1. Introduction
The study of social and economic inequality seems to belong to social sciences and humanities. However, based mostly on economic and econophysics studies, analyses of income and wealth data in terms of mathematical quantities such as the Lorenz curve [
1] and the related Gini index [
2,
3,
4] are trying to grasp an ”objective” measure of overall inequality in distributions [
5,
6,
7,
8,
9].
Given that most interesting distributions have infinite support, the norms on their space are not equivalent. That is why there are numerous measures of distance between distributions. Clearly, the Kullback–Leibler divergence is the most popular one. It is well known that to produce a good estimate of the KL divergence using a limited sample is not easy. That is one of the reasons why several generalization and particular alternatives have been developed. Some are for a specific family of distributions [
10,
11]; others are better suited to a specific field [
12,
13]. Our work falls into the latter category, aiming to propose a divergence well adapted to economic or wealth inequalities. The adaptation and generalization of divergences should meet certain criteria The reader can find an overview and new advances in [
14,
15] in that direction. More recent developments can be found in [
16,
17,
18,
19,
20], and a recent review in [
21].
Certainly, the Gini index is only one among many possible approaches and does not replace the study of the distributions themselves [
22]. In this sense, the density of the Gini index in the Lorenz curve—the gintropy—whose precise definition will be given below, includes the total information on the probability density function (PDF) of such distributions.
In an earlier work we introduced this quantity called gintropy [
23] and demonstrated its entropy-like properties: for all income PDFs it is non-negative, has a single maximum exactly at the average value and shows overall the corresponding convexity in terms of the cumulative rich population as well as in terms of the cumulative wealth. Based on this property, we propose that gintropy may better reflect the inequality concentrated on the middle class with average income for which much more statistical data are available than for the richest segment of the income and wealth distributions.
In this paper we attempt to generalize this concept to a gintropic distance measure between two PDFs, making it possible to draw a distance graph between countries with varying inequality. By doing so we also investigate the generalization potential in replacing the obvious variable, the income value x, with its monotonic function, . That provides the analyzers with some freedom in using differently weighted f-gintropy concepts, e.g., using or any other quantity behaving coherently with the original one but possibly magnifying some effects. Indeed, we observe a finer distinguishing power by using functions of x, describe in a later section.
This article is constructed as follows: First, we review the definitions of gintropy and f-gintropy, controlling their entropy-like properties. Then we construct the f-gintropic divergence measure in analogy to the entropic divergence and study its basic mathematical properties. Finally, based on available data on regional and national income distributions, we develop an inequality distance map. We suggest using these maps as a ”first sight” tool for judging the real effect of inequalities on the population parts near the average.
2. Gintropy, f-Gintropy and Gintropic Divergence
The Gini index is a number between zero and one characterizing the inequality inherent in income and wealth distributions. Its definition,
can be used for deriving expressions of
G in terms of cumulative distributions of the population and the wealth or income possessed by them. These cumulatives,
plotted against each other present the Lorenz curve in the
plane. This curve is restricted to the unit square, since
,
are the total normalized values, while
and
both vanish.
The gintropy,
, occurs as a density of the Gini index in this map and shows entropy-like features. Based on this, to any probability density function (PDF), such as
, one may construct an individual gintropy
. It is interesting to note that the half of the Gini index also can be viewed as the integral of gintropy over any of the cumulatives:
As such the value represents the area between the Lorenz curve and the diagonal in the plane.
The function
is non-negative, and shows a definite convexity. Furthermore
is maximal at
. Indeed, for several common PDFs
, it resembles entropy formulas suggested so far. For example, for an exponential PDF the classical formula,
, arises; for a Pareto distribution
, we obtain a Tsallis q-entropy formula
. The particular value,
, resembles the entanglement entropy,
with
being the density operator, used in some quantum computing calculations. These analogies are elaborated in [
23].
In the present paper we attempt to generalize this construction to a possible use of another quantity’s cumulative tail more integral than the original variable, x. Moreover, based on this, we construct an entropic divergence measure for the purpose of using it as an ”inequality distance” between PDFs based on their generalized Lorenz curve behavior, comprised in the quantity f-gintropy.
Let be an absolute continuous PDF over . To begin with, we consider only P and do not use any subscript related to it. Later, when considering two different PDFs and constructing their f-gintropic distance measure, we shall retain such indices.
Let
f be a monotonic, non-negative differentiable function with
Assume that the expectation value,
exists. Let the truncated f-moment be defined as
and we use the original tail-cumulative
defined in Equation (
2). Inverting the above definitions, one notes that
and
. Hence, also
.
The
f-Gini index is constructed based on the geometry of the Lorenz curve. First, one easily proves that
Second, the corresponding Gini index is defined as the difference between these two integrals
Let us first prove the statement about the sum in Equation (
6). The first integral can be expanded as
while the second similarily as
The second integral can be rewritten by exchanging the dummy integration variables
x and
y among each other,
Then we interchange the order of integration to arrive at
Indeed, the sum of Equations (
8) and (
11) becomes
Here, obviously the two integrals inside the square bracket can be unified in a single integral proving that
Inspecting a general Lorenz curve drawn in the unit square on the
plane, it is obvious that the area between the curve and diagonal represents the half of the Gini index, defined in Equation (
7), as the difference of integrals.
