confidence data of the target model only. The effect of the ratio of labeled and unlabeled data on the test accuracy of the substitute model was also experimentally explored, as shown in
Figure 6.
The reason for obtaining such results may be that the substitute model is trained with both labeled and unlabeled data and should learn knowledge mainly from supervised learning. More unlabeled data will interfere with the substitute model’s effective learning of labeled data, so more labeled data than unlabeled data are involved in the training. On the other hand, it is known from the experimental results that adding a small amount of unlabeled data are superior to completely using only labeled data, which indicates that the substitute model does learn knowledge from unlabeled data and the training of the substitute model needs the participation of unlabeled data.
- (4)
Extent of reduction of queries
Our solution is dedicated to reducing queries and costs in several aspects. First, the found data are selected using the idea of instance selection. Two datasets, Intel-image and Fashion-MNIST, are reduced from 16,450 and 40,626 data to 3786 and 10,759 data, respectively. We also examined the case where, instead of using instance selection to pick, 3786 and 10,759 samples were randomly selected. The final impact of the two cases on the attack experiments is shown in
Table 5. The test accuracies of the substitute models trained with the data selected using instance selection are 2.67% and 4.67% higher, respectively, compared to random selection, which proves the advantage of instance selection.
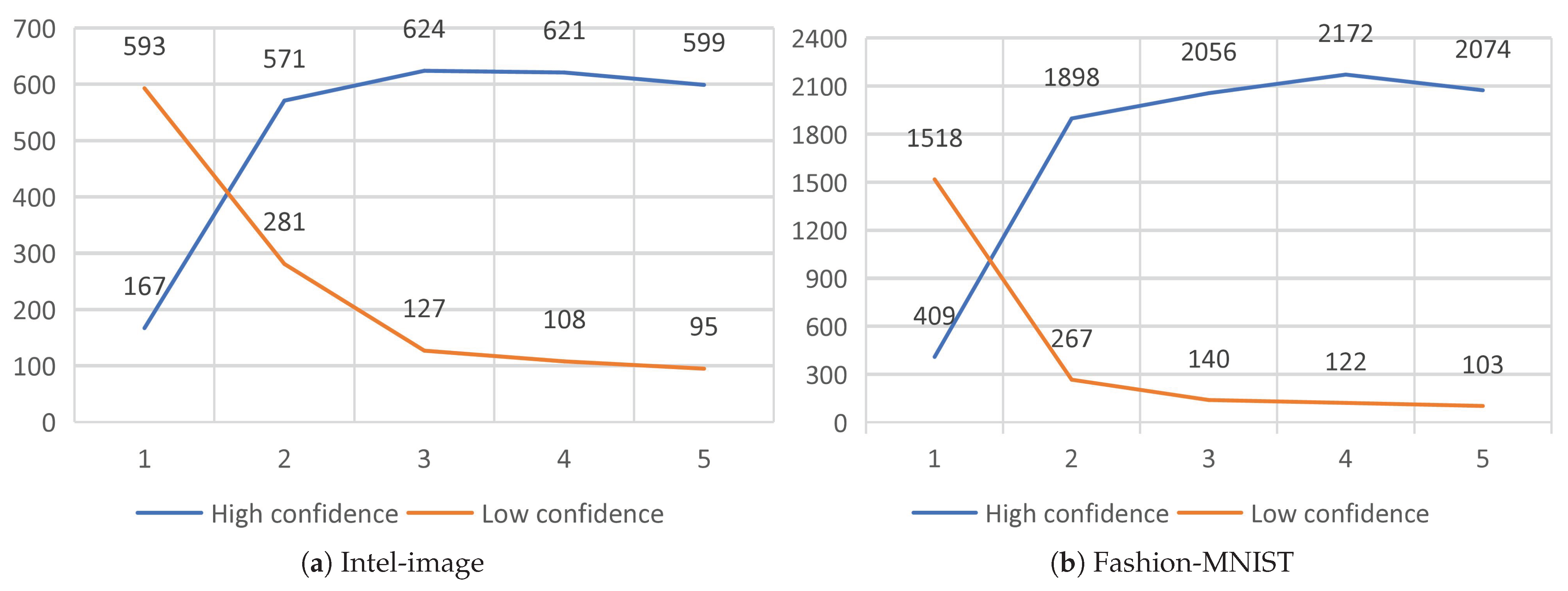
Second, the substitute model’s approach of querying only low-confidence data to reduce the budget greatly reduces the number of queries to the target model. To achieve the purpose of budget reduction, instead of querying all the training data of the substitute model at one time, we use five substitution epochs in batches to train the substitute model. Such an approach is beneficial to reduce the number of queries to the target model. As shown in
Figure 7, the substitute model needs more confidence data in the first substitute epoch. After the training of the first substitute epoch, the classification ability of the substitute model is greatly improved. The confidence data are greatly increased, which means that only a small portion of the data needs to be used to query the target model, reducing the cost. At the same time, the data of the substitute model with confidence show an increasing trend, which illustrates the effectiveness of the training substitute model method.