We are interested further in its equivalent forms. We would like to view
also as an expectation value of something. We utilize the forms (
8) and (
9) to write
Exchanging the integration variables again and reordering the integrations, an equivalent expression emerges
Now we fix a few requirements for the function
. To map
between zero and one
is necessary. To interpret the f-Gini index as an expectation of an absolute value of difference, the strict monotonity property,
for
and equivalently
for
is required. Fulfilling these requirements, one obtains that
is also the half of the sum of Equations (
14) and (
15):
This agrees with the original definition for and follows its form ready for data evaluation.
Based on the above, it is natural to introduce f-gintropy as
This quantity has the following properties, based on the already discussed restrictions on , i.e., and :
It is never negative, .
It is zero for and only, or at and .
It is maximal at the value, fulfilling .
It has a single maximum only, either as a function of x or or .
The f-gintropy, , like the entropy, is everywhere concave on and .
We give a short analysis of the above statements as follows.
is positive if
, since for all
in the above integral one has
. For the opposite choice of
x, when
, we rewrite the gintropy expression as
Again, due to the monotonity of f for all in the integration range, we have . That finishes the proof of . It is also obvious from the above expressions that equality occurs only if using or .
Let us turn now to the discussion of concavity. For that purpose we calculate the first and second derivatives of gintropy w.r.s.p to
and
. These are obtained in turn from the
x-derivative,
This quantity changes sign exactly where and nowhere else.
The
- and
-derivatives can be obtained using the
and
values shown earlier in the text. One calculates
Due to the strict monotonity of
f, we have
, and therefore, the second derivative of f-gintropy is always negative. We similarly arrive at the same conclusion in terms of
:
Let us recall that the Gini index and its generalization can be written as an integral over the gintropy, .
We built the f-gintropic divergence measure following the construction pattern of the Kullback–Leibler divergence. It is also in line with the idea how Csiszár’s f-divergence has been introduced [
24,
25]. For recent advances of the f-divergence and its estimate see, e.g., [
26,
27]. The main difference is that while the
f-entropy due to Csiszár replaces the logarithm of the probability with a general function in the entropy formula, we generalize the tail cut integral of the income to a function of it. The latter function will be restricted, as discussed later.
Instead of using the PDFs, we suggest applying a similar formula to the gintropies. Since the original gintropy function is not normalized, we use its normalized version
with
Then
behaves as a PDF mathematically: its integral over the possible
-range is unity, and it is everywhere non-negative. Analogous to the definition of classical entropic divergences, we propose a Kullback–Leibler type Gini divergence between the distributions
and
as
It is straightforward to generalize further by using a general convex function s instead of the logarithm with and . One immediately realizes that iff almost surely and in general, based on the convexity inherent in the definition.