Finally, we reduce the required queries from 16,450 and 40,626 to 1204 and 2150 on the Intel-image and Fashion-MNIST datasets, requiring only 7.32% and 5.30% of the original data to be queried, which significantly improves the efficiency and reduces the expense.
- (5)
Degree of substitution of substitute models
Two target models trained on Azure using Intel-image and Fashion-MNIST, respectively, were attacked using our scheme. The degree of substitution of the obtained substitute models is shown in
Table 6.
- (6)
Evade an advanced defense method
A well-known defense method against model extraction attacks, PRADA, was proposed by Juuti et al. [
14]. They observed that (1) benign queries to the target model by normal users tend to match or approach a normal distribution and (2) the query samples used by attackers are deliberately generated and selected in order to detect the most information, and thus the query sequences used tend to deviate from a normal distribution.
For a query sequence
and the corresponding query result
, PRADA first calculates the distribution of distances
:
The Shapiro–Wilk Test (a normal distribution test) is then used to determine whether it is a potential attack sequence.
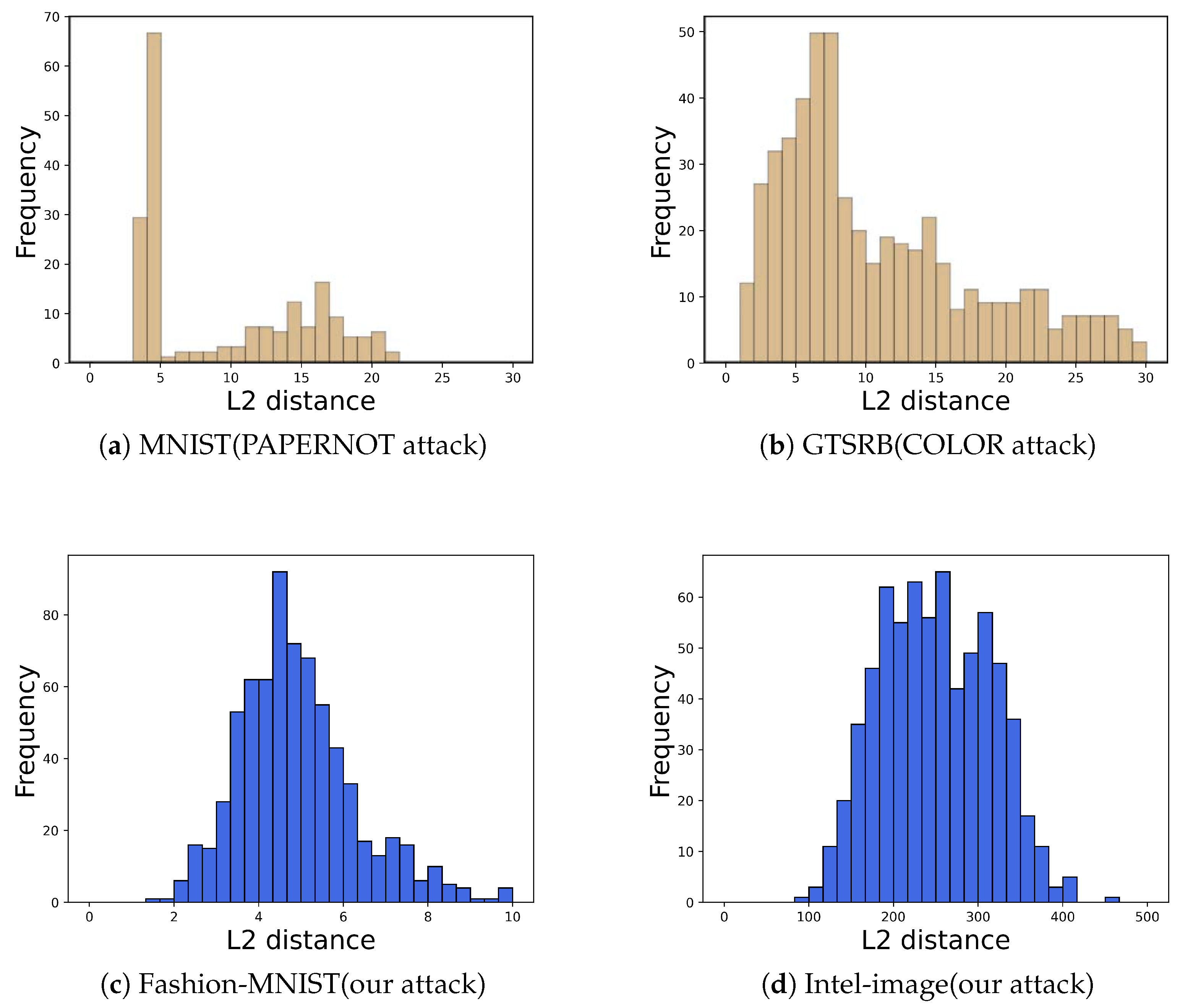
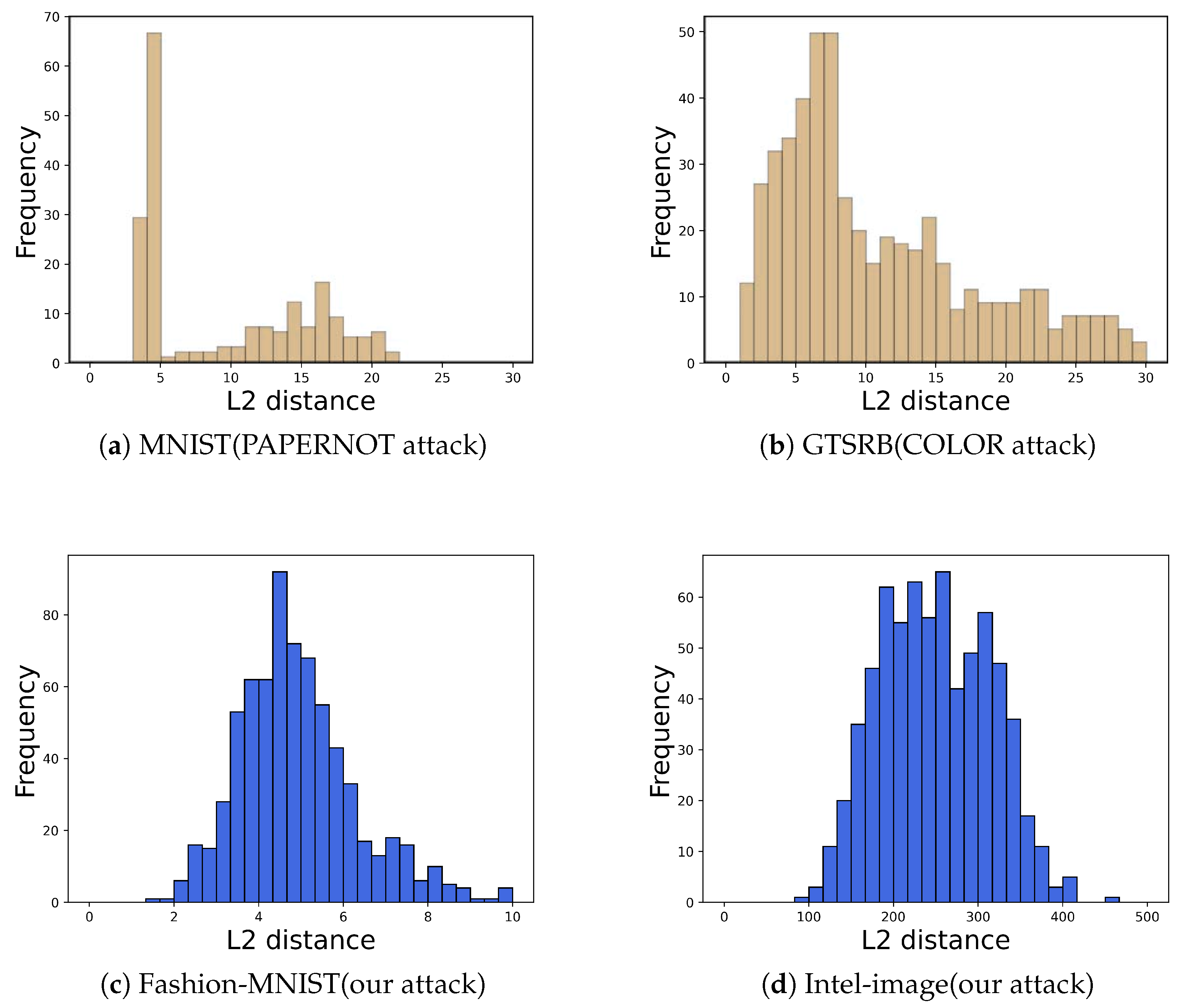
We applied PRADA to detect our attack and obtained histograms of the distribution of query sequences
for the two datasets Intel-Image (PRADA hyperparameters
= 0.91) and Fashion-Mnist (PRADA hyperparameters
= 0.86) shown in
Figure 8. The results show that our query sequence
corresponds to an essentially normal distribution. Thus, PRADA does not detect our attack. This is because our attack uses natural image data to query the target model instead of using synthetic samples to query the target model.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}