Analogous to the definition of mutual information, the mutual gintropy,
, can also be introduced as the gintropic divergence between the joint distribution and the product of the subdistributions:
3. Example: Gintropic Distance Ranking of Income Data
We will exemplify the use of gintropic distance reconsidering the income distribution data studied in [
28]. Data for Australia (2011), Hungary (2015), Japan (2015), USA (2013) and Cluj county, Romania (2005) are used. These are the same data as the ones used in [
28], and they were selected for statistical studies due to their free availability and higher resolutions in the income intervals, allowing for a precise construction of relevant quantities. The data for Cluj county are exhaustive from a social security database, containing the income of all registered employee from that region [
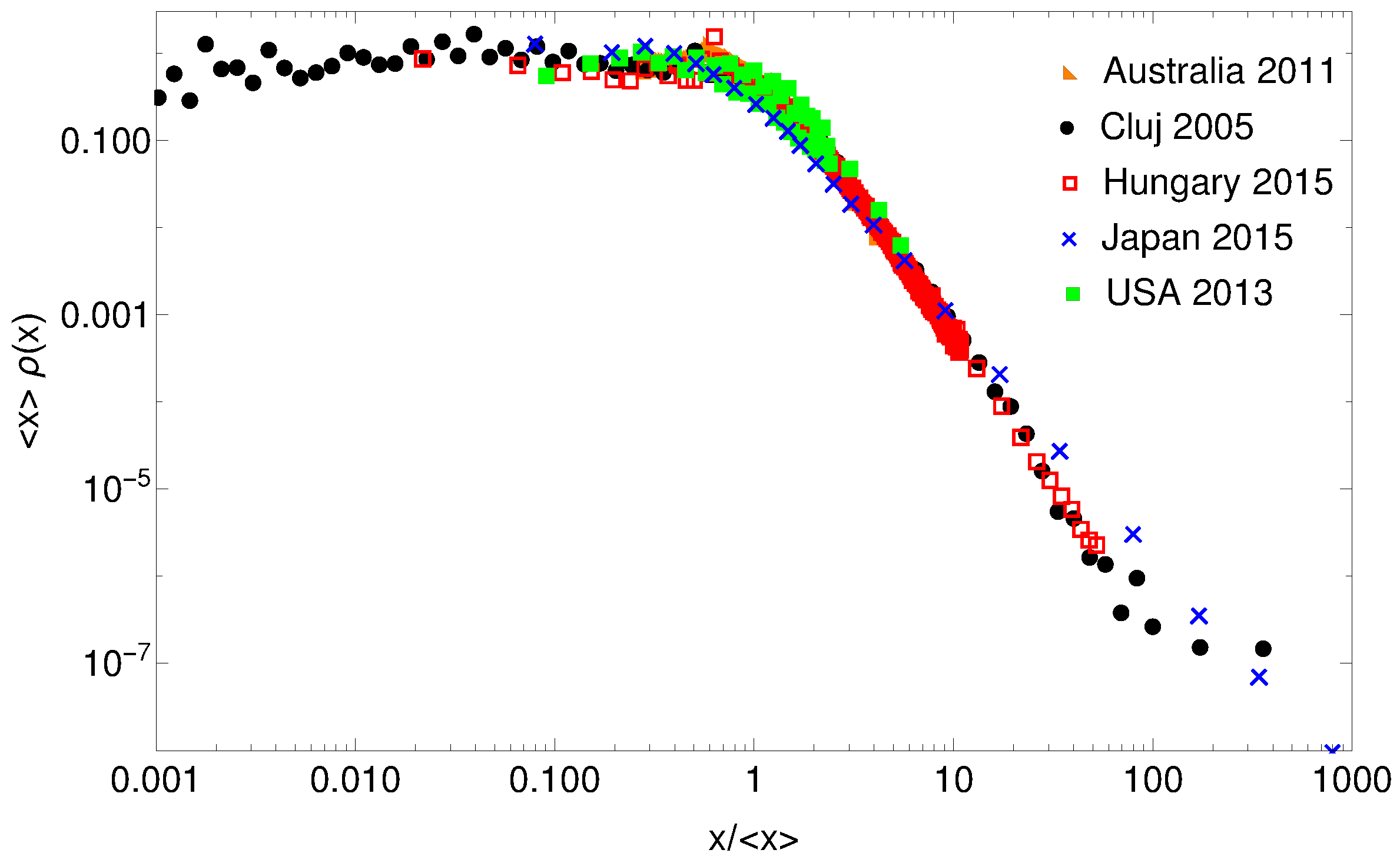
29]. To use a common scale and to collapse the distributions as much as possible, we consider for each case the normalized income, i.e., income relative to the average value. The probability density functions of these distributions for the whole normalized income ranges are plotted in
Figure 1. They look very similar on log-log scale, and only the data for Japan seems to have a different scaling in the high income region. On such a log-log representation, the probability density functions of normalized income for Hungary and Cluj county (Romania) seem to collapse perfectly, which is definitely a consequence of the closely related economic history of these two countries.
One can learn from population biology that in many cases the use of the probability density function is not the best methodology to illustrate the relevant differences in abundance [
30]. For heavy-tailed distributions, the generally used log-log scales (such as in
Figure 1) is appropriate to illustrate scaling, but it does not offer relevant information for those parts of the distribution where the majority of the individuals are. Therefore in illustrating these differences, instead of the mathematically well-defined probability density function, a special frequency histogram, the Preston plot [
31], is used. When illustrating social inequalities in form of income, we are in a similar situation. As an alternative to the probability density, from the income distribution data one can construct a normalized gintropy
by estimating numerically both cumulative functions,
and
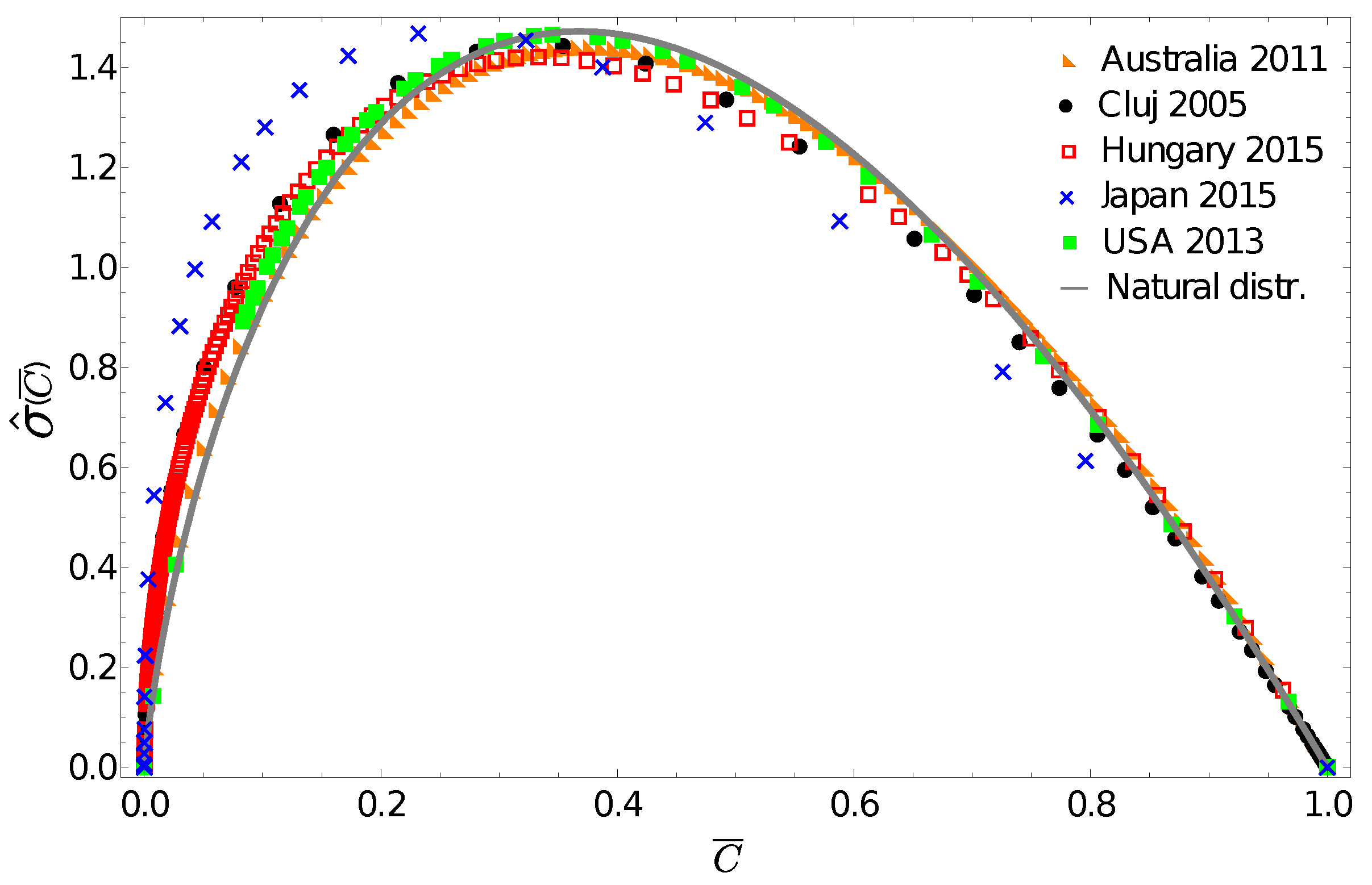
, from the data themselves. In contrast to the probability density function, this quantity will peak in the vicinity of the average income, i.e., characterizing the income regions where the majority of the population is to be found.
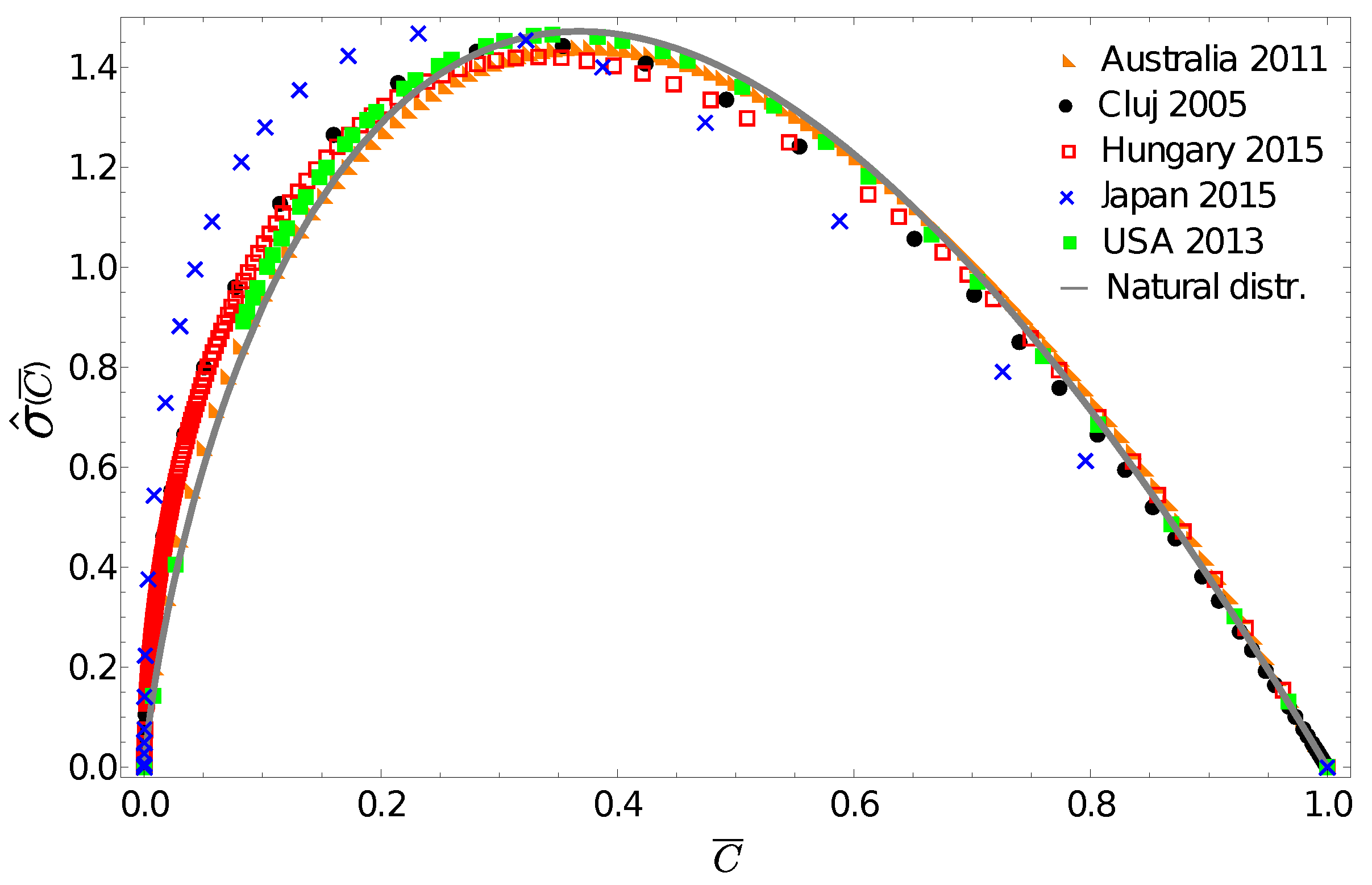
Figure 2 presents these gintropy functions in comparison to the one expected for the natural (exponential) distribution:
Figure 2 again reveals the fact that the income distribution for Japan seems to be very different, and surprisingly, we see that the gintropy curve for Australia is the closest to the one for the natural distribution. The gintropies,
, for Hungary and Cluj county are also quite close to that of the natural distribution. All these results confirm again what we have known for a long time: both income and wealth distributions tend to have an exponential shape when restricted to the middle class of a society [
32,
33].
Gintropic distances can be calculated using the well-known Kullback–Leibler divergences for the
functions.
Approximating the above integral from the interpolated experimental data for
, we thus determine a quantity that characterizes the gintropic differences between income distributions among different countries. In
Table 1 we indicate these values and also consider the distance relative to the normalized gintropy which is characteristic to the natural distribution
. This table again suggests that while focusing on the relevant (larger) part of the society, the income distribution in Australia and the USA are close to the expected natural distribution. On the other hand, Hungary, Romania and Japan seem to be different: an interesting and unexpected result. Such a methodology based on the gintropy instead of the commonly used probability density function could definitely be useful in cases where one prefers to group countries in clusters according to their most abundant income categories.
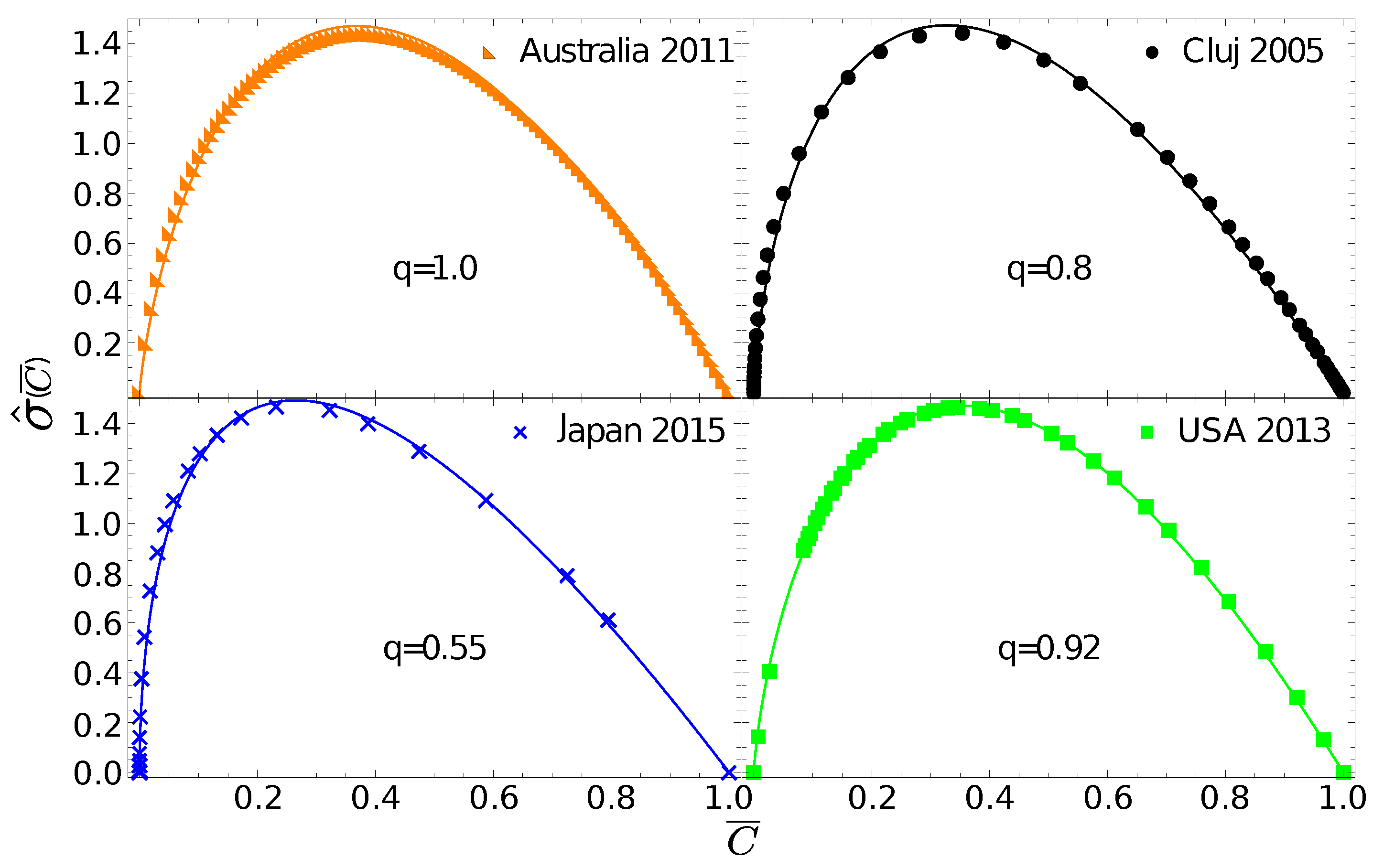
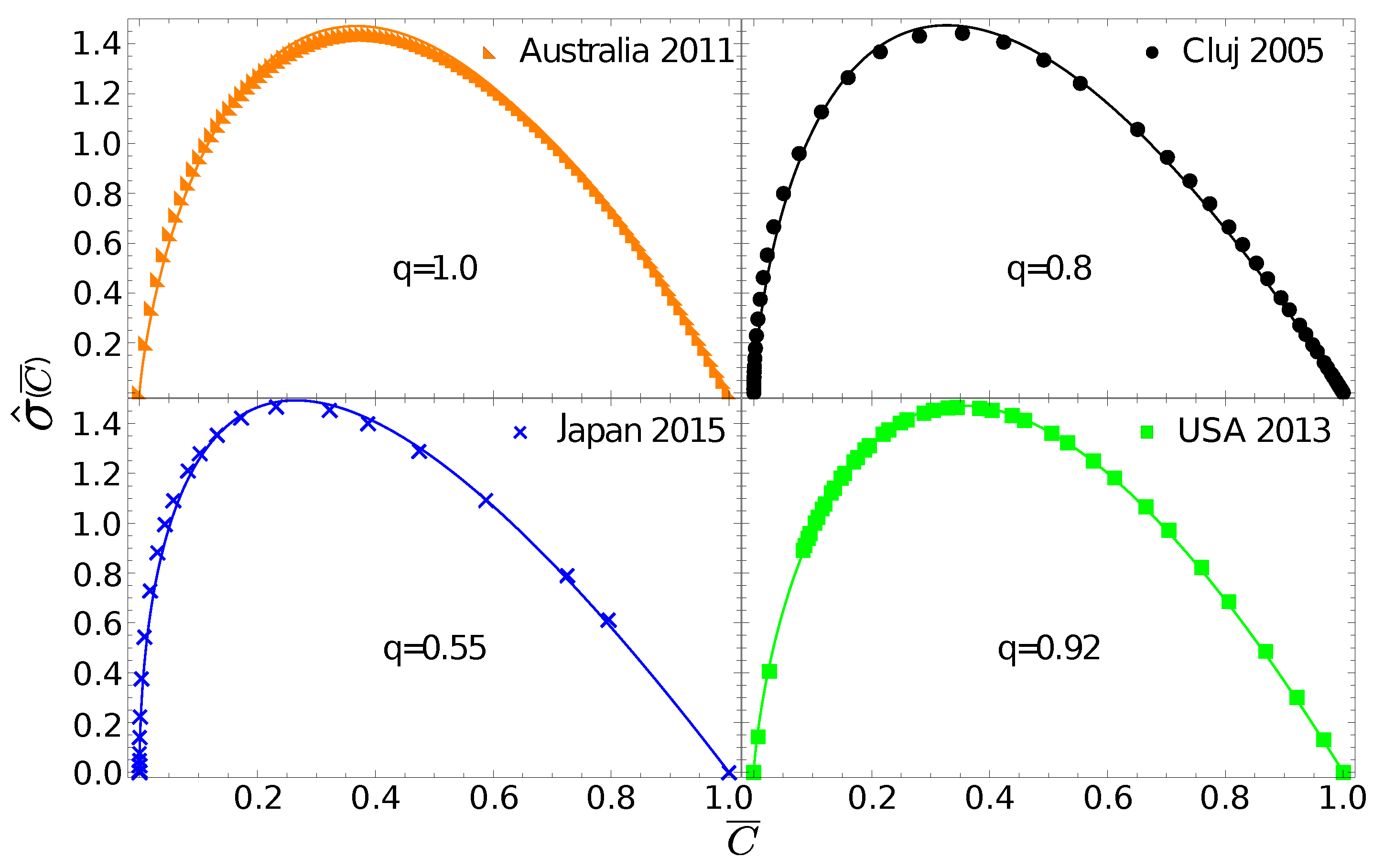
One can now go further and test whether the
gintropy, associated to
, can be fitted with the gintropy for the Tsallis–Pareto distribution with
:
The corresponding normalized gintropy is proportional to the Tsallis q-entropy form [
23]:
In
Figure 3 we fit the experimental gintropy curves with the one given in Equation (
30). The best fit parameter,
, for Australia again suggests that in this case the natural distribution is relevant since Equation (
30) in the limit
leads to Equation (
27). For Cluj county and Hungary, the best fit is obtained with
, for the USA we get
, and for Japan we obtain
.
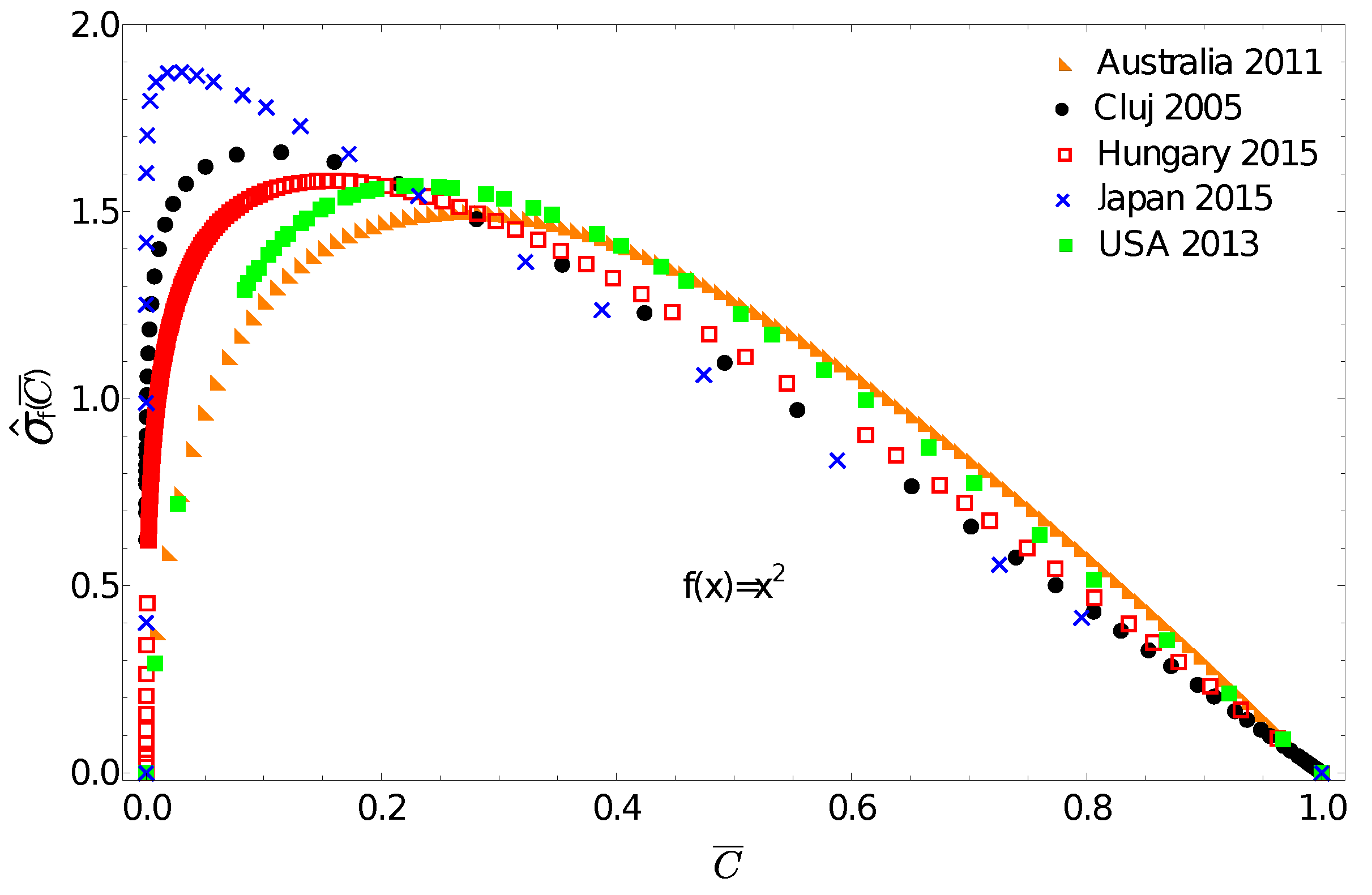
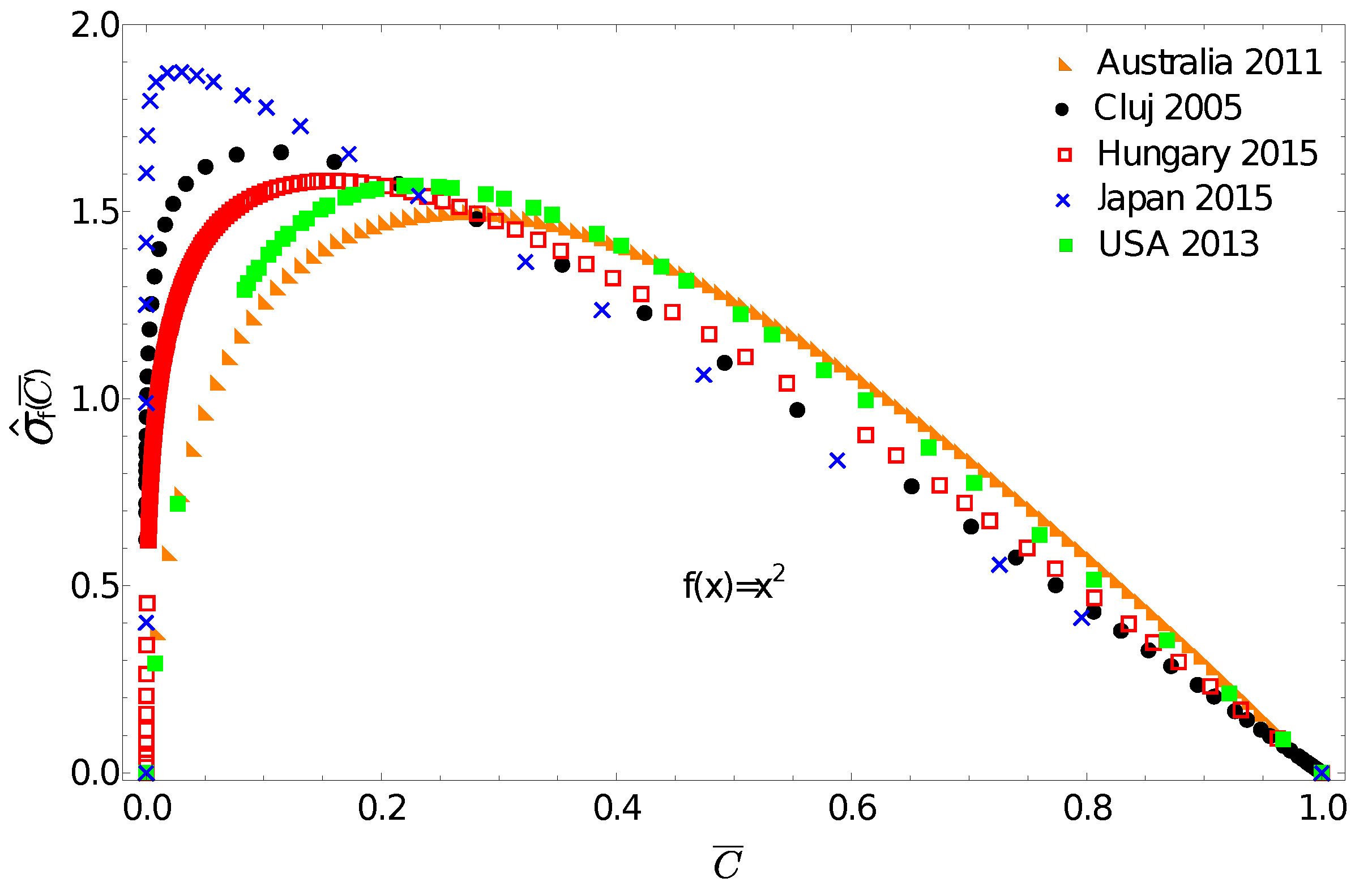
One can now use the above discussed income distributions to exemplify the application potential of the f-gintropy. We choose a simple convex function and construct the corresponding normalized f-gintropy for all the income distributions. Such a choice is justified if: (i) instead of income one considers some other socioeconomic metrics that depend on its square or (ii) if we intend to amplify differences at large income values. In this latter case, any convex-shaped function can serve this purpose.
The obtained curves are plotted in
Figure 4. A first immediate consequence of using the f-gintropy instead of the usual gintropy is that the
curves become more strongly separated. Japan and Australia are again the two extremes. In such a representation, one can distinguish between the income distributions in Hungary and Cluj county that appeared to be very close before. A Kullback–Leibler distance matrix, similar to the one shown in
Table 1, is now constructed for the f-gintropy with the
choice. To proceed, we used a second order interpolation method to estimate the Kullback–Leibler divergence for the f-gintropy in the
representation. The results are given in
Table 2. According to the values from
Table 2, Australia and the USA form a clear cluster, and similarly Hungary with Cluj county and Japan continues to be in a separate cluster. While the similarities between Australia and the USA together with the ones between Hungary and Romania are easy to interpret, Japan’s position seems to be more surprising. These results might confirm some earlier hypotheses according to which the Japanese taxation and redistribution system is perfectly balanced, neither highly redistributive nor too capitalistic [
34]. Interestingly, their income redistribution policies seem to be closer to those in former socialist countries rather than the ones with consecrated free market economies. In such a view, the results obtained here make sense.






{kind=link}
{kind=link}
{kind=link}
{kind=link